
Overrelaxed Sinkhorn–Knopp Algorithm for Regularized Optimal Transport


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
1.1. Accelerations of the Sinkhorn–Knopp Algorithm
1.2. Overview and Contributions
2. Sinkhorn Algorithm
2.1. Discrete Optimal Transport
2.2. Regularized Optimal Transport
2.3. Sinkhorn–Knopp Algorithm
3. Regularized Nonlinear Acceleration of the Sinkhorn–Knopp Algorithm
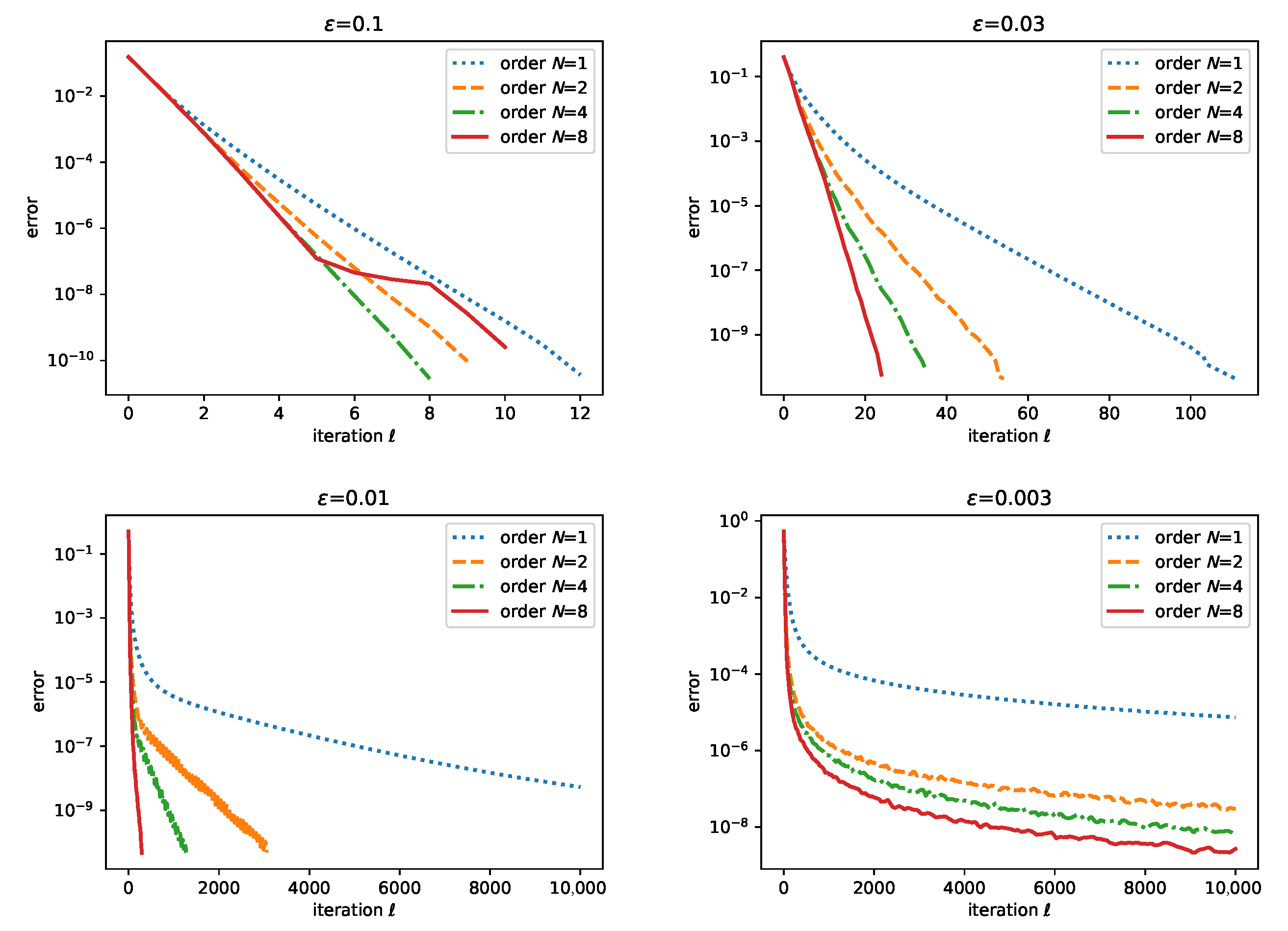
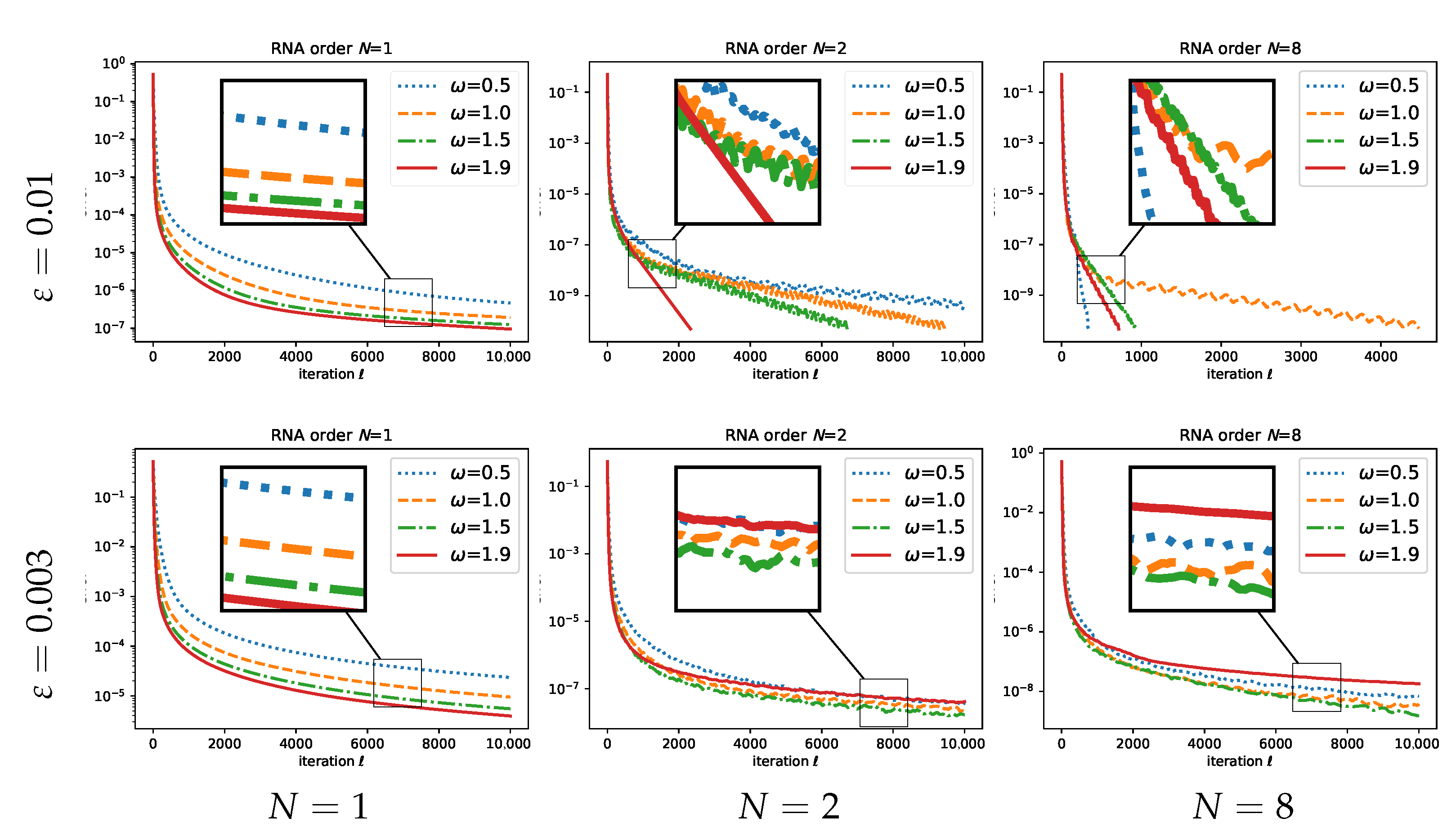
3.1. Regularized Nonlinear Acceleration
3.2. Application to SK
