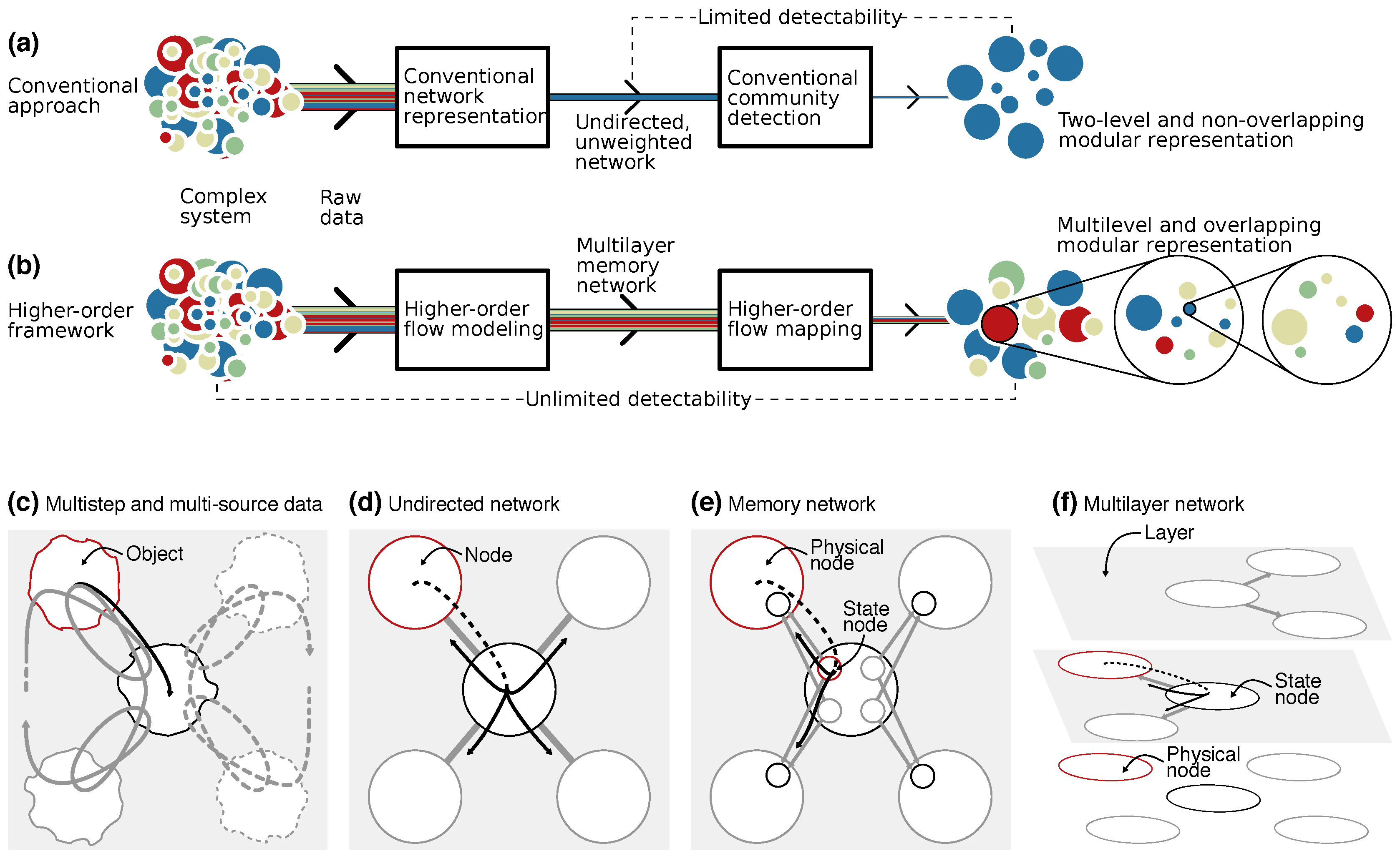
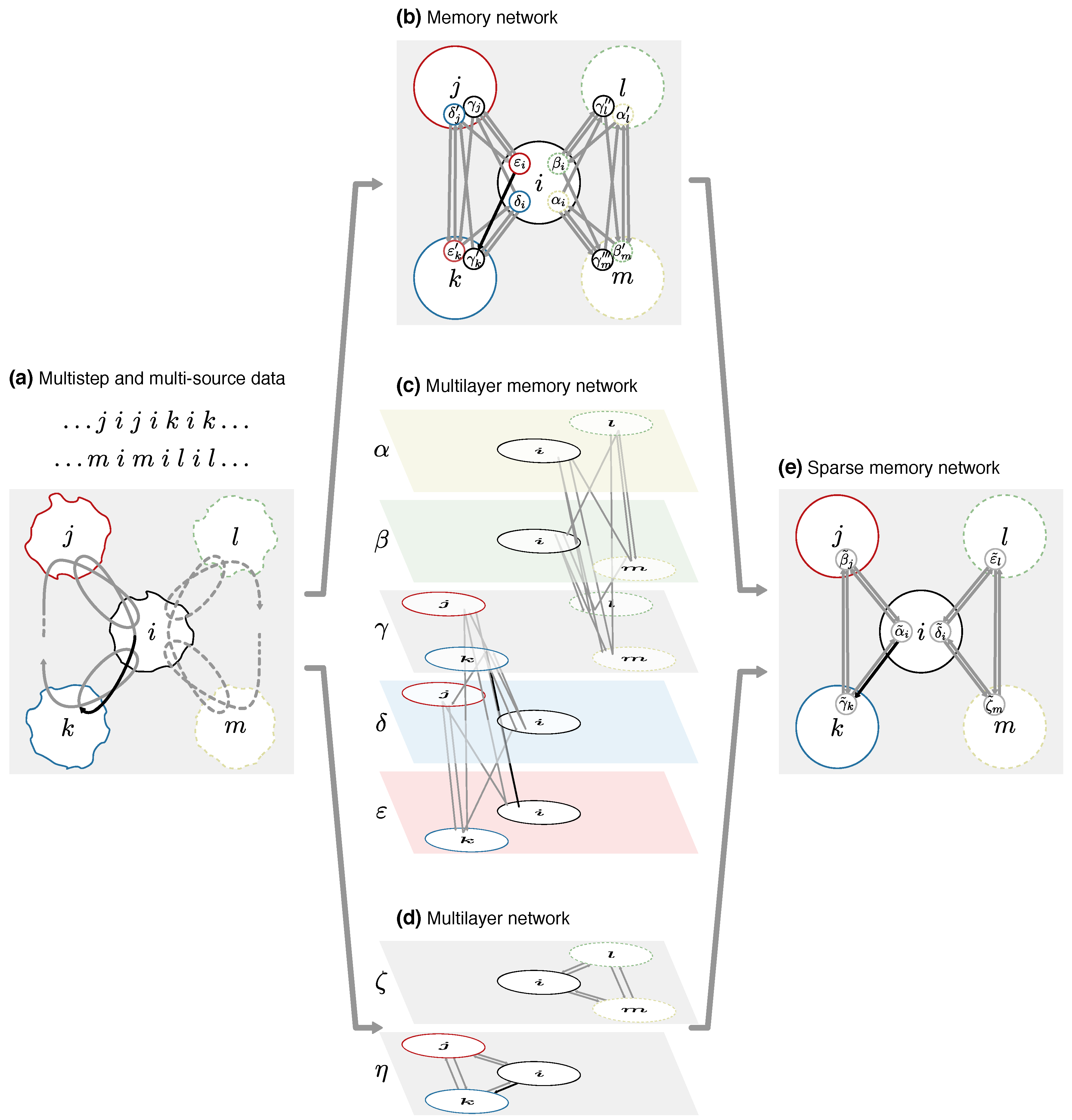
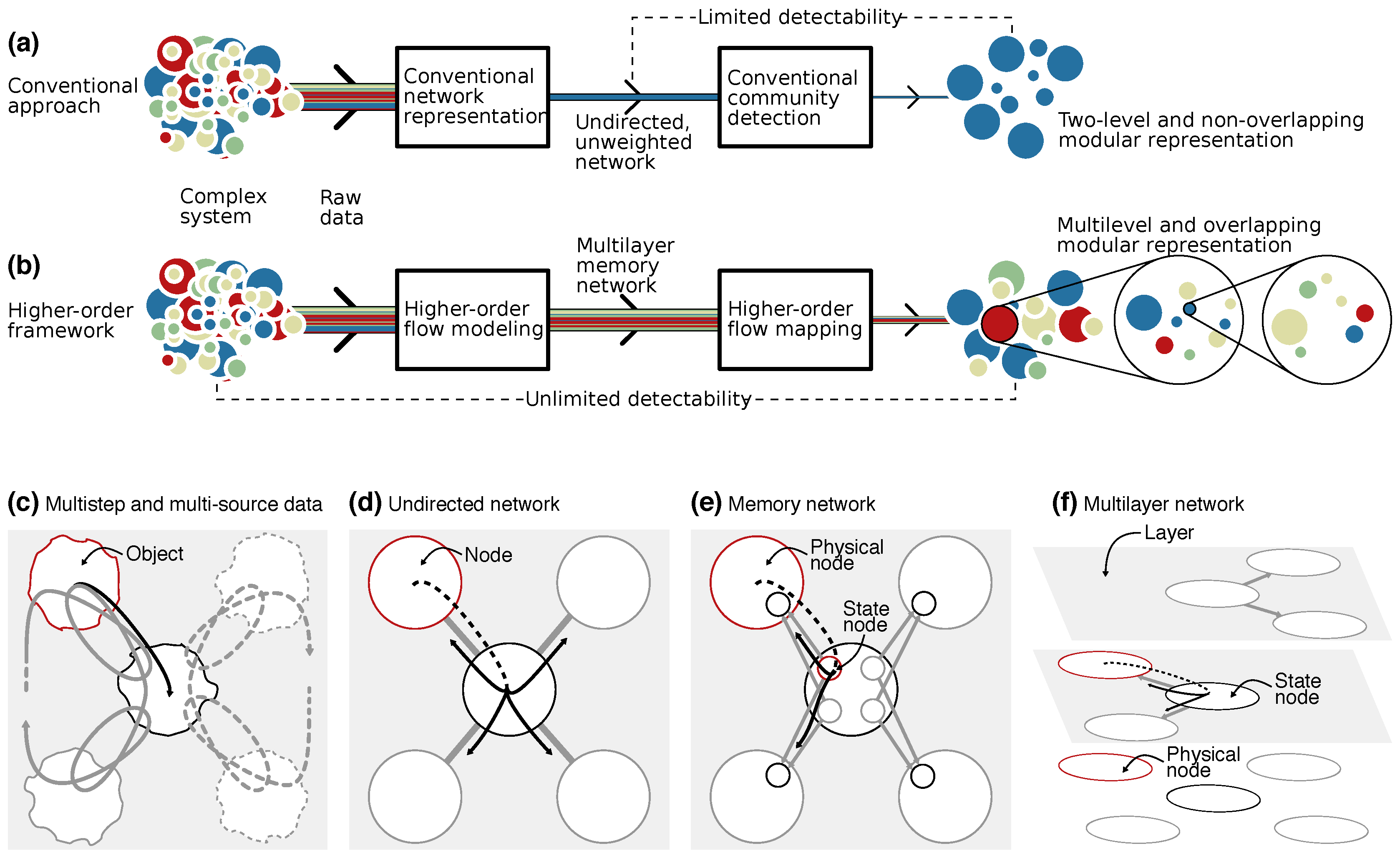
While networks and higher-order models make it possible to describe flows through complex systems, they remain highly complex even when abstracted to nodes and links. Thousands or millions of nodes and links can bury valuable information. To reveal this information, many times it is indispensable to comprehend the organization of large complex systems by assigning nodes into modules with community-detection algorithms. Here we show how the community-detection method known as the map equation can operate on sparse memory networks and allow for versatile mapping of network flows from multistep, multi-source, and temporal data.
3.1. The Map Equation for First-Order Network Flows
When simplifying and highlighting network flows with possibly nested modules, the map equation measures how well a modular description compresses the flows [
29]. Because compressing data is dual to finding regularities in the data [
30], minimizing the modular description length of network flows is dual to finding modular regularities in the network flows. For describing movements within and between modules, the map equation uses code books that connect node visits, module exits, and module entries with code words. To estimate the shortest average description length of each code book, the map equation takes advantage of Shannon’s source coding theorem and measures the Shannon entropy of the code word use rates [
30]. Moreover, the map equation uses a hierarchically nested code structure designed such that the description can be compressed if the network has modules in which a random walker tends to stay for a long time. Therefore, with a random walker as a proxy for real flows, minimizing the map equation over all possible network clusterings reveals important modular regularities in network flows.
