1. Introduction
Many computer science students will get the impression, at least when taught the basics on the Chomsky hierarchy in their course on Formal Languages, that finite automata are fairly simple devices, and hence it is expected that typical decidability questions on finite automata are easy ones. In fact, for instance, the non-emptiness problem for finite automata is solvable in polynomial time, as well as the uniform word problem. (Even tighter descriptions of the complexities can be given within classical complexity theory, but this is not so important for our presentation here, as we mostly focus on polynomial versus exponential time.) This contrasts to the respective statements for higher levels of the Chomsky hierarchy.
However, this impression is somewhat misled. Finite automata can be also viewed as edge-labeled directed graphs, and as many combinatorial problems are harder on directed graphs compared to undirected ones, it should not come as such a surprise that many interesting questions are actually NP-hard for finite automata.
We will study hard problems for finite automata under the perspective of the Exponential Time Hypothesis (ETH) and variants thereof, as surveyed in [
1]. In particular, using the famous sparsification lemma [
2], ETH implies that there is no
algorithm for
Satisfiability (SAT) of
m-clause 3CNF formulae with
n variables, or 3SAT for short. Notice that for these reductions to work, we have to start out with 3SAT (i.e., with Boolean formulae in conjunctive normal form where each clause contains (at most) three literals), as it seems unlikely that sparsification also works for general formulae in conjunctive normal form; see [
3]. Occasionally, we will also use SETH (Strong ETH); this hypothesis implies that there is no
algorithm for solving the satisfiability problem (CNF-)SAT for general Boolean formulae in conjunctive normal form with
n variables for any
.
Recall that the
notation suppresses polynomial factors, measured in the overall input length. This notation is common in exact exponential-time algorithms, as well as in parameterized algorithms, as it allows to focus on the decisive exponential part of the running time. We refer the reader to textbooks like [
4,
5,
6].
Let us now briefly yet more thoroughly discuss the objects and questions that we are going to study in the following. Mostly, we consider finite-state automata that read input words over the input alphabet Σ one-way, from left to right, and they accept when entering a final state upon reading the last letter of the word. We only consider deterministic finite automata (DFAs) and nondeterministic finite automata (NFAs). The language (set of words) accepted by a given automaton A is denoted by . For these classical devices, both variants of the membership problem are solvable in polynomial time and they are therefore irrelevant to the complexity studies we are going to undertake.
Rather, we are going to study the following three problems. In each case, we clarify the natural parameters that come with the input, as we will show algorithms whose running times depend on these parameters, and, more importantly, we will prove lower bounds for such algorithms based on (S)ETH.
Problem 1 (Universality).
Given an automaton A with input alphabet Σ, is ? Parameters are the number q of states of A and the size of Σ.
Problem 2 (Equivalence).
Given two automata with input alphabet Σ, is ? Parameters are an upper bound q on the number of states of and the size of Σ.
Clearly,
Universality reduces to
Equivalence by choosing the automaton
such that
. Also, all these problems can be solved by computing the equivalent (minimal) deterministic automata, which requires time
. In particular, notice that minimizing a DFA with
s states takes time
with Hopcroft’s algorithm, so that the running time of first converting a
q-state NFA into an equivalent DFA (
) and then minimizing a
-state DFA (in time
). Our results on these problems for NFAs are summarized in
Table 1. The functions refer to the exponents, so, e.g., according to the first row, we will show in this paper that there is no
algorithm for
Universality for
q-state NFAs with unary input alphabets.
Problem 3 (Intersection).
Given k automata , each with input alphabet Σ, is ? Parameters are the number of automata k, an upper bound q on the number of states of the automata , and the size of Σ.
For (
Emptiness of)
Intersection, our results are summarized in
Table 2, whose entries are to be read similar to those of
Table 1.
All these problems are already computationally hard for tally NFAs, i.e., NFAs on unary inputs. Hence, we will study these first, before turning towards larger input alphabets. The classical complexity status of these and many more related problems is nicely surveyed in [
7]. The classical complexity status of the mentioned problems is summarized in
Table 3. Notice that (only) the last problem is also hard on deterministic finite automata.
