Detection and Monitoring of Bottom-Up Cracks in Road Pavement Using a Machine-Learning Approach


Abstract
1. Introduction
- Inadequate mix design (e.g., excessive asphalt binder, or poor-quality asphalt binder, or aggregates);
- Inadequate structural design (e.g., unsuitable road geometry, underestimated traffic load, insufficient layer thickness, and poor joint construction or location);
- Inadequate construction quality (e.g., poor compaction and poor patching after utility cuts);
- The increase in the traffic volume or of the number of vehicles with high axle loads;
- Repeated traffic loading (fatigue);
- Asphalt binder aging (i.e., oxidation of the binder resulting in a stiffer and more viscous material that is not able to hold the superficial aggregates that are pulled away by traffic);
- Temperature (e.g., temperature cycling, freeze-thaw cycle, and low temperatures);
- Moisture (e.g., excessive moisture in the subgrade);
- Decreasing in pavement load supporting characteristics (i.e., loss in base, subbase or subgrade);
- Reflective crack from an underlying layer (e.g., due to bottom-up cracking propagation, or presence of rigid objects);
- Traffic start and stops;
- Mechanical dislodging by uncommon traffic (e.g., studded tires, snowplow blades, or tracked vehicles);
- Vibrations induced by the traffic, work zones, or natural events (e.g., earthquakes);
- Maintenance policy pursued (e.g., failure- or condition-based).
State of the Art about Technological Solutions Used to Detect Concealed Distresses in Road Pavements
2. Objectives
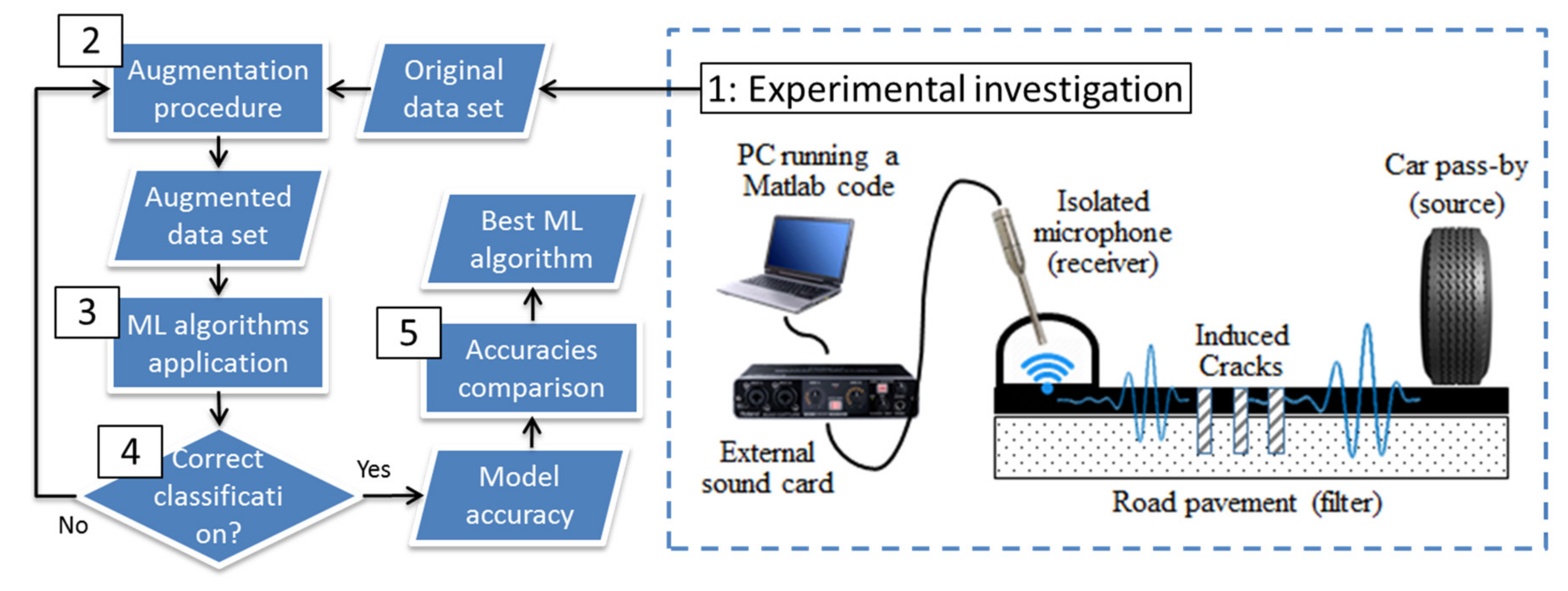
3. Innovative Method
3.1. The Method
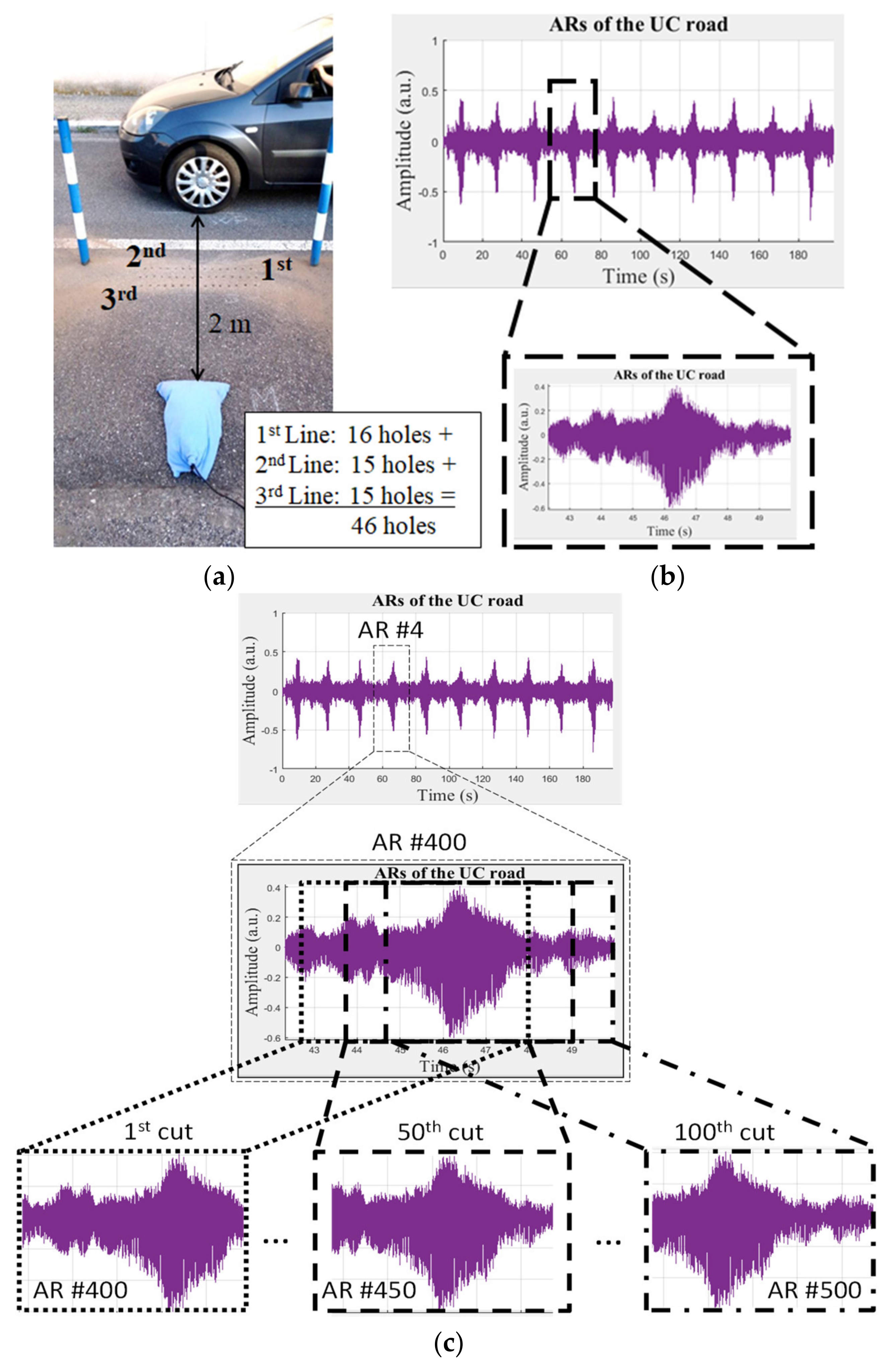
