Hadoop vs. Spark: Impact on Performance of the Hammer Query Engine for Open Data Corpora



Abstract
:1. Introduction
- a detailed description of the architecture of the prototype, which will help us in analyzing performance;
- the algorithm that implements the critical step of our blind querying technique (Step 4, see Section 3.3) is precisely described; its variants necessary to adapt it to Hadoop and Spark are also presented;
- an extensive study about performance of Hadoop and Spark implementations is reported;
- a critical analysis of performance is done, in order to compare the compared solutions;
- we report the lessons we learned by the analysis of execution times, and we give some behavioral guidelines for developers wishing to transform non algorithms into Map-Reduce algorithms.
2. Related Works
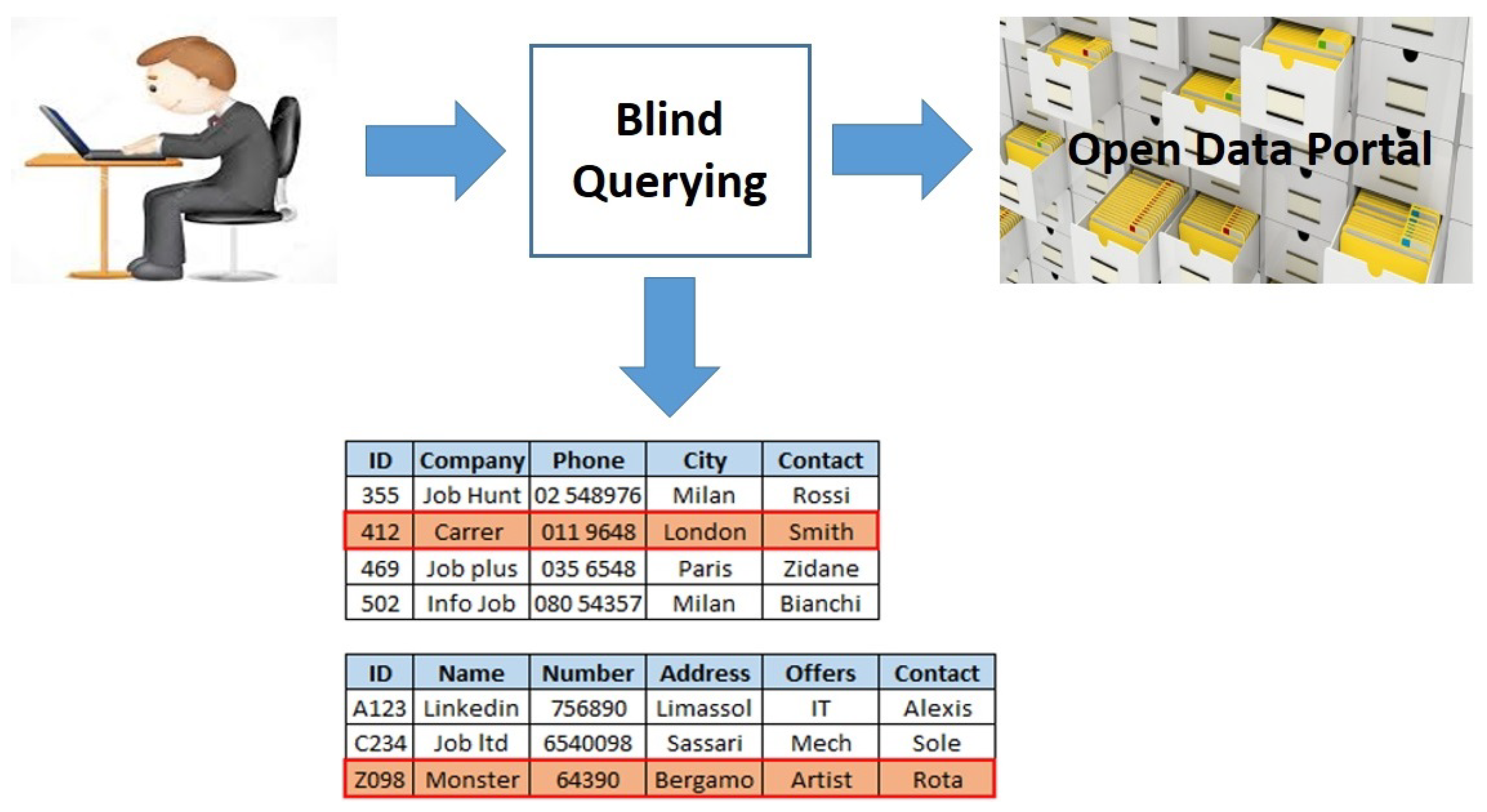
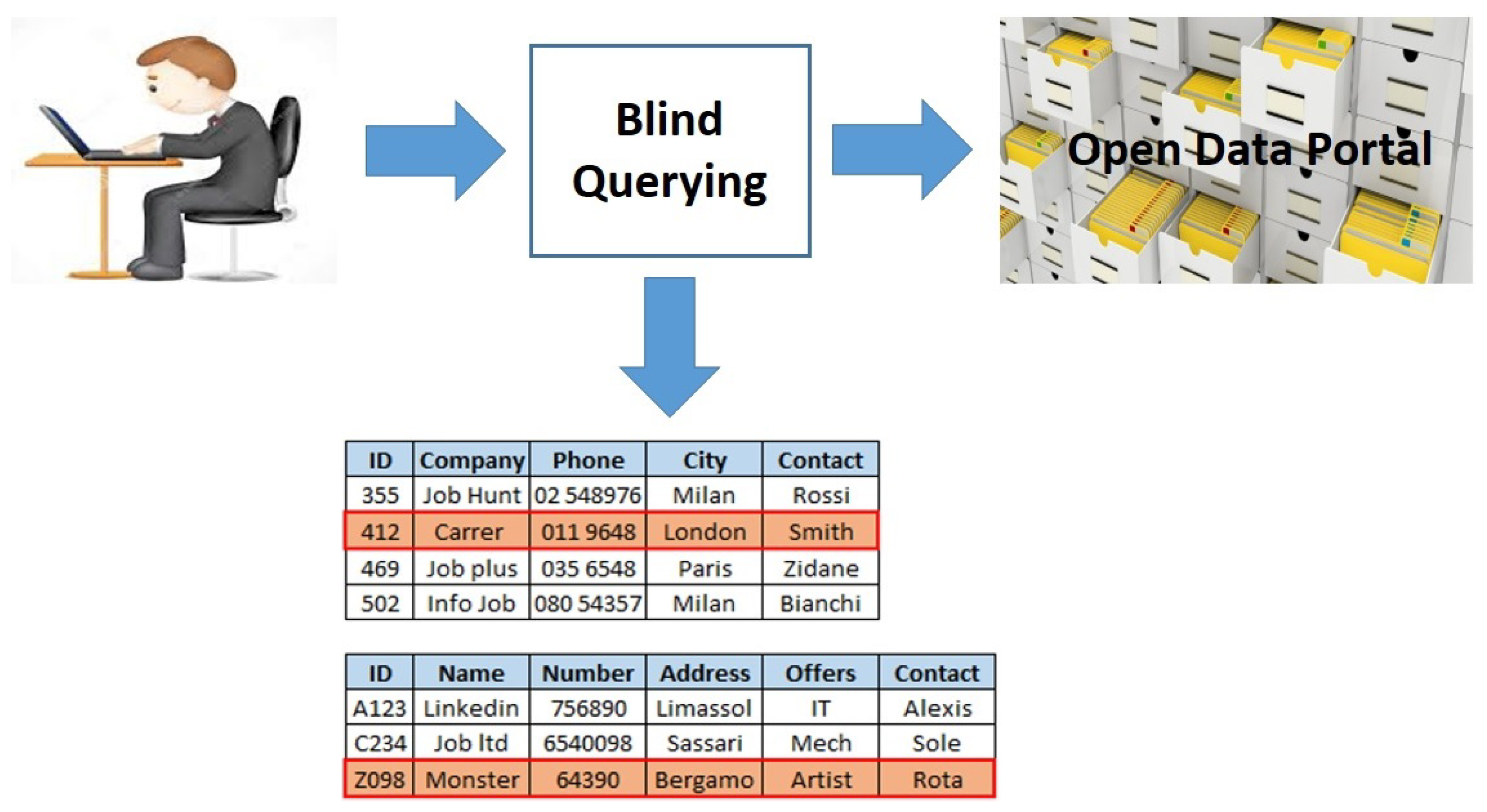
3. A Framework for Blind Querying
3.1. Concepts, Definitions and Problem
3.2. Pre-Processing
- Scanning the Portal. The portal, containing data sets to add to the corpus C, is scanned, in order to get the complete list of available data sets.
- Retrieving Meta-data of data sets. From the portal, for each data set, its meta-data and schema are retrieved.
- Building the Catalog. The catalog of the corpus is built, in order to collect meta-data and schemas of data sets.
3.3. Retrieval Technique
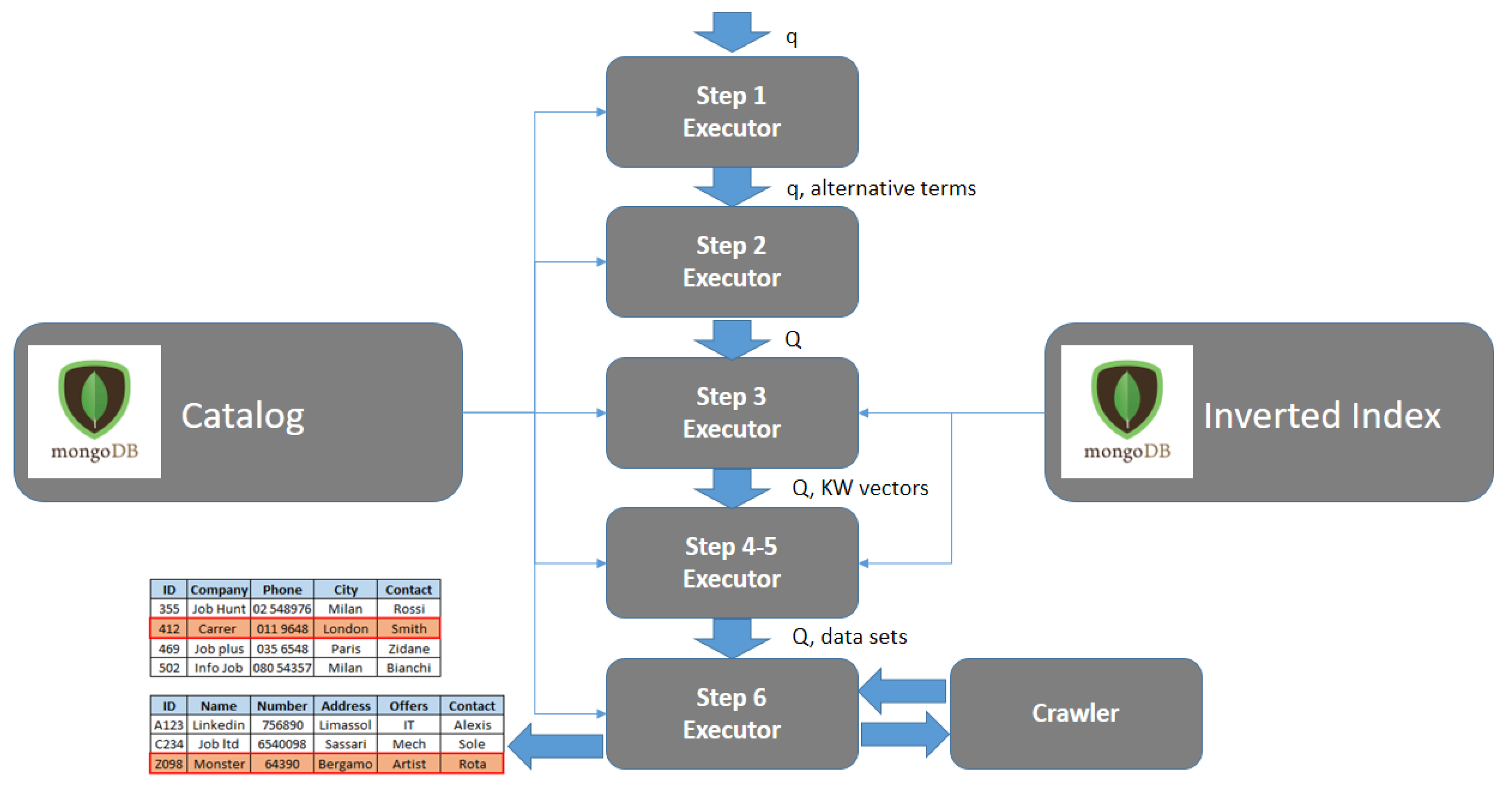
- Step 1: Term Extraction and Retrieval of Alternative Terms. The set of terms is extracted from within the query q. Then, for each term , the set of similar terms is built. A term either if it is lexicographically similar (based on the Jaro-Winkler similarity measure [26]) or semantically similar (synonym) based on WordNet dictionary, or a combination of both. Terms in are actually present in the catalog of the corpus.
- Step 2: Generation of Neighbour Queries. For each term , alternative terms are used to derive, from the original query q, the Neighbour Queries , i.e., queries which are similar to q. Both q and the derived neighbour queries are in the set Q of queries to process.
- Step 3: Keyword Selection. For each query to process , keywords are selected from terms in , in order to find the most representative/informative terms for finding potentially relevant data sets (introduced and extensively described in [1]).For each query , its keyword vector K(nq) is computed: it is represented as a vector K(nq) = [, …, ]; the accompanying vector (nq) = [, …, ] represents the weight of each term in vector K(nq); each weight is the result of the previous steps, on the basis of (lexical or semantic) similarity with respect to original terms (see [2]).
- Step 4: VSM Data Set Retrieval. For each query , the selected keywords are used to retrieve data sets based on the Vector Space Model [25] approach: in this way, the set of possibly relevant data sets is obtained. Notice that we select only data sets with a similarity measure krm (cosine similarity with respect to a query ) greater than or equal to a minimum threshold th_krm.Specifically, given a data set , vectoris the vector of weights of each keyword for data set , obtained through the inverted index (refer to [2] for details).The Keyword-based Relevance Measure for data set with respect to query is the cosine of the angle between vectors and W().When , the data set is associated with all the keywords of the original query.
- Step 5: Schema Fitting. The full set of field names in each query is compared with the schema of each selected data set, in order to compute the Schema Fitting Degree . Data sets whose schema better fits the query will be more relevant than other data sets. For this reason (refer to [2]), the relevance measure of a data set is defined as a weighted composition of keyword relevance measure and schema fitting degree . A minimum threshold th_rm is set, to select relevant data sets.
- Step 6: Instance Filtering. Instances of relevant data sets are processed (i.e., downloaded from the portal and filtered) in order to filter out and keep only the objects that satisfy the selection condition. The result set is so far built: it is a collection of JSON objects.
4. Map-Reduce: Approach and Frameworks
4.1. The Map-Reduce Approach
- Map primitive: this primitive is a programmer-defined function that processes (usually) small parts of input data in order to generate a set of intermediate key/value pairs. Keys will play the role of grouping values in the next Reduce step.
- Reduce primitive: this primitive is a programmer-defined function that takes the set of key/value pairs generated in the Map phase and aggregate pairs with the same key.
- distributing data to computing nodes;
- collecting key/value pairs;
- distributing key/value pairs to nodes, in order to aggregate them.
Iterative Algorithms
4.2. Hadoop vs. Spark
- a data storage layer called Hadoop Distributed File System (HDFS) [28], which provides storage support to process, both for input data and for intermediate results;
- a data processing layer called Hadoop Map-Reduce Framework, which distributes and coordinates computation on the cluster; the basic component, which actually handles task execution, is named YARN (Yet Another Resource Negotiator) [29].
- Input data are transferred from persistent memory to main memory, subdivided in many RDDs; these RDDs are read-only for next tasks.
- Computational tasks are performed by worker nodes; they access RDDs and generate new RDDs;
- A RDD is resilient because the framework keeps track of the process that has generated it. In case of loss of its content (due to space limitations in main memory), the framework rebuilds the RDD, by re-executing the tasks that have generated the lost RDD.
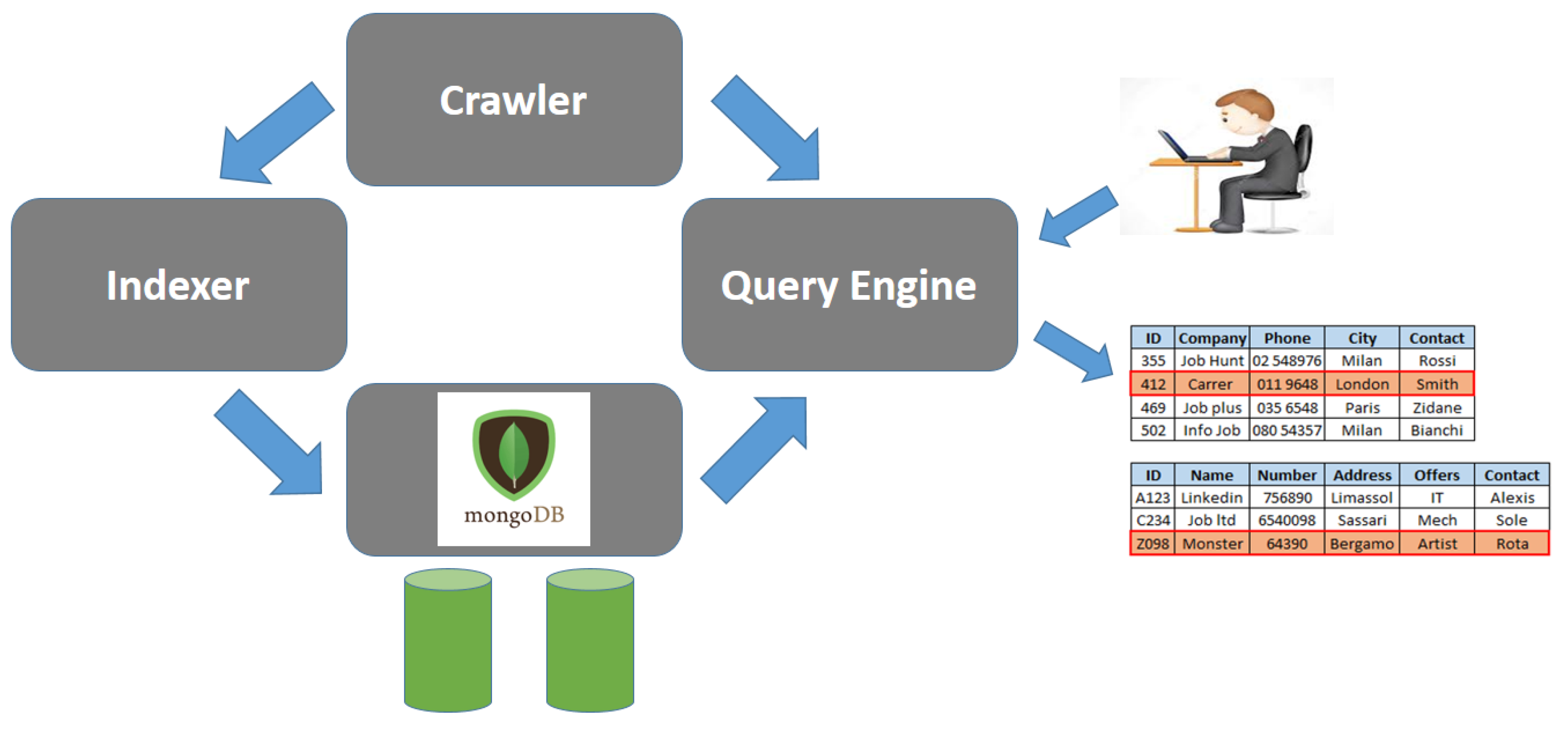
5. The Hammer Prototype
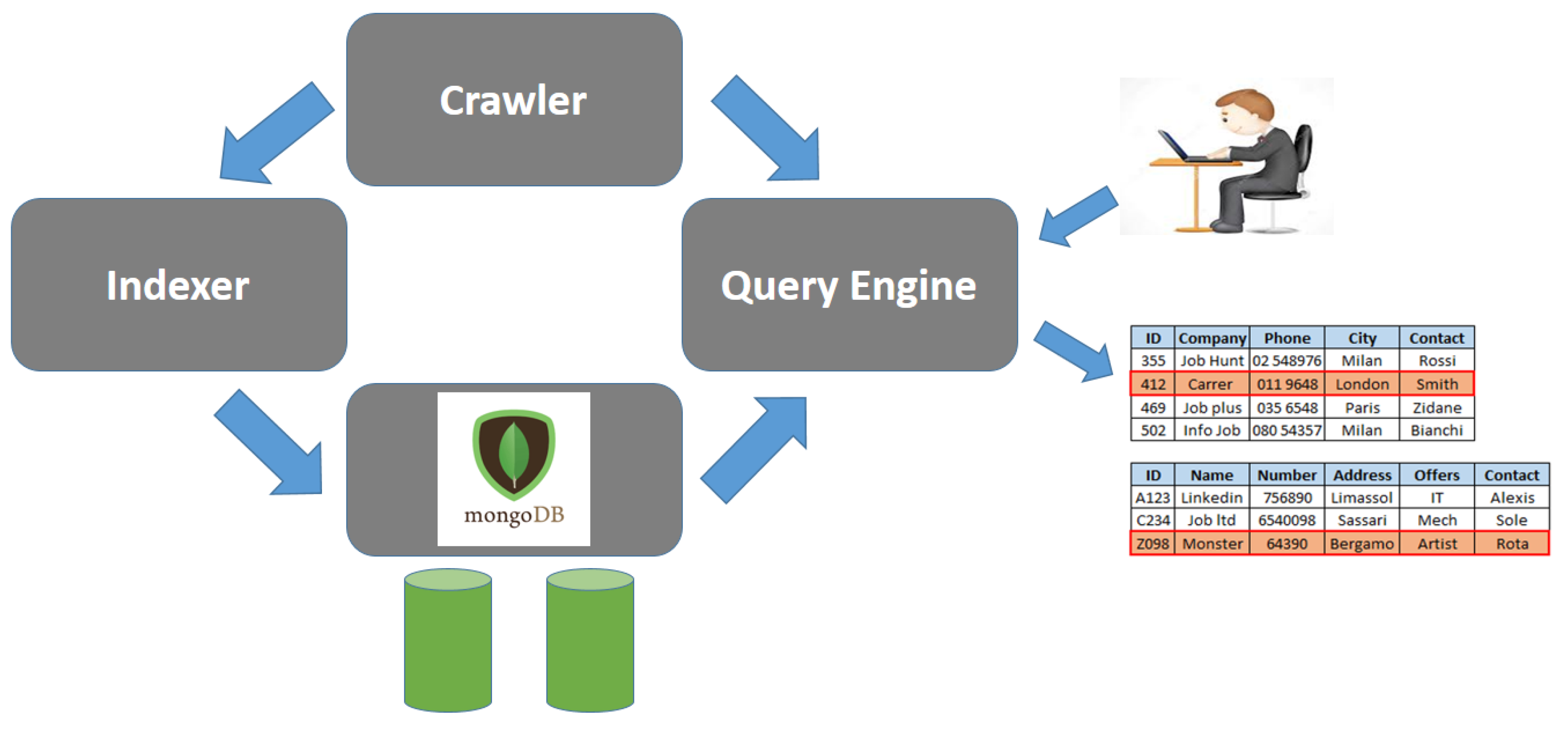
5.1. Architecture of the Hammer Prototype
- The Indexer gets meta-data concerning data sets, without downloading the instances, and builds an Inverted Index; at the same time, the catalog of the corpus is built. Both the catalog and the inverted index are stored as collections of JSON objects within a MongoDB database.
- The Query Engine is exploited by users to actually retrieve data sets. The query is processed on the basis of the inverted index and meta-data stored in MongoDB. For data sets matching the query or some neighbour query, their instances are actually retrieved and filtered, in order to produce the output results.
- The Crawler is a service component exploited both by the indexer and by the query engine to access the Open Data portal, in order to get either meta-data about published data sets or instances.
- MongoDB NoSQL DBMS provides storage support. We decided to adopt it due to the flexibility provided by the fact that it stores JSON objects in heterogeneous collections in a native way; this way, the prototype can be easily evolved and the database can be easily adapted.
5.2. Step 4/5 Executor: Basic Algorithm
| Algorithm 1: Algorithm for Step 4. | |
| Procedure Step4/5_Executor(Q, , ) | |
| Begin | |
| 1. | MongoDB_Clear_FoundDS() |
| 2. | For Each do |
| 3. | Process_Query(q, ) |
| End For Each | |
| 4. | Evaluate_RM() |
| End Procedure |
- At line 1, function MongoDB_Clear_FoundDS is called. It resets the content of a MongoDB collection called FoundDS: this collection has to store data set descriptors that satisfy at least one query .
- The For Each loop on line 2 calls (line 3) procedure Process_Query for each query . This procedure stores data set descriptors possibly found for query q in the MongoDB collection FoundDS.
- Algorithm 2 reports the pseudo-code of procedure Process_Query, which actually implements Step 4, for each single query . We now describe its work in detail:
- The procedure receives a query q and the minimum threshold for the keyword relevance measure .
- On line 2, the set of data set descriptors is set to be empty. Furthermore, on line 3, function MongoDB_Get_FoundDS gets the set of data set descriptors already found for previous processed queries in Q.
- The For Each loop on line 4 iterates for each term t in the set of terms extracted for query q by Step 3 Executor.In particular, for each term t, the loop queries the inverted index stored within a MongoDB collection: function MongoDB_DS_for_term_Except queries the inverted index and returns the set of data set descriptors that contain term t; however, data sets already present in collection FoundDS are not retrieved by the function, in order to optimize the process: in fact, if a data set has been already found by a previous query, there is no need to consider it again in Step 4.Specifically, the If instruction on line 5 assigns the content of the set of data set descriptors retrieved from the inverted index directly to if is empty (for the first processed term); otherwise (Else branch on line 7), the new set of data set descriptors retrieved from the inverted index is intersected with the previous one. Only data sets common to both operands of ∩ have a descriptor in its output: consequently, progressively narrows at each iteration.Finally, line 8 checks if the set is empty: if this happens, it means that no data sets satisfying the query are in the corpus.
- Once completed the first For Each loop, it is necessary to evaluate the keyword relevance measure for each data set in . Line 9 sets to empty the set of selected data sets .
- The loop on line 10 actually makes the computation of the keyword relevance measure for each data set in . On line 11, the cosine similarity between terms in data set (vector W) and terms in the query q is computed (by function CosineSimilarity).On line 12, the If instruction compares with the threshold : if the former is greater than or equal to the latter, the descriptor is added to the set ; otherwise, it is discarded.
- Finally, line 14 checks if the set is not empty: if so, the set of descriptors contained in is appended to the MongoDB colelction FoundDS by procedure MongoDB_Add_FoundDS. This terminates procedure Process_Query.
- Let us come back to procedure Step4/5_Executor. After Step 4 is concluded, Step 5 is performed on line 4, by calling procedure Evaluate_RM, reported in Algorithm 3. It is described in detail hereafter:
- -
- The goal of this procedure is computing the Schema Fitting Degree (r sfd) for all data sets selected by Step 4, in order to compute the overall relevance measure . Similarly to Step 4, descriptors of data sets to work on are stored in the MongoDB collection named FoundDS, while descriptors of data sets to produce as output of the step are stored in the MongoDB collection called ResultDS. Line 1 calls procedure MongoDB_Clear_ResultDS to clear this collection.
- -
- Before starting the iterative process, line 2 initializes the set of data set descriptors to produce as output (); line 3 reads the set of data set descriptors produced by Step 4 from the MongoDB collection FoundDS.
- -
- The For Each loop on line 4 operates on each data set descriptor, in order to evaluate the best relevance measure ; before starting the inner loop, line 8 reads the schema of the data set from the catalog stored in MongoDB.
- -
- The inner loop on line 7 evaluates the data set against each query .Specifically, line 8 computes the relevance measure by calling function Compute_SFD_and_RM, that computes the sfd and, based on it, the relevance measure rm, which is assigned to variable .Line 9 compares this value with the former best value for the data set and, if the new value is greater than the old one, it becomes (line 10) the new best value and (line 11) the data set is associated with the corresponding query.
- -
- The last action of the outer loop is the comparison of the relevance measure with respect to the threshold : if the measure is greater than or equal to the threshold (line 12), the data set descriptor is added to the output set (Line 13).
- -
- Finally, after the outer loop, if the set is not empty (Line 14), it is stored to the ResultDS collection in MongoDB.
| Algorithm 2: Procedure for extracting relevant data sets for a query. | |
| Procedure Process_Query(q, ) | |
| Begin | |
| 1. | DS: set-of |
| 2. | := ∅ |
| 3. | MongoDB_Get_FoundDS() |
| 4. | For Each do |
| 5. | If Then |
| 6. | MongoDB_DS_for_term_Except(t, ) |
| Else | |
| 7. | MongoDB_DS_for_term_Except(t, ) |
| End If | |
| 8. | if Then End Procedure |
| End For Each | |
| 9. | |
| 10. | For Each do |
| 11. | CosineSimilarity(, ) |
| 12. | If Then |
| 13. | |
| End If | |
| End For Each | |
| 14. | If Then |
| 15. | MongoDB_Add_FoundDS() |
| End If | |
| End Procedure |
| Algorithm 3: Pseudo-code of procedure Evaluate_RM, performing Step 5. | |
| Procedure Evaluate_RM(Q, ) | |
| Begin | |
| 1. | MongoDB_Clear_ResultDS() |
| 2. | |
| 3. | MongoDB_Get_FoundDS() |
| 4. | For Each do |
| 5. | MongoDB_Get_Ds_Schema() |
| 6. | |
| 7. | For Each do |
| 8. | Compute_SFD_and_RM(, , q) |
| 9. | If Then |
| 10. | |
| 11. | |
| End If | |
| End For Each | |
| 12. | If do |
| 13. | |
| End If | |
| End For Each | |
| 14. | If Then |
| 15. | MongoDB_Save_ResultDS(ResultDS) |
| End If | |
| End Procedure |
5.3. Evolving Step4/5 Executor toward Map-Reduce
- The first part of procedure Step4/5_Executor (lines from 1 to 3), which performs Step 4, becomes the Map phase: each Map task executes procedure Process_Query on one single query. Consequently, the number of parallel tasks coincides with the number of queries in Q.
- The second part of procedure Step4/5_Executor (line 4) becomes the Reduce phase: results produced by the Map phase are collected and evaluated against queries in Q, by calling procedure Evaluate_RM.
| Algorithm 4: Generic Map-Reduce version of Step4/5_Executor. | |
| Procedure Step4/5_Executor(Q, , ) | |
| Begin | |
| 1. | MongoDB_Clear_FoundDS() |
| 2. | For Each do |
| 3. | Schedule_Map_Task(ProcessQuery(q, )) |
| End For Each | |
| 4. | Schedule_Reduce_Task(Evaluate_RM(Q, )) |
| End Procedure |
5.4. Enhancing Step 4: Exploiting High-Level Abstractions Provided by Spark
| Algorithm 5: Procedure Step4/5_Executor implemented as a Spark v2 program. | |
| Procedure Step4/5_Executor(Q, , , I, D) | |
| Begin | |
| 1. | = |
| 1a. | Q.select("q_id", explode("KW")) |
| 1b. | .join(I on"kw==term") |
| 1c. | .select("q_id", "kw", "w", explode("ds_id")); |
| 2. | := .groupBy("q_id", "ds_id").aggregate("kw").as("K") |
| 3. | := |
| 3a. | .join(Q on "q_id") |
| 3b. | .map(t ->{ t.krm:=CosineSimilarity(q.KW, q.W, q.K) }) |
| 3c. | .filter("krm ≥ ")) |
| 3d. | .select("q_id", "ds_id", "krm") |
| 3e. | .collect() |
| 4. | := |
| 4a. | .join(Don"ds_id") |
| 4b. | .map(e->{e.rm:=Compute_RM(e.krm, e.schema, e.KW)}) |
| 4c. | .filter("rm ≥ ") |
| 5. | := |
| 5a. | .groupBy("q_id", "ds_id").max("rm") |
| 5b. | .join(on"q_id and ds_id and rm").select("ds_id", "rm", "q_id") |
| 5c. | .collect() |
| End Procedure |
- On line 1, the temporary sdataset named is computed: it has to contain tuples associating a query (by its identifier q_id) with a keyword kw and a data set (by its identifier ds_id) that contains that keyword. See the structure in Table 1.Line 1a flattens vector KW in tuples describing queries: this is necessary to associate the query with data set identifiers through the inverted index. Notice the explode operation in the select operation, which transforms the nested tuples into flat tuples (one tuple for each element in the vector).Line 1b. performs a join with the sdataset I, that contains the inverted index (notice the join condition after the on). The resulting table contains vector DS, with data set identifiers: for this reason, the select operation on line 1c exploits the explode operation, in order to flatten the tuples by unnesting fields ds_id.
- Line 2 prepares sdataset in order to aggregate common terms between a query and a data set.Specifically, a groupBy operation is performed, in order to group tuples having the same q_id and ds_id. The subsequent aggregate operation aggregates single values of field kw into one single vector, which is given the name K.The resulting temporary sdataset is named ; its structure is shown in Table 1.
- The actual computation of the value (keyword relevance measure) for each data set with respect to a query is computed on line 3.Specifically, line 3a joins the previous temporary sdataset with sdatasetQ, in order to get again the KW vector of keywords with weights. This vector is necessary to compute the cosine similarity.Line 3b actually computes the cosine similarity, which is the value of the new field krm. This is performed by explicitly performing a nap operation: for each tuple handled by means of the iterator t, the code within braces after the -> is executed. This code calls function CosineSimilarity to compute the relevance measure and extend the tuple with field krm.Notice that the programmer explicitly schedules Map tasks. Nevertheless, it is not excluded that other operations are scheduled as Map tasks, such as unnesting: this is autonomously performed by the framework.The operation ends by filtering tuples with value of field krm greater than or equal to the minimum threshold (line 3c) and by subsequently restructuring the sdataset (line 3d).Notice the final collect operation: this is necessary to force Spark to actually perform the computation. In fact, Spark does not execute the program until it is not forced to do that. The collect operation is one possibility.
- In order to evaluate the Schema Fitting Degree and, on its basis, the relevance measure , it is necessary to retrieve the schema of each data set. Data set schemas are stored in the sdatasetD.On line 4a, the temporary data set obtained by line 3, named , is joined with sdatasetD (the join condition is equality of fields with the same name).Map tasks are scheduled: on each tuple e (iterator over the sdataset) function Compute_RM is called. This function receives the keyword relevance measure krm, the schema of the data set, the vector KW of keywords in the query. A new field named rm is added to the tuple handled by e.On line 4c, only tuples with value of field rm greater than or equal to the minimum threshold are selected. These become the new temporary sdataset .
- Finally, line 5 provides the final sdataset . Since in the sdataset the same data set might be associated with more than one query, in order to be compliant with the other implementations, it is necessary to take the best association.Consequently, line 5a groups tuples on the basis of field ds_id; then, it computes the maximum value for field rm.Line 5b joins tuples describing groups with original tuples in sdataset , on the basis of the value of the common field rm: this way, the query identifier q_id is associated with ds_id.
5.5. Other Executors Implemented by Means of Map-Reduce
6. Experimental Campaign
6.1. Experimental Settings
6.1.1. Execution Environments
- Environment is a cluster of two nodes powered by Hadoop technology; each node has 3 GB RAM shared among three virtual CPUs; the total amount of RAM available for executors is 6 GB.
- Environment is a single node powered by Spark technology (standalone mode); the total RAM is 3 GB, shared among three virtual CPUs.
- Environment is a cluster of two nodes powered by Spark technology; each node has 3 GB RAM shared among three virtual CPUs; thus, the cluster is equipped with six virtual CPUs that share 6 GB RAM.
6.1.2. Configurations of the Hammer Query Engine
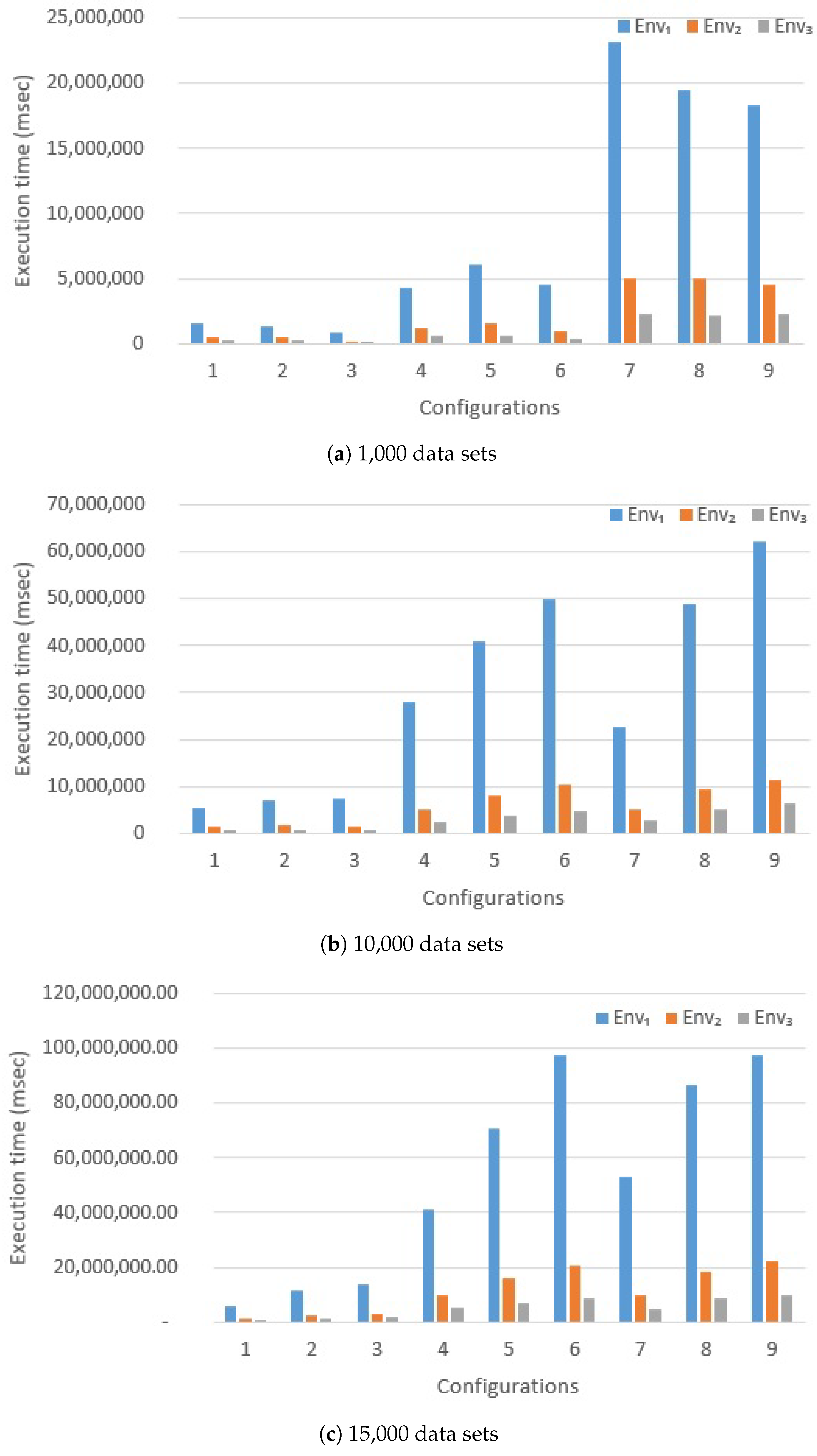
- Parameter max_neigh determines the maximum number of neighbor queries to generate from the original query q. We chose three values: maximum 10 neighbor queries (configurations , and ), maximum 100 neighbor queries (configurations , and ) and maximum 1000 neighbor queries (configurations , and ). The greater the value, the harder the work to perform to evaluate each query to process against the inverted index.
- Parameter th_krm determines the minimum threshold for selecting data sets based on the VSM method, on the basis of information present in the inverted index (Step 4 of the retrieval technique, see Section 3.3). We considered two different values: 0.2 (for configurations and , and , and ) and 0.3 (for configurations , and ). The smaller its value, the greater the number of data sets to retrieve and to process.
- Parameter th_rm determines the minimum threshold for selecting data sets based on the overall relevance measure (Step 5 of the retrieval technique, see Section 3.3). We considered two different values: 0.2 (for configurations and , and , and ) and 0.3 (for configurations , and ). The smaller its value, the greater the number of data sets to retrieve and to process.
- Parameter th_sim denotes the minimum threshold of string similarity used to select alternative terms on the basis of string similarity (Step 1 of the retrieval technique, see Section 3.3). We considered two different values: 0.9 (for configurations and , and , and ) and 0.8 (for configurations , and ). The lower the value, the larger the number of alternative terms retrieved on the basis of string similarity. However, for each term in the original query, we always limit the maximum number of alternative terms chosen on the basis of string similarity to 3.
6.1.3. Sample Corpora
6.1.4. Query
6.2. Results
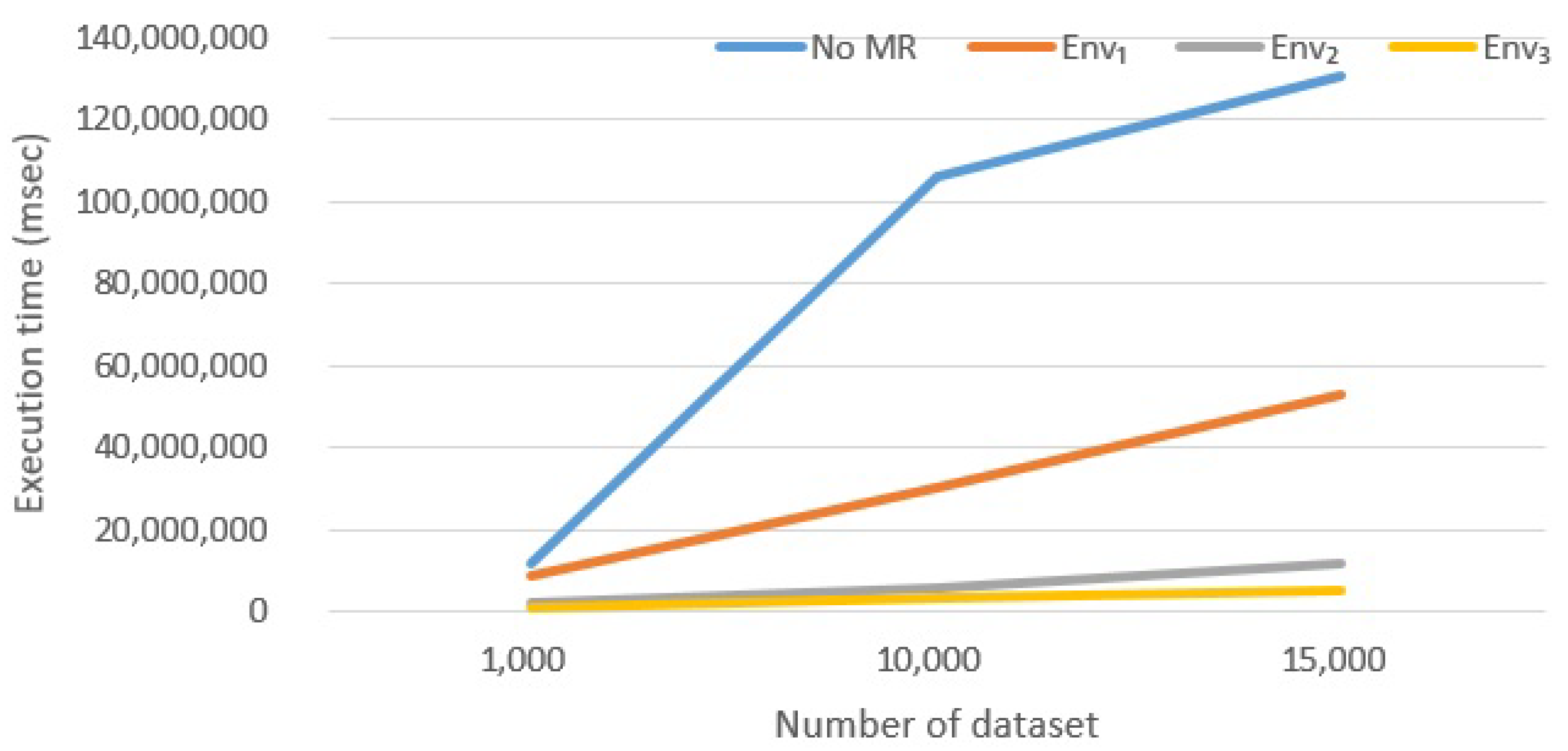
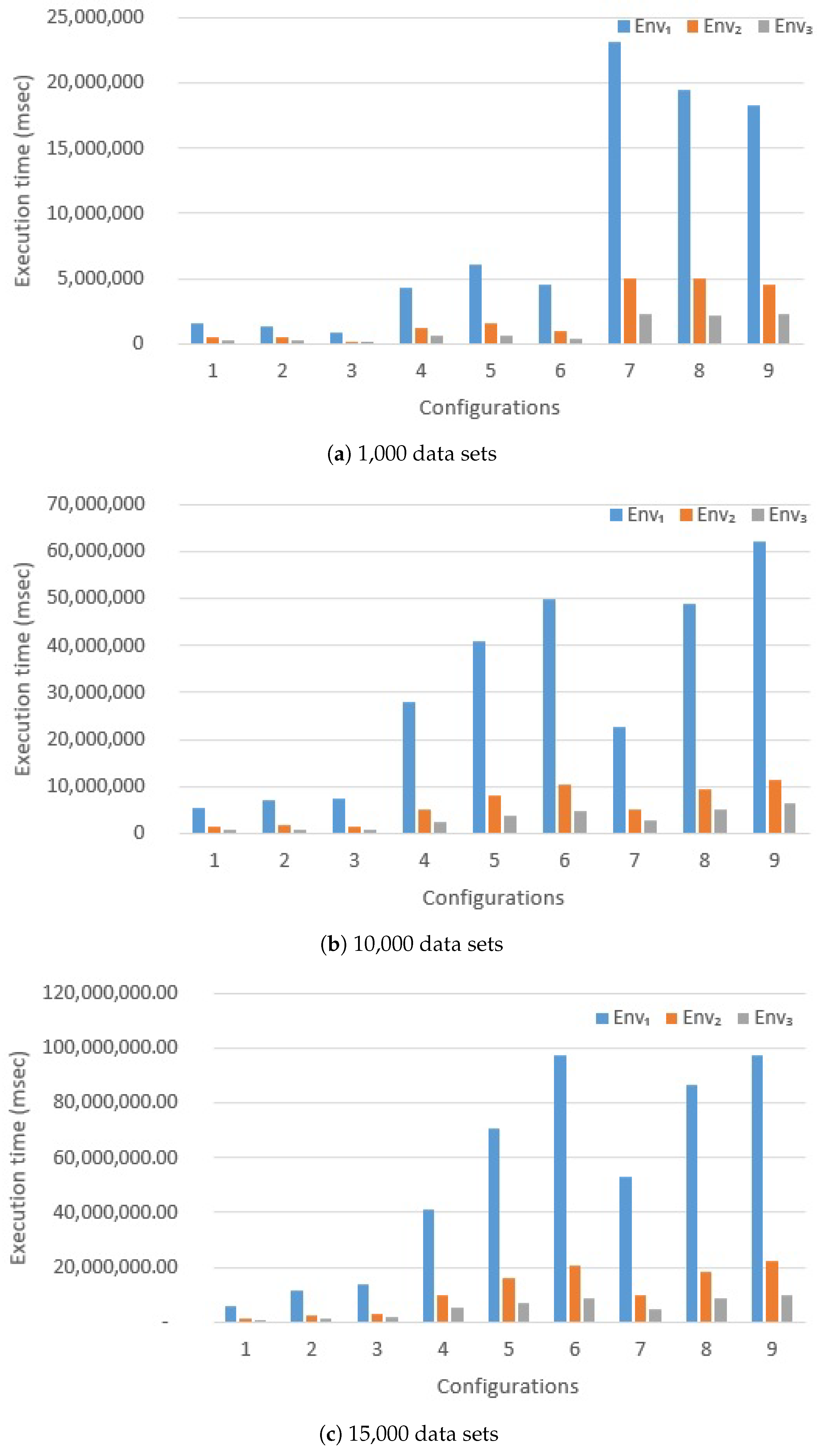
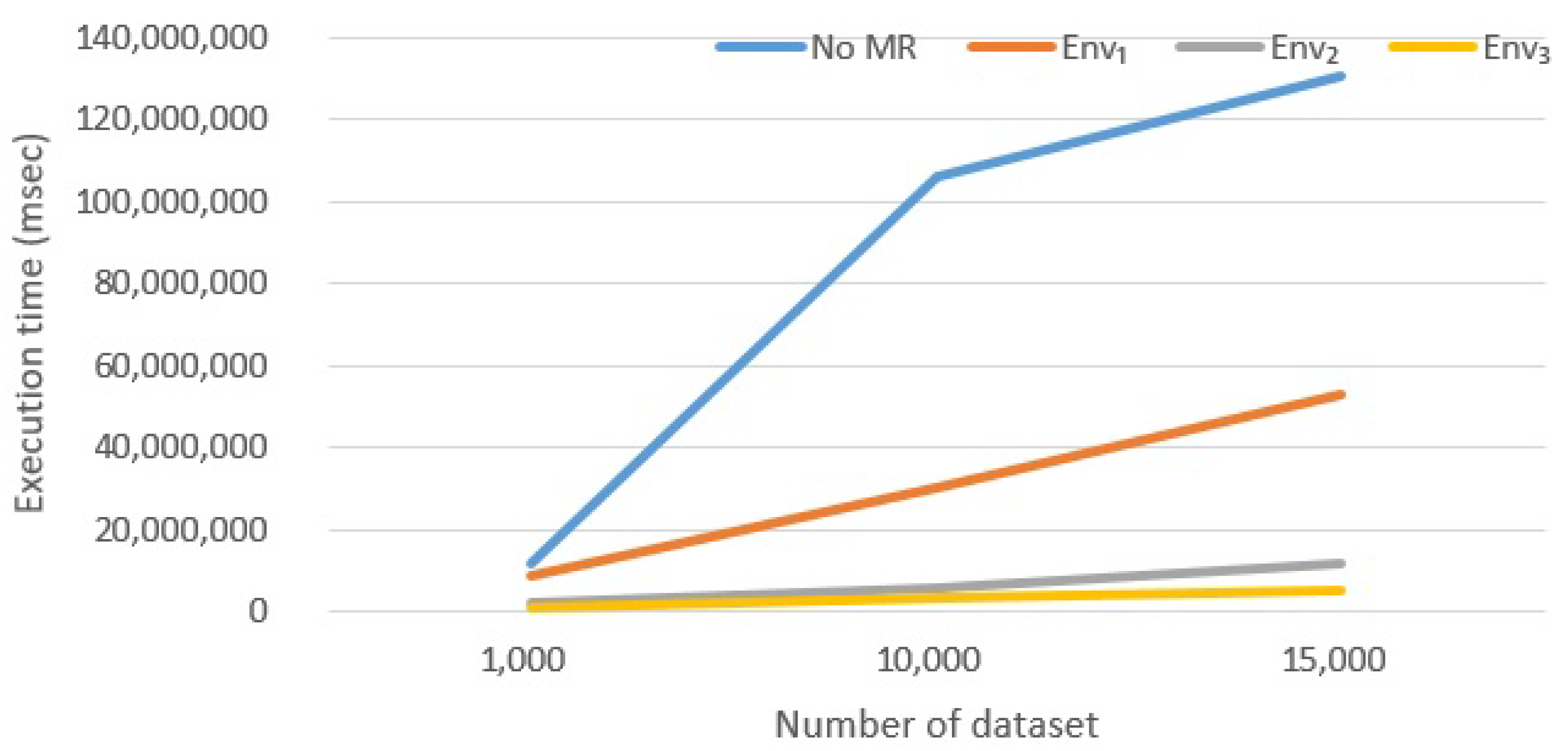
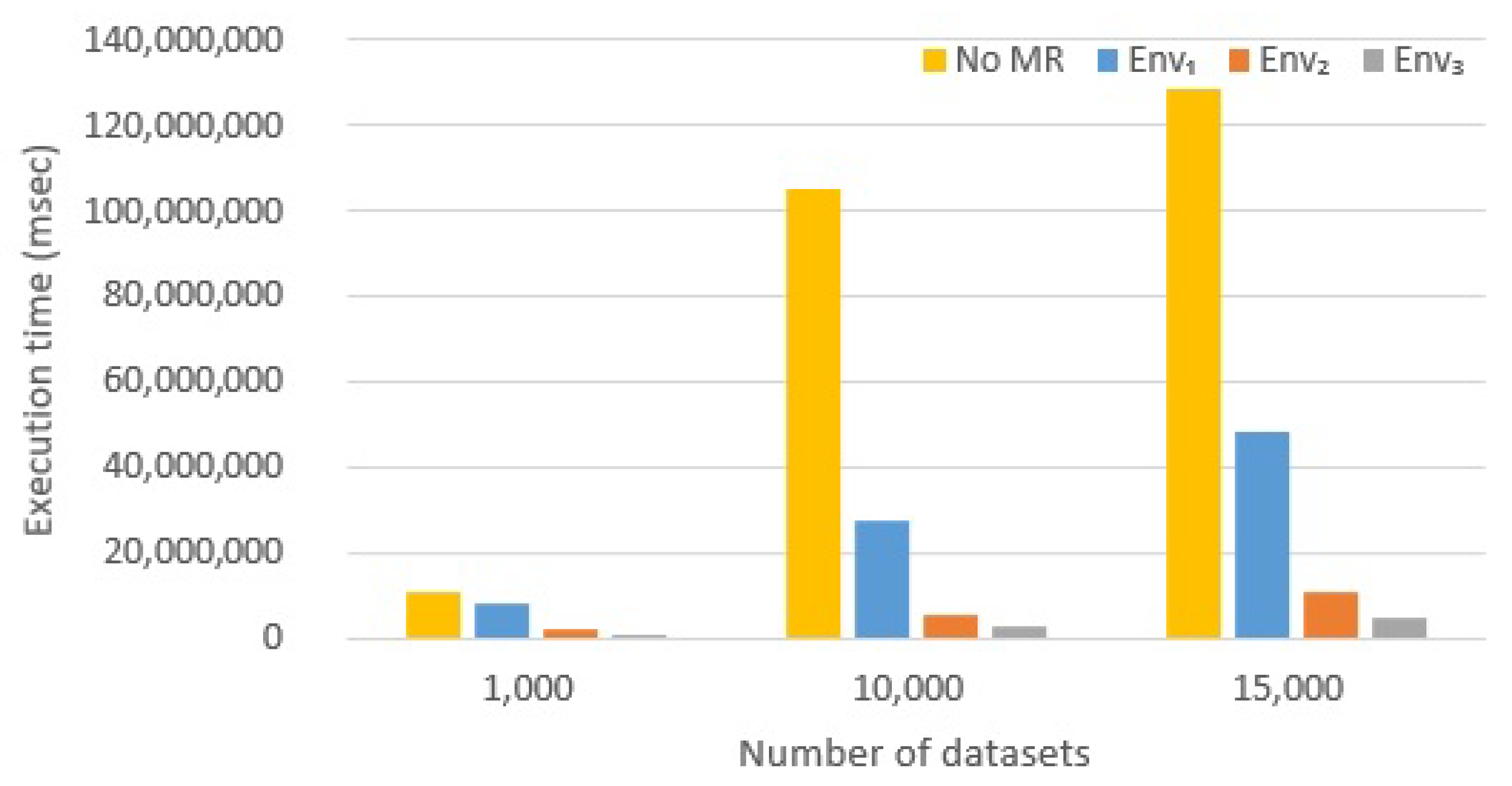
6.2.1. Effect of Introducing Map-Reduce
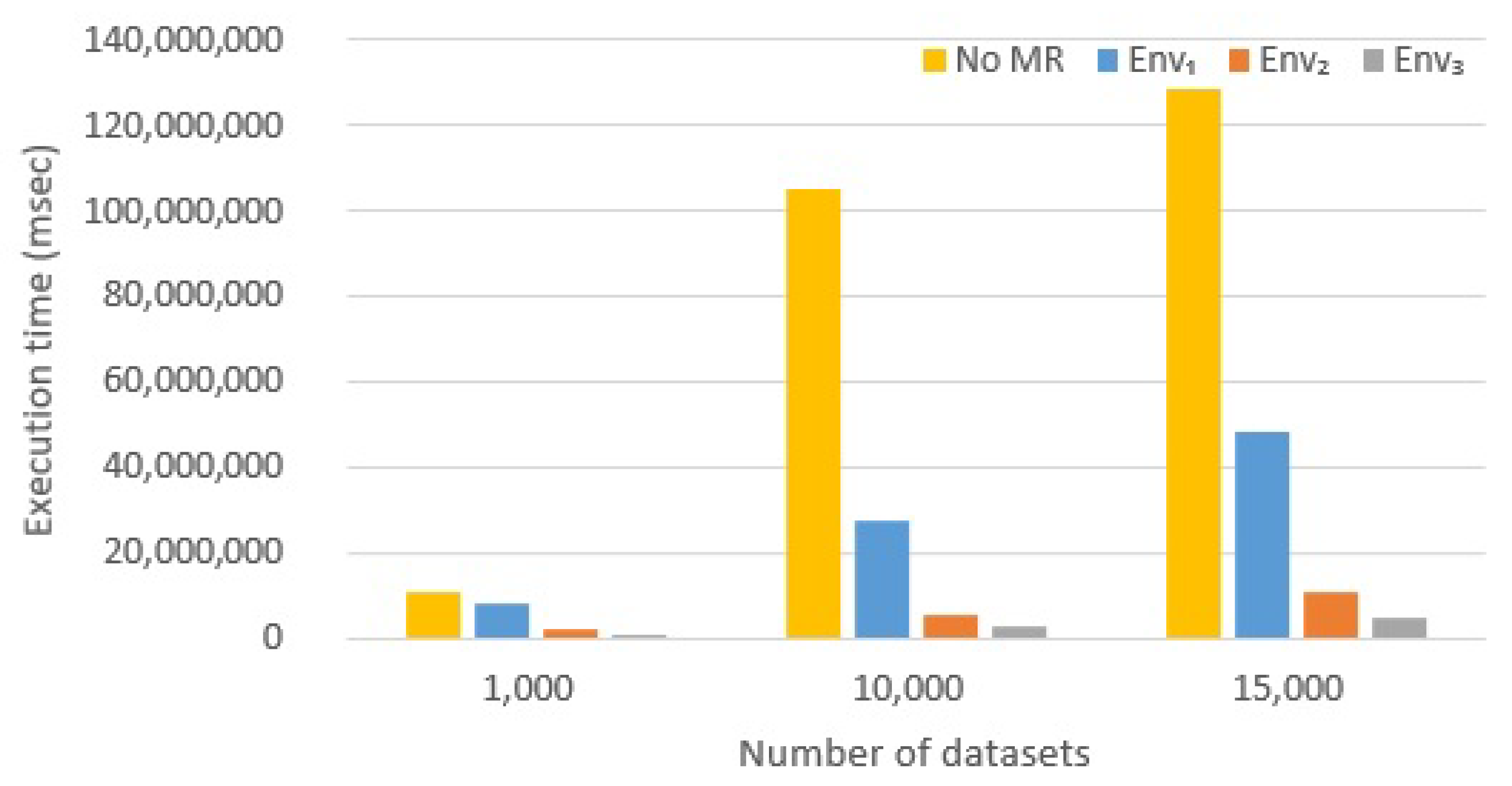
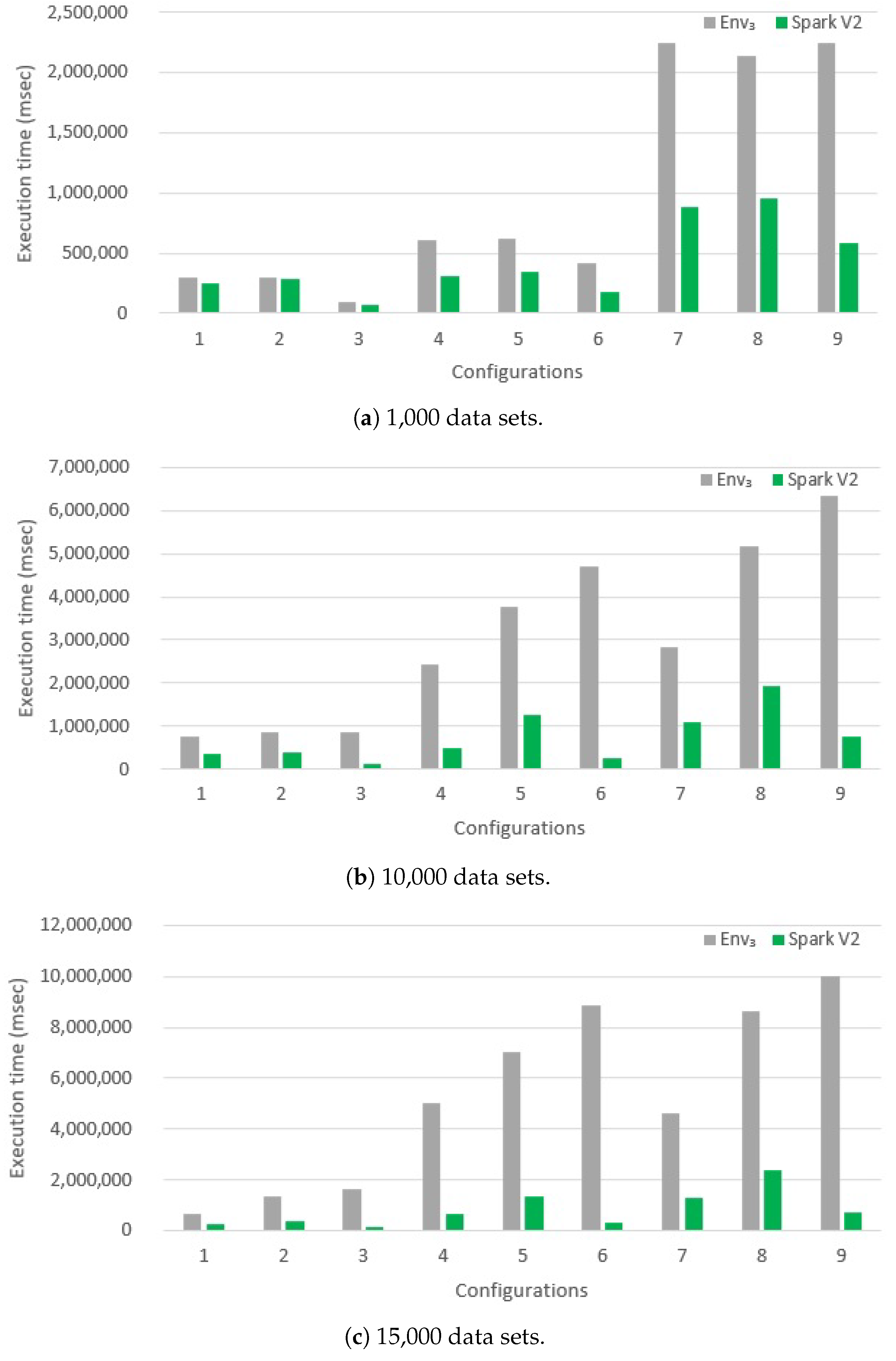
6.2.2. Hadoop vs. Spark Comparison
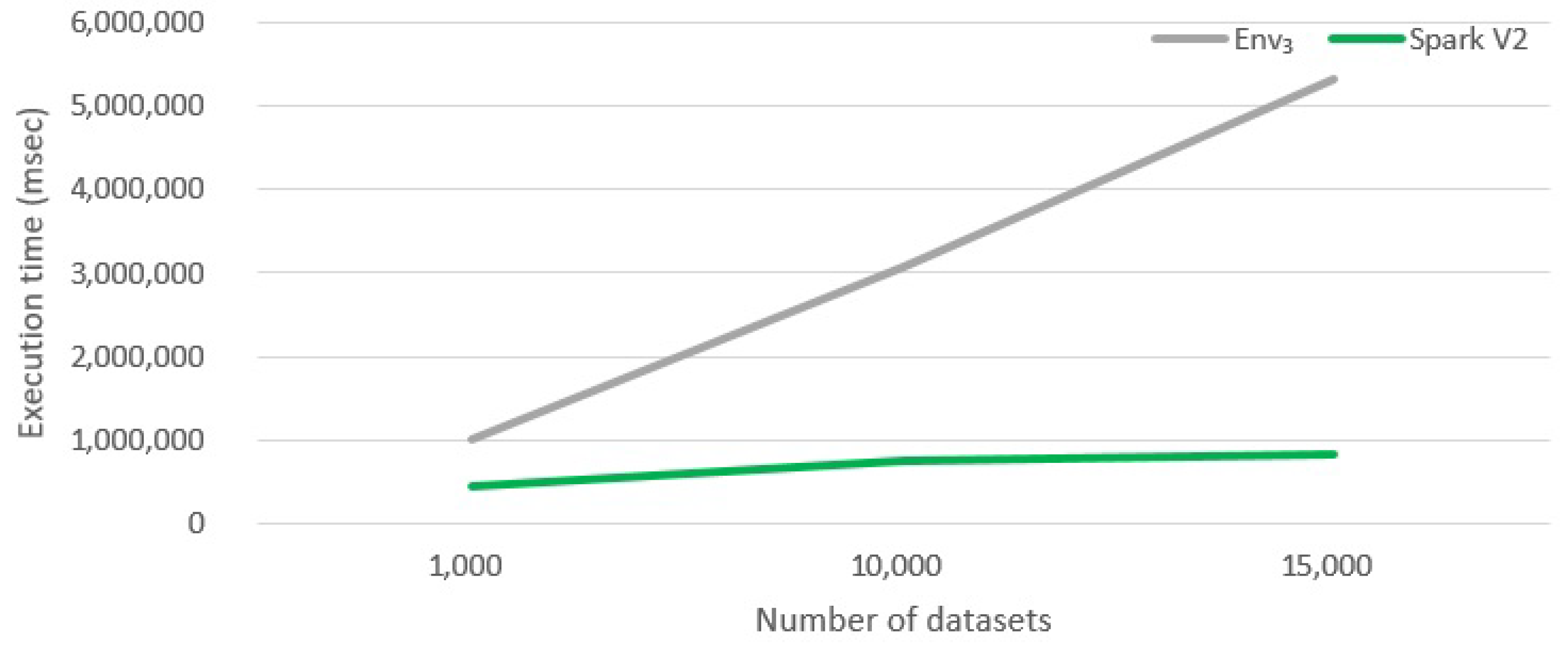
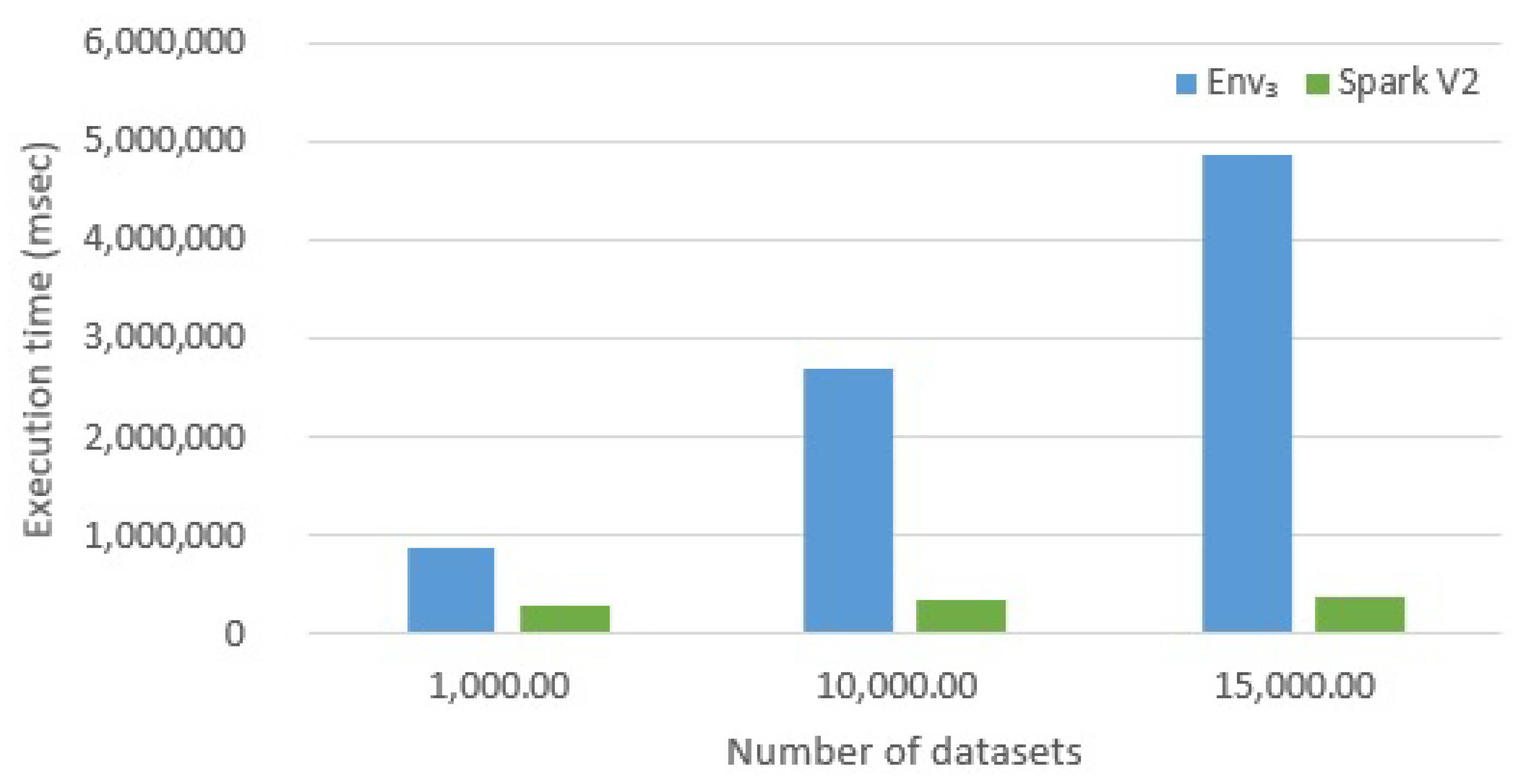
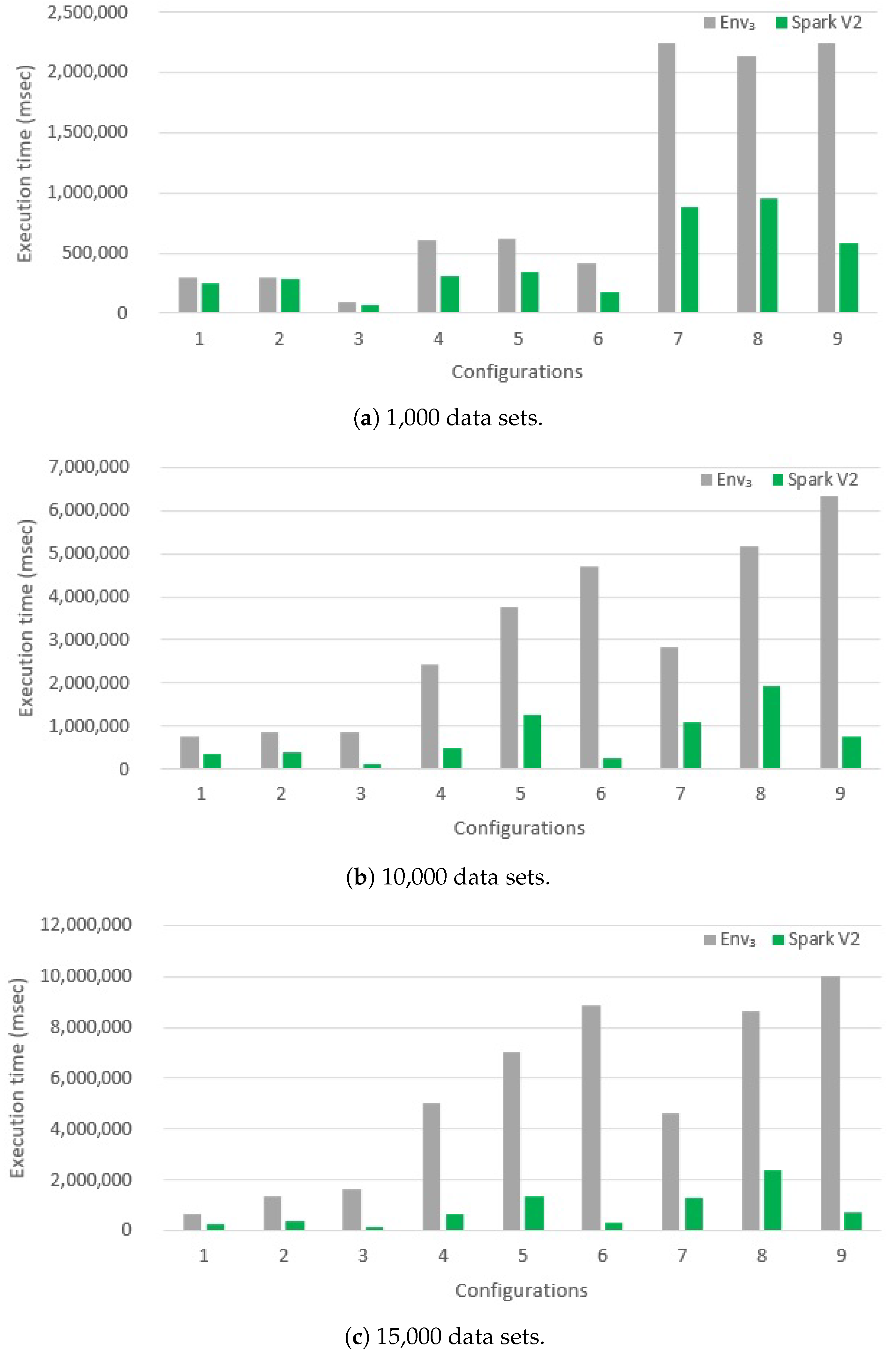
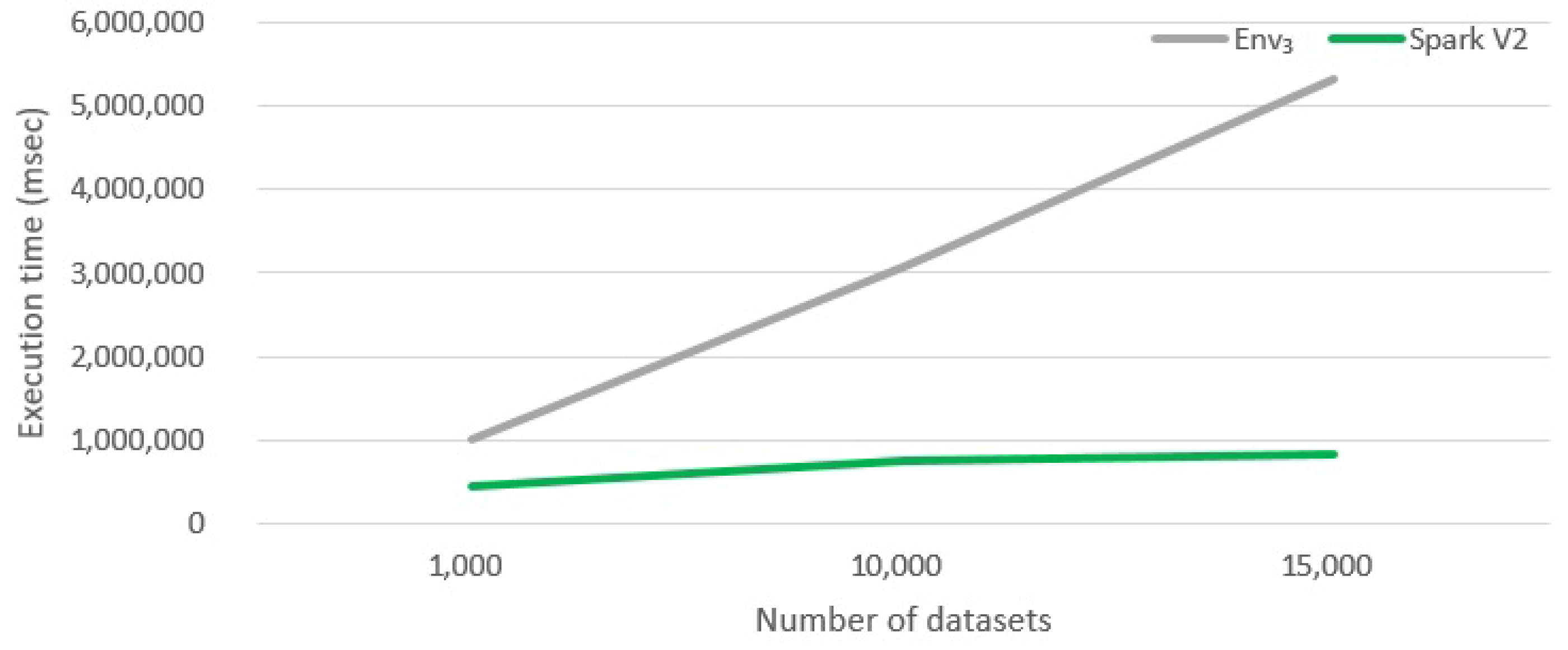
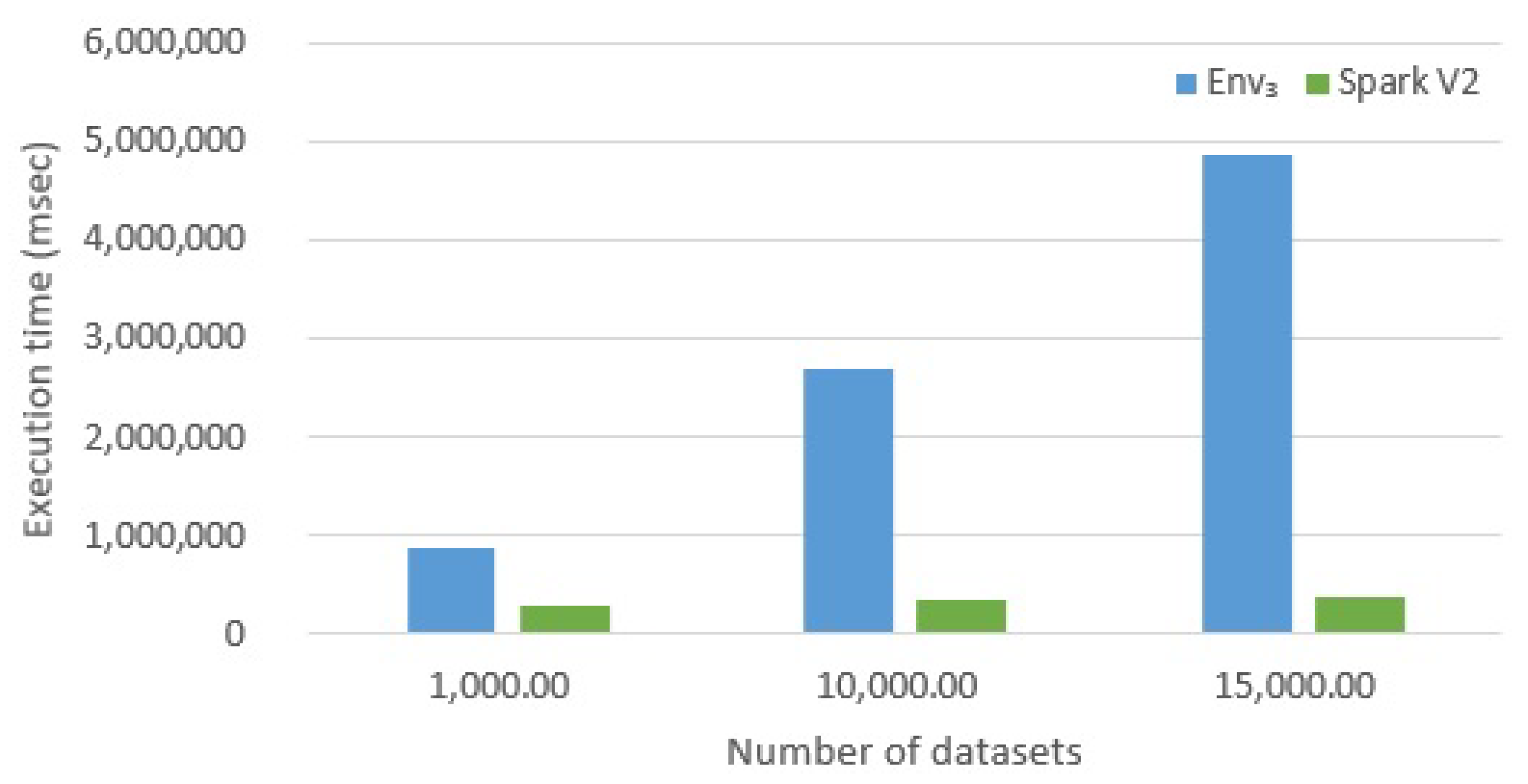
6.2.3. Evaluating Version Spark V2
7. Lessons We Learned and Behavioral Guidelines
- Spark is a very efficient framework, due to the fact that it does not rely on the HDFS to coordinate tasks. In fact, the basic Map-Reduce version of the algorithm (presented in Section 5.3) shares a very limited amount of data among parallel tasks, i.e., query descriptors. However, since synchronization is performed always through HDFS, Hadoop is much slower than Spark.However, frameworks evolve: our experiment were conducted with Hadoop version 2. The new Hadoop version 3 (just released) promises to be much more efficient. Generally, Hadoop is always slower than Spark: it works with mass memory and cannot cache the data in memory, but Hadoop 3 should work up to 30% faster than the oldest version. The major difference is that version 3 provides better optimization, better and usability and a series of architectural improvements.
- Hadoop is anyway able to improve performance, if compared to the No Map-Reduce version. Anyway, developers do not have to expect incredible improvements: in our case, with n executors, the final execution time is not , the No Map-Reduce execution time. Probably, increasing the number of nodes, we will get excellent results even with Hadoop but with a significant increase in costs.
- Spark is so effective because it coordinates parallel tasks: by building a DAG (Direct Acyclic Graph): it computes an execution plan that is shared to all nodes. In contrast, Hadoop does not offer this feature: tasks are executed in a totally non-coordinate way.
- Parallel tasks that continuously access MongoDB (and, we can expect, any other DBMS) are certainly slower than algorithms specifically designed to exploit Map-Reduce in a native way. Nevertheless, our experiments show that Spark, which is not overloaded by HDFS, performs very well, even for algorithms that are not originally designed as Map-Reduce algorithms.
- The dataset abstraction provided by Spark (that we denoted as sdataset) is extremely interesting. First of all, it allows for avoiding complex technicalities concerned with the management of the execution environment. Second, it allows developers to think at a higher level of abstraction, compared with traditional procedural programming.
- High-level abstractions provided by Spark are certainly very interesting and, in many cases, effective to reduce the development time. However, developers lose control of execution and optimization: it may happen that the level of abstractions is too high. If developers want to achieve the best performance, they probably have to scale down to low-level primitives (but, in this case, Spark programs become hard to write).
- In our context, the HDFS is not exploited for computation. However, it is a good tool to share persistent data to nodes in the cluster, especially very large data sets. Spark does not provide a similar functionality. Again, the new Hadoop version 3 could produce interesting surprises in terms of performance with large data sets.
- Minimal effort. If the goal of developers is to migrate a classical algorithm to a first Map-Reduce version, by paying the minimal effort, this could be easily obtained, without changing the global structure of the algorithm. However, this can be done if the algorithm is structured as loops of complex tasks/procedures. Furthermore, connections to a DBMS can be maintained.We suggest adopting the Spark framework, that, in general, provides better performance, even with database connections.
- Privilege performance. If the goal of developers is to privilege performance, algorithms must be redesigned as pure Map-Reduce algorithms.
- Simplicity of design. Abstractions provided by Spark are quite effective in order to strongly simplify the design (or redesign) of an algorithm. This could be a good choice for making the development process effective and efficient.
- Hadoop or Spark? Notice that the two frameworks are not in conflict, even though the reader might think this. In fact, they can co-exist without any problem. Hadoop was created as an engine for processing large amounts of existing data: it has a low level of abstraction that allows for performing complex manipulations but can cause learning difficulties. Spark is faster, with a lot of great high-level tools and functions that can simplify the design and the development. If the algorithms or the processes do not require special features, Spark is always the most reasonable choice. However, there are situations in which the size of data is so large that the main memory of computing nodes could not be enough, causing Spark to significantly slow down. In these cases, Spark can operate on top of Hadoop and has many good libraries like Spark SQL or Spark MLlib.
8. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Pelucchi, M.; Psaila, G.; Toccu, M.P. Building a query engine for a corpus of open data. In Proceedings of the 13th International Conference on Web Information Systems and Technologies (WEBIST 2017), Porto, Portugal, 25–27 April 2017; pp. 126–136. [Google Scholar]
- Pelucchi, M.; Psaila, G.; Toccu, M. Enhanced Querying of Open Data Portals. In Proceedings of the International Conference on Web Information Systems and Technologies (WEBIST 2017), Porto, Portugal, 25–27 April 2017; Springer: Cham, Switzerland, 2017; pp. 179–201. [Google Scholar]
- Pelucchi, M.; Psaila, G.; Maurizio, T. The challenge of using Map-Reduce to query open data. In Proceedings of the 6th International Conference on Data Science, Technology and Applications (DATA 2017), Madrid, Spain, 24–26 July 2017; pp. 331–342. [Google Scholar]
- Braunschweig, K.; Eberius, J.; Thiele, M.; Lehner, W. The State of Open Data. In Proceedings of the 21st World Wide Web 2012 (WWW2012) Conference, Lyon, France, 16–20 April 2012. [Google Scholar]
- Liu, J.; Dong, X.; Halevy, A.Y. Answering Structured Queries on Unstructured Data. In Proceedings of the WebDB 2006, Chicago, IL, USA, 30 June 2006; Volume 6, pp. 25–30. [Google Scholar]
- Schwarte, A.; Haase, P.; Hose, K.; Schenkel, R.; Schmidt, M. FedX: A federation layer for distributed query processing on linked open data. In Proceedings of the Extended Semantic Web Conference, Heraklion, Crete, Greece, 29 May–2 June 2011; Springer: Berlin, Germany, 2011; pp. 481–486. [Google Scholar]
- Dean, J.; Ghemawat, S. MapReduce: Simplified data processing on large clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- Shvachko, K.; Kuang, H.; Radia, S.; Chansler, R. The hadoop distributed file system. In Proceedings of the 2010 IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST), Incline Village, NV, USA, 3–7 May 2010; pp. 1–10. [Google Scholar]
- Bu, Y.; Howe, B.; Balazinska, M.; Ernst, M.D. HaLoop: Efficient iterative data processing on large clusters. Proc. VLDB Endow. 2010, 3, 285–296. [Google Scholar] [CrossRef]
- Borthakur, D.; Gray, J.; Sarma, J.S.; Muthukkaruppan, K.; Spiegelberg, N.; Kuang, H.; Ranganathan, K.; Molkov, D.; Menon, A.; Rash, S.; et al. Apache Hadoop goes realtime at Facebook. In Proceedings of the 2011 ACM SIGMOD International Conference on Management of Data, Athens, Greece, 12–16 June 2011; ACM: New York, NY, USA, 2011; pp. 1071–1080. [Google Scholar]
- Zaharia, M.; Xin, R.S.; Wendell, P.; Das, T.; Armbrust, M.; Dave, A.; Meng, X.; Rosen, J.; Venkataraman, S.; Franklin, M.J.; et al. Apache spark: A unified engine for big data processing. Commun. ACM 2016, 59, 56–65. [Google Scholar] [CrossRef]
- Gu, L.; Li, H. Memory or time: Performance evaluation for iterative operation on hadoop and spark. In Proceedings of the 2013 IEEE 10th International Conference on High Performance Computing and Communications & 2013 IEEE International Conference on Embedded and Ubiquitous Computing (HPCC_EUC), Zhangjiajie, China, 13–15 November 2013; pp. 721–727. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the OSDI 2016, Savannah, GA, USA, 2–4 November 2016; Volume 16, pp. 265–283. [Google Scholar]
- Low, Y.; Gonzalez, J.E.; Kyrola, A.; Bickson, D.; Guestrin, C.E.; Hellerstein, J. Graphlab: A new framework for parallel machine learning. arXiv, 2014; arXiv:1408.2041. [Google Scholar]
- Burdick, D.R.; Ghoting, A.; Krishnamurthy, R.; Pednault, E.P.D.; Reinwald, B.; Sindhwani, V.; Tatikonda, S.; Tian, Y.; Vaithyanathan, S. Systems and Methods for Processing Machine Learning Algorithms in a MapReduce Environment. U.S. Patent 8,612,368, 17 December 2013. [Google Scholar]
- Meng, X.; Bradley, J.; Yavuz, B.; Sparks, E.; Venkataraman, S.; Liu, D.; Freeman, J.; Tsai, D.; Amde, M.; Owen, S.; et al. Mllib: Machine learning in apache spark. J. Mach. Learn. Res. 2016, 17, 1235–1241. [Google Scholar]
- Wu, X.; Zhu, X.; Wu, G.Q.; Ding, W. Data mining with big data. IEEE Trans. Knowl. Data Eng. 2014, 26, 97–107. [Google Scholar]
- Lin, X. Mr-apriori: Association rules algorithm based on mapreduce. In Proceedings of the 2014 5th IEEE International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 27–29 June 2014; pp. 141–144. [Google Scholar]
- Oruganti, S.; Ding, Q.; Tabrizi, N. Exploring Hadoop as a platform for distributed association rule mining. In Proceedings of the Fifth International Conference on Future Computational Technologies and Applications (FUTURE COMPUTING 2013), Valencia, Spain, 27 May–1 June 2013; pp. 62–67. [Google Scholar]
- Chang, L.; Wang, Z.; Ma, T.; Jian, L.; Ma, L.; Goldshuv, A.; Lonergan, L.; Cohen, J.; Welton, C.; Sherry, G.; et al. HAWQ: A massively parallel processing SQL engine in hadoop. In Proceedings of the 2014 ACM SIGMOD International Conference On Management of Data, Snowbird, UT, USA, 22–27 June 2014; ACM: New York, NY, USA, 2014; pp. 1223–1234. [Google Scholar]
- Chung, W.C.; Lin, H.P.; Chen, S.C.; Jiang, M.F.; Chung, Y.C. JackHare: A framework for SQL to NoSQL translation using MapReduce. Autom. Softw. Eng. 2014, 21, 489–508. [Google Scholar] [CrossRef]
- Kononenko, O.; Baysal, O.; Holmes, R.; Godfrey, M. Mining Modern Repositories with Elasticsearch. In Proceedings of the 11th Working Conference on Mining Software Repositories (MSR), Hyderabad, India, 29–30 June 2014. [Google Scholar]
- Shahi, D. Apache Solr: An Introduction. In Apache Solr; Springer: Berlin, Germany, 2015; pp. 1–9. [Google Scholar]
- Croft, W.B.; Metzler, D.; Strohman, T. Search Engines: Information Retrieval in Practice; Addison-Wesley Reading: Boston, NA, USA, 2010; Volume 283. [Google Scholar]
- Manning, C.D.; Raghavan, P.; Schütze, H. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2008; Volume 1. [Google Scholar]
- Winkler, W.E. The State of Record Linkage and Current Research Problems; Statistical Research Division, U.S. Census Bureau: Washington, DC, USA, 1999.
- White, T. Hadoop: The Definitive Guide; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2012. [Google Scholar]
- Borthakur, D. The hadoop distributed file system: Architecture and design. Hadoop Proj. Website 2007, 11, 21. [Google Scholar]
- Vavilapalli, V.K.; Murthy, A.C.; Douglas, C.; Agarwal, S.; Konar, M.; Evans, R.; Graves, T.; Lowe, J.; Shah, H.; Seth, S.; et al. Apache hadoop yarn: Yet another resource negotiator. In Proceedings of the 4th annual Symposium on Cloud Computing, Santa Clara, CA, USA, 1–3 October 2013; ACM: New York, NY, USA, 2013; p. 5. [Google Scholar]
- Ekanayake, J.; Li, H.; Zhang, B.; Gunarathne, T.; Bae, S.H.; Qiu, J.; Fox, G. Twister: A runtime for iterative mapreduce. In Proceedings of the 19th ACM International Symposium on High Performance Distributed Computing, Chicago, IL, USA, 21–25 June 2010; ACM: New York, NY, USA, 2010; pp. 810–818. [Google Scholar]
- Zhang, Y.; Gao, Q.; Gao, L.; Wang, C. Imapreduce: A distributed computing framework for iterative computation. J. Grid Comput. 2012, 10, 47–68. [Google Scholar] [CrossRef]
- Zaharia, M.; Chowdhury, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Spark: Cluster computing with working sets. HotCloud 2010, 10, 95. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sdataset | Set-of |
|---|---|
| Q | <q_id, KW: vector-of(<kw, w>)> |
| I | <term, DS: vector-of(< ds_id>) > |
| D | <ds_id, schema: vector-of(<term, role, weight>) |
| <q_id, kw, ds_id> | |
| <q_id, ds_id, K: vector-of(<kw, w>)> | |
| <q_id, ds_id, krm> |
| Environment | Technology | Nodes | Virtual CPUs | Total RAM |
|---|---|---|---|---|
| Hadoop | 2 | 6 | 6 GB | |
| Spark | 1 | 3 | 3 GB | |
| Spark | 2 | 6 | 6 GB |
| Configuration | max_neigh | th_krm | th_rm | th_sim |
|---|---|---|---|---|
| 10 | 0.2 | 0.2 | 0.9 | |
| 10 | 0.2 | 0.2 | 0.8 | |
| 10 | 0.3 | 0.3 | 0.9 | |
| 100 | 0.2 | 0.2 | 0.9 | |
| 100 | 0.2 | 0.2 | 0.8 | |
| 100 | 0.3 | 0.3 | 0.9 | |
| 1000 | 0.2 | 0.2 | 0.9 | |
| 1000 | 0.2 | 0.2 | 0.8 | |
| 1000 | 0.3 | 0.3 | 0.9 |
| 1000 Data Sets | Step 1 | Step 2 | Step 3 | Step 4 | Step 5 | Step 6 | Total |
| 69,699 | 150 | 5277 | 1,410,492 | 158,891 | 610,013 | 2,254,522 | |
| 83,689 | 102 | 1844 | 1,001,012 | 171,160 | 556,510 | 1,814,317 | |
| 137,742 | 143 | 1440 | 895,619 | 152,791 | 27,897 | 1,215,632 | |
| 128,504 | 163 | 1082 | 5,075,391 | 79,785 | 554,400 | 5,839,325 | |
| 159,436 | 109 | 1884 | 6,796,491 | 836,515 | 583,513 | 8,377,948 | |
| 133,152 | 125 | 987 | 5,821,900 | 73,433 | 49,266 | 6,078,863 | |
| 164,107 | 166 | 1206 | 29,952,490 | 55,401 | 463,736 | 30,637,106 | |
| 173,785 | 127 | 1649 | 24,480,779 | 694,722 | 651,068 | 26,002,130 | |
| 133,349 | 127 | 1273 | 23,848,456 | 84,014 | 46,749 | 24,113,968 | |
| 10,000 Data Sets | Step 1 | Step 2 | Step 3 | Step 4 | Step 5 | Step 6 | Total |
| 125,162 | 133 | 8289 | 6,247,375 | 1,774,413 | 494,387 | 8,649,759 | |
| 145,730 | 142 | 1442 | 8,940,382 | 1,793,918 | 563,101 | 11,444,715 | |
| 257,793 | 75 | 995 | 11,585,182 | 559,855 | 111,507 | 12,515,407 | |
| 265,262 | 190 | 1277 | 44,882,444 | 1,374,816 | 464,295 | 46,988,284 | |
| 127,091 | 125 | 1615 | 54,313,736 | 11,374,301 | 521,144 | 66,338,012 | |
| 94,438 | 75 | 847 | 84,234,220 | 349,861 | 197,854 | 84,877,295 | |
| 87,629 | 64 | 1238 | 36,259,183 | 1,250,844 | 349,380 | 37,948,338 | |
| 157,812 | 117 | 2051 | 66,990,740 | 12,107,156 | 746,812 | 80,004,688 | |
| 204,534 | 129 | 1386 | 104,930,839 | 505,326 | 163,578 | 105,805,792 | |
| 15,000 Data Sets | Step 1 | Step 2 | Step 3 | Step 4 | Step 5 | Step 6 | Total |
| 109,365 | 50 | 6263 | 6,367,932 | 805,445 | 683,549 | 7,972,604 | |
| 130,563 | 385 | 979 | 13,668,545 | 875,351 | 690,821 | 15,366,644 | |
| 224,922 | 139 | 1026 | 16,693,411 | 1,097,360 | 122,420 | 18,139,278 | |
| 294,392 | 153 | 1091 | 51,177,294 | 2,852,516 | 523,599 | 54,849,045 | |
| 170,759 | 193 | 1750 | 72,817,934 | 20,378,100 | 673,203 | 94,041,939 | |
| 103,225 | 72 | 661 | 128,535,201 | 689,922 | 213,775 | 129,542,856 | |
| 71,493 | 93 | 1719 | 67,185,486 | 3,118,435 | 457,630 | 70,834,856 | |
| 190,613 | 139 | 2486 | 90,892,440 | 23,580,870 | 771,655 | 115,438,203 | |
| 161,401 | 198 | 1787 | 128,640,058 | 1,163,036 | 242,773 | 130,209,253 |
| Step 1 | Step 2 | Step 3 | Step 4 | Step 5 | Step 6 | Total | |
| 49,954 | 105 | 3789 | 1,067,387 | 89,904 | 419,777 | 1,630,916 | |
| 59,981 | 71 | 1324 | 757,514 | 96,846 | 382,959 | 1,298,695 | |
| 98,722 | 100 | 1034 | 677,758 | 86,452 | 19,197 | 883,263 | |
| 92,101 | 114 | 777 | 3,840,793 | 45,144 | 381,507 | 4,360,436 | |
| 114,270 | 76 | 1353 | 5,143,232 | 473,317 | 401,541 | 6,133,789 | |
| 95,432 | 87 | 709 | 4,405,712 | 41,550 | 33,902 | 4,577,392 | |
| 117,618 | 116 | 866 | 22,666,491 | 31,347 | 319,117 | 23,135,555 | |
| 124,554 | 89 | 1184 | 18,525,784 | 393,088 | 448,029 | 19,492,728 | |
| 95,573 | 89 | 914 | 18,047,275 | 47,537 | 32,170 | 18,223,558 | |
| Step 1 | Step 2 | Step 3 | Step 4 | Step 5 | Step 6 | Total | |
| 12,170 | 64 | 819 | 182,765 | 15,345 | 341,675 | 552,838 | |
| 12,144 | 60 | 225 | 172,772 | 16,442 | 344,312 | 545,955 | |
| 22,020 | 86 | 205 | 123,625 | 15,536 | 16,169 | 177,641 | |
| 19,871 | 83 | 141 | 890,814 | 10,057 | 305,142 | 1,226,108 | |
| 22,414 | 49 | 261 | 1,110,737 | 83,602 | 337,270 | 1,554,333 | |
| 16,904 | 65 | 127 | 941,497 | 9991 | 28,069 | 996,653 | |
| 20,189 | 89 | 148 | 4,631,174 | 6872 | 304,278 | 4,962,750 | |
| 23,781 | 59 | 289 | 4,561,780 | 81,840 | 378,912 | 5,046,661 | |
| 22,619 | 71 | 156 | 4,445,672 | 11,872 | 27,817 | 4,508,207 | |
| Step 1 | Step 2 | Step 3 | Step 4 | Step 5 | Step 6 | Total | |
| 6211 | 77 | 856 | 97,479 | 9511 | 188,150 | 302,284 | |
| 6156 | 62 | 247 | 78,478 | 9512 | 204,319 | 298,774 | |
| 11,540 | 102 | 207 | 64,805 | 10,804 | 7431 | 94,889 | |
| 11,196 | 84 | 147 | 487,033 | 3423 | 101,937 | 603,820 | |
| 11,051 | 56 | 285 | 460,746 | 42,592 | 101,783 | 616,513 | |
| 8784 | 67 | 127 | 388,326 | 5643 | 14,703 | 417,650 | |
| 11,148 | 99 | 152 | 2,076,886 | 4416 | 152,356 | 2,245,057 | |
| 10,979 | 66 | 305 | 1,923,165 | 51,733 | 156,590 | 2,142,838 | |
| 12,386 | 75 | 157 | 2,219,314 | 3836 | 13,466 | 2,249,234 |
| Step 1 | Step 2 | Step 3 | Step 4 | Step 5 | Step 6 | Total | |
| 96,230 | 85 | 5275 | 3,664,468 | 1,322,651 | 350,531 | 5,439,240 | |
| 112,044 | 91 | 918 | 5,244,081 | 1,337,190 | 399,251 | 7,093,575 | |
| 198,203 | 48 | 633 | 6,795,418 | 417,317 | 79,061 | 7,490,680 | |
| 203,945 | 122 | 813 | 26,326,300 | 1,024,791 | 329,195 | 27,885,166 | |
| 97,713 | 80 | 1028 | 31,858,330 | 8,478,428 | 369,502 | 40,805,081 | |
| 72,608 | 48 | 539 | 49,408,525 | 260,787 | 140,283 | 49,882,790 | |
| 67,373 | 41 | 788 | 21,268,230 | 932,382 | 247,718 | 22,516,532 | |
| 121,333 | 75 | 1305 | 39,294,169 | 9,024,700 | 529,506 | 48,971,088 | |
| 157,255 | 83 | 882 | 61,548,359 | 376,671 | 115,980 | 62,199,230 | |
| Step 1 | Step 2 | Step 3 | Step 4 | Step 5 | Step 6 | Total | |
| 18,623 | 56 | 1002 | 901,137 | 280,039 | 344,775 | 1,545,632 | |
| 19,998 | 68 | 199 | 968,779 | 291,047 | 356,721 | 1,636,812 | |
| 39,058 | 46 | 158 | 1,330,173 | 93,359 | 63,953 | 1,526,747 | |
| 41,487 | 83 | 173 | 4,392,227 | 183,535 | 307,911 | 4,925,416 | |
| 19,370 | 62 | 231 | 6,228,201 | 1,479,875 | 349,425 | 8,077,164 | |
| 16,938 | 29 | 98 | 10,130,264 | 60,038 | 111,021 | 10,318,388 | |
| 13,047 | 41 | 189 | 4,684,841 | 191,352 | 214,286 | 5,103,756 | |
| 25,700 | 61 | 296 | 7,254,463 | 1,704,038 | 411,768 | 9,396,326 | |
| 27,347 | 75 | 203 | 11,092,073 | 82,351 | 110,652 | 11,312,701 | |
| Step 1 | Step 2 | Step 3 | Step 4 | Step 5 | Step 6 | Total | |
| 9452 | 63 | 1050 | 446,641 | 129,776 | 174,026 | 761,008 | |
| 9011 | 79 | 219 | 529,375 | 117,673 | 188,706 | 845,063 | |
| 18,057 | 49 | 163 | 759,816 | 47,116 | 21,842 | 847,043 | |
| 20,138 | 84 | 180 | 2,159,509 | 70,524 | 176,915 | 2,427,350 | |
| 9906 | 72 | 249 | 2,701,601 | 880,321 | 175,523 | 3,767,672 | |
| 9404 | 30 | 104 | 4,610,965 | 31,309 | 56,121 | 4,707,933 | |
| 5712 | 46 | 190 | 2,661,610 | 71,846 | 105,054 | 2,844,458 | |
| 13,173 | 66 | 324 | 4,132,891 | 771,158 | 245,783 | 5,163,395 | |
| 11,117 | 88 | 208 | 6,224,426 | 30,077 | 66,208 | 6,332,124 |
| Step 1 | Step 2 | Step 3 | Step 4 | Step 5 | Step 6 | Total | |
| 79,009 | 29 | 4408 | 4,775,258 | 606,463 | 423,296 | 5,888,463 | |
| 94,323 | 224 | 689 | 10,249,925 | 659,099 | 427,799 | 11,432,059 | |
| 162,491 | 81 | 722 | 12,518,246 | 826,261 | 75,810 | 13,583,611 | |
| 212,678 | 89 | 768 | 38,377,416 | 2,147,812 | 324,245 | 41,063,008 | |
| 123,362 | 112 | 1232 | 54,605,547 | 15,343,763 | 416,889 | 70,490,905 | |
| 74,573 | 42 | 465 | 96,387,450 | 519,479 | 132,383 | 97,114,392 | |
| 51,649 | 54 | 1210 | 50,381,822 | 2,348,037 | 283,393 | 53,066,165 | |
| 137,705 | 81 | 1750 | 68,159,465 | 17,755,300 | 477,857 | 86,532,158 | |
| 116,601 | 115 | 1258 | 96,466,081 | 875,712 | 150,340 | 97,610,107 | |
| Step 1 | Step 2 | Step 3 | Step 4 | Step 5 | Step 6 | Total | |
| 18,639 | 25 | 809 | 942,283 | 130,175 | 357,763 | 1,449,694 | |
| 15,782 | 154 | 168 | 2,072,424 | 145,164 | 347,329 | 2,581,021 | |
| 37,310 | 49 | 176 | 2,703,332 | 195,522 | 63,648 | 3,000,037 | |
| 41,833 | 80 | 188 | 9,397,267 | 390,018 | 299,062 | 10,128,448 | |
| 21,482 | 68 | 264 | 12,910,417 | 2,916,485 | 363,245 | 16,211,961 | |
| 17,548 | 31 | 108 | 20,408,651 | 125,260 | 109,565 | 20,661,163 | |
| 12,658 | 46 | 204 | 92,838,15 | 393,117 | 224,765 | 9,914,605 | |
| 27,944 | 68 | 321 | 14,424,530 | 3,400,795 | 398,221 | 18,251,879 | |
| 26,909 | 86 | 217 | 22,155,578 | 171,715 | 115,647 | 22,470,152 | |
| Step 1 | Step 2 | Step 3 | Step 4 | Step 5 | Step 6 | Total | |
| 9762 | 26 | 879 | 444,505 | 50,496 | 148,585 | 654,253 | |
| 7341 | 182 | 175 | 1,058,477 | 72,370 | 203,713 | 1,342,258 | |
| 16,910 | 58 | 193 | 1,492,059 | 86,309 | 37,498 | 1,633,027 | |
| 19,457 | 95 | 188 | 4,627,830 | 254,045 | 146,739 | 5,048,354 | |
| 9366 | 80 | 274 | 5,935,994 | 919,258 | 166,406 | 7,031,378 | |
| 8061 | 36 | 111 | 8,743,991 | 56,670 | 50,373 | 8,859,242 | |
| 6615 | 54 | 221 | 4,272,484 | 246,609 | 105,990 | 4,631,973 | |
| 11,850 | 80 | 348 | 7,256,341 | 1,255,804 | 135,068 | 8,659,491 | |
| 11,609 | 93 | 219 | 9,869,213 | 73,973 | 45,676 | 10,000,783 |
| 1000 Data Sets | Step 1 | Step 2 | Step 3 | Step 4 | Step 5 | Step 6 | Total |
| 17,231 | 56 | 307 | 34,855 | 9297 | 187,456 | 249,202 | |
| 17,545 | 41 | 98 | 45,909 | 10,955 | 216,205 | 290,753 | |
| 32,890 | 67 | 82 | 21,395 | 12,443 | 7863 | 74,740 | |
| 31,910 | 55 | 58 | 160,793 | 3942 | 107,867 | 304,625 | |
| 31,496 | 37 | 113 | 162,115 | 49,055 | 107,704 | 350,520 | |
| 25,035 | 44 | 50 | 128,205 | 6499 | 15,558 | 175,391 | |
| 31,773 | 65 | 60 | 685,682 | 5086 | 161,219 | 883,885 | |
| 31,291 | 44 | 121 | 694,931 | 59,583 | 165,700 | 951,670 | |
| 35,301 | 50 | 62 | 532,704 | 4418 | 14,249 | 586,784 | |
| 10,000 Data Sets | Step 1 | Step 2 | Step 3 | Step 4 | Step 5 | Step 6 | Total |
| 9303 | 68 | 1062 | 45,887 | 125,741 | 175,371 | 357,432 | |
| 8869 | 85 | 221 | 60,440 | 114,015 | 190,165 | 373,795 | |
| 17,773 | 53 | 165 | 28,167 | 45,651 | 22,011 | 113,820 | |
| 19,821 | 90 | 182 | 211,685 | 68,331 | 178,282 | 478,391 | |
| 9750 | 77 | 252 | 213,426 | 852,953 | 176,880 | 1,253,338 | |
| 9256 | 32 | 105 | 168,783 | 30,336 | 56,555 | 265,067 | |
| 5622 | 49 | 192 | 902,706 | 69,612 | 105,866 | 1,084,047 | |
| 12,966 | 71 | 328 | 914,883 | 747,183 | 247,683 | 1,923,114 | |
| 10,942 | 94 | 210 | 662,619 | 29,142 | 66,720 | 769,727 | |
| 15,000 Data Sets | Step 1 | Step 2 | Step 3 | Step 4 | Step 5 | Step 6 | Total |
| 10,199 | 25 | 923 | 48,677 | 49,986 | 156,749 | 266,559 | |
| 7670 | 172 | 184 | 64,115 | 71,638 | 214,906 | 358,685 | |
| 17,667 | 55 | 203 | 29,880 | 85,437 | 39,558 | 172,800 | |
| 20,328 | 90 | 197 | 224,558 | 251,477 | 154,802 | 651,452 | |
| 9785 | 76 | 288 | 226,405 | 909,965 | 175,549 | 1,322,068 | |
| 8422 | 34 | 117 | 179,047 | 56,097 | 53,141 | 296,858 | |
| 6911 | 51 | 232 | 957,602 | 244,116 | 111,814 | 1,320,726 | |
| 12,380 | 76 | 366 | 970,519 | 1,243,109 | 142,489 | 2,368,939 | |
| 12,129 | 88 | 230 | 594,276 | 73,225 | 48,186 | 728,134 |
| Configuration | max_neigh | 1000 Data Sets | 10,000 Data Sets | 15,000 Data Sets |
|---|---|---|---|---|
| 72.30% | 62.88% | 73.86% | ||
| 10 | 71.58% | 61.98% | 74.40% | |
| 72.66% | 59.85% | 74.89% | ||
| 74.67% | 59.34% | 74.87% | ||
| 100 | 73.21% | 61.51% | 74.96% | |
| 75.30% | 58.77% | 74.97% | ||
| 75.51% | 59.33% | 74.92% | ||
| 1000 | 74.97% | 61.21% | 74.96% | |
| 75.57% | 58.79% | 74.96% |
| max_neigh | 1000 Data Sets | 10,000 Data Sets | 15,000 Data Sets | |
| 33.90% | 28.42% | 24.62% | ||
| 10 | 42.04% | 23.07% | 22.58% | |
| 20.11% | 20.38% | 22.09% | ||
| 28.12% | 17.66% | 24.67% | ||
| 100 | 25.34% | 19.79% | 23.00% | |
| 21.77% | 20.69% | 21.28% | ||
| 21.45% | 22.67% | 18.68% | ||
| 1000 | 25.89% | 19.19% | 21.09% | |
| 24.74% | 18.19% | 23.02% | ||
| max_neigh | 1000 Data Sets | 10,000 Data Sets | 15,000 Data Sets | |
| 18.53% | 13.99% | 11.11% | ||
| 10 | 23.01% | 11.91% | 11.74% | |
| 10.74% | 11.31% | 12.02% | ||
| 13.85% | 8.70% | 12.29% | ||
| 1000 | 10.05% | 9.23% | 9.97% | |
| 9.12% | 9.44% | 9.12% | ||
| 9.70% | 12.63% | 8.73% | ||
| 1000 | 10.99% | 10.54% | 10.01% | |
| 12.34% | 10.18% | 10.25% |
| Configurations | max_neigh | 1000 Data Sets | 10,000 Data Sets | 15,000 Data Sets |
|---|---|---|---|---|
| 82.44% | 46.97% | 40.74% | ||
| 10 | 97.32% | 44.23% | 26.72% | |
| 78.77% | 13.44% | 10.58% | ||
| 50.45% | 19.71% | 12.90% | ||
| 100 | 56.86% | 33.27% | 18.80% | |
| 41.99% | 5.63% | 3.35% | ||
| 39.37% | 38.11% | 28.51% | ||
| 1000 | 44.41% | 37.25% | 27.36% | |
| 26.09% | 12.16% | 7.28% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pelucchi, M.; Psaila, G.; Toccu, M. Hadoop vs. Spark: Impact on Performance of the Hammer Query Engine for Open Data Corpora. Algorithms 2018, 11, 209. https://doi.org/10.3390/a11120209
Pelucchi M, Psaila G, Toccu M. Hadoop vs. Spark: Impact on Performance of the Hammer Query Engine for Open Data Corpora. Algorithms. 2018; 11(12):209. https://doi.org/10.3390/a11120209
Chicago/Turabian StylePelucchi, Mauro, Giuseppe Psaila, and Maurizio Toccu. 2018. "Hadoop vs. Spark: Impact on Performance of the Hammer Query Engine for Open Data Corpora" Algorithms 11, no. 12: 209. https://doi.org/10.3390/a11120209
APA StylePelucchi, M., Psaila, G., & Toccu, M. (2018). Hadoop vs. Spark: Impact on Performance of the Hammer Query Engine for Open Data Corpora. Algorithms, 11(12), 209. https://doi.org/10.3390/a11120209