
Is One Teacher Model Enough to Transfer Knowledge to a Student Model?




Abstract
:1. Introduction
- We propose an approach to simultaneously transfer learning from multiple teachers to another neural network: more than one neural network can simultaneously transfer its learning to another neural network;
- Improve Romero’s idea [2] by reducing to only one cycle of training instead of two and by effectively transferring the learning between any kind of network.
2. Related Work
3. Proposed Methods
3.1. Analyzing Romero’s Approach
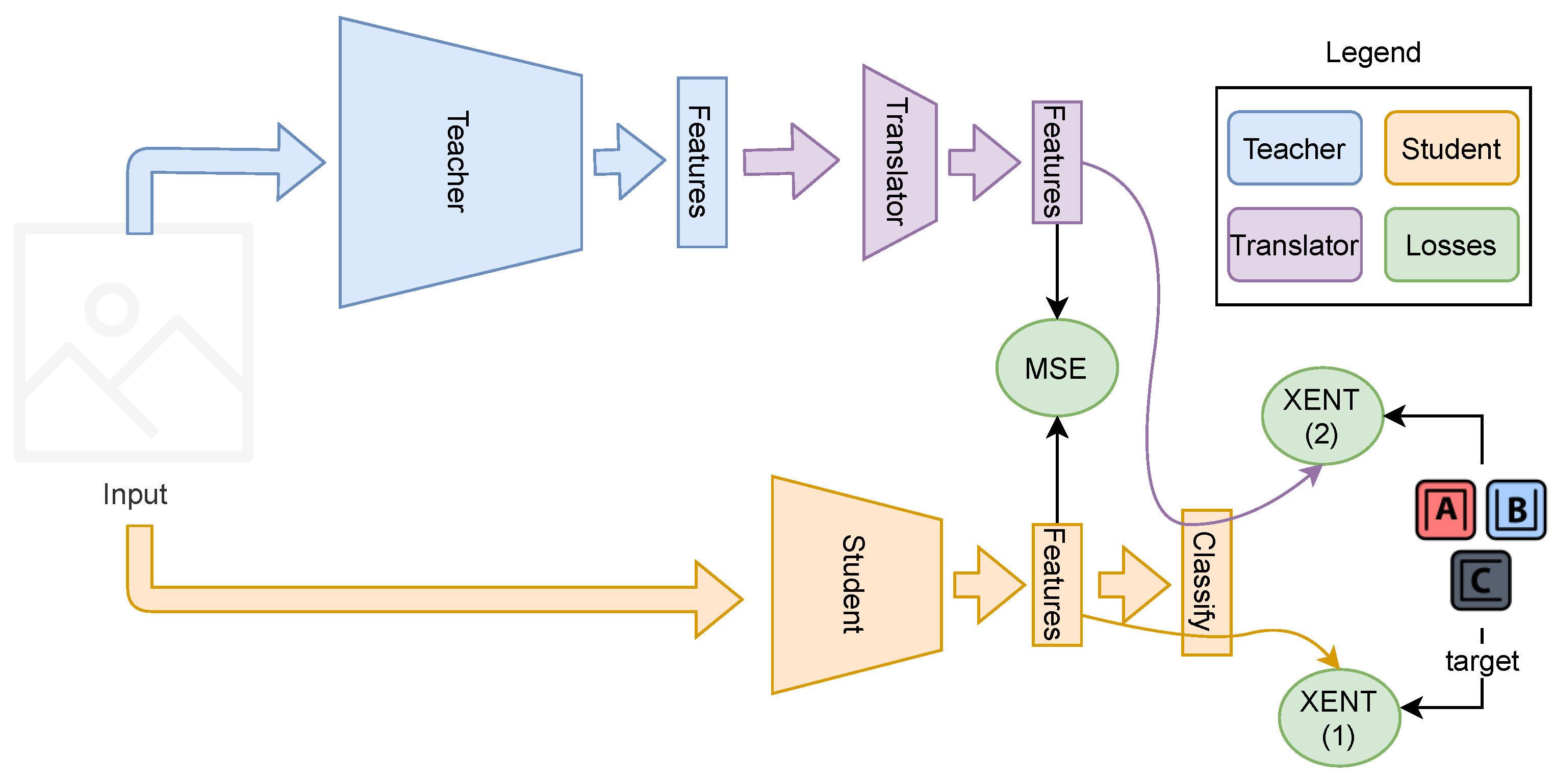
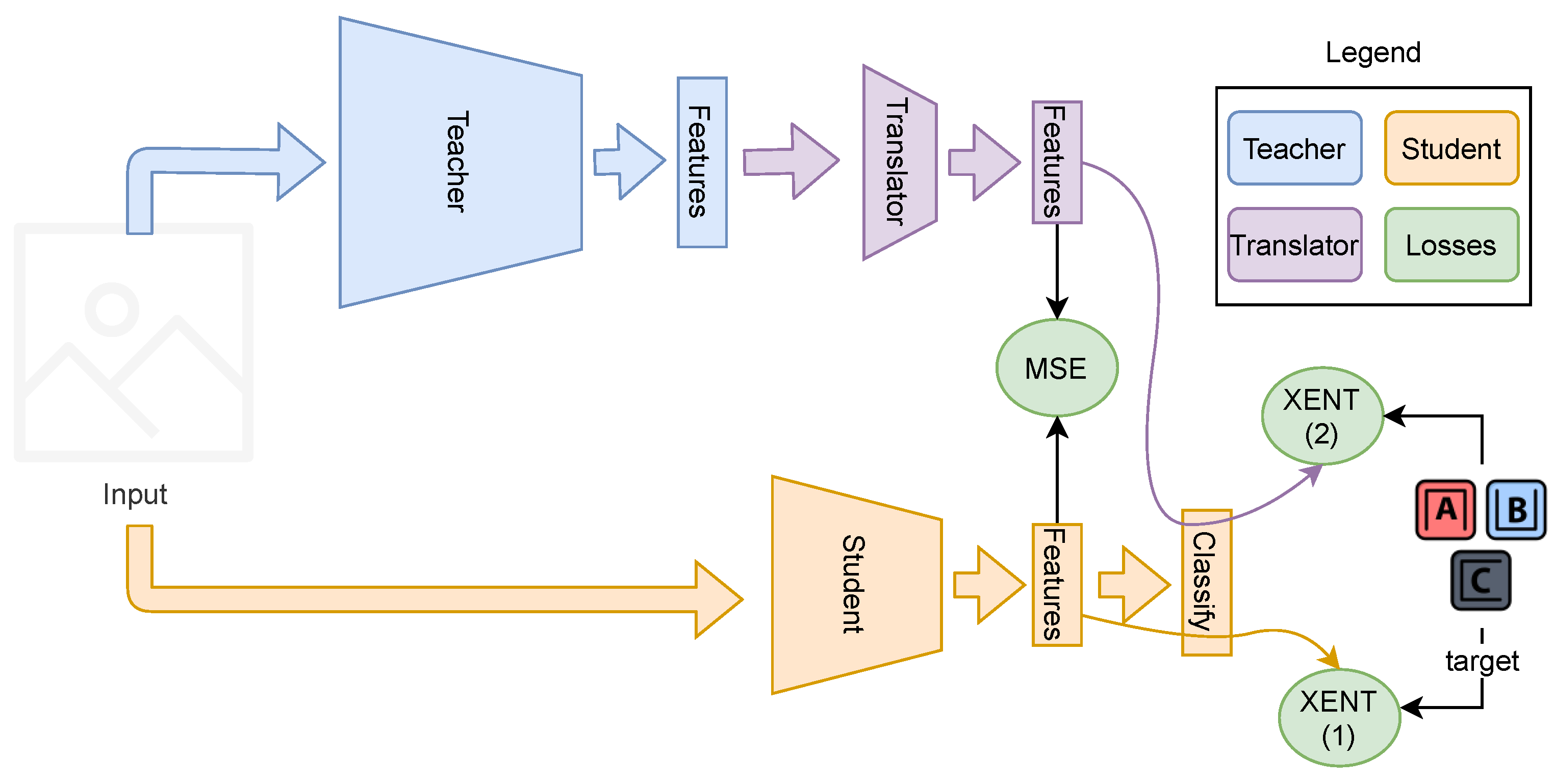
3.2. Our Proposal
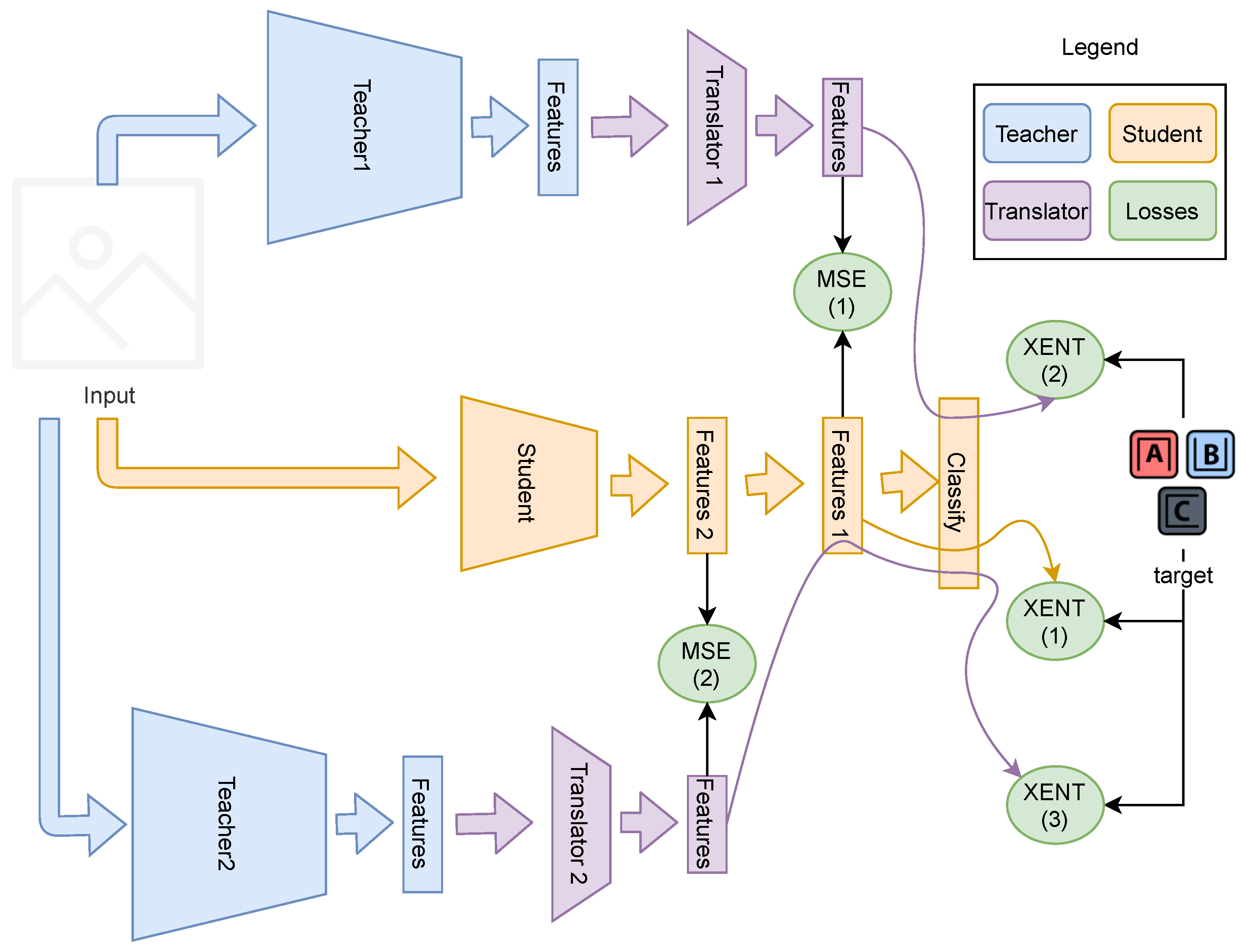
3.3. More Than One Teacher
| Algorithm 1 Training step with more than one teacher |
| Input: |
| : the batched data |
| : the number of teachers |
| : the translator for teacher i |
| : the feature layers of the student |
| : the student model before the features layer of the transfer |
| : the teacher models |
|
3.4. Implementation Details
3.5. Data Augmentation
4. Datasets
5. Experiments
- In a first group of experiments, we want to understand whether the hypotheses of the problems found in the Romero model can be overcome;
- The second group of experiments serves to evaluate our proposed solution in which we add the translator linked to the new loss function;
- A last group of experiments aims to evaluate the introduction of more than one teacher for a single student.
