Experimenting the Automatic Recognition of Non-Conventionalized Units in Sign Language


Abstract
1. Introduction
1.1. Sign Language Linguistics
- Fully Lexical Signs (FLSs): they correspond to the core of popular annotation systems. They are conventionalized units; a FLS may either be a content sign or a function sign (which roughly correspond to nouns and verbs in English). FLSs are identified by ID-glosses (Glossing is the practice of writing down a sign-by-sign equivalent using words (glosses) in English (or another written language). ID-glosses are more robust that simple glosses, as they are unique identifiers for the root morpheme of signs, which are unique identifiers, related to the form of the sign only, without consideration for meaning.
- Partially Lexical Signs (PLSs): they are formed by the combination of conventional and non-conventional elements, the latter being highly context-dependent. Thus, they can not be listed in a dictionary. They include:
- -
- Depicting Signs (DSs) or illustrative structures.
- -
- Pointing Signs (PTSs) or indexing signs.
- -
- Fragment Buoys (FBuoys) for the holding of a fragment or the final posture of a two-handed lexical sign, usually on the weak hand (i.e., the left hand for a right-handed person and vice versa).
- Non Lexical Signs (NLSs), including Fingerspelled Signs (FSs) for proper names or when the sign is unknown, Gestures (Gs) for non-lexicalized gestures, which may be culturally shared or idiosyncratic, and Numbering Signs (NSs).
1.2. Automatic Continuous Sign Language Recognition: State of the Art
1.2.1. Specific corpora used for Continuous Lexical Sign Recognition
1.2.2. Continuous Lexical Sign Recognition Experiments: Frameworks and Results
1.2.3. Experiments Outside the Field of Continuous Lexical Sign Recognition
1.3. Limitations of the Current Acceptation of Continuous Sign Language Recognition
2. Materials and Methods
2.1. Better Corpora for Continuous Sign Language Recognition
2.1.1. A Few Corpora Made by Linguists
2.1.2. Dicta-Sign–LSF–v2: A Linguistic-Driven Corpus with Fine and Consistent Annotation
2.2. Redefining Continuous Sign Language Recognition
2.2.1. Formalization
- a SL video sequence of T frames.
- an intermediate representation of X, often called features.
- a learning and prediction model.
- Y the element(s) of interest from X, that are to be recognized.
- an estimation of Y.
- a dictionary of G lexical sign glosses.
Case of CLexSR
Our Proposed Approach of General CSLR

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SLR Type | Recognition Objective Y | Metrics |
|---|---|---|
| Usual CLexSR | WER | |
| CSLR: |
2.2.2. Relevant Metrics
Frame-Wise
Unit-Wise
- Counting units within a certain temporal window : , and F1First, we propose a rather straightforward counting function that consists of positively counting a unit if and only if there exists a unit of the same class in , within a certain margin (temporal window) —respectively, a unit is counted positively if and only if there exists a unit of the same class in , within a certain margin .In this configuration, precision, recall and F1-score are named , and F1.
- Counting units with thresholds and on their normalized temporal intersection: , and F1.The authors of [46] proposed and applied a similar but refined set of metrics, adapted for human action recognition and localization, both in space and time. Because our data are only labeled in time, we set aside the space metrics, although they would definitely be useful with adapted annotations. In this setting, and are calculated by finding the best matching units. For each unit in the list , one can define the best match unit in as the one maximizing the normalized temporal overlap between units (and a symmetric formula for the best match in of a unit ). The counting function between two units then returns a positive value if:
- The number of frames that are part of both units is sufficiently large with respect to the number of frames in the detected set, i.e., the detected excess duration is sufficiently small.
- The number of frames that are part of both units is sufficiently large with respect to the number frames in the ground truth set, i.e., a sufficiently long duration of the unit has been found.
The main integrated metric can finally be defined as follows:Other interesting values include , and F, which correspond to counting matches as units with at least one intersecting frame.
2.3. Proposal for a Generalizable and Compact Continuous Sign Language Recognition Framework
2.3.1. Signer Representation
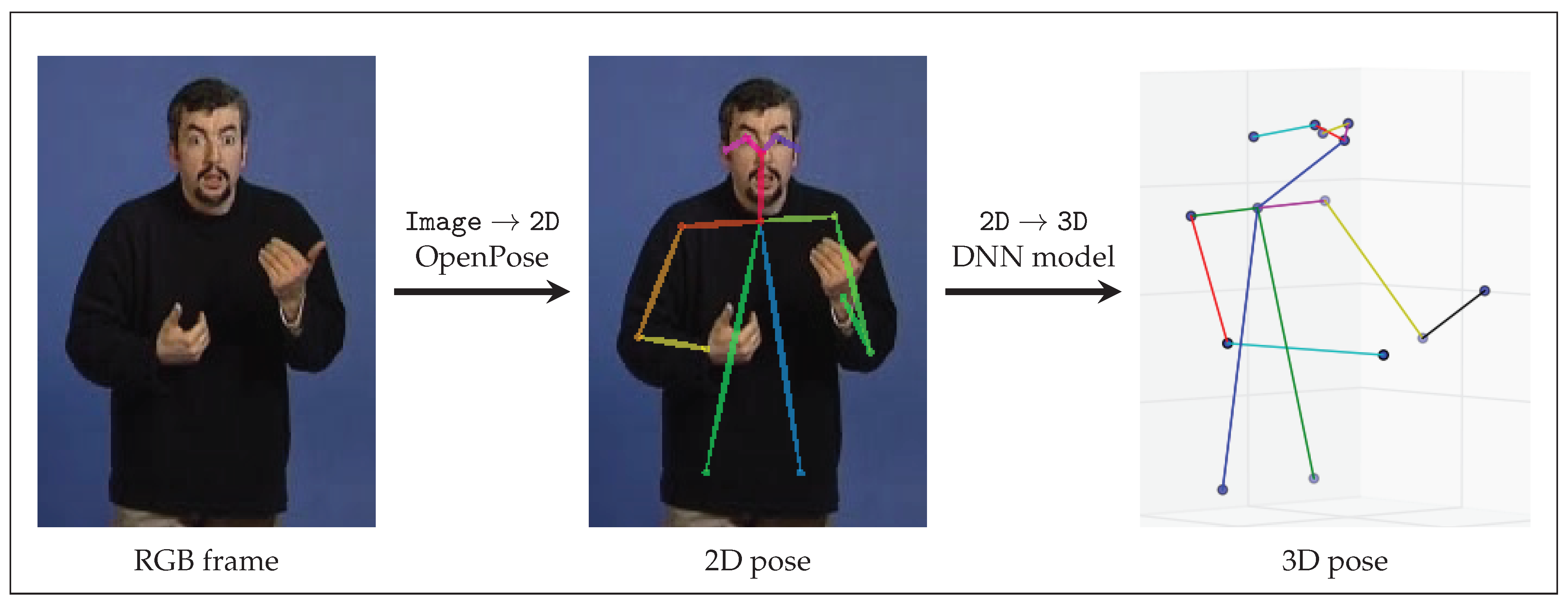
Upper Body: Image → 2D, Image → 3D, Image → 2D → 3D
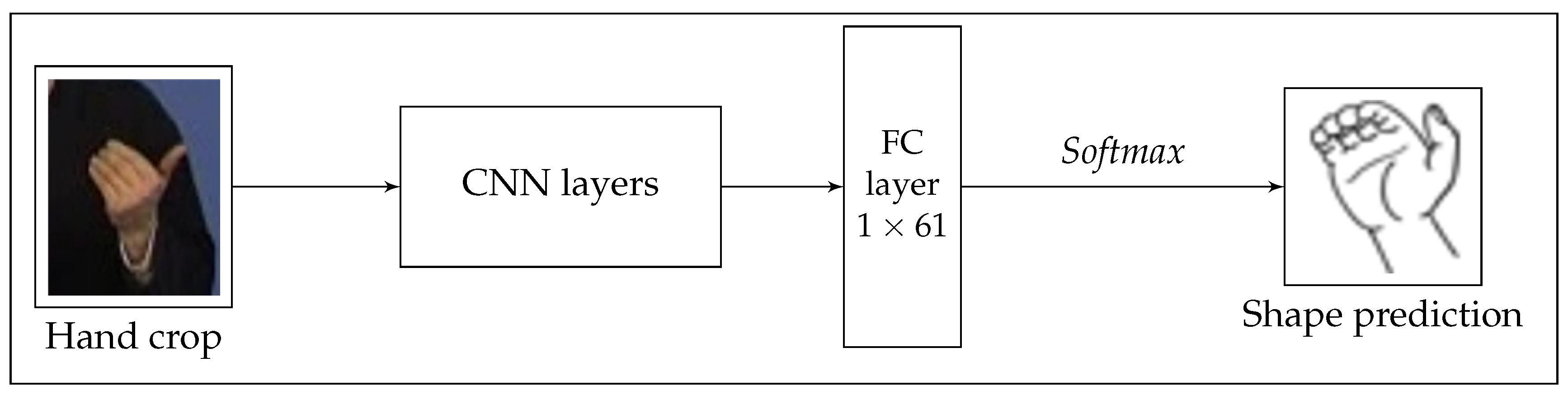
Hands
Face and Head Pose
Final Signer Representation: From Raw Data to Relevant Features
- the previously introduced raw data:
- : vector of hand shapes probabilities for both hands, with size 122 ( scalars per hand).
