Predicting Intentions of Pedestrians from 2D Skeletal Pose Sequences with a Representation-Focused Multi-Branch Deep Learning Network

 ,
, 
Abstract
1. Introduction
2. Related Work
2.1. Skeleton-Based Human Action Recognition
- The ones that make use of recurrent cells;
- The ones that make use of convolutional cells;
- The ones that make use of an attention mechanism;
- The ones that do not focus on Euclidean data structure but a graph data structure.
2.1.1. Recurrent Neural Networks (RNN)
2.1.2. Convolutional Neural Network (CNN)
2.1.3. Attention Mechanisms
2.1.4. Geometric Deep-Learning
2.2. Pedestrian Intention Prediction
3. Materials and Methods
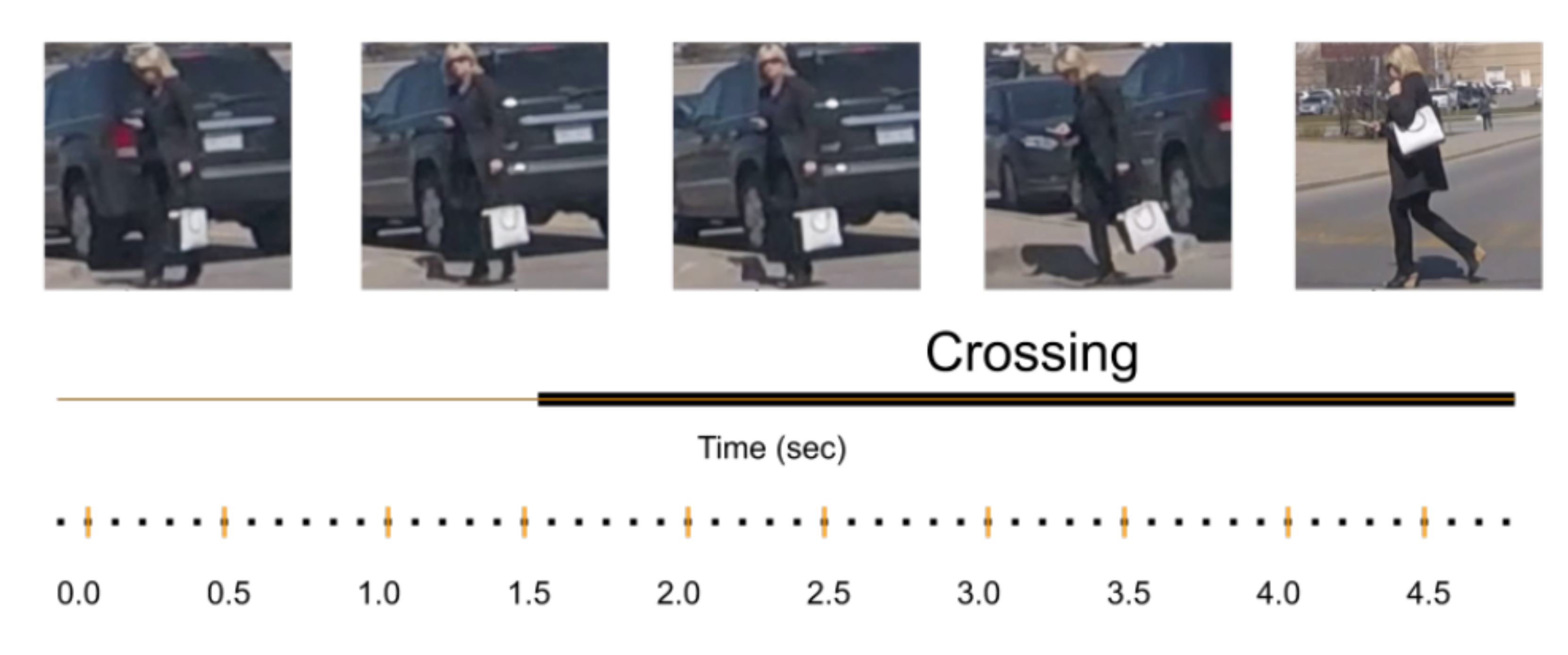
3.1. Experimental Data Set
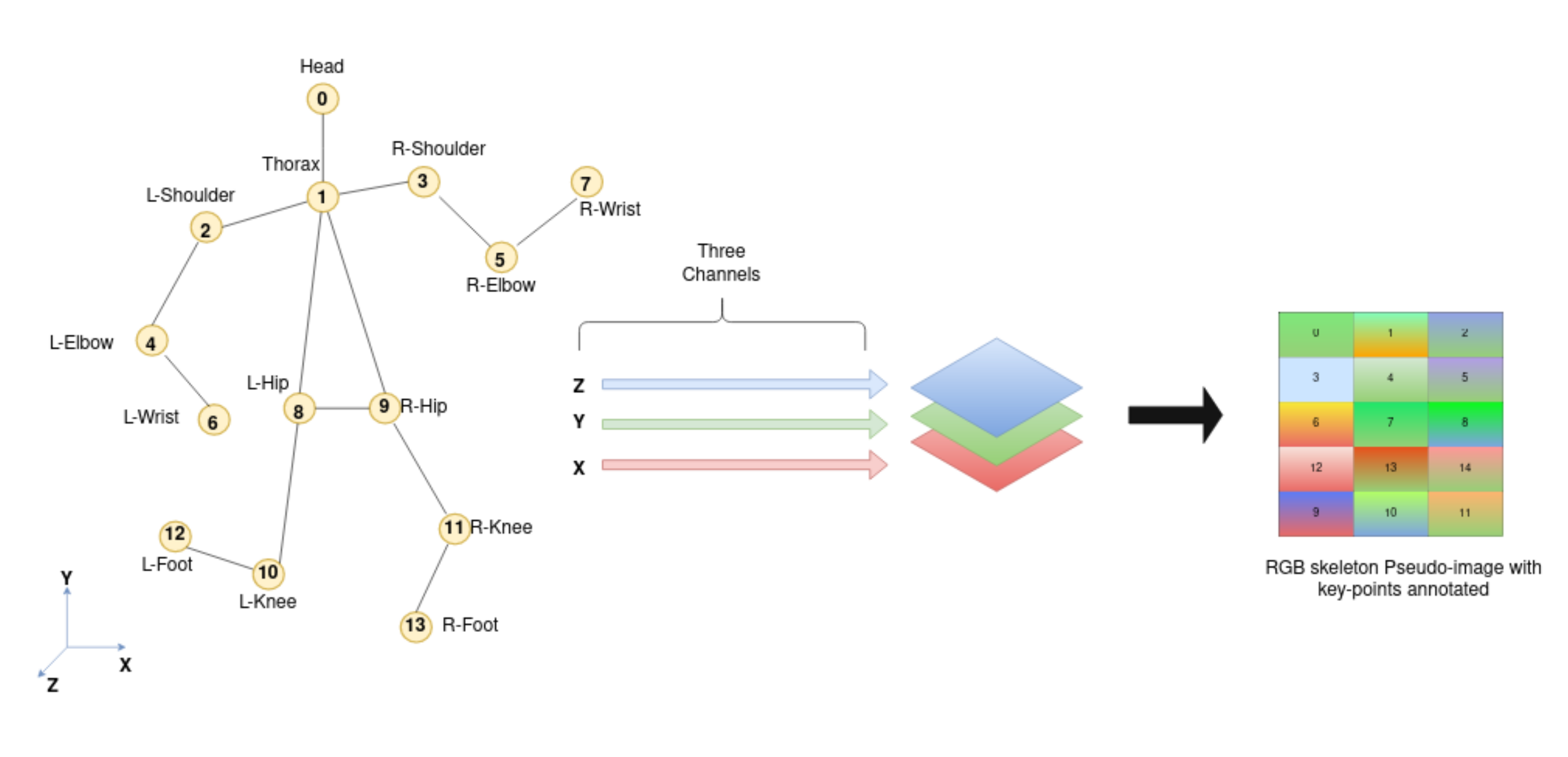
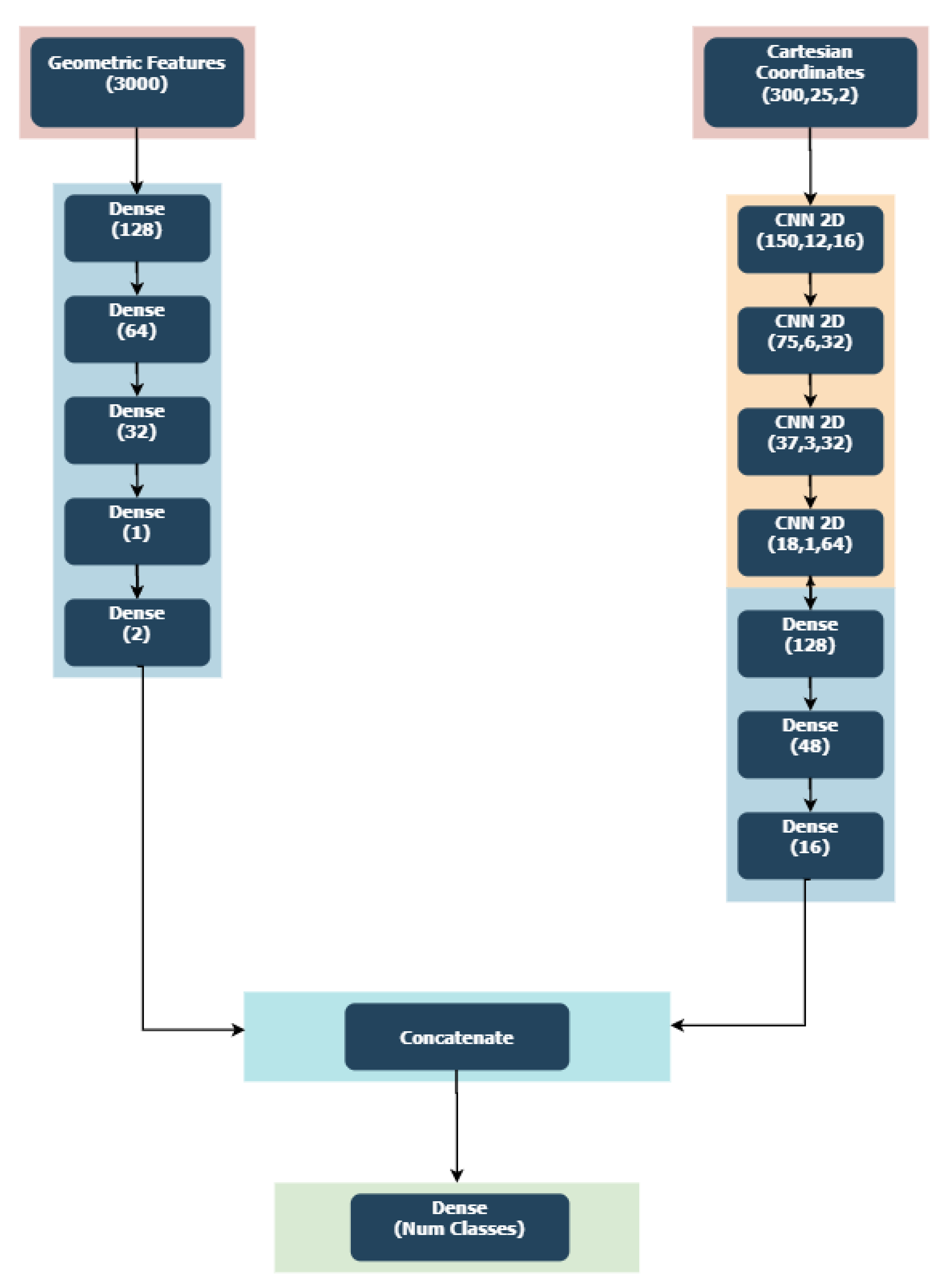
3.2. SPI-Net Architecture
3.2.1. Geometric Features Branch
- The inherent structure of the data captured in an unsupervised manner thanks to the reconstruction of the auto-encoder and its abstraction ability. Some of the important and discriminating information in the data set would then be retained.
