Abstract
Sequential pattern mining is a fundamental data mining task with application in several domains. We study two variants of this task—the first is the extraction of frequent sequential patterns, whose frequency in a dataset of sequential transactions is higher than a user-provided threshold; the second is the mining of true frequent sequential patterns, which appear with probability above a user-defined threshold in transactions drawn from the generative process underlying the data. We present the first sampling-based algorithm to mine, with high confidence, a rigorous approximation of the frequent sequential patterns from massive datasets. We also present the first algorithms to mine approximations of the true frequent sequential patterns with rigorous guarantees on the quality of the output. Our algorithms are based on novel applications of Vapnik-Chervonenkis dimension and Rademacher complexity, advanced tools from statistical learning theory, to sequential pattern mining. Our extensive experimental evaluation shows that our algorithms provide high-quality approximations for both problems we consider.
1. Introduction
Sequential pattern mining [1] is a fundamental task in data mining and knowledge discovery, with applications in several fields, from recommender systems and e-commerce to biology and medicine. In its original formulation, sequential pattern mining requires to identify all frequent sequential patterns, that is, sequences of itemsets that appear in a fraction at least of all the transactions in a transactional dataset, where each transaction is a sequence of itemsets. The threshold is a user-specified parameter and its choice must be, at least in part, be informed by domain knowledge. In general, sequential patterns describe sequences of events or actions that are useful for predictions in many scenarios.
Several exact methods have been proposed to find frequent sequential patterns. However, the exact solution of the problem requires processing the entire dataset at least once, and often multiple times. For large, modern sized datasets, this may be infeasible. A natural solution to reduce the computation is to use sampling to obtain a small random portion (sample) of the dataset, and perform the mining process only on the sample. It is easy to see that by analyzing only a sample of the data the problem cannot be solved exactly, and one has to rely on the approximation provided by the results of the mining task on the sample. Therefore, the main challenge in using sampling is on computing a sample size such that the frequency of the sequential patterns in the sample is close to the frequency that would be obtained from the analysis on the whole dataset. Relating the two quantities using standard techniques (e.g., Hoeffding inequality and union bounds) does not provide useful results, that is, small sample sizes. In fact, such procedures require the knowledge of the number of all the sequential patterns in the dataset, which is impractical to compute in a reasonable time. So, one has to resort to loose upper bounds that usually result in sample sizes that are larger than the whole dataset. Recently, tools from statistical learning (e.g.,Vapnik-Chervonenkis dimension [2] and Rademacher complexity [3]) have been successfully used in frequent itemsets mining [4,5], a frequent pattern mining task where transactions are collections of items, showing that accurate and rigorous approximations can be obtained from small samples of the entire dataset. While sampling has previously been used in the context of sequential pattern mining (e.g., Reference [6]), to the best of our knowledge no sampling algorithm providing a rigorous approximation of the frequent sequential patterns has been proposed.
In several applications, the analysis of a dataset is performed to gain insight on the underlying generative process of the data. For example, in market basket analysis one is interested in gaining knowledge on the behaviour of all the customers, which can be modelled as a generative process from which the transactions in the dataset have been drawn. In such a scenario, one is not interested in sequential patterns that are frequent in the dataset, but in sequential patterns that are frequent in the generative process, that is, whose probability of appearing in a transaction generated from the process is above a threshold . Such patterns, called true frequent patterns, have been introduced by Reference [7], which provides a Vapnik-Chervonenkis (VC) dimension based approach to mine true frequent itemsets. While there is a relation between the probability that a pattern appears in a transaction generated from the process and its frequency in the dataset, one cannot simply look at patterns with frequency above in the dataset to find the ones with probability above in the process. Moreover, due to the stochastic nature of the data, one cannot identify the true frequent patterns with certainty, and approximations are to be sought. In such a scenario, relating the probability that a pattern appears in a transaction generated from the process with its frequency in the dataset using standard techniques is even more challenging. Hoeffding inequality and union bounds require to bound the number of all the possible sequential patterns that can be generated from the process. Such bound is infinite if one considers all possible sequential patterns (e.g., does not bound the pattern length). To the best of our knowledge, no method to mine true frequent sequential patterns has been proposed.
1.1. Our Contributions
In this work, we study two problems in sequential pattern mining—mining frequent sequential patterns and mining true frequent sequential patterns. We propose efficient algorithms for these problems, based on the concepts of VC-dimension and Rademacher complexity. In this regard, our contributions are:
- We define rigorous approximations of the set of frequent sequential patterns and the set of true frequent sequential patterns. In particular, for both sets we define two approximations: one with no false negatives, that is, containing all elements of the set; and one with no false positives, that is, without any element that is not in the set. Our approximations are defined in terms of a single parameter, which controls the accuracy of the approximation and is easily interpretable.
- We study the VC-dimension and the Rademacher complexity of sequential patterns, two advanced concepts from statistical learning theory that have been used in other mining contexts, and provide algorithms to efficiently compute upper bounds for both. In particular, we provide a simple, but still effective in practice, upper bound to the VC-dimension of sequential patterns by relaxing the upper bound previously defined in Reference [8]. We also provide the first efficiently computable upper bound to the Rademacher complexity of sequential patterns. We also show how to approximate the Rademacher complexity of sequential patterns.
- We introduce a new sampling-based algorithm to identify rigorous approximations of the frequent sequential patterns with probability , where is a confidence parameter set by the user. Our algorithm hinges on our novel bound on the VC-dimension of sequential patterns, and it allows to obtain a rigorous approximation of the frequent sequential patterns by mining only a fraction of the whole dataset.
- We introduce efficient algorithms to obtain rigorous approximations of the true frequent sequential patterns with probability , where is a confidence parameter set by the user. Our algorithms use the novel bounds on the VC-dimension and on Rademacher complexity that we have derived, and they allow to obtain accurate approximations of the true frequent sequential patterns, where the accuracy depends on the size of the available data.
- We perform an extensive experimental evaluation analyzing several sequential datasets, showing that our algorithms provide high-quality approximations, even better than guaranteed by their theoretical analysis, for both tasks we consider.
1.2. Related Work
Since the introduction of the frequent sequential pattern mining problem [1], a number of exact algorithms has been proposed for this task, ranging from multi-pass algorithms using the anti-monotonicity property of the frequency function [9], to prefix-based approaches [10], to works focusing on the closed frequent sequences [11].
The use of sampling to reduce the amount of data for the mining process while obtaining rigorous approximations of the collection of interesting patterns has been successfully applied in many mining tasks. Raïssi and Poncelet [6] provided a theoretical bound on the sample size for a single sequential pattern in a static dataset using Hoeffding concentration inequalities, and they introduced a sampling approach to build a dynamic sample in a streaming scenario using a biased reservoir sampling. Our work is heavily inspired by the work of Riondato and Upfal [4,5], which introduced advanced statistical learning techniques for the task of frequent itemsets and association rules mining. In particular, in Reference [4] they employed the concept of VC-dimension to derive a bound on the sample size needed to obtain an approximation of the frequent itemsets and association rules from a dataset, while in Reference [5] they proposed a progressive sampling approach based on an efficiently computable upper bound on the Rademacher complexity of itemsets. VC-dimension has also been used to approximate frequent substrings in collections of strings [12], and the related concept of pseudo-dimension has been used to mine interesting subgroups [13]. Rademacher complexity has also been used in graph mining [14,15,16], to design random sampling approaches for estimating betweenness centralities in graphs [17].
Other works have studied the problem of approximating frequent sequential patterns using approaches other than sampling. In Reference [18], the dataset is processed in blocks with a streaming algorithm, but the intermediate sequential patterns returned may miss many frequent sequential patterns. More recently, Reference [8] introduced an algorithm to process the datasets in blocks using a variable, data-dependent frequency threshold, based on an upper bound to the empirical VC-dimension, to mine each block. Reference [8] defines an approximation for frequent sequential patterns that is one of the definitions we consider in this work. The intermediate results obtained after analyzing each block have probabilistic approximation guarantees, and after analyzing all blocks the output is the exact collection of frequent sequential patterns. While these works, in particular Reference [8], are related to our contributions, they do not provide sampling algorithms for sequential pattern mining.
To the best of our knowledge, Reference [7] is the only work that considers the extraction of frequent patterns w.r.t. an underlying generative process, based on the concept of empirical VC-dimension of itemsets. While we use the general framework introduced by Reference [7], the solution proposed by Reference [7] requires to solve an optimization problem that is tailored to itemsets and, thus, not applicable to sequential patterns; in addition, computing the solution of such problem could be relatively expensive. Reference [19] considers the problem of mining significant patterns under a similar framework, making more realistic assumptions on the underlying generative process compared to commonly used tests (e.g., Fisher’s exact test).
Several works have been proposed to identify statistically significant patterns where the significance is defined in terms of the comparison of patterns statistics. Few methods [20,21,22] have been proposed to mine statistically significant sequential patterns. These methods are orthogonal to our approach, which focuses on finding sequential patterns that are frequent with respect to (w.r.t.) an underlying generative distribution.
2. Preliminaries
We now provide the definitions and concepts used throughout the article. We start by introducing the task of sequential pattern mining and formally define the two problems which are the focus of this work: approximating the frequent sequential patterns and mining sequential patterns that are frequently generated from the underlying generative process. We then introduce two tools from statistical learning theory, that is, the VC-dimension and the Rademacher complexity, and the related concept of maximum deviation.