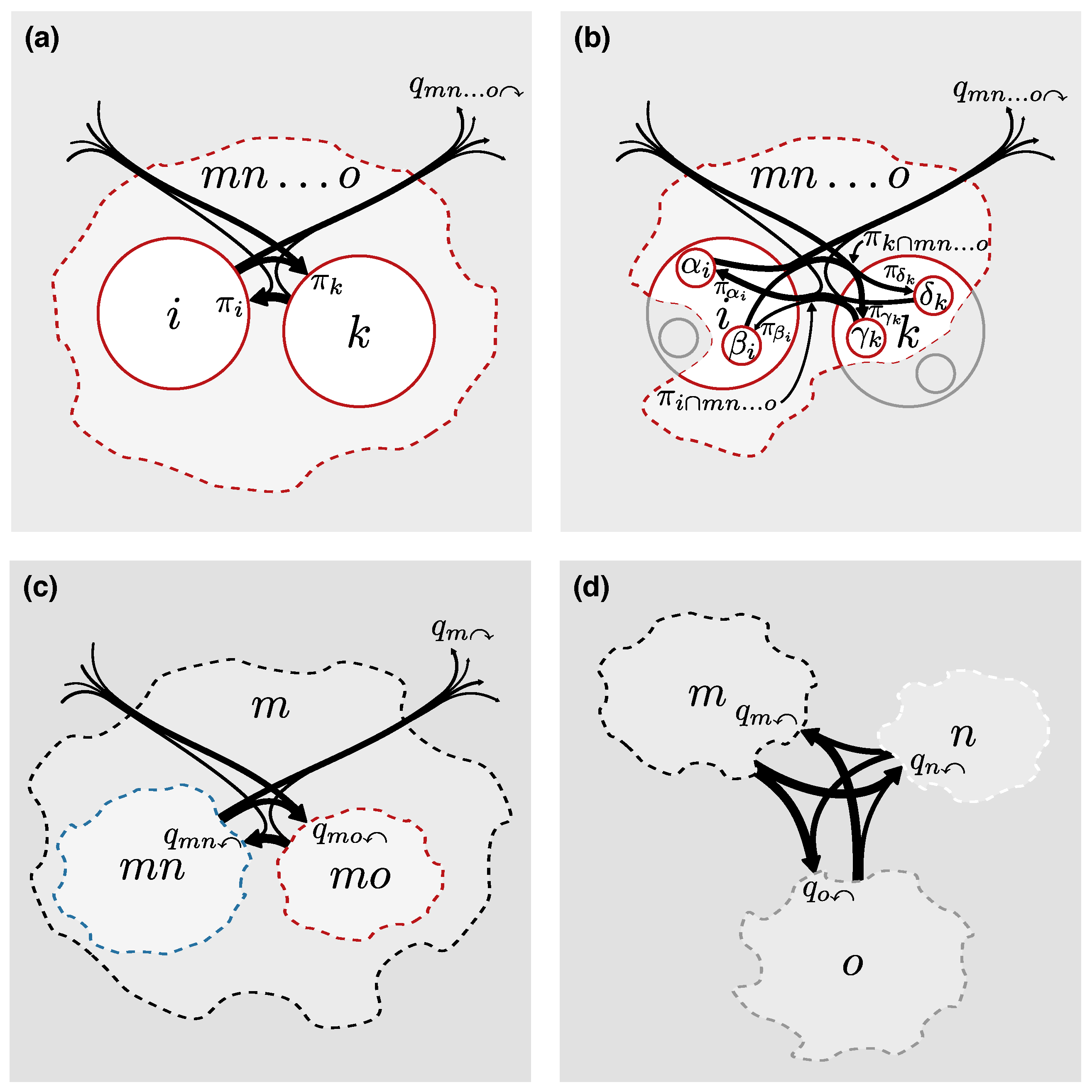
In detail, the map equation measures the minimum average description length for a multilevel map
of
N physical nodes clustered into
M modules, for which each module
m has a submap
with
submodules, for which each submodule
has a submap
with
submodules, and so on (
Figure 3). In each submodule
at the finest level, the code word use rate for exiting a module is
and the total code word use rate for also visiting nodes in a module is
such that the average code word length is
Weighting the average code word length of the code book for module
at the finest level by its use rate gives the contribution to the description length,
In each submodule
m at intermediate levels, the code word use rate for exiting to a coarser level is
and for entering the
submodules
at a finer level is
Therefore, the total code rate use in submodule
m is
which gives the average code word length
Weighting the average code word length of the code book for module
m at intermediate levels by its use rate, and adding the description lengths of submodules at finer levels in a recursive fashion down to the finest level in Equation (14), gives the contribution to the description length,
At the coarsest level, there is no coarser level to exit to, and the code word use rate for entering the
M submodules
at a finer level is
such that the total code rate use at the coarsest level is
which gives the average code word length
Weighting the average code word length of the code book at the coarsest level by its use rate, and adding the description lengths of submodules at finer levels from Equation (19) in a recursive fashion, gives the multilevel map equation [
31]
To find the multilevel map that best represents flows in a network, we seek the multilevel clustering of the network that minimizes the multilevel map equation over all possible multilevel clusterings of the network (see Algorithm 1 in
Section 4).
