
Adaptive Versioning in Transactional Memory Systems †



Abstract
1. Introduction
1.1. Contributions
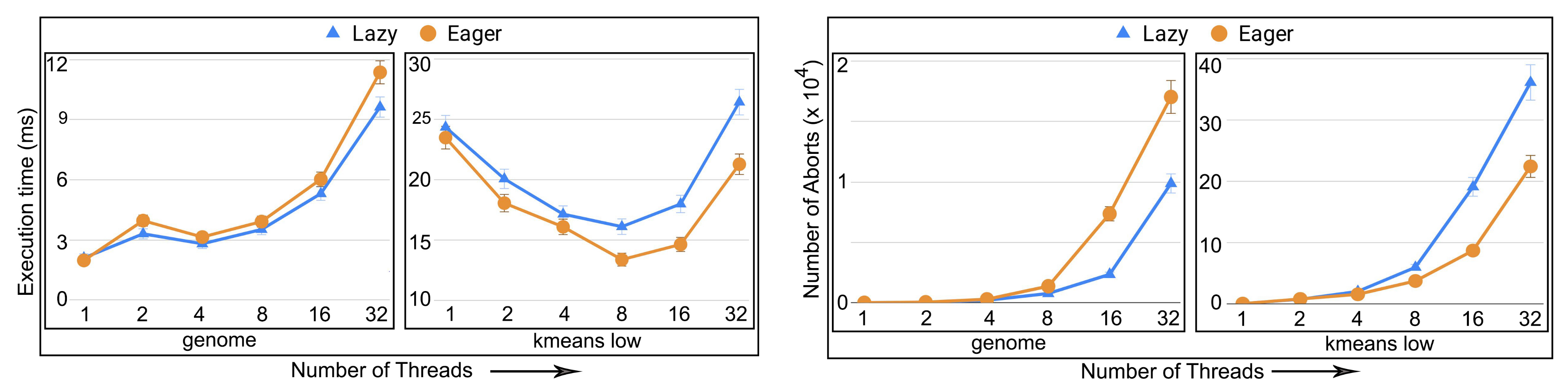
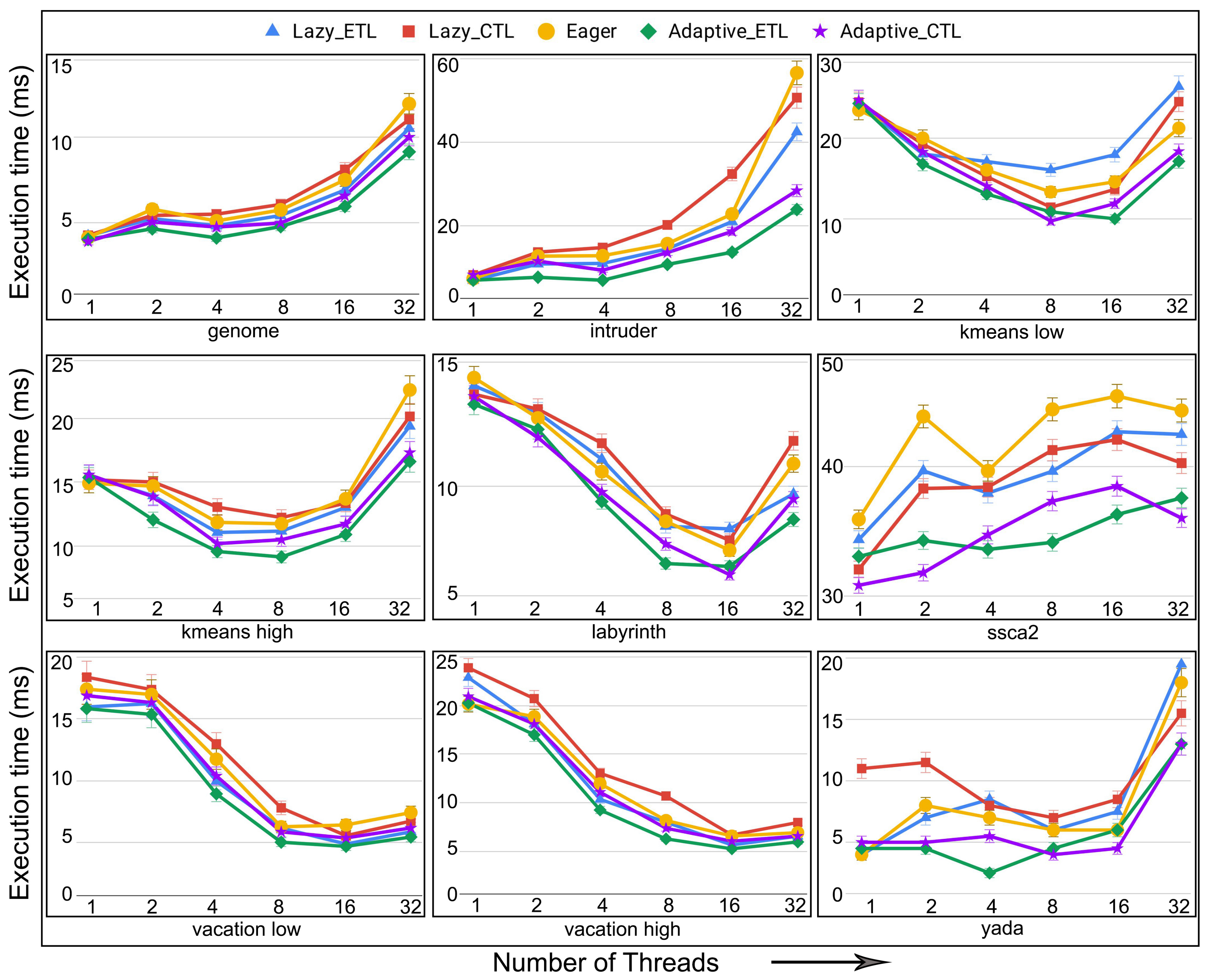
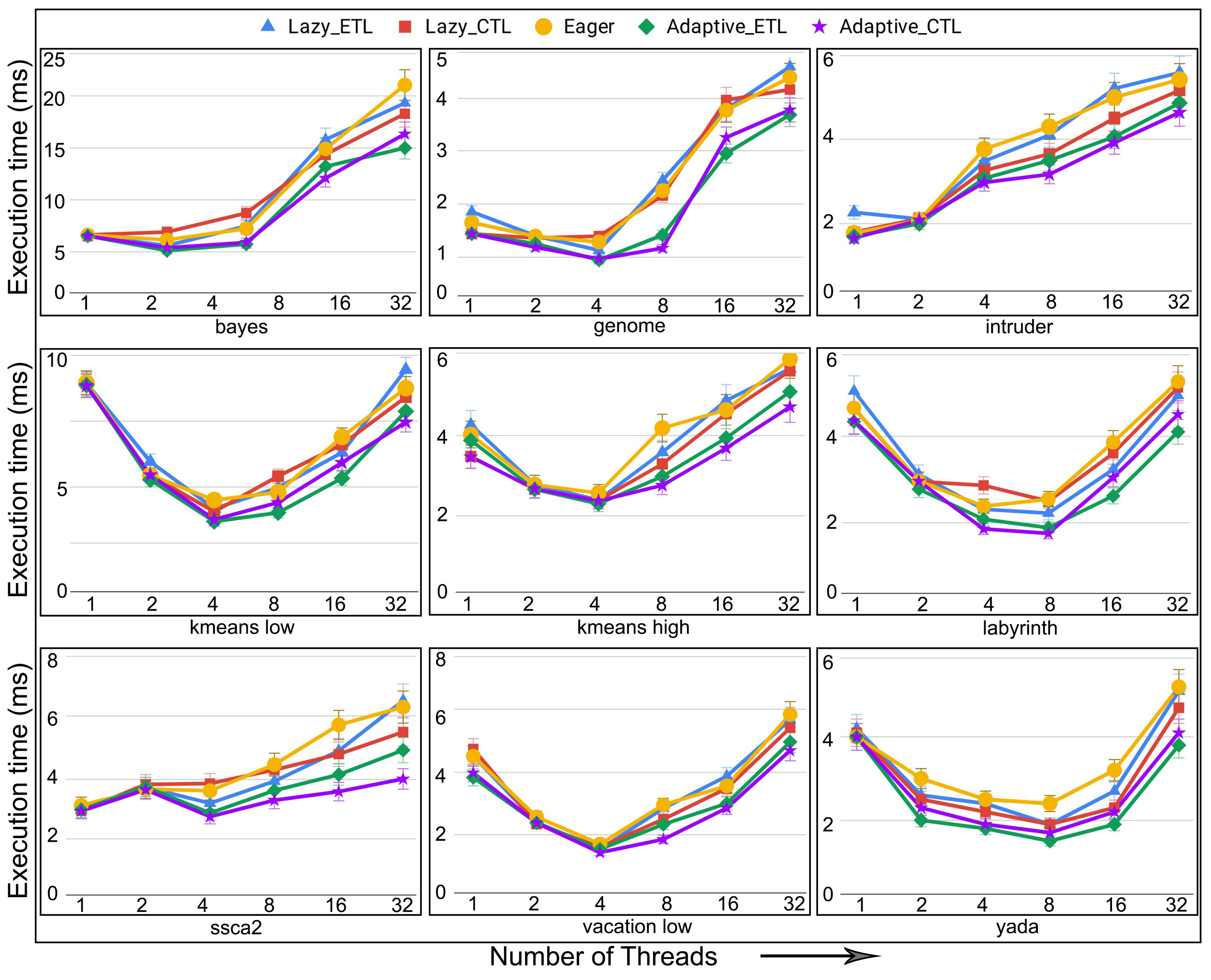
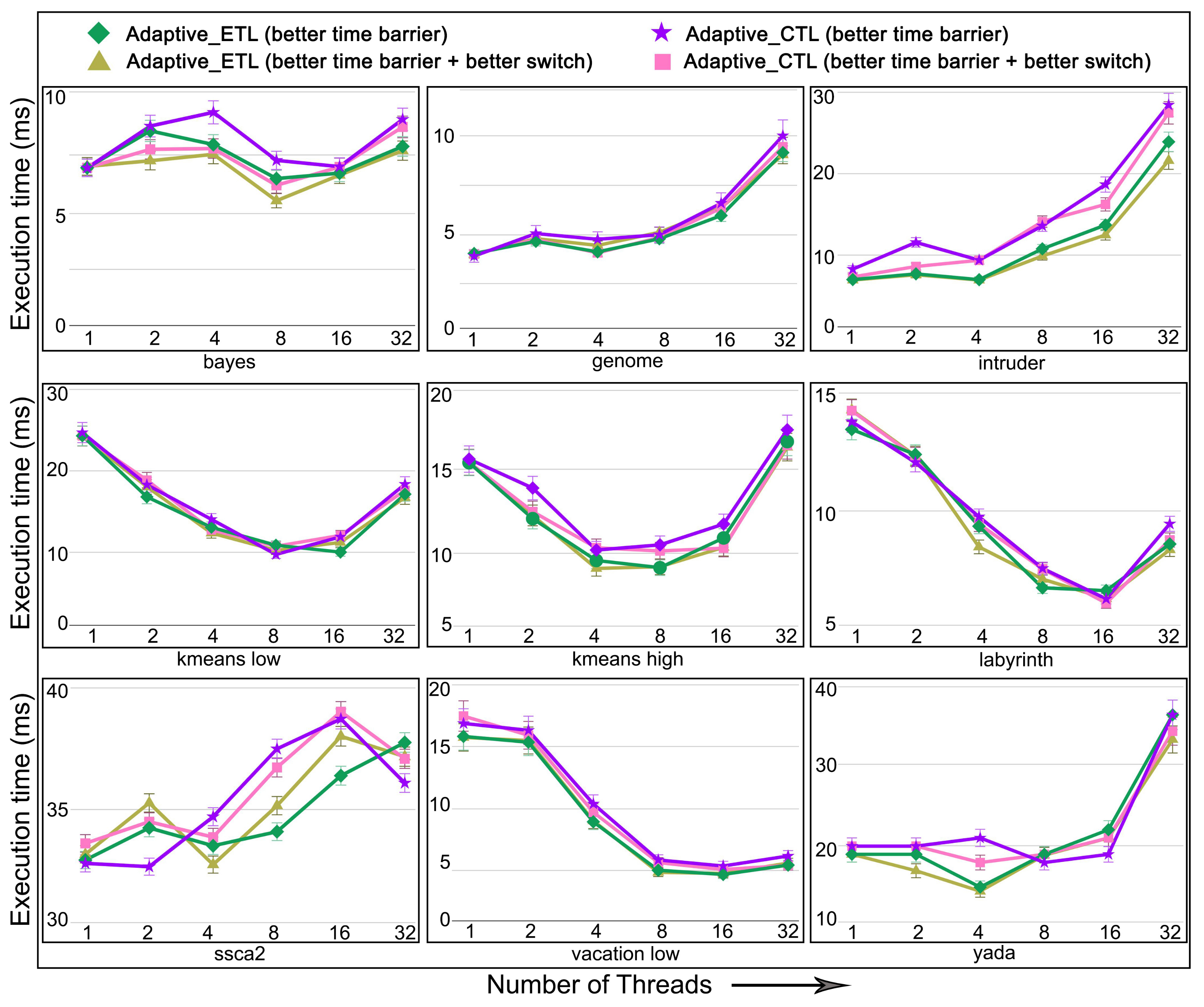
- execution time: the total time to complete executing a set of transactions. This is the time interval from the beginning of the first transaction executed until the last transaction finishes and commits. In a dynamic setting, the execution time translates to throughput, the number of committed transactions per time step.