3.2. Experimental Investigation and Data Set Generation
3.3. The Machine Learning Classifiers Used
- Multilayer perceptron (MLP);
- Convolutional neural network (CNN).
- Random forest classifier (RFC): an ensemble learning method for classification that operates by constructing a set of decision trees and returning the class that is the mode of the classes (classification) of the individual trees [38];
- Support vector classifier (SVC): a supervised learning classifier with associated learning algorithms that can perform a nonlinear classification, implicitly mapping the model inputs into high-dimensional feature spaces.
- SVC with linear kernel;
- SVC with radial basis function (RBF) kernel;
- SVC with polynomial kernel.
4. Results and Discussions
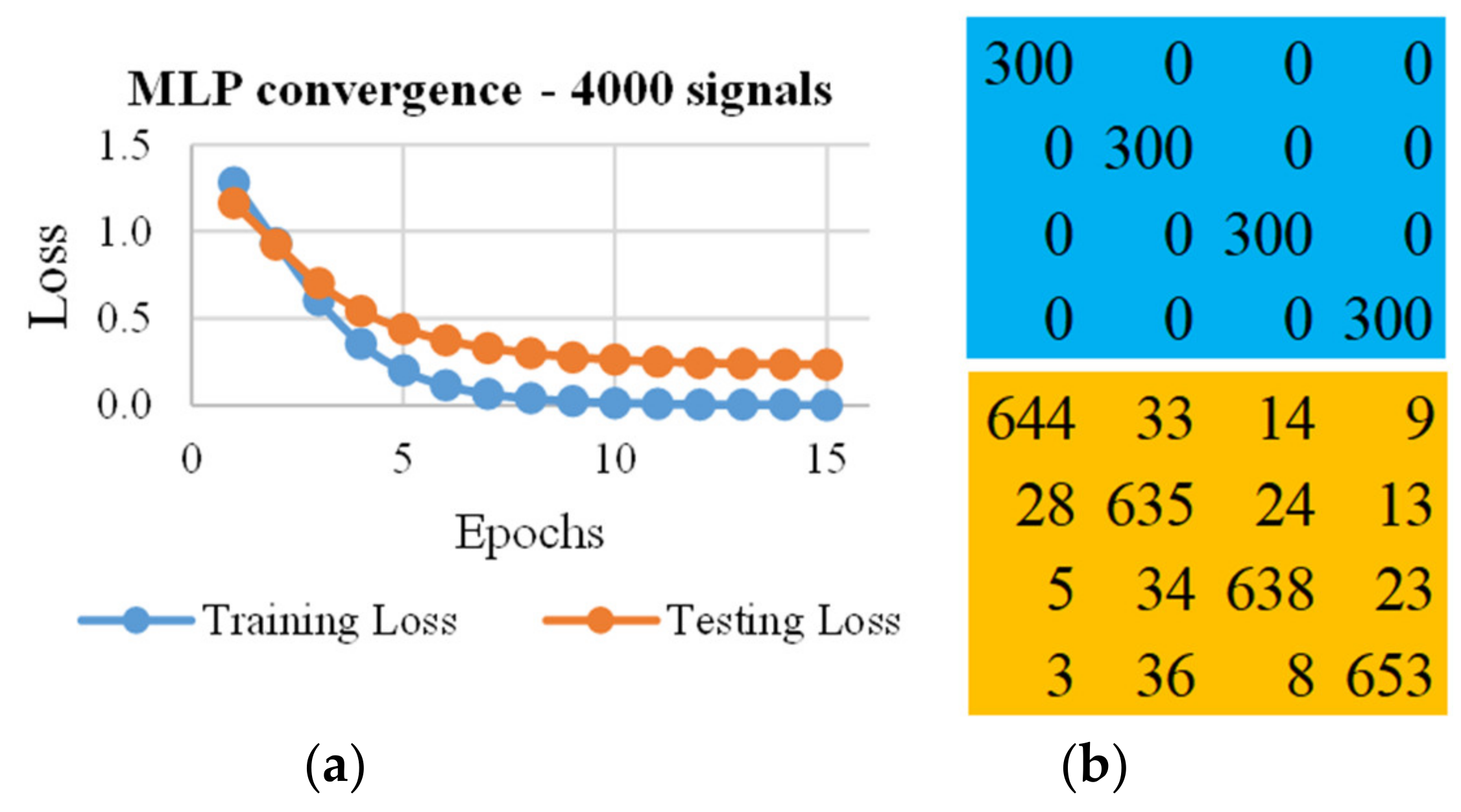
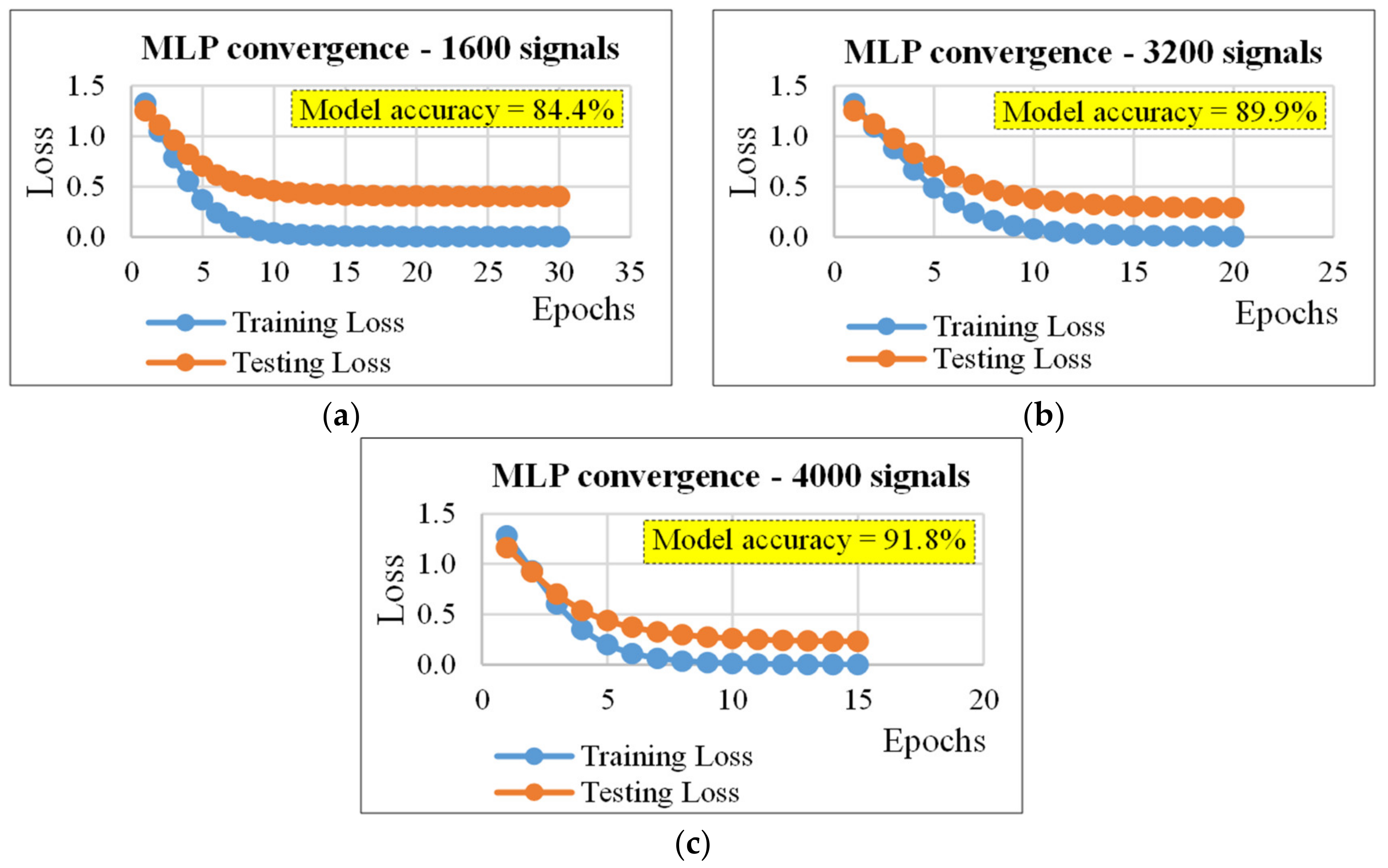
