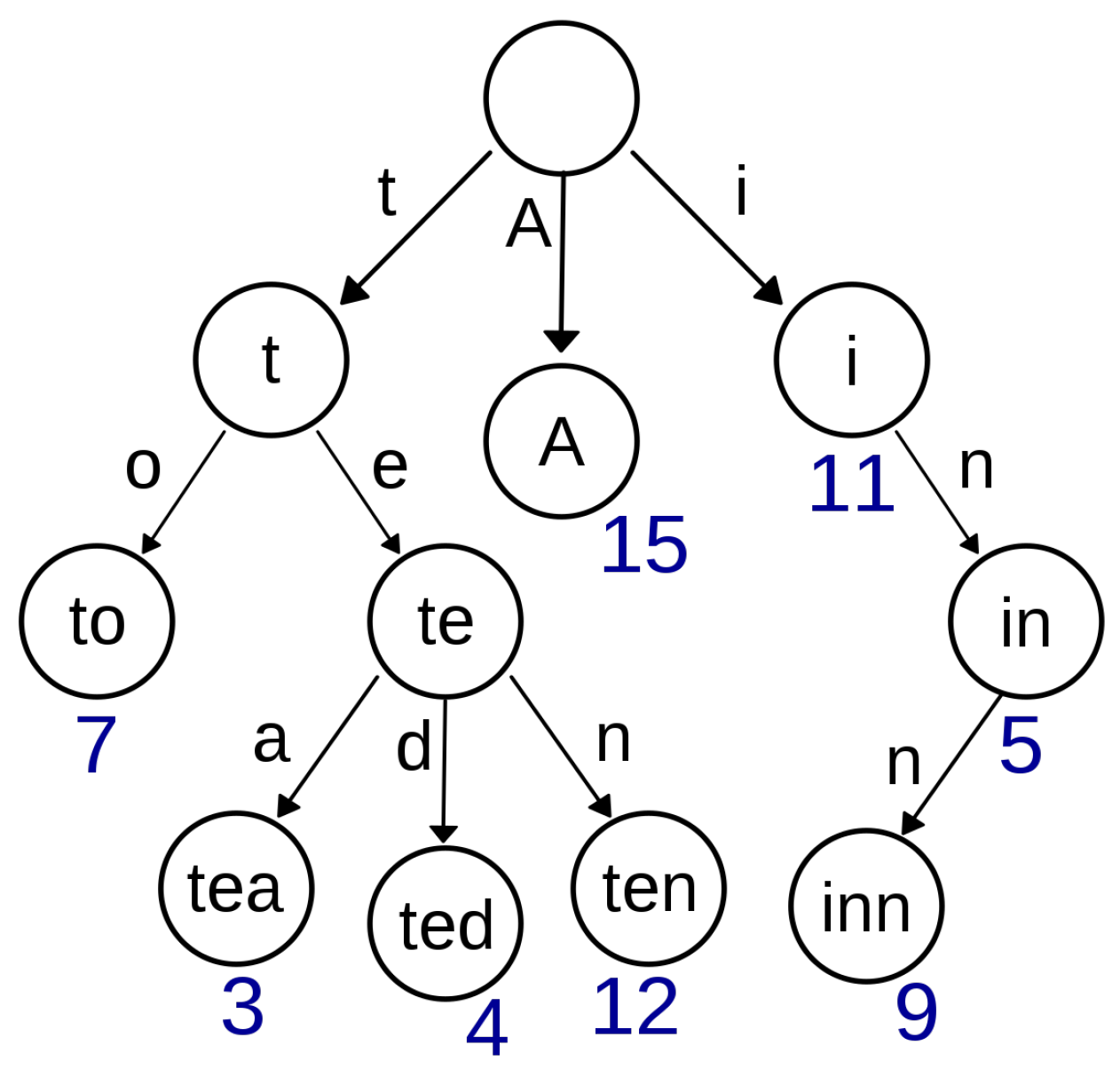
A trie encodes a set of strings, represented by concatenating the characters of the edges along the path from the root node to each corresponding leaf. The common prefixes are collapsed such that each string prefix corresponds to a unique path.
4.1. The Trie Solution
The problem specification stipulates that the size of the grid should be equal to , where n is the size of the given word that should be placed in the first column, and m is the number of columns of the optimal solution. If the optimisation function is defined to maximize the characters’ weight sums, then it is very probable that an optimal solution will be obtained for big values of m, and so an approach could start for the maximal value of m, which decreases successively.
