2. Basic Definitions
Wishing to avoid any ambiguity in further discussions, we begin with key definitions of risk and ambiguity in relationships between the manufacturer and its supplier. There is a wide specter of different definitions of risk and uncertainty. In this study, we follow Knight’s [
16] view and his numerous followers. The uncertainty is the absence of certainty in our knowledge, or, in other words, a situation wherein it is impossible to precisely describe future outcomes. In the Knightian sense, the risk is measurable uncertainty, which is possible to calculate.
Similar to many other risk evaluators, we assume that the notion of risk can be described as the expected value of an undesirable outcome, that is, the product of two characteristics, the probability of an undesirable event (that is, a negative deviation of the delayed supply or failure to reach the planned supply target), and the impact or severity, that is, an expected loss in the case of the disruption affecting the supply of products across organizations in a supply network. In a situation with several possible accidents, we admit that the total risk is the sum of the risks for different accidents (see, e.g., [
11,
17,
18]).
In the model considered below, an “event” is the observable discrete change in the state of the SC or its components. A “risk driver” is a factor, a driving force that may be a cause of the undesirable unforeseen event, such as disruptions, breakdowns, defects, mistakes in the design and planning, shortages of material in supply in the SC, etc. In this paper, we study the situations with an “observable uncertainty” where there is an objective opportunity to register, for a pre-specified period of time, the adverse events in the relationships between the components in the SC. Such a registration list, called a “risk protocol”, provides us the information whether or not the events are undesirable and, in the case if the event is undesirable what are its risk drivers and possible loss (see [
12,
19]). Such statistics in the risk protocols permits the decision maker to quantitatively evaluate a contribution of each driver and the total (entropy-based) observable information in the SC.
There exists a wide diversity of risk types, risk drivers, and options for their mitigation in the SC. Their taxonomy lies beyond the scope of this paper. Many authors noticed that if a researcher tries to analyze potential failures/disruptions of all the suppliers in a SC or their absolute majority, he/she encounters a simply impractical and unrealistic problem demanding an astronomic amount of time and budget. Moreover, the supply chain control of the root node of the supply chain is much more important than the control of any of its successors ([
6,
8]).
Consider a tree-type graph representing the hierarchical structure of an industrial supply chain Define the “parent layer”, called also the “main layer”, as consisting of a single node, as follows: L0 = {n0} where n0 is the single node of the parent layer. Called also the original equipment manufacturer (OEM), or the root node. OEM is a firm (or company) that creates an end product, for, instance, assembles and creates an automobile.
Define a layer (also denoted as layer s) as the set of nodes which are on the same distance s from the root node n0 in the underlying graph of the SC.
Layer 1 (also called Tier 1) are the companies supplying components directly to the OEM that set up the chain. In a typical supply chain, companies in Tier 2 supply the companies in Tier 1; Tier 3 supplies Tier 2, and so on. Tiered supply chains are common in industries such as aerospace or automotive manufacturing where the final product consists of many complex components and sub-assemblies.
Define a “cut” (also called a “cross-section”) as a union of all the layers , from 0 to s. It is evident that , S.
Assume that, for each node of the SC, the list of risk drivers is known, each being a source of different adverse events in the nodes of the SC. For simplicity, but without loss of generality, assume that any adverse event is caused by a single risk driver (otherwise, one can split such a multi-drive event into several elementary events each one being caused by a single driver). Here N is the total number of all the drivers.
Another basic assumption to be used in this work is that the drive factors are mutually dependent. It means, for example, that an unfavorable technological decision or an environmental pollution, that is, caused by a technology-based driver in some component at Tier 2 may lead to an adverse event in supply operations to a node at Tier 1. A technological mistake at Tier 3 may be a source of a delayed supply to Tier 2, and so on. In general, any factors f happening at tier s may be depending on a factor f′ at an earlier tier s + 1, f = 1,…, N; f′ = 1,…, N; s = 1,…, S. Below, the dependencies will be described with the help of the N × N matrix of relative probabilities.
The following Markovian property is assumed to take place. Assume that the dependence between any factor in tier s, on the one hand, and the factors in the lower tiers s + 1, s + 2,…, S actually exists only for the factors in a pair of neighboring tiers (s, s + 1), where s = 0,1,…, S. Moreover, assume that the pitfalls and any defective decisions do not flow downwards, that is, any risk factor in tier s does not depend upon the risk drivers in the nodes of higher layers, numbered s − 1, s − 2,…, 1.
In each layer s, when computing the probability of risk drivers f occurring in the nodes of the layer s, two types of adverse events have a place. First, there are the events (called “primary events” and denoted by Afprime(s)) that have happened in the nodes of layer s and which are caused by the risk driver f, f = 1,…, N. Second, there are the events (called “secondary events” and denoted by Afsecond(s + 1, s)) that have happened in the nodes of the next layer (s ± 1) but have an indirect impact upon inverse events in s, since the risk factors are dependent. More precisely, different drivers f′ in s+1 have impact upon the driver f in layer s, f = 1,…, N; f′ = 1,…, N; s = 1,2,…, S.
The impact from f′ to f is estimated with the help of the transition probability matrix M which is defined below and computed from the data in the risk protocols.
Denote by Aj(s) the following events:
Af(s) = {risk driver f is the source of various adverse events in supply to all the nodes of layer s}, f = 1,…, N, s = 0,1,…, S.
Denote by pf(s) = Pr (Af(s)) the probability that the risk driver f is the source of different adverse events in supply in layer s,
= Pr {the risk driver fi is the cause of adverse event on the layer s only}
Denote by pfprime(s) = Pr (Af prime(s)) the probability that the risk driver f is the source of different adverse events in layer s, and which are caused by the risk driver f. These probabilities are termed as “primary”. Next, denote by pfsecond(s) = Pr (Af second(s)) the probability that the risk driver f is a source of different adverse events in layer s which is a result of the indirect effect on the f by the risk drivers f′ that have caused the adverse events in layer s+1; these probabilities are termed as “secondary”.
Introduce the following notation:
= Pr {the risk driver fi is the cause of adverse event on the layer s only}
= Pr {the risk driver is the cause of adverse effect on the layer s as the result of the risk drivers on the layers s + 1}.
For simplicity, and without loss of generality, suppose that the list of risk drivers
is complete for each layer. Then the following holds
Denote .
Then the vector of risk driver probabilities
can be decomposed into two vectors as
where
is the vector of drivers’ primary probabilities and
the vector of drivers’ secondary probabilities.
For any layer
s, define the transition matrix
of conditional probabilities of the risk drivers on layer s that are obtained as the result of risk drivers existing on layer
s + 1
Next, define the matrices
of the primary drivers’ probabilities as
Define the complete transition matrices as
From (5) and (6) it follows that
or
In the matrix form, Equation (8) can be rewritten as
The following claim is true.
Claim.
The following relation holds:
The proof is straightforward and skipped here.
3. Information Entropy as a Measure of Supply Chain Complexity
Information entropy is defined by Shannon as follows [
20]. Given a set of events
E = {
e1,…,
en} with a priori probabilities of event occurrence
P = {
p1,…,
pn},
pi ≥ 0, such that
pi + …
+ pn = 1, the entropy function
H is defined by
In order to yield all necessary information on the SC complexity issues, this paper uses the data recording of all adverse events occurred. The enterprise is to collect and store the data about main adverse events that occurred and led to economic losses in the enterprise, compensation cost, as well as the statistical analysis of the recorded data. Such requirement also applies to the registration of information about control of compliance of target and actual environmental characteristics.
Similar to [
12], for each node
u, consider an information database called a ‘risk protocol’. This is a registration list of most important events that have occurred in the node during a pre-specified time period. The protocol provides us the information whether or not the events are undesirable and, in the latter case, what are its risk drivers and possible losses.
This data is recorded in tables TBLu, representing lists of events in each node u during a certain time period T (e.g., month, or year). Each row in the table corresponds to an individual event occurring in a given node at a certain time moment (for example, a day). We use symbol f as an index of risk drivers, F as the total number of risk drivers, and r as an index of the event (row). The value zrf at the intersection of column f and row r is equal to 1 if the risk factor f is a source of the adverse event r, and 0—otherwise. The last column, F + 1, in each row (r) contains the magnitude of economic loss caused by the corresponding event r.
As far as the tables TBLu, for all the nodes belonging to a certain arbitrary SC layer, says, are derived, all the tables are gathered into the Cut_Table CTs for the entire SC cut. Let Rs(u) denote the total number of observed adverse (critical) events in a node u of cut Cs during a certain planning period. If such cut contains n(s) nodes, the total number of critical events in it is Ns = ∑u=1,…,n(s) Rs(u). Assume that there are F risk drivers. For each risk driver f (f = 1, …, F), we can compute the number Ns(u, f) of critical events caused by driver f in the node u and the total number Ns(f) of critical events in all nodes of cut Cs, as registered in the risk protocols.
The relative frequency
ps(
f) of that driver
f is the source of different critical events in nodes of
s and can be treated as the estimation of the corresponding probability. Then we compute the latter probability as
Then ∑f ps(f) = 1.
For the sake of simplicity of further analysis, our model applies to the case when the critical events are independent within the same tier and the losses are additive (these assumptions will be relaxed in our future research). For any node
u from
s, we can define corresponding probabilities
ps(
u, f) of the event that a driver
f is the source of adverse events in node
uThis paper treats the ps(u, f) values defined by Equation(3) as probabilities of events participating in calculation of the entropy function in Equation (1).
The main idea of the suggested entropic approach is that the information entropy in this study estimates the average amount of information contained in a stream of critical events of the risk protocol. Thus the entropy characterizes our uncertainty, or the absence of knowledge, about the risks. The idea here is that the less the entropy is, the more information and knowledge about risks is available for the decision makers.
The entropy value can be computed iteratively for each cut of the SC. Assume that the nodes of a cut Cs−1, are defined at step (iteration) s − 1. Denote by Ts all supplier-nodes in the supply layer s of the given tree. Let Ls(Ts) denote the total losses defined by the risk protocol and summed up for all nodes of cut Cs in tiers Ts: Ls(Ts) = ∑u∈Ts cs(u). Further, let LT denote the total losses for all nodes of the entire chain. Thus, Ls(Ts) are contributions of the suppliers of cut Cs into the total losses LT.
Then Ls(Ts)/LT define the relative losses in the s-truncated supply chain. The relative contribution of lower tiers, that is, of those with larger s values, are, respectively, (LT − Ls(Ts))/LT. One can observe that the larger is the share (LT − Ls(Ts))/LT in comparison with Ls(Ts)/LT, the less is the available information about the losses in the cut Cs. For example, if the ratio Ls(Ts)/LT = 0.2, this case give us less information about the losses in cut Cs in comparison with the opposite case of Ls(Ts)/LT = 0.8. This argument motivates us to take the ratios (LT − Ls(Ts))/LT as the coefficients (weights) of the entropy (or, of our unawareness) about the economic losses incurred by adverse events affecting the environmental quality. In other words, the latter coefficients weigh the lack of our knowledge about the losses; as far as the number s grows, these coefficients become less and less significant.
Then the total entropy of all nodes
u included into the cut
s will be defined as
where the weighted entropy in each node
u is computed as
Let xu = 1 if node u from Ts is included into s, and xu = 0, otherwise.
Then the total entropy of all nodes included into the cut
s will be defined as
where
H(
u) is defined in (15).
Computations of ps(u, f) as well as the summation over risk factors f are taken in the risk event protocols for all the events related to nodes u from Ts. As far as entropy values are found for each node, the vulnerability to risks over the supply chain is measured as a total entropy of the s-truncated supply chain subject to the restricted losses.
Define the weighted entropy for each cut
s as
where
We assume that the weight satisfies the following conditions:
- (i)
is decreasing;
- (ii)
;
- (iii)
.
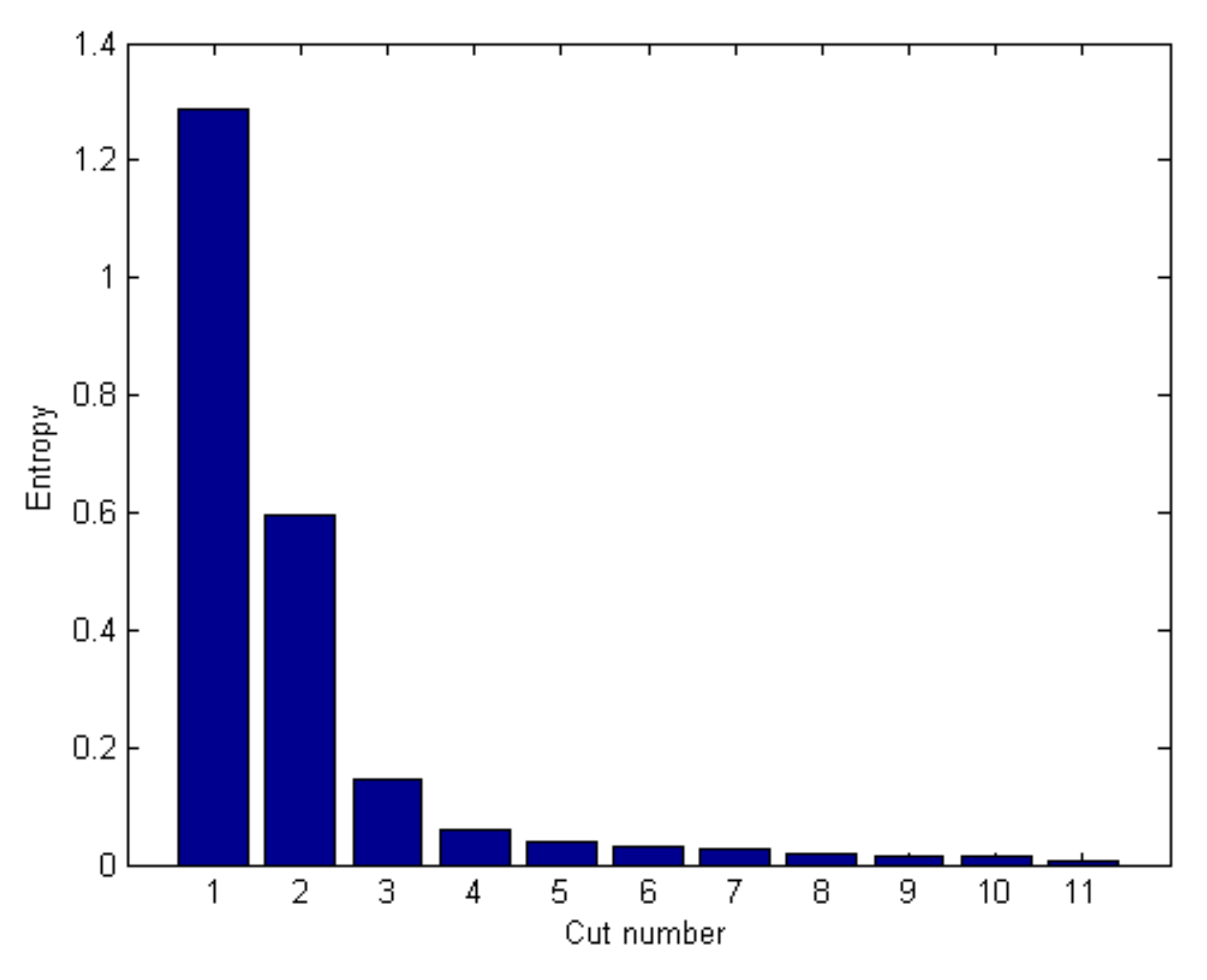
Define the “variation of relative entropy” depending upon the cut number is
The following claim is valid:
Theorem.
For the process of sequentially computing of the relative entropy variation (REV), for any fixed value , there exists the layer number s* for which it holds: .
Proof. For simplicity, we assume that the entropy of any layer depends only upon the information of the neighbor layers, that is,
Let us exploit the following Formula for the entropy of combined system (see [
21]):
Applying it for the entropy
of cut
. We have
Using the latter Formula for cut
, we obtain
From Formulas (20) and (21), we obtain that
Here denotes the conditional entropy of the layer s−1 under the condition that the probabilities and entropy of layer s are found.
Denote, for convenience, and .
Using the definition of the weighted entropy and Formula (21), we obtain
Using the Formula of the conditional entropy, the definitions of events
, probabilities
and matrices
, we can write that
Using Formula (22) we can write
Since the following relations are valid,
we obtain that
Therefore, for any accuracy level ε, we can select the number of a cut
for which
The truncated part of the SC containing only layers of the cut possesses the required level of the entropy variation. The theorem is proved.
The theorem permits the decision maker to define the decreased size of the SC model, such that the decreased number of the layers in the SC model is sufficient for planning and coordinating the knowledge about the risks in the relations between the SC components, without the loss of essential information about the risks.
4. Entropy-Based Algorithm for Complexity Assessment
This section summarizes theoretical findings of the previous sections for obtaining a decreased SC model on which planning and coordination of supplies can be done without loss of essential information.
Input data of the algorithm:
the given number N of risk drivers,
weight functions selected by the decision maker,
probabilities pfprime(s) = Pr (Af prime(s)) that the risk driver f is the direct source of the supply failure/delay in layer s, which are caused by risk driver f,
probabilities pfsecond(s) = Pr (Af second(s)) that the risk driver f is the source of the supply failure/delay in layer s, which is a result of the indirect effect on the f by the risk drivers f′ of supply delay in layer s + 1; these probabilities are termed as secondary.
transition probability matrices , s = 0, 1,2,…, k.
Step 1. Using the entropy Formulas (11)–(17), calculate entropy of the layer 0:
Step 2. Using Formulas (2)–(9), compute the matrix
, and vector
Step 3. Compute the corrected vector of probabilities for the layer , using Formula
and corrected entropy for layer
Step 4. For s = 2,3,…, using matrix , vector compute sequentially the corrected vectors of probabilities for the layers :
Step 5. Compute
Step 7. For
s − 1,2,…, compute
As the stopping rule use the following rule:
Stop at the cut for which holds.
Then the reduced SC model contains only the cut .



{kind=link}