4.1. Multilayer Perceptron
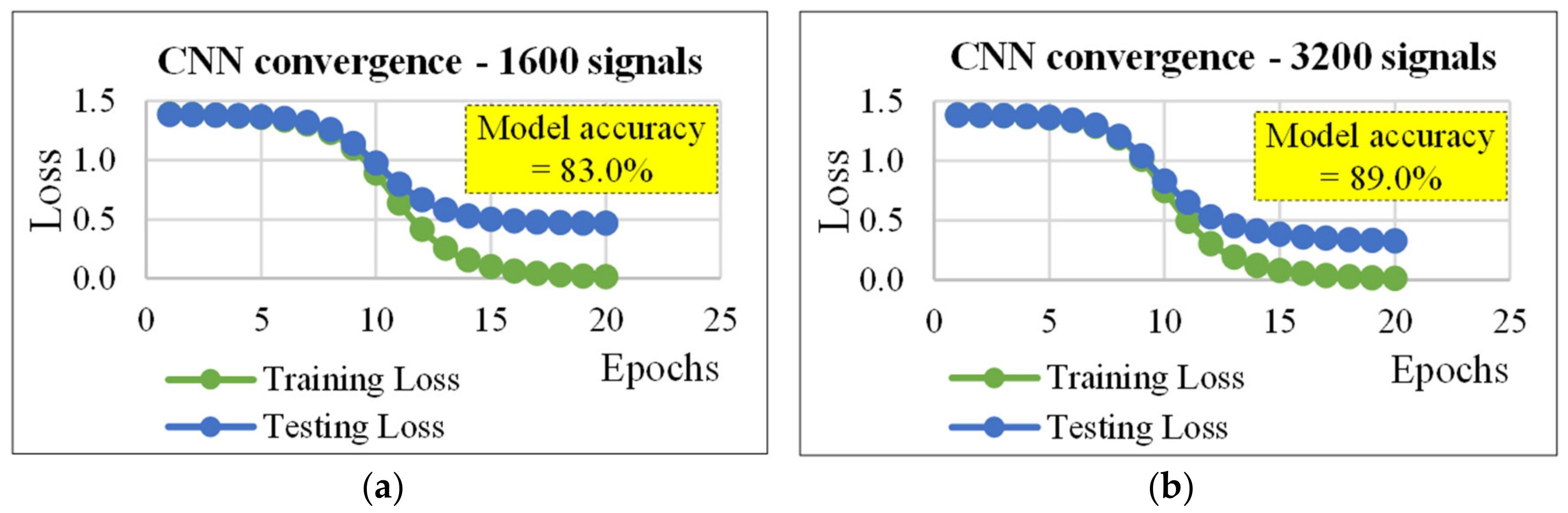
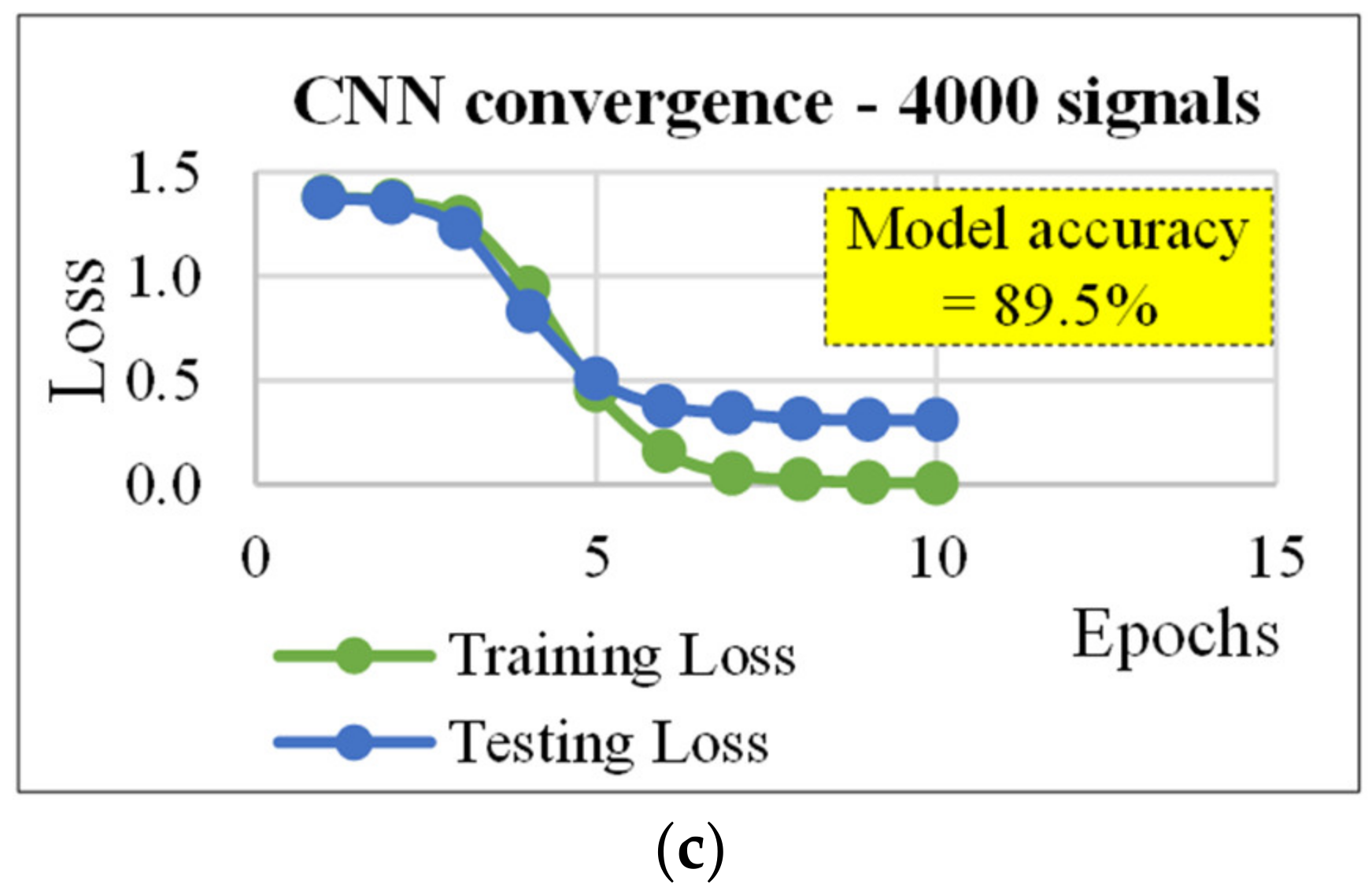
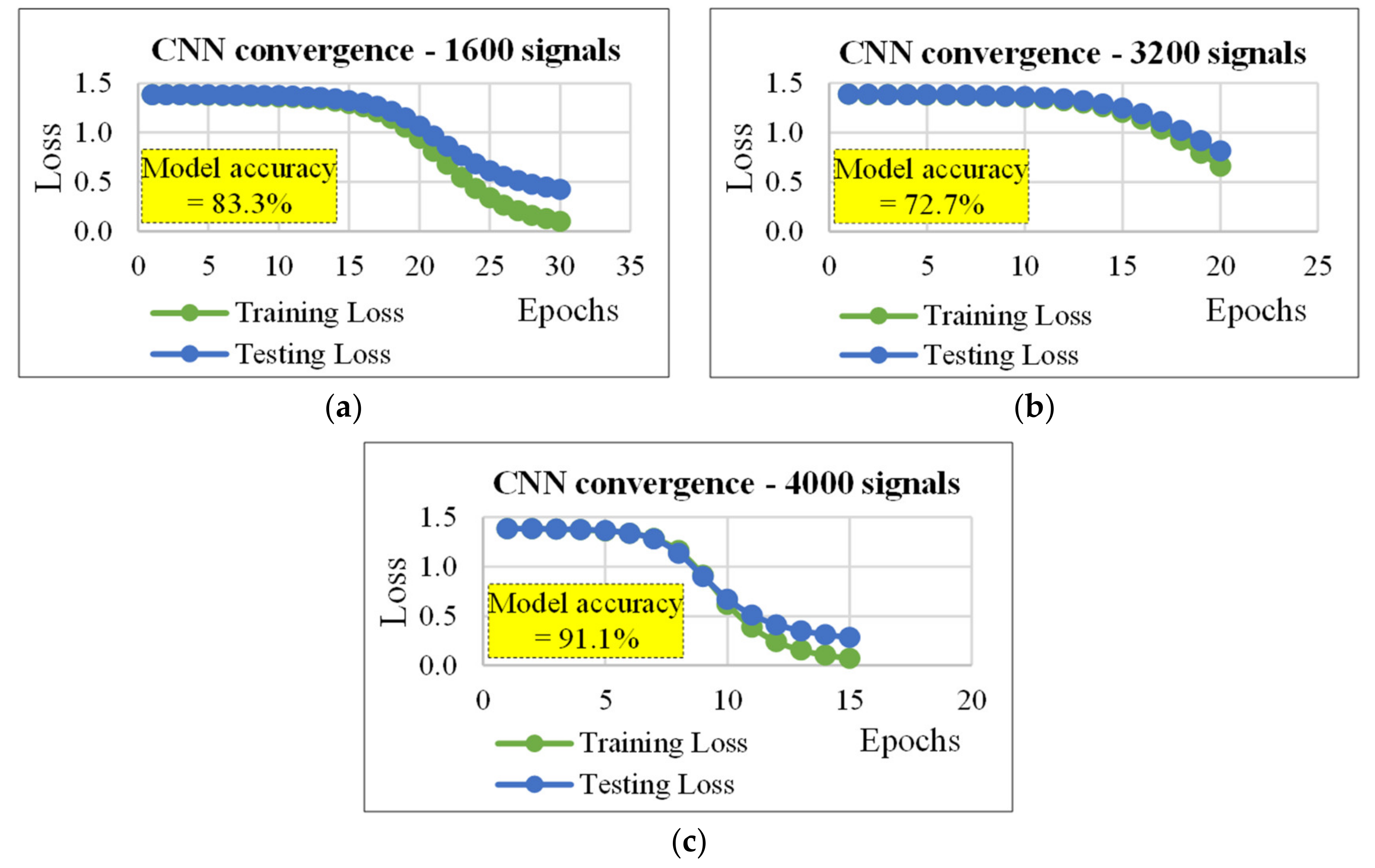
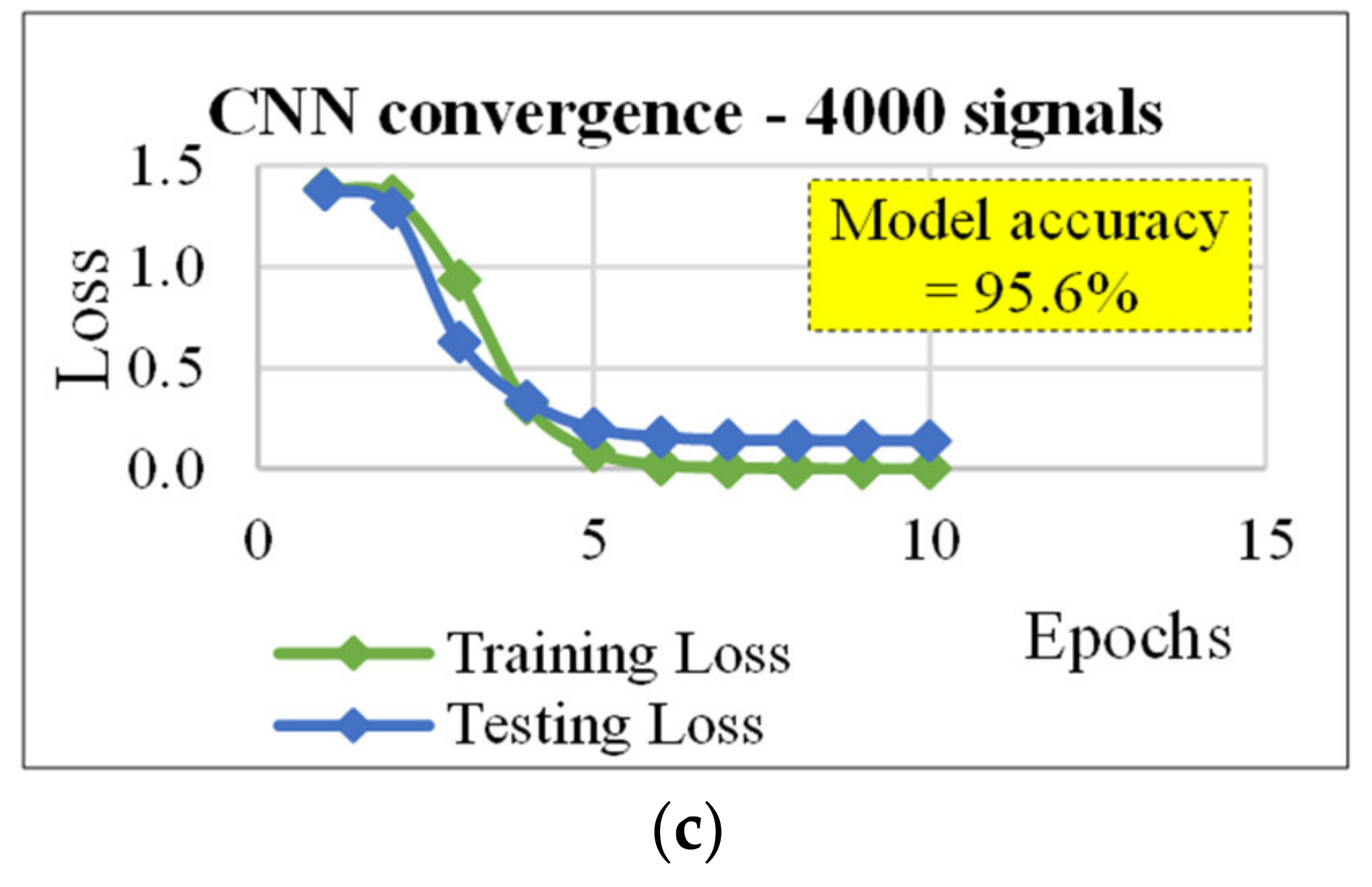
4.2. CNN for Classification
4.3. Random Forest Classifier
4.4. Support Vector Classifier
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Moghaddam, T.B.; Karim, M.R.; Abdelaziz, M. A review on fatigue and rutting performance of asphalt mixes. Sci. Res. Essays 2011, 6, 670–682. [Google Scholar]
- Gedafa, D.S. Performance Prediction and Maintenance of Flexible Pavement. In Proceedings of the 2007 Mid-Continent Transportation Research Symposium, Ames, IA, USA, 16 August 2007; pp. 16–17. [Google Scholar]
- Lekei, E.E.; Ngowi, A.V.; London, L. Undereporting of Acute Pesticide Poisoning in Tanzania: Modelling Results from Two Cross-Sectional Studies. Environ. Health 2016, 15, 18. [Google Scholar] [CrossRef]
- Celauro, C.; Praticò, F.G. Asphalt mixtures modified with basalt fibres for surface courses. Constr. Build. Mater. 2018, 170, 245–253. [Google Scholar] [CrossRef]
- Pop, M.-D.; Proștean, O. A comparison between smart city approaches in road traffic management. Procedia Soc. Behav. Sci. 2018, 238, 29–36. [Google Scholar] [CrossRef]
- The European Parliament and the Council of the European Union. Directive 2010/40/EU of the European Parliament and of the Council of 7 July 2010 on the framework for the deployment of Intelligent Transport Systems in the field of road transport and for interfaces with other modes of transport (Text with EEA relevance). 2010. Available online: https://www.cita.lu/uploads/its/Directive_2010-40-EU_EN.pdf (accessed on 20 January 2020).
