Understanding Contrail Business Processes through Hierarchical Clustering: A Multi-Stage Framework

 ,
,  ,
,  and
and
Abstract
1. Introduction
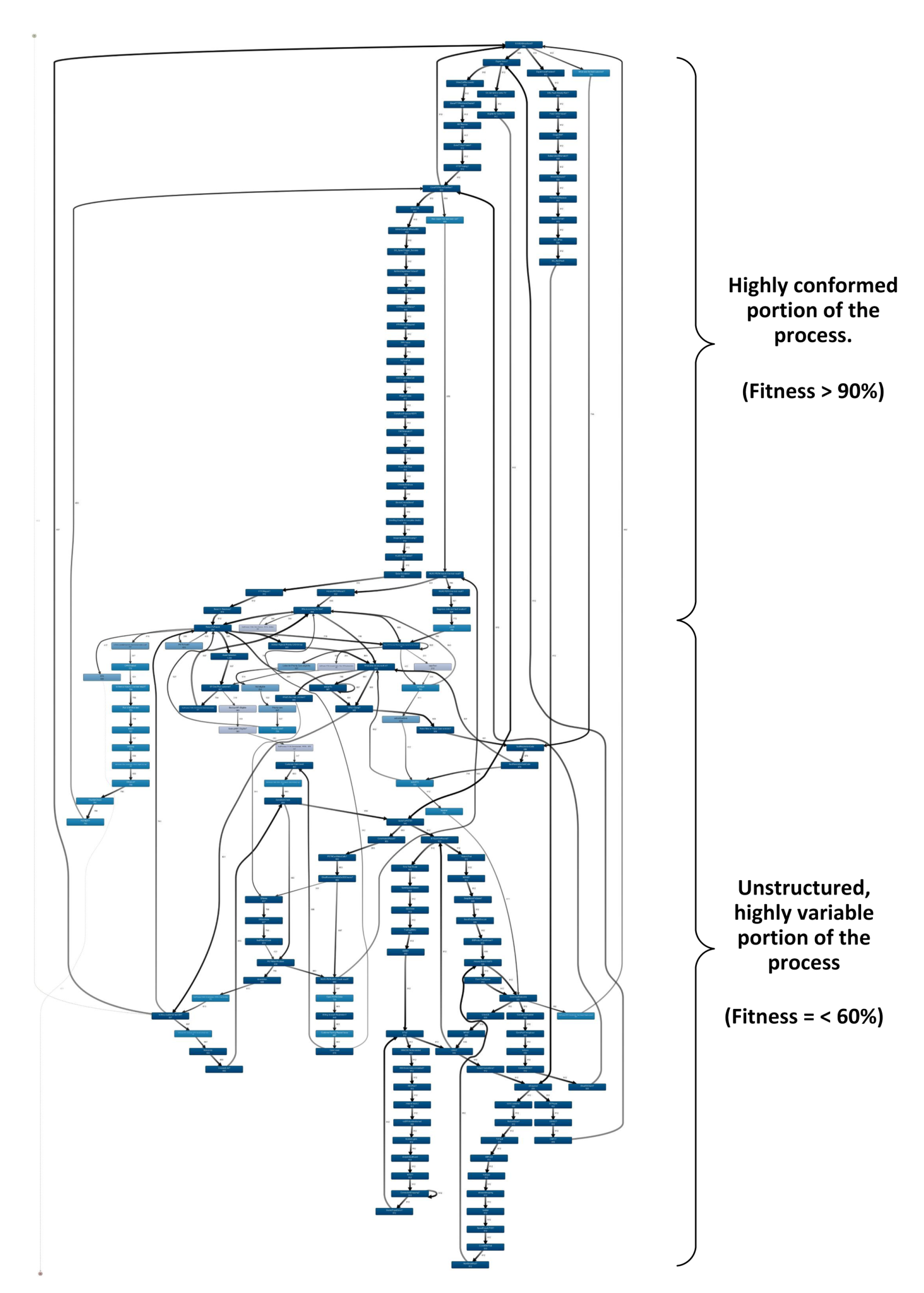
- We introduced a unique type of business process termed as contrail processes, which are the result of the complex business-oriented thought process of the organisations, detailed in Section 3.1. Contrail processes are difficult to analyse by applying general process mining techniques as they present a mixture of both simple and highly variable process models. Deeper insights of these processes allows better analysis and improvement in the considered business process.
