Algorithm 1 shows the sketch of the proposed algorithm, and its details are given next.
4.2. Cycle Detection
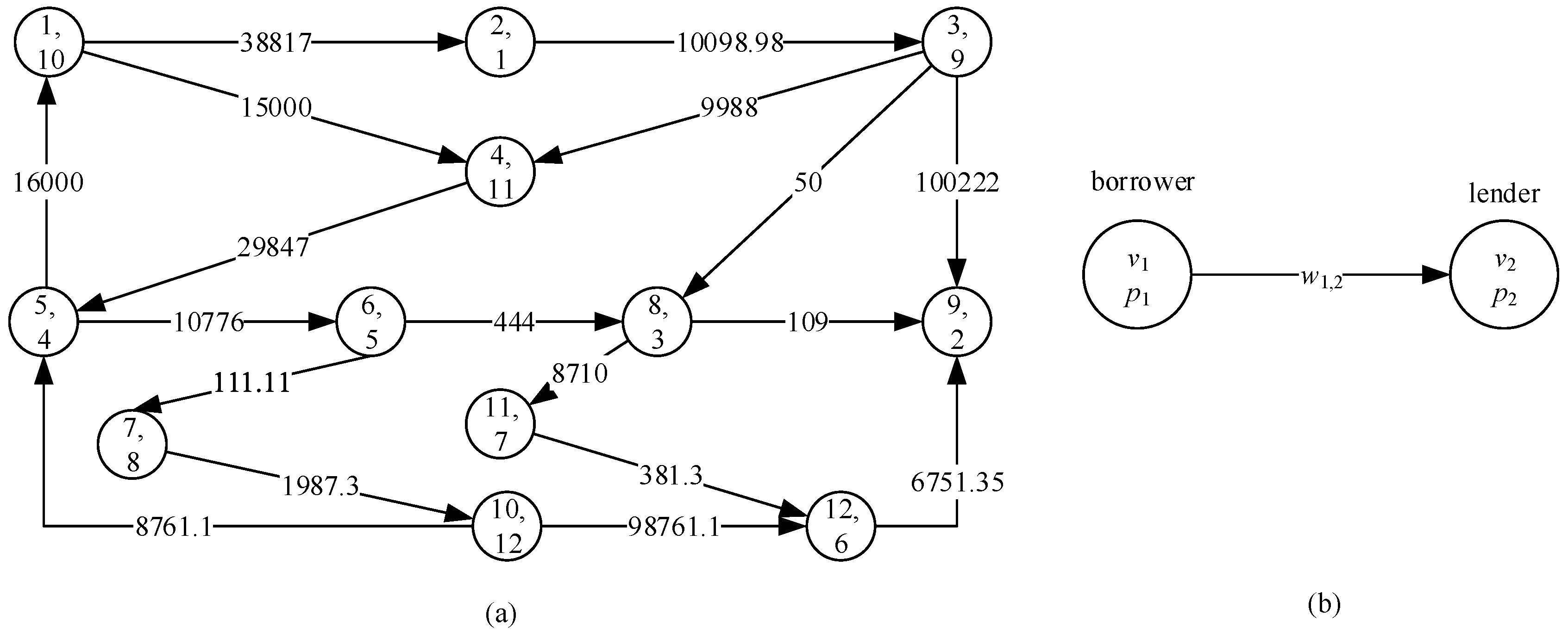
Proposition 2. Given a digraph , if is a directed cycle, then these vertices belong to the same strongly connected components of .
This is the basis of step 2 of Algorithm 1. There are several efficient algorithms to calculate strongly connected components (SCCs) of a digraph, so we do not discuss the detail of step 2 of Algorithm 1. After SCCs are obtained, the cycles can be detected in each SCC. The cycle calculation is the core of Algorithm 1.
Because the problem needs visit the vertices according their priorities, cycle should be detected using DFS. For large-scale graphs, the recursive DFS will cause out-of-memory exception, so we need an iterative version. The following data structures are adopted.
Stack is used to store the visited sequence of vertices. Its interfaces include:
Push() to push into .
Pop() to pop an element of .
Peek() to return the top element of without popping out it.
Search() to return the index of in , and it returns −1 if is not in .
Clear() to clear the to empty.
SubList() to return the sub-sequence of from index to ().
IsEmpty() to return false if is not empty, and return true if is empty.
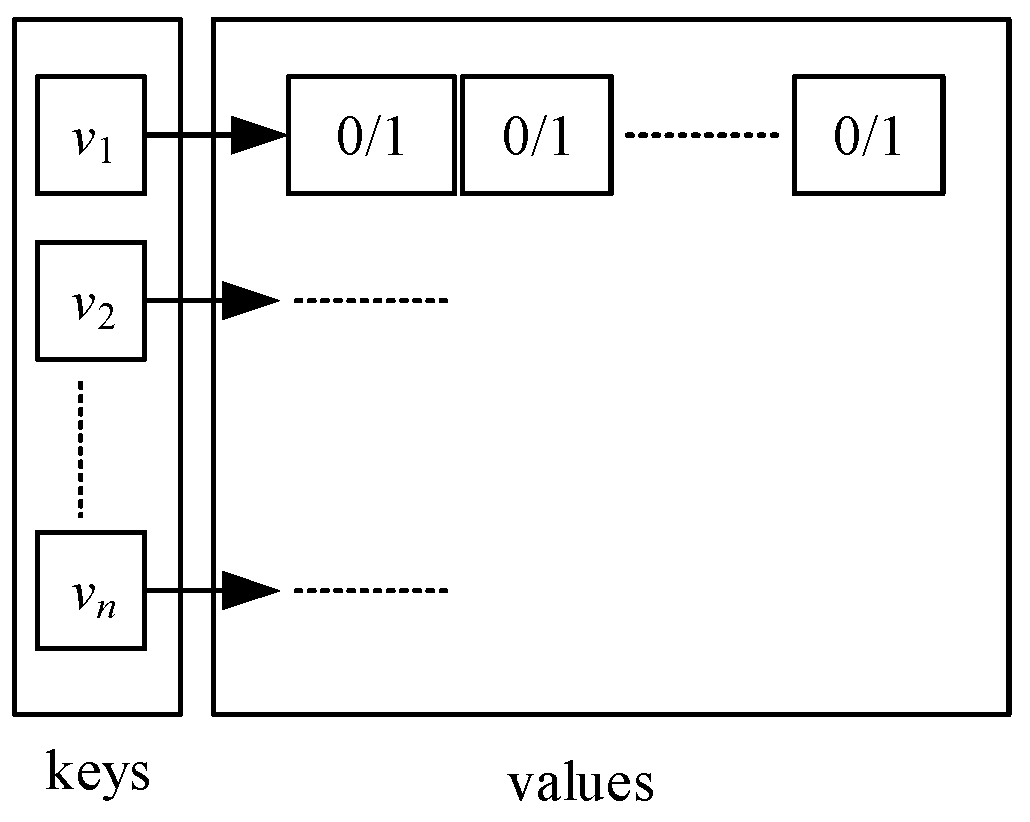
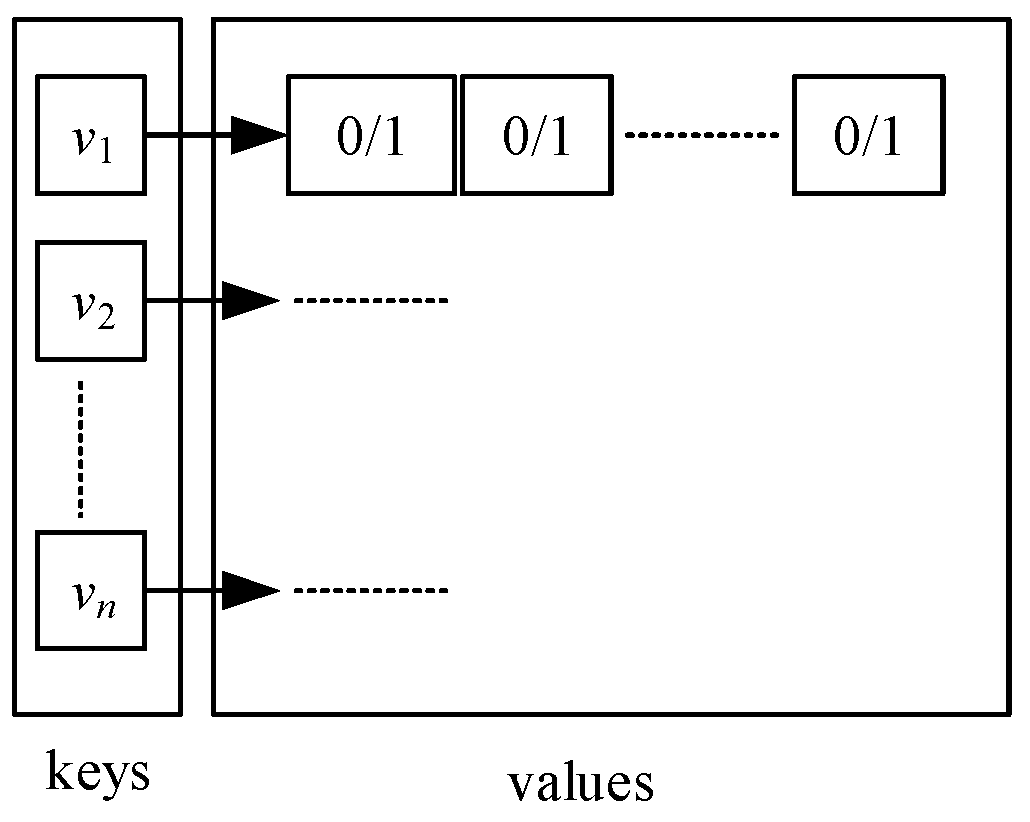
Key-value pair table
is applied to record each neighbor vertex of a visited vertex is visited or not. As shown in
Figure 2, each key (
) is a vertex that is unique in the whole table. Each
has a list of values, and each value is either 0 or 1 representing the corresponding neighboring vertex of
is unvisited or not. It has the following interfaces:
Clear() to reset all values of key to 0.
Sum() to return the sum of values of key . The sum represents the number of neighboring vertices have been visited until now.
GetFirst() to return the first unvisited neighboring vertex of .
Set() to set the value of neighboring vertex of to 1.
Minimum heap is applied to store vertices based on their priorities, due to the high-efficiency of sorting and deleting members in heap. It only has one function, GetFirst(H), to get the vertex of the highest priority.
Algorithm 4 gives the cycle detection algorithm. It is a multi-threading parallel algorithm. Line 2 forks threads, and all of the threads run in parallel (line 4). Each thread gets an SCC (line 5), and calls Fun to detect and remove cycles (line 6).
The set of vertices is stored in a minimum heap H. The outer while loop (lines 12~40) detects cycles starting from each vertex of . Lines 13~17 initialize variables. For a given vertex, , the inner while loop (lines 18~36) detects all of the cycles including . Let be the top element of . If all its neighbor vertices are visited (line 20), pop it out and clear the status of all its neighbor vertices. Otherwise, get the first unvisited neighbor vertex of and visit it. In further, if is not in (line 27), is pushed into . If is in and (line 29), than the sub-list of from to the top element is a cycle. If cannot find any cycle, delete it from graph (line 38).
