
Reduction of Video Capsule Endoscopy Reading Times Using Deep Learning with Small Data

 , , , ,
, , , , 
Abstract
1. Introduction
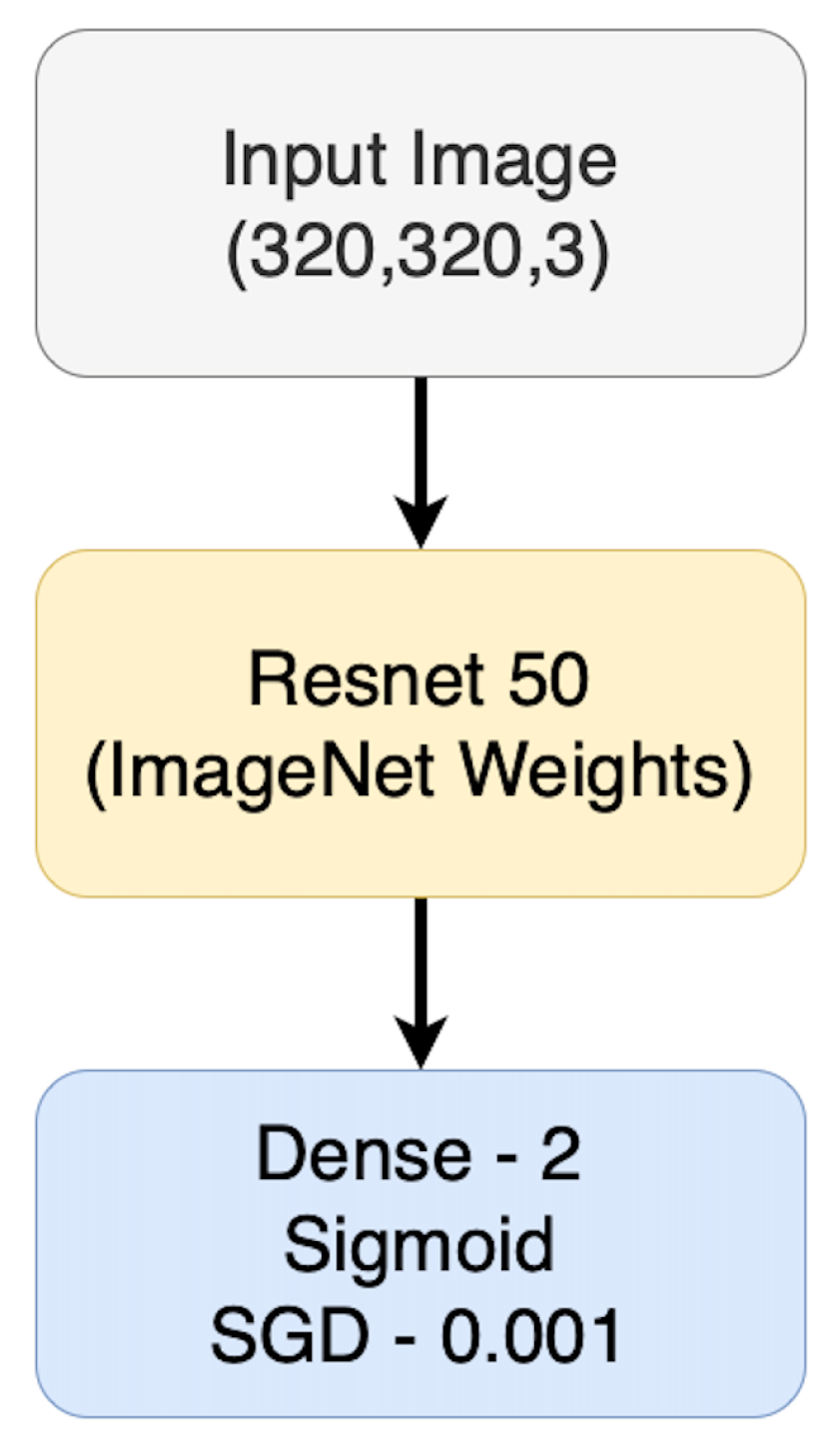
2. Materials and Methods
3. Results
4. Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| VCE | Video Capsule Endoscopy |
| CNN | Convolutional Neural Network |
References
- Byrne, F.M.; Donnellan, F. Artificial intelligence and capsule endoscopy: Is the truly “smart” capsule nearly here? Gastrointest. Endosc. 2019, 89, 195–197. [Google Scholar] [CrossRef] [PubMed]
- Pogorelov, K.; Suman, S.; Azmadi Hussin, F.; Saeed Malik, A.; Ostroukhova, O.; Riegler, M.; Halvorsen, P.; Hooi Ho, S.; Goh, K.L. Bleeding detection in wireless capsule endoscopy videos - Color versus texture features. J. Appl. Clin. Med. Phys. 2019, 20, 141–154. [Google Scholar] [CrossRef] [PubMed]
- Iddan, G.; Meron, G.; Glukhovsky, A.; Swain, P. Wireless capsule endoscopy. Nature 2000, 405, 405–417. [Google Scholar] [CrossRef] [PubMed]
- Rondonotti, E.; Pennazio, M.; Toth, E.; Koulaouzidis, A. How to read small bowel capsule endoscopy: A practical guide for everyday use. Endosc. Int. Open 2020, 8, E1220–E1224. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.H.; Lim, Y.J. Artificial Intelligence in Capsule Endoscopy: A Practical Guide to Its Past and Future Challenges. Diagnostics 2021, 11, 1722. [Google Scholar] [CrossRef]
- Beg, S.; Card, T.; Sidhu, R.; Wronska, E.; Ragunath, K.; Ching, H.L.; Koulaouzidis, A.; Yung, D.; Panter, S.; Mcalindon, M.; et al. The impact of reader fatigue on the accuracy of capsule endoscopy interpretation. Dig. Liver Dis. 2021, 53, 1028–1033. [Google Scholar] [CrossRef]
- Lewis, B.S.; Eisen, G.M.; Friedman, S. A pooled analysis to evaluate results of capsule endoscopy trials. Endoscopy 2005, 37, 960–965. [Google Scholar] [CrossRef]
- Xavier, S.; Monteiro, S.; Magalhães, J.; Rosa, B.; Moreira, M.J.; Cotter, J. Capsule endoscopy with PillCamSB2 versus PillCamSB3: Has the improvement in technology resulted in a step forward? Rev. Española Enfermedades Dig. 2018, 110, 155–159. [Google Scholar] [CrossRef]
- Buscaglia, J.M.; Giday, S.A.; Kantsevoy, S.V.; Clarke, J.O.; Magno, P.; Yong, E.; Mullin, G.E. Performance characteristics of the suspected blood indicator feature in capsule endoscopy according to indication for study. Clin. Gastroenterol. Hepatol. 2008, 6, 298–301. [Google Scholar] [CrossRef]
