1. Introduction
Data envelopment analysis (DEA) is a prominent technique for the non-parametric relative efficiency analysis of a set of decision-making units (DMUs) drawn from a similar production process [
1]. DEA models are used in both operation research and data mining literature [
2]. Some of the traditional properties of production functions, such as the monotonicity and convexity of the inputs and outputs, that are fundamental in DEA models are often found to be attractive in some data mining models where datasets are noisy and model resistance to learning noise is necessary [
3]. An important aspect of DEA models is the reliability of DMU efficiency scores. It is generally accepted that the DEA efficiency estimates are reliable when the sample size is large [
4]. Since the reliability of the DEA scores is dependent on the sample size, Cooper et al. [
5] have suggested the following rule for the minimum number (
n) of DMUs for reliable DEA analysis (each DMU has
m inputs and
s outputs):
For small-size datasets, where violations of the minimum number of DMUs specified by Equation (1a) frequently occur, dimensionality reduction (also known as variable reduction or variable selection) approaches are frequently used to select a subset of variables to satisfy Equation (1a). A variety of variable selection approaches are available in the literature. Among these variable selection approaches are statistical [
6], regression [
7], efficiency contribution measure [
8], bootstrapping [
9], hypothesis testing [
10], variable aggregation [
11] and statistical experiment designs [
12]. Variable selection approaches are criticized extensively for applying parametric procedures and linear relationship assumptions for selecting variables to determine an unknown non-linear and non-parametric efficiency frontier. Nataraja and Johnson [
13] provide a good description of some of these procedures and their pros and cons.
Pendharkar [
14] proposed a competing approach to the dimensionality reduction/variable selection problem called the ensemble DEA. In his approach, traditional DEA analysis is conducted for all possible input and output combinations, and the efficiency scores of each DEA model for each DMU are averaged as an ensemble efficiency score for a DMU. Drawing from machine learning literature, Pendharkar [
14] showed that the ensemble efficiency score is a reliable estimate of the “true” efficiency of a DMU. Even for small datasets, certain combinations of inputs will satisfy the criterion set by Equation (1a), while others will violate it, but the average ensemble score will be closer to the true efficiency of the DMU and will be reliable. Pendharkar [
14] also proposed an exhaustive search procedure to generate all possible input and output combinations, and proposed a formula to compute the number of unique DEA models that need to be run to compute an average ensemble score. This number
N of unique DEA models may be computed using the following formula:
Using Banker et al.’s [
15] variable-returns-to-scale (VRS) DEA BCC model, and data and models obtained from a few studies in the literature, Pendharkar [
14] showed that the ensemble DEA model provides a better ranking of DMUs than the models proposed in a few studies from the literature.
This research investigates the additional properties and statistical distribution of the ensemble DEA model scores. It is shown that there are added benefits of ensemble efficiency scores. In particular, the ensemble efficiency scores maximize entropy, meaning that the DMU ranking distribution generated by the ensemble efficiency scores has a lower bias when compared to some competing radial and non-radial variable selection models recently reported in the literature, and second, the ensemble efficiency scores may be normally distributed under certain restrictive assumptions. The normal distribution of the efficiency score feature is particularly attractive because returns-to-scale hypothesis testing may be conducted by using traditional difference-in-means parametric statistical procedures. Both of these features are tested using data and models reported in a published study [
16]. The rest of the paper is organized as follows: In
Section 2, the basic DEA radial and non-radial models, ensemble DEA model and Entropy criterion for comparing different DEA models are described. In
Section 3, using Iranian gas company data, the results of ensemble DEA models are compared with the results of variable selection models used in Toloo and Babaee’s [
16] study. Additionally, in
Section 3, the properties of the ensemble DEA scores are investigated in terms of the entropy criterion and their statistical distributions. In
Section 4, the paper concludes with a summary and directions for future research.