- The separability of classes thanks to Linear Discriminant Analysis projection of the instances in the latent space.
| Algorithm 1: Auto-encoder with statistical separability constraint training algorithm |
 |
3.2.2. Cartesian Coordinates Features Branch
4. Results
4.1. Evaluation Setup
4.2. Implementation Details
- Training the Geometric features branch:
- -
- Training the auto-encoder with a separability constraint term: We use a standard feed-forward non-recurrent MLP, the dimensions of which are . We use a value of fixed for the LDA constraint term ponderation in the modified reconstruction cost function. To address the vanishing gradient problem, each perceptron in the given auto-encoder network uses the LeakyRelu [77] activation function. For regularization purposes, we use Dropout [78] (), regularization with and batch normalization [79] after each layer. We choose Adam () [80] as the optimizer, with an annealing learning rate that drops from to . In order to obtain a good separability in the latent space with the LDA separability constraint, we choose to send all the training examples at once for the auto-encoder training and select a batch size of 240.
- -
- Training the Encoder part for classification: we recover the encoder part of the auto-encoder, then train a classifier with weights initialized via the auto-encoder. We use the same values of the Adam optimizer for training. We, however, divide the training set into 30 batches of size 8. We use ReduceLROnPlateau with a factor of 0.2 and patience of 10.
- Training the Cartesian features branch: The Cartesian features branch is composed of four 2D-convolution blocks composed of 2D-convolution layers (kernel size × 3). Similarly to the auto-encoder, we use the LeakyRelu activation function, regularization with and a Dropout value of 0.5. Each convolution layer is then followed by a Batch Normalization layer and an Average Pooling layer. The fully connected layers following the spatio-temporal features extraction done by convolutions is then completely similar to any other Dense layer of the Geometric feature branch for hyper-parameters tuning. We choose Adam () with a learning rate that drops from to and ReduceLROnPlateau with a factor of 0.5, patience of 5, cooldown of 5 and a batch size of 8.
- Concatenating the branches: We then remove the classification layer of each branch and concatenate those two networks deprived of their last layer into a single one. It allows us to keep the previously learned weights of each network independently. We then add a classification layer in which the weights are initialized randomly after the concatenated layer of the obtained network. Finally, we fine-tune the entire network, from pre-trained weights to the randomly initialized classification layer. We get our presented SPI-Net: a late fusion and fine-tuned version of the Geometric and Cartesian features branches. As proposed in [81], we increase the batch size over time during the training and therefore fine-tune the approach with two different trainings on the same SPI-network with two different batch sizes. For the first training, we use Adam with a learning rate that drops from to , ReduceLROnPlateau with a factor of 0.5, patience of 25 and a batch size of 8. For the second one, we use Adam with a learning rate that drops from to and ReduceLROnPlateau with a factor of 0.5, patience of 25 and a batch size of 240.
4.3. Results on JAAD Data Set
5. Discussion and Future Works
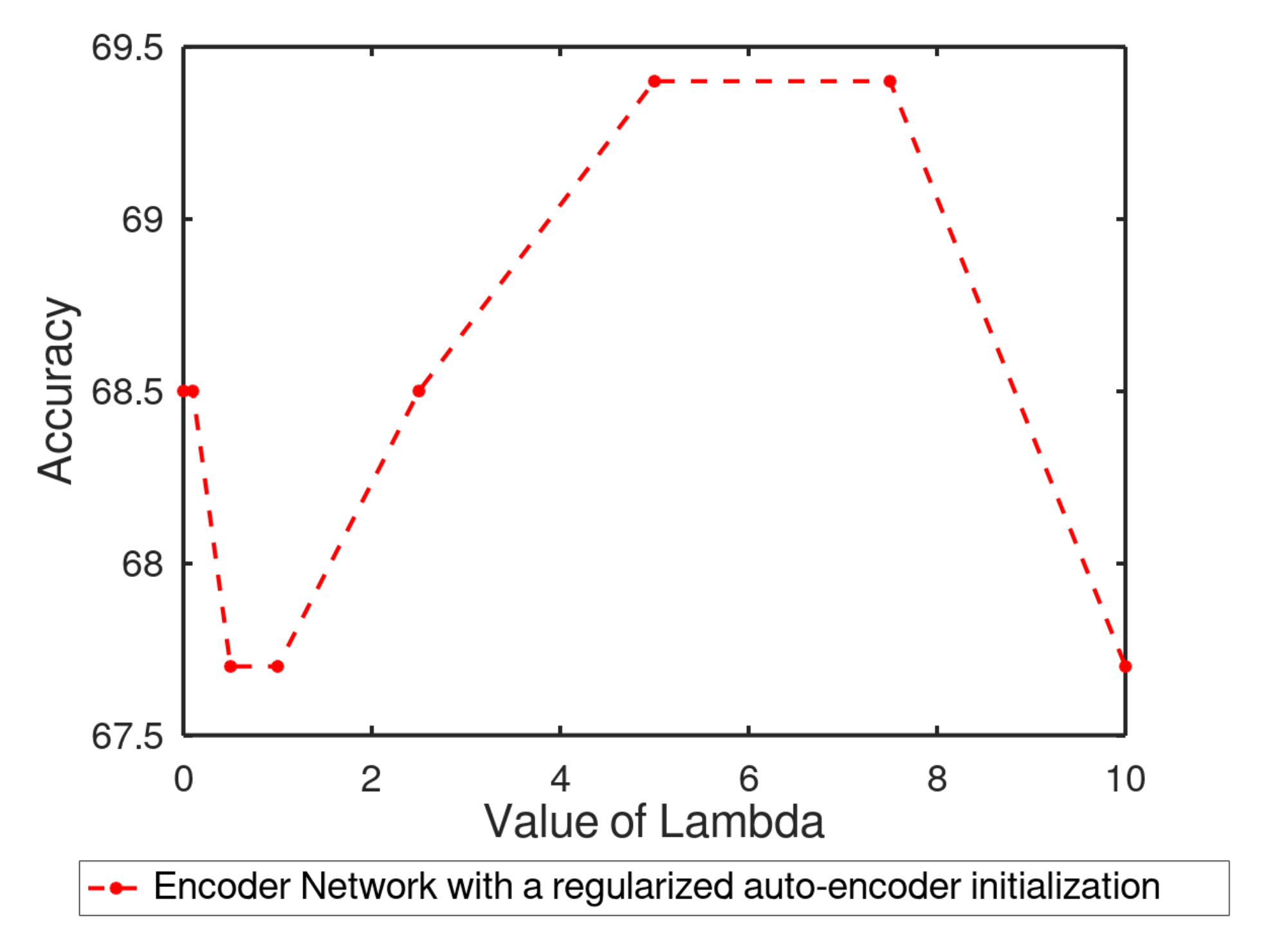
- Ablation studies: From Table 1, we figure that solely using the Geometric features branch alone cannot produce a satisfactory performance for the C/NC task: since most of the prior to crossing actions are strongly correlated to global spatial motion of the pedestrian in the scene, the usage of only relative Euclidean distances between key-points is missing necessary information such as spatial dynamics or sequential modeling. However, the Geometric features branch still seems to capture some information only relative to the orientation and dynamics of the skeleton in the data without explicit temporal modeling or global spatial information. For this study, it was of interest to investigate if using the data projected into the latent space provided more information compared to the initial Geometric features input without fine-tuning the entire approach and updating the weights of the network. Table 1 shows that, by using the same binary classifier on the projected data in the bottleneck obtained from a classical auto-encoder, a simple LDA finds slightly more meaning in the data than the initial Geometric features input. Moreover, the latent space representation obtained by our regularized auto-encoder seems to be a little bit more informative than a regular auto-encoder latent space representation. In Figure 8, we evaluate the correspondence between the value of for the supervised separability constraint part and prediction accuracy. Afterward, we