3.2. kNN Classification and Clustering in Dual Space
Here, we consider points in dual space
. Given two dual points
and
, we define as
the distance between
and
in
. In the context of this work, we utilize the Euclidean distance metric, which is defined as
where
,
denote the values of
,
along the
i dimension in
. For example, in Hough-X space, the distance between the dual points
is computed as
.
Definition 1. DukNN: Given a dual point dp, a data-set of dual points Y and an integer k, the k nearest neighbors of dp from Y, denoted as , is a set of k points from Y such that and , .
Definition 2. DukNN Classification: Given a dual point dp, a training dual points data-set Y, and a set of classes where the dual points of Y belong, the classification process produces a pair (,), where is the majority class to which dp belongs.
Definition 3. Clustering: Given a finite data-set of dual points = {, ,..., } in , and number of clusters K, the clustering procedure produces K partitions of such that among all K partitions (clusters) ,,..., find one that minimizes where is the number of dual points in cluster .
Note that the aforementioned dual methods act as a feature extraction technique. More specifically, they extract the dual point of each of the coordinates of a mobile user trajectory. The k nearest neighbors algorithm is then applied on dual points features and allowed to return dual points, whose distance from the query dual point is less than the distance from the rest of the training dual points. Considering the Hough-X transformation of attribute x or y, the search area is a circle with the center being the query point and a radius such that k nearest neighbors exist. If we assume Hough-X of attributes, the k nearest neighbor search area is four-dimensional with complex hypercube geometry.
3.4. Problem Formulation
In the context of this study, the problem of privacy preservation when dealing with spatio-temporal databases goes one step further, and is related to the work [
9]. The spatio-temporal data is the location data of a number of mobile users along with the time-stamp of each position, as shown in
Table 1. Through the SMaRT system, we have in our disposal offline trajectory data that give us information about Hough-X, as well as Hough-Y of spatial data
. Hence, for each database record per time-stamp, that is, the mobile user trajectory point, we can consider the values of four attributes
(as in
Table 1) along with the values of an additional eight attributes’
(as in
Table 2).
So, we have chosen to anonymize dual point attributes by employing the
k-NN method, which enables us to form the
k-anonymity set of each mobile object per time-stamp, as depicted in
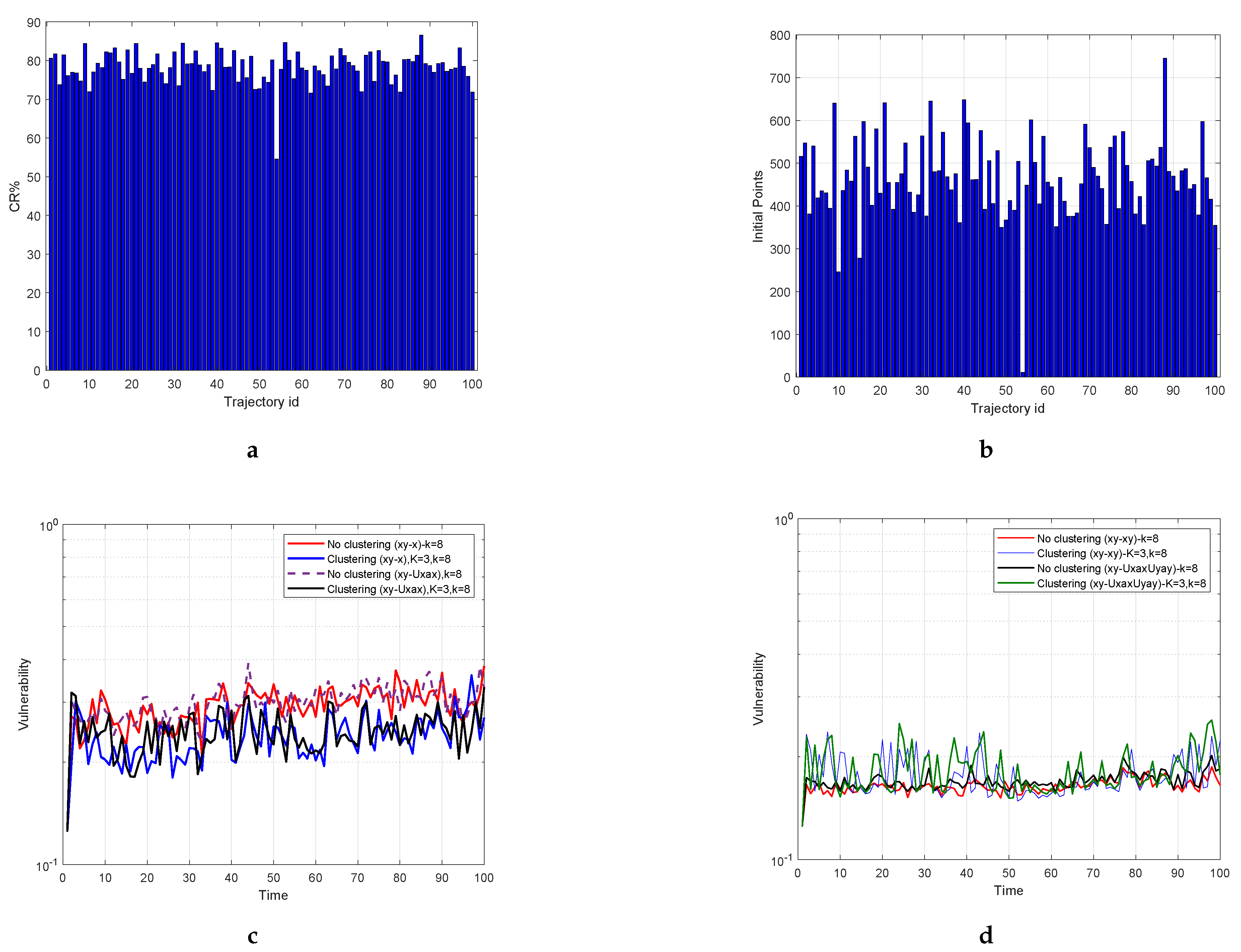
Table 3. The data anonymization is handled both as a clustering and a no-clustering problem. In both approaches, the anonymity set is formed again by the
k nearest neighbors IDS. For each mobile user
i and per time-stamp
l, we compute its
k nearest neighbors IDS and keep them in a vector with form
for
. In
Table 3, an example of such sets for
N mobile users’ dual points is presented. For each user, we measure the number of the
k nearest neighbors dual points that remained the same from one time-stamp to another.
By employing the dual transformation methods as described in
Section 3.1, the
k-anonymity set of mobile users is formulated based on their dual points. Hence, an alternative definition for the
k-anonymity is as follows:
Definition 10. (-anonymity). A transformed database record is k-anonymous with respect to Hough-X dual points—that is, velocity and intersection attributes or , if discrete records in the same specific time-stamp τ at least have the same dual point attributes so that no record of k is distinguished from its neighboring records.
Remark 1. As we already mentioned in [9], k-anonymization intuitively hides each individual among others. This means that linking cannot be performed with confidence greater than . Nevertheless, k-anonymity may not protect users against the unveiling of dual point attributes. 3.5. System Model
Here, we consider a spatio-temporal database with
N records—that is,
N moving objects in the
plane. Each record
represents the spatial coordinates of the mobile user
j in time-stamp
, or point
i of its trajectory
j [
15]. From the location coordinates
, we can extract the corresponding dual points by employing the methods described in
Section 3.1. Suppose a trajectories database
of equal length
L in which each trajectory is represented via a sequence of
L triples, that is,
.
For each point i in trajectory j, we define in four-dimensional space a vector which denotes the dual points array. Hence, we can redefine and store the trajectory j as .
The privacy preservation of
k-NN query in trajectory databases is addressed with the use of two different methods. The first one is entitled dual-based
k-NN (
) which applies
k-NN directly onto dual points, while the second one is called dual-based clustering
k-NN (
). The main difference between these two methods lies in the fact that the latter is applied in clustered dual point data. In addition, the operations involved in addressing a
k-NN query are thoroughly described in Algorithms 1 and 2, respectively.
| Algorithm 1 DukNN |
- 1:
input The number of k nearest neighbors - 2:
input The number of mobile users N - 3:
input The dual points array of N users in L time-stamps - 4:
outputk nearest neighbors indexes of N users in L time-stamps - 5:
for to L do - 6:
for to N do - 7:
Apply k-NN for the dual points of all users in order to identify the set of k-NN indexes of user j in time-stamp i - 8:
end for - 9:
end for
|
| Algorithm 2 DuCLkNN |
- 1:
input The number of k nearest neighbors - 2:
input The number of mobile users N - 3:
input The dual points array of N users in L time-stamps - 4:
outputk-NN indexes of N users in L time-stamps - 5:
Apply K-Means of dual points of N users for the L time-stamps - 6:
fordo - 7:
for do - 8:
Apply k-NN method between the dual point of user j and the dual point of users inside the cluster of user j in time-stamp i and find the set of k-NN indexes - 9:
end for - 10:
end for
|
In the case of employing the Algorithm 1 in order to run a k-NN query, we must focus on a specific time-period during which we will have in our disposal the dual point of all users’ locations. Given that each user stands in the same sub-trajectory during the study period, the privacy is preserved in that segment since the k nearest neighbors remain unchanged. On the other hand, in the case of employing Algorithm 2, the clustering step is ahead; we can again claim that the clusters composition remains the same, since the clustering method is applied in dual space and mobile users have the same dual point. As a result, the k nearest neighbors inside the cluster will remain the same. Hence, without loss of generality, in both cases, the privacy is piecewise preserved, except for the points of discontinuity (known as characteristic points) where the motion characteristics may change.
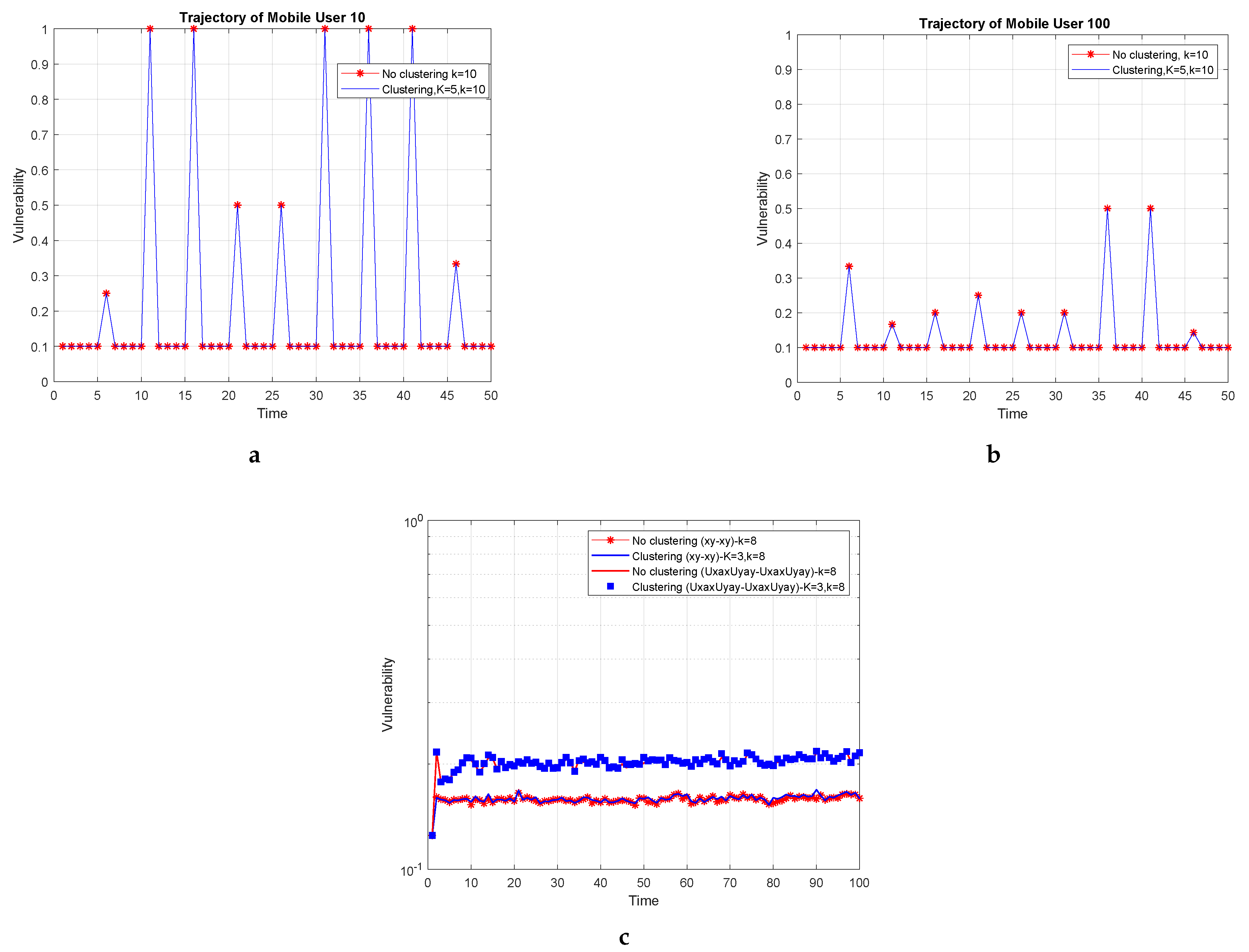
3.6. Vulnerability and Storage Efficiency
In this paper, we assume the mobile users’ trajectory on a real map with small velocities; thus, we use the Hough-X transform, since an object’s motion is mapped to the dual point. To answer a k-NN query, the following steps are performed:
Decompose the k-NN query into queries for the and projection.
For each projection, get the dual k-NN query by using a Hough-X transform.
Return the anonymity set, which contains the trajectories IDS that satisfy the dual k-NN query in each projection.
In following, the analysis is focused on the robustness estimation of the proposed approach based on Hough-X. Specifically, the ensuing steps are followed:
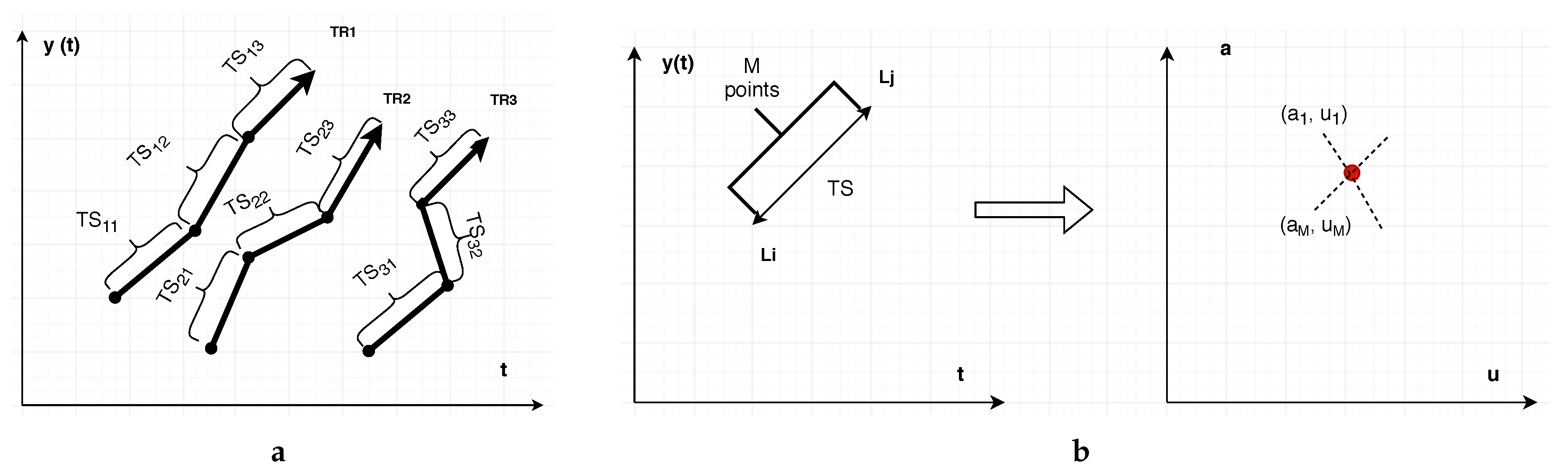
Split the initial trajectory into a number of linear sub-trajectories, each of which consists of the same number of M spatial points.
Apply Hough-X in each part.
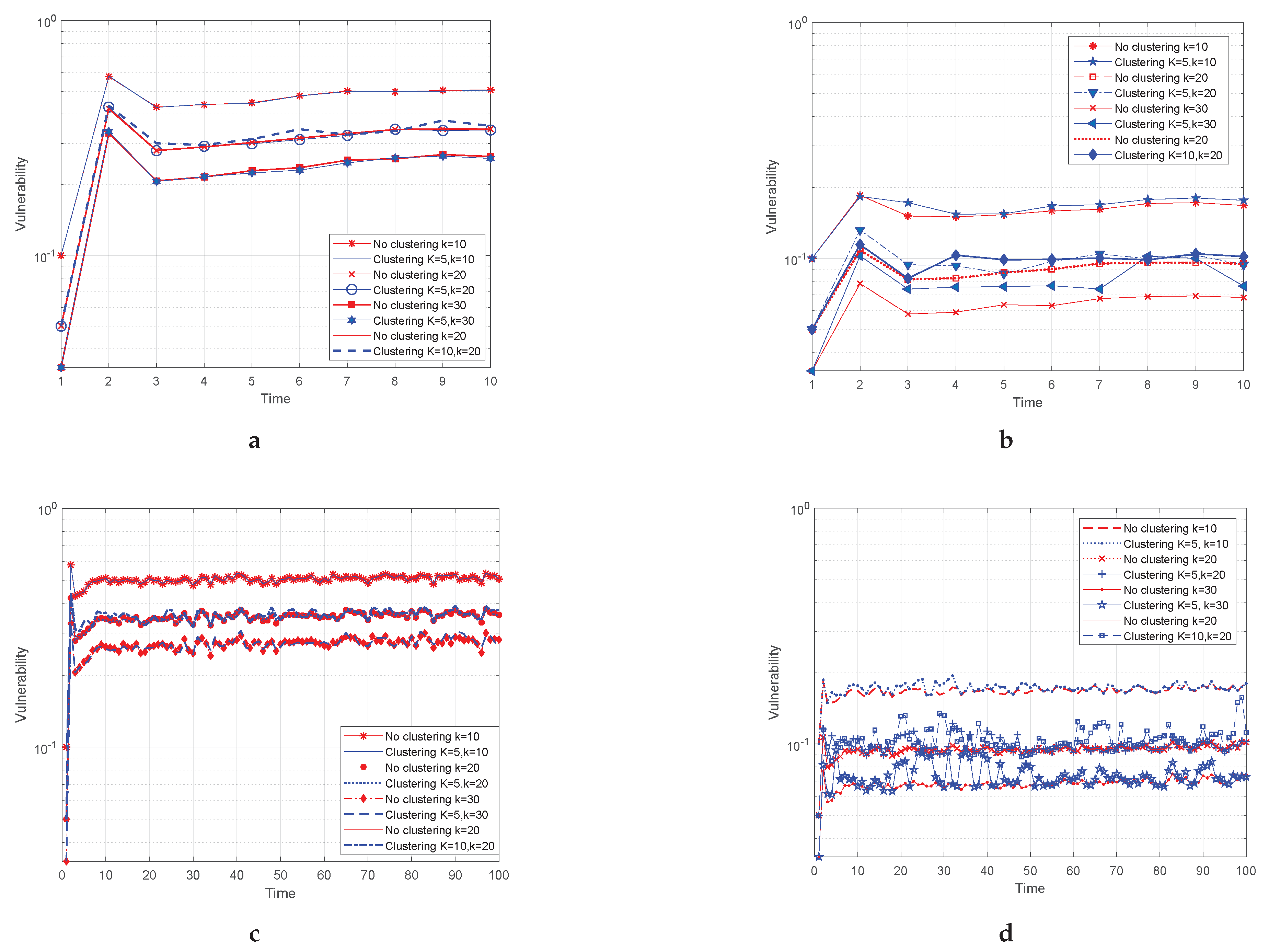
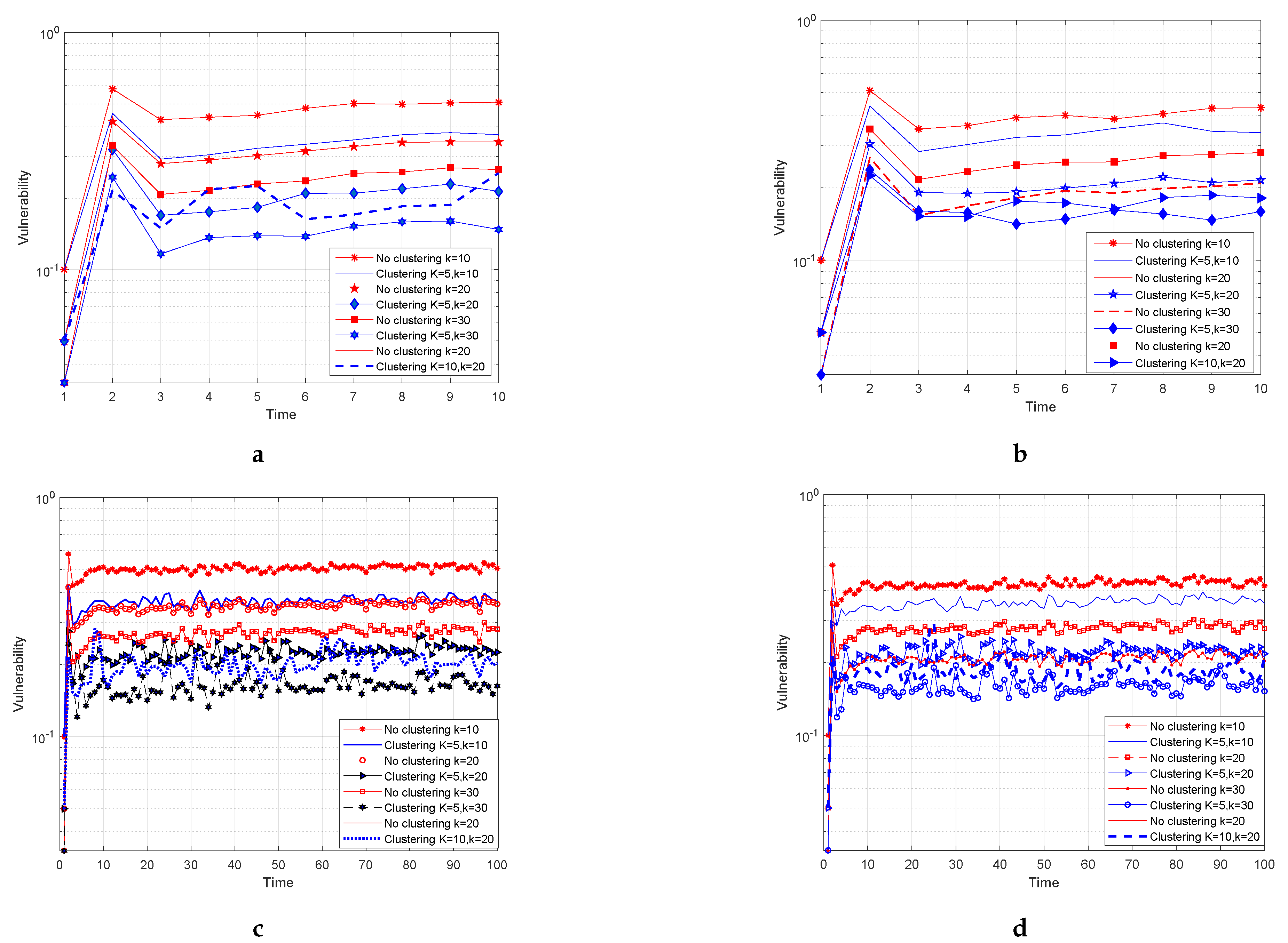
Suppose that M is the number of points of the trajectory, which a dual point represents, and D is the number of dual points, which describe the trajectory projection or in dual space. Therefore, the whole trajectory has a length equal to spatial points, for which should hold. In the following, we camouflage a mobile user who keeps track of a linear trajectory or or its corresponding dual point with the k nearest neighboring dual points, which is very probable to remain the same in the next timestamp. Actually, while users move onto the linear sub-trajectory, which relates to the same dual point, the k-NN set will remain intact. Therefore, for as long as it happens, we can claim that the k-anonymity holds. Indeed, the privacy preservation is reinforced by a factor M that formulates the so-called vulnerability level to .
We recall the spatial data security metric that we have already defined in [
9] for the quantification and measure of the robustness of our methods. Again, the vulnerability remains equal to
in dual point space. Nonetheless, the definition of vulnerability in the initial dataset is measured as the following. Since the points inside a sub-trajectory are protected by the same dual points, it is obvious that their vulnerability is considerably reduced to
; this aspect entails that with a probability equal to
, an intruder can distinguish the identity of a mobile user. The same holds for all sub-trajectories. Hence, the vulnerability in each projection is defined as:
where
and
is the vulnerability measure based on Hough-X in projection
and
, accordingly.
Next, the vulnerability in each projection is combined, and the total vulnerability is written as in the following equation:
where
represents all combinations of
M points that correspond to 2 dual points of the initial trajectory.
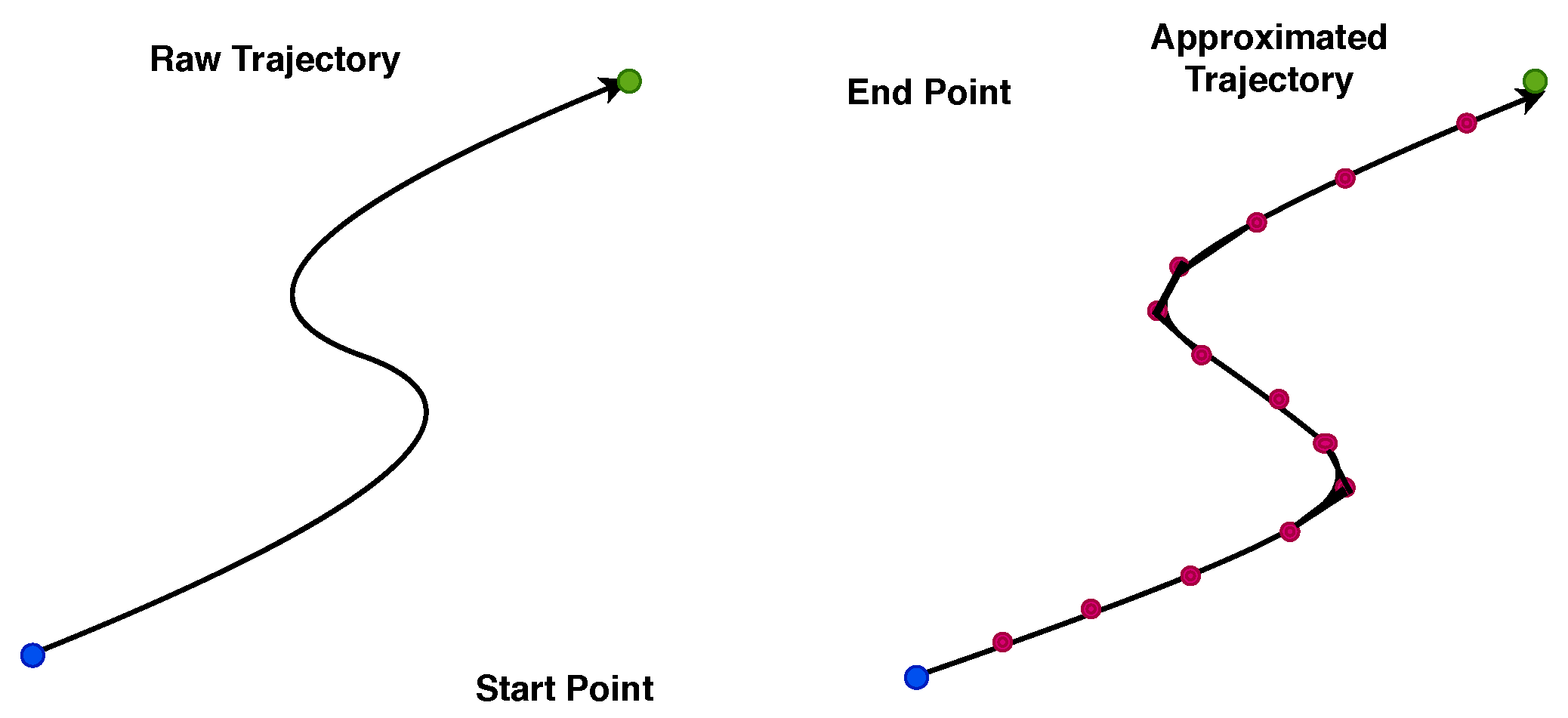
Several trajectory compression approaches have been proposed aiming at reducing the trajectory’s size. An initial discrimination classifies the compression methods either as offline (after trajectory generation) or online (instantly as objects move). The data compression constitutes a method that decreases the size of the data in order to limit the memory space and ameliorate the efficiency of storage, processing, and/or transmission without loss of information. Various trajectory compression algorithms exist in literature that try to balance the tradeoff between accuracy and storage size. We refer to some major ones—namely, distance-based, velocity-based, semantic, similarity-based, and priority queue [
4]. The proposed Hough-X based approach achieves trajectory compression suitable for either a single or multiple trajectory set. Without loss of information, Hough-X maps each linear sub-trajectory spatial point to its representative dual point.
Compression can be achieved by applying dimensionality transformation to increase the storage efficiency of the data. Suppose we reduce three-dimensional data
to Hough-X space of
, that is,
. Storage space-saving is achieved through the number of available dual points
D, being less than the number of points
M in the corresponding linear sub-trajectory; hence, achieving in the whole trajectory
or
, where for example,
M spatial points correspond to one dual point, as shown in
Figure 1. This conserves space and achieves more compression, as depicted in
Figure 3, and thus it is expected to have a greater impact on large-scale spatio-temporal databases.
Potentially, by employing a dual method based on Hough-X, we could generate a trajectory codebook by applying Hough-X transformation to all linear sub-trajectories of a given set of trajectories in a map region. In the training step, dual points that stem from the same linear part are similar and must be grouped into the same cluster; also, each cluster is assigned to a single representative vector, called a dual code-vector. Hence, each trajectory inside the codebook is represented by its dual points.
At this point, we should note that the Hough method acts as a clustering one. Actually, K-means is a popular method for both clustering and codebook design. In the coding step, each input dual points vector is compressed to the nearest dual code-vector referenced by a simple index. The index of the matched code-vector in the codebook is then transmitted to the decoder over a channel and is used by the decoder in order to retrieve the similar trajectory dual points from an identical codebook. The key operation is that it is stored and transmits the index of the dual code-vector, rather than the entire code-vector.
As a result, the recommended schema is space-compressed because of the duality, and also more robust in comparison with the suggested methods in previous works [
9,
12].
3.7. Privacy Preservation Analysis
Privacy relates to individual data protection and the human right to be able to determine the information about themselves that is to be hidden. Privacy-preserving data management includes
k-anonymity, a noted method for data anonymization before publication, which has also been studied in the context of trajectory data. Authors in [
16] claim that given a set of trajectories, the objective of the data publication is to transform them into some
k-anonymized form in order to prevent original data publication, putting at risk the privacy of individuals related with the data. In addition, they mention that an intruder, who knows a sub-trajectory of the original trajectory of an individual, may utilize it with the aim of extracting the whole trajectory of that person based on the published data. Finally, they recognize an upper bound for the re-identification probability of the whole trajectory within the released data, namely
, where the parameter
k reflects the expected level of privacy.
Our solution transforms the original spatial point into the dual-point one using bijective mapping, such as Hough. This technique allows for a k-NN search directly on the transformed points, thus providing stronger location privacy. Assuming an insecure Transformed Database Management System (TDBMS) possibly located at a third party (e.g., a service provider in the cloud), an attacker sees its environment. In particular, the attacker has access to the transformed database, to the queries upon the transformed data, as well as to the results. Also, we suppose that the attacker is aware of the dual transformation scheme and aims to retrieve the original database executing Hough-X and/or Hough-Y algorithms with respect to the size of the database. Nonetheless, in our proposed paper, we aim to prevent an attacker from obtaining the original database, as it is possible that they may occupy extra knowledge about this original database. To better evaluate the power of the transformation scheme, we taxonomize the attacks into different levels based on the possessed knowledge.
Level 1: The attacker only observes the transformed database.
Level 2: Except the transformed database, the attacker is familiar with a set of plain tuples of the original database, but does not know the corresponding encoded values of those tuples in the transformed database.
Level 3: Apart from the transformed database, the attacker observes a set of tuples in the original database, and thus knows the corresponding encoded values of those tuples.
A few cryptography-based approaches, such as homomorphic encryption (HE), verifiable computation (VC), and secure multi-party computation (MPC) have been designed in order to provide secure big-data processing in the Cloud [
17]. However, other approaches, such as Asymmetric Key Cryptography and trusted Public Key Infrastructure have been developed over the years in order to support privacy preservation in the spatio-temporal domain. The basic idea behind these techniques is to encrypt the identity of the user prior to sending it to the service provider. In this way, the service provider does not have any knowledge about the real identity of the individual who initiated the
k-NN query. To prevent an external adversary from linking queries to the same mobile object, its pseudonym has to be secure. For this reason, we are concerned about pseudonyms’ recovery, as well as registration protocols consisting of three entities, namely, Users (U), Identity Provider (IP), and Service Providers (SP). Recall that they are based on Brand’s credentials and have been suggested by Brand in the context of "The New System" with the aim of making the communication more reliable and secure. We believe that the adoption of these protocols will reinforce the identity privacy of mobile objects and the spatio-temporal databases at large. For the sake of completeness, the main steps of these protocols, along with the privacy preservation properties they offer, are presented.
The mobile user, U performs the following protocol in order to retrieve a set of pseudonyms with the identity provider (IP):
Initially, user U chooses random values where e is known only to user U, then computes the quantity and finally sends it to IP ().
Secondly, IP recovers the quantity , collects random quantities and computes the product , where .
Thirdly, user U creates the ’s according to the equation for and computes the quantity . Hence, the corresponding user creates m pseudonyms and values , such that for .
A mobile user U registers a pseudonym
with a service provider
presenting the pseudonyms
and uncovering the value
encoded in
. The user with the service provider
performs the following proof of knowledge, provided that
, so as the tuple
will be a valid one.
Then, the service provider stores the tuple and associates it with either a new or an existing user account. Through this protocol, it is demonstrated that the user owns the pseudonyms and proves that the disclosed value is actually the value encoded in .
The privacy preservation lies in the following facts:
The service provider cannot find out any additional information about the quantities encoded in , except for the disclosed value .
The random set is created so that nobody (user, identity provider) can control its end value.
The e is randomly selected from the user so that it can remain unknown to the IP. The user also computes a secret key , one for each pseudonym ; this proves that the user is aware of it without unveiling it.
The assumption of the Discrete Logarithm in a group of prime order q along with the values () ensures that any malicious user , irrespective of the level of knowledge they possess about the Original and Transformed Database, even if they engage a pseudonym recovery protocol to the IP and obtain a valid pseudonym , has negligible probability that it is the value encoded in the public key P.
Suppose there is a mobile user who has initiated a discrete number of k-NN queries with different pseudonyms for each one. The unlinkability that the aforementioned protocols provide relates with the service provider’s incapability to connect to the IP with the different pseudonyms to that mobile user and validate that they belong to the same user. Thus, the privacy preservation of that user identity is achieved.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}