| Algorithm 1 RNA SK Algorithm in the Log Domain. |
| Require: , , Set , , , , and Set and , while do , , , , end while return |
3.3. Discussion
4. Sinkhorn–Knopp with Successive Overrelaxation
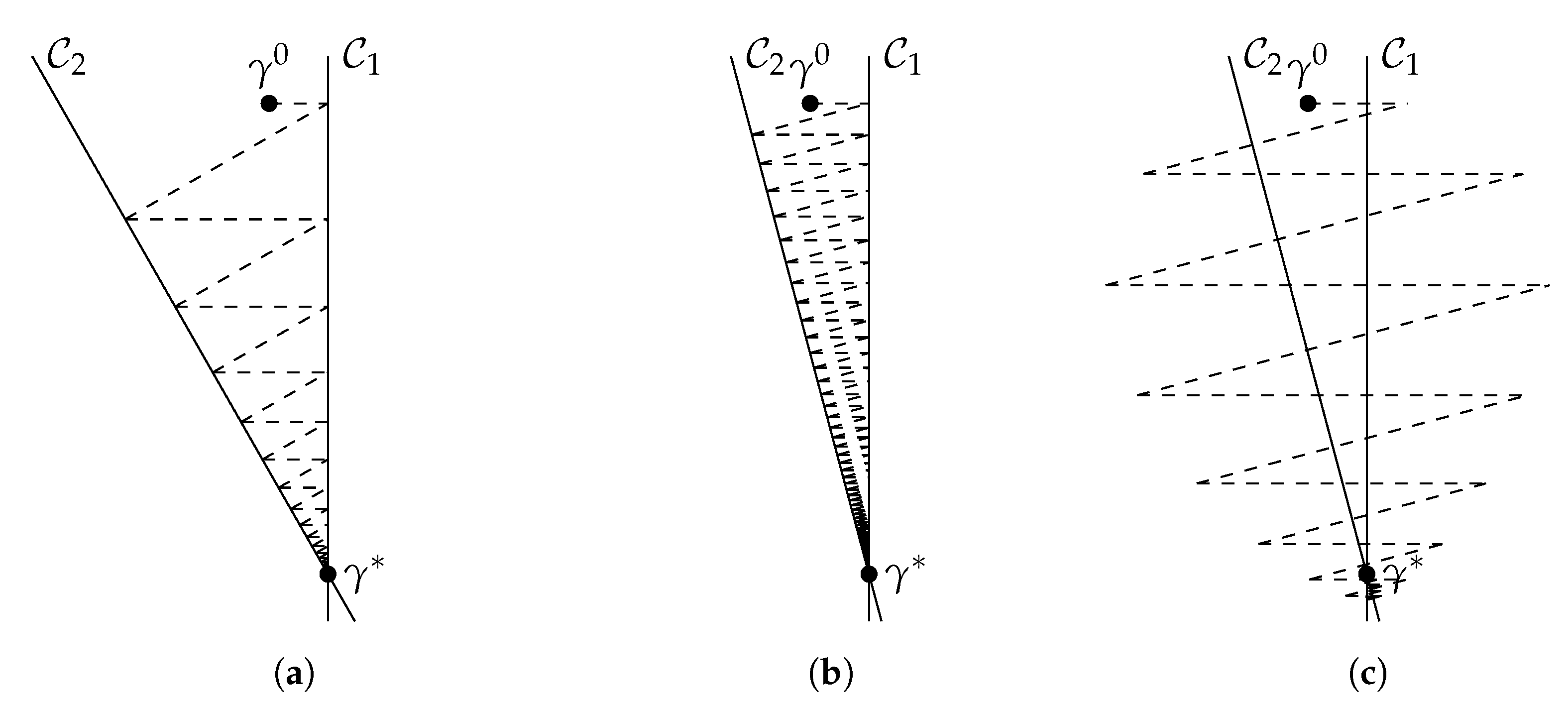
4.1. Overrelaxed Projections
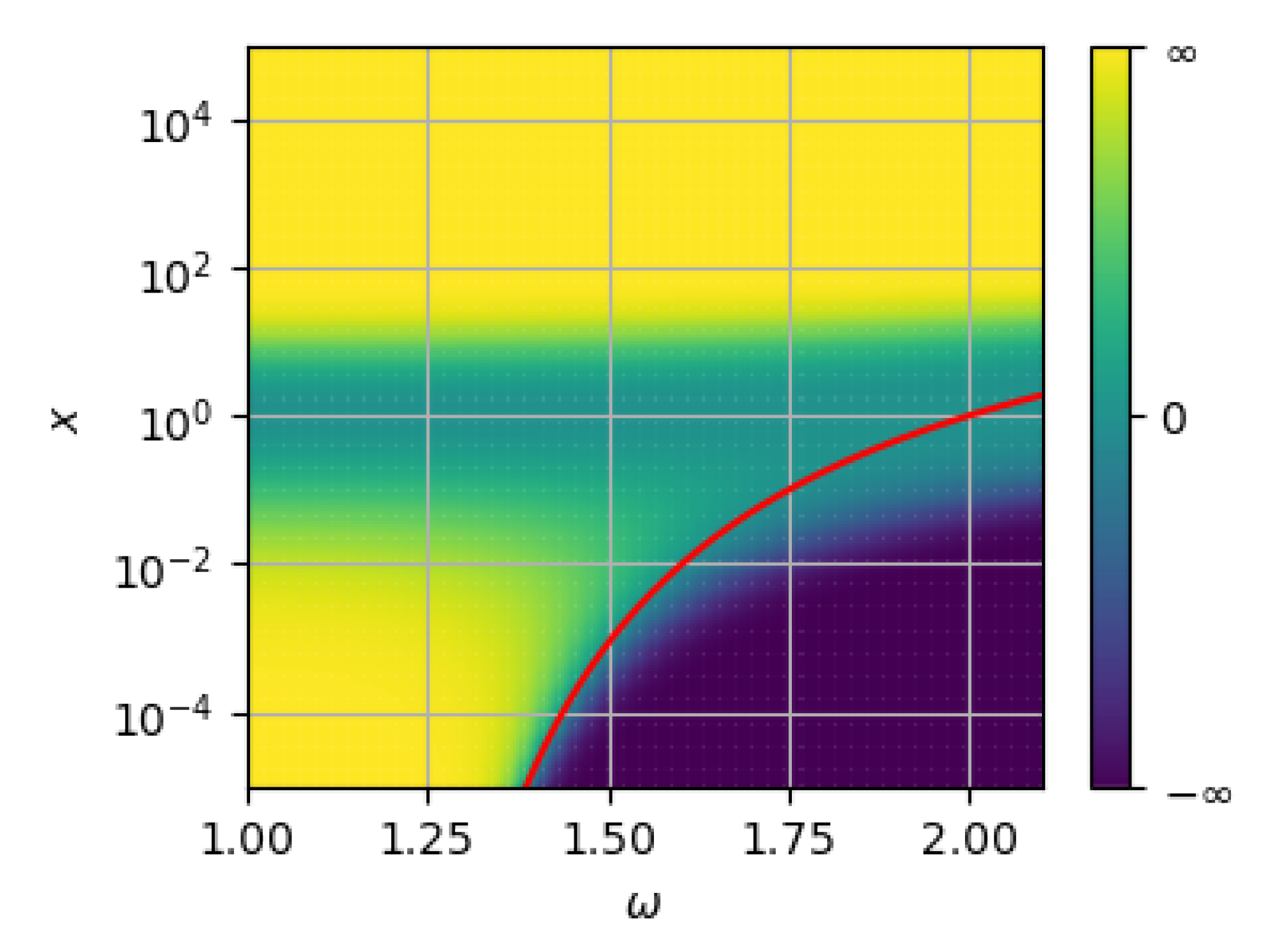