The proposed solution follows a letter-by-letter approach, and the design analysis considers a specified size of the grid.
Data representation: The words of the dictionary are represented using a complex data structure that contains tries; the number is equal to the maximum size of the words from the dictionary (e.g., for our dictionary). We have words that contains 1, 2, ..., letters. This way, we have words represented only as full paths—from root to leaves—in the tries.
The roots of the corresponding tries are stored in an array of lengths, —; so, is the root of the trie that stores the words with lengths equal to n.
The decision of using tries increases the space complexity, but facilitates a very good time complexity, since in order to fill a crossword grid, as specified in the problem specification, we need words of specific lengths. These tries could be created one time and stored, potentially as the first step of the algorithm. The time complexity of creating these tries is not very high since a single dictionary traversal is required; for each new word, the path corresponding to its letters is followed and new nodes (corresponding to the contained letters) are added when necessary. So, the time complexity is for this operation.
For each trie, the first level contains an array of 26 roots for the words starting with each alphabet letter. We propose a special trie representation, in which each node of a trie contains:
A letter—;
An array with a length equal to 26——for the children nodes (one for each letter);
A number——which is obtained from a binary representation with 26 digits that reflects the possible continuations:
- -
0 on the position i means that there is not a subtrie corresponding the ith letter;
- -
1 on the position i means that there is a subtrie corresponding the ith letter.
Example: if for one particular node there are subtries that continue only with the letters A and D, the will be 37748736, which has the following binary representation: 10010000000000000000000000.
This binary code is very important in the fast verification of the possible letters that could be placed in a new position.
For the node that represents the root of such a tree, the attribute is empty.
The words are obtained from the leaf nodes and correspond to the letters on the path from root to them.
In order to fill the crossword grid, three matrices ( and ), which all have the same size as the grid (), are used:
memorizes pointers to the nodes from that correspond to each letter of the words written horizontally (on rows)s;
memorizes pointers to the nodes from that correspond to each letter of the words written vertically (in columns);
memorizes each position the index of the last letter put into the grid—, and the binary code of the possible letters that could be placed on that position——this code is obtained through the intersection (and operation) of the binary codes stored in the corresponding pointed nodes of the first two matrices. The type of the elements is defined by a data structure with two fields—.
In addition, a position that indicates the current position in the grid completion is used:
The algorithm: The algorithm is in essence a backtracking algorithm that fills the cells step by step in columns, starting with the first which is known. So, it is a letter-by-letter algorithm that relies on prefix verification.
The and matrices are first initialized with the pointers to the nodes that correspond to the letters of the given word that should appear on the first column. In , the nodes (from ) follow a path that represents the given word, and in we will have pointers to the nodes from that correspond to the specified first letters in the rows.
The letter in a new position is chosen from the letters obtained by the intersection of the set of the possible letters that allow horizontal words (it creates possible prefixes in rows)—given from the code stored in the node —and the set of possible letters that allow vertical words (creates possible prefixes in columns)—given from the code stored in the node . The intersection is obtained by applying the operation (denoted by ) to the codes , and it is stored in the . The letters from this intersection are considered in order and the index of the current chosen letter is stored into .
For the first letter in a column j the set of possible letters is given by ; no intersection operation is needed.
If the result of the operation between the codes of the nodes stored into and is zero (the intersection is empty), then a step back is executed and the letter in the position is changed by taking the next possible letter in the corresponding intersection set. Additionally, when all the possible letters from the intersection were verified, and moving forward is not possible, a step back is executed again.
So, the
back_step function is defined as:
procedureback_step( )
|
The function
set_letter has the responsibility of setting a new letter in the current position.
functionset_letter( ) first_index if then if then else ▹ the root node corresponding to letter in return else return
|
The function first_index returns the position of the first bit equal to 1 in the binary representation of and set it to 0; setting this bit to 0 is needed in order to emphasize that it has been verified. Additionally, in this way the next call of the function FIRST_INDEX will return the position of the next bit equal to 1.
There is always a left position since we have a word in the first column, and the UP function will be called only when
.
functionup() return functionleft() return
|
The procedure
moves the current position to the next cell in the grid, and sets the corresponding value of the
attribute in
:
proceduremove_next( ) if position.i>0 then else
|
Using these functions, we may define the scheme of the overall algorithm—Algorithm 1.