- A multi-stage framework is proposed to identify business-logic driven clusters from unlabelled process log with contrail-type characteristics. We decomposed raw process log into smaller and understandable clusters of process instances that possess a common business logic. Thus, opening the door of further in-depth process analysis, such as identification of bottlenecks, deviated paths and outlier detection.
- We presented the experimental results of case-level clustering in the context of (i) machine learning: by illustrating an accuracy of the discovered clusters through classification results from several machine learning algorithms, and (ii) process mining: by revealing the impact on the fitness metric of process model generated for each discovered cluster.
2. Literature Review
3. Proposed Methodology
3.1. Introducing the ‘Contrail Process’
3.2. Multi-Stage Framework for Process Log Simplification
- Case level feature extraction: Attributes of each individual case of the process log represented as a feature set.
- Feature selection: Feature selection in the unsupervised environment is a trade-off between several selected features and accuracy of the performed clustering [20]. We used selective set of features which can reveal the natural grouping of the cases among the process log. Approaches such as wrapper [28] and Multi-objective Feature Selection [20] resulted in the selection of most discriminating features for clustering but the focus of this work is to consider all those features which present a business perspective of grouping within the data. We concluded our feature selection based on several quality level parameters as proposed in [20], implemented through RapidMiner tool. These quality metrics are:
- Correlation: It is a Pearson correlation coefficient between the attributes and the labels of the feature set.
- ID-ness: It measures the unique attributes in the data. Higher the ID-ness, lower the quality of attribute for clustering.
- Stability: It is a measure of constant values in attributes. It is calculated as (2):where is the number of rows with the most frequent non-missing values divided by , the total number of data rows with non-missing values. Higher the stability, lower the quality of attribute for clustering.
