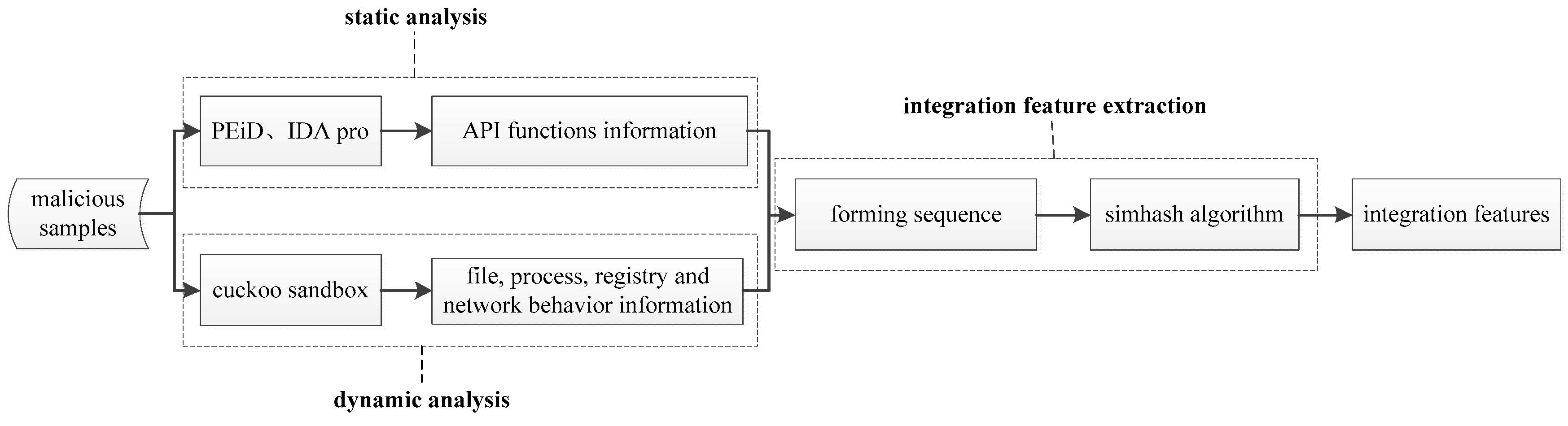
Figure 1.
The process of the simhash-based integrative feature extraction algorithm. (PEiD (PE iDentifier), IDA Pro (Interactive Disassembler Professional)).
Figure 1.
The process of the simhash-based integrative feature extraction algorithm. (PEiD (PE iDentifier), IDA Pro (Interactive Disassembler Professional)).
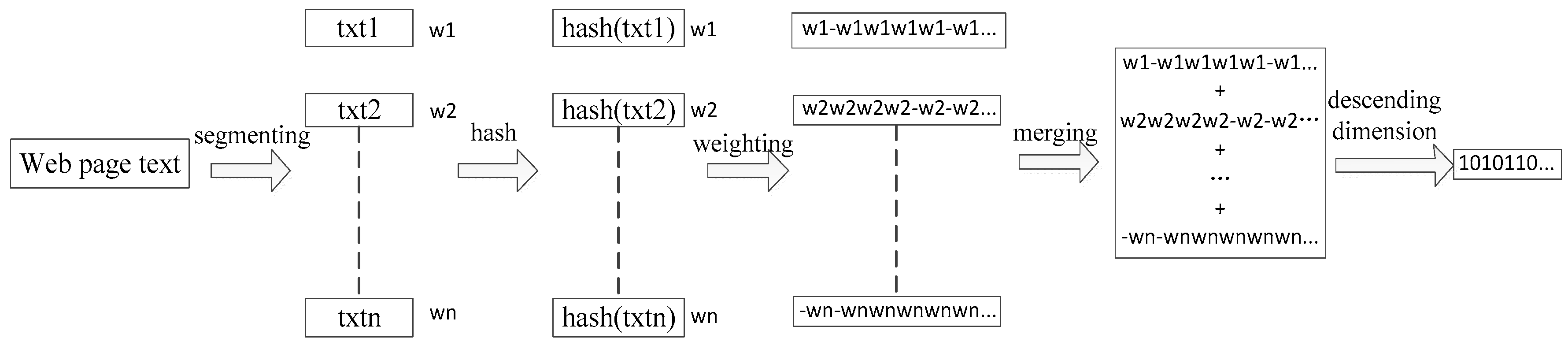
Figure 2.
