1. Introduction
Nowadays, there a number of classification techniques that have been applied to various real-world applications, i.e., graph convolutional networks for text classification [
1], automated classification of epileptic electroencephalogram (EEG) signals [
2], iris cognition [
3], and anomaly detection [
4]. Associative classification (AC) is a well-known classification technique that was first introduced by Lui et al. [
5]. It is a combination of two data-mining techniques, association rule mining, and classification. Association rule mining discovers the relationship between items in a dataset. Meanwhile, classification aims to predict the class label of any given instance from learning-labeled dataset. AC focuses on finding Class Association Rules (CARs) that satisfy certain minimum support and confidence thresholds in the form
, where
x is a set of attribute values and
c is a class label. AC has been reported in the literature to outperform other traditional classifiers [
6,
7,
8,
9,
10,
11,
12,
13], In addition, a CAR is an if–then rule that can be easily understood by general users. Therefore, AC is applied in many fields, i.e., phishing website detection [
6,
7,
11], heart disease prediction [
8,
9], groundwater detection [
12], and detection of low-quality information in social networks [
10].
In traditional AC algorithms, minimum support threshold is a significant key parameter that is used to select frequent ruleitems and to then eliminate frequent ruleitems in which confidence values do not satisfy minimum confidence. This manner leads to a large number of frequent ruleitems. Nguyen and Nguyen [
14] demonstrated that the number of 4 million frequent ruleitems can be generated when the minimum support threshold is set to 1%. Moreover, a number of AC-based techniques, i.e., Classification-based Association (CBA) [
5], Fast Associative Classification Algorithm (FACA) [
11], CAR-Miner-diff [
14], Predictability-Based Class Collative Class Association Rules (PCAR) [
15], Weighted Classification Based on Association Rules (WCBA) [
16], and Fast Classification Based on Association Rules (FCBA) [
17], create all possible CARs in order to determine a set of valid CARs that can be used in the classification process. Recently, Active Pruning Rules (APR) [
13] has been proposed as a novel evaluation method. APR can be used to avoid generating all CARs. However, the exhaustive search for finding rules in classifiers may cause an issue in large datasets or low minimum support. Creating candidate CARs consumes intensive computational times and memory. The minimal process of candidate generation is still challenging because it is quite affected in terms of training time, input/output (I/O) overheads, and memory usage [
18].
In this paper, a new algorithm is proposed to directly generate a small number of efficient CARs for classification. A vertical data format [
19] is used to represent ruleitems associated with their transaction IDs. The intersection technique is used to easily calculate support and confidence values from the format. The ruleitems with 100% of confidence will be added to the classifier as a CAR. Whenever a CAR with 100% confidence is found, the transaction associated with the CAR will be removed by using a set difference to avoid generating redundant CARs. Finally, a compact classifier is built for classification. In conclusion, the contribution of this paper is as follows.
To avoid pruning and sorting processes, the proposed algorithm directly generates CARs with 100% confidence to build compact classifiers. The CARs with 100% confidence are anticipated to result in high prediction rates.
The proposed algorithm eliminates unnecessary transactions to avoid generating redundant CARs in each stage.
Simple set theories, intersection, and set difference are exploited to reduce computational time used in mining process and to reduce memory consumption.
This paper is structured as follows. In
Section 2, related works of AC are described. The basic definitions are delineated in
Section 3. The proposed algorithm is introduced in
Section 4. The discussion on the experimental results is in
Section 5. Lastly, the conclusion of the study is stated in
Section 6.
2. Related Work
In the past, AC-based algorithms have been proposed and studied. The study’s objective is to understand some drawbacks and to increase the effectiveness of the algorithms. Lui et al. [
5] introduced the CBA algorithm which integrated association rule mining and classification. The process of the CBA algorithm is divided into two steps. First, CARs are generated based on the famous search method the Apriori algorithm [
20]. Second, CARs are sorted and then pruned to select efficient CARs in a classifier. The CBA algorithm was proven to produce a lower error rate than C4.5 [
21]. Unfortunately, the CBA algorithm encounters a large number of candidate generation problems due to Apriori inheritance which finds all possible frequent rules at each level.