- : 2D raw hand pose vector, size 126 ([21 2D landmarks plus 21 confidence scores]).
- : 2D raw body pose vector, size 28 (14 2D landmarks).
- : 3D raw body pose vector, size 42 (14 3D landmarks).
- : 2D raw face/head pose vector, size 140 (70 2D landmarks).
- : 3D raw face/head pose vector, size 204 (68 3D landmarks).
- a relevant preprocessed body/face/head feature vector that can be used in combination with or as an alternative to raw data. Indeed, raw values are highly correlated, with a lot of redundancy, they can be difficult to interpret and are not always meaningful for SLR. We take inspiration from previous work in gesture recognition [61,62] and first compute pairwise positions and distances, as well as joint angles and orientations (wrist, elbow and shoulder), plus first and second order derivatives. In order to reduce the dimensionality of the face/head feature vector, the following components are computed: three Euler angles for the rotation of the head, plus first and second-order derivatives, mouth size (horizontal and vertical distances), relative motion of each eyebrow to parent eye center and position of nose landmark with respect to body center. The detection of contacts between hands and specific locations of the body is known to increase recognition accuracy [63]. Therefore, the feature vector also includes the relative position between each wrist and the nose, plus first and second-order derivatives. Moreover, because SLs make intensive use of hands, their relative arrangement is crucial [64]. Therefore, we also compute the relative position and distance of one wrist to the other, plus first and second order derivatives. We also derived a relevant 2D feature vector, in the same manner as the 3D one. In this case, positions, distances and angles are actually projected positions, distances and angles on the 2D plane. Finally, we get:
- : 2D feature vector, size 96.
- : 3D feature vector, size 176.
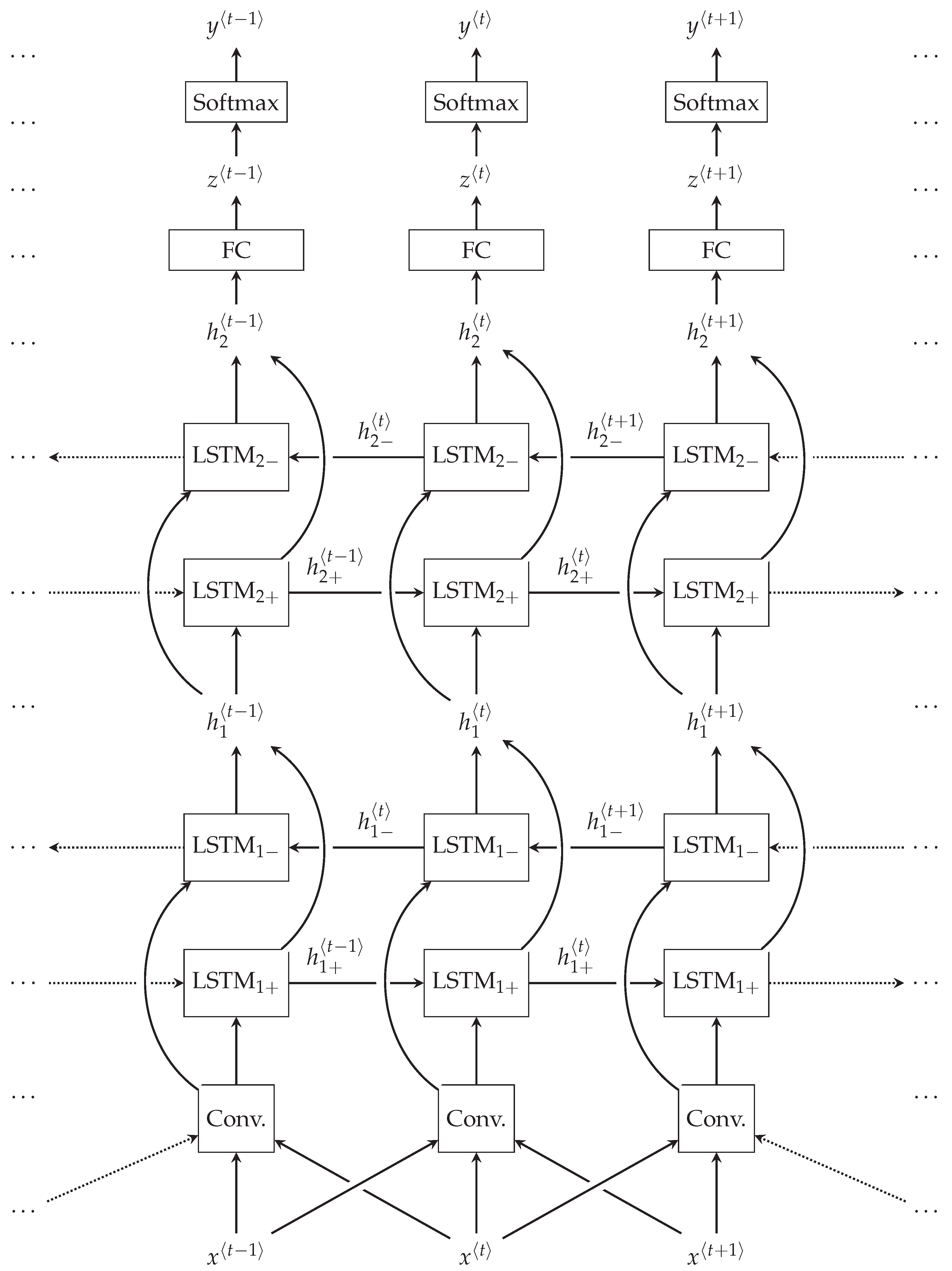
2.3.2. Learning Model
3. Results and Discussion
3.1. Quantitative Assessment
3.1.1. General Settings
- Frame-wise accuracy (not necessarily informative, as detailed in Section 2.2.2).
- Frame-wise F1-score.
- Unit-wise margin-based F1-score F1, with margin frames (half a second).
- Unit-wise normalized intersection-based F1-score F, with (counting positive recognition for units with at least one intersecting frame), as well as the associated integral value .
- Network parameters: One BLSTM layer; 50 units in each LSTM cell; 200 convolutional filters as a first neural layer, with a kernel width of size 3.
- Training hyperparameters: A batch size of 200 sequences; A dropout rate of 0.5; No weight penalty in the learning loss; Samples arranged with a sequence length of 100 frames.
- The training loss is the weighted binary/categorical cross-entropy.
- The gradient descent optimizer is RMSProp [56].
- A cross-validation split of the data is realized in a signer-independent fashion, with 12 signers in the training set, 2 in the validation set and 2 in the test set.
- Each run consists of 150 epochs. Only the best model was retained, in terms of performance on the validation set. During training, only the frame-wise F1-score was used to make this decision.