- Praticò, F.G.; Moro, A.; Ammendola, R. Potential of fire extinguisher powder as a filler in bituminous mixes. J. Hazard. Mater. 2010, 173, 605–613. [Google Scholar] [CrossRef] [PubMed]
- Praticò, F.G.; Vaiana, R.; Gallelli, V. Transport and Traffic Management by Micro Simulation Models: Operational Use and Performance of Roundabouts; WIT Transactions on the Built Environment: Southampton, UK, 2012; Volume 128, pp. 383–394. [Google Scholar]
- Cafiso, S.; D’Agostino, C.; Delfino, E.; Montella, A. From manual to automatic pavement distress detection and classification. In Proceedings of the 5th IEEE International Conference on Models and Technologies for Intelligent Transportation Systems (MT-ITS), Naples, Italy, 26–28 June 2017; pp. 433–438. [Google Scholar]
- Schnebele, E.; Tanyu, B.F.; Cervone, G.; Waters, N. Review of remote sensing methodologies for pavement management and assessment. Eur. Transp. Res. Rev. 2015, 7, 1–19. [Google Scholar] [CrossRef]
- Benedetto, A.; Tosti, F.; Bianchini Ciampoli, L.; D’Amico, F. An overview of ground-penetrating radar signal processing techniques for road inspections. Signal Process. 2017, 132, 201–209. [Google Scholar] [CrossRef]
- Katicha, S.W.; Flintsch, G.; Bryce, J.; Ferne, B. Wavelet denoising of TSD deflection slope measurements for improved pavement structural evaluation. Comput. Civ. Infrastruct. Eng. 2014, 29, 399–415. [Google Scholar] [CrossRef]
- Carlos, M.R.; Aragon, M.E.; Gonzalez, L.C.; Escalante, H.J.; Martinez, F. Evaluation of detection approaches for road anomalies based on accelerometer readings - Addressing who’s who. IEEE Trans. Intell. Transp. Syst. 2018, 19, 3334–3343. [Google Scholar] [CrossRef]
- Praticó, F.G.; Moro, A.; Ammendola, R. Factors affecting variance and bias of non-nuclear density gauges for porous european mixes and dense-graded friction courses. Balt. J. Road Bridg. Eng. 2009, 4, 99–107. [Google Scholar] [CrossRef]
- Praticò, F.G.; Vaiana, R. A study on the relationship between mean texture depth and mean profile depth of asphalt pavements. Constr. Build. Mater. 2015, 101, 72–79. [Google Scholar] [CrossRef]
- Licitra, G.; Teti, L.; Cerchiai, M. A modified Close Proximity method to evaluate the time trends of road pavements acoustical performances. Appl. Acoust. 2014, 76, 169–179. [Google Scholar] [CrossRef]
- Morgan, P.A.; Watts, G.R. A novel approach to the acoustic characterisation of porous road surfaces. Appl. Acoust. 2003, 64, 1171–1186. [Google Scholar] [CrossRef]
- Lak, M.A.; Degrande, G.; Lombaert, G. The effect of road unevenness on the dynamic vehicle response and ground-borne vibrations due to road traffic. Soil Dyn. Earthq. Eng. 2011, 31, 1357–1377. [Google Scholar] [CrossRef]
- Ouma, Y.O.; Hahn, M. Pothole detection on asphalt pavements from 2D-colour pothole images using fuzzy c-means clustering and morphological reconstruction. Autom. Constr. 2017, 83, 196–211. [Google Scholar] [CrossRef]
- Barbosa, R.S. Vehicle dynamic response due to pavement roughness. J. Braz. Soc. Mech. Sci. Eng. 2011, 33, 302–307. [Google Scholar] [CrossRef]
- Zhang, Y.; McDaniel, J.G.; Wang, M.L. Estimation of pavement macrotexture by principal component analysis of acoustic measurements. J. Transp. Eng. 2014, 140, 1–11. [Google Scholar] [CrossRef]
- Zelelew, H.M.; Papagiannakis, A.T.; De León Izeppi, E.D. Pavement macro-texture analysis using wavelets. Int. J. Pavement Eng. 2013, 14, 725–735. [Google Scholar] [CrossRef]
- Subirats, P.; Dumoulin, J.; Legeay, V.; Barba, D. Automation of pavement surface crack detection using the continuous wavelet transform. In Proceedings of the International Conference on Image Processing, Atlanta, GA, USA, 8–11 October 2006; pp. 3037–3040. [Google Scholar]
- Ouma, Y.O.; Hahn, M. Wavelet-morphology based detection of incipient linear cracks in asphalt pavements from RGB camera imagery and classification using circular Radon transform. Adv. Eng. Inform. 2016, 30, 481–499. [Google Scholar] [CrossRef]
- Zalama, E.; Gómez-García-Bermejo, J.; Medina, R.; Llamas, J. Road crack detection using visual features extracted by gabor filters. Comput. Civ. Infrastruct. Eng. 2014, 29, 342–358. [Google Scholar] [CrossRef]
- Hassan, N.; Mathavan, S.; Kamal, K. Road crack detection using the particle filter. In Proceedings of the 23rd IEEE International Conference on Automation and Computing (ICAC), Huddersfield, UK, 7–8 September 2017. [Google Scholar]
- Sitara, S.N. Review and analysis of crack detection and classification techniques based on crack types. Int. J. Appl. Eng. Res. 2018, 13, 6056–6062. [Google Scholar]
- Moussa, G.; Hussain, K. A new technique for automatic detection and parameters estimation of pavement crack. In Proceedings of the 4th International Multi-Conference on Engineering and Technological Innovation, Orlando, FL, USA, 19 July 2011; Volume 2, pp. 11–16. [Google Scholar]
- Sun, D.; Zhang, K.; Shen, S. Analyzing spatiotemporal traffic line source emissions based on massive didi online car-hailing service data. Transp. Res. Part D Transp. Environ. 2018, 62, 699–714. [Google Scholar] [CrossRef]