evaluate the necessity of using a pre-trained encoder network for classification initialized with an auto-encoder training. By comparing the results from the same network with He’s weights initialization [64] prior to any auto-encoder training to the entire geometric branch approach, we show that using an auto-encoder to initialize the network’s weights helps to a certain extent the network’s accuracy. From Table 2, we can deduce that by taking into consideration both spatial and temporal features in the Cartesian coordinate system, we obtain better results than by only considering relative distances of given key-points of the pedestrian skeleton. We can also conclude that the usage of the Tree Structure Skeleton Image (TSSI) [76] normalization improves the results of the Cartesian branch for the C/NC task considerably. Such normalization is therefore relevant as it only changes the size of the image input and therefore does not change the network’s architecture much while becoming better for the task it was designed for. Finally, Table 3, shows that by merging and fine-tuning both Geometric and Cartesian features branches into a single network, we can achieve better results for the C/NC task than by considering each branch independently.
- Inference time: SPI-Net manages to preserve the information in a Euclidean grid space while keeping a coherent skeleton spatial structure and only uses 2D-convolutions and Dense layers in its architecture. It allows us to keep the advantages of convolutions in terms of parallel computing while capturing spatial and temporal features. Moreover, since SPI-Net only uses classic deep-learning operations, it could be easily implemented in any Deep Learning frameworks and also in any neural hardware solution like Intel Movidius©, or FPGA without redefining any operations. For this study, we implement it by Keras [84] backend in Tensorflow [85]. Therefore, the knowledge of the optimization of euclidean data structure networks proposed in both libraries is conserved compared to approaches based on Graph Networks where basic operations need to be redefined and one might lose speed efficiency in the process. Since our SPI-Net approach has only ∼0.57 M parameters, its speed can reach around one inference every 0.25 ms on one GPU (i.e., RTX 2080ti), or every 0.67 ms on one CPU (i.e., Intel Core i7 8700K), which is roughly 100 times faster than the current state-of-the-art Graph Convolutional Network [58] approach, the average speed of which takes 23 ms on two GPUs (i.e., two GTX 1080).Referring to human reaction times, visual skeletal representations are known to be sufficient for humans to describe and understand biological motion, specifically in the case of human motions [86] (i.e., walking, running). It comforts us in the idea of only working with skeleton-based models rather than image-based models. Thompson et al. [87] documented that the average reaction time to detect visual stimuli is approximately 180–200 ms: Kemp et al. [88] show that a visual stimulus takes around 20–40 ms to reach the brain, which leads to an average of 140–180 ms “inference time” for a human once the data reached the brain. SPI-Net relies on the Cascaded Pyramid Network (CPN) algorithm [14] to extract pose sequences before determining pedestrians’ intentions. Therefore, one could argue that the pose extraction feature should be compared to the time to reach the brain information and SPI-Net should be compared to the average “inference time” for a human once the data reached the brain. Since the CPN took approximately 60 ms per frame to extract pedestrian poses, the overall approach is roughly two to three times faster than the average human reaction time to a stimulus.
- Image sampling and pose estimation method: Necessary step of an intention prediction model of which the analysis of the posture is an essential component. One major drawback of our work is to rely on pose estimation algorithms. However, similarly to the OSI model, our approach relies on independent implementations of methods for specific tasks. It leads to a practical methodology: interchanging the pose estimation algorithms does not compromise the SPI-Net approach. Currently, one of the main limitations of a 2D pose estimation is the ability to deal with pedestrian occlusions in a two-dimensional space. Therefore, in order to improve the pose detection, the question of adding a third dimension may arise. Currently, the methods for estimating 3D poses are much less mature than those for 2D pose estimation. One of the main reasons, to this day, has been the lack of reliable data sets available [89]. However, our pipeline makes it easy to keep up with the state-of-the-art in this field without completely disrupting the SPI-Net approach for intention prediction. Compared to image-based approaches, if major advances are made in the computer vision field and more specifically for pose estimation, SPI-Net could still be relevant.
