
Subspace Detours Meet Gromov–Wasserstein



{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Background
2.1. Classical Optimal Transport
2.1.1. Kantorovitch Problem
2.1.2. Knothe–Rosenblatt Rearrangement
2.2. Subspace Detours and Disintegration
2.2.1. Disintegration
2.2.2. Coupling on the Whole Space
2.3. Gromov–Wasserstein
3. Subspace Detours for GW
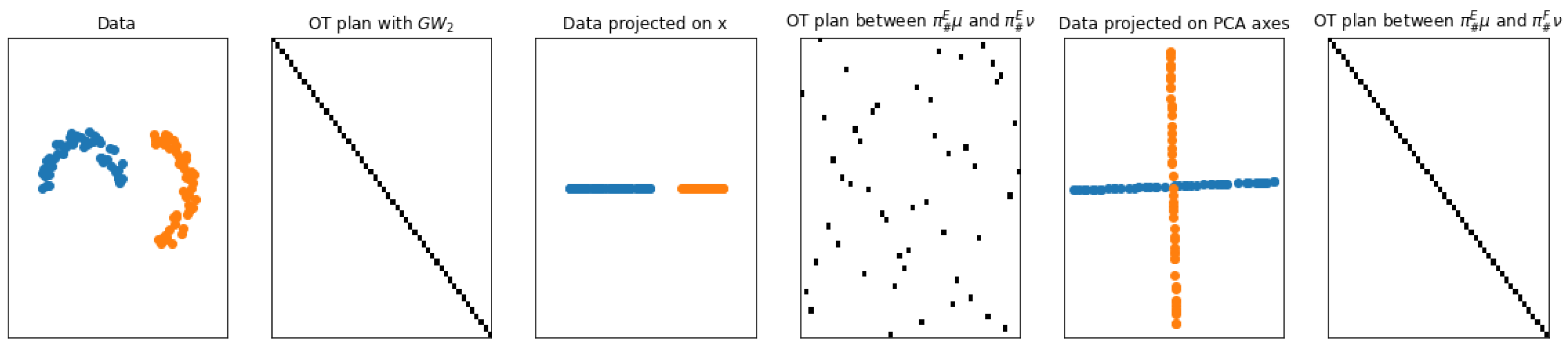
3.1. Motivations
3.2. Properties
3.3. Closed-Form between Gaussians
3.4. Computation of Inner-GW between One-Dimensional Empirical Measures
| Algorithm 1 North-West corner rule |
|
3.5. Illustrations
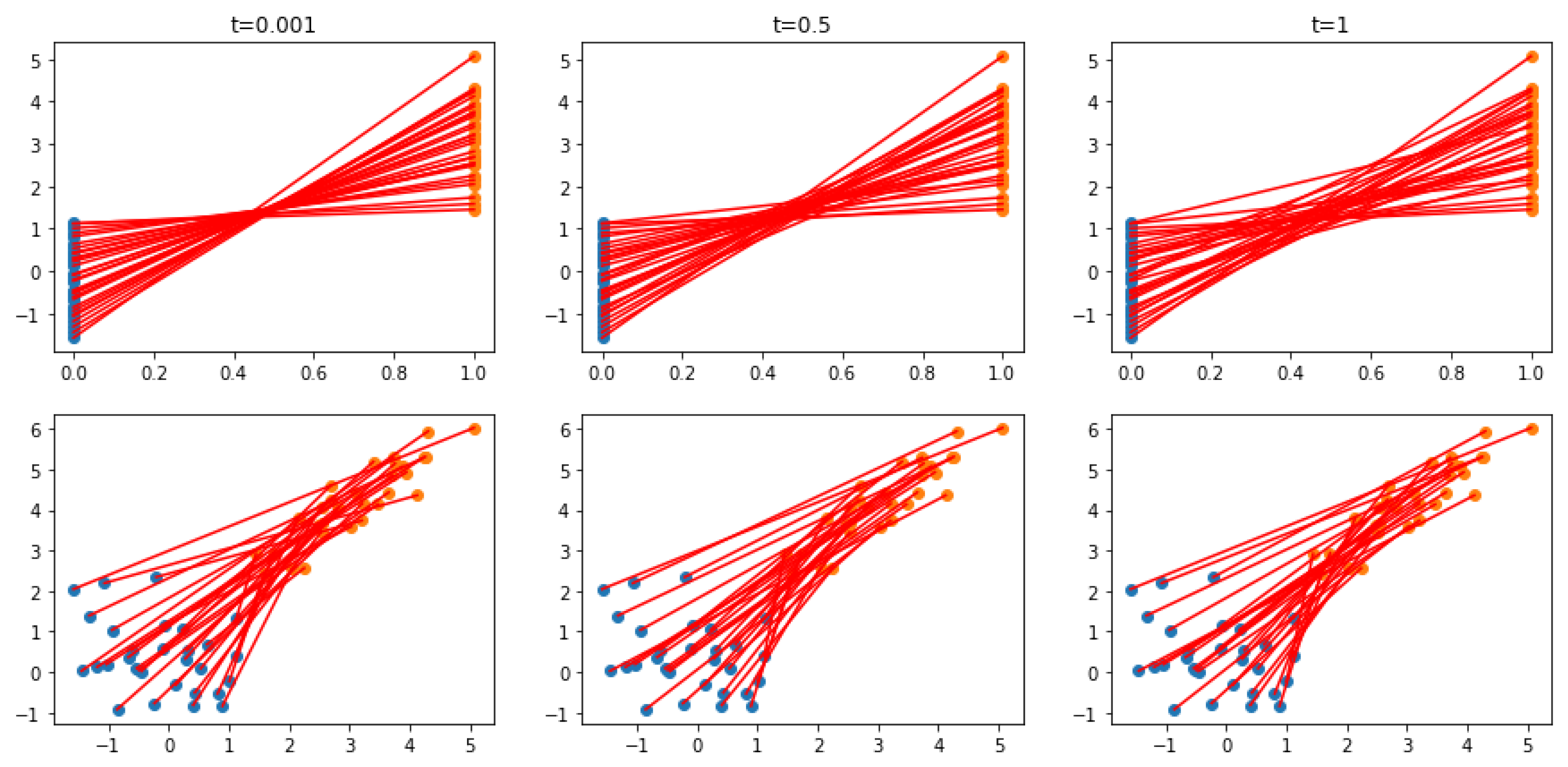
4. Triangular Coupling as Limit of Optimal Transport Plans for Quadratic Cost
4.1. Construction of the Hadamard–Wasserstein Problem
4.2. Properties
- The problem (12) always admits a minimizer.
- is a pseudometric (i.e., it is symmetric, non-negative, , and it satisfies the triangle inequality).
- is invariant to reflection with respect to axes.
- is a continuous map, therefore, L is less semi-continuous. Hence, by applying Lemma 2.2.1 of [26], we observe that is less semi-continuous for the weak convergence of measures.Now, as is a compact set (see the proof of Theorem 1.7 in [19] for the Polish space case and of Theorem 1.4 for the compact metric space) and is less semi-continuous for the weak convergence, we can apply the Weierstrass theorem (Memo 2.2.1 in [26]), which states that (12) always admits a minimizer.
- See Theorem 16 in [25].
- For invariances, we first look at the properties that must be satisfied by T in order to have: where .We find that because, denoting as the canonical basis, we have:which implies that:However, implies , and therefore:If we take for T the reflection with respect to axis, then it satisfies well. Moreover, it is a good equivalence relation, and therefore, we have a distance on the quotient space.
4.3. Solving Hadamard–Wasserstein in the Discrete Setting
5. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| OT | Optimal Transport |
| GW | Gromov–Wasserstein |
| KR | Knothe–Rosenblatt |
| MI | Monge–Independent |
| MK | Monge–Knothe |
| PCA | Principal Component Analysis |
| POT | Python Optimal Transport |
Appendix A. Subspace Detours
Appendix A.1. Proofs
Appendix A.2. Closed-Form between Gaussians
Appendix A.2.1. Quadratic GW Problem
Appendix A.2.2. Closed-Form between Gaussians for Monge–Independent
Appendix B. Knothe–Rosenblatt
Appendix B.1. Properties of (12)
Appendix B.2. Proof of Theorem 3
References
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Courty, N.; Flamary, R.; Tuia, D.; Rakotomamonjy, A. Optimal transport for domain adaptation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1853–1865. [Google Scholar] [CrossRef] [PubMed]
- Mémoli, F. Gromov–Wasserstein distances and the metric approach to object matching. Found. Comput. Math. 2011, 11, 417–487. [Google Scholar] [CrossRef]
