
Lexicographic Unranking of Combinations Revisited


Abstract
1. Introduction
Combinatorial Context
- In the lexicographic order, we say that A is smaller than B if and only if both combinations have the same (possibly empty) prefix such that and if in addition .
- In the co-lexicographic order, we say that A is smaller than B if and only if the finite sequence is smaller than for the lexicographic order.
- If A is smaller than B for a given order, then, for the reverse order, B is smaller that A.
2. Unranking through Factoradics: A New Strategy
2.1. Link between the Factorial Number System and Permutations
| Algorithm 1 Unranking a permutation. | ||
| 1: function Extract(F,n,k) | ||
| 1: function UnrankingPermutation(n,u) | 2: P ← [0,1,…,n − 1] | |
| 2: F ← factoradic(u) | 3: L ← [0,…,0] | ▷ k components |
| 3. while do | 4. for i from 0 to do | |
| 4: | 5: | |
| 5: return | 6: | |
| 7: return L | ||
| factoradic: computes the factoradic of u; | ||
| length: computes the number of components in F; | ||
| append: appends the element i at the end of F; | ||
| remove: removes from F the element at index i. | ||
2.2. Combinations Unranking through Factoradics
- We define a bijection between the combinations of k elements among n and a subset of the permutations of n elements.
- We transform the combination rank u into the rank of the appropriate permutation.
- We build (the prefix of) the permutation of rank by using Algorithm 1.
- The values of for all have been computed and stored in F.
- The value of (which has not been determined yet, as we enter the loop) is at least m.
- The variable holds the rank of the sequence (note that ) among all sequences satisfying the condition of Fact 2 with and .
| Algorithm 2 Unranking a combination. | ||
| 1: function RankConversion(n,k,u) | ||
| 2: F ← [0,…,0] ▷ n components in F | ||
| 3: i ← 0 | ||
| 4: m ← 0 | ||
| 5: while i < k do | ||
| 1: function UnrankingCombination(n,k,u) 2: u′ ← RankConversion(n,k,u) 3: p ← UnrankingPermutation(n,u′) 4: return the first k elements of p | 6: b ← binomial(n − 1 − m − i,k − 1 − i) | |
| 7: if b > u then | ||
| 8: F[n − 1 − i] ← m | ||
| 9: i ← i + 1 | ||
| 10: else | ||
| 11: u ← u − b | ||