2. DEA Preliminaries, Ensemble DEA Model, Entropy Criterion for DEA Model Comparisons and Statistical Distribution of Ensemble Scores
The basic DEA model assumes
n DMUs, with each DMU consisting of
m different inputs that produce
s different outputs. The input and output vectors are semi-positive, and for DMU
j (
j = 1, …,
n), the space for the input and output vectors (
xj,
yj) ϵ
. For a DMU
o, its relative efficiency may be computed by using the linear programming model under the constant returns-to-scale assumption. This efficiency is computed by solving the following model:
subject to:
where
vi and
ur are the weights associated with the
ith input and
jth output, respectively. The constant
ε > 0 is infinitesimally non-Archimedean. The model (2a)–(2d) is often called the primary CCR model [
1], and its dual is written as follows:
subject to:
The VRS BCC model augments the system (2e)–(2h) by adding the following constraint:
The aforementioned models are radial DEA models that are criticized for not providing input or output projections (for inefficient DMUs) that satisfy Pareto optimality conditions [
17]. Fare and Lovell [
18] independently proposed radial DEA models that allow for input or output reductions at variable rates. The radial version of the CCR model is mathematically represented in the following dual form:
subject to:
Pendharkar [
14] proposed an ensemble DEA model based on the popularity of ensemble models in machine learning literature. The ensemble DEA model requires an exhaustive search procedure using a binary vector
z whose components indicate whether an input or output is considered in performing DEA analysis. The dimension of this binary vector is (
m +
s).
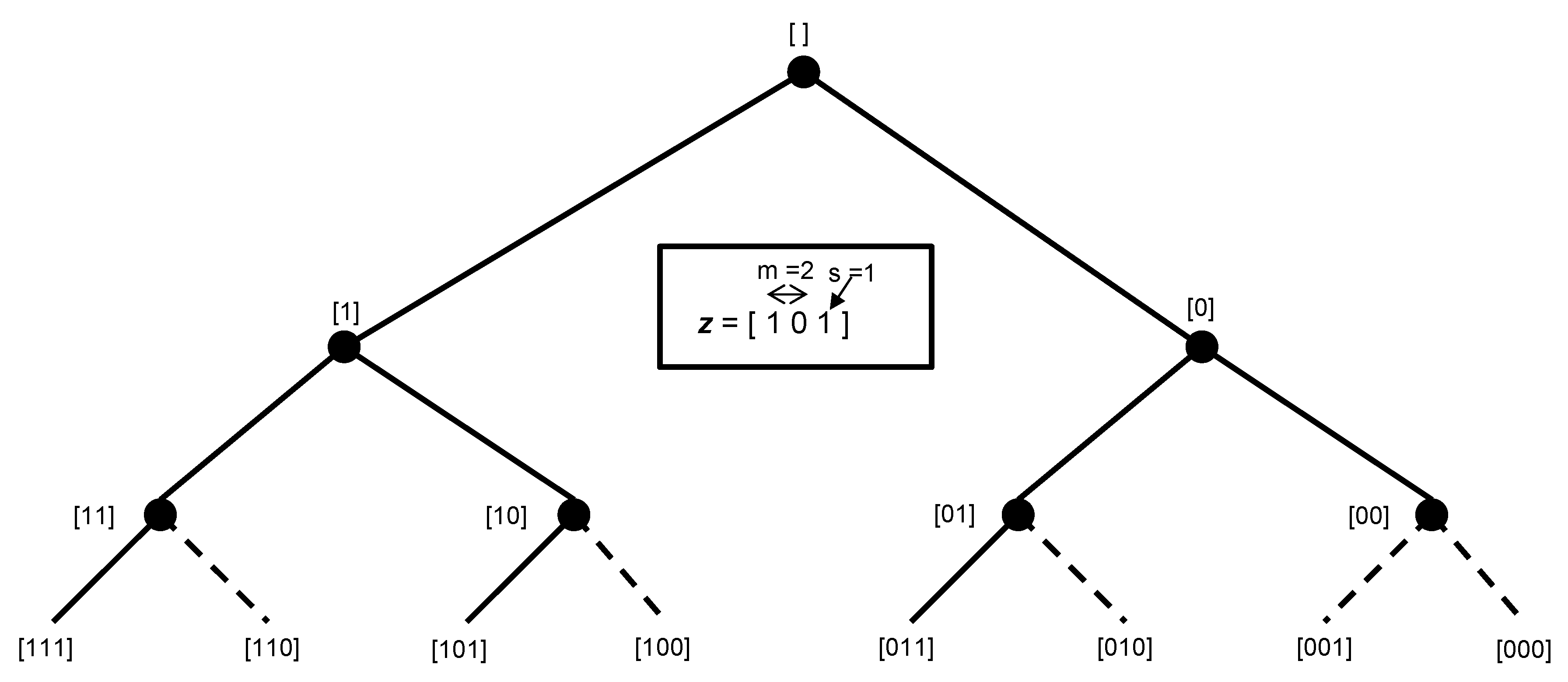
Figure 1 illustrates the
z vector and exhaustive search tree for two-input-and-one-output datasets. The exhaustive tree is pruned (dotted edges) for models that have either no inputs or no outputs. DEA analysis is then conducted on the remaining models, and the efficiency results of each model for each DMU are averaged and used as ensemble DEA scores. To illustrate the ensemble DEA approach on a two-input-and-one-output dataset, a CCR DEA analysis using partial Cobb–Douglas production function data on US economic growth between 1899 and 1910 [
19] is conducted.