- Zhang, K.; Sun, D.J.; Shen, S.; Zhu, Y. Analyzing spatiotemporal congestion pattern on urban roads based on taxi GPS data. J. Transp. Land Use 2017, 10, 675–694. [Google Scholar] [CrossRef]
- Tong, Z.; Gao, J.; Zhang, H. Recognition, location, measurement, and 3D reconstruction of concealed cracks using convolutional neural networks. Constr. Build. Mater. 2017, 146, 775–787. [Google Scholar] [CrossRef]
- El-Basyouny, M.; Jeong, M.G. Prediction of the MEPDG asphalt concrete permanent deformation using closed form solution. Int. J. Pavement Res. Technol. 2014, 7, 397–404. [Google Scholar]
- Moghadas Nejad, F.; Zakeri, H. An expert system based on wavelet transform and radon neural network for pavement distress classification. Expert Syst. Appl. 2011, 38, 7088–7101. [Google Scholar] [CrossRef]
- Shi, A.; Yu, X.H. Structural damage detection using artificial neural networks and wavelet transform. In Proceedings of the IEEE International Conference on Computational Intelligence for Measurement Systems and Applications (CIMSA), Tianjin, China, 2–4 July 2012; pp. 7–11. [Google Scholar]
- Gajewski, J.; Sadowski, T. Sensitivity analysis of crack propagation in pavement bituminous layered structures using a hybrid system integrating Artificial Neural Networks and Finite Element Method. Comput. Mater. Sci. 2014, 82, 114–117. [Google Scholar] [CrossRef]
- Wang, X.; Hu, Z. Grid-based pavement crack analysis using deep learning. In Proceedings of the 4th International Conference on Transportation Information and Safety (ICTIS), Banff, AB, Canada, 8–10 August 2017; pp. 917–924. [Google Scholar]
- Mokhtari, S.; Wu, L.; Yun, H.B. Comparison of supervised classifcation techniques for vision-based pavement crack detection. Transp. Res. Rec. 2016, 2595, 119–127. [Google Scholar] [CrossRef]
- Majidifard, H.; Jahangiri, B.; Buttlar, W.G.; Alavi, A.H. New machine learning-based prediction models for fracture energy of asphalt mixtures. Meas. J. Int. Meas. Confed. 2019, 135, 438–451. [Google Scholar] [CrossRef]
- Fedele, R.; Praticò, F.G.; Carotenuto, R.; Della Corte, F.G. Energy savings in transportation: Setting up an innovative SHM method. Math. Model. Eng. Probl. 2018, 5, 323–330. [Google Scholar] [CrossRef]
- Fedele, R.; Praticò, F.G.; Carotenuto, R.; Della Corte, F.G. Damage detection into road pavements through acoustic signature analysis: First results. In Proceedings of the 24th International Congress on Sound and Vibration (ICSV), London, UK, 23–27 July 2017. [Google Scholar]
- Fedele, R.; Della Corte, F.G.; Carotenuto, R.; Praticò, F.G. Sensing road pavement health status through acoustic signals analysis. In Proceedings of the 13th Conference on PhD Research in Microelectronics and Electronics (PRIME), Giardini Naxos, Italy, 12–15 June 2017; pp. 165–168. [Google Scholar]
- Nguyen, S.T.; To, Q.D.; Vu, M.N. Extended analytical solutions for effective elastic moduli of cracked porous media. J. Appl. Geophys. 2017, 140, 34–41. [Google Scholar] [CrossRef]
- Kim, D.S.; Lee, J.S. Propagation and attenuation characteristics of various ground vibrations. Soil Dyn. Earthq. Eng. 2000, 19, 115–126. [Google Scholar] [CrossRef]
- Fedele, R.; Praticò, F.G. Monitoring infrastructure asset through its acoustic signature. In Proceedings of the INTER-NOISE and NOISE-CON Congress and Conference Proceedings, Madrid, Spain, 30 September 2019. [Google Scholar]
- Fedele, R.; Praticò, F.G.; Pellicano, G. The prediction of road cracks through acoustic signature: Extended finite element modeling and experiments. J. Test. Eval. 2021, 49, 2230–2237. [Google Scholar] [CrossRef]
- Google Brain Tensorflow. Available online: https://www.tensorflow.org/tutorials/ (accessed on 20 January 2020).
- Cournapeau, D. Scikit-Learn. Available online: https://scikit-learn.org/stable/ (accessed on 20 January 2020).
- Jain, A.K.; Mao, J.; Mohiuddin, K.M. Artificial neural networks: A tutorial. Computer 1996, 29, 31–44. [Google Scholar] [CrossRef]
- Basheer, I.A.; Hajmeer, M. Artificial neural networks: Fundamentals, computing, design, and application. J. Microbiol. Methods 2000, 43, 3–31. [Google Scholar] [CrossRef]
- Praticò, F.G. On the dependence of acoustic performance on pavement characteristics. Transp. Res. Part D Transp. Environ. 2014, 29, 79–87. [Google Scholar] [CrossRef]
- Fedele, R.; Merenda, M.; Praticò, F.G.; Carotenuto, R.; Della Corte, F.G. Energy harvesting for IoT road monitoring systems. Instr. Mes. Metr. 2018, 17, 605–623. [Google Scholar] [CrossRef]
- Merenda, M.; Praticò, F.G.; Fedele, R.; Carotenuto, R.; Della Corte, F.G. A real-time decision platform for the management of structures and infrastructures. Electronics 2019, 8, 1–22. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| D a | Variables of the Network | ||||
|---|---|---|---|---|---|
| Best Data Set Partition b | # of Nodes c | # of Epochs/Learning Rate | Batch Size (Signals) | Model Accuracy (%) | |
| 40 | n.a. d | n.a. | n.a. | n.a. | l.c. d |
| 400 | n.a. | n.a. | n.a. | n.a. | l.c. |
| 800 | n.a. | n.a. | n.a. | n.a. | l.c. |
| 1600 | 60/40 | 2000/2000 | 30/0.098 | 16 | 84.4 |
| 3200 | 40/60 | 700/700 | 20/0.098 | 16 | 89.9 |
| 4000 | 30/70 | 350/350 | 15/0.224 | 16 | 91.8 |
- a Data set size, i.e., the number of signals used to feed the network.