5.1. Hypothesis Validation
5.2. Analysis of the Proposed Method with a Single Teacher and Student
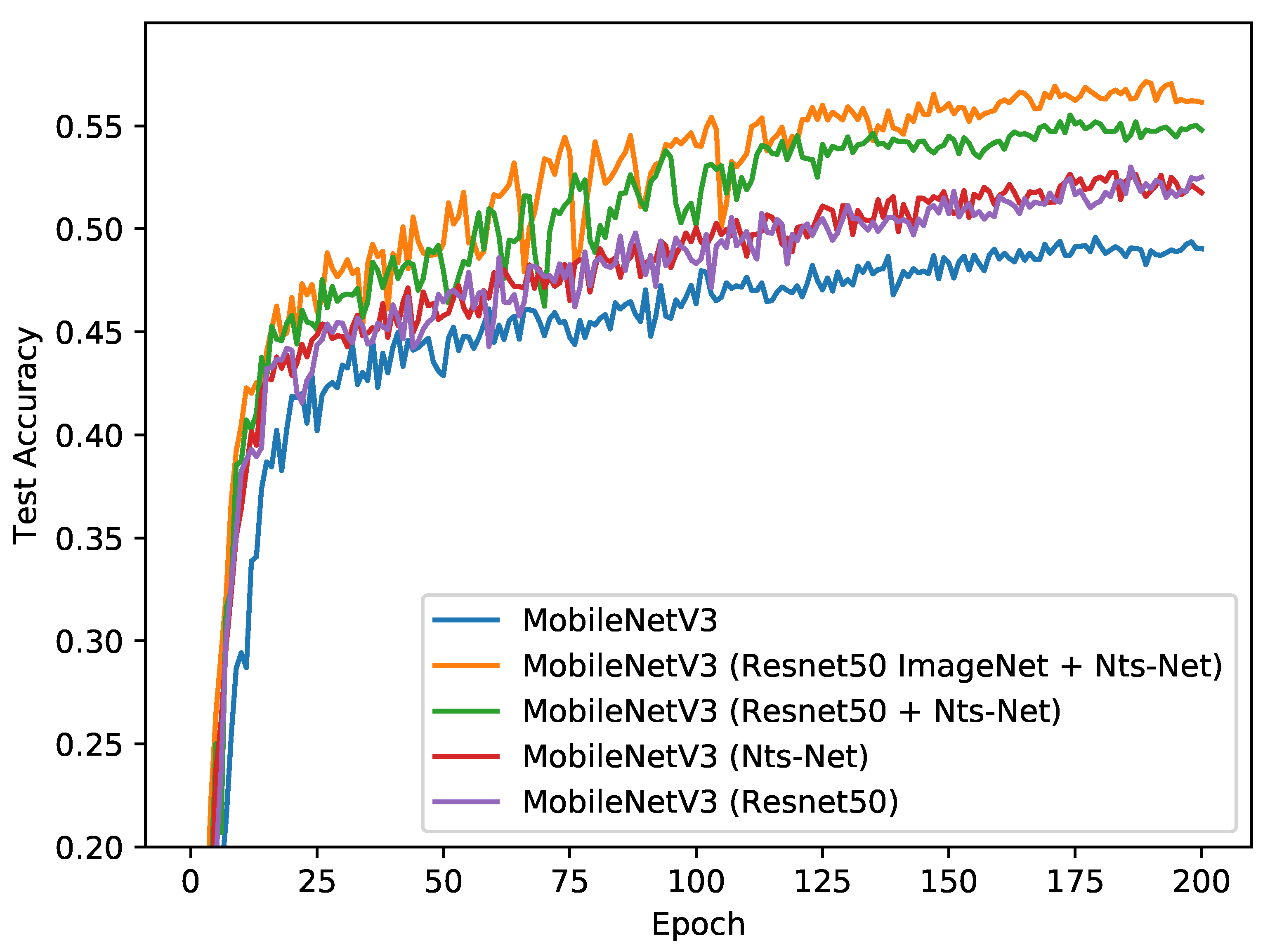
5.3. Analysis of the Proposed Solution Using More Than One Teacher
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Gatta, C.; Bengio, Y. FitNets: Hints for Thin Deep Nets. In Proceedings of the 3rd International Conference on Learning Representations, ICLR, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Ahn, S.; Hu, S.X.; Damianou, A.; Lawrence, N.D.; Dai, Z. Variational information distillation for knowledge transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9163–9171. [Google Scholar]
- Tung, F.; Mori, G. Similarity-preserving knowledge distillation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 23 July 2019; pp. 1365–1374. Available online: https://openaccess.thecvf.com/content_ICCV_2019/papers/Tung_Similarity-Preserving_Knowledge_Distillation_ICCV_2019_paper.pdf (accessed on 11 November 2021).
- Srinivas, S.; Fleuret, F. Knowledge transfer with jacobian matching. arXiv 2018, arXiv:1803.00443. [Google Scholar]
- Lee, S.H.; Kim, D.H.; Song, B.C. Self-supervised knowledge distillation using singular value decomposition. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 339–354. [Google Scholar]