| Algorithm 4. Detect Cycles of a Weighted Directed Graph |
| 1. | Function DetectCycle() |
| 2. | Fork K threads |
| 3. | |
| 4. | for each thread do in parallel |
| 5. | the next SCC to detect and remove cycle |
| 6. | Fun() |
| 7. | end for |
| 8. | return |
| 9. | end function |
| 10. | Function Fun() // is a SCC of , is in heap H |
| 11. | |
| 12. | while do |
| 13. | GetFirst(H) |
| 14. | Clear() |
| 15. | Clear() |
| 16. | Push() |
| 17. | flag false |
| 18. | while (flag=false and isEmpty()=false) |
| 19. | Peek() |
| 20. | if |sum| then |
| 21. | Pop() |
| 22. | Clear() |
| 23. | else |
| 24. | GetFirst() |
| 25. | Set() |
| 26. | k=Search() |
| 27. | if then |
| 28. | Push() |
| 29. | else if then |
| 30. | SubList()// is a cycle |
| 31. | |
| 32. | RemoveCycle(,) |
| 33. | flag true |
| 34. | end if |
| 35. | end if |
| 36. | end while |
| 37. | if flag=false then |
| 38. | Delete() |
| 39. | end if |
| 40. | end while |
| 41. | return |
| 42. | end function |
When a cycle is detected, it should be removed at once using RemoveCycle (line 32) shown in Algorithm 5. The first for loop (lines 3–7) finds the cycle weight. The second for loop (lines 8–20) decreases all of the arc weights of by . If the weight of an arc becomes 0, delete this arc (line 11). In further, if the in-degree or out-degree of a vertex becomes 0, delete this vertex (lines 13 and 16).
| Algorithm 5. Remove a Cycle |
| 1. | Function RemoveCycle(,)//, |
| 2. | |
| 3. | for to do |
| 4. | if then |
| 5. | |
| 6. | end if |
| 7. | end for |
| 8. | for to do |
| 9. | |
| 10. | |
| 11. | if then |
| 12. | |
| 13. | if then |
| 14. | Delete() |
| 15. | end if |
| 16. | if then |
| 17. | Delete() |
| 18. | end if |
| 19. | end if |
| 20. | end for |
| 21. | end function |
Proposition 3. Given a strongly connected component , Algorithm 4 can terminate with .
Proof. Let be the vertex with the highest priority in SCC , i.e., is the minimal. From , DFS is used to visit this SCC. Let be the current visiting vertex.
Case 1. has no outgoing arc or all its neighbor vertices are visited in previous steps. In this case, , and should be popped out from .
Case 1-1. If , becomes empty, so the inner while (line 18) exits and flag=false. This result means no cycle can be detected from , so is deleted (line 38).
Case 1-2. If , the inner while (line 18) goes on checking the top element of .
Case 2. has at least one unvisited outgoing arc. In this case, we select one unvisited neighbor vertex to continue searching.
Case 2-1. If , a cycle is detected (line 29). This cycle is removed by Algorithm 5. Because equals to at least one arc's weight, Algorithm 5 deletes at least one arc. Finally, flag=true, and the inner while loop exits.