In the second part of the paper, we are extending our research in two directions: we consider further hard problems on finite automata, more specifically, the question of whether a given DFA accepts an aperiodic language, and questions related to synchronizing words, and we also look at finite automata that work on objects different from strings.
In all the problems we study, we sometimes manage to show that the known or newly presented algorithms are in some sense tight, assuming (S)ETH, while there are also always cases where we can observe some gaps between lower and upper bounds. Without making this explicit in each case, such situations obviously pose interesting question for future research. Also, the mentioned second part of the paper can only be seen as a teaser to look more carefully into computationally hard complexity questions related to automata, expressions, grammars etc. Most of the results have been presented in a preliminary form at the conference CIAA in Seoul, 2016; see [
8].
2. Universality, Equivalence, Intersection: Unary Inputs
The simplest interesting question on tally finite automata is the following one. Given an NFA
A with input alphabet
, is
? In [
9], the corresponding problem for regular expressions was examined and shown to be CoNP-complete. This problem is also known as NEC (
Non-empty Complement). As the reduction given in [
9] starts off from 3SAT, we can easily analyze the proof to obtain the following result. In fact, it is often a good strategy to first start off with known NP-hardness results to see how these can be interpreted in terms of ETH-based lower bounds. However, as we can also see with this example, this recipe does not always yield results that match known upper bounds. However, the analysis often points to weak spots of the hardness construction, and the natural idea is to attack these weak spots afterwards. This is exactly the strategy that we will follow in this first problem that we consider in this paper.
We are sketching the construction for NP-hardness (as a reduction from 3SAT as in the paper of Stockmeyer and Meyer) in the following for tally NFAs.
Let
F be a given CNF formula with variables
.
F consists of the clauses
. After a little bit of cleanup, we can assume that each variable occurs at most once in each clause. Let
be the first
n prime numbers. It is known that
. To simplify the following argument, we will only use that
, as shown in ([
10], Satz, p. 214). If a natural number
z satisfies
then
z represents an assignment
α to
with
. Then, we say that
z satisfies
F if this assignment satisfies
F. Clearly, if
for some
, then
z cannot represent any assignment, as
is neither 0 nor 1. (This case does not occur for
.) There is a DFA for
with
states. Moreover, there is even an NFA
for
with at most
many states.
To each clause
with variables
occurring in
, for a suitable injective index function
, there is a unique assignment
to these variables that falsifies
. This assignment can be represented by the language
with
being uniquely determined by
for
. As
(3SAT),
can be accepted by a DFA with at most
states. Hence,
can be accepted by an NFA with at most
many states. In conclusion, there is an NFA
A for
with at most
many states with
iff
F is satisfiable. For the correctness, it is crucial to observe that if
for some
, then also
. Hence, if
, then
for some
. As
,
ℓ represents an assignment
α that does not falsify each clause (by construction of the sets
), so that
α satisfies the given formula. Conversely, if
α satisfies
F, then
α can be represented by an integer
z,
. Now,
as it represents an assignment, but neither
for any
, as
. Observe that in the more classical setting, this proves that
Non-
Universality is NP-hard.
We like to emphasize a possible method to ETH-based results, namely, analyzing known NP-hardness reductions first and then refining them to get improved ETH-based results.
Unless ETH fails, for any , there is no -time algorithm for deciding, given a tally NFA A on q states, whether .
Assume that, for any
, there was an
-time algorithm
for deciding, given a tally NFA
A on
q states, whether
. Consider some 3SAT formula with
n variables and
m clauses. We can assume (by the Sparsification Lemma) that this 3SAT instance is sparse. We already described the construction of [
9] above. So, we can obtain in polynomial time an NFA with
many states as an instance of
Universality. This instance can be solved in time
by
. Hence,
can be used to solve the given 3SAT instance in time
in the interesting range of
, which contradicts ETH. To formally do the necessary computations in the previous theorem (and similar results below), dealing with logarithmic terms in the exponent, we need to understand the correctness of some computations in the
notation. We exemplify such a computation in the following.
Lemma 1. : .
Proof. This statement can be seen by the following line, using the rule of l’Hospital.