2.1. Sequential Pattern Mining
Let be a finite set of elements called items. is also called the ground set. An itemset P is a (non-empty) subset of , that is, . A sequential pattern is a finite ordered sequence of itemsets, with . A sequential pattern p is also called a sequence. The length of p is defined as the number of itemsets in p. The item-length of p is the sum of the sizes of the itemsets in p, that is,
where is the number of items in itemset . A sequence is a subsequence of another sequence , denoted by , if and only if there exist integers such that , . If a is a subsequence of b, then b is called a super-sequence of a, denoted by .
Let denote the set of all the sequences which can be built with itemsets containing items from . A dataset is a finite bag of (sequential) transactions where each transaction is a sequence from . A sequence p belongs to a transaction if and only if . For any sequence p, the support set of p in is the set of transactions in to which p belongs: . The support of p in is the cardinality of the set , that is the number of transactions in to which p belongs: . Finally, the frequency of p in is the fraction of transactions in to which p belongs:
A sequence p is closed w.r.t. if for each of its super-sequences we have , or, equivalently, none of its super-sequence has support equal to . We denote the set of all closed sequences in with .
Example 1.
Consider the following dataset as example:
The dataset above has 4 transactions. The first one, , it is a sequence of length and item-length . The frequency of in , is 3/4, since it is contained in all transactions but . Note that the sequence occurs three times as a subsequence of , but contributes only once to the frequency of . The sequence is not a subsequence of because the order of the itemsets in the two sequences is not the same. Note that from the definitions above, an item can only occur once in an itemset, but it can occur multiple times in different itemsets of the same sequence. Finally, the sequence , whose frequency is 3/4, is a closed sequence, since its frequency is higher than the frequency of each of its super-sequences.
Section 2.1.1 and Section 2.1.2 formally define the two problems we are interested in.
2.1.1. Frequent Sequential Pattern Mining
Given a dataset and a minimum frequency threshold , frequent sequential pattern (FSP) mining is the task of reporting the set of all the sequences whose frequency in is at least , and their frequencies:
In the first part of this work, we are interested in finding the set by only mining a sample of the dataset . Note that given a sample of the dataset , one cannot guarantee to find the exact set and has to resort to approximations of . Thus, we are interested in finding rigorous approximations of . In particular, we consider the approximation of defined in Reference [8].
Definition 1.
Given , an ε-approximation of is defined as a set of pairs :
that has the following properties:
- contains a pair for every ;
- contains no pair such that ;
- for every , it holds .
(Note that while Reference [8] introduced the definition of -approximation of , it did not provide a sampling algorithm to find such approximation for a given .)
Intuitively, the approximation contains all the frequent sequential patterns that are in (i.e., there are no false negatives) and no sequential pattern that has frequency in much below . In addition, provides a good approximation of the actual frequency of the sequential pattern in , within an error , arbitrarily small.
Depending on the application, one may be interested in a different approximation of , where all the sequential patterns in the approximation are frequent sequential patterns in the whole dataset.
Definition 2.
Given , a false positives free (FPF) ε-approximation of is defined as a set of pairs :
that has the following properties:
- contains no pair such that ;
- contains all the pairs such that ;
- for every , it holds .
The approximation does not contain false positives, that is, sequences with . In addition, it does not miss sequences with and, similarly to the -approximation, we have that, for every pair in , it gives a good approximation of the actual frequency of the sequential patterns in , within an error , arbitrarily small.
2.1.2. True Frequent Sequential Pattern Mining
In several applications, the dataset is a sample of transactions independently drawn from an unknown probability distribution on . In such a scenario, the dataset is a finite bag of independent identically distributed (i.i.d.) samples from . For any sequence , the real support set of p is the set of sequences in to which p belongs: . We define the true frequency of p w.r.t. as the probability that a transaction sampled from contains p:
In this scenario, the final goal of the data mining process on is to gain a better understanding of the process generating the data, that is, of the distribution , through the true frequencies , which are unknown and only approximately reflected in the dataset . Therefore, we are interested in finding the sequential patterns with true frequency at least for some . We call these sequential patterns the true frequent sequential patterns (TFSPs) and denote their set as:
Note that, given a finite number of random samples from (e.g., the dataset ), it is not possible to find the exact set , and one has to resort to approximations of . Analogously to the two approximations defined for the FSPs, now we define two approximations of the TFSPs, depending on the application we are interested in: the first one that does not have false negatives, while the second one that does not contain false positives.
Definition 3.
Given , a μ-approximation of is defined as a set of pairs :
that has the following properties:
- contains a pair for every ;
- contains no pair such that ;
- for every , it holds .
Definition 4.
Given , a false positives free (FPF) μ-approximation of is defined as a set of pairs :
that has the following properties:
- contains no pair such that ;
- contains all the pairs such that ;
- for every , it holds .
2.2. VC-Dimension
The Vapnik-Chervonenkis (VC) dimension [2,23] of a space of points is a measure of the complexity or expressiveness of a family of indicator functions, or, equivalently, of a family of subsets, defined on that space. A finite bound on the VC-dimension of a structure implies a bound of the number of random samples required to approximately learn that structure.
We define a range space as a pair , where X is a finite or infinite set and , the range set, is a finite or infinite family of subsets of X. The members of X are called points, while the members of are called ranges. Given , we define the projection of in A as . We define as the power set of A, that is the set of all the possible subsets of A, including the empty set ∅ and A itself. If , then A is said to be shattered by . The VC-dimension of a range space is the cardinality of the largest set shattered by the space.
Definition 5.
Let be a range space and . The empirical VC-dimension of on B is the maximum cardinality of a subset of B shattered by . The VC-dimension of is defined as .
Example 2.
Let be the set of all the points in and let be the set of subsets , with , that is . Let us consider the set , containing 3 points . It is not possible to find a range whose intersection with the set Y is , since all the ranges , with , containing x and z, also contain y. Then, must be less than 3. Consider now the set , containing only 2 points . It is easy to see that Y is shattered by , so .
The main application of VC-dimension in statistics and learning theory is to derive the sample size needed to approximately “learn” the ranges, as defined below.
Definition 6.
Let be a range space. Given , a bag B of elements taken from X is an ε-bag of X if for all , we have
Theorem 1.
There is a constant such that if is a range space of VC-dimension , and , then a bag B of m elements taken with independent random extractions with replacement from X, where
is an ε-bag of X with probability
The universal constant c has been experimentally estimated to be at most [24]. In the remaining of this work, we will use . Note that Theorem 1 holds also when d is an upper bound to the empirical VC-dimension of on B [25]. In that case, the bag B itself is an -bag of X.
2.3. Rademacher Complexity
The Rademacher complexity [3,23,26] is a tool to measure the complexity of a family of real-valued functions. Bounds based on the Rademacher complexity depend on the distribution of the dataset, differently from the ones based on VC-dimension that are distribution independent.
Let be a dataset of n transactions . For each , let be an independent Rademacher random variable (r.v.) that takes value 1 or , each with probability . Let be a set of real-valued functions. The empirical Rademacher complexity on is defined as follows:
where the expectation is taken w.r.t. the Rademacher r.v. ’s.
The Rademacher complexity is a measure of the expressiveness of the set . A specific combination of ’s represents a splitting of into two random sub-samples and . For a function , represents a good approximation of over if n is sufficiently large. represents instead the difference between over the two random sub-samples and . By considering the expected value of the supremum of this difference over the set , we get the empirical Rademacher complexity. Therefore, the intuition is that if is small, the dataset is sufficiently large to ensure a good estimate of for every . In this work, we study the Rademacher complexity of sequential patterns, which has not been explored before.
2.4. Maximum Deviation
Let be a probability distribution over a domain set . Let be a set of functions that go from to . Given a function , we define the expectation of f as:
and, given a sample Z of n observations drawn from , the empirical average of f on Z as:
The maximum deviation is defined as the largest difference between the expectation of a function f and its empirical average on sample Z as:
We now use the maximum deviation to capture quantities of interest for the two mining tasks we consider in this work.
In the frequent pattern mining scenario, we aim to find good estimates for for each pattern p. The frequency is the expectation of a Bernoulli random variable (r.v.) which is 1 if the pattern p appears in a transaction t drawn uniformly at random from :
Let be a sample of transactions drawn uniformly and independently at random from . We define the frequency as the fraction of transactions of where p appears. In this scenario, we have that the frequency of p on and the frequency of p on the sample represent, respectively, the expectation and the empirical average of a function associated with a pattern p. Thus, the maximum deviation is:
In the true frequent pattern mining scenario, we aim to find good estimates for for each pattern p. Note that the true frequency is the expectation of a Bernoulli r.v. which is 1 if the pattern p appears in a transaction drawn from . Moreover, it is easy to prove that the observed frequency of a pattern p in a dataset of transactions drawn from is an unbiased estimator for , that is: .
Therefore, the true frequency and the frequency observed on the dataset represent, respectively, the expectation and the empirical average of a function associated with a pattern p. Thus, the maximum deviation is:
In the next sections, we provide probabilistic upper bounds to the maximum deviation using the VC-dimension and Rademacher complexity which can therefore be used for frequent pattern mining and true frequent pattern mining scenarios.