Case 2-2. If is not visited, is pushed into and while loop continues.
Case 2-3. If is in stack but , it continues finding the next vertex to visit.
Note that Case 1-2, Case 2-2 and Case 2-3 will fall into Case 1-1 or Case 2-1 finally, so each iteration of outer while loop deletes an arc or vertex at least. Therefore, when Algorithm 4 finishes.
Remark 1. Algorithm 4 cannot detect all cycles of a given SCC, because a cycle may be broken when another one is removed.
4.3. Time Complexity Analysis
Let be, respectively, the average in-degree and out-degree of vertices.
In Algorithm 2, the for consumes to compute the in- and out-degree of all vertices. When no vertex can be deleted, the while only needs to scan all vertices. When only one vertex can be deleted in each iteration, it consumes .
Algorithm 3 is very simple, whose time complexity is .
Let be the length of cycle as the input of Algorithm 5. The first for consumes . If only one arc can be deleted, the second for consumes . In the worst case, arcs of this cycle are all deleted, then the second for consumes .
For function
Fun(
) of Algorithm 4, in the worst case, each iteration of the inner
while detects a cycle, and each cycle only deletes one arc using Algorithm 5, so this function calls
times Algorithm 5. Obviously, the longest cycle is of length
, and the shortest one is of length 2, so the average length of cycles is
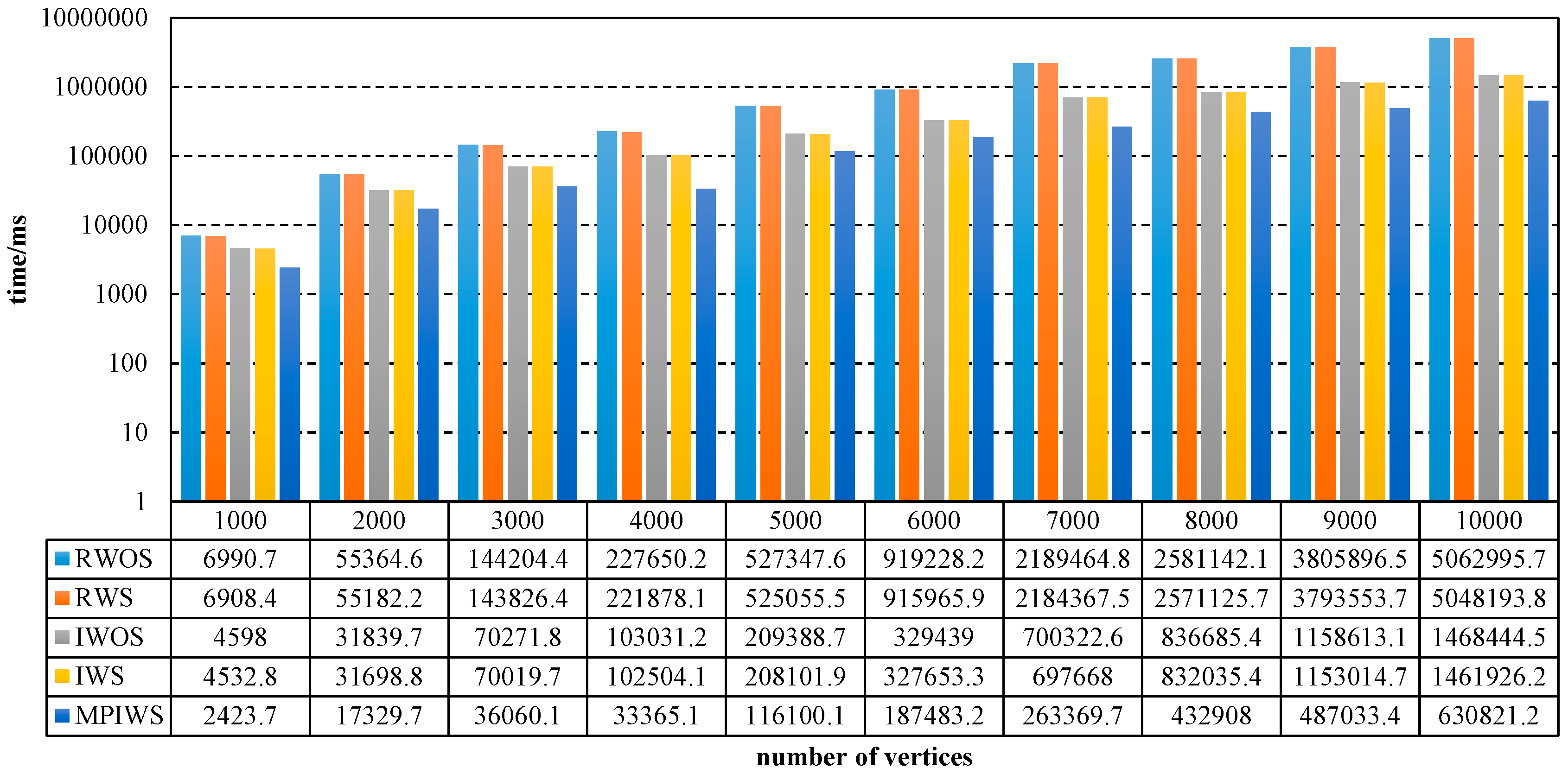
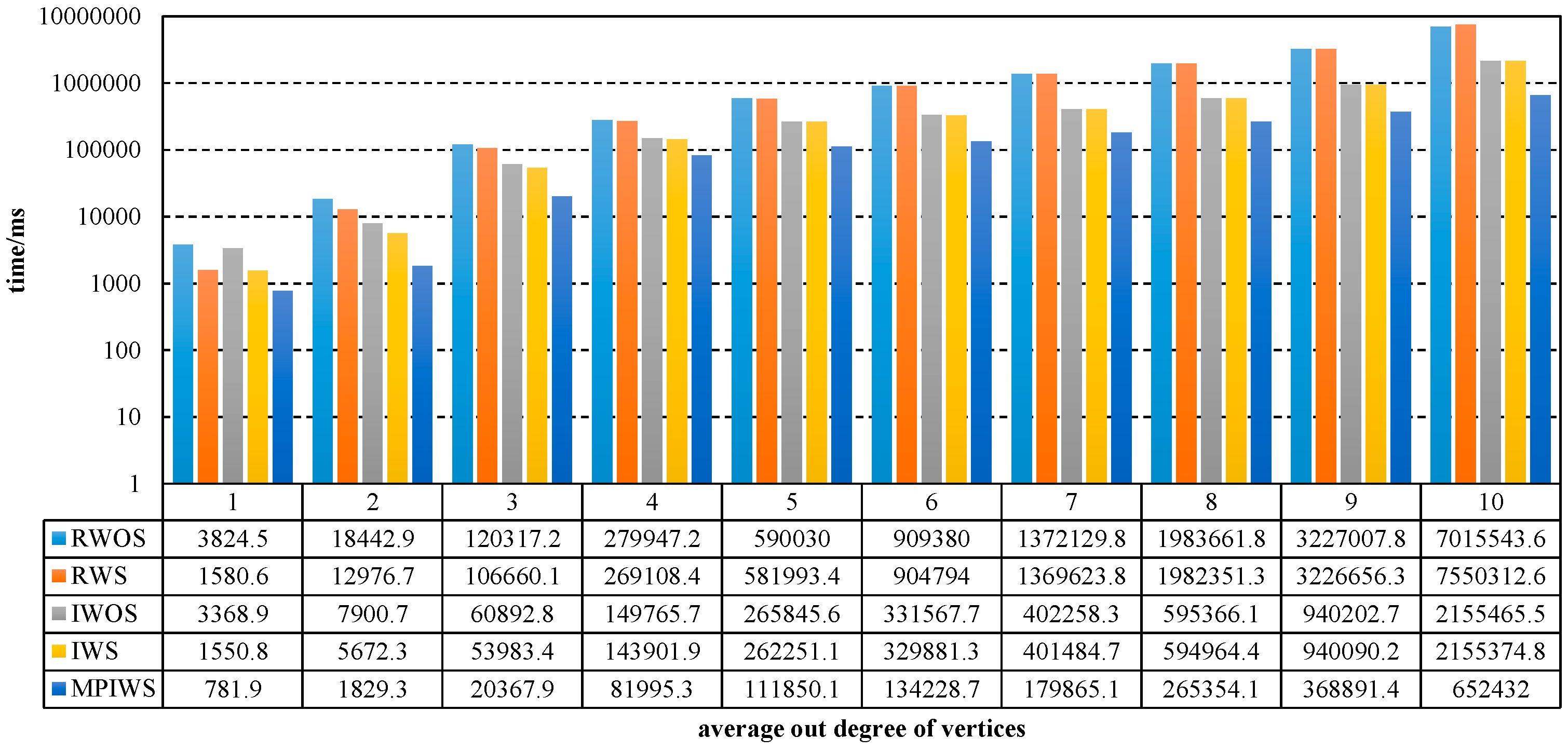
If has SCCs, each thread deals with SCCs on average. Therefore, the worst time complexity is .