- Shiotani, A.; Honda, K.; Kawakami, M.; Kimura, Y.; Yamanaka, Y.; Fujita, M.; Matsumoto, H.; Tarumi, K.I.; Manabe, N.; Haruma, K. Analysis of small-bowel capsule endoscopy reading by using Quickview mode: Training assistants for reading may produce a high diagnostic yield and save time for physicians. J. Clin. Gastroenterol. 2012, 46, 92–95. [Google Scholar] [CrossRef]
- Dray, X.; Iakovidis, D.; Houdeville, C.; Jover, R.; Diamantis, D.; Histace, A.; Koulaouzidis, A. Artificial intelligence in small bowel capsule endoscopy-current status, challenges and future promise. J. Gastro Hepatol. 2021, 36, 12–19. [Google Scholar] [CrossRef] [PubMed]
- Noya, F.; Álvarez-González, M.A.; Benitez, R. Automated angiodysplasia detection from wireless capsule endoscopy. In Proceedings of the 2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Jeju, Korea, 11–15 July 2017; pp. 3158–3161. [Google Scholar]
- Iakovidis, D.K.; Koulaouzidis, A. Software for enhanced video capsule endoscopy: Challenges for essential progress. Nat. Rev. Gastroenterol. Hepatol. 2015, 12, 172–186. [Google Scholar] [CrossRef] [PubMed]
- Muruganantham, P.; Balakrishnan, S.M. Attention aware deep learning model for wireless capsule endoscopy lesion classification and localization. J. Med. Biol. Eng. 2022, 42, 157–168. [Google Scholar] [CrossRef]
- Hosoe, N.; Horie, T.; Tojo, A.; Sakurai, H.; Hayashi, Y.; Limpias Kamiya, K.J.L.; Sujino, T.; Takabayashi, K.; Ogata, H.; Kanai, T. Development of a Deep-Learning Algorithm for Small Bowel-Lesion Detection and a Study of the Improvement in the False-Positive Rate. J. Clin. Med. 2022, 11, 3682. [Google Scholar] [CrossRef] [PubMed]
- Ding, Z.; Shi, H.; Zhang, H.; Zhang, H.; Tian, S.; Zhang, K.; Cai, S.; Ming, F.; Xie, X.; Liu, J.; et al. Artificial intelligence-based diagnosis of abnormalities in small-bowel capsule endoscopy. Endoscopy 2022. [Google Scholar] [CrossRef]
- Son, G.; Eo, T.; An, J.; Oh, D.J.; Shin, Y.; Rha, H.; Kim, Y.J.; Lim, Y.J.; Hwang, D. Small Bowel Detection for Wireless Capsule Endoscopy Using Convolutional Neural Networks with Temporal Filtering. Diagnostics 2022, 12, 1858. [Google Scholar] [CrossRef]
- Raut, V.; Gunjan, R.; Shete, V.V.; Eknath, U.D. Small Bowel Gastrointestinal tract disease segmentation and classification in wireless capsule endoscopy using intelligent deep learning model. Comput. Methods Biomech. Biomed. Eng. Imaging Vis. 2022, 1–17. [Google Scholar] [CrossRef]
- Aoki, T.; Yamada, A.; Kato, Y.; Saito, H.; Tsuboi, A.; Nakada, A.; Niikura, R.; Fujishiro, M.; Oka, S.; Ishihara, S.; et al. Automatic detection of various abnormalities in capsule endoscopy videos by a deep learning-based system: A multicenter study. Gastrointest. Endosc. 2021, 93, 165–173. [Google Scholar] [CrossRef]