3. VC-Dimension of Sequential Patterns
In this section, we apply the statistical learning theory concept of VC-dimension to sequential patterns. First, we define the range space associated with a sequential dataset. Then, we show a computable efficient upper bound on the VC-dimension and, finally, we present two applications of such upper bound. The first one is to compute the size of a sample that guarantees to obtain a good approximation for the problem of mining the frequent sequential patterns. The second one is to compute an upper bound on the maximum deviation to mine the true frequent sequential patterns.
Remember that a range space is a pair where X contains points and contains ranges. For a sequential dataset, X is the dataset itself, while contains the sequential transactions that are the support set for some sequential patterns.
Definition 7.
Let be a sequential dataset consisting of sequential transactions and let be its ground set. Let be the set of all sequences built with itemsets containing item from . We define to be a range space associated with such that:
- is the set of sequential transactions in the dataset;
- is a family of sets of sequential transactions such that for each sequential pattern p, the set is the support set of p on .
The VC-dimension of this range space is the maximum size of a set of sequential transactions that can be shattered by the support sets of the sequential patterns.
Example 3.
Consider the following dataset as an example:
The dataset above has 4 transactions. We now show that the VC-dimension of the range space associated with is 2. Let us consider the set . The power set of A is . A is shatter by since the projection of in A is equal to (remember that ):
Since and A is shattered by , then the range space associated with has VC-dimension . Analogously, the sets ,, and are shattered by . The set is instead not shattered by : since , there is not a sequential pattern such that . The sets and are not shattered by either: there is not a sequential pattern such that or . Thus, the VC-dimension of the range space associated with is exactly 2.
The exact computation of the (empirical) VC-dimension of the range space associated with a dataset is computationally expensive. The s-index, introduced by Servan-Schreiber et al. [8], provides an efficiently computable upper bound on the VC-dimension of sequential patterns. Such upper bound is based on the notion of capacity of a sequence p. The capacity of a sequence p is the number of distinct subsequences of p, that is, . The exact capacity can be computed using the algorithm described in Reference [27], but it is computationally expensive and may be prohibitive for large datasets. Instead, Reference [8] proposed an algorithm to compute a more efficient upper bound . Let us consider that a first simple bound is given by , that may be a loose upper bound of because it is obtained by considering all the items contained in all the itemsets in p as distinct, that is, the capacity of the sequence p is if and only if all the items contained in all the itemsets of the sequence p are different. The bound proposed by Reference [8] can be computed as follows. When p contains, among others, two itemsets A and B such that , subsequences of the form with are considered twice in , “generated” once from A and once from B. To avoid over-counting such subsequences, Reference [8] proposes to consider only the ones “generated” from the longest itemset that can generate them. Then, the s-index is defined as follows.
Definition 8
([8]). Let be a sequential dataset. The s-index of is the maximum integer s such that contains at least s different sequential transactions with upper bound to their capacities at least , such that no one of them is a subset of another, that is the s sequential transactions form an anti-chain.
The following result from Reference [8] shows that the s-index is an upper bound to the VC-dimension of the range space for sequential patterns in .
Theorem 2
(Lemma 3 [8]). Let be a sequential dataset with s-index s. Then, the range space corresponding to has VC-dimension .
While an upper bound to the s-index can be computed in a streaming fashion, it still requires to check whether a transaction is a subset of the set of other transactions currently maintained in memory and that define the current value of the s-index. In addition, the computation of the upper bound on the capacity of a sequence p requires to check whether the itemsets of p are subsets of each others. To avoid such expensive operations, we define an upper bound to the s-index, that we call s-bound, which does not require to check whether the transactions form an anti-chain.
Definition 9.
Let be a sequential dataset. The s-bound of is the maximum integer s such that contains at least s different sequential transactions with item-length at least s.
Algorithm 1 shows the pseudo-code to compute an upper bound to the s-bound in a streaming fashion. It uses an ordered set to maintain in memory the set of transactions that define the current value of the s-bound. The ordered set stores pairs composed by a transaction and its item-length, sorted by decreasing item-length. In addition, it uses a hash set to speed up the control on the equal transactions.
In practice, it is quite uncommon that the long sequences that define the value of the s-index are subsequences of other sequences, thus, removing the anti-chain constraint, the bound does not deteriorate. In addition, the usage of the naive algorithm to compute the upper bound on , that is , it is equivalent to consider the transactions that have item-length at least s to calculate the s-bound, making the computation much faster without worsening the bound on the VC-dimension in practice.
| Algorithm1: SBoundUpp(): computation of an upper bound on the s-bound. |
 |
3.1. Compute the Sample Size for Frequent Sequential Pattern Mining
In this section, we show how to compute a sample size m for a random sample S of transactions taken from such that the maximum deviation is bounded by , that is, , for a user-defined value , using the upper bound on the VC-dimension defined above. Such result underlies the sampling algorithm that will be introduced in Section 5. Algorithm 2 shows how to compute a sample size that guarantees that with probability . This algorithm is used in the sampling algorithm (Section 5).
Theorem 3
(Proof in Appendix A). Let S be a random sample of m transactions taken with replacement from the sequential dataset and . Let d be the s-bound of . If
then with probability at least .
| Algorithm2: ComputeSampleSize(): computation of the sample size such that with probability . |
| Data: Dataset ; . Result: The sample size m. 1 SBoundUpp(); 2 ; 3 return m; |
3.2. Compute an Upper Bound to the Max Deviation for the True Frequent Sequential Patterns
In this section, we show how to compute an upper bound on the maximum deviation for the true frequent sequential pattern mining problem, that is, , using the upper bound on the empirical VC-dimension. Such result underlies the strategy for mining the true frequent sequential patterns that will be introduced in Section 6.
We define a range space associated with the generative process as a range space where the points and the range set . The s-bound of the dataset , as defined above, is an upper bound on the empirical VC-dimension of the range space associated with computed on . Algorithm 3 shows how to compute an upper bound on the maximum deviation that is used in the true frequent sequential pattern mining algorithm (Section 6).
Theorem 4
(Proof in Appendix A). Let be a finite bag of i.i.d. samples from an unknown probability distribution π on and . Let d be the s-bound of . If
then with probability at least .
| Algorithm3: ComputeMaxDevVC(): computation of an upper bound on the max deviation for the true frequent sequential pattern mining problem. |
| Data: Dataset ; . Result: Upper bound to the max deviation . 1 SBoundUpp(); 2 ; 3 return ; |
4. Rademacher Complexity of Sequential Patterns
In this section we introduce the Rademacher complexity of sequential patterns. We propose a method for finding an efficiently computable upper bound to the empirical Rademacher complexity of sequential patterns (similar to what has been done in Reference [5] for itemsets) and a method for approximating it. In the true frequent pattern mining scenario, these results will be useful for defining a quantity which is an upper bound to the maximum deviation with high probability.
The introduction of the Rademacher complexity of sequential patterns requires the definition of a set of real-valued functions. We define, for each pattern , the indicator function as:
where t is a transaction. Given a transaction t of a dataset with n transactions, is 1 if p appears in t, otherwise it is 0. We define the set of real-valued functions as the family of these indicator functions. The frequency of p in can be defined using the indicator function : The (empirical) Rademacher complexity on a given dataset is defined as:
where the expectation is taken w.r.t. the Rademacher r.v. , that is, conditionally on the dataset . The connection between the Rademacher complexity of sequential patterns and the maximum deviation is given by the following theorem, which derives from standard results in statistical learning theory (Thm. 3.2 in Reference [3]).
Theorem 5.
With probability at least :
The naïve computation of the exact value of is expensive since it requires to mine all patterns from and to generate all possible combination values of the Rademacher variables for the computation of the expectation. In the next sections we present an efficiently computable upper bound on the Rademacher complexity of sequential patterns and a simple method that approximates it, which are useful to find, respectively, an upper bound and an approximation to .
4.1. An Efficiently Computable Upper Bound to the Rademacher Complexity of Sequential Patterns
For any pattern , let us define the following -dimensional vector
and let , where are the transactions of . Note that all the infinite sequences of the universe which do not appear in are associated with the vector of zeros. This implies the finiteness of the size of : . In addition, defining as the number of sequential patterns that appear in , we have that potentially , since there may be two or more patterns associated with the same vector (i.e., these patterns appear exactly in the same transactions).
The following two theorems derive from known results of statistical learning theory (Thm. 3.3 of Reference [3]). Both theorems have been used for mining frequent itemsets [5], and can be applied for sequential pattern mining.
Theorem 6.
(Massart’s Lemma)
where indicates the Euclidean norm.
The following theorem is a stronger version of the previous one.
Theorem 7.
Let be the function
then
The upper bound on of Theorem 7 is not directly applicable to sequential pattern mining since it requires to mine every pattern that appear in in order to determine the entire set . However, the set is related to the set of closed sequential patterns on . The following two results give us an upper bound to the size of which depends on the number of closed sequential patterns of .
Lemma 1
(Proof in Appendix A). Consider a subset W of the dataset , . Let be the set of closed sequential patterns in whose support set in is W, that is, , with . Then the number C of closed sequential patterns in with W as support set satisfies: .