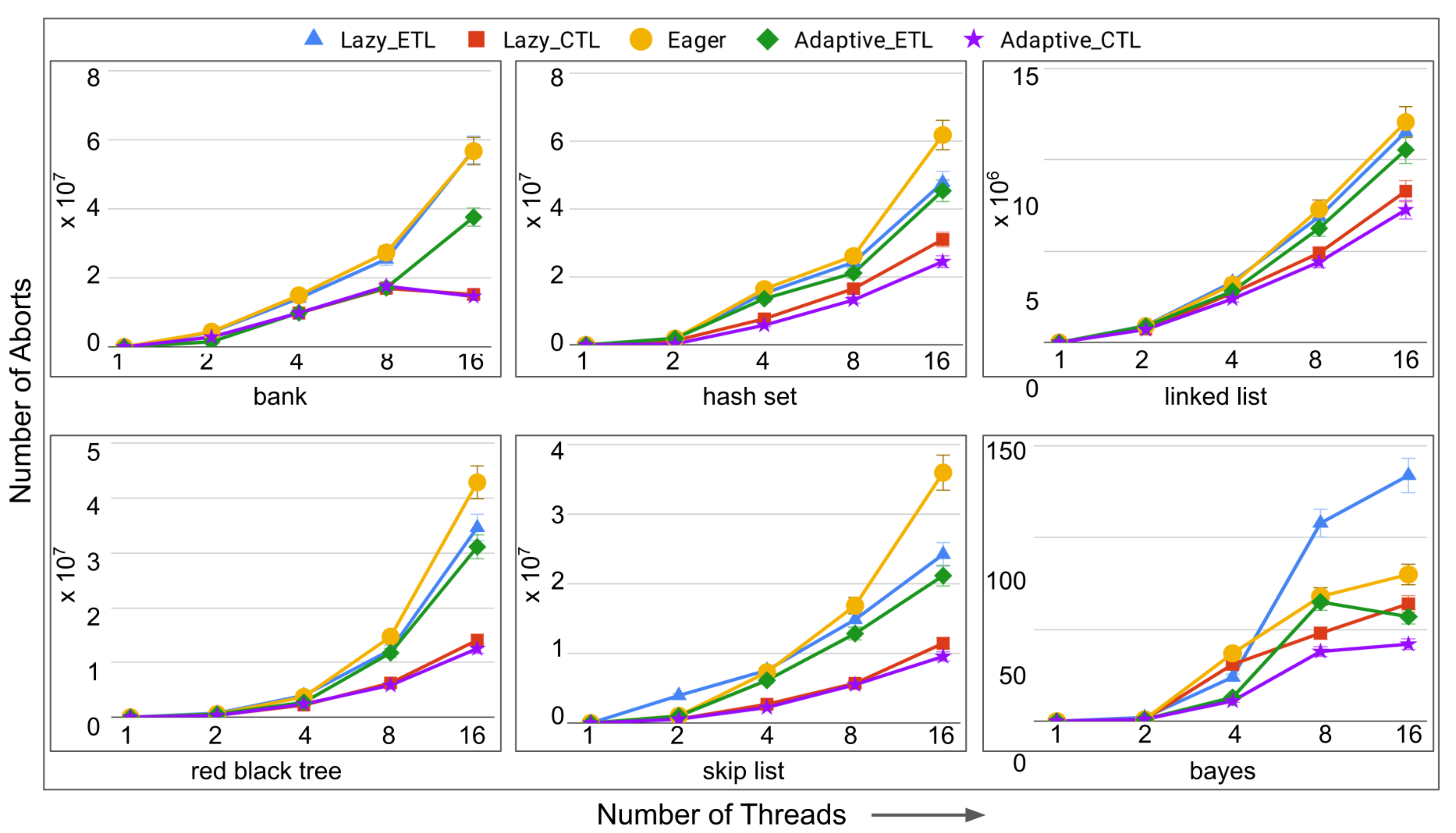
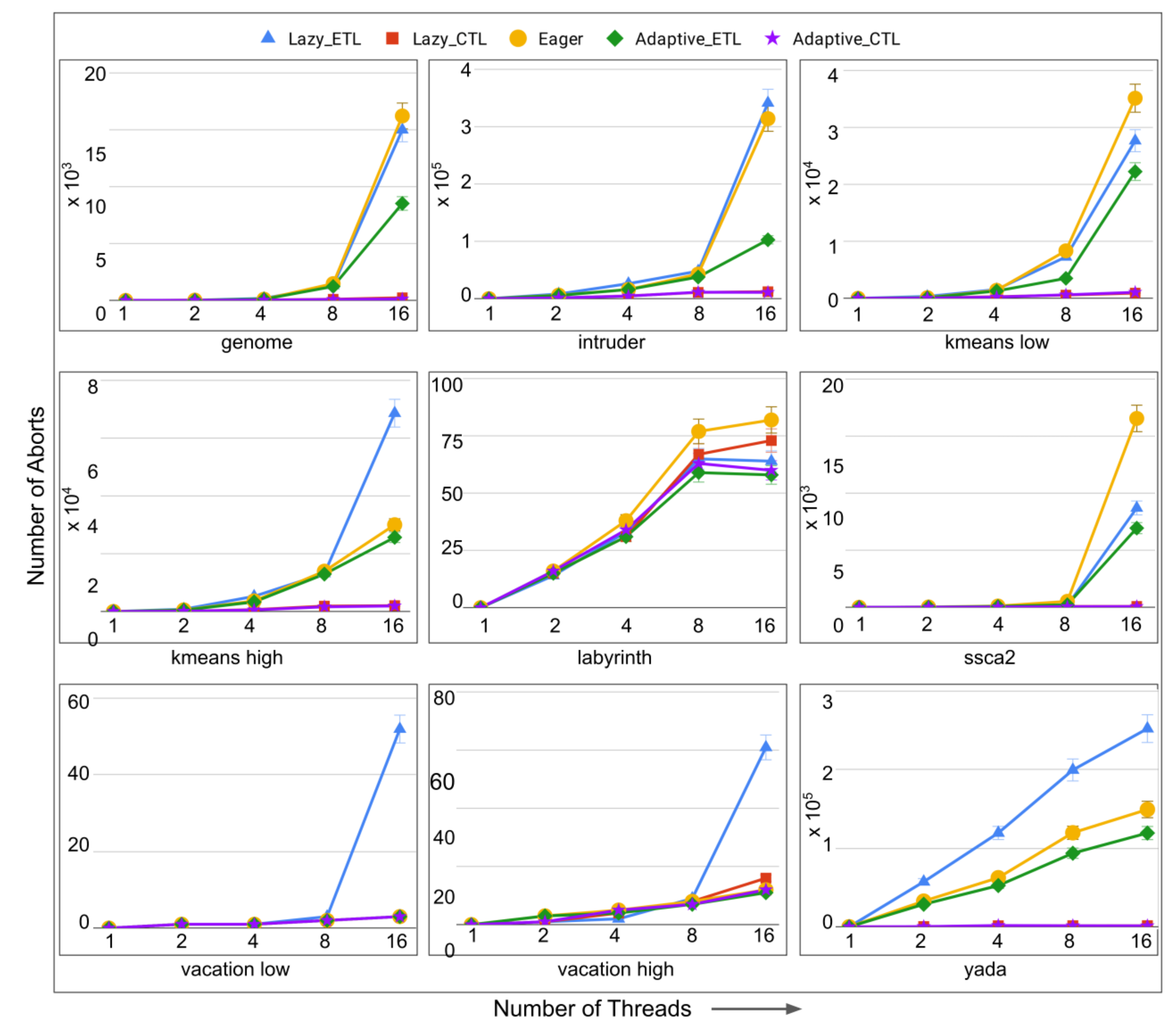
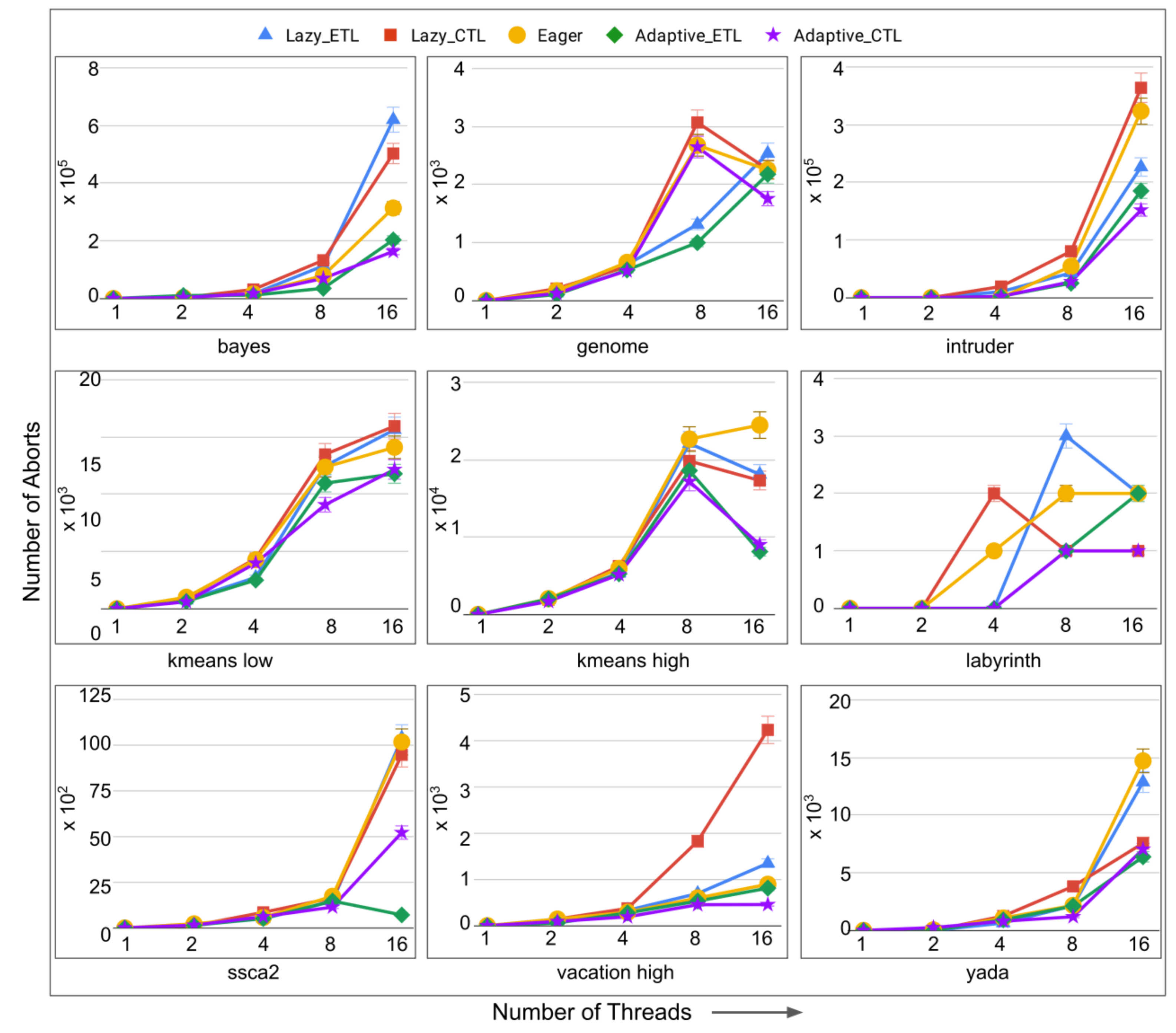
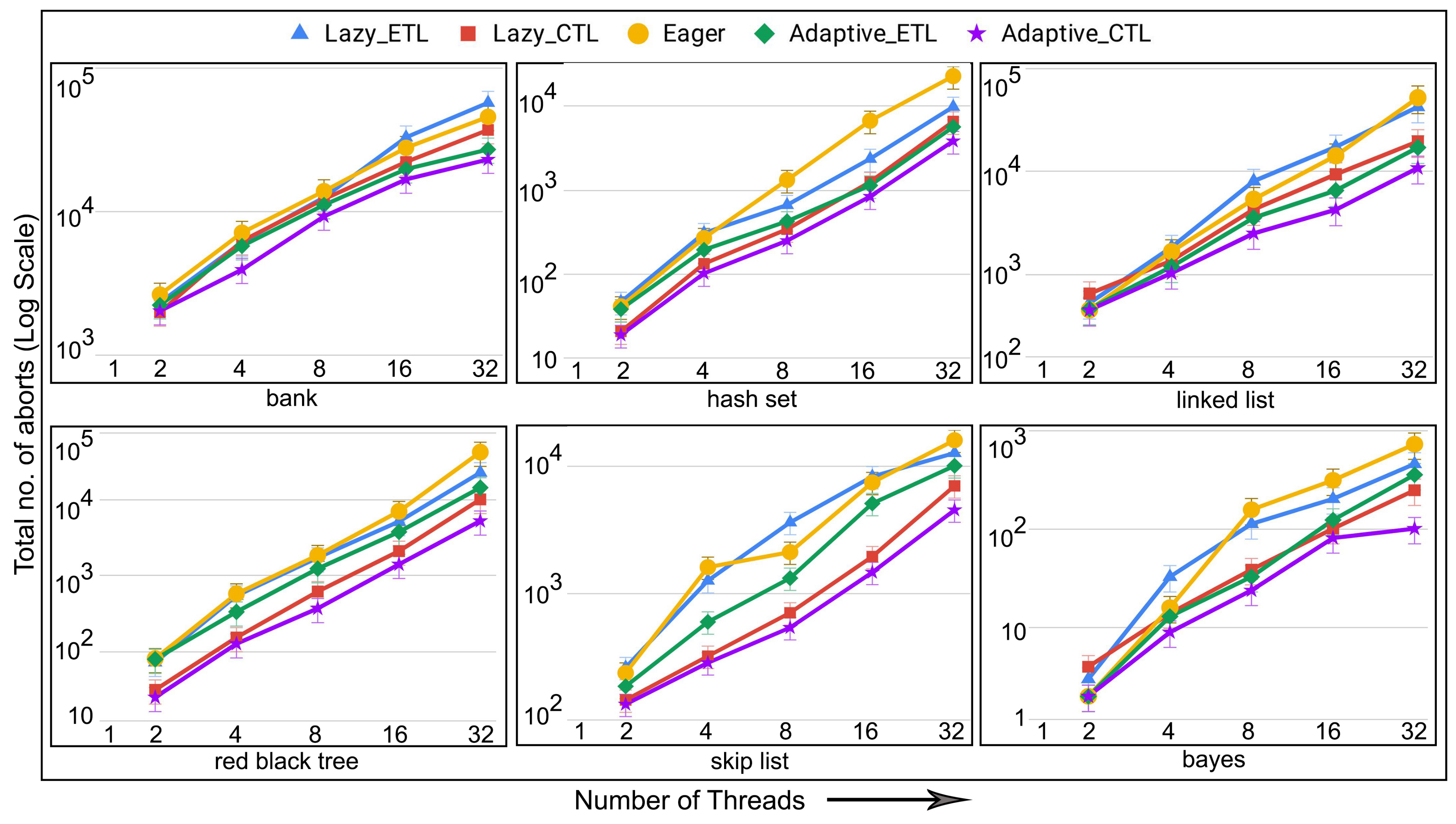
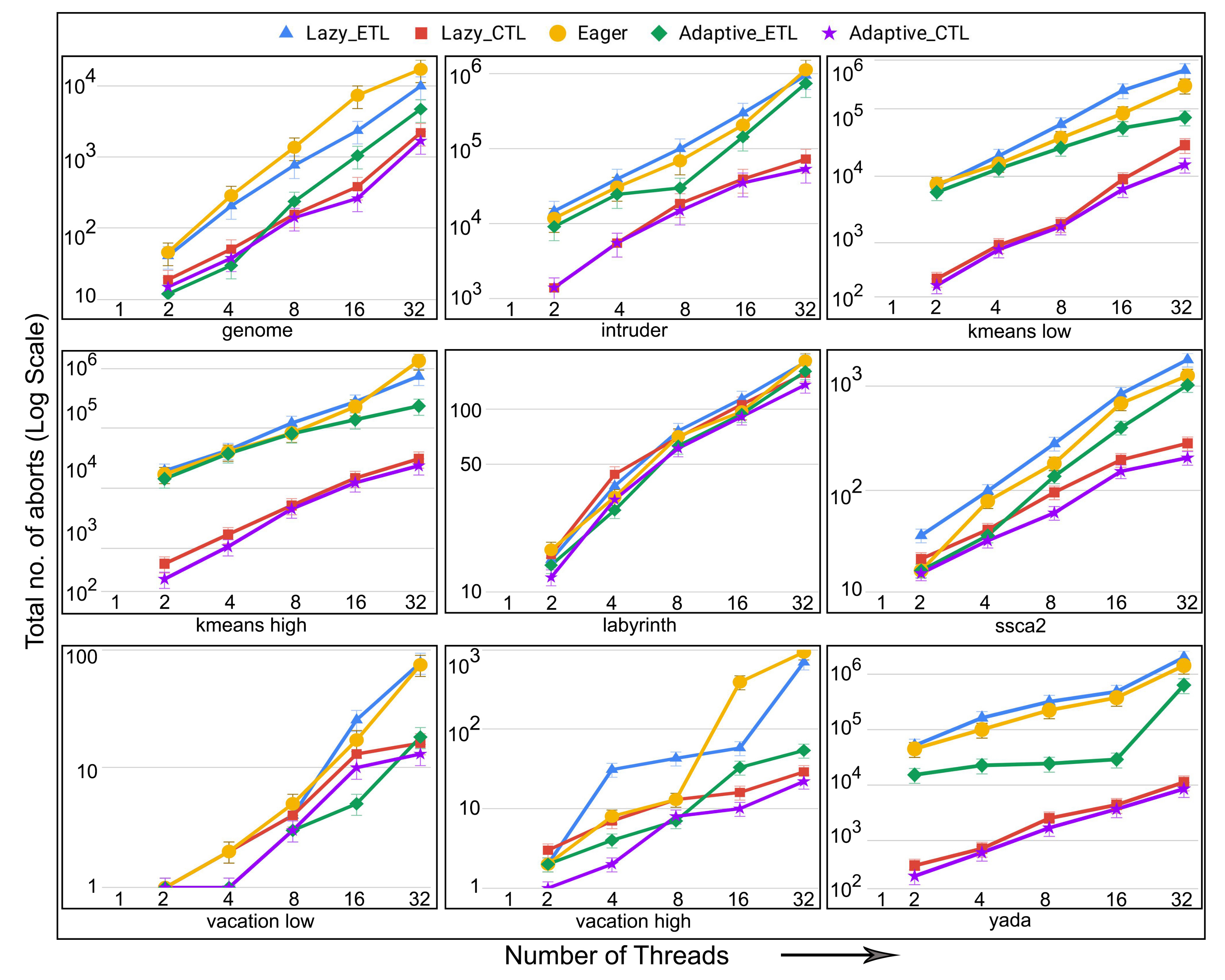
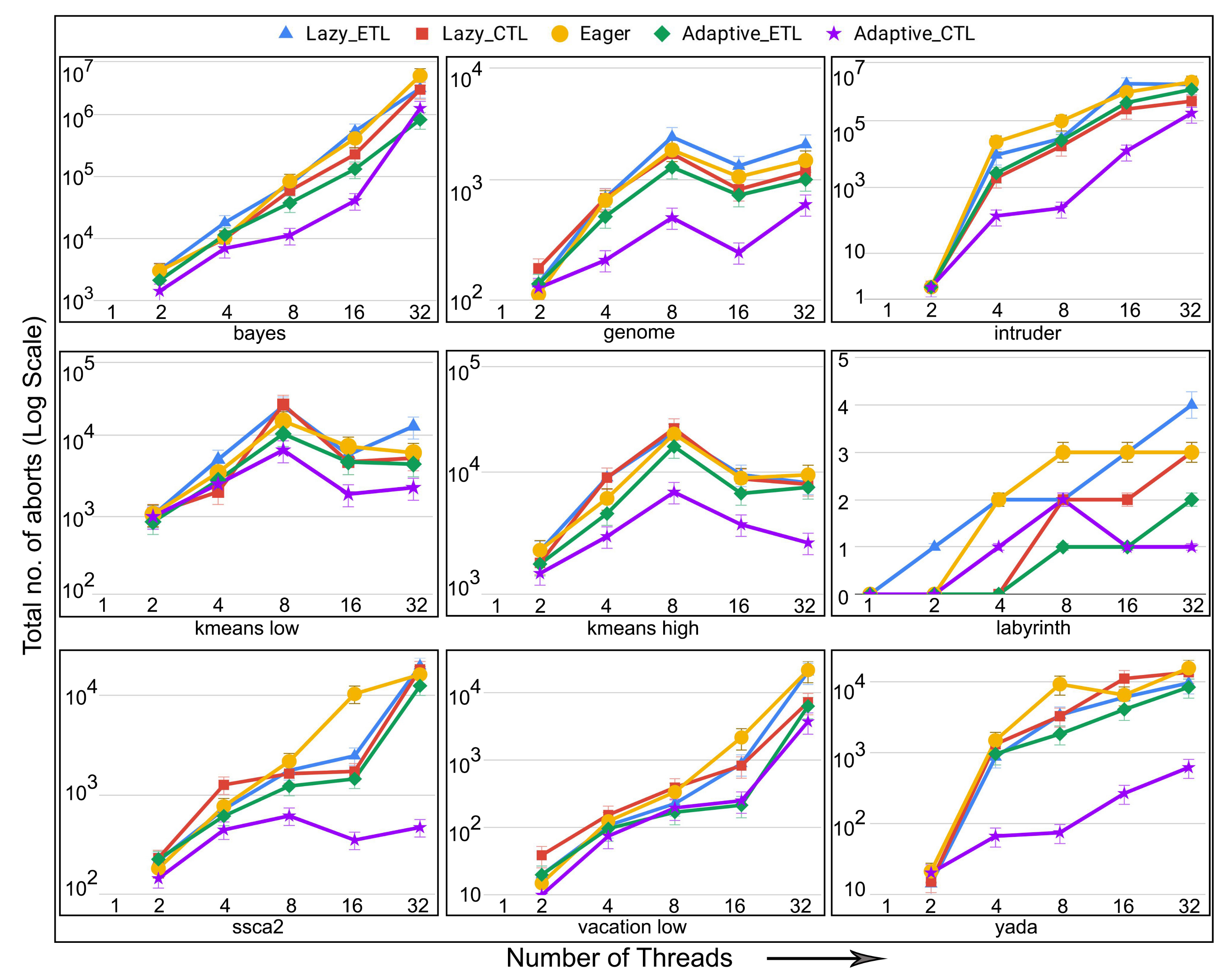
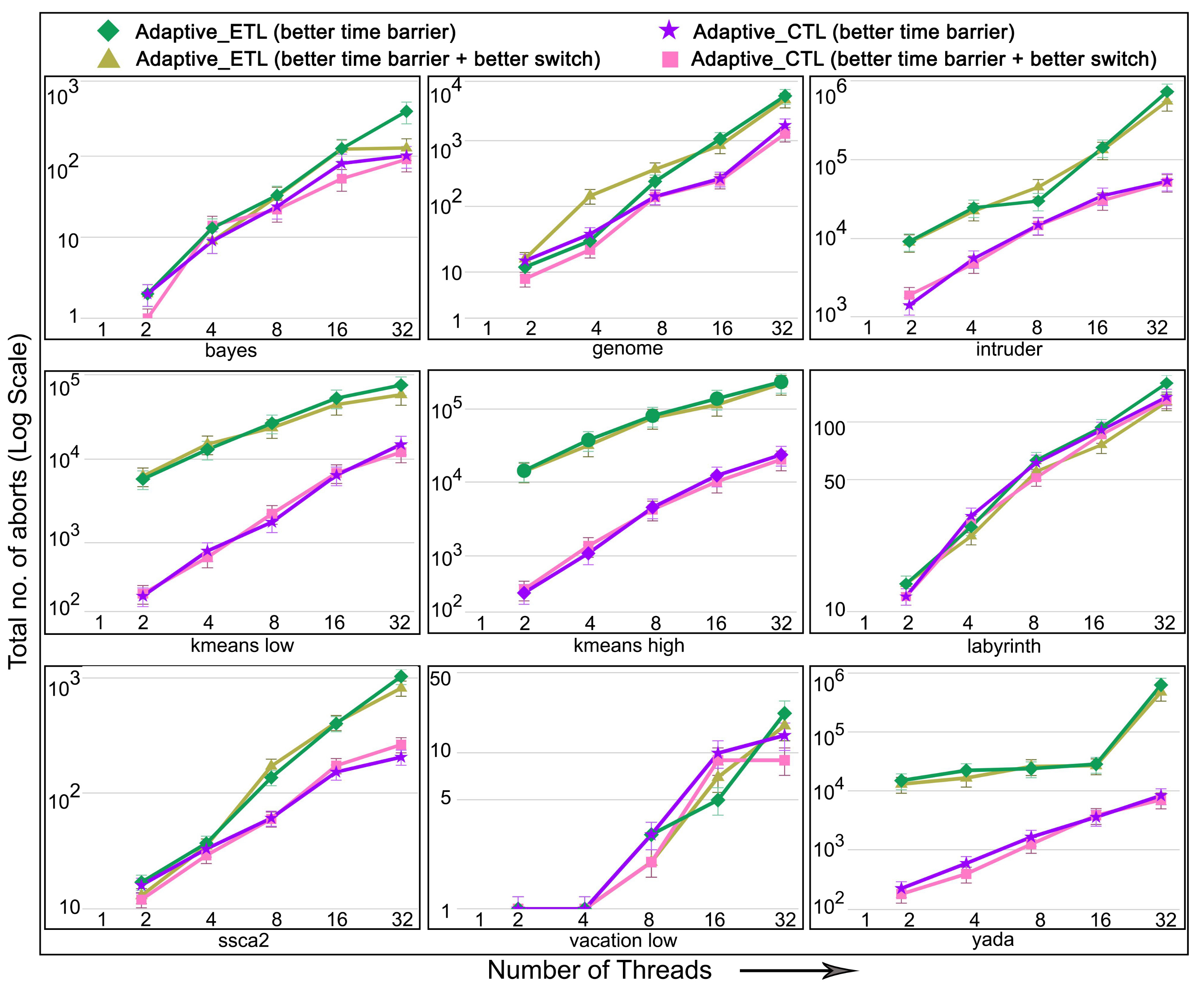
- number of aborts: the total number of transaction aborts until the current time. If compared with the total number of transaction commits until the current time, it provides abort-to-commit ratio (ACR), a useful metric. The number of aborts directly affect execution time since it is likely that the execution time increases with the increasing number of aborts requiring more number of transaction restarts.
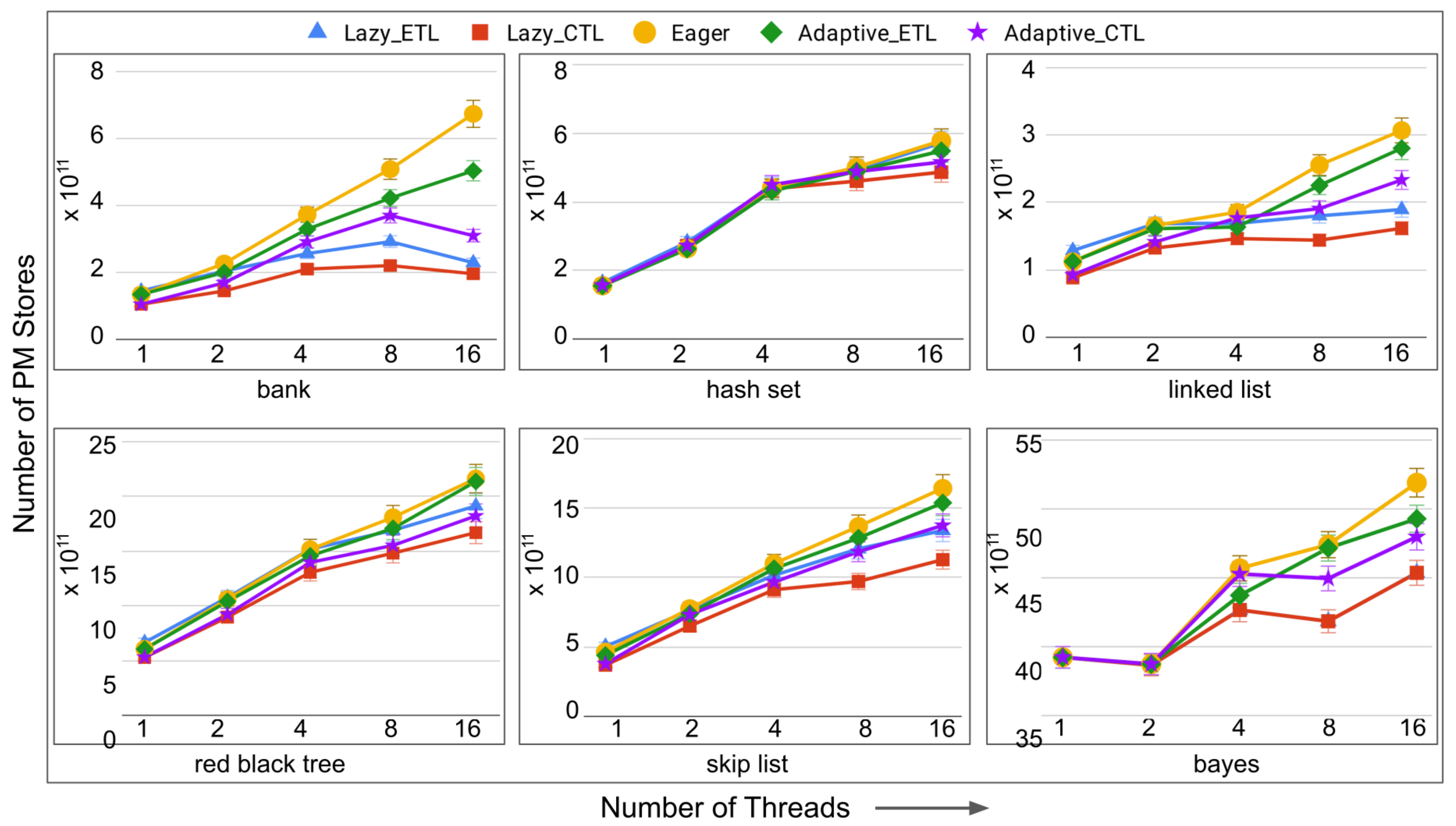
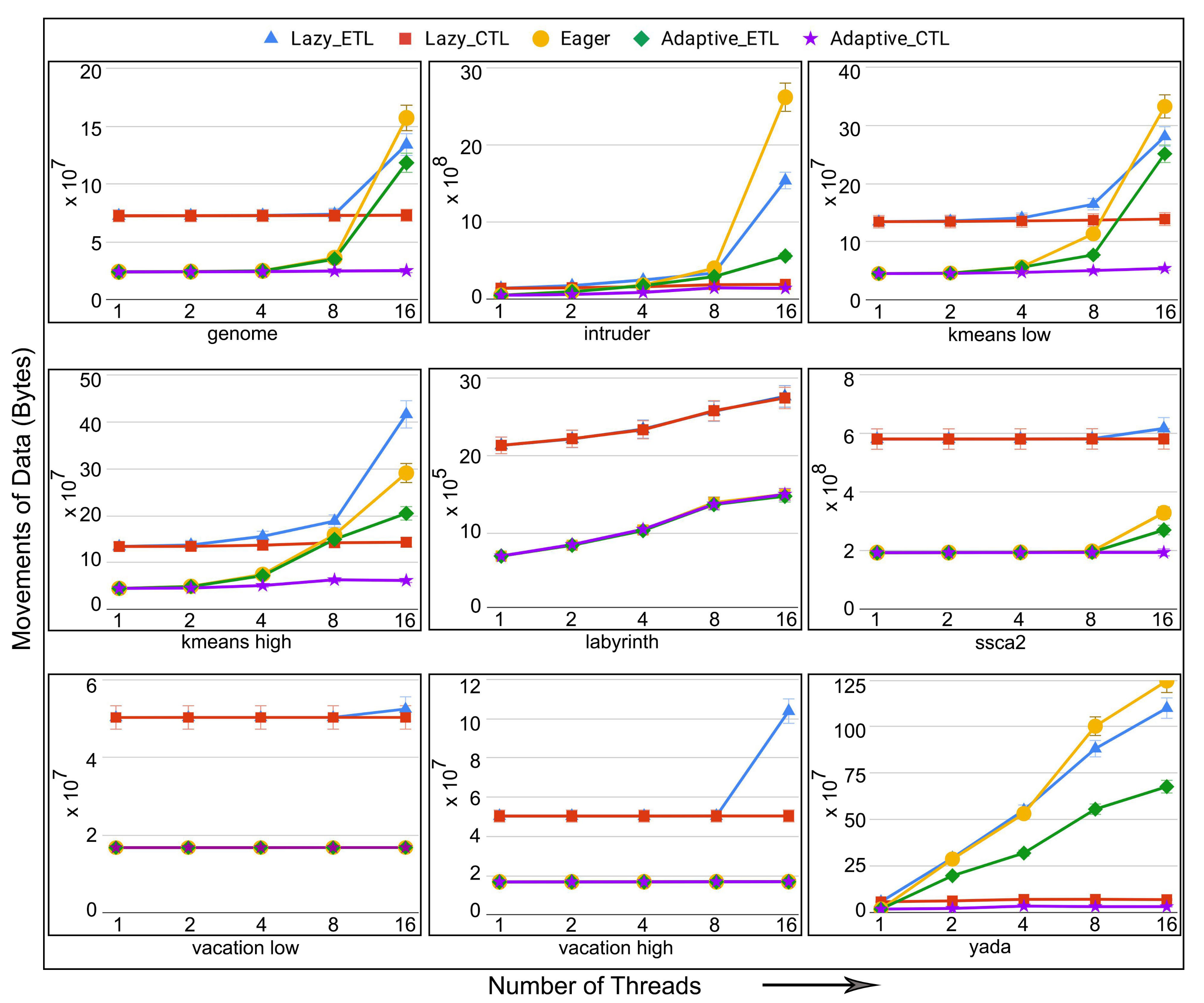
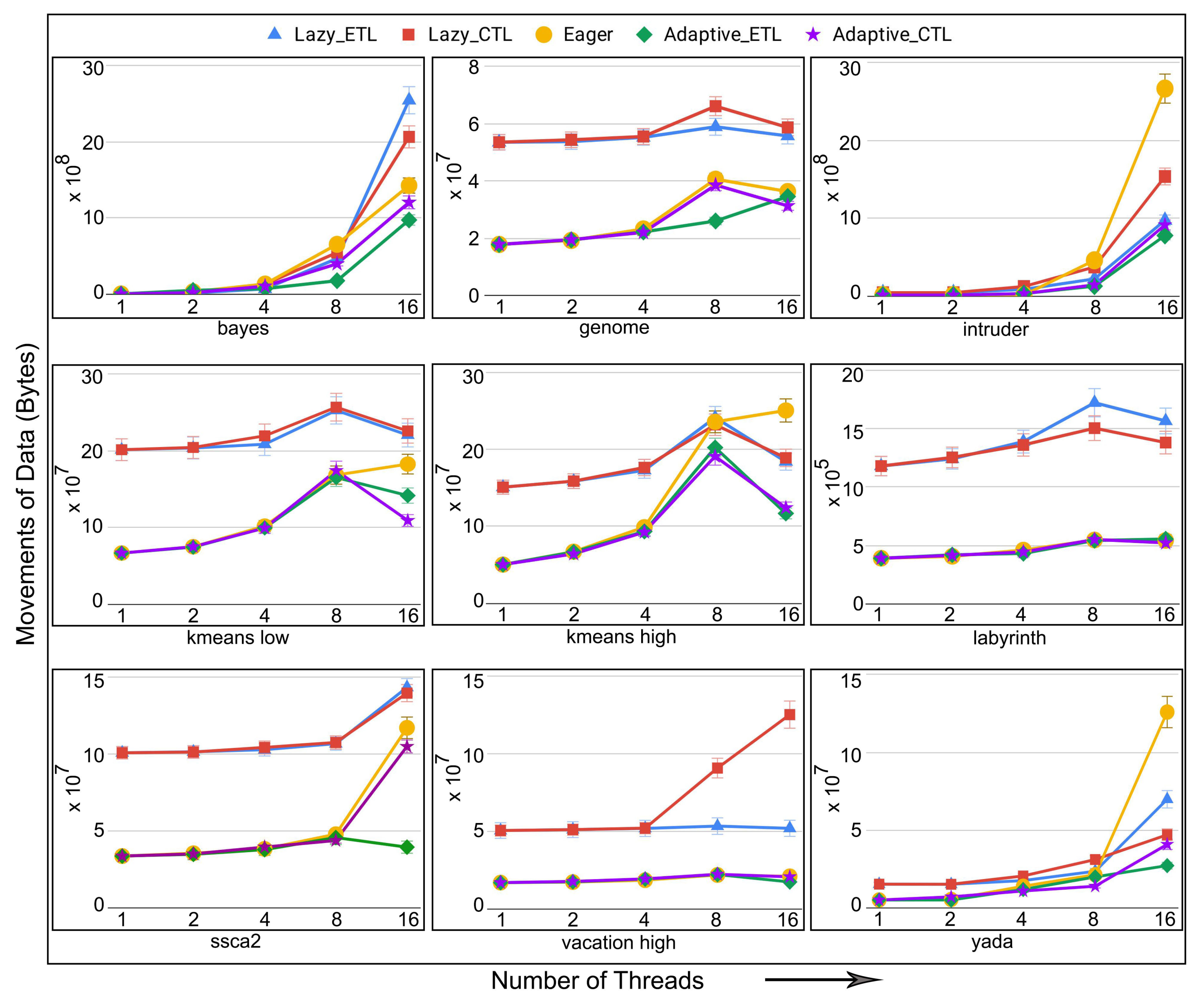