- Missing values: It measure the percentage of attributes with missing values.
- Defining a distance matrix: The event log of the real-world business process may contain different data types, including logical, nominal, ordinal and numerical data. It is vital to identify the difference between selected features of the cases using a distance matrix. A Distance matrix helps to identify the centroid distance between selected features. In this paper we used Gower distance measure [29] which was introduced in 1971 and it is a measure of distances between pairs of variables and combining those distances to a single value for each of the pair.
- Identification of an optimal number of clusters: This step is to specify the optimal number of clusters k to be produced using the distance matrix. In this paper, we used a Silhouette average [30] for identification of the number of optimal clusters through Partitioning Around Medoids (PAM) algorithm. Each of the identified clusters is re-considered for further clustering using the same procedure, until stopping criteria of further clustering is achieved.
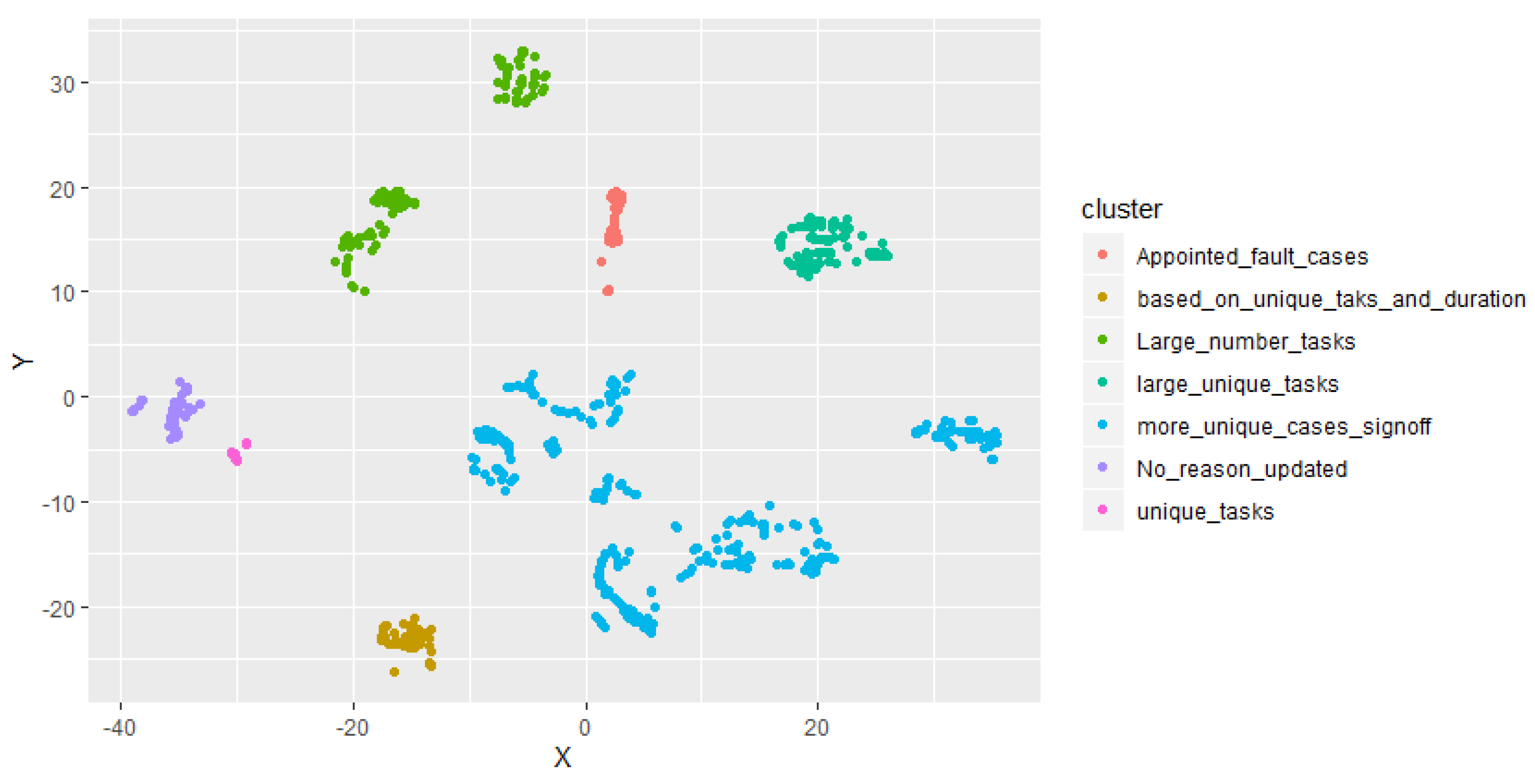
- Label process data: Once clusters are identified, cases that belong to each cluster are labelled with a meaningful business context that is exhibited in the cluster. The label of each cluster is derived from the collective business logic presented in the cases which belong to that specific cluster. For example, cases are labelled as ‘handled by agent’ if all cases in that cluster represent the trend that they are monitored and updated by an organisation’s employee agent handling the business process.
3.3. Stopping Criteria for Further Clustering
4. Implementation
4.1. Stage-1: Identification of High-Level Business Classes
4.1.1. Data Collection
4.1.2. Analyse the Event Log
4.1.3. Rule Based Mining
4.2. Stage-2: Novel Hierarchical Clustering
4.2.1. Case Level Feature Extraction
4.2.2. Feature Selection
4.2.3. Defining a Distance Matrix
4.2.4. Identification of Optimal Clusters through Novel Hierarchical Clustering (NoHiC) Algorithm
| Algorithm 1 High-level pseudo-code description of Novel Hierarchical Clustering (NoHiC) |