Table 1 illustrates the results of our DEA analysis and resulting ensemble scores. The two inputs were labor in person-hours worked per year and the amount of capital invested. The output was the total annual production. The results of the analysis show that the traditional DEA with
z = [111] does not provide unique rankings (for the years 1901 and 1902 receive the same efficiency score), but the ensemble DEA model provides unique DMU rankings. Pendharkar’s [
14] study provides a theoretical basis for the reliability of ensemble DEA scores.
The maximum entropy (ME) principle has been applied to DEA DMU ranking distribution [
20] and model comparisons [
21]. The ME principle measures the DMU ranking bias by using a more general family of distributions [
22]. Several statistical distributions can be characterized as ME densities [
23]. The ME distributions are the least biased distributions obtained by imposing moment constraints that are inherent in the data [
21]. To obtain the ME for a given set of DMUs and their efficiencies, normalized ranks are first obtained by computing
, for each DMU, and then computing the ME for a certain model
z as follows:
The ME for the DEA models in
Table 1 are ME
111 = 2.4768, ME
101 = 2.4775 and ME
011 = 2.4757. The model with labor as an input and production as an output (
z = [101]) has the highest entropy and has the least bias, with a maximum difference between DMU efficiencies for closely ranked DMUs for the years 1901 and 1902. The ensemble entropy is 2.4769, and since it is an average of all
z-vector combinations, the comparison benchmark for ensemble entropy is the model with
z = [111]. The ensemble entropy is higher than the benchmark. The highest possible entropy value or upper bound (UB) for a model is given by the following expression:
The ME
UB for the data in
Table 1 is 2.485, and the ensemble entropy is very close to the maximum value. It is important to note that obtaining the maximum value is not always desirable, but it provides a theoretical benchmark estimate for a completely unbiased normalized DMU score distribution.
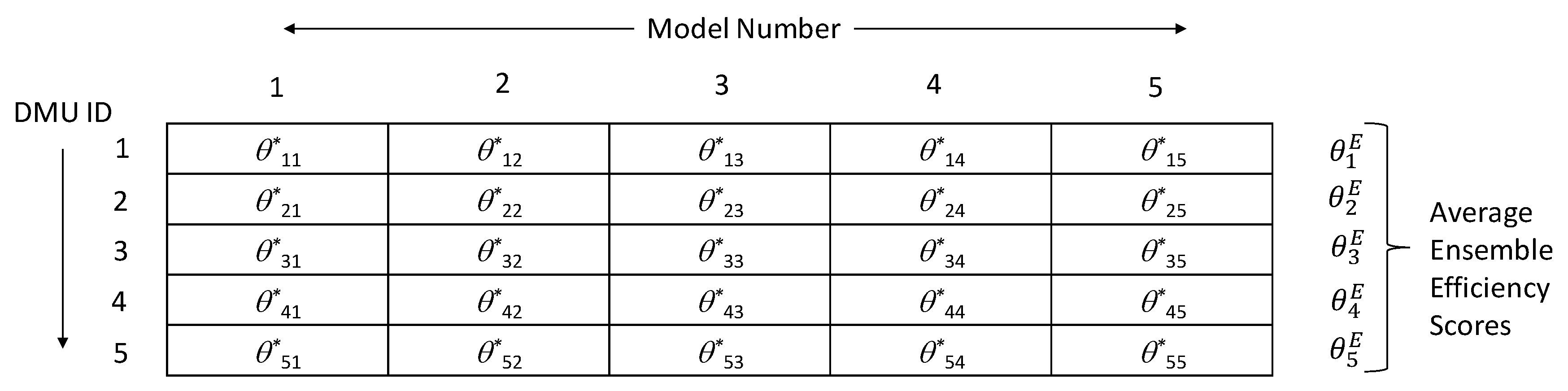
To compute ensemble efficiency scores, an
n × m matrix
E of DEA efficiency scores is necessary. The rows of such a matrix are the numbers of DMUs, and the columns are the numbers of models given by the numbers of eligible models considered in computing ensemble efficiency scores. This number of eligible models will have an upper bound given by
N, computed using Equation (1b). The elements of this matrix will be efficiency scores for each DMU computed for a given model identified by column number.