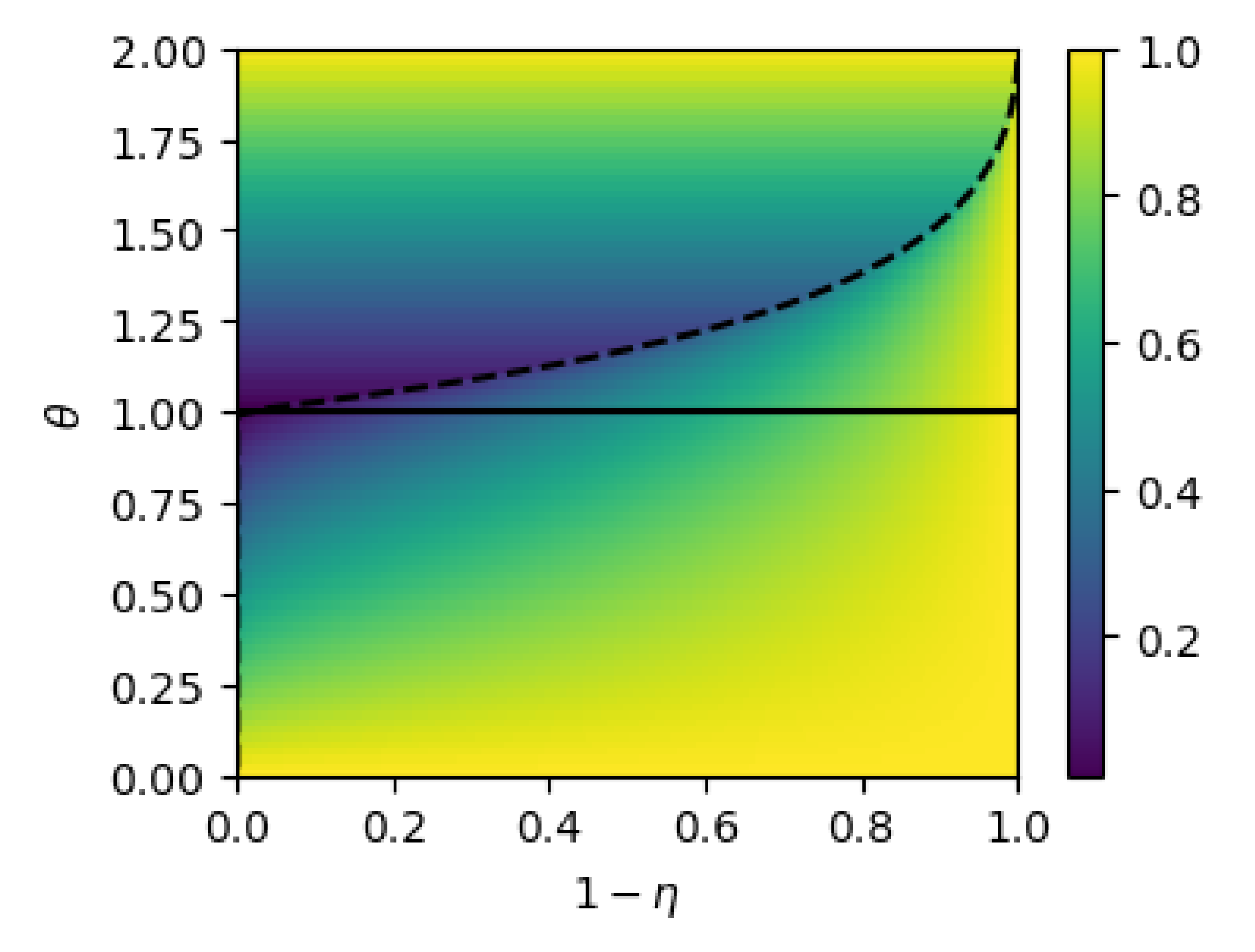
4.2. Lyapunov Function
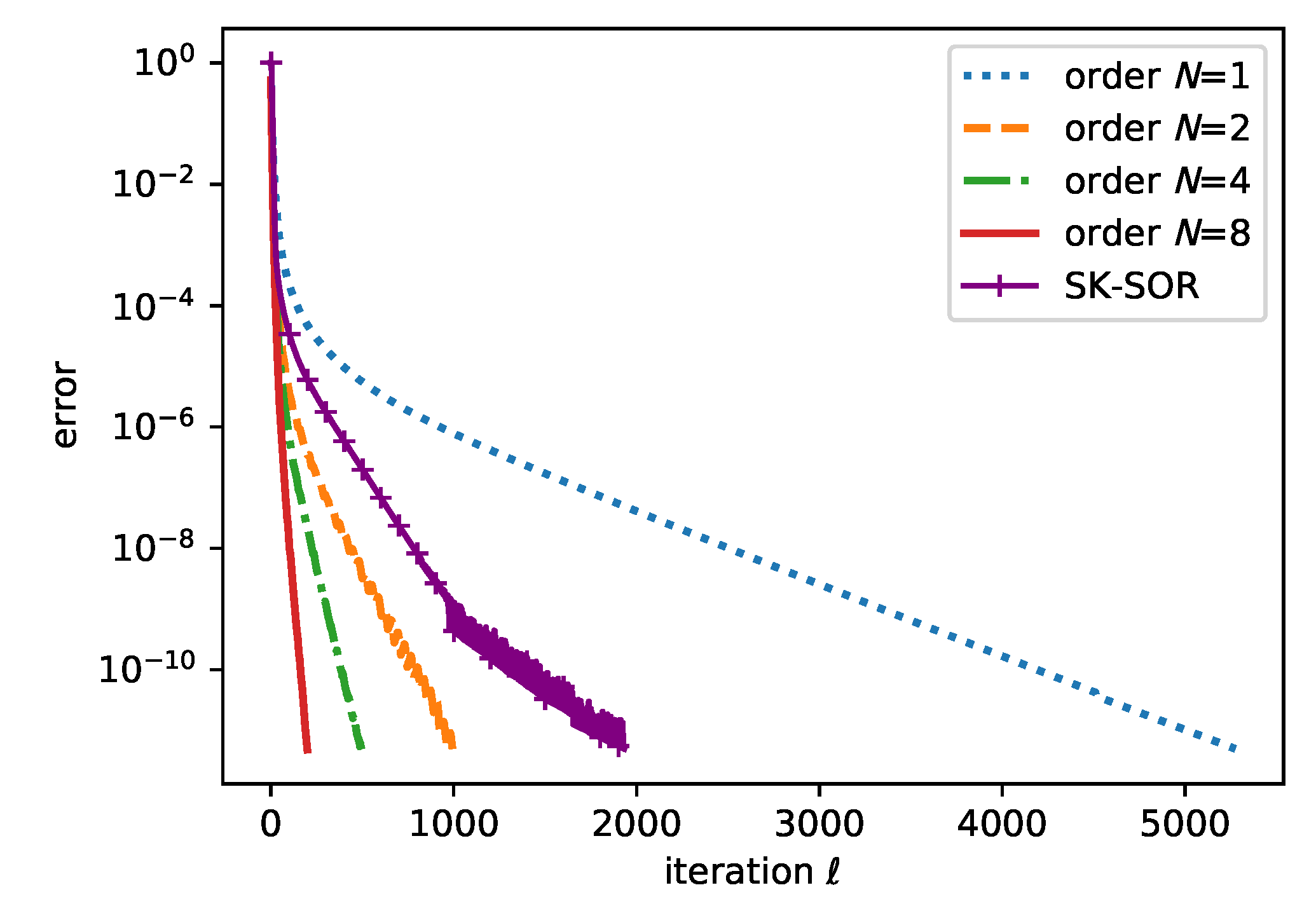
4.3. Proposed Algorithm
- it allows choosing arbitrarily the parameter that will be used eventually when the algorithm is close to convergence (we motivate what are good choices for in Section 4.4);
- it is also an easy approach to having an adaptive method, as the approximation of has a negligible cost (it only requires solving a one-dimensional problem that depends on the smallest value of , which can be done in a few iterations of Newton’s method).
