Machine Learning-Guided Dual Heuristics and New Lower Bounds for the Refueling and Maintenance Planning Problem of Nuclear Power Plants †


Abstract
1. Introduction
2. Problem Statement
2.1. Production Assets
2.2. Time Step Discretization
2.3. Decision Variables and Objective Function
2.4. Description of the Constraints
3. Related Work
3.1. Solving Methods
3.2. Reductions by Pre-Processing
3.3. Dual Bounds for the Euro/Roadef Challenge 2010
3.4. Milp Formulations
4. Mathematical Programming Relaxations
4.1. Relaxing Only Constraints CT6 and CT12
4.2. Parametric Surrogate Relaxations
4.3. Preprocessing Reductions and Dual Bounds
5. Dual Bounds by Scenario Decomposition
| Algorithm 1 Partitioning HC matheuristic to maximize the diversity of scenarios. |
| Input: |
| - the maximal number of scenario in a subset of the partition; |
| - , the matrix for distances between scenarios s and ; |
| - nbIter, maximal number of hill climbing iterations; |
| Initialization: |
| - compute , ; |
| - re-index the scenarios such that ; |
| - set for defining an initial partition of ; |
| forit from 1 to nbIter: |
| for to : |
| for to N: |
| reoptimize subsets solving (54) in with |
| end for |
| end for |
| if no improvement was provided in the last MILP resolutions then break |
| end for |
| return the partition of : |
- The local optimization may be stopped before the optimality proof, only the improvement of a feasible solution in a given time limit is on interest. In such case, it is important to implement the warmstart previously mentioned, to ensure having a steepest descent heuristic: the local optimization will improve or keep the current solution given as warmstart.
- In the loop re-optimizing (54) with with for all , many local reoptimizations are independent dealing with independent sub-sets, which allows for designing a parallel implementation.
- One may wonder why the classical k-means algorithm is not used instead of Algorithm 1. A first reason is that cardinality constraints are not provided in the standard k-means algorithm. One may try to repair the cardinality constraints after standard k-means iterations. Even in such scheme, k-means was not designed to partition the points in many subsets N with few elements, usually, k-means works fine with . On the contrary, the numerical property is favorable to an Algorithm 1 matheuristic. A second reason to prefer Algorithm 1 is that the objective function is a straightforward indicator of the data. Using a clustering algorithm, one may wish to minimize a dissimilarity. Considering dissimilarity indicators like , it is a deformation of the input data, and this is not a mathematical distance with a triangle inequality which also makes the clustering procedure non standard.
6. Computational Results
6.1. Computational Experiments and Parameters
6.2. Data Characteristics
6.3. Branch & Bound Solving Characteristics
6.4. Lower Bounds for Dataset A
- for instance A1: we measure 1191 s (nearly 20 min) for the total MILP computations, and summing Cplex time we find nearly 135 s (2 min 15 s).
- for instance A2: we measure 10,385 s (nearly three hours) for the total MILP computations, and summing Cplex time we find 2100 s (i.e., 35 min).
- for instance A3: we measure 11,835 (more than three hours) for the total MILP computations, and summing Cplex time we find 2418 s (i.e., nearly 40 min).
6.5. Lower Bounds for Datasets B and X
6.5.1. Dual Bounds Computable in Less Than One Hour
6.5.2. Dual Bounds Decomposing Scenario by Scenario
6.5.3. Dual Bounds with Partial Scenario Decomposition
6.6. New Dual Bounds for the Euro/Roadef Challenge 2010
7. Conclusions and Perspectives
Author Contributions
Funding
Conflicts of Interest
References
- Talbi, E.G. Combining metaheuristics with mathematical programming, constraint programming and machine learning. Ann. Oper. Res. 2016, 240, 171–215. [Google Scholar] [CrossRef]
- Jourdan, L.; Basseur, M.; Talbi, E.G. Hybridizing exact methods and metaheuristics: A taxonomy. Eur. J. Oper. Res. 2009, 199, 620–629. [Google Scholar] [CrossRef]
- Peschiera, F.; Dell, R.; Royset, J.; Haït, A.; Dupin, N.; Battaïa, O. A novel solution approach with ML-based pseudo-cuts for the Flight and Maintenance Planning problem. OR Spectr. 2020, 1–30. [Google Scholar] [CrossRef]
- Li, Y.; Ergun, O.; Nemhauser, G. A dual heuristic for mixed integer programming. Oper. Res. Lett. 2015, 43, 411–417. [Google Scholar] [CrossRef]
- Bixby, E.; Fenelon, M.; Gu, Z.; Rothberg, E.; Wunderling, R. MIP: Theory and practice-closing the gap. In System Modelling and Optimization; Powell, M.J.D., Scholtes, S., Eds.; Springer: Boston, MA, USA, 2000. [Google Scholar]
- Wolsey, L.A. Integer Programming; Springer: Berlin, Germany, 1998. [Google Scholar]
- Lodi, A. The heuristic (dark) side of MIP solvers. In Hybrid Metaheuristics; Talbi, E.G., Ed.; Springer: Berlin, Germany, 2013; pp. 273–284. [Google Scholar]
- Dupin, N.; Parize, R.; Talbi, E. Matheuristics to stabilize column generation: Application to a technician routing problem. Matheuristics 2018, 2018, 1–10. [Google Scholar]
- Glover, F. Surrogate constraints. Oper. Res. 1968, 16, 741–749. [Google Scholar] [CrossRef]
- Rogers, D.; Plante, R.; Wong, R.; Evans, J. Aggregation and disaggregation techniques and methodology in optimization. Oper. Res. 1991, 39, 553–582. [Google Scholar] [CrossRef]
- Clautiaux, F.; Hanafi, S.; Macedo, R.; Voge, M.; Alves, C. Iterative aggregation and disaggregation algorithm for pseudo-polynomial network flow models with side constraints. Eur. J. Oper. Res. 2017, 258, 467–477. [Google Scholar] [CrossRef]
- Riedler, M.; Jatschka, T.; Maschler, J.; Raidl, G. An iterative time-bucket refinement algorithm for a high-resolution resource-constrained project scheduling problem. Int. Trans. Oper. Res. 2020, 27, 573–613. [Google Scholar] [CrossRef]
- Müller, B.; Muñoz, G.; Gasse, M.; Gleixner, A.; Lodi, A.; Serrano, F. On Generalized Surrogate Duality in Mixed-Integer Nonlinear Programming. In Integer Programming and Combinatorial Optimization; Bienstock, D., Zambelli, G., Eds.; Springer: Cham, Germany, 2020; pp. 322–337. [Google Scholar]
- Porcheron, M.; Gorge, A.; Juan, O.; Simovic, T.; Dereu, G. Challenge ROADEF/EURO 2010: A Large-Scale Energy Management Problem with Varied Constraints. Available online: https://www.fondation-hadamard.fr/sites/default/files/public/bibliotheque/roadef-euro2010.pdf (accessed on 15 June 2020).
