Variable Selection in Time Series Forecasting Using Random Forests


Abstract
1. Introduction
1.1. Time Series Forecasting and Random Forests
1.2. A Framework to Assess the Performance of Random Forests in Time Series Forecasting
1.3. Aim of the Study
2. Methods and Data
2.1. Methods
2.1.1. Definition of ARMA and ARFIMA Models
2.1.2. Simulation of ARMA and ARFIMA Models
2.1.3. Forecasting Using ARMA and ARFIMA Models
2.1.4. Forecasting Using Naïve Methods
2.1.5. Forecasting Using the Theta Method
2.1.6. Random Forests
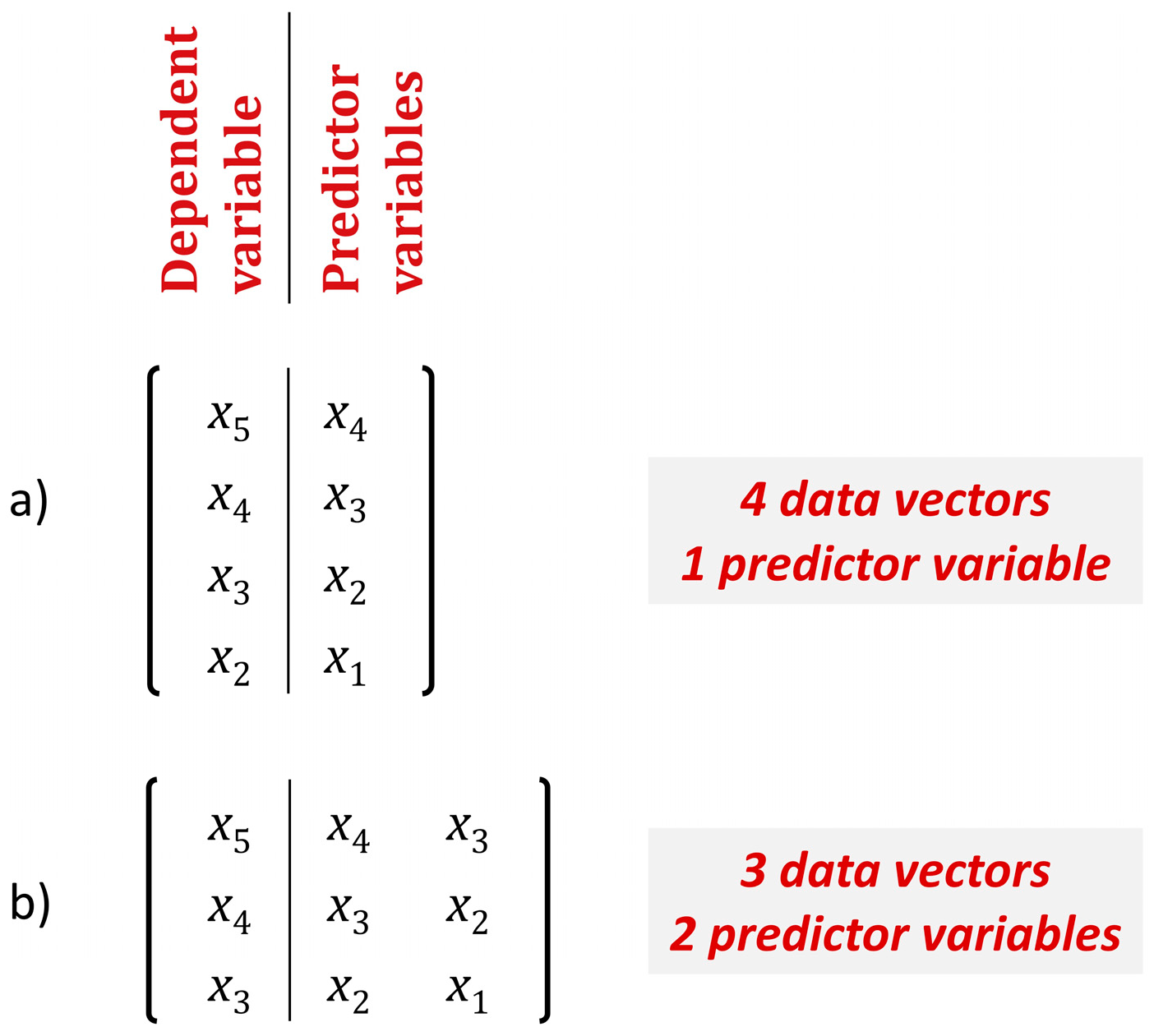
2.1.7. Time Series Forecasting Using Random Forests
2.1.8. Summary of the Methods
2.1.9. Metrics
2.2. Data
2.2.1. Simulated Time Series
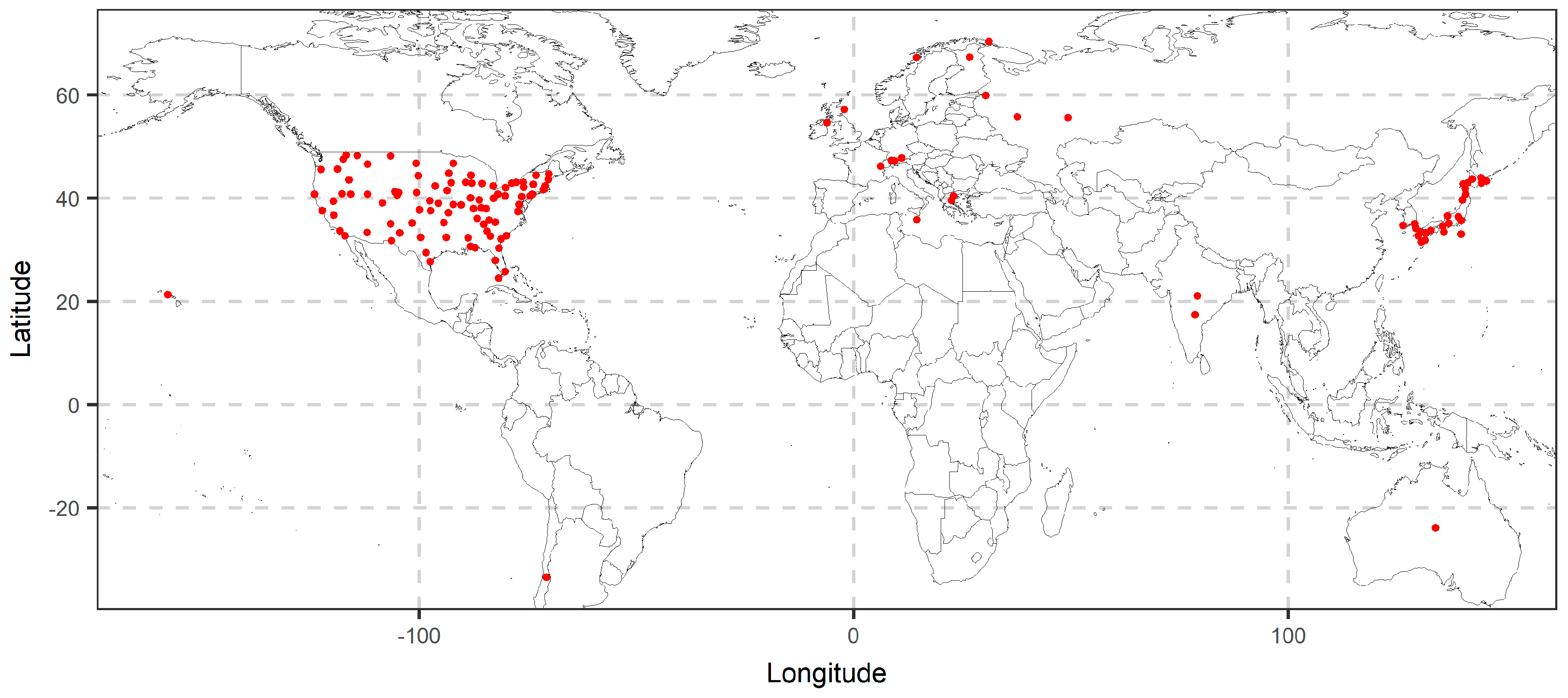
2.2.2. Temperature Dataset
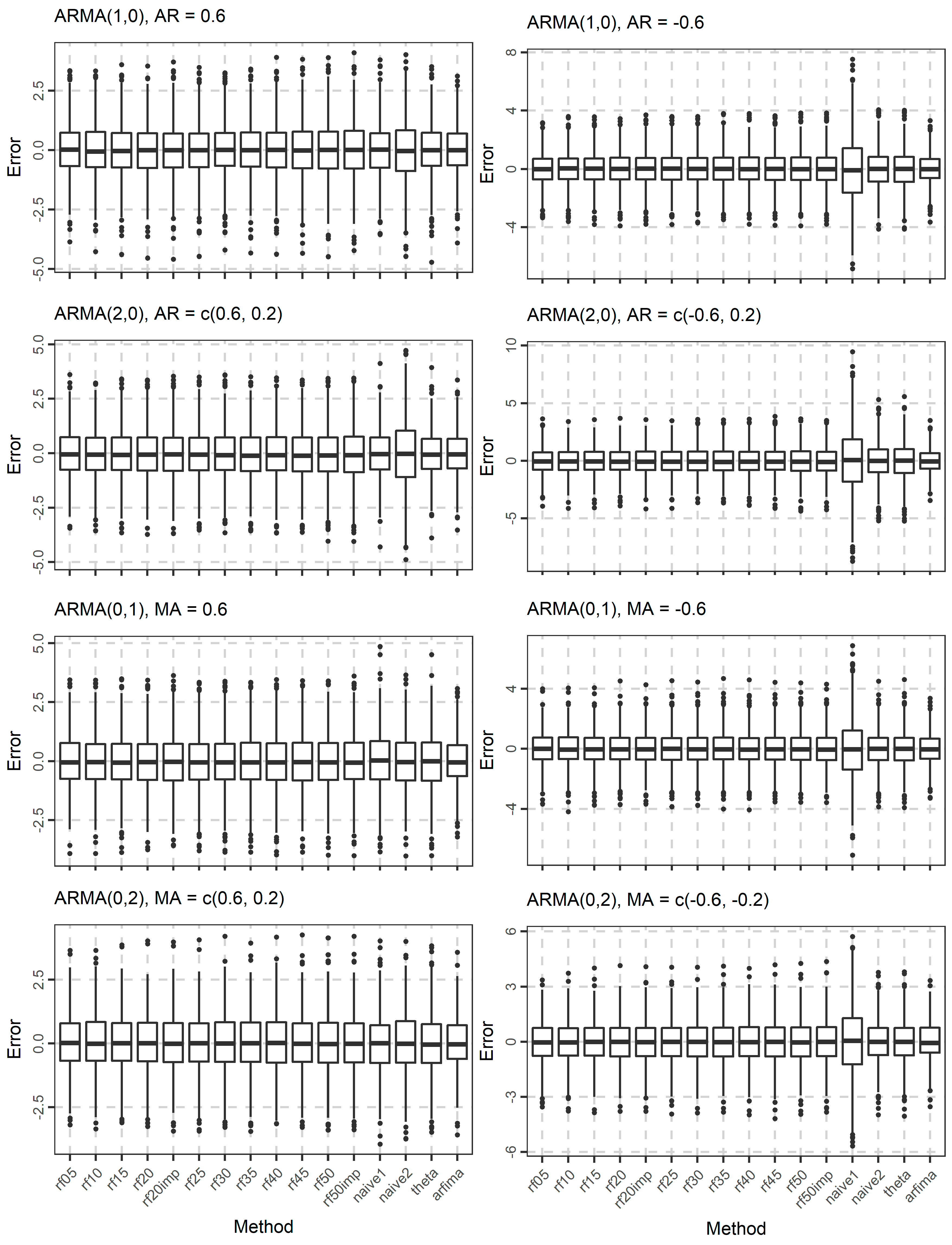
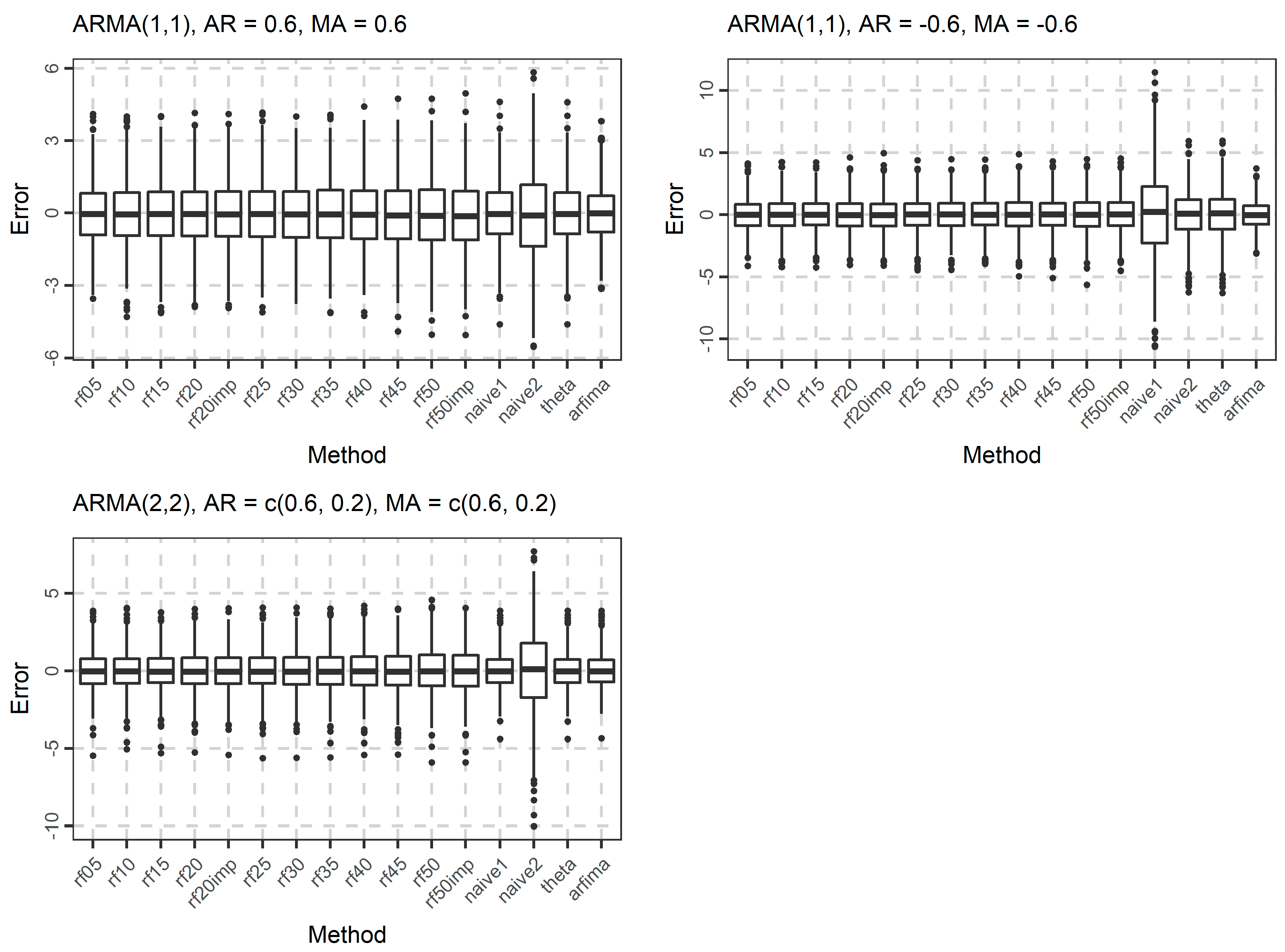
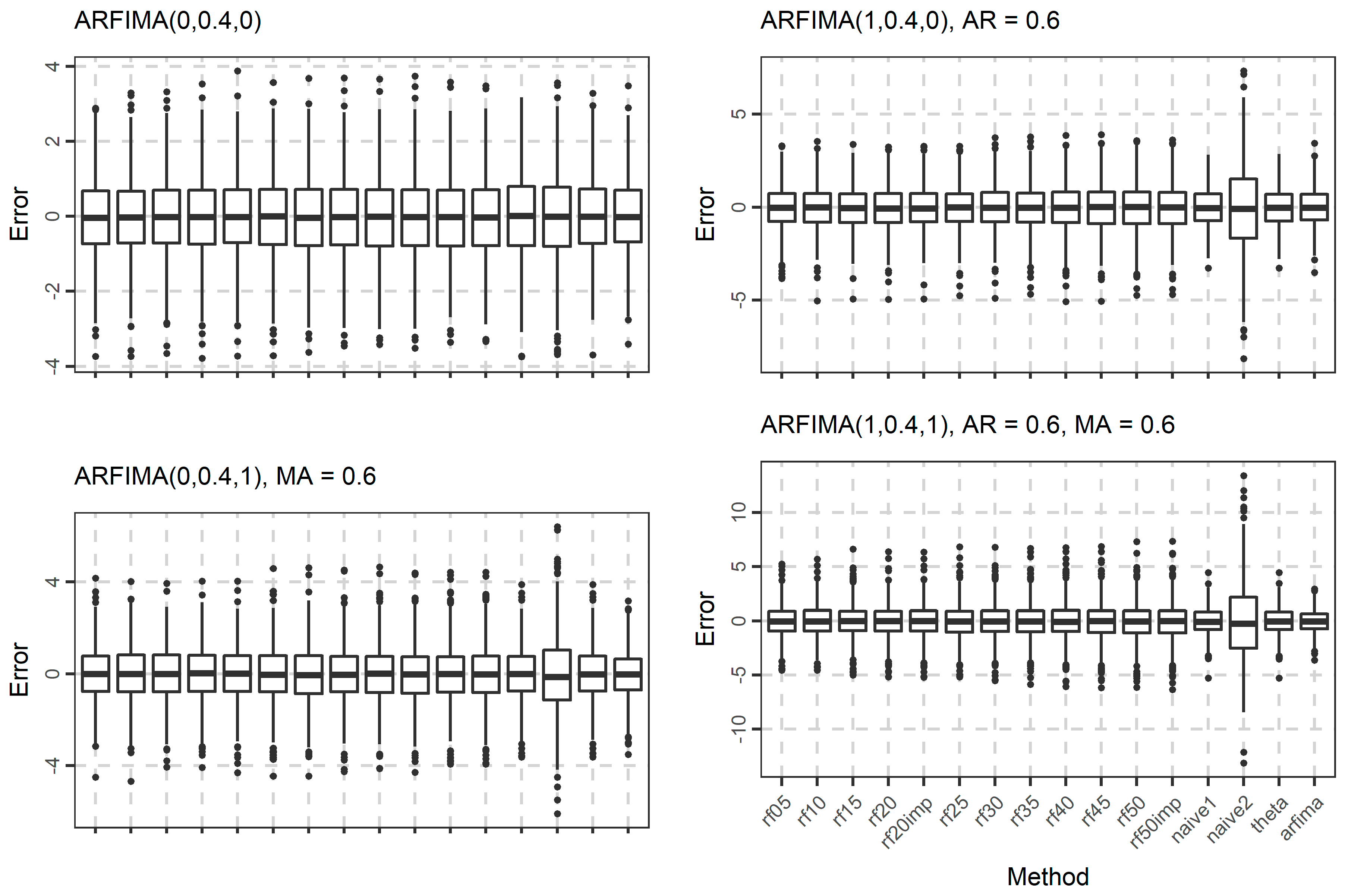
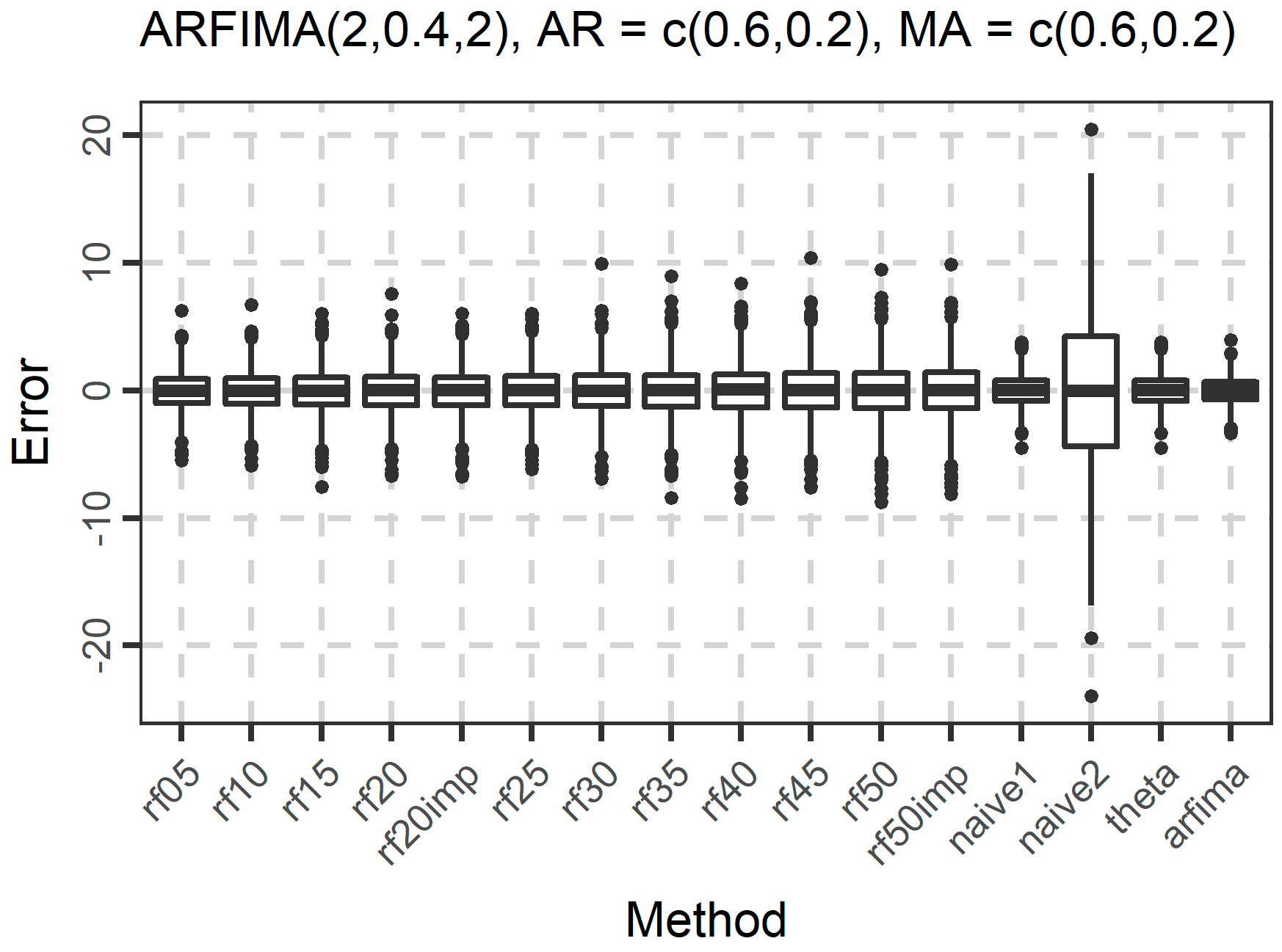
3. Results
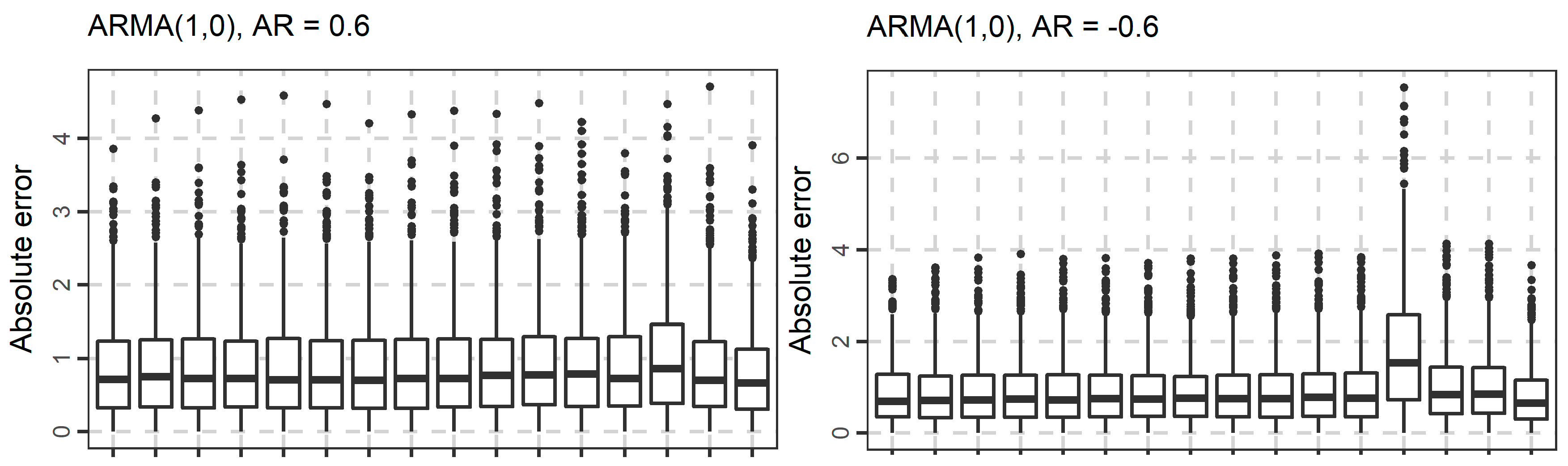
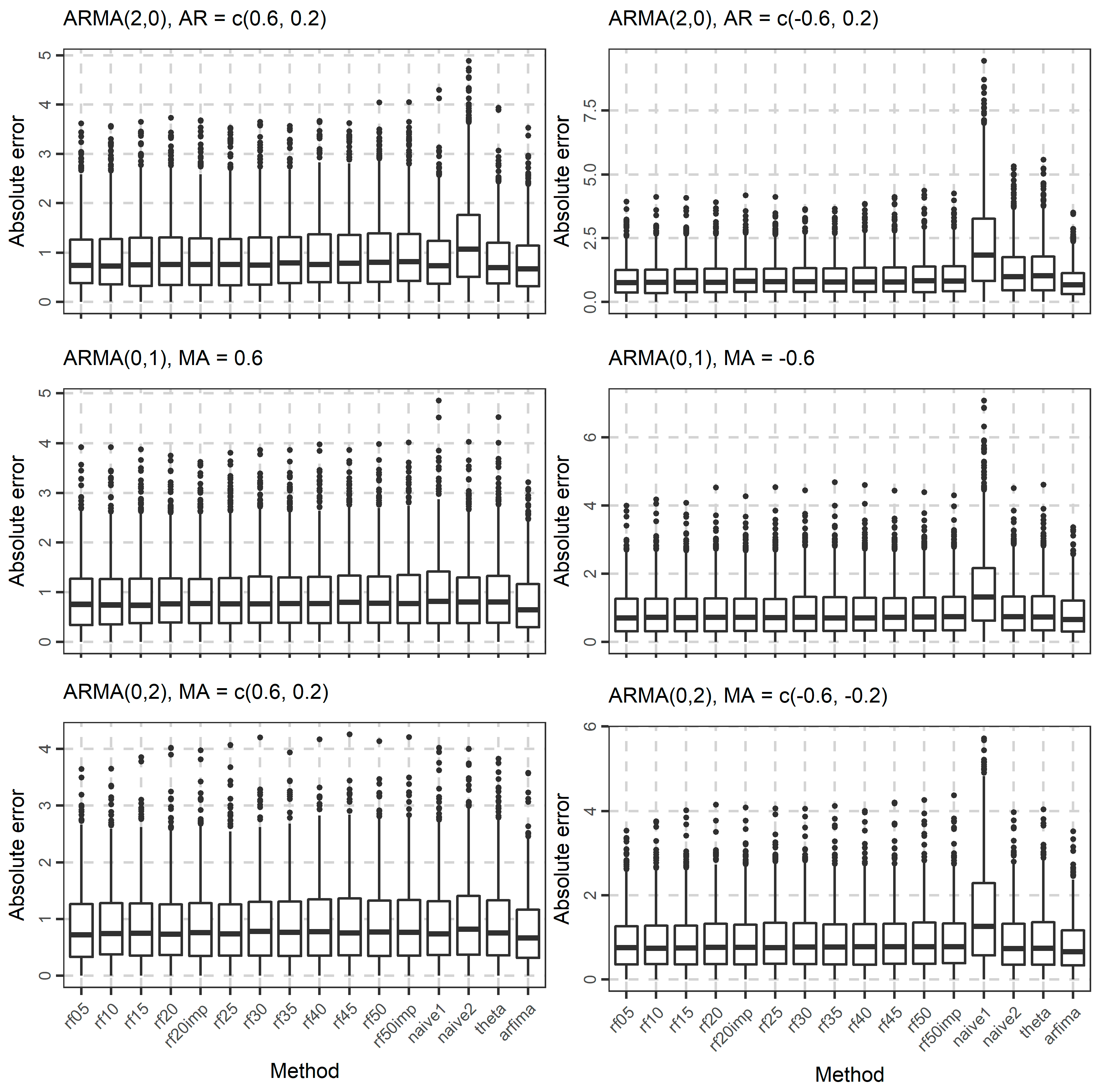
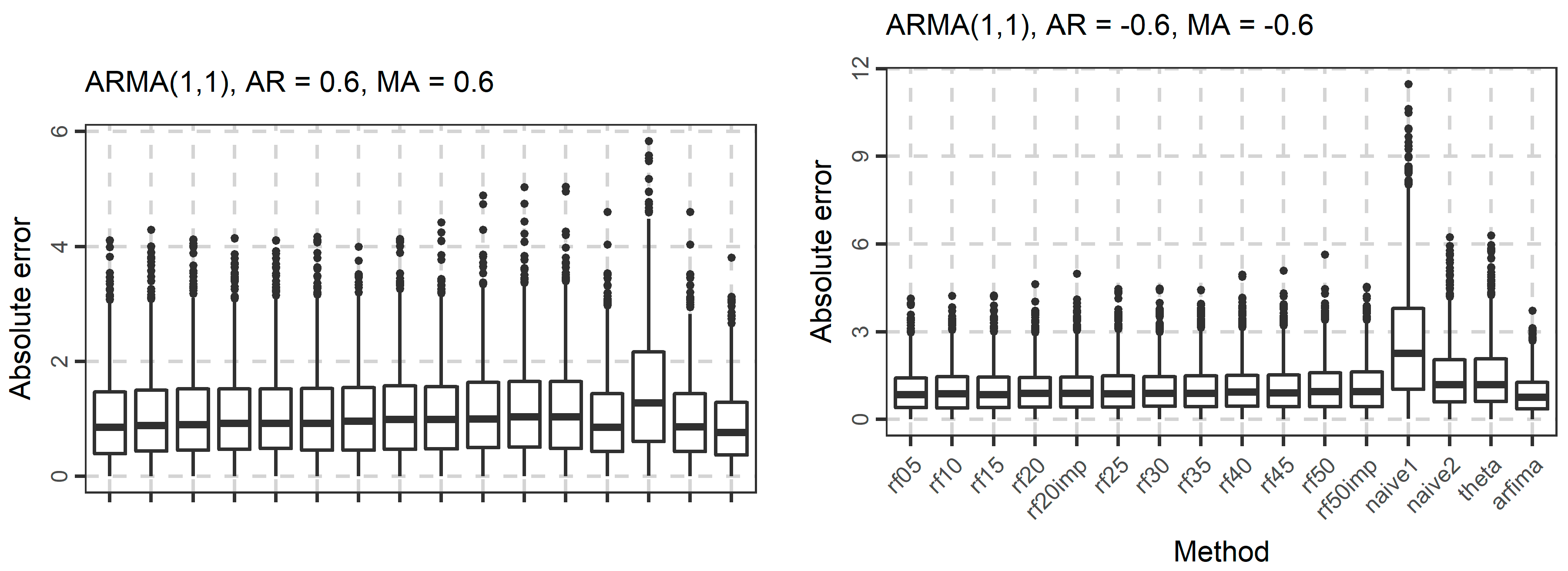
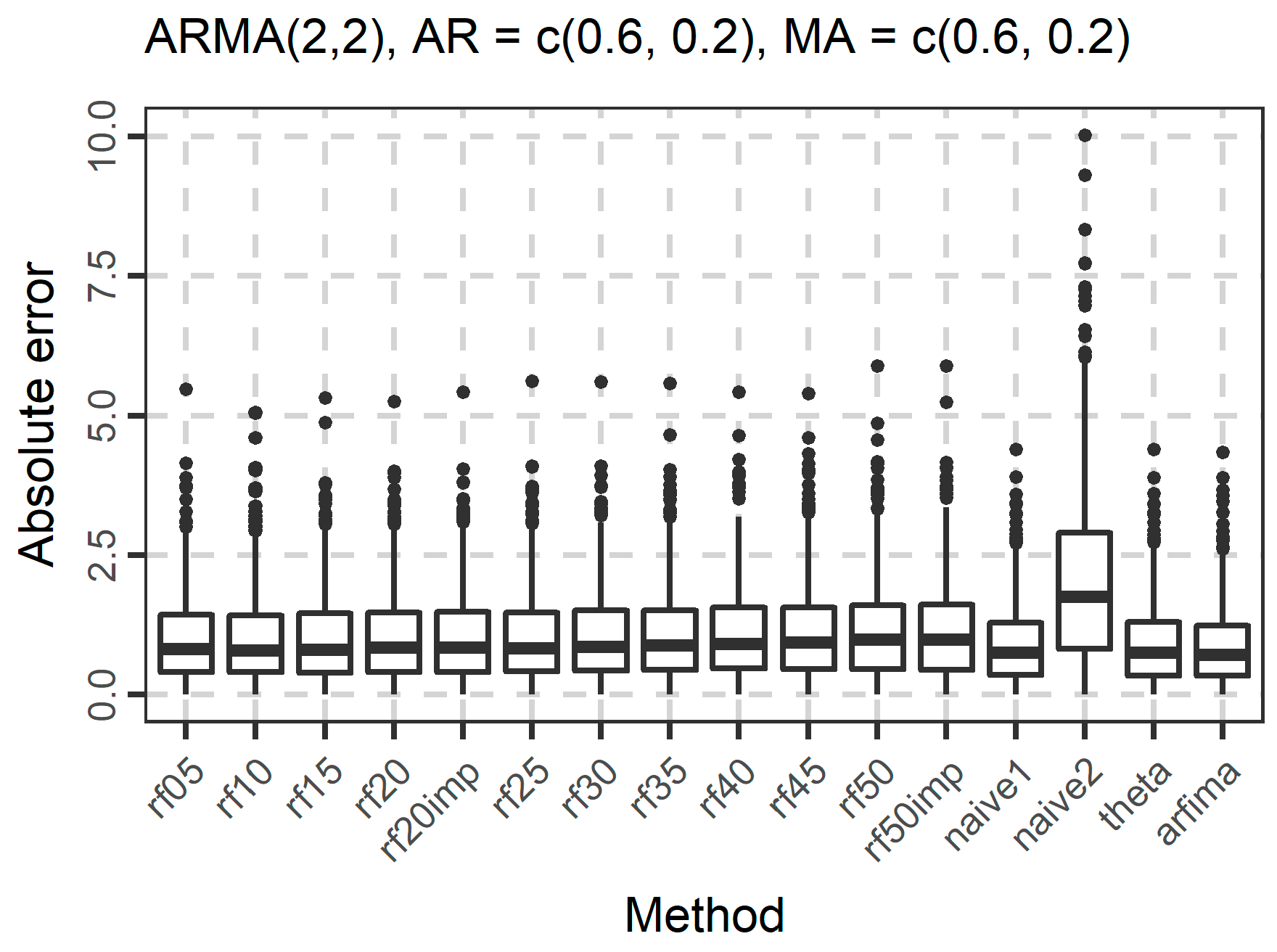
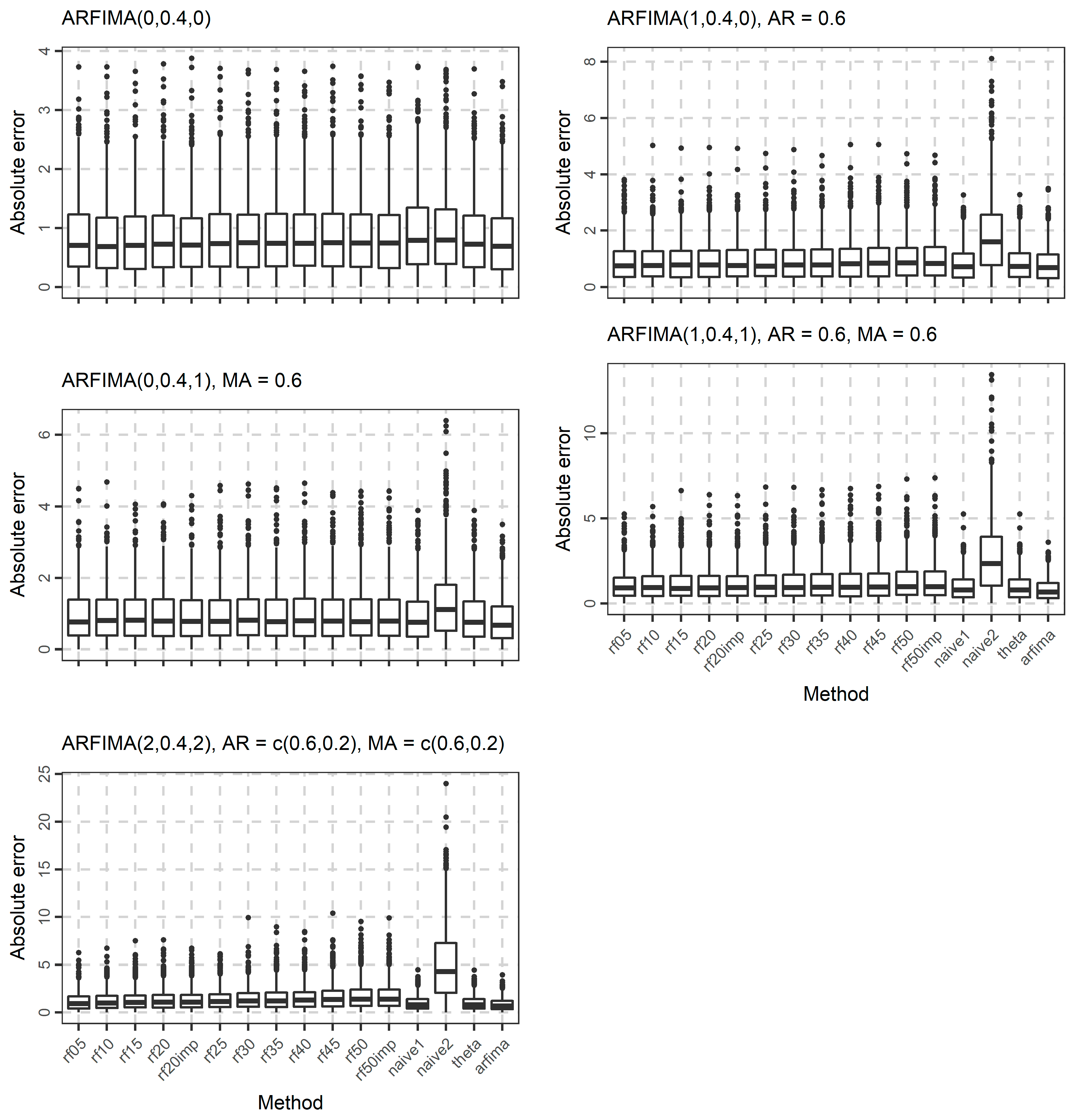
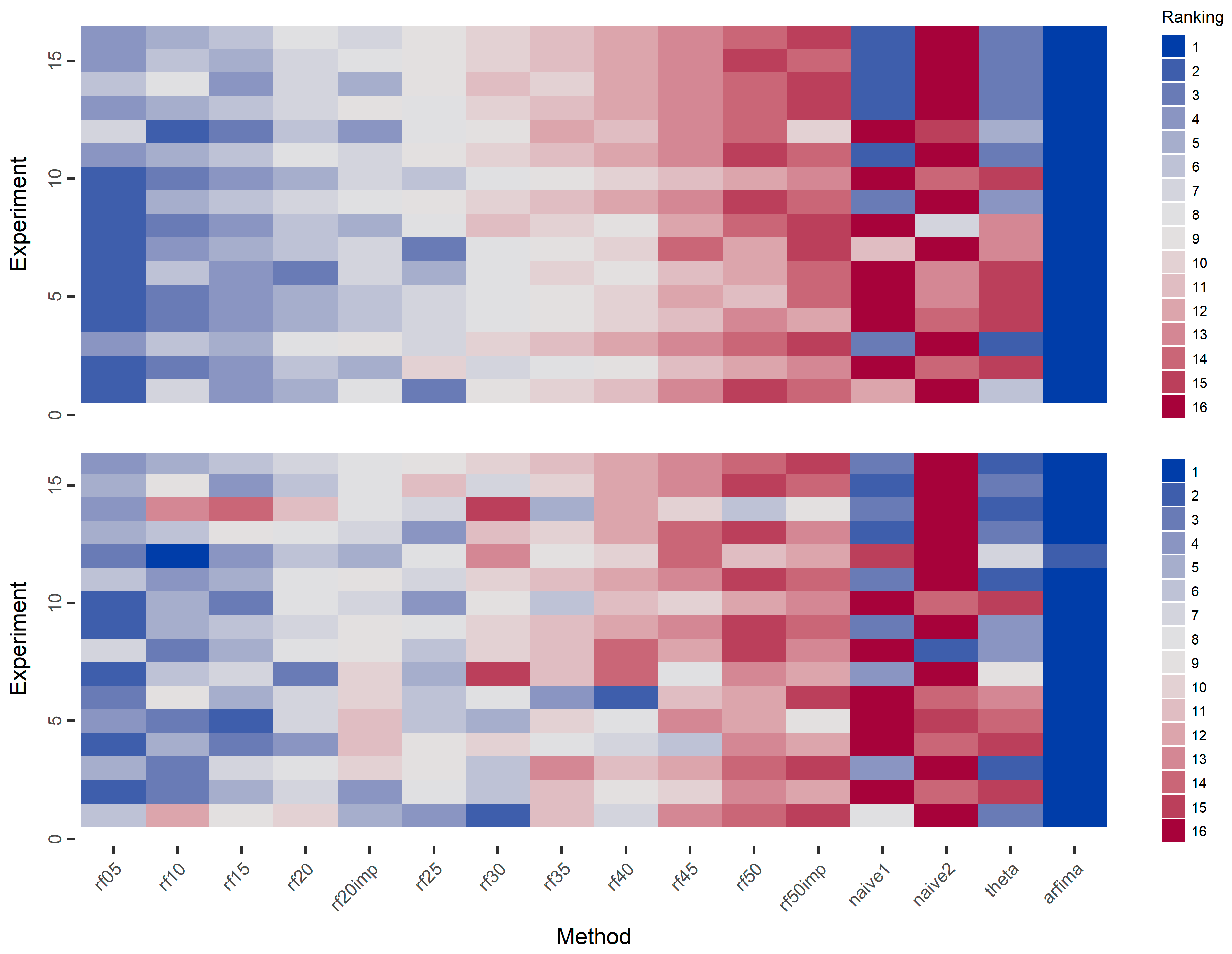
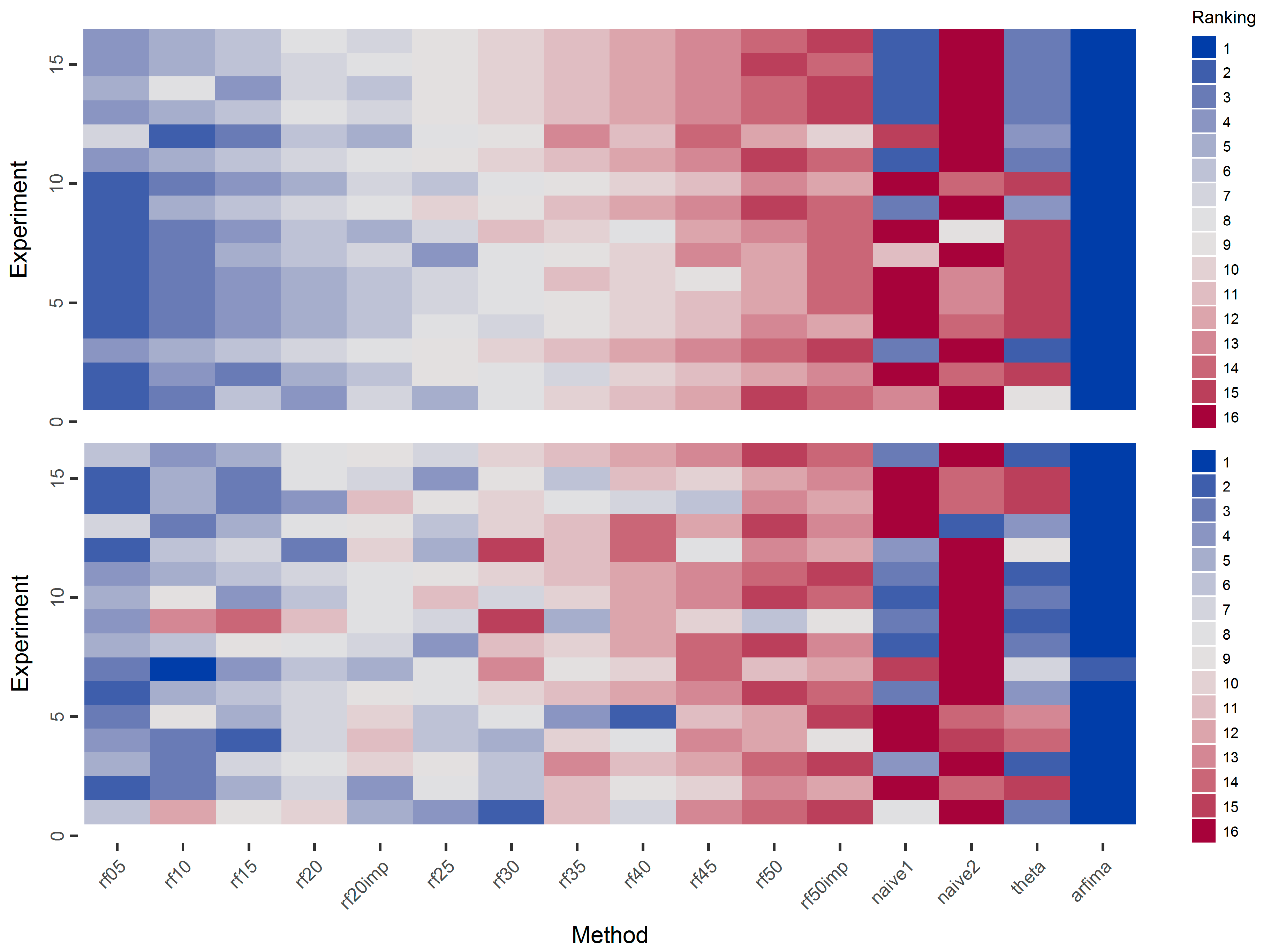
3.1. Simulations
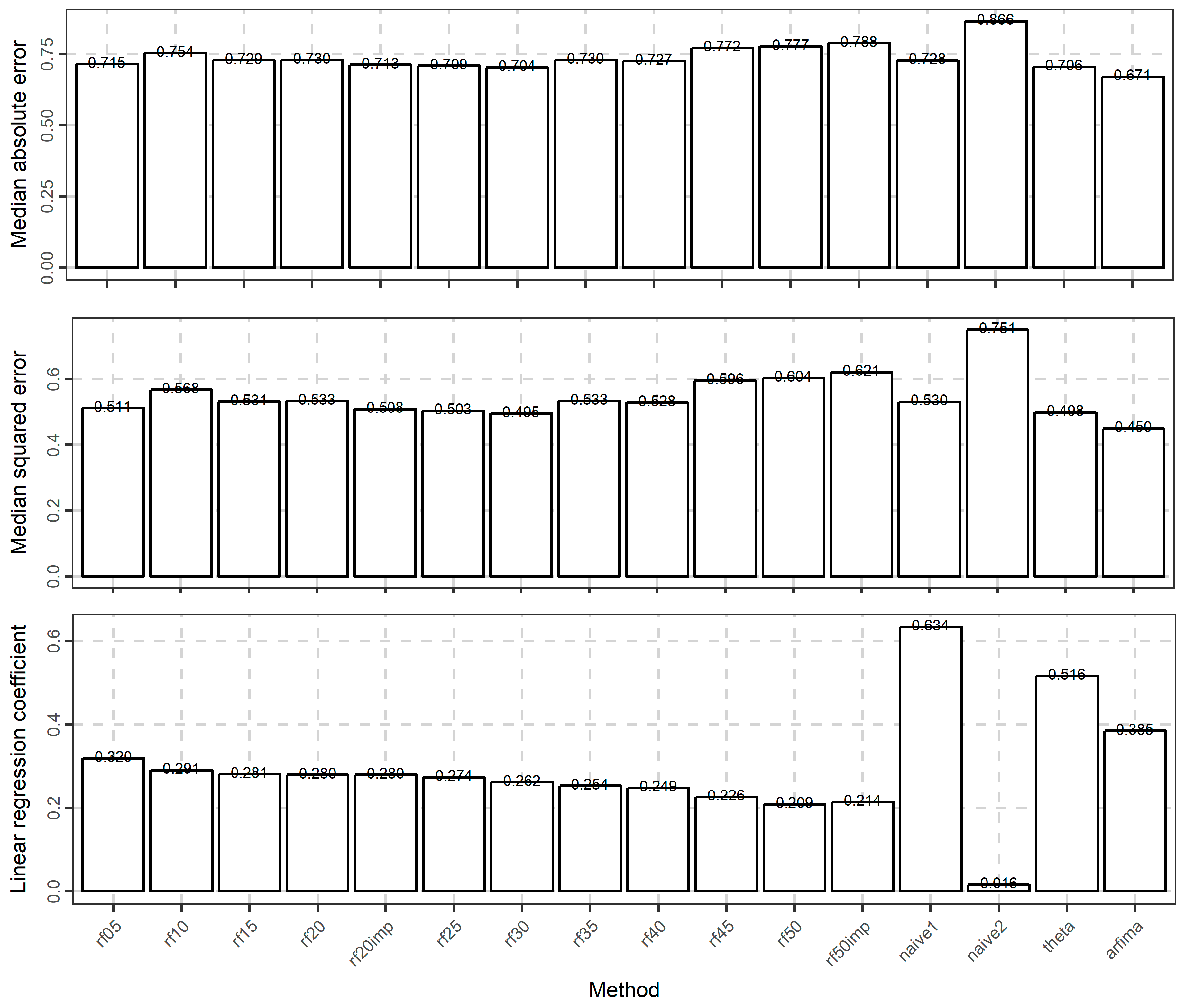
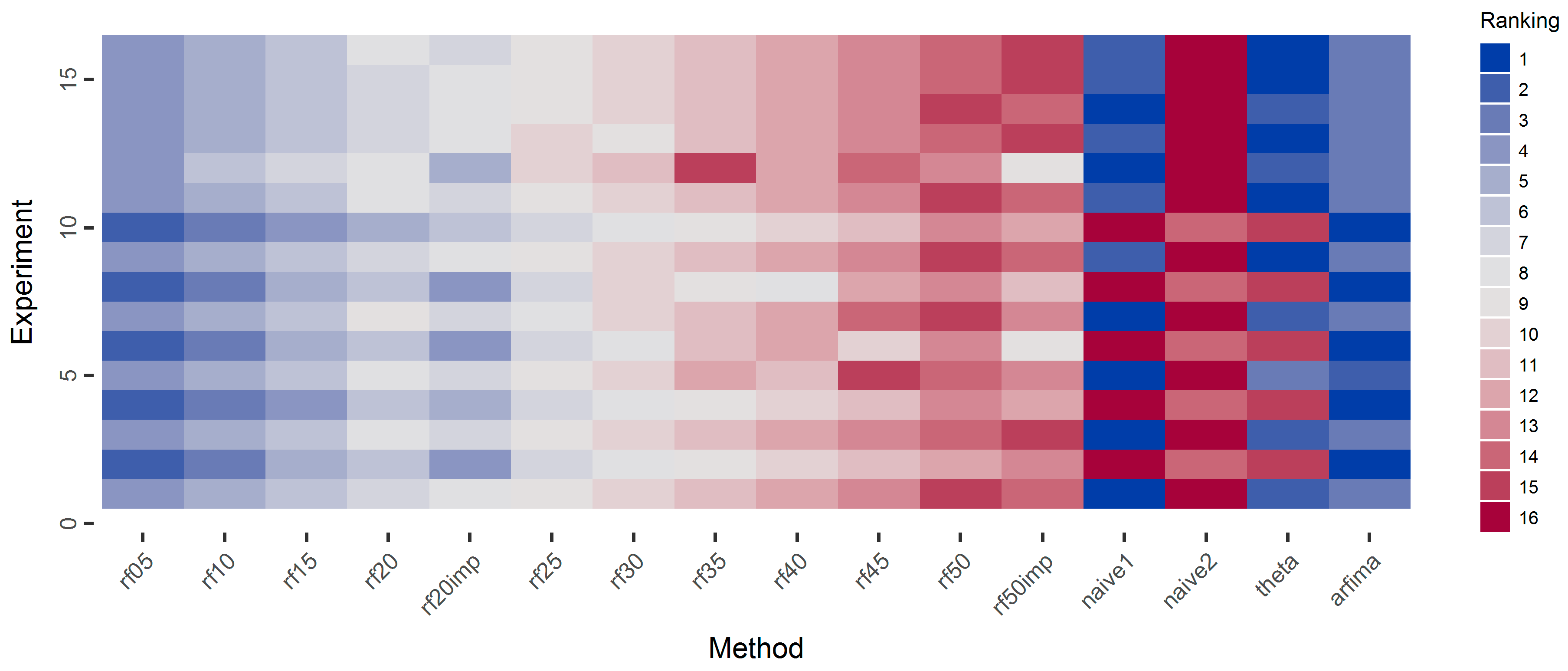
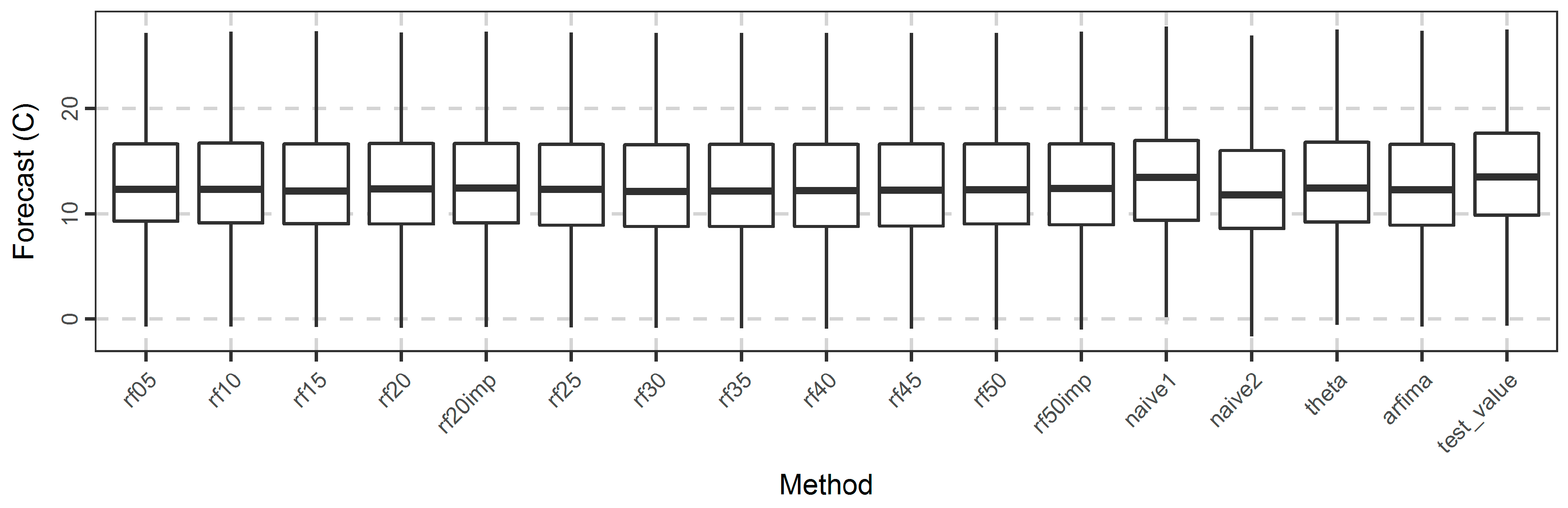
