1. Introduction
A Knowledge Graph (KG), also known as a knowledge base, is a structured representation of knowledge about our world. Many KGs, such as WordNet [
1], Freebase [
2], DBpedia [
3], and NELL [
4], have been constructed to provide extremely useful resources for a broad range of applications, including question answering [
5], information extraction [
6], and recommendation systems [
7,
8]. In general, a KG is a collection of triples or facts, composed of entities that represent real-world objects and relations that express the relationships between entities, in the form of (
head entity, relation, tail entity) abbreviated as
. These triples thus can be formalized as a directed multi-relational graph, where nodes denote entities and one edge directed from node
h to
t indicates the relation
r between them. Despite the compact structure of such triples, KG is still hard to manipulate due to its symbolic nature.
In order to express the latent semantic information and facilitate the manipulation of KG, knowledge graph embedding has been proposed and quickly became a popular research topic in recent years. The main idea of KG embedding is to embed entities and relations into a low-dimensional continuous vector space. Such vectorial representations of KG can further benefit a wide variety of downstream tasks such as KG completion [
9], entity resolution [
10], and relation extraction [
11]. Early works on this topic developing the embedding model solely relied on the observed triples in KG and were incapable of encoding sparse entities. Therefore, more and more researchers have managed to improve the embedding models by adding extra useful information beyond KG triples. Among these studies, combining first order logic rules with the existing embedding model has gained increasing attention, as rules introduce rich background information and are extremely useful for knowledge acquisition and inference.
There are two kinds of logical rules employed by previous works, i.e., hard rules, which are handcrafted by experts, and soft rules, which are extracted with certain confidences from knowledge graphs themselves. Hard rules require costly manual effort to create or validate and hold with no exception, while soft rules can be extracted automatically and efficiently via a modern rule mining system and better handle unseen and noisy facts. Therefore, many researchers tend to improve KG embeddings by equipping the KG embedding model with soft rules. Minervini et al. [
12] pioneered employing the soft equivalence and inversion rules to regularize embeddings. Ding et al. [
13] imposed an approximate entailment constraint on relation embeddings with soft rules. Guo et al. [
14] proposed RUGEand learned KG embeddings with iterative guidance from soft rules. However, the former two methods cannot support the transitivity and composition rules, which are very common in the real world, while RUGE assumes all the groundings of one soft rule have the same confidence as the rule and takes these groundings as the regularization terms to only constrain new derived facts, their confidences being the weights of these terms. By contrast, we assume the groundings are independent, and the probability of the soft rule is determined by the likelihood of its groundings whose constituent facts are combined with logical connectives (e.g., ∧ and ⇒). In this way, the logical background knowledge about facts contained in soft rules can inject into embeddings through jointly training with KG facts. Given the groundings of each soft rule, embeddings can be used to estimate the likelihood of the rule to its confidence, making the facts in the groundings obey its logical background knowledge in a probabilistic manner.
On the other hand, generating all groundings of one rule is costly, since the number of candidate entities is usually very large. Nevertheless, many groundings are meaningless and unnecessary, for example, given a logical rule
, groundings like
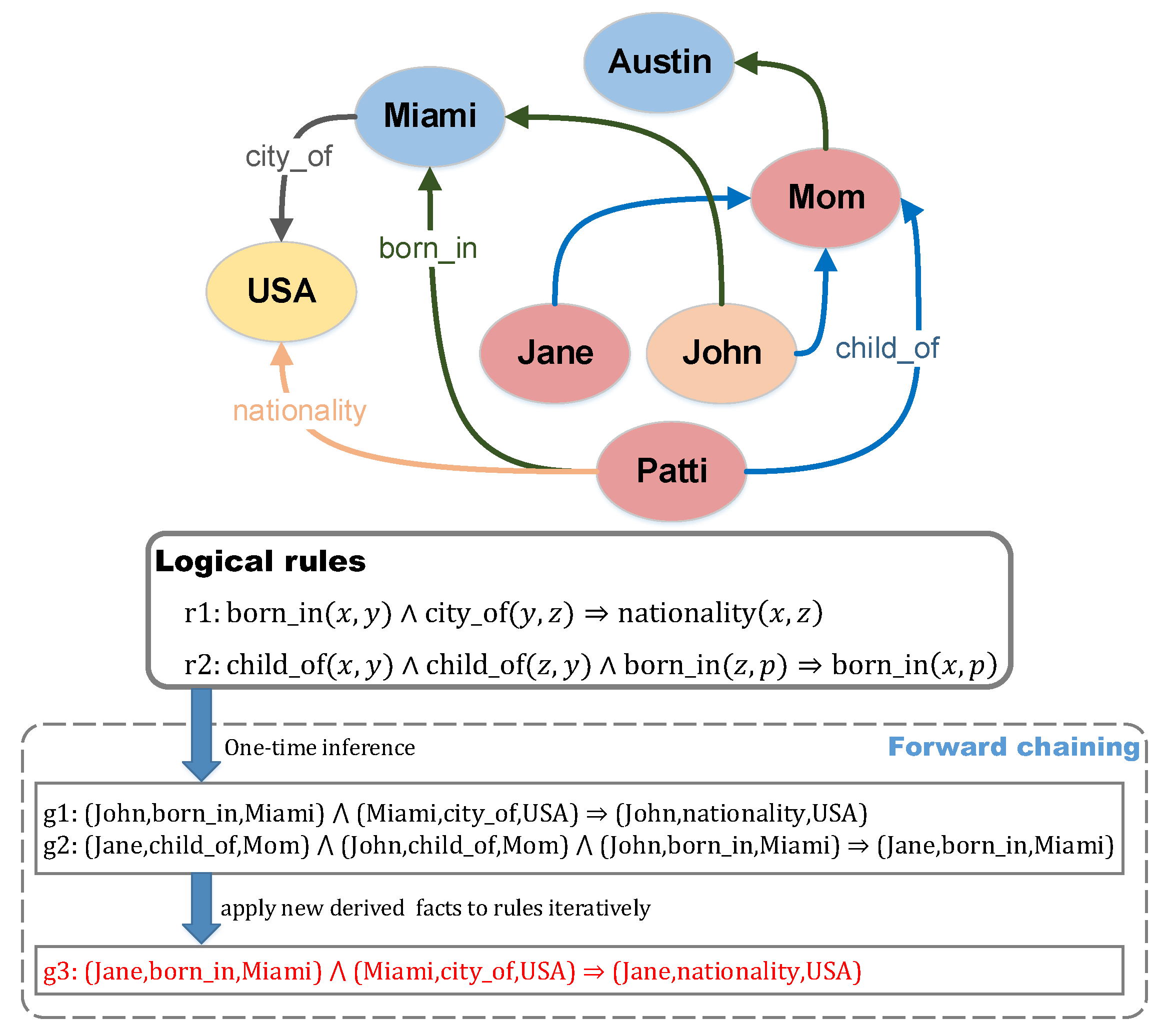
are useless. Therefore, most of the existing methods perform one time logical inference over logical rules and observed KG facts to generate valid groundings for modeling rules. However, they ignore forward chaining inference, which can further apply new derived facts to rules iteratively to generate more valid groundings. As far as we are concerned, the logical rules can be modeled more accurately with more valid groundings. As shown in
Figure 1, given a toy KG at the top and two rules
r1,r2 in the middle, we can only generate groundings
g1 and
g2 after applying the facts of KG to these rules via one time inference, as previous works did. However, according to forward chaining, we can further generate
g3 by applying a new fact (Jane,born_in,Miami) to rule
r1.
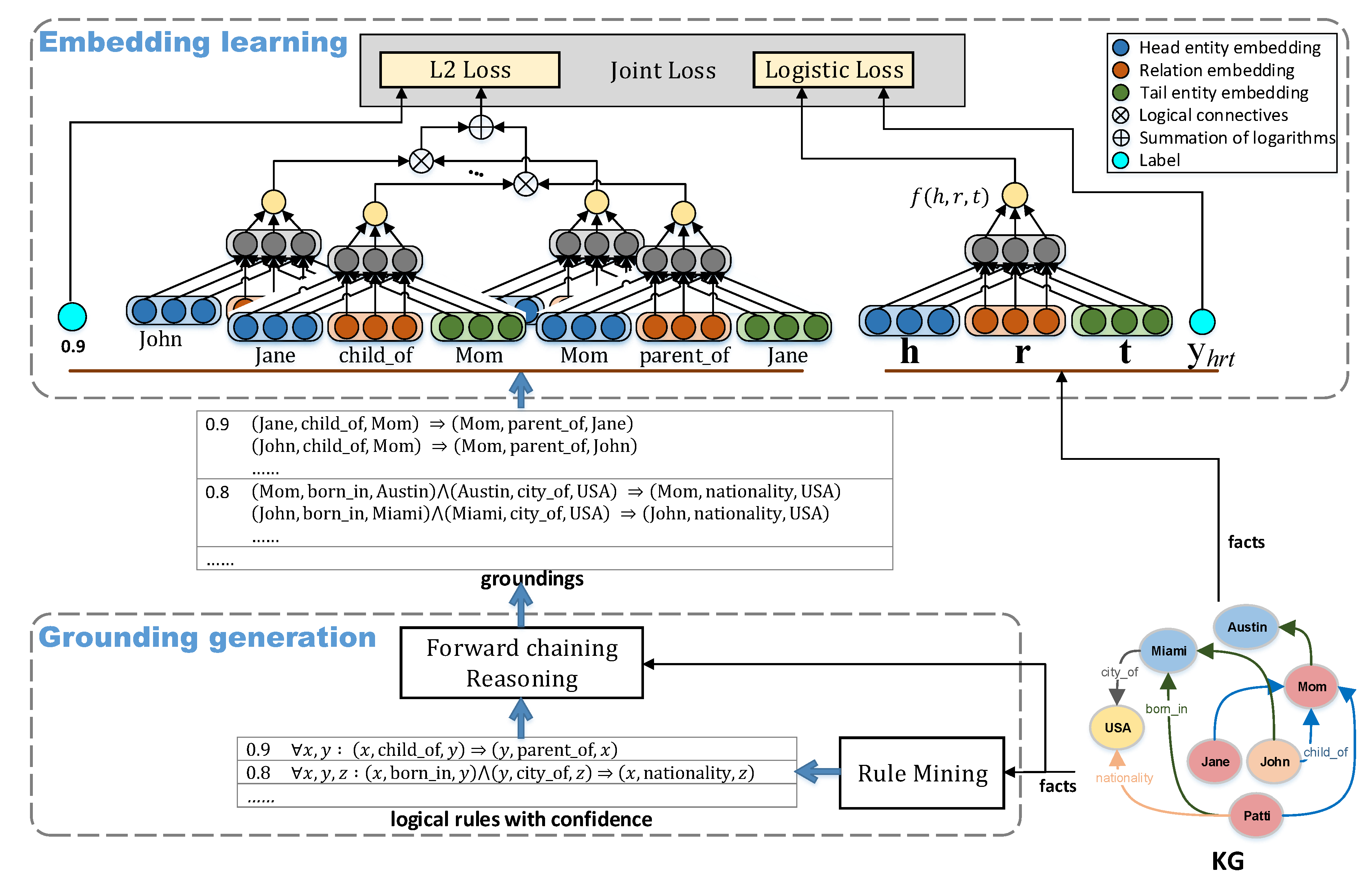
Based on these observations, this paper proposes Soft Logical Rules enhanced Embedding (SoLE), a novel paradigm of KG embedding enhanced with a joint training algorithm over soft rules and KG facts, as well as forward chaining inference over logical rules. Specifically, SoLE contains two stages: grounding generation and embedding learning. In the first stage, we extract soft rules with certain confidences via a modern rule mining system and then use the rule engine to perform forward chaining over these soft rules and KG facts to generate more groundings. At the stage of embedding learning, we devise a joint training algorithm that learns KG embeddings using both KG facts and soft rules simultaneously. Here, facts are modeled by the existing KG embedding method, groundings are modeled by t-norm fuzzy logics, and soft rules are modeled by their corresponding groundings. The confidence of one soft rule is treated as the probability this rule holds. Then, the Mean Squared Error (MSE) between the confidences of soft rules and the likelihood of these rules determined by their groundings is used to estimate these rules. In this way, the facts in groundings can capture the logical background knowledge of soft rules so as to learn better embeddings. Finally, the algorithm learns the embeddings by summing up to minimizing a global loss over both the loss function for KG facts and the L2 loss for soft rules.
We empirically evaluated SoLE with the link prediction task on two large scale public KGs, Freebase and DBpedia. Experimental results indicated that: (i) SoLE significantly and consistently outperformed the basic embedding models and the state-of-the-art models with soft rules; (ii) compared to the work RUGE [
14], our joint training algorithm achieved significantly better performance; and (iii) compared to one time inference, forward chaining indeed helped to learn more predictive embeddings.
Our main contributions are summarized as follows:
We devise a novel joint training algorithm that learns KG embeddings using both KG facts and soft rules simultaneously. Through this joint training, the background knowledge of soft rules can be directly injected into embeddings.
We introduce forward chaining inference to KG embedding model with logical rules, so as to generate more valid groundings for better modeling rules. As far as we know, this is the first attempt to use forward chaining for generating groundings.
We present an empirical evaluation that demonstrates the benefits of our joint algorithm and forward chaining.
The remainder of this paper is organized as follows. We first give some preliminaries about our work in
Section 2 and review the related works in
Section 3. Then, we detail our approach in
Section 4. After that, experiments and results are reported in
Section 5. Finally, we conclude our work in
Section 6.
2. Preliminaries
In this section, we introduce two necessary preliminaries, i.e., knowledge graph embedding and forward chaining, for readers to follow the rest of the paper.
2.1. Knowledge Graph Embedding
A KG contains a set of entities , a set of relations , and a set of triples or facts . The symbols h, r, and t denote head entity, relation, and tail entity, respectively, in a triple . An example of such a triple can be (Paris, isCapitalOf, France).
KG embedding aims to embed all entities and relations into a low-dimensional continuous vector space, usually as vectors or matrices called embeddings. A typical KG embedding technique consists of three steps as follows. First, the assumptions of the entities and relations vector space should be given. Entities are usually represented as vectors, i.e., deterministic points in the vector space, and relations are typically taken as operations in the vector space, which can be represented as vectors, matrices, or tensors. Then, a score function will be defined based on these assumptions to measure the plausibility of each fact in KG. Facts observed in the KG tend to have larger scores than those that have not been observed. Finally, embeddings can be obtained by maximizing the total plausibility of all facts measured by the score function.
Based on the different design of score functions, the KG embedding techniques can be categorized into three types: translation based models, linear models, and neural network based models. We now briefly describe these types and introduce a commonly used model for each type. The readers can see [
15,
16] for a thorough review.
2.1.1. Translation Based Models
Translation based models assume entities and relations are both represented as vectors. They measure the plausibility of a fact as the distance between two entities, usually after a translation carried out by the relation. For a true triple, after being translated by the relation, the head entity is close to the tail entity in the embeddings’ vector space.
TransE: TransE [
17] is the most representative translation based model. Entities and relations are represented as vectors in space
. For a triple
,
,
, and
are denoted as vectors of entities
and relation
r respectively. The score function of TransE is then defined as the negative distance between
and
, i.e.,
The score of
is expected to be large if it holds. The training process of TransE is to minimize a pairwise ranking loss function as follows:
where
is a set of sampled negative examples and
is a margin hyperparameter separating positive examples from negative ones. Here, the observed triples in
are treated as positive examples, and the negative ones are generated by corrupting either the head entity or the tail entity of observed triples with the random entities sampled uniformly from
.
2.1.2. Linear Models
Linear models assume that entities are represented as vectors and relations as matrices. They measure the plausibility of a fact as the similarity between two entities, usually after a linear mapping operation via the relation. In this case, for a true triple, the head entity can be linearly mapped, by the relation matrix, to somewhere close to the tail entity in the embeddings’ vector space.
ComplEx: ComplEx [
18] is the most commonly used linear model. Entities and relations are represented as vectors in complex space
. Given any triple
, a multi-linear dot product is used to score the triple. Thus, the score function is defined as follows:
where the
function takes the real part of a complex value and the
function constructs a diagonal matrix from
;
is the conjugate of
;
is the
entry of a vector. The higher the score, the more likely the triple holds. For the prediction of triples, ComplEx further devises a function
, which maps the score
to a continuous truth value from the range of
, i.e.,
where the
function denotes the sigmoid function. ComplEx learns the entity and relation embeddings by minimizing the logistic loss function, i.e.,
where
is the label of a positive or negative triple
and
is the same one defined in Equation (
2).
2.1.3. Neural Network Based Models
Neural network based models assume that entities and relations are represented as vectors. They exploit a multi-layer neural network with nonlinear features to measure the plausibility of facts. For a triple , neural network models take its vector representations , , and as input and then output the probability of the triple to be true after the feed-forward process.
ConvE: ConvE [
19] is a neural network based model where the latent semantics of input entities and relations are modeled by convolutional and fully connected layers. Entities and relations are represented as vectors in space
. The score function is defined as follows:
where
and
denote a 2D reshaping of
and
, respectively; the
function concatenates two matrices
and
;
denotes a set of filters; * denotes a convolution operator; the
function reshapes the tensor produced by the convolution layer into a vector;
denotes a nonlinear function. ConvE applies the sigmoid function
as the last layer activation to the score, which is
, and learns the embeddings by minimizing the following binary cross-entropy loss function:
where the definitions of
, and
are the same as the above Equation (
5).
2.2. Logical Rule and Forward Chaining
In this paper, we refer to a logical rule as a Horn clause (a subset statements of first order logic) rule, represented in the form of an implication
, where
and
q are positive atoms. The left side of the implication “⇒” is known as the premise, i.e., a conjunction of several atoms, and the right side the conclusion, which contains a single atom. Given a KG
, an atom can be
, where
are variables from
and “
” is a concrete relation. An example of a logical rule over
can be:
which means that if two entities are linked by relation “
”, then they should also be linked by relation “
”.
When we propositionalize a logical rule by instantiating all variables in the rule with concrete entities in , we get a grounding of the rule (or a ground rule). For instance, one grounding of the above example rule can be: . Apparently, propositionalizing rules to get all groundings is costly, since the entity vocabulary is large. Nevertheless, many groundings are meaningless and unnecessary, such as . Therefore, in practice, we take as valid groundings only those whose premise triples are observed in or derived from , while the conclusion triples are not observed in .
The key role of logical rules is that we can perform reasoning through them over a given KG to derive new facts. The process of reasoning starts from the premises of a rule to reach a certain conclusion. That means if some facts in KG are the instances of the premises in a rule, the conclusion instance then can be derived. There are several methods to perform the reasoning. Forward chaining is one of the main methods, which typically works in the way of three phase cycles, also named the match-select-act cycle. More precisely, in one cycle, forward chaining firstly matches the current observed or derived facts in KG against the premises of all known rules to find out the satisfied rules. Then, it selects one rule via some strategies from these satisfied rules. Lastly, it derives the conclusion of the selected rule and puts it into KG as a new fact if it is not in KG. The cycle is repeated until no more new facts are derived.
Notably, during the process of forward chaining, when we derive a new fact from a rule, we also get its grounding, whose conclusion is this new fact. Therefore, we can obtain plenty of corresponding groundings of rules after performing forward chaining inference.
3. Related Work
Recent years have witnessed growing interest in developing KG embedding models. Most of the existing works learn embeddings based solely on the observed triples in KG, which suffer from the problem of data sparsity. To alleviate such a problem and learn better embeddings, many researchers tried to utilize extra useful information, such as textual descriptions, entity types, relation paths, and first order logic rules.
Since rules introduce rich background information and are useful for knowledge acquisition and inference, combining KG embedding with logical rules becomes a focus of current research. There are two kinds of logical rules employed by previous works, i.e., hard rules, which are manually created or validated, and soft rules, which are extracted from knowledge graphs themselves. As for hand rules, Wang et al. [
20] first devised a framework using logical rules as constraints to refine the embedding model, and Wei et al. [
21] attempted to combine rules and the embedding model via Markov logic networks. In their works, rules were modeled separately from the embedding model, employed as post-processing steps, and thus, failed to learn more predictive embeddings. Subsequently, Rocktaschel et al. [
22] and Guo et al. [
23] proposed joint models, which embedded KG facts and ground rules simultaneously. Although their works also learned embeddings jointly, they were not able to support the uncertainty of soft rules. In addition, Demeester et al. [
24] imposed a partial ordering on relation embeddings through implication rules to avoid the costly propositionalization, and Minervini et al. [
25] utilized rules to regularize the embedding model via adversarial sets.
As for soft rules, Minervini et al. [
12] considered the soft equivalence and inversion rules to regularize embeddings. Ding et al. [
13] added a non-negativity constraint on entity embeddings and approximate entailment constraint on relation embeddings with soft rules. Guo et al. [
14] proposed RUGE and considered employing soft rules. This enabled an embedding model to learn simultaneously from KG triples, derived triples in an iterative manner, where each iteration alternated between a soft label prediction stage, that was to predict soft labels for derived triples by groundings and currently learned embeddings, and an embedding rectification stage, that was to update current embeddings by KG triples and derived triples. All these methods either cannot support the transitivity and composition rules or are incapable of encoding the correlation of facts contained in soft rules, while our method injects such background knowledge of rules into KG embeddings by jointly training soft rules and KG triples. Furthermore, a recent work [
26] conducted rule learning and embedding learning iteratively to explore the mutual benefits between them so that the learned soft rules could improve embedding quality. Qu et al. [
27] modeled logical rules via the Markov logic network and inferred the unobserved triples (i.e., hidden variables) to improve KG embeddings. In contrast to them, our method enhanced KG embeddings through directly injecting the background knowledge of soft rules, which was much easier to conduct.
5. Experiment
When conducting experiments on SoLE, we wanted to explore the following two questions:
Whether the devised joint training algorithm and the introduction of forward chaining of SoLE really provided benefits for embeddings compared to the state-of-the-art KG embedding models with soft rules: To test this, we evaluated the performance of SoLE on the link prediction task, which has been widely applied in previous KG embedding works.
Considering the groundings generated by forward chaining, whether they were more helpful for embeddings than those generated by one time inference and to what degree if this is true: To do this, we compared the effect of forward chaining and one time inference on the link prediction task and analyzed the results.
Besides, we will discuss the influence of the PCA confidence threshold on our method, the convergence of the training process in SoLE, and the whole runtime of SoLE. Notably, we used the TensorFlow framework (GPU) along with Python 3.6 to conduct our experiments. All experiments were executed on a Linux server with processor Intel(R) Xeon(R) Gold 5118 CPU @ 2.30 GHz, 128 GB RAM, and an NVIDIA GeForce GTX 1080 GPU.
5.1. Evaluation Task
We evaluated our method on the link prediction task. This task aimed to complete a triple with the head entity or tail entity missing, which meant to predict given or given , i.e., to answer a query or .
5.2. Experimental Setup
5.2.1. Datasets and Configuration
Two datasets were used in our experiments, including FB15Kand DB100K. FB15K, first released by Bordes et al. [
17], is a subset of a large collaborative knowledge base Freebase, while DB100K, created by Guo et al. [
14], was generated from the large knowledge graph DBpedia. For both datasets, triples were split into training, validation, and test sets, which were used for embeddings’ learning, hyper-parameter tuning, and evaluation, respectively. The detailed statistics of the datasets are shown in
Table 1.
In the rule mining module of the grounding generation stage, we extracted rules from the training sets of the datasets. We further set the maximum rule length to two and the PCA confidence threshold to 0.8, which was empirically optimal, as shown in
Section 5.3.2. Besides, we used the minimum of head coverage, one restriction defined in AMIE+, which quantifies the ratio of the known true facts that are implied by the mined rule, and set it to 0.8. This means that we regarded high quality rules as the rules whose head coverage was not less than 0.8 and discarded those unsatisfied ones. Based on these settings, we obtained 457 rules and 126,423 groundings from FB15K, as well as 16 rules and 15,982 groundings from DB100K. Some extracted rules are shown in
Table 2, where the universal quantification is omitted and the atoms of these rules are represented as binary relations for simplicity.
5.2.2. Evaluation Metrics
To evaluate the quality of embeddings on link prediction, we used the standard protocol Mean Reciprocal Rank (MRR) and HITS@N (
n = 1, 3, 10). For each triple
in test sets
, we replaced the head entity
with all entities in
one by one and calculated their scores. Then, we ranked these scores in descending order and got the rank of the correct entity
denoted by
. We performed the same process by replacing the tail entity
and obtained another rank denoted by
. Then, the metric MRR could be calculated by:
The metric HITS@N can be calculated by
, which indicates the proportion of the triples whose ranks are not larger than
n. Notably, there were two settings, i.e., the “raw” setting and the “filtered” setting (see [
17]), when calculating these metrics. Our results are reported in the “filtered” setting, where metrics were computed after removing all the other known triples appearing in the training, validation, or test sets from the ranking triples.
5.2.3. Comparison Settings
We compared our method with two groups of KG embedding models. One contained the basic embedding models, which rely only on observed triples, including TransE [
17], a translation based model, ComplEx [
18], DisMult [
33], and ANALOGY [
34], which are linear models, and ConvE [
19] and R-GCN+ [
35], which are neural network based models. Another contained the state-of-the-art methods, which incorporate soft rules, including RUGE [
14], IterE [
26], pLogicNet [
27], ComplEx-NNE+AER [
13], and ComplEx
[
12].
We further evaluated our method in two different additional settings: (i) SoLE_OTI, which uses the groundings generated by One Time Inference instead of forward chaining; and (ii) SoLE-NNE, which requires all the elements in the entity embeddings lie in the range of [0, 1]. This setting was designed for the fair comparison with the method ComplEx-NNE+AER, which imposes the same constraint on entity embeddings.
5.2.4. Implementation Details
We directly took the results of the two groups of baselines on FB15K and DB100K from [
13] and [
26] except for ComplEx. Since our method was based on ComplEx, we re-implemented ComplEx on the TensorFlow framework based on the code provided by Trouillon
(https://github.com/ttrouill/complex). Then, we reported the result of ComplEx based on our implementation. Besides, the result of IterE was evaluated on the sparse version of FB15K (FB15K-sparse) whose validation and test sets only contained sparse entities with 18,544 and 22,013 triples, respectively. Thus, we also evaluated our method on the FB15K-sparse dataset to compare with IterE.
For a fair comparison, we created 100 mini-batches on the two datasets for SoLE. During training, we applied grid search for the best hyperparameters based on the MRR metric on the validation set, with at most 1000 epochs over the training set and grounding set. Specifically, we initialized the embedding parameters
randomly with a uniform distribution from range
and used the Adam optimization algorithm with the learning rate initially set to 0.001. Then, we tuned the embedding dimensionality
, the number of negatives per positive triple
, and the
regularization weight
. The optimal parameters for ComplEx, followed by [
13], were
on FB15K and
on DB100K. The optimal parameters for SoLE were
on FB15K, and
on DB100K. We also applied these parameters on SoLE_OTI and SoLE-NNE.
5.3. Results
5.3.1. Link Prediction Results
Table 3 shows the link prediction results of SoLE, SoLE-NNE, and the baselines on the test sets of FB15K (or FB15K-sparse) and DB100K. From the results, we can see that SoLE-NNE outperformed all the baselines in the MRR and HITS@1 metrics on both datasets. Without the non-negativity constraints on entities (NNE), SoLE still achieved the best performance in HITS@1. Specifically, compared to the model ComplEx on which SoLE was based, SoLE achieved an improvement of 11.6% in MRR and 18.4% in HITS@1 on FB15K, as well as an improvement of 5.9% in MRR and 15.9% in HITS@1 on DB100K. Since more rules were extracted from FB15K and more groundings were generated, the improvements on FB15K were more significant than those on DB100K. Besides, compared to the state-of-the-art baselines, which also incorporated soft rules, our method surpassed not only ComplEx
, RUGE, and ComplEx-NNE+AER after applying the NNE constraint to SoLE and pLogicNet, but also IterE on the sparse test sets of FB15K. As we can see from the results marked by “*” in
Table 3, SoLE achieved an improvement of 6.4% in MRR and 9.6% in HITS@1 on FB15K compared to IterE. The results demonstrated that the devised joint algorithm for soft rules and the introduction of forward chaining indeed improved KG embeddings, and our method was superior to the baseline methods.
Moreover,
Table 4 shows the link prediction results achieved by SoLE and SoLE_OTI on FB15K (the results on DB100K are the same). From
Table 3 and
Table 4, we can observe that compared to the method RUGE, which generated groundings via one time inference and constrained the derived triples by soft rules, SoLE_OTI significantly outperformed RUGE in MRR and HITS@1, which indicated that our joint training algorithm was superior to RUGE.
5.3.2. Influence of the Confidence Threshold
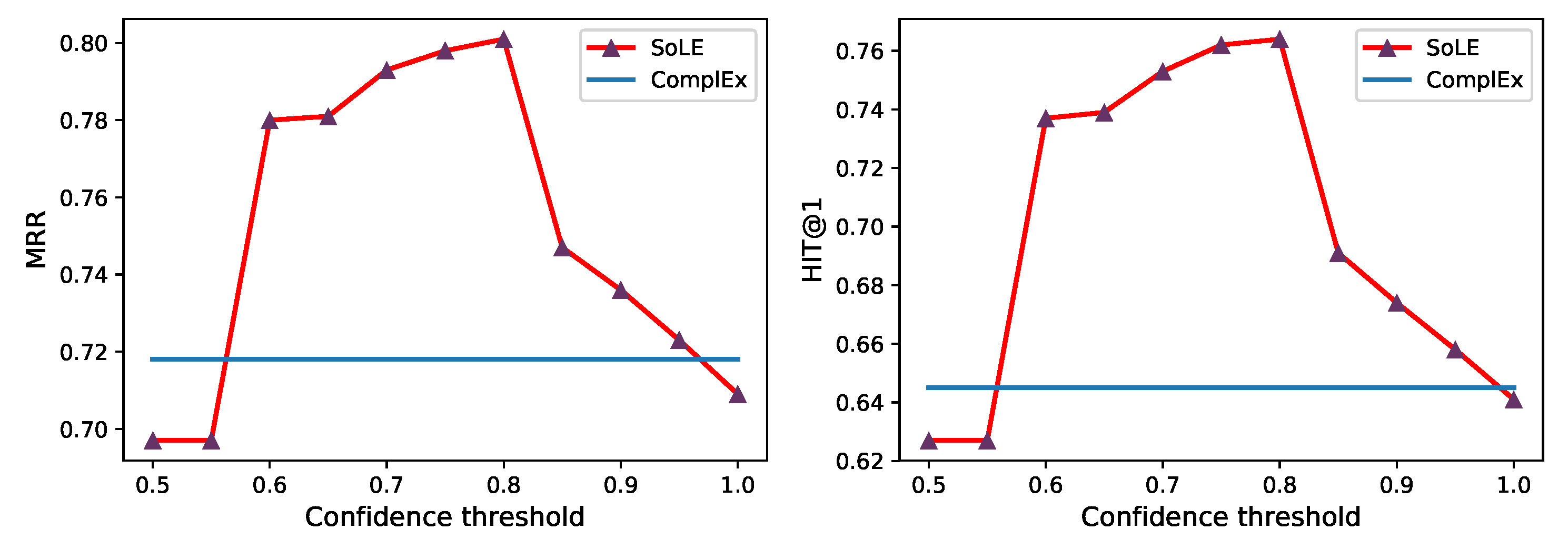
Here, we investigate how the confidence threshold influenced the performance of our method. We conducted the link prediction experiments on FB15K, where the hyper-parameters were fixed to the optimal configurations and the confidence thresholds were varied from 0.5 to 1.0 with an increment of 0.05.
Figure 3 reports the results of MRR and HITS@1 achieved by SoLE with various thresholds. From the results, we can see that these two metrics had the same trend, and they both achieved the best performance when the threshold was 0.8. Thresholds higher than 0.8 will have a smaller number of rules, which can be extracted in the grounding generation stage, while ones lower than that might introduce too many less credible rules. Therefore, after the threshold exceeded 0.8, the performance decreased when the threshold grew, and after it was lower than that, the performance also decreased when the threshold decreased. Based on this observation, we assigned the confidence threshold to 0.8 in SoLE and obtained the best performance.
5.3.3. Comparison of Forward Chaining and One Time Inference
We further investigated the effectiveness of forward chaining by comparing it with one time inference. Since a small amount of rules was extracted from the dataset DB100K and the groundings generated by forward chaining and one time inference were the same, we only conducted the comparison experiment on FB15K.
Table 4 shows the results achieved by SoLE with one time inference and forward chaining. From the results, we can observe that forward chaining slightly, but not statistically significantly outperformed one time inference.
In order to figure out why the improvement was not obvious, we analyzed the different groundings generated by forward chaining and one time inference. We mainly explored the conclusions of the groundings that indicated the new derived triples.
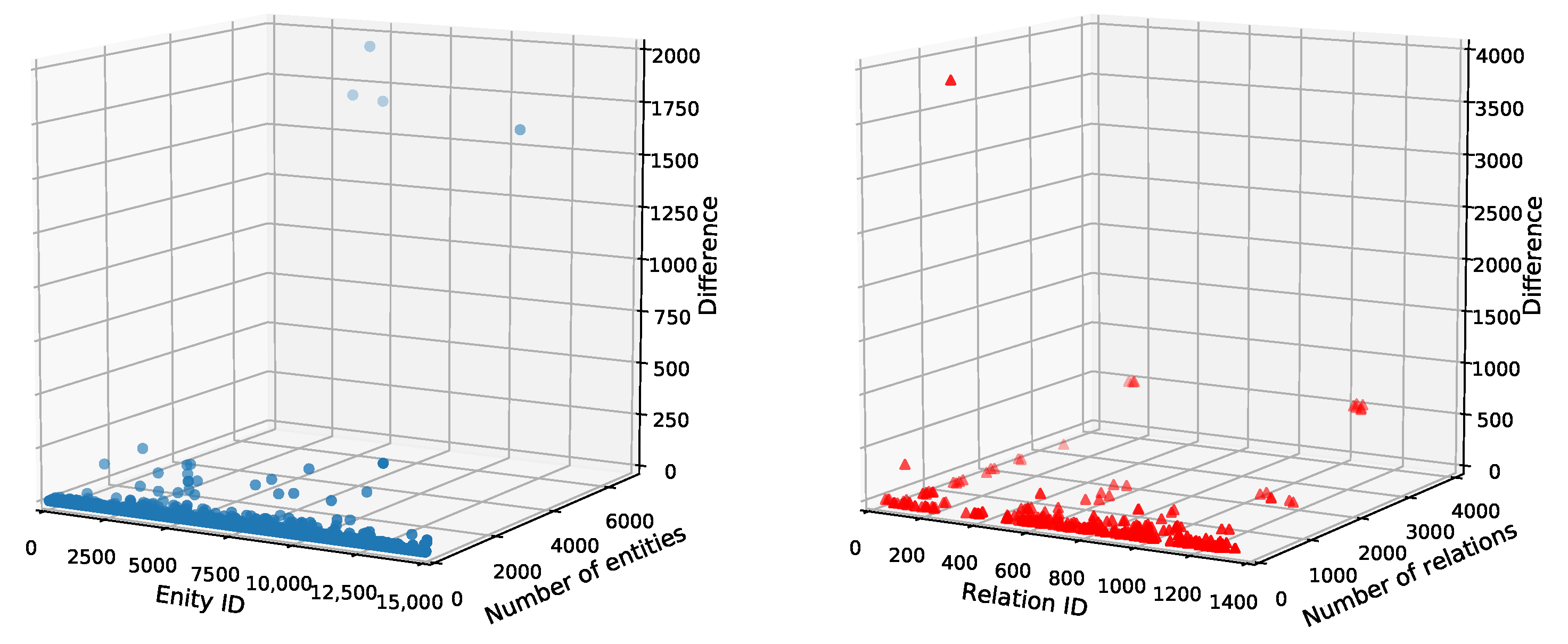
Figure 4 depicts the distributions of entities and relations in the conclusions. The X-axis denotes the entity/relation ID used in our code representing entities/relations; the Y-axis denotes the number of the entities/relations involved in the conclusions of the groundings generated by one time inference; and the Z-axis denotes the difference between the number of the entities/relations from forward chaining and the ones from one time inference. In the left picture of
Figure 4, four entities, each one had a large number in the groundings generated by one time inference, accounting for 32% of the total difference, and 92% of 13,537 entities in the conclusions had the difference value less than one. Meanwhile, in the right picture, 14 out of 299 relations in the conclusions accounted for 99.99% of the total differences when they already had a large number in the conclusions w.r.t. one time inference.
These data indicated that most of the entities and relations in the more derived triples from forward chaining had already shown up quite a few times in the conclusions of the groundings from one time inference where they may have contributed to learning good embeddings, while the embeddings of other entities and relations may not be improved too much because of their same low frequencies.
Though the improvement was not significant, forward chaining indeed helped learn better embeddings. We took out 14 relations from the groundings, which accounted for the mostly differences, and obtained the link prediction results on the test sets of FB15K only containing these relations.
Table 5 gives these 14 relations, and
Table 6 shows the results of link prediction. The results showed that forward chaining helped SoLE learn better embeddings for these relations even though many of them had shown up more than 3000 times in the groundings of SoLE_OTI. Furthermore, we chose the other three relations and constructed a query for each relation where its missing entity appeared more times in the groundings of SoLE than SoLE_OTI.
Table 7 shows these queries and the results after performing the queries. From the top five entities and their scores in the results, we can observe that SoLE not only obtained the right entity as the first rank, but it also had a higher score than SoLE_OTI. The above analysis demonstrated the superiority of forward chaining to one time inference.
5.3.4. Runtime and Convergence
At last, we discuss the runtime of SoLE and the convergence of the training process in the embedding learning stage.
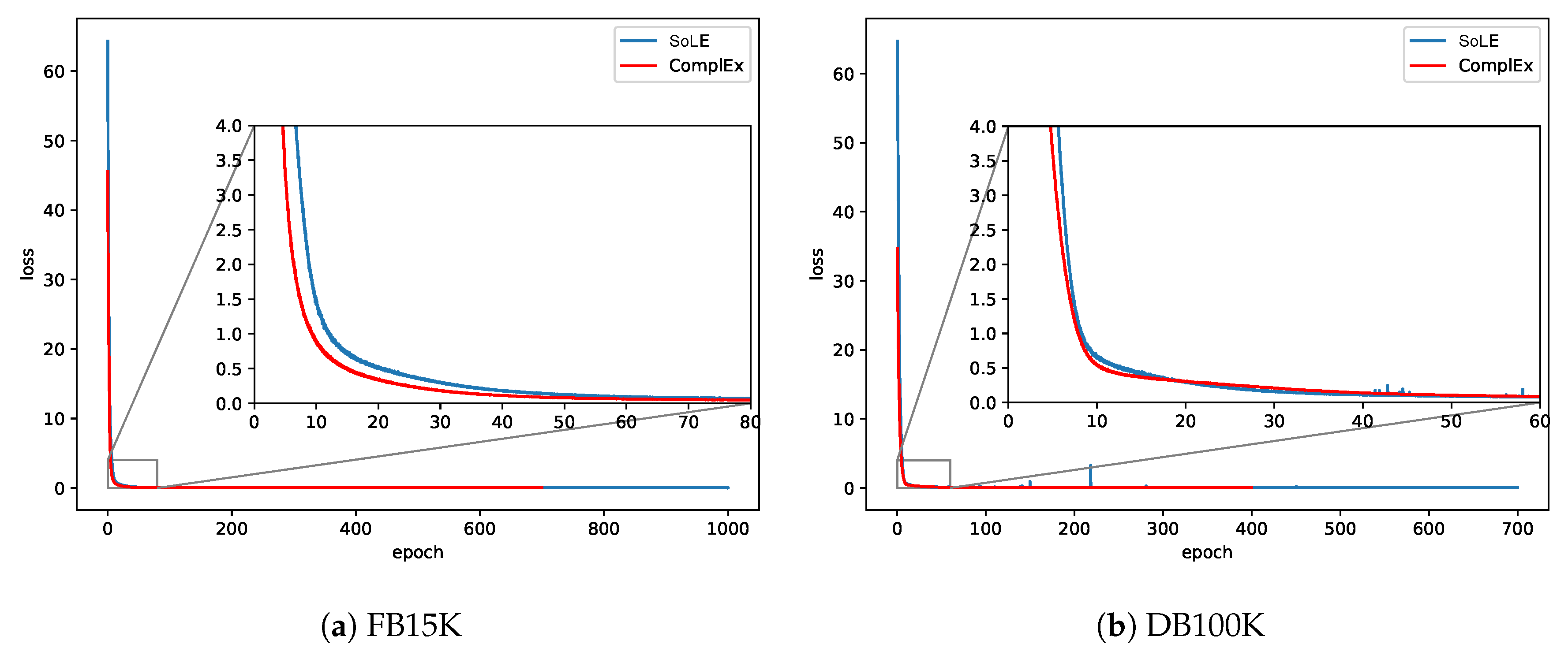
Figure 5a,b shows the convergence of SoLE on FB15K and DB100K, respectively, compared to ComplEx. We can see that the convergence times of ComplEx and SoLE were very close, both around 50 epochs on FB15K and 40 epochs on DB100K, respectively, which indicated that integrating additional rules would not affect the convergence of the training process too much.
Table 8 lists the runtime of SoLE required for its two stages and ComplEx required for model training on FB15K and DB100K. The training time per epoch of SoLE was approximately two times longer than ComplEx, since SoLE computed the additional gradient of the loss function for soft rules. Besides, we can see that the grounding generation stage of SoLE was quite efficient and cost very little time considering the whole runtime.
6. Conclusions and Future Work
This paper proposed Soft Logical Rules enhanced Embedding (SoLE), a novel paradigm of KG embedding, which was enhanced with a joint training algorithm that learned entity and relation embeddings using both soft rules and KG facts simultaneously, as well as forward chaining inference over logical rules to generate more valid groundings. Specifically, SoLE contained two stages: grounding generation and embedding learning. In the first stage, we extracted soft rules with certain confidences via modern rule mining system and then used the rule engine to perform forward chaining inference over these soft rules and KG facts to generate more groundings. At the stage of embedding learning, we devised a joint training algorithm to optimize over both KG facts and soft rules simultaneously where groundings of soft rules were modeled by t-norm fuzzy logics and soft rules were modeled by their corresponding groundings. The truth values calculated by the groundings were used to estimate soft rules, where the confidence of one soft rule was treated as the probability it held. SoLE then amounted to minimizing a global loss over both the loss function for KG facts and the L2 loss for soft rules. In this manner, the facts in groundings could capture the logical background knowledge in these rules so as to learn better embeddings. To sum up, this paper devised a novel joint training algorithm that directly injected the background knowledge of soft rules into embeddings and introduced forward chaining to KG embedding model with logical rules. Experimental results on benchmark KGs showed that our method achieved consistent improvements over the state-of-the-art baselines.
This research brought up some questions in need of further investigation. Firstly, our method could only support the Horn clause rules, which exclude negative atoms. Some other types of logical rules, such as , cannot be extracted and performed by our method since KG does not contain negative triples. Secondly, our method may not be suitable for the extremely large scale KG with a large amount of relations and facts. Given this kind of KG, massive rules would be extracted, and the cost for performing forward chaining would be intolerant due to the high degree of space and time complexity. For future work, we would like to investigate the possibility of modeling all kinds of soft rules using only relation embeddings to avoid grounding, which might be space and time inefficient with regard to the extremely large scale KG.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