- Iakovidis, D.K.; Georgakopoulos, S.V.; Vasilakakis, M.; Koulaouzidis, A.; Plagianakos, V.P. Detecting and Locating Gastrointestinal Anomalies Using Deep Learning and Iterative Cluster Unification. IEEE Trans. Med. Imaging 2018, 37, 2196–2210. [Google Scholar] [CrossRef]
- Koulaouzidis, A.; Iakovidis, D.K.; Yung, D.E.; Rondonotti, E.; Kopylov, U.; Plevris, J.N.; Toth, E.; Eliakim, A.; Johansson, G.W.; Marlicz, W.; et al. KID Project: An internet-based digital video atlas of capsule endoscopy for research purposes. Endosc. Int. Open 2017, 5, 477–483. [Google Scholar] [CrossRef]
- Fernandez-Urien, I.; Carretero, C.; Borobio, E.; Borda, A.; Estevez, E.; Galter, S.; Gonzalez-Suarez, B.; Gonzalez, B.; Lujan, M.; Martinez, J.L.; et al. KID Project: An internet-based digital video atlas of capsule endoscopy for research purposes. World J. Gastroenterol. 2014, 20, 14472. [Google Scholar] [CrossRef]
- Amiri, Z.; Hassanpour, H.; Beghdadi, A. Feature extraction for abnormality detection in capsule endoscopy images. Biomed. Signal Process. Control 2022, 71, 103219. [Google Scholar] [CrossRef]
- Caroppo, A.; Leone, A.; Siciliano, P. Deep transfer learning approaches for bleeding detection in endoscopy images. Comput. Med Imaging Graph. 2021, 88, 1–8. [Google Scholar] [CrossRef]
- Vasilakakis, M.; Sovatzidi, G.; Iakovidis, D.K. Explainable classification of weakly annotated wireless capsule endoscopy images based on a fuzzy bag-of-colour features model and brain storm optimization. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2021; pp. 488–498. [Google Scholar]
- Vieira, P.M.; Freitas, N.R.; Lima, V.B.; Costa, D.; Rolana, C.; Lima, C.S. Multi-pathology detection and lesion localization in WCE videos by using the instance segmentation approach. Artif. Intell. Med. 2021, 119, 102141. [Google Scholar] [CrossRef]
- Jain, S.; Seal, A.; Ojha, A.; Yazidi, A.; Bures, J.; Tacheci, I.; Krejcar, O. A deep CNN model for anomaly detection and localization in wireless capsule endoscopy images. Comput. Biol. Med. 2021, 137, 104789. [Google Scholar] [CrossRef]
- Jain, S.; Seal, A.; Ojha, A.; Krejcar, O.; Bureš, J.; Tachecí, I.; Yazidi, A. Detection of abnormality in wireless capsule endoscopy images using fractal features. Comput. Biol. Med. 2020, 127, 104094. [Google Scholar] [CrossRef]