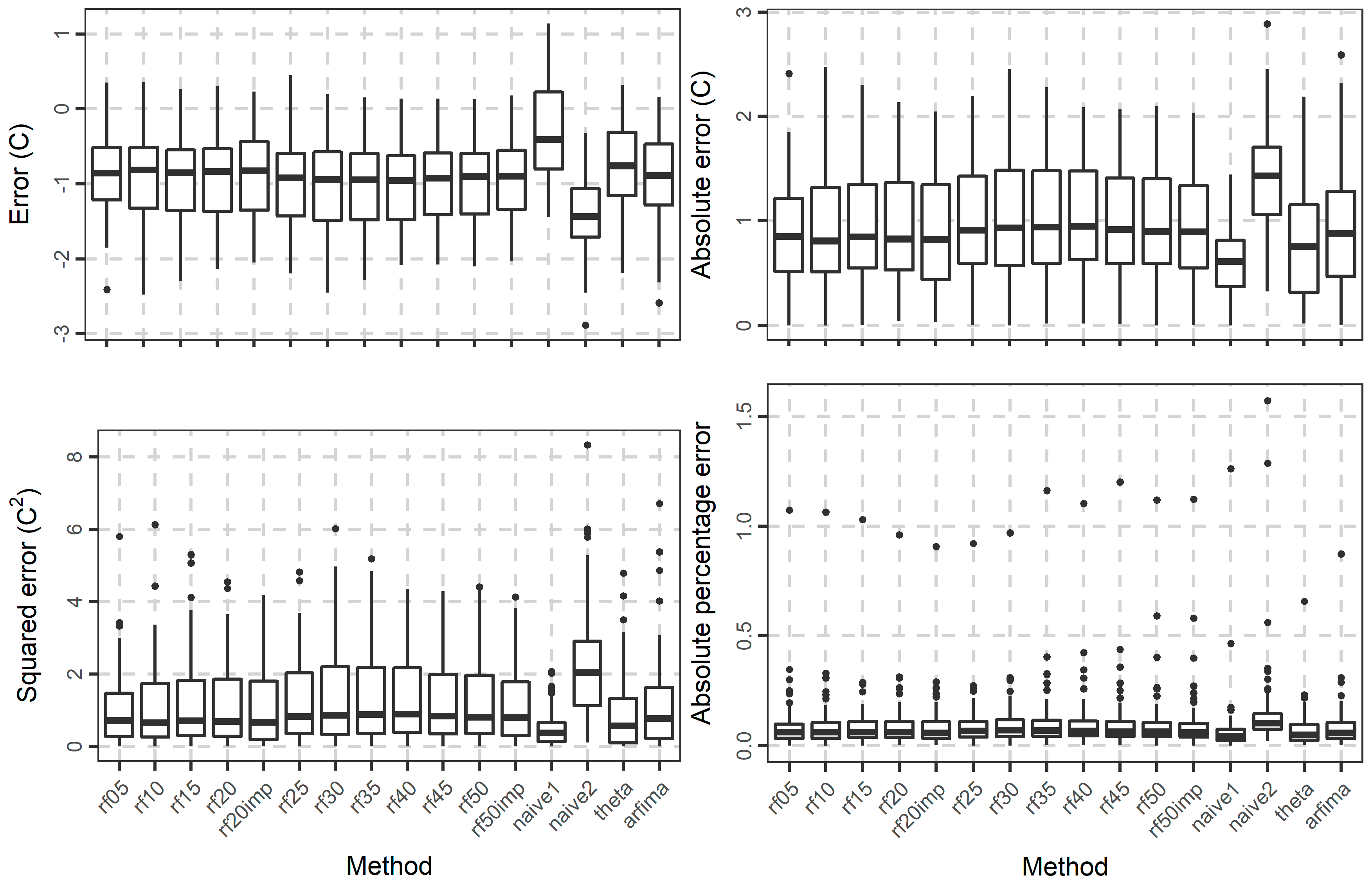
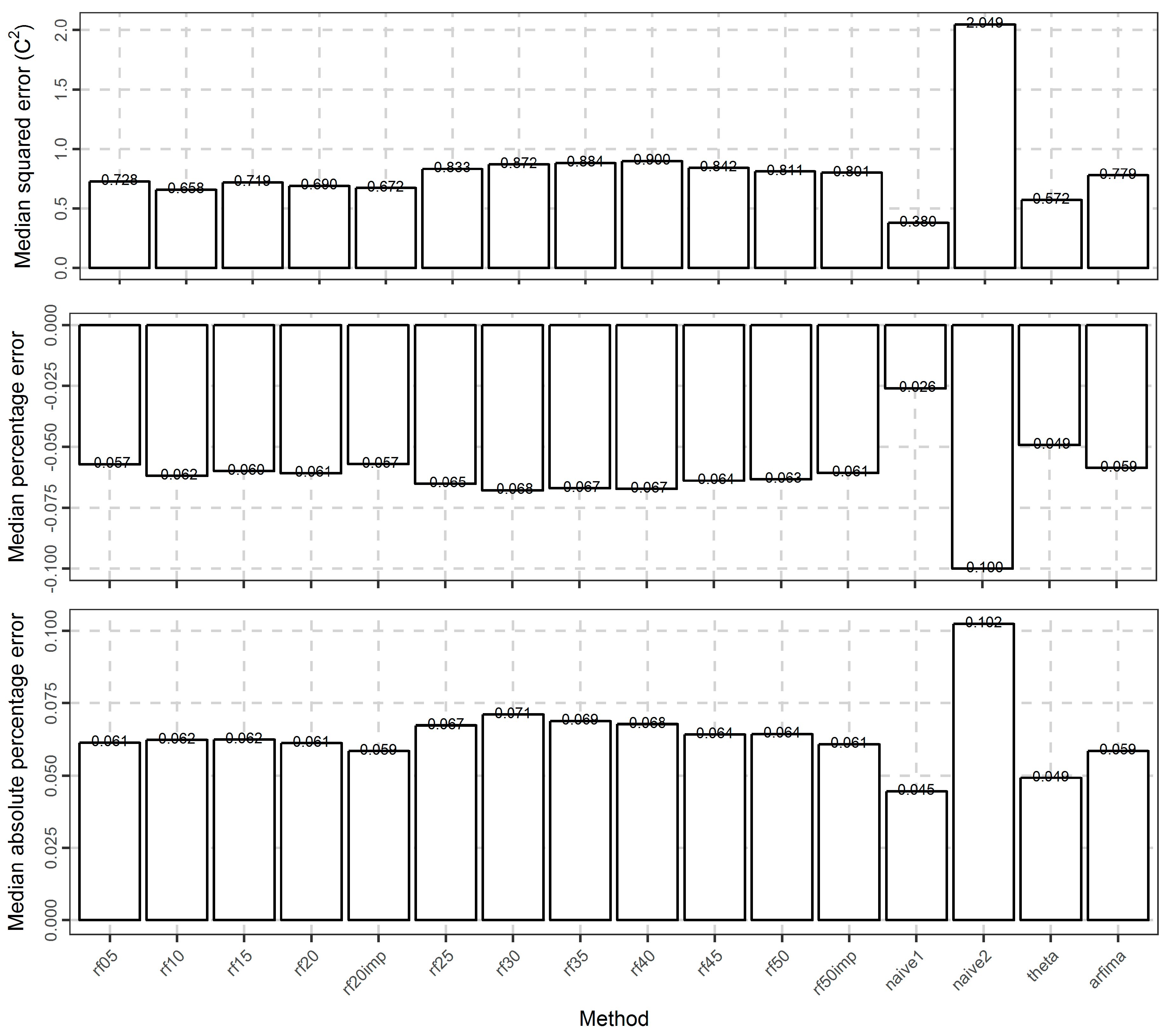
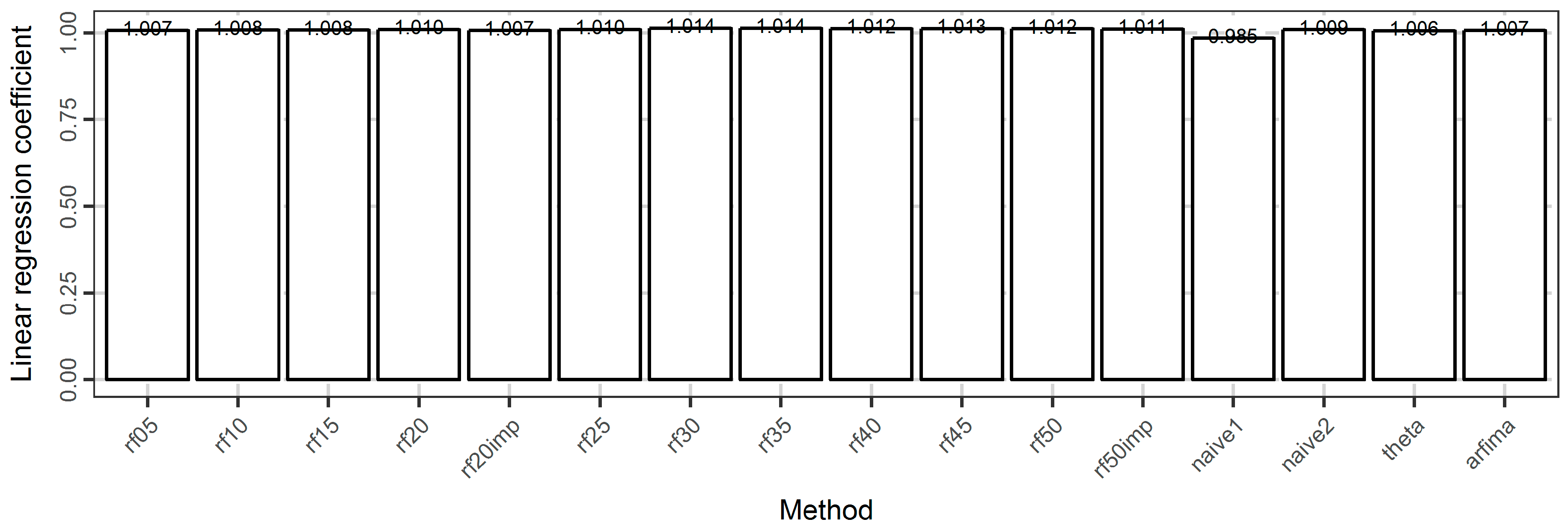
3.2. Temperature Analysis
4. Discussion
5. Conclusions
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A
References
- Shmueli, G. To explain or to predict? Stat. Sci. 2010, 25, 289–310. [Google Scholar] [CrossRef]
- Bontempi, G.; Taieb, S.B.; Le Borgne, Y.A. Machine learning strategies for time series forecasting. In Business Intelligence (Lecture Notes in Business Information Processing); Aufaure, M.A., Zimányi, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; Volume 138, pp. 62–77. [Google Scholar] [CrossRef]
- De Gooijer, J.G.; Hyndman, R.J. 25 years of time series forecasting. Int. J. Forecast. 2006, 22, 443–473. [Google Scholar] [CrossRef]
- Fildes, R.; Nikolopoulos, K.; Crone, S.F.; Syntetos, A.A. Forecasting and operational research: A review. J. Oper. Res. Soc. 2008, 59, 1150–1172. [Google Scholar] [CrossRef]
- Weron, R. Electricity price forecasting: A review of the state-of-the-art with a look into the future. Int. J. Forecast. 2014, 30, 1030–1081. [Google Scholar] [CrossRef]
- Hong, T.; Fan, S. Probabilistic electric load forecasting: A tutorial review. Int. J. Forecast. 2016, 32, 914–938. [Google Scholar] [CrossRef]
- Taieb, S.B.; Bontempi, G.; Atiya, A.F.; Sorjamaa, A. A review and comparison of strategies for multi-step ahead time series forecasting based on the NN5 forecasting competition. Expert Syst. Appl. 2012, 39, 7067–7083. [Google Scholar] [CrossRef]
- Mei-Ying, Y.; Xiao-Dong, W. Chaotic time series prediction using least squares support vector machines. Chin. Phys. 2004, 13, 454–458. [Google Scholar] [CrossRef]
- Faraway, J.; Chatfield, C. Time series forecasting with neural networks: A comparative study using the air line data. J. R. Stat. Soc. C Appl. Stat. 1998, 47, 231–250. [Google Scholar] [CrossRef]
- Yang, B.S.; Oh, M.S.; Tan, A.C.C. Machine condition prognosis based on regression trees and one-step-ahead prediction. Mech. Syst. Signal Process. 2008, 22, 1179–1193. [Google Scholar] [CrossRef]
- Zou, H.; Yang, Y. Combining time series models for forecasting. Int. J. Forecast. 2004, 20, 69–84. [Google Scholar] [CrossRef]
- Papacharalampous, G.A.; Tyralis, H.; Koutsoyiannis, D. Forecasting of geophysical processes using stochastic and machine learning algorithms. In Proceedings of the 10th World Congress of EWRA on Water Resources and Environment “Panta Rhei”, Athens, Greece, 5–9 July 2017. [Google Scholar]
- Pérez-Rodríguez, J.V.; Torra, S.; Andrada-Félix, J. STAR and ANN models: Forecasting performance on the Spanish “Ibex-35” stock index. J. Empir. Financ. 2005, 12, 490–509. [Google Scholar] [CrossRef]
- Khashei, M.; Bijari, M. A novel hybridization of artificial neural networks and ARIMA models for time series forecasting. Appl. Soft Comput. 2011, 11, 2664–2675. [Google Scholar] [CrossRef]
- Yan, W. Toward automatic time-series forecasting using neural networks. IEEE Trans. Neural Netw. Lear. Stat. 2012, 23, 1028–1039. [Google Scholar] [CrossRef]
- Babu, C.N.; Reddy, B.E. A moving-average filter based hybrid ARIMA–ANN model for forecasting time series data. Appl. Soft Comput. 2014, 23, 27–38. [Google Scholar] [CrossRef]
- Lin, L.; Wang, F.; Xie, X.; Zhong, S. Random forests-based extreme learning machine ensemble for multi-regime time series prediction. Expert Syst. Appl. 2017, 85, 164–176. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Scornet, E.; Biau, G.; Vert, J.P. Consistency of random forests. Ann. Stat. 2015, 43, 1716–1741. [Google Scholar] [CrossRef]
- Biau, G.; Scornet, E. A random forest guided tour. Test 2016, 25, 197–227. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning, 2nd ed.; Springer: New York, NY, USA, 2009. [Google Scholar] [CrossRef]
- Verikas, A.; Gelzinis, A.; Bacauskiene, M. Mining data with random forests: A survey and results of new tests. Pattern Recognit. 2011, 44, 330–349. [Google Scholar] [CrossRef]
- Herrera, M.; Torgo, L.; Izquierdo, J.; Pérez-García, R. Predictive models for forecasting hourly urban water demand. J. Hydrol. 2010, 387, 141–150. [Google Scholar] [CrossRef]
- Dudek, G. Short-term load forecasting using random forests. In Proceedings of the 7th IEEE International Conference Intelligent Systems IS’2014 (Advances in Intelligent Systems and Computing), Warsaw, Poland, 24–26 September 2014; Filev, D., Jabłkowski, J., Kacprzyk, J., Krawczak, M., Popchev, I., Rutkowski, L., Sgurev, V., Sotirova, E., Szynkarczyk, P., Zadrozny, S., Eds.; Springer: Cham, Switzerland, 2015; Volume 323, pp. 821–828. [Google Scholar] [CrossRef]
- Chen, J.; Li, M.; Wang, W. Statistical uncertainty estimation using random forests and its application to drought forecast. Math. Probl. Eng. 2012, 2012, 915053. [Google Scholar] [CrossRef]
- Naing, W.Y.N.; Htike, Z.Z. Forecasting of monthly temperature variations using random forests. APRN J. Eng. Appl. Sci. 2015, 10, 10109–10112. [Google Scholar]
- Nguyen, T.T.; Huu, Q.N.; Li, M.J. Forecasting time series water levels on Mekong river using machine learning models. In Proceedings of the 2015 Seventh International Conference on Knowledge and Systems Engineering (KSE), Ho Chi Minh City, Vietnam, 8–10 October 2015. [Google Scholar] [CrossRef]
- Kumar, M.; Thenmozhi, M. Forecasting stock index movement: A comparison of support vector machines and random forest. In Indian Institute of Capital Markets 9th Capital Markets Conference Paper; Indian Institute of Capital Markets: Vashi, India, 2006. [Google Scholar] [CrossRef]
- Kumar, M.; Thenmozhi, M. Forecasting stock index returns using ARIMA-SVM, ARIMA-ANN, and ARIMA-random forest hybrid models. Int. J. Bank. Acc. Financ. 2014, 5, 284–308. [Google Scholar] [CrossRef]
- Kane, M.J.; Price, N.; Scotch, M.; Rabinowitz, P. Comparison of ARIMA and Random Forest time series models for prediction of avian influenza H5N1 outbreaks. BMC Bioinform. 2014, 15. [Google Scholar] [CrossRef] [PubMed]
- Genuer, R.; Poggi, J.M.; Tuleau-Malot, C. Variable selection using random forests. Pattern Recognit. Lett. 2010, 31, 2225–2236. [Google Scholar] [CrossRef]
- Oshiro, T.M.; Perez, P.S.; Baranauskas, J.A. How many trees in a random forest? In Machine Learning and Data Mining in Pattern Recognition (Lecture Notes in Computer Science); Perner, P., Ed.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 154–168. [Google Scholar] [CrossRef]
- Probst, P.; Boulesteix, A.L. To tune or not to tune the number of trees in random forest? arXiv 2017, arXiv:1705.05654v1. [Google Scholar]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling; Springer: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Díaz-Uriarte, R.; De Andres, S.A. Gene selection and classification of microarray data using random forest. BMC Bioinform. 2006, 7. [Google Scholar] [CrossRef] [PubMed]
- Makridakis, S.; Hibon, M. Confidence intervals: An empirical investigation of the series in the M-competition. Int. J. Forecast. 1987, 3, 489–508. [Google Scholar] [CrossRef]
- Makridakis, S.; Hibon, M. The M3-Competition: Results, conclusions and implications. Int. J. Forecast. 2000, 16, 451–476. [Google Scholar] [CrossRef]
- Pritzsche, U. Benchmarking of classical and machine-learning algorithms (with special emphasis on bagging and boosting approaches) for time series forecasting. Master’s Thesis, Ludwig-Maximilians-Universität München, München, Germany, 2015. [Google Scholar]
- Bagnall, A.; Cawley, G.C. On the use of default parameter settings in the empirical evaluation of classification algorithms. arXiv 2017, arXiv:1703.06777v1. [Google Scholar]
- Salles, R.; Assis, L.; Guedes, G.; Bezerra, E.; Porto, F.; Ogasawara, E. A framework for benchmarking machine learning methods using linear models for univariate time series prediction. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 2338–2345. [Google Scholar] [CrossRef]
- Bontempi, G. Machine Learning Strategies for Time Series Prediction. European Business Intelligence Summer School, Hammamet, Lecture. 2013. Available online: https://pdfs.semanticscholar.org/f8ad/a97c142b0a2b1bfe20d8317ef58527ee329a.pdf (accessed on 25 September 2017).
- McShane, B.B. Machine Learning Methods with Time Series Dependence. Ph.D. Thesis, University of Pennsylvania, Philadelphia, PA, USA, 2010. [Google Scholar]
- Bagnall, A.; Bostrom, A.; Large, J.; Lines, J. Simulated data experiments for time series classification part 1: Accuracy comparison with default settings. arXiv 2017, arXiv:1703.09480v1. [Google Scholar]
- Box, G.E.P.; Jenkins, G.M. Some recent advances in forecasting and control. J. R. Stat. Soc. C Appl. Stat. 1968, 17, 91–109. [Google Scholar] [CrossRef]
- Wei, W.W.S. Time Series Analysis, Univariate and Multivariate Methods, 2nd ed.; Pearson Addison Wesley: Boston, MA, USA, 2006; ISBN 0-321-322116-9. [Google Scholar]
- Thissen, U.; Van Brakel, R.; De Weijer, A.P.; Melssena, W.J.; Buydens, L.M.C. Using support vector machines for time series prediction. Chemom. Intell. Lab. 2003, 69, 35–49. [Google Scholar] [CrossRef]
- Zhang, G.P. An investigation of neural networks for linear time-series forecasting. Comput. Oper. Res. 2001, 28, 1183–1202. [Google Scholar] [CrossRef]
- Lawrimore, J.H.; Menne, M.J.; Gleason, B.E.; Williams, C.N.; Wuertz, D.B.; Vose, R.S.; Rennie, J. An overview of the Global Historical Climatology Network monthly mean temperature data set, version 3. J. Geophys. Res. 2011, 116. [Google Scholar] [CrossRef]
- Assimakopoulos, V.; Nikolopoulos, K. The theta model: A decomposition approach to forecasting. Int. J. Forecast. 2000, 16, 521–530. [Google Scholar] [CrossRef]
- Kuhn, M. Building predictive models in R using the caret package. J. Stat. Softw. 2008, 28. [Google Scholar] [CrossRef]
- Kuhn, M.; Wing, J.; Weston, S.; Williams, A.; Keefer, C.; Engelhardt, A.; Cooper, T.; Mayer, Z.; Kenkel, B.; The R Core Team; et al. Caret: Classification and Regression Training, R package version 6.0-76; 2017. Available online: https://cran.r-project.org/web/packages/caret/index.html (accessed on 7 September 2017).
- The R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2017. [Google Scholar]
- Hemelrijk, J. Underlining random variables. Stat. Neerl. 1966, 20, 1–7. [Google Scholar] [CrossRef]
- Fraley, C.; Leisch, F.; Maechler, M.; Reisen, V.; Lemonte, A. Fracdiff: Fractionally Differenced ARIMA aka ARFIMA(p,d,q) Models, R package version 1.4-2. 2012. Available online: https://rdrr.io/cran/fracdiff/ (accessed on 2 December 2012).
- Hyndman, R.J.; O’Hara-Wild, M.; Bergmeir, C.; Razbash, S.; Wang, E. Forecast: Forecasting Functions for Time Series and Linear Models, R package version 8.1. 2017. Available online: https://rdrr.io/cran/forecast/ (accessed on 25 September 2017).
- Hyndman, R.J.; Khandakar, Y. Automatic time series forecasting: The forecast package for R. J. Stat. Softw. 2008, 27. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Athanasopoulos, G. Forecasting: Principles and Practice; OTexts: Melbourne, Australia, 2013. Available online: http://otexts.org/fpp/ (accessed on 25 September 2017).
- Hyndman, R.J.; Billah, B. Unmasking the Theta method. Int. J. Forecast. 2003, 19, 287–290. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Koehler, A.B.; Ord, J.K.; Snyder, R.D. Forecasting with Exponential Smoothing: The State Space Approach; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and Regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Cortez, P. Data mining with neural networks and support vector machines using the R/rminer tool. In Advances in Data Mining. Applications and Theoretical Aspects (Lecture Notes in Artificial Intelligence); Perner, P., Ed.; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6171, pp. 572–583. [Google Scholar] [CrossRef]
- Cortez, P. Rminer: Data Mining Classification and Regression Methods, R package version 1.4.2. 2016. Available online: https://rdrr.io/cran/rminer/ (accessed on 2 September 2016).
- Hyndman, R.J.; Koehler, A.B. Another look at measures of forecast accuracy. Int. J. Forecast. 2006, 22, 679–688. [Google Scholar] [CrossRef]
- Alexander, D.L.J.; Tropsha, A.; Winkler, D.A. Beware of R2: Simple, unambiguous assessment of the prediction accuracy of QSAR and QSPR models. J. Chem. Inf. Model. 2015, 55, 1316–1322. [Google Scholar] [CrossRef] [PubMed]
- Gramatica, P.; Sangion, A. A historical excursus on the statistical validation parameters for QSAR models: A clarification concerning metrics and terminology. J. Chem. Inf. Model. 2016, 56, 1127–1131. [Google Scholar] [CrossRef] [PubMed]
- Warnes, G.R.; Bolker, B.; Gorjanc, G.; Grothendieck, G.; Korosec, A.; Lumley, T.; MacQueen, D.; Magnusson, A.; Rogers, J. Gdata: Various R Programming Tools for Data Manipulation, R package version 2.18.0. 2017. Available online: https://cran.r-project.org/web/packages/gdata/index.html (accessed on 6 June 2017).
- Wickham, H. Ggplot2: Elegant Graphics for Data Analysis, 2nd ed.; Springer International Publishing: Cham, Switzerland, 2016. [Google Scholar] [CrossRef]
- Wickham, H.; Hester, J.; Francois, R.; Jylänki, J.; Jørgensen, M. Readr: Read Rectangular Text Data, R package version 1.1.1; 2017; Available online: https://cran.r-project.org/web/packages/readr/index.html (accessed on 16 May 2017).
- Wickham, H. Reshaping data with the reshape package. J. Stat. Softw. 2007, 21. [Google Scholar] [CrossRef]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Section | Brief Explanation |
|---|---|---|
| arfima | 2.1.3 | Uses fitted ARMA or ARFIMA models |
| naïve1 | 2.1.4 | Forecast equal to the last observed value, Equation (16) |
| naïve2 | 2.1.4 | Forecast equal to the mean of the fitted set, Equation (17) |
| theta | 2.1.5 | Uses the theta method |
| rf | 2.1.7 | Uses random forests, Equation (20) |
| Method | Application in Section 3 |
|---|---|
| 1st case in Section 2.1.3 | Simulations from the family of ARMA models |
| 2nd case in Section 2.1.3 | Simulations from the family of ARFIMA models, with d ≠ 0 |
| 2nd case in Section 2.1.3 | Temperature data |
| Method | Explanatory Variables |
|---|---|
| rf05, rf10, rf15, rf20, rf25, rf30, rf35, rf40, rf45, rf50 | Uses the last 5, …, 50 variables |
| rf20imp, rf50imp | Uses the most important variables from the last 20 and 50 variables respectively |
| Metric | Equation | Range | Metric Values for Perfect Forecast |
|---|---|---|---|
| error | (21) | [−∞, ∞] | 0 |
| absolute error | (22) | [0, ∞] | 0 |
| squared error | (23) | [0, ∞] | 0 |
| percentage error | (24) | [−∞, ∞] | 0 |
| absolute percentage error | (25) | [0, ∞] | 0 |
| linear regression coefficient | (36) | [−∞, ∞] | 1 |
| Experiment | Model | Parameters |
|---|---|---|
| 1 | ARMA(1, 0) | φ1 = 0.6 |
| 2 | ARMA(1, 0) | φ1 = −0.6 |
| 3 | ARMA(2, 0) | φ1 = 0.6, φ2 = 0.2 |
| 4 | ARMA(2, 0) | φ1 = −0.6, φ2 = 0.2 |
| 5 | ARMA(0, 1) | θ1 = 0.6 |
| 6 | ARMA(0, 1) | θ1 = −0.6 |
| 7 | ARMA(0, 2) | θ1 = 0.6, θ2 = 0.2 |
| 8 | ARMA(0, 2) | θ1 = −0.6, θ2 = −0.2 |
| 9 | ARMA(1, 1) | φ1 = 0.6, θ1 = 0.6 |
| 10 | ARMA(1, 1) | φ1 = −0.6, θ1 = −0.6 |
| 11 | ARMA(2, 2) | φ1 = 0.6, φ2 = 0.2, θ1 = 0.6, θ2 = 0.2 |
| 12 | ARFIMA(0, 0.40, 0) | |
| 13 | ARFIMA(1, 0.40, 0) | φ1 = 0.6 |
| 14 | ARFIMA(0, 0.40, 1) | θ1 = 0.6 |
| 15 | ARFIMA(1, 0.40, 1) | φ1 = 0.6, θ1 = 0.6 |
| 16 | ARFIMA(2, 0.40, 2) | φ1 = 0.6, φ2 = 0.2, θ1 = 0.6, θ2 = 0.2 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tyralis, H.; Papacharalampous, G. Variable Selection in Time Series Forecasting Using Random Forests. Algorithms 2017, 10, 114. https://doi.org/10.3390/a10040114
Tyralis H, Papacharalampous G. Variable Selection in Time Series Forecasting Using Random Forests. Algorithms. 2017; 10(4):114. https://doi.org/10.3390/a10040114
Chicago/Turabian StyleTyralis, Hristos, and Georgia Papacharalampous. 2017. "Variable Selection in Time Series Forecasting Using Random Forests" Algorithms 10, no. 4: 114. https://doi.org/10.3390/a10040114
APA StyleTyralis, H., & Papacharalampous, G. (2017). Variable Selection in Time Series Forecasting Using Random Forests. Algorithms, 10(4), 114. https://doi.org/10.3390/a10040114