An Architectural Based Framework for the Distributed Collection, Analysis and Query from Inhomogeneous Time Series Data Sets and Wearables for Biofeedback Applications

 , and
, and
Abstract
:1. Introduction
2. Approach and Implementation
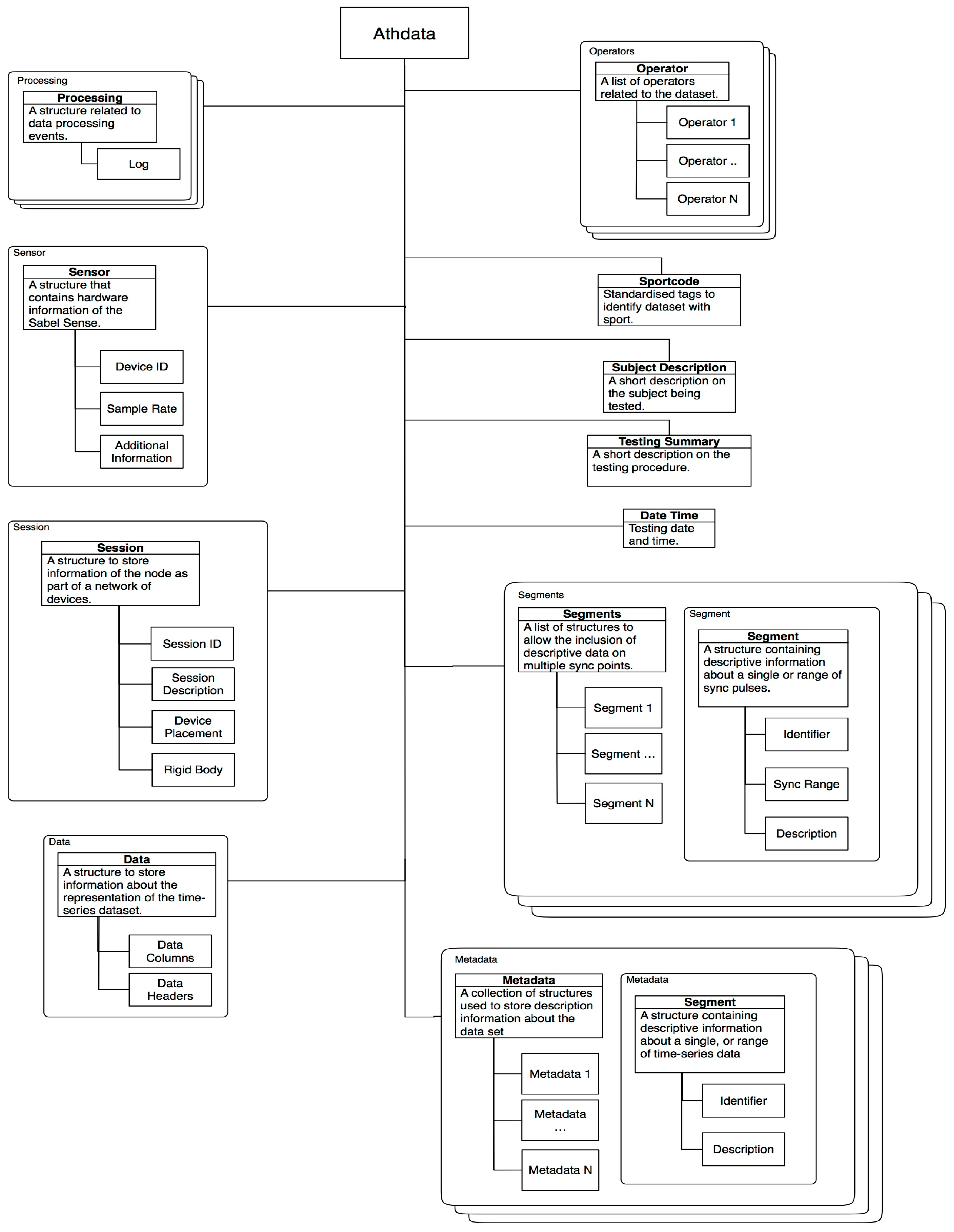