3.1.2. Baseline Results for Signer Representation #16
3.1.3. Influence of Signer Representation
- Using preprocessed data instead of raw values is always beneficial to the model performance, whatever the linguistic category. For linguistic annotations with few training instances like PTSs or FBuoys, the model is not even able to converge with raw data.
- In the end, it appears that 3D estimates do not always improve the model performance, compared to 2D data. FLSs and FBuoys are better recognized when using 3D, while DSs and PTSs should be predicted using 2D data. However, this surprising result might stem from the limited quality of the 3D estimates that we used. True 3D data (instead of estimates trained on motion capture recordings) might indeed be more reliable thus beneficial in any case.
- In terms of hand representation, it appears that the Deep Hand model is beneficial when recognizing FLSs, while OpenPose estimates alone correspond to the best choice—or very close to it—for the other linguistic categories. The fact that Deep Hand alone performs quite well for the recognition of FLSs and not for the other types of units could be explained by the fact that FLSs use a large variety of hand shapes, whereas other units like DSs use few hand shapes, but are rather very determined by the hand orientation, that is not captured by Deep Hand. In other words, it is likely that DSs give a more balanced importance to all hand parameters than FLSs.
3.1.4. Signer-Independence and Task-Independence
- Signer-dependent and task-dependent (SD-TD):
- we randomly pick 60% of the videos for training, 20% for validation and 20% for testing. Some signers and tasks are shared across the three sets.
- Signer-independent and task-dependent (SI-TD):
- we randomly pick 10 signers for training, 3 signers for validation and 3 signers for testing. All tasks are shared across the three sets.
- Signer-dependent and task-independent (SD-TI):
- we randomly pick five tasks for training, two tasks for validation and one task for testing. All signers are shared across the three sets.
- Signer-independent and task-independent (SI-TI):
- we randomly pick eight signers for training, four signers for validation and four signers for testing; three tasks for training, three tasks for validation and two tasks for testing. This roughly corresponds to a 55%-27%-18% training–validation–testing split in terms of video count. Notably in this setting, a fraction of the videos has to be left out—videos that correspond to signers in the training set, and tasks in the other sets, etc. In the end, it is thus expected that the amount of training data is more likely to be a limiting factor than for the three previously described configurations.
3.2. Qualitative Analysis on Test Set
Video S7_T2_A10, Frames 660–790 (Figure 9)
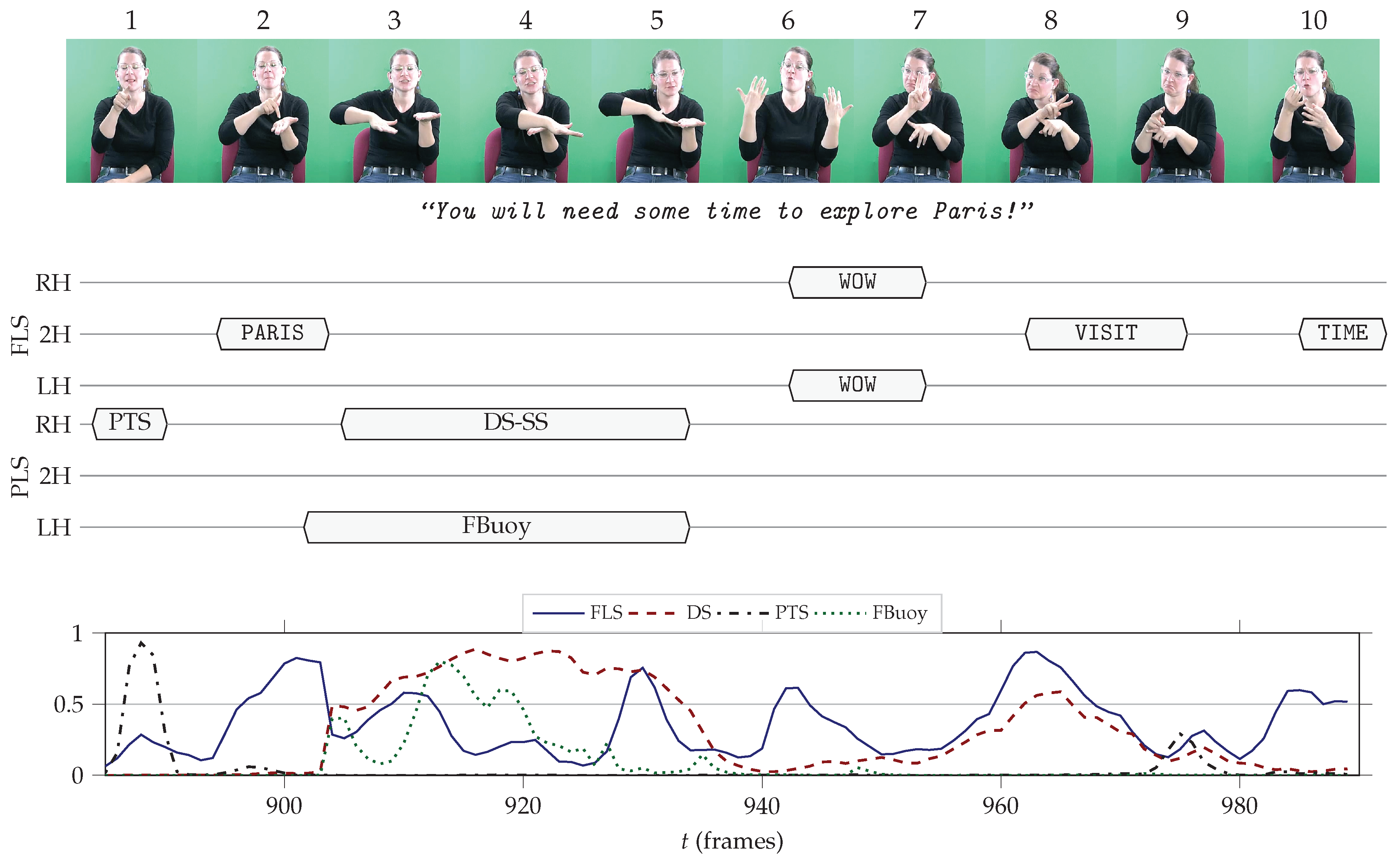
Video S7_T2_A10, Frames 885–990 (Figure 10)
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| Machine Learning and Image Processing | |
| BLSTM | Bidirectional LSTM |
| CNN | Convolutional Neural Network |
| CRF | Conditional Random Field |
| CTC | Connectionist Temporal Classification |
| DNN | Deep Neural Network |
| DTW | Dynamic Time Warping |
| EM | Expectation Maximization |
| FC | Fully Connected |
| fps | frames per second |
| HMM | Hidden Markov Model |
| HOG | Histogram of Oriented Gradients |
| LSTM | Long Short-Term Memory |
| NMT | Neural Machine Translation |
| OP | OpenPose [47] |
| RCNN | Recurrent Convolutional Neural Network |
| RGB | Red-Green-Blue |
| RNN | Recurrent Neural Network |
| SVM | Support Vector Machine |
| WER | Word Error Rate |
| Sign Language | |
| ASL | American Sign Language |
| ChSL | Chinese Sign Language |
| CLexSR | Continuous Lexical Sign Recognition |
| CSL | Continuous Sign Language |
| CSLR | Continuous Sign Language RecognitionAlgorithms |
| DGS | German Sign Language (Deutsche Gebärdensprache) |
| DTS | Danish Sign Language (Dansk Tegnsprog) |
| GR | Gesture Recognition |
| HS | Hand shape |
| LSF | French Sign Language (Langue des Signes Française) |
| NZSL | New Zealand Sign Language |
| SD | Signer-Dependent (see signer-dependent) |
| SGI | Highly Iconic Structure (Structure de Grande Iconicité) [68] |