A simple example where is depicted in Figure 1. Note first of all that each super-sequence of but not of has support lower than the support of , and each super-sequence of but not of has support lower than the support of . Let be the subsequence of transaction restricted to only the sequences and , preserving the relative order of their itemsets. Then which implies , , and be lower than . Therefore each super-sequence of both and has support lower than the support of (i.e. equal to the one of ). Thus, and are closed sequences in with the same support set W.
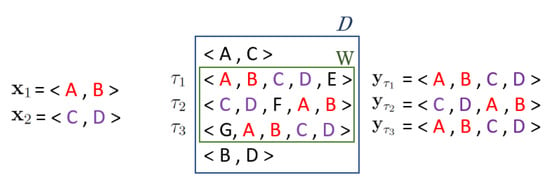
Figure 1.
Graphical representation of the case . Sequences and are closed sequences in with the same support set W.
Note that the previous lemma represents a sequential patterns version of Lemma 3 of Reference [5] for itemsets, where the upper bound to the number of closed itemsets in with W as support set is one (this holds by the nature of the itemsets where the notion of ‘‘ordering” is not defined). Lemma 1 is crucial for proving the following lemma which provides a bound on the size of the set of binary vectors.
Lemma 2
(Proof in Appendix A). and , that is, each vector of different from is associated with at least one closed sequential pattern in .
Combining a partitioning of with the previous lemma we can define a function , an upper bound to the function w of Theorem 7, which is efficient to compute with a single scan of . Let be the set of items that appear in the dataset and be its increasing ordering by their support in (ties broken arbitrarily). Given an item a, let be its support set on . Let denote the increasing ordering of the transactions by the number of items contained that come after a w.r.t. the ordering (ties broken arbitrarily). Let , where and . Let us focus on partitioning . Let and let a be the item in p which comes before any other item in p w.r.t. the order . Let be the transaction containing p which comes before any other transaction containing p w.r.t. the order . We assign p to the set . Remember that an item can appear multiple times in a sequence. Given a transaction , is the number of items in (counted with their multiplicity) equal to a or that come after a in . Let be the multiplicity of a in . For each , , let be the number of transactions in that contain exactly k items (counted with their multiplicity) equal to a or located after a in the ordering , with exactly m repetitions of a. Let . The following lemma gives us an upper bound to the size of .
Lemma 3
Combining the following partitioning of as
with the previous lemma, we obtain
Now we are ready to define the function , which can be used to obtain an efficiently computable upper bound to . The following lemma represents the analogous of Lemma 5 of Reference [5], adjusted for sequential patterns. Let be the average item-length of the transactions of , that is, . Let be the maximum item-length of the transactions of , that is, . Let be an item-length threshold, with . Let be the bag of transactions of with item-length greater than . Let be the set of the binary vectors associated with all possible non-empty sub-bags of .
Lemma 4
(Proof in Appendix A). Given an item a in , we define the following quantity:
Let be the function
Then,
For a given value of , the function can be compute with a single scan of the dataset, since it requires to know for each and for each , , . The values , , and the support of each item and consequently the ordering are obtained during the dataset creation. Thus, it is sufficient to look at each transaction , sorting the items that appear in according to , and, for each item of , keep track of its multiplicity , compute and increase by one . Finally, since is convex and has first and second derivatives w.r.t. s everywhere in , its global minimum can be computed using a non-linear optimization solver. This procedure has to be repeated for each possible value of in .
However, one could choose a particular schedule of values of to be tested, instead of taking into account each possible value, achieving a value of the function near to its minimum. A possible choice is to look at the restricted interval , given two positive values for and , instead of investigating the whole interval . This choice is motivated by the fact that in Lemma 4 the value of gives us an idea of which term of the summation is dominant (the one based on closed sequential patterns or the one based on binary vectors). If is close to then the number of binary vectors we count could be high, the dominant term is the one based on the set of binary vectors, and we expect the upper bound to be high. Instead, if is close to then the upper bound to the number of closed sequential patterns we count could be high, and the set of binary vectors we take into account is small. In this case, the dominant term is the one based on the closed sequential patterns, and the value of the upper bound could be high (since we count many sequential patterns with item-length greater than that instead would be associated with a small number of binary vectors). Thus, the best value of will be the one that is larger than and smaller than , enough to count not too many closed sequential patterns and binary vectors.
Finally, we define ComputeMaxDevRadeBound as the procedure for computing an upper bound to where, once the upper bound to the Rademacher complexity is computed using Algorithm 4, the upper bound to is obtained by
The pseudo-code of the algorithm for computing the upper bound to follows.
| Algorithm4: RadeBound(): algorithm for bounding the empirical Rademacher complexity of sequential patterns |
 |
4.2. Approximating the Rademacher Complexity of Sequential Patterns
The previous section presents an efficiently computable upper bound to the Rademacher of sequential patterns, which does not require any extraction of frequent sequences from a given dataset. Here we present a simple method that gives us an approximation of the Rademacher complexity of sequential patterns, which provides a tighter bound to the maximum deviation compared to the ones previously presented.
In the definition of the Rademacher complexity, a given combination of the Rademacher r.v. splits the dataset of n transactions in two sub-samples and : each transaction associated with 1 and goes respectively into and . For a given sequential pattern , let and be respectively the number of transactions of and in which p appears. Thus, the Rademacher complexity can be rewritten as follows:
In our approximation method we generate a single combination of the Rademacher r.v. , instead of generating every possible combination and then taking the expectation. Given , the approximation of is
The first step of the procedure is to mine frequent sequential patterns from and , given a frequency threshold . Let and be the sets of sequential patterns with support greater or equal than in and , respectively. Let us define the following quantities:
and
If then , since each pattern p that is not frequent in both sub-samples has lower than . Instead, if the entire procedure is repeated with . Note that, since the Rademacher complexity is a non-negative quantity, it is not necessary to look at patterns in since their ’s values are negative. The pseudo-code of the method for finding an approximation of is presented in Algorithm 5. The extraction of frequent sequences from the two sub-samples can be done using one of the many algorithms for mining frequent sequential patterns.
| Algorithm5: RadeApprox(): algorithm for approximating the Rademacher complexity of sequential patterns. |
 |
Finally, we define ComputeMaxDevRadeApprox as the procedure for computing an approximation of where, once the approximation of the Rademacher complexity is computed using Algorithm 5, the approximation of is obtained by:
5. Sampling-Based Algorithm for Frequent Sequential Pattern Mining
We now present a sampling algorithm for frequent sequential pattern mining. The aim of this algorithm is to reduce the amount of data to consider to mine the frequent sequential patterns, in order to speed up the extraction of the sequential patterns and to reduce the amount of memory required. We define a random sample as a bag of m transactions taken uniformly and independently at random, with replacement, from . Obtaining the exact set from a random sample is not possible, thus we focus on obtaining an -approximation with probability at least , where is a confidence parameter, whose value, with , is provided in input by the user. Intuitively, if a random sample is sufficiently large, then the set of frequent sequential patterns extracted from the random sample well approximates the set . The challenge is to find the number of transactions that are necessary to obtain the desired -approximation. To compute such sample size, our approach uses the VC-dimension of sequential patterns (see Section 3.1).
Theorem 8.
Given , let S be a random sample of size m sequential transactions taken independently at random with replacement from the dataset such that with probability at least . Then, given , the set is an ε-approximation to with probability at least .
Proof.
Suppose that . In such a scenario, we have that for all sequential patterns , it results . This also holds for the sequential patterns in . Therefore, the set satisfies Property 3 from Definition 1. It also means that for all , , so such and also satisfies Property 1. Now, let be a sequential pattern such that . Then, , that is , which allows us to conclude that also has Property 2 from Definition 1. Since we know that with probability at least , then the set is an -approximation to with probability at least , which concludes the proof. □
Theorem 8 provides a simple sampling-based algorithm to obtain an -approximation to with probability : take a random sample of m transactions from such that the maximum deviation is bounded by , that is, ; report in output the set . As illustrated in Section 3.1, such sample size can be computed using an efficient upper bound on the VC-dimension, given in input the desired upper bound on the maximum deviation (see Algorithm 2). Note that such sample size can not be computed with the Rademacher complexity, since the sample size appears in both terms of the right-hand side of Equation (23). Thus, it is not possible to fix the value of the bound on the maximum deviation to compute the sample size that provides such guarantees. Algorithm 6 shows the pseudo-code of the sampling algorithm.
We now provide the respective theorem to find a FPF -approximation.
Theorem 9.
Given , let S be a random sample of size m sequential transactions taken independently at random with replacement from the dataset such that with probability . Then, given , the set is a FPF ε-approximation to with probability .
Proof.
Suppose that . In such a scenario, we have that for all sequential patterns , it results . This also holds for the sequential patterns in . Therefore, the set satisfies Property 3 from Definition 2. It also means that for all , , so such and also satisfies Property 1. Now, let be a sequential pattern such that . Then, , that is , which allows us to conclude that also has Property 2 from Definition 2. Since we know that with probability at least , then the set is a FPF -approximation to with probability at least , which concludes the proof. □
| Algorithm6: Sampling-Based Algorithm for Frequent Sequential Pattern Mining. |
| Data: Dataset ; ; . Result: Set that is an -approximation (resp. a FPF -approximation) to with probability . 1 ComputeSampleSize( 2 sample of m transactions taken independently at random with replacement from ; 3 ; /* resp. to obtain a FPF -approximation */ 4 return; |
As explained above, the sample size m can be computed with Algorithm 2 that uses an efficient upper bound on the VC-dimension of sequential patterns. Then, the sample is generated taking m transactions uniformly and independently at random, with replacement, from . Finally, the mining of the sample S can be performed with any efficient algorithm for the exact mining of frequent sequential patterns. Figure 2 depicts a block diagram representing the relations between the algorithms presented in this work.