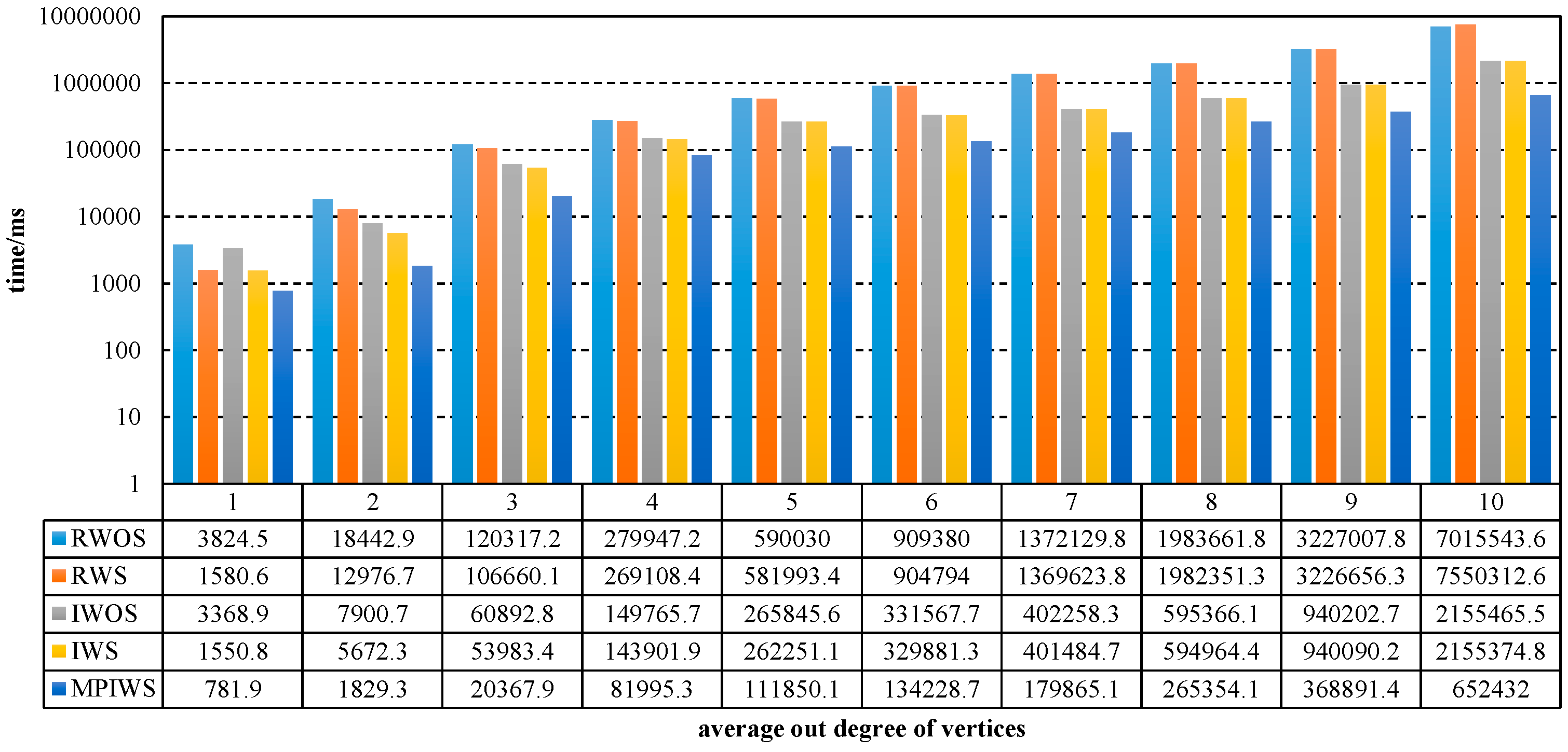
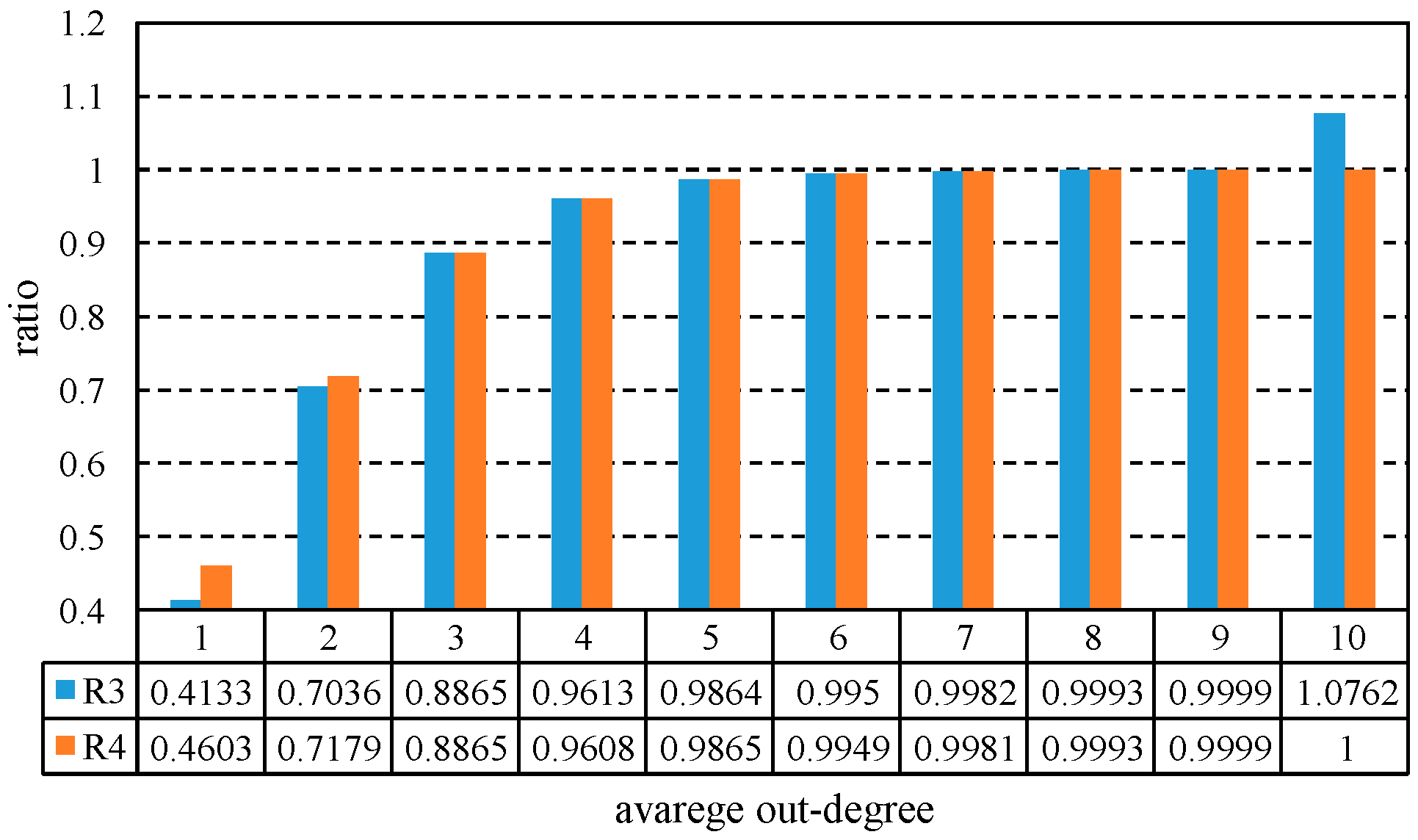
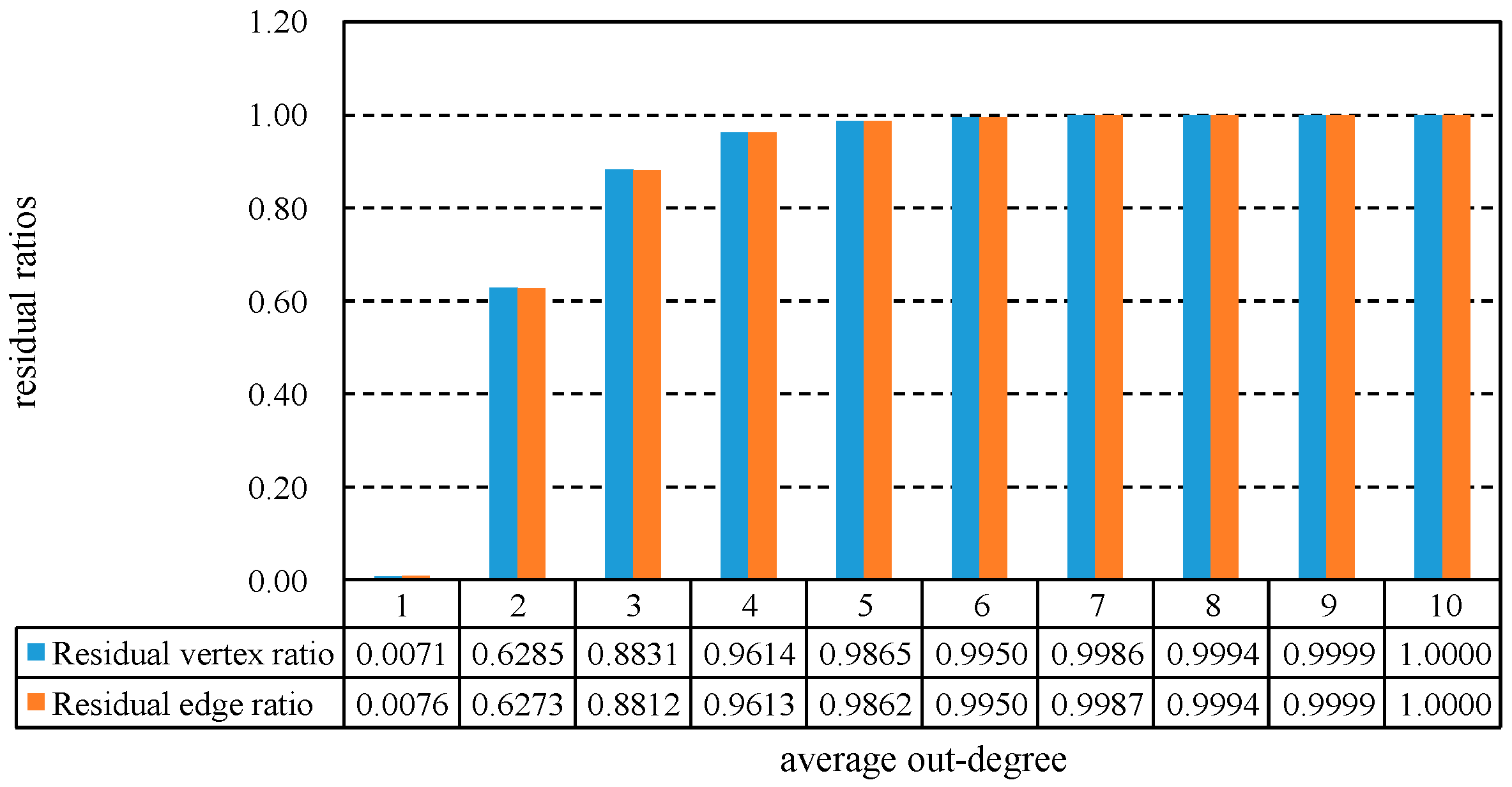
The time complexity of Algorithm 1 is the sum of Algorithms 2–4. In the worst case, the digraph has only one SCC, so its time complexity is .