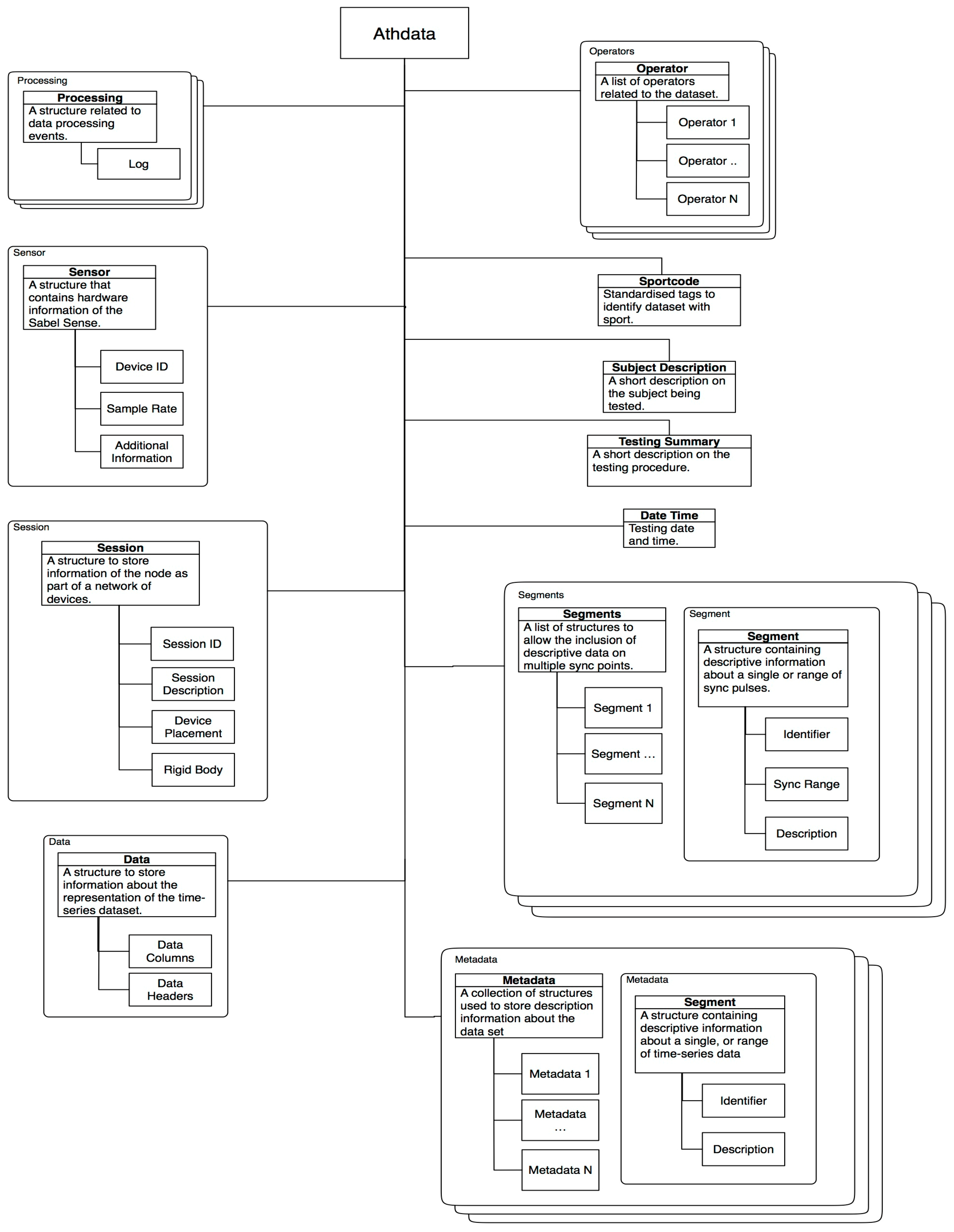
2.1. Homogenenous Datastructure for Inhomogenous Datasets
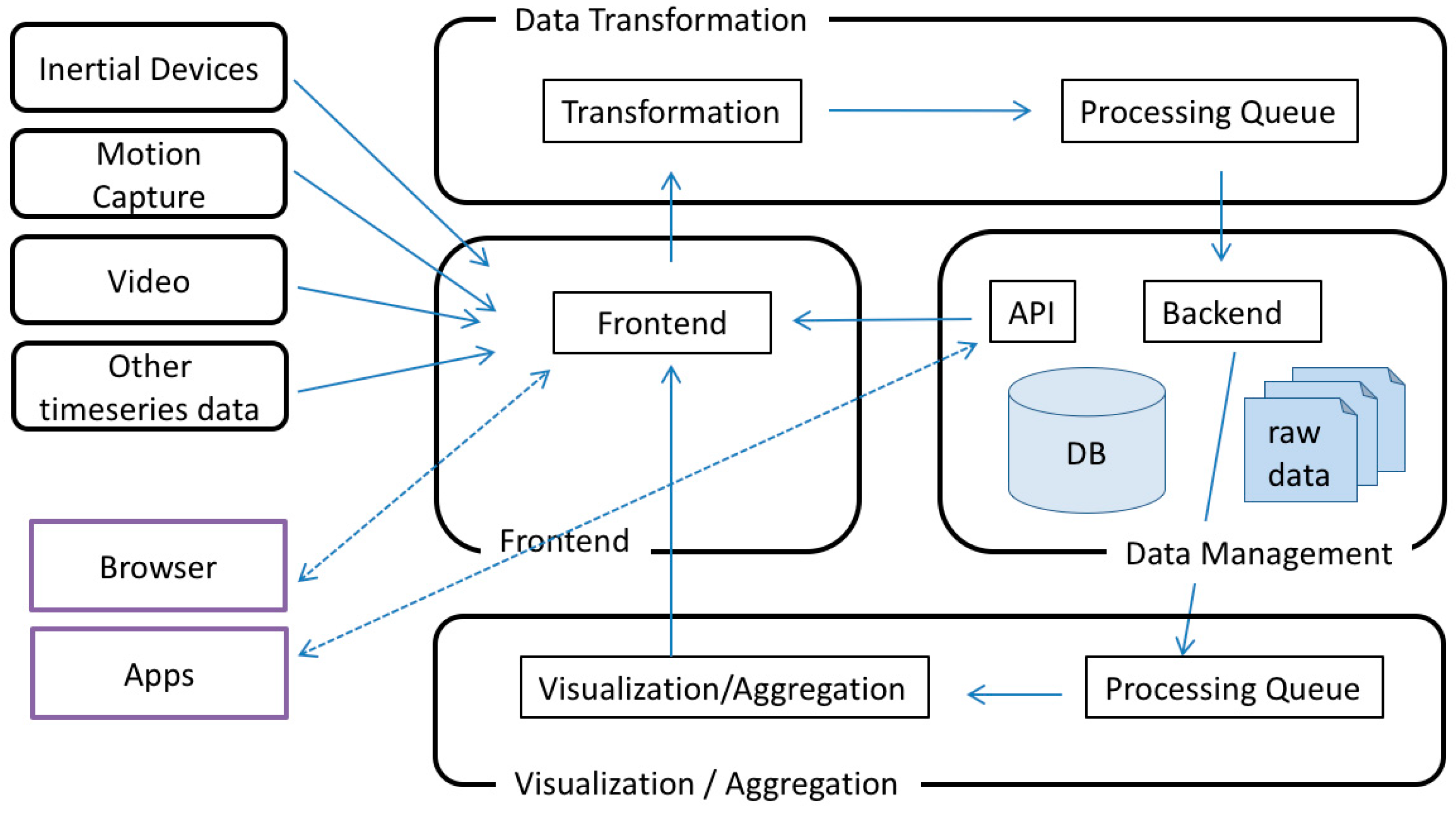
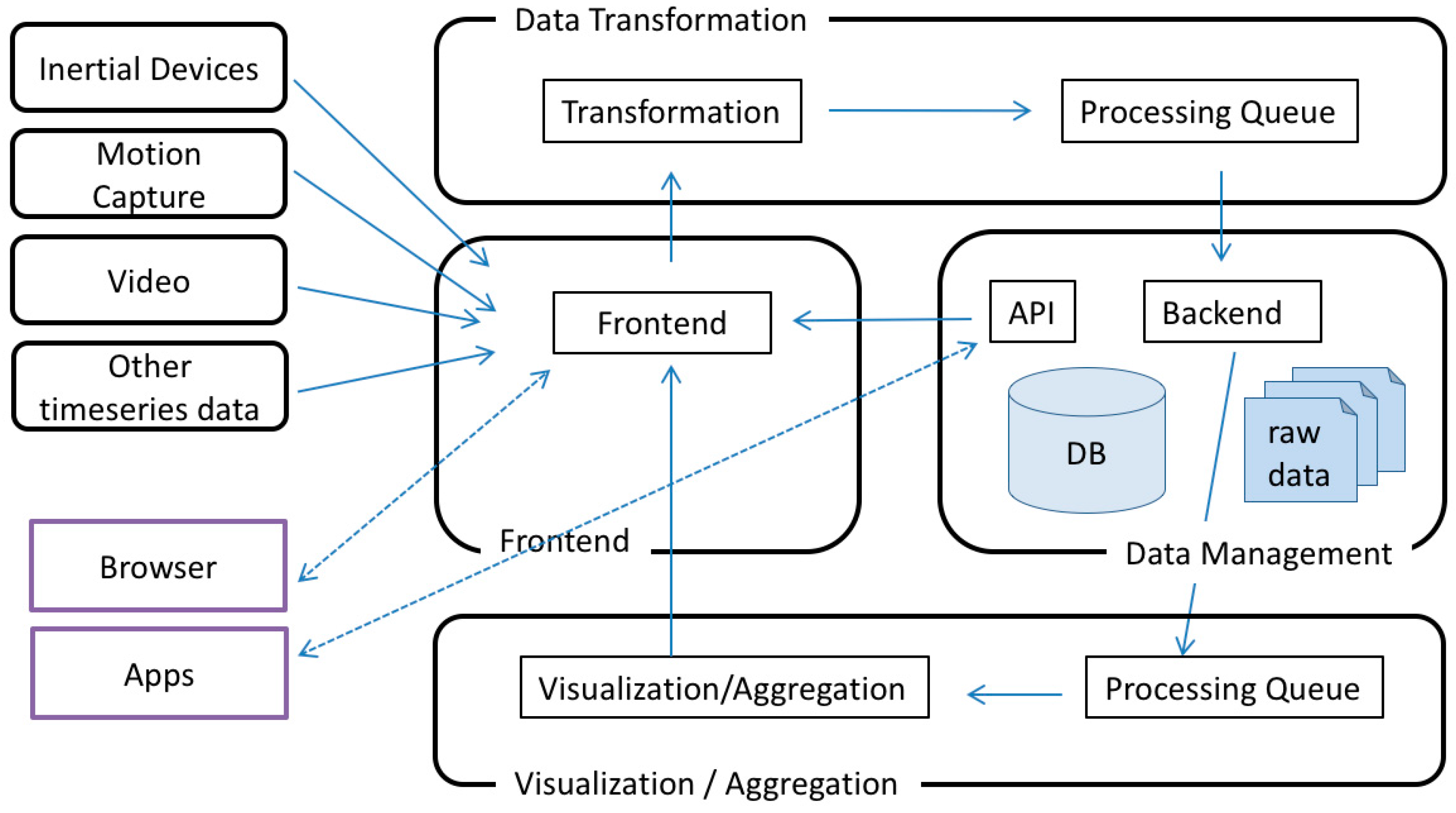
2.2. Framework for the Aggregation and Visualisation of Inhomogeneous Data Sources
