Mapping a Guided Image Filter on the HARP Reconfigurable Architecture Using OpenCL


Abstract
1. Introduction
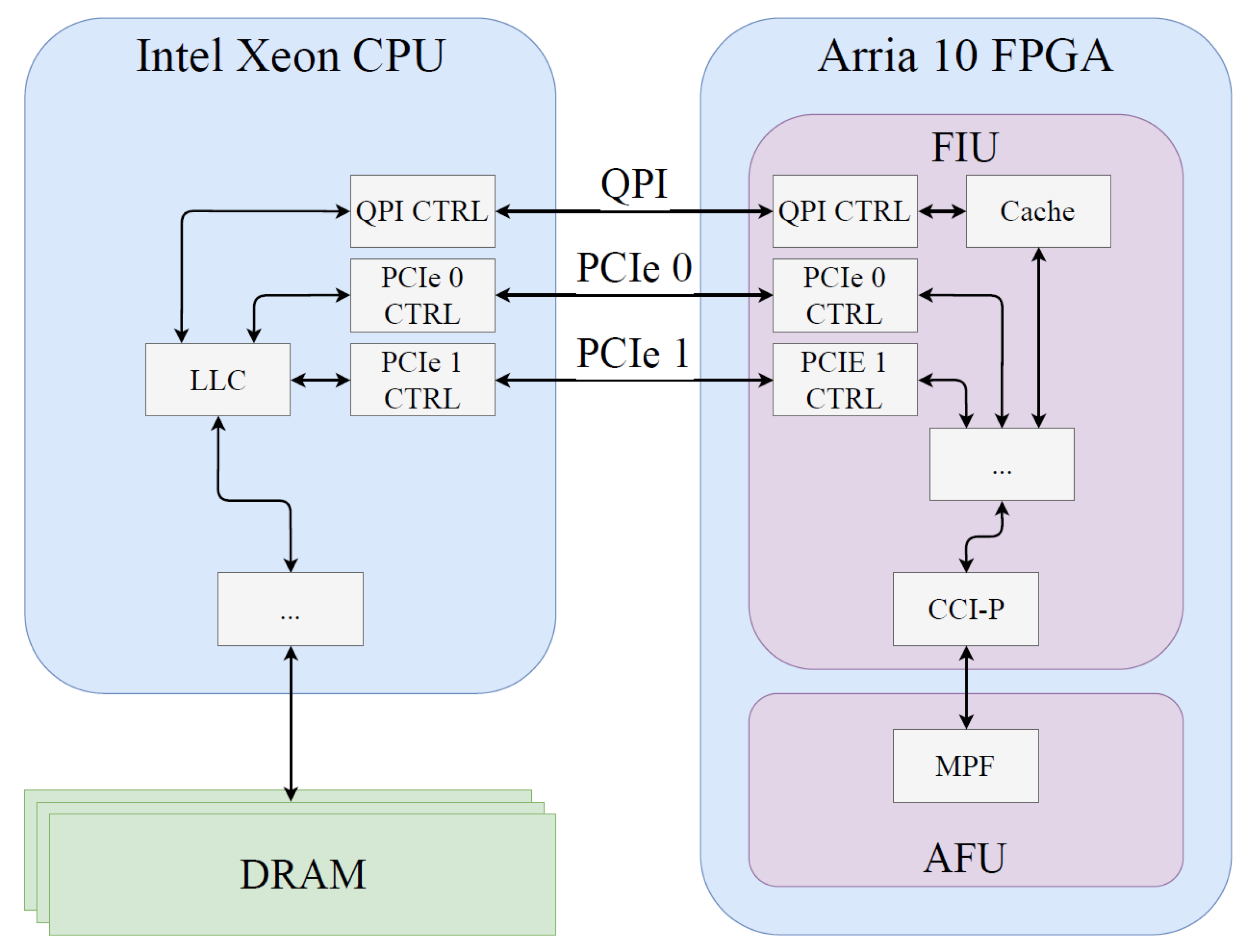
2. FPGAs and the HARP Platform
2.1. The HARP Platform
2.2. Core-Cache Interface
2.3. FPGA Cache
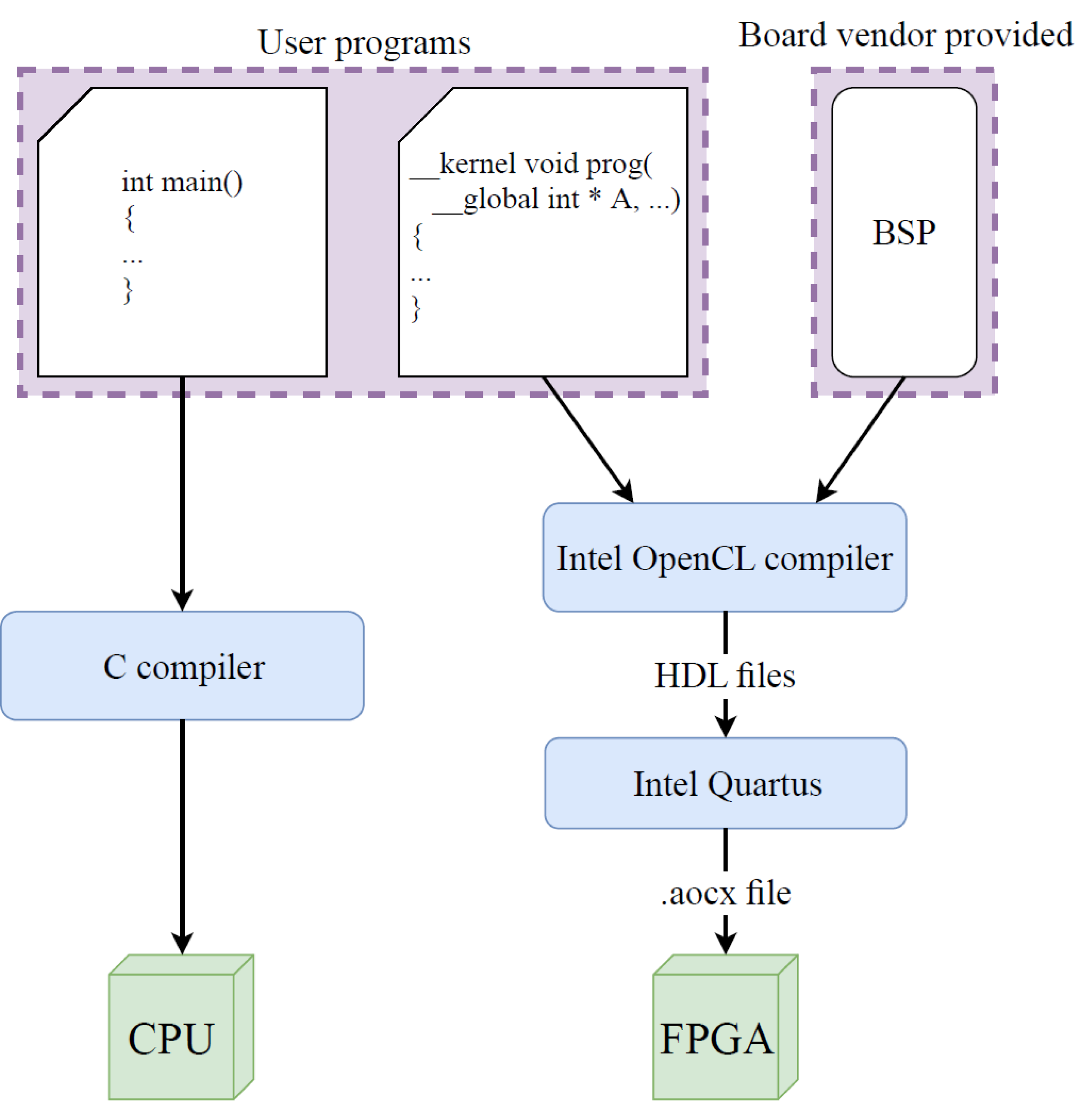
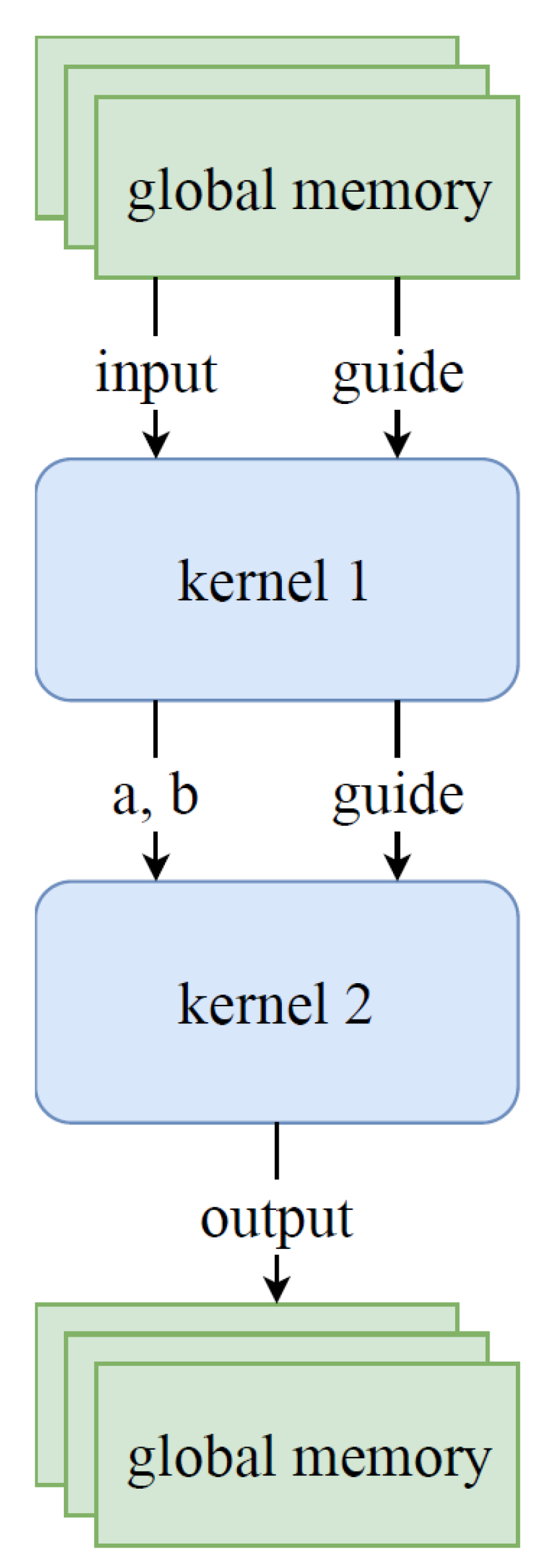
3. OpenCL on HARPv2
3.1. OpenCL Kernel Types
3.2. OpenCL Kernel Programming
3.3. Performance Tuning Phase
3.4. Profiling Reports
- Stall (%): indicates the percentage of the overall profiled time frame that the memory access causes a pipeline stall. Since a pipeline stall is not desired, the preferable stall-value is 0%.
