1. Introduction
Clustering is an unsupervised way of exploring the data and its distribution by grouping data points into a number of clusters [
1,
2]. The aim of clustering is to find the internal structure of the data and is therefore exploratory in nature. Clustering is used in many engineering applications, for example, in a search for data clustering in Google Scholar [
3], which reveals thousands of entries year-wise [
4]; in social networking sites to identify the cohesive group of friends; and in online shopping sites to group customers with similar behavior based on their past purchase records. It is further used in satellite image processing to identify land use land cover [
5,
6] and to locate the sensitive regions during an earthquake [
7]. It is also used in biomedical applications [
8] and software effort estimation [
9].
In the literature, most of the unsupervised learning methods in particular clustering can be categorized into a crisp or probabilistic-based approach to cluster the data [
10,
11,
12]. These clustering algorithms are found to work extensively well on linearly separable datasets, but the clustering accuracy drastically decreases with a multi-modal, multi-class overlap dataset with higher dimensionality and a large number of samples, because they fail to explore the underlying structure of the data [
13]. Among different clustering algorithms, k-means is a widely used crisp-based approach for clustering the dataset [
14]. The k-means algorithm requires apriori information of the number of clusters. The clustering is performed iteratively by random initialization of cluster centers, and groups the samples using some similarity measures (distance criteria) [
14,
15]. The Kohonen Network (KN) [
16] is a crisp-based neural network clustering algorithm. The KN uses a competitive learning mechanism to extract knowledge in the form of weights (cluster centers), iteratively [
17]. The Expectation Maximization (EM) algorithm is a widely used, probabilistic-based approach, in which likelihood estimation of the data points to the cluster is performed [
18]. EM uses a Gaussian Mixture Model (GMM) to cluster the datasets. The GMM algorithm is a useful model selection tool with which to estimate the likelihood of data distribution by fitting the finite mixture model [
19].
The common problems in most of the aforementioned algorithms are in estimating the number of clusters prior to, and that converge to, local optima [
20,
21]. This results in low clustering efficiency for nonlinearly separable datasets in which the samples of different classes overlap. To overcome the problems involved with these conventional clustering approaches, there is a need for an efficient clustering algorithm that takes care of feature learning [
22] and cluster prediction [
23]. The automatic prediction of the number of clusters can be statistically determined using the model selection approach [
24]. To perform efficient clustering, it is crucial to choose the right feature learning technique. Therefore, the useful data representations are first extracted using the Extreme Learning Machine (ELM)-based feature learning technique [
25,
26]. ELM is a non-iterative feature learning technique that uses a single hidden layer [
27]. ELM has many advantages over iterative feature learning algorithms such as gradient-based methods. The problem with gradient-based methods is that they are mostly iterative in nature, do not guarantee convergence to global minima, and are computationally expensive. ELM computes the weights between the hidden and output layer in one step with better generalization [
25]. ELM was initially used for classification and regression [
26]; recently, Huang et al., 2014 [
28] proposed the Unsupervised ELM (US-ELM) to solve the clustering problem. In their study, the number of clusters is assigned apriori and feature extracted data is clustered using k-means algorithm [
28].
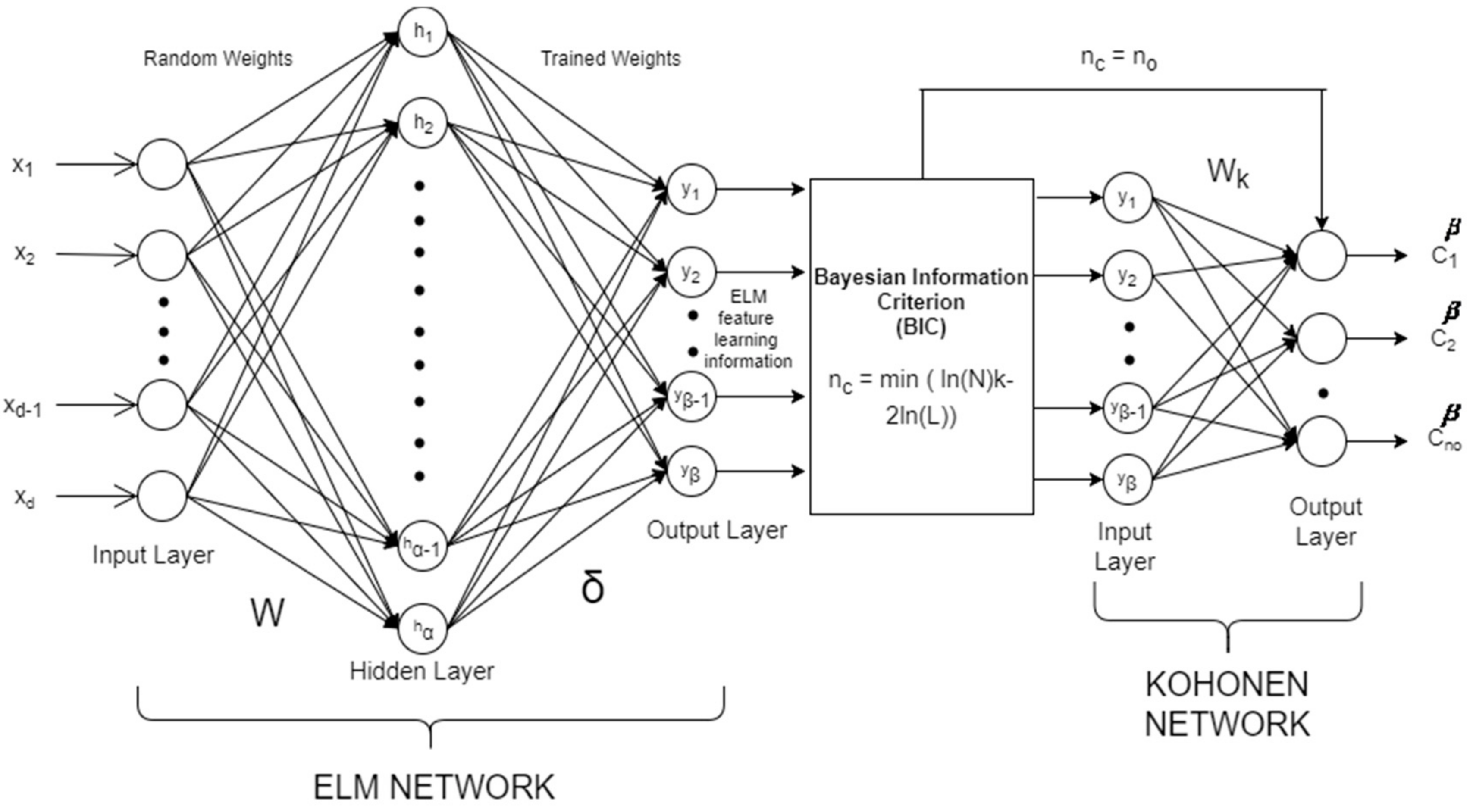
In this paper, we propose the Bayesian Extreme Learning Machine Kohonen Network (BELMKN) framework for clustering the datasets. The BELMKN framework consists of three levels, namely, feature learning, cluster prediction, and partitional clustering. In the first level, ELM-based feature learning utilizes transformations of data to extract useful features from the original data [
28]. An elegant selection of features can greatly decrease the workload and simplify the subsequent design process. Generally, ideal features should be of use in distinguishing patterns belonging to different clusters; this helps to overcome the dataset that is prone to noise for better extraction and interpretation. In the next level, the model selection technique such as Bayesian Information Criterion (BIC) [
29] can be used to predict the number of clusters from the ELM feature-extracted information. In the final level, the number of clusters predicted and the ELM feature-extracted data is given to the Kohonen Network to perform the clustering task. The performance of the proposed BELMKN framework is compared with the four clustering methods, namely, k-means [
14], Self-Organizing Maps (SOM) [
16], EM algorithm [
18], and US-ELM [
28]. The performance of the clustering algorithms is compared by applying 3 synthetic datasets and 10 standard benchmark datasets obtained from the UCI repository (
https://archive.ics.uci.edu/ml/index.php).
The rest of the paper is organized as follows.
Section 2 presents the architecture diagram of the proposed BELMKN framework with a high-level description of the pseudo code.
Section 3 discusses the illustrative examples (3 synthetic datasets) that are applied to the different clustering algorithms for comparison.
Section 4 presents the results and discussion of various clustering methods by applying them to the ten benchmark datasets. Further, the effect of various parameters on clustering accuracy is discussed, and the paper is concluded in
Section 5.
3. Illustrative Example
In this section, we illustrate the proposed BELMKN framework by applying it to three synthetic datasets, as shown in
Figure 2. The obtained results of BELMKN are compared with the state-of-the-art clustering methods, namely, k-means [
14], SOM [
16], EM [
18], and USELM [
28].
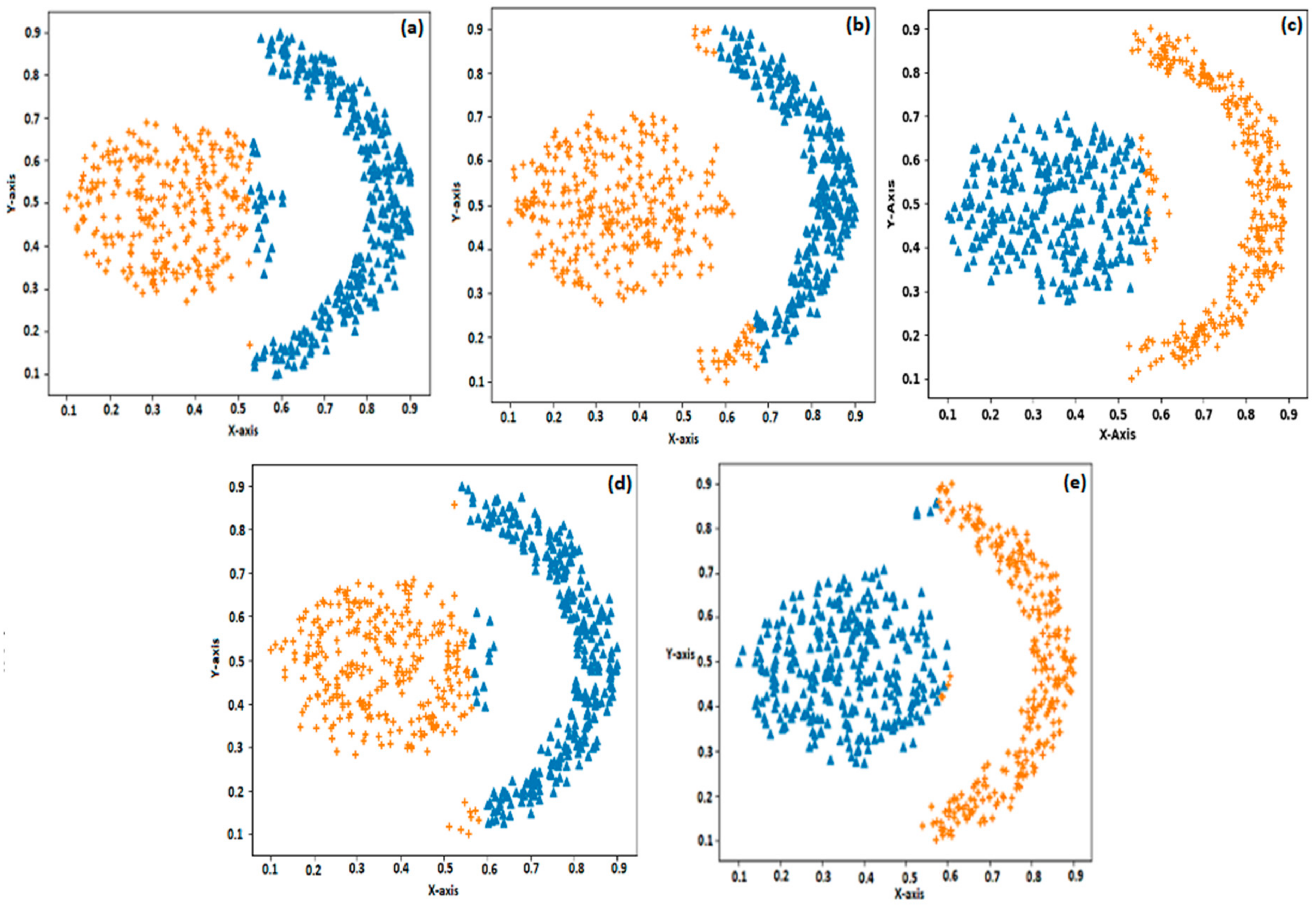
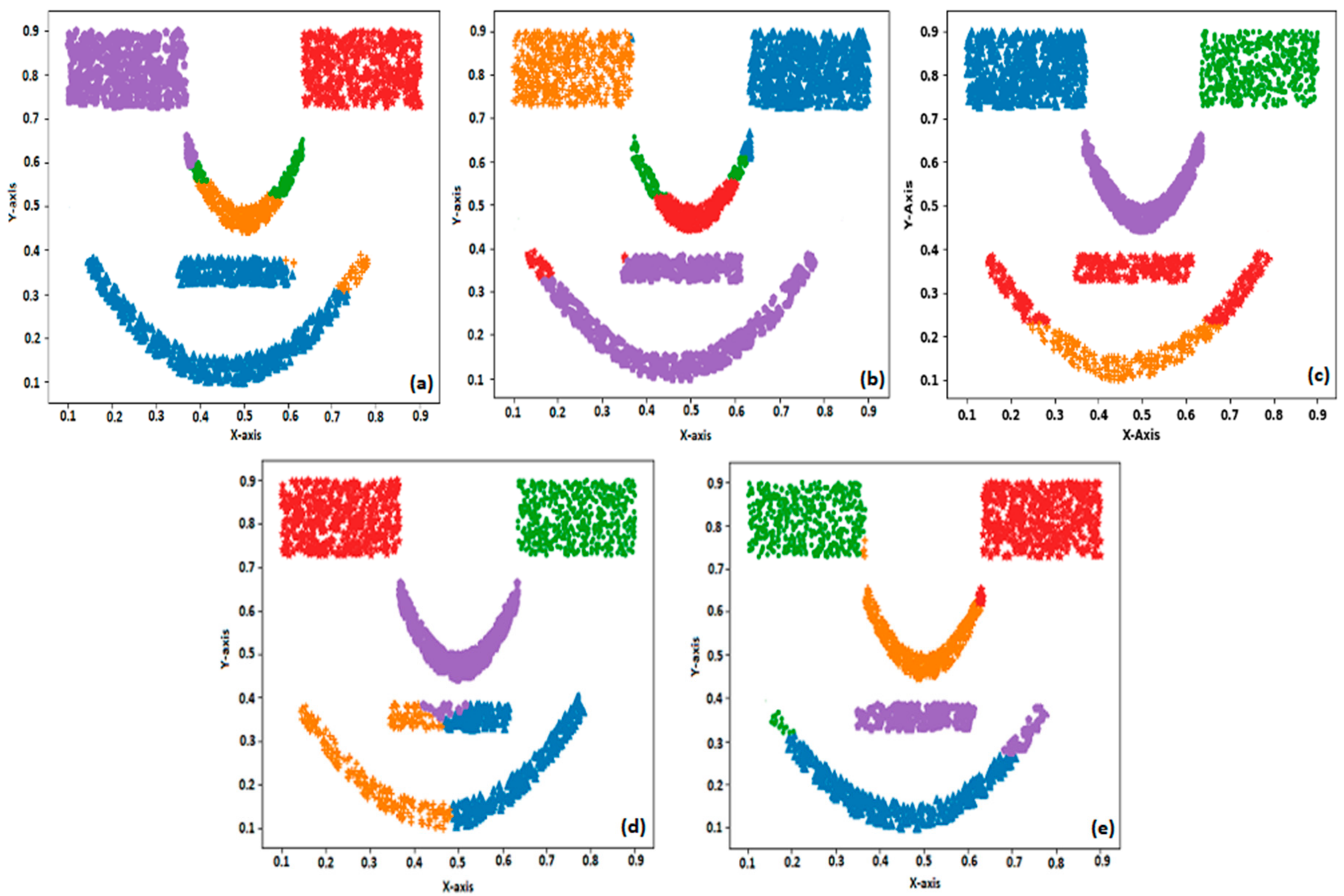
The first synthetic dataset consists of 400 samples and 4 classes in which each class consists of 100 samples and the data distribution is linearly separable. The second dataset consists of 600 samples and 2 classes in which each class consists of 300 samples. The spatial distribution of the second dataset appears as a flame pattern. The third dataset shows the spatial distribution of the face pattern. This dataset consists of 2200 samples and 5 classes with each class consisting of 500, 500, 200, and 500 samples. Here, two classes that form the eyes and nose are linearly separable, whereas the other two parts are nonlinearly separable. The second and third synthetic datasets are more complex to cluster effectively and efficiently.
For each of the synthetic datasets, the BELMKN and other four state-of-the-art clustering methods are applied. The BELMKN uses ELM to perform feature learning with the parameter values set empirically. The feature extracted information from the ELM network is given to BIC as input for cluster prediction. The optimal number of clusters predicted by BIC decides the number of output neurons of the Kohonen Network. The number of hidden neurons is set as 10, 40, and 20, respectively, for the three synthetic datasets.
Figure 2 shows that the clustering of the first synthetic dataset using all the clustering methods used in this study resulted in 100% accuracy. This is because all the classes in this dataset are linearly separable. The second dataset (flame pattern) is nonlinearly separable between two classes. We can observe from
Figure 3a–e that US-ELM performs better than k-means, SOM, and EM, whereas compared to US-ELM the proposed BELMKN performed better. For the face pattern dataset, the EM algorithm performs better when compared to SOM and k-means as EM algorithm assigns cluster centers probabilistically, whereas k-means and SOM involve crisp-based clustering; the outcome of these clustering methods are shown in
Figure 4a–c. Using ELM network, we perform feature learning initially by transforming the data samples in which the assignment of cluster centers become easier for k-means and SOM. It is evident that US-ELM (ELM with k-means) is able to capture nonlinearity well due to ELM-based feature learning but fails to cluster efficiently due to the drawbacks of k-means. In particular, the US-ELM fails to capture the mouth part of face pattern in the dataset, as shown in
Figure 4d. This problem is overcome using the proposed BELMKN framework, as shown in
Figure 4e.
Overall the proposed BELMKN performs better than all the four methods for the three synthetic datasets. This is due to ELM capturing the nonlinearity in the dataset followed by BIC to predict the number of clusters accurately and finally; the Kohonen network uses competitive learning to cluster the dataset efficiently. Among the conventional methods (k-means, SOM, EM), BELMKN and USELM performed better, which shows the importance of using ELM-based feature learning. Hence, we can use BELMKN for clustering linear, as well as nonlinear, synthetic datasets efficiently.
4. Results and Discussion
In this section, we present the results obtained using BELMKN framework on 10 benchmark datasets from the UCI Database Repository [
31,
32]. Initially, we describe the characteristics of the dataset, and then we present the results for the number of clusters predicted by BIC with ELM-based feature learning; this is compared to BIC applied on the original dataset. Finally, we compare the clustering performance of BELMKN with other well-known clustering algorithms, namely, k-means [
14], SOM [
16], EM [
33], and USELM [
28]. The algorithms were tested on a computer with the Core-i3 processor, 4 GB RAM, Python 2.7, and Windows 10 OS.
4.1. Dataset Description
In the literature, 10 benchmark datasets are widely used to compare the performance of the proposed algorithm. The number of samples, their input dimension, and the number of clusters are shown in
Table 1. The BELMKN framework uses three phases on each dataset to extract the clustering accuracy, i.e., ELM for feature learning, and this feature-extracted information is used for cluster prediction using BIC. The feature-extracted information with the predicted number of clusters is given as the input to Kohonen network to compute overall clustering accuracy. The description of the datasets used is as follows:
- Dataset 1:
The Cancer dataset consists of 2 classes that categorize the tumor as either malignant or benign. It contains 569 samples and 30 attributes.
- Dataset 2:
The Dermatology dataset is based on the differential diagnosis of erythemato-squamous diseases in dermatology. It consists of 366 samples, 34 attributes, and 6 classes.
- Dataset 3:
The E. coli dataset is based on the cellular localization sites of proteins. It contains 327 samples, 7 attributes, and 5 classes.
- Dataset 4:
The Glass dataset is based on the oxide content of each glass type. It contains 214 samples, 9 attributes, and 6 classes.
- Dataset 5:
The Heart dataset is based on the diagnosis of heart disease. It contains 270 samples, 13 attributes, and 2 classes.
- Dataset 6:
The Horse dataset is to classify whether the horse will die, survive, or be euthanized. The dataset contains 364 samples, 27 attributes, and 3 classes.
- Dataset 7:
The Iris dataset is based on the width and length of the sepals and petals of 3 varieties (classes) of flowers, namely, setosa, virginica andversicolor, with 150 samples and 4 attributes.
- Dataset 8:
The Thyroid dataset is based on whether the thyroid is over-function, normal-function, or under-function (3 classes). The dataset contains 215 samples and 5 attributes.
- Dataset 9:
The Vehicle dataset is used to classify a vehicle into 4 classes given the silhouette. The dataset contains 846 samples and 18 attributes.
- Dataset 10:
The Wine dataset is obtained from the chemical analysis of wine obtained from 3 different cultivators (3 classes). The dataset contains 178 samples and 13 attributes.
4.2. Analysis of Cluster Prediction
The Bayesian Information Criterion (BIC) is used to predict the number of clusters for the given dataset. The actual data and the feature extracted data (i.e., by applying ELM) for different datasets are given as input to BIC to predict the number of clusters, as shown in
Table 2. In this table, we can observe that there is a difference in the number of clusters predicted by BIC when it is applied directly to the original dataset. The Cancer dataset, using BIC, both with and without ELM-based feature learning, was not able to predict the number of clusters given by the dataset. The ELM-based learning with BIC is not able to predict Heart dataset. This is because ELM is overfitting Cancer and Heart datasets, and, as a result, BIC is not able to capture the number of clusters, whereas in all other cases the prediction is accurate. In case of
E. coli, Glass and Horse dataset when BIC applied directly to the original dataset the number of clusters is predicted to be 4, 3, and 2 respectively, instead of 5, 6, and 3. This is because ELM-based feature learning is able to capture the underlying nonlinear distribution of these datasets. Overall, by applying ELM we have carried out a nonlinear feature extraction of the original data, thereby discarding the redundant data that helps BIC to obtain the best partition for the entire data. Hence, prediction accuracy is 80% in the case of ELM-based feature learning with BIC, whereas it is 60% when BIC is applied directly to the dataset. As a result, by using ELM-BIC we are able to obtain the exact number of clusters as given by the dataset.
4.3. Effect of Parameter Settings
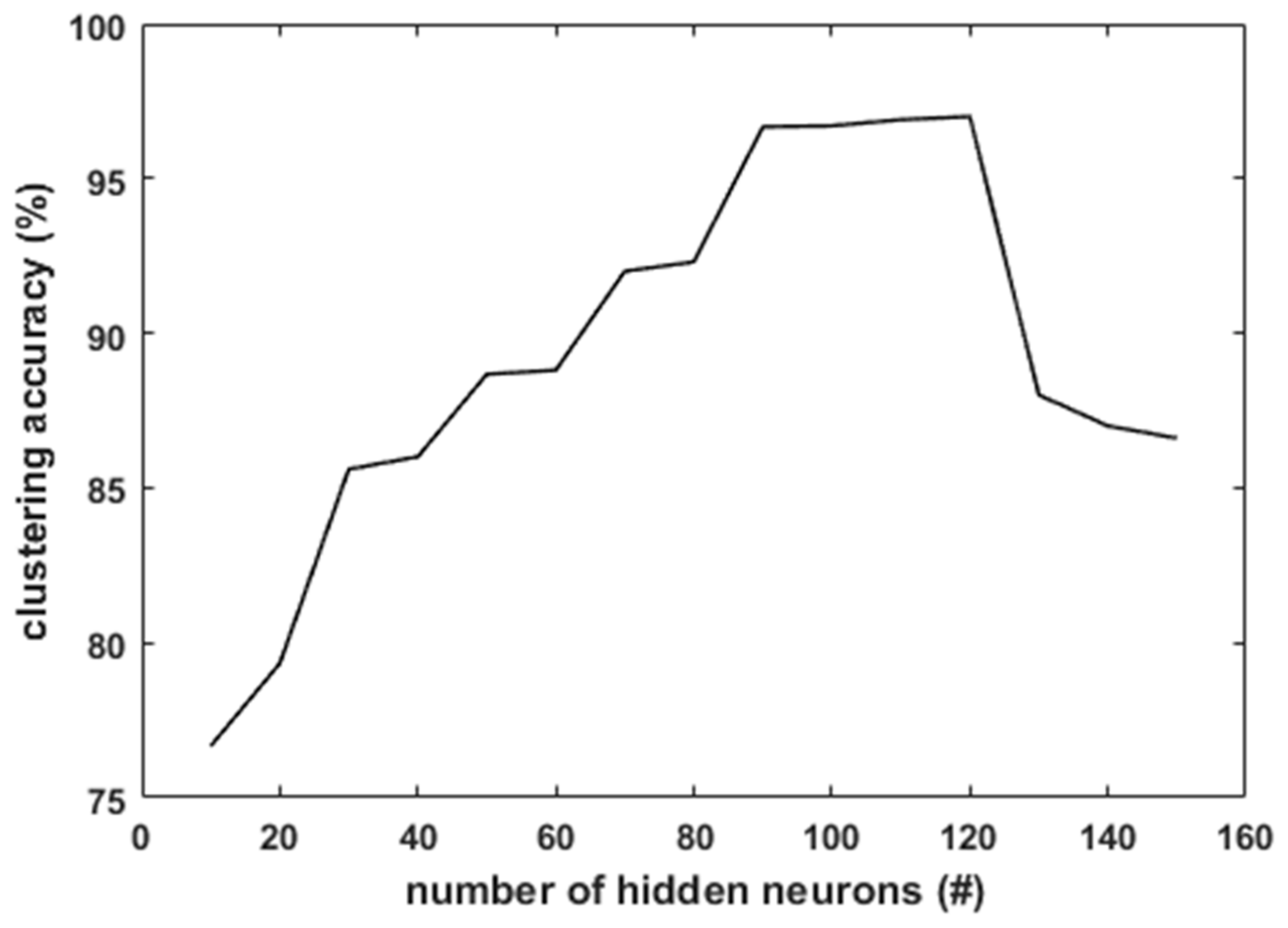
In BELMKN, it is observed that the performance of clustering and convergence rate of the ELM network depends on the number of hidden neurons. ELM requires a sufficient number of hidden neurons to capture the nonlinearity, as it contains only one hidden layer. The number of hidden neurons varied in multiples of 10 from 10 to 150 for each dataset. The variation of the clustering accuracy with the number of hidden neurons for the Iris dataset is shown in
Figure 5. It is observed that with 10 hidden neurons, clustering accuracy is less, as class 2 and class 3 samples overlap. This leads to underfitting. Although it is very difficult to determine the exact number of hidden neurons for a given dataset, we can get an approximate estimate by empirically trying different values. It is observed that for Iris Dataset, with 120 hidden neurons, the maximum accuracy is achieved. With further increase in the hidden neurons, the clustering accuracy is observed to decrease due to overfitting. In comparison with the US-ELM [
28], in which 97% clustering accuracy was obtained for 1000 hidden neurons, the proposed BELMKN framework uses only 120 hidden neurons to obtain 97% clustering accuracy. Hence, we can observe that BELMKN provides a significant improvement by reducing the number of hidden neurons, which saves computational time.
The other ELM parameter values used are tradeoff parameter , sigma . The parameters and are varied as in the above sequences empirically for each of the 10 datasets. It is observed that with negative orders of magnitude of the hyperparameter , a smoother fit is obtained. On increasing the value of , overfitting is observed. On increasing the value of , which signifies the number of nearest neighbours, overfitting is also observed.
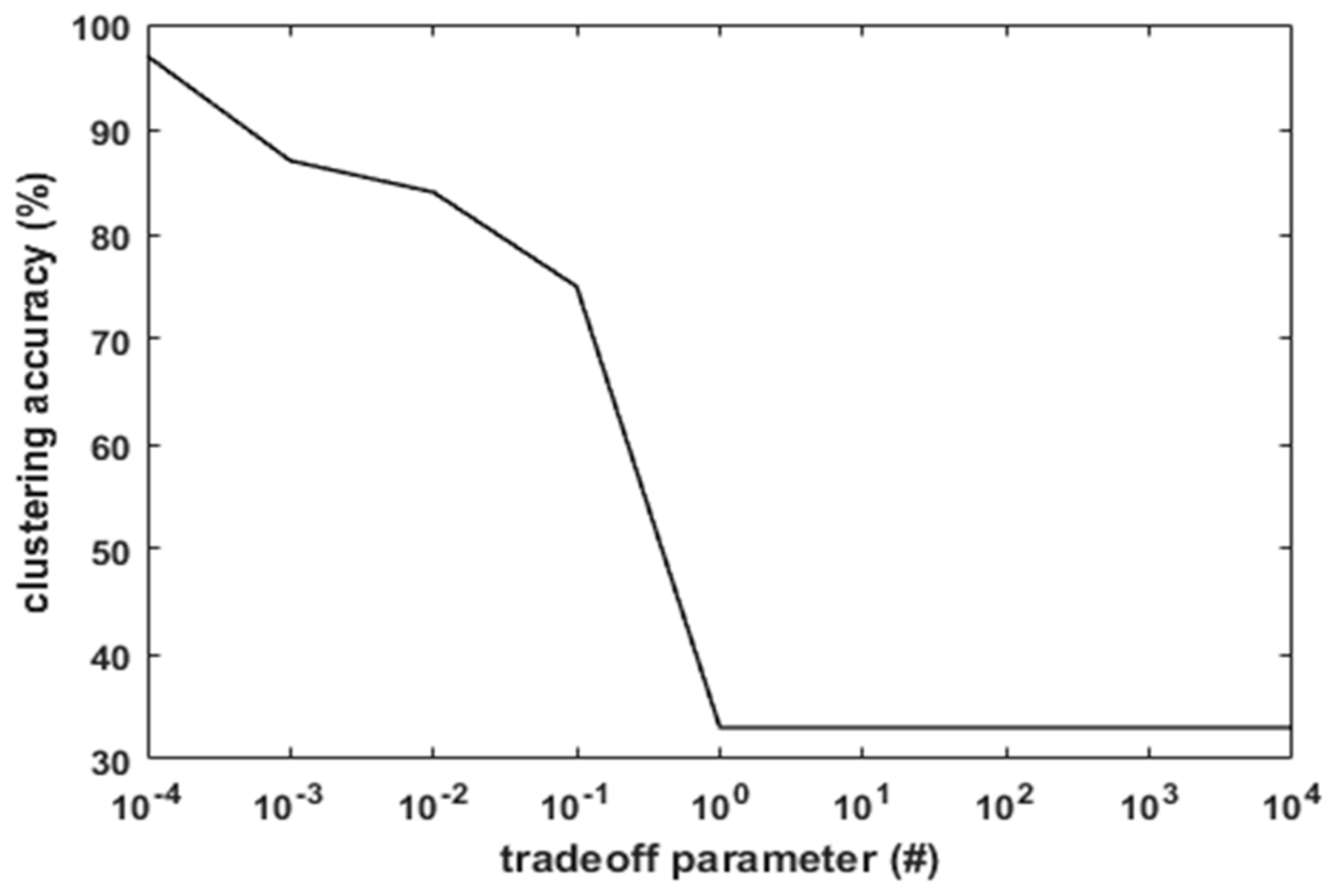
For the Iris dataset, by assigning
= 50, the effect of
on the clustering accuracy is presented in
Figure 6. With
, the clustering accuracy is maximum, which is 97%. With
, the accuracy is observed to decrease to 85%. On further increase in the value of
, the accuracy decreases from 85% to 75%. Hence, it is essential to select the optimal values of the parameters to achieve higher accuracy. Similarly, the parameter setting is done for the remaining datasets.
4.4. Analysis of Clustering Accuracy Using BELMKN
The proposed BELMKN framework is applied to the 10 datasets from UCI repository. The parameters to the ELM network are set empirically as discussed above, and the outputs of the ELM network with BIC cluster prediction are given to the Kohonen network. Hence, the proposed method is a fully automated clustering approach. This automated approach is observed to perform better than the USELM [
28] and the traditional clustering approaches such as k-means, SOM, and EM for most of the datasets.
The performance of k-means is observed to be the least for all the datasets. This is because in k-means, the initial centroids are randomly assigned, and cluster centers are iteratively computed. Followed by k-means is SOM, also a linear clustering technique due to the absence of hidden layer. Though k-means and SOM are efficient at grouping linearly separable datasets; SOM overcomes the disadvantage of the k-means approach by using the neighborhood concept, i.e., in SOM the weights of the winning neuron and those neurons within its vicinity (neighborhood threshold) are updated. In
Table 3, when we apply k-means and SOM algorithms to Iris dataset, we observe that the class 1 (50 samples), which is linearly separable, is grouped correctly, whereas the grouping of the remaining 100 samples (50 samples of class 2 and 50 samples of class 3) results in more misclassification, as they are nonlinearly separable. Hence, we can observe that k-means and SOM algorithms do not capture the nonlinearity in the dataset. When these algorithms are applied to Glass dataset, it is observed that the overall clustering accuracy is greater but the individual class efficiency is lower, as class 1 and class 2 are dominant in terms of accuracy, with majority of the samples present in these classes (i.e., 70 and 76 samples, respectively), leaving fewer samples to the remaining classes (i.e., class 3, class 4, and class 5 contain 13, 9, and 17 samples, respectively).
The overall accuracy for the k-means in Vehicle dataset seems better; this is due to some of the classes data points tend to dominate, and in some case it is sparse; suppose centers are picked in dominated classes; this results slightly better accuracy. Also, the sparse data points are not fully clustered with better accuracy into the respective classes. Overall, it is observed that the accuracy reduces when the sparse data points are overlapped on the dominated data points. From
Table 3, we can also observe that the EM algorithm performs better than k-means and SOM. EM clustering is performed probabilistically, unlike k-means and SOM, which use the crisp assignment of the samples to the clusters. When compared to k-means, SOM, and EM algorithms, USELM performs better. In USELM, ELM performs non-linear feature learning, and the extracted features are given to k-means for clustering [
28]. In USELM, there is no automatic prediction of the number of clusters [
3]; it also suffers from the drawbacks of k-means. In the proposed BELMKN framework, non-linearity is captured well, similarly to USELM network, but the problem of cluster prediction is overcome and the clustering accuracy is improved by using Kohonen Network as the partitional clustering algorithm. Overall, it is observed that the proposed BELMKN framework performs the best among all the clustering techniques used in this study.
In
Table 4, the average clustering accuracy for all the clustering techniques with 10 datasets is shown. In this table, we observe that BELMKN has the highest average clustering accuracy, followed by US-ELM. Among traditional clustering methods, EM is better than k-means, and SOM is better than the k-means algorithm. In
Table 5, the sum of the ranks for all the datasets taken from
Table 3 for each of the clustering techniques is presented. By ranking the sum of ranks, the proposed BELMKN is better than all other clustering methods. This is followed by USELM, whereas EM is better than SOM and k-means, and SOM is better than k-means.
5. Conclusions
This paper presents the Bayesian Extreme Learning Machine Kohonen Network (BELMKN) framework, which consists of three levels, to improve the clustering accuracy of the nonlinearly distributed dataset. ELM is used for feature learning, followed by BIC a model selection technique to extract the optimal number of clusters and the Kohonen Network for clustering the dataset. It is also observed that the performance of the BELMKN network depends on the number of parameters such as the tradeoff parameter (), the number of nearest neighbours (), and the number of hidden neurons (), which have to be set empirically for each dataset. These parameters need to be fine-tuned to avoid overfitting or underfitting.
The clustering task is successfully accomplished by applying 10 benchmark datasets from the UCI machine learning repository using the process of partitional clustering using the BELMKN. The clustering performance is compared with k-means, Self-Organizing Maps, the EM Algorithm, and USELM. From the results obtained, we can conclude that BELMKN is reliable and involves efficient clustering in terms of accuracy, which can also be used on complex datasets.
Although the results are very promising, there is still room for improvement. For example, it is challenging to generate optimal cluster centers with a big dataset with a varying number of dimensions (i.e., some class data points may have fewer samples in comparison with others); this may provide opportunities for further research. In addition, the clustering of the big dataset by implementing the BELMKN as a hierarchical clustering may provide better clustering efficiency. It will be useful to investigate these topics further.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}