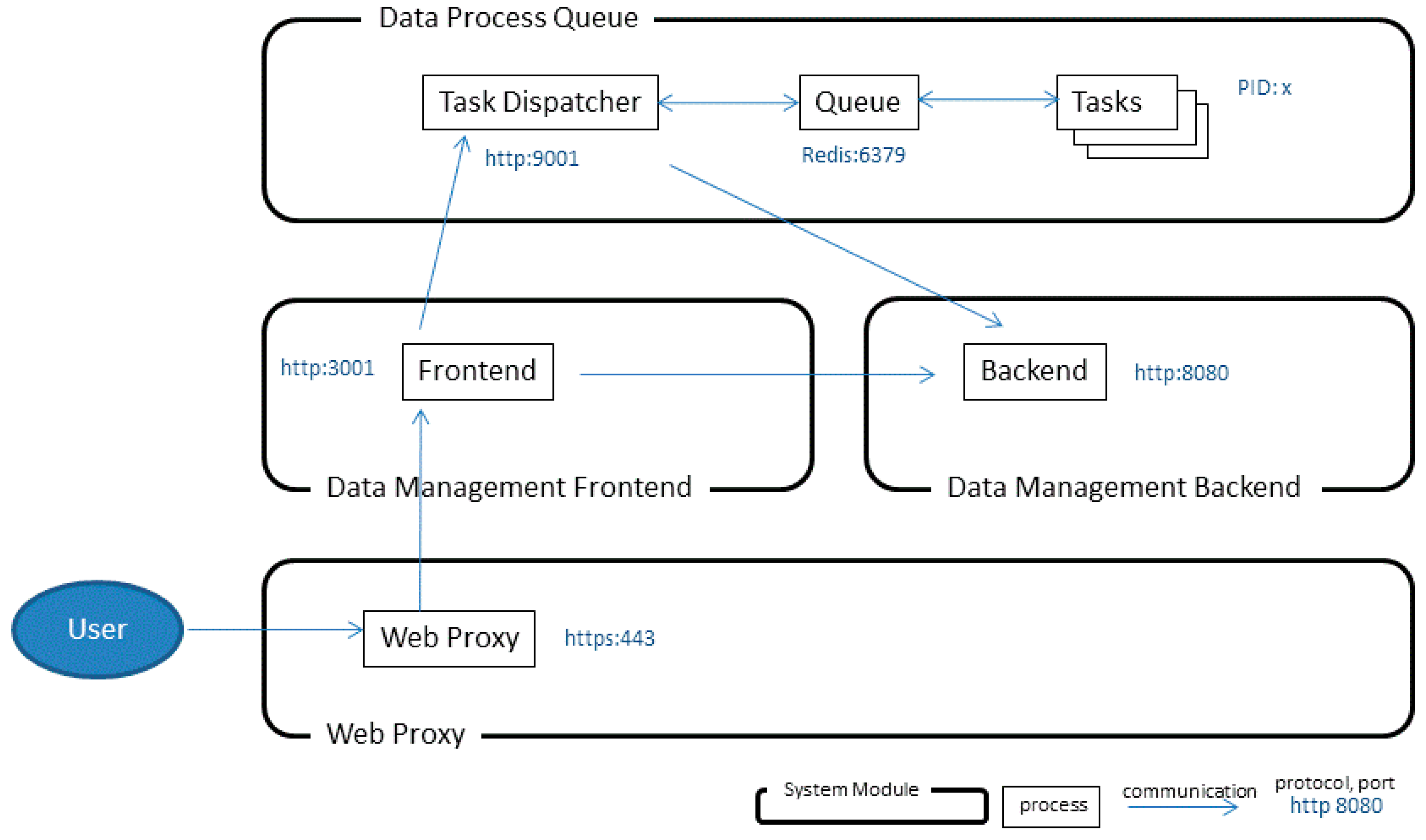
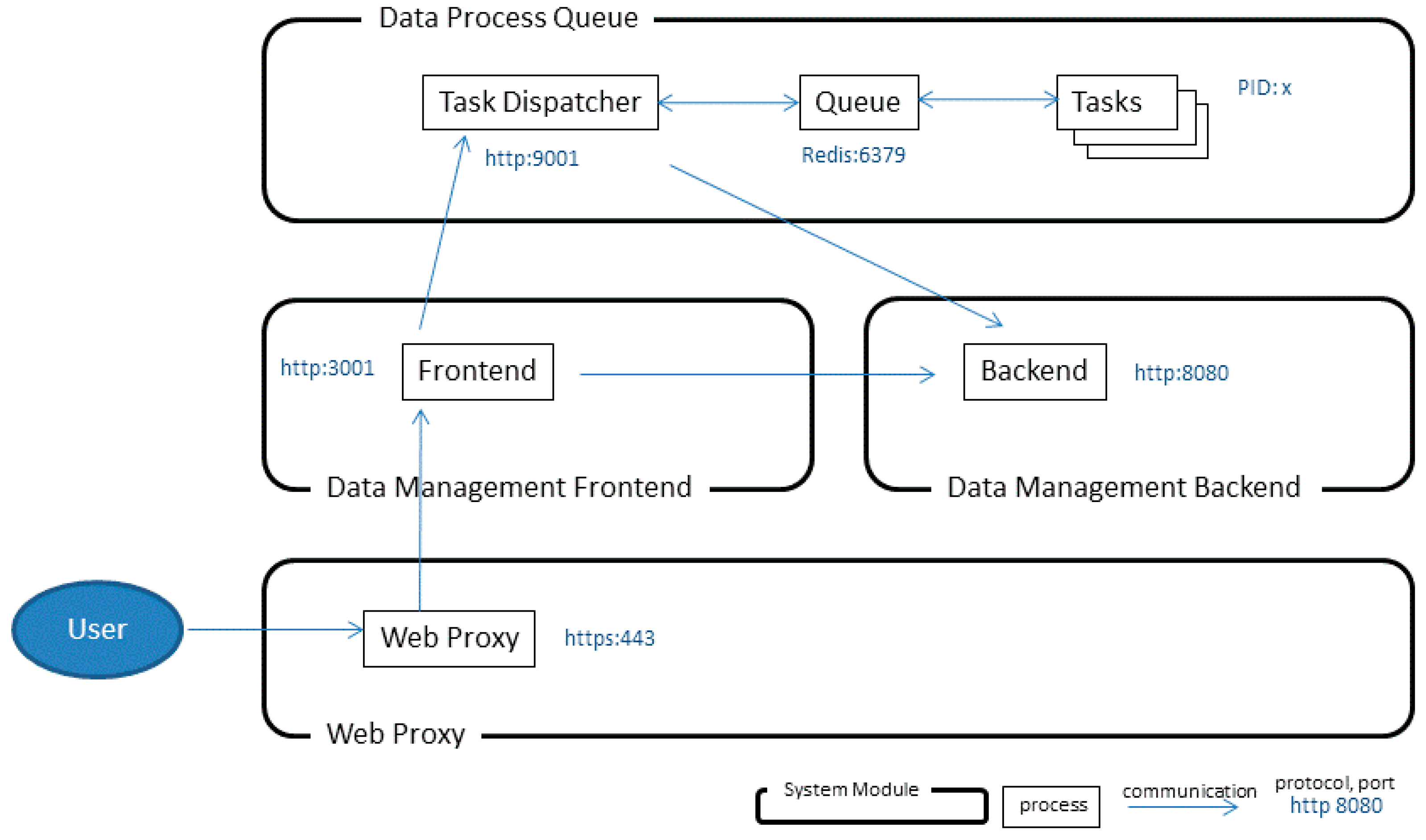
2.3. System Framework
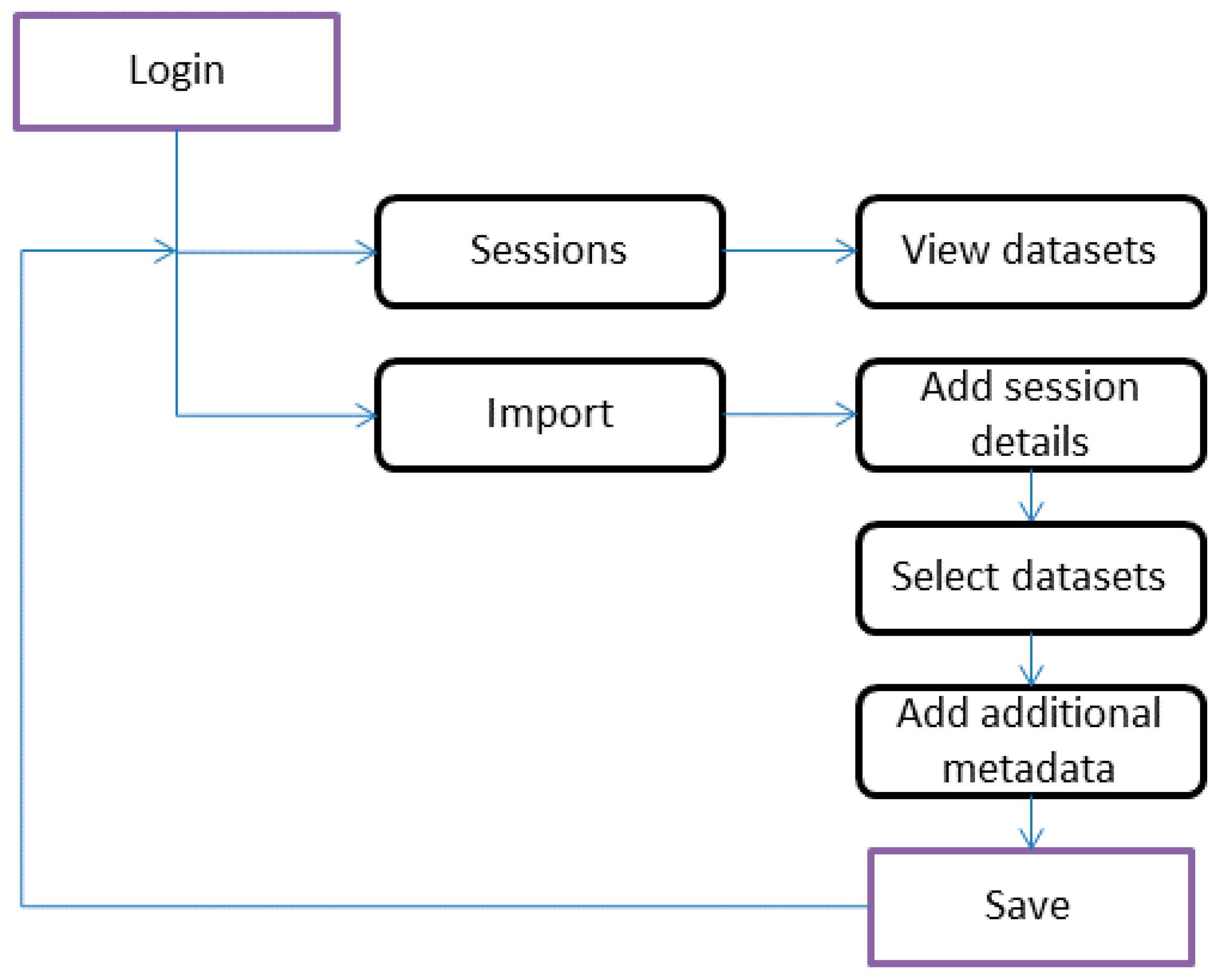
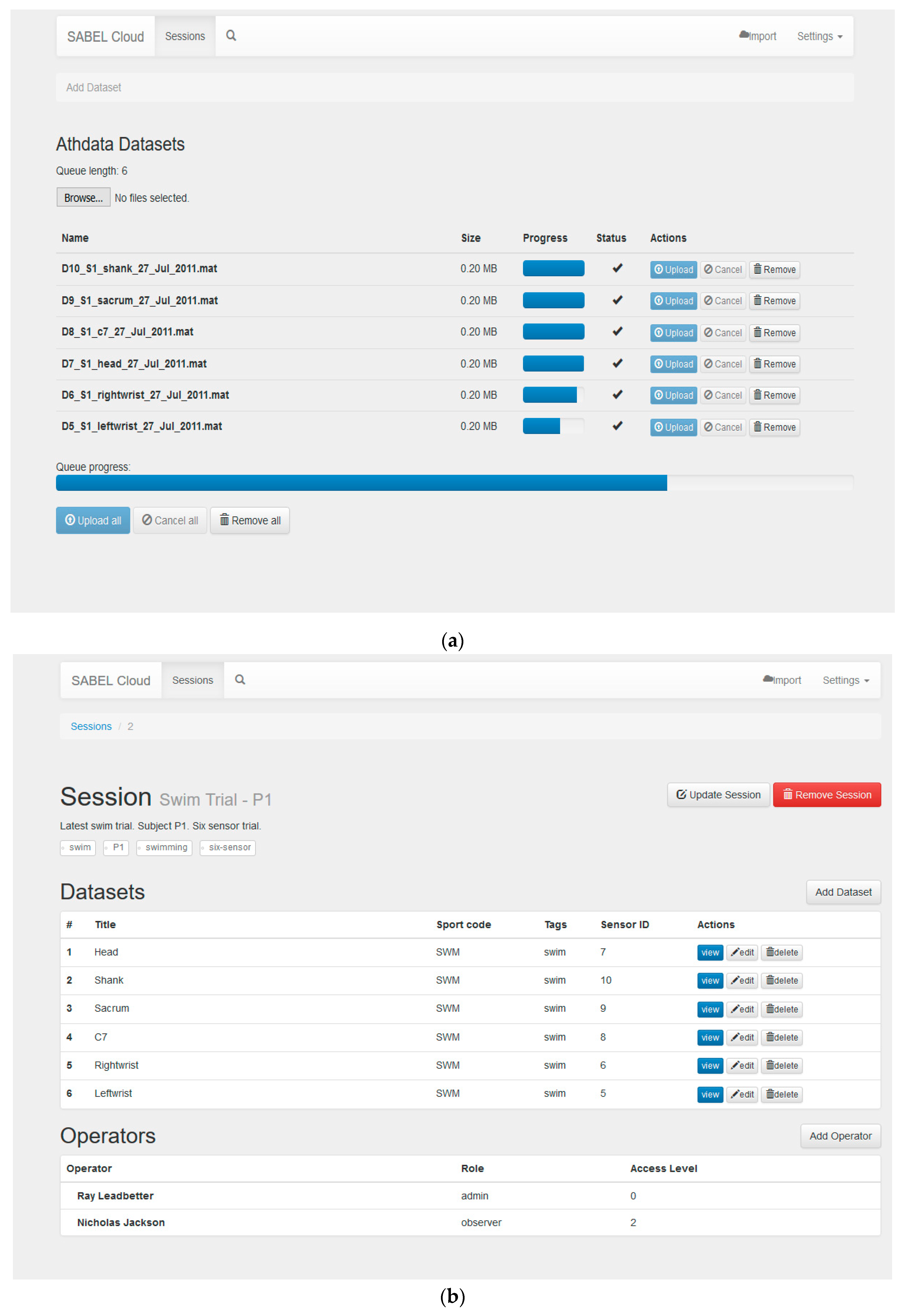
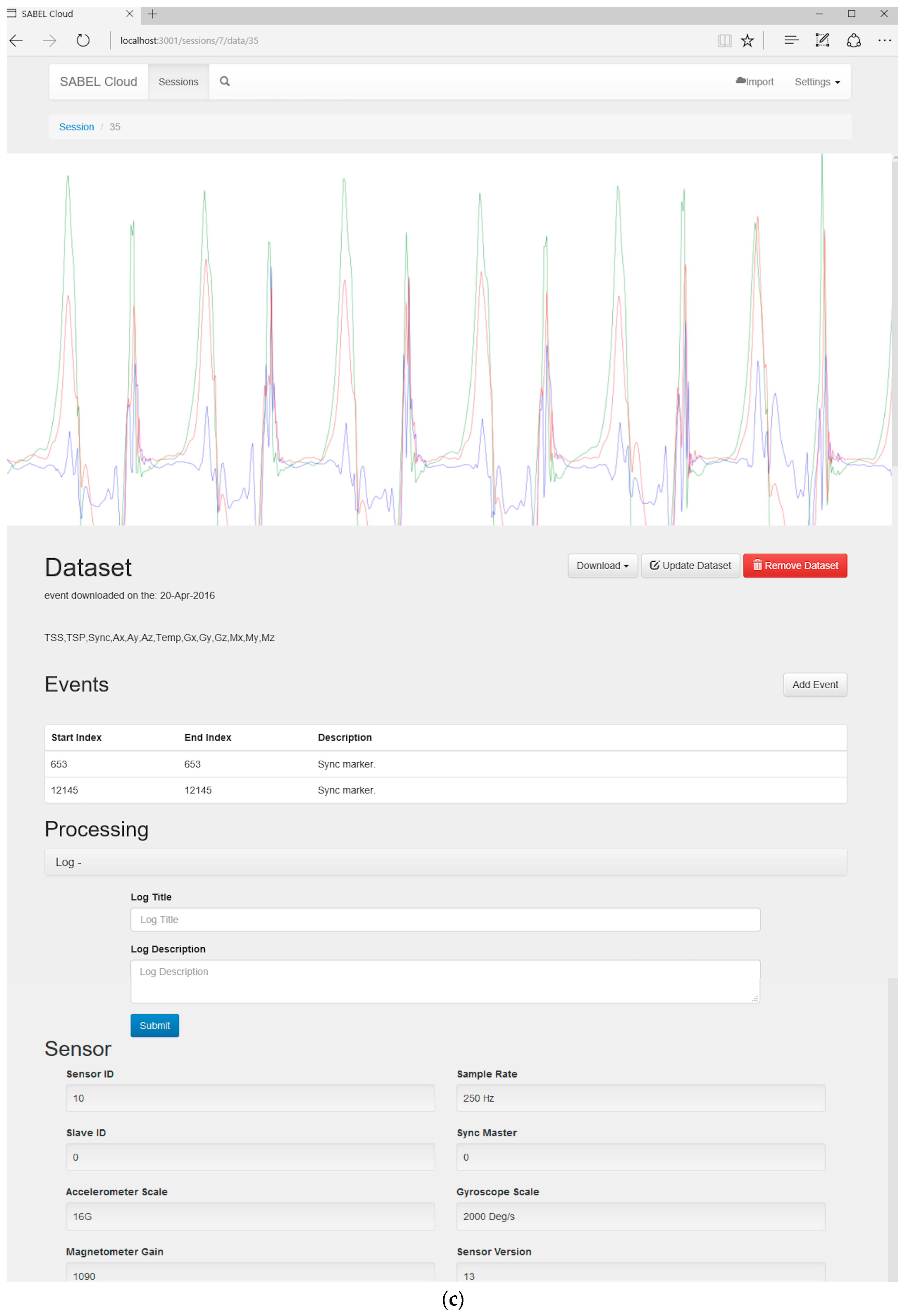
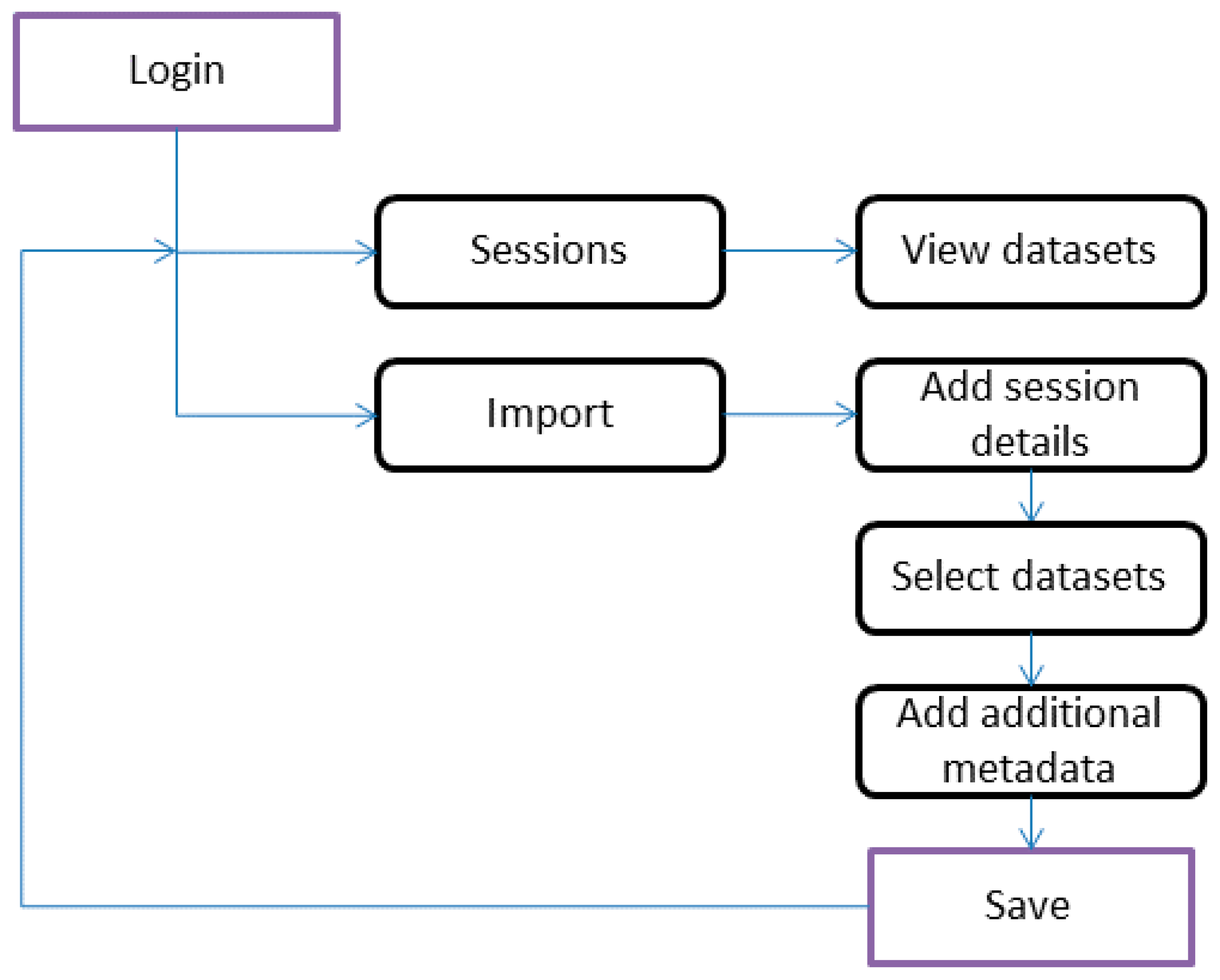