Figure 2 illustrates a five-DMU-and-five-model matrix. The ensemble efficiency score (
) for each DMU is computed using the following formula:
A few observations can be made about any row
i ϵ {1, …,
n} of the ensemble efficiency score matrix. First, all the elements of a given row are an independent computation of efficiency scores by the same DMU under a different model number with its unique set of input(s) and output(s). Second, in all the elements of a given row, the DMU is maximizing its efficiency given its model constraints. Thus, each row represents independent evaluations by a DMU under the maximum decisional efficiency (MDE) principle [
24]. The MDE principle was introduced by Troutt [
25] to develop a function to the aggregate the performance of multiple decision-makers. The underlying assumption of the MDE principle is that all decision-makers seek to maximize their decisional efficiencies. Troutt [
26] later used the MDE approach to rank DMUs and showed that DMUs deemed efficient under MDE are also efficient when ranked using the DEA. For a linear aggregator function, such as the one used in Equation (2j), Troutt [
26] illustrated that the decisional efficiencies
θ can be described by the following probability density function (pdf):
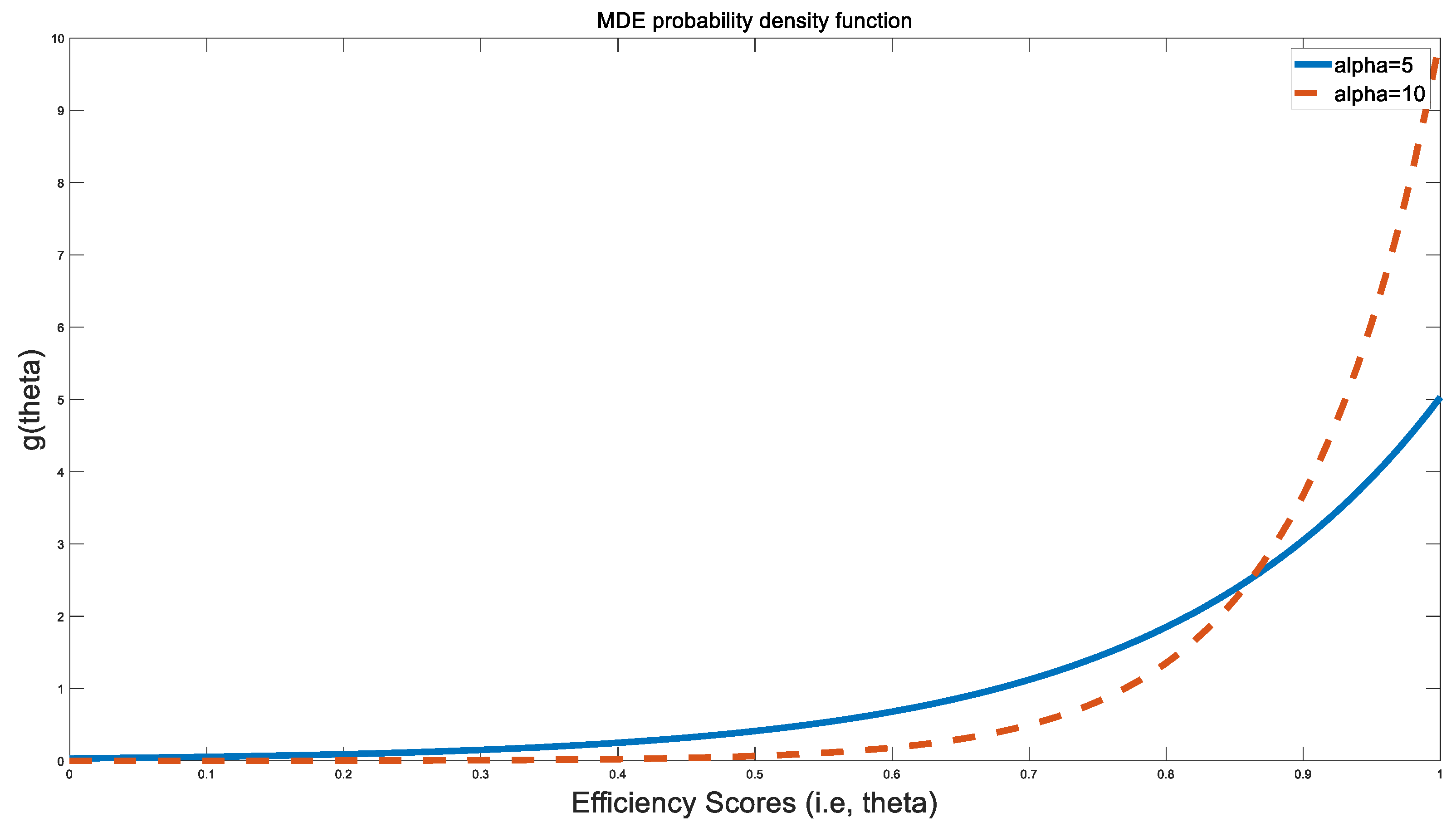
The pdf in (2k) is monotone, increasing on its interval with a mode at
θ = 1 (see Figure 5 for illustration). Using the laws of probability, the value of
cα =
α (
eα − 1)
−1. Since each element in a given row of the ensemble efficiency score matrix is an independent evaluation by a decision-maker (i.e., a DMU in an ensemble model) trying to maximize its decisional efficiency
for
j = {1, …,
m}, the probability density function for each row (DMU) can be written as:
The central limit theorem mentions that the cumulative distribution functions (cdfs) of the sums of independently identically distributed random variables asymptotically converge to a Gaussian cdf. The ensemble efficiency scores are normalized sums of independent efficiency assessments that will be distributed with a pdf given by (2l). These sums can be considered independent and identically distributed if