| SI | Signer-Independent (see signer-independent) |
| SL | Sign Language |
| SLR | Sign Language Recognition |
| SLT | Sign Language Translation |
| SLU | Sign Language Understanding |
| TD | Task Dependent |
| TI | Task Independent |
| T-S | Situational Transfer |
| T-P | Transfer of Persons |
| T-FS | Transfer of Form and Size |
| Sign Language annotation categories | |
| FLS | Fully Lexical Sign |
| PLS | Partially Lexical Sign |
| DS | Depicting Sign |
| DS-L | DS-Location (of an entity) |
| DS-M | DS-Motion (of an entity) |
| DS-SS | DS-Size&Shape (of an entity) |
| DS-G | DS-Ground (spatial or temporal reference) |
| PTS | Pointing Sign |
| FBuoy | Fragment Buoy |
| NLS | Non Lexical Sign |
| FS | Fingerspelled Sign |
| NS | Numbering Sign |
| G | Gesture |
Appendix A. Performance Metrics for Temporal Data: Details and Illustration

Appendix A.1. Frame-Wise Metrics
Appendix A.2. Unit-Wise Metrics
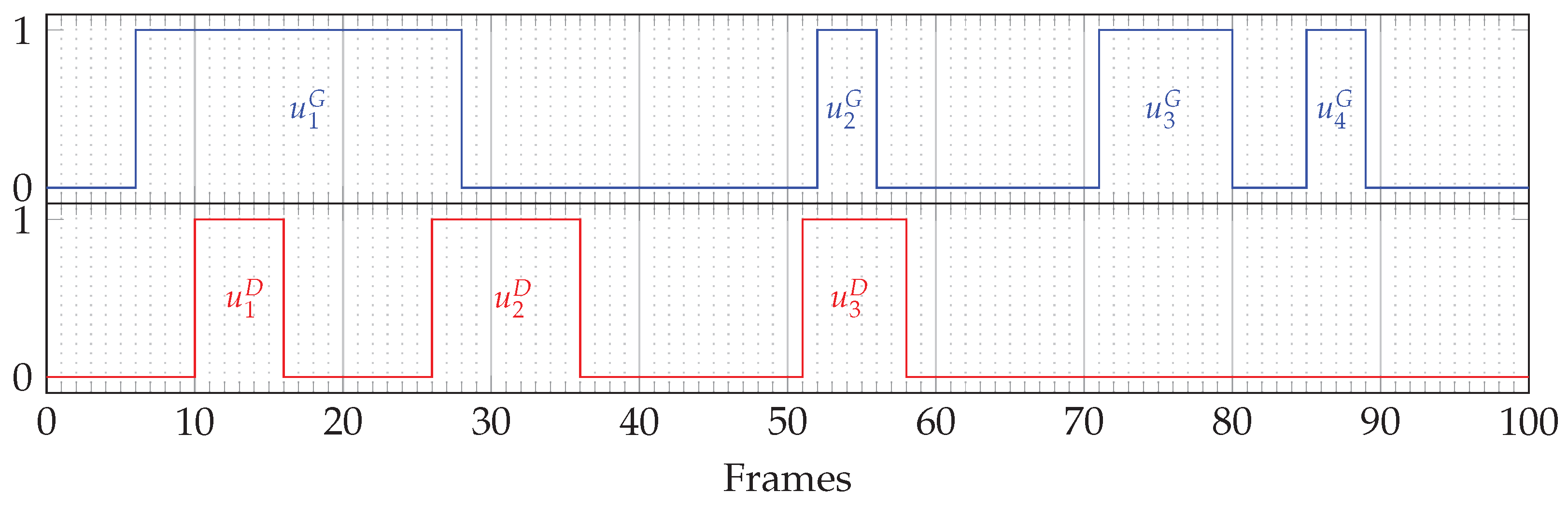
Appendix A.2.1. , ,
- The closest unit from is unit , with 4 frames of shift between their respective centers.
- The closest unit from is unit , with 14 frames of shift between their respective centers.
- The closest unit from is unit , with 0.5 frame of shift between their respective centers.
- The closest unit from is unit , with 4 frames of shift between their respective centers.
- The closest unit from is unit , with 0.5 frame of shift between their respective centers.
- The closest unit from is unit , with 21 frames of shift between their respective centers.
- The closest unit from is unit , with 32.5 frames of shift between their respective centers.
Appendix A.2.2. , ,
- The best match for unit is unit , with 7 intersecting frames over the 7 frames of .
- The best match for unit is unit , with 3 intersecting frames over the 11 frames of .
- The best match for unit is unit , with 5 intersecting frames over the 8 frames of .
- The best match for unit is unit , with 10 intersecting frames over the 23 frames of .
- The best match for unit is unit , with 5 intersecting frames over the 5 frames of .
- The best match for unit is any unit , because there is no intersection.
- The best match for unit is any unit , because there is no intersection.

References
- Stokoe, W.C. Sign Language Structure: An Outline of the Visual Communication Systems of the American Deaf. Studies in Linguistics. Stud. Linguist. 1960, 8, 269–271. [Google Scholar]
- Cuxac, C. French Sign Language: Proposition of a Structural Explanation by Iconicity. In Proceedings of the 1999 International Gesture Workshop on Gesture and Sign Language in Human-Computer Interaction; Springer: Berlin, Germany, 1999; pp. 165–184. [Google Scholar]
- Pizzuto, E.A.; Pietrandrea, P.; Simone, R. Verbal and Sign Languages. Comparing Structures, Constructs, Methodologies; Mouton De Gruyter: Berlin, Germany, 2007. [Google Scholar]
- Liddell, S.K. An Investigation into the Syntactic Structure of American Sign Language; University of California: San Diego, CA, USA, 1977. [Google Scholar]
- Meier, R.P. Elicited imitation of verb agreement in American Sign Language: Iconically or morphologically determined? J. Mem. Lang. 1987, 26, 362–376. [Google Scholar] [CrossRef]
- Johnston, T.; De Beuzeville, L. Auslan Corpus Annotation Guidelines; Centre for Language Sciences, Department of Linguistics, Macquarie University: Sydney, Australia, 2014. [Google Scholar]
- Johnston, T. Creating a corpus of Auslan within an Australian National Corpus. In Proceedings of the 2008 HCSNet Workshop on Designing the Australian National Corpus, Sydney, Australia, 4–5 December 2008. [Google Scholar]
- Belissen, V.; Gouiffès, M.; Braffort, A. Dicta-Sign-LSF-v2: Remake of a Continuous French Sign Language Dialogue Corpus and a First Baseline for Automatic Sign Language Processing. In Proceedings of the 12th International Conference on Language Resources and Evaluation (LREC 2020), Marseille, France, 11–16 May 2020. [Google Scholar]
- Sallandre, M.A.; Balvet, A.; Besnard, G.; Garcia, B. Étude Exploratoire de la Fréquence des Catégories Linguistiques dans Quatre Genres Discursifs en LSF. Available online: https://journals.openedition.org/lidil/7136 (accessed on 24 November 2020).