- Gardi, F.; Nouioua, K. Local Search for Mixed-Integer Nonlinear Optimization: A Methodology and an Application. Lect. Notes Comput. Sci. 2011, 6622, 167–178. [Google Scholar]
- Brandt, F.; Bauer, R.; Völker, M.; Cardeneo, A. A constraint programming-based approach to a large-scale energy management problem with varied constraints. J. Sched. 2013, 16, 629–648. [Google Scholar] [CrossRef]
- Dupin, N.; Talbi, E.G. Dual Heuristics and New Lower Bounds for the Challenge EURO/ROADEF 2010. Matheuristics 2016, 2016, 60–71. [Google Scholar]
- Khemmoudj, M. Modélisation et Résolution de Systèmes de Contraintes: Application au Problème de Placement des Arrêts et de la Production des Réacteurs Nucléaires d’EDF. Ph.D. Thesis, University Paris 13, Villetaneuse, France, 2007. [Google Scholar]
- Griset, R. Méthodes pour la Résolution Efficace de Très Grands Problèmes Combinatoires Stochastiques. Application à un Problème Industriel d’EDF: Application à un Problème Industriel d’EDF. Ph.D. Thesis, Université de Bordeaux, Bordeaux, France, 2018. [Google Scholar]
- Dupin, N. Tighter MIP formulations of the discretised Unit Commitment Problem with min-stop ramping constraints. EURO J. Comput. Optim. 2017, 5, 149–176. [Google Scholar] [CrossRef]
- Dupin, N.; Talbi, E. Parallel matheuristics for the discrete unit commitment problem with min-stop ramping constraints. Int. Trans. Oper. Res. 2020, 27, 219–244. [Google Scholar] [CrossRef]
- Froger, A.; Gendreau, M.; Mendoza, J.; Pinson, E.; Rousseau, L. Maintenance scheduling in the electricity industry: A literature review. Eur. J. Oper. Res. 2015, 251, 695–706. [Google Scholar] [CrossRef]
- Dupin, N. Modélisation et Résolution de Grands Problèmes Stochastiques Combinatoires: Application à la Gestion de Production d’électricité. Ph.D. Thesis, University of Lille, Lille, France, 2015. [Google Scholar]
- Dupin, N.; Talbi, E. Matheuristics to Optimize Refueling and Maintenance Planning of Nuclear Power Plants. Available online: https://arxiv.org/pdf/1812.08598.pdf (accessed on 15 June 2020).
- Jost, V.; Savourey, D. A 0–1 integer linear programming approach to schedule outages of nuclear power plants. J. Sched. 2013, 16, 551–566. [Google Scholar] [CrossRef]
- Lusby, R.; Muller, L.; Petersen, B. A solution approach based on Benders decomposition for the preventive maintenance scheduling problem of a stochastic large-scale energy system. J. Sched. 2013, 16, 605–628. [Google Scholar] [CrossRef]
- Rozenknop, A.; Calvo, R.W.; Alfandari, L.; Chemla, D.; Létocart, L. Solving the electricity production planning problem by a column generation based heuristic. J. Sched. 2013, 16, 585–604. [Google Scholar] [CrossRef]
- Final Results and Ranking of the ROADEF/EURO Challenge 2010. Available online: https://www.roadef.org/challenge/2010/en/results.php (accessed on 15 June 2020).