- Kornblith, S.; Shlens, J.; Le, Q.V. Do better imagenet models transfer better? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 2661–2671. [Google Scholar]
- Yang, Z.; Luo, T.; Wang, D.; Hu, Z.; Gao, J.; Wang, L. Learning to navigate for fine-grained classification. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 420–435. [Google Scholar]
- Agarwal, N.; Sondhi, A.; Chopra, K.; Singh, G. Transfer learning: Survey and classification. In Smart Innovations in Communication and Computational Sciences; Springer: Berlin/Heidelberg, Germany, 2021; pp. 145–155. [Google Scholar]
- Goodfellow, I.J.; Warde-Farley, D.; Mirza, M.; Courville, A.; Bengio, Y. Maxout networks. arXiv 2013, arXiv:1302.4389. [Google Scholar]
- Landro, N. Features Transfer Learning. Available online: https://gitlab.com/nicolalandro/features_transfer_learning (accessed on 11 November 2021).
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; University of Toronto: Toronto, ON, Canada, 2009; Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.222.9220&rep=rep1&type=pdf (accessed on 11 November 2021).
- Khosla, A.; Jayadevaprakash, N.; Yao, B.; Fei-Fei, L. Novel Dataset for Fine-Grained Image Categorization. In Proceedings of the First Workshop on Fine-Grained Visual Categorization, Colorado Springs, CO, USA, 20–25 June 2011; Available online: https://people.csail.mit.edu/khosla/papers/fgvc2011.pdf (accessed on 11 November 2021).
