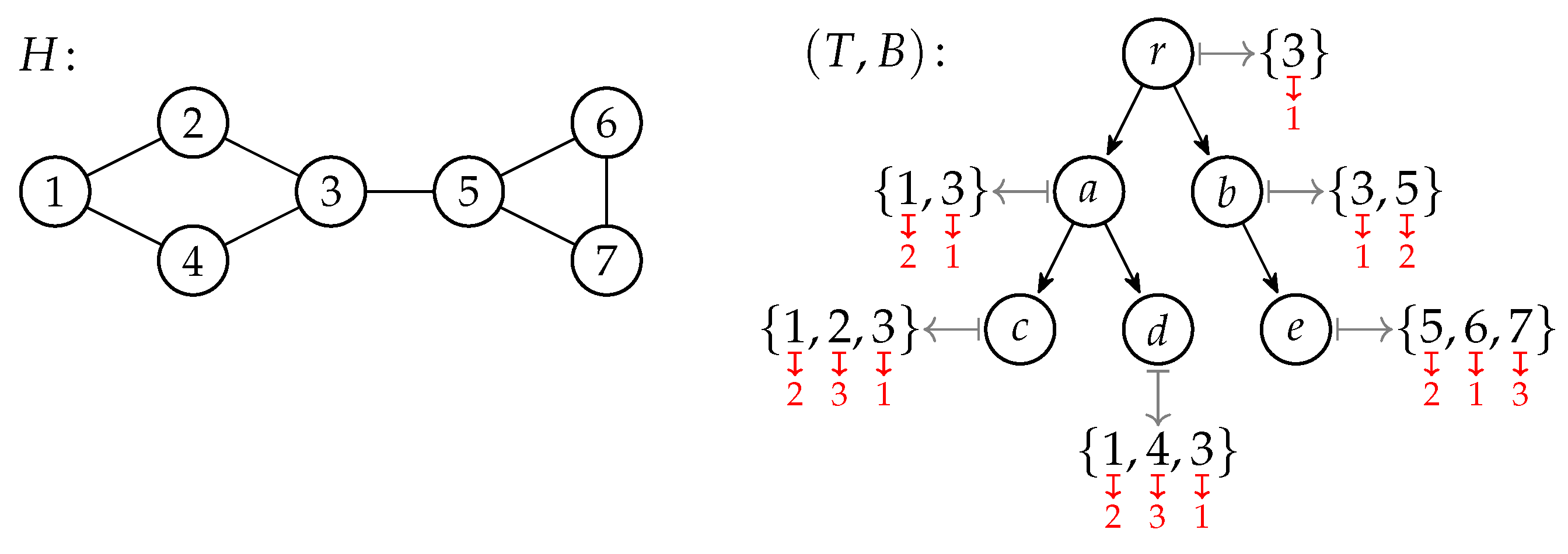
We place a dot on the variables bound by weak quantifiers to make them easier to spot. For example, in the quantifier is weak, but neither are (since x is used in two literals joined by a conjunction, namely in and ) nor (since depends on y in ). We have , but , and , but .
Admittedly, the definition of weakness is a bit technical, but note that there is a rather simple sufficient condition for an existentially-bound variable x to be weak: If it is not used in universal bindings and is used in only one literal that is not an inequality, then x is weak. This condition almost always suffices for identifying the weak variables, although there are of course exceptions like .
Our objective is now to simultaneously remove all weak quantifiers from a formula without increasing the strong quantifier rank by more than a constant factor or the number of strong variables by more than a constant. We first prove this only for existential weak quantifiers in the below theorem (by considering only formulas that do not have weak universal quantifiers). Once we have achieved this, a comparatively simple syntactic duality argument allows us to extend the claim to all formulas in Theorem 4.