Notice that by our assumption. ☐
We are now trying to strengthen the assertion of the previous theorem. There are actually two weak spots in the mentioned reduction: (a) The
ϵ-term in the statement of the theorem is due to logarithmic factors introduced by encodings with prime numbers; however, the encodings suggested in [
9] leave rather big gaps of numbers that are not coding any useful information. (b) The
-term is due to writing down all possible reasons for not satisfying any clause, which needs about
many states (ignoring logarithmic terms) on its own; so, we are looking for a problem that allows for cheaper encodings of conflicts. To achieve our goals, we need the following theorem, see [
5], Theorem 14.6.
Theorem 1. Unless ETH fails, there is no -time algorithm for deciding if a given m-edge n-vertex graph has a (proper) 3-coloring.
As it seems to be hard to find proof details anywhere in the literature, we provide them in the following.
Proof. Namely, in some standard NP-hardness reduction (from 3SAT via 3-Not-All-Equal-SAT), we could first sparsify the given 3SAT instance, obtaining an instance with N variables and M clauses. Also, we can assume that . The 3-NAE-SAT instance would replace each clause of the 3SAT instance by and , where is a special new variable. Hence, this instance has variables and clauses. The 3-coloring instance that we then obtain has vertices and edges in the variable gadgets, as well as vertices and edges in the clause gadgets, plus edges to connect the clause with the variable gadgets. Hence, in particular . This rules out -time algorithms for solving 3-Coloring on m-edge graphs. ☐
The previous result can be used, together with the sketched ideas, to prove the following theorem.
Theorem 2. Unless ETH fails, there is no -time algorithm for deciding, given a tally NFA A on q states, whether .
Proof. We are now explaining a reduction from 3-
Coloring to
tally NFA
Universality. Let
be a given graph with vertices
.
E consists of the edges
. Let
is a prime and
. To simplify the following argument, we will only use that the expected number of primes below
n is at least
, as shown in [
10], Satz, p. 214. Hence we can assume
P contains at least
primes
for
. (For the sake of clarity of presentation, we ignore some small multiplicative constants here and in the following.)
We group the vertices of V into blocks of size . A coloring within such a block can be encoded by a number between 0 and . Hence, a coloring is described by an l-tuple of numbers.
If a natural number
z satisfies
where
is representing the encoding of a block, then
z is an encoding of a coloring of some vertex from
V.
There is a DFA for
with at most
states, where
j is number that does not represent a valid coloring of the
k-th block. Similarly, there is also a DFA for
with this number of states (only the set of final states changes). Moreover, there is even an NFA
for
with at most
states.
To formally describe invalid colorings, we also need a function that associates the block number to a given vertex index (where the coloring information can be found), and partial functions for each vertex index j, yielding the coloring of vertex . We can cyclically extend by setting whenever is defined.
For each edge
with end vertices
with
there are three colorings of
that violate the properness condition. We can capture such a violation in the language
.
is regular, as
with
being finite, as
. So,
can be accepted by a DFA with at most
states, ignoring constant factors. Hence,
can be accepted by an NFA with at most
many states. In conclusion, there is an NFA
A for
with at most
many states with
iff
G is 3-colorable.
For the correctness, it is crucial to observe that if for some , then also . Hence, if , then for some . As , r represents a coloring c that does not color any edge improperly (by construction of the sets ). Conversely, if c properly colors G, then c can be represented by an integer z, . Now, as it represents a coloring, but neither for any , as .
Observe that in the more classical setting, this proves that Universality is CoNP-hard.