 |
5. Results and Discussion
5.1. Measuring the Accuracy of the Clusters
5.1.1. Are the Resultant Clusters Well Segregated?
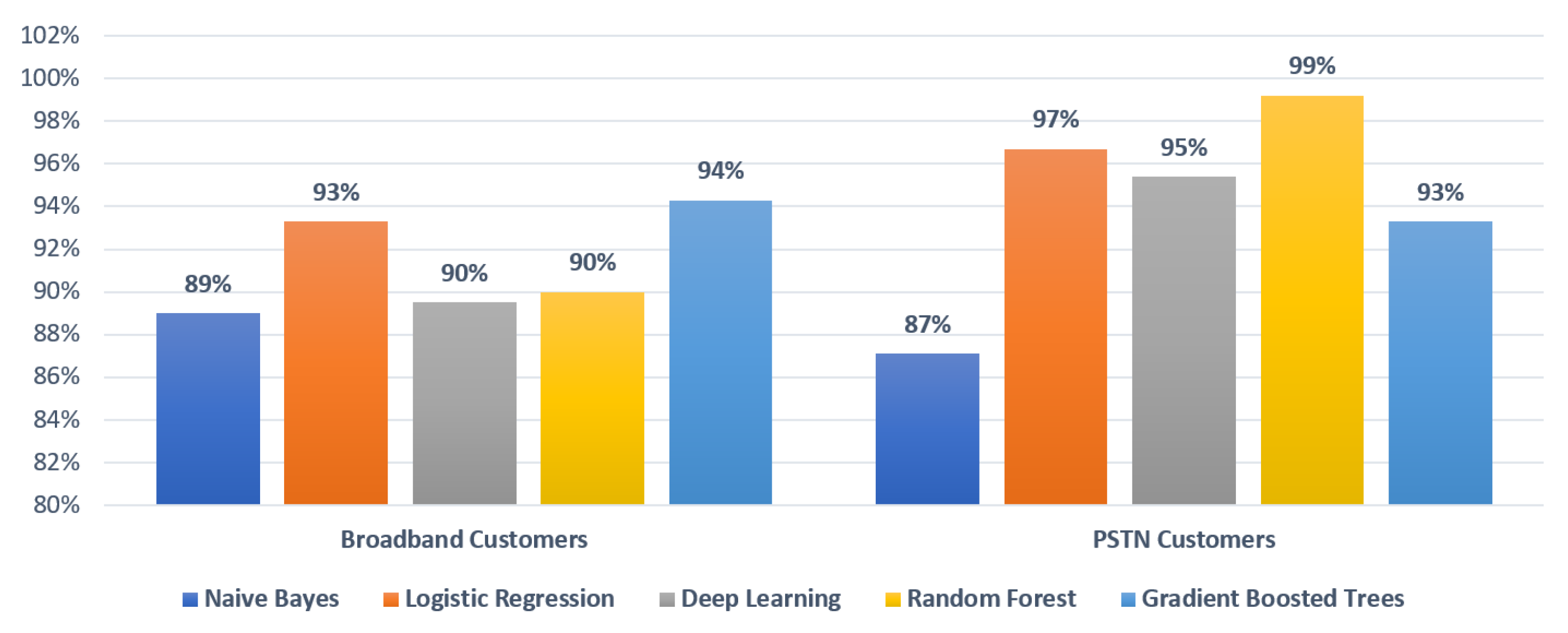
5.1.2. What Is the Classification Accuracy?
5.1.3. What Is an Impact on Fitness of Log?
5.2. Comparison with Other Trace Clustering Techniques
- Nodes per discovered cluster (N)
- Arcs per discovered cluster (A)
- Average connection degree ()
- Density (D):
- Cyclomatic number (): Number of the linearly independent cycles:
- Coefficient of connectivity ():
- Coefficient of network complexity ():
- Average number of event classes per cluster: Measure of partitioning of the traces based on functionality. Better clustering technique should have minimal event classes per cluster [32].