- Temporal tracking of pedestrians: In the real world, there are usually more pedestrians on the streets passing and occluding each other, which requires sophisticated mechanisms not only for their detection but for their temporal tracking without mixing their identity over time. In order to compare SPI-Net to the literature on JAAD, our current approach completely omits such issue and relies on the ground truth spatial coordinates and individual IDs of each pedestrian provided by the data set. To address a better follow-up of the protagonists in the scene and to avoid mixing the dynamics of two protagonists due to a change of camera angle, future research will focus on building an end-to-end framework based on unlabeled coordinates of pedestrians, temporal tracking of pedestrians and SPI-Net for intention prediction. Current research direction tends to evaluate the benefits of using a pose estimation model sequentially based on pose matching for tracking [90,91,92,93] compared to a frame by frame pose estimation model [14,94,95,96] combined with more naive identifications approaches [97,98] that are supposedly faster.
- Data set size: A recurrent barrier to using deep-learning is small data sets. Even though JAAD is one of the most complete data sets for pedestrians intents, the number of instances present in the data set is still undersized to use the generalization ability of neural networks to its finest. In the present work, we had to focus a lot on regularization techniques present in the literature to avoid over-fitting. It is, therefore, necessary to extend the total number of instances for such task. Our model is directly extensible to other input formats with different 2D or 3D skeletal data structures: the proposed approach can therefore be applied to a broader family of applications that discover the intentions of moving subjects. However, to use the generalization ability of neural networks to its finest on such small data sets, future research will focus on proposing a tool to enrich the existing databases on human skeletal dynamics by combining both Geometric features and Cartesian features in order to generate skeleton dynamics that are coherent both spatially and sequentially.
- Continuous intention prediction of pedestrians: SPI-Net showed that one could link the dynamics of a pedestrian to its discrete intention faster and better. Consequently, future research will focus on using SPI-Net to build a multi-modal architecture taking as input information such as skeleton, image semantic segmentation and qualitative information where discrete intention prediction could be used to infer the continuous trajectories describing the future movement of the pedestrian and therefore propose an intention prediction of pedestrians framework for both discrete and continuous intention prediction.
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Donahue, J.; Anne Hendricks, L.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2625–2634. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. arXiv 2014, arXiv:1412.0767. [Google Scholar]
- Varol, G.; Laptev, I.; Schmid, C. Long-term temporal convolutions for action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1510–1517. [Google Scholar] [CrossRef] [PubMed]
- Wu, C.Y.; Zaheer, M.; Hu, H.; Manmatha, R.; Smola, A.J.; Krähenbühl, P. Compressed Video Action Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. Advances in Neural Information Processing Systems, 2014; pp. 568–576. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.749.5720&rep=rep1&type=pdf (accessed on 9 December 2020).
- Zhang, B.; Wang, L.; Wang, Z.; Qiao, Y.; Wang, H. Real-time action recognition with enhanced motion vector CNNs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2718–2726. [Google Scholar]
- Sevilla-Lara, L.; Liao, Y.; Güney, F.; Jampani, V.; Geiger, A.; Black, M.J. On the integration of optical flow and action recognition. In Proceedings of the German Conference on Pattern Recognition, Stuttgart, Germany, 9–12 October 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 281–297. [Google Scholar]
- Pop, D.; Rogozan, A.; Chatelain, C.; Nashashibi, F.; Bensrhair, A. Multi-Task Deep Learning for Pedestrian Detection, Action Recognition and Time to Cross Prediction. IEEE Access 2019. [Google Scholar] [CrossRef]
- Vemulapalli, R.; Arrate, F.; Chellappa, R. Human action recognition by representing 3d skeletons as points in a lie group. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 588–595. [Google Scholar]
- Du, Y.; Wang, W.; Wang, L. Hierarchical recurrent neural network for skeleton based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1110–1118. [Google Scholar]
- Liu, J.; Shahroudy, A.; Xu, D.; Wang, G. Spatio-Temporal LSTM with Trust Gates for 3D Human Action Recognition. arXiv 2016, arXiv:1607.07043. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition. arXiv 2018, arXiv:1801.07455. [Google Scholar]
- Chen, Y.; Tian, Y.; He, M. Monocular Human Pose Estimation: A Survey of Deep Learning-based Methods. arXiv 2020, arXiv:2006.01423. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, Z.; Peng, Y.; Zhang, Z.; Yu, G.; Sun, J. Cascaded Pyramid Network for Multi-Person Pose Estimation. arXiv 2017, arXiv:1711.07319. [Google Scholar]
- Rasouli, A.; Kotseruba, I.; Tsotsos, J.K. Are they going to cross? In A benchmark dataset and baseline for pedestrian crosswalk behavior. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 206–213. [Google Scholar]
- Rasouli, A.; Kotseruba, I.; Tsotsos, J.K. Agreeing to cross: How drivers and pedestrians communicate. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Redondo Beach, CA, USA, 11–14 June 2017; pp. 264–269. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Baccouche, M.; Mamalet, F.; Wolf, C.; Garcia, C.; Baskurt, A. Sequential deep learning for human action recognition. In International Workshop on Human Behavior Understanding; Springer: Berlin/Heidelberg, Germany, 2011; pp. 29–39. [Google Scholar]