As ETH rules out -algorithms for solving 3-Coloring on m-edge graphs with n vertices, we can assume that we have as an upper bound on the number q of states of the NFA instance constructed as described above. If there would be an -time algorithm for Universality of q-state tally NFAs, then we would find an algorithm for solving 3-Coloring that runs in time This would contradict ETH. ☐
How good is this improved bound? There is a pretty easy algorithm to solve the universality problem. First, transform the given tally NFA into an equivalent tally DFA, then turn it into a DFA accepting the complement and check if this is empty. The last two steps are clearly doable in linear time, measured in the size of the DFA obtained in the first step. For the conversion of a
q-state tally NFA into an equivalent
-state DFA, it is known that
is possible but also necessary [
11]. The precise estimate on
is
also known as Landau’s function. It is tightly related to the prime number estimate for
we have already seen. So, in a sense, the ETH bound poses the question if there are other algorithms to decide universality for tally NFAs, radically different from the proposed one, not using DFA conversion first. Let us mention that there have been indeed proposal for different algorithms to test universality for NFAs; we only refer to [
12], but we are not aware of any accompanying complexity analysis that shows the superiority of that approach over the classical one. Conversely, it might be possible to tighten the upper bound.
Notice that this problem is trivial for tally DFAs by state complementation and hence reduction to the polynomial-time solvable emptiness problem.
We now turn to the equivalence problem for tally NFAs. As an easy corollary from Theorem 2, we obtain the next result.
Corollary 1. Unless ETH fails, there is no -time algorithm for deciding equivalence of two NFAs and on at most q states and input alphabet .
We are finally turning towards
Tally-DFA-
Intersection and also towards
Tally-NFA-
Intersection. CoNP-completeness of this problem, both for DFAs and for NFAs, was indicated in [
13], referring to [
9,
14]. We make this more explicit in the following, in order to also obtain some ETH-based results.
Theorem 3. Let k tally DFAs with input alphabet be given, each with at most q states. If ETH holds, then there is no algorithm with that decides if in time .
Proof. We revisit our previous reduction (from an instance of 3-Coloring with and to some NFA instance for Universality), which delivered the union of many simple sets , each of which can be accepted by a DFA whose automaton graph is a simple cycle. These DFAs have states each. The complements of these languages can be also accepted by DFAs of the same size. Ignoring constants, originally the union of many such sets was formed. Considering now the intersection of the complements of the mentioned simple sets, we obtain a lower bound if and or, a bit weaker, if .
Finally, we can always merge two automata into one using the product construction. This allows us to halve the number of automata while squaring the size of the automata. This trade-off allows to optimize the values for k and q.
Assume we have an algorithm with running time , then we get can reduce 3-Coloring with m edges to intersection of automata each of size bounded by , and hence solving it in time , a contradiction. Similarly, there can be no algorithm with running time . ☐
Proposition 1. Let k tally DFAs with input alphabet be given, each with at most q states. There is an algorithm that decides if in time .
Proof. For the upper bound there are basically two algorithms; the natural approach to solve this intersection problem would be to first build the product automaton, which is of size
, and then solve the emptiness problem in linear time on this device. This gives an overall running time of
; also see Theorem 8.3 in [
15]. On the other hand, we can test all words up to length
. As each DFA has at most
q states in each DFA, processing a word enters a cycle in at most
q steps. Also the size of the cycle in each DFA is bounded by
q. The least common multiple of all integers bounded by
q, i.e.,
, where
ψ is the second Chebyshev function, is bounded by
; see Propositions 3.2 and 5.1. in [
16]. This yields an upper bound
of the running time. ☐
Hence in the case where the exponent is dominated by k, the upper and lower bound differ by a factor of , and in the other case by a factor of .
Remark 1. From the perspective of parameterized complexity, we could also (alternatively) only look at the parameter q, as in the case of DFAs (after some cleaning; as there are no more than many functions available as state transition functions, multiplied by choices of final state sets, as well as by the q choices of initial states); the corresponding bound for NFAs is worse. However, the corresponding algorithm for solving Tally-DFA-Intersection for q-state DFAs is far from practical for any . We can slightly improve our bound on k by observing that from the potential choices of final state sets for each of the choices of transition functions and initial states, at most one is relevant for the question at hand, as the intersection of languages accepted by DFAs with identical transition functions and initial states is accepted by one DFA with the same transition function and initial state whose set of final states is just the intersection of the sets of final states of the previously mentioned DFAs; if this intersection turns out to be empty, then also the intersection of the languages in question is empty. Hence, we can assume that . A further improvement is due to the following modified algorithm: First, we construct DFAs that accept the complements of the languages accepted by . Then, we build an NFA that accepts . Notice that has about at most states by using some standard construction. If we check the corresponding DFA for Universality, this would take, altogether, time for unary input alphabets.