- Benoist, T.; Estellon, B.; Gardi, F.; Megel, R.; Nouioua, K. Localsolver 1. x: A black-box local-search solver for 0-1 programming. 4OR 2011, 9, 299–316. [Google Scholar] [CrossRef]
- Anghinolfi, D.; Gambardella, L.; Montemanni, R.; Nattero, C.; Paolucci, M.; Toklu, N. A Matheuristic Algorithm for a Large-Scale Energy Management Problem. Lect. Notes Comput. Sci. 2012, 7116, 173–181. [Google Scholar]
- Brandt, F. Solving a Large-Scale Energy Management Problem with Varied Constraints. Master’s Thesis, Karlsruhe Institute of Technology, Karlsruhe, Germany, 2010. [Google Scholar]
- Gavranović, H.; Buljubasić, M. A Hybrid Approach Combining Local Search and Constraint Programming for a Large Scale Energy Management Problem. RAIRO Oper. Res. 2013, 47, 481–500. [Google Scholar] [CrossRef]
- Godskesen, S.; Jensen, T.; Kjeldsen, N.; Larsen, R. Solving a real-life, large-scale energy management problem. J. Sched. 2013, 16, 567–583. [Google Scholar] [CrossRef][Green Version]
- Dell’Amico, M.; Diaz, J. Constructive Heuristics and Local Search for a Large-Scale Energy Management Problem. EURO Conference 2011, Lisboa. Available online: http://www.roadef.org/challenge/2010/files/talks/S04%20-%20Diaz%20Diaz.pdf (accessed on 15 June 2020).
- Gorge, A.; Lisser, A.; Zorgati, R. Stochastic nuclear outages semidefinite relaxations. Comput. Manag. Sci. 2012, 9, 363–379. [Google Scholar] [CrossRef]
- Data Instances of the ROADEF/EURO Challenge 2010. Available online: https://www.roadef.org/challenge/2010/en/instances.php (accessed on 15 June 2020).
- Joncour, C. Problèmes de Placement 2D et Application à L’ordonnancement: Modélisation par la Théorie des Graphes et Approches de Programmation Mathématique. Ph.D. Thesis, Université Bordeaux, Bordeaux, France, 2010. [Google Scholar]
- Dupin, N.; Talbi, E. Multi-objective Robust Scheduling to maintain French nuclear power plants. In Proceedings of the 6th International Conference on Metaheuristics and Nature Inspired Computing (META 2016), Marrakech, Morocco, 27–31 October 2016; pp. 1–10. [Google Scholar]
- Savelsbergh, M. Preprocessing and probing techniques for mixed integer programming problems. ORSA J. Comput. 1994, 6, 445–454. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| with | Scheduling constraints denoted CT14 to CT21 in [14]. |
| Nuclear power plants (Type 2, T2). | |
| Flexible (Type 1, T1) power plants. | |
| Cycles related to T2 units, for initial conditions. | |
| Stochastic scenarios. | |
| Production time steps, index t denotes period | |
| Weekly time steps to plan outage dates. | |
| Subset of time periods involved in constraint c. | |
| Subset of outages involved in constraint c. |
| Maximal fuel level remaining in cycle k to process outage . | |
| Fuel level “Bore O” of cycle k | |
| Proportional cost to the final remaining fuel levels for scenario s. | |
| Proportional cost to the refueled quantity at outage k. | |
| Production costs for T1 unit j at time period t and scenario s. | |
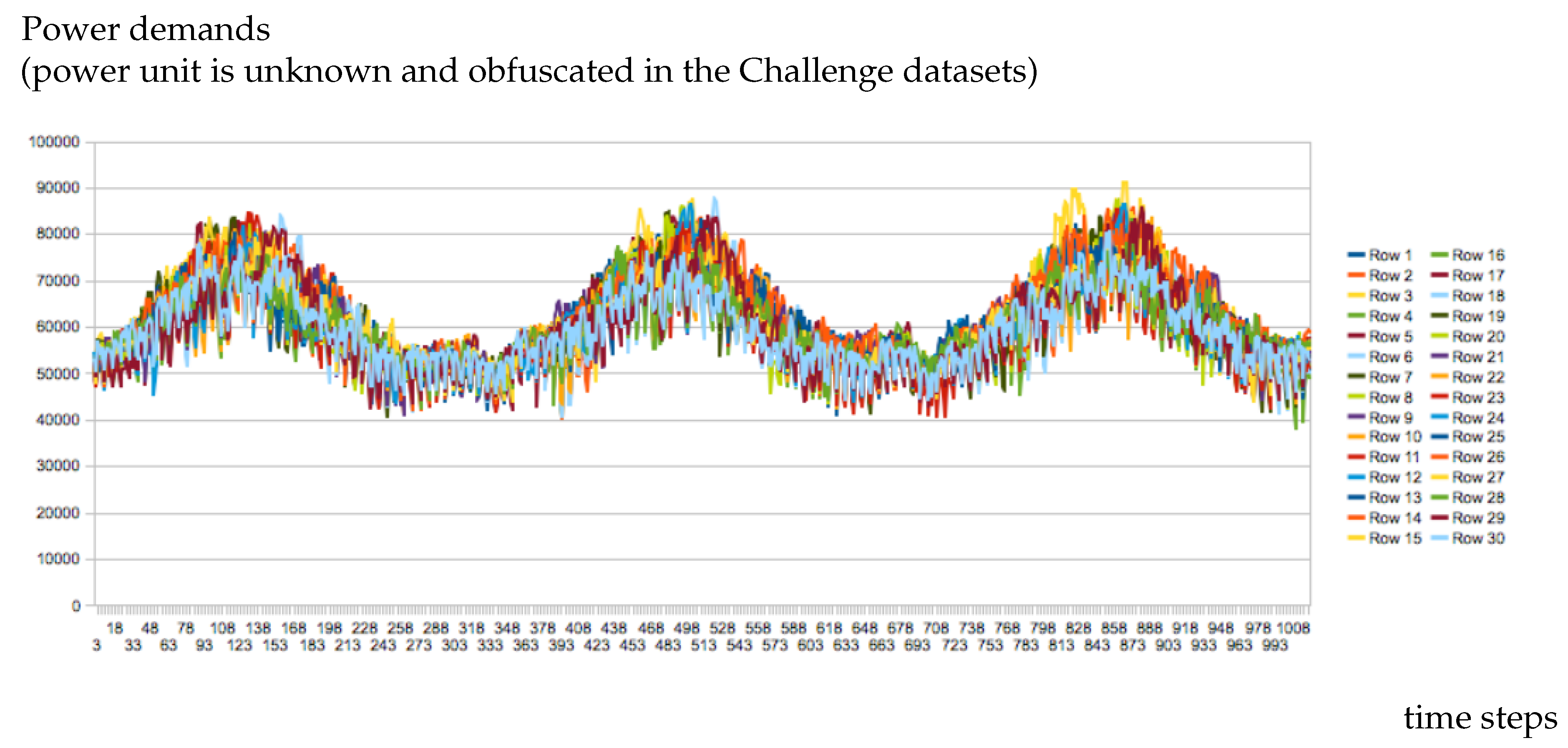
| Power demands at time step t for the scenario s. | |