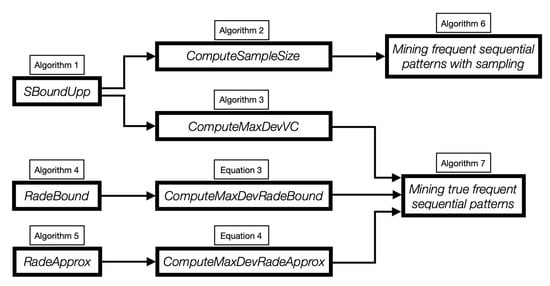
Figure 2.
Block diagram representing the relations between our algorithms.
6. Algorithms for True Frequent Sequential Pattern Mining
In this section, we describe our approach to find rigorous approximations to the TFSPs. In particular, given a dataset , that is a finite bag of i.i.d. samples from an unknown probability distribution on , a minimum frequency threshold and a confidence parameter , we aim to find rigorous approximations of the TFSPs w.r.t. , defined in Definitions 3 and 4, with probability at least .
The intuition behind our approach is the following. If we know an upper bound on the maximum deviation, that is , we can identify a frequency threshold (resp. ) such that the set is a FPF -approximation (resp. is a -approximation) of . The upper bound on the maximum deviation can be computed, as illustrated in the previous sections, with the empirical VC-dimension and with the Rademacher complexity.
We now describe how to identify the threshold that allows to obtain a FPF -approximation. Suppose that . In such a scenario, we have that every sequential pattern , and so that has , has a frequency . Hence, the only sequential patterns that can have frequency in greater or equal to , are those with true frequency at least . The intuition is that if we find a such that , we know that all the sequences , that are not true frequent w.r.t , can not be in . The following theorem formalizes the strategy to obtain a FPF -approximation. Algorithm 7 shows the pseudo-code to mine the true frequent sequential patterns.
Theorem 10 shows how to compute a corrected threshold such that the set is a FPF -approximation of , that is, only contains sequential patterns that are in . It guarantees that with high probability the set does not contain false positives but it has not guarantees on the number of false negatives, that is, sequential patterns that are in but not in . On the other hand, we might be interested in finding all the true frequent sequential patterns in . The following result shows how to identify a threshold such that the set contains all the true frequent sequential patterns in with high probability, that is, is a -approximation of . Note that while Theorem 11 provides guarantees on false negatives, it does not provide guarantees on the number of false positives in .
Algorithm 7 shows the pseudo-code of the two strategies to mine the true frequent sequential patterns. To compute an upper bound on the maximum deviation, it is possible to use Algorithm 3 based on the empirical VC-dimension or the two procedures ComputeMaxDevRadeBound (Equation (34)) and ComputeMaxDevRadeApprox (Equation (40)) based on the Rademacher complexity. The mining of can be performed with any efficient algorithm for the exact mining of frequent sequential patterns. Figure 2 shows the relations between the algorithms we presented for mining true frequent sequential patterns.
Theorem 10.
Given , such that with probability at least , and given , the set , with , is a FPF μ-approximation of the set with probability at least .
Proof.
Suppose that . Thus, we have that for all the sequential patterns , it results . This also holds for the sequential patterns in . Therefore, the set satisfies Property 3 of Definition 4. Let be a sequential pattern such that , that is, it is not a true frequent sequential pattern w.r.t. . Then, , that is, , which allows us to conclude that also has Property 1 from Definition 4. Now, let be a sequential pattern such that . Then, , that is , which allows us to conclude that also has Property 2 from Definition 4. Since we know that with probability at least , then the set is a FPF -approximation of with probability at least , which concludes the proof. □
Theorem 11.
Given , such that with probability at least , and given , the set , with , is a μ-approximation of the set with probability at least .
Proof.
Suppose that . Thus, we have that for all the sequential patterns , it results . This also holds for the sequential patterns in . Therefore, the set satisfies Property 3 of Definition 3. It also means that for all , , that is, , which allows us to conclude that also has Property 1 from Definition 3. Now, let be a sequential pattern such that . Then, , that is , which allows us to conclude that also has Property 2 from Definition 3. Since we know that with probability at least , then the set is a -approximation of with probability at least , which concludes the proof. □
| Algorithm7: Mining the True Frequent Sequential Patterns. |
| Data: Dataset ; ; Result: Set that is a FPF -approximation (resp. -approximation) to with probability . 1 ComputeMaxDeviationBound(); 2 ; /* resp. to obtain a -approximation */ 3 return; |
7. Experimental Evaluation
In this section, we report the results of our experimental evaluation on multiple datasets to assess the performance of the algorithms we proposed in this work. The goals of the evaluation are the following:
- Assess the performance of our sampling algorithm. In particular, to asses whether with probability the sets of frequent sequential patterns extracted from samples are -approximations, for the first strategy, and FPF -approximations, for the second one, of . In addition, we compared the performance of the sampling algorithm with the ones to mine the full datasets in term of execution time.
- Assess the performance of our algorithms for mining the true frequent sequential patterns. In particular, to assess whether with probability the set of frequent sequential patterns extracted from the dataset with the corrected threshold does not contain false positives, that is, it is a FPF -approximation of , for the first method, and contains all the TFSPs, that is, it is a -approximation of , for the second method. In addition, we compared the results obtained with the VC-dimension and with the Rademacher complexity, both used to compute an upper bound on the maximum deviation.
Since no sampling algorithm for rigorously approximating the set of frequent sequential patterns and no algorithm to mine true frequent sequential patterns have been previously proposed, we do not consider other methods in our experimental evaluation.
7.1. Implementation and Environment
The code to compute the bound on the VC-dimension (Algorithm 1) and to perform the evaluation has been developed in Java and executed using version 1.8.0_201. The code to compute the bound and the approximation to the Rademacher Complexity (resp. Algorithms 4 and 5) has been developed in C++. We have performed all our experiments on the same machine with 512 GB of RAM and 2 Intel(R) Xeon(R) CPU E5-2698 v3 @ 2.3GHz. To mine sequential patterns, we used the PrefixSpan [10] implementation provided by the SPMF library [28]. We used NLopt [29] as non-linear optimization solver. Our open-source implementation and the code developed for the tests, including scripts to reproduce all results, are available online [30].
7.2. Datasets
In this section, we describe the datasets we used in our evaluation. We first describe the dataset used to evaluate our sampling algorithm for FSP mining, and then the datasets used for TFSP mining. All datasets are obtained starting from the following real datasets:
- BIBLE: a conversion of the Bible into sequence where each word is an item;
- BMS1: contains sequences of click-stream data from the e-commerce website Gazelle;
- BMS2: contains sequences of click-stream data from the e-commerce website Gazelle;
- FIFA: contains sequences of click-stream data from the website of FIFA World Cup 98;
- KOSARAK: contains sequences of click-stream data from an Hungarian news portal;
- LEVIATHAN: is a conversion of the novel Leviathan by Thomas Hobbes (1651) as a sequence dataset where each word is an item;
- MSNBC: contains sequences of click-stream data from MSNBC website and each item represents the category of a web page;
- SIGN: contains sign language utterance.
All the datasets used are publicly available online [31] and the code to generate the pseudo-artificial datasets, as described in the following sections, is provided [30]. The characteristics of the datasets are reported in Table 1.

Table 1.
Datasets characteristics. For each dataset , we report the number of transactions, the total number of items, the average transaction item-length and the maximum transaction item-length.
7.2.1. FSP Mining
The typical scenario for the application of sampling is that the dataset to mine is very large, sometimes even too large to fit in the main memory of the machine. Thus, in applying sampling techniques, we aim to reduce the size of such dataset, considering only a sample of it, in order to obtain an amount of data of reasonable size. Since the number of transactions in each real dataset (shown in Table 1) is fairly limited, we replicated each dataset to reach modern datasets sizes. For each real dataset, we fixed a replication factor and we created a new dataset, replicating each transaction in the dataset a number of times equal to the replication factor. Then, the input data for the sampling algorithm is the new enlarged dataset. The replication factors used are the following: BIBLE and FIFA = 200x; BMS1, BMS2 and KOSARAK = 100x; LEVIATHAN = 1000x; MSNBC = 10x and SIGN = 10,000x.
7.2.2. TFSP Mining
To evaluate our algorithms to mine the true frequent sequential patterns, we need to know which are the sequential patterns that are frequently generated from the unknown generative process . In particular, we need a ground truth of the true frequencies of the sequential patterns. We generated pseudo-artificial datasets by taking some of the datasets in Table 1 as ground truth for the true frequencies of the sequential patterns. For each ground truth, we created four new datasets by sampling sequential transactions uniformly at random from the original dataset. All the new datasets have the same number of transactions of the respectively ground truth, that is, the respectively original dataset. We used the original datasets as ground truth and we executed our evaluation in the new (sampled) datasets. Therefore, the true frequency of a sequential pattern is its frequency in the original dataset, that is, its frequency in the original dataset is exactly the same that such pattern would have in an hypothetical infinite number of transactions generated by the unknown generative process .