- Avola, D.; Bernardi, M.; Cinque, L.; Foresti, G.L.; Massaroni, C. Exploiting recurrent neural networks and leap motion controller for the recognition of sign language and semaphoric hand gestures. IEEE Trans. Multimed. 2018, 21, 234–245. [Google Scholar] [CrossRef]
- Zhang, S.; Liu, X.; Xiao, J. On geometric features for skeleton-based action recognition using multilayer lstm networks. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; IEEE: New York City, NY, USA, 2017; pp. 148–157. [Google Scholar]
- Shukla, P.; Biswas, K.K.; Kalra, P.K. Recurrent neural network based action recognition from 3D skeleton data. In Proceedings of the 2017 13th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS), Jaipur, India, 4–7 December 2017; IEEE: New York City, NY, USA, 2017; pp. 339–345. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. Ntu rgb+ d: A large scale dataset for 3d human activity analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1010–1019. [Google Scholar]
- Zhang, P.; Lan, C.; Xing, J.; Zeng, W.; Xue, J.; Zheng, N. View adaptive recurrent neural networks for high performance human action recognition from skeleton data. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2117–2126. [Google Scholar]
- Elias, P.; Sedmidubsky, J.; Zezula, P. Motion Images: An Effective Representation of Motion Capture Data for Similarity Search. In Similarity Search and Applications; Amato, G., Connor, R., Falchi, F., Gennaro, C., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 250–255. [Google Scholar]
- Sedmidubsky, J.; Elias, P.; Zezula, P. Effective and Efficient Similarity Searching in Motion Capture Data. Multimed. Tools Appl. 2018, 77, 12073–12094. [Google Scholar] [CrossRef]
- Ke, Q.; Bennamoun, M.; An, S.; Sohel, F.; Boussaid, F. A new representation of skeleton sequences for 3d action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3288–3297. [Google Scholar]
- Pham, H.H.; Khoudour, L.; Crouzil, A.; Zegers, P.; Velastin, S.A. Learning to recognise 3D human action from a new skeleton-based representation using deep convolutional neural networks. IET Comput. Vis. 2018, 13, 319–328. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Cao, C.; Lan, C.; Zhang, Y.; Zeng, W.; Lu, H.; Zhang, Y. Skeleton-Based Action Recognition with Gated Convolutional Neural Networks. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 3247–3257. [Google Scholar] [CrossRef]
- Ludl, D.; Gulde, T.; Curio, C. Simple yet efficient real-time pose-based action recognition. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; IEEE: New York City, NY, USA, 2019; pp. 581–588. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Devineau, G.; Moutarde, F.; Xi, W.; Yang, J. Deep learning for hand gesture recognition on skeletal data. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; IEEE: New York City, NY, USA, 2018; pp. 106–113. [Google Scholar]
- Weng, J.; Liu, M.; Jiang, X.; Yuan, J. Deformable pose traversal convolution for 3d action and gesture recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 136–152. [Google Scholar]
- Li, C.; Wang, P.; Wang, S.; Hou, Y.; Li, W. Skeleton-based action recognition using LSTM and CNN. In Proceedings of the 2017 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Hong Kong, China, 10–14 July 2017; IEEE: New York City, NY, USA, 2017; pp. 585–590. [Google Scholar]
- Ullah, A.; Ahmad, J.; Muhammad, K.; Sajjad, M.; Baik, S.W. Action recognition in video sequences using deep bi-directional LSTM with CNN features. IEEE Access 2017, 6, 1155–1166. [Google Scholar] [CrossRef]
- Schuster, M.; Paliwal, K.K.; General, A. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- Maghoumi, M.; LaViola Jr, J.J. DeepGRU: Deep gesture recognition utility. In Proceedings of the International Symposium on Visual Computing, Lake Tahoe, NV, USA, 7–9 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 16–31. [Google Scholar]
- Song, S.; Lan, C.; Xing, J.; Zeng, W.; Liu, J. An end-to-end spatio-temporal attention model for human action recognition from skeleton data. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Fan, Z.; Zhao, X.; Lin, T.; Su, H. Attention-Based Multiview Re-Observation Fusion Network for Skeletal Action Recognition. IEEE Trans. Multimed. 2019, 21, 363–374. [Google Scholar] [CrossRef]
- Hou, J.; Wang, G.; Chen, X.; Xue, J.H.; Zhu, R.; Yang, H. Spatial-temporal attention res-TCN for skeleton-based dynamic hand gesture recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Gori, M.; Monfardini, G.; Scarselli, F. A new model for learning in graph domains. In Proceedings of the 2005 IEEE International Joint Conference on Neural Networks, 2005, Montreal, QC, Canada, 31 July–4 August 2005; IEEE: New York City, NY, USA, 2005; Volume 2, pp. 729–734. [Google Scholar]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Trans. Neural Netw. 2008, 20, 61–80. [Google Scholar] [CrossRef]
- Bronstein, M.M.; Bruna, J.; LeCun, Y.; Szlam, A.; Vandergheynst, P. Geometric deep learning: Going beyond euclidean data. IEEE Signal Process. Mag. 2017, 34, 18–42. [Google Scholar] [CrossRef]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Yu, P.S. A comprehensive survey on graph neural networks. arXiv 2019, arXiv:1901.00596. [Google Scholar] [CrossRef]
- Zhang, X.; Xu, C.; Tian, X.; Tao, D. Graph Edge Convolutional Neural Networks for Skeleton Based Action Recognition. arXiv 2018, arXiv:1805.06184. [Google Scholar] [CrossRef] [PubMed]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LO, USA, 2–7 February 2018. [Google Scholar]
- Li, C.; Cui, Z.; Zheng, W.; Xu, C.; Yang, J. Spatio-Temporal Graph Convolution for Skeleton Based Action Recognition. arXiv 2018, arXiv:1802.09834. [Google Scholar]