| 12: m ← m + 1 | ||
| 13: ▷F is the factoradic decomposition | ||
| 14: return composition(F) | ||
| binomial(n,k) computes the value of ; | ||
| composition(F): computes the integer whose factoradic is F. | ||
3. Classical Unranking Algorithms
3.1. Unranking through the Recursive Method
| Algorithm 3 Recursive Unranking. | |
| 1: function UnrankingRecursive(n,k,u) 2: L ← RecGeneration(n,k,u) 3: L′ ← [0,…,0] ▷ k components 4: for i from 0 to k − 1 do 5: L′[i] ← n − 1 − L[k − 1 − i] 6: return L′ | 1: function RecGeneration(n,k,u) 2: if k = 0 then 3: return [] 4: if n = k then 5: return [0,1,2,…,k − 1] 6: b ← binomial(n − 1,k − 1) 7: if u < b then 8: R ← RecGeneration(n − 1,k − 1,u) 9: append(R,n − 1) 10: return R 11: else 12: return RecGeneration(n−1,k,u−b) |
3.2. Unranking through Combinadics
| Algorithm 4 Unranking a combination. |
| 1: function UnrankingViaCombinadic() |
| 2. ▹k components |
| 3. |
| 4. |
| 5. for i from 0 to do |
| 6. |
| 7. |
| 8. while do |
| 9. |
| 10. |
| 11. |
| 12. |
| 13. return L |
| Algorithm 5 Unranking a combination (alternative algorithm). |