While there are several advantages with the multilevel description, including potentially better compression and effectively eliminated resolution limit [
32], for simplicity researchers often choose two-level descriptions. In this case, there are no intermediate submodules and the two-level map equation is
3.2. The Map Equation for Higher-Order Network Flows
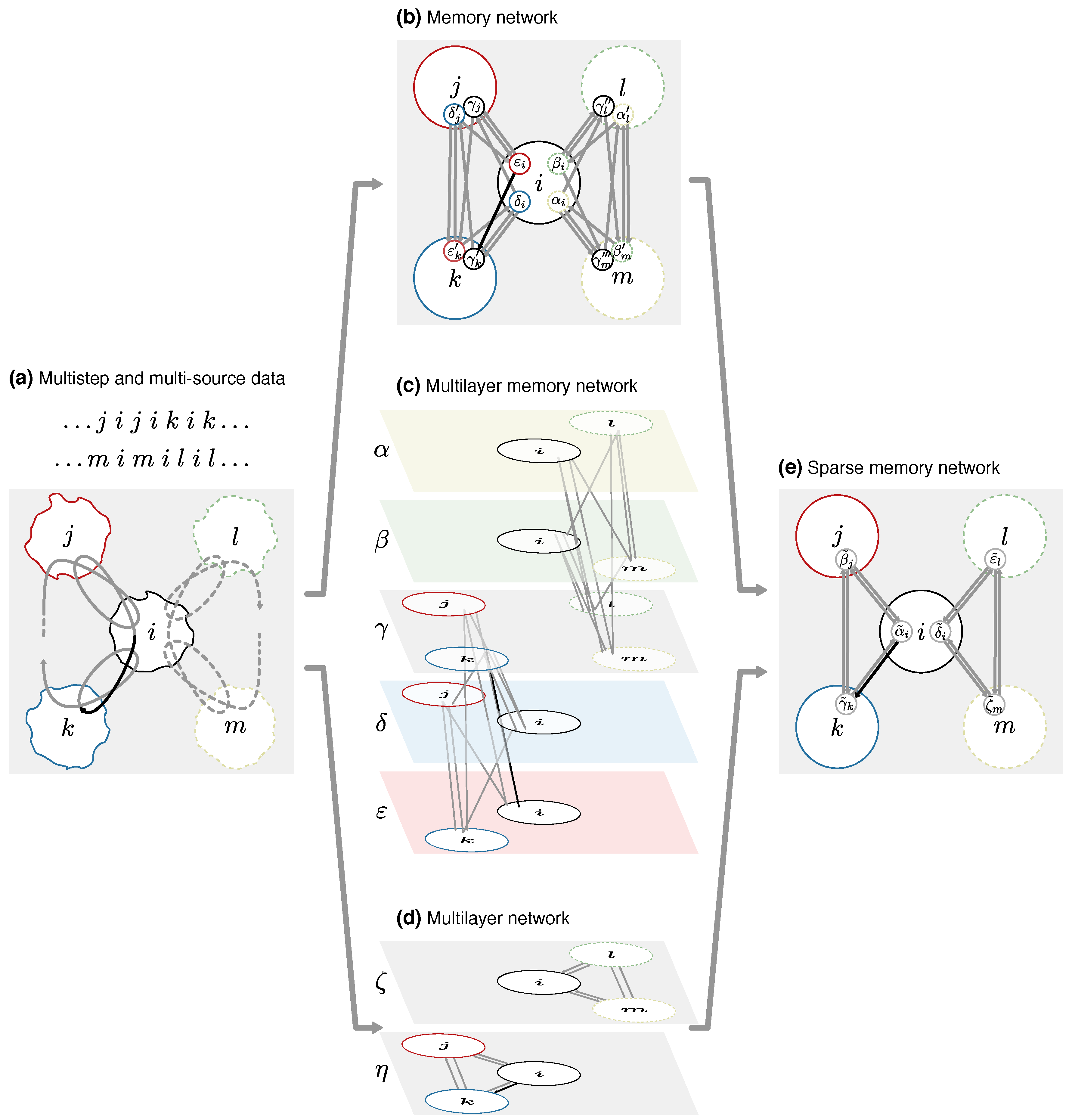
The map equation for first-order network flows measures the description length of a random walker stepping between physical nodes within and between modules. This principle remains the same also for higher-order network flows, although higher-order models guide the random walker between physical nodes with the help of state nodes. Therefore, extending the map equation to higher-order network flows, including those described by memory, multilayer, and sparse memory networks, is straightforward. Equations (11) to (24) remain the same with
and
. The only difference is at the finest level (
Figure 3b). State nodes of the same physical node assigned to the same module should share code word, or they would not represent the same object. That is, if multiple state nodes
of the same physical node
i are assigned to the same module
, we first sum their probabilities to obtain the visit rate of physical node
i in module
,
In this way, the frequency weighted average code word length in submodule codebook