The algorithm was parameterized with the start position in order to allow its usage for the parallel implementation, for the sequential case
.
| Algorithm 1 |
| ▹—the list of the resulted solution |
| ▹—store the optimal solution |
|
| ▹ matrices initialisation |
@set the nodes from in corresponding to the given word (first column) @set the nodes from in corresponding to the given word (first column) MOVE_NEXT() repeat set_letter (position) if then if (then ▹ if solution @save the solution into the list of solutions— if optimal_solution() then @save the solution as optimal— else MOVE_NEXT() else BACK_STEP() until
|
The most important characteristics and benefits of the algorithm are:
The usage of tries to find the possible prefixes;
The codes attached to each node of the tries (which reflect the possible continuation); using the codes in the nodes of the tries facilitates a very fast verification of the possible paths to solutions using the operation on bits;
The codes saved in the cells of the matrix, as an intersection of the corresponding cells in and matrices.
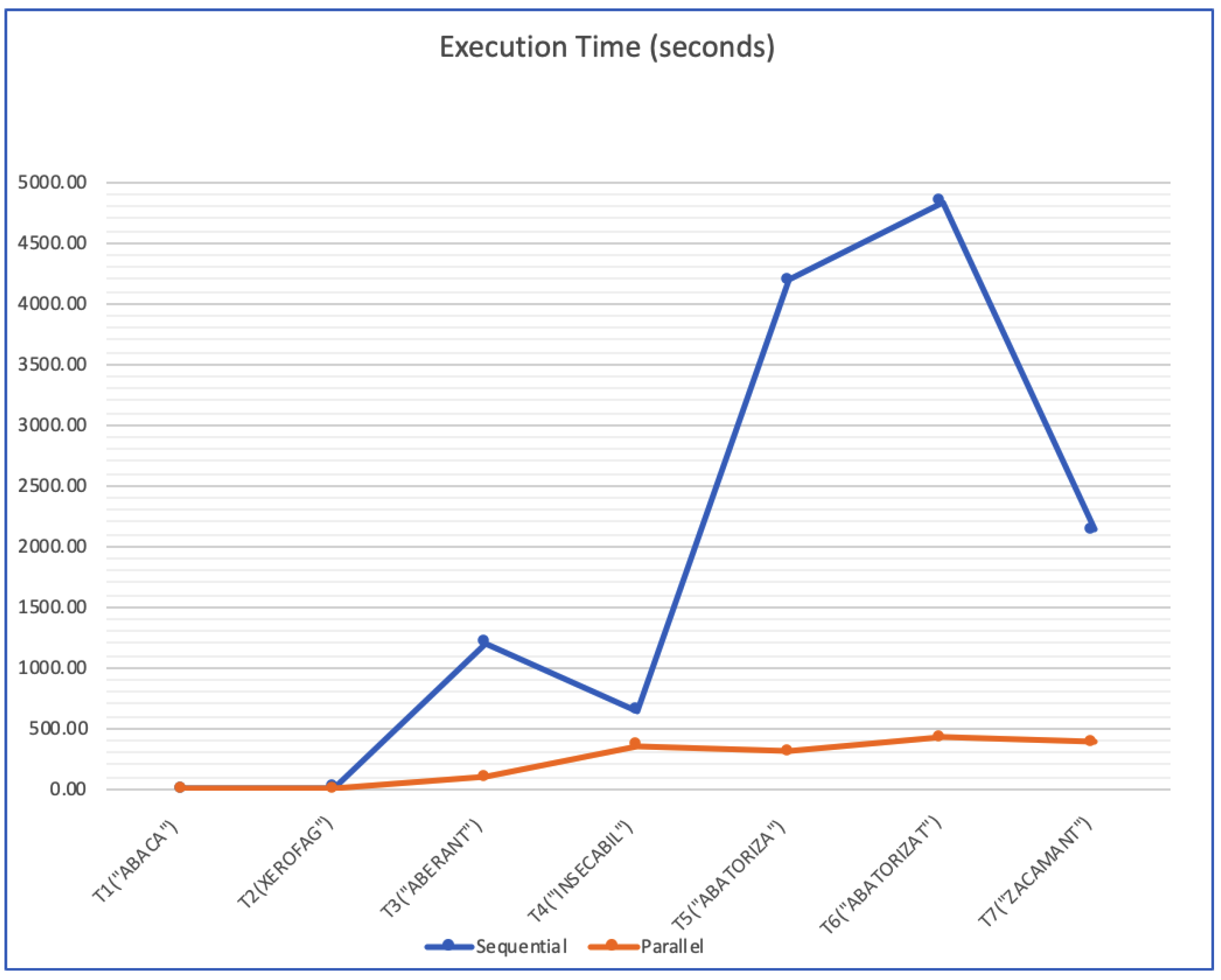
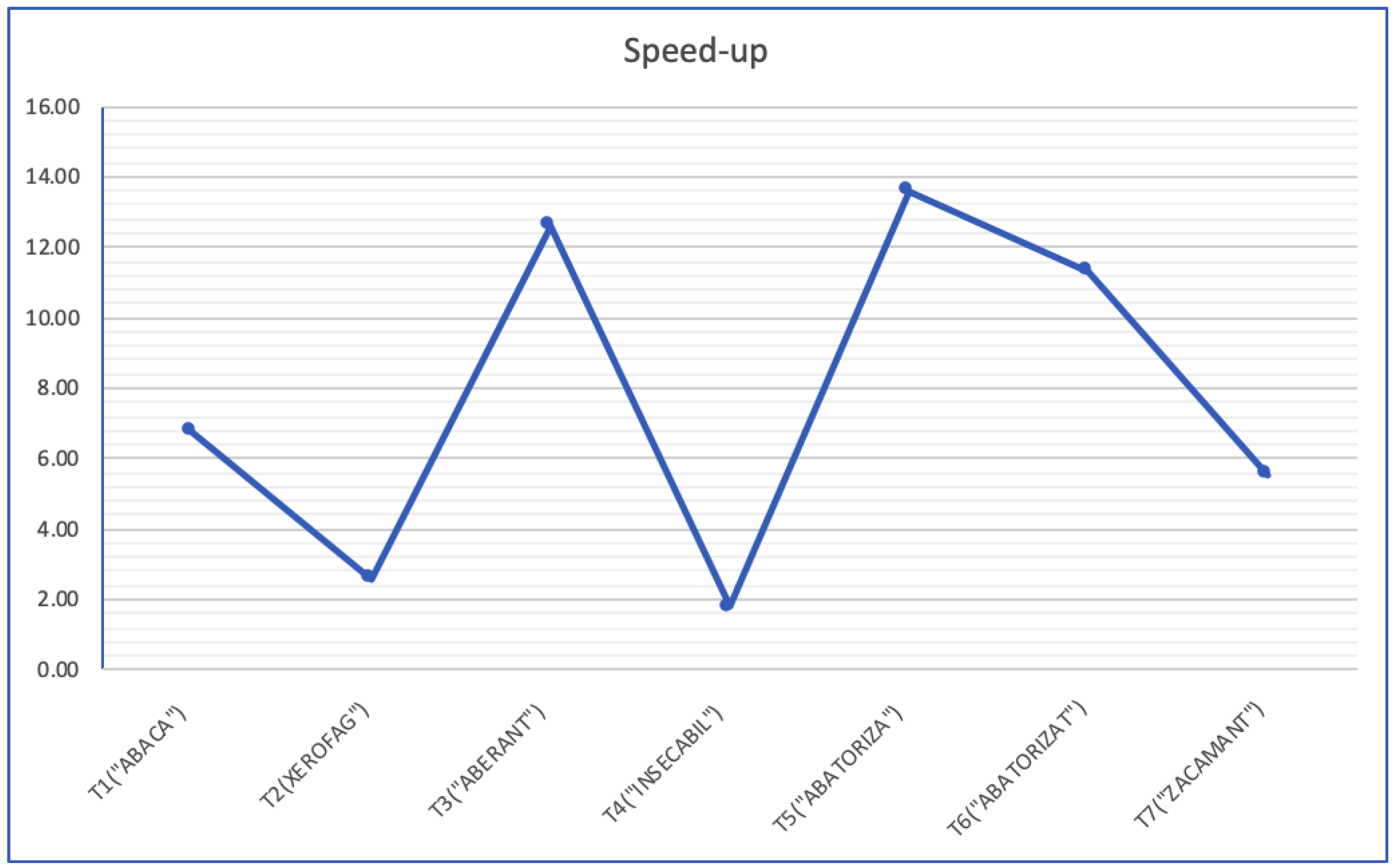
The performance of this algorithm depends on the size of the grid, but most importantly on the number of words of a certain size.