| Algorithm 2 Overrelaxed SK Algorithm (SK-SOR). |
| Require: , , Set , , , and while do , end while return |
| Algorithm 3 Overrelaxed SK Algorithm (SK-SOR) in the Log Domain. |
| Require: , , Set , , , and while do , , end while return |
4.4. Acceleration of the Local Convergence Rate
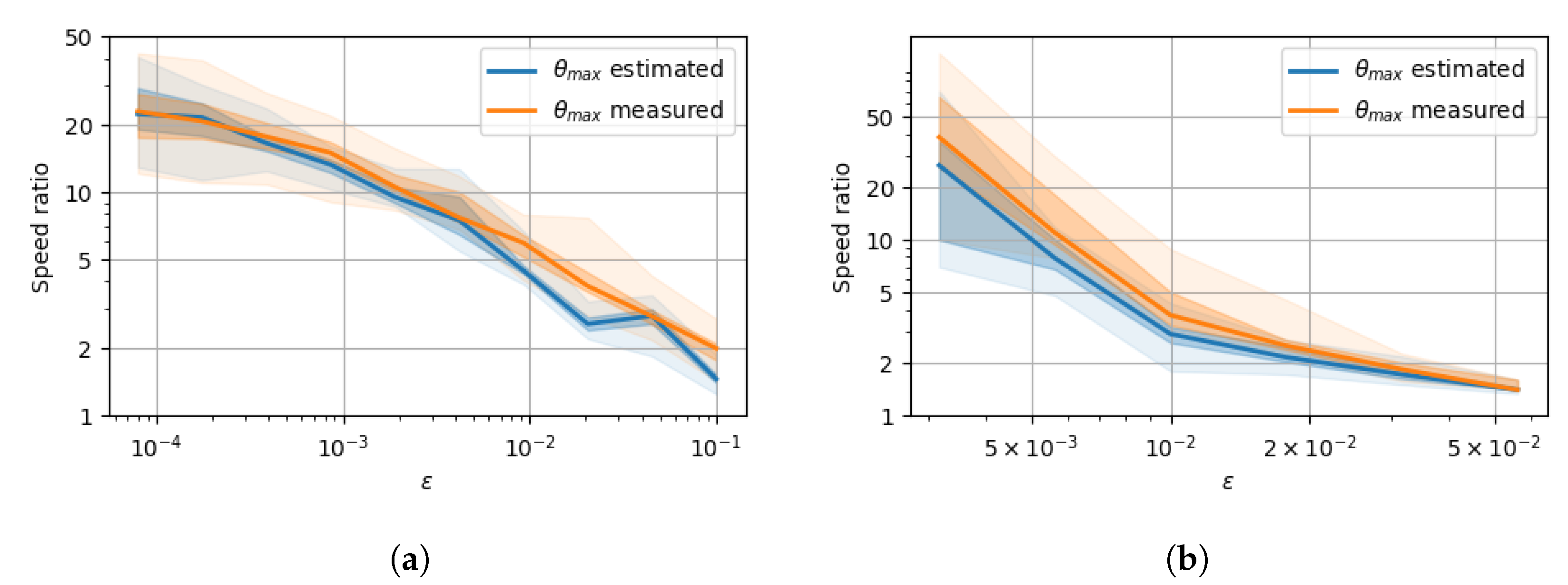
5. Experimental Results
6. Conclusions and Perspectives
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Rubner, Y.; Tomasi, C.; Guibas, L.J. The Earth Mover’s Distance As a Metric for Image Retrieval. Int. J. Comput. Vis. 2000, 40, 99–121. [Google Scholar] [CrossRef]
- Cuturi, M. Sinkhorn distances: Lightspeed computation of optimal transport. In Proceedings of the Advances in Neural Information Processing Systems 27, Lake Tahoe, NV, USA, 5–8 December 2013; pp. 2292–2300. [Google Scholar]
- Sinkhorn, R. A relationship between arbitrary positive matrices and doubly stochastic matrices. Ann. Math. Stat. 1964, 35, 876–879. [Google Scholar] [CrossRef]
- Seguy, V.; Cuturi, M. Principal geodesic analysis for probability measures under the optimal transport metric. In Proceedings of the Advances in Neural Information Processing Systems 29, Montreal, QC, Canada, 7–12 December 2015; pp. 3312–3320. [Google Scholar]
- Courty, N.; Flamary, R.; Tuia, D.; Rakotomamonjy, A. Optimal Transport for Domain Adaptation. arXiv 2015, arXiv:1507.00504. [Google Scholar] [CrossRef] [PubMed]
- Frogner, C.; Zhang, C.; Mobahi, H.; Araya-Polo, M.; Poggio, T. Learning with a Wasserstein Loss. arXiv 2015, arXiv:1506.05439. [Google Scholar]
- Montavon, G.; Müller, K.R.; Cuturi, M. Wasserstein Training of Restricted Boltzmann Machines. In Proceedings of the Advances in Neural Information Processing Systems 30, Barcelona, Spain, 29 November–10 December 2016; pp. 3718–3726.