| Outage duration for maintenance and refueling at cycle k. | |
| Conversion factor between power and fuel in time step t, constant in the data. | |
| Maximal offline T2 power at week w for CT21 constraint c. | |
| Latency in the resource requirement in CT19 constraint c for outage . | |
| Maximal number of outages under maintenance at week w for CT20 constraint c. | |
| Probability of scenario s. | |
| Minimal power for T1 unit j at time period t and scenario s. | |
| Maximal power for T1 unit j at time period t and scenario s. | |
| Maximal generated power at time step t. | |
| Proportion of fuel that can be kept during reload in cycle k at plant i | |
| Maximal quantity of resource in CT19 constraint c. | |
| Minimal refueling at outage k. | |
| Maximal refueling at outage k. | |
| Spacing/overlapping value defined by CT14-CT18 constraints. | |
| Maximal fuel level at production cycle k. | |
| Index of the first time step of week w. | |
| Last possible beginning week for outage k of T2 plant i. | |
| First, possible outage week for cycle k. | |
| Length of the resource usage in CT19 constraint c for outage . | |
| Week of the production time step t. | |
| Initial fuel stock of T2 plant i. |
| CT1: for all production time step and all scenario , the total production of T1 and T2 power plants must equalize the demands . |
| CT2: for all production time step and all scenario , the production domain of T1 plant describes exactly the continuous domain |
| CT3: the productions of T2 power plants are null during the weeks of outage . |
| CT4-CT5: for each period and each scenario , the production domain of T1 plant describes exactly the continuous domain when its fuel level is superior to . |
| CT7: the refueling level for outage k of T2 plant i describes the continuous domain . |
| CT8: the initial fuel stock for T2 unit i is , known and common for all scenario s. |
| CT9: the fuel stock variation during a production campaign of a cycle between t and , is proportional to the power produced by i at time step t, with a proportional factor . |
| CT10: during an outage, the fuel stock variation is the sum of the refueling level and a certain amount of unspent fuel, calculated with a proportional loss with factor to the residual fuel before refueling. |
| CT11: the fuel level is in for cycle k of T2 unit i. The fuel level must be lower than to process outage . |
| CT13: outage must begin between weeks and . The maintenance checks follow the order of set without skipping maintenance: if outage is processed, it must follow the cycle k. |
| CT14: For all constraint , a subset of outages, have to be spaced by at least weeks: for , it is a minimal spacing from the beginning of a previous outage to the beginning of a next outage, for , it is a maximal number of weeks where two outages can overlap. |
| CT15: CT15 are similar to CT14 with sets and parameters , applying only on a time interval . |
| CT16: for each constraint , a subset of outages have to be spaced by at least weeks from the beginning of the previous outage to the beginning of the next outage. |