4.2. Parallel Implementation
The algorithm has good potential for parallelisation, and we have developed a hybrid parallel implementation using an MPI (Message Passing Interface) and multithreading. We have chosen this hybrid parallelisation in order to allow using distributed memory and not only shared memory architectures.
Let P be the number of MPI processes and each of these uses a number of T threads (a thread pool of size T). Each process will create the necessary tries from the dictionary file. The space complexity of these structures is not very high, and so, it is worth carrying out this duplication.
The first parallelisation that we may identify relies on the observation that there are several possibilities to set the cell value in the position
; these possible letters are given by the bit code of the node stored in
. Still, in order to allow a parallelisation control independent of the given word that should be placed in the first column, the entire set of alphabet letters is distributed throughout the processes. An exemplification of this is given in
Figure 2. In this way, the responsibility of one process is to find the solutions that have one of the letters assigned to said process in the position
.
Since the proposed solution is a hybrid one (multiprocessing combined with multithreading), each process will use a thread pool of size T able to execute the associated tasks that lead to the solution finding.
For the parallelisation at the threads level, the tasks are defined based on the construction of a list of pairs of letters , where is a potential letter to be placed in the position and in the position (Procedure PAIR_TASK). In this way, the maximal parallelisation degree increases to an adequate value—. Each task will define and use its own matrices and .
More concretely, if we consider the case of four processes with the letter distribution described in
Figure 2, the first process will create
tasks that correspond to all the pairs that are formed by the Cartesian product between the following two sets:
and
.
The program executed by each MPI process is described by Algorithm 2.
| Algorithm 2MPI program |
| — | ▹ each process read the dictionary and create the tries |
| — | ▹ each process creates a thread-pool with T threads |
| — | ▹ create an empty list where solutions will be placed |
| — | ▹ set a variable where the optimal solution will be placed |
| — | ▹ balanced distribution of the set A over the P processes |
| ▹ (A contains all 26 letters of the alphabet) |
| ▹ each process i will have a subset of A () |
| ▹ for each pair of a task is created and submitted to the thread-pool |
| for each pair ) of the Cartesian product do |
| @submit pair_task to the thread pool |
| @wait for all tasks to finalize |
| @aggregate all the solutions and the optimal solution in the process with |
The final aggregation of all found solutions and also the optimal solution, which it is obtained through a -type operation, is carried out in the first MPI process (). This means that after all the tasks are executed, each process sends to the process with a rank equal to 0 the value of the optimal function obtained for the solutions it found. The process 0 computes the global optimal value and sends it back to all the other processes. The processes that have optimal solutions save their optimal solutions.
procedurePair_Task() if eligible to be placed on then @set the values to correspond to letter else EXIT if eligible to be placed on then @set the values to correspond to letter else EXIT @call
|
Analysis
The decision to distribute the letters between the processes was based on the fact that we intended to define a parallel algorithm for which the degree of parallelism could be controlled independently on the given word to be placed in the first column. The value of gives, more precisely, the letters that could be placed in the position , but these are value dependent, and so not appropriate for the MPI process definition.
Even if, theoretically, the algorithm allows us to define 26 MPI processes, it is more efficient from the cost point of view to define fewer processes (to decrease the probability of having processes that do not have effective tasks to execute). A good average would be to assign 3–4 letters per process, and also to use a cyclic distribution for assigning letters to processes.
The presented solution leads to a multiprocessing parallelisation degree equal to 26, and the hybrid degree of parallelism (through multiprocessing and multiprogramming) is . The degree of paralelism could be improved if we consider pairs of letters distributed to the processes instead of simple letters. Using this variant, each process (from p processes) will receive a list that contains of pairs of two letters. In this case, a task created by a process will be defined by three letters—the first two are given from a pair distributed to the process and they are used for setting the positions and , and the third is one from the entire alphabet and is supposed to be placed in the position . This would allow a degree of parallelism bounded by . This idea could be generalized to tuples of k letters, and the obtained degree of parallelism would be bounded by . So, the number of MPI processes could be increased by defining a more general algorithm that distributes tuples of letters and not just single letters to the processes.
The reason for this generalisation is the possible need to engage many more processes in the computation, which is very plausible when using big clusters.



{kind=link}
{kind=link}
{kind=link}
{kind=link}