- Rolet, A.; Cuturi, M.; Peyré, G. Fast Dictionary Learning with a Smoothed Wasserstein Loss. In Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS), Cadiz, Spain, 9–11 May 2016; Volume 51, pp. 630–638. [Google Scholar]
- Schmitz, M.A.; Heitz, M.; Bonneel, N.; Ngole, F.; Coeurjolly, D.; Cuturi, M.; Peyré, G.; Starck, J.L. Wasserstein dictionary learning: Optimal transport-based unsupervised nonlinear dictionary learning. SIAM J. Imaging Sci. 2018, 11, 643–678. [Google Scholar] [CrossRef]
- Dessein, A.; Papadakis, N.; Rouas, J.L. Regularized optimal transport and the rot mover’s distance. J. Mach. Learn. Res. 2018, 19, 590–642. [Google Scholar]
- Rabin, J.; Papadakis, N. Non-convex Relaxation of Optimal Transport for Color Transfer Between Images. In Proceedings of the NIPS Workshop on Optimal Transport for Machine Learning (OTML’14), Quebec, QC, Canada, 13 December 2014. [Google Scholar]
- Chizat, L.; Peyré, G.; Schmitzer, B.; Vialard, F.X. Scaling Algorithms for Unbalanced Transport Problems. arXiv 2016, arXiv:1607.05816. [Google Scholar] [CrossRef]
- Altschuler, J.; Weed, J.; Rigollet, P. Near-linear time approximation algorithms for optimal transport via Sinkhorn iteration. In Proceedings of the Advances in Neural Information Processing Systems 31, Long Beach, CA, USA, 4–9 December 2017; pp. 1961–1971. [Google Scholar]
- Alaya, M.Z.; Berar, M.; Gasso, G.; Rakotomamonjy, A. Screening sinkhorn algorithm for regularized optimal transport. arXiv 2019, arXiv:1906.08540. [Google Scholar]
- Polyak, B. Some methods of speeding up the convergence of iteration methods. USSR Comput. Math. Math. Phys. 1964, 4, 1–17. [Google Scholar] [CrossRef]
- Ghadimi, E.; Feyzmahdavian, H.R.; Johansson, M. Global convergence of the Heavy-ball method for convex optimization. arXiv 2014, arXiv:1412.7457. [Google Scholar]
- Zavriev, S.K.; Kostyuk, F.V. Heavy-ball method in nonconvex optimization problems. Comput. Math. Model. 1993, 4, 336–341. [Google Scholar] [CrossRef]
- Ochs, P. Local Convergence of the Heavy-ball Method and iPiano for Non-convex Optimization. arXiv 2016, arXiv:1606.09070. [Google Scholar] [CrossRef]
- Anderson, D.G. Iterative procedures for nonlinear integral equations. J. ACM 1965, 12, 547–560. [Google Scholar] [CrossRef]
- Scieur, D.; d’Aspremont, A.; Bach, F. Regularized Nonlinear Acceleration. In Proceedings of the Advances in Neural Information Processing Systems 30, Barcelona, Spain, 5–10 December 2016; pp. 712–720. [Google Scholar]
- Scieur, D.; Oyallon, E.; d’Aspremont, A.; Bach, F. Online regularized nonlinear acceleration. arXiv 2018, arXiv:1805.09639. [Google Scholar]
- Young, D.M. Iterative Solution of Large Linear Systems; Elsevier: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Peyré, G.; Chizat, L.; Vialard, F.X.; Solomon, J. Quantum Optimal Transport for Tensor Field Processing. arXiv 2016, arXiv:1612.08731. [Google Scholar]
- Dvurechensky, P.; Gasnikov, A.; Kroshnin, A. Computational optimal transport: Complexity by accelerated gradient descent is better than by Sinkhorn’s algorithm. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1367–1376. [Google Scholar]
- Lin, T.; Ho, N.; Jordan, M. On the efficiency of the Sinkhorn and Greenkhorn algorithms and their acceleration for optimal transport. arXiv 2019, arXiv:1906.01437. [Google Scholar]