- total number of data movements (for persistent TM systems only): the total number of movements of data to and from the original memory addresses. The execution time of transactions in persistent memory is directly affected by the number of reads and writes to the PM. The total number of reads and writes to the persistent memory addresses can also be defined as the total number of movements of data to and from the memory addresses. Thus, minimizing the total number of data movements decreases the total execution time of the transactions in PM.
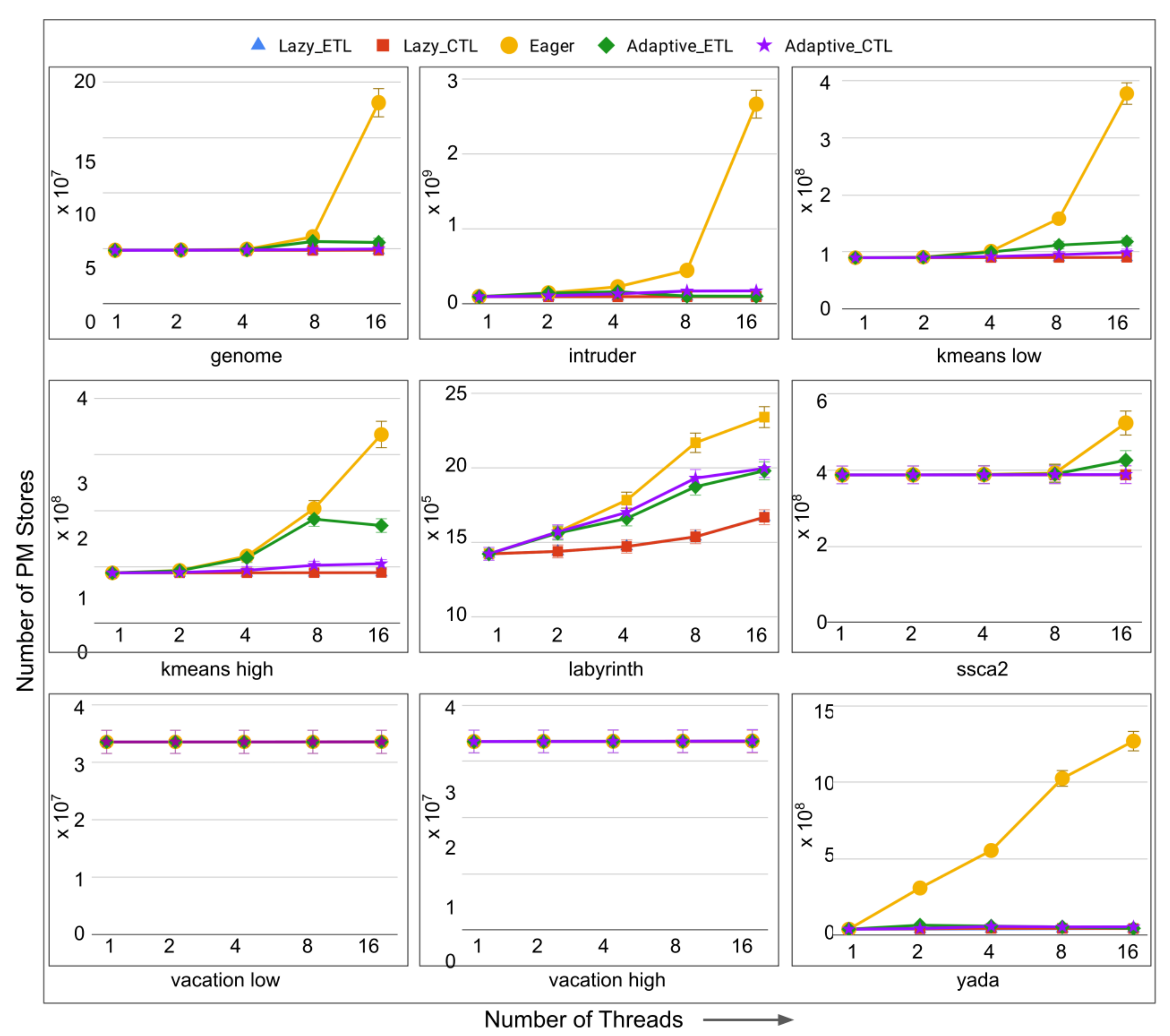
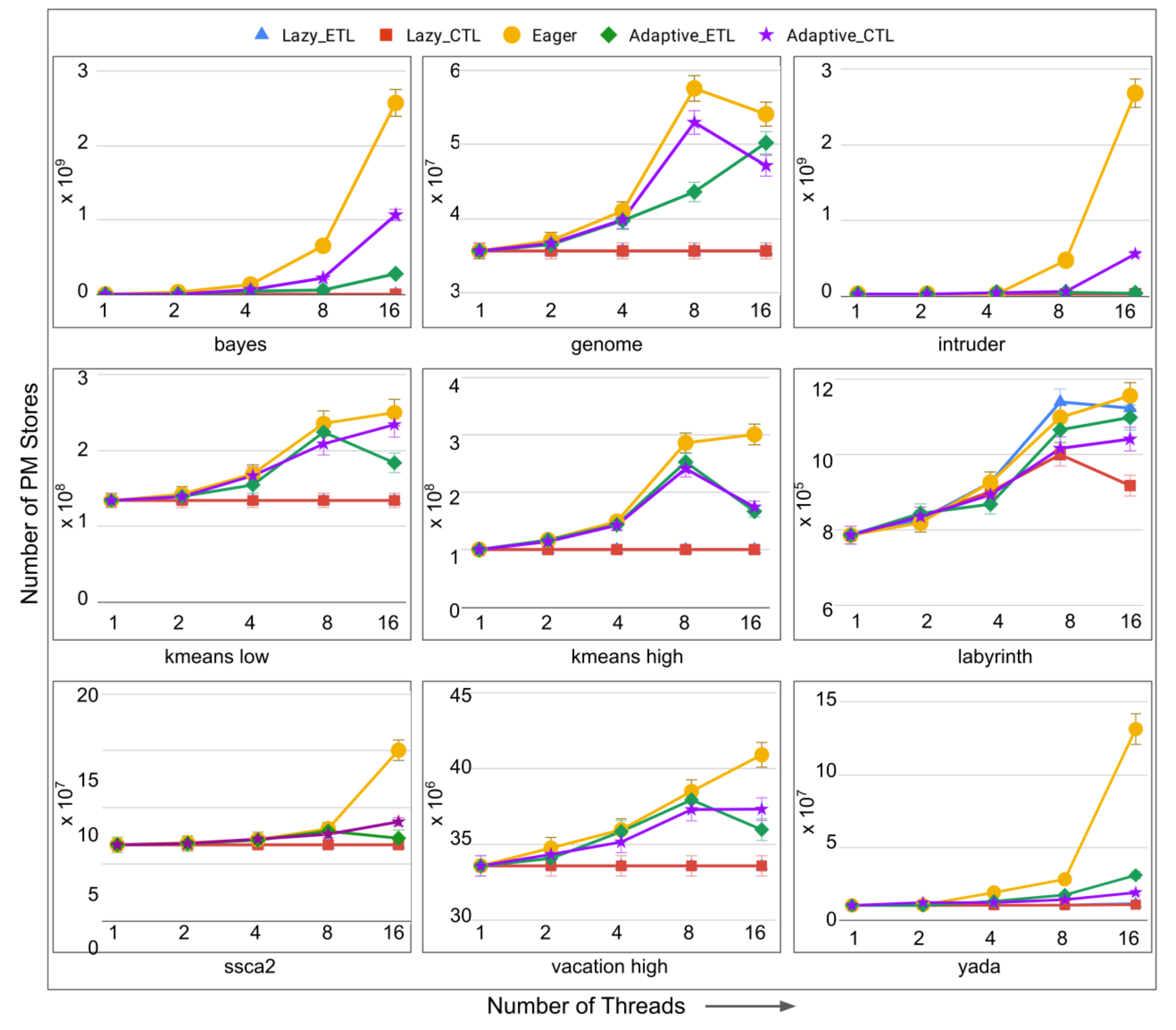
- total number of stores to persistent memory (for persistent TM systems only): the total number of writes to the persistent memory addresses. The motivation behind this performance metric is as follows. It has been heavily advocated that persistent memories significantly outperform traditional dynamic random access memories (DRAMs) due to low standby power, higher memory density, and much lower cost/bit [30,31]. However, persistent memories suffer from the write endurance problem, i.e., every persistent memory (PM) unit can sustain a very limited number of writes (i.e., stores) before it wears-out. Minimizing the total number of stores to the PM helps in mitigating the write-endurance problem in PM.
- (Section 4) We introduce a novel versioning approach, Adaptive, that switches between eager and lazy versioning dynamically at runtime, and provide two models of Adaptive that are suitable for persistent memory and non-persistent TM systems, respectively.
- (Section 5) We discuss the limitations of basic design of Adaptive for non-persistent TM system and present two optimizations.
- (Section 6) We evaluate experimentally the performance of Adaptive in both persistent and non-persistent TM systems using five micro-benchmarks and 8 complex benchmarks from STAMP and STAMPEDE suites, report the results, and provide observations.