α1 =
α2 = … =
αn. Under the restrictive assumption that
α1 =
α2 = … =
αn, the ensemble efficiency scores are guaranteed to asymptotically converge to a normal distribution by the central limit theorem. In practice, however, the ensemble efficiency scores are not entirely random or perfectly identically distributed (due to the slight likely variation of Equation (2l)’s
αi parameters for each row), and each ensemble model does introduce a degree of mild randomization. For mild differences in the row pdf parameters
αi, where
α1 ≈
α2 ≈ … ≈
αn, the ensemble efficiency scores are likely to be normally distributed. A reader may note that under ideal conditions, where
α1 =
α2 = … =
αn and individual DMU scores follow Equation (2l)’s distribution, the entropy of the ensemble scores will be highest and close to the highest upper bound mentioned in Equation (2i) because the distribution in Equation (2i) has a mode of 1 (see Figure 5). Thus, it may be argued that the likelihood of normality of the ensemble scores increases when the entropy of the ensemble scores is closer to its upper bound given by Equation (2i). It is important to note that an entropy equal to the exact value of the upper bound given by Equation (2i) is undesirable because at that value, the distribution is a uniform distribution where all the DMUs are fully efficient for all the models. The entropy of the pdf in Equation (2k) is maximized on the interval [0, 1] when the mean of the distribution is greater than 0.5 [
27]. Additionally, another important aspect of the distribution of the ensemble efficiency scores is that both the rows and columns of ensemble efficiency scores (
Figure 2) play a role in the pdf of the ensemble efficiency scores because the rows represent sampling from the MDE distributions and the columns represent sampling from the distribution of the sums of independent variables. Larger sample sizes increase the statistical reliability and robustness of the results.