| CT17: for each constraint , a subset of outages have to be spaced by at least weeks from the end of the previous outage to the end of the next outage. |
| CT18: for each constraint , a subset of outages have to be spaced by at least weeks from the end of the previous outage to the beginning of the next outage. |
| CT19: for each constraint , a subset of outages shares a common resource (which can be a single specific tool or maintenance team) with forbid simultaneous usage of this resource. and indicate respectively the start and the length of the resource usage and the maximal quantity of the resource. |
| CT20: for each constraint , at most outages among a subset overlap in weeks . |
| CT21: for each constraint , a time period is associated where the offline power of T2 plants due to maintenance operations must be lower than . |
| Binaries to indicate the beginning week for maintenance checks k of T2 unit i. | |
| Power production of T2 unit i at cycle k at t for scenario s, 0 if t is not in cycle k. | |
| Power production of T1 unit j at time step t for scenario s. | |
| Refueling quantity for outage k of T2 unit i. | |
| Fuel stock of T2 unit i at the end of the optimizing horizon at scenario s. | |
| Fuel level at the beginning of production cycle k of T2 unit i. | |
| Fuel level before the refueling of T2 unit i, after production cycle k. |
| Data | I | J | K | S | T | W | nbVar0 | nbVar1 | Gap | nbVar2 | nbVar3 | Gap |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A1 | 10 | 11 | 6 | 10 | 1750 | 250 | 3892 | 463 | 88.10% | 483 | 424 | 12.22% |
| A2 | 18 | 21 | 6 | 20 | 1750 | 250 | 7889 | 961 | 87.82% | 892 | 761 | 14.69% |
| A3 | 18 | 21 | 6 | 20 | 1750 | 250 | 8162 | 875 | 89.28% | 841 | 698 | 17.00% |
| A4 | 30 | 31 | 6 | 30 | 1750 | 250 | 17,465 | 1798 | 89.71% | 1998 | 1493 | 25.28% |
| A5 | 28 | 31 | 6 | 30 | 1750 | 250 | 15,357 | 2797 | 81.79% | 2750 | 2494 | 9.31% |
| B6 | 50 | 25 | 6 | 50 | 5817 | 277 | 24,563 | 3466 | 85.89% | 3467 | 3054 | 11.91% |
| B7 | 48 | 27 | 6 | 50 | 5565 | 265 | 35,768 | 6435 | 82.01% | 9052 | 5846 | 35.42% |
| B8 | 56 | 19 | 6 | 121 | 5817 | 277 | 69,653 | 22,482 | 67.72% | 30,626 | 20,763 | 32.20% |
| B9 | 56 | 19 | 6 | 121 | 5817 | 277 | 69,306 | 25,351 | 63.42% | 35,307 | 23,675 | 32.95% |
| B10 | 56 | 19 | 6 | 121 | 5565 | 265 | 29,948 | 4236 | 85.86% | 5084 | 3790 | 25.45% |
| X11 | 50 | 25 | 6 | 50 | 5817 | 277 | 20,081 | 3478 | 82.68% | 3499 | 3216 | 8.09% |
| X12 | 48 | 27 | 6 | 50 | 5523 | 263 | 27,111 | 4348 | 83.96% | 5321 | 4035 | 24.17% |
| X13 | 56 | 19 | 6 | 121 | 5817 | 277 | 30,154 | 4697 | 84.42% | 4403 | 4104 | 6.79% |
| X14 | 56 | 19 | 6 | 121 | 5817 | 277 | 30,691 | 5378 | 82.48% | 6088 | 4879 | 19.86% |
| X15 | 56 | 19 | 6 | 121 | 5523 | 263 | 27,233 | 3992 | 85.34% | 4372 | 3618 | 17.25% |
| [16].1 | [16].2 | LB(4) | LB(5) | LB | LB | LB | LB | LB | LB | |
|---|---|---|---|---|---|---|---|---|---|---|
| MILP | MILP | LP | LP + cuts | MILP | MILP | MILP | MILP | |||
| M = 1 | M = 1 | M = 1 | M = 1 | M = 1 | M = 2 | M = 3 | M = 5 | |||