in Equation (13) becomes
where the sum is over all physical nodes that have state nodes assigned to module
. In this way, the map equation can measure the modular description length of state-node-guided higher-order flows between physical nodes.
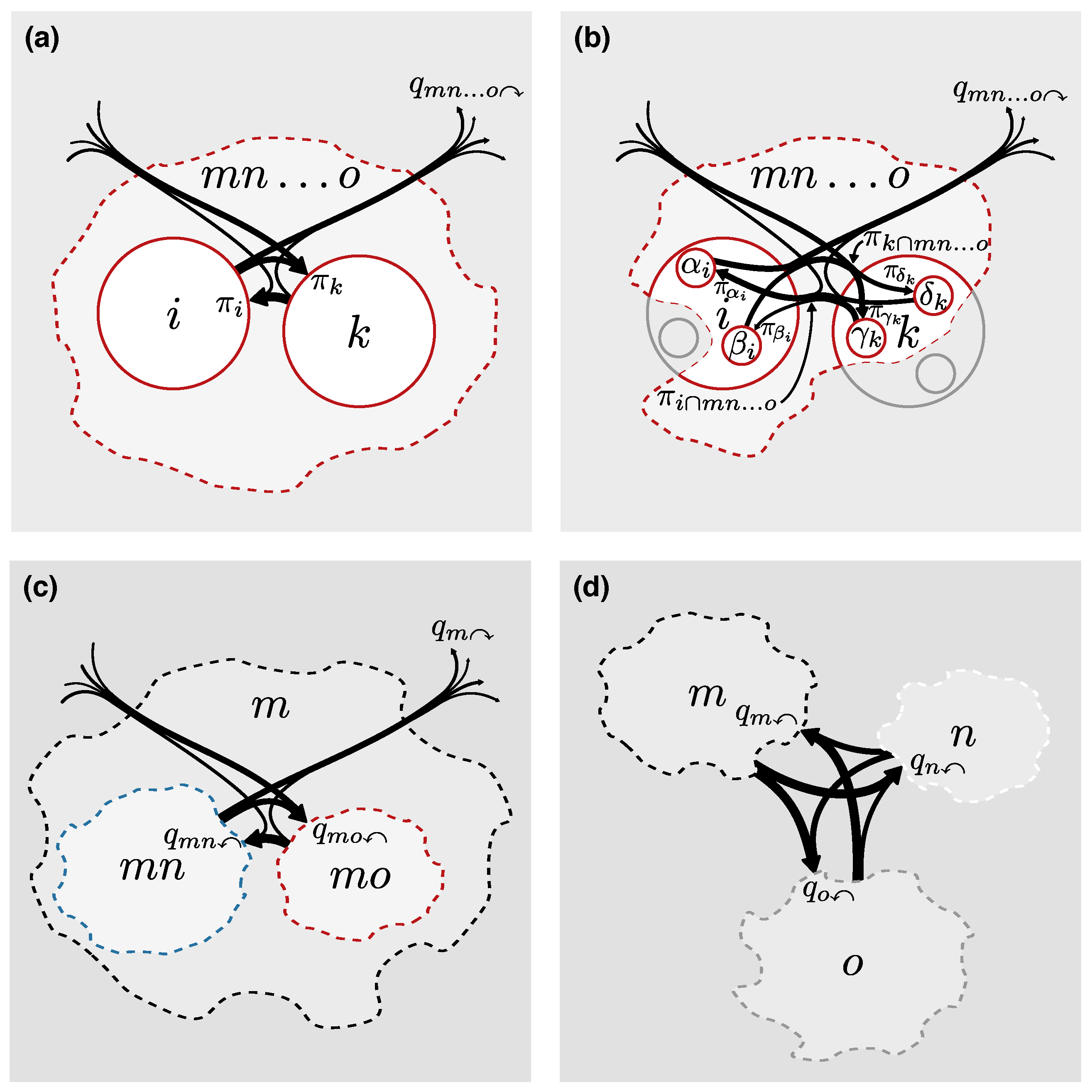
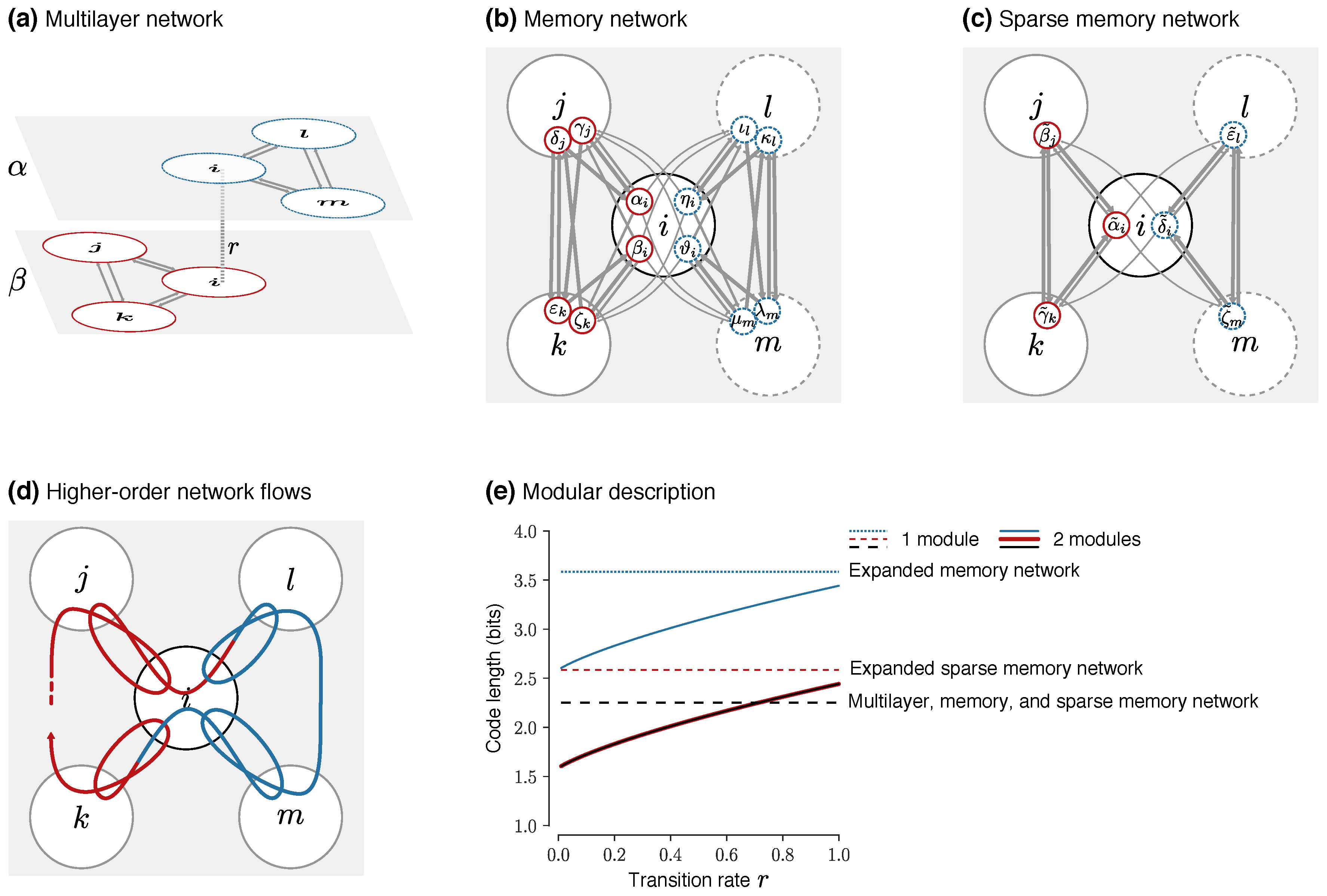
To illustrate that the separation between physical nodes and state nodes matters when clustering higher-order network flows, we cluster the red state nodes and the dashed blue state nodes in
Figure 4 in two different modules overlapping in the center physical node. For a more illustrative example, we also allow transitions between red and blue nodes at rate
r/2 in the center physical node. In the memory and sparse memory networks, the transitions correspond to links from state nodes in physical node
i to state nodes in the other module with relative weight
r/2 and to the same module with relative weight
/2 (Figurs
Figure 4b,c). In the multilayer network, the transitions correspond to relax rate
r according to Equation (6), since relaxing to any layer in physical node
i with equal link weights in both layers means that one half of relaxed flows switch layer (
Figure 4a). Independent of the relax rate, in these symmetric networks the node visit rates are uniformly distributed:
for each of the six state nodes in the multilayer and sparse memory networks, and