- Occupancy (%): the percentage of the overall profiled time frame that a memory instruction is issued. In a pipelined implementation, the best performance is achieved when every clock cycle a loop iteration stage can be issued. Therefore, the most desired value for the occupancy is 100%.
- Bandwidth (MB/s): the average memory bandwidth of a memory access.
- Bandwidth efficiency (%): the percentage of loaded memory that is actually used by the kernel. Since data is loaded by reading memory words, it is possible that parts of the loaded word are not used by the kernel. In the optimal case, all loaded data is used. Therefore, an efficiency of 100% is desired.
3.5. Design Exploration Time
4. Benchmarking OpenCL Performance on HARP
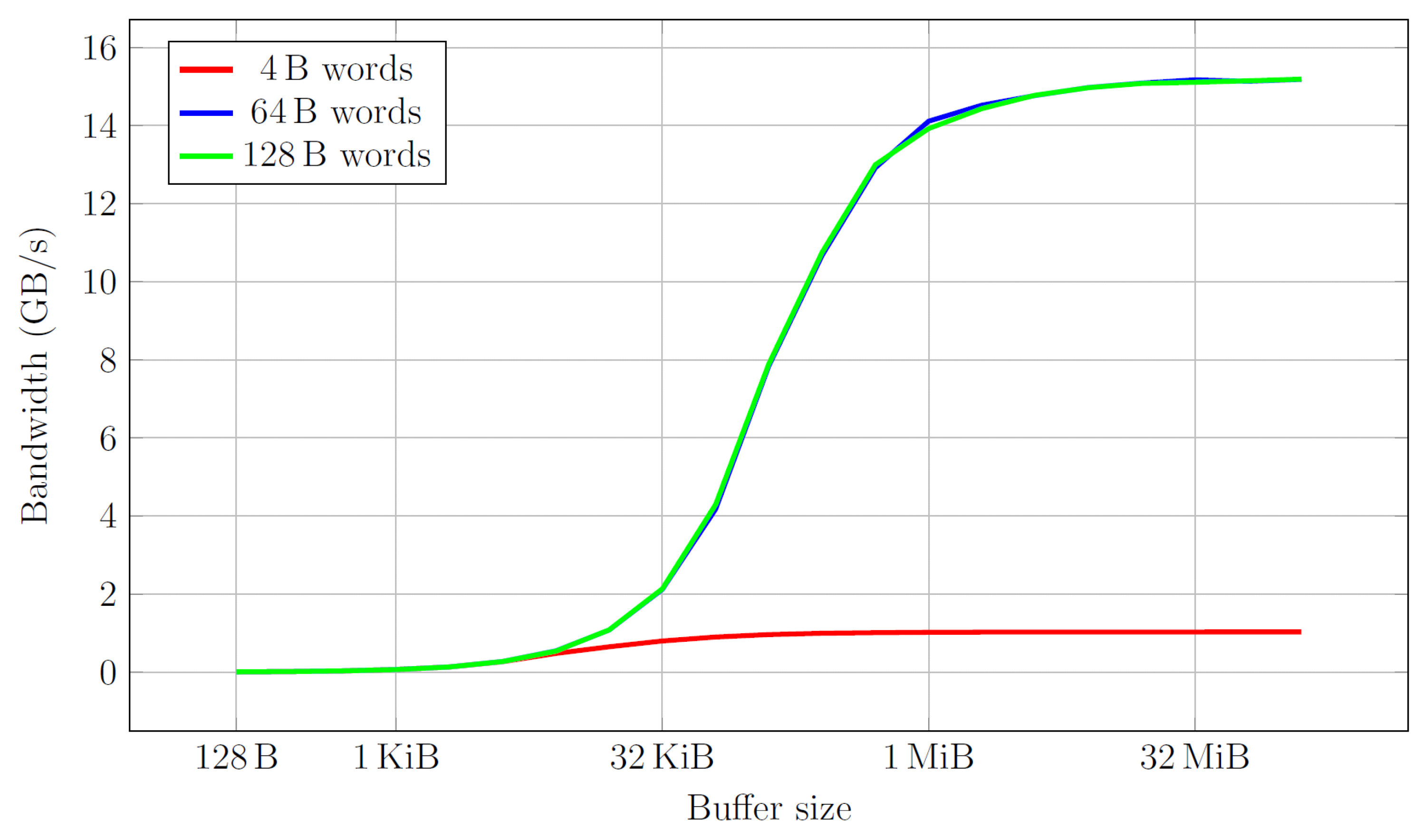
4.1. Bandwidth
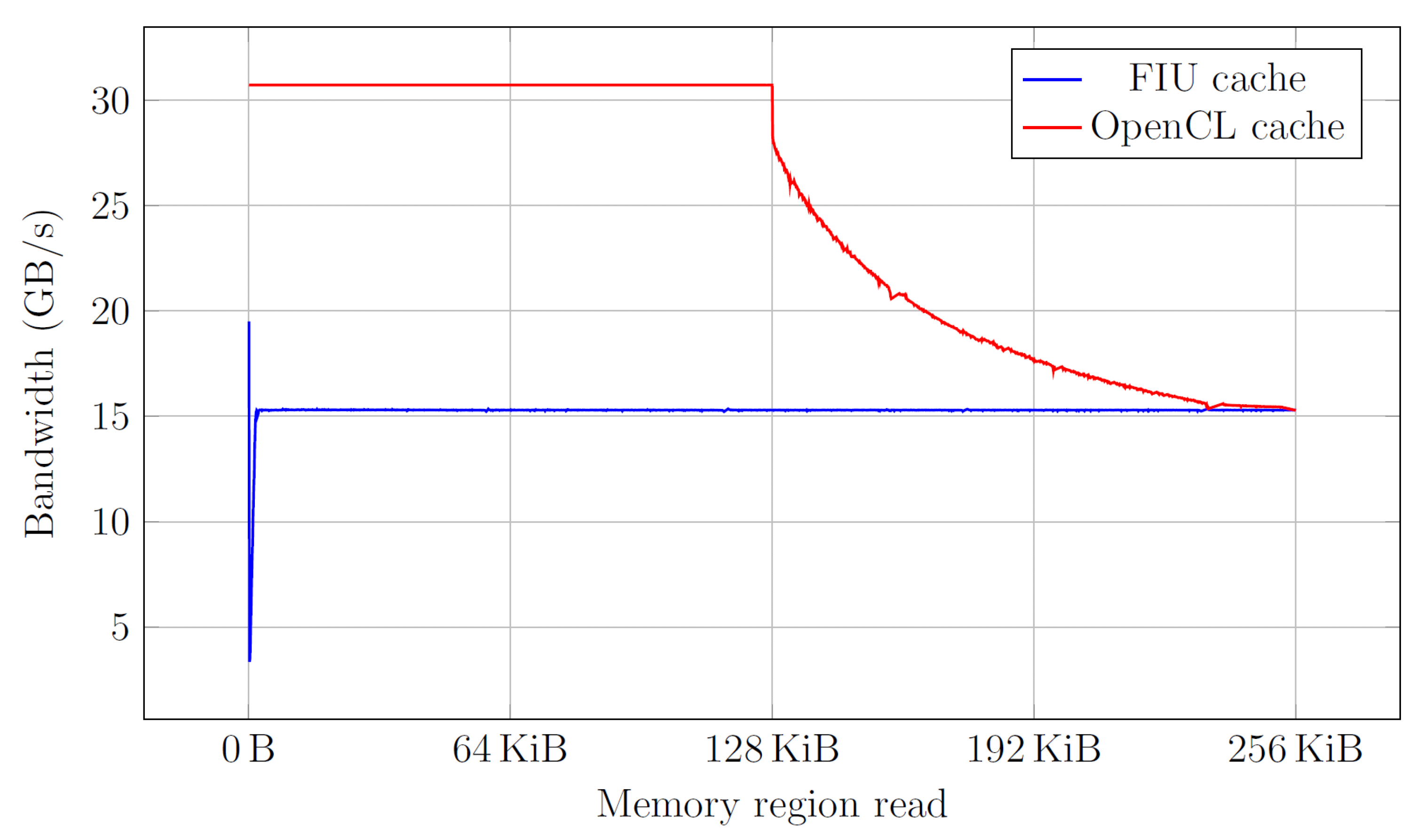
4.2. FPGA Cache
4.3. OpenCL Cache
1 __kernel void
2 __attribute__ (( task ))
3 cache_read (
4 __global volatile ulong8 ∗ restrict src, dst,
5 unsigned int lines )
6 {
7 ulong8 output = ( ulong8 ) (0) ;
8 for ( unsigned int i = 0; i<ITERATIONS; i ++) {
9 unsigned int index = i%lines ;
10 output += src[index];
11 }
12 ∗dst = output;
13 }
Listing 1: Kernel code used to test the cache effectiveness of OpenCL.
4.4. Shared Virtual Memory