| A1 | 5.09% | 2.31% | 0.54% | 0.08% | 0.29% | 0.09% | 0.03% | 0.02% | 0.02% | 0.01% |
| A2 | 10.83% | 4.09% | 1.42% | 0.33% | 0.64% | 0.35% | 0.24% | 0.22% | 0.21% | 0.21% |
| A3 | 10.72% | 3.77% | 1.85% | 0.71% | 1.06% | 0.48% | 0.36% | 0.35% | 0.34% | 0.33% |
| A4 | 26.07% | 8.22% | 3.36% | 2.38% | 2.82% | 1.93% | 1.33% | 1.27% | 1.27% | 1.22% |
| A5 | 24.22% | 9.70% | 4.25% | 3.24% | 3.46% | 2.80% | 2.38% | 2.16% | 2.01% | 2.14% |
| Total | 14.20% | 5.24% | 2.11% | 1.19% | 1.49% | 1.00% | 0.77% | 0.71% | 0.68% | 0.69% |
| [16].1 | [16].2 | LB(1) | LB(1) | LB(2) | LB(2) | LB(3) | LB(3) | |
|---|---|---|---|---|---|---|---|---|
| Gap | Gap | t(s) | Gap | t(s) | Gap | t(s) | Gap | |
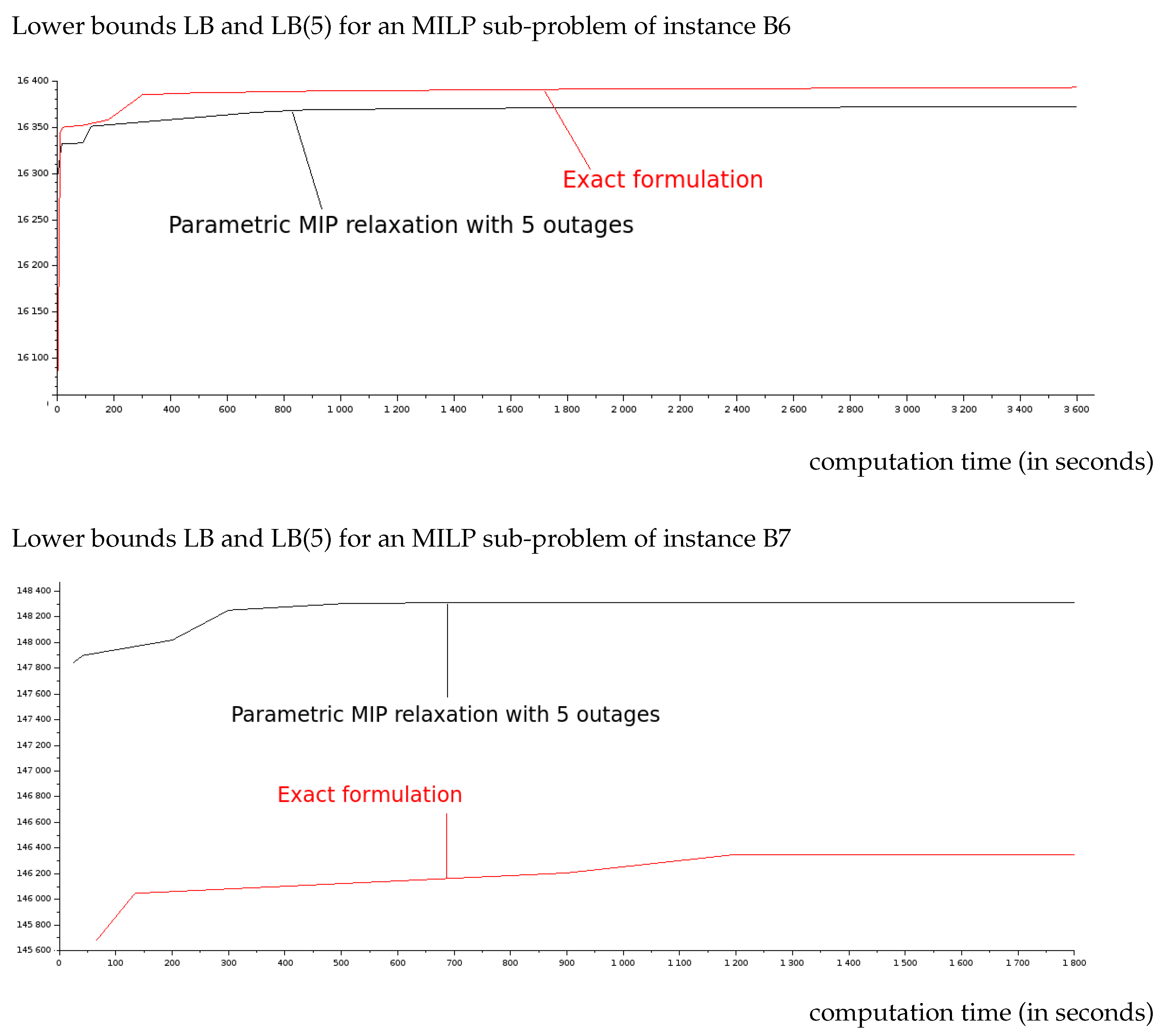
| B6 | 56.44% | 16.58% | 99 | 14.95% | 210 | 11.74% | 419 | 11.67% |
| B7 | 52.86% | 15.58% | 86 | 13.40% | 310 | 11.18% | 954 | 11.16% |
| B8 | 65.32% | 23.60% | 811 | 20.34% | 4485 | 17.37% | 17.1k | 16.92% |
| B9 | 63.30% | 21.72% | 911 | 18.78% | 4415 | 15.83% | 19k | 15.36% |
| B10 | 60.92% | 18.03% | 283 | 16.47% | 650 | 13.43% | 1308 | 13.42% |
| X11 | 57.81% | 15.40% | 116 | 12.91% | 257 | 11.18% | 472 | 11.07% |
| X12 | 52.65% | 14.22% | 118 | 12.29% | 257 | 10.30% | 574 | 10.28% |
| X13 | 66.20% | 18.53% | 315 | 16.01% | 832 | 14.28% | 1662 | 14.11% |
| X14 | 64.67% | 17.21% | 344 | 14.95% | 926 | 13.23% | 1761 | 13.11% |
| X15 | 61.76% | 16.83% | 376 | 16.13% | 756 | 13.52% | 1378 | 13.49% |
| Total | 60.15% | 17.80% | 3458 | 15.64% | 7.6k | 13.22% | 42.6k | 11.65% |
| [16].1 | [16].2 | LB(0) | LB(0) | LB(1) | LB(1) | LB(2) | LB(2) | |
|---|---|---|---|---|---|---|---|---|
| Gap | Gap | t(s) | Gap | t(s) | Gap | t(s) | Gap | |
| B6 | 56.44% | 16.58% | 82 | 18.12% | 124 | 14.89% | 356 | 11.67% |
| B7 | 52.86% | 15.58% | 66 | 15.34% | 181 | 13.39% | 991 | 11.16% |
| B8 | 65.32% | 23.60% | 221 | 23.12% | 1215 | 20.20% | 218k | 16.92% |
| B9 | 63.30% | 21.72% | 282 | 21.73% | 1776 | 18.71% | 218k | 15.36% |
| B10 | 60.92% | 18.03% | 224 | 18.64% | 573 | 16.46% | 1030 | 13.42% |
| X11 | 57.81% | 15.40% | 92 | 14.44% | 436 | 12.84% | 1267 | 11.07% |
| X12 | 52.65% | 14.22% | 117 | 13.90% | 496 | 12.27% | 1137 | 10.28% |
| X13 | 66.20% | 18.53% | 261 | 17.90% | 424 | 15.86% | 1701 | 14.11% |
| X14 | 64.67% | 17.21% | 270 | 16.84% | 861 | 14.87% | 3887 | 13.11% |
| X15 | 61.76% | 16.83% | 421 | 18.03% | 1528 | 16.10% | 6931 | 13.49% |
| Total | 60.15% | 17.80% | 2036 | 17.84% | 13k | 15.58% | 453k | 13.07% |
| Primal | [16] | Gap | Our Duals | Gap | t(s) | Model | Cuts | M | |
|---|---|---|---|---|---|---|---|---|---|
| B6 | 83,424.7 M | 69,592 M | 16.58% | 79,179.4 M | 5.09% | 3202 | LB(5) | yes | 10 |
| B7 | 81,099.7 M | 68,528 M | 15.58% | 76,139.8 M | 6.20% | 3529 | LB(5) | yes | 5 |
| B8 | 81,899.7 M | 62,594 | 23.60% | 67,352.4 M | 17.79% | 1521 | LB(2) | no | 1 |
| B9 | 81,689.5 M | 63,991 | 21.72% | 68,566.3 M | 16.13% | 1602 | LB(2) | no | 1 |
| B10 | 77,767.0 M | 63,747 | 18.03% | 72,213.9 M | 7.14% | 2040 | LB(5) | yes | 2 |
| ∑ B | 405,880.6 M | 328,452 M | 19.11% | 363,452 M | 10.49% | ||||
| X11 | 79,007.6 M | 66,931 | 15.40% | 74,431.2 M | 5.92% | 1209 | LB(5) | yes | 2 |