3. The Non-Tally Case
In the classical setting, the automata problems that we study are harder for binary (and larger) input alphabet sizes (PSPACE-complete; for instance, see [
17]). Also, notice that the best-known algorithms are also slower in this case. This should be reflected in the lower bounds that we can obtain for them (under ETH), too.
Let us describe a modification (and in a sense a simplification) of our reduction from 3-Coloring. Let be an undirected graph. We construct an NFA A (on a ternary alphabet for simplicity) as follows. Σ corresponds to the set of colors with which we like to label the vertices of the graph. The state set is . W.l.o.g., . For and , we add the following transitions.
if or if ;
(for ) if or if ;
.
Moreover, s is the only initial and all states are final states. If , then this corresponds to a coloring via , , that is not proper. Namely, z drives the A through the states s, , , …, , s for some and some . By construction, this is only possible if , establishing the claim. Conversely, if is a coloring that is improper, then there is an edge, say, , such that for some . Then, , where , . Namely, this z will drive A through the states s, , , …, , s.
Hence, for the constructed automaton A, if and only if there is some proper coloring of G. For such a proper coloring c, , where , .
As , the number of states of A is . So, we can conclude a lower bound of the form . We are now further modifying this construction idea to obtain the following tight bound.
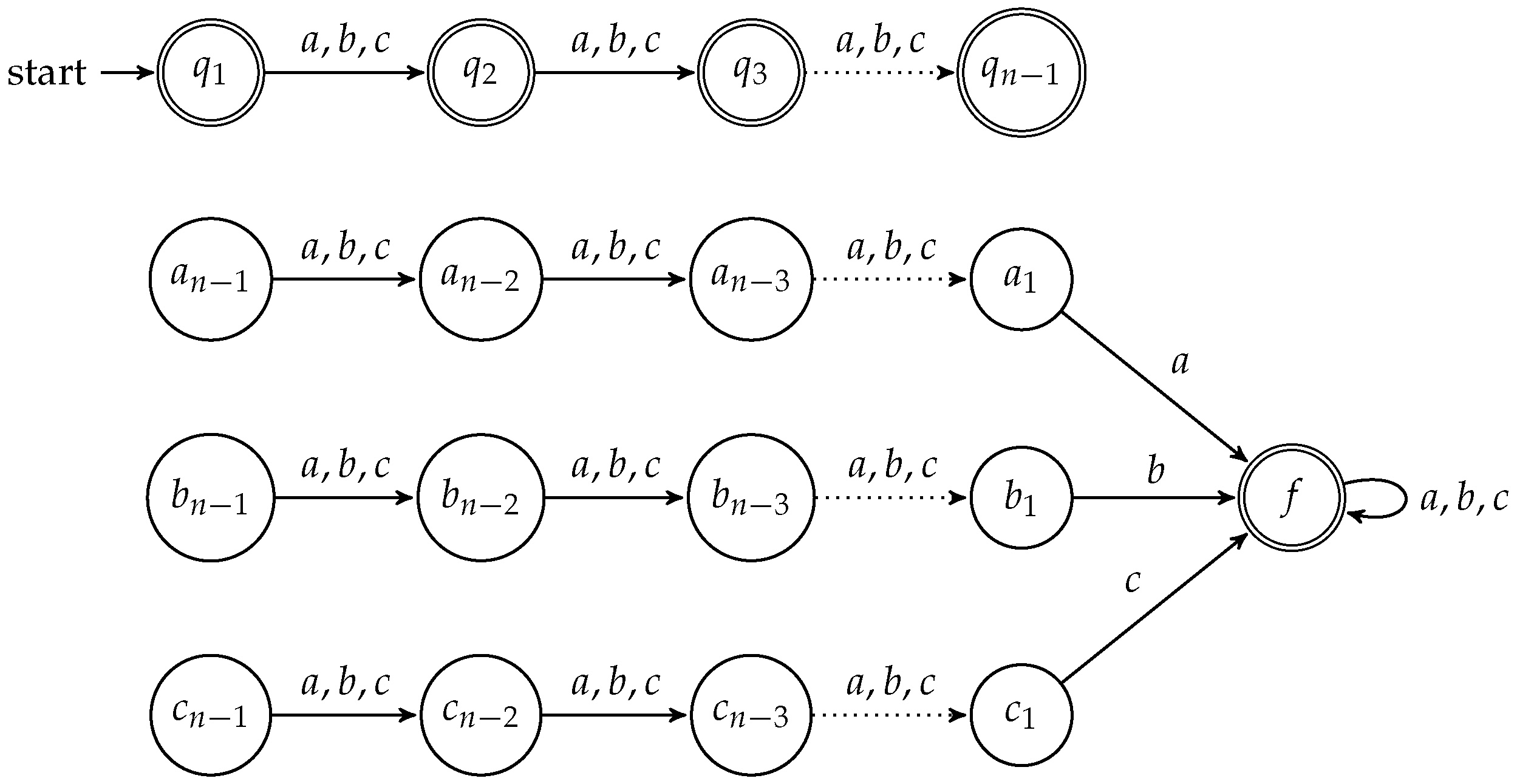
Theorem 4. Assuming ETH, there is no algorithm for solving Universality for q-state NFAs with binary input alphabets that runs in time .
Proof. As we can encode the union of all the NFAs above more succinct we get a better bound. Let
be an undirected graph, and
as above. Let
represent three colors. Then there is a natural correspondence of a word in
to a coloring of the graph, where the
i-th letter in the words corresponds to the color of
. We construct an automaton with
states, as sketched in
Figure 1. Notice that this figure only shows the backbone of the construction. Additionally, for each edge
with
in the graph, we add three types of transitions to the automaton:
,
,
. These three transitions are meant to reflect the three possibilities to improperly color the given graph due to assigning
and
the same color. Inputs of length
n encode a coloring of the vertices. First notice that the automaton will accept every word of length not equal to
n. Namely, words shorter than
n can drive the automaton into one of the states
through