| 1: function UnrankingViaCombinadic2() |
| 2: ▹k components |
| 3. |
| 4. for i from 0 to do |
| 5. if then |
| 6: else |
| 7: while true do |
| 8: |
| 9: |
| 10: |
| 11: if then exit the loop |
| 12: |
| 13: |
| 14: return L |
4. Improving Efficiency and Realistic Complexity Analysis
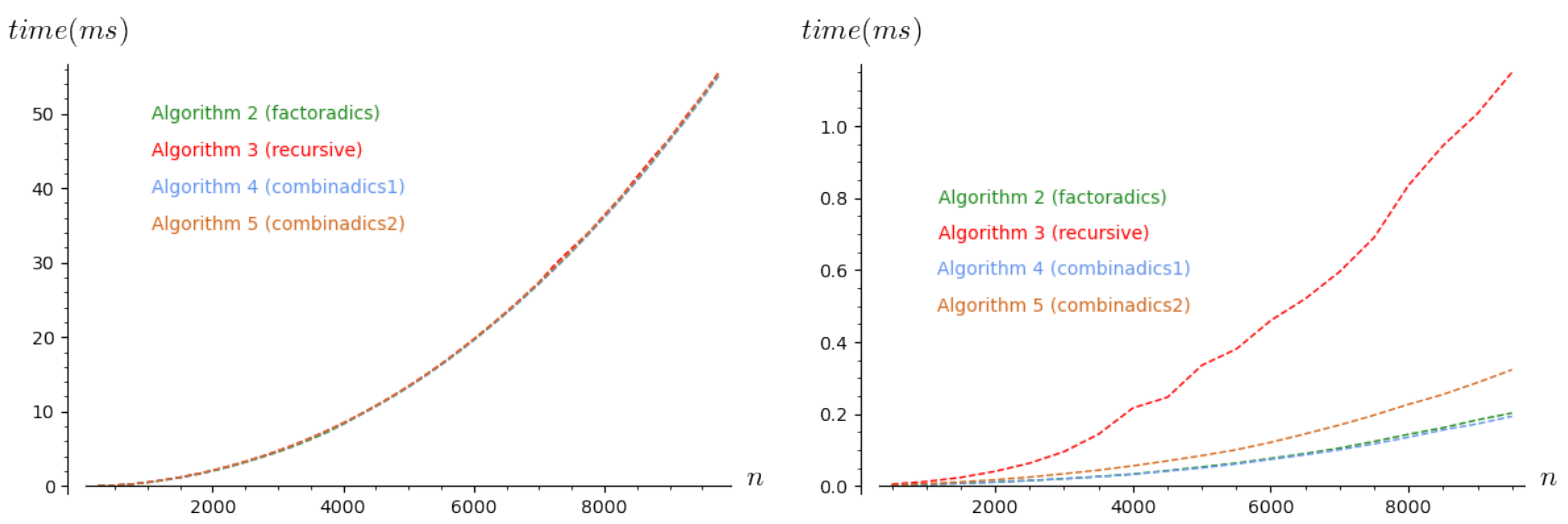
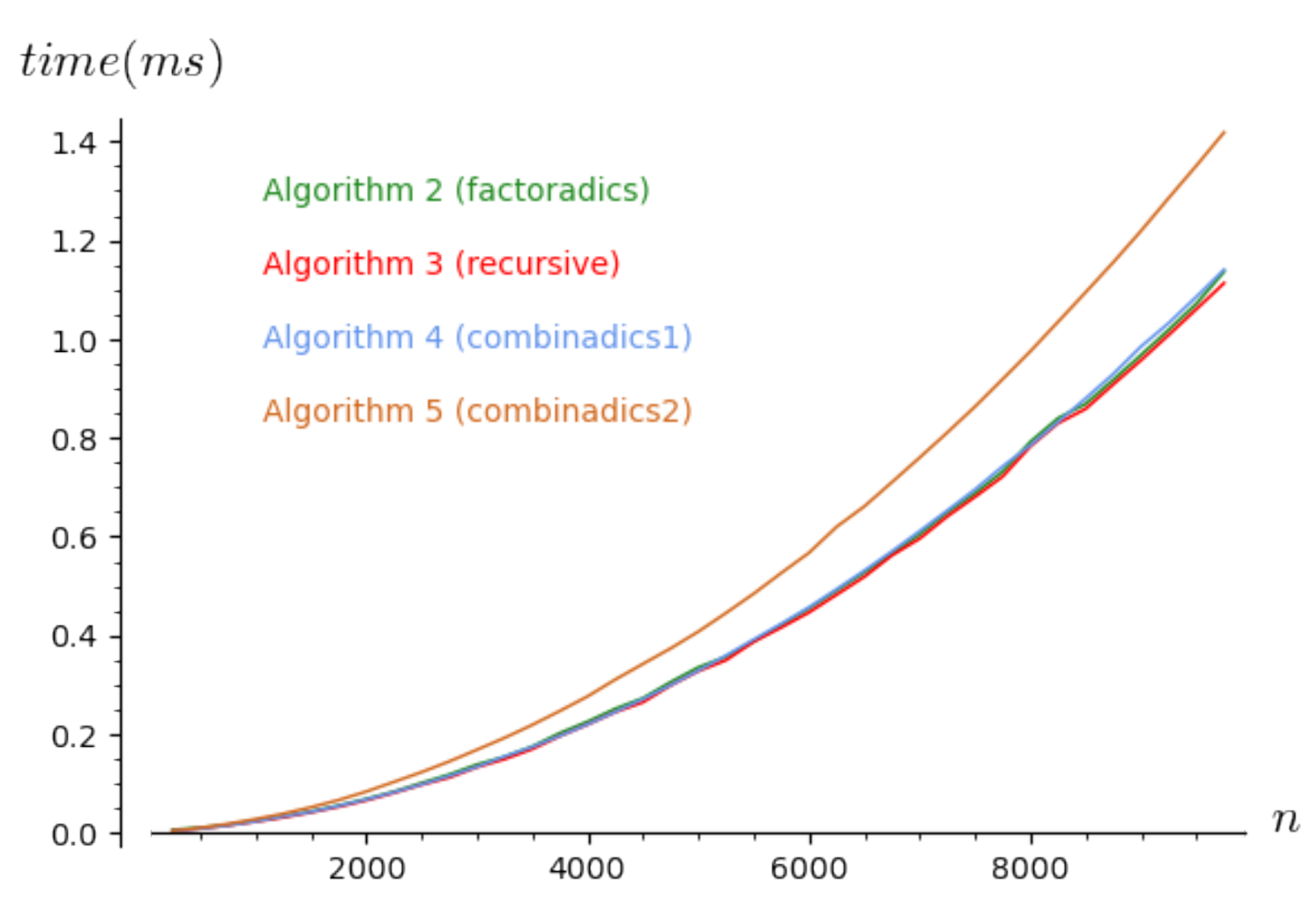
4.1. First Experiments to Visualize the Time Complexity in a Real Context
4.2. Improving the Implementations of the Algorithms
| Algorithm 6 Unranking a combination with optimization. |
| 1: function OptimizedUnrankingCombination() |
| 2: ▹k components |
| 3: |
| 4: ; |
| 5: while do ▹ Invariant: |
| 6: |
| 7: if then |
| 8: |
| 9: |
| 10: |
| 11: else |
| 12: |
| 13: |
| 14: |
| 15: if then |
| 16: return L |
| Algorithm 7 Recursive method with optimizations. | |
| 1: function OptimizedUnranking- Recursive(n,k,u) 2: L ← [0,…,0] ▷ k components 3: b ← binomial(n,k) 4: UnrankTR(L,0,0,n,k,u,b) 5: return L | 1: function UnrankTR(L,i,m,n,k,u,b) 2: if k = 0 then do nothing 3: else if k = n then 4: for j from 0 to k − 1 do 5: L[i + j] ← m + j 6: else 7: b ← b/n 8: if u < b then 9: L[i] ← m 10: b ← (k − 1) · b 11: UnrankTR(L,i + 1,m + 1,n − 1,k − 1,u,b) 12: else 13: u ← u − b 14: b ← (n − k) · b 15: UnrankTR(L,i,m + 1,n − 1,k,u,b) |
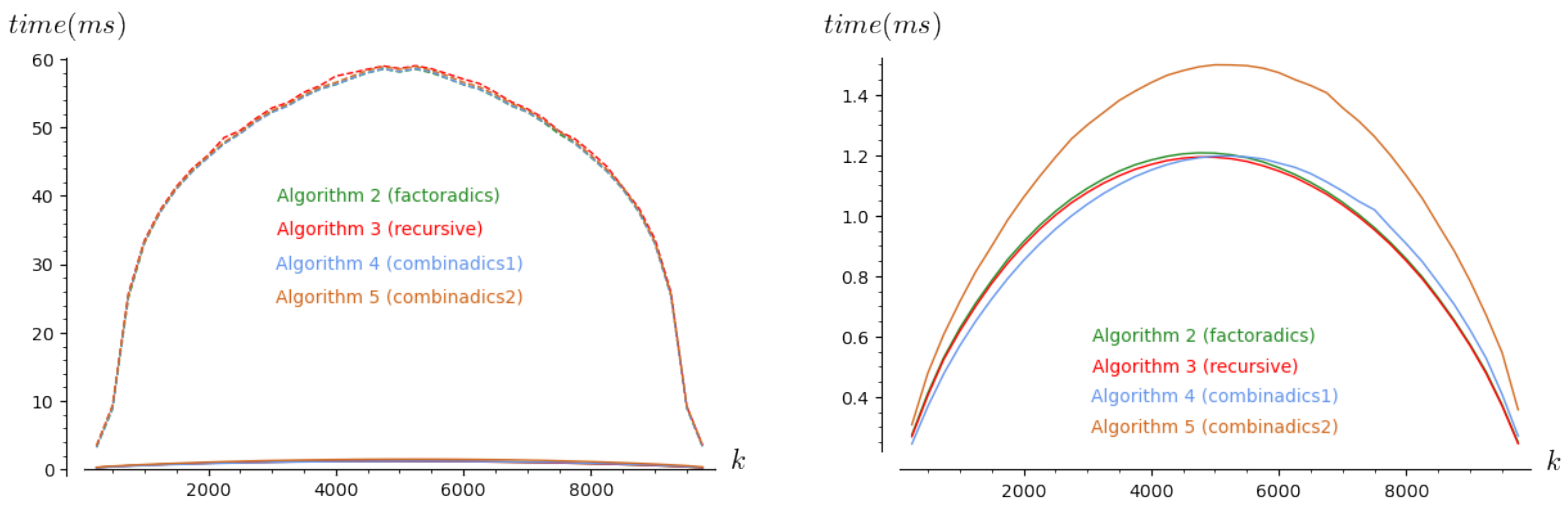
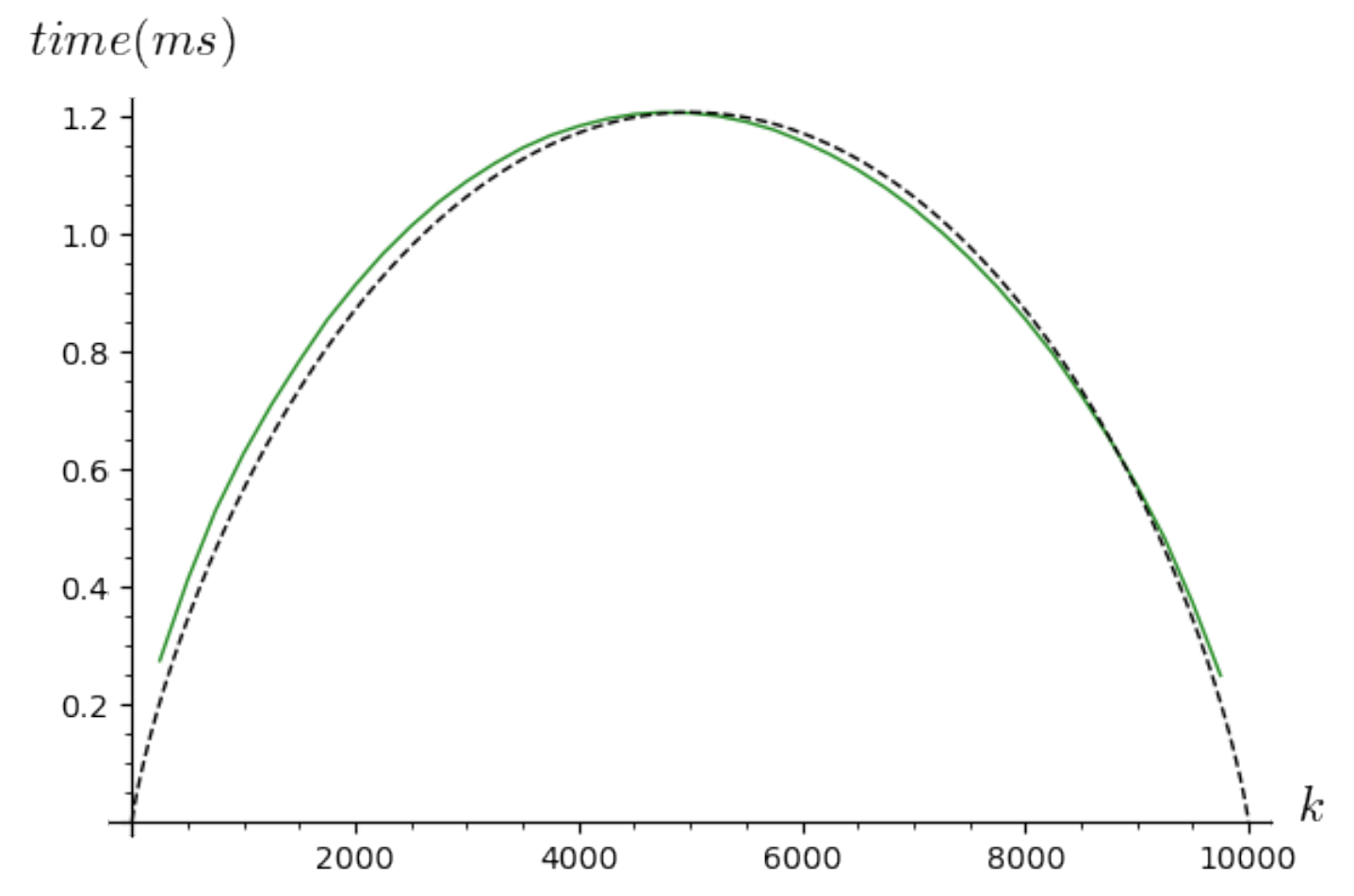
4.3. Realistic Complexity Analysis
5. Extensions of the Algorithmic Context
5.1. Objects Counted by Multinomial Coefficients
| Algorithm 8 Unranking a combination with repetitions. |
| 1: function UnrankingCombinationWithRepetitions() |
| 2: ▷n components in M |
| 3. |
| 4: |
| 5: for i from downto 1 do |
| 6: |
| 7: |
| 8: |
| 9: |
| 10: for j from 0 to do |
| 11: |
| 12: |
| 13: return |
| division: returns the pair corresponding respectively to the quotient and the remainder of |
| the integer division of s by t. |
- The values of for all have been computed and stored in F.
- The values of (which has not been determined yet, as we enter the loop) are equal to the factoradics of the rank in the combinations of elements among possible elements.
- The variable holds the rank of the runs that must be still unranked.
5.2. Objects Counted by k-Permutations
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shablya, Y.; Kruchinin, D.; Kruchinin, V. Method for Developing Combinatorial Generation Algorithms Based on AND/OR Trees and Its Application. Mathematics 2020, 8, 962. [Google Scholar] [CrossRef]
- Grebennik, I.; Lytvynenko, O. Developing software for solving some combinatorial generation and optimization problems. In Proceedings of the 7th International Conference on Application of Information and Communication Technology and Statistics in Economy and Education, Sofia, Bulgaria, 3–4 November 2017; pp. 135–143. [Google Scholar]
- Tamada, Y.; Imoto, S.; Miyano, S. Parallel Algorithm for Learning Optimal Bayesian Network Structure. J. Mach. Learn. Res. 2011, 12, 2437–2459. [Google Scholar]
- Myers, A.F. k-out-of-n:G System Reliability With Imperfect Fault Coverage. IEEE Trans. Reliab. 2007, 56, 464–473. [Google Scholar] [CrossRef]
- Bodini, O.; Genitrini, A.; Naima, M. Ranked Schröder Trees. In Proceedings of the Sixteenth Workshop on Analytic Algorithmics and Combinatorics, ANALCO 2019, San Diego, CA, USA, 6 January 2019; pp. 13–26. [Google Scholar] [CrossRef]
- Ali, N.; Shamoon, A.; Yadav, N.; Sharma, T. Peptide Combination Generator: A Tool for Generating Peptide Combinations. ACS Omega 2020, 5, 5781–5783. [Google Scholar] [CrossRef] [PubMed]
- Ruskey, F. Combinatorial Generation; 2003; (unpublished); Available online: https://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.93.5967 (accessed on 15 March 2021).
- Knuth, D.E. The Art of Computer Programming, Volume 4A, Combinatorial Algorithms; Addison-Wesley Professional: Boston, MA, USA, 2011. [Google Scholar]
- Skiena, S. The Algorithm Design Manual, Third Edition; Texts in Computer Science; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar] [CrossRef]
- Ryabko, B.Y. Fast enumeration of combinatorial objects. Discret. Math. Appl. 1998, 8, 163–182. [Google Scholar] [CrossRef]
- Nijenhuis, A.; Wilf, H.S. Combinatorial Algorithms; Computer Science and Applied Mathematics; Academic Press: New York, NY, USA, 1975. [Google Scholar]
- Flajolet, P.; Zimmermann, P.; Van Cutsem, B. A calculus for the random generation of labelled combinatorial structures. Theor. Comput. Sci. 1994, 132, 1–35. [Google Scholar] [CrossRef]
- Martínez, C.; Molinero, X. A generic approach for the unranking of labeled combinatorial classes. Random Struct. Algorithms 2001, 19, 472–497. [Google Scholar] [CrossRef]
- Kokosinski, Z. Algorithms for Unranking Combinations and their Applications. In Proceedings of the Seventh IASTED/ISMM International Conference on Parallel and Distributed Computing and Systems, Washington, DC, USA, 19–21 October 1995; Hamza, M.H., Ed.; IASTED/ACTA Press: Calgary, AB, Canada, 1995; pp. 216–224. [Google Scholar]
- Pascal, E. Sopra una formula numerica. G. Di Mat. 1887, 25, 45–49. [Google Scholar]
- Beckenbach, E.F.; Pólya, G. Applied Combinatorial Mathematics; R.E. Krieger Publishing Company: Malabar, FL, USA, 1981. [Google Scholar]
- Laisant, C.A. Sur la numération factorielle, application aux permutations. Bull. Soc. Math. Fr. 1888, 16, 176–183. [Google Scholar] [CrossRef]
- Fisher, R.A.; Yates, F. Statistical Tables for Biological, Agricultural and Medical Research; Oliver & Boyd: London, UK, 1948. [Google Scholar]
- Bonet, B. Efficient algorithms to rank and unrank permutations in lexicographic order. In AAAI Workshop on Search in AI and Robotics—Technical Report; The AAAI Press: Menlo Park, CA, USA, 2008; pp. 142–151. [Google Scholar]
- Bodini, O.; Genitrini, A.; Peschanski, F. A Quantitative Study of Pure Parallel Processes. Electron. J. Comb. 2016, 23, 39. [Google Scholar] [CrossRef]
- Durstenfeld, R. Algorithm 235: Random Permutation. Commun. ACM 1964, 7, 420. [Google Scholar] [CrossRef]
- Buckles, B.P.; Lybanon, M. Algorithm 515: Generation of a Vector from the Lexicographical Index [G6]. ACM Trans. Math. Softw. 1977, 3, 180–182. [Google Scholar] [CrossRef]
- Er, M.C. Lexicographic ordering, ranking and unranking of combinations. Int. J. Comput. Math. 1985, 17, 277–283. [Google Scholar] [CrossRef]
- Flajolet, P.; Sedgewick, R. Analytic Combinatorics; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Flajolet, P.; Sedgewick, R. An Introduction to the Analysis of Algorithms, 2nd ed.; Addison Wesley: Boston, MA, USA, 2013. [Google Scholar]
- Kreher, D.L.; Stinson, D.R. Combinatorial Algorithms: Generation, Enumeration, and Search; CRC Press: Boca Raton, FL, USA, 1999. [Google Scholar]
- McCaffrey, J. Generating the mth Lexicographical Element of a Mathematical Combination. MSDN. 2004. Available online: http://docs.microsoft.com/en-us/previous-versions/visualstudio/aa289166(v=vs.70) (accessed on 15 March 2021).
- The Sage Developers. SageMath, the Sage Mathematics Software System (Version 9.2). 2020. Available online: https://www.sagemath.org/ (accessed on 15 March 2021).
- Butler, B. Function kSubsetLexUnrank, MATLAB Central File Exchange. 2015. Available online: http://fr.mathworks.com/matlabcentral/fileexchange/53976-combinatorial-numbering-rank-and-unrank (accessed on 15 March 2021).
- Bostan, A.; Chyzak, F.; Giusti, M.; Lebreton, R.; Lecerf, G.; Salvy, B.; Schost, E. Algorithmes Efficaces en Calcul Formel, 10th ed.; Printed by CreateSpace: Palaiseau, France, 2017; 686p. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time in ms | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Sample | Sagemath | Maple | Mathematica | Matlab | ||||||
| Our Algo. | v. 9.0 | v. 9.2 | v. 2020.0 | v. 12.1.1.0 | v. R2020b | |||||
| Implem. | in C | Their Algo. | New Algo. | Their Algo. | Our Algo. | Their Algo. | Our Algo. | Their Algo. | Our Algo. | |
| 0.05464 | 2.6045 | 2.9672 | 78.2 | 2.12 | 0.44176 | 4.3145 | 3996.6 | 3041.2 | ||
| 0.06052 | 8.8903 | 2.4784 | 614 | 2.96 | 0.34608 | 3.9547 | 3520.6 | 3380.0 | ||
| 0.17496 | 15.8968 | 8.7929 | 1180 | 13.2 | 5.9131 | 11.823 | 11,846 | 9315.2 | ||
| 0.27524 | 96.3589 | 8.0500 | 6130 | 19.2 | 4.9624 | 13.067 | 11,087 | 9879.4 | ||
| 10,000 | 1.2554 | 191.03 | 31.665 | too long | 65.1 | 21.906 | 39.935 | too long | too long | |
| 10,000 | 2.3849 | 2245.6 | 29.027 | too long | 97.9 | 29.916 | 46.452 | too long | too long | |
| k | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|---|
| n | ||||||||||
| 1 | 0 | 1 | ||||||||
| 2 | 0 | 3 | 2 | |||||||
| 3 | 0 | 6 | 8 | 3 | ||||||
| 4 | 0 | 10 | 20 | 15 | 4 | |||||
| 5 | 0 | 15 | 40 | 45 | 24 | 5 | ||||
| 6 | 0 | 21 | 70 | 105 | 84 | 35 | 6 | |||
| 7 | 0 | 28 | 112 | 210 | 224 | 140 | 48 | 7 | ||
| 8 | 0 | 36 | 168 | 378 | 504 | 420 | 216 | 63 | 8 | |
| k | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|---|
| n | ||||||||||
| 1 | 0 | 0 | ||||||||
| 2 | 0 | 2 | 0 | |||||||
| 3 | 0 | 5 | 5 | 0 | ||||||
| 4 | 0 | 9 | 16 | 9 | 0 | |||||
| 5 | 0 | 14 | 35 | 35 | 14 | 0 | ||||
| 6 | 0 | 20 | 64 | 90 | 64 | 20 | 0 | |||
| 7 | 0 | 27 | 105 | 189 | 189 | 105 | 27 | 0 | ||
| 8 | 0 | 35 | 160 | 350 | 448 | 350 | 160 | 35 | 0 | |
| Rank, u | Reversed Rank, | Combinadic of | Combination of Rank u |
|---|---|---|---|
| 0 | 14 | (4, 5) | (0, 1) |
| 1 | 13 | (3, 5) | (0, 2) |
| 2 | 12 | (2, 5) | (0, 3) |
| 3 | 11 | (1, 5) | (0, 4) |
| 4 | 10 | (0, 5) | (0, 5) |
| 5 | 9 | (3, 4) | (1, 2) |
| 6 | 8 | (2, 4) | (1, 3) |
| 7 | 7 | (1, 4) | (1, 4) |
| 8 | 6 | (0, 4) | (1, 5) |
| 9 | 5 | (2, 3) | (2, 3) |
| 10 | 4 | (1, 3) | (2, 4) |
| 11 | 3 | (0, 3) | (2, 5) |
| 12 | 2 | (1, 2) | (3, 4) |
| 13 | 1 | (0, 2) | (3, 5) |
| 14 | 0 | (0, 1) | (4, 5) |
| k | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|---|
| n | ||||||||||
| 1 | 1 | 2 | ||||||||
| 2 | 1 | 5 | 3 | |||||||
| 3 | 1 | 9 | 11 | 4 | ||||||
| 4 | 1 | 14 | 26 | 19 | 5 | |||||
| 5 | 1 | 20 | 50 | 55 | 29 | 6 | ||||
| 6 | 1 | 27 | 85 | 125 | 99 | 41 | 7 | |||
| 7 | 1 | 35 | 133 | 245 | 259 | 161 | 55 | 8 | ||
| 8 | 1 | 44 | 196 | 434 | 574 | 476 | 244 | 71 | 9 | |
| k | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|---|
| n | ||||||||||
| 1 | 0 | 0 | ||||||||
| 2 | 0 | 0 | 1 | |||||||
| 3 | 0 | 0 | 4 | 2 | ||||||
| 4 | 0 | 0 | 10 | 10 | 3 | |||||
| 5 | 0 | 0 | 20 | 30 | 18 | 4 | ||||
| 6 | 0 | 0 | 35 | 70 | 63 | 28 | 5 | |||
| 7 | 0 | 0 | 56 | 140 | 168 | 112 | 40 | 6 | ||
| 8 | 0 | 0 | 84 | 252 | 378 | 336 | 180 | 54 | 7 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Genitrini, A.; Pépin, M. Lexicographic Unranking of Combinations Revisited. Algorithms 2021, 14, 97. https://doi.org/10.3390/a14030097
Genitrini A, Pépin M. Lexicographic Unranking of Combinations Revisited. Algorithms. 2021; 14(3):97. https://doi.org/10.3390/a14030097
Chicago/Turabian StyleGenitrini, Antoine, and Martin Pépin. 2021. "Lexicographic Unranking of Combinations Revisited" Algorithms 14, no. 3: 97. https://doi.org/10.3390/a14030097
APA StyleGenitrini, A., & Pépin, M. (2021). Lexicographic Unranking of Combinations Revisited. Algorithms, 14(3), 97. https://doi.org/10.3390/a14030097