7.3. Sampling Algorithm Results
In this section, we describe the results obtained with our sampling algorithm (Algorithm 6). As explained above, the typical scenario to apply sampling is that the dataset to mine is very large. Thus, we aim to reduce the size of such dataset, considering only a sample of it. In addition, from the sample, we aim to obtain a good approximation of the results that would have been obtained from the entire dataset. In all our experiments we fixed and . The steps of the evaluation are the following (Algorithm 6): given a dataset as input, we compute the sample size m, using Algorithm 2, to obtain an -approximation (resp. FPF -approximation) with probability at least . Then, we extract a random sample S of m transactions from and we run the algorithm to mine the frequent sequential patterns on S. Finally, we verify whether the set of frequent sequential patterns extracted from the sample is a -approximation (resp. FPS -approximation) to . For each dataset we repeat the experiment 5 times, and then we compute the fraction of times the sets of frequent sequential patterns extracted from the samples have the properties described in Definition 1 (resp. Definition 2). Table 2 shows the results.
Table 2.
Sampling algorithms results. For each enlarged dataset , we report , the ratio between the sample size and the size of the enlarged dataset , Max_Abs_Err, the maximum , and Avg_Abs_Err, the average , over the 5 samples and with the set of frequent sequential patterns extracted from , the percentage of -approximations obtained over the 5 samples and the percentage of FPF -approximations obtained over the 5 samples.
We observe that the samples obtained from the datasets are about 2 to 5 times smaller than the whole datasets. Moreover, in all the runs for all the datasets, we obtain an -approximation (resp. FPF -approximation). Such results are even better than the theoretical guarantees, that ensure to obtain such approximations with probability at least 90%. We also reported Max_Abs_Err and Avg_Abs_Err , where is the set of frequent sequential patterns extracted from the sample , (since we run each experiment 5 times, there are 5 samples). They represent the maximum and the average, over the 5 runs, of the maximum absolute difference between the frequency that the sequential patterns have in the entire dataset and that they have in the sample, over all the sequential patterns extracted from the sample. Again, the results obtained are better than the theoretical guarantees, that ensure a maximal absolute difference lower than .
Figure 3 shows the comparison between the average execution time of the sampling algorithm and the average execution time of the mining of the entire dataset, over the 5 runs. For all the datasets, the sampling algorithm requires less time than the mining of the whole dataset. For BMS1 and BMS2, the mining of the whole dataset is very fast since the number of frequent sequential patterns extracted from it is low. Thus, there is not a large difference between the execution time to mine the whole dataset and the execution time for the sampling algorithm, which is most due to the computation of the sample size. Similar results between our sampling algorithm and the mining of the whole dataset have also been obtained with KOSARAK and MSNBC. As expected, for all the datasets, the execution time of the sampling algorithm to obtain an -approximation is larger than the execution time of the sampling algorithm to obtain a FPF -approximation, since the minimum frequency threshold used in the first case is lower, resulting in a higher number of extracted sequential patterns.
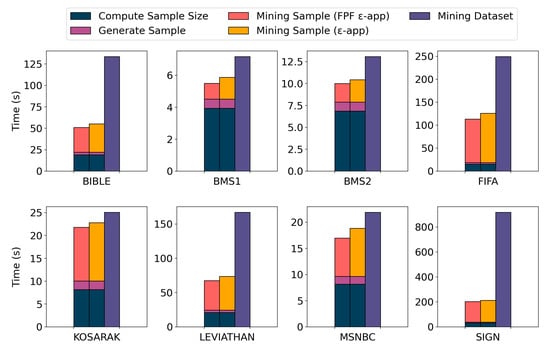
Figure 3.
Execution time of the sampling algorithm. The execution time required to mine the whole dataset, and the execution times of the sampling algorithm to obtain an -approximation and a false positives free (FPF) -approximation are reported. For the sampling algorithms, we show the execution time to compute the sample size, the execution time to generate the sample, and the execution time to mine the sample.
We now discuss some of the patterns extracted from the MSNBC dataset, for which richer information regarding the data is available. In particular, in MSNBC each transaction contains the sequence of click-stream data generated by a single view on the MSNBC website by a user, and each item represents the category of a visited webpage, such “frontpage”, “news”, “sports”, and so forth.
The two most frequent sequential patterns extracted in the enlarged datasets with a classic FSP algorithm are single categories, that is, sequential patterns of item-length 1: is the most frequent while is the second one. They are also the two most frequent sequential patterns extracted in all the five samples using our sampling algorithms. The most frequent sequential patterns with item-length greater than one are the sequential patterns and . For , 75% of the transactions in which it appears there is at least an instance of such pattern where the two items are consecutive. This means that users visited two consecutive webpages of the same category, “frontpage”, or that they refreshed the same page twice, while in the 25% of the transactions in which it appears users visited webpages of other categories between the two “frontpage” webpages. Instead, for the percentage of transactions in which the three items are consecutive is 59%. We also observed similar results with other categories: sequential patterns that are sequences of the same item, and so of the same category, have higher frequency. This fact highlights that users usually visit more frequently pages of the same category or that they refresh multiple times the same pages.
The most frequent sequential patterns that are not sequences of the same item are combinations of the items “frontpage” and “news”, for example, , and . Surprisingly, the item “on-air” alone is more frequent that the item “news” alone. This means that users visit “news” webpages coming from a “frontpage” more frequently than “on-air” webpages, though they visit more frequently “on-air” webpages.
7.4. True Frequent Sequential Patterns Results
In this section, we describe the results of our algorithms for mining the true frequent sequential patterns. In all these experiments, we fixed . First of all, for each real dataset we generated 4 pseudo-artificial datasets , from the same ground truth. We mined the set , and we compared it with the TFSPs, that is, the set , where is the ground truth. Such experiments aim to verify whether the sets of the FSPs extracted from the pseudo-artificial datasets contain false positives and miss some TFSPs. Table 3 shows the fractions of times that the set contains false positives and misses TFSPs from the ground truth. We ran this evaluation over the four datasets , , of the same size from the same ground truth and we reported the average. For each dataset, we report the results with two frequency thresholds . In almost all the cases, the FSPs mined from the pseudo-artificial datasets contain false positives and miss some TFSPs. In particular, with lower frequency thresholds (and, therefore, a larger number of patterns), the fraction of times we find false positives and false negatives usually increases. These results emphasize that, in general, the mining of the FSPs is not enough to learn interesting features of the underlying generative process of the data, and techniques like the ones introduced in this work are necessary.
Table 3.
Average fraction of times that , with a pseudo-artificial dataset, contains false positives, Times FPs, and misses true frequent sequential patterns (TFSPs) (false negatives), Times FNs, over 4 datasets from the same ground truth.
Then, we compute and compare the upper bounds to the maximum deviation introduced in the previous sections, since our strategy to find an approximation to the true frequent sequential patterns hinges on finding a tight upper bound to the maximum deviation. For each pseudo-artificial dataset, we computed the upper bound to the maximum deviation using the VC-dimension based bound (ComputeMaxDevVC, Algorithm 3), the Rademacher complexity based bound (ComputeMaxDevRadeBound, Equation (34)), and the Rademacher complexity approximation (ComputeMaxDevRadeApprox, Equation (40)). Table 4 shows that the two methods for computing the upper bound to the maximum deviation using an upper to the empirical VC-dimension and Rademacher complexity are similar for BMS1 and BMS2, but for the other samples the VC-dimension-based algorithm is better than the one based on the Rademacher complexity bound by a factor between 2 and 3, that is, . Tighter upper bounds to the maximum deviation are provided by the method that uses the approximation of the Rademacher complexity.
Table 4.
Comparison of the upper bound to the maximum deviation achieved respectively by ComputeMaxDevVC, ComputeMaxDevRadeBound, and ComputeMaxDevRadeApprox for each dataset. We show averages , maximum values , and standard deviations for each dataset and method over the 4 pseudo-artificial datasets.
In our implementation of Algorithm 4 to compute an upper bound to the empirical Rademacher complexity of sequential patterns, we compute several upper bounds associated with different integer values of for fixed values of and , taking the minimum bound among those computed. In our experiments, we fixed and . In practice, by increasing the value of we observe a decreasing trend of the upper bound value until a minimum value is reached. Then, by increasing again the value of the value of the upper bound increases until it converges to the one achieved with . In addition, for each pseudo-artificial dataset the value of associated with the minimum value of the upper bound to the maximum deviation is always found in , with , .