Before giving the detailed proof, we briefly sketch the overall idea: Using simple syntactic transformations, we can ensure that all weak quantifiers follow in blocks after universal quantifiers (and, by assumption, all universal quantifiers are strong). We can also ensure that inequality literals directly follow the blocks of weak quantifiers and are joined by conjunctions. If the inequality literals following a block happen to require that all weak variables from the block are different (that is, if for all pairs and of different weak variables there is an inequality ), then we can remove the weak quantifiers and at the (typical single) place where is used, we use a color instead. For instance, if is used in the literal , we replace the literal by . If is used for instance in , we replace this by . In this way, for each block we get an equivalent formula to which we can apply Theorem 2. A more complicated situation arises when the inequality literals in a block “do not require complete distinctness,” but this case can also be handled by considering all possible ways in which the inequalities can be satisfied in parallel. In result, all weak quantifiers get removed and for each block a constant number of new quantifiers are introduced. Since each block follows a different universal quantifier, the new total quantifier rank is at most the strong quantifier rank times a constant factor; and the new number of variables is only a constant above the number of original strong variables.
Proof of Theorem 3. Let
be given. We first apply a number of simple syntactic transformations to move the weak quantifiers directly behind universal quantifiers and to move inequality literals directly behind blocks of weak quantifiers. Then we show how sets of inequalities can be “completed” if necessary. Finally, we inductively transform the formula in such a way that Theorem 2 can be applied repeatedly. As a running example of how the different syntactic transformations work, we use the (semantically not very sensible) formula
In this formula, the (only) universally quantified variable, c, is strong since the existential binding depends on it via . The variable a is strong since depends in it, once more via . Finally, z is strong since it is used is two parts of a conjunction: .
Preliminaries: It will be useful to require that all weak variables are different. Thus, as long as necessary, when a variable is bound by a weak quantifier and once more by another quantifier, replace the variable used by the weak quantifier by a fresh variable. Note that this may increase the number of distinct (weak) variables in the formula, but we will get rid of all of them later on anyway. From now on, we may assume that the weak variables are all distinct from one another and also from all other variables.
It will also be useful to assume that starts with a universal quantifier. If this is not the case, replace by the equivalent formula where v is a fresh variable. This increases the quantifier rank by at most 1.
Finally, it will also be useful to assume that the formula has been “flattened” as in the proof Theorem 1 (one can loosely think of this as bringing the formula “locally into disjunctive normal form”): We use the distributive laws of propositional logic to repeatedly replace subformulas of the form by and by . Note that this transformation does not change which variables are weak.
For our running example, applying the described preprocessing yields:
Syntactic transformations I: blocks of weak quantifiers. The first interesting transformation is the following: We wish to move weak quantifiers “as far up the syntax tree as possible.” To achieve this, we apply the following equivalences as long as possible by always replacing the left-hand side (and also commutatively equivalent formulas) by the right-hand side:
Note that does not contain since we made all weak variables distinct and, of course, by we mean a strong quantifier.
Once the transformations have been applied exhaustively, all weak quantifiers will be directly preceded in
by either a universal quantifier or another weak quantifier. This means that all weak quantifiers are now arranged in blocks inside
, each block being preceded by a universal quantifier.
Syntactic transformations II: weak and strong literals. In order to apply color coding later on, it will be useful to have only three kinds of literals in :
Let us call all other kinds of literals bad. This includes literals like or that contain a relation symbol and some weak variables, but also inequalities involving a weak and a strong variable, equalities involving two weak variables, or an equality literal like the one in . Finally, literals involving the successor function and weak variables are also bad.
In order to get rid of the bad literals, we will replace them by equivalent formulas that do not contain any bad literals. The idea is that we bind the variable or term that we wish to get rid of using a new existential quantifier. In order to avoid introducing too many new variables, for all of the following transformations we use the set of fresh variables , , and so on, where we may need more than one of these variables per literal, but will need no more than (recall that is the maximum arity of relation symbols in ).
Let
be a bad literal, that is, let it contain a weak variable
, but neither be a weak equality nor a weak inequality. Replace
by
. Here,
is our notation for the substitution of the term
by
in
. The number
i is chosen minimally so that
does not already contain
. Since this transformation reduces the number of weak variables in
and does not introduce a bad literal (
is a weak equality and hence “good”), sooner or later we will have gotten rid of all bad literals. For each literal we use at most
new variables from the
(more precisely, at most
in case
contains only unary or no relation symbols and
is something like
, causing two replacements). Overall, we get that
is equivalent to a formula without any bad literals in which we use at most
additional variables and whose quantifier rank is larger than that of
by at most
. Note that the transformation ensures that weak variables stay weak. Applied to our example formula, we get:
Syntactic transformations III: accumulating weak inequalities. We now wish to move all weak inequalities to the “vicinity” of the corresponding block of weak quantifiers. More precisely, just as we did earlier, we apply the following equivalences (interpreted once more as rules that are applied from left to right):
Note that these rules do not change which variables are weak. When these rules can no longer be applied, the weak inequality are “next” to their quantifier block, that is, each subformula starting with weak quantifiers has the form
where the
contain no weak inequalities while all
are weak inequalities.
For our example formula, we get:
Finally, we now swap each block of weak quantifiers with the following disjunction, that is, we apply the following equivalence from left to right:
If necessary, we rename weak variables to ensure once more that they are unique. For our example, the different transformations yield:
Let us spell out the different , , and contained in the above formula: First, there is one block of weak variables () following at the beginning. There is only a single formula for this block, which equals with and . Second, there are two blocks of weak variables ( and ) following , which are followed by (new) formulas and . The first is of the form and the second of the form . There are no and we have . We have and we have .
We make the following observation at this point: Inside each
, each of the variables
to
is used at most once outside of weak inequalities. The reason for this is that rules (
7) and (
8) ensure that there are no disjunctions inside the
that involve a weak variable
. Thus, the requirement “in any subformula of
of the form
only
or
—but not both—may use
in a literal that is not a weak inequality” from the definition of weak variables just boils down to “
may only be used once in
in a literal that is not a weak inequality.” Since weak variables cannot be present in strong literals, this means, in particular, that
is now only used in (at most) a single weak equality
and otherwise only in weak inequalities.
Syntactic transformations IV: completing weak inequalities. The last step before we can apply the color coding method is to “complete” the conjunctions of weak inequalities. After all the previous transformations have been applied, each block of weak quantifiers has now the form where the are all weak inequalities (between some or all pairs of to ) and contains no weak inequalities involving the (but may contain one weak equality for each ). Of course, the weak variables need not be to , but let us assume this to keep to notation simple.
The formula expresses that some of the variables must be different. If the formula encompasses all possible weak inequalities between distinct and , then the formula would require that all must be distinct—exactly the situation in which color coding can be applied. However, some weak inequalities may be “missing” such as in the formula : This formula requires that to must be distinct and that must be different from —but it would be allowed that equals or . Indeed, it might be the case that the only way to make true is to make equal to . This leads to a problem in the context of color coding: We want to color , , and differently, using, say, red, green, and blue. In order to ensure , we must give a color different from blue. However, it would be wrong to color it red or green or using a new color like yellow since each would rule out being equal or different from either or —and each possibility must be considered to ensure that we miss no assignment that makes true.
The trick at this point is to reduce the problem of missing weak inequalities to the situation where all weak inequalities are present by using a large disjunction over all possible ways to unify weak variables without violating the weak inequalities.
In detail, let us call a partition of the set allowed by the if the following holds: For each and any two different none of the is the inequality . In other words, the do not forbid that the elements of any are identical. Clearly, the partition with is always allowed by any , but in the earlier example, the partition would be allowed, while would not be.
We introduce the following notation: For a partition
we will write
for
. We claim the following:
Claim 1. For any weak inequalities we have Proof. For the implication from left to right, assume that for some (not necessarily distinct) . The elements induce a natural partition where two variables and are in the same set if and only if . Then, clearly, for all i and j with and any and we have . Thus, all inequalities in are satisfied and, hence, the right-hand side holds.