- Diamantis, D.E.; Iakovidis, D.K.; Koulaouzidis, A. Look-behind fully convolutional neural network for computer-aided endoscopy. Biomed. Signal Process. Control 2019, 49, 192–201. [Google Scholar] [CrossRef]
- Guo, X.; Yuan, Y. Triple ANet: Adaptive abnormal-aware attention network for WCE image classification. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; pp. 293–301. [Google Scholar]
- Raut, V.; Gunjan, R. Transfer learning based video summarization in wireless capsule endoscopy. Int. J. Inf. Technol. 2022, 1–8. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Huang, G.; Li, Y.; Pleiss, G.; Liu, Z.; Hopcroft, J.E.; Weinberger, K.Q. Snapshot ensembles: Train 1, get m for free. arXiv 2017, arXiv:1704.00109. [Google Scholar]
- Leenhardt, R.; Li, C.; Le Mouel, J.P.; Rahmi, G.; Saurin, J.C.; Cholet, F.; Boureille, A.; Amiot, X.; Delvaux, M.; Duburque, C.; et al. CAD-CAP: A 25,000-image database serving the development of artificial intelligence for capsule endoscopy. Endosc. Int. Open 2020, 8, 415–420. [Google Scholar] [CrossRef]
- Xie, X.; Xiao, Y.F.; Zhao, X.Y.; Li, J.J.; Yang, Q.Q.; Peng, X.; Nie, X.B.; Zhou, J.Y.; Zhao, Y.B.; Yang, H.; et al. Development and Validation of an Artificial Intelligence Model for Small Bowel Capsule Endoscopy Video Review. JAMA Netw. Open 2022, 5, 2221992. [Google Scholar] [CrossRef]
- Saito, H.; Aoki, T.; Aoyama, K.; Kato, Y.; Tsuboi, A.; Yamada, A.; Fujishiro, M.; Oka, S.; Ishihara, S.; Matsuda, T.; et al. Automatic detection and classification of protruding lesions in wireless capsule endoscopy images based on a deep convolutional neural network. Gastrointest. Endosc. 2020, 92, 144–151. [Google Scholar] [CrossRef]
- Aoki, T.; Yamada, A.; Aoyama, K.; Saito, H.; Tsuboi, A.; Nakada, A.; Niikura, R.; Fujishiro, M.; Oka, S.; Ishihara, S.; et al. Automatic detection of erosions and ulcerations in wireless capsule endoscopy images based on a deep convolutional neural network. Gastrointest. Endosc. 2019, 89, 357–363. [Google Scholar] [CrossRef]
- Ding, Z.; Shi, H.; Zhang, H.; Meng, L.; Fan, M.; Han, C.; Zhang, K.; Ming, F.; Xie, X.; Liu, H.; et al. Gastroenterologist-Level Identification of Small-Bowel Diseases and Normal Variants by Capsule Endoscopy Using a Deep-Learning Model. Nat. Rev. Gastroenterol. 2019, 157, 1044–1054. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Video Name | Total Frames | Number of Abnormal Segments | Reduced Number of Frames | Abnormal Segments Detected |
|---|---|---|---|---|
| KID Video 1 | 28,480 (95 min) | 22 | 616 (2 min) | 3 |