- Si, C.; Chen, W.; Wang, W.; Wang, L.; Tan, T. An Attention Enhanced Graph Convolutional LSTM Network for Skeleton-Based Action Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Varytimidis, D.; Alonso-Fernandez, F.; Duran, B.; Englund, C. Action and intention recognition of pedestrians in urban traffic. arXiv 2018, arXiv:1810.09805. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems 25; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Saleh, K.; Hossny, M.; Nahavandi, S. Real-time Intent Prediction of Pedestrians for Autonomous Ground Vehicles via Spatio-Temporal DenseNet. arXiv 2019, arXiv:1904.09862. [Google Scholar]
- Gujjar, P.; Vaughan, R. Classifying Pedestrian Actions In Advance Using Predicted Video Of Urban Driving Scenes. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 2097–2103. [Google Scholar] [CrossRef]
- Chaabane, M.; Trabelsi, A.; Blanchard, N.; Beveridge, R. Looking Ahead: Anticipating Pedestrians Crossing with Future Frames Prediction. arXiv 2019, arXiv:1910.09077. [Google Scholar]
- Fang, Z.; López, A.M. Is the Pedestrian going to Cross? Answering by 2D Pose Estimation. arXiv 2018, arXiv:1807.10580. [Google Scholar]
- Marginean, A.; Brehar, R.; Negru, M. Understanding pedestrian behaviour with pose estimation and recurrent networks. In Proceedings of the 2019 6th International Symposium on Electrical and Electronics Engineering (ISEEE), Galati, Romania, 18–20 October 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Ghori, O.; Mackowiak, R.; Bautista, M.; Beuter, N.; Drumond, L.; Diego, F.; Ommer, B. Learning to Forecast Pedestrian Intention from Pose Dynamics. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1277–1284. [Google Scholar] [CrossRef]
- Gantier, R.; Yang, M.; Qian, Y.; Wang, C. Pedestrian Graph: Pedestrian Crossing Prediction Based on 2D Pose Estimation and Graph Convolutional Networks. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 2000–2005. [Google Scholar] [CrossRef]
- Ridel, D.; Rehder, E.; Lauer, M.; Stiller, C.; Wolf, D. A Literature Review on the Prediction of Pedestrian Behavior in Urban Scenarios. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 3105–3112. [Google Scholar] [CrossRef]
- Xie, D.; Shu, T.; Todorovic, S.; Zhu, S.C. Learning and inferring “dark matter” and predicting human intents and trajectories in videos. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1639–1652. [Google Scholar] [CrossRef]
- Wei, P.; Liu, Y.; Shu, T.; Zheng, N.; Zhu, S. Where and Why are They Looking? In Jointly Inferring Human Attention and Intentions in Complex Tasks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; IEEE Computer Society: Los Alamitos, CA, USA, 2018; pp. 6801–6809. [Google Scholar] [CrossRef]
- Liu, B.; Adeli, E.; Cao, Z.; Lee, K.H.; Shenoi, A.; Gaidon, A.; Niebles, J.C. Spatiotemporal Relationship Reasoning for Pedestrian Intent Prediction. arXiv 2020, arXiv:2002.08945. [Google Scholar] [CrossRef]
- Ranga, A.; Giruzzi, F.; Bhanushali, J.; Wirbel, E.; Pérez, P.; Vu, T.H.; Perrotton, X. VRUNet: Multi-Task Learning Model for Intent Prediction of Vulnerable Road Users. arXiv 2020, arXiv:2007.05397. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. arXiv 2015, arXiv:1502.01852. [Google Scholar]
- Hornik, K. Approximation capabilities of multilayer feedforward networks. Neural Netw. 1991, 4, 251–257. [Google Scholar] [CrossRef]
- Rehder, E.; Kloeden, H.; Stiller, C. Head detection and orientation estimation for pedestrian safety. In Proceedings of the 17th International IEEE Conference on Intelligent Transportation Systems (ITSC), Qingdao, China, 8–11 October 2014; IEEE: New York City, NY, USA, 2014; pp. 2292–2297. [Google Scholar]
- Köhler, S.; Goldhammer, M.; Zindler, K.; Doll, K.; Dietmeyer, K. Stereo-vision-based pedestrian’s intention detection in a moving vehicle. In Proceedings of the 2015 IEEE 18th International Conference on Intelligent Transportation Systems, Las Palmas, Spain, 15–18 September 2015; IEEE: New York City, NY, USA, 2015; pp. 2317–2322. [Google Scholar]
- Flohr, F.; Dumitru-Guzu, M.; Kooij, J.F.; Gavrila, D.M. A probabilistic framework for joint pedestrian head and body orientation estimation. IEEE Trans. Intell. Transp. Syst. 2015, 16, 1872–1882. [Google Scholar] [CrossRef]
- Schulz, A.T.; Stiefelhagen, R. Pedestrian intention recognition using latent-dynamic conditional random fields. In Proceedings of the 2015 IEEE Intelligent Vehicles Symposium (IV), Seoul, Korea, 28 June–1 July 2015; IEEE: New York City, NY, USA, 2015; pp. 622–627. [Google Scholar]
- Rasouli, A.; Kotseruba, I.; Tsotsos, J.K. Towards Social Autonomous Vehicles: Understanding Pedestrian-Driver Interactions. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 729–734. [Google Scholar] [CrossRef]
- Dey, D.; Terken, J. Pedestrian interaction with vehicles: Roles of explicit and implicit communication. In Proceedings of the 9th International Conference on Automotive User Interfaces and Interactive Vehicular Applications, Oldenburg, Germany, 24–27 September 2017; pp. 109–113. [Google Scholar]
- Schneemann, F.; Heinemann, P. Context-based detection of pedestrian crossing intention for autonomous driving in urban environments. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 2243–2248. [Google Scholar]
- Yang, F.; Sakti, S.; Wu, Y.; Nakamura, S. Make Skeleton-based Action Recognition Model Smaller, Faster and Better. arXiv 2019, arXiv:1907.09658. [Google Scholar]
- Baradel, F.; Wolf, C.; Mille, J. Human Activity Recognition with Pose-driven Attention to RGB. In Proceedings of the BMVC 2018—29th British Machine Vision Conference, Newcastle, UK, 2–6 September 2018; pp. 1–14. [Google Scholar]
- Liu, J.; Shahroudy, A.; Xu, D.; Wang, G. Spatio-temporal lstm with trust gates for 3d human action recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 816–833. [Google Scholar]
- Yang, Z.; Li, Y.; Yang, J.; Luo, J. Action Recognition with Spatio-Temporal Visual Attention on Skeleton Image Sequences. arXiv 2018, arXiv:1801.10304. [Google Scholar] [CrossRef]
- Maas, A.L. Rectifier Nonlinearities Improve Neural Network Acoustic Models. 2013. Available online: https://ai.stanford.edu/~amaas/papers/relu_hybrid_icml2013_final.pdf (accessed on 9 December 2020).
