
Reversed Lempel–Ziv Factorization with Suffix Trees †


Abstract
1. Introduction
1.1. Our Contribution
- in time using bits (excluding the read-only text T), or
- in time using bits,
- in time using bits (excluding the read-only text T), or
- in time using bits,
1.2. Related Work
1.3. Structure of This Article
2. Preliminaries
- returns the leaf-rank of the leaf ;
- returns the depth of the node v, which is the number of nodes on the path between v and the root (exclusive) such that root has depth zero;
- returns the level-ancestor of the on depth d; and
- returns the lowest common ancestor (LCA) of u and v.
3. Reversed LZ Factorization
3.1. Coding
3.2. Factorization Algorithm
- ; or
- and have the longest common prefix of length ℓ.
3.2.1. Overview
| Algorithm 1: Algorithm of Section 3.2.2 computing the non-overlapping reversed LZ factorization. The function is described in Section 3.3. |
 |
3.2.2. One-Pass Algorithm in Detail
3.2.3. Time Complexity
3.3. Determining the Referred Position
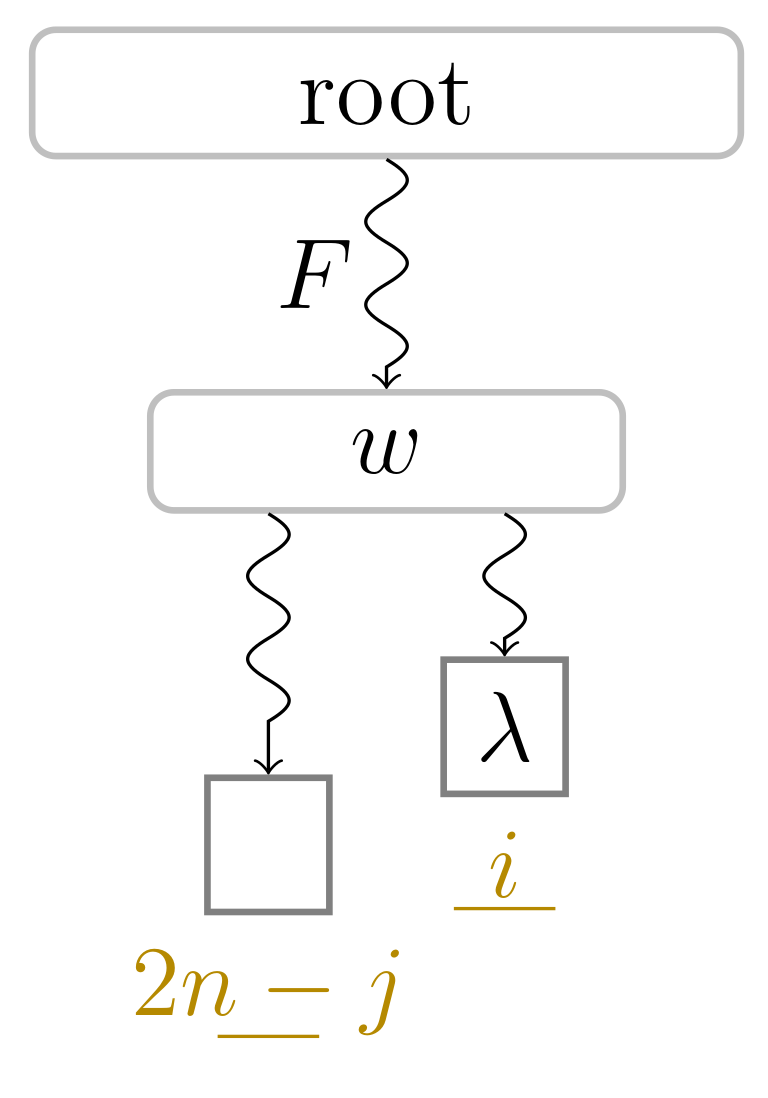
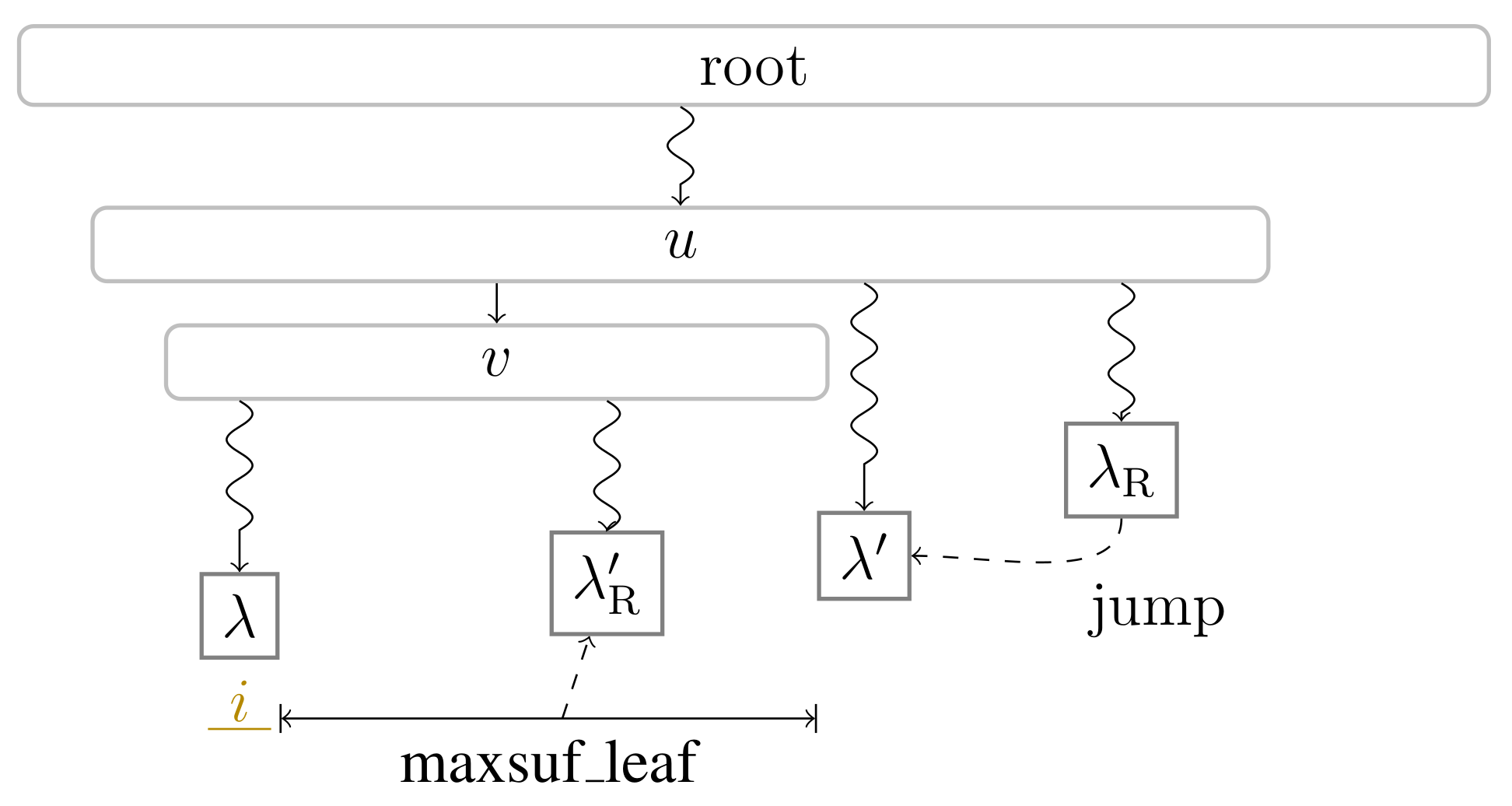
- returning the maximum among all suffix numbers of the leaves in the subtree rooted in v.
| Algorithm 2: Determining the referred positions in a second pass described in Section 3.3. |
 |
4. Computing
4.1. Adaptation of the Single-Pass Algorithm
4.2. Algorithm of Crochemore et al.
- returning the leaf with the maximum suffix number among all leaves whose leaf-ranks are in .
- If (meaning is to the right of and there is no leaf between and ), we terminate.
- Otherwise, we set to the leaf with the largest suffix number among the leaves with leaf-ranks in the range . If , we set and recurse. Otherwise we terminate.
5. Open Problems
5.1. Overlapping Reversed LZ Factorization
5.2. Computing in Linear Time with Compressed Space
5.3. Applications in Compressors
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Flip Book





















References
- Kolpakov, R.; Kucherov, G. Searching for gapped palindromes. Theor. Comput. Sci. 2009, 410, 5365–5373. [Google Scholar] [CrossRef]
- Storer, J.A.; Szymanski, T.G. Data compression via textural substitution. J. ACM 1982, 29, 928–951. [Google Scholar] [CrossRef]
- Crochemore, M.; Langiu, A.; Mignosi, F. Note on the greedy parsing optimality for dictionary-based text compression. Theor. Comput. Sci. 2014, 525, 55–59. [Google Scholar] [CrossRef]
- Weiner, P. Linear Pattern Matching Algorithms. In Proceedings of the 14th Annual Symposium on Switching and Automata Theory (swat 1973) SWAT, Iowa City, IA, USA, 15–17 October 1973; pp. 1–11. [Google Scholar]
- Sugimoto, S.; Tomohiro, I.; Inenaga, S.; Bannai, H.; Takeda, M. Computing Reversed Lempel–Ziv Factorization Online. Available online: http://stringology.org/papers/PSC2013.pdf#page=115 (accessed on 15 April 2021).
- Chairungsee, S.; Crochemore, M. Efficient Computing of Longest Previous Reverse Factors. In Proceedings of the Computer Science and Information Technologies, Yerevan, Armenia, 28 September–2 October 2009; pp. 27–30. [Google Scholar]
- Badkobeh, G.; Chairungsee, S.; Crochemore, M. Hunting Redundancies in Strings. In International Conference on Developments in Language Theory; LNCS; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6795, pp. 1–14. [Google Scholar]
- Chairungsee, S. Searching for Gapped Palindrome. Available online: https://www.sciencedirect.com/science/article/pii/S0304397509006409 (accessed on 15 April 2021).
- Charoenrak, S.; Chairungsee, S. Palindrome Detection Using On-Line Position. In Proceedings of the 2017 International Conference on Information Technology, Singapore, 27–29 December 2017; pp. 62–65. [Google Scholar]
- Charoenrak, S.; Chairungsee, S. Algorithm for Palindrome Detection by Suffix Heap. In Proceedings of the 2019 7th International Conference on Information Technology: IoT and Smart City, Shanghai China, 20–23 December 2019; pp. 85–88. [Google Scholar]
- Blumer, A.; Blumer, J.; Ehrenfeucht, A.; Haussler, D.; McConnell, R.M. Building the Minimal DFA for the Set of all Subwords of a Word On-line in Linear Time. In International Colloquium on Automata, Languages, and Programming; LNCS; Springer: Berlin/Heidelberg, Germany, 1984; Volume 172, pp. 109–118. [Google Scholar]
- Ehrenfeucht, A.; McConnell, R.M.; Osheim, N.; Woo, S. Position heaps: A simple and dynamic text indexing data structure. J. Discret. Algorithms 2011, 9, 100–121. [Google Scholar] [CrossRef]
- Gagie, T.; Hon, W.; Ku, T. New Algorithms for Position Heaps. In Annual Symposium on Combinatorial Pattern Matching; LNCS; Springer: Berlin/Heidelberg, Germany, 2013; Volume 7922, pp. 95–106. [Google Scholar]
- Crochemore, M.; Iliopoulos, C.S.; Kubica, M.; Rytter, W.; Walen, T. Efficient algorithms for three variants of the LPF table. J. Discret. Algorithms 2012, 11, 51–61. [Google Scholar] [CrossRef]
- Manber, U.; Myers, E.W. Suffix Arrays: A New Method for On-Line String Searches. SIAM J. Comput. 1993, 22, 935–948. [Google Scholar] [CrossRef]
- Dumitran, M.; Gawrychowski, P.; Manea, F. Longest Gapped Repeats and Palindromes. Discret. Math. Theor. Comput. Sci. 2017, 19, 205–217. [Google Scholar]
- Gusfield, D. Algorithms on Strings, Trees, and Sequences: Computer Science and Computational Biology; Cambridge University Press: Cambridge, UK, 1997. [Google Scholar]
- Nakashima, Y.; Tomohiro, I.; Inenaga, S.; Bannai, H.; Takeda, M. Constructing LZ78 tries and position heaps in linear time for large alphabets. Inf. Process. Lett. 2015, 115, 655–659. [Google Scholar] [CrossRef]
- Ziv, J.; Lempel, A. A universal algorithm for sequential data compression. IEEE Trans. Inf. Theory 1977, 23, 337–343. [Google Scholar] [CrossRef]
- Ziv, J.; Lempel, A. Compression of individual sequences via variable-rate coding. IEEE Trans. Inf. Theory 1978, 24, 530–536. [Google Scholar] [CrossRef]
- Fischer, J.; Tomohiro, I; Köppl, D.; Sadakane, K. Lempel–Ziv Factorization Powered by Space Efficient Suffix Trees. Algorithmica 2018, 80, 2048–2081. [Google Scholar] [CrossRef]
- Köppl, D. Non-Overlapping LZ77 Factorization and LZ78 Substring Compression Queries with Suffix Trees. Algorithms 2021, 14, 44. [Google Scholar] [CrossRef]
- Sadakane, K. Compressed Suffix Trees with Full Functionality. Theory Comput. Syst. 2007, 41, 589–607. [Google Scholar] [CrossRef]
- Belazzougui, D.; Cunial, F. Indexed Matching Statistics and Shortest Unique Substrings. In International Symposium on String Processing and Information Retrieval; LNCS; Springer: Cham, Switzerland, 2014; Volume 8799, pp. 179–190. [Google Scholar]
- Franek, F.; Holub, J.; Smyth, W.F.; Xiao, X. Computing Quasi Suffix Arrays. J. Autom. Lang. Comb. 2003, 8, 593–606. [Google Scholar]
- Crochemore, M.; Ilie, L. Computing Longest Previous Factor in linear time and applications. Inf. Process. Lett. 2008, 106, 75–80. [Google Scholar] [CrossRef]
- Belazzougui, D.; Cunial, F.; Kärkkäinen, J.; Mäkinen, V. Linear-time String Indexing and Analysis in Small Space. ACM Trans. Algorithms 2020, 16, 17:1–17:54. [Google Scholar] [CrossRef]
- Goto, K.; Bannai, H. Space Efficient Linear Time Lempel–Ziv Factorization for Small Alphabets. In Proceedings of the 2014 Data Compression Conference, Snowbird, UT, USA, 26–28 March 2014; pp. 163–172. [Google Scholar]
- Kärkkäinen, J.; Kempa, D.; Puglisi, S.J. Lightweight Lempel–Ziv Parsing. In International Symposium on Experimental Algorithms; LNCS; Springer: Berlin/Heidelberg, Germany, 2013; Volume 7933, pp. 139–150. [Google Scholar]
- Kosolobov, D. Faster Lightweight Lempel–Ziv Parsing. In International Symposium on Mathematical Foundations of Computer Science; LNCS; Springer: Berlin/Heidelberg, Germany, 2015; Volume 9235, pp. 432–444. [Google Scholar]
- Belazzougui, D.; Puglisi, S.J. Range Predecessor and Lempel–Ziv Parsing. In Proceedings of the Twenty-Seventh Annual ACM-SIAM Symposium on Discrete Algorithms, Arlington, VA, USA, 10–12 January 2016; pp. 2053–2071. [Google Scholar]
- Okanohara, D.; Sadakane, K. An Online Algorithm for Finding the Longest Previous Factors. In European Symposium on Algorithms; LNCS; Springer: Berlin/Heidelberg, Germany, 2008; Volume 5193, pp. 696–707. [Google Scholar]
- Prezza, N.; Rosone, G. Faster Online Computation of the Succinct Longest Previous Factor Array. In Conference on Computability in Europe; LNCS; Springer: Cham, Switzerland, 2020; Volume 12098, pp. 339–352. [Google Scholar]
- Bannai, H.; Inenaga, S.; Köppl, D. Computing All Distinct Squares in Linear Time for Integer Alphabets. In Proceedings of the 28th Annual Symposium on Combinatorial Pattern Matching (CPM 2017), Warsaw, Poland, 4–6July 2017; Volume 78, LIPIcs. pp. 22:1–22:18. Available online: https://link.springer.com/chapter/10.1007/978-3-662-48057-1_16 (accessed on 16 April 2021).
- Jacobson, G. Space-efficient Static Trees and Graphs. In Proceedings of the 30th Annual Symposium on Foundations of Computer Science Research, Triangle Park, NC, USA, 30 October–1 November 1989; pp. 549–554. [Google Scholar]
- Clark, D.R. Compact Pat Trees. Ph.D. Thesis, University of Waterloo, Waterloo, ON, Canada, 1996. [Google Scholar]
- Baumann, T.; Hagerup, T. Rank-Select Indices Without Tears. In Proceedings of the Algorithms and Data Structures—16th International Symposium, WADS 2019, Edmonton, AB, Canada, 5–7 August 2019; LNCS. Volume 11646, pp. 85–98. [Google Scholar]
- Munro, J.I.; Navarro, G.; Nekrich, Y. Space-Efficient Construction of Compressed Indexes in Deterministic Linear Time. In Proceedings of the Twenty-Eighth Annual ACM-SIAM Symposium on Discrete Algorithms, Barcelona, Spain, 16–19 January 2017; pp. 408–424. [Google Scholar]
- Burrows, M.; Wheeler, D.J. A Block Sorting Lossless Data Compression Algorithm; Technical Report 124; Digital Equipment Corporation: Palo Alto, CA, USA, 1994. [Google Scholar]
- Lempel, A.; Ziv, J. On the Complexity of Finite Sequences. IEEE Trans. Inf. Theory 1976, 22, 75–81. [Google Scholar] [CrossRef]
- Fischer, J.; Mäkinen, V.; Navarro, G. Faster entropy-bounded compressed suffix trees. Theor. Comput. Sci. 2009, 410, 5354–5364. [Google Scholar] [CrossRef]
- Manacher, G.K. A New Linear-Time “On-Line” Algorithm for Finding the Smallest Initial Palindrome of a String. J. ACM 1975, 22, 346–351. [Google Scholar] [CrossRef]
- Apostolico, A.; Breslauer, D.; Galil, Z. Parallel Detection of all Palindromes in a String. Theor. Comput. Sci. 1995, 141, 163–173. [Google Scholar] [CrossRef][Green Version]
- Köppl, D. Exploring Regular Structures in Strings. Ph.D. Thesis, TU Dortmund, Dortmund, Germany, 2018. [Google Scholar]
- Grossi, R.; Vitter, J.S. Compressed Suffix Arrays and Suffix Trees with Applications to Text Indexing and String Matching. SIAM J. Comput. 2005, 35, 378–407. [Google Scholar] [CrossRef]
- Fleischer, L.; Shallit, J.O. Words Avoiding Reversed Factors, Revisited. arXiv 2019, arXiv:1911.11704. [Google Scholar]



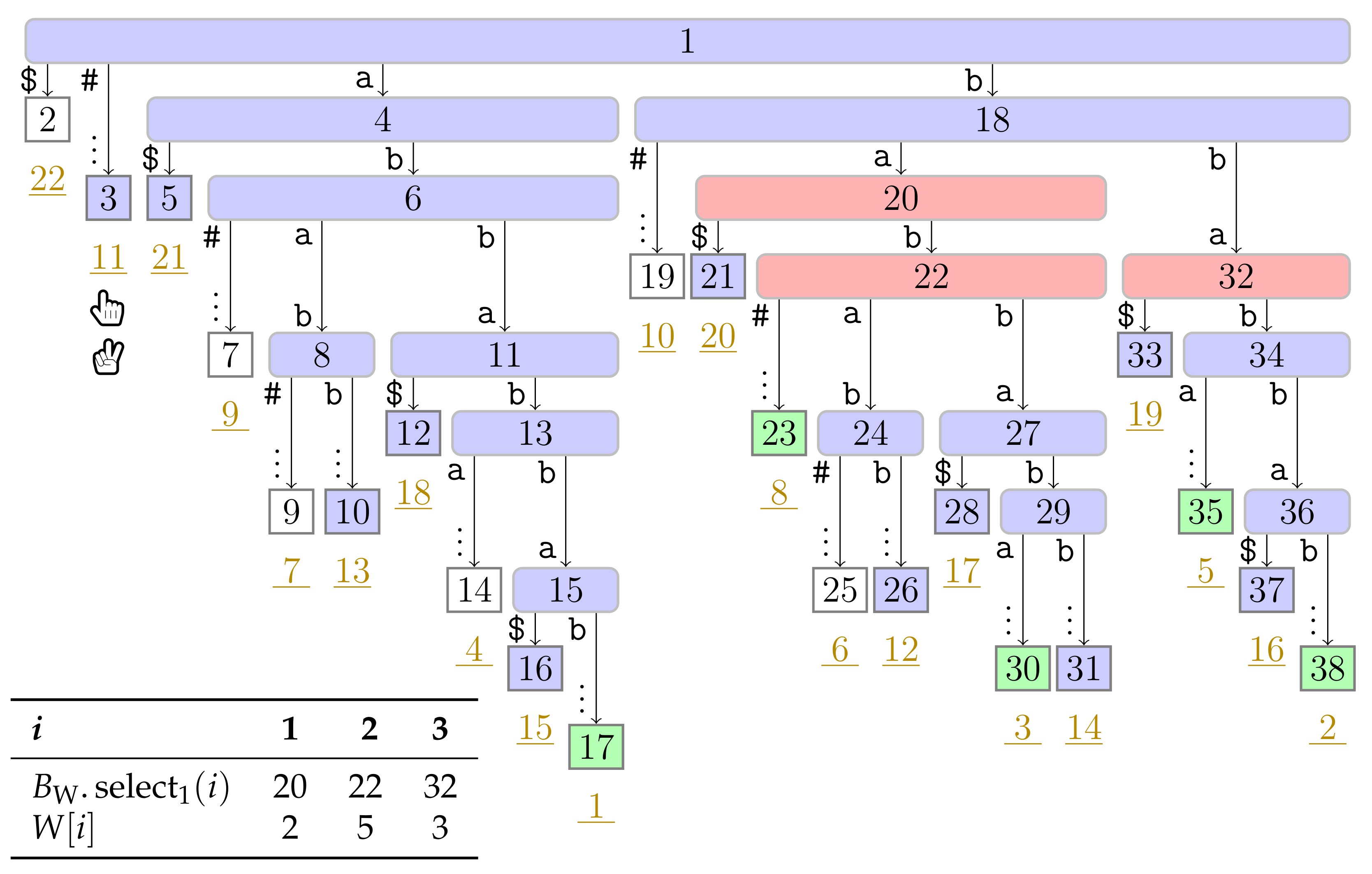
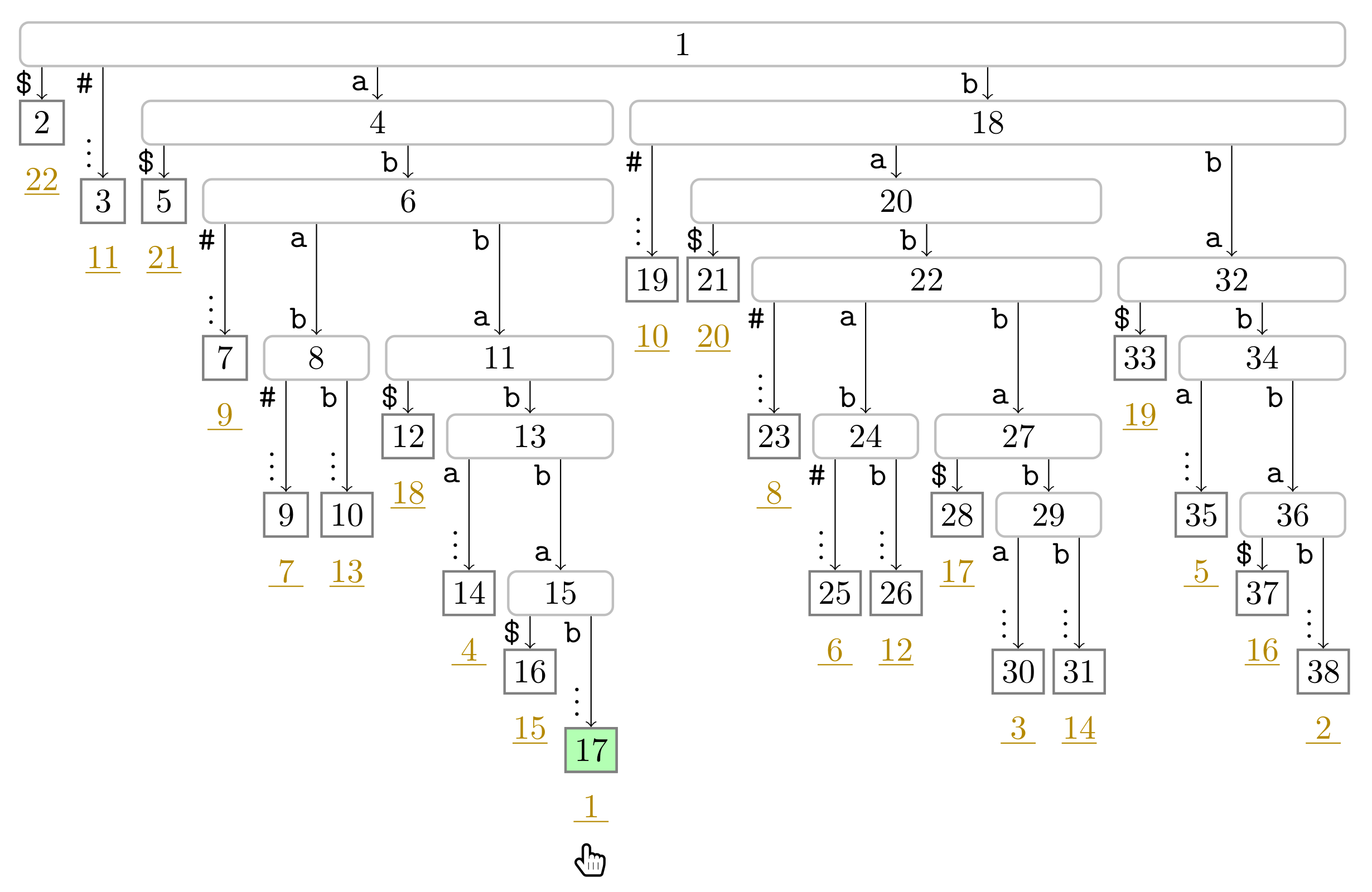
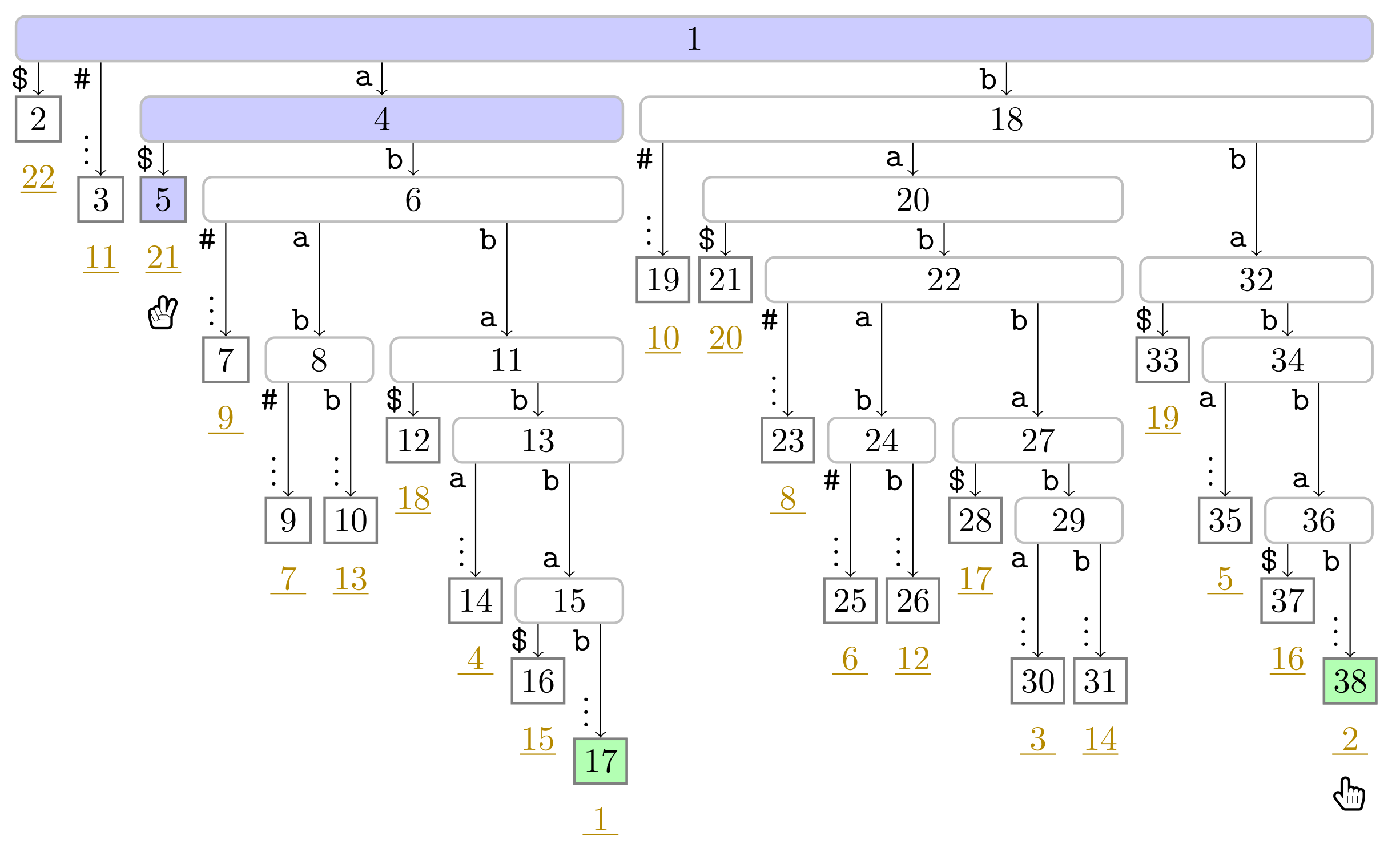
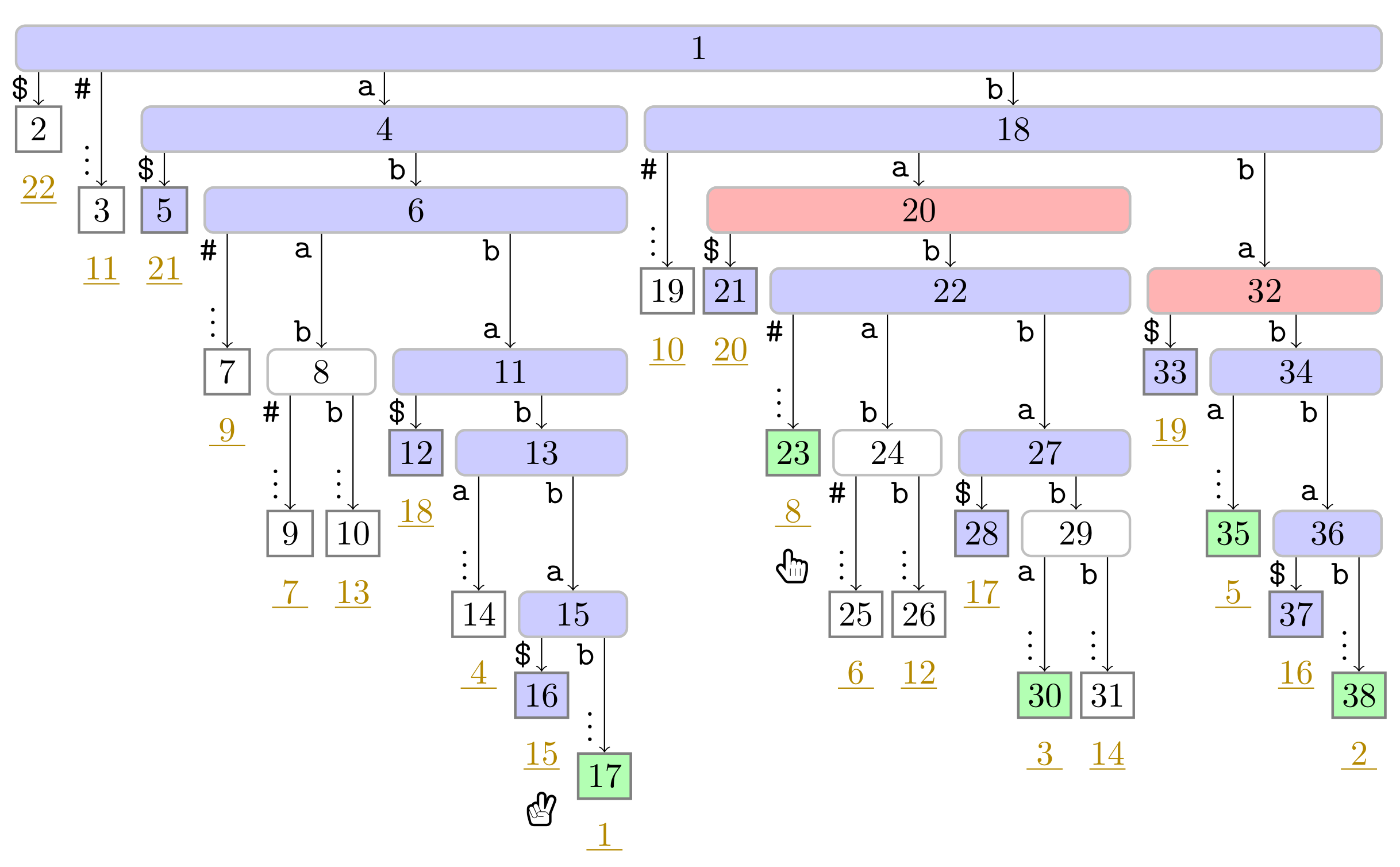
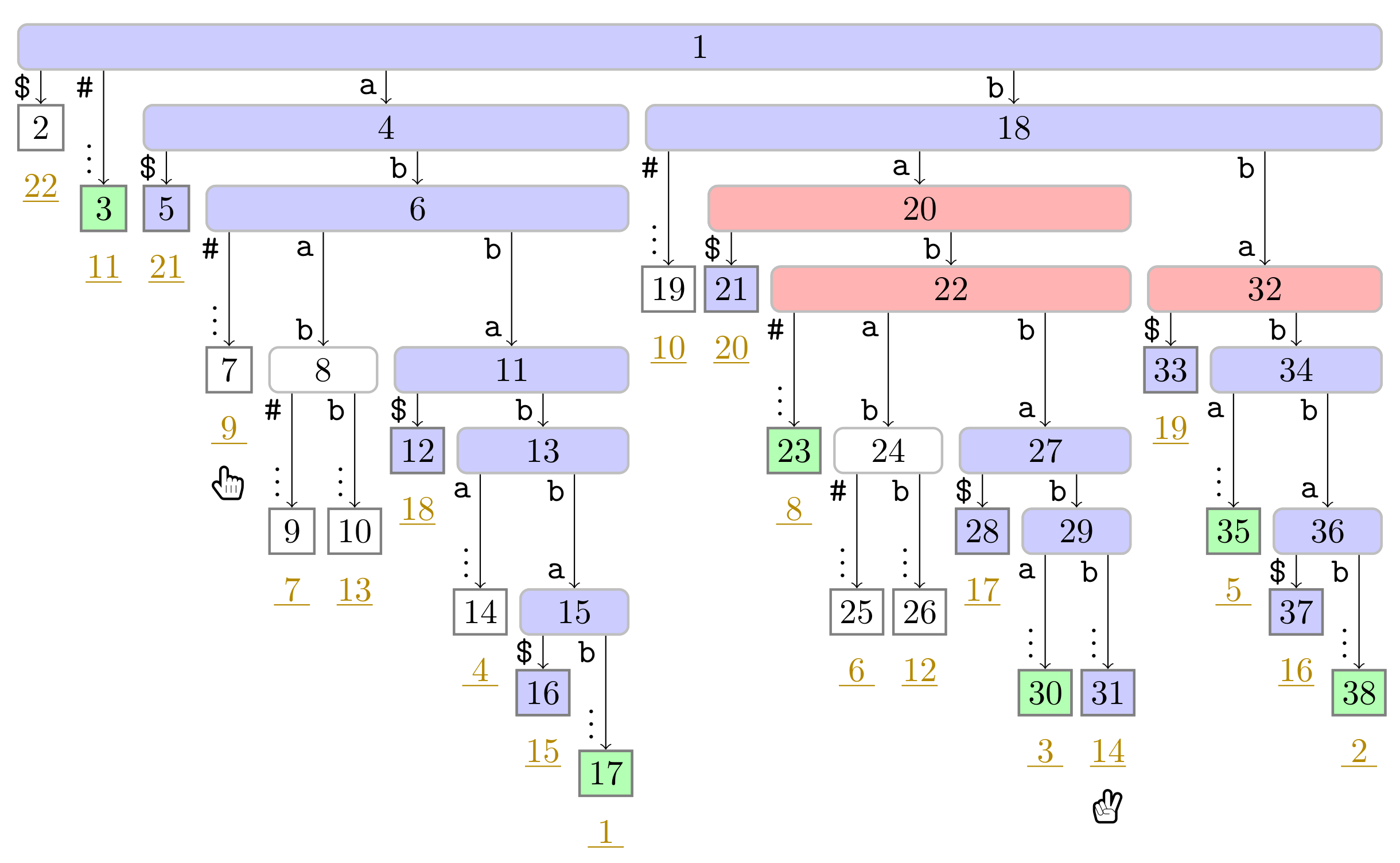
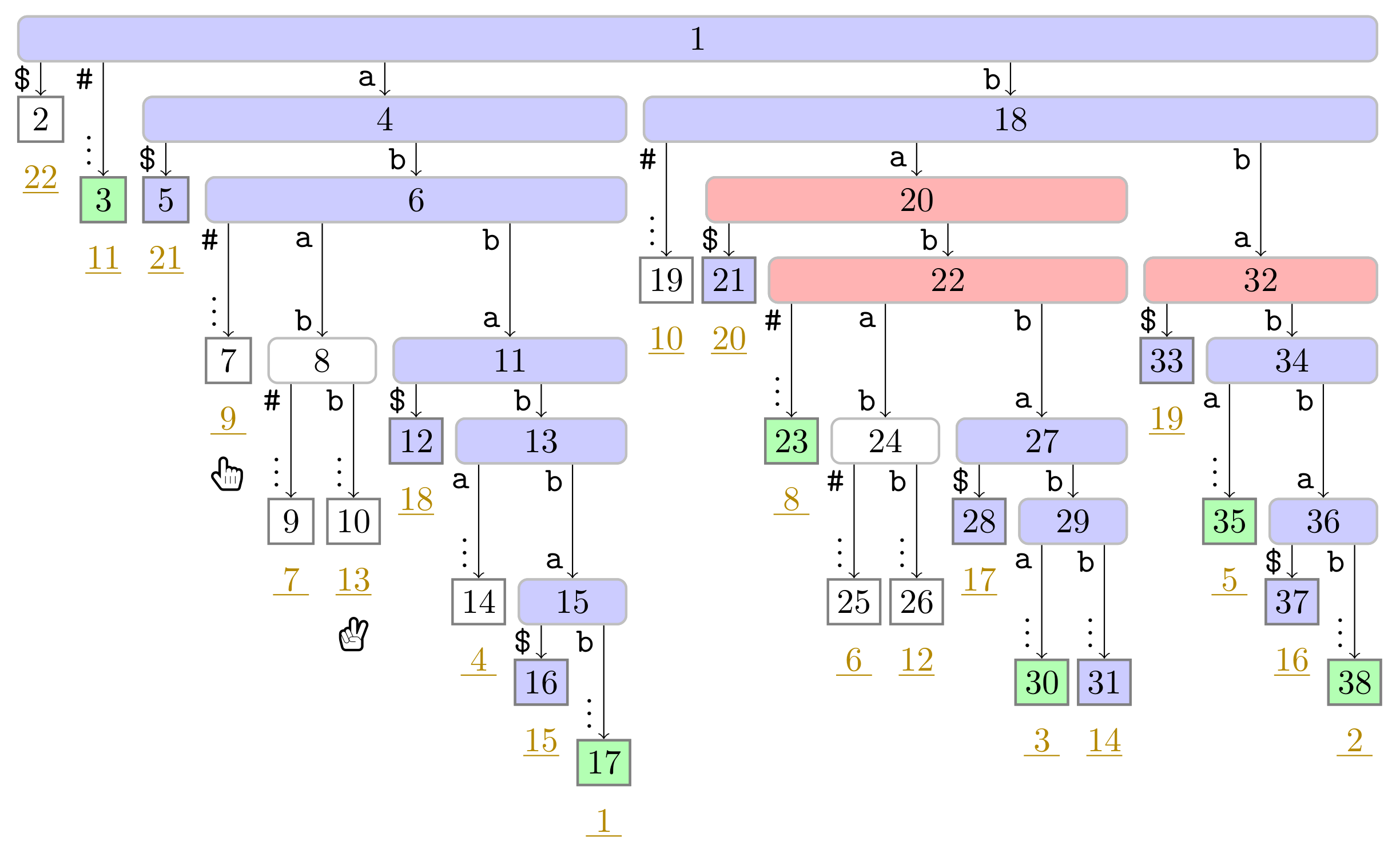
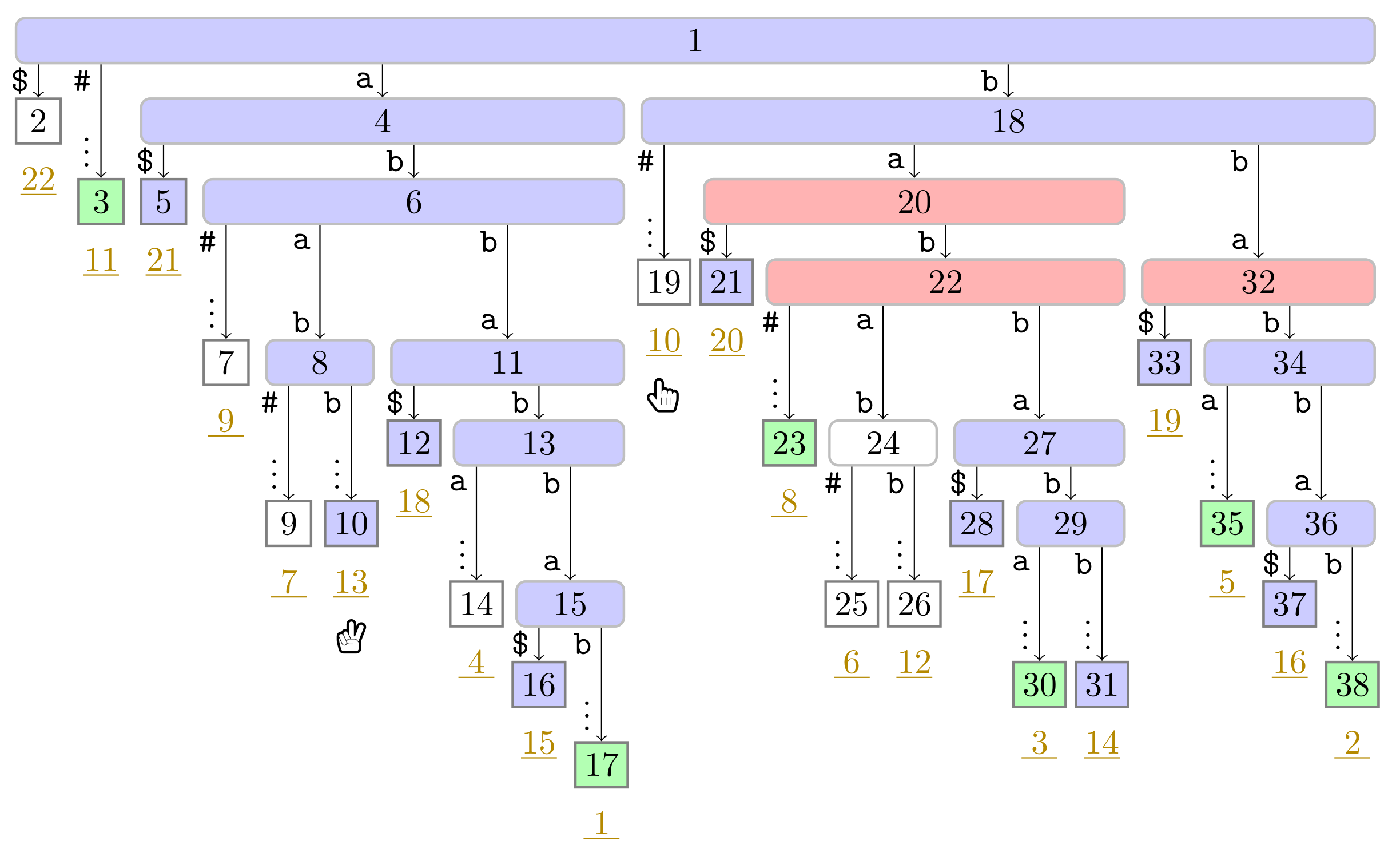
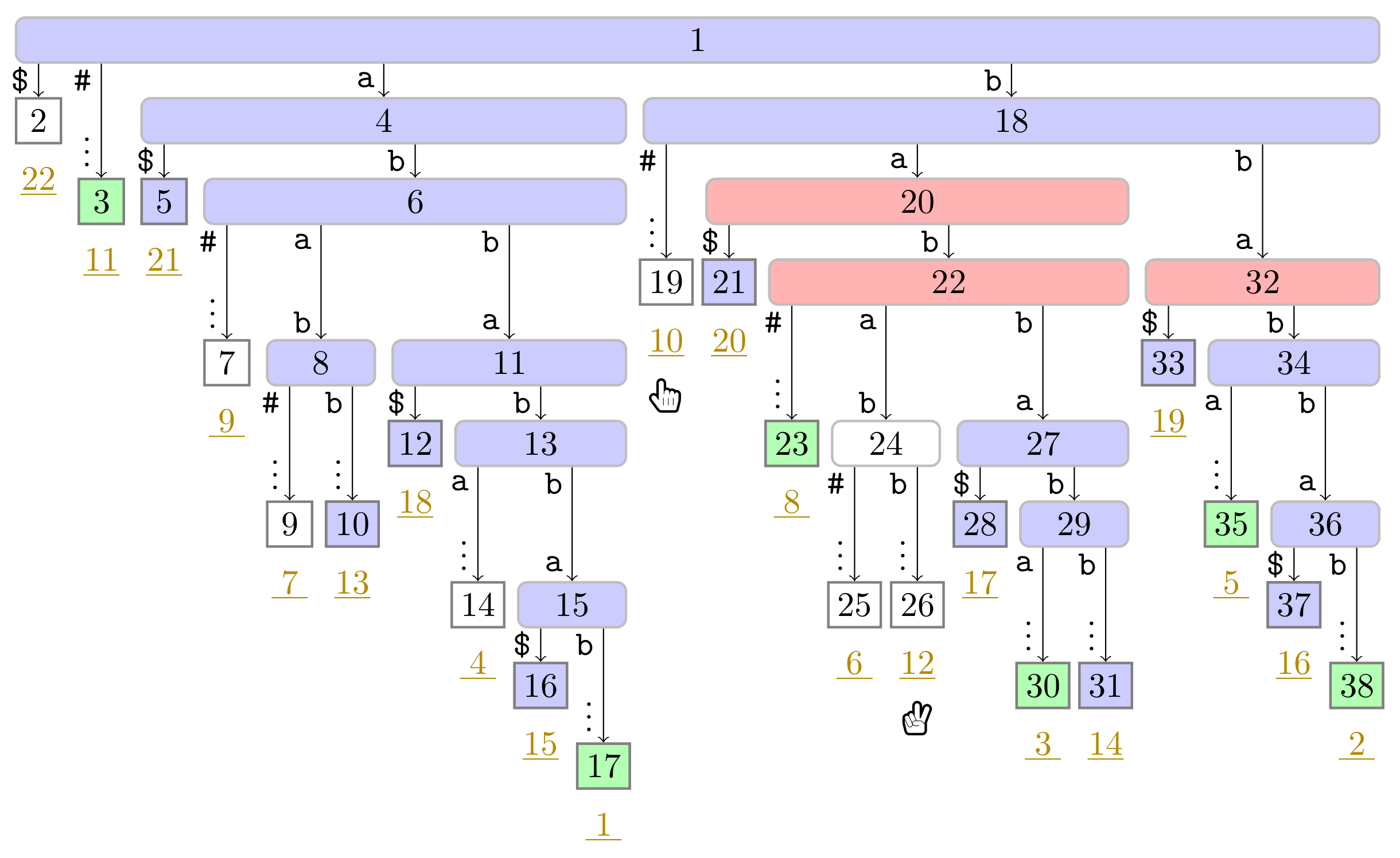
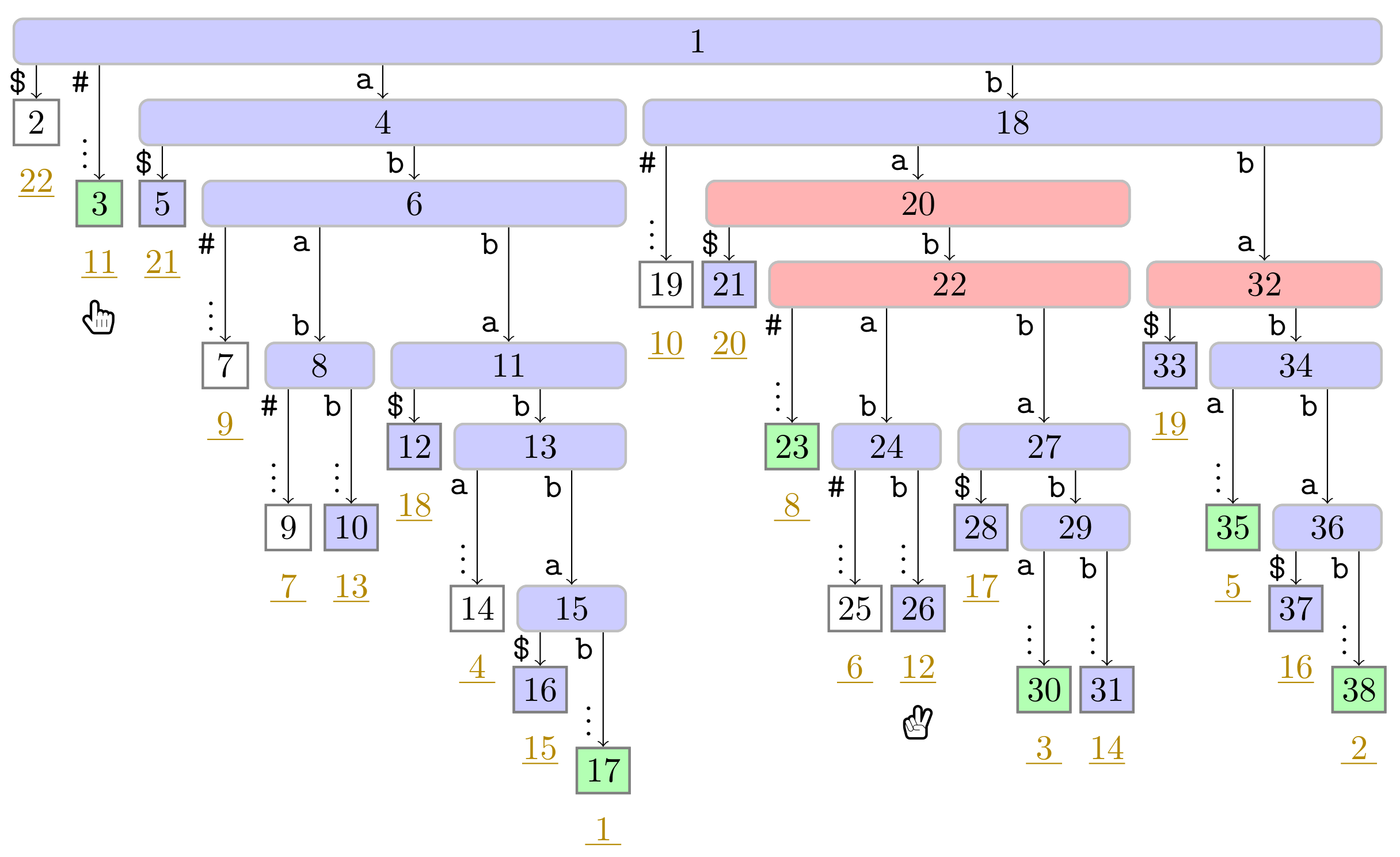
 ), the phrase leaves are colored in green (
), the phrase leaves are colored in green ( ). Player 1 and 2 are represented by the hands
). Player 1 and 2 are represented by the hands  and
and  , respectively, pointing to the respective leaves they visited during the first turn.
), the phrase leaves are colored in green (). Player 1 and 2 are represented by the hands and , respectively, pointing to the respective leaves they visited during the first turn.
, respectively, pointing to the respective leaves they visited during the first turn.
), the phrase leaves are colored in green (). Player 1 and 2 are represented by the hands and , respectively, pointing to the respective leaves they visited during the first turn.
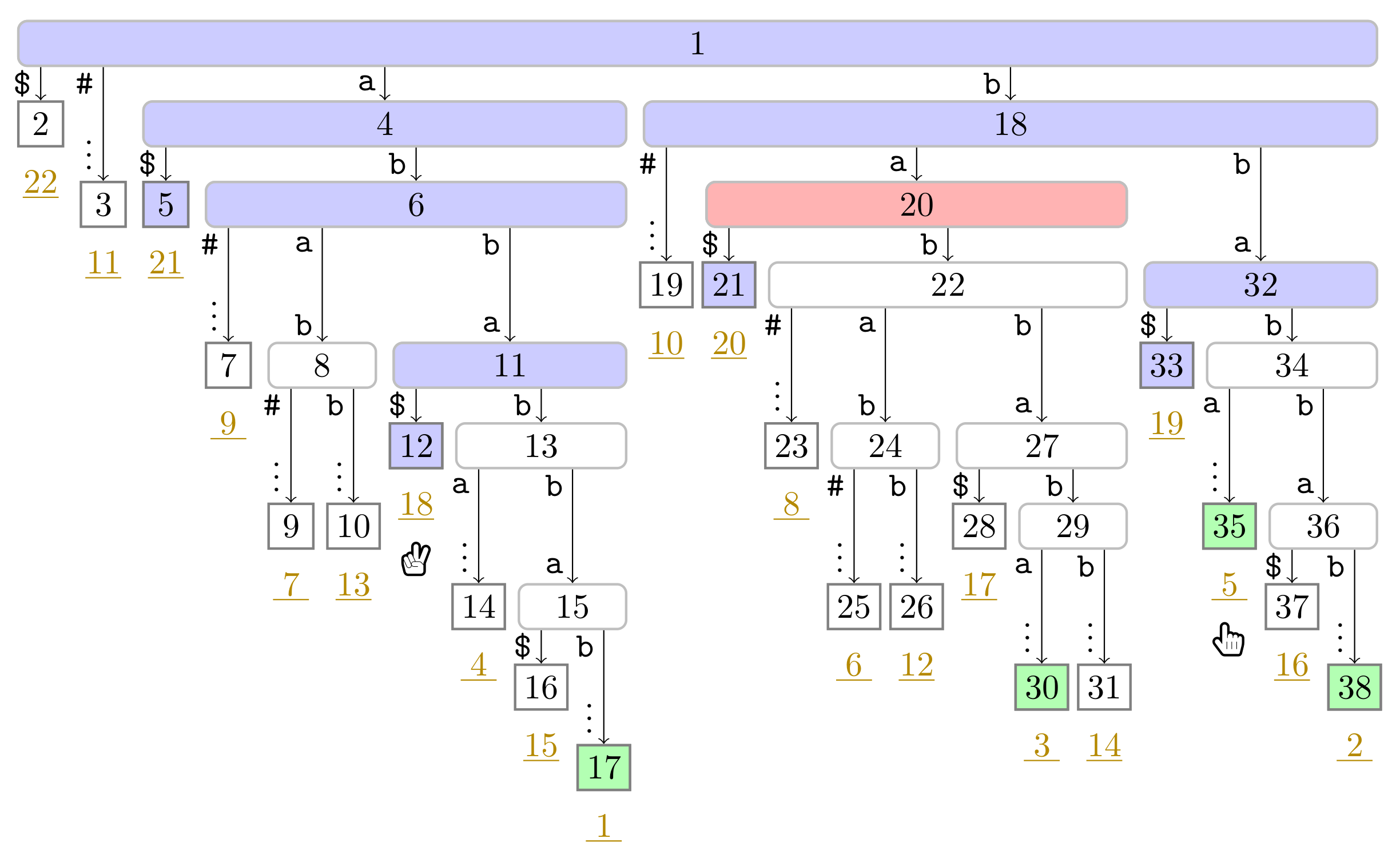
 ). In this figure, Player 1 just finished her turn on making the node with preorder number 32 the witness w of the leaf with suffix number 5. With w we know that the factor starting at text position 5 has the length and that the next phrase leaf has suffix number 8. For visualization purposes, we left the hand () of Player 2 below the leaf of her last turn.
). In this figure, Player 1 just finished her turn on making the node with preorder number 32 the witness w of the leaf with suffix number 5. With w we know that the factor starting at text position 5 has the length and that the next phrase leaf has suffix number 8. For visualization purposes, we left the hand () of Player 2 below the leaf of her last turn.
). In this figure, Player 1 just finished her turn on making the node with preorder number 32 the witness w of the leaf with suffix number 5. With w we know that the factor starting at text position 5 has the length and that the next phrase leaf has suffix number 8. For visualization purposes, we left the hand () of Player 2 below the leaf of her last turn.
). In this figure, Player 1 just finished her turn on making the node with preorder number 32 the witness w of the leaf with suffix number 5. With w we know that the factor starting at text position 5 has the length and that the next phrase leaf has suffix number 8. For visualization purposes, we left the hand () of Player 2 below the leaf of her last turn. ), and the bit vector of length 38 (the maximum preorder number of an node) storing a one at the entries , and 32, i.e., the preorder numbers of the witnesses, which are colored red (). During the second pass described in Section 3.3, we compute W storing the referred positions in the order of the witness ranks (left table).
), and the bit vector of length 38 (the maximum preorder number of an node) storing a one at the entries , and 32, i.e., the preorder numbers of the witnesses, which are colored red (). During the second pass described in Section 3.3, we compute W storing the referred positions in the order of the witness ranks (left table).
), and the bit vector of length 38 (the maximum preorder number of an node) storing a one at the entries , and 32, i.e., the preorder numbers of the witnesses, which are colored red (). During the second pass described in Section 3.3, we compute W storing the referred positions in the order of the witness ranks (left table).
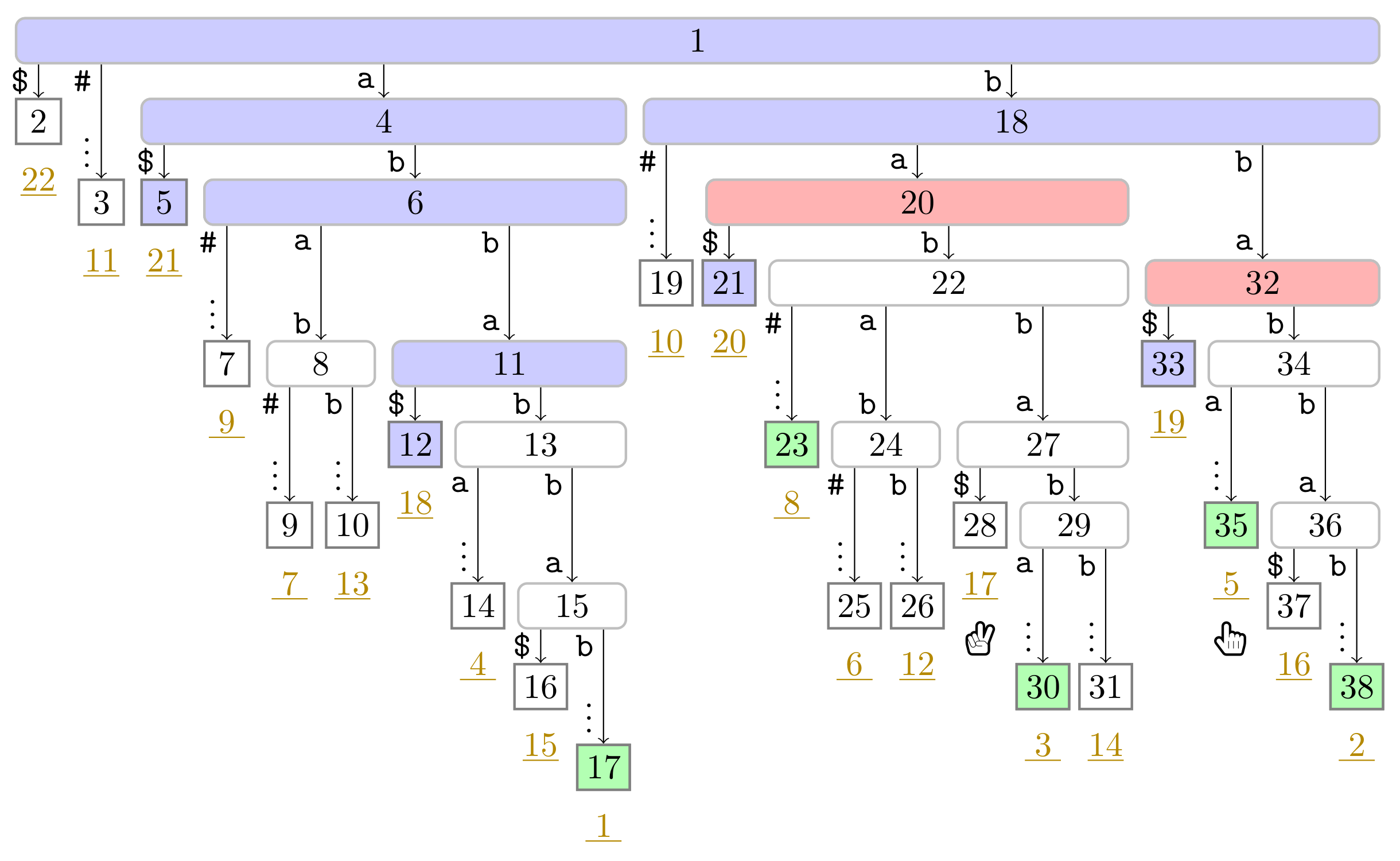
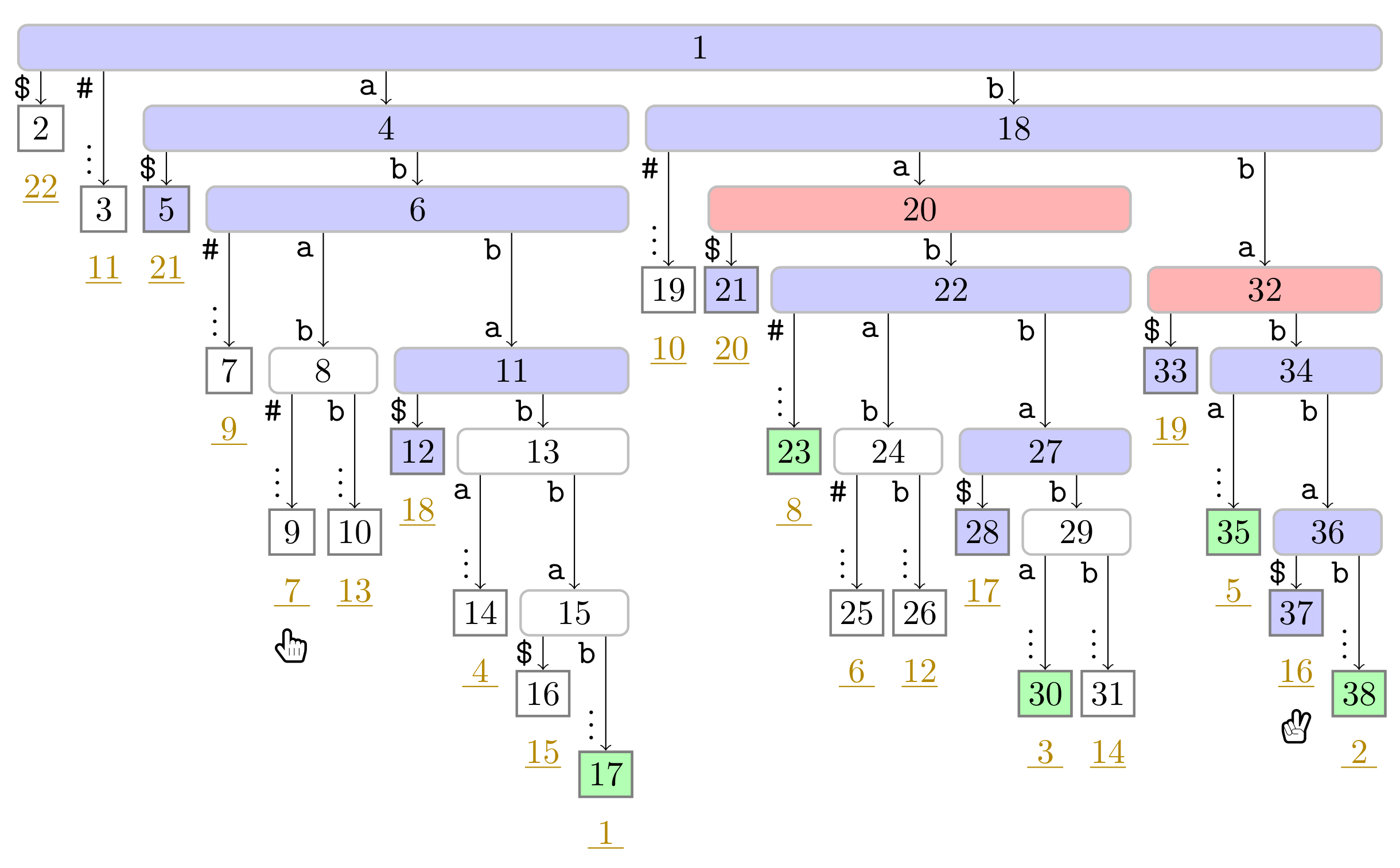
), and the bit vector of length 38 (the maximum preorder number of an node) storing a one at the entries , and 32, i.e., the preorder numbers of the witnesses, which are colored red (). During the second pass described in Section 3.3, we compute W storing the referred positions in the order of the witness ranks (left table). ). Curly arcs symbolize paths that can visit multiple nodes (which are not visualized). When visiting the lowest ancestor of marked in for computing , Player 1 determines such that she can skip the nodes on the path from the root to the leaf for computing (these nodes are symbolized by the curly arc highlighted in yellow (
). Curly arcs symbolize paths that can visit multiple nodes (which are not visualized). When visiting the lowest ancestor of marked in for computing , Player 1 determines such that she can skip the nodes on the path from the root to the leaf for computing (these nodes are symbolized by the curly arc highlighted in yellow ( ) on the right). There are leaves and with suffix numbers of at least and , respectively, since otherwise w would not have been marked in by Player 2.
). Curly arcs symbolize paths that can visit multiple nodes (which are not visualized). When visiting the lowest ancestor of marked in for computing , Player 1 determines such that she can skip the nodes on the path from the root to the leaf for computing (these nodes are symbolized by the curly arc highlighted in yellow () on the right). There are leaves and with suffix numbers of at least and , respectively, since otherwise w would not have been marked in by Player 2.
) on the right). There are leaves and with suffix numbers of at least and , respectively, since otherwise w would not have been marked in by Player 2.
). Curly arcs symbolize paths that can visit multiple nodes (which are not visualized). When visiting the lowest ancestor of marked in for computing , Player 1 determines such that she can skip the nodes on the path from the root to the leaf for computing (these nodes are symbolized by the curly arc highlighted in yellow () on the right). There are leaves and with suffix numbers of at least and , respectively, since otherwise w would not have been marked in by Player 2.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Bits of Working Space (Excluding the Read-Only Text T) | ||
|---|---|---|
| Reference | Type | Time |
| [21] ([Corollary 3.7]) | overlapping LZSS | |
| [34] ([Lemma 6]) | ||
| [22] ([Theorem 1]) | non-overlapping LZSS | |
| [22] ([Theorem 3]) | ||
| Bits of Working Space | ||
| Reference | Type | Time |
| [21] ([Corollary 3.4]) | overlapping LZSS | |
| [34] ([Lemma 6]) | ||
| [22] ([Theorem 1]) | non-overlapping LZSS | |
| [22] ([Theorem 3]) | ||
| SST | CST | |
|---|---|---|
| Time | ||
| Space |
| Operation | SST Time | CST Time |
|---|---|---|
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Köppl, D. Reversed Lempel–Ziv Factorization with Suffix Trees. Algorithms 2021, 14, 161. https://doi.org/10.3390/a14060161
Köppl D. Reversed Lempel–Ziv Factorization with Suffix Trees. Algorithms. 2021; 14(6):161. https://doi.org/10.3390/a14060161
Chicago/Turabian StyleKöppl, Dominik. 2021. "Reversed Lempel–Ziv Factorization with Suffix Trees" Algorithms 14, no. 6: 161. https://doi.org/10.3390/a14060161
APA StyleKöppl, D. (2021). Reversed Lempel–Ziv Factorization with Suffix Trees. Algorithms, 14(6), 161. https://doi.org/10.3390/a14060161