The process of the simhash algorithm.
Figure 2.
The process of the simhash algorithm.
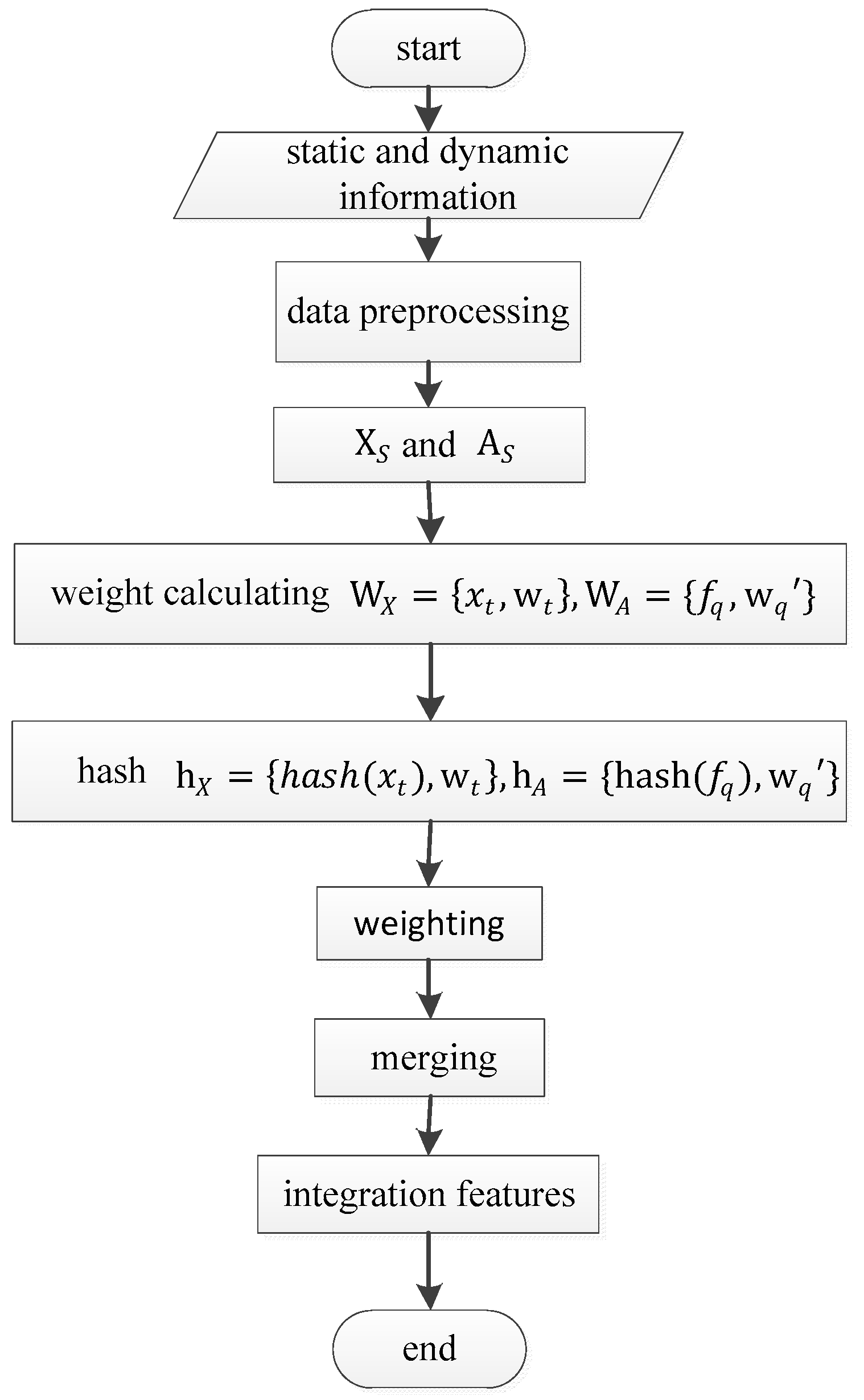
Figure 3.
Integrative feature extraction.
Figure 3.
Integrative feature extraction.
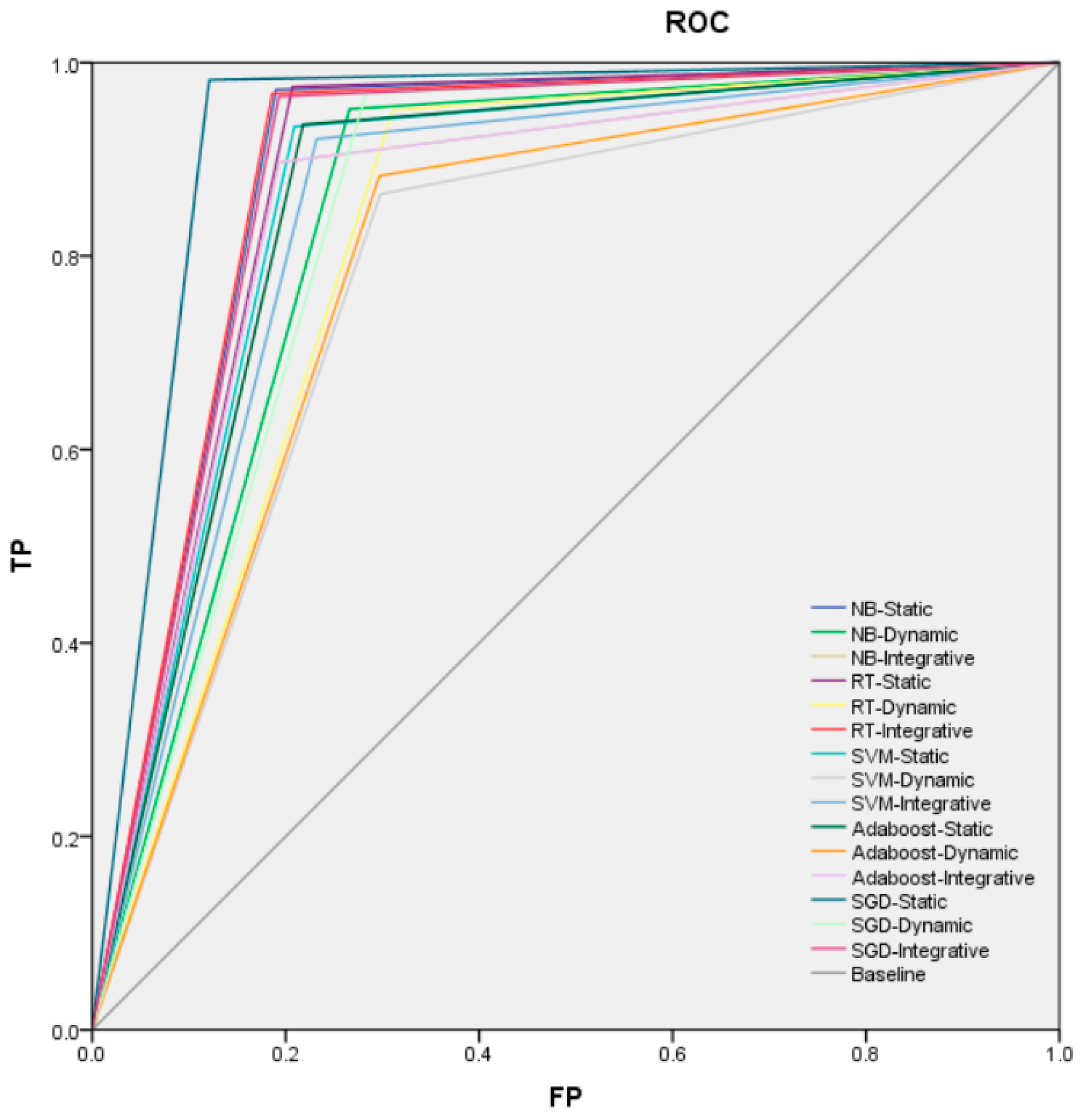
Figure 4.
The ROC (Receiver Operating Characteristic curve, ROC) curve of the algorithms. TP (True Positive rate, TP), FP (False Positive, FP), NB (Naive Bayes, NB), SGD (Stochastic Gradient Descent, SGD), SVM (Support Vector Machine, SVM), Ada (Adaboost, Ada) and RT (Random Trees, RT).
Figure 4.
The ROC (Receiver Operating Characteristic curve, ROC) curve of the algorithms. TP (True Positive rate, TP), FP (False Positive, FP), NB (Naive Bayes, NB), SGD (Stochastic Gradient Descent, SGD), SVM (Support Vector Machine, SVM), Ada (Adaboost, Ada) and RT (Random Trees, RT).
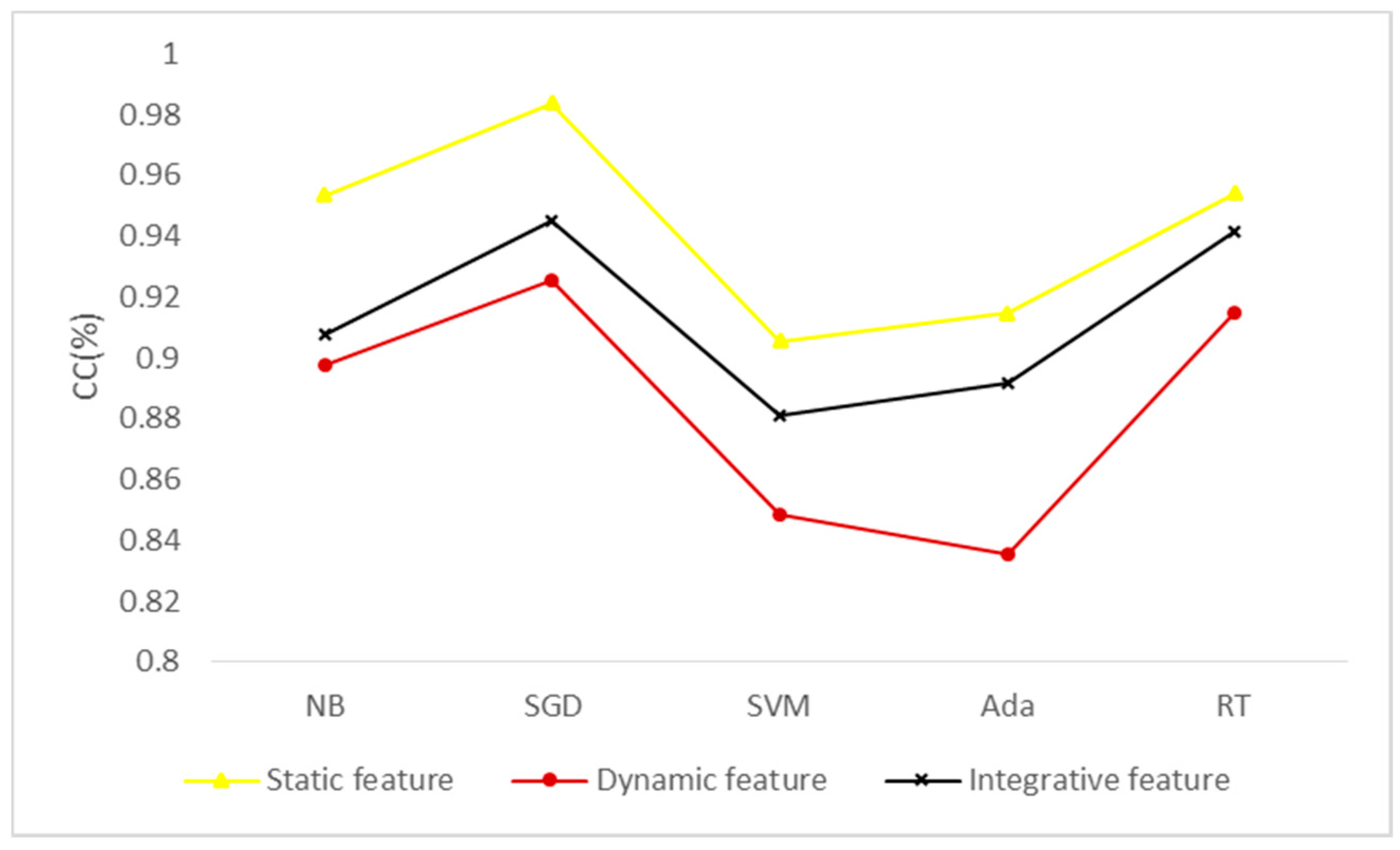
Figure 5.
Classification effect of different types of features under different algorithms. CC (Correctly Classified rate, CC), NB (Naive Bayes, NB), SGD (Stochastic Gradient Descent, SGD), SVM (Support Vector Machine, SVM), Ada (Adaboost, Ada) and RT (Random Trees, RT).
Figure 5.
Classification effect of different types of features under different algorithms. CC (Correctly Classified rate, CC), NB (Naive Bayes, NB), SGD (Stochastic Gradient Descent, SGD), SVM (Support Vector Machine, SVM), Ada (Adaboost, Ada) and RT (Random Trees, RT).
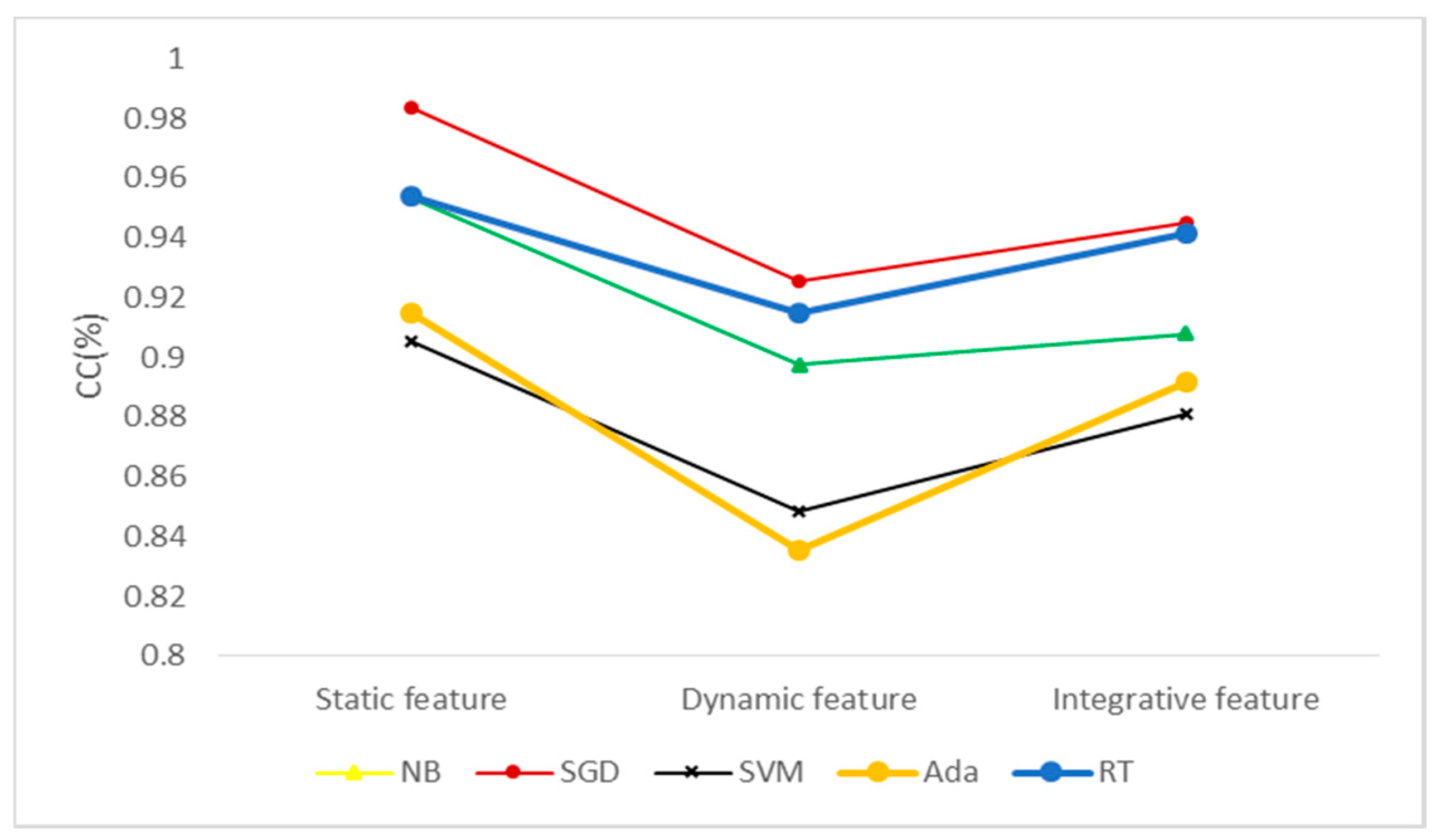
Figure 6.
Classification effect of different algorithms under different types of features. CC (Correctly Classified rate, CC), NB (Naive Bayes, NB), SGD (Stochastic Gradient Descent, SGD), SVM (Support Vector Machine, SVM), Ada (Adaboost, Ada) and RT (Random Trees, RT).
Figure 6.
Classification effect of different algorithms under different types of features. CC (Correctly Classified rate, CC), NB (Naive Bayes, NB), SGD (Stochastic Gradient Descent, SGD), SVM (Support Vector Machine, SVM), Ada (Adaboost, Ada) and RT (Random Trees, RT).
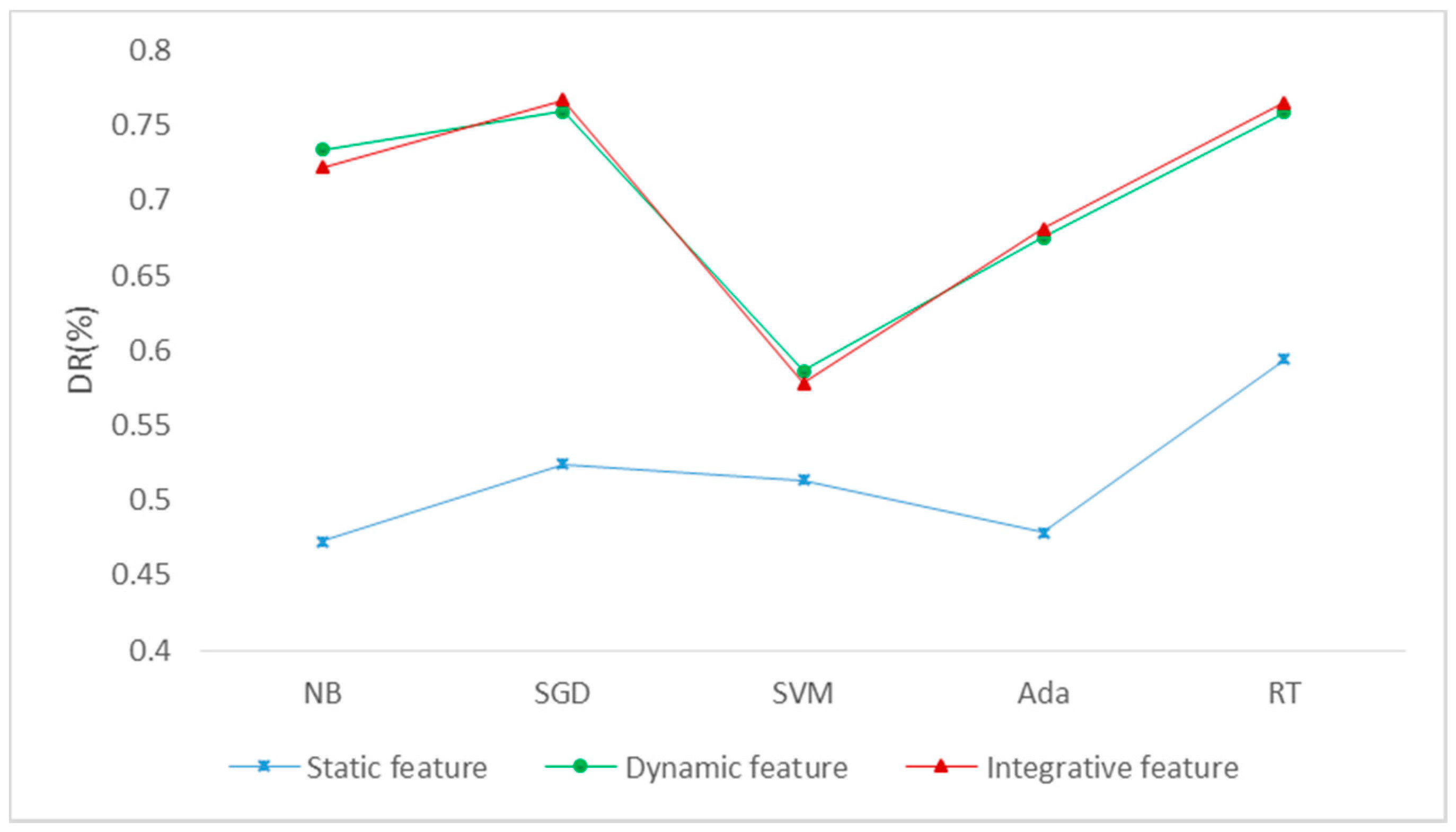
Figure 7.
The obfuscated-detection results. DR (Detection Rate, DR), NB (Naive Bayes, NB), SGD (Stochastic Gradient Descent, SGD), SVM (Support Vector Machine, SVM), Ada (Adaboost, Ada) and RT (Random Trees, RT).
Figure 7.
The obfuscated-detection results. DR (Detection Rate, DR), NB (Naive Bayes, NB), SGD (Stochastic Gradient Descent, SGD), SVM (Support Vector Machine, SVM), Ada (Adaboost, Ada) and RT (Random Trees, RT).
Table 1.
Malware Information.
Table 1.
Malware Information.
| Class | Amount | Average Volume (KB) | Min-Volume (Byte) | Max-Volume (KB) |
|---|
| Backdoor | 2200 | 48 | 3500 | 9277 |
| Trojan | 2350 | 147.7 | 215 | 3800 |
| Virus | 1048 | 71.1 | 1500 | 1278 |
| Worm | 351 | 199.3 | 394 | 3087 |
Table 2.
Configuration Information.
Table 2.
Configuration Information.
| Property Item | Host | Virtual Host | Virtual Guest |
|---|
| Operating System | window7 64-bit | Ubuntu 16.04 64-bit | window7 32-bit |
| Running Memory | 16 G | 4 G | 2 G |
| Processor | Core i5-4690 | Core i5-4690 | Core i5-4690 |
| Hard Disk | 1 T | 120.7 G | 20 G |
| Software Configuration | IDA pro 6.8; PEiD; VMware workstation 11; inetsim-1.2.6; cuckoo sandbox 2.0-rc2; wireshark 2.2.6; process monitor |
Table 3.
The results of the naive Bayes algorithm.CC (Correctly Classified rate, CC), TP (True Positive rate, TP), TN (True Negative, TN), FP (False Positive, FP), FN (False Negative, FN), T (training Time, T).
Table 3.
The results of the naive Bayes algorithm.CC (Correctly Classified rate, CC), TP (True Positive rate, TP), TN (True Negative, TN), FP (False Positive, FP), FN (False Negative, FN), T (training Time, T).
| Feature Type | Naive Bayes |
|---|
| CC | TP | TN | FP | FN | T |
|---|
| Static feature | 0.953590 | 0.973 | 0.810 | 0.190 | 0.027 | 0.32s |
| Dynamic feature | 0.897578 | 0.952 | 0.734 | 0.266 | 0.048 | 0.07s |
| Integrative feature | 0.908021 | 0.925 | 0.773 | 0.227 | 0.075 | 0.12s |
Table 4.
The results of the stochastic gradient descent algorithm. CC (Correctly Classified rate, CC), TP (True Positive rate, TP), TN (True Negative, TN), FP (False Positive, FP), FN (False Negative, FN), T (training Time, T).
Table 4.
The results of the stochastic gradient descent algorithm. CC (Correctly Classified rate, CC), TP (True Positive rate, TP), TN (True Negative, TN), FP (False Positive, FP), FN (False Negative, FN), T (training Time, T).
| Feature Type | Stochastic Gradient Descent |
|---|
| CC | TP | TN | FP | FN | T |
|---|
| Static feature | 0.983857 | 0.982 | 0.879 | 0.121 | 0.018 | 406.79s |
| Dynamic feature | 0.925664 | 0.968 | 0.717 | 0.283 | 0.032 | 126.68s |
| Integrative feature | 0.945034 | 0.965 | 0.807 | 0.193 | 0.035 | 83.08s |
Table 5.
The results of the support vector machine algorithm. CC (Correctly Classified rate, CC), TP (True Positive rate, TP), TN (True Negative, TN), FP (False Positive, FP), FN (False Negative, FN), T (training Time, T).
Table 5.
The results of the support vector machine algorithm. CC (Correctly Classified rate, CC), TP (True Positive rate, TP), TN (True Negative, TN), FP (False Positive, FP), FN (False Negative, FN), T (training Time, T).
| Feature Type | Support Vector Machine |
|---|
| CC | TP | TN | FP | FN | T |
|---|
| Static feature | 0.905541 | 0.934 | 0.791 | 0.219 | 0.066 | 1.57s |
| Dynamic feature | 0.848652 | 0.865 | 0.702 | 0.298 | 0.135 | 0.96s |
| Integrative feature | 0.881117 | 0.921 | 0.768 | 0.232 | 0.079 | 1.26s |
Table 6.
The results of the AdaBoost algorithm. CC (Correctly Classified rate, CC), TP (True Positive rate, TP), TN (True Negative, TN), FP (False Positive, FP), FN (False Negative, FN), T (training Time, T).
Table 6.
The results of the AdaBoost algorithm. CC (Correctly Classified rate, CC), TP (True Positive rate, TP), TN (True Negative, TN), FP (False Positive, FP), FN (False Negative, FN), T (training Time, T).
| Feature Type | AdaBoost |
|---|
| CC | TP | TN | FP | FN | T |
|---|
| Static feature | 0.914763 | 0.936 | 0.782 | 0.218 | 0.064 | 0.27s |
| Dynamic feature | 0.835647 | 0.883 | 0.703 | 0.297 | 0.117 | 0.11s |
| Integrative feature | 0.892046 | 0.897 | 0.807 | 0.193 | 0.103 | 0.14s |
Table 7.
The results of the random trees algorithm. CC (Correctly Classified rate, CC), TP (True Positive rate, TP), TN (True Negative, TN), FP (False Positive, FP), FN (False Negative, FN), T (training Time, T).
Table 7.
The results of the random trees algorithm. CC (Correctly Classified rate, CC), TP (True Positive rate, TP), TN (True Negative, TN), FP (False Positive, FP), FN (False Negative, FN), T (training Time, T).
| Feature Type | Random Trees |
|---|
| CC | TP | TN | FP | FN | T |
|---|
| Static feature | 0.954179 | 0.975 | 0.793 | 0.217 | 0.025 | 2.01s |
| Dynamic feature | 0.914794 | 0.951 | 0.689 | 0.311 | 0.049 | 1.41s |
| Integrative features | 0.941315 | 0.968 | 0.814 | 0.196 | 0.032 | 1.73s |
Table 8.
The obfuscated-detection results of models trained by different types of features. DR (Detection Rate, DR), NB (Naive Bayes, NB), SGD (Stochastic Gradient Descent, SGD), SVM (Support Vector Machine, SVM), Ada (Adaboost, Ada) and RT (Random Trees, RT).
Table 8.
The obfuscated-detection results of models trained by different types of features. DR (Detection Rate, DR), NB (Naive Bayes, NB), SGD (Stochastic Gradient Descent, SGD), SVM (Support Vector Machine, SVM), Ada (Adaboost, Ada) and RT (Random Trees, RT).
| Feature Type | DR |
|---|
| NB | SGD | SVM | Ada | RT |
|---|
| Static feature | 0.4726 | 0.5243 | 0.5137 | 0.4783 | 0.5939 |
| Dynamic feature | 0.7339 | 0.7595 | 0.5861 | 0.6754 | 0.7589 |
| Integrative features | 0.7220 | 0.7669 | 0.578 | 0.6812 | 0.7652 |










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}