- Von Agris, U.; Kraiss, K.F. Towards a Video Corpus for Signer-Independent Continuous Sign Language Recognition. In Proceedings of the 2007 International Gesture Workshop on Gesture and Sign Language in Human-Computer Interaction, Lisbon, Portugal, 23–25 May 2007. [Google Scholar]
- Forster, J.; Schmidt, C.; Hoyoux, T.; Koller, O.; Zelle, U.; Piater, J.H.; Ney, H. RWTH-PHOENIX-Weather: A Large Vocabulary Sign Language Recognition and Translation Corpus. In Proceedings of the 8th International Conference on Language Resources and Evaluation (LREC 2012), Istanbul, Turkey, 21 May 2012. [Google Scholar]
- Forster, J.; Schmidt, C.; Koller, O.; Bellgardt, M.; Ney, H. Extensions of the Sign Language Recognition and Translation Corpus RWTH-PHOENIX-Weather. In Proceedings of the 9th International Conference on Language Resources and Evaluation (LREC 2014), Reykjavik, Iceland, 26–31 May 2014. [Google Scholar]
- Koller, O.; Forster, J.; Ney, H. Continuous Sign Language Recognition: Towards Large Vocabulary Statistical Recognition Systems Handling Multiple Signers. Comput. Vis. Image Underst. 2015, 141, 108–125. [Google Scholar] [CrossRef]
- Metzger, M. Sign Language Interpreting: Deconstructing the Myth of Neutrality; Gallaudet University Press: Washington, DC, USA, 1999. [Google Scholar]
- Huang, J.; Zhou, W.; Zhang, Q.; Li, H.; Li, W. Video-based Sign Language Recognition without Temporal Segmentation. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Braffort, A. Reconnaissance et Compréhension de Gestes, Application à la Langue des Signes. Ph.D. Thesis, Université de Paris XI, Orsay, France, 28 June 1996. [Google Scholar]
- Vogler, C.; Metaxas, D. Adapting Hidden Markov Models for ASL Recognition by Using Three-dimensional Computer Vision Methods. In Proceedings of the 1997 IEEE International Conference on Systems, Man, and Cybernetics. Computational Cybernetics and Simulation, Orlando, FL, USA, 12–15 October 1997. [Google Scholar]
- Koller, O.; Ney, H.; Bowden, R. Deep Hand: How to Train a CNN on 1 Million Hand Images When Your Data is Continuous and Weakly Labelled. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Koller, O.; Zargaran, S.; Ney, H.; Bowden, R. Deep Sign: Hybrid CNN-HMM for Continuous Sign Language Recognition. In Proceedings of the 2016 British Machine Vision Conference (BMVC), York, UK, 19–22 September 2016. [Google Scholar]
- Camgoz, N.C.; Hadfield, S.; Koller, O.; Bowden, R. SubUNets: End-to-End Hand Shape and Continuous Sign Language Recognition. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Cui, R.; Liu, H.; Zhang, C. Recurrent Convolutional Neural Networks for Continuous Sign Language Recognition by Staged Optimization. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Koller, O.; Zargaran, S.; Ney, H. Re-Sign: Re-Aligned End-to-End Sequence Modelling with Deep Recurrent CNN-HMMs. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Luong, T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-based Neural Machine Translation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Lisbon, Portugal, 2015; pp. 1412–1421. [Google Scholar] [CrossRef]
- Guo, D.; Zhou, W.; Li, H.; Wang, M. Hierarchical LSTM for Sign Language Translation. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Pu, J.; Zhou, W.; Li, H. Iterative Alignment Network for Continuous Sign Language Recognition. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–21 June 2019. [Google Scholar]
- Guo, D.; Tang, S.; Wang, M. Connectionist Temporal Modeling of Video and Language: A Joint Model for Translation and Sign Labeling. In Proceedings of the 28th International Joint Conference on Artificial Intelligence; AAAI Press: Palo Alto, CA, USA, 2019. [Google Scholar]
- Guo, D.; Wang, S.; Tian, Q.; Wang, M. Dense Temporal Convolution Network for Sign Language Translation. In Proceedings of the 28th International Joint Conference on Artificial Intelligence; AAAI Press: Palo Alto, CA, USA, 2019. [Google Scholar]
- Yang, Z.; Shi, Z.; Shen, X.; Tai, Y.W. SF-Net: Structured Feature Network for Continuous Sign Language Recognition. arXiv 2019, arXiv:1908.01341. [Google Scholar]
- Zhou, H.; Zhou, W.; Li, H. Dynamic Pseudo Label Decoding for Continuous Sign Language Recognition. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019. [Google Scholar]
- Koller, O.; Camgoz, C.; Ney, H.; Bowden, R. Weakly Supervised Learning with Multi-Stream CNN-LSTM-HMMs to Discover Sequential Parallelism in Sign Language Videos. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2306–2320. [Google Scholar] [CrossRef] [PubMed]
- Von Agris, U.; Knorr, M.; Kraiss, K.F. The Significance of Facial Features for Automatic Sign Language Recognition. In Proceedings of the 2008 8th IEEE International Conference on Automatic Face & Gesture Recognition, Amsterdam, The Netherlands, 17–19 September 2008. [Google Scholar]
- Koller, O.; Zargaran, S.; Ney, H.; Bowden, R. Deep Sign: Enabling Robust Statistical Continuous Sign Language Recognition via Hybrid CNN-HMMs. Int. J. Comput. Vis. 2018, 126, 1311–1325. [Google Scholar] [CrossRef]
- Camgoz, N.C.; Koller, O.; Hadfield, S.; Bowden, R. Sign Language Transformers: Joint End-to-end Sign Language Recognition and Translation. In Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–18 June 2020. [Google Scholar]
- Camgoz, N.C.; Hadfield, S.; Koller, O.; Ney, H.; Bowden, R. Neural Sign Language Translation. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Metaxas, D.N.; Liu, B.; Yang, F.; Yang, P.; Michael, N.; Neidle, C. Recognition of Nonmanual Markers in American Sign Language (ASL) Using Non-Parametric Adaptive 2D-3D Face Tracking. In Proceedings of the 8th International Conference on Language Resources and Evaluation (LREC 2012), Istanbul, Turkey, 23 May 2012. [Google Scholar]
- Yanovich, P.; Neidle, C.; Metaxas, D.N. Detection of Major ASL Sign Types in Continuous Signing For ASL Recognition. In Proceedings of the 10th International Conference on Language Resources and Evaluation (LREC 2016), Portorož, Slovenia, 23 May 2012. [Google Scholar]
- Edwards, A.D. Progress in Sign Language Recognition. In Proceedings of the 1997 International Gesture Workshop on Gesture and Sign Language in Human-Computer Interaction; Springer: Berlin, Germany, 1997; pp. 13–21. [Google Scholar]
- Schembri, A. British Sign Language Corpus Project: Open Access Archives and the Observer’s Paradox. In Proceedings of the Language Resources and Evaluation Conference, Marrakech, Morocco, 28–30 May 2008. [Google Scholar]
- Prillwitz, S.; Hanke, T.; König, S.; Konrad, R.; Langer, G.; Schwarz, A. DGS Corpus Project-Development of a Corpus Based Electronic Dictionary German Sign Language/German. In Proceedings of the Satellite Workshop to the 6th International Conference on Language Resources and Evaluation (LREC 2008), Marrakech, Morocco, 26–27 May 2008. [Google Scholar]
- Meurant, L.; Sinte, A.; Bernagou, E. The French Belgian Sign Language Corpus A User-Friendly Searchable Online Corpus. In Proceedings of the 7th workshop on the Representation and Processing of Sign Languages: Corpus Mining, Portorož, Slovenia, 23–28 May 2016. [Google Scholar]
- Neidle, C.; Vogler, C. A New Web Interface to Facilitate Access to Corpora: Development of the ASLLRP Data Access Interface (DAI). Available online: https://www.ucviden.dk/en/publications/workshop-proceedings-5th-workshop-on-the-representation-and-proce (accessed on 24 November 2020).
- Crasborn, O.A.; Zwitserlood, I. The Corpus NGT: An Online Corpus for Professionals and Laymen. In Proceedings of the 3rd Workshop on the Representation and Processing of Sign Languages: Construction and Exploitation of Sign Language Corpora. Satellite Workshop to the 6th International Conference on Language Resources and Evaluation (LREC 2008); ELRA: Paris, France, 2008; pp. 44–49. [Google Scholar]
- Crasborn, O.; Zwitserlood, I.; Ros, J. Corpus NGT. In An Open Access Digital Corpus of Movies with Annotations of Sign Language of the Netherlands (Video Corpus). Centre for Language Studies, Radboud University Nijmegen. 2008. Available online: http://www.ru.nl/corpusngtuk (accessed on 24 November 2020).
- LIMSI; IRIT. Dicta-Sign-LSF-v2. Available online: https://hdl.handle.net/11403/dicta-sign-lsf-v2 (accessed on 24 November 2020).
- Vermeerbergen, M.; Leeson, L.; Crasborn, O. Simultaneity in Signed Languages: Form and Function; John Benjamins Publishing: Amsterdam, The Netherlands, 2007. [Google Scholar]
- Wolf, C.; Lombardi, E.; Mille, J.; Celiktutan, O.; Jiu, M.; Dogan, E.; Eren, G.; Baccouche, M.; Dellandréa, E.; Bichot, C.E.; et al. Evaluation of video activity localizations integrating quality and quantity measurements. Comput. Vis. Image Underst. 2014, 127, 14–30. [Google Scholar] [CrossRef]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wei, S.E.; Ramakrishna, V.; Kanade, T.; Sheikh, Y. Convolutional Pose Machines. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Xiang, D.; Joo, H.; Sheikh, Y. Monocular Total Capture: Posing Face, Body, and Hands in the Wild. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Zhao, R.; Wang, Y.; Benitez-Quiroz, C.F.; Liu, Y.; Martinez, A.M. Fast and Precise Face Alignment and 3D Shape Reconstruction from a Single 2D Image. In Proceedings of the 2016 European Conference on Computer Vision (ECCV); Springer: Berlin, Germany, 2016; pp. 590–603. [Google Scholar]
- LIMSI; CIAMS. MOCAP1. Available online: https://hdl.handle.net/11403/mocap1/v1 (accessed on 24 November 2020).
- Chollet, F. Keras. 2015. Available online: https://keras.io (accessed on 24 November 2020).
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the 27th International Conference on Machine Learning (ICML10), Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Tieleman, T.; Hinton, G. Lecture 6.5—RmsProp: Divide the gradient by a running average of its recent magnitude. COURSERA Neural Netw. Mach. Learn. 2012, 4, 26–31. [Google Scholar]
- Braffort, A.; Choisier, A.; Collet, C.; Cuxac, C.; Dalle, P.; Fusellier, I.; Gherbi, R.; Jausions, G.; Jirou, G.; Lejeune, F.; et al. Projet LS-COLIN. Quel Outil de Notation pour Quelle Analyse de la LS. Available online: https://www.irit.fr/publis/TCI/Dalle/rlsf01_LS_COLIN.pdf (accessed on 24 November 2020).
- Simon, T.; Joo, H.; Matthews, I.; Sheikh, Y. Hand Keypoint Detection in Single Images using Multiview Bootstrapping. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional Architecture for Fast Feature Embedding. In Proceedings of the 22nd ACM international conference on Multimedia, Utrecht, The Netherlands, 25–29 October 2020. [Google Scholar]
- Bulat, A.; Tzimiropoulos, G. How far are we from solving the 2D & 3D Face Alignment problem? (and a dataset of 230,000 3D facial landmarks). In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Granger, N.; el Yacoubi, M.A. Comparing Hybrid NN-HMM and RNN for Temporal Modeling in Gesture Recognition. In Proceeding of Advances in Neural Information Processing Systems (NIPS 2017); Springer: Berlin, Germany, 2017; pp. 147–156. [Google Scholar]
- Wu, D.; Pigou, L.; Kindermans, P.J.; Le, N.D.H.; Shao, L.; Dambre, J.; Odobez, J.M. Deep Dynamic Neural Networks for Multimodal Gesture Segmentation and Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1583–1597. [Google Scholar] [CrossRef] [PubMed]
- Dilsizian, M.; Metaxas, D.; Neidle, C. Linguistically-driven Framework for Computationally Efficient and Scalable Sign Recognition. In Proceedings of the 11th International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Battison, R. Phonological Deletion in American Sign Language. Sign Lang. Stud. 1974, 5, 1–19. [Google Scholar] [CrossRef]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to Forget: Continual Prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef] [PubMed]
- Pigou, L.; Van Den Oord, A.; Dieleman, S.; Van Herreweghe, M.; Dambre, J. Beyond Temporal Pooling: Recurrence and Temporal Convolutions for Gesture Recognition in Video. Int. J. Comput. Vis. 2018, 126, 430–439. [Google Scholar] [CrossRef]
- Belissen, V.; Gouiffès, M.; Braffort, A. Improving and Extending Continuous Sign Language Recognition: Taking Iconicity and Spatial Language into account. In Proceedings of the 9th Workshop on the Representation and Processing of Sign Languages: Sign Language Resources in the Service of the Language Community, Technological Challenges and Application Perspectives, Marseille, France, 11–16 May 2020. [Google Scholar]
- Cuxac, C. La Langue des Signes Française (LSF): Les Voies de l’Iconicité. Available online: https://pascal-francis.inist.fr/vibad/index.php?action=getRecordDetail&idt=238688 (accessed on 24 November 2020).










| Paper | RWTH-Phœnix-Weather | SIGNUM | Continuous SLR100 | |||
|---|---|---|---|---|---|---|
| SD | SI | SD | SI | SD | SI | |
| Von Agris et al. [31] | - | - | - | - | ||
| Koller et al. [13] | - | - | - | - | ||
| Koller et al. [18] | - | - | - | - | ||
| Koller et al. [19] | - | - | - | - | ||
| Camgoz et al. [20] | - | - | - | - | - | |
| Cui et al. [21] | - | - | - | - | - | |
| Koller et al. [22] | - | - | - | |||
| Koller et al. [32] | - | - | - | - | ||
| Huang et al. [15] | - | - | - | - | ||
| Guo et al. [24] | - | - | - | - | ||
| Pu et al. [25] | - | - | - | - | ||
| Guo et al. [26] | - | - | - | - | ||
| Guo et al. [27] | - | - | - | |||
| Zhou et al. [29] | - | - | - | - | ||
| Yang et al. [28] | - | - | - | - | ||
| Koller et al. [30] | - | - | - | - | - | |
| Camgoz et al. [33] | - | - | - | - | - | |
| Corpus (SL) | Signers | Hrs. | Discourse Type | Translation | Annotation Outside Lexicon | Used for | |
|---|---|---|---|---|---|---|---|
| Categories | Consistent | ||||||
| [15] CSLR100 (ChSL) | 50 | 100 | Artificial | - | - | SLR | |
| [11] RWTH-PW (DGS) | 9 | 11 | Interpreted | German | - | SLR | |
| [10] SIGNUM (DGS) | 25 | 5 | Artificial | Ger./Eng. | - | SLR | |
| [41] NCSLGR (ASL) | 7 | 2 | Mixed | - | PTSs, DSs, FSs | Yes | SLR & linguistics |
| [7] Auslan Corpus | 100 | 150 | Natural | - | PTSs, DSs, Constructed action | No | Linguistics |
| [38] BSLCP | 249 | 180 | Natural | English | PTSs, DSs, FBuoys | No | Linguistics |
| [39] DGS Korpus | 330 | 50–300 | Natural | Ger./Eng. | Mouthing | No | Linguistics |
| [40] LSFB Corpus | 100 | 150 | Natural | French | DSs | No | Linguistics |
| [42] Corpus NGT | 92 | 72 | Natural | Dutch | DSs, Mouthing | No | Linguistics |
| [8] Dicta-Sign–LSF–v2 | 16 | 11 | Natural | French | PTSs, DSs, FSs, FBuoys, NSs, Gs | Yes | SLR & linguistics |
| # of Occurrences | # of Signs with a Smaller or Equal # of Occurrences | # of Signs with a Greater # of Occurrences |
|---|---|---|
| 0 | 0 | 2081 |
| 1 | 585 | 1496 |
| 10 | 1556 | 525 |
| 20 | 1789 | 292 |
| 50 | 1997 | 84 |
| 100 | 2051 | 30 |
| 200 | 2072 | 9 |
| 400 | 2080 | 1 |
| FLS | PLS | NLS | Total | ||||
|---|---|---|---|---|---|---|---|
| DS | PTS | FBuoy | NS | FS | |||
| Non blank frames | 205530 | 60794 | 23045 | 14359 | 3830 | 1941 | 309,499 |
| % | 66.4% | 19.7% | 7.5% | 4.6% | 1.2% | 0.6% | |
| Cumulative % | 66.4% | 86.1% | 93.6% | 98.2% | 99.4% | 100.0% | |
| manual-unit | 24565 | 3606 | 3651 | 589 | 155 | 118 | 32,684 |
| % | 75.2% | 11.0% | 11.2% | 1.7% | 0.5% | 0.4% | |
| Cumulative % | 75.2% | 86.2% | 97.4% | 99.1% | 99.6% | 100.0% | |
| Avg. frames/unit | 8.4 | 16.8 | 6.3 | 24.4 | 24.7 | 16.4 | |
| Avg. duration (ms) | 335 | 674 | 252 | 975 | 988 | 658 | |
| # | Configuration | Corresponding Feature Vectors and Size (Section 2.3.1) | Total Size | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Body and Face | Hands | ||||||||||||
| OP | HS | 28 | 42 | 140 | 204 | 126 | 122 | 96 | 176 | ||||
| 1 | 2D | Raw | ✓ | ✓ | 168 | ||||||||
| 2 | ✓ | ✓ | ✓ | ✓ | 294 | ||||||||
| 3 | ✓ | ✓ | ✓ | ✓ | 290 | ||||||||
| 4 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | 416 | ||||||
| 5 | Features | ✓ | 96 | ||||||||||
| 6 | ✓ | ✓ | ✓ | 222 | |||||||||
| 7 | ✓ | ✓ | ✓ | 218 | |||||||||
| 8 | ✓ | ✓ | ✓ | ✓ | ✓ | 344 | |||||||
| 9 | 3D | Raw | ✓ | ✓ | 246 | ||||||||
| 10 | ✓ | ✓ | ✓ | ✓ | 372 | ||||||||
| 11 | ✓ | ✓ | ✓ | ✓ | 368 | ||||||||
| 12 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | 494 | ||||||
| 13 | Features | ✓ | 176 | ||||||||||
| 14 | ✓ | ✓ | ✓ | 302 | |||||||||
| 15 | ✓ | ✓ | ✓ | 298 | |||||||||
| 16 | ✓ | ✓ | ✓ | ✓ | ✓ | 424 | |||||||
| Frame-Wise | Unit-Wise | |||||
|---|---|---|---|---|---|---|
| Acc | F1 (P/R) | F (P/R) | F (P/R) | |||
| FLS | 0.83 | 0.64 (0.56/0.74) | 0.86 (0.76/0.98) | 0.78 (0.65/0.98) | 0.52 | |
| 0.01 | 0.01 (0.02/0.02) | 0.02 (0.02/0.03) | 0.04 (0.05/0.01) | 0.03 | ||
| DS | 0.95 | 0.40 (0.35/0.49) | 0.48 (0.36/0.74) | 0.44 (0.32/0.72) | 0.31 | |
| 0.01 | 0.04 (0.07/0.08) | 0.06 (0.07/0.06) | 0.06 (0.07/0.06) | 0.04 | ||
| PTS | 0.97 | 0.31 (0.41/0.26) | 0.46 (0.40/0.56) | 0.45 (0.39/0.55) | 0.33 | |
| 0.01 | 0.02 (0.07/0.05) | 0.04 (0.06/0.10) | 0.05 (0.06/0.11) | 0.03 | ||
| FBuoy | 0.98 | 0.14 (0.25/0.10) | 0.13 (0.12/0.15) | 0.19 (0.22/0.18) | 0.11 | |
| 0.01 | 0.04 (0.07/0.04) | 0.03 (0.02/0.05) | 0.04 (0.05/0.05) | 0.03 | ||
| Frame-Wise | Unit-Wise | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Body and Face | Hands | Acc | F1 (P/R) | F (P/R) | F (P/R) | ||||
| OP | HS | ||||||||
| Fully Lexical Sign | 2D | Raw | 0.80 | 0.58 (0.51/0.68) | 0.57 (0.75/0.46) | 0.75 (0.76/0.73) | 0.42 | ||
| ✓ | 0.79 | 0.16 (0.44/0.10) | 0.45 (0.87/0.30) | 0.34 (0.68/0.23) | 0.19 | ||||
| ✓ | 0.82 | 0.55 (0.56/0.55) | 0.83 (0.85/0.80) | 0.75 (0.76/0.74) | 0.45 | ||||
| ✓ | ✓ | 0.80 | 0.19 (0.52/0.12) | 0.60 (0.86/0.46) | 0.42 (0.61/0.32) | 0.26 | |||
| Features | 0.86 | 0.68 (0.65/0.71) | 0.88 (0.81/0.97) | 0.78 (0.66/0.94) | 0.56 | ||||
| ✓ | 0.85 | 0.66 (0.61/0.73) | 0.85 (0.75/0.99) | 0.79 (0.67/0.98) | 0.57 | ||||
| ✓ | 0.84 | 0.63 (0.60/0.66) | 0.87 (0.78/0.99) | 0.75 (0.61/0.96) | 0.49 | ||||
| ✓ | ✓ | 0.85 | 0.69(0.60/0.82) | 0.87 (0.78/0.98) | 0.81 (0.69/0.98) | 0.59 | |||
| 3D | Raw | 0.81 | 0.42 (0.56/0.34) | 0.68 (0.81/0.59) | 0.57 (0.64/0.52) | 0.32 | |||
| ✓ | 0.82 | 0.47 (0.59/0.40) | 0.82 (0.82/0.82) | 0.64 (0.65/0.64) | 0.40 | ||||
| ✓ | 0.83 | 0.45 (0.64/0.34) | 0.73 (0.87/0.62) | 0.62 (0.76/0.52) | 0.38 | ||||
| ✓ | ✓ | 0.80 | 0.37 (0.51/0.29) | 0.73 (0.83/0.66) | 0.58 (0.66/0.51) | 0.34 | |||
| Features | 0.83 | 0.65 (0.55/0.78) | 0.84 (0.73/0.99) | 0.73 (0.59/0.97) | 0.51 | ||||
| ✓ | 0.87 | 0.69(0.66/0.73) | 0.89 (0.81/0.98) | 0.80 (0.69/0.95) | 0.57 | ||||
| ✓ | 0.86 | 0.69(0.64/0.75) | 0.90(0.82/0.99) | 0.83(0.73/0.97) | 0.60 | ||||
| ✓ | ✓ | 0.83 | 0.64 (0.56/0.74) | 0.86 (0.76/0.98) | 0.78 (0.65/0.98) | 0.52 | |||
| Depicting Sign | 2D | Raw | 0.92 | 0.24 (0.18/0.36) | 0.20 (0.14/0.34) | 0.22 (0.16/0.37) | 0.15 | ||
| ✓ | 0.94 | 0.30 (0.24/0.40) | 0.35 (0.24/0.62) | 0.34 (0.23/0.59) | 0.21 | ||||
| ✓ | 0.92 | 0.10 (0.08/0.13) | 0.28 (0.19/0.56) | 0.28 (0.18/0.55) | 0.16 | ||||
| ✓ | ✓ | 0.93 | 0.36 (0.27/0.53) | 0.40 (0.27/0.77) | 0.42 (0.28/0.81) | 0.27 | |||
| Features | 0.95 | 0.41 (0.37/0.46) | 0.33 (0.25/0.48) | 0.32 (0.24/0.47) | 0.25 | ||||
| ✓ | 0.97 | 0.55 (0.54/0.56) | 0.67(0.58/0.78) | 0.68(0.60/0.78) | 0.44 | ||||
| ✓ | 0.95 | 0.43 (0.37/0.52) | 0.40 (0.29/0.64) | 0.37 (0.26/0.62) | 0.26 | ||||
| ✓ | ✓ | 0.97 | 0.59(0.53/0.66) | 0.61 (0.50/0.81) | 0.64 (0.53/0.81) | 0.46 | |||
| 3D | Raw | 0.97 | 0.24 (0.68/0.14) | 0.32 (0.66/0.21) | 0.32 (0.65/0.21) | 0.23 | |||
| ✓ | 0.90 | 0.28 (0.18/0.60) | 0.39 (0.26/0.75) | 0.41 (0.27/0.80) | 0.24 | ||||
| ✓ | 0.94 | 0.14 (0.13/0.16) | 0.31 (0.25/0.43) | 0.24 (0.18/0.34) | 0.15 | ||||
| ✓ | ✓ | 0.88 | 0.25 (0.16/0.62) | 0.32 (0.20/0.80) | 0.25 (0.15/0.81) | 0.17 | |||
| Features | 0.93 | 0.36 (0.27/0.53) | 0.25 (0.16/0.55) | 0.22 (0.14/0.50) | 0.17 | ||||
| ✓ | 0.97 | 0.50 (0.52/0.49) | 0.52 (0.44/0.63) | 0.55 (0.46/0.70) | 0.37 | ||||
| ✓ | 0.92 | 0.34 (0.24/0.57) | 0.29 (0.18/0.72) | 0.25 (0.16/0.60) | 0.17 | ||||
| ✓ | ✓ | 0.95 | 0.40 (0.35/0.49) | 0.48 (0.36/0.74) | 0.44 (0.32/0.72) | 0.31 | |||
| Frame-Wise | Unit-Wise | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Body and Face | Hands | Acc | F1 (P/R) | F (P/R) | F (P/R) | ||||
| OP | HS | ||||||||
| Pointing Sign | 2D | Raw | —— Not converged —— | ||||||
| ✓ | 0.97 | 0.23 (0.25/0.21) | 0.28 (0.24/0.34) | 0.24 (0.19/0.33) | 0.21 | ||||
| ✓ | —— Not converged —— | ||||||||
| ✓ | ✓ | 0.97 | 0.14 (0.22/0.10) | 0.22 (0.26/0.18) | 0.22 (0.26/0.18) | 0.18 | |||
| Features | 0.97 | 0.14 (0.27/0.10) | 0.31 (0.35/0.29) | 0.21 (0.22/0.20) | 0.12 | ||||
| ✓ | 0.97 | 0.30 (0.40/0.24) | 0.46 (0.38/0.59) | 0.45(0.37/0.59) | 0.29 | ||||
| ✓ | 0.97 | 0.14 (0.17/0.12) | 0.51(0.41/0.67) | 0.28 (0.21/0.41) | 0.17 | ||||
| ✓ | ✓ | 0.97 | 0.32(0.41/0.27) | 0.48 (0.42/0.58) | 0.43 (0.35/0.58) | 0.32 | |||
| 3D | Raw | —— Not converged —— | |||||||
| ✓ | 0.97 | 0.04 (0.10/0.03) | 0.17 (0.24/0.13) | 0.17 (0.24/0.13) | 0.12 | ||||
| ✓ | —— Not converged —— | ||||||||
| ✓ | ✓ | 0.96 | 0.15 (0.16/0.13) | 0.30 (0.32/0.28) | 0.22 (0.22/0.21) | 0.13 | |||
| Features | 0.96 | 0.11 (0.13/0.10) | 0.37 (0.28/0.54) | 0.24 (0.19/0.35) | 0.12 | ||||
| ✓ | 0.96 | 0.27 (0.26/0.28) | 0.48 (0.35/0.72) | 0.44 (0.32/0.67) | 0.31 | ||||
| ✓ | 0.97 | 0.09 (0.13/0.06) | 0.43 (0.42/0.43) | 0.24 (0.20/0.28) | 0.12 | ||||
| ✓ | ✓ | 0.97 | 0.31 (0.41/0.26) | 0.46 (0.40/0.56) | 0.45(0.39/0.55) | 0.33 | |||
| Fragment Buoy | 2D | Raw | ⋆ | ⋆ | —— Not converged —— | ||||
| Features | 0.97 | 0.24 (0.26/0.23) | 0.16 (0.12/0.24) | 0.24 (0.21/0.29) | 0.15 | ||||
| ✓ | 0.98 | 0.32(0.43/0.26) | 0.17 (0.15/0.20) | 0.25 (0.26/0.23) | 0.16 | ||||
| ✓ | 0.98 | 0.23 (0.40/0.16) | 0.14 (0.16/0.13) | 0.22 (0.32/0.17) | 0.15 | ||||
| ✓ | ✓ | 0.96 | 0.30 (0.24/0.39) | 0.19(0.12/0.40) | 0.24 (0.16/0.46) | 0.15 | |||
| 3D | Raw | ⋆ | ⋆ | —— Not converged —— | |||||
| Features | 0.98 | 0.13 (0.31/0.08) | 0.15 (0.20/0.12) | 0.20 (0.35/0.14) | 0.12 | ||||
| ✓ | 0.98 | 0.31 (0.43/0.25) | 0.19(0.15/0.26) | 0.26(0.24/0.30) | 0.16 | ||||
| ✓ | 0.98 | 0.12 (0.35/0.07) | 0.16 (0.25/0.12) | 0.21 (0.41/0.14) | 0.13 | ||||
| ✓ | ✓ | 0.98 | 0.14 (0.25/0.10) | 0.13 (0.12/0.15) | 0.19 (0.22/0.18) | 0.11 | |||
| Frame-Wise | Unit-Wise | ||||||
|---|---|---|---|---|---|---|---|
| SI | TI | Acc | F1 (P/R) | F (P/R) | F (P/R) | ||
| FLS | 0.78 | 0.57 (0.48/0.71) | 0.77 (0.69/0.88) | 0.72 (0.61/0.90) | 0.47 | ||
| ✓ | 0.78 | 0.54 (0.46/0.67) | 0.79 (0.72/0.88) | 0.72 (0.62/0.86) | 0.46 | ||
| ✓ | 0.79 | 0.56 (0.52/0.62) | 0.83 (0.77/0.91) | 0.73 (0.65/0.85) | 0.48 | ||
| ✓ | ✓ | 0.65 | 0.45 (0.34/0.72) | 0.67 (0.60/0.80) | 0.65 (0.53/0.89) | 0.39 | |
| DS | 0.94 | 0.26 (0.41/0.20) | 0.30 (0.35/0.28) | 0.31 (0.39/0.28) | 0.20 | ||
| ✓ | 0.92 | 0.30 (0.43/0.26) | 0.33 (0.39/0.30) | 0.35 (0.43/0.33) | 0.22 | ||
| ✓ | 0.92 | 0.24 (0.38/0.21) | 0.33 (0.37/0.38) | 0.32 (0.37/0.35) | 0.19 | ||
| ✓ | ✓ | 0.92 | 0.11 (0.22/0.08) | 0.19 (0.23/0.18) | 0.18 (0.25/0.16) | 0.11 | |
| PTS | 0.96 | 0.20 (0.19/0.25) | 0.35 (0.28/0.52) | 0.26 (0.21/0.41) | 0.18 | ||
| ✓ | 0.97 | 0.15 (0.28/0.12) | 0.30 (0.37/0.30) | 0.23 (0.29/0.23) | 0.15 | ||
| ✓ | 0.96 | 0.20 (0.26/0.19) | 0.40 (0.38/0.42) | 0.30 (0.29/0.33) | 0.20 | ||
| ✓ | ✓ | 0.94 | 0.07 (0.09/0.11) | 0.20 (0.21/0.31) | 0.11 (0.11/0.20) | 0.07 | |
| FBuoy | 0.97 | 0.19 (0.22/0.20) | 0.12 (0.11/0.26) | 0.21 (0.18/0.36) | 0.12 | ||
| ✓ | 0.94 | 0.10 (0.20/0.07) | 0.11 (0.15/0.19) | 0.11 (0.15/0.14) | 0.08 | ||
| ✓ | 0.93 | 0.07 (0.07/0.07) | 0.06 (0.05/0.09) | 0.08 (0.06/0.10) | 0.05 | ||
| ✓ | ✓ | 0.98 | 0.01 (0.01/0.01) | 0.02 (0.01/0.09) | 0.02 (0.01/0.09) | 0.01 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Belissen, V.; Braffort, A.; Gouiffès, M. Experimenting the Automatic Recognition of Non-Conventionalized Units in Sign Language. Algorithms 2020, 13, 310. https://doi.org/10.3390/a13120310
Belissen V, Braffort A, Gouiffès M. Experimenting the Automatic Recognition of Non-Conventionalized Units in Sign Language. Algorithms. 2020; 13(12):310. https://doi.org/10.3390/a13120310
Chicago/Turabian StyleBelissen, Valentin, Annelies Braffort, and Michèle Gouiffès. 2020. "Experimenting the Automatic Recognition of Non-Conventionalized Units in Sign Language" Algorithms 13, no. 12: 310. https://doi.org/10.3390/a13120310
APA StyleBelissen, V., Braffort, A., & Gouiffès, M. (2020). Experimenting the Automatic Recognition of Non-Conventionalized Units in Sign Language. Algorithms, 13(12), 310. https://doi.org/10.3390/a13120310