Finally, we evaluated the performance of our two strategies to mine an approximation of the true frequent sequential patterns, the first one with guarantees on the false positives and the second one with guarantees on the false negatives, using the upper bounds on the maximum deviation computed above. We considered the two tightest upper bounds, that are and , computed respectively using the empirical VC-dimension and an approximation of the empirical Rademacher complexity. From each pseudo-artificial dataset, we mined the FSPs using , for the first strategy, and , for the second one, respectively computed using Theorems 10 and 11, and we compared the sequential patterns extracted with the TFSPs from the ground truth. Table 5 shows the results for the strategy with guarantees on the false positives. Using to compute the corrected frequency threshold , our algorithm performs better than the theoretical guarantees in all the runs, since the number of times the output contains false positives is always equal to zero, while the theory guarantees a probability of at least to obtain the correct approximation. Obviously, this also happens using to compute the corrected frequency threshold , since . We also computed the average fraction of TFSPs reported in the output by the algorithm, that is, , since we aim to obtain as many TFSPs as possible. For all the datasets, it is possible to notice that the results obtained with the Rademacher complexity are better than the ones obtained with the VC-dimension, since the Rademacher allows to obtain a higher percentage of TFSPs in output. Table 6 shows the results for the strategy with guarantees on the false negatives. Similar to the previous case, our algorithm performs better than the theoretical guarantees in all the runs, since the number of times the algorithm misses some TFSPs is always equal to zero, with both the VC-dimension and the Rademacher complexity based results. We also report the average fractions of patterns in the output that are TFSPs, that is, , since we are interested in obtaining all the TFSPs but with less false positives as possible. Again, the results with the Rademacher complexity are better than the ones obtained with the VC-dimension, since the number of sequential patterns in the output of the algorithm that are TFSPs is higher using the Rademacher complexity.
Table 5.
Results of our algorithm for the TFSPs with guarantees on the false positives in 4 pseudo-artificial datasets for each ground truth. The table reports the frequency thresholds used in the experiments, the number of TFSPs in the ground truth, the number of times the output contains false positives using as frequency threshold and the average fraction of the reported TFSPs in the output using such frequency threshold, the number of times the output contains false positives using and the average fraction of the reported TFSPs in the output using such frequency threshold.
Table 6.
Results of our algorithm for the TFSPs with guarantees on the false negatives in 4 pseudo-artificial datasets for each ground truth. The table reports the frequency thresholds used in the experiments, the number of TFSPs in the ground truth, the number of times the output of the algorithm misses some TFSPs using as frequency threshold and the average fraction of sequential patterns that are TFSPs in the output using such frequency threshold, the number of times the output of the algorithm misses some TFSPs using and the average fraction of sequential patterns that are TFSPs in the output using such frequency threshold.
We now we briefly analyze the sequential patterns extracted from the MSNBC dataset using our TFSP algorithms. Since we considered the FSP extracted from the whole dataset as ground truth, that is, as TFSP, the considerations reported for the most frequent sequential patterns extracted from the whole dataset and from the samples (see previous section) are still valid for the true frequent sequential patterns that have higher frequency.
Using , as shown in Table 5 and Table 6, we find 97 true frequent sequential patterns. In the four pseudo-artificial datasets we extracted on average ≈126 and ≈230 sequential patterns with guarantees on the false negatives, using respectively the approximation on the Rademacher complexity and the VC-dimension. With the algorithms with guarantees on the false positives, we mined ≈74 and ≈54 sequential patterns, respectively.
is the most frequent sequential pattern that is a TFSP but that it is not returned by our algorithm with guarantees on the false positives using the VC-dimension, that is, it is one of the allowed false negatives, in all the four pseudo-artificial datasets. Instead, the corresponding algorithm that uses the approximation of the Rademacher complexity always returned such sequential pattern as a TFSP. The most frequent sequential patterns that are true frequent but that are not returned by our algorithm with guarantees on the false positives using the approximation of the Rademacher complexity are in two pseudo-artificial datasets, and and both in one pseudo-artificial dataset. Instead, the most frequent sequential patterns that are not true frequent but that are returned by our algorithms with guarantees on the false negatives, that is, they are some of the allowed false positives, are , in three pseudo-artificial datasets and in one, for both strategies.
8. Discussion
In this work, we studied two tasks related to sequential pattern mining: frequent sequential pattern mining and true frequent sequential pattern mining. For both tasks, we defined rigorous approximations and designed efficient algorithms to extract such approximations with high confidence using advanced tools from statistical learning theory. In particular, we devised an efficient sampling-based algorithm to approximate the set of frequent sequential patterns in large datasets using the concept of VC-dimension. We also devised efficient algorithms to mine the true frequent sequential patterns using VC-dimension and Rademacher complexity. Our extensive experimental evaluation shows that our sampling algorithm for mining frequent sequential patterns produces accurate approximations using samples that are small fractions of the whole datasets, thus vastly speeding up the sequential pattern mining task on very large datasets. For mining true frequent sequential patterns, our experimental evaluation shows that our algorithms obtain high-quality approximations, even better than guaranteed by their theoretical analysis. In addition, our evaluation shows that the upper bound on the maximum deviation computed using the approximation of the Rademacher complexity allows to obtain better results than the ones obtained with the upper bound on the maximum deviation computed using the empirical VC-dimension.
Author Contributions
Conceptualization, D.S., A.T., and F.V.; methodology, D.S., A.T., and F.V.; software, D.S. and A.T.; validation, D.S., A.T., and F.V.; formal analysis, D.S., A.T., and F.V.; investigation, D.S. and A.T.; resources, F.V.; data curation, D.S. and A.T.; writing—original draft preparation, D.S., A.T., and F.V.; writing—review and editing, D.S., A.T., and F.V.; visualization, D.S. and A.T.; supervision, F.V.; project administration, F.V.; funding acquisition, F.V. All authors have read and agreed to the published version of the manuscript.
Funding
Part of this work was supported by the University of Padova grant STARS: Algorithms for Inferential Data Mining, and by MIUR, the Italian Ministry of Education, University and Research, under PRIN Project n. 20174LF3T8 AHeAD (Efficient Algorithms for HArnessing Networked Data). and under the initiative “Departments of Excellence” (Law 232/2016).
Conflicts of Interest
The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
Appendix A. Missing Proofs
In this appendix we present the proofs not included in the main text.
Theorem 3.
Let S be a random sample of m transactions taken with replacement from the sequential dataset and . Let d be the s-bound of . If
then with probability at least .
Proof.
From Theorem 1 in the main text we know that S is an -bag for with probability at least . This means that for all we have
Given a sequence and its support set on , that is the range , and from the definition of range set of a sequential dataset, we have
and
Thus, with probability . □
Theorem 4.
Let be a finite bag of i.i.d. samples from an unknown probability distribution π on and . Let d be the s-bound of . If
then with probability at least .
Proof.
The proof is analogous to the proof of Theorem 3, when we consider the dataset a random sample of a fixed size and we aim to compute an upper bound on the maximum deviation between the true frequency of a sequence and its frequency in . □
Lemma 1.
Consider a subset W of the dataset , . Let be the set of closed sequential patterns in whose support set in is W, that is, , with . Then the number C of closed sequential patterns in with W as support set satisfies: .
Proof.
The proof is organized in such a way: first, we show that the basic cases and hold, second, we prove the cases for .
Let us consider the case where W is a particular subset of for which no sequence has W as support set in . Thus, is an empty set and . The case is trivial, since it could happen that only one closed sequential pattern has W as support set in .
Now, before proving the cases for a generic value of C in , we start by considering the case . Let , be two sequences with W as support set. Assume that each super-sequence of but not of has support lower than the support of , and each super-sequence of but not of has support lower than the support of . Now, let us focus on super-sequences of both and . Let be a transaction of W. We define as the subsequence of restricted to only the sequences and , preserving the relative order of their itemsets. For instance, let , and , where are itemsets: thus, . Now, if the support set of in W does not coincide with W, that is, , then for each transaction we have . Note that this could happen because the set of itemsets of and may not appear in the same order in all transactions. Hence each super-sequence of both and has support lower than the support of (that is equal to the support of ). Thus, each super-sequence of has a lower support compared to the support of , for . This implies that and are closed sequences in and since their support set is W, they belong to . Thus, the case could happen.
Now we generalize this concept for a generic number C of closed sequential patterns, where . Let be a set of C sequential patterns with W as support set. Assume that each super-sequence of but not of has support lower than the support of , for each with . Let be the power set of H without the empty set and the sets made of only one sequence, that is, . So, in there are every possible subset of H of size greater than one. For a transaction and , we define as the subsequence of restricted to , that is, to only the sequences , preserving the relative order of their itemsets. If there exits a transaction such that the support set of in W does not coincide with W, that is, , then for each transaction we have . Hence each super-sequence made of only sequences of has support lower than the support of , for . Thus, each super-sequence of has a lower support compared to the support of , for . This implies that all sequences of H are closed sequence in and since their support set is W, they belong to . □
Lemma 2.
and , that is, each vector of different from is associated with at least one closed sequential pattern in .
Proof.
Let , where . Let be a sequence of non-empty support set in , that is, . There are two possibilities: p is or is not a closed sequence in . If p is not a closed sequence, then there exists a closed super-sequence with support equal to the support of p, so with . Thus, is associated with at least one closed sequence. Combining this with the fact that each vector is associated with at least one sequence and Lemma 1, then each vector of different from is associated with at least one closed sequential pattern of . To conclude our proof is sufficient to show that there are no closed sequences associated with the vector . Let . Note that . For each , there always exists a super-sequence such that . This implies that each sequence of is not closed. Thus, and . □
Lemma 3.