- b Percentage of signals used as training and testing samples (e.g., 60/40 = 60% for training and 40% for testing).
- c Number of nodes used for each hidden layers (e.g., 50/50 = 50 nodes for the hidden layer #1, and 50 nodes for the hidden layer #2).
- d n.a. = not available because of lack of convergence; l.c. = lack of convergence of the testing with the training phase.
| D a | Variables of the Network | |||||
|---|---|---|---|---|---|---|
| Best Dataset Partition b | # of Nodes c | # of Epochs/Learning Rate | # of Filters/Kernel/Stride d | Pool Size/ Pool Stride e | Model Accuracy (%) | |
| 40 | n.a. f | n.a. | n.a. | n.a. | n.a. | l.c. f |
| 400 | n.a. | n.a. | n.a. | n.a. | n.a. | l.c. |
| 800 | n.a. | n.a. | n.a. | n.a. | n.a. | l.c. |
| 1600 | 50/50 | 1000/1000 | 20/0.224 | 10/30/5 | 10/5 | 83.0 |
| 3200 | 30/70 | 700/700 | 20/0.224 | 10/30/5 | 10/5 | 89.0 |
| 4000 | 20/80 | 500/500 | 10/0.61 | 10/30/5 | 10/5 | 89.5 |
- a Data set size, i.e., the number of signals used to feed the network.
- b Percentage of signals used as training and testing samples (e.g., 60/40 = 60% for training and 40% for testing).
- c Number of nodes used for each hidden layers (e.g., 50/50 = 50 nodes for the hidden layer #1, and 50 nodes for the hidden layer #2).
- d # of filters = number of filters used in the convolution layer; kernel = length of the convolution window;stride = stride length of the convolution.e pool size = size of the window that makes the pooling; pool stride = stride of the pooling window
- f n.a. = not available because of lack of convergence; l.c. = lack of convergence of the testing with the training phase.
| D a | Variables of the Network | |||||
|---|---|---|---|---|---|---|
| Best Dataset Partition b | # of Nodes c | # of Epochs/Learning Rate | # of Filters/Kernel/Stride d | Pool Size/Pool Stride e | Model Accuracy (%) | |
| MLP | ||||||
| 1600 | 60/40 | 2000/2000 | 30/0.098 | n.a. f | n.a. | 84.4 |
| 3200 | 40/60 | 700/700 | 20/0.098 | n.a. | n.a. | 89.9 |
| 4000 | 30/70 | 350/350 | 15/0.224 | n.a. | n.a. | 91.8 |
| CNN (with same convolutional and pooling layers of Table 2) | ||||||
| 1600 | 60/40 | 2000/2000 | 30/0.098 | 10/30/5 | 10/5 | 83.3 |
| 3200 | 40/60 | 700/700 | 20/0.098 | 10/30/5 | 10/5 | 72.7 |
| 4000 | 30/70 | 350/350 | 15/0.224 | 10/30/5 | 10/5 | 91.1 |
| CNN (number of optimization filters) | ||||||
| 1600 | 60/40 | 2000/2000 | 30/0.098 | 100/30/5 | 10/5 | 87.2 |
| 3200 | 40/60 | 700/700 | 20/0.098 | 100/30/5 | 10/5 | 90.5 |
| 4000 | 30/70 | 350/350 | 15/0.224 | 150/30/5 | 10/5 | 95.6 |
- a Data set size, i.e., the number of signals used to feed the network.
- b Percentage of signals used as training and testing samples (e.g., 60/40 = 60% for training and 40% for testing).
- c Number of nodes used for each hidden layers (e.g., 50/50 = 50 nodes for the hidden layer #1, and 50 nodes for the hidden layer #2).
- d # of filters = number of filters used in the convolution layer; kernel = length of the convolution window;stride = stride length of the convolution.
- e pool size = size of the window that makes the pooling; pool stride = stride of the pooling windowf n.a. = not available, because is not required by the MLP.
| Dataset Size | Parameters of the Classifier | ||
|---|---|---|---|
| Best Dataset Partition | # of Estimators | Model Accuracy (%) | |
| 40 | 60/40 | 100 | 31.3 |
| 400 | 60/40 | 100 | 41.3 |
| 800 | 80/20 | 100 | 58.1 |
| 1600 | 80/20 | 100 | 73.8 |
| 3200 | 80/20 | 100 | 90.3 |
| 4000 | 80/20 | 100 | 91.0 |
| Dataset Size | Parameters of the Classifier | |||
|---|---|---|---|---|
| Best Dataset Partition | Kernel Coefficient | Penalty Parameter | Model Accuracy (%) | |
| 40 | 30/70 | 0.014 | 1.3 | 32.1 |
| 400 | 80/20 | 0.012 | 1.3 | 56.3 |
| 800 | 80/20 | 0.012 | 1.9 | 64.4 |
| 1600 | 80/20 | 0.012 | 1.7 | 87.5 |
| 3200 | 70/30 | 0.012 | 1.7 | 97.5 |
| 4000 | 80/20 | 0.012 | 1.7 | 99.1 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Praticò, F.G.; Fedele, R.; Naumov, V.; Sauer, T. Detection and Monitoring of Bottom-Up Cracks in Road Pavement Using a Machine-Learning Approach. Algorithms 2020, 13, 81. https://doi.org/10.3390/a13040081
Praticò FG, Fedele R, Naumov V, Sauer T. Detection and Monitoring of Bottom-Up Cracks in Road Pavement Using a Machine-Learning Approach. Algorithms. 2020; 13(4):81. https://doi.org/10.3390/a13040081
Chicago/Turabian StylePraticò, Filippo Giammaria, Rosario Fedele, Vitalii Naumov, and Tomas Sauer. 2020. "Detection and Monitoring of Bottom-Up Cracks in Road Pavement Using a Machine-Learning Approach" Algorithms 13, no. 4: 81. https://doi.org/10.3390/a13040081
APA StylePraticò, F. G., Fedele, R., Naumov, V., & Sauer, T. (2020). Detection and Monitoring of Bottom-Up Cracks in Road Pavement Using a Machine-Learning Approach. Algorithms, 13(4), 81. https://doi.org/10.3390/a13040081