Li et al. [
22] presented the Classification based on Multiple Association Rules (CMAR) algorithm. Unlike CBA, CMAR adopts a Frequent pattern tree (FP-tree) and a Cosine R-tree (CR-tree) for rule generation and classification phases. It divides the subset in FP-tree to search frequent ruleitems and then adds the frequent ruleitems to CR-tree according to their frequencies. Hence, CMAR only needs to scan the database once. The CMAR algorithm uses multiple rules to predict unseen instances based on chi-square method. In the experiment, CMAR was compared with CBA and C4.5 in terms of accuracy. The experimental result shows that CMAR performs better than the others.
Abdelhamid [
6] proposed an Enhanced Multi-label Classifier-based Associative Classification (eMCAC) for phishing website detection. It generates rules with multiple class labels from a single dataset without recursive learning. The eMCAC algorithm applies a vertical data format to represent datasets. The support and confidence values for a multi-label rule are calculated based on the average support and confidence values of all classes. The class is assigned to the test instance if attribute values are fully matched to the rule’s antecedent. The experimental results show that the eMCAC algorithm outperforms CBA, PART, C4.5, jRiP, and MCAR [
23] on the real-world phishing data in terms of accuracy.
Hadi et al. [
11] proposed the FACA algorithm for phishing website detection. It applies a Diffset [
24] in the rule-generation process to increase the speed of classifier building time. First, the FACA algorithm discovers k-ruleitems by extending frequent (k − 1)-ruleitems. Then, ruleitems are ranked according to the number of attribute values, confidence, support, and occurrence. To predict unseen data, the FACA algorithm utilizes the All Exact Match Prediction Method. The method matches unseen data with all CARs in the classifiers. Next, unseen data are assigned to the class label with the highest count. From the experimental result, the FACA algorithm outperforms CBA, CMAR, MCAR, and ECAR [
25] in terms of accuracy.
Song and Lee [
15] introduced Predictability-Based Collective Class Association Rule algorithm (PCAR) to enhance rule evaluation. The PCAR algorithm uses inner cross-validation between the test dataset and train dataset to calculate a predictability value of CARs. Then, CARs are ranked according to rule predictive values, rule confidence, rule support, rule antecedent length, and rule occurrences. Finally, the full-matching method is applied to assign a class label for unseen data. To evaluate the performance of PCAR, PCAR was compared with C4.5, RIPPER, CBA, and MCAR on the accuracy, and PCAR was shown to outperform the others.
Alwidian et al. [
16] proposed the WCBA algorithm to enhance the accuracy of a classifier based on the weighting technique. WCBA assumes that the importance of attributes is not equal. For example, in medicine, some attributes are more important than other attributes for prediction. Consequently, weights of all attributes are assigned by experts in the domain. Then, the weighted method is used to select useful CARs and a statistical measure is used for the pruning process. In addition, CARs are priors sorted by using the harmonic mean, which is an average value between support and confidence. The WCBA algorithm is more significantly accurate than CBA, CMAR, MCAR, FACA, and ECBA. However, the WCBA algorithm generates CARs based on the Apriori technique that scans the database many times.
Rajab proposed [
13] the Active Pruning Rule (APR) algorithm. The new pruning process was introduced in APR. CARs are ranked by confidence, support, and rule length. Each training instance is matched over a set of CARs. The first rule that matches an instance is added to the classifier. Then, instances containing the first rule are removed. The support and confidence of remaining rules are recalculated, and all CARs are re-ranked. The APR algorithm was proven to reduce the size of the classifier and to maintain predictive accuracy performance. However, the APR algorithm still has to face a massive number of candidates from a rule-generation process. From previous works, the advantages and disadvantages are shown in
Table 1.
The previous algorithms on AC generally result in high predictability of rules. However, most of them produce k-ruleitems from (k − 1)-ruleitems. They have to calculate supports when a new ruleitems is recovered. To calculate support and confidence values, they have to search all transactions in databases multiple times. Moreover, a huge number of candidate CARs are generated and pruned later to reduce unnecessary CARs. To reduce the problems, the proposed algorithm will directly generate efficient CARs for classification so that the pruning and sorting processes are not necessary. The efficient CARs in our works are rules with 100% confidence which are generated based on the idea that some attribute values can immediately indicate the class label if all attribute values belong to a class label. To easily check attribute values belonging to any class label, vertical data representation is used in the proposed algorithm. Furthermore, simple set theories, intersection, and set difference are adapted to easily calculate support and confidence values without scanning a database multiple times.