4.5. Benchmark Results
5. Guided Image Filtering
5.1. Algorithm
| Algorithm 1: Guided image filter algorithm. Note: “” denotes point-wise multiplication (also known as the Hadamard product). |
| Input: Filtering input I, guidance image G, radius r, regularization parameter Output: Filtering output O
|
5.2. OpenCL Code
5.2.1. Streaming Data I/O
1 __attribute__(( packed ))
2 struct guide_image
3 {
4 <type> R;
5 <type> G;
6 <type> B;
7 };
Listing 2: Structure used to vectorize image channels. Attribute “packed” creates a continuous data stream without padding.
5.2.2. Kernels
5.2.3. Channels
1 #pragma OPENCL EXTENSION cl_altera_channels : enable
2 channel struct struct_a_b ch_0 attribute (( depth (128) ));
3 channel struct guide ch_1 attribute (( depth (128) ));
4 …
5 __kernel void guided_filter_0 ( global struct image ∗ restrict input ,
6 global struct guide ∗ restrict guide )
7 {
8 …
9 write_channel_altera (ch_0 , output_buf );
10 write_channel_altera (ch_1 , guide_buf_out );
11 }
12
13 __kernel void guided_filter_1 ( global struct image ∗ restrict output )
14 {
15 struct image_filtered input_buf = read_channel_altera ( ch_0 );
16 struct guide guide_buf = read_channel_altera ( ch_1 )
17 …
18 }
Listing 3: Use of OpenCL channels between two kernels.