1.2. Organization
2. Related Work
2.1. Non-Persistent (Volatile) TM Systems
2.2. Persistent TM Systems
3. Model and Preliminaries
3.1. Persistent Memory Model
3.2. Non-Persistent Memory Model
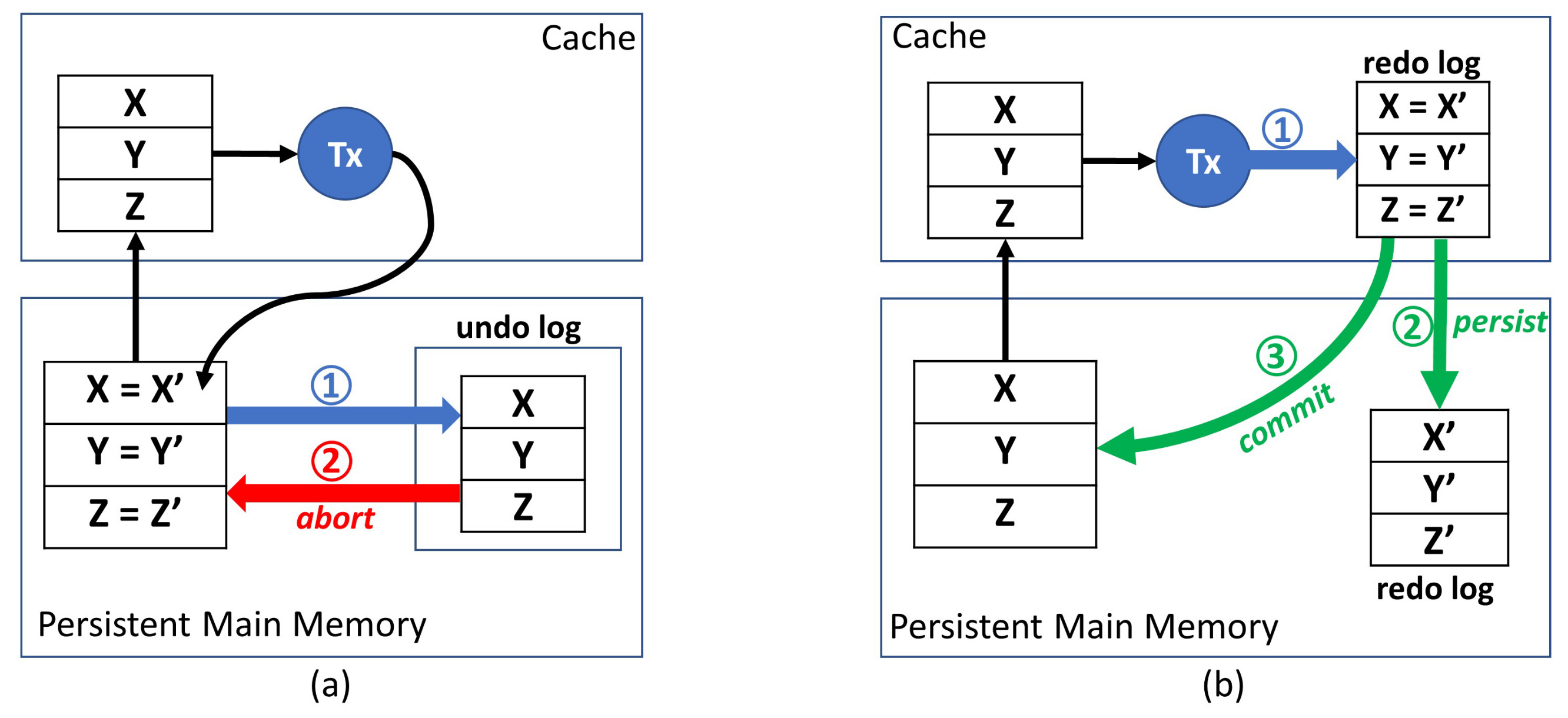
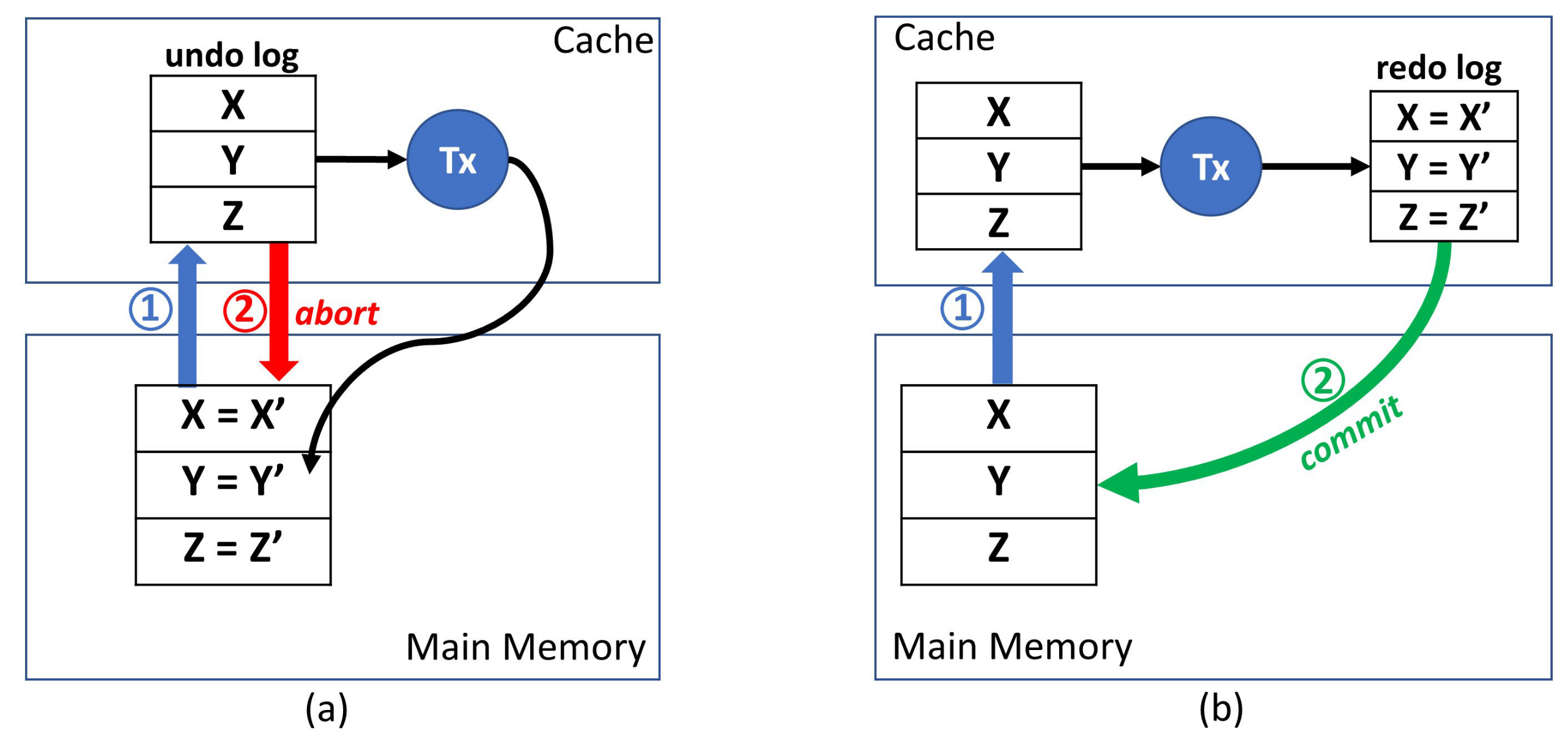
3.3. Eager Versioning
3.4. Lazy Versioning
3.5. Conflict Detection and Resolution
3.6. Supporting Durable Transactions in TinySTM
4. Basic Adaptive Versioning
| Algorithm 1: Adaptive for a transaction T at any time |
| 1 number of transaction commits until t executed using versioning; 2 number of transaction commits until t executed using versioning; 3 number of transaction aborts until t executed using versioning; 4 number of transaction aborts until t executed using versioning; 5 ; ; 6 current versioning method for transactions running in a thread; // 7 Transactional Memory System type; // /* Initially, at , choose the versioning method based on workload size (if available), otherwise randomly */ 8 if then 9 if information on read and write sets is available then 10 write set of transaction T; 11 read set of transaction T; 12 if then 13 ; Execute T using versioning; 14 else ; Execute T using versioning; 15 else Execute T using either eager or lazy versioning; /* At any time , choose the versioning method based on abort-to-commit ratio (ACR) */ 16 else if then // Adaptivefor persistent memories 17 , ; 18 , ; 19 if () ∨ (() ∧ ()) then 20 Execute T using versioning; 21 else 22 Execute T using versioning; 23 else if then // Adaptivefor non-persistent memories 24 , ; 25 if (() ∧ ()) then 26 ; 27 else if (() ∧ ()) then 28 ; 29 Execute T using versioning method; |
4.1. High Level Overview
4.2. Adaptive for Persistent Memories
- ; average abort ratio of transactions in Adaptive (using total aborts in both eager and lazy versioning).
- ; average abort ratio of transactions in Adaptive executed using eager versioning.
- ; abort to commit ratio of transactions in Adaptive executed using eager versioning.
- ; abort to commit ratio of transactions in Adaptive executed using lazy versioning.
Computation of Switching Threshold in Persistent Memories
4.3. Computation of Total Number of Stores to Persistent Memories
4.4. Adaptive for Non-Persistent Transactional Memories
- Suppose the versioning currently used is . If , then is switched to (i.e., ) and T will be executed using lazy versioning.
- Suppose the versioning method currently used is . If , then is switched to (i.e., ) and T will be executed using eager versioning.
Computing Switching Thresholds and
- Case 1: If , then
- Case 2: If , then
- Case 3: If , then
4.5. Contention Management
- suicide: T aborts and restarts immediately.
- kill (aka aggressive):T kills and continues its execution.
- delay: T aborts immediately but waits until the contended memory location is released before restarting. This increases the chance of the transaction to commit with no interruption upon retry, but may increase total execution time.