- Lin, T.; Ho, N.; Jordan, M. On efficient optimal transport: An analysis of greedy and accelerated mirror descent algorithms. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 3982–3991. [Google Scholar]
- Thibault, A.; Chizat, L.; Dossal, C.; Papadakis, N. Overrelaxed sinkhorn-knopp algorithm for regularized optimal transport. arXiv 2017, arXiv:1711.01851. [Google Scholar]
- Lehmann, T.; von Renesse, M.K.; Sambale, A.; Uschmajew, A. A note on overrelaxation in the Sinkhorn algorithm. arXiv 2020, arXiv:2012.12562. [Google Scholar]
- Benamou, J.D.; Carlier, G.; Cuturi, M.; Nenna, L.; Peyré, G. Iterative Bregman projections for regularized transportation problems. SIAM J. Sci. Comput. 2015, 37, A1111–A1138. [Google Scholar] [CrossRef]
- Bregman, L.M. The relaxation method of finding the common point of convex sets and its application to the solution of problems in convex programming. USSR Comput. Math. Math. Phys. 1967, 7, 200–217. [Google Scholar] [CrossRef]
- Peyré, G.; Cuturi, M. Computational optimal transport. Found. Trends Mach. Learn. 2019, 11, 355–607. [Google Scholar] [CrossRef]
- Solomon, J.; de Goes, F.; Peyré, G.; Cuturi, M.; Butscher, A.; Nguyen, A.; Du, T.; Guibas, L. Convolutional Wasserstein Distances: Efficient Optimal Transportation on Geometric Domains. ACM Trans. Graph. 2015, 34, 1–11. [Google Scholar] [CrossRef]
- Richardson, L.F. IX. The approximate arithmetical solution by finite differences of physical problems involving differential equations, with an application to the stresses in a masonry dam. Philos. Trans. R. Soc. Lond. Ser. A Contain. Pap. A Math. Phys. Character 1911, 210, 307–357. [Google Scholar]
- Iutzeler, F.; Hendrickx, J.M. A generic online acceleration scheme for optimization algorithms via relaxation and inertia. Optim. Methods Softw. 2019, 34, 383–405. [Google Scholar] [CrossRef]
- Schmitzer, B. Stabilized sparse scaling algorithms for entropy regularized transport problems. arXiv 2016, arXiv:1610.06519. [Google Scholar] [CrossRef]
- Knight, P.A. The Sinkhorn–Knopp algorithm: Convergence and applications. SIAM J. Matrix Anal. Appl. 2008, 30, 261–275. [Google Scholar] [CrossRef]
- Ciarlet, P. Introduction à l’Analyse Numérique Matricielle et à l’Optimisation; Masson: Manchester, UK, 1982. [Google Scholar]
- Chizat, L. Unbalanced Optimal Transport: Models, Numerical Methods, Applications. Ph.D. Thesis, Université Paris Dauphine, Paris, France, 2017. [Google Scholar]
- Hadjidimos, A. On the optimization of the classical iterative schemes for the solution of complex singular linear systems. SIAM J. Algebr. Discret. Methods 1985, 6, 555–566. [Google Scholar] [CrossRef]







Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Thibault, A.; Chizat, L.; Dossal, C.; Papadakis, N. Overrelaxed Sinkhorn–Knopp Algorithm for Regularized Optimal Transport. Algorithms 2021, 14, 143. https://doi.org/10.3390/a14050143
Thibault A, Chizat L, Dossal C, Papadakis N. Overrelaxed Sinkhorn–Knopp Algorithm for Regularized Optimal Transport. Algorithms. 2021; 14(5):143. https://doi.org/10.3390/a14050143
Chicago/Turabian StyleThibault, Alexis, Lénaïc Chizat, Charles Dossal, and Nicolas Papadakis. 2021. "Overrelaxed Sinkhorn–Knopp Algorithm for Regularized Optimal Transport" Algorithms 14, no. 5: 143. https://doi.org/10.3390/a14050143
APA StyleThibault, A., Chizat, L., Dossal, C., & Papadakis, N. (2021). Overrelaxed Sinkhorn–Knopp Algorithm for Regularized Optimal Transport. Algorithms, 14(5), 143. https://doi.org/10.3390/a14050143