An Optimized Differential Step-Size LMS Algorithm




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. System Model
3. Autocorrelation Matrix of the Coefficients Error
4. ODSS-LMS Algorithm
4.1. Minimum MSD Value
4.2. Optimum Step-Size Derivation
4.3. Simplified Version
4.4. Practical Considerations
| Algorithm 1: ODSS-LMS-G algorithm. |
| Initialization: |
| • |
| • , where c is a small positive constant |
| • |
| • |
| Parameters , known or estimated |
| , with |
| For time index : |
| • |
| • |
| If time index , with : |
| • (i.e., step-size of the NLMS algorithm) |
| • |
| • |
| else: |
| • |
| • |
| • |
| • |
| • |
| • |
| • |
| Algorithm 2: ODSS-LMS-W algorithm. |
| Initialization: • • • , where c is a small positive constant • • Parameters , known or estimated , with For time index : • If time index , with : • (i.e., step-size of the NLMS algorithm) • • • else: • • • • • • • |
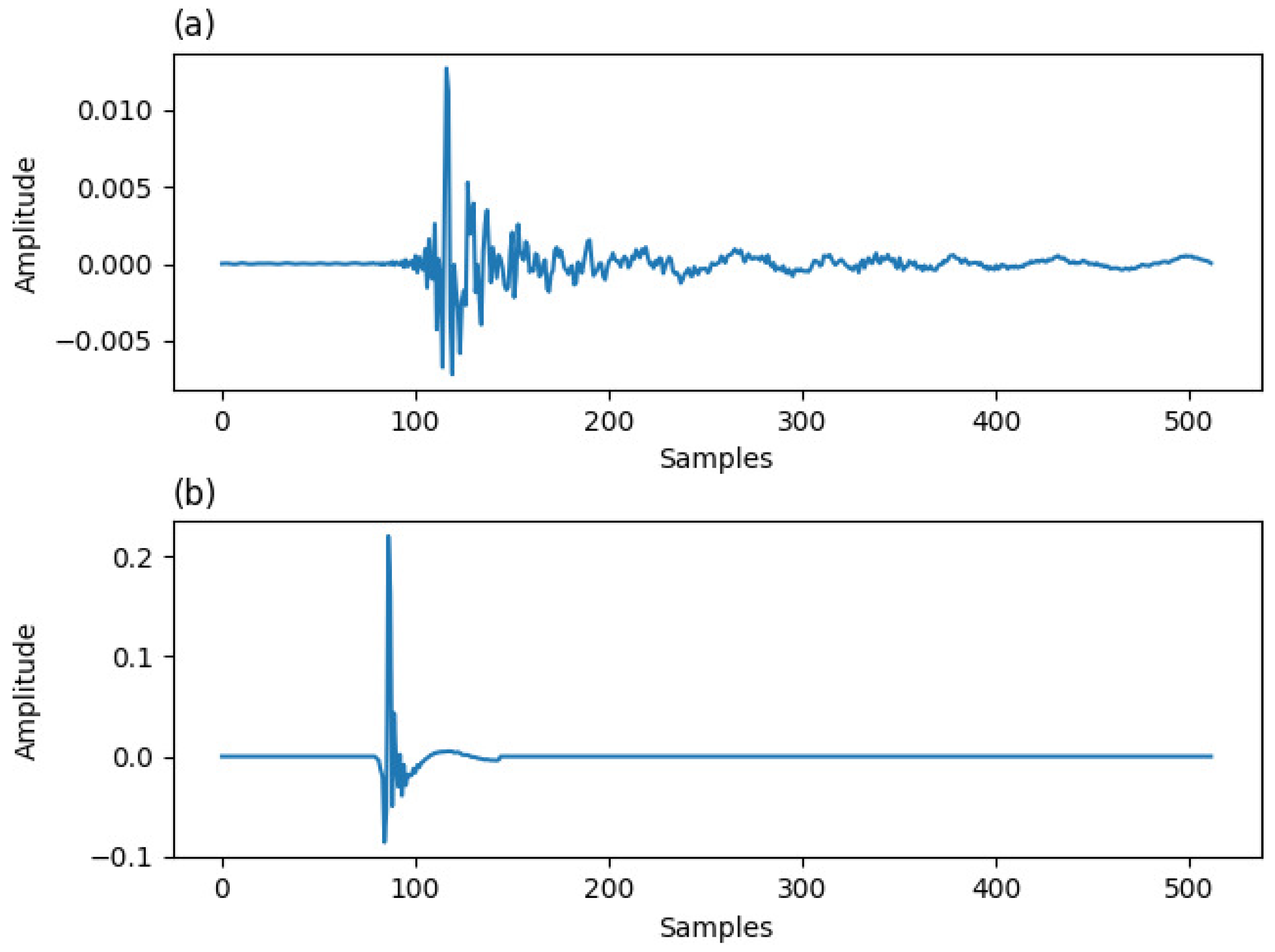
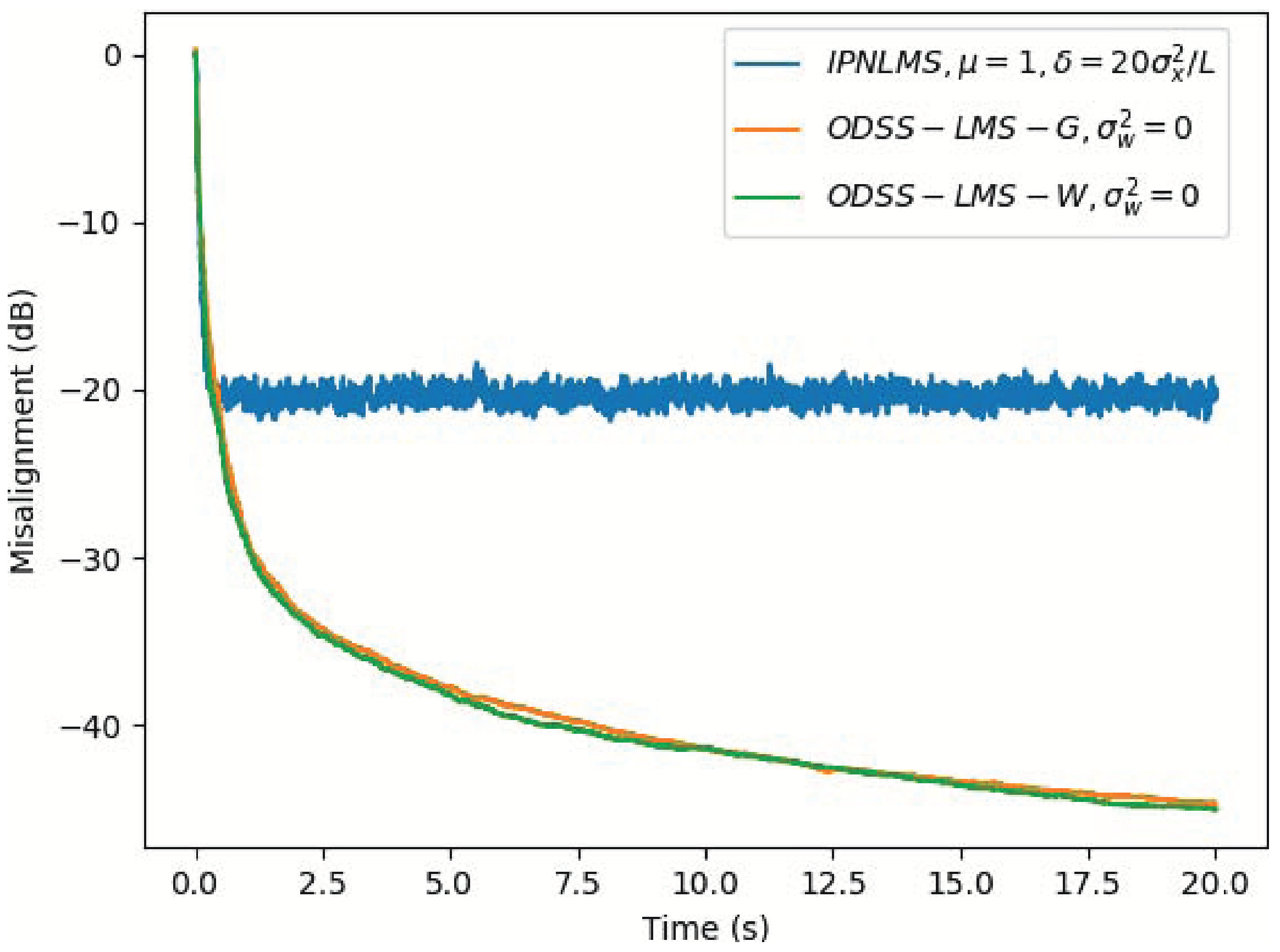
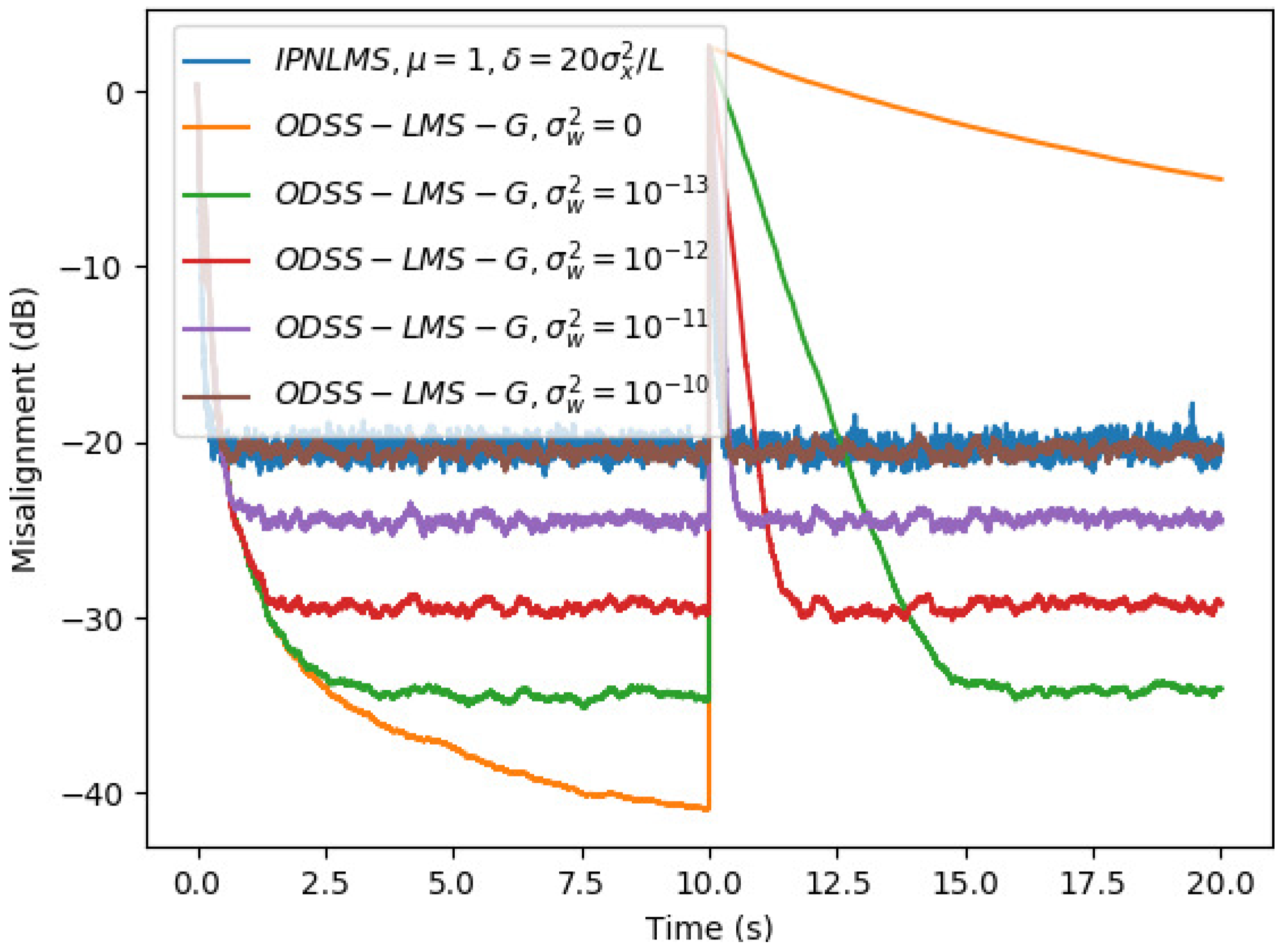
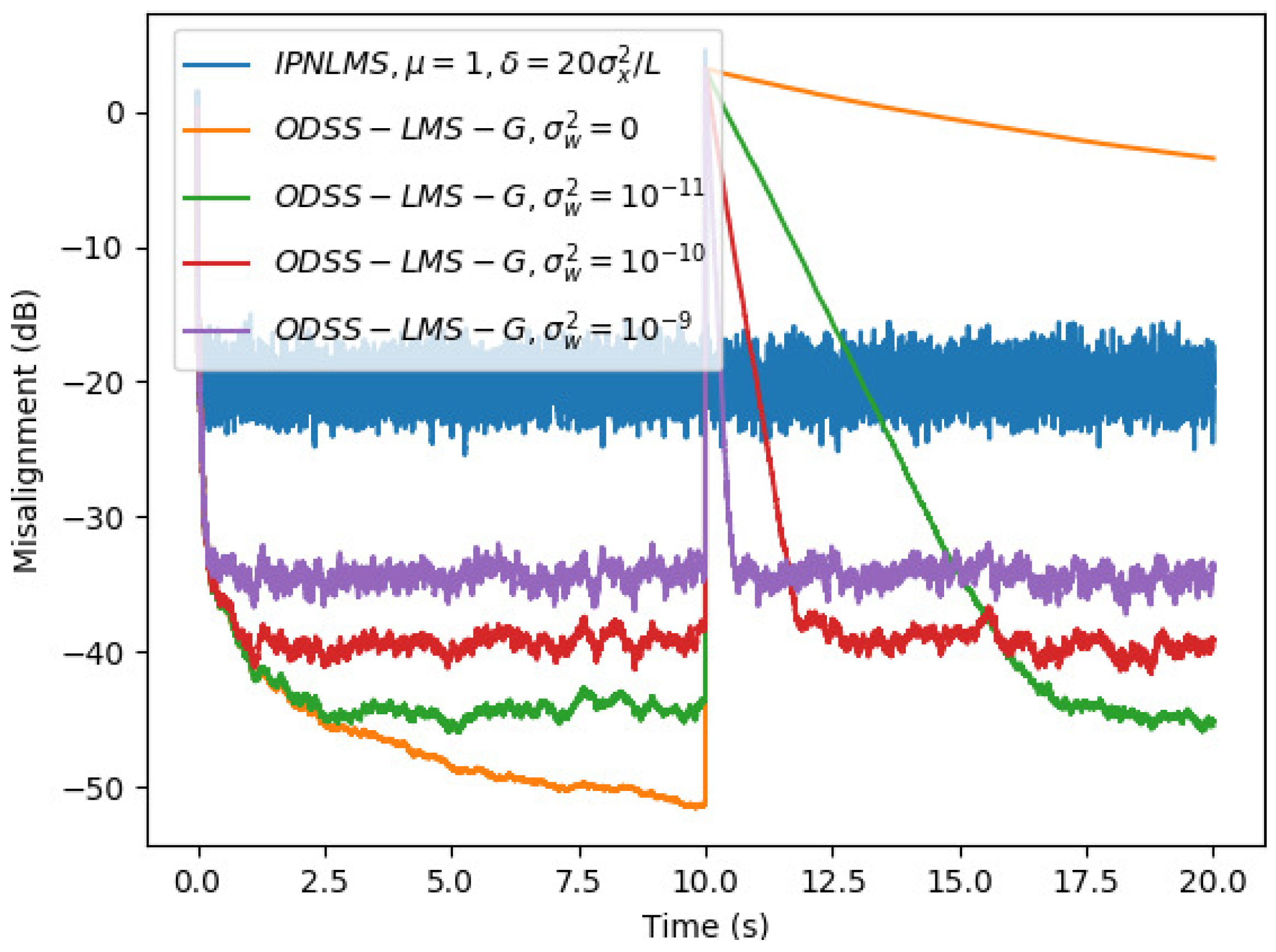
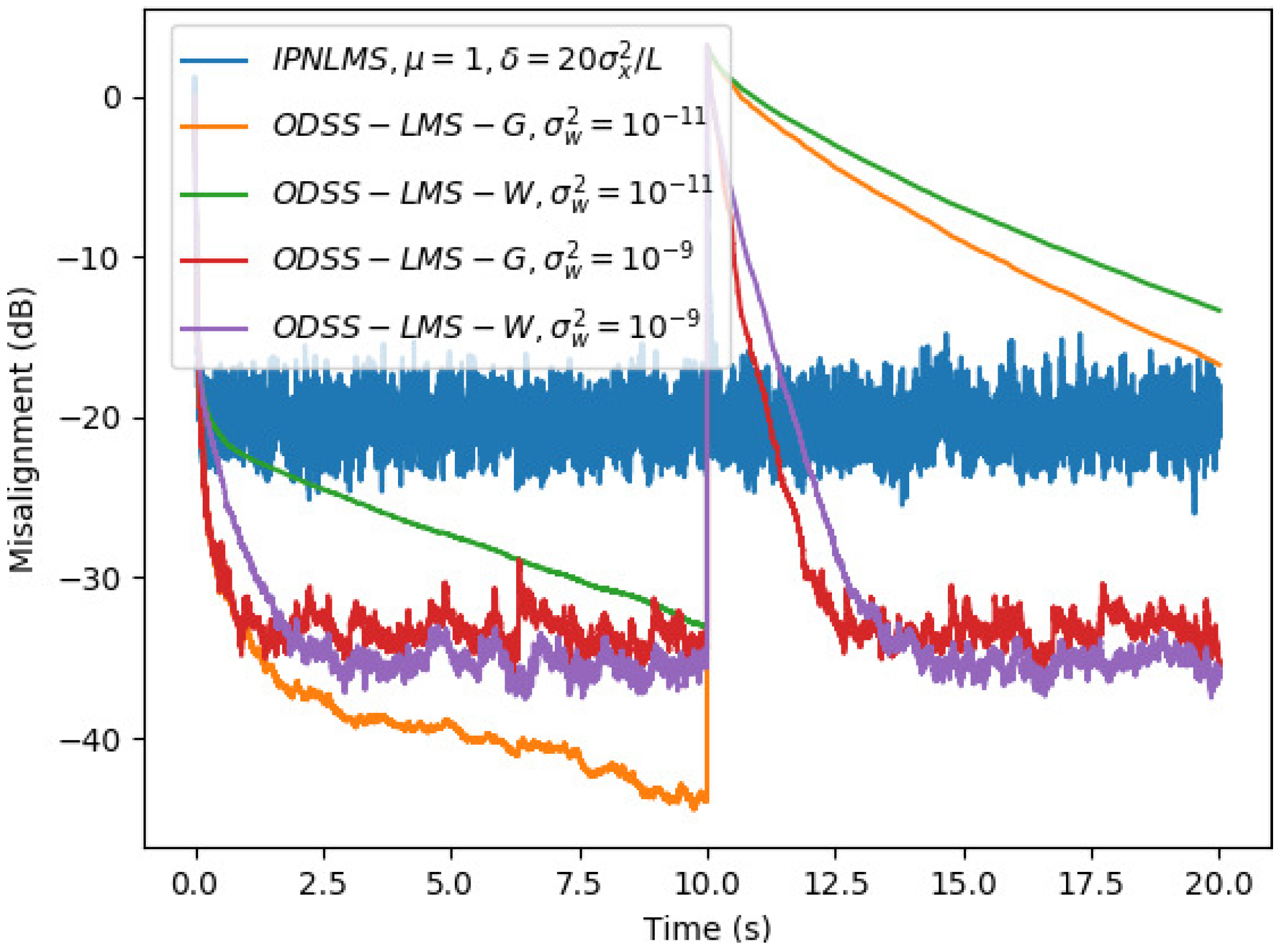
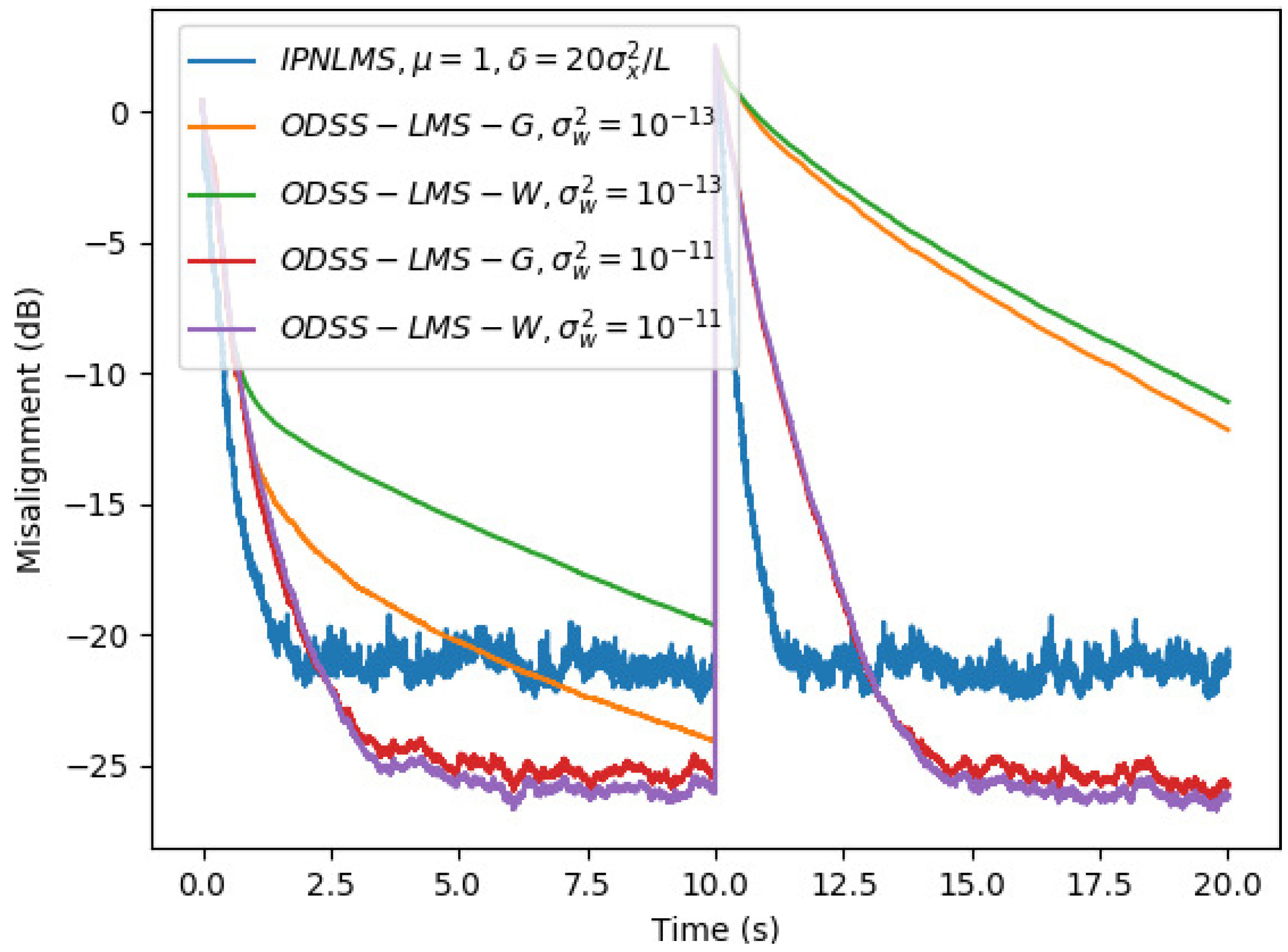
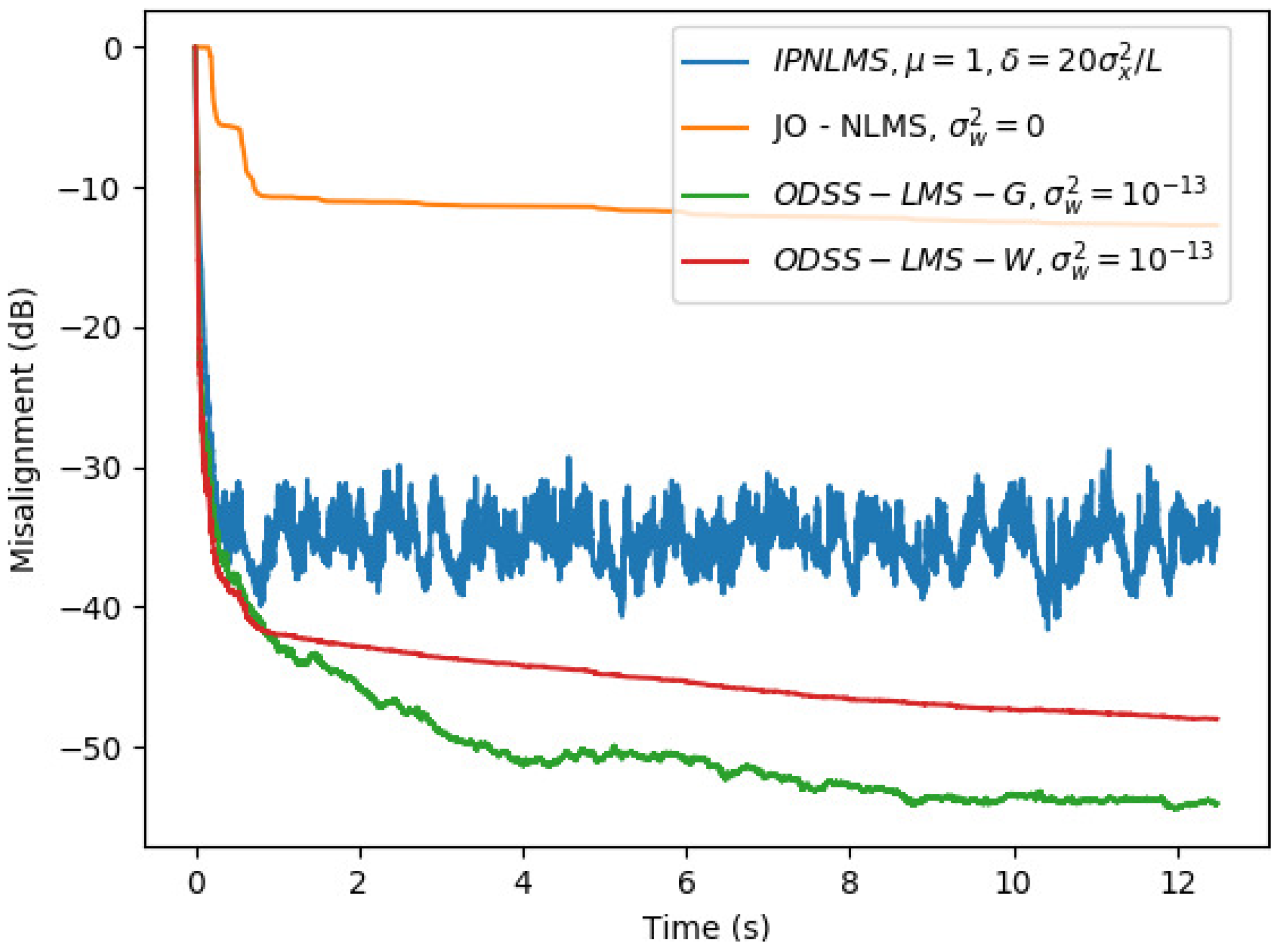
5. Simulation Results
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Widrow, B. Least-Mean-Square Adaptive Filters; Haykin, S.S., Widrow, B., Eds.; Wiley: Hoboken, NJ, USA, 2003. [Google Scholar]
- Duttweiler, D.L. Proportionate normalized least-mean-squares adaptation in echo cancelers. IEEE Trans. Speech Audio Process. 2000, 8, 508–518. [Google Scholar] [CrossRef]
- Gay, S.L. An efficient, fast converging adaptive filter for network echo cancellation. In Proceedings of the Conference Record of Thirty-Second Asilomar Conference on Signals, Systems and Computers (Cat. No.98CH36284), Pacific Grove, CA, USA, 1–4 November 1998; pp. 394–398. [Google Scholar]
- Benesty, J.; Gay, S.L. An improved PNLMS algorithm. In Proceedings of the 2002 IEEE International Conference on Acoustics, Speech, and Signal Processing, Orlando, FL, USA, 13–17 May 2002. [Google Scholar]
- Deng, H.; Doroslovački, M. Proportionate adaptive algorithms for network echo cancellation. IEEE Trans. Signal Process. 2006, 54, 1794–1803. [Google Scholar] [CrossRef]
- Das Chagas de Souza, F.; Tobias, O.J.; Seara, R.; Morgan, D.R. A PNLMS algorithm with individual activation factors. IEEE Trans. Signal Process. 2010, 58, 2036–2047. [Google Scholar] [CrossRef]
- Liu, J.; Grant, S.L. Proportionate adaptive filtering for block-sparse system identification. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 623–630. [Google Scholar] [CrossRef]
- Gu, Y.; Jin, J.; Mei, S. ℓ0 norm constraint LMS algorithm for sparse system identification. IEEE Signal Process. Lett. 2009, 16, 774–777. [Google Scholar]
- Loganathan, P.; Khong, A.W.H.; Naylor, P.A. A class of sparseness-controlled algorithms for echo cancellation. IEEE Trans. Audio Speech Lang. Process. 2009, 17, 1591–1601. [Google Scholar] [CrossRef]
- Li, Y.; Wang, Y.; Sun, L. A proportionate normalized maximum correntropy criterion algorithm with correntropy induced metric constraint for identifying sparse systems. Symmetry 2018, 10, 683. [Google Scholar] [CrossRef]
- Rusu, A.G.; Ciochină, S.; Paleologu, C. On the step-size optimization of the LMS algorithm. In Proceedings of the 42nd International Conference on Telecommunications and Signal Processing, Budapest, Hungary, 1–3 July 2019; pp. 168–173. [Google Scholar]
- Ciochină, S.; Paleologu, C.; Benesty, J.; Grant, S.L.; Anghel, A. A family of optimized LMS-based algorithms for system identification. In Proceedings of the 2016 24th European Signal Processing Conference (EUSIPCO), Budapest, Hungary, 29 August–2 September 2016; pp. 1803–1807. [Google Scholar]
- Enzner, G.; Buchner, H.; Favrot, A.; Kuech, F. Acoustic echo control. In Academic Press Library in Signal Processing; Academic Press: Cambridge, MA, USA, 2014; Volume 4, pp. 807–877. [Google Scholar]
- Shin, H.-C.; Sayed, A.H.; Song, W.-J. Variable step-size NLMS and affine projection algorithms. IEEE Signal Process. Lett. 2004, 11, 132–135. [Google Scholar]
- Benesty, J.; Rey, H.; Rey Vega, L.; Tressens, S. A nonparametric VSS-NLMS algorithm. IEEE Signal Process. Lett. 2006, 13, 581–584. [Google Scholar] [CrossRef]
- Park, P.; Chang, M.; Kong, N. Scheduled-stepsize NLMS algorithm. IEEE Signal Process. Lett. 2009, 16, 1055–1058. [Google Scholar] [CrossRef]
- Huang, H.-C.; Lee, J. A new variable step-size NLMS algorithm and its performance analysis. IEEE Trans. Signal Process. 2012, 60, 2055–2060. [Google Scholar] [CrossRef]
- Song, I.; Park, P. A normalized least-mean-square algorithm based on variable-step-size recursion with innovative input data. IEEE Signal Process. Lett. 2012, 19, 817–820. [Google Scholar] [CrossRef]
- Isserlis, L. On a formula for the product-moment coefficient of any order of a normal frequency distribution in any number of variables. Biometrika 1918, 12, 134–139. [Google Scholar] [CrossRef]
- Iqbal, M.A.; Grant, S.L. Novel variable step size NLMS algorithms for echo cancellation. In Proceedings of the 2008 IEEE International Conference on Acoustics, Speech and Signal Processing, Las Vegas, NV, USA, 31 March–4 April 2008; pp. 241–244. [Google Scholar]
- Paleologu, C.; Ciochină, S.; Benesty, J. Variable step-size NLMS algorithm for under-modeling acoustic echo cancellation. IEEE Signal Process. Lett. 2008, 15, 5–8. [Google Scholar] [CrossRef]
- Strassen, V. Gaussian Elimination is not Optimal. Numer. Math. 1969, 13, 354–356. [Google Scholar] [CrossRef]
- Coppersmith, D.; Winograd, S. Matrix multiplication via arithmetic progressions. J. Symb. Comput. 1990, 9, 251–280. [Google Scholar] [CrossRef]
- Ciochină, S.; Paleologu, C.; Benesty, J. An optimized NLMS algorithm for system identification. Signal Process. 2016, 118, 115–121. [Google Scholar] [CrossRef]
- ITU. Digital Network Echo Cancellers, ITU-T Recommendation G 168; ITU: Geneva, Switzerland, 2002. [Google Scholar]
- Hoyer, P.O. Non-negative matrix factorization with sparseness constraints. J. Mach. Learn. Res. 2001, 49, 1208–1215. [Google Scholar]








© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rusu, A.-G.; Ciochină, S.; Paleologu, C.; Benesty, J. An Optimized Differential Step-Size LMS Algorithm. Algorithms 2019, 12, 147. https://doi.org/10.3390/a12080147
Rusu A-G, Ciochină S, Paleologu C, Benesty J. An Optimized Differential Step-Size LMS Algorithm. Algorithms. 2019; 12(8):147. https://doi.org/10.3390/a12080147
Chicago/Turabian StyleRusu, Alexandru-George, Silviu Ciochină, Constantin Paleologu, and Jacob Benesty. 2019. "An Optimized Differential Step-Size LMS Algorithm" Algorithms 12, no. 8: 147. https://doi.org/10.3390/a12080147
APA StyleRusu, A.-G., Ciochină, S., Paleologu, C., & Benesty, J. (2019). An Optimized Differential Step-Size LMS Algorithm. Algorithms, 12(8), 147. https://doi.org/10.3390/a12080147