- Chowdhury, S.; Miller, D.; Needham, T. Quantized Gromov–Wasserstein. In Proceedings of the Machine Learning and Knowledge Discovery in Databases, Research Track—European Conference, ECML PKDD 2021, Bilbao, Spain, 13–17 September 2021; Proceedings, Part III. Oliver, N., Pérez-Cruz, F., Kramer, S., Read, J., Lozano, J.A., Eds.; Springer: Berlin/Heidelberg, Germany, 2021; Volume 12977, pp. 811–827. [Google Scholar] [CrossRef]
- Alvarez-Melis, D.; Jegelka, S.; Jaakkola, T.S. Towards optimal transport with global invariances. In Proceedings of the The 22nd International Conference on Artificial Intelligence and Statistics, PMLR, Naha, Japan, 16–18 April 2019; pp. 1870–1879. [Google Scholar]
- Cai, Y.; Lim, L.H. Distances between probability distributions of different dimensions. arXiv 2020, arXiv:2011.00629. [Google Scholar]
- Mémoli, F. On the use of Gromov-Hausdorff Distances for Shape Comparison. In Proceedings of the 4th Symposium on Point Based Graphics, PBG@Eurographics 2007, Prague, Czech Republic, 2–3 September 2007; Botsch, M., Pajarola, R., Chen, B., Zwicker, M., Eds.; Eurographics Association: Switzerland, Geneve, 2007; pp. 81–90. [Google Scholar] [CrossRef]
- Sturm, K.T. The space of spaces: Curvature bounds and gradient flows on the space of metric measure spaces. arXiv 2012, arXiv:1208.0434. [Google Scholar]
- Peyré, G.; Cuturi, M.; Solomon, J. Gromov–Wasserstein averaging of kernel and distance matrices. In Proceedings of the International Conference on Machine Learning, PMLR, New York, NY, USA, 19–24 June 2016; pp. 2664–2672. [Google Scholar]
- Cuturi, M. Sinkhorn distances: Lightspeed computation of optimal transport. Adv. Neural Inf. Process. Syst. 2013, 26, 2292–2300. [Google Scholar]
- Scetbon, M.; Peyré, G.; Cuturi, M. Linear-Time Gromov Wasserstein Distances using Low Rank Couplings and Costs. arXiv 2021, arXiv:2106.01128. [Google Scholar]
- Vayer, T.; Flamary, R.; Courty, N.; Tavenard, R.; Chapel, L. Sliced Gromov–Wasserstein. Adv. Neural Inf. Process. Syst. 2019, 32, 14753–14763. [Google Scholar]
- Fatras, K.; Zine, Y.; Majewski, S.; Flamary, R.; Gribonval, R.; Courty, N. Minibatch optimal transport distances; analysis and applications. arXiv 2021, arXiv:2101.01792. [Google Scholar]
- Muzellec, B.; Cuturi, M. Subspace Detours: Building Transport Plans that are Optimal on Subspace Projections. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; Wallach, H.M., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E.B., Garnett, R., Eds.; 2019; pp. 6914–6925. [Google Scholar]
- Bogachev, V.I.; Kolesnikov, A.V.; Medvedev, K.V. Triangular transformations of measures. Sb. Math. 2005, 196, 309. [Google Scholar] [CrossRef] [Green Version]
- Knothe, H. Contributions to the theory of convex bodies. Mich. Math. J. 1957, 4, 39–52. [Google Scholar] [CrossRef]
- Rosenblatt, M. Remarks on a multivariate transformation. Ann. Math. Stat. 1952, 23, 470–472. [Google Scholar] [CrossRef]
- Villani, C. Optimal Transport: Old and New; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2008; Volume 338. [Google Scholar]
- Santambrogio, F. Optimal transport for applied mathematicians. Birkäuser NY 2015, 55, 94. [Google Scholar]
- Jaini, P.; Selby, K.A.; Yu, Y. Sum-of-Squares Polynomial Flow. In Proceedings of the 36th International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 3009–3018. [Google Scholar]
- Carlier, G.; Galichon, A.; Santambrogio, F. From Knothe’s transport to Brenier’s map and a continuation method for optimal transport. SIAM J. Math. Anal. 2010, 41, 2554–2576. [Google Scholar] [CrossRef] [Green Version]
- Bonnotte, N. Unidimensional and Evolution Methods for Optimal Transportation. Ph.D. Thesis, Université Paris-Sud, Paris, France, 2013. [Google Scholar]
- Ambrosio, L.; Gigli, N.; Savaré, G. Gradient Flows: In Metric Spaces and in the Space of Probability Measures; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Niles-Weed, J.; Rigollet, P. Estimation of wasserstein distances in the spiked transport model. arXiv 2019, arXiv:1909.07513. [Google Scholar]
- Chowdhury, S.; Mémoli, F. The gromov–wasserstein distance between networks and stable network invariants. Inf. Inference A J. IMA 2019, 8, 757–787. [Google Scholar] [CrossRef] [Green Version]
- Vayer, T. A Contribution to Optimal Transport on Incomparable Spaces. Ph.D. Thesis, Université de Bretagne Sud, Vannes, France, 2020. [Google Scholar]
- Paty, F.P.; Cuturi, M. Subspace robust wasserstein distances. In Proceedings of the 36th International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 5072–5081. [Google Scholar]
- Rasmussen, C.E. Gaussian processes in machine learning. In Summer School on Machine Learning; Springer: Berlin/Heidelberg, Germany, 2003; pp. 63–71. [Google Scholar]
- Von Mises, R. Mathematical Theory of Probability and Statistics; Academic Press: Cambridge, MA, USA, 1964. [Google Scholar]
- Salmona, A.; Delon, J.; Desolneux, A. Gromov–Wasserstein Distances between Gaussian Distributions. arXiv 2021, arXiv:2104.07970. [Google Scholar]
- Weed, J.; Bach, F. Sharp asymptotic and finite-sample rates of convergence of empirical measures in Wasserstein distance. Bernoulli 2019, 25, 2620–2648. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.; Zheng, Z.; Chen, E.; Cuturi, M.; Jordan, M. On projection robust optimal transport: Sample complexity and model misspecification. In Proceedings of the International Conference on Artificial Intelligence and Statistics, PMLR, Virtual, 13–15 April 2021; pp. 262–270. [Google Scholar]
- Burkard, R.E.; Klinz, B.; Rudolf, R. Perspectives of Monge Properties in Optimization. Discret. Appl. Math. 1996, 70, 95–161. [Google Scholar] [CrossRef] [Green Version]
- Flamary, R.; Courty, N.; Gramfort, A.; Alaya, M.Z.; Boisbunon, A.; Chambon, S.; Chapel, L.; Corenflos, A.; Fatras, K.; Fournier, N.; et al. POT: Python Optimal Transport. J. Mach. Learn. Res. 2021, 22, 1–8. [Google Scholar]
- Bogo, F.; Romero, J.; Loper, M.; Black, M.J. FAUST: Dataset and evaluation for 3D mesh registration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3794–3801. [Google Scholar]
- Fiedler, M. Algebraic connectivity of graphs. Czechoslov. Math. J. 1973, 23, 298–305. [Google Scholar] [CrossRef]
- Hagberg, A.; Swart, P.; Chult, D.S. Exploring Network Structure, Dynamics, and Function Using NetworkX; Technical Report; Los Alamos National Lab. (LANL): Los Alamos, NM, USA, 2008.
- Wu, J.P.; Song, J.Q.; Zhang, W.M. An efficient and accurate method to compute the Fiedler vector based on Householder deflation and inverse power iteration. J. Comput. Appl. Math. 2014, 269, 101–108. [Google Scholar] [CrossRef]
- Xu, H.; Luo, D.; Carin, L. Scalable Gromov–Wasserstein learning for graph partitioning and matching. Adv. Neural Inf. Process. Syst. 2019, 32, 3052–3062. [Google Scholar]
- Chowdhury, S.; Needham, T. Generalized spectral clustering via Gromov–Wasserstein learning. In Proceedings of the International Conference on Artificial Intelligence and Statistics, PMLR, Virtual, 13–15 April 2021; pp. 712–720. [Google Scholar]
- Vayer, T.; Courty, N.; Tavenard, R.; Flamary, R. Optimal transport for structured data with application on graphs. In Proceedings of the 36th International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6275–6284. [Google Scholar]
- Lacoste-Julien, S. Convergence rate of frank-wolfe for non-convex objectives. arXiv 2016, arXiv:1607.00345. [Google Scholar]
- Peyré, G.; Cuturi, M. Computational optimal transport: With applications to data science. Found. Trends® Mach. Learn. 2019, 11, 355–607. [Google Scholar] [CrossRef]
- Nagar, R.; Raman, S. Detecting approximate reflection symmetry in a point set using optimization on manifold. IEEE Trans. Signal Process. 2019, 67, 1582–1595. [Google Scholar] [CrossRef] [Green Version]
- Billingsley, P. Convergence of Probability Measures; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bonet, C.; Vayer, T.; Courty, N.; Septier, F.; Drumetz, L. Subspace Detours Meet Gromov–Wasserstein. Algorithms 2021, 14, 366. https://doi.org/10.3390/a14120366
Bonet C, Vayer T, Courty N, Septier F, Drumetz L. Subspace Detours Meet Gromov–Wasserstein. Algorithms. 2021; 14(12):366. https://doi.org/10.3390/a14120366
Chicago/Turabian StyleBonet, Clément, Titouan Vayer, Nicolas Courty, François Septier, and Lucas Drumetz. 2021. "Subspace Detours Meet Gromov–Wasserstein" Algorithms 14, no. 12: 366. https://doi.org/10.3390/a14120366
APA StyleBonet, C., Vayer, T., Courty, N., Septier, F., & Drumetz, L. (2021). Subspace Detours Meet Gromov–Wasserstein. Algorithms, 14(12), 366. https://doi.org/10.3390/a14120366