- back-off: T uses an exponential back-off mechanism to resolve conflict.
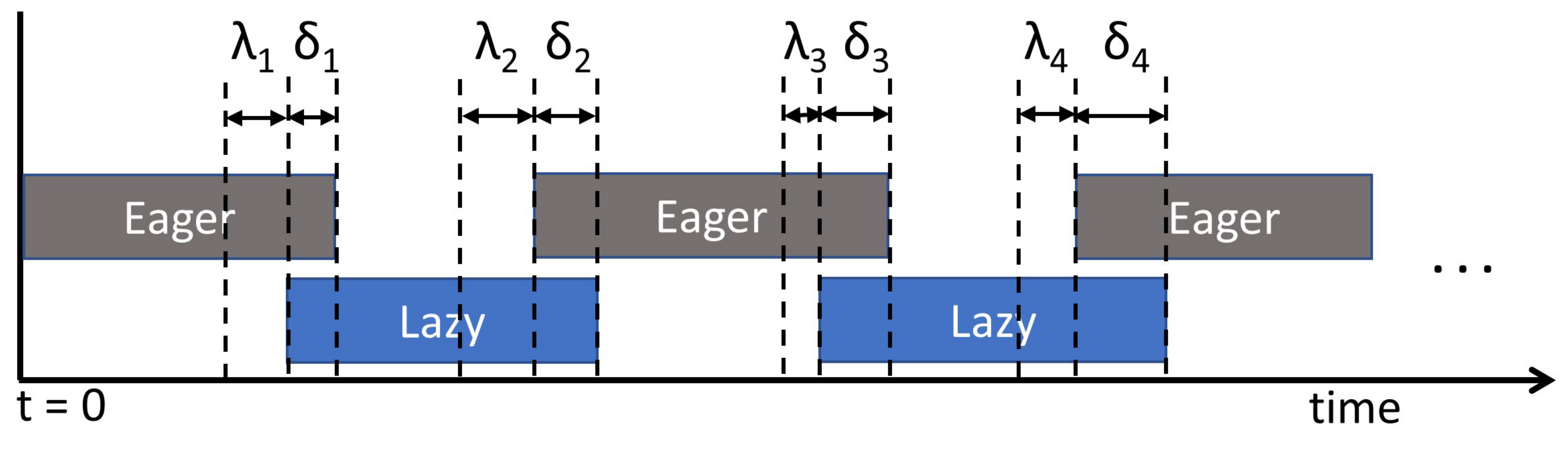
4.6. Time Barrier Requirement and Design
| Algorithm 2: Basic Time Barrier Design |
| 1 new transaction arrived for execution; 2 set of other transactions arrived before T; 3 versioning method for currently running transactions; 4 new versioning method computed for the transaction T; 5 if () then // i.e., and are complement of each other in the set {} 6 if (there is no transaction such that is executing using when T wants to execute) then 7 ; 8 Start executing T using ; 9 else 10 Wait until each transaction finish execution; |
5. Optimizations on Basic Adaptive Versioning
5.1. Limitation of Basic Adaptive in Non-Persistent Memories
5.2. Better Time Barrier Design
| Algorithm 3: Better Time Barrier Design |
| 1 new transaction arrived for execution; 2 set of other transactions arrived before T; 3 versioning method for currently running transactions; 4 new versioning method computed for the transaction T; 5 if () then 6 ; 7 Execute T using ; 8 if (T conflicts with ) then 9 Abort T; 10 else if (T conflicts with ) then 11 Handle conflict between T and using the contention management technique; |
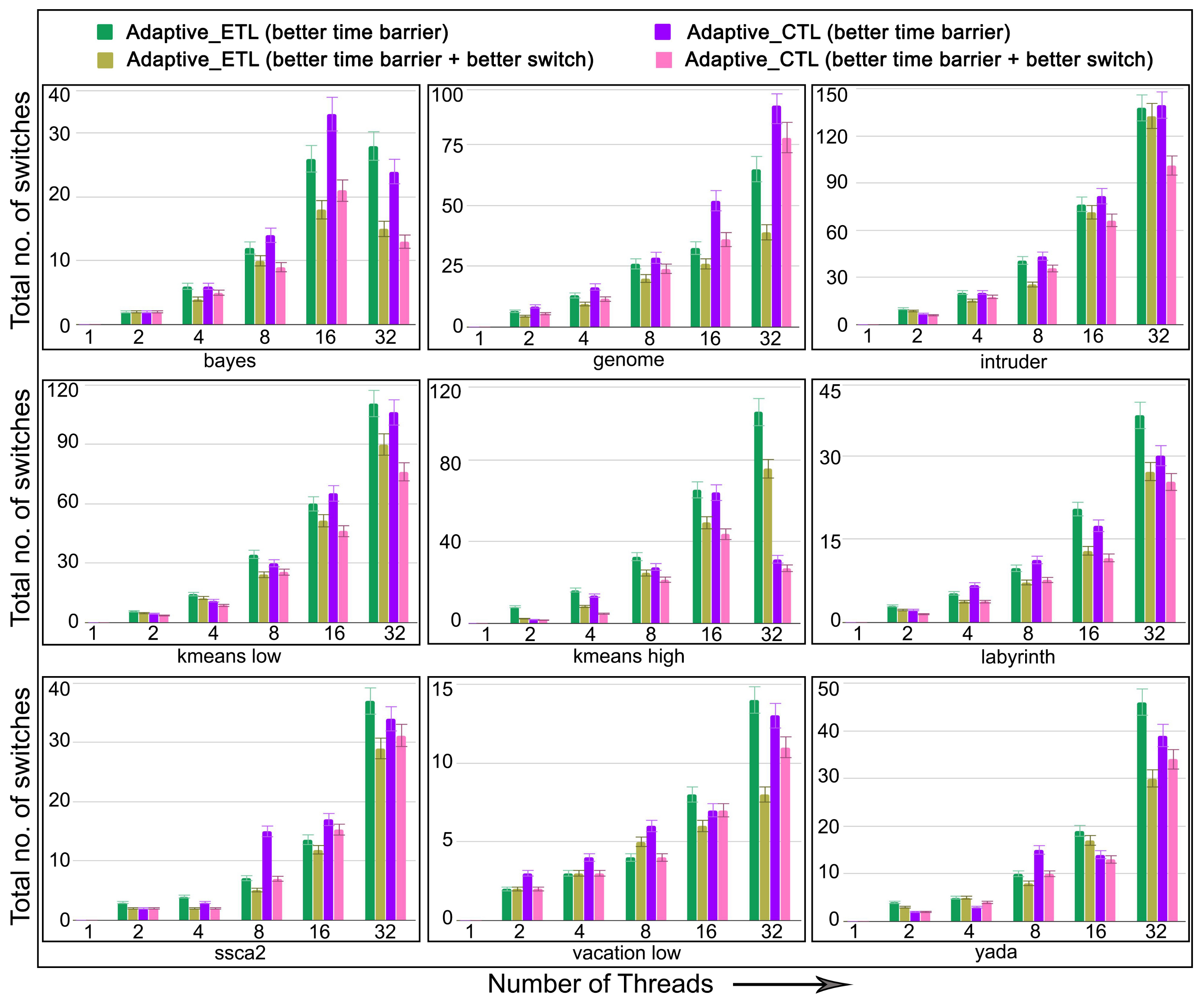
5.3. Better Switching Mechanism Design
6. Experimental Evaluation
6.1. Experimental Setup
| Algorithm 4: Better Switching Mechanism Design |
| 1 new transaction arrived for execution; 2 versioning method for currently running transactions; 3 new versioning method computed for the transaction T; 4 the timestamp at which the versioning satisfies to switch from to ; 5 switching interval threshold; 6 time taken by the transactions arrived on or after timestamp t to finish their executions; 7 if ( for time ) then 8 ; // switch the versioning method to at timestamp 9 Execute T using ; |
6.2. Persistent Memory Emulation
6.3. Benchmarks
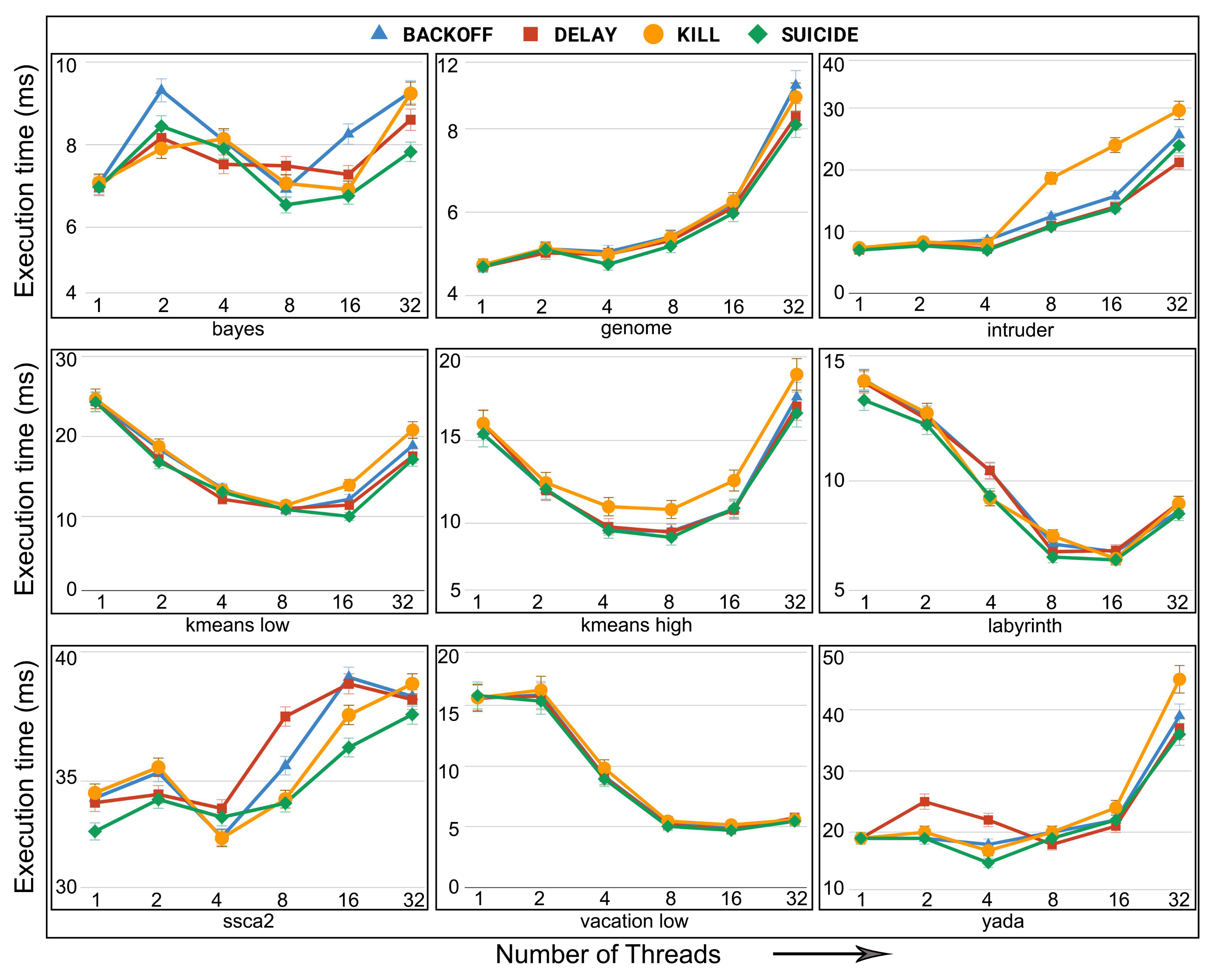
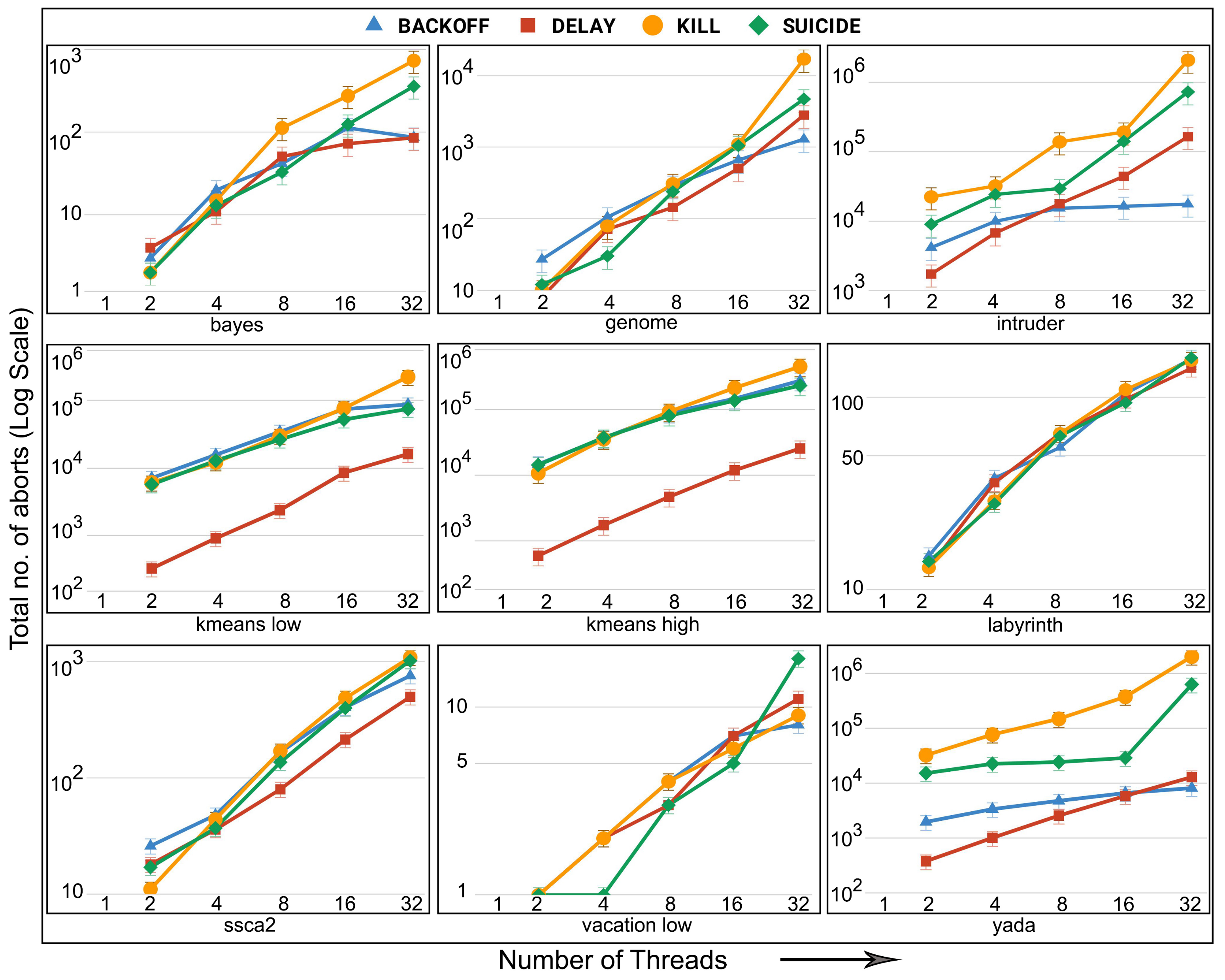
- STAMP: STAMP is a well-known and widely-used benchmark. It consists of eight applications: bayes, genome, intruder, kmeans, labyrinth, ssca2, vacation, and yada of varying complexity. These applications span a variety of computing domains as well as runtime transactional characteristics such as varying transaction lengths, read and write set sizes, and amounts of contention [23].
- STAMPEDE: Recently, Nguyen et al. [29] argued that the programming model and data structures used in STAMP benchmarks suffer from performance bottlenecks. They then modified the programming structure of these benchmarks in a way the bottlenecks can be removed. They finally provided a set of rewritten STAMP benchmarks calling them STAMPEDE benchmarks.
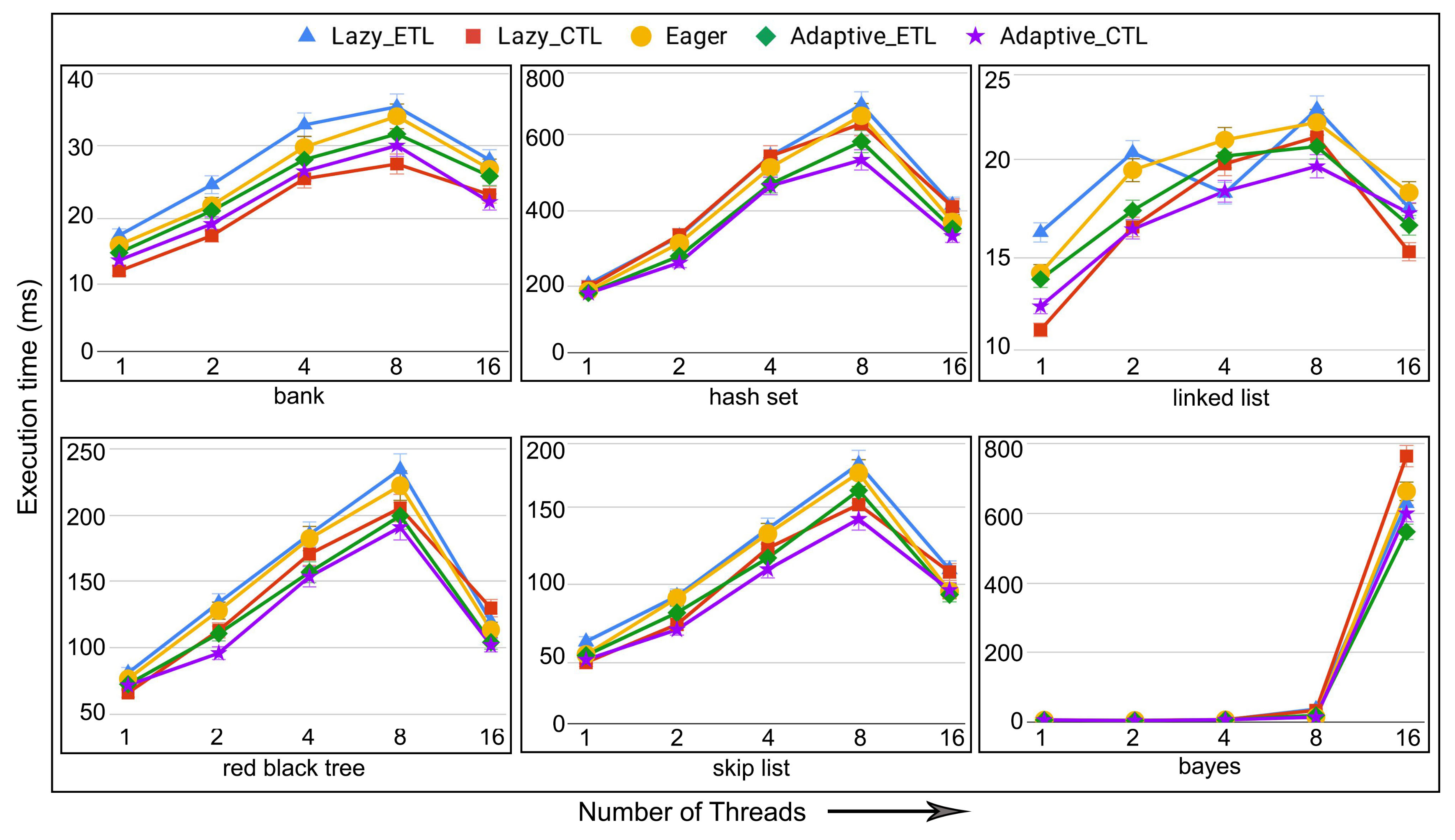
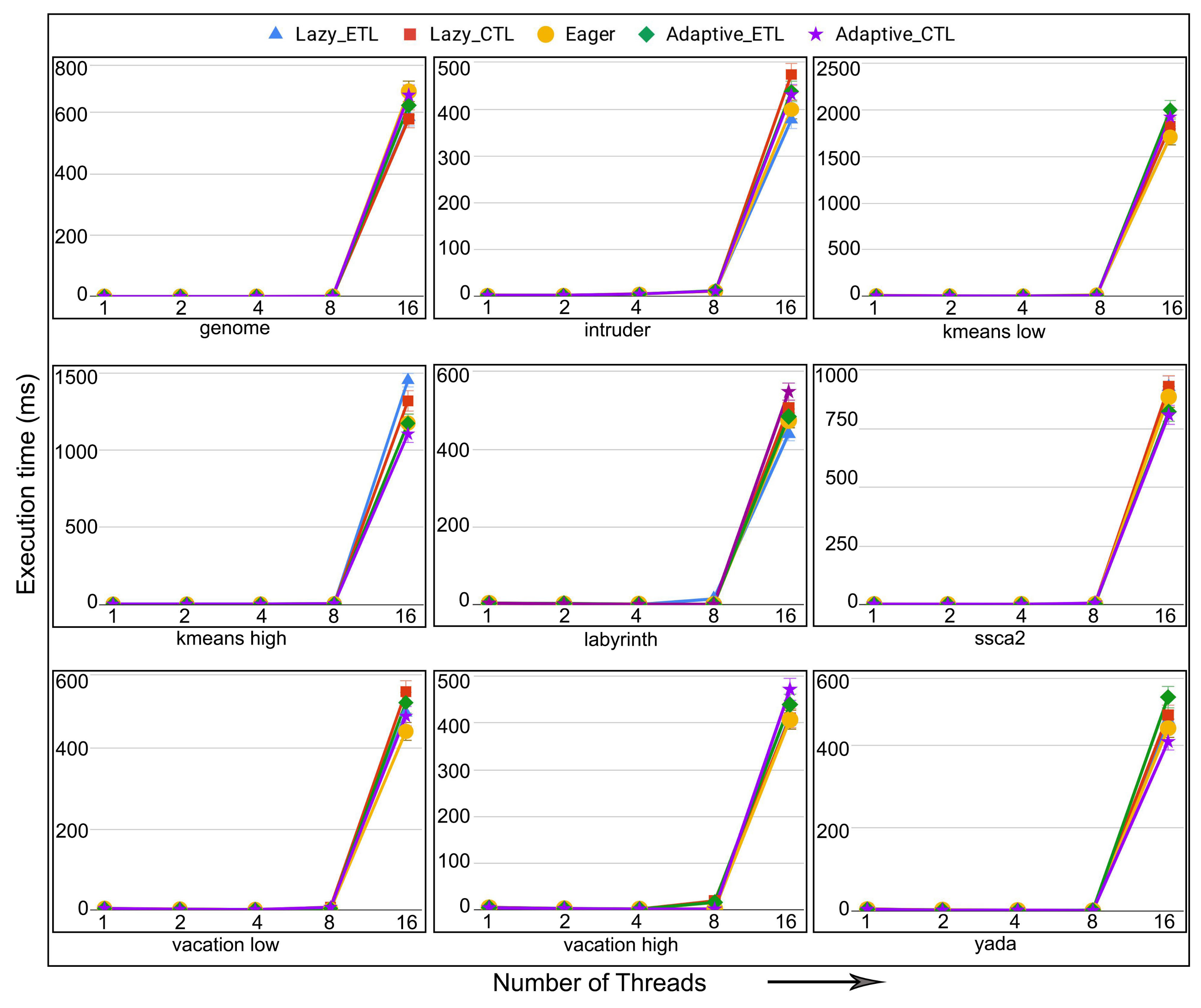
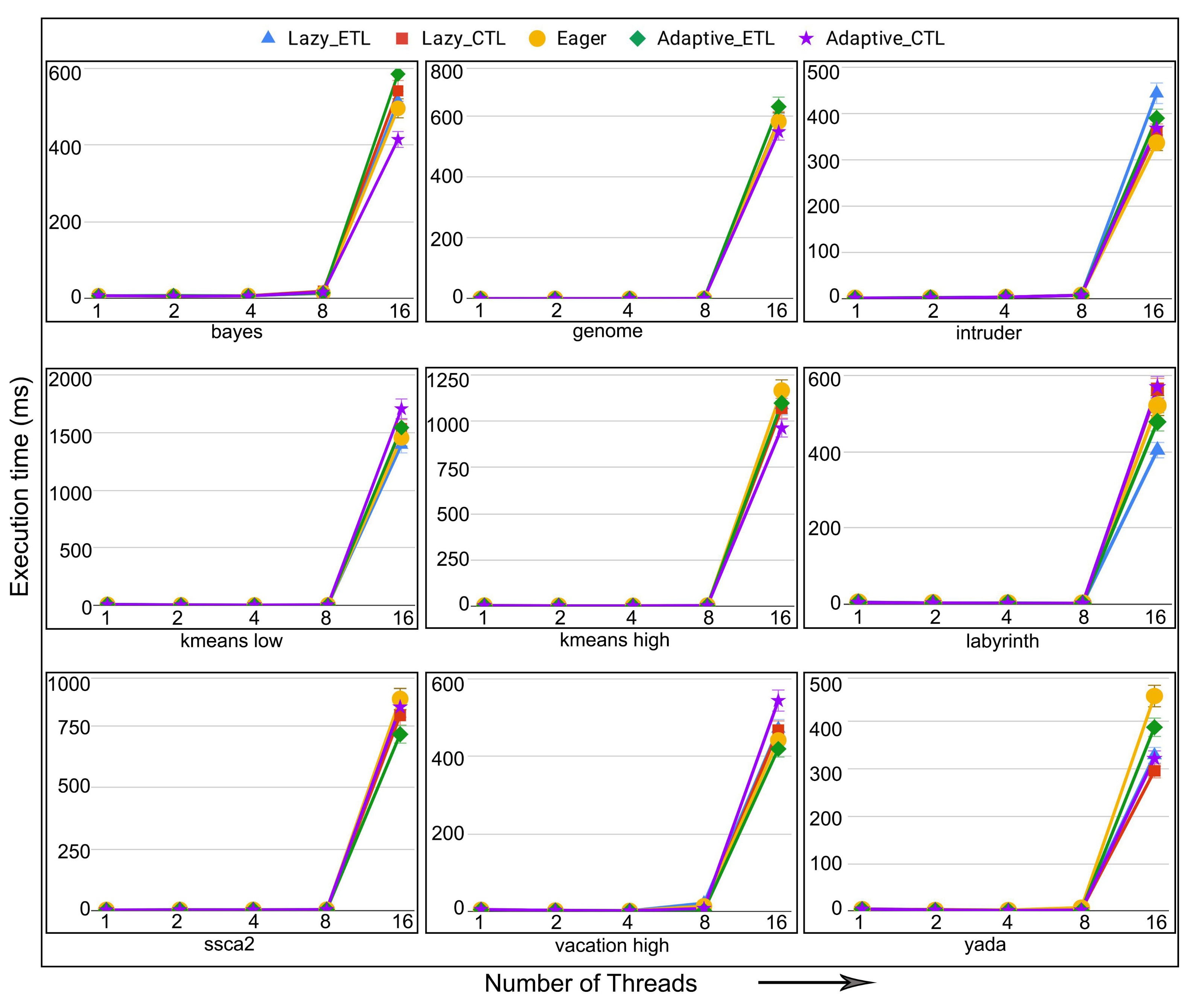
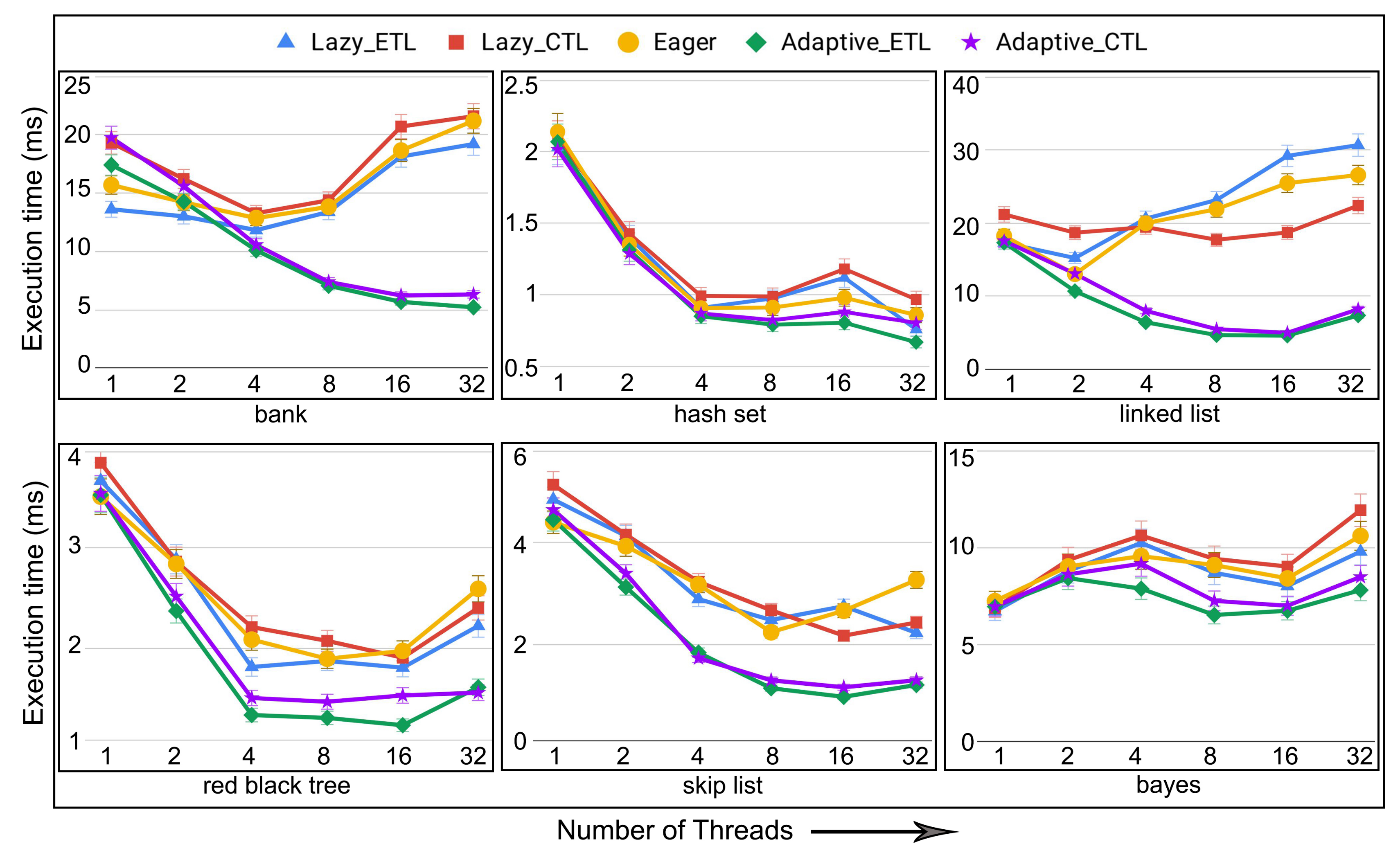
6.4. Evaluation of Adaptive in Persistent Memories