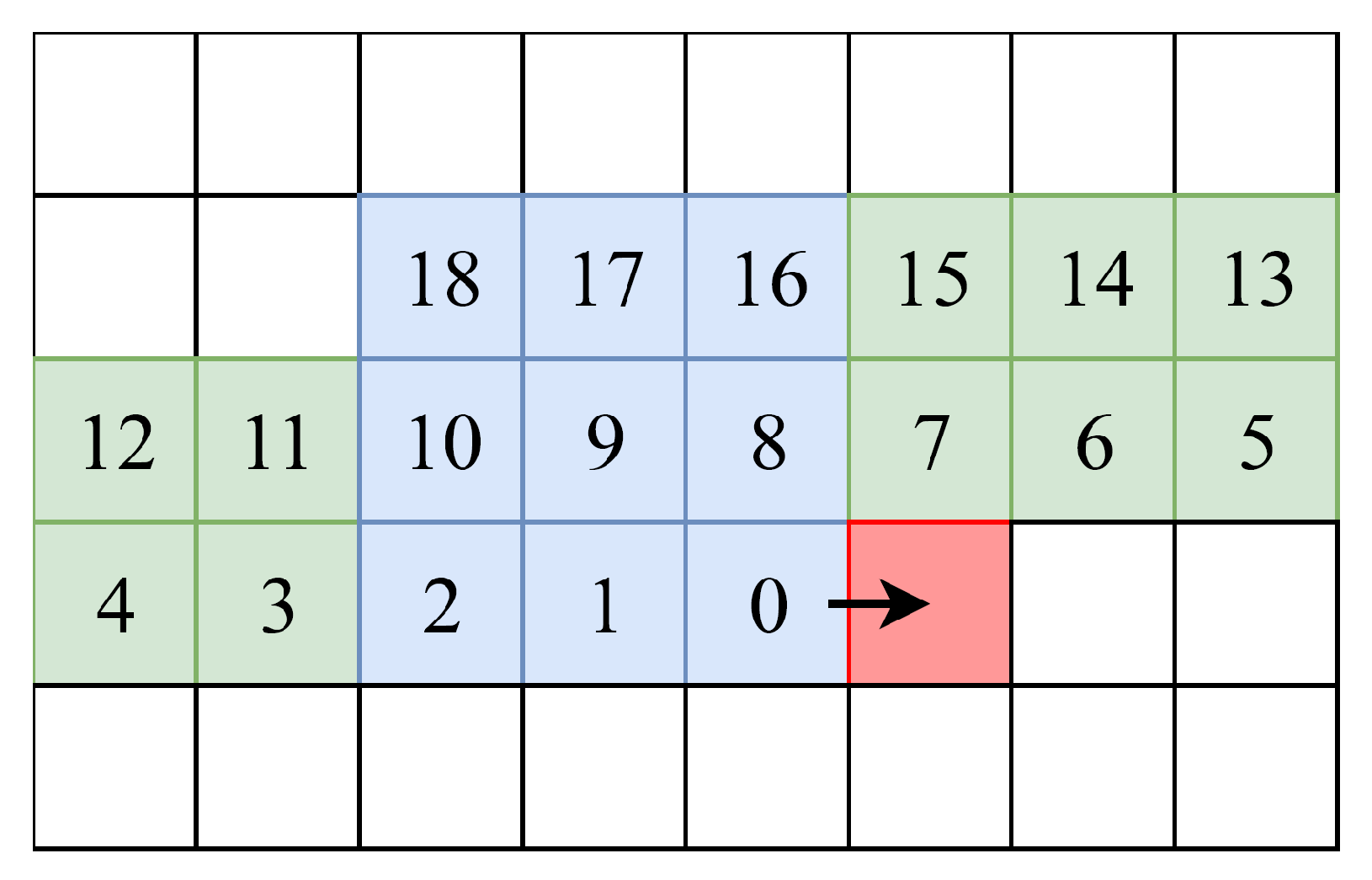
5.2.4. Sliding Window
1 void kernel_0 (global struct image ∗ restrict input) {
2 int px=0;
3 while(px < image_size) {
4 #pragma unroll
5 for ( int i = shift_register_size - 1; i > 0; --i) {
6 shift_register [i] = shift_register [i - 1];
7 }
8 shift_register[0] = input[px];
9 int mean = 0;
10 #pragma unroll
11 for ( int i = 0; i < 2 ∗ R + 1; i ++) {
12 #pragma unroll
13 for (int j = 0; j < 2 ∗ R + 1; j++) {
14 int value = shift_register [i ∗ IMAGE_WIDTH + j];
15 mean += value ;
16 }
17 }
18 mean = mean / ((2∗ R+1) ∗(2∗ R +1) );
19 }
20 }
Listing 4: Sliding window implementation.
5.2.5. Shared Virtual Memory
5.2.6. Fixed-Point Calculations
1 int fixed_point = (int) (floating_point_input ∗ (1 << fractional_bits ));
2 …
3 float floating_point_output = ((float) fixed_point) / (1 << fractional_bits );
Listing 5: In-line fixed-point conversion code.
6. Experimental Results
6.1. Design Space Exploration
1 __kernel guided_filter(struct image ∗ I, struct guide ∗ G) {
2 count = 0;
3 while(count++ < image_width∗image_height) {
4 <#pragma unroll>
5 for all shift_registers
6 reg[i] = reg[i - 1];
7
8 <#pragma unroll>
9 for (int i = 0; i < 2 ∗ RADIUS + 1; i++) {
10 <#pragma unroll>
11 for (int j = 0; j < 2 ∗ RADIUS + 1; j++) {
12 Steps 1-3 / Steps 4-5
13 }
14 }
15 }
16 }
Listing 6: Places for pragmas in the kernel code.
6.2. Runtime Measurements
6.3. Impact of the OpenCL Cache
6.4. Impact of SVM
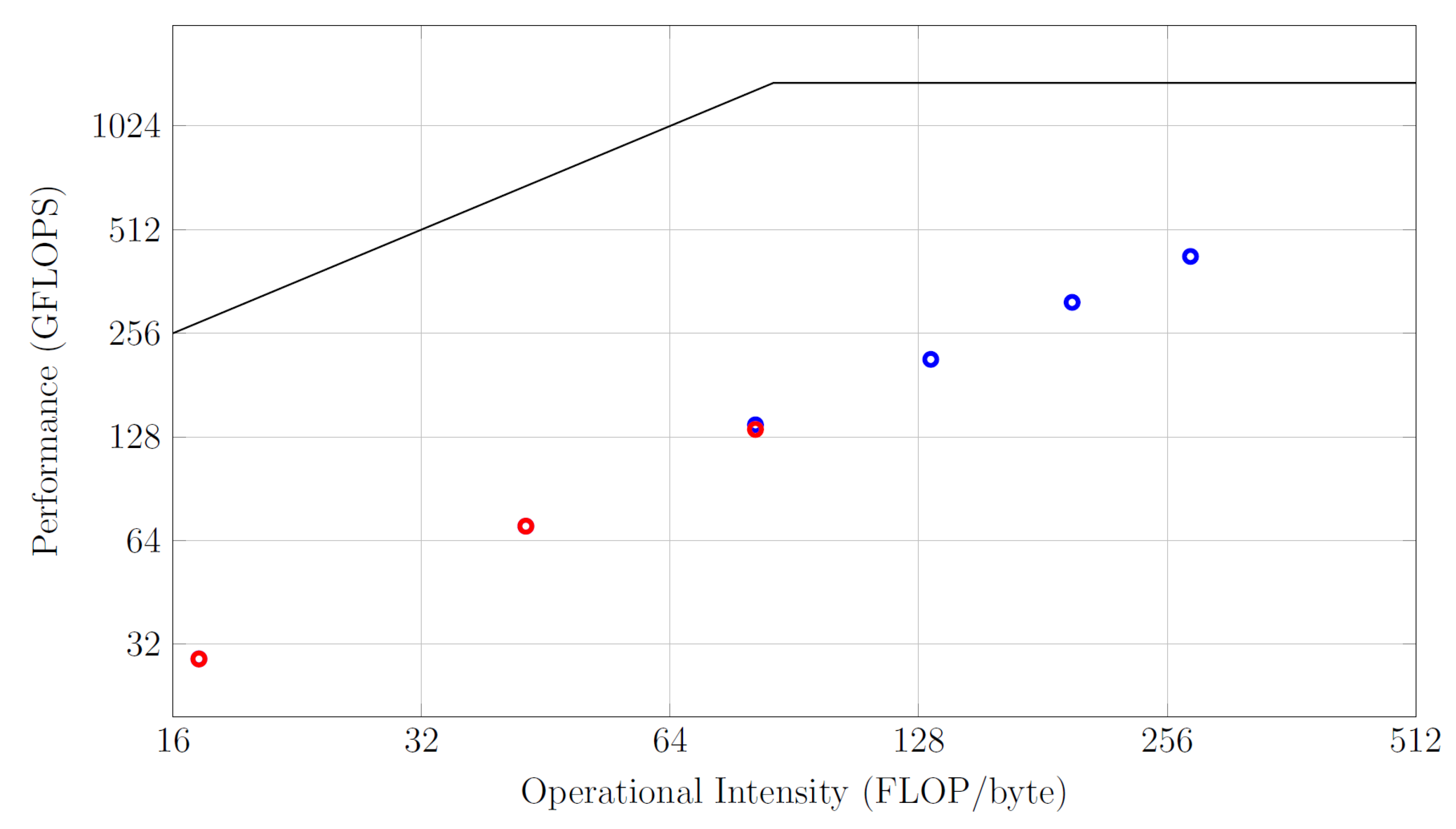
6.5. Roofline Performance Model
7. Related Work
8. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Dennard, R.H.; Gaensslen, F.H.; Rideout, V.L.; Bassous, E.; LeBlanc, A.R. Design of ion-implanted MOSFET’s with very small physical dimensions. IEEE J. Solid-State Circuits 1974, 9, 256–268. [Google Scholar] [CrossRef]
- Hennessy, J.L.; Patterson, D.A. A new golden age for computer architecture. Commun. ACM 2019, 62, 48–60. [Google Scholar] [CrossRef]
- Oliver, N.; Sharma, R.R.; Chang, S.; Chitlur, B.; Garcia, E.; Grecco, J.; Grier, A.; Ijih, N.; Liu, Y.; Marolia, P.; et al. A Reconfigurable Computing System Based on a Cache-Coherent Fabric. In Proceedings of the 2011 International Conference on Reconfigurable Computing and FPGAs (ReConFig), Cancun, Mexico, 30 November–2 December 2011; pp. 80–85. [Google Scholar]
- Rahamneh, S.; Sawalha, L. An OpenCL-Based Acceleration for Canny Algorithm Using a Heterogeneous CPU-FPGA Platform. In Proceedings of the 2019 IEEE 27th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), San Diego, CA, USA, 28 April–1 May 2019; p. 322. [Google Scholar] [CrossRef]
- Gupta, P. Accelerating Datacenter Workloads, Keynote at FPL 2016; Lausanne, Switzerland, 2016.
- Kao, C.; Lai, J.; Chien, S. VLSI Architecture Design of Guided Filter for 30 Frames/s Full-HD Video. IEEE Trans. Circuits Syst. Video Technol. 2014, 24, 513–524. [Google Scholar] [CrossRef]
- Flynn, M.J.; Rudd, K.W. Parallel Architectures. ACM Comput. Surv. 1996, 28, 67–70. [Google Scholar] [CrossRef]
- Stitt, G.; Gupta, A.; Emas, M.N.; Wilson, D.; Baylis, A. Scalable Window Generation for the Intel Broadwell+Arria 10 and High-Bandwidth FPGA Systems. In Proceedings of the 2018 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays (FPGA ’18), Monterey, CA, USA, 25–27 February 2018; ACM Press: New York, NY, USA, 2018; pp. 173–182. [Google Scholar] [CrossRef]
- Intel. An Introduction to the Intel QuickPath Interconnect; Technical report 320412–001US; Intel: Santa Clara, CA, USA, January 2009. [Google Scholar]
- Intel. Acceleration Stack for Intel Xeon CPU with FPGAs Core Cache Interface (CCI-P) Reference Manual MNL-1092; Technical report; Intel: Santa Clara, CA, USA, 2018. [Google Scholar]
- Khronos. The OpenCL Specification 1.2. 2012. Available online: https://www.khronos.org/registry/OpenCL/specs/opencl-1.2.pdf (accessed on 27 July 2019).
- Munshi, A. The OpenCL specification. In Proceedings of the 2009 IEEE Hot Chips 21 Symposium (HCS), Stanford, CA, USA, 23–25 August 2009; pp. 1–314. [Google Scholar] [CrossRef]
- Intel. FPGA SDK for OpenCL™ Programming Guide; Technical report UG-OCL002; Intel: Santa Clara, CA, USA, 2017. [Google Scholar]
- Intel. FPGA SDK for OpenCL™ Pro Best Practices Guide UG-OCL003; Technical report; Intel: Santa Clara, CA, USA, 2018. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Guided Image Filtering. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1397–1409. [Google Scholar] [CrossRef]
- Stacey, A.; Maddern, W.; Singh, S. Fast Light Field Disparity Estimation via a Parallel Filtered Cost Volume Approach. In Computer Vision—ACCV 2018; Jawahar, C.V., Li, H., Mori, G., Schindler, K., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2019; pp. 256–268. [Google Scholar]
- Williams, S.; Waterman, A.; Patterson, D. Roofline: An insightful visual performance model for multicore architectures. Commun. ACM 2009, 52, 65–76. [Google Scholar] [CrossRef]
- Parker, M. Understanding Peak Floating-Point Performance Claims; White Paper WP-01222-1.1; Intel: Santa Clara, CA, USA, February 2017. [Google Scholar]
- Kareem, P.; Khan, A.; Kyung, C. Memory efficient self guided image filtering. In Proceedings of the 2017 International SoC Design Conference (ISOCC), Seoul, Korea, 5–8 November 2017; pp. 308–309. [Google Scholar] [CrossRef]
- Chang, C.; Huang, I.; Lin, M.; Kuang, S. Design and implementation of a low-cost guided image filter for underwater image enhancement. In Proceedings of the 2017 IEEE Conference on Dependable and Secure Computing, Taipei, Taiwan, 7–10 August 2017; pp. 296–299. [Google Scholar] [CrossRef]
- Ttofis, C.; Kyrkou, C.; Theocharides, T. A Low-Cost Real-Time Embedded Stereo Vision System for Accurate Disparity Estimation Based on Guided Image Filtering. IEEE Trans. Comput. 2016, 65, 2678–2693. [Google Scholar] [CrossRef]
- Ishikawa, A.; Fukushima, N.; Maruoka, A.; Iizuka, T. Halide and GENESIS for Generating Domain-Specific Architecture of Guided Image Filtering. In Proceedings of the 2019 IEEE International Symposium on Circuits and Systems (ISCAS), Sapporo, Japan, 26–29 May 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Wang, Z.; He, B.; Zhang, W.; Jiang, S. A performance analysis framework for optimizing OpenCL applications on FPGAs. In Proceedings of the 2016 IEEE International Symposium on High Performance Computer Architecture (HPCA), Barcelona, Spain, 12–16 March 2016; pp. 114–125. [Google Scholar] [CrossRef]
- Momeni, A.; Tabkhi, H.; Ukidave, Y.; Schirner, G.; Kaeli, D. Exploring the Efficiency of the OpenCL Pipe Semantic on an FPGA. ACM SIGARCH Comput. Archit. News 2016, 43, 52–57. [Google Scholar] [CrossRef]
- Zohouri, H.R.; Podobas, A.; Matsuoka, S. Combined Spatial and Temporal Blocking for High-Performance Stencil Computation on FPGAs Using OpenCL. In Proceedings of the 2018 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays (FPGA ’18), Monterey, CA, USA, 25–27 February 2018; ACM Press: New York, NY, USA, 2018; pp. 153–162. [Google Scholar] [CrossRef]
- Fan, Q.; Chen, D.; Yuan, L.; Hua, G.; Yu, N.; Chen, B. A General Decoupled Learning Framework for Parameterized Image Operators. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef] [PubMed]
- Wu, X.; Wang, R.; Li, Y.; Liu, K. Parallel Computing Implementation for Real-Time Image Dehazing Based on Dark Channel. In Proceedings of the 2018 IEEE 20th International Conference on High Performance Computing and Communications; IEEE 16th International Conference on Smart City; IEEE 4th International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Exeter, UK, 28–30 June 2018; pp. 1–5. [Google Scholar] [CrossRef]










{kind=link}
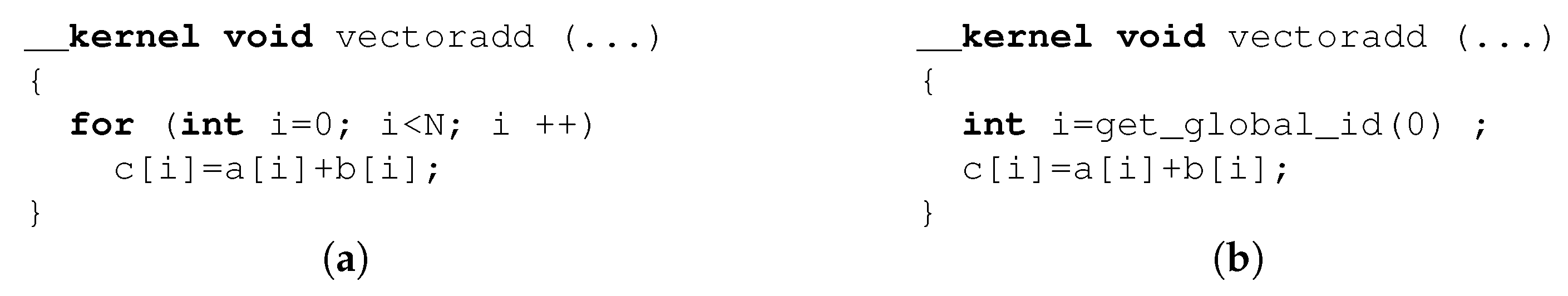{kind=link}
{kind=link}
{kind=link}
{kind=link}
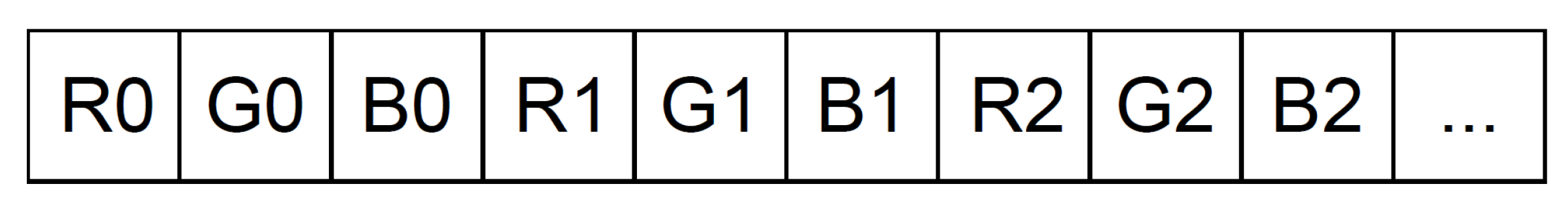{kind=link}
{kind=link}
{kind=link}
{kind=link}
| QPI | PCIe Gen.3×8 | |
|---|---|---|
| width | 16 bits | 8 bits |
| max #transfers per second | 6.4 GT/s | 8 GT/s |
| maximum raw unidirectional bandwidth | 12.8 GB/s | 7.88 GB/s |
| Step | FLOPS | Radius = 3 | Radius = 6 |
|---|---|---|---|
| 1 | 294 | 1014 | |
| 2 | 6 | 6 | 6 |
| 3 | 5 | 5 | 5 |
| 4 | 98 | 338 | |
| 5 | 1 | 1 | 1 |
| Total/px | 32 + 32r + 22 | 406 | 1366 |
| Total/image | 3(32 + 32r + 22)*1920*1080 |
| Resource | No Pragmas | Inner Loops | Both Loops | Shift Registers |
|---|---|---|---|---|
| Logic | 61% | 65% | 93% | 90% |
| LUT | 27% | 29% | 40% | 39% |
| RAM | 46% | 49% | 94% | 41% |
| DSP | 20% | 28% | 87% | 87% |
| II | 48 | 48 | 1 | 1 |
| Profile | Execution Time | GOPS | Frames/s |
|---|---|---|---|
| Kernel Execution | 18.20 ms | 139 | 54 |
| Total Execution | 22.06 ms | 114 | 45 |
| Memory Operation | Occupancy | Bandwidth | Efficiency |
|---|---|---|---|
| Filtering Input | 48.6% | 1371.6 MB/s | 100% |
| Guidance Input | 48.6% | 343.0 MB/s | 100% |
| Filtering Output | 48.5% | 1459.9 MB/s | 100% |
| Memory Operation | OpenCL Cache Hit Rate |
|---|---|
| Filtering input | 81.5% |
| Guidance Input | 95.4% |
| Profile | Execution Time | GOPS | Frames/s |
|---|---|---|---|
| SVM | 22.06 ms | 114 | 45 |
| Memory Buffer | 32.72 ms | 77 | 30 |
| #Pixels in Parallel | Kernel Execution Time |
|---|---|
| 1 | 18.20 ms |
| 2 | 9.45 ms |
| 4 | 20.00 ms |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Faict, T.; D’Hollander, E.H.; Goossens, B. Mapping a Guided Image Filter on the HARP Reconfigurable Architecture Using OpenCL. Algorithms 2019, 12, 149. https://doi.org/10.3390/a12080149
Faict T, D’Hollander EH, Goossens B. Mapping a Guided Image Filter on the HARP Reconfigurable Architecture Using OpenCL. Algorithms. 2019; 12(8):149. https://doi.org/10.3390/a12080149
Chicago/Turabian StyleFaict, Thomas, Erik H. D’Hollander, and Bart Goossens. 2019. "Mapping a Guided Image Filter on the HARP Reconfigurable Architecture Using OpenCL" Algorithms 12, no. 8: 149. https://doi.org/10.3390/a12080149
APA StyleFaict, T., D’Hollander, E. H., & Goossens, B. (2019). Mapping a Guided Image Filter on the HARP Reconfigurable Architecture Using OpenCL. Algorithms, 12(8), 149. https://doi.org/10.3390/a12080149