We have
Proof.
represents a subset of the set of all those subsequences of that are made of only items equal to a or that come after a in , with item-length at least two and with at least one occurrence of a. Let us focus on finding an upper bound to . In order to build such a generic subsequence of , it is sufficient to select i occurrences of a among the available, with , and choose j items among the remaining items different from a. Note that if , then j must be greater than 0. Thus, using the fact that the sum of for is equal to , we have
where the first inequality holds because some sequences of are counted more times. Since , the thesis holds. □
Lemma 4.
Given an item a in , we define the following quantity:
Let be the function
Then,
Proof.
Let us consider the function w from Theorem 7. For a given value of , we have that , since not all the binary vectors of necessarily belong to . Thus:
where . For each binary vector the maximum number of 1’s is ||. Thus,
By using the definition of Euclidean norm, we have that, for any sequence ,
Note that each closed sequential pattern p with can only appear in transactions of and, consequently, it is associated with a binary vector of and not of . Thus, defining as the set of closed sequential patterns of with item-length lower or equal to and using Lemma 2 we can use the sum over as an upper bound on the sum over :
Note that the vector of provides a .
Now let us focus on the first term of the sum. The set can be broken using the Equation 29 in the sum over
plus the sum over (i.e., the set of closed sequential patterns with item-length in )
where is the set of closed sequential patterns of with item-length in . Since the set of items of the sequences in is a subset of , we have
For any , by the anti-monotonicity support property for sequential patterns. An upper bound to the size of can be computed in two ways, depending on the value of . If , we can use Lemma 3:
If we have to count the number of possible closed sequential patterns with at least one item equal to a and with item-length in that we can build from items of :
Finally, using the quantities ,k,m and g previously defined and indicator functions we can merge the right-hand sides of the last two inequalities
Thus, rearranging all the terms we reach the definition of . Using the above arguments and the best value of which minimizes the function we have that for any , . Since (by Theorem 7), we conclude that
References
- Agrawal, R.; Srikant, R. Mining sequential patterns. In Proceedings of the Eleventh International Conference on Data Engineering, Taipei, China, 6–10 March 1995; pp. 3–14. [Google Scholar]
- Vapnik, V.N.; Chervonenkis, A.Y. On the Uniform Convergence of Relative Frequencies of Events to Their Probabilities. In Measures of Complexity; Vovk, V., Papadopoulos, H., Gammerman, A., Eds.; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Boucheron, S.; Bousquet, O.; Lugosi, G. Theory of classification: A survey of some recent advances. ESAIM Probab. Stat. 2005, 9, 323–375. [Google Scholar] [CrossRef]
- Riondato, M.; Upfal, E. Efficient discovery of association rules and frequent itemsets through sampling with tight performance guarantees. ACM Trans. Knowl. Discov. D 2014, 8, 20. [Google Scholar] [CrossRef]
- Riondato, M.; Upfal, E. Mining frequent itemsets through progressive sampling with rademacher averages. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 22–27 August 2015; pp. 1005–1014. [Google Scholar]
- Raïssi, C.; Poncelet, P. Sampling for sequential pattern mining: From static databases to data streams. In Proceedings of the Seventh IEEE International Conference on Data Mining (ICDM 2007), Omaha, NE, USA, 28–31 October 2007; pp. 631–636. [Google Scholar]
- Riondato, M.; Vandin, F. Finding the true frequent itemsets. In Proceedings of the 2014 SIAM International Conference on Data Mining, Philadelphia, PA, USA, 28 April 2014; pp. 497–505. [Google Scholar]
- Servan-Schreiber, S.; Riondato, M.; Zgraggen, E. ProSecCo: Progressive sequence mining with convergence guarantees. Knowl. Inf. Syst. 2020, 62, 1313–1340. [Google Scholar] [CrossRef]
- Srikant, R.; Agrawal, R. Mining sequential patterns: Generalizations and performance improvements. In Advances in Database Technology–EDBT ’96, Proceedings of the International Conference on Extending Database Technology, Avignon, France, 25–29 March 1996; Springer: Berlin/Heidelberg, Germany, 1996; pp. 1–17. [Google Scholar]
- Pei, J.; Han, J.; Mortazavi-Asl, B.; Wang, J.; Pinto, H.; Chen, Q.; Dayal, U.; Hsu, M.C. Mining sequential patterns by pattern-growth: The prefixspan approach. IEEE Trans. Knowl. Data Eng. 2004, 16, 1424–1440. [Google Scholar]
- Wang, J.; Han, J.; Li, C. Frequent closed sequence mining without candidate maintenance. IEEE Trans. Knowl. Data Eng. 2007, 19, 1042–1056. [Google Scholar] [CrossRef]
- Pellegrina, L.; Pizzi, C.; Vandin, F. Fast Approximation of Frequent k-mers and Applications to Metagenomics. J. Comput. Biol. 2019, 27, 534–549. [Google Scholar] [CrossRef] [PubMed]
- Riondato, M.; Vandin, F. MiSoSouP: Mining interesting subgroups with sampling and pseudodimension. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19 July 2018; pp. 2130–2139. [Google Scholar]
- Al Hasan, M.; Chaoji, V.; Salem, S.; Besson, J.; Zaki, M.J. Origami: Mining representative orthogonal graph patterns. In Proceedings of the Seventh IEEE International Conference on Data Mining (ICDM 2007), Omaha, NE, USA, 28–31 October 2007; pp. 153–162. [Google Scholar]
- Corizzo, R.; Pio, G.; Ceci, M.; Malerba, D. DENCAST: distributed density-based clustering for multi-target regression. J. Big Data 2019, 6, 43. [Google Scholar] [CrossRef]
- Cheng, J.; Fu, A.W.c.; Liu, J. K-isomorphism: privacy preserving network publication against structural attacks. In Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data, Indianapolis, Indiana, 6–11 June 2010; pp. 459–470. [Google Scholar]
- Riondato, M.; Upfal, E. ABRA: Approximating betweenness centrality in static and dynamic graphs with rademacher averages. ACM Trans. Knowl. Discov. D 2018, 12, 1–38. [Google Scholar] [CrossRef]
- Mendes, L.F.; Ding, B.; Han, J. Stream sequential pattern mining with precise error bounds. In Proceedings of the Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 941–946. [Google Scholar]
- Pellegrina, L.; Riondato, M.; Vandin, F. SPuManTE: Significant Pattern Mining with Unconditional Testing. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 1528–1538. [Google Scholar]
- Gwadera, R.; Crestani, F. Ranking Sequential Patterns with Respect to Significance. In Advances in Knowledge Discovery and Data Mining; Zaki, M.J., Yu, J.X., Ravindran, B., Pudi, V., Eds.; Springer: Berlin, Germany, 2010; Volume 6118. [Google Scholar]
- Low-Kam, C.; Raïssi, C.; Kaytoue, M.; Pei, J. Mining statistically significant sequential patterns. In Proceedings of the IEEE 13th International Conference on Data Mining, Dallas, TX, USA, 7–10 December 2013; pp. 488–497. [Google Scholar]
- Tonon, A.; Vandin, F. Permutation Strategies for Mining Significant Sequential Patterns. In Proceedings of the IEEE International Conference on Data Mining (ICDM), Beijing, China, 8–11 November 2019; pp. 1330–1335. [Google Scholar]
- Mitzenmacher, M.; Upfal, E. Probability and Computing: Randomization and Probabilistic Techniques in Algorithms and Data Analysis; Cambridge University Press: New York, NY, USA, 2017. [Google Scholar]
- Löffler, M.; Phillips, J.M. Shape fitting on point sets with probability distributions. In Algorithms–ESA 2009, Proceedings of the European Symposium on Algorithms, Copenhagen, Denmark, 7–9 September 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 313–324. [Google Scholar]
- Li, Y.; Long, P.M.; Srinivasan, A. Improved bounds on the sample complexity of learning. J. Comput. Syst. Sci. 2001, 62, 516–527. [Google Scholar] [CrossRef]
- Shalev-Shwartz, S.; Ben-David, S. Understanding machine learning: From theory to algorithms; Cambridge University Press: New York, NY, USA, 2014. [Google Scholar]
- Egho, E.; Raïssi, C.; Calders, T.; Jay, N.; Napoli, A. On measuring similarity for sequences of itemsets. Data Min. Knowl. Discov. 2015, 29, 732–764. [Google Scholar] [CrossRef][Green Version]
- Fournier-Viger, P.; Lin, J.C.W.; Gomariz, A.; Gueniche, T.; Soltani, A.; Deng, Z.; Lam, H.T. The SPMF open-source data mining library version 2. In Machine Learning and Knowledge Discovery in Databases; Berendt, B., Ed.; Springer: Cham, Switzerland, 2016; Volume 9853, pp. 36–40. [Google Scholar]
- Johnson, S.G. The NLopt Nonlinear-Optimization Package. 2014. Available online: https://nlopt.readthedocs.io/en/latest/ (accessed on 10 April 2020).
- GitHub. VCRadSPM: Mining Sequential Patterns with VC-Dimension and Rademacher Complexity. Available online: https://github.com/VandinLab/VCRadSPM (accessed on 10 April 2020).
- SPMF Datasets. Available online: https://www.philippe-fournier-viger.com/spmf/index.php?link=datasets.php (accessed on 10 April 2020).



© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).