3. Comparing Variable Selection Models and Ensemble Model Using Gas Company Data and Entropy Criterion
For small datasets, many input or output variables are aggregated so that the selected variables satisfy the heuristic given in Equation (1a). There are two problems with all the variable selection approaches. First, they use an artificial criterion to select variables for a non-linear and non-parametric approach. Any artificial/subjective criterion will make some assumptions that are harder to justify. Second, these techniques have several selection parameters and thresholds that often lead to inconsistencies in applying these techniques. For example, Toloo and Babaee [
16] illustrate three problems with a variable selection approach and suggested an improved approach. By contrast, the ensemble DEA approach does not make any assumptions, and for small datasets, trying out different input and output combinations and aggregating efficiency scores provide more reliable efficiency estimates than variable selection models. Part of the reason for the stability of ensemble DEA efficiency scores is that, even for small datasets, some DEA models in an ensemble will always satisfy the heuristic given in Equation (1a), which will increase the reliability of the ensemble efficiency scores due to model averaging. This stability of ensemble efficiency scores is illustrated by comparing ensemble scores with the results of models from Toloo and Babaee’s [
16] study and using the entropy criterion.
To compare the results, the dataset from Toloo and Babaee’s [
16] study is used. The dataset consists of three inputs and four outputs from an Iranian gas company. The inputs are budget (
x1), staff (
x2) and cost (
x3). The outputs are customers (
y1), the length of the gas network (
y2), the volume delivered (
y3) and gas sales (
y4).
Table 2 lists these data.
Table 3 lists the efficiency scores of the ensemble DEA with the CCR and BCC models and models used by Toloo and Babaee [