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| PAIS | Process-Aware Information Systems |
| BTIIC | BT Ireland Innovation Centre |
| BT | British Telecom |
| CDP | Customer Diagnostic Process |
| CBA | Classification Based on Association |
| CRD | Customer Relationship Department |
| PSTN | Public Switched Telephone Network |
| BPI | Business Process Intelligence |
References
- De Leoni, M.; van der Aalst, W.M.; Dees, M. A general process mining framework for correlating, predicting and clustering dynamic behavior based on event logs. Inf. Syst. 2016, 56, 235–257. [Google Scholar] [CrossRef]
- Van Der Aalst, W. Process Mining: Data Science in Action; Springer: Berlin/Heidelberg, Germany, 2016; pp. 243–297. [Google Scholar]
- Lingitz, L.; Gallina, V.; Ansari, F.; Gyulai, D.; Pfeiffer, A.; Monostori, L. Lead time prediction using machine learning algorithms: A case study by a semiconductor manufacturer. Procedia Cirp 2018, 72, 1051–1056. [Google Scholar] [CrossRef]
- De Alvarenga, S.C.; Barbon, S., Jr.; Miani, R.S.; Cukier, M.; Zarpelão, B.B. Process mining and hierarchical clustering to help intrusion alert visualization. Comput. Secur. 2018, 73, 474–491. [Google Scholar] [CrossRef]
- Rojas, E.; Munoz-Gama, J.; Sepúlveda, M.; Capurro, D. Process mining in healthcare: A literature review. J. Biomed. Inform. 2016, 61, 224–236. [Google Scholar] [CrossRef] [PubMed]
- Le, M.; Gabrys, B.; Nauck, D. A hybrid model for business process event and outcome prediction. Expert Syst. 2017, 34, e12079. [Google Scholar] [CrossRef]
- Buijs, J.C.; Van Dongen, B.F.; van Der Aalst, W.M. On the role of fitness, precision, generalization and simplicity in process discovery. In OTM Confederated International Conferences “on the Move to Meaningful Internet Systems”; Springer: Berlin/Heidelberg, Germany, 2012; pp. 305–322. [Google Scholar]
- Van Der Aalst, W.; Adriansyah, A.; De Medeiros, A.K.A.; Arcieri, F.; Baier, T.; Blickle, T.; Bose, J.C.; Van Den Brand, P.; Brandtjen, R.; Buijs, J.; et al. Process mining manifesto. In International Conference on Business Process Management, Proceedings of the BPM 2011: Business Process Management Workshops, Clermont-Ferrand, France, 30 August–2 September 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 169–194. [Google Scholar]
- Bogarín Vega, A.; Cerezo Menéndez, R.; Romero, C. Discovering learning processes using inductive miner: A case study with learning management systems (LMSs). Psicothema 2018, 30, 322–329. [Google Scholar]
- Bose, R.J.C.; van der Aalst, W.M. Process diagnostics using trace alignment: Opportunities, issues, and challenges. Inf. Syst. 2012, 37, 117–141. [Google Scholar] [CrossRef]
- Song, M.; Günther, C.W.; Van der Aalst, W.M. Trace clustering in process mining. In International Conference on Business Process Management, Proceedings of the BPM 2008: Business Process Management Workshops, Milan, Italy, 2–4 September 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 109–120. [Google Scholar]
- Thaler, T.; Ternis, S.F.; Fettke, P.; Loos, P. A Comparative Analysis of Process Instance Cluster Techniques. Wirtschaftsinformatik 2015, 2015, 423–437. [Google Scholar]
- Veiga, G.M.; Ferreira, D.R. Understanding spaghetti models with sequence clustering for ProM. In International Conference on Business Process Management, Proceedings of the BPM 2009: Business Process Management Workshops, Ulm, Germany, 8–10 September 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 92–103. [Google Scholar]