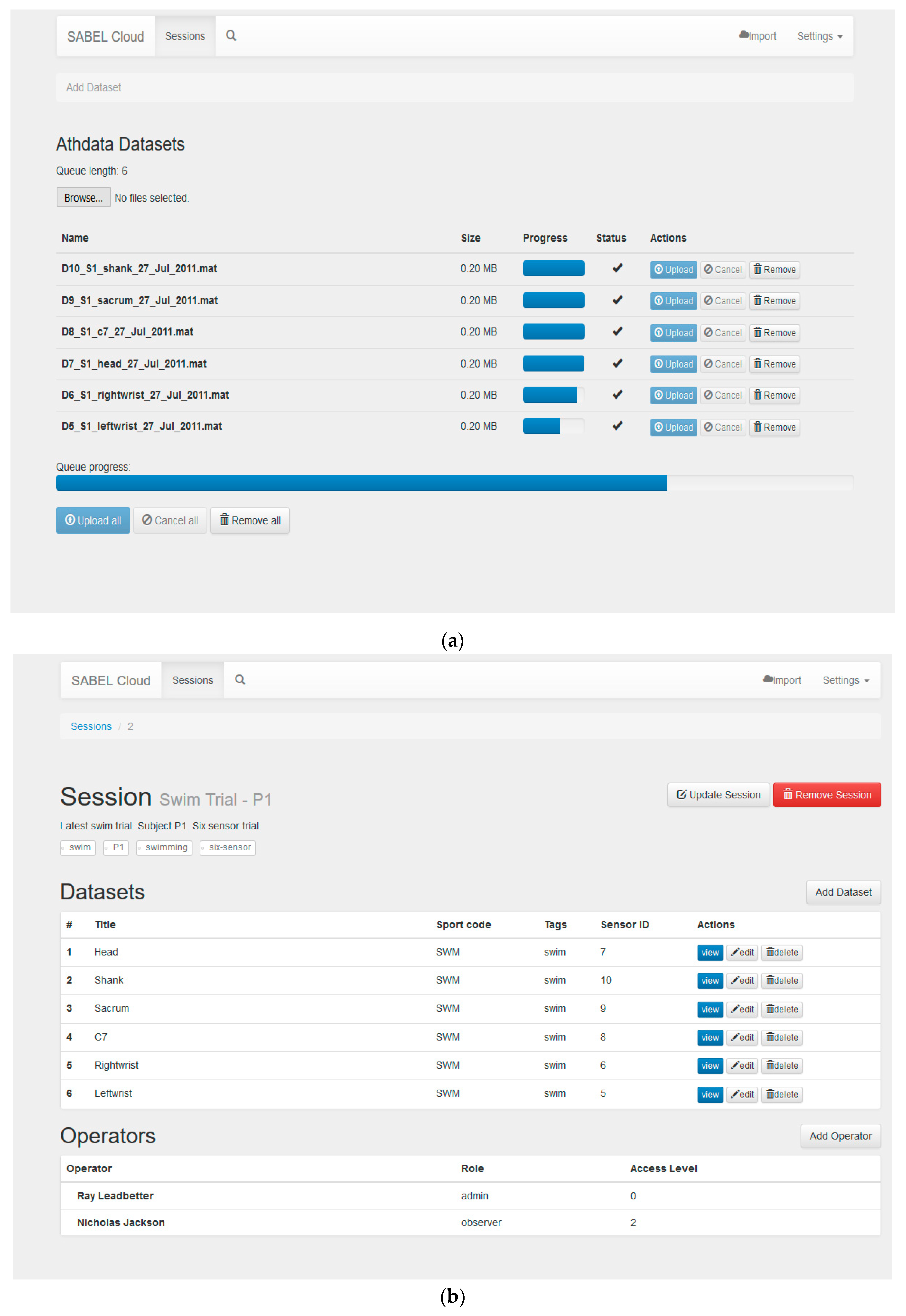
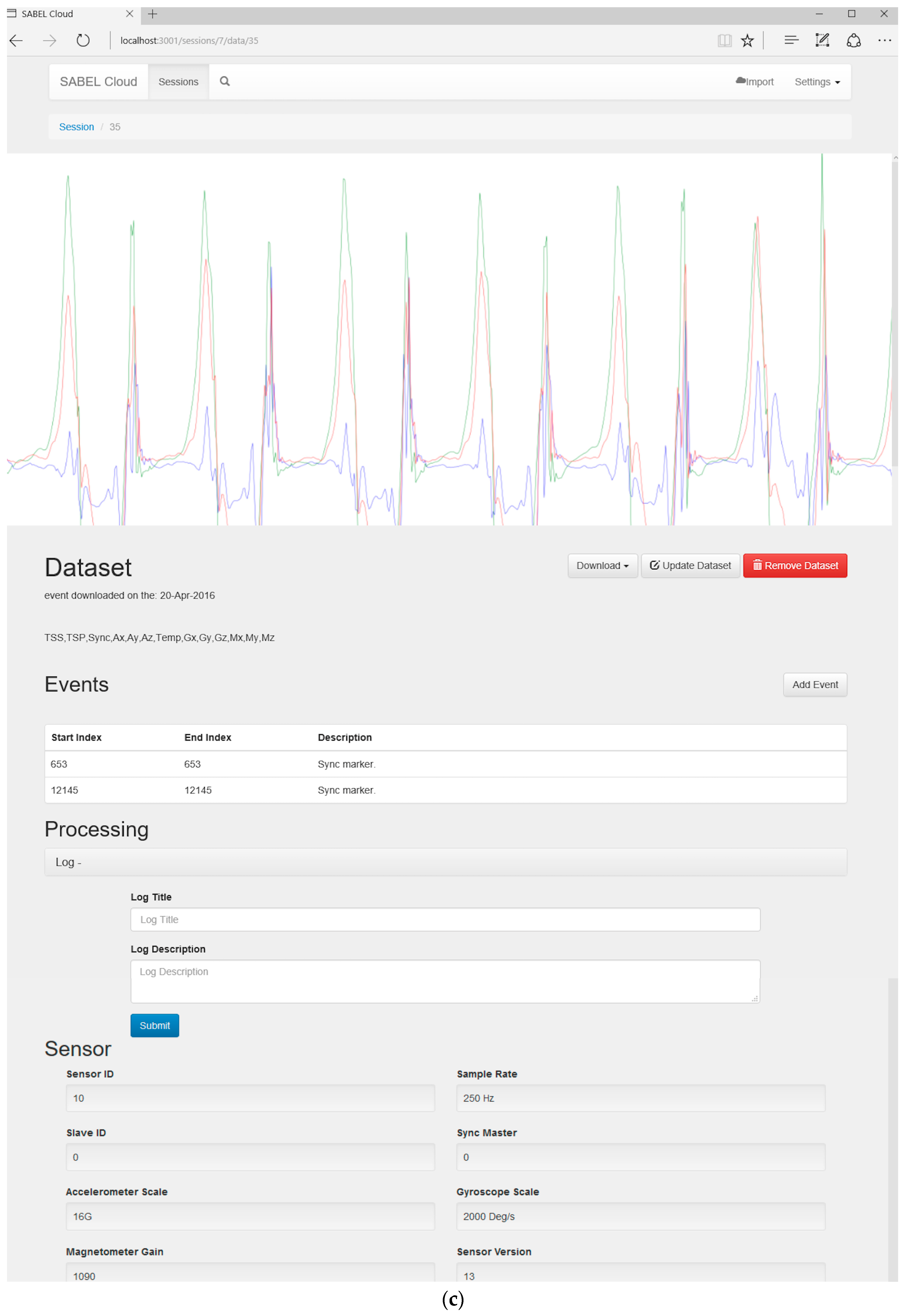
2.4. User Interface and User Workflow
2.5. System Implementation
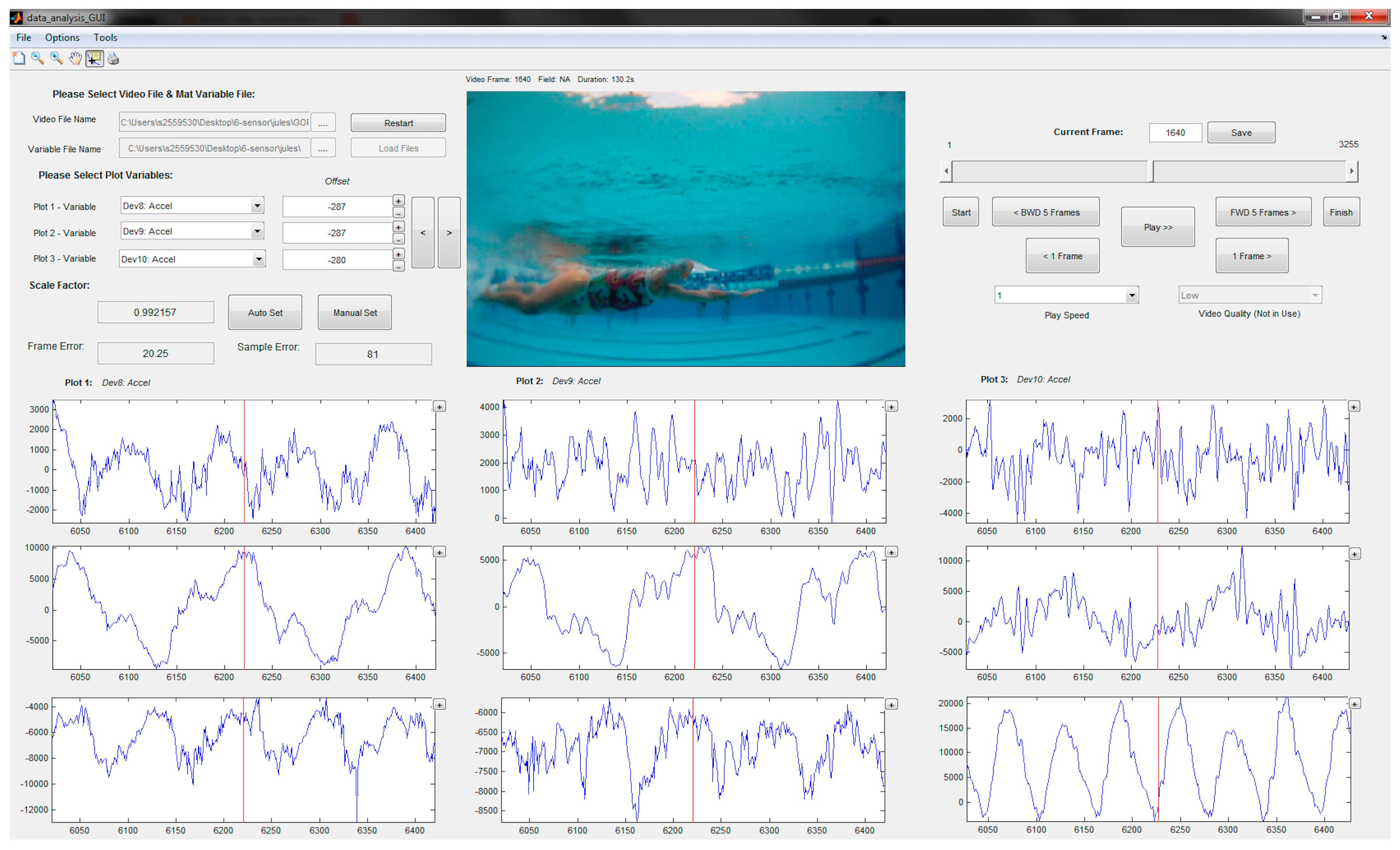
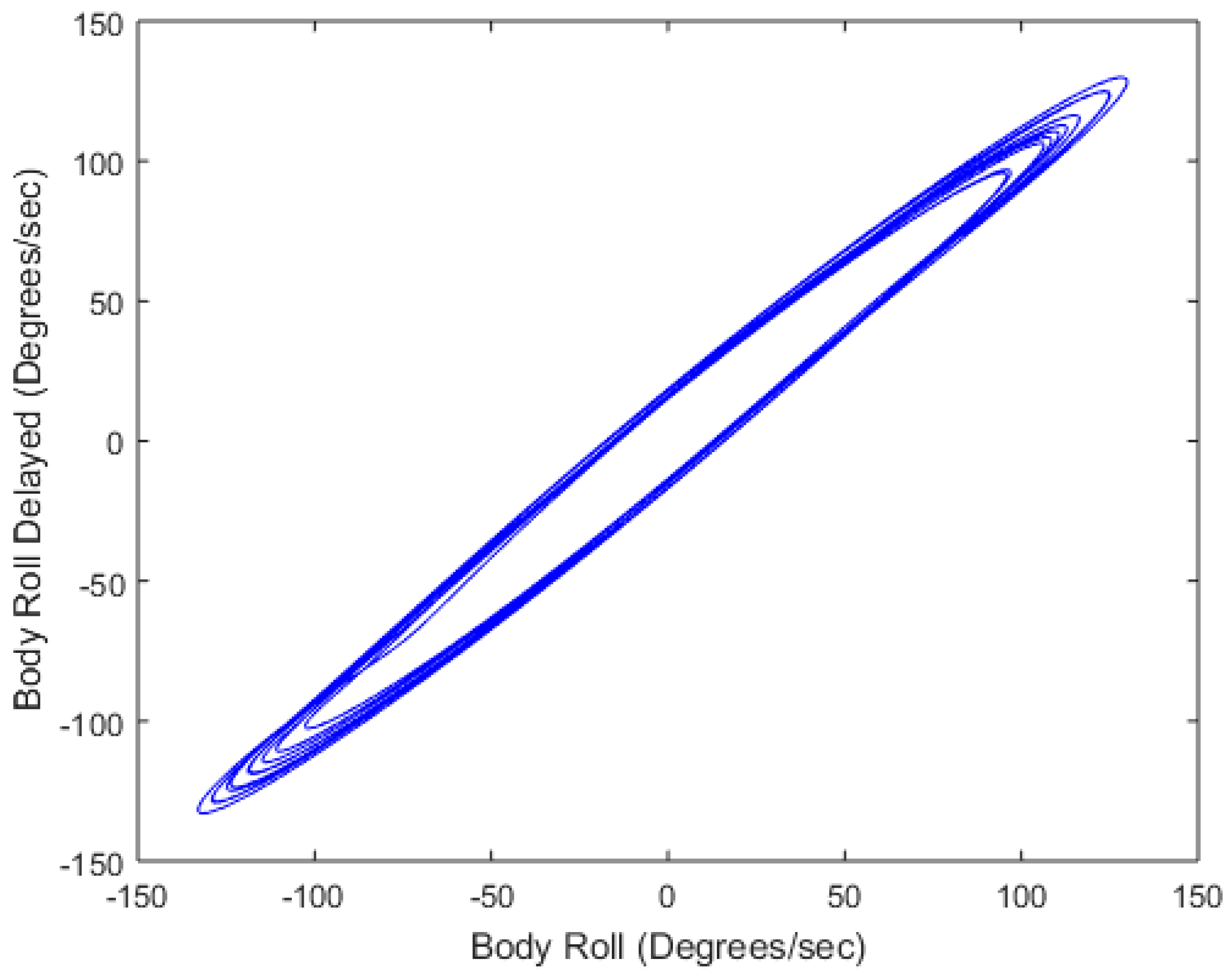
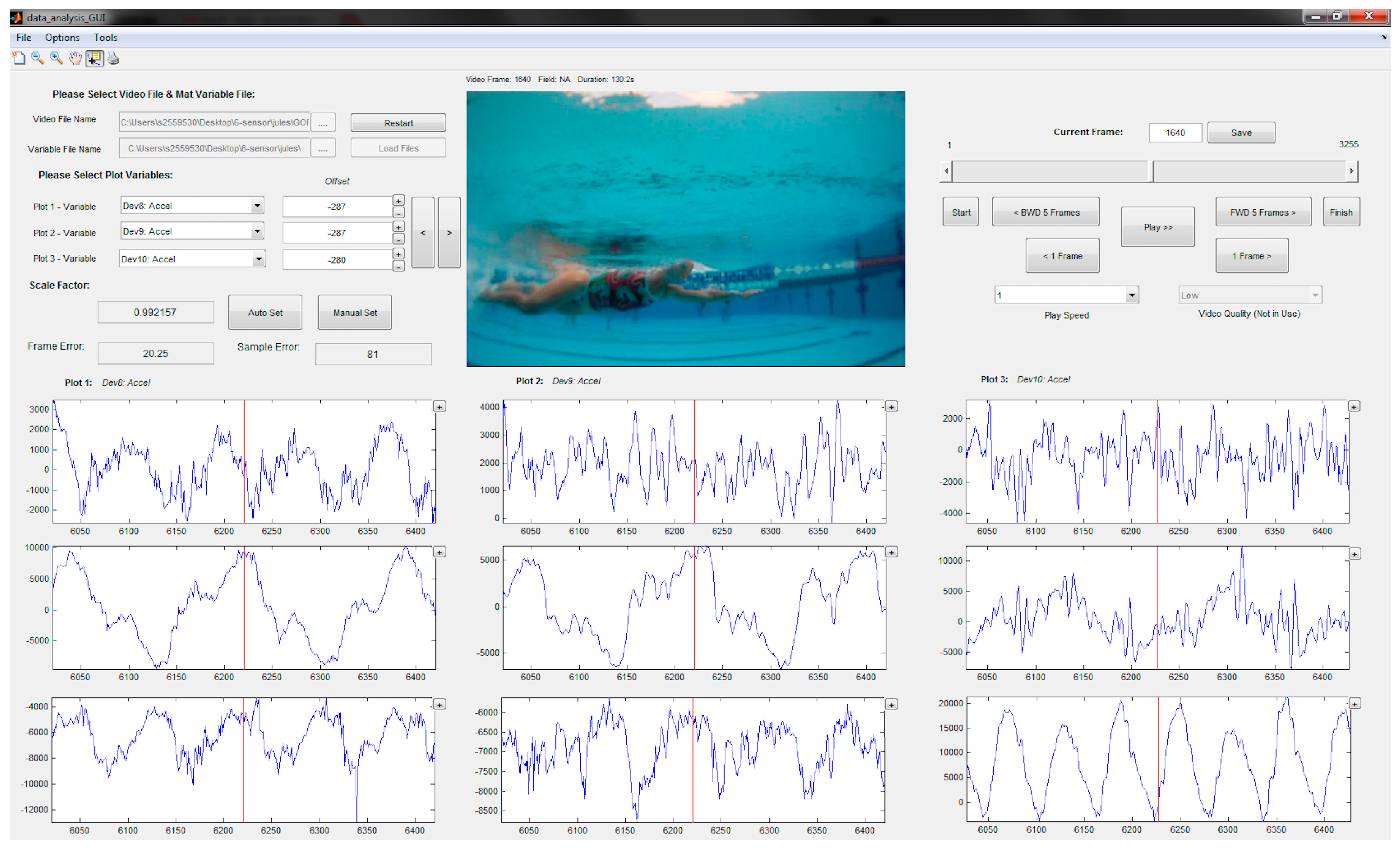