For the other direction, suppose that is a model of the right hand side for some to . Then there must be a partition that is allowed by the such that is also a model of . Furthermore, each is actually present in this last formula: If is one of the , then by the very definition of “ is allowed for the ” we must have that and lie in different and —which, in turn, implies that is present in . □
Applied to the example
from above, the claim states the following: Since there are three partitions that are allowed by these literals (namely the one in which each variable gets its own equivalence class, the one where
and
are put into one class, and the one where
and
are put into one class) we have:
The claim has the following corollary:
Corollary 2. For any weak inequalities involving only variables from we have
.
As in the previous transformations we now apply the equivalence from the corollary from left to right. If we create copies of
during this process, we rename the weak variables in these copies to ensure, once more, that each weak variable is unique. In our example formula
, there is only one place where the transformation changes anything: The middle weak quantifier block (the
block). For the first and the last block, the literals
and
, respectively, already rule out all partitions except for the trivial one. For the middle block, however, there are no weak inequalities at all and, hence, there are now two allowed partitions: First,
, but also
. This means that we get a copy of the middle block where
and
are required to be different—and we renumber them to
and
:
Of course, for our particular example, the introduction of and is superfluous insofar as it is not necessary to introduce the special case “force and to be different” in addition to the already present case “do not care whether and are different or not.” It is only with more complex weak inequalities like that the syntactic transformation becomes really necessary.
Applying color coding: we are now ready to apply the color coding technique; more precisely, to repeatedly apply Theorem 2 to the formula . Before we do so, let us summarize the structure of :
All weak quantifiers come in blocks, and each such block either directly follows a universal quantifier or follows a disjunction after a universal quantifier. In particular, on any root-to-leaf path in the syntax tree of between any two blocks of weak quantifiers there is at least one universal quantifier.
All blocks of weak quantifiers have the form
for some partition
and for some
in which the only literals that contain any
are of the form
for a strong variable
y that is bound by an existential quantifier inside
. Furthermore, none of these weak equality literals is in the scope of a universal quantifier inside
. (Of course, all variables in
are in the scope of a universal quantifier since we added one at the start, but the point is that none of the
is in the scope of a universal quantifier that is inside
.)
In
there may be several blocks of weak quantifiers, but at least one of them (let us call it
) must have the form (
10) where
contains no weak variables other than
to
. (For instance, in our example formula, this is the case for the blocks starting with
, for
, and for
, but not for
since, here, the corresponding
contains all of the rest of the formula.) In our example, we could choose
and would then have
We build a new formula
from
as follows: We replace each occurrence of a weak equality
in
for some weak variable
and some strong variable
y by the formula
. In our example, where
and
we would get
An important observation at this point is that contains no weak variables any longer, while no additional variables have been added. In particular, the quantifier rank of equals the strong quantifier rank of and the number of variables in equals the number of strong variables in .
Note that the literals and also are positive since the formulas are in negation normal form. Hence, they have the following monotonicity property: If some structure together with some assignment to the free variables is a model of or , but a literal or is false, the structure will still be a model if we replace the literal by a tautology.
For simplicity, in the following, we assume that
to
are just
to
. Additionally, for simplicity we assume that
contains no free variables when, in fact, it can. However, these variables cannot be any of the variables
y for which we make changes and, thus, it keeps the notation simpler to ignore the additional free variables here. The following statement simply holds for all assignments to them:
Claim 2. Let . Then for each structure , the following are equivalent:
- 1.
.
- 2.
There are elements with and such that whenever , , and .
- 3.
There is an l-coloring of such that .
Proof. For the proof of the claim, it will be useful to apply some syntactic transformations to and . Just like the many transformations we encountered earlier, these transformations yield equivalent formulas and, thus, it suffices to prove the claim for them (since the claim is about the models of and ). However, these transformations are needed only to prove the claim, they are not part of the “chain of transformations” that is applied to the original formula (they increase the number of strong variables far too much).