- Han, K.J.; Narayanan, S.S. A robust stopping criterion for agglomerative hierarchical clustering in a speaker diarization system. In Proceedings of the Eighth Annual Conference of the International Speech Communication Association, Antwerp, Belgium, 27–31 August 2007. [Google Scholar]
- De Weerdt, J.; Vanden Broucke, S.; Vanthienen, J.; Baesens, B. Active trace clustering for improved process discovery. IEEE Trans. Knowl. Data Eng. 2013, 25, 2708–2720. [Google Scholar] [CrossRef]
- De Koninck, P.; De Weerdt, J. Multi-objective trace clustering: Finding more balanced solutions. In International Conference on Business Process Management, Proceedings of the BPM 2016: Business Process Management Workshops Rio de Janeiro, Brazil, 18–22 September 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 49–60. [Google Scholar]
- Agrawal, R.; Imieliński, T.; Swami, A. Mining association rules between sets of items in large databases. In Proceedings of the 1993 ACM SIGMOD International Conference on Management of Data, Washington, DC, USA, 26–28 May 1993; pp. 207–216. [Google Scholar]
- Taylor, P.N.; Kiss, S. Rule-mining and clustering in business process analysis. In International Conference on Innovative Techniques and Applications of Artificial Intelligence, Proceedings of the SGAI 2018: Artificial Intelligence XXXV, Cambridge, UK, 11–13 December 2018; Springer: Cham, Switzerland, 2018; pp. 237–249. [Google Scholar]
- Thabtah, F.; Mahmood, Q.; McCluskey, L.; Abdel-Jaber, H. A new Classification based on Association Algorithm. In Journal of Information & Knowledge Management; World Scientific: Washington, DC, USA, 2010; pp. 55–64. [Google Scholar]
- Mierswa, I.; Wurst, M. Information preserving multi-objective feature selection for unsupervised learning. In Proceedings of the 8th Annual Conference on Genetic and Evolutionary Computation, Seattle, WA, USA, 8–12 July 2006; pp. 1545–1552. [Google Scholar]
- Greco, G.; Guzzo, A.; Pontieri, L.; Sacca, D. Mining expressive process models by clustering workflow traces. In Pacific-Asia Conference on Knowledge Discovery and Data Mining, Proceedings of the PAKDD 2004: Advances in Knowledge Discovery and Data Mining, Sydney, Australia, 26–28 May 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 52–62. [Google Scholar]
- Van der Aalst, W.M.; Rubin, V.; Verbeek, H.; van Dongen, B.F.; Kindler, E.; Günther, C.W. Process mining: A two-step approach to balance between underfitting and overfitting. Softw. Syst. Model. 2010, 9, 87. [Google Scholar] [CrossRef]
- Rozinat, A.; Van der Aalst, W.M. Conformance checking of processes based on monitoring real behavior. Inf. Syst. 2008, 33, 64–95. [Google Scholar] [CrossRef]
- Contrail Shots. 2020. Available online: https://www.flickr.com/groups/contrails/pool/with/50114576393/ (accessed on 25 September 2020).
- Unterstrasser, S.; Stephan, A. Far field wake vortex evolution of two aircraft formation flight and implications on young contrails. Aeronaut. J. 2020, 124, 667–702. [Google Scholar] [CrossRef]
- Abd Ellatif, M.; Shaaban, E.M.; Amin, M.A. Detecting Deviations in Business Processes Using Process Mining. In Proceedings of the 2019 14th International Conference on Computer Engineering and Systems (ICCES), Cairo, Egypt, 17 December 2019; pp. 49–54. [Google Scholar]
- Aguwa, C.; Olya, M.H.; Monplaisir, L. Modeling of fuzzy-based voice of customer for business decision analytics. Knowl.-Based Syst. 2017, 125, 136–145. [Google Scholar] [CrossRef]