16]. Using formula (1b), a total of 105 unique DEA models were used to compute the DEA ensemble efficiency score.
The entropies of the Ensemble CCR, Ensemble BCC, Non-Radial and Radial models were 2.616, 2.621, 2.615 and 2.599, respectively. The MEUB from Equation (2i) is 2.639. Comparing the Ensemble CCR with the Non-Radial and Radial CCR models shows that the Ensemble CCR model has a higher entropy. Only the VRS Ensemble BCC model has a higher entropy than the Ensemble CCR model. The standard deviations of the Ensemble BCC model are mostly lower than the CCR model’s as well. More importantly, the Ensemble CCR model generates unique rankings for the DMUs, whereas the Non-Radial and Radial models generate a tie for three DMUs. The Ensemble BCC model also generates unique rankings, but the differences occur at the third decimal place. The Ensemble BCC efficiency scores for DMU 10, 12 and 13 were 0.960, 0.959 and 0.962, respectively.
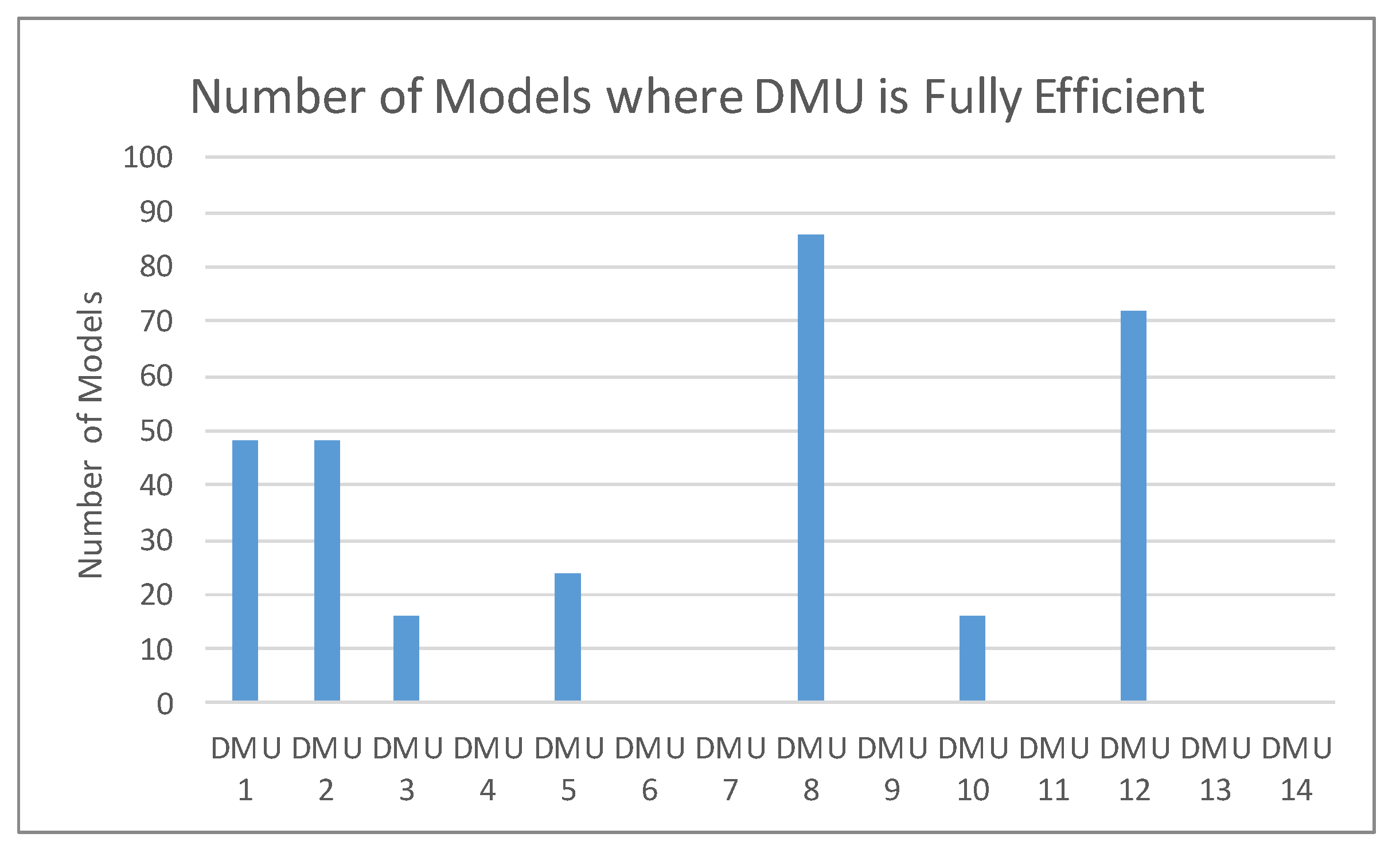
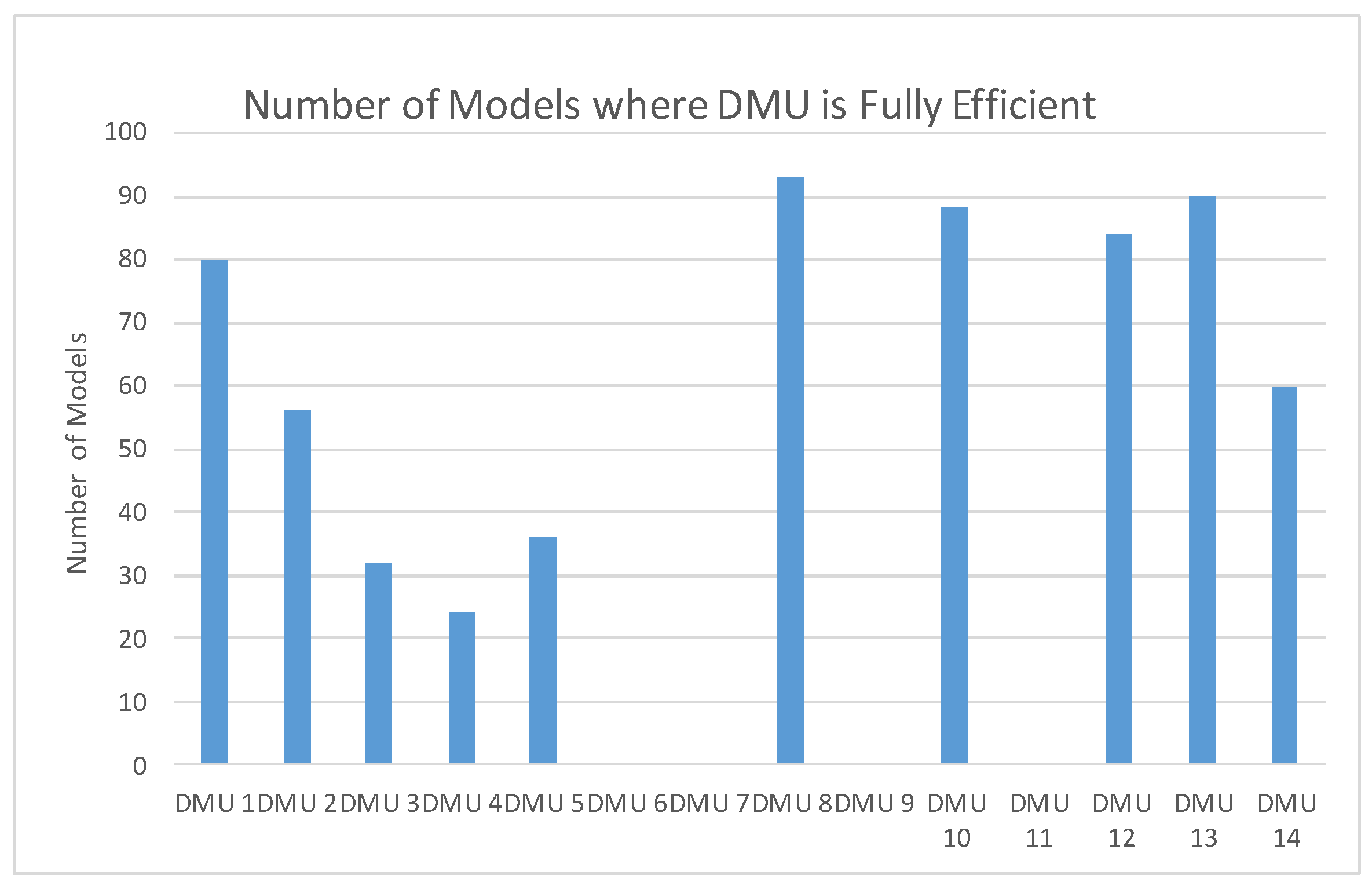
Figure 3 and
Figure 4 illustrate the numbers of models (out of 105 total models) where a DMU was fully efficient. These figures are useful for understanding to what extent the assumption
α1 ≈
α2 ≈ … ≈
αn was satisfied for the theoretical normal distribution of the ensemble efficiency scores. For these parameters to be similar, the expectation is that a similar number of fully efficient DMUs should exist across all models. Clearly, some DMUs are never fully efficient under any of 105 models and the assumption of identical distributions is violated. While the assumption is violated,
Figure 4 illustrates that some DMUs, e.g., 1, 8, 10, 12 and 13, have a somewhat similar number of fully efficient DMUs to others. These ensemble scores of these DMUs may be considered as normalized random sums generated from identical distributions (such as Distribution 1). All of these DMUs have ensemble efficiency scores greater than 0.95. Similarly, DMUs 5, 6 and 11, in