6.5. Evaluation of Adaptive in Non-Persistent Memories
7. Concluding Remarks
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Herlihy, M.; Moss, J.E.B. Transactional Memory: Architectural Support for Lock-free Data Structures. In Proceedings of the ISCA, San Diego, CA, USA, 16–19 May 1993; pp. 289–300. [Google Scholar]
- Shavit, N.; Touitou, D. Software Transactional Memory. Distrib. Comput. 1997, 10, 99–116. [Google Scholar] [CrossRef]
- Intel. 2012. Available online: http://software.intel.com/en-us/blogs/2012/02/07/transactional-synchronization-in-haswell (accessed on 4 February 2021).
- Haring, R.; Ohmacht, M.; Fox, T.; Gschwind, M.; Satterfield, D.; Sugavanam, K.; Coteus, P.; Heidelberger, P.; Blumrich, M.; Wisniewski, R.; et al. The IBM Blue Gene/Q Compute Chip. IEEE Micro 2012, 32, 48–60. [Google Scholar] [CrossRef]
- Nakaike, T.; Odaira, R.; Gaudet, M.; Michael, M.M.; Tomari, H. Quantitative comparison of hardware transactional memory for Blue Gene/Q, zEnterprise EC12, Intel Core, and POWER8. In Proceedings of the ISCA, Portland, Oregon, 13–17 June 2015; pp. 144–157. [Google Scholar] [CrossRef]
- Cain, H.W.; Michael, M.M.; Frey, B.; May, C.; Williams, D.; Le, H.Q. Robust architectural support for transactional memory in the power architecture. In Proceedings of the ISCA, Tel Aviv, Israel, 23–27 June 2013; pp. 225–236. [Google Scholar] [CrossRef]
- Bocchino, R.L.; Adve, V.S.; Chamberlain, B.L. Software transactional memory for large scale clusters. In Proceedings of the PPoPP, Salt Lake City, UT, USA, 20–23 February 2008; pp. 247–258. [Google Scholar]
- Fung, W.W.L.; Singh, I.; Brownsword, A.; Aamodt, T.M. Hardware transactional memory for GPU architectures. In Proceedings of the MICRO, Porto Alegre, Brazil, 3–7 December 2011; pp. 296–307. [Google Scholar]
- Manassiev, K.; Mihailescu, M.; Amza, C. Exploiting Distributed Version Concurrency in a Transactional Memory Cluster. In Proceedings of the PPoPP, Manhattan, NY, USA, 29–31 March 2006; pp. 198–208. [Google Scholar]
- Ananian, C.S.; Asanovic, K.; Kuszmaul, B.C.; Leiserson, C.E.; Lie, S. Unbounded Transactional Memory. In Proceedings of the HPCA, San Francisco, CA, USA, 12–16 February 2005; pp. 316–327. [Google Scholar]
- Hammond, L.; Wong, V.; Chen, M.; Carlstrom, B.D.; Davis, J.D.; Hertzberg, B.; Prabhu, M.K.; Wijaya, H.; Kozyrakis, C.; Olukotun, K. Transactional Memory Coherence and Consistency. SIGARCH Comput. Archit. News 2004, 32, 102. [Google Scholar] [CrossRef]
- Moore, K.E. LogTM: Log-Based Transactional Memory. In Proceedings of the HPCA, Austin, TA, USA, 11–15 February 2006; pp. 258–269. [Google Scholar]
- Rajwar, R.; Herlihy, M.; Lai, K. Virtualizing Transactional Memory. In Proceedings of the ISCA; IEEE Computer Society: Washington, DC, USA, 2005; pp. 494–505. [Google Scholar] [CrossRef]
- RSTM. Available online: http://www.cs.rochester.edu/research/synchronization/rstm/index.shtml (accessed on 14 February 2019).