| KID Video 2 | 117,565 (391 min) | 86 | 956 (3 min) | 10 |
| KID Video 3 | 74,762 (249 min) | 11 | 4522 (15 min) | 8 |
| Model | n | Mean | Variance | t-calc | t-crit | df | p |
|---|---|---|---|---|---|---|---|
| Single Network | 119 | 0.176 | 0.147 | 11.72 | 1.98 | 118 | |
| Ensemble No Aug | 119 | 0.714 | 0.206 |
| Video Name | Total Frames | Number of Abnormal Segments | Reduced Number of Frames | Abnormal Segments Detected |
|---|---|---|---|---|
| KID Video 1 | 28,480 (95 min) | 22 | 10,747 (36 min) | 21 |
| KID Video 2 | 117,565 (391 min) | 86 | 10,960 (37 min) | 53 |
| KID Video 3 | 74,762 (249 min) | 11 | 33,963 (113 min) | 11 |
| Video Name | Total Frames | Number of Abnormal Segments | Reduced Number of Frames | Abnormal Segments Detected |
|---|---|---|---|---|
| KID Video 1 | 28,480 (95 min) | 22 | 14,828 (49 min) | 22 |
| KID Video 2 | 117,565 (391 min) | 86 | 84,672 (282 min) | 86 |
| KID Video 3 | 74,762 (249 min) | 11 | 27,099 (90 min) | 11 |
| Model | n | Mean | Variance | t-calc | t-crit | df | p |
|---|---|---|---|---|---|---|---|
| Ensemble No Aug | 119 | 0.714 | 0.206 | 6.87 | 1.98 | 118 | |
| Ensemble With Aug | 119 | 1 | 0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Morera, H.; Warman, R.; Anudu, A.; Uche, C.; Radosavljevic, I.; Reddy, N.; Kayastha, A.; Baviriseaty, N.; Mhaskar, R.; Borkowski, A.A.; et al. Reduction of Video Capsule Endoscopy Reading Times Using Deep Learning with Small Data. Algorithms 2022, 15, 339. https://doi.org/10.3390/a15100339
Morera H, Warman R, Anudu A, Uche C, Radosavljevic I, Reddy N, Kayastha A, Baviriseaty N, Mhaskar R, Borkowski AA, et al. Reduction of Video Capsule Endoscopy Reading Times Using Deep Learning with Small Data. Algorithms. 2022; 15(10):339. https://doi.org/10.3390/a15100339
Chicago/Turabian StyleMorera, Hunter, Roshan Warman, Azubuogu Anudu, Chukwudumebi Uche, Ivana Radosavljevic, Nikhil Reddy, Ahan Kayastha, Niharika Baviriseaty, Rahul Mhaskar, Andrew A. Borkowski, and et al. 2022. "Reduction of Video Capsule Endoscopy Reading Times Using Deep Learning with Small Data" Algorithms 15, no. 10: 339. https://doi.org/10.3390/a15100339
APA StyleMorera, H., Warman, R., Anudu, A., Uche, C., Radosavljevic, I., Reddy, N., Kayastha, A., Baviriseaty, N., Mhaskar, R., Borkowski, A. A., Brady, P., Singh, S., Mullin, G., Lezama, J., Hall, L. O., Goldgof, D., & Vidyarthi, G. (2022). Reduction of Video Capsule Endoscopy Reading Times Using Deep Learning with Small Data. Algorithms, 15(10), 339. https://doi.org/10.3390/a15100339