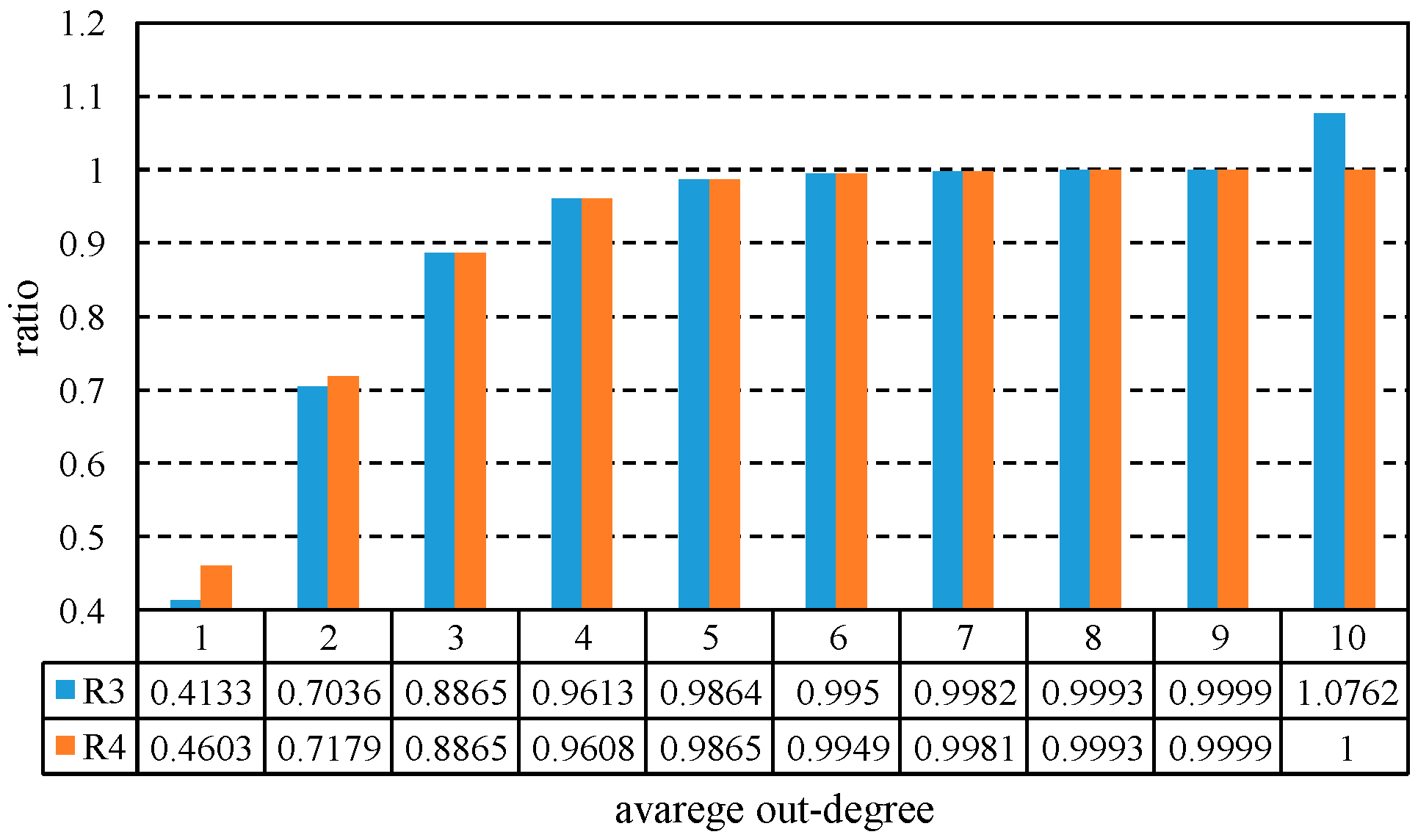
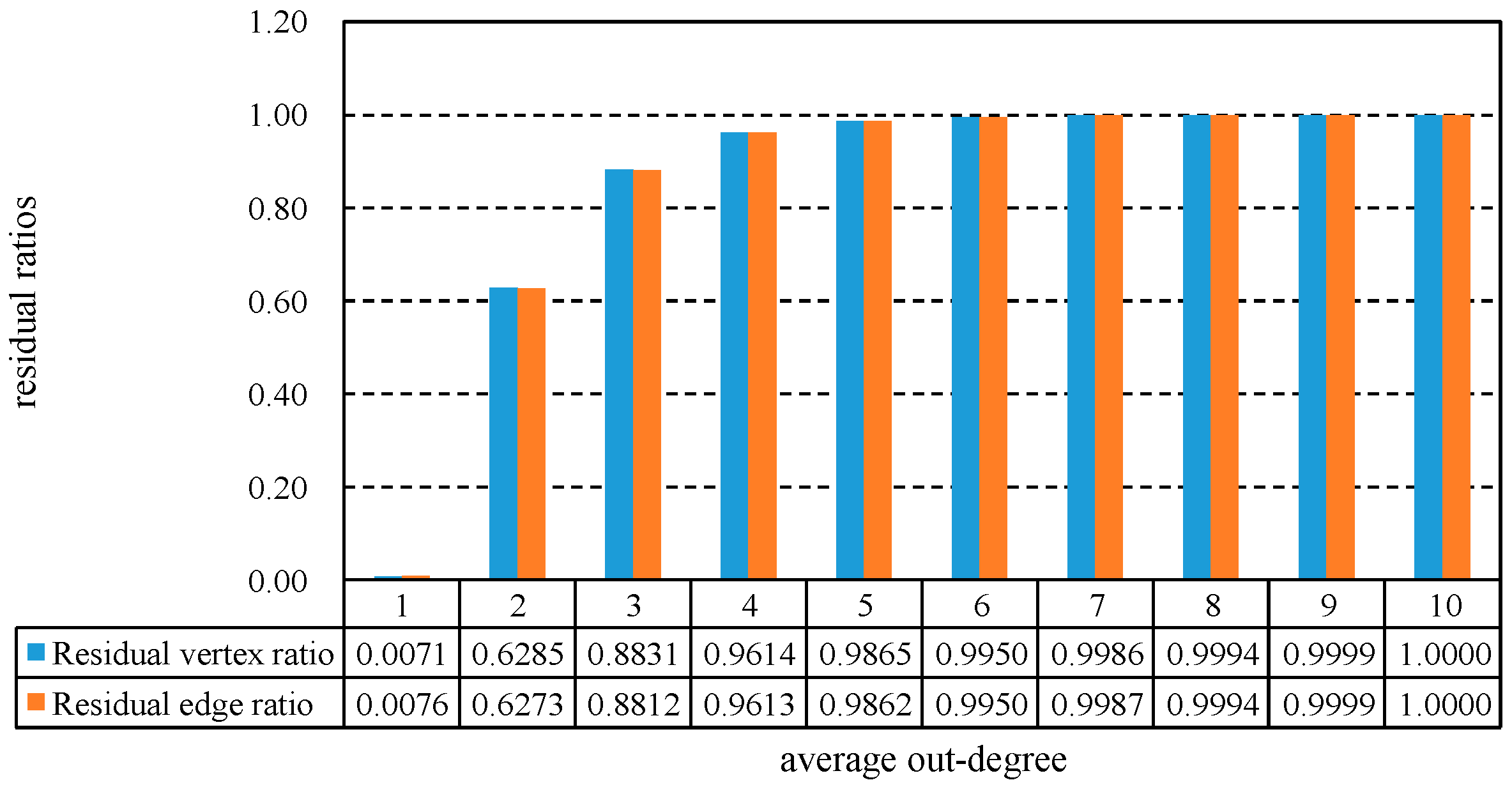
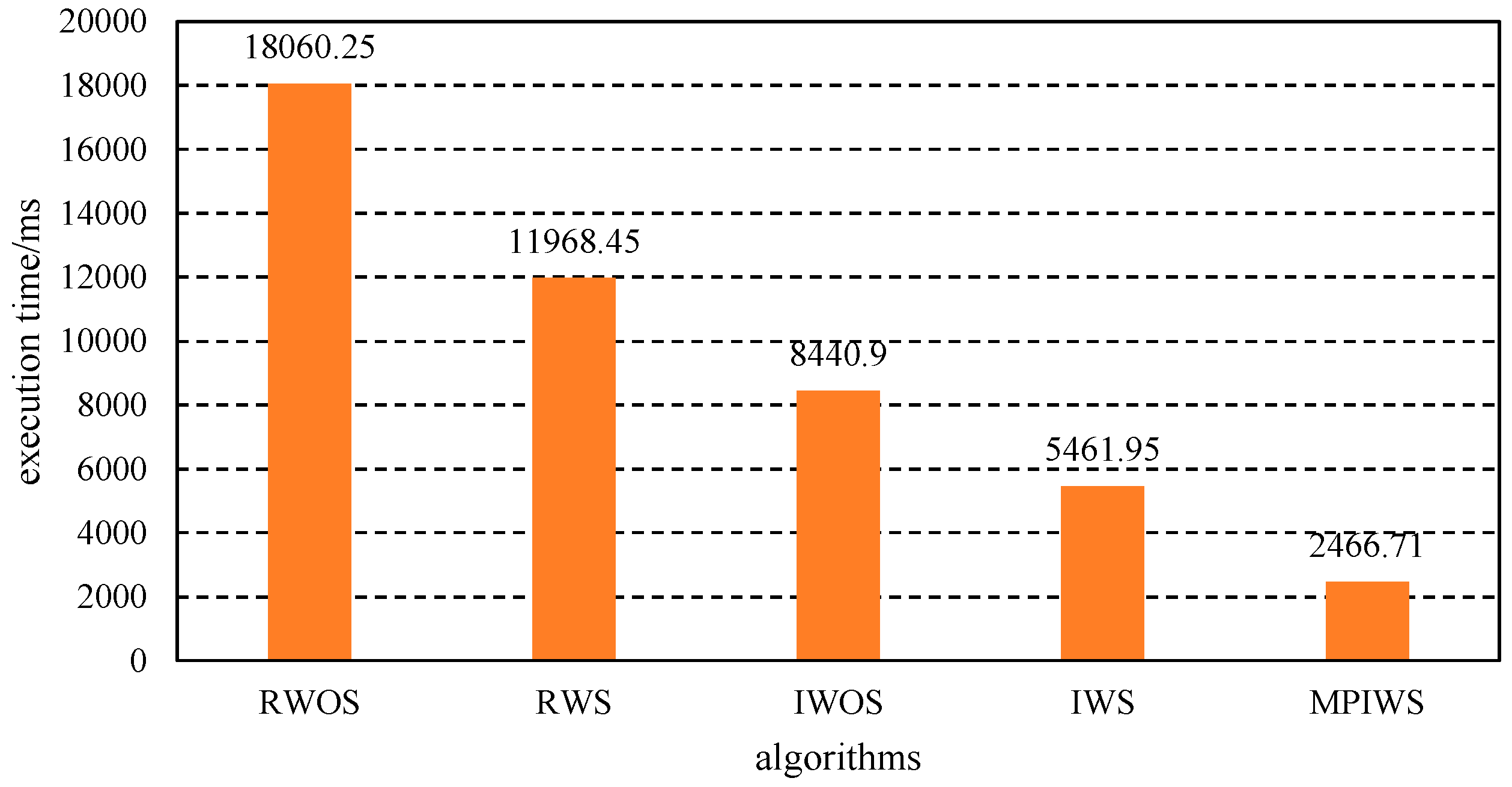