Figure 4, have no fully efficient scores, and these may also be considered as random normalized sums generated from identically distributed pdfs (such as Distribution 2).
The ensemble scores for this dataset appear to be random normalized sums from two or more pdfs of the forms given in Equation (2k). Given that these are independent random normalized sums, it can be easily shown that the product of two or more independent MDE pdfs is also an MDE pdf.
Figure 5 illustrates two sample MDE pdfs for two different values of alpha. The entropy of an MDE pdf is maximized when the mean of a distribution is greater than 0.5 [
27]. For the ensemble BCC model, from
Table 3, this criterion is satisfied. The lowest value of the ensemble BCC score is 0.57, which is greater than the mean of 0.5 required to maximize entropy and higher than the lowest values for the efficiency scores for the radial, non-radial and ensemble CCR models. As a result, the ensemble BCC model appears to maximize its entropy slightly better than the ensemble CCR model.
While ensemble scores have a minor violation of an identical distribution for some DMUs, a formal test of the normality of the distribution of the ensemble efficiency scores was conducted.
Table 4 illustrates the results of these tests. The Shapiro–Wilk statistic for the Ensemble CCR model is 0.944, and that for the Ensemble BCC model is 0.876, which, at 14 degrees of freedom, are non-significant, consistent the null hypothesis that the efficiency score distribution is normally distributed at the 95% level of statistical significance.
A paired sample t-test for the difference in mean efficiency scores between the Ensemble CCR and the Ensemble BCC models gives a |t|-value of 3.524, which is significant at the 99% level of statistical significance (df = 13), indicating that a variable returns-to-scale relationship exists between inputs and outputs. The normality of the ensemble efficiency score distributions increases the power of parametric statistical tests.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}