| X12 | 77,564.0 M | 66,558 | 14.22% | 72,819.4 M | 6.15% | 3449 | LB(5) | yes | 10 |
| X13 | 76,288.5 M | 62,155 | 18.53% | 70,236.7 M | 7.93% | 1735 | LB(5) | no | 1 |
| X14 | 76,149.8 M | 63,045 | 17.21% | 70,279.3 M | 7.71% | 1741 | LB(5) | no | 1 |
| X15 | 74,388.4 M | 61,866 | 16.83% | 68,624.8 M | 7.75% | 3045 | LB(5) | yes | 3 |
| ∑ X | 383,531.7 M | 320,555 M | 16.42% | 35,639 M | 7.08% | ||||
| Total | 789,572.7 M | 649,007 M | 17.80% | 719,843.6 M | 8.83% |
| [16] | LB(4) | LB(4) | LB(4) | LB(5) | LB(5) | LB(5) | LB | LB | |
|---|---|---|---|---|---|---|---|---|---|
| LP | LP + cuts | MILP | LP | LP + cuts | MILP | LP + cuts | MILP | ||
| B6 | 16.58% | 7.24% | 7.06% | 6.84% | 5.67% | 5.48% | 5.31% | 5.48% | 5.07% |
| B7 | 15.58% | 7.68% | 7.54% | 7.23% | 6.82% | 6.68% | 6.34% | 7.99% | 7.55% |
| B8 | 23.60% | 13.86% | 13.68% | 13.52% | 12.75% | 12.41% | 12.22% | 16.16% | 16.16% |
| B9 | 21.72% | 12.70% | 12.55% | 12.40% | 11.96% | 11.72% | 11.51% | 15.81% | 15.81% |
| B10 | 18.03% | 8.53% | 8.41% | 8.33% | 7.52% | 7.39% | 7.32% | 7.53% | 7.01% |
| X11 | 15.40% | 7.95% | 7.81% | 7.64% | 6.33% | 6.17% | 6.04% | 5.66% | 5.36% |
| X12 | 14.22% | 7.58% | 7.50% | 7.42% | 6.81% | 6.73% | 6.68% | 6.88% | 6.49% |
| X13 | 18.53% | 10.74% | 10.37% | 10.12% | 8.65% | 8.31% | 8.14% | 7.82% | 7.46% |
| X14 | 17.21% | 10.00% | 9.81% | 9.62% | 8.27% | 8.06% | 7.91% | 8.10% | 7.76% |
| X15 | 16.83% | 10.21% | 10.11% | 10.02% | 9.06% | 9.16% | 8.99% | 9.11% | 8.82% |
| Total | 17.80% | 9.65% | 9.49% | 9.32% | 8.40% | 8.21% | 8.05% | 9.09% | 8.79% |
| [16] | LB(5) | LB | LB(5) | LB | LB(5) | LB | |
|---|---|---|---|---|---|---|---|
| M= | 1 | 1 | 2 | 2 | 3 | 3 | |
| B6 | 16.58% | 5.48% | 5.48% | 5.26% | 5.30% | 5.19% | 5.26% |
| B7 | 15.58% | 6.68% | 7.99% | 6.37% | 7.81% | 6.28% | 7.79% |
| B8 | 23.60% | 12.41% | 16.16% | 12.13% | 16.23% | 12.05% | 16.14% |
| B9 | 21.72% | 11.72% | 15.81% | 11.47% | 15.76% | 11.39% | 15.70% |
| B10 | 18.03% | 7.39% | 7.53% | 7.14% | 7.33% | 7.05% | 7.25% |
| X11 | 15.40% | 6.17% | 5.66% | 5.92% | 5.42% | 5.83% | 5.34% |
| X12 | 14.22% | 6.73% | 6.88% | 6.43% | 6.58% | 6.31% | 6.50% |
| X13 | 18.53% | 8.31% | 7.82% | 8.03% | 7.53% | 7.93% | 7.44% |
| X14 | 17.21% | 8.06% | 8.10% | 7.76% | 7.81% | 7.66% | 7.73% |
| X15 | 16.83% | 9.06% | 9.11% | 8.74% | 8.78% | 8.62% | 8.69% |
| Total | 17.80% | 8.21% | 9.09% | 7.94% | 8.90% | 7.84% | 8.83% |
| [16] | LB(5) | LB | LB(5) | LB | LB(5) | LB | |
| M= | 1 | 1 | 5 | 5 | 10 | 10 | |
| B6 | 16.58% | 5.48% | 5.48% | 5.13% | 5.23% | 5.09% | 5.21% |
| B7 | 15.58% | 6.68% | 7.99% | 6.20% | 7.76% | 6.14% | 7.76% |
| B8 | 23.60% | 12.41% | 16.16% | 11.97% | 16.16% | 11.95% | 16.15% |
| B9 | 21.72% | 11.72% | 15.81% | 11.32% | 15.75% | 11.24% | 15.73% |
| B10 | 18.03% | 7.39% | 7.53% | 6.96% | 7.21% | 6.90% | 7.18% |
| X11 | 15.40% | 6.17% | 5.66% | 5.76% | 5.29% | 5.71% | 5.27% |
| X12 | 14.22% | 6.73% | 6.88% | 6.20% | 6.41% | 6.15% | 6.35% |
| X13 | 18.53% | 8.31% | 7.82% | 7.85% | 7.34% | 7.81% | 7.31% |
| X14 | 17.21% | 8.06% | 8.10% | 7.57% | 7.69% | 7.50% | 7.65% |