- Solorio-Fernández, S.; Carrasco-Ochoa, J.A.; Martínez-Trinidad, J.F. A review of unsupervised feature selection methods. Artif. Intell. Rev. 2020, 53, 907–948. [Google Scholar] [CrossRef]
- Gower, J.C. A general coefficient of similarity and some of its properties. Biometrics 1971, 27, 857–871. [Google Scholar] [CrossRef]
- Park, H.S.; Jun, C.H. A simple and fast algorithm for K-medoids clustering. Expert Syst. Appl. 2009, 36, 3336–3341. [Google Scholar]
- Hahsler, M.; Johnson, I.; Kliegr, T.; Kucha, J. Associative Classification in R: Arc, arulesCBA, and rCBA. R J. 2019, 9, 254–267. [Google Scholar] [CrossRef]
- Bose, R.J.C.; van der Aalst, W.M. Trace clustering based on conserved patterns: Towards achieving better process models. In International Conference on Business Process Management, Proceedings of the BPM 2009: Business Process Management Workshops, Ulm, Germany, 8–10 September 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 170–181. [Google Scholar]
- Delias, P.; Doumpos, M.; Grigoroudis, E.; Matsatsinis, N. A non-compensatory approach for trace clustering. Int. Trans. Oper. Res. 2019, 26, 1828–1846. [Google Scholar] [CrossRef]
- Van der Aalst, W.M.; Weijters, A.J. Process mining: A research agenda. Comput. Ind. 2004, 53, 231–244. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subcategory | Related Cases | Complete | Number of Cases |
|---|---|---|---|
| in Process Log | Cases | Used in Study | |
| Broadband | 47% | 89% | 736 |
| PSTN | 53% | 90% | 844 |
| # | Sequences | Support | Target Business Class |
|---|---|---|---|
| 1 | (120>3913) | 0.63 | Broadband customers |
| 2 | (3913>4172) | 0.52 | Broadband customers |
| 3 | (120>3913) & (3913>4172) | 0.52 | Broadband customers |
| 4 | (120>3913) & (3913>4172) & (4172>2372) | 0.52 | Broadband customers |
| 5 | (120>3913) & (4172>2372) | 0.52 | PSTN customers |
| 6 | (3913>4172) & (4172>2372) | 0.52 | PSTN customers |
| 7 | (4172>2372) | 0.52 | PSTN customers |
| 8 | (2486>120) | 0.49 | PSTN customers |
| Feature_ID | Feature Details | Denoted by | Feature Type | Correlation | ID-Ness | Stability | Missing |
|---|---|---|---|---|---|---|---|
| Duration | Duration of task | Statistical | Weak | No | No | No | |
| Num_tasks | total number of appeared tasks within the process | aT | Statistical | Weak | No | No | No |
| Num_unique | total number of unique tasks | uT | Statistical | Weak | No | No | No |
| Num_rep | total number of tasks which are repeated | rT | Statistical | Strong | No | No | No |
| Department | Department handling the case | dH | Business | No | No | Strong | Yes |
| End progress | Case conclusion remarks | cR | Business | No | No | Strong | No |
| Exit-1 | Exit comment #1 entered by agent | eC1 | Business | Strong | No | Weak | Yes |
| Exit-2 | Exit comment #2 entered by agent | eC2 | Business | No | No | No | No |
| Exit-3 | Exit comment #3 entered by agent | eC3 | Business | No | No | No | No |
| Case_ID | Duration | Num_TASKS | Num_UNIQUE | End Progress | Exit 2 | Exit 3 |
|---|---|---|---|---|---|---|
| C_01 | 404 | 511 | 292 | End Call | Not selected | appointedFault |
| C_02 | 146 | 377 | 233 | End Call | Sent to WS for ENG | nonAppointedFault |
| C_03 | 366 | 314 | 204 | Progress Saved | 0 | Service Outage |
| C_04 | 333 | 317 | 204 | End Call | 0 | Service Outage |
| C_05 | 367 | 351 | 218 | End Call | No reason given | No reason given |
| C_06 | 754 | 353 | 223 | Progress Saved | Fixed by restarting Hub | 0 |
| C_07 | 169 | 298 | 187 | End Call | No reason given | nonAppointedFault |
| C_08 | 231 | 285 | 184 | End Call | No reason given | nonAppointedFault |