. Also, as argued below, the automaton can accept all words longer than
n, starting with an improper coloring coding of the word, as this can drive the automaton into state
f. Further, our construction enables the check of an improper coloring. A coloring is improper if to vertices that are connected have the same color, so we should accept a word
iff
and
and
. Pick such a word and assume, without a loss of generality, that
. Then the automaton will accept
w, since the additional edge
allows for an accepting run terminating in the state
f. Note that the automaton accepts all words of length at most
. Also, it accepts a word of length at least
n iff the prefix of length
n corresponds to a bad coloring. Hence the automaton accepts all words iff all colorings are bad.
The converse direction is also easily seen. Assume there is a valid coloring represented by a word
. Assume by contradiction that this word is accepted by the automaton. As the word has length
n an accepting run has to terminate in
f, and so one of the edges added to the automaton backbone as shown in
Figure 1 has to be part of this run. Assume, without a loss of generality, that this is the edge
. Then
, as the edge was chosen and since this run leads to
f, also the letter at position
has to equal
a. However, as
this is not valid coloring, hence the assumption that the word is accepted by the automaton was false. Hence, if there is a valid coloring the automaton does not accept all words.
It is simple to change the construction given above to get away with binary input alphabets (instead of ternary ones), for instance, by encoding a as 00, b as 01 and c as 10. ☐
We are now turning towards DFA-Intersection and also to NFA-Intersection. In the classical perspective, both are PSPACE-complete problems. An adaptation of our preceding reduction from 3-Coloring, considering DFAs each with states obtained from a graph instance , yields the next result, where upper and lower bounds perfectly match.
In the following proposition we have parameters k the number of automata, q the maximum size of these automata, and n the input length. The parameters are both upper bounded by n. Recall that the notation drops polynomial factors in n even though n is not explicitly mentioned in the expression.
Proposition 2. There is no algorithm that, given k DFAs (or NFAs) with arbitrary input alphabet, each with at most q states, decides if in time unless ETH fails. Conversely, there is an algorithm that, given k DFAs (or NFAs) with arbitrary input alphabet, each with at most q states, decides if in time .