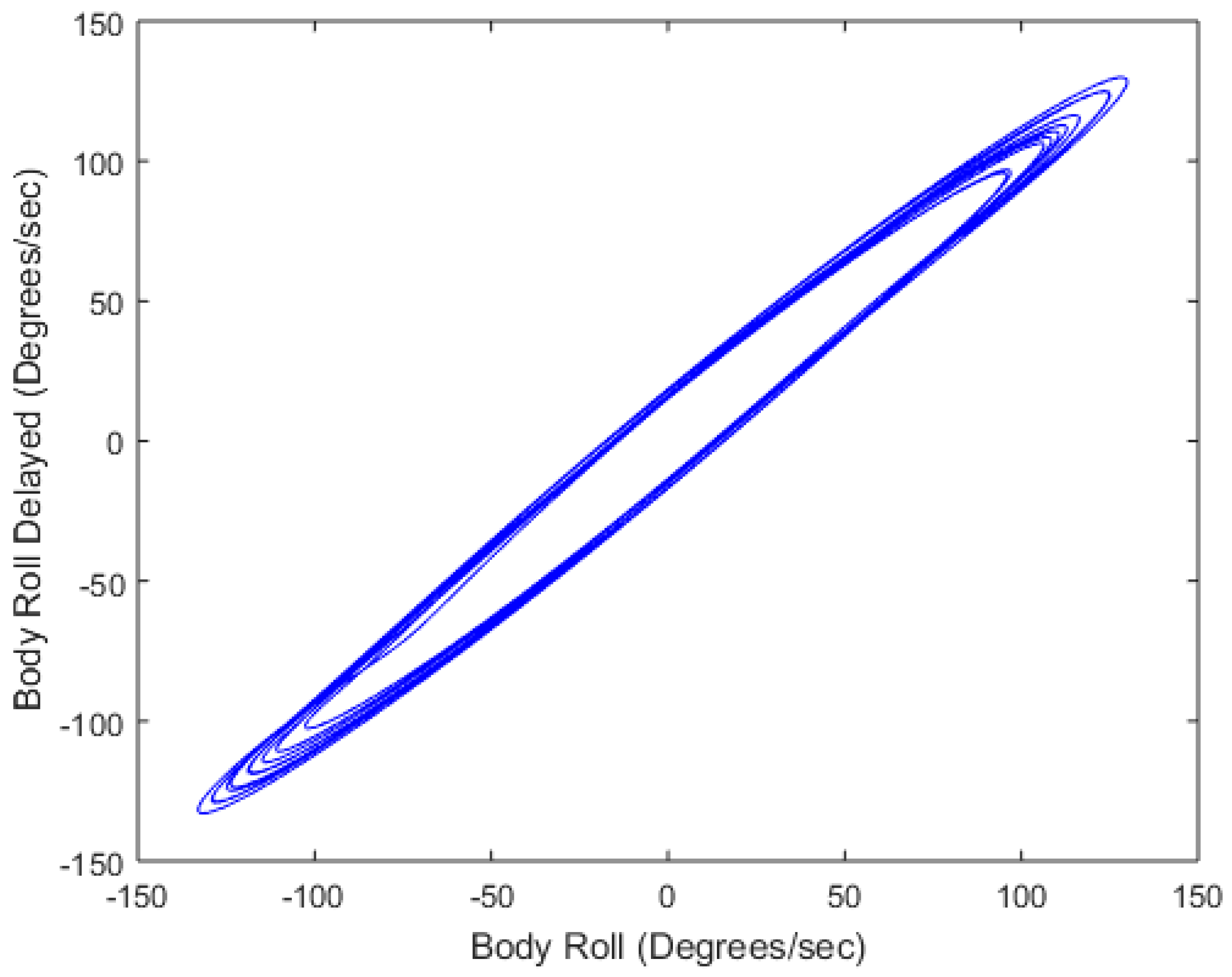
3. Sample Application
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- James, D.A. The application of inertial sensors in elite sports monitoring. In The Engineering of Sport 6; Springer: New York, NY, USA, 2006; pp. 289–294. [Google Scholar]
- Wisbey, B.; Montgomery, P.G.; Pyne, D.B.; Rattray, B. Quantifying movement demands of AFL football using GPS tracking. J. Sci. Med. Sport 2010, 13, 531–536. [Google Scholar] [CrossRef] [PubMed]
- Neville, J.; Wixted, A.; Rowlands, D.; James, D. Accelerometers: An underutilized resource in sports monitoring. In Proceedings of the 2010 Sixth International Conference on Intelligent Sensors, Sensor Networks and Information Processing (ISSNIP), Brisbane, Australia, 7–10 December 2010; pp. 287–290.
