
Intelligent Network Intrusion Prevention Feature Collection and Classification Algorithms


Abstract
1. Introduction
2. Literature Review
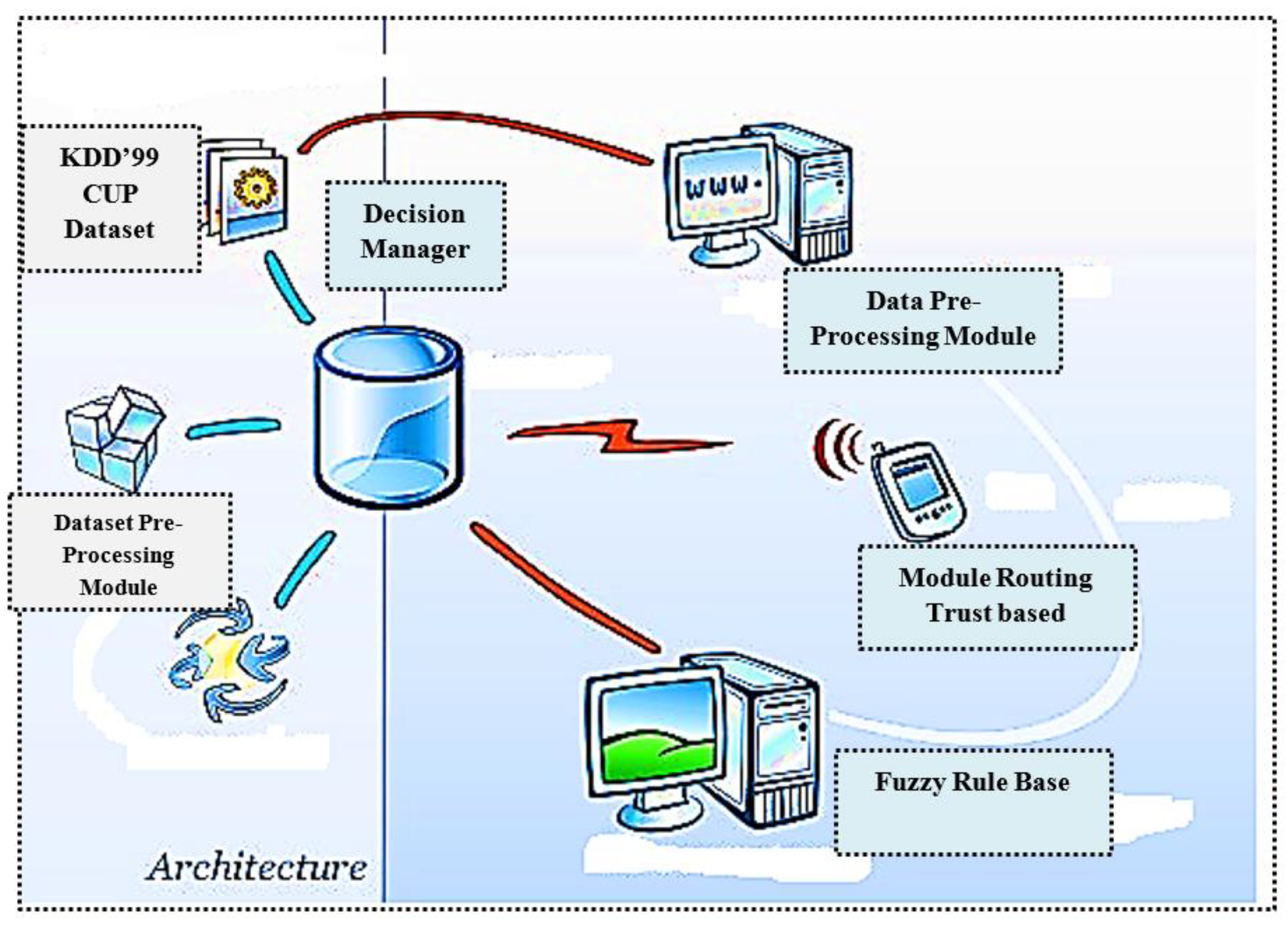
3. The Architecture of System ISTID
3.1. Proposed Algorithm
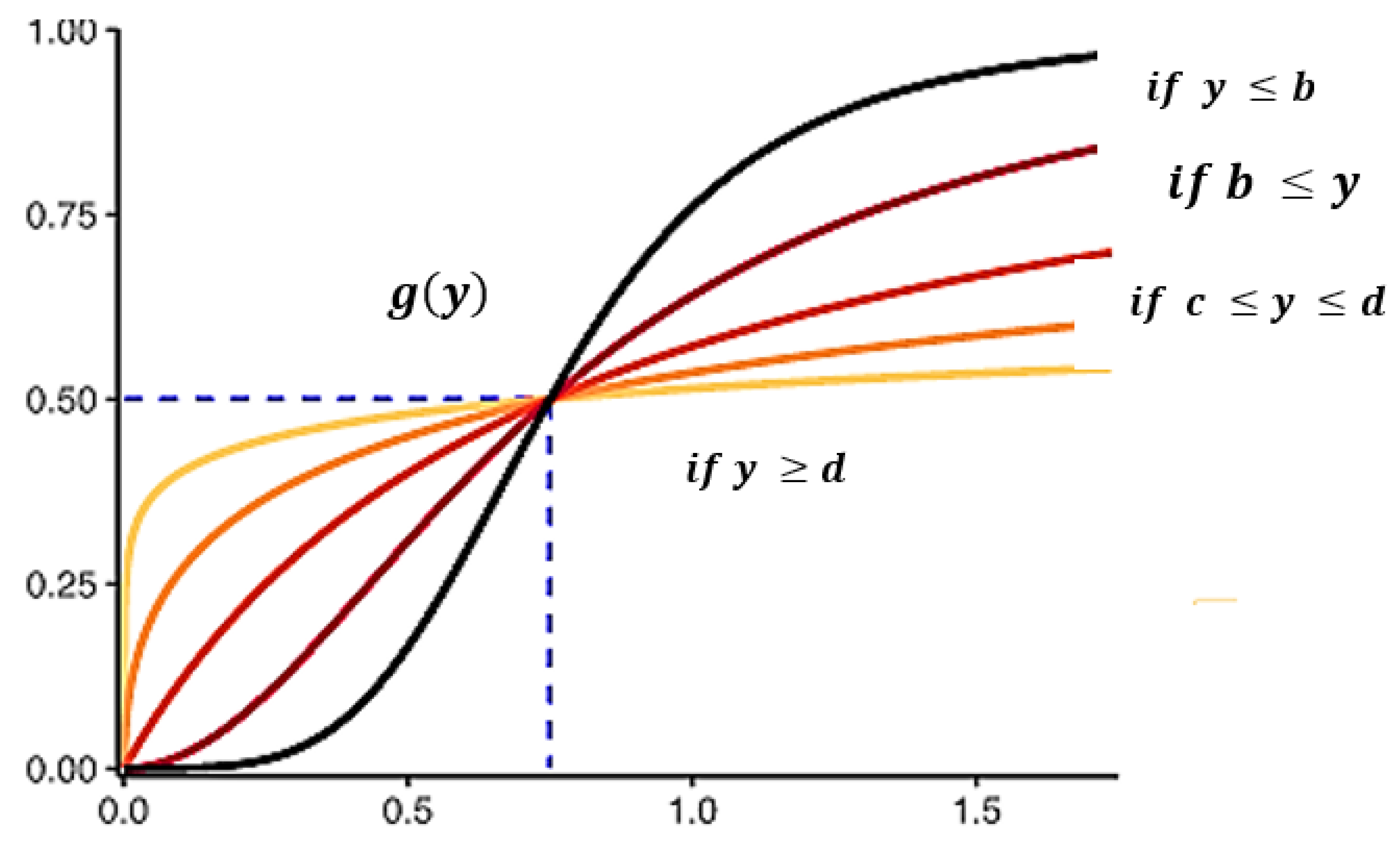
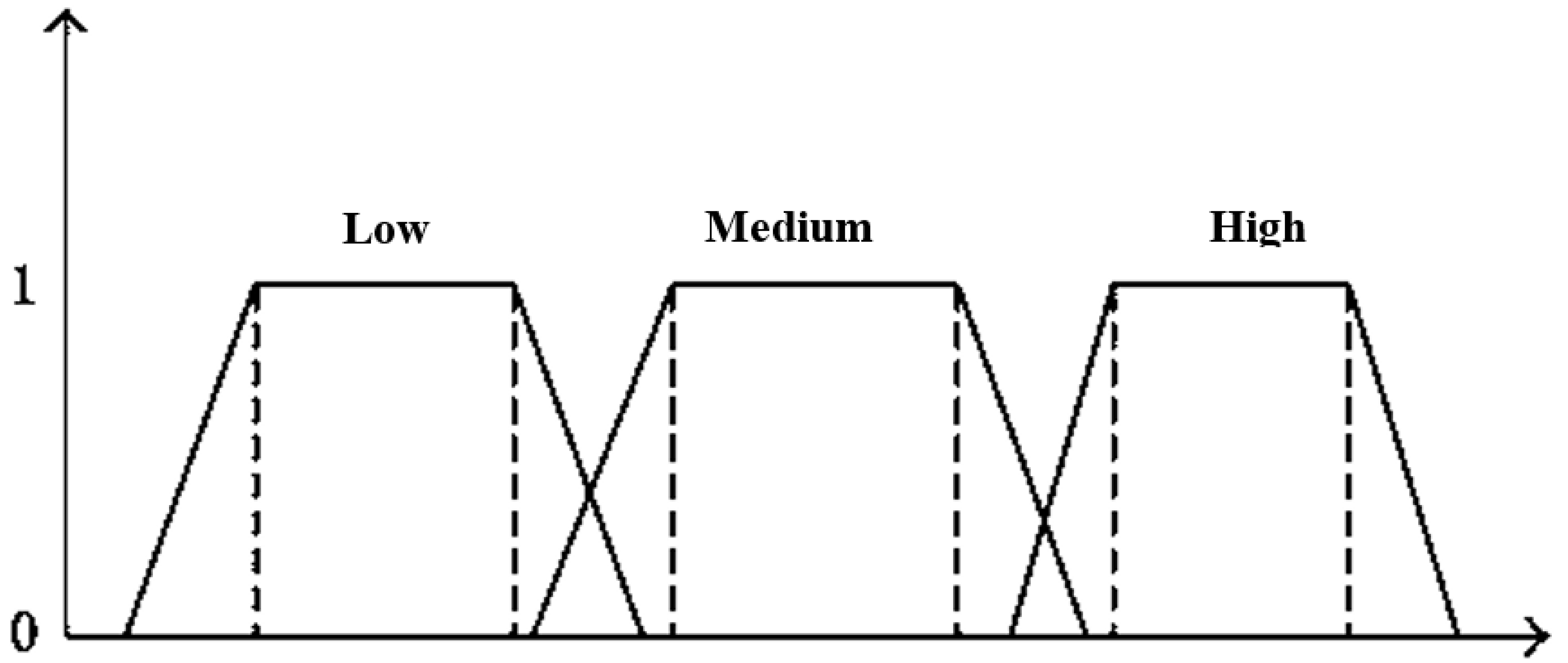
3.2. Pre-Processing Normalized Data
| Algorithm 1 |
| Input; Dataset |
| Output: Groups of Classifications |
| Step 1—Choose the first chromosomes. |
| Step 2—Submit fuzzy chromosome membership function |
| Step 3—Assess the fitness of chromosomes |
| Step 4—Using threshold values to pick a new population |
| Step 5—Apply time restrictions |
| Step 6—While the population is present |
| i. Compare the process immediately |
| ii. Place the ranking comparing values instantaneously |
| iii. Comparison of performance interval |
| iv. Forms weight population |
| Step 7—Crossover with the next community for every community of weight |
| Step 8—Again, add exercise |
| Step 9—When, |
| Mutate performance |
| Else |
| Step 10—Form policy based on conduct |