Proof. The hardness is by adaptation of the the 3-
Coloring reduction we gave for
Universality. For parameters
k and
q, we take a graph with
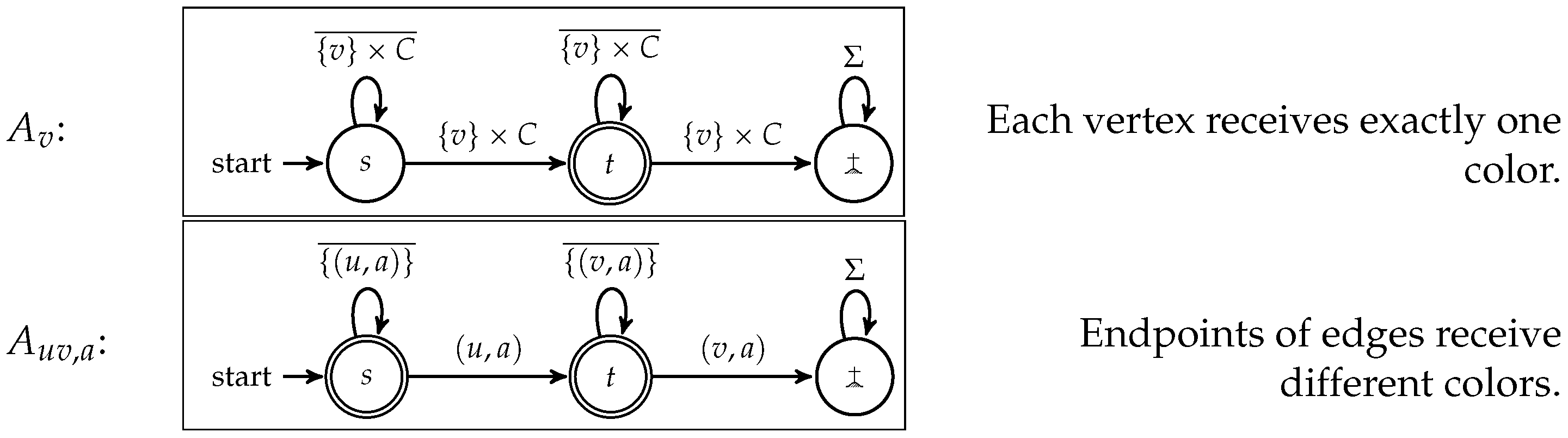
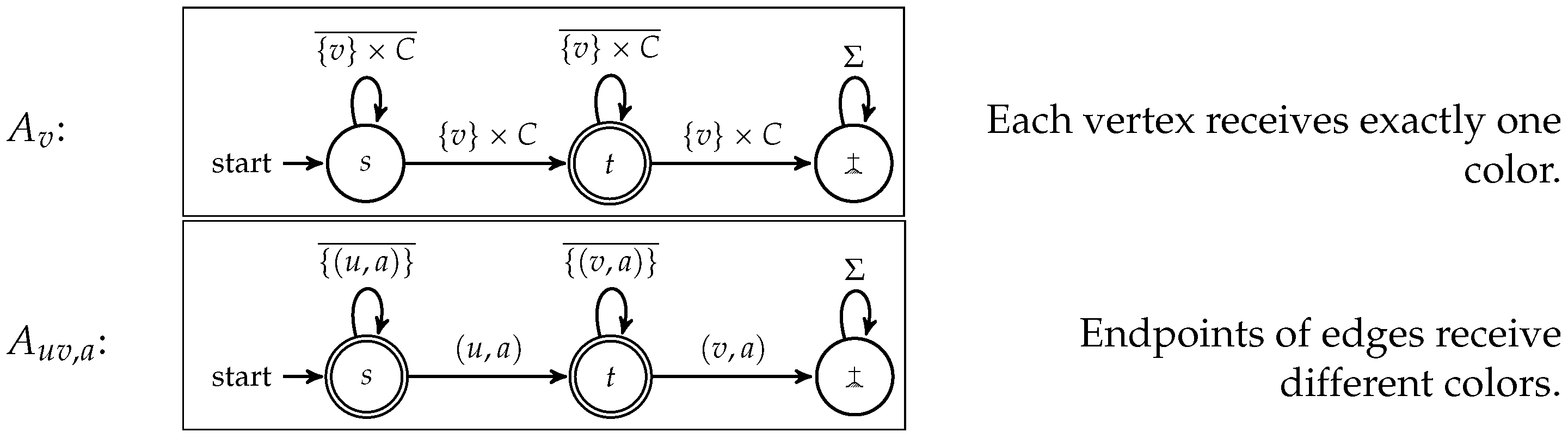
. In this proof, we neglect the use of some ceiling functions for the sake of readability. For the DFAs, choose the alphabet
,
. The states are
s,
t,
![Algorithms 10 00024 i001]()
. For each vertex
v, we define the DFA
, and for each edge
and each color
a, we define the DFA
, as described in
Figure 2. Clearly, we have
many of these DFAs
.