- Cutmore, T.R.; James, D.A. Sensors and sensor systems for psychophysiological monitoring: A review of current trends. J. Psychophysiol. 2007, 21, 51–71. [Google Scholar] [CrossRef]
- McNab, T.; James, D.A.; Rowlands, D. iPhone sensor platforms: Applications to sports monitoring. Proc. Eng. 2011, 13, 507–512. [Google Scholar] [CrossRef]
- Wixted, A.J.; Billing, D.C.; James, D.A. Validation of trunk mounted inertial sensors for analysing running biomechanics under field conditions, using synchronously collected foot contact data. Sports Eng. 2010, 12, 207–212. [Google Scholar] [CrossRef]
- Stamm, A.; James, D.A.; Thiel, D.V. Velocity profiling using inertial sensors for freestyle swimming. Sports Eng. 2013, 16, 1–11. [Google Scholar] [CrossRef]
- Spratford, W.; Portus, M.; Wixted, A.; Leadbetter, R.; James, D.A. Peak outward acceleration and ball release in cricket. J. Sport Sci. 2015, 33, 754–760. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.B.; Ohgi, Y.; James, D.A. Sensor fusion: Let’s enhance the performance of performance enhancement. Proc. Eng. 2012, 34, 795–800. [Google Scholar] [CrossRef]
- Ride, J.; Ringuet, C.; Rowlands, D.; Lee, J.; James, D. A sports technology needs assessment for performance monitoring in swimming. Proc. Eng. 2013, 60, 442–447. [Google Scholar] [CrossRef]
- Deng, Z.; Yang, P.; Zhao, Y.; Zhao, X.; Dong, F. Life-Logging Data Aggregation Solution for Interdisciplinary Healthcare Research and Collaboration. In Proceedings of the 2015 IEEE International Conference on Computer and Information Technology; Ubiquitous Computing and Communications; Dependable, Autonomic and Secure Computing; Pervasive Intelligence and Computing (CIT/IUCC/DASC/PICOM), Liverpool, UK, 26–28 October 2015; pp. 2315–2320.
- McGregor, A.; Bennett, D.; Majumdar, S.; Nandy, B.; Melendez, J.O.; St-Hilaire, M.; Lau, D.; Liu, J. A Cloud-Based Platform for Supporting Research Collaboration. In Proceedings of the 2015 IEEE 8th International Conference on Cloud Computing, New York, NY, USA, 27 June–2 July 2015; pp. 1107–1110.
- Kambona, K.; Boix, E.G.; De Meuter, W. An Evaluation of Reactive Programming and Promises for Structuring Collaborative Web Applications. In Proceedings of the 7th Workshop on Dynamic Languages and Applications, New York, NY, USA, 1 July 2013. [CrossRef]
- Ringuet-Riot, C.J.; Hahn, A.; James, D.A. A structured approach for technology innovation in sport. Sports Technol. 2013, 6, 137–149. [Google Scholar] [CrossRef]
- Winter, S.C.; Lee, J.B.; Leadbetter, R.I.; Gordon, S.J. Validation of a single inertial sensor for measuring running kinematics overground during a prolonged run. J. Fit. Res. 2016, 5, 14–23. [Google Scholar]
- Gleadhill, S.; Lee, J.B.; James, D.A. The development and validation of using inertial sensors to monitor postural change in resistance exercise. J. Biomech. 2016, 49, 1259–1263. [Google Scholar] [CrossRef] [PubMed]
- Espinosa, H.G.; Lee, J.B.; Keogh, J.; Grigg, J.; James, D.A. On the use of inertial sensors in educational engagement activities. Proc. Eng. 2015, 1, 262–266. [Google Scholar] [CrossRef]
- The Sports Performance Laboratory, National Institute of Fitness and Sports, Kanoya, Japan. Available online: http://splab.nifs-k.ac.jp/function/ or http://splab.nifs-k.ac.jp/ (accessed on 30 January 2017).
- James, D.A.; Wixted, A. ADAT: A Matlab toolbox for handling time series athlete performance data. Proc. Eng. 2011, 13, 451–456. [Google Scholar] [CrossRef]
- Ride, J.R.; James, D.A.; Lee, J.B.; Rowlands, D.D. A distributed architecture for storing and processing multi channel multi-sensor athlete performance data. Proc. Eng. 2012, 34, 403–408. [Google Scholar] [CrossRef]
- Tilkov, S.; Vinoski, S. Node. js: Using JavaScript to build high-performance network programs. IEEE Internet Comp. 2010, 14, 80. [Google Scholar] [CrossRef]
- Demšar, J.; Curk, T.; Erjavec, A.; Gorup, Č.; Hočevar, T.; Milutinovič, M.; Možina, M.; Polajnar, M.; Toplak, M.; Starič, A.; et al. Orange: Data mining toolbox in Python. J. Mach Lng. Res. 2013, 14, 2349–2353. [Google Scholar]
- James, D.A.; Leadbetter, R.I.; Neeli, M.R.; Burkett, B.J.; Thiel, D.V.; Lee, J.B. An integrated swimming monitoring system for the biomechanical analysis of swimming strokes. Sports Technol. 2011, 4, 141–150. [Google Scholar] [CrossRef]
- Rowlands, D.; James, D.; Lee, J.B. Visualization of wearable sensor data during swimming for performance analysis. Sports Technol. 2013, 6, 130–136. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Site 1: Wearable Technology Enterprise | |||
| Data Source | Description | Sample Bandwidth | Interpretation |
| Inertial sensor (SABEL Sense) | 9 DoF inertial sensors | 9 × (25–250) Hz | Extensive data processing |
| 3D Motion Capture (Vicon, Oxford, UK) [15] * | 20 markers | 20 × 50 Hz | Conversion from gait model to frame of reference data |
| 2D Video Data (Panasonic HC-V759M) [15] * | 50 Hz HD video | 45 Mbps | For visual comparison |
| Site 2: Sports Teaching and Research Lab | |||
| Inertial sensor (SABEL Sense) [9] * | 4 × 9 DoF inertial sensors | 36 × 100 Hz | Data processing for swimming analysis |
| 2D Video data (GoPro San Mateo, CA, USA) [9] * | 25 Hz HD underwater video | 12 Mbps | Visual comparison for temporal kinematic measures |
| Inertial sensor (SABEL Sense) [16] * | 8 × 9 DoF inertial sensors | 72 × 100 Hz | Data processing for vertebra analysis during lifting |
| 3D Motion Capture (Optitrack, Corvallis, OR, USA) [16] * | 6× markers | 6 × 100 Hz | Marker positional change for frame of reference data |
| 2D Video Data (Panasonic HC-V759M) [16] * | 25 Hz HD video | 12 Mbps | Visual comparison |
| Inertial Sensor (SABEL Sense) [17] * | 1 × 9 DoF inertial sensors | 9 × 100 Hz | Data processing for gait analysis |
| 3D Motion Capture (Vicon) [17] * | Helen Hayes marker model | 19 × 100 Hz | Conversion from lower body model to frame of reference data |
| 2 Plate Force Platform (Bertec, Fairfax, VA, USA) [17] * | 8 × 3 DoF piezoelectric load cells | 8 × 100 Hz–500 Hz | Orthogonal force production data |
| Site 3: National Sports Institute [18] | |||
| Force Platform under Athletics Track (Tec Gihan, Kyoto, Japan) | Composed 6-axis force sensors | 6 × 1 k–5 kHz | Conversion to power output, distance, speed, velocity |
| 3D Motion Capture (Motion Analysis Co, Santa Rosa, CA, USA) | 16 infrared cameras | 3 × 16 markers × 250 Hz (32 markers/subject) | Calculation from 3d data to distance, velocity, angle, acceleration, COM, etc. |
| Object Tracking System (ChyronHego Co, New York, NY, USA) | Wireless object tracking system | 30 players × 11 items × 20 Hz | To measure speed, distance, HR, trajectory, heading direction |
| Force Platform for Baseball Mount and Batter’s Box (Tec Gihan) | 13 × 6-axis force plates | 13 × 6 × 1–5 kHz | To analyse reaction force, movement of COP, time differences between players |
| High Speed Cameras (NAC Image Technology, Tokyo, Japan) | 500 Hz HD video | 1920 × 1080 pixels × 500 Hz | For visual analysis and confirmation |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.; Rowlands, D.; Jackson, N.; Leadbetter, R.; Wada, T.; James, D.A. An Architectural Based Framework for the Distributed Collection, Analysis and Query from Inhomogeneous Time Series Data Sets and Wearables for Biofeedback Applications. Algorithms 2017, 10, 23. https://doi.org/10.3390/a10010023
Lee J, Rowlands D, Jackson N, Leadbetter R, Wada T, James DA. An Architectural Based Framework for the Distributed Collection, Analysis and Query from Inhomogeneous Time Series Data Sets and Wearables for Biofeedback Applications. Algorithms. 2017; 10(1):23. https://doi.org/10.3390/a10010023
Chicago/Turabian StyleLee, James, David Rowlands, Nicholas Jackson, Raymond Leadbetter, Tomohito Wada, and Daniel A. James. 2017. "An Architectural Based Framework for the Distributed Collection, Analysis and Query from Inhomogeneous Time Series Data Sets and Wearables for Biofeedback Applications" Algorithms 10, no. 1: 23. https://doi.org/10.3390/a10010023
APA StyleLee, J., Rowlands, D., Jackson, N., Leadbetter, R., Wada, T., & James, D. A. (2017). An Architectural Based Framework for the Distributed Collection, Analysis and Query from Inhomogeneous Time Series Data Sets and Wearables for Biofeedback Applications. Algorithms, 10(1), 23. https://doi.org/10.3390/a10010023