for each of the twelve state nodes in the memory network. For illustration, if we incorrectly treat state nodes as physical nodes in the map equation, Equations (11) to (24), the one-module clustering of the memory network with twelve virtual physical nodes,
, has code length
The corresponding two-module clustering of the memory network with twelve virtual physical nodes,
, has code length
Therefore, the two-module clustering gives best compression for all relax rates (
Figure 4e). For the sparse memory network with six virtual physical nodes, the one-module clustering,
, has code length
and the two-module clustering,
, has code length
While the two-module clustering again gives best compression for all relax rates, the code lengths are shifted by 1 bit compared with the memory network with twelve virtual physical nodes (
Figure 4e). Same dynamics but different code length. These expanded solutions with virtual physical nodes do not capture the important and special role that physical nodes play as representatives of a system’s objects.
Properly separating state nodes and physical nodes as in Equation (
26) instead gives equal code lengths for identical clusterings irrespective of representation. For example, the one-module clustering of the memory network with twelve state nodes,
, and the sparse memory network with six state nodes,
, have identical code length
because visits to a physical node’s state nodes in the same module are aggregated according to Equation (
25) such that those state nodes share code words and the encoding represents higher-order flows between a system’s objects. Similarly, the two-module clustering of the memory network with twelve state nodes,
, and the sparse memory network with six state nodes,
, have identical code length
That is, same dynamics give same code length for identical clusterings with proper separation of state nodes and physical nodes.
For these solutions with physical nodes and state nodes that properly capture higher-order network flows, the overlapping two-module clustering gives best compression with relax rate
(
Figure 4e). In this example, the one-module clustering can for sufficiently high relax rate better compress the network flows than the two-module clustering. Compared with the expanded clusterings with virtual physical nodes where this cannot happen, the one-module clustering gives a relatively shorter code length thanks to code word sharing between state nodes in physical node
i. In general, modeling higher-order network flows with physical nodes and state nodes, and accounting for them when mapping the network flows, gives overlapping modular clusterings that do not depend on the particular representation but only on the actual dynamical patterns.



{kind=link}
{kind=link}
{kind=link}
{kind=link}