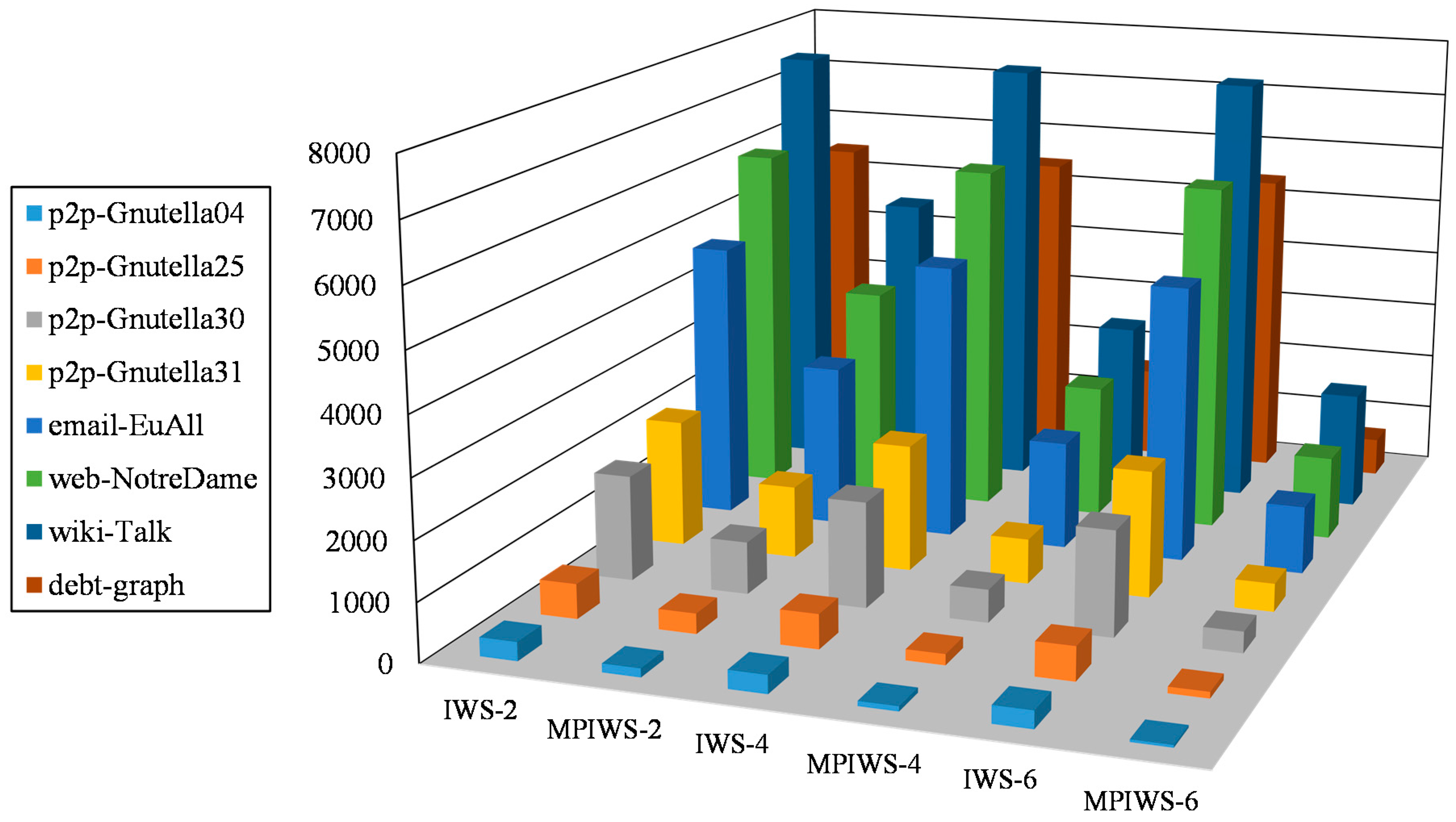

{kind=link}
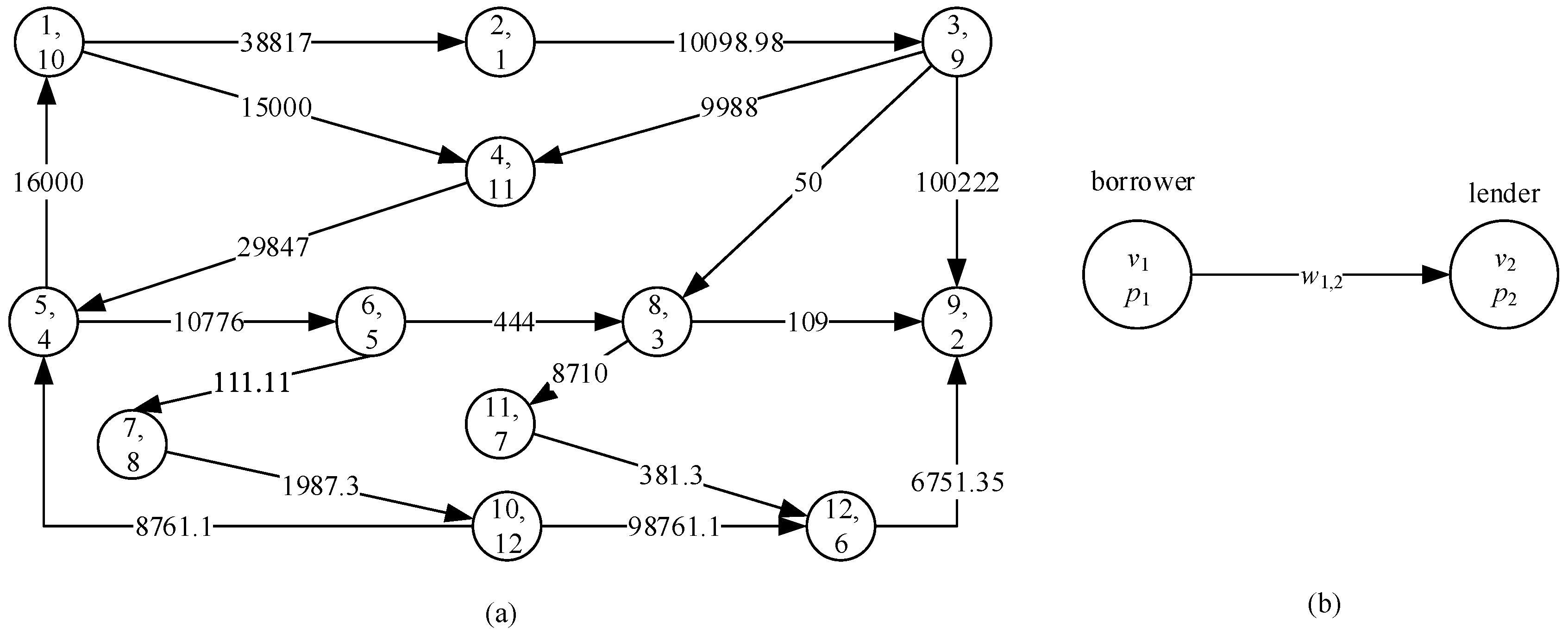
{kind=link}
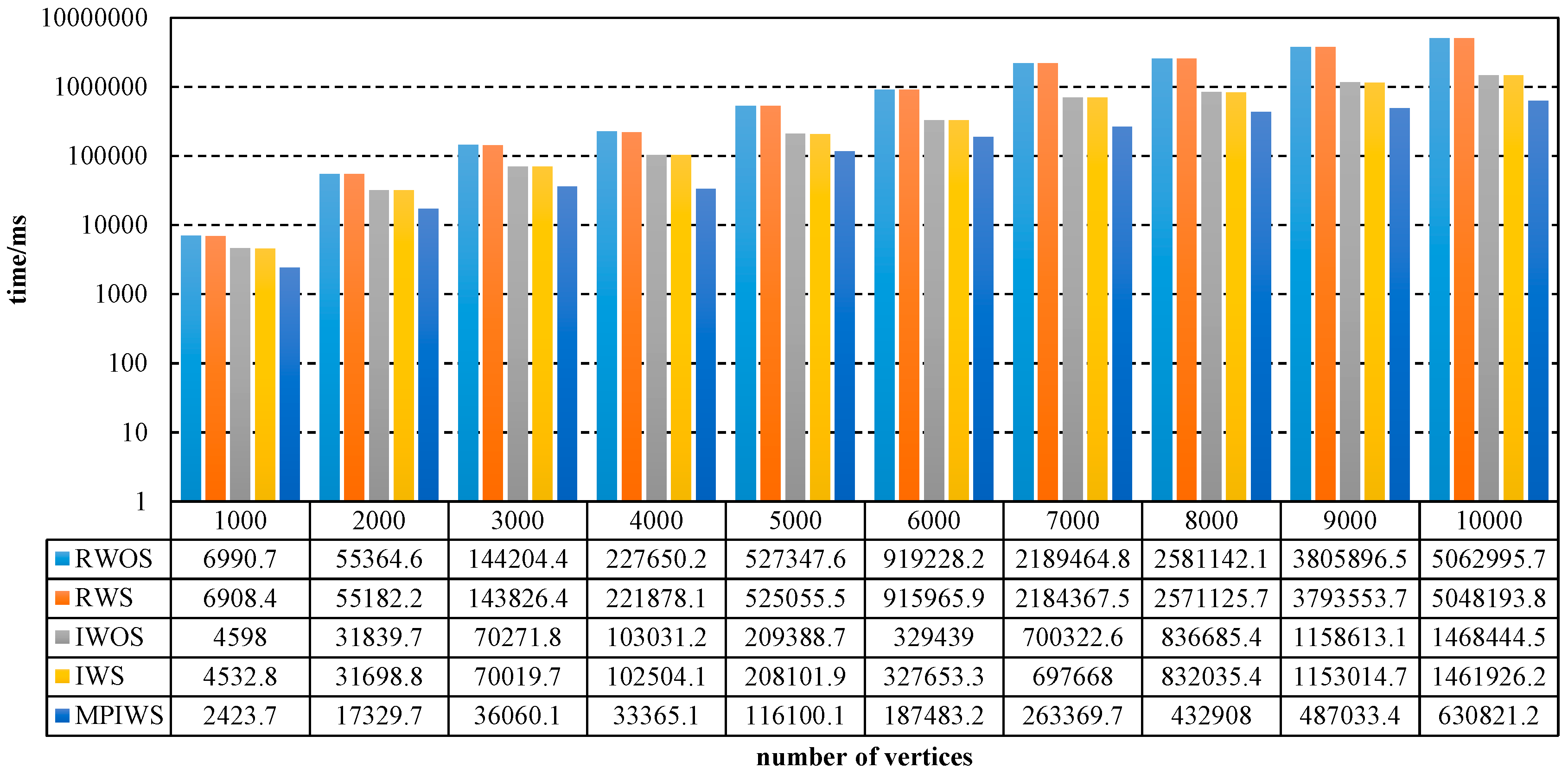{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}