| Case_ID | Duration | # of Tasks | # of Unique Tasks | End Progress | Exit 2 | Exit 3 |
|---|---|---|---|---|---|---|
| C_722 | 5 | 143 | 123 | End Call | Outcome | Refer to legacy No Connection |
| C_1221 | 4 | 143 | 123 | End Call | Outcome | Refer to legacy No Connection |
| Case_ID | Duration | # of Tasks | # of Unique Tasks | End Progress | Exit 2 | Exit 3 |
|---|---|---|---|---|---|---|
| C_131 | 14358 | 186 | 154 | Progress Saved | 0 | 0 |
| C_982 | 503 | 443 | 271 | End Call | Outcome | Booked_appointment |
| Minimum Support | Accuracy | Sensitivity | F1 Score |
|---|---|---|---|
| 30% | 97.22% | 94.00% | 97.14% |
| 35% | 98.12% | 96.20% | 98.00% |
| 40% | 94.40% | 88.80% | 94.11% |
| 45% | 94.40% | 88.80% | 94.11% |
| Number of Events | Event Classes | Mean Events Per Case | Mean Classes Per Case | Start Event Classes | End Event Classes | |
|---|---|---|---|---|---|---|
| CDP | 276635 | 1947 | 277 | 178 | 9 | 74 |
| BPI | 262200 | 36 | 20 | 12 | 1 | 13 |
| CDP | BPI | |||||
|---|---|---|---|---|---|---|
| Identified clusters | Business Perspective | Avg. Fitness Per Cluster | Identified Clusters | Business Perspective | Avg. Fitness Per Cluster | |
| NoHiC | 11 | Yes | 0.87 | 6 | Yes | 0.75 |
| ActiTraC | 9 | No | 0.81 | 9 | No | 0.66 |
| K-Gram_AHC | 4 | No | 0.8 | 4 | No | 0.63 |
| TR_AHC | 4 | No | 0.77 | 4 | No | 0.63 |
| MR_AHC | 4 | No | 0.78 | 4 | No | 0.63 |
| SMR_AHC | 4 | No | 0.82 | 4 | No | 0.74 |
| NSMR_AHC | 4 | No | 0.77 | 4 | No | 0.37 |
| Avg.N | Avg.A | D | Avg. | Avg. | Avg. | |||
|---|---|---|---|---|---|---|---|---|
| CDP | NoHiC | 580 | 915.67 | 3.06 | 0.003 | 336.67 | 1.58 | 0.05 |
| ActiTraC | 571.18 | 993.36 | 2.85 | 0.01 | 423.18 | 1.74 | 0.06 | |
| K-Gram_AHC | 707.25 | 1311.75 | 2.93 | 0.004 | 425.5 | 1.6 | 0.05 | |
| TR_AHC | 816.25 | 1311.25 | 3.22 | 0.001 | 496 | 1.61 | 0.04 | |
| MR_AHC | 789.25 | 1255.75 | 3.19 | 0.002 | 467.5 | 1.59 | 0.04 | |
| SMR_AHC | 814.75 | 1293 | 3.14 | 0.001 | 479.25 | 1.59 | 0.04 | |
| NSMR_AHC) | 697 | 1121.5 | 3.11 | 0.003 | 425.5 | 1.61 | 0.05 | |
| BPI | NoHiC | 24 | 41.75 | 3.47 | 0.06 | 18.75 | 1.74 | 0.27 |
| ActiTraC | 32.73 | 59.91 | 3.6 | 0.05 | 28.18 | 1.83 | 0.24 | |
| K-Gram_AHC | 26.75 | 50.75 | 3.47 | 0.06 | 25 | 1.9 | 0.27 | |
| TR_AHC | 29.5 | 57.75 | 3.74 | 0.06 | 29.25 | 1.96 | 0.26 | |
| MR_AHC | 28.5 | 50.75 | 3.47 | 0.06 | 25 | 1.9 | 0.27 | |
| SMR_AHC | 26.25 | 47 | 3.59 | 0.06 | 23.5 | 1.92 | 0.28 | |
| NSMR_AHC) | 35 | 71.25 | 4.05 | 0.05 | 37.25 | 2.04 | 0.24 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tariq, Z.; Khan, N.; Charles, D.; McClean, S.; McChesney, I.; Taylor, P. Understanding Contrail Business Processes through Hierarchical Clustering: A Multi-Stage Framework. Algorithms 2020, 13, 244. https://doi.org/10.3390/a13100244
Tariq Z, Khan N, Charles D, McClean S, McChesney I, Taylor P. Understanding Contrail Business Processes through Hierarchical Clustering: A Multi-Stage Framework. Algorithms. 2020; 13(10):244. https://doi.org/10.3390/a13100244
Chicago/Turabian StyleTariq, Zeeshan, Naveed Khan, Darryl Charles, Sally McClean, Ian McChesney, and Paul Taylor. 2020. "Understanding Contrail Business Processes through Hierarchical Clustering: A Multi-Stage Framework" Algorithms 13, no. 10: 244. https://doi.org/10.3390/a13100244
APA StyleTariq, Z., Khan, N., Charles, D., McClean, S., McChesney, I., & Taylor, P. (2020). Understanding Contrail Business Processes through Hierarchical Clustering: A Multi-Stage Framework. Algorithms, 13(10), 244. https://doi.org/10.3390/a13100244