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A.; Jawahar, C. Cats and dogs. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3498–3505. [Google Scholar]
- Wah, C.; Branson, S.; Welinder, P.; Perona, P.; Belongie, S. The Caltech-UCSD Birds-200-2011 Dataset; Technical Report CNS-TR-2011-001; California Institute of Technology: Pasadena, CA, USA, 2011. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. (IJCV) 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Nawaz, S.; Calefati, A.; Caraffini, M.; Landro, N.; Gallo, I. Are These Birds Similar: Learning Branched Networks for Fine-grained Representations. In Proceedings of the 2019 International Conference on Image and Vision Computing New Zealand (IVCNZ), Dunedin, New Zealand, 2–4 December 2019; pp. 1–5. [Google Scholar]
- Landro, N. 131 Dog’s Species Classification. Available online: https://github.com/nicolalandro/dogs_species_prediction (accessed on 11 November 2021).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Targ, S.; Almeida, D.; Lyman, K. Resnet in resnet: Generalizing residual architectures. arXiv 2016, arXiv:1603.08029. [Google Scholar]
- Frankle, J.; Carbin, M. The lottery ticket hypothesis: Finding sparse, trainable neural networks. arXiv 2018, arXiv:1803.03635. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Baseline | KD | Romero | T1S | T1S + Aug. |
|---|---|---|---|---|---|
| Cifar10 | |||||
| Lenet5 | 65.43 | 64.84 | 62.11 | 64.12 | 65.49 |
| AlexNet | 72.75 | 70.93 | 70.38 | 73.74 | 73.99 |
| MobileNetV2 | 74.82 | 63.22 | 64.92 | 77.53 | 81.60 |
| Resnet18 | 78.76 | 82.64 | 82.35 | 80.81 | 83.52 |
| Cifar100 | |||||
| Lenet5 | 28.34 | 32.62 | 29.72 | 33.86 | 33.65 |
| AlexNet | 35.86 | 36.93 | 37.96 | 40.49 | 38.12 |
| MobileNetV2 | 31.31 | 29.03 | 31.26 | 43.25 | 39.47 |
| Resnet18 | 51.82 | 46.42 | 46.03 | 60.77 | 54.18 |
| Name | Without Teacher | With Teacher |
|---|---|---|
| MobileNetV2 | 42.5 | 49.2 |
| Dataset | Student | Baseline | Romero | KD | T1 | T2 |
|---|---|---|---|---|---|---|
| Cifar10 | Lenet5 | 64.12 | 60.64 | 61.01 | 64.77 | 64.89 |
| Cifar10 | Mobilenetv3 | 60.98 | 62.12 | 60.59 | 64.42 | 64.29 |
| Cifar100 | Lenet5 | 32.60 | 32.37 | 33.57 | 34.25 | 34.09 |
| Cifar100 | Mobilenetv3 | 30.26 | 30.29 | 25.22 | 31.78 | 33.17 |
| Student | Teacher/s | Pretrained | Accuracy |
|---|---|---|---|
| MobileNetV3 | - | - | 49.59 |
| MobileNetV3 | Resnet50 | SOD | 53.00 |
| MobileNetV3 | Resnet50, Nts-Net | SOD, SOD | 55.53 |
| MobileNetV3 | Resnet50, Nts-Net | ImageNet, SOD | 57.15 |
| Student | Teacher/s | Teacher Train | Student Train | Accuracy |
|---|---|---|---|---|
| - | Resnet50 | Cifar10 | - | 82.39 |
| Inceptionv3 | - | - | Cifar10 | 72.81 |
| Inceptionv3 | Resnet50 | ImageNet | Cifar10 | 91.39 |
| Inceptionv3 | Resnet50, Nts-Net | ImageNet, SOD | Cifar10 | 92.00 |
| Inceptionv3 | Resnet50 | Cifar10 | Cifar10 | 92.10 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Landro, N.; Gallo, I.; La Grassa, R. Is One Teacher Model Enough to Transfer Knowledge to a Student Model? Algorithms 2021, 14, 334. https://doi.org/10.3390/a14110334
Landro N, Gallo I, La Grassa R. Is One Teacher Model Enough to Transfer Knowledge to a Student Model? Algorithms. 2021; 14(11):334. https://doi.org/10.3390/a14110334
Chicago/Turabian StyleLandro, Nicola, Ignazio Gallo, and Riccardo La Grassa. 2021. "Is One Teacher Model Enough to Transfer Knowledge to a Student Model?" Algorithms 14, no. 11: 334. https://doi.org/10.3390/a14110334
APA StyleLandro, N., Gallo, I., & La Grassa, R. (2021). Is One Teacher Model Enough to Transfer Knowledge to a Student Model? Algorithms, 14(11), 334. https://doi.org/10.3390/a14110334