| X15 | 16.83% | 9.06% | 9.11% | 8.52% | 8.60% | 8.46% | 8.56% |
| Total | 17.80% | 8.21% | 9.09% | 7.76% | 8.79% | 7.70% | 8.76% |
| Primal | [16].1 | [16].2 | [17] | New Lower Bound | Gap | Bound | M | Time/S | ||
|---|---|---|---|---|---|---|---|---|---|---|
| A1 | 169,474.5 M | [32] | 5.09% | 2.31% | 0.04% | 169,460.6069 M | 0.01% | LB | 10 | OPT |
| A2 | 145,956.7 M | [32] | 10.83% | 4.09% | 0.25% | 145,669.1154 M | 0.20% | LB | 10 | OPT |
| A3 | 154,277.2 M | [32] | 10.72% | 3.77% | 0.37% | 153,770.2050 M | 0.33% | LB | 10 | OPT |
| A4 | 111,494.0 M | [15] | 26.07% | 8.22% | 1.52% | 110,130.2886 M | 1.22% | LB | 5 | 2400 |
| A5 | 124,543.9 M | [15] | 24.22% | 9.70% | 2.55% | 122,035.5788 M | 2.01% | LB | 3 | 2400 |
| ∑ A | 705,746.3 M | 14.20% | 5.24% | 0.83% | 701,065.7947 M | 0.66% | ||||
| B6 | 83,424.7 M | [28] | 56.44% | 16.58% | 5.30% | 79,394.9322 M | 4.83% | LB | 5 | 3600 |
| B7 | 81,099.7 M | [15] | 52.82% | 15.50% | 6.22% | 76,499.2099 M | 5.67% | LB(5) | 10 | 3600 |
| B8 | 81,899.7 M | [15] | 65.31% | 23.57% | 12.37% | 72,322.5889 M | 11.69% | LB(5) | 10 | 3600 |
| B9 | 81,689.5 M | [15] | 63.28% | 21.67% | 11.59% | 72,811.7201 M | 10.87% | LB(5) | 10 | 3600 |
| B10 | 77,767.0 M | [15] | 60.92% | 18.03% | 7.32% | 72,462.8317 M | 6.82% | LB(5) | 10 | 1800 |
| ∑ B | 405,880.6 M | 59.74% | 19.08% | 8.56% | 373,491.2828 M | 7.98% | ||||
| X11 | 79,007.6 M | [15] | 57.75% | 15.29% | 5.45% | 75,183.0108 M | 4.84% | LB | 5 | 3600 |
| X12 | 77,564.0 M | [15] | 52.63% | 14.19% | 6.65% | 72,986.7523 M | 5.90% | LB | 5 | 3600 |
| X13 | 76,288.5 M | [15] | 66.20% | 18.53% | 7.59% | 70,988.40356 M | 6.95% | LB | 5 | 1800 |
| X14 | 76,149.8 M | [15] | 64.67% | 17.21% | 7.82% | 70,549.09524 M | 7.35% | LB | 5 | 1800 |
| X15 | 74,388.4 M | [15] | 61.76% | 16.83% | 8.11% | 68,821.7327 M | 7.48% | LB | 5 | 1800 |
| ∑ X | 383,398.3 M | 60.55% | 16.39% | 7.11% | 358,421.1372 M | 6.49% | ||||
| ∑ BX | 789,278.9 M | 60.13% | 17.77% | 7.85% | 731,912.4200 M | 7.25% | ||||
| Total | 1,495,025.2 M | 38.45% | 11.85% | 4.54% | 1,432,978.2147 M | 4.14% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dupin, N.; Talbi, E.-G. Machine Learning-Guided Dual Heuristics and New Lower Bounds for the Refueling and Maintenance Planning Problem of Nuclear Power Plants. Algorithms 2020, 13, 185. https://doi.org/10.3390/a13080185
Dupin N, Talbi E-G. Machine Learning-Guided Dual Heuristics and New Lower Bounds for the Refueling and Maintenance Planning Problem of Nuclear Power Plants. Algorithms. 2020; 13(8):185. https://doi.org/10.3390/a13080185
Chicago/Turabian StyleDupin, Nicolas, and El-Ghazali Talbi. 2020. "Machine Learning-Guided Dual Heuristics and New Lower Bounds for the Refueling and Maintenance Planning Problem of Nuclear Power Plants" Algorithms 13, no. 8: 185. https://doi.org/10.3390/a13080185
APA StyleDupin, N., & Talbi, E.-G. (2020). Machine Learning-Guided Dual Heuristics and New Lower Bounds for the Refueling and Maintenance Planning Problem of Nuclear Power Plants. Algorithms, 13(8), 185. https://doi.org/10.3390/a13080185