We can compute the intersection for each block of
automata into a single DFA in polynomial time (with respect to
q). This can be most easily seen by performing a multi-product construction. Hence, given a block of
automata
with transition function
, we output the new block automaton
whose set of states
corresponds to all (
q many) ternary numbers, interpreted as
-tuples in {
s,
t,
![Algorithms 10 00024 i001]()
}
. We output a transition in the table of
in the following situation:
So, we have to look up times the tables of the ’s, where each of the look-ups takes roughly time.
This way, we obtain an automaton with q states and we reduce the number of DFAs to . Hence, we got k DFAs each with q states. If there was an algorithm solving DFA-Intersection in time , then this would result in an algorithm solving 3-Coloring in time , contradicting ETH.
Conversely, given k DFAs with arbitrary input alphabet, each with at most q states (q is fixed), we can turn these into one DFA with states by the well-known product construction, which allows us to solve the DFA-Intersection question in time . ☐
Remark 2. The proof of the previous theorem also implies that no such algorithm even if restricted to any infinite subset of tuples in time can exist, unless ETH fails. Especially, if q is fixed to a constant greater than 2, no algorithm in time can exist, unless ETH fails.
We can encode the large alphabet of the previous construction into the binary one, but we get a weaker result. In particular, the DFAs
and
in this revised construction have
states, and not constantly many as before. This means that we have to spell out the paths between the states
s and
t, but this is not necessary with the trash state
![Algorithms 10 00024 i001]()
.
Proposition 3. There is no algorithm that, given k DFAs with binary input alphabet, each with at most q states, decides if in time or , unless ETH fails.
Proof. We reduce this case to the case of unbounded alphabet size. Assume we are given k DFAs over the alphabet Σ, where . We encode each letter of Σ by a word of length (block code) over the alphabet .
In general, when converting an automaton from an alphabet Σ to an alphabet , the size of the automaton might increase by a factor of , as one might need to build a tree distinguishing all words of length .
But we already know that, for the unbounded alphabet size, the lower bound is achieved by using only the automata from that proof (see
Figure 2). These automata are special, as there are at most
many edges leaving each state, while all other edges loop.
Hence, we only increase the number of states (and also edges) by a factor or . ☐
The following proposition gives a matching upper bound:
Proposition 4. There is an algorithm that, given k DFAs with binary input alphabet, each with at most q states, decides if in time .
Proof. We will actually give two algorithms that solve this problem. One has a running time of and one a running time of . The result then follows.
(a) We can first construct the product automaton of the DFAs , which is a DFA with at most many states. In this automaton, one can test emptiness in time linear in the number of states.
(b) For the other algorithm, notice that for a fixed number q, a large number k of automata seems not to increase the complexity of the intersection problem, as there are only finitely many different DFAs with at most q many states. Intersection is easy to compute for DFAs with the same underlying labeled graph. On binary alphabets, each state has exactly two outgoing edges. Thus, there are possible choices for the outgoing edges of each state. Hence in total there are different such DFAs. By merging first all DFAs with the same graph structure we can assume that . We can now proceed as in (a). ☐
Let us conclude this section with a kind of historical remark, linking three papers from the literature that can also be used as a starting point for ETH-based results on DFA-
Intersection. