An Introduction of NoSQL Databases Based on Their Categories and Application Industries †


Abstract
:1. Introduction
2. Related Work
2.1. Relational Database Model (RDM)
- The name of this relation is Students;
- The names of the attributes in this relation are SID, name, telephone, and birthday, respectively;
- The domain of each attribute is a collection of acceptable data values for the attribute, for example, the acceptable data value of attribute birthday is date;
- There are five data records in this relation.
- Key constraint: A relation must have a unique and minimal primary key;
- Domain constraint: An attribute value of a relation must be an atomic one belonging to the corresponding domain of the attribute;
- Entity integrity constraint: Some principles for a primary key;
- Referential integrity constraint: Some principles for a foreign key.
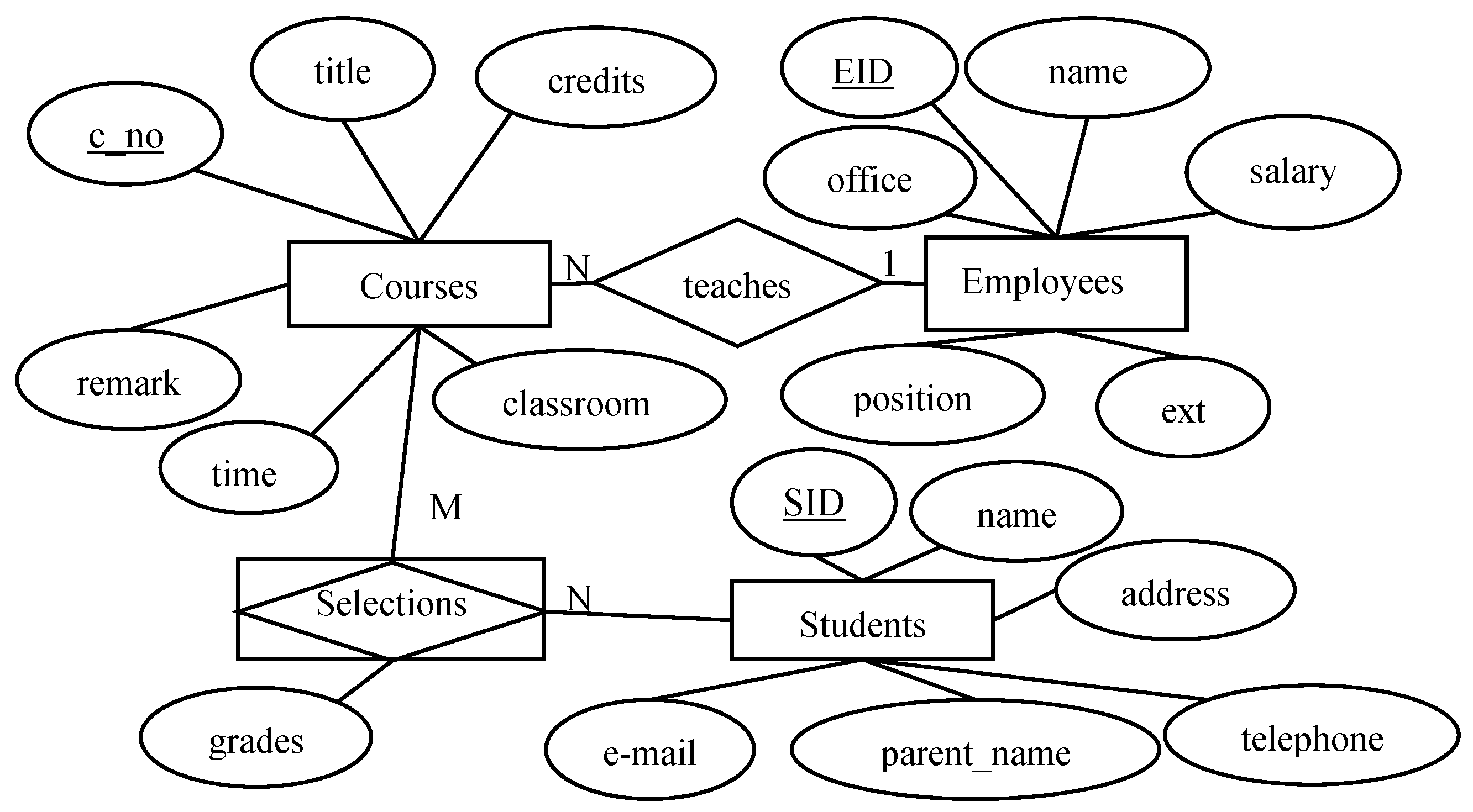
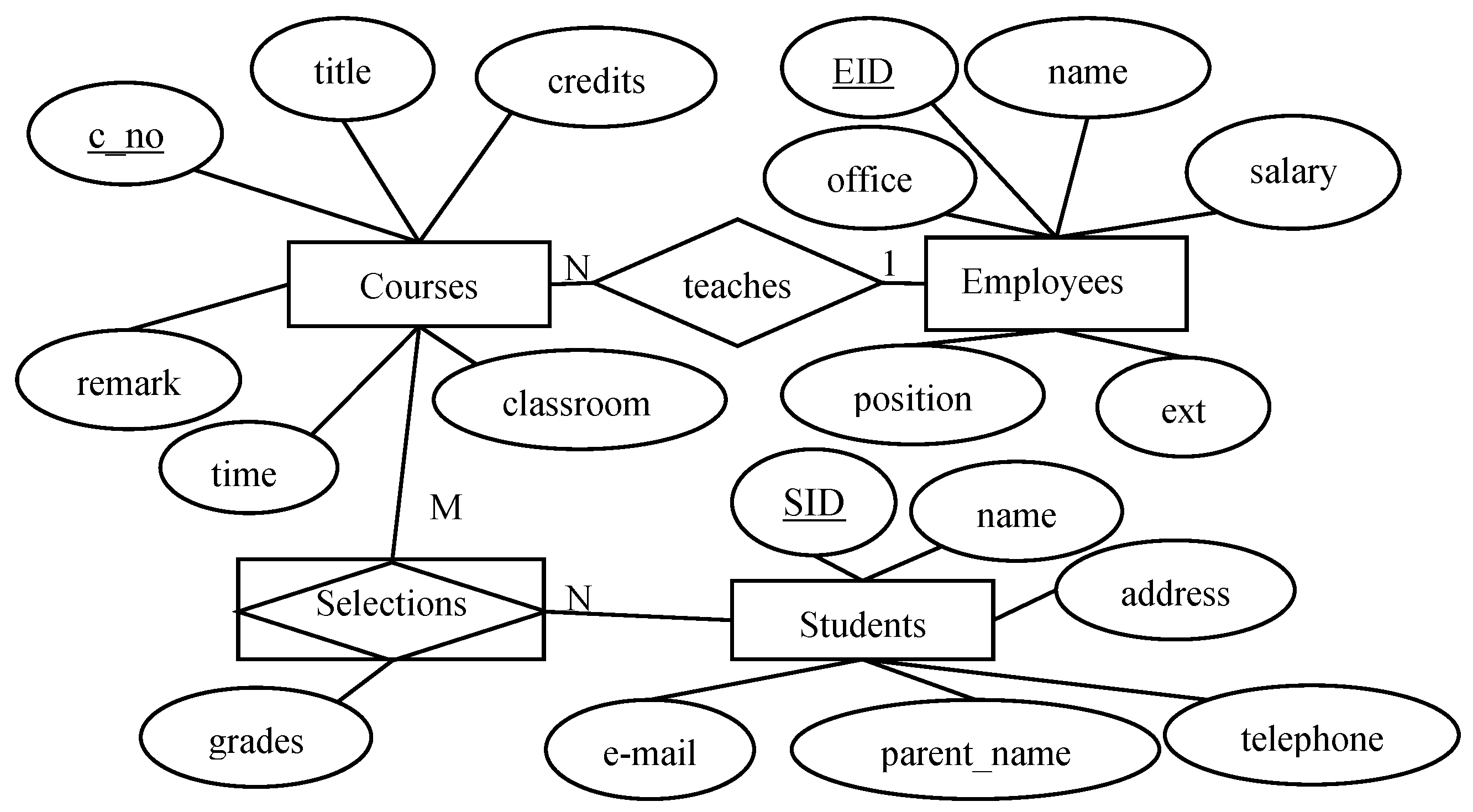
2.2. Entity-Relationship Model (ER-Model)
- A student can select many courses and vice versa;
- An employee can teach many courses, but a course can only be taught by an employee.
2.3. Big Data
- Volume: It refers to the large-scale growth of data volume faced by enterprises.
- Variety: It refers to the type of data including a variety of texts, videos, pictures, geographic locations, and information generated by sensors.
- Value: It refers to the commercial value of the data after analysis. In the case of video, for example, one-hour of video, in continuous monitoring, the information that may be useful is only one or two seconds. Therefore, how to refine the value of data more quickly through powerful machine learning algorithms is an important issue of big data.
- Velocity: It refers to that enterprises not only need to know how to quickly collect data, but also must know how to process, analyze, and pass back the results to users to meet their immediate needs.
2.4. NoSQL Databases
- Non-relational: NoSQL databases do not use relational database model, neither does support SQL join operations. In addition, unlike RDBs to obtain advanced data through join operations, NoSQL databases do not support join operations, the related data needs to be stored together to improve the speed of data access.
- Distributed: Data in NoSQL databases is usually stored in different servers and the locations of the stored data are managed by metadata.
- Open-source: Unlike most RDBs that require a fee to purchase, most NoSQL databases are open source and free to download.
- Horizontally scalable: Increase or decrease multiple normal servers to meet the data processing capacity of NoSQL database.
- Schema-free: Unlike RDBs need to define database schema before inserting data, NoSQL databases do not need to do this. Therefore, NoSQL databases can flexibly add data.
- Easy replication support: NoSQL databases mostly support master-slave replication or peer-to-peer replication, making it easier for NoSQL databases to ensure high availability.
- Simple API: The NoSQL database provides APIs for network delivery, data collection, etc. for programmers to use, so that programmers do not need to design additional programs to make writing programs easier.
- BASE is an abbreviation for “basically available, soft-state, and eventual consistency,” and the meanings are described as follows.
- (1)
- Basically available: The DB system can execute and always provide services. Some parts of the DB system may have partial failures and the rest of the DB system can continue to operate. Some NoSQL DBs typically keep several copies of specific data on different servers, which allows the DB system to respond to all queries even if few of the servers fail.
- (2)
- Soft-state: The DB system does not require a state of strong consistency. Strong consistency means that no matter which replication of a certain data is updated, all later reading operations of the data must be able to obtain the latest information.
- (3)
- Eventual consistency: The DB system needs to meet the consistency requirement after a certain time. Sometimes the DB may be in an inconsistent state. For example, some NoSQL DBs keep multiple copies of certain data on multiple servers. However, these copies may be inconsistent in a short time, which may happen when a copy of the data is updated while the other copies continue to have data from the old version. Eventually, the replication mechanism in the NoSQL DB system will update all replicas to be consistent.
2.5. The Survey Papers of NoSQL Databases
- (1)
- Hecht and Jablonski [6] evaluated the relevant technologies of some of the four common NoSQL database categories (i.e., key value store, document Store, wide column store, and graph databases) to assist users in selecting an appropriate NoSQL database. Related technologies include data models, queries, concurrency controls, partitions, and replication.
- (2)
- Lourenço et al. [7] compared several quality attributes for several NoSQL databases. The evaluated NoSQL databases contain Aerospike, Cassandra, Couchbase, CouchDB, HBase, MongoDB, and Voldemort, while the quality attributes include availability, consistency, durability, maintainability, read and write performance, recovery time, reliability, robustness, scalability, and stabilization time.
- (3)
- Corbellini et al. [8] reviewed the basic concepts of four common categories of NoSQL databases and compared some databases for each category. In addition, this paper also discussed how to select an appropriate NoSQL database from existing databases. The decision-making factors include data analysis, hardware scalability (horizontally scalable and BASE [3,4]), flexibility schema, fast deployment of servers (replication and sharding configuration), distributed technology, etc.
- (4)
- Khazaei et al. [9] illustrated the basic concepts of four popular NoSQL database models and evaluated some databases for each model. In this paper, the authors discussed several factors to be considered in order to select an appropriate NoSQL database, such as data model, access patterns, queries, non-functional requirements (including data access performance, replication, partition, horizontally scalable, BASE [3,4], software development and maintenance, etc.).
- (5)
- Gessert et al. [10] linked functional requirements, non-functional requirements in the NoSQL database to the used technologies, and provided decision trees to assist users in selecting the appropriate NoSQL database, where:
- (a)
- Functional requirements include sorting, full-text search, and so on;
- (b)
- Non-functional requirements include data scalability, elasticity, and so on;
- (c)
- Used technologies include sharding, replication, storage management, and query processing;
- (d)
- Evaluated NoSQL databases contain MongoDB, Redis, HBase, Riak, and Cassandra.
- (6)
- Davoudian et al. [11] clarified four factors for deciding a suitable NoSQL database, such as data model, consistency model, data partitioning, and CAP theorem, and further explained the available strategies, features, advantages, and disadvantages for them. This is helpful for selecting an appropriate NoSQL database.
3. The Categories of NoSQL Databases
3.1. Wide Column Store
- A row key is an identification that has a unique value used to identify a specific record, similar to the primary key of a relation in RDB.
- A timestamp (abbreviated as ts) is an integer used to identify a specific version of a data value.
- At least one column family that has the format of “Family: Qualifier = Value,” where “Family” is the name of a column family, “Qualifier” is the name of a column qualifier, and “Value” is a real value of a column qualifier stored in text.
- The name of a column family need to be defined when the table is created, but the name of a column qualifier does not.
- Users can find the actual data value through the value of a specific row key, the name of a specific column family, the name of a specific column qualifier, and the value of a specific timestamp.
- Products_Inventory is the name of the inventory table, which contains two column families, products, and inventory, and has three records with the product codes P001, P002, and P003 as the values of three row keys, respectively;
- An increasing integer ti (i = 1, 2, …, 18) is the value of timestamp for each column qualifier when a data value of a column qualifier is inserted into the table;
- Column family products includes four column qualifiers: Classes, title, descriptions, price, and their data values, for example, are “TV”, “SONY 55 inch 4K OLED Smart Networked TV”, “TBD”, and “24999”, respectively;
- Column family inventory includes two column qualifiers: Quantity, place, and their data values, for example, are “10” and “1A”, respectively.
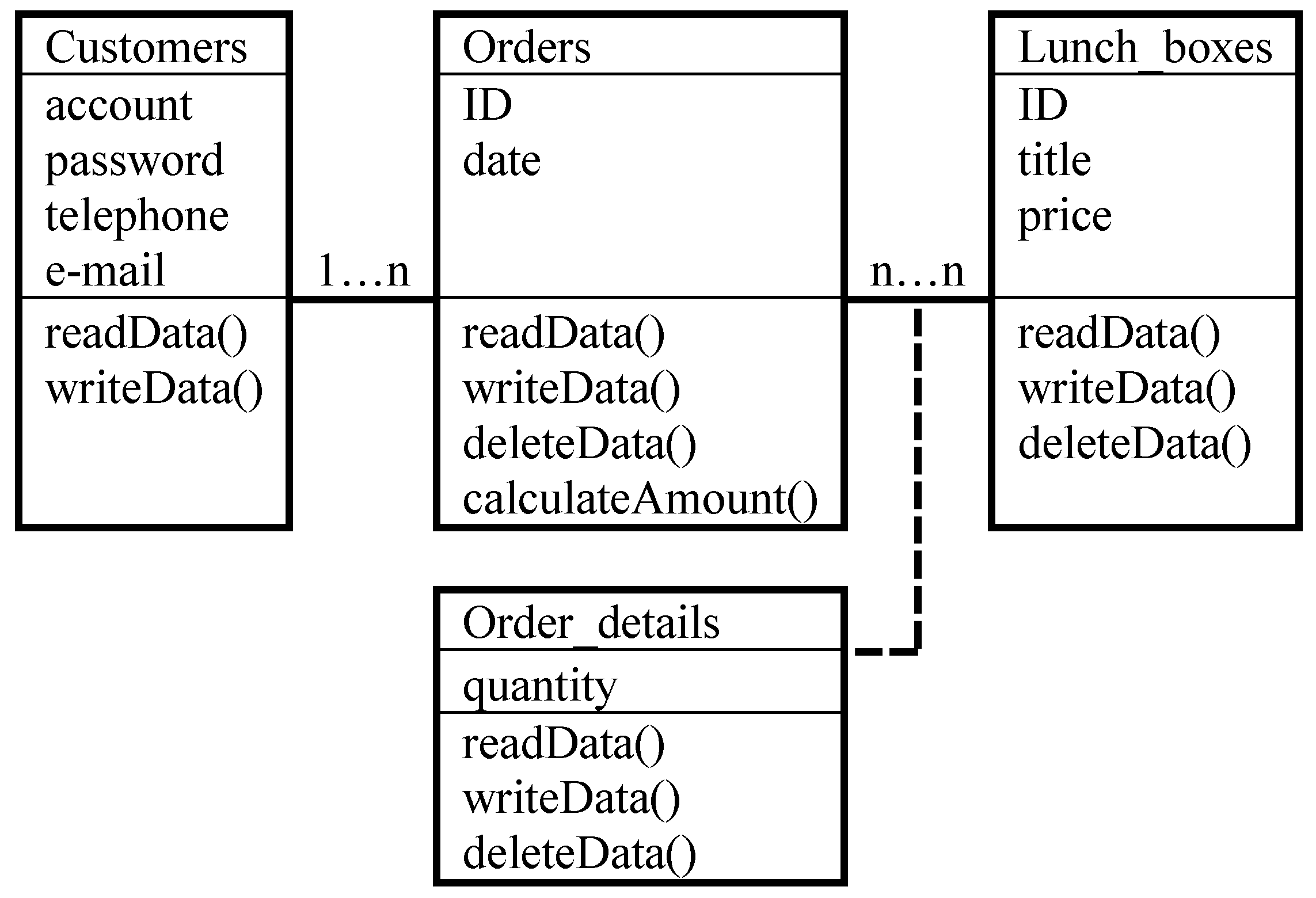
3.2. Document Store
- A collection is a group of documents. The documents within a collection are usually related to the same subject, such as employees, products, and so on.
- A document is a set of ordered key-value pairs, where key is a string used to reference a particular value, and value can be either a string or a document.
- JSON (JavaScript Object Notation), BSON (Binary JSON), and XML (eXtensible Markup Language) are formats commonly used to define documents.
- Embedded documents are documents within documents. An embedded document enables users to store related data in a single document to improve database performance.
- Document store databases do not require users to formally specify the structure of documents prior to adding documents to a collection. Therefore, document databases are called schemaless ones. Application programs should verify rules about the structure of a document.
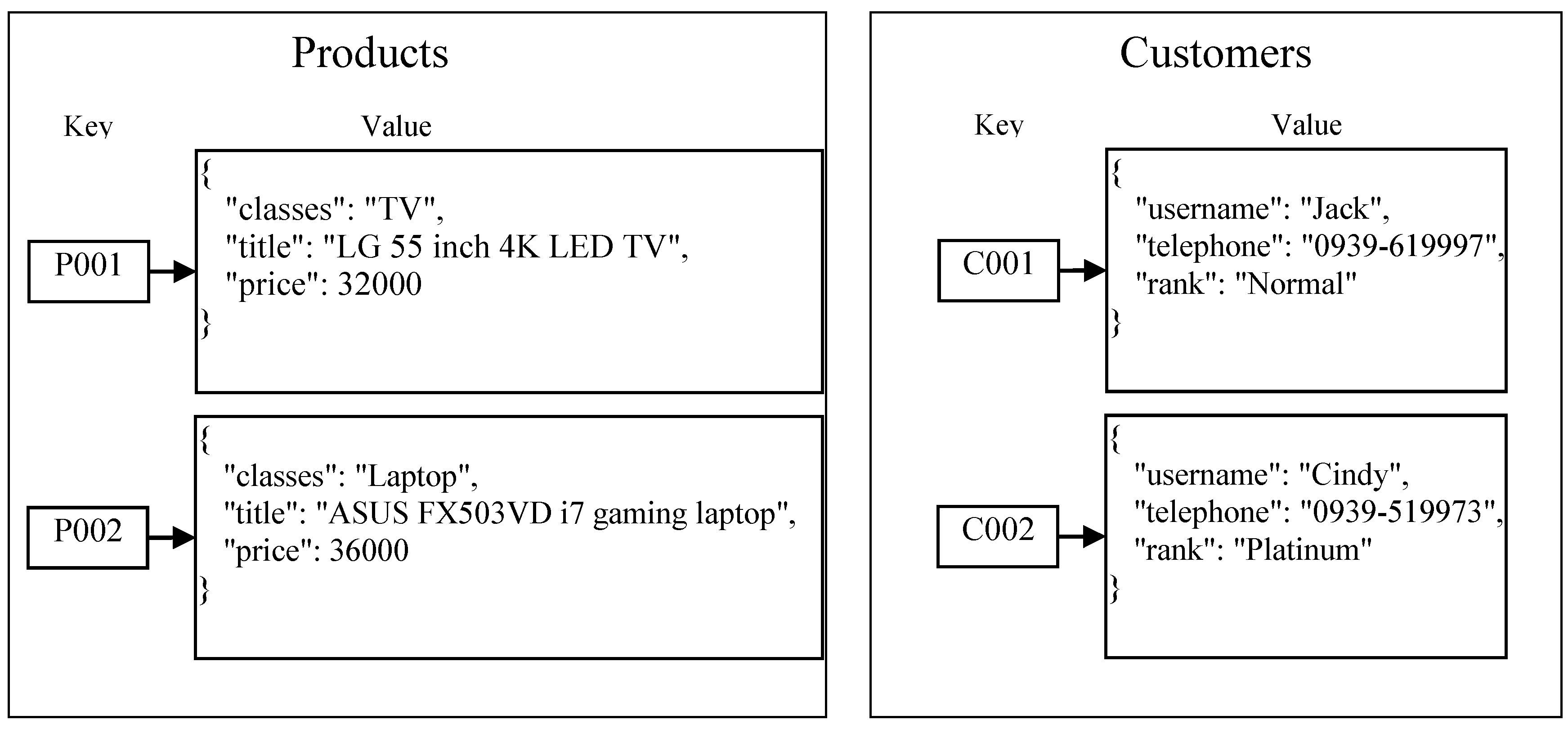
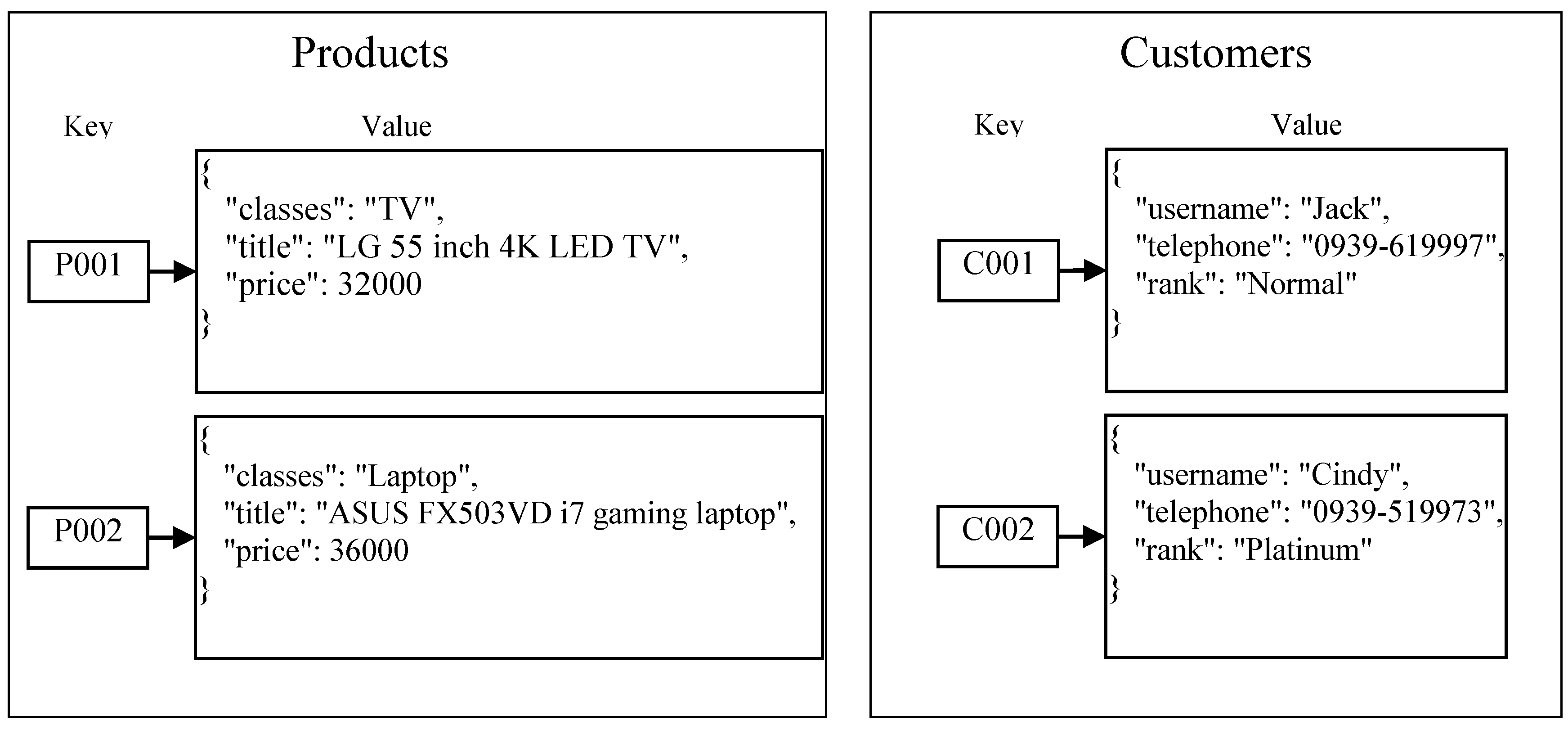
3.3. Key Value Store
- Key is a string used to identify a unique value;
- Value is an object whose value can be a simple string, numeric value, or a complex BLOB (binary large object), JSON object, image, audio, and so on;
- In key value store databases, operations on values are derived from keys. Users can retrieve, set, and delete a value by a key;
- A namespace is a logical data structure that can contain any number of key-value pairs.
- The key in the namespace “Products” is the ID of products, and the value is the details about products;
- The key in the namespace “Customers” is the ID of customers, and the value is the details about customers.
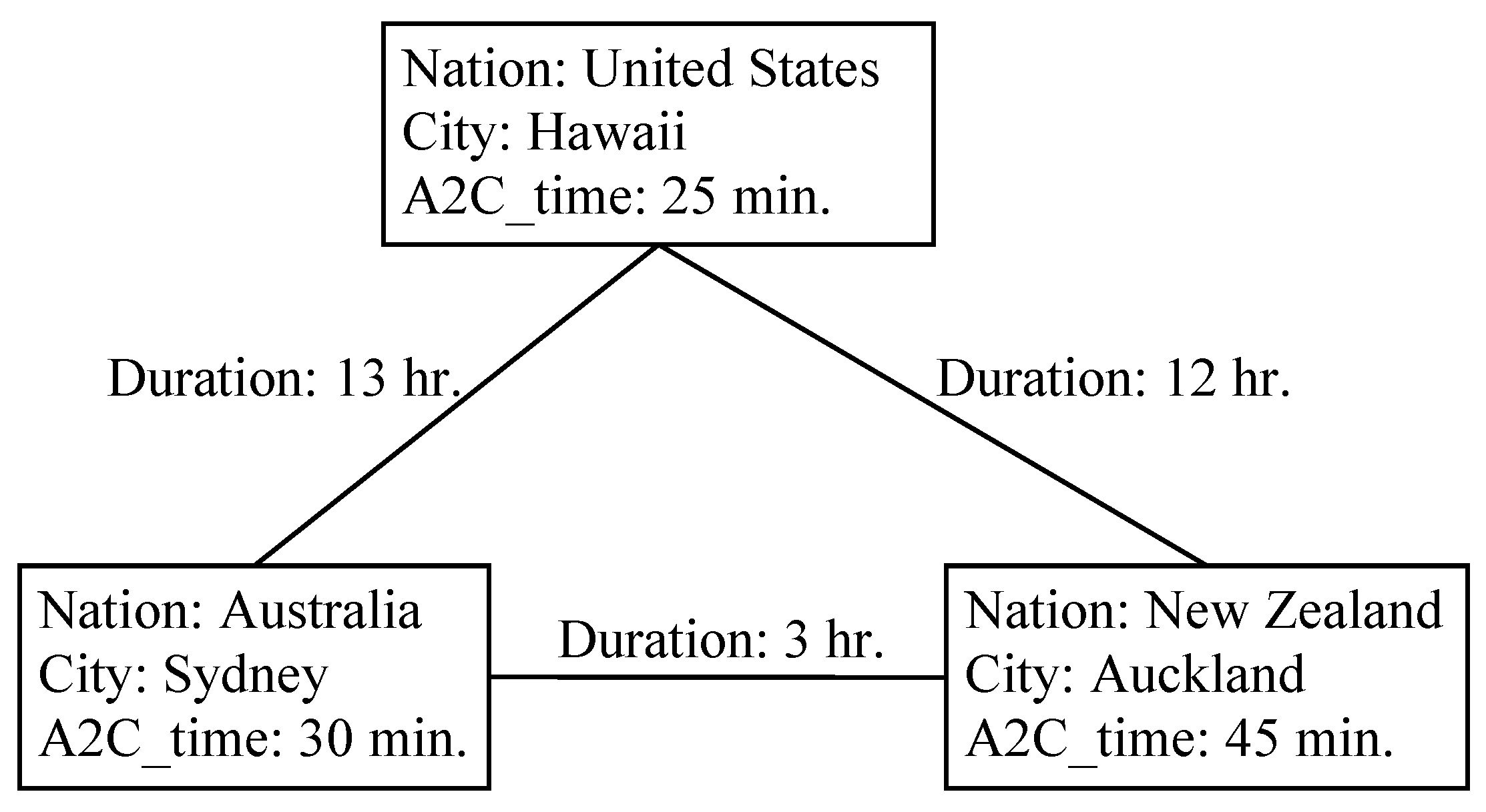
3.4. Graph Databases
- A vertex is an entity instance, which is equivalent to a tuple in RDM;
- An edge is used to define the relationship between vertices;
- Each vertex and edge contains any number of attributes that store the actual data value.
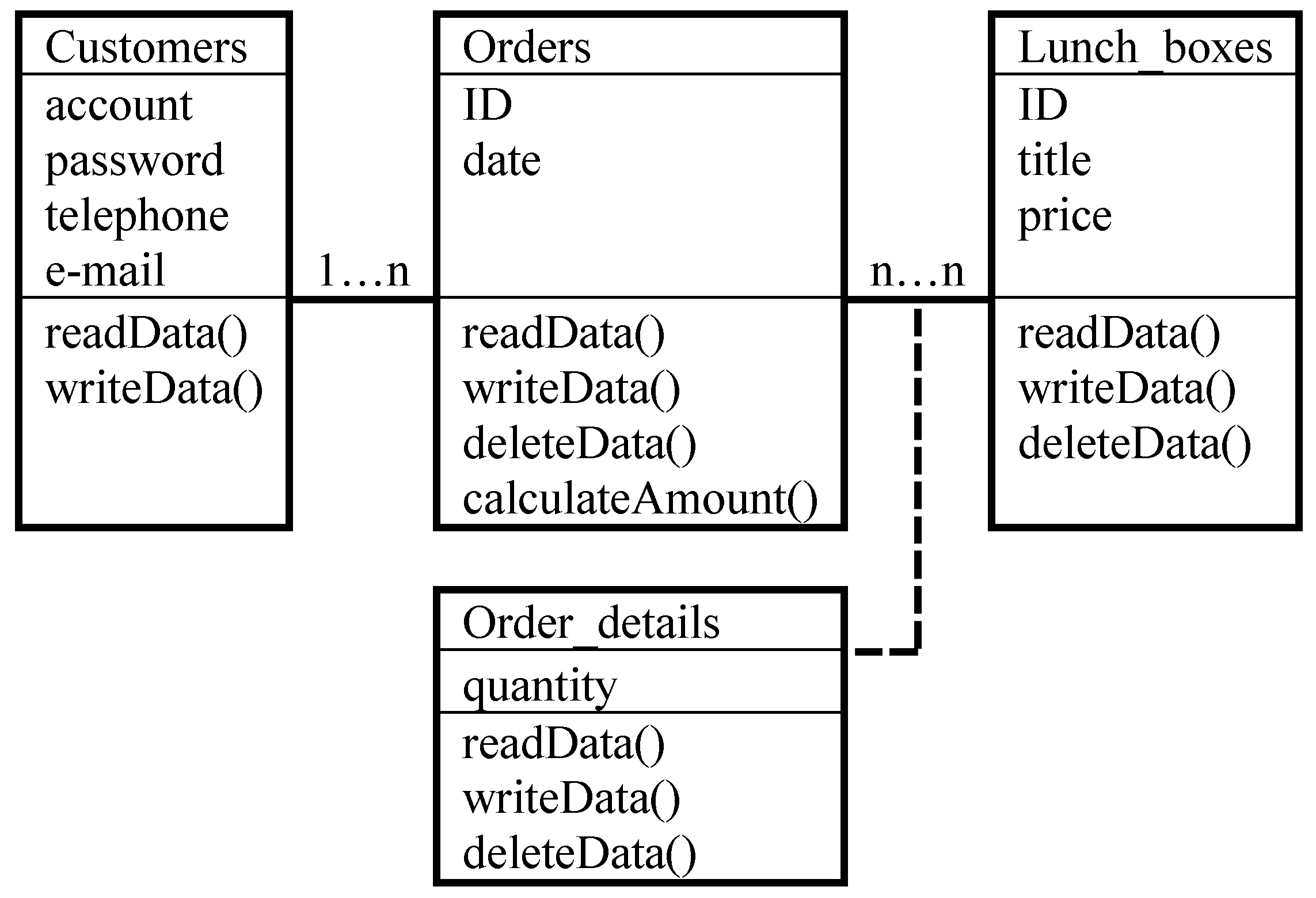
3.5. Multimodel Databases
3.6. Object Databases
3.7. Grid and Cloud Database Solutions
3.8. XML Databases
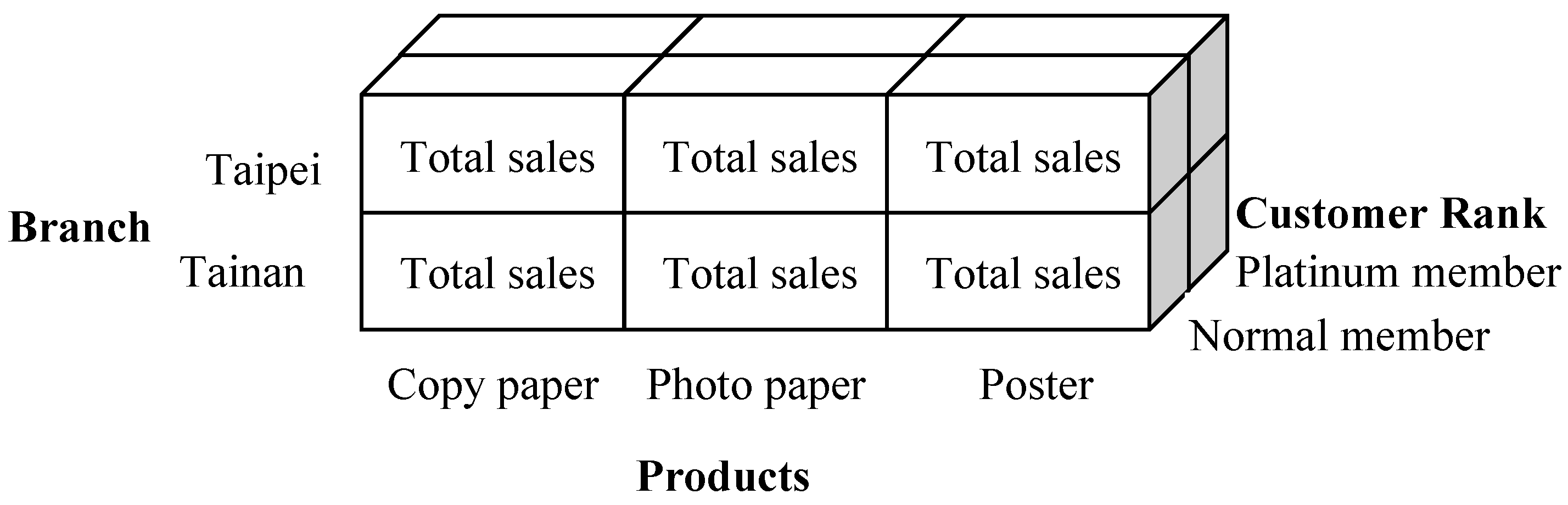
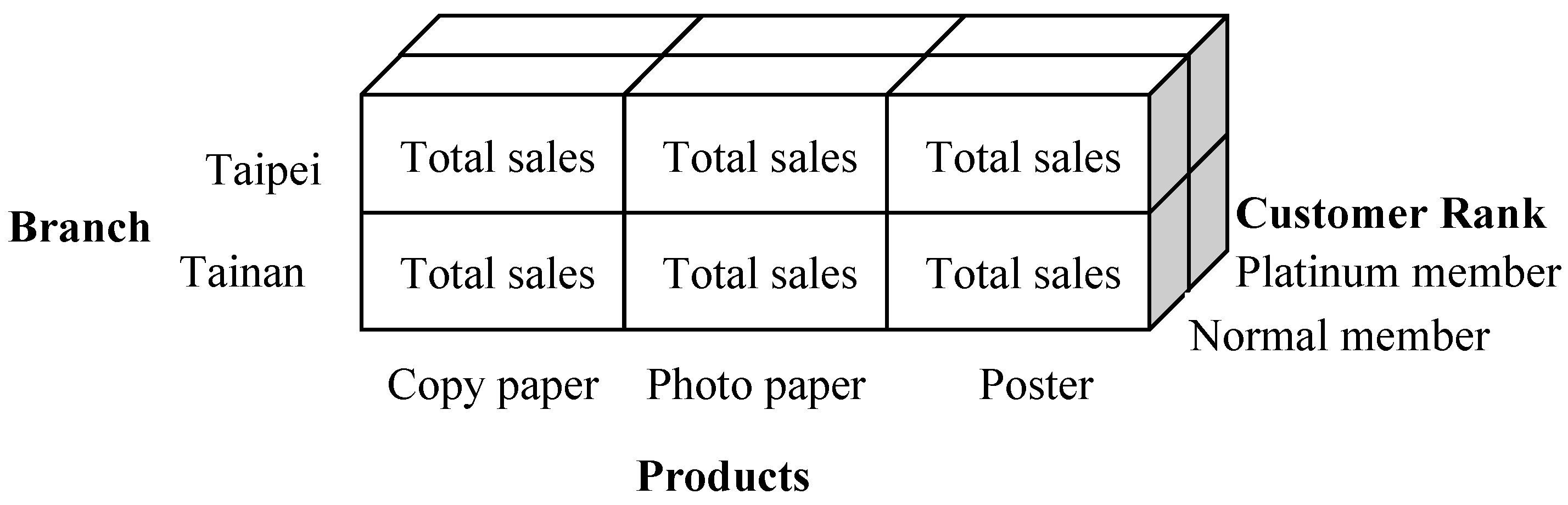
3.9. Multidimensional Databases
3.10. Multivalue Databases
3.11. Event Sourcing
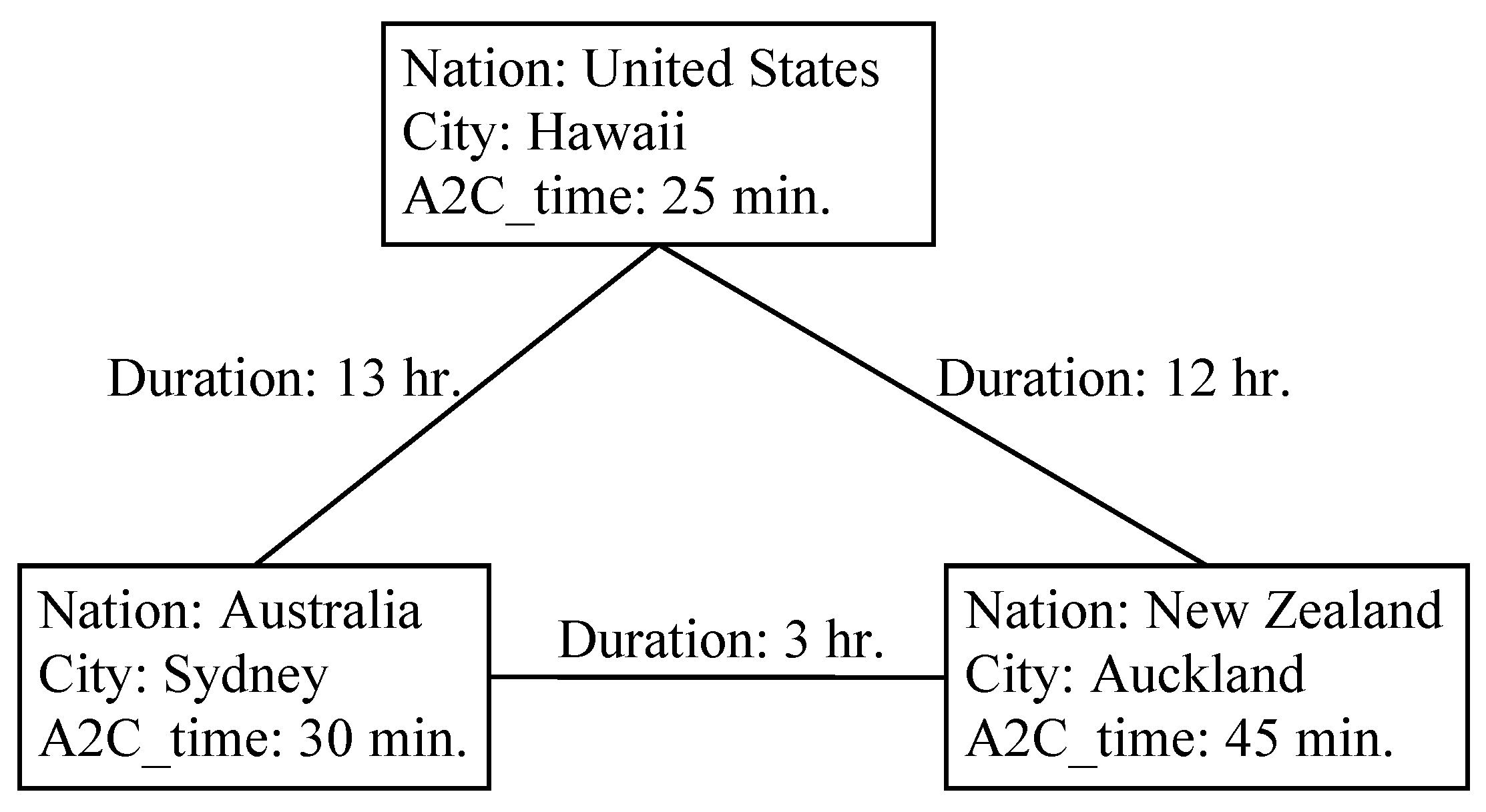
3.12. Time Series Databases (TSDBs)
3.13. Scientific and Specialized DBs
3.14. Other NoSQL Related Databases
3.15. Unresolved and Uncategorized
3.16. Summary
4. Choose an Appropriate Database
4.1. The Principles of Database Selection
- Understand the current problems, goals, and challenges of the corporate operation database.
- The engineers of the IT center or database administrators (DBAs) must decide to continue using the current RDB or change using a NoSQL database based on the needs of enterprise and their expertise.
- If changing to use a NoSQL database, the IT engineers or DBA first select a suitable category of NoSQL databases based on the features and formats of the enterprise’s operating data.
- When deciding which NoSQL database to choose, the IT engineers or DBA can make a decision according to the needs of the enterprise, the characteristics of each database, as well as the reputation and popularity of each database on websites (for example, DB-Engines Ranking website [15], vschart [25]). The more websites we query for this information, the more accurate the reputation and popularity of each database, and the more we can find the right NoSQL database.
4.2. Database Selection Case 1
- The most suitable category of NoSQL database is the wide column store because access to the database often requires searching for data in a specific field.
- According to the DB-Engines Ranking website [15], the wide column store databases that are more commonly discussed on the internet are Apache Cassandra and Apache HBase.
- According to the experimental results of Chen et al. [26], the time of Apache HBase to read data is less than that of Apache Cassandra. Therefore, Apache HBase is recommended as the NoSQL database used by the enterprise.
4.3. Database Selection Case 2
- Since the newspaper needs to collect files generated by a large number of instant messages such as tens of thousands of online news and related readers’ messages every day, it is necessary to replace the RDB with a NoSQL database.
- There are fifteen categories of NoSQL databases available, and the category found to be suitable for storing news multimedia materials is the document store.
- According to the DB-Engines Ranking website [15], the document store database that is often discussed on the internet has two NoSQL databases, MongoDB and Couchbase Server. Since the former has a higher market share than the latter, it is recommended to use MongoDB as the NoSQL database for the company.
4.4. Database Selection Case 3
- This corporation intends to promote “online recommendation system optimization” to recommend suitable products for each customer who visits the website of this corporation.
- To achieve the goal, the database must join a large number of customer and product data quickly to analyze in time the needs and trends of customers to products.
- However, the RDB this company used cannot meet the above requirement.
- The most suitable category of NoSQL database for the enterprise is graph databases because graph databases is the most suitable for the recommendation system as described in Table 7.
- According to the statistics of DB-Engines Ranking website [15], the most discussed NoSQL database in graph databases are Neo4j and FlockDB.
- Since Neo4j has the best market share among all graph databases [27]; thereby, Neo4j is recommended as the NoSQL database used by this enterprise.
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chen, H.A. Database System: Concept, Design, and Implementation, 3rd ed.; XBOOK MARKETING Co., Ltd.: Taipei, Taiwan, 2013. (In Chinese) [Google Scholar]
- NoSQL Databases. Available online: http://nosql-database.org/ (accessed on 20 January 2019).
- Pi, S.J. Establish the Cornerstone of Big Data: NoSQL Database Technique, 2nd ed.; TopTeam Information Co., Ltd.: Taipei, Taiwan, 2016. (In Chinese) [Google Scholar]
- Lu, J.H. Challenge Big Data, How to Process Big Data in Facebook, Google, Amazon? Use NoSQL to Get 10 Billion Annual Hard Disk Data, 2nd ed.; TopTeam Information Co., Ltd.: Taipei, Taiwan, 2015. (In Chinese) [Google Scholar]
- Sullivan, D. NoSQL for Mere Mortals, 1st ed.; Pearson P T R: London, UK, 2015. [Google Scholar]
- Hecht, R.; Jablonski, S. NoSQL Evaluation: A Use Case Oriented Survey. In Proceedings of the 2011 International Conference on Cloud and Service Computing, Hong Kong, China, 12–14 December 2011. [Google Scholar]
- Lourenço, J.R.; Cabral, B.; Carreiro, P.; Vieira, M.; Bernardino, J. Choosing the right NoSQL database for the job: A quality attribute evaluation. J. Big Data 2015, 2, 18:1–18:26. [Google Scholar] [CrossRef]
- Corbellini, A.; Mateos, C.; Zunino, A.; Godoy, D.; Schiaffino, S. Persisting big-data: The NoSQL landscape. Inf. Syst. 2016, 63, 1–23. [Google Scholar] [CrossRef]
- Khazaei, H.; Fokaefs, M.; Zareian, S.; Beigi-Mohammadi, N.; Ramprasad, B.; Shtern, M.; Gaikwad, P.; Litoiu, M. How do I Choose the Right NoSQL Solution? A Comprehensive Theoretical and Experimental Survey. Big Data Inf. Anal. 2016, 1, 185–216. [Google Scholar]
- Gessert, F.; Wingerath, W.; Friedrich, S.; Ritter, N. NoSQL database systems: A survey and decision guidance. Softw.-Intensiv. Cyber-Phys. Syst. 2017, 32, 353–365. [Google Scholar] [CrossRef]
- Davoudian, A.; Chen, L.; Liu, M. A Survey on NoSQL Stores. ACM Comput. Surv. (CSUR) 2018, 51, 40:1–40:43. [Google Scholar] [CrossRef]
- Dimiduk, N.; Khurana, A. HBase in Action, 1st ed.; Oreilly & Associates Inc.: New York, NY, USA, 2012. [Google Scholar]
- Lu, J.H. Hadoop: Practical Technical Handbook, 2nd ed.; TopTeam Information Co., Ltd.: Taipei, Taiwan, 2014. (In Chinese) [Google Scholar]
- George, L. HBase: The Definitive Guide, 1st ed.; Oreilly & Associates Inc.: New York, NY, USA, 2011. [Google Scholar]
- DB-Engines Ranking. Available online: https://db-engines.com/en/ranking (accessed on 4 March 2018).
- Multi-Model Databases (Wikipedia). Available online: https://en.wikipedia.org/wiki/Multi-model_database (accessed on 15 June 2018).
- Wu, R.H. Object-Oriented System Analysis and Design: An MDA Approach with UML, 4th ed.; BestWise Co., Ltd.: Taipei, Taiwan, 2013. (In Chinese) [Google Scholar]
- Document-Oriented Database (Wikipedia). Available online: https://en.wikipedia.org/wiki/Document-oriented_database (accessed on 15 June 2018).
- Multidimensional Databases. Available online: https://docs.oracle.com/cd/E12478_01/rpas/pdf/150/html/classic_client_user_guide/basic_rpas_concepts/multidimensional_databases.htm (accessed on 5 May 2018).
- MultiValue (Wikipedia). Available online: https://en.wikipedia.org/wiki/MultiValue (accessed on 15 June 2018).
- Introducing to Event Sourcing. Available online: https://msdn.microsoft.com/en-us/library/jj591559.aspx#sec1 (accessed on 16 January 2018).
- Time Series Database (Wikipedia). Available online: https://en.wikipedia.org/wiki/Time_series_database (accessed on 16 January 2018).
- Time Series (Wikipedia). Available online: https://en.wikipedia.org/wiki/Time_series (accessed on 16 January 2018).
- Central Weather Bureau. Available online: https://www.cwb.gov.tw/eng/index.htm (accessed on 10 July 2018).
- vsChart.com: The Comparison Wiki: Database List. Available online: http://vschart.com/list/database/ (accessed on 18 February 2019).
- Chen, C.Y.; Chang, B.R.; Tsai, H.F.; Guo, C.L. Empirical Analysis of High Efficient Remote Cloud Data Center Backup Using HBase and Cassandra. Sci. Progr. 2014, 2015, 1–10. [Google Scholar]
- Neo4j: Walmart Case Study. Available online: https://neo4j.com/case-studies/walmart/ (accessed on 10 December 2018).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Table Name: Students | |||
|---|---|---|---|
| SID: Char(5) | Name: Char(10) | Telephone: Char(11) | Birthday: Date (dd/mm/yy) |
| S0001 | Alice | 05-65976597 | 10/4/1994 |
| S0002 | Dora | 06-45714571 | 15/5/1995 |
| S0003 | Ella | 07-57865869 | 20/6/1996 |
| S0004 | Kevin | 06-57995611 | 22/7/1997 |
| S0005 | Leo | 05-12899821 | 26/8/1998 |
| ER-Model Elements | Symbols |
|---|---|
| Entity |  |
| Weak Entity |  |
| Relationship-Entity (Bridge Entity) |  |
| Relationship |  |
| Identifying Relationship |  |
| Attribute |  |
| Key Attribute |  |
| Composite Attribute |  |
| Multivalued Attribute |  |
| Table Name: Products_Inventory | |||
|---|---|---|---|
| Row Key | ts | Column Family Products | Column Family Inventory |
| P001 | t1 | Products: Classes = “TV” | |
| t2 | Products: Title = “SONY 55 inch 4K OLED Smart Networked TV” | ||
| t3 | Products: Descriptions = “TBD” | ||
| t4 | Products: Price = “24999” | ||
| t5 | Inventory: Quantity = “10” | ||
| t6 | Inventory: Place = “1A” | ||
| P002 | t7 | Products: Classes = “Laptop” | |
| t8 | Products: Title = “ACER SF514 14-inch laptop” | ||
| t9 | Products: Descriptions = “TBD” | ||
| t10 | Products: Price = “31000” | ||
| t11 | Inventory: Quantity = “20” | ||
| t12 | Inventory: Place = “2A” | ||
| P003 | t13 | Products: Classes = “Mobile phone” | |
| t14 | Products: Title = “ZenFone 5Z” | ||
| t15 | Products: Descriptions = “TBD” | ||
| t16 | Products: Price = “5000” | ||
| t17 | Inventory: Quantity = “8” | ||
| t18 | Inventory: Place = “2B” | ||
| Table Name: Students | |||
|---|---|---|---|
| SID | Name | Society | |
| First_Name | Last_Name | ||
| S001 | Frank | Lee | {Pop music, Choir} |
| S002 | George | Lu | {Choir, Poetry} |
| S003 | Hank | Wu | {Computer, Guitar} |
| S004 | Ivy | Lin | {Computer, Pop music} |
| S005 | Jack | Chen | {Pop music, Guitar} |
| S006 | Kevin | Yang | {Computer, Poetry} |
| Time (dd/mm/yy) | Person | Current Enrolment Number |
|---|---|---|
| 22/12/2018 12:30 | Amy | 1 |
| 25/12/2018 10:40 | Ruby | 2 |
| 28/12/2018 13:20 | Cindy | 3 |
| 29/12/2018 14:10 | John | 4 |
| 30/12/2018 15:00 | Mary | 5 |
| 31/12/2018 16:50 | Zoe | 6 |
| Measurement Time (dd/mm/yy) | Air Quality Index (AQI) | The Density of PM2.5 |
|---|---|---|
| 01/01/2018 00:00 | 156 | 45 |
| 01/01/2018 01:00 | 101 | 29 |
| 01/01/2018 02:00 | 97 | 19 |
| … | … | … |
| 31/12/2018 21:00 | 133 | 34 |
| 31/12/2018 22:00 | 135 | 36 |
| 31/12/2018 23:00 | 141 | 43 |
| Categories of NoSQL Databases | Suitable Data Features |
|---|---|
| Wide Column Store | Three-dimensional data. Applications that often search for specific field data. |
| Document Store | Semi-structured files, such as XML, JSON, and so on. |
| Key Value Store | One-dimensional data, which is stored in key-value pairs. |
| Graph Databases | Data stored in a graphic structure. Suitable for data of social network relations, recommendation systems, and so on. |
| Multimodel Databases | Determine data features suitable processing based on the data format of a specific database. |
| Object Databases | The object-oriented concepts are used to describe the data itself and the relationship among the data. Suitable for computer aided design (CAD) and office automation. |
| Grid and Cloud Database Solutions | Applications that need to search recent access data frequently. |
| XML Databases | Data stored in XML files. |
| Multidimensional Databases | Applications that often analyze data in multiple dimensions. |
| Multivalue Databases | Data with multivalued attributes or composite attributes. |
| Event Sourcing | Data with events that occurred in the past for tracking the status of something. |
| Time Series Databases | Data related to time series. |
| Other NoSQL Related Databases | Unable to know. |
| Scientific and Specialized DBs | Data suitable for scientific research or computing. |
| Unresolved and Uncategorized | Data based on the data format of a specific database. |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.-K.; Lee, W.-Z. An Introduction of NoSQL Databases Based on Their Categories and Application Industries. Algorithms 2019, 12, 106. https://doi.org/10.3390/a12050106
Chen J-K, Lee W-Z. An Introduction of NoSQL Databases Based on Their Categories and Application Industries. Algorithms. 2019; 12(5):106. https://doi.org/10.3390/a12050106
Chicago/Turabian StyleChen, Jeang-Kuo, and Wei-Zhe Lee. 2019. "An Introduction of NoSQL Databases Based on Their Categories and Application Industries" Algorithms 12, no. 5: 106. https://doi.org/10.3390/a12050106
APA StyleChen, J.-K., & Lee, W.-Z. (2019). An Introduction of NoSQL Databases Based on Their Categories and Application Industries. Algorithms, 12(5), 106. https://doi.org/10.3390/a12050106