3. Basic Definitions
Let be a finite set of all attributes in dataset. is a set of classes, is a set of transactions containing itemset x, and is the number of transactions containing x.
Definition 1. An item can be described as an attribute containing a value , denoted as .
Definition 2. An itemset is the set of items, denoted as .
Definition 3. A ruleitem is of the form , which represents an association between itemsets and class in a dataset; basically, it is represented in the form .
Definition 4. The length of a ruleitem is the number of items, denoted as .
Definition 5. The absolute support of ruleitem r is the number of transactions containing r, denoted as . The support of r can be found from (1). Definition 6. The confidence of ruleitem is the ratio of the number of transactions that contains the itemset in class in and the number of transactions containing the itemset, as in (2). Definition 7. Frequent ruleitem is a ruleitem in which support is not less than the minimum support threshold ().
Definition 8. Class Association Rule (CAR) is a frequent ruleitem in which confidence is not less than the minimum confidence threshold ().
4. The Proposed Algorithm
In this section, a new algorithm, called the Efficient Class Association Rule Generation (ECARG) algorithm, is presented. The pseudo code of the proposed algorithm is shown in Algorithm 1.
| Algorithm 1: Efficient Class Association Rule Generation (ECARG) algorithm main process |
![Algorithms 13 00299 i001]() |
First, 1-frequent ruleitems are generated (line 1). To quickly find 1-frequent ruleitems, the proposed algorithm takes the advantage of a vertical data format to calculate the support of the ruleitems. The support of the ruleitems can be obtained from
. If any 1-ruleitem does not meet the minimum support threshold, it will not be extended with the other ruleitems. Moreover, the confidence of the frequent ruleitems can be calculated from Equation (
2) by using the vertical data format. If the confidence of the ruleitem is 100%, the ruleitems will be added to the classifier directly (line 7); otherwise, it will be considered extended with the others (line 5).
After discovering the most effective CAR with 100% confidence, the transaction IDs associated with the CAR will be removed to avoid redundant CARs (line 8). To remove the transaction IDs, a set difference plays an important role in our algorithm. Let be a CAR with 100% confidence and T be a set of ruleitems in the same class of . For all , the new transaction IDs of is . Then, the new transaction IDs, support, and confidence values of all rules are updated (line 9).
In each iteration, if there is no CAR with 100% confidence, the ruleitem r with the highest confidence will be first to be considered extended in a breadth-first search manner. It will be combined with other ruleitems in the same class until the new CAR has 100% confidence (line 5). If is extended with to be and , then . After the extended CAR is added to the classifier, the transaction IDs associated with the CAR will be removed. Finally, if no ruleitem satisfies the minimum support threshold, the CAR generation will be stopped.
The proposed algorithm continues to find a default class in order to insert it to the classifier. The class with the most remaining transaction IDs is selected as the default class (line 12).
To demonstrate the examples, the dataset in
Table 2 is used as example data. The minimum support and confidence thresholds are set to 2 and 50%, respectively.
The vertical data format represents associated transaction IDs of 1-ruleitem, as shown in
Table 3. The last 2 columns of
Table 3 show the support and confidence of ruleitems that are calculated. From
Table 2, the
value in
occurs in transaction IDs 5, 6, 7, and 9, denoted as
. Class
A is in transaction IDs 1, 2, 3, 4, 8, and 9, denoted as
, while class
B is in transaction IDs 5, 6, and 7, denoted as
. The transaction IDs containing
are
, so the supports of
are 1. The rule
will not be extended because its support is less than the minimum support threshold. Transaction IDs containing
are
, so the supports of
are 3. Hence, this rule is a frequent ruleitem.
The confidence of can be obtained from . The confidence of is not 100% so it will be extended, whereas the confidence of is , so it is the first CAR added to the classifier.
After discovering the first CAR, the transaction IDs associated with the CAR will be removed. From
Table 3, if
is found, the class will absolutely be
A. Hence,
does not need to be extended with the other attribute values and transaction IDs 1, 2, 3, and 4 should be removed. The ECARG algorithm adopts a set difference, which can help to remove transaction IDs more conveniently.
For example,
and
. The new transaction IDs of
. Then, the new transaction IDs, support, and confidence values of all rules are updated as shown in
Table 4.
From
Table 4, there is no CAR with 100% confidence.
has the maximum confidence, and
is a subset of
. Hence, the new rule
is found with 100% confidence. Then the extension of
is stopped. For 2-ruleitem extended from
, there is only one rule with 100% confidence and it is added to the classifier as the second CAR.
After the second CAR is added to classifiers, the transaction IDs associated with CAR are removed. The remaining transaction IDs are shown in
Table 5. There is only one ruleitem that satisfies the minimum support threshold: the ruleitem
which does not meet 100% of confidence. No ruleitem passes the minimum support threshold to be extended with the ruleitem
so CAR generation is stopped.
With the remaining transaction IDs in
Table 5, the ECARG algorithm continues to find a default class and to add it to the classifier. In this step, the class with the most relevant transaction IDs is selected as the default class. In
Table 5, class
A remains in transaction IDs 8 and 9 while class
B remains in transaction ID 7. The remaining transaction IDs are relevant to class
A the most, so the default class is
A. In case the number of associated remaining transaction IDs with each class is not changed, the majority class in the classifier is the default class. Finally, all CARs in the classifier are shown in
Table 6.
To observe the effect of 100% confidence ruleitems, we tested another version of ECARG, ECARG2. The difference in ECARG2 is ruleitem extension. If a ruleitem with 100% confidence cannot be found from the extension, the ruleitem with the highest confidence will be selected as a CAR and added to classifiers. For example, in
Table 5, ruleitem
is the only ruleitem that satisfies the minimum support and minimum confidence. Hence, ECARG2 selects the ruleitem as the third CAR. The associated transaction IDs are removed, and the remaining transaction ID is shown in
Table 7. There is only one transaction ID with class
B. Consequently, the default class is
B. Finally, all CARs from ECARG2 are shown in
Table 8.
5. Experimental Setting and Result
The experiments were implemented and tested on a system with the following environment: Intel Core i3-6100u 2.3 GHz processor with 8 GB DDR4 main memory, running Microsoft Windows 10 64-bit version. Our algorithm is compared with the well-known algorithms CBA, CMAR, and FACA. All algorithms were implemented in java. The implementing java version of the CBA algorithm using CR-tree is from WEKA [
26]. The implementation of CMAR in JAVA is from [
27]. Four algorithms are tested on 14 datasets from the UCI Machine Learning Repository. The characteristics of the datasets are shown in
Table 9. Ten-fold cross-validation is used to divide testing instances and training instances based on previous works [
12,
17,
23,
26,
27]. Accuracy rates, the number of CARs, classifier building times, and memory consumption are used to measure the performance of the four algorithms.
To study the sensitivity of thresholds on the ECARG algorithm, we set different minimum support thresholds and different minimum confidence thresholds in the experiment. First, we set the minimum support thresholds from 1% to 4% and analyze different minimum confidence thresholds between 60%, 70%, 80%, and 90%.
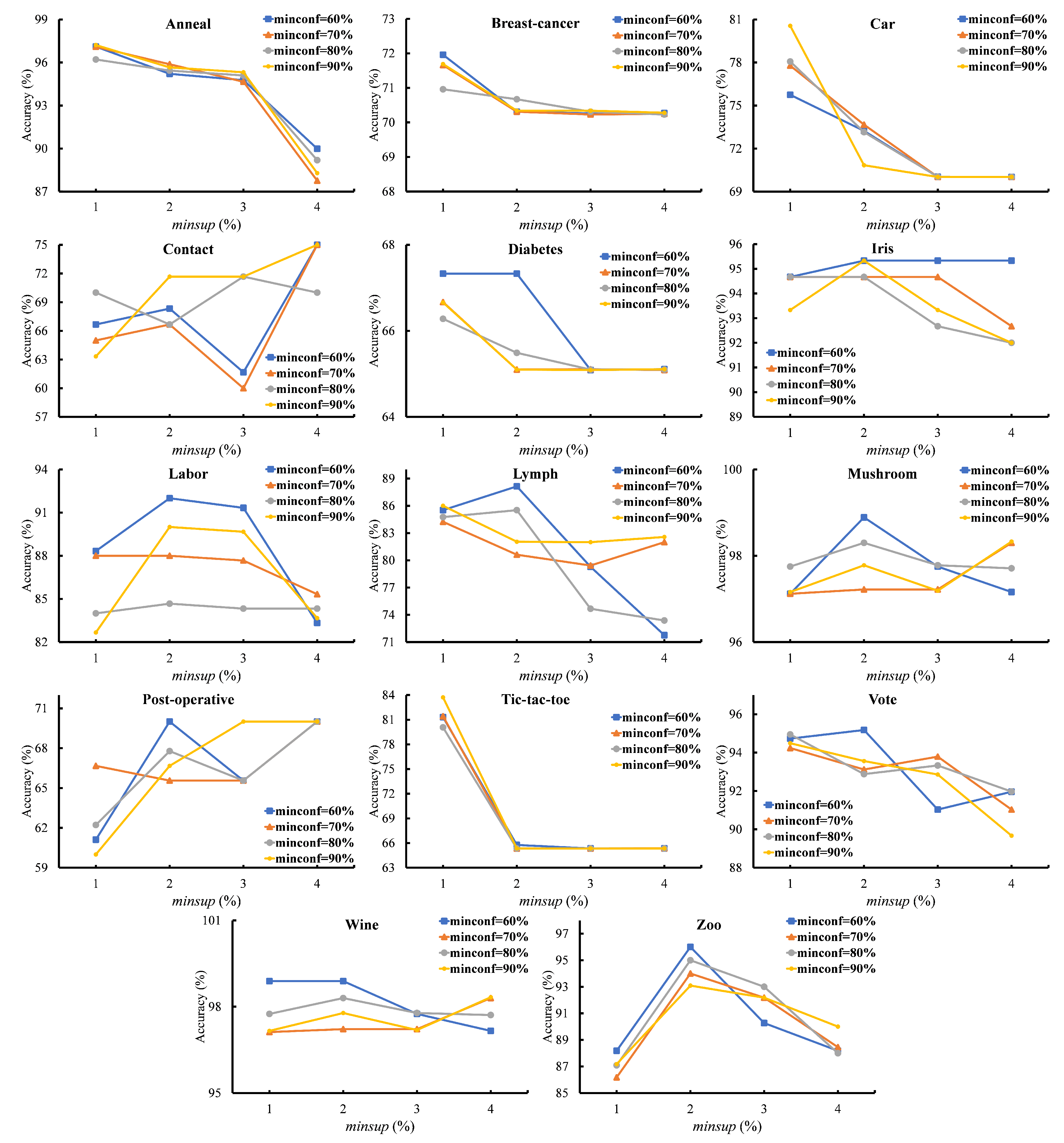
Figure 1 shows the accuracy rates of all datasets. The results show that, when the minimum support thresholds are increased, the accuracy rates are decreased. If the minimum confidence thresholds are increased, the accuracy rates are slightly down.
The highest accuracy rates are given in most datasets, Diabetes, Iris, Labor, Lymph, Mushroom, Post-operative, Tic-tac-toe, Vote, Wine, and Zoo, when minimum support and minimum confidence are set to 2% and 60%, respectively. Therefore, the minimum support is set to 2%, and minimum confidence is set to 60% in the next experiments.
Table 10 reports the accuracy rates of the CBA, CMAR, FACA, ECARG, and ECARG2 algorithms on the UCI datasets. The results show that both of our algorithms outperform the others on average. This gain resulting from the methodology found the most efficient rule in each iteration and eliminated redundant rules simultaneously. To be more precise, we further analyzed the win-lost-tie records. Based on
Table 10, the win-lost-tie records of the ECARG2 algorithm against CBA, CMAR, FACA, and ECARG in terms of accuracy are 11-3-0, 11-3-0, and 9-4-1, 8-6-0, respectively. We can observe that ECARG gives an accuracy slightly less than ECARG2. However, the ECARG algorithm results in the highest accuracy in 6 of 14 datasets.
Table 11 shows the average number of CARs generated from CBA, CMAR, FACA, ECARG, and ECARG2 algorithms. The result shows that the CMAR algorithm generates the highest number of rules, while the ECARG algorithm generates the lowest. In particular, the ECARG algorithm generates 8 CARs on average against 14 datasets whereas the CBA, CMAR, FACA, and ECARG2 algorithms derive 19, 240, 13, and 18 CARs on average, respectively. The accomplishment of the proposed algorithm is the discovery of the most efficient CAR in each iteration and the elimination of unnecessary transaction IDs that leads to redundant CARs.
Table 12 shows the average classifier building time of the proposed algorithm against CBA, CMAR, and FACA. The experimental result clearly shows that our algorithm is the fastest among all algorithms in the 14 datasets. ECARG takes fewer seconds to construct the classifier than CBA, CMAR, FACA, and ECARG2 by 2.134, 0.307, 2.883, and 0.0162, respectively. This can be explained by the fact that CBA and FACA uses an Apriori-style approach to generate candidates. When the value for minimum support is low on large datasets, it is costly to handle a large number of candidate ruleitems. The CMAR algorithm based on FP-growth is better than CBA and FACA in some cases, but it takes more classifier-generating time than ECARG and ECARG2.
Table 13 reveals the memory consumption in the classifier building process of all 5 algorithms. The results show that ECARG consumes less memory than CBA, CMAR, FACA, and ECARG2 by 22.62 MB, 73.15 MB, 36.57 MB, and 0.98 MB, respectively. The memory consumption of ECARG is the best since it eliminates unnecessary data in each iteration. From the result in
Table 14, our proposed algorithm gives a higher F-measure on average than the other algorithms. In particular, the ECARG2 outperformed CBA, CMAR, FACA, and ECARG by 3.82%, 25.38%, 25.38%, 12.74%, and 1.84%, respectively.
Table 15 shows standard deviations of accuracy rate, the number of generated rules, building times, memory consumption, and F-measure of ECARG. The standard deviation values of building time and memory consumption are low and show that the building time and memory consumption in each fold is approximately marginal. The standard deviation values of the number of generated rules are relevant.
The standard deviation values of accuracy rates and F-measure show that the values of accuracy rates and F-measure in each fold are marginally different on almost all datasets. However, when evaluating the small datasets, Contact-lenses, Labor, Lymph, and Post-operative, the standard deviation values are high because 10-fold cross-validation splits a very small testing set that can potentially affect the efficiency of the classifier. For example, the Contact-lenses dataset composes only 2 or 3 transactions in each testing set. Consequently, only one false classification occurs in the testing set and then reduces the accuracy rate dramatically.
From the experimental results, the ECARG algorithm outperforms CBA, CMAR, and FACA in terms of accuracy rate and the number of generated rules. A key achievement of the ECARG algorithm is that the technique generates valid rules with 100% confidence to build classifiers. The high confidence demonstrates the high possibility of class occurrences occurring in an itemset. Therefore, the ECARG algorithm produces a small classifier but gives high accuracy. While the CBA, CMAR, and FACA algorithms build classifiers from CARs that meet the minimum confidence threshold, some of the CARs have low confidences so they may predict incorrect classese and then the accuracies of CBA, CMAR, and FACA are lower than the proposed algorithm in the most dataset.
Moreover, ECARG outperforms the others in terms of building time and memory consumption. This key achievement applies simple set theories, i.e., intersection and set difference, processing on vertical data, which can potentially reduce time and memory consumption. Furthermore, the search space can be reduced as unnecessary transactions are eliminated in each stage and, therefore, the classifier building time is minimized.
6. Conclusions
This paper proposes algorithms to enhanced associative classification. Unlike the traditional algorithms, the proposed algorithms do not need a sorting and pruning process. Candidate generation is carried out by attempting to select a first general rule with the highest accuracy. Moreover, a search space is reduced early by cutting down items with low statistical significance. Furthermore, a vertical data format, intersection, and set difference methods are applied to calculate support and confidence and to remove unnecessary transaction IDs, decreasing computation time and memory consumption.
The experiments were conducted on 14 UCI datasets. The experimental results show that the ECARG algorithm outperforms the CBA, CMAR, and FACA algorithms in terms of accuracy by 4.78%, 17.79%, and 1.35%, respectively. Furthermore, ECARG generates smaller rules than the other algorithms in almost all datasets. In addition, ECARG results in the most optimal classifier-generating time and memory usage on average. We can conclude that the proposed algorithm gives a compact classifier with a high accuracy rate, improves computation time, and reduces memory usage.
However, the ECARG algorithm does not well perform on imbalanced datasets, such as Breast, Car, Diabetes, and Post-operative. This is because the ECARG algorithm tends to find 100% confidence CARs and to eliminate unnecessary transactions. Therefore, ruleitems belonging to minority classes will not meet the minimum support threshold or 100% confidence and they are eliminated accordingly. Consequently, the classifier cannot classify the minority class correctly.




{kind=link}