In
there will be some occurrences of literals of the form
. For each such occurrence, there will be exactly one subformula in
of the form
where
contains
. We now apply two syntactic transformations: First, we replace
y in
by a fresh new variable
(that is, we replace all free occurrences of
y inside
by
and we replace the leading
by
). Second, we “move all
to the front” by simply deleting all occurrences of
from
, resulting in a formula
, and then adding the block
before
. As an example, if we apply these transformations to
, the first transformation yields
and the second one yield the new
In
, we apply exactly the same transformations, only now the literals we look for are not
, but
. We still apply the same renaming of
y (namely to
and not to
) as in
and apply the same movement of the quantifiers. This results in a new formula
of the form
. For
we get the new
and
is now the inner part without the quantifiers.
Let us now prove the claim. The first two items are trivially equivalent by the definition of .
The second statement implies the third: To show this, for we first set and then add to, say, in order to create a correct partition. This setting clearly ensures that whenever holds in , we also have holding in . Since differs from only on the literals of the form (which got replaced by ), since we just saw that when holds in , the replacements holds in , and since has the monotonicity property (by which it does matter when more literals of the form hold in than did in ), we get the third statement.
The third statement implies the second: Let an l-coloring of be given with . Since , there must now be elements such that . We define new elements as follows: If , let . Otherwise, let be an arbitrary element of . We show in the following that the constructed in this way can be used in the second statement, that is, we claim that and the have the distinctness property from the claim.
First, recall that is of the form (because of the syntactic transformations we applied for the purposes of the proof of this claim) and contains literals of the form , where the are the free variables for which the values are now plugged in. We claim that , that is, we claim that if we plug in to for the free variables to in and we plug in to for the (additional) free variables to in , then holds in . To see this, recall that holds and is identical to except that got replaced by . In particular, by construction of the , whenever holds in with being set to (that is, whenever ), we clearly also have that holds in with being set to and being set to (since we let whenever ). Then, by the monotonicity property, we know that will hold.
Second, we argue that the distinctness property holds, that is, whenever , , and . However, our construction ensured that we always have for the s with . In particular, and for implies that and lie in two different color classes and are, hence, distinct. □
By the claim, is equivalent to there being an l-coloring of such that ( was a block in our main formula of the form where there are no weak variables other than the ). We now apply Theorem 2 to (as ), which yields a new formula (called in the theorem) with the property . The interesting thing about is, of course, that it has the same quantifier rank and the same number of variables as plus some constant. Most importantly, we already pointed out earlier that does not contain any weak variables and, hence, the quantifier rank of is the same as the strong quantifier rank of and the number of variables in is the same as the number of strong variables in —plus some constant.
Applying this transformation to our running example
and choosing as
once more the subformula starting with
, we would get the following formula (ignoring the technical issues how, exactly, the hashing is implemented, see the proof of Theorem 2 for the details):
We can now repeat the transformation to replace each block
in this way. Observe that in each transformation we can reuse the variables (in particular,
p and
q) introduced by the color coding:
In conclusion, we see that we can transform the original formula to a new formula with the following properties:
We added new variables and quantifiers to compared to during the first transformation steps, but the number we added depended only on the signature (it was the maximum arity of relations in plus possibly 2).
We then removed all weak variables from in .
We added some variables to each time we applied Theorem 2 to a block . The number of variables we added is constant since Theorem 2 adds only a constant number of variables and since we can always reuse the same set of variables each time the theorem is applied.
We also added some quantifiers to each time we applied Theorem 2, which increases the quantifier rank of compared to by more than a constant. However, the essential quantifiers we add are and these are always added directly after a universal quantifier or directly after a disjunction after a universal quantifier. Since the strong quantifier rank of is at least the quantifier rank of where we only consider the universal quantifiers (the “universal quantifier rank”), the two added nested quantifiers per universal quantifiers can add to the quantifier rank of at most twice the universal quantifier rank.
Putting it all together, we see that is equivalent to , that has a quantifier rank that is at most , and the contains at most variables.