Genetic Fuzzy Cognitive Temporal Adaptive Algorithm
4. Result and Discussion
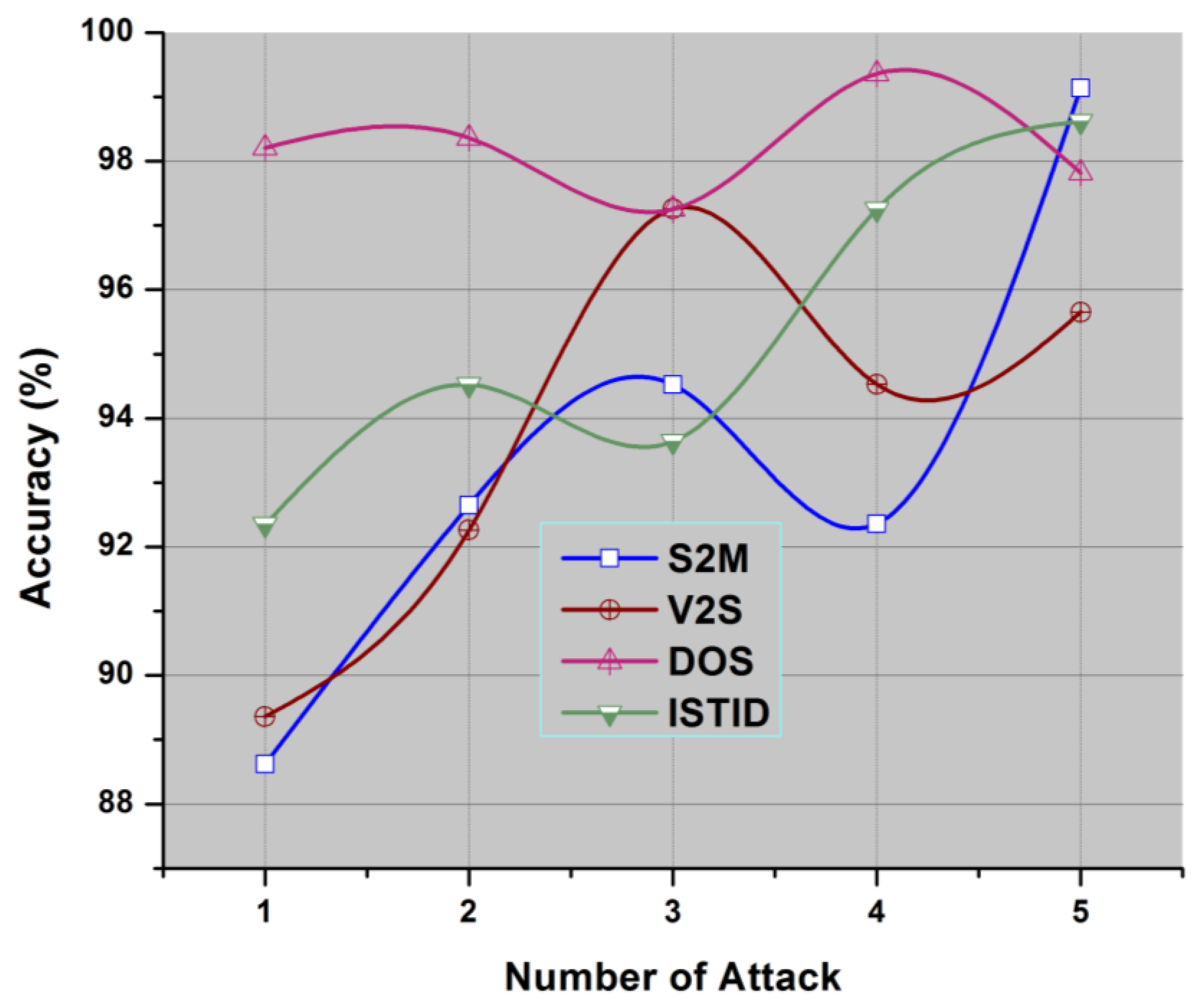
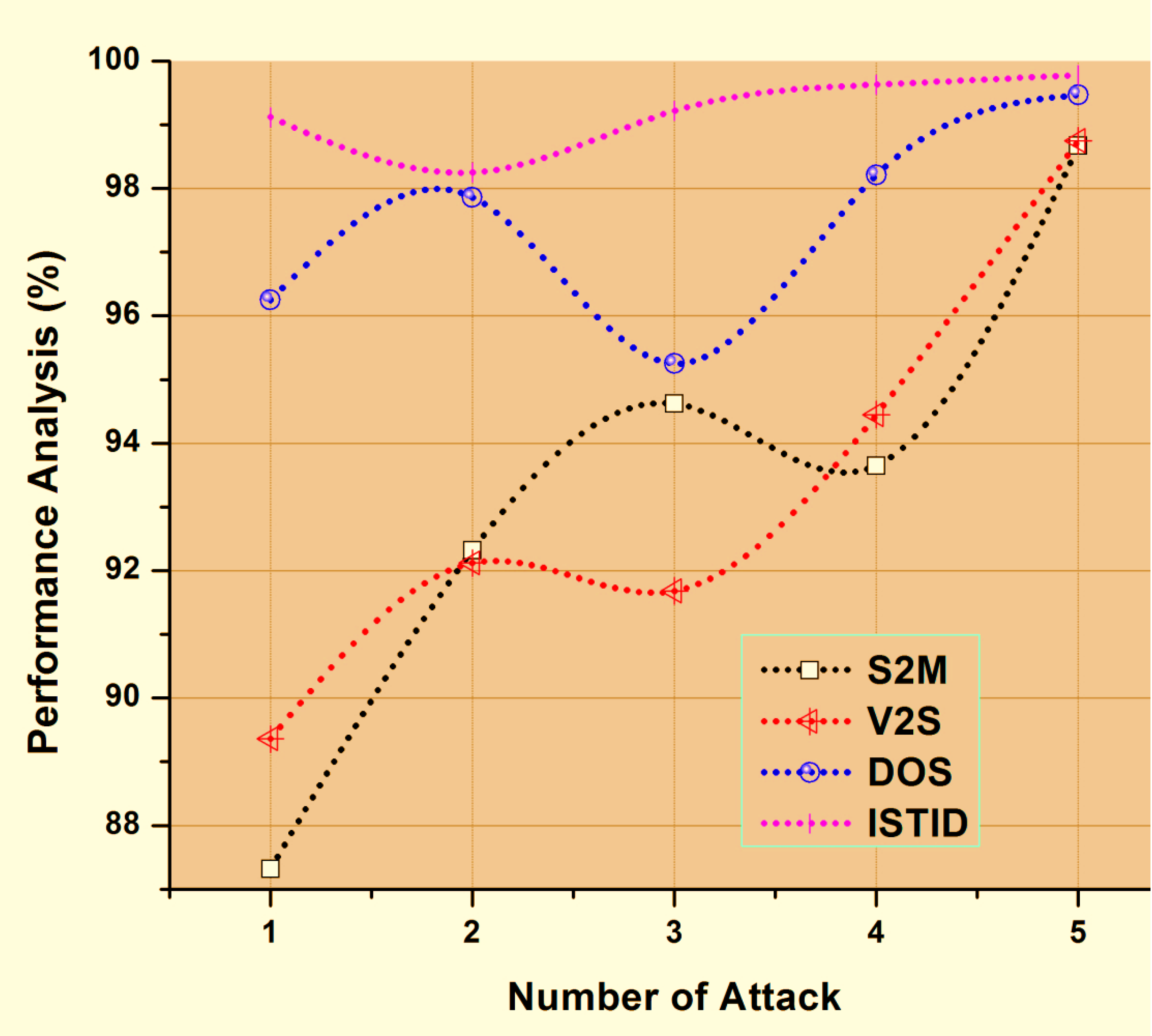
4.1. Performance Analysis
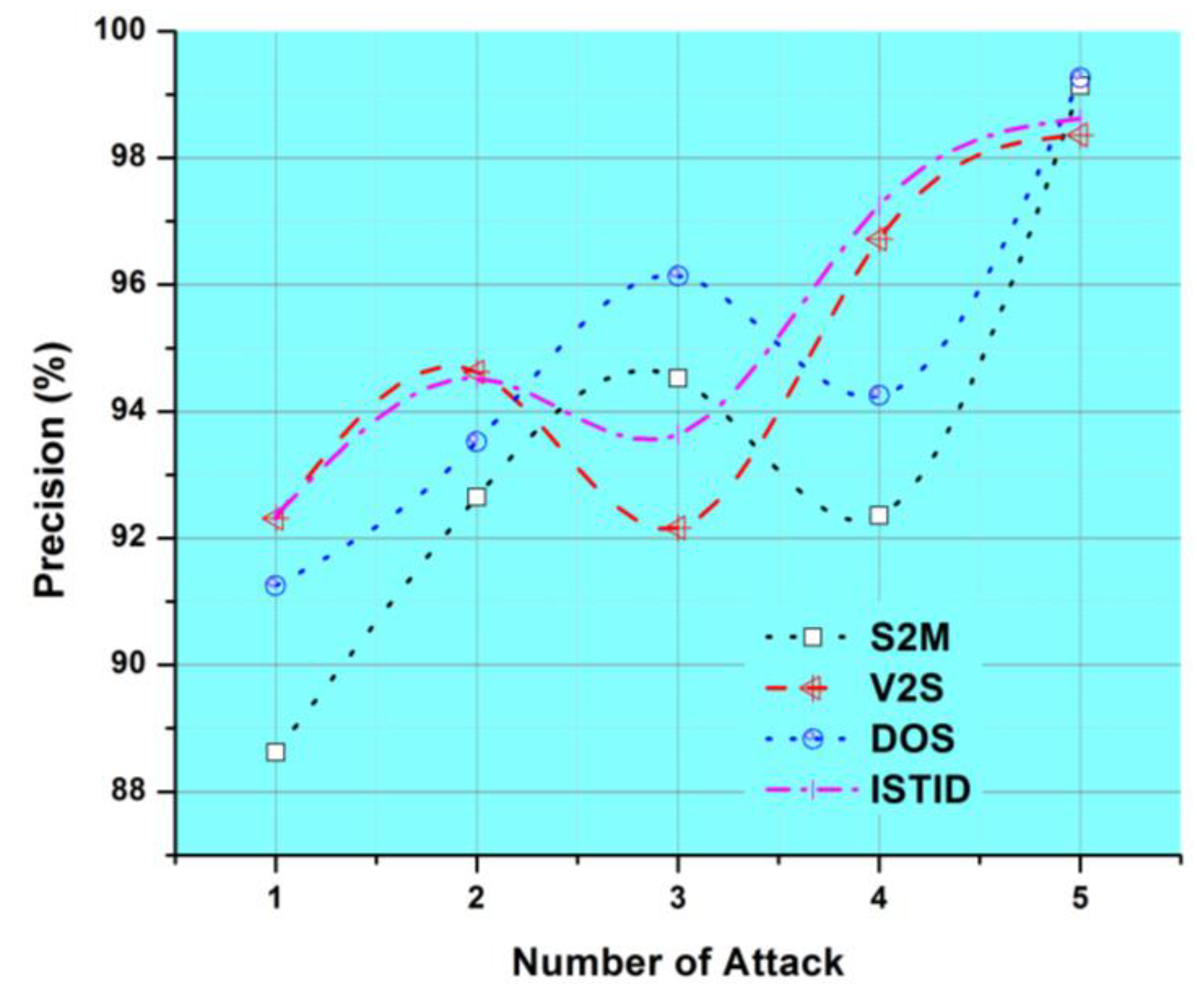
4.2. Precision
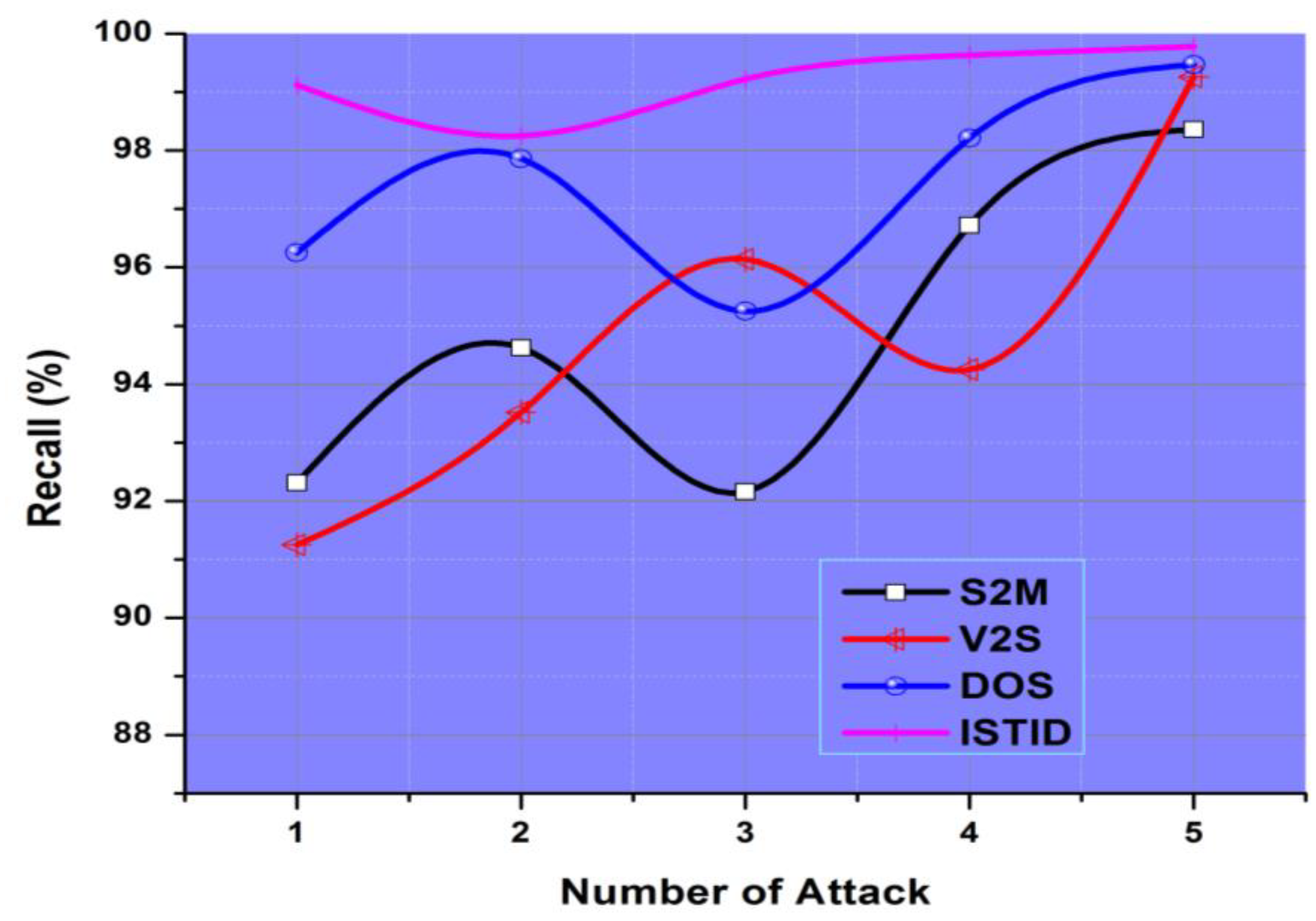
4.3. Recall
4.4. G-Measure
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sultana, N.; Chilamkurti, N.; Peng, W.; Alhadad, R. Survey on SDN based network intrusion detection system using machine learning approaches. Peer Peer Netw. Appl. 2019, 12, 493–501. [Google Scholar] [CrossRef]
- Nguyen, T.G.; Phan, T.V.; Nguyen, B.T.; So-In, C.; Baig, Z.; Sanguanpong, S. Search: A Collaborative and Intelligent NIDS Architecture for SDN-Based Cloud IoT Networks. IEEE Access 2019, 7, 107678–107694. [Google Scholar] [CrossRef]
- Selvakumar, B.; Muneeswaran, K. Firefly Algorithm Based Feature Selection for Network Intrusion Detection. Comput. Secur. 2019, 81, 148–155. [Google Scholar]
- Wang, Q.; Lu, P. Research on Application of Artificial Intelligence in Computer Network Technology. Int. J. Pattern Recognit. Artif. Intell. 2019, 33, 1959015. [Google Scholar] [CrossRef]
- Chaabouni, N.; Mosbah, M.; Zemmari, A.; Sauvignac, C.; Faruki, P. Network Intrusion Detection for IoT Security Based on Learning Techniques. IEEE Commun. Surv. Tutor. 2019, 21, 2671–2701. [Google Scholar] [CrossRef]
- Salo, F.; Nassif, A.B.; Essex, A. Dimensionality reduction with IG-PCA and ensemble classifier for network intrusion detec-tion. Comput. Netw. 2019, 148, 164–175. [Google Scholar] [CrossRef]
- Chapaneri, R.; Shah, S. A Comprehensive Survey of Machine Learning-Based Network Intrusion Detection. In Blockchain Technology and Innovations in Business Processes; Springer Science and Business Media LLC: Berlin, Germany, 2018; pp. 345–356. [Google Scholar]
- Khan, F.A.; Gumaei, A.; Derhab, A.; Hussain, A. A novel two-stage deep learning model for efficient network intrusion detection. IEEE Access. 2019, 7, 30373–30385. [Google Scholar] [CrossRef]
- Faris, H.; Ala’M, A.Z.; Heidari, A.A.; Aljarah, I.; Mafarja, M.; Hassonah, M.A.; Fujita, H. An intelligent system for spam de-tection and identification of the most relevant features based on evolutionary random weight networks. Inf. Fusion 2019, 48, 67–83. [Google Scholar] [CrossRef]
- Zhang, W.; Zhang, Z.; Chao, H.C.; Guizani, M. Toward Intelligent Network Optimization in Wireless Networking: An Au-to-Learning Framework. IEEE Wirel. Commun. 2019, 26, 76–82. [Google Scholar] [CrossRef]
- Rajagopal, S.; Kundapur, P.P.; Hareesha, K.S. A Stacking Ensemble for Network Intrusion Detection Using Heterogeneous Datasets. Secur. Commun. Netw. 2020, 2020, 4586875. [Google Scholar] [CrossRef]
- Liu, Y.; Zhu, L. A new intrusion detection and alarm correlation technology based on neural network. EURASIP J. Wirel. Commun. Netw. 2019, 2019, 109. [Google Scholar] [CrossRef]
- Adebowale, M.; Lwin, K.; Sánchez, E.; Hossain, M. Intelligent web-phishing detection and protection scheme using integrated features of Images, frames and text. Expert Syst. Appl. 2019, 115, 300–313. [Google Scholar] [CrossRef]
- Alagrash, Y.; Drebee, A.; Zirjawi, N. Comparing the Area of Data Mining Algorithms in Network Intrusion Detection. J. Inf. Secur. 2020, 11, 96983. [Google Scholar] [CrossRef][Green Version]
- Alazzam, H.; Sharieh, A.; Sabri, K.E. A feature selection algorithm for intrusion detection system based on Pigeon Inspired Optimizer. Expert Syst. Appl. 2020, 148, 113249. [Google Scholar] [CrossRef]
- Ye, K. Key Feature Recognition Algorithm of Network Intrusion Signal Based on Neural Network and Support Vector Machine. Symmetry 2019, 11, 380. [Google Scholar] [CrossRef]
- Xylogiannopoulos, K.F.; Karampelas, P.; Alhajj, R. Detecting DDoS Attacks. In Developments in Information Security and Cyber-Netic Wars; IGI Global: Hershey, PA, USA, 2019; pp. 121–139. [Google Scholar]
- Cui, Z.; Du, L.; Wang, P.; Cai, X.; Zhang, W. Malicious code detection based on CNNs and multi-objective algorithm. J. Parallel Distrib. Comput. 2019, 129, 50–58. [Google Scholar] [CrossRef]
- Zhiqiang, L.; Mohi-Ud-Din, G.; Bing, L.; Jianchao, L.; Ye, Z.; Zhijun, L. Modeling Network Intrusion Detection System Using Feed-Forward Neural Network Using UNSW-NB15 Dataset. In Proceedings of the 2019 IEEE 7th International Conference on Smart Energy Grid Engineering (SEGE), Ontario, ON, Canada, 12–14 August 2019; Institute of Electrical and Electronics Engineers (IEEE): New York, NY, USA, 2019; pp. 299–303. [Google Scholar]
- Papamartzivanos, D.; Marmol, F.G.; Kambourakis, G. Introducing Deep Learning Self-Adaptive Misuse Network Intrusion Detection Systems. IEEE Access 2019, 7, 13546–13560. [Google Scholar] [CrossRef]
- Dwivedi, S.; Vardhan, M.; Tripathi, S.; Shukla, A.K. Implementation of adaptive scheme in evolutionary technique for anomaly-based intrusion detection. Evol. Intell. 2019, 13, 103–117. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, X.; Jin, L.; Wang, X.; Guo, D. Network Intrusion Detection: Based on Deep Hierarchical Network and Original Flow Data. IEEE Access 2019, 7, 37004–37016. [Google Scholar] [CrossRef]
- Sahingoz, O.K.; Buber, E.; Demir, O.; Diri, B. Machine learning based phishing detection from URLs. Expert Syst. Appl. 2019, 117, 345–357. [Google Scholar] [CrossRef]
- Suresh, A.; Udendhran, R.; Balamurgan, M.; Varatharajan, R. A Novel Internet of Things Framework Integrated with Real Time Monitoring for Intelligent Healthcare Environment. J. Med. Syst. 2019, 43, 165. [Google Scholar] [CrossRef] [PubMed]
- Pajila, P.J.B.; Julie, E.G. Detection of DDoS Attack Using SDN in IoT: A Survey. In Advances on P2P, Parallel, Grid, Cloud and Internet Computing; Springer Science and Business Media LLC: Berlin, Germany, 2019; pp. 438–452. [Google Scholar]
- Wang, F.; Jiang, D.; Wen, H.; Song, H. Adaboost-based security level classification of mobile intelligent terminals. J. Supercomput. 2019, 75, 7460–7478. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attacks | Precision (%) | Recall (%) | G-Measure (%) | Performance Analysis (%) |
|---|---|---|---|---|
| DoS | 88.62 | 92.31 | 91.25 | 92.35 |
| S2M | 92.65 | 94.62 | 93.52 | 94.52 |
| Probe | 94.52 | 92.16 | 96.14 | 93.64 |
| V2S | 92.36 | 96.72 | 94.25 | 97.25 |
| ISTID | 99.14 | 98.36 | 99.26 | 98.62 |
| Attacks | Precision (%) | Recall (%) | G-Measure (%) | Performance Analysis (%) |
|---|---|---|---|---|
| DoS | 91.23 | 88.12 | 88.24 | 98.25 |
| S2M | 94.62 | 96.35 | 96.23 | 99.64 |
| Probe | 97.85 | 94.62 | 97.82 | 99.72 |
| V2S | 98.67 | 99.82 | 99.25 | 99.29 |
| ISTID | 95.62 | 98.26 | 99.75 | 99.32 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Selva, D.; Nagaraj, B.; Pelusi, D.; Arunkumar, R.; Nair, A. Intelligent Network Intrusion Prevention Feature Collection and Classification Algorithms. Algorithms 2021, 14, 224. https://doi.org/10.3390/a14080224
Selva D, Nagaraj B, Pelusi D, Arunkumar R, Nair A. Intelligent Network Intrusion Prevention Feature Collection and Classification Algorithms. Algorithms. 2021; 14(8):224. https://doi.org/10.3390/a14080224
Chicago/Turabian StyleSelva, Deepaa, Balakrishnan Nagaraj, Danil Pelusi, Rajendran Arunkumar, and Ajay Nair. 2021. "Intelligent Network Intrusion Prevention Feature Collection and Classification Algorithms" Algorithms 14, no. 8: 224. https://doi.org/10.3390/a14080224
APA StyleSelva, D., Nagaraj, B., Pelusi, D., Arunkumar, R., & Nair, A. (2021). Intelligent Network Intrusion Prevention Feature Collection and Classification Algorithms. Algorithms, 14(8), 224. https://doi.org/10.3390/a14080224