- Dalessandro, L.; Spear, M.F.; Scott, M.L. NOrec: Streamlining STM by Abolishing Ownership Records. In Proceedings of the PPOPP, Bangalore, India, 9–14 January 2010; pp. 67–78. [Google Scholar] [CrossRef]
- Dragojevic, A.; Guerraoui, R.; Kapalka, M. Stretching Transactional Memory. In Proceedings of the PLDI, Dublin, Ireland, 15–20 June 2009; pp. 155–165. [Google Scholar] [CrossRef]
- Zhao, J.; Li, S.; Yoon, D.H.; Xie, Y.; Jouppi, N.P. Kiln: Closing the Performance Gap Between Systems with and without Persistence Support. In Proceedings of the MICRO, Shanghai, China, 22–26 April 2013; pp. 421–432. [Google Scholar]
- Coburn, J.; Caulfield, A.M.; Akel, A.; Grupp, L.M.; Gupta, R.K.; Jhala, R.; Swanson, S. NV-Heaps: Making Persistent Objects Fast and Safe with Next-generation, Non-volatile Memories. In Proceedings of the ASPLOS, Newport Beach, CA, USA, 5–11 May 2011; pp. 105–118. [Google Scholar]
- Volos, H.; Tack, A.J.; Swift, M.M. Mnemosyne: Lightweight Persistent Memory. In Proceedings of the ASPLOS, Newport Beach, CA, USA, 5–11 May 2011; pp. 91–104. [Google Scholar]
- Narayanan, D.; Hodson, O. Whole-system Persistence. In Proceedings of the ASPLOS, London, UK, 3–7 March 2012; pp. 401–410. [Google Scholar]
- Liu, M.; Zhang, M.; Chen, K.; Qian, X.; Wu, Y.; Zheng, W.; Ren, J. DudeTM: Building Durable Transactions with Decoupling for Persistent Memory. In Proceedings of the ASPLOS, Xi’an, China, 8–12 April 2017; pp. 329–343. [Google Scholar]
- Wan, H.; Lu, Y.; Xu, Y.; Shu, J. Empirical study of redo and undo logging in persistent memory. In Proceedings of the NVMSA, Deagu, Korea, 17–19 August 2016; pp. 1–6. [Google Scholar]
- Minh, C.C.; Chung, J.; Kozyrakis, C.; Olukotun, K. STAMP: Stanford Transactional Applications for Multi-Processing. In Proceedings of the IISWC, Seattle, WA, USA, 14–16 September 2008; pp. 35–46. [Google Scholar]
- Poudel, P.; Sharma, G. An Adaptive Logging Framework for Persistent Memories. In Proceedings of the SSS, Tokyo, Japan, 4–7 November 2018; pp. 32–49. [Google Scholar] [CrossRef]
- Poudel, P.; Sharma, G. Adaptive Versioning in Transactional Memories. In Proceedings of the SSS, Pisa, Italy, 22–25 October 2019; pp. 277–295. [Google Scholar] [CrossRef]
- Felber, P.; Fetzer, C.; Marlier, P.; Riegel, T. Time-Based Software Transactional Memory. IEEE Trans. Parallel Distrib. Syst. 2010, 21, 1793–1807. [Google Scholar] [CrossRef]
- Felber, P.; Fetzer, C.; Riegel, T. Dynamic performance tuning of word-based software transactional memory. In Proceedings of the PPOPP, Salt Lake City, UT, USA, 20–23 February 2008; pp. 237–246. [Google Scholar]
- Herlihy, M.; Luchangco, V.; Moir, M.; Scherer, W.N., III. Software Transactional Memory for Dynamic-sized Data Structures. In Proceedings of the PODC, Boston, MA, USA, 13–16 July 2003; pp. 92–101.
- Nguyen, D.; Pingali, K. What Scalable Programs Need from Transactional Memory. In Proceedings of the ASPLOS, Xi’an, China, 8–12 April 2017; pp. 105–118. [Google Scholar]
- Liu, H.; Chen, D.; Jin, H.; Liao, X.; He, B.; Hu, K.; Zhang, Y. A Survey of Non-Volatile Main Memory Technologies: State-of-the-Arts, Practices, and Future Directions. J. Comput. Sci. Technol. 2021, 36, 4–32. [Google Scholar] [CrossRef]
- Asadinia, M.; Sarbazi-Azad, H. Chapter One—Introduction to non-volatile memory technologies. In Durable Phase-Change Memory Architectures; Asadinia, M., Sarbazi-Azad, H., Eds.; Advances in Computers; Elsevier: Amsterdam, The Netherlands, 2020; Volume 118, pp. 1–13. [Google Scholar]
- Damron, P.; Fedorova, A.; Lev, Y.; Luchangco, V.; Moir, M.; Nussbaum, D. Hybrid transactional memory. In Proceedings of the ASPLOS, San Jose, CA, USA, 21–25 October 2006; pp. 336–346. [Google Scholar] [CrossRef]
- Kumar, S.; Chu, M.; Hughes, C.J.; Kundu, P.; Nguyen, A.D. Hybrid transactional memory. In Proceedings of the PPOPP, Manhattan, NY, USA, 29–31 March 2006; pp. 209–220. [Google Scholar]
- Dalessandro, L.; Carouge, F.; White, S.; Lev, Y.; Moir, M.; Scott, M.L.; Spear, M.F. Hybrid NOrec: A case study in the effectiveness of best effort hardware transactional memory. In Proceedings of the ASPLOS, Newport Beach, CA, USA, 5–11 May 2011; pp. 39–52. [Google Scholar]
- Alistarh, D.; Kopinsky, J.; Kuznetsov, P.; Ravi, S.; Shavit, N. Inherent limitations of hybrid transactional memory. Distrib. Comput. 2018, 31, 167–185. [Google Scholar] [CrossRef]
- Ruan, W.; Spear, M.F. Hybrid Transactional Memory Revisited. In Proceedings of the DISC, Tokyo, Japan, 5–9 October 2015; pp. 215–231. [Google Scholar]
- Riegel, T.; Marlier, P.; Nowack, M.; Felber, P.; Fetzer, C. Optimizing hybrid transactional memory: The importance of nonspeculative operations. In Proceedings of the SPAA, San Jose, CA, USA, 4–6 June 2011; pp. 53–64. [Google Scholar]
- Lev, Y.; Moir, M.; Nussbaum, D. PhTM: Phased transactional memory. In Proceedings of the Workshop on Transactional Computing (Transact), Portland, Oregon, 16 August 2007. [Google Scholar]
- De Carvalho, J.P.L.; Araujo, G.; Baldassin, A. Revisiting phased transactional memory. In Proceedings of the ICS, Florence, Italy, 12–15 September 2017; pp. 25:1–25:10. [Google Scholar] [CrossRef]
- De Carvalho, J.P.L.; Araujo, G.; Baldassin, A. The Case for Phase-Based Transactional Memory. IEEE Trans. Parallel Distrib. Syst. 2019, 30, 459–472. [Google Scholar] [CrossRef]
- The Persistent Memory Development Kit (PMDK). Available online: https://github.com/pmem/pmdk/ (accessed on 14 February 2019).
- Dulloor, S.R.; Kumar, S.; Keshavamurthy, A.; Lantz, P.; Reddy, D.; Sankaran, R.; Jackson, J. System Software for Persistent Memory. In Proceedings of the EuroSys, Amsterdam, The Netherlands, 14–16 April 2014; pp. 15:1–15:15. [Google Scholar]
- Avni, H.; Levy, E.; Mendelson, A. Hardware Transactions in Nonvolatile Memory. In Proceedings of the DISC, Tokyo, Japan, 5–9 October 2015; pp. 617–630. [Google Scholar]
- Genç, K.; Bond, M.D.; Xu, G.H. Crafty: Efficient, HTM-Compatible Persistent Transactions. In Proceedings of the PLDI; Association for Computing Machinery: New York, NY, USA, 2020; pp. 59–74. [Google Scholar] [CrossRef]
- Joshi, A.; Nagarajan, V.; Cintra, M.; Viglas, S. DHTM: Durable Hardware Transactional Memory. In Proceedings of the ISCA; IEEE Press: New York City, NY, USA, 2018; pp. 452–465. [Google Scholar] [CrossRef]
- Castro, D.; Baldassin, A.; Barreto, J.; Romano, P. SPHT: Scalable Persistent Hardware Transactions. In Proceedings of the FAST, Santa Clara, CA, USA, 22–25 February 2021. [Google Scholar]
- Optane DC Persistent Memory. Available online: https://www.intel.com/content/www/us/en/architecture-and-technology/optane-dc-persistent-memory.html (accessed on 25 February 2021).
- Baldassin, A.; Murari, R.; de Carvalho, J.P.L.; Araujo, G.; Castro, D.; Barreto, J.; Romano, P. NV-PhTM: An Efficient Phase-Based Transactional System for Non-volatile Memory. In Proceedings of the Euro-Par; Malawski, M., Rzadca, K., Eds.; Springer: New York City, NY, USA, 2020; Volume 12247, pp. 477–492. [Google Scholar]
- Krishnan, R.M.; Kim, J.; Mathew, A.; Fu, X.; Demeri, A.; Min, C.; Kannan, S. Durable Transactional Memory Can Scale with Timestone. In Proceedings of the ASPLOS; Association for Computing Machinery: New York, NY, USA, 2020; pp. 335–349. [Google Scholar] [CrossRef]
- Gu, J.; Yu, Q.; Wang, X.; Wang, Z.; Zang, B.; Guan, H.; Chen, H. Pisces: A Scalable and Efficient Persistent Transactional Memory. In Proceedings of the 2019 USENIX Conference on Usenix Annual Technical Conference, Renton, WA, USA, 10–12 July 2019; pp. 913–928. [Google Scholar]
- Kolli, A.; Pelley, S.; Saidi, A.G.; Chen, P.M.; Wenisch, T.F. High-Performance Transactions for Persistent Memories. In Proceedings of the ASPLOS, Atlanta, GA, USA, 2–3 April 2016; pp. 399–411. [Google Scholar] [CrossRef]
- Lu, Y.; Shu, J.; Sun, L.; Mutlu, O. Loose-Ordering Consistency for persistent memory. In Proceedings of the ICCD, Seoul, Korea, 19–22 Ocotober 2014; pp. 216–223. [Google Scholar] [CrossRef]
- Memaripour, A.; Badam, A.; Phanishayee, A.; Zhou, Y.; Alagappan, R.; Strauss, K.; Swanson, S. Atomic In-Place Updates for Non-Volatile Main Memories with Kamino-Tx. In Proceedings of the Twelfth European Conference on Computer Systems; Association for Computing Machinery: New York, NY, USA, 2017; pp. 499–512. [Google Scholar] [CrossRef]
- Izraelevitz, J.; Kelly, T.; Kolli, A. Failure-Atomic Persistent Memory Updates via JUSTDO Logging. In Proceedings of the ASPLOS, Atlanta, GA, USA, 2–3 April 2016; pp. 427–442. [Google Scholar]
- Coburn, J.; Bunker, T.; Schwarz, M.; Gupta, R.; Swanson, S. From ARIES to MARS: Transaction Support for Next-generation, Solid-state Drives. In Proceedings of the SOSP, Farmington, PA, USA, 3–6 November 2013; pp. 197–212. [Google Scholar]
- Shin, S.; Tirukkovalluri, S.K.; Tuck, J.; Solihin, Y. Proteus: A Flexible and Fast Software Supported Hardware Logging Approach for NVM. In Proceedings of the MICRO, Boston, MA, USA, 14–18 Ocotober 2017; pp. 178–190. [Google Scholar]
- Chatzistergiou, A.; Cintra, M.; Viglas, S. REWIND: Recovery Write-Ahead System for In-Memory Non-Volatile Data-Structures. PVLDB 2015, 8, 497–508. [Google Scholar]
- Lu, Y.; Shu, J.; Sun, L. Blurred Persistence: Efficient Transactions in Persistent Memory. Trans. Storage 2016, 12, 3:1–3:29. [Google Scholar] [CrossRef]
- Keidar, I.; Perelman, D. Multi-versioning in Transactional Memory. In Transactional Memory. Foundations, Algorithms, Tools, and Applications: COST Action Euro-TM IC1001; Guerraoui, R., Romano, P., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 150–165. [Google Scholar] [CrossRef]
- Sharma, G.; Busch, C. A Competitive Analysis for Balanced Transactional Memory Workloads. Algorithmica 2012, 63, 296–322. [Google Scholar] [CrossRef]
- Sharma, G.; Busch, C. Window-Based Greedy Contention Management for Transactional Memory: Theory and Practice. Distrib. Comput. 2012, 25, 225–248. [Google Scholar] [CrossRef]
- Attiya, H.; Gramoli, V.; Milani, A. A Provably Starvation-Free Distributed Directory Protocol. In Proceedings of the SSS, New York City, NY, USA, 20–22 September 2010; pp. 405–419. [Google Scholar]
- Guerraoui, R.; Herlihy, M.; Pochon, B. Toward a Theory of Transactional Contention Managers. In Proceedings of the PODC, Las Vegas, NA, USA, 17–20 July 2005; pp. 258–264. [Google Scholar]
- Ansari, M.; Luján, M.; Kotselidis, C.; Jarvis, K.; Kirkham, C.C.; Watson, I. Steal-on-Abort: Improving Transactional Memory Performance through Dynamic Transaction Reordering. In Proceedings of the HiPEAC, Munich Germany, 2–4 June 2009; pp. 4–18. [Google Scholar]
- III, W.N.S.; Scott, M.L. Advanced contention management for dynamic software transactional memory. In Proceedings of the PODC, Las Vegas, NA, USA, 17–20 July 2005; pp. 240–248. [Google Scholar]
- Schneider, J.; Wattenhofer, R. Bounds on contention management algorithms. Theor. Comput. Sci. 2011, 412, 4151–4160. [Google Scholar] [CrossRef][Green Version]
- Attiya, H.; Epstein, L.; Shachnai, H.; Tamir, T. Transactional Contention Management as a Non-Clairvoyant Scheduling Problem. Algorithmica 2010, 57, 44–61. [Google Scholar] [CrossRef]
- Attiya, H.; Milani, A. Transactional scheduling for read-dominated workloads. J. Parallel Distrib. Comput. 2012, 72, 1386–1396. [Google Scholar] [CrossRef]
- Keidar, I.; Perelman, D. On Avoiding Spare Aborts in Transactional Memory. Theory Comput. Syst. 2015, 57, 261–285. [Google Scholar] [CrossRef]






























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Constraint | Eager Versioning | Lazy Versioning |
|---|---|---|
| Memory Update | performs in-place memory update | updates are written to memory at the commit time |
| allows to read most recent data | reads are intercepted and redirected | |
| Reading Overhead | directly from in-place | to the redo log area to read recent |
| memory | uncommitted data | |
| Persist Ordering | requires to ensure persist ordering for | requires only one persist ordering |
| (only for persistent TMs) | each memory write in a transaction [19] | for each transaction [19,21] |
| transaction aborts are costly as the | transaction commits are costly as the | |
| Data Movement | memory updates need to be rolled back | updates need to be written back to |
| to consistent state using undo log | original memory using redo log |
| Versioning | |||
|---|---|---|---|
| Lazy | Eager | ||
| Conflict | Lazy | TCC [11], Norec [15], RSTM [14], SwissTM [16] | None |
| Eager | UTM [10], VTM [13], RSTM [14], SwissTM [16] | UTM [10], LogTM [12], RSTM [14] | |
| Benchmark | Application | Description | RW Set | Contention |
|---|---|---|---|---|
| bank | banking | implements banking transactions | small | low |
| red black tree | BST | balances the nodes of binary tree | small | low |
| hash set | data structure | stores information using hashing | medium | low |
| linked list | data structure | maintains linear collection of data | medium | medium |
| skip list | data structure | maintains linked hierarchy of subsequences | medium | low |
| bayes | machine learning | learns a structure of a Bayesian network | large | high |
| genome | bioinformatics | performs gene sequencing | medium | low |
| intruder | security | detects network intrusions | medium | high |
| kmeans | data mining | implements k-means clustering | small | low |
| labyrinth | engineering | routes paths in maze | large | high |
| ssca2 | scientific | creates efficient graph representation | small | low |
| vacation | OLTP | emulates travel reservation system | medium | low/medium |
| yada | scientific | refines a Delaunay mesh | large | medium |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Poudel, P.; Sharma, G. Adaptive Versioning in Transactional Memory Systems. Algorithms 2021, 14, 171. https://doi.org/10.3390/a14060171
Poudel P, Sharma G. Adaptive Versioning in Transactional Memory Systems. Algorithms. 2021; 14(6):171. https://doi.org/10.3390/a14060171
Chicago/Turabian StylePoudel, Pavan, and Gokarna Sharma. 2021. "Adaptive Versioning in Transactional Memory Systems" Algorithms 14, no. 6: 171. https://doi.org/10.3390/a14060171
APA StylePoudel, P., & Sharma, G. (2021). Adaptive Versioning in Transactional Memory Systems. Algorithms, 14(6), 171. https://doi.org/10.3390/a14060171