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Smith, S.L.; Kindermans, P.J.; Ying, C.; Le, Q.V. Don’t Decay the Learning Rate, Increase the Batch Size. arXiv 2017, arXiv:1711.00489. [Google Scholar]
- Fang, H.S.; Xie, S.; Tai, Y.W.; Lu, C. RMPE: Regional Multi-person Pose Estimation. arXiv 2016, arXiv:1612.00137. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. arXiv 2016, arXiv:1611.08050. [Google Scholar]
- Chollet, F. Keras. 2015. Available online: https://keras.io (accessed on 9 December 2020).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: tensorflow.org (accessed on 9 December 2020).
- Johansson, G. Visual perception of biological motion and a model for its analysis. Percept. Psychophys. 1973, 14, 201–211. [Google Scholar] [CrossRef]
- Thompson, P.; Colebatch, J.; Brown, P.; Rothwell, J.; Day, B.; Obeso, J.; Marsden, C. Voluntary stimulus-sensitive jerks and jumps mimicking myoclonus or pathological startle syndromes. Mov. Disord. Off. J. Mov. Disord. Soc. 1992, 7, 257–262. [Google Scholar] [CrossRef] [PubMed]
- Kemp, B.J. Reaction time of young and elderly subjects in relation to perceptual deprivation and signal-on versus signal-off conditions. Dev. Psychol. 1973, 8, 268. [Google Scholar] [CrossRef]
- Yang, W.; Ouyang, W.; Wang, X.; Ren, J.; Li, H.; Wang, X. 3D Human Pose Estimation in the Wild by Adversarial Learning. arXiv 2018, arXiv:1803.09722. [Google Scholar]
- Xiu, Y.; Li, J.; Wang, H.; Fang, Y.; Lu, C. Pose Flow: Efficient Online Pose Tracking. arXiv 2018, arXiv:1802.00977. [Google Scholar]
- Ning, G.; Huang, H. LightTrack: A Generic Framework for Online Top-Down Human Pose Tracking. arXiv 2019, arXiv:1905.02822. [Google Scholar]
- Xiao, B.; Wu, H.; Wei, Y. Simple Baselines for Human Pose Estimation and Tracking. arXiv 2018, arXiv:1804.06208. [Google Scholar]
- Raaj, Y.; Idrees, H.; Hidalgo, G.; Sheikh, Y. Efficient Online Multi-Person 2D Pose Tracking With Recurrent Spatio-Temporal Affinity Fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Fang, H.S.; Xie, S.; Tai, Y.W.; Lu, C. RMPE: Regional Multi-person Pose Estimation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Papandreou, G.; Zhu, T.; Kanazawa, N.; Toshev, A.; Tompson, J.; Bregler, C.; Murphy, K. Towards Accurate Multi-person Pose Estimation in the Wild. arXiv 2017, arXiv:1701.01779. [Google Scholar]
- Iqbal, U.; Gall, J. Multi-Person Pose Estimation with Local Joint-to-Person Associations. arXiv 2016, arXiv:1608.08526. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; IEEE: New York City, NY, USA, 2017; pp. 3645–3649. [Google Scholar]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Accuracy |
|---|---|
| LDA on Geometric features branch input | 51.6% |
| LDA on the classic Encoder ( = 0) | 53.2% |
| LDA on the regularized Encoder ( = 5) | 54.0% |
| Encoder (He initialization [64]) | 66.9% |
| Encoder with a classic auto-encoder ( = 0) | 68.5% |
| Encoder with a regularized auto-encoder ( = 5) | 69.4% |
| Method | Accuracy |
|---|---|
| Cartesian feature branch without spatial joint reordering trick | 83.1% |
| Cartesian feature branch with spatial joint reordering trick | 88.7% |
| Method | Accuracy |
|---|---|
| Alexnet + Context [15] | 63.0% |
| Alexnet + SVM [50] | 74.4% |
| Alphapose + LSTM [56] | 78.0% |
| Res-EnDec [53] | 81.0% |
| ST-DenseNet [52] | 84.76% |
| auto-encoder + Prediction [54] | 86.7% |
| Openpose + Keypoints [55] | 88.0% |
| Alexnet + SVM + Context [50] | 89.4% |
| CPN + GCN [58] | 91.9% |
| CPN + Geometric branch () | 69.4% |
| CPN + Cartesian branch | 88.7% |
| CPN + SPI-Net () | 94.4% |
| Geometric Branch | Cartesian Branch | SPI-Net | ||||
|---|---|---|---|---|---|---|
| Ground Truth | Crossing | Not Crossing | Crossing | Not Crossing | Crossing | Not Crossing |
| Crossing | 37 | 25 | 57 | 5 | 60 | 2 |
| Not Crossing | 16 | 46 | 9 | 53 | 5 | 57 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gesnouin, J.; Pechberti, S.; Bresson, G.; Stanciulescu, B.; Moutarde, F. Predicting Intentions of Pedestrians from 2D Skeletal Pose Sequences with a Representation-Focused Multi-Branch Deep Learning Network. Algorithms 2020, 13, 331. https://doi.org/10.3390/a13120331
Gesnouin J, Pechberti S, Bresson G, Stanciulescu B, Moutarde F. Predicting Intentions of Pedestrians from 2D Skeletal Pose Sequences with a Representation-Focused Multi-Branch Deep Learning Network. Algorithms. 2020; 13(12):331. https://doi.org/10.3390/a13120331
Chicago/Turabian StyleGesnouin, Joseph, Steve Pechberti, Guillaume Bresson, Bogdan Stanciulescu, and Fabien Moutarde. 2020. "Predicting Intentions of Pedestrians from 2D Skeletal Pose Sequences with a Representation-Focused Multi-Branch Deep Learning Network" Algorithms 13, no. 12: 331. https://doi.org/10.3390/a13120331
APA StyleGesnouin, J., Pechberti, S., Bresson, G., Stanciulescu, B., & Moutarde, F. (2020). Predicting Intentions of Pedestrians from 2D Skeletal Pose Sequences with a Representation-Focused Multi-Branch Deep Learning Network. Algorithms, 13(12), 331. https://doi.org/10.3390/a13120331