This concludes the proof of Theorem 3. □
Proof. Given a formula that contains both existential and universal weak quantifiers, we apply a syntactic preprocessing that “separates these quantifiers and moves them before their dual strong quantifiers.” The key observation that makes these transformations possible in the mixed case is that weak existential and weak universal quantifiers commute: For instance, since and cannot depend on one another by the core property of weak quantifiers ( cannot contain and cannot contain ). Once we have sufficiently separated the quantifiers, we can repeatedly apply Theorem 3 or its dual to each block individually.
As a running example, let us use the following formula
:
which mixes existential and universal weak variables rather freely.
Similar to the proof of Theorem 3, for technical reasons we first add the superfluous quantifiers for a fresh strong variable v at the beginning of the formula.
Our main objective is to get rid of alternations of weak universal and weak existential quantifiers without a strong quantifier in between. In the example, this is the case, for instance, for . We get rid of these situations by pushing all quantifiers (weak or strong) down as far as possible (later on, when we apply Theorem 3, we will push them up once more). Let us write to indicate that x may be a weak or a strong variable.
If
does not contain
as a free variable, we can apply the below four equivalences from left to right (and, of course, commutatively equivalent ones). Note that since the definition of weak variables forbids that a universally bound variable depends on an existential weak variable (and vice versa), the condition “
does not contain
” is true, in particular, whenever
is weak and
starts with a universal quantifier in the first two lines or with an existential quantifier in the last two lines.
Furthermore, we also apply the following general equivalences as long as possible:
Applied to our example, we would get:
As a final transformation, we “sort” the operands of disjunctions and conjunctions: We replace a subformula
in
by
and we replace
by
, whenever
contains no weak universal variables, but
does, and also whenever
contains no weak existential variables, but
does. For our example, this means that we get the following:
The purpose of the transformations was to achieve the situation described in the next claim:
Claim 3. Assume that the above transformations have been applied exhaustively to ϕ and assume ϕ contains both existential and universal weak variables. Consider the maximal subformulas of ϕ that contain no weak universal variables and the maximal subformulas of ϕ that contain no weak existential variables. Then for some i and some γ one of the following formulas is a subformula of ϕ: or .
In our example, there is only a single maximal , namely , and a single maximal , namely . The claim holds since is a subformula for .
Proof. Consider any among the . Since is maximal but is not all of , there must be a among the such that either or is also a subformula of . Let us call it and consider the minimal subformula of that contains and starts with a quantifier.
This quantifier cannot be a weak quantifier: Suppose it is
(the case
is perfectly symmetric). Since we can no longer apply one of the equivalences (
11)–(
18), the formula
must have the form
(where the
are not of the form
) such that all
contain
(otherwise (
11) would be applicable) and such that none of the
is of the form
(otherwise (
15) would be applicable). This implies that all
start with a quantifier. Since
was minimal to contain
, we conclude that one
must be
and another one must be
. Then,
contains a weak existential variable, namely
, which we ruled out.
Since does not start with a weak quantifier, it must start with a strong quantifier. If it is , by the same argument as before we get that must have the form with some equal to and some other equal to . Then, we have found the desired subformula of if we set to . If the strong quantifier is , a perfectly symmetric argument shows that must have the form with some , which implies the claim for . □
The importance of the claim for our argument is the following: As long as still contains both existential and universal weak variables, we still find a subformula or that contains only existential or universal weak variables such that if we go up from this subformula in the syntax tree of , the next quantifier we meet is a strong quantifier. This means that we can now apply Theorem 3 or its dual to this subformula, getting an equivalent new formula or whose quantifier rank equals the strong quantifier rank of or , respectively, times a constant factor. Furthermore, similar to the argument at the end of the proof of Theorem 3 where we processed one after another, each time a replacement takes place, there is a strong quantifier that contributes to the strong quantifier rank of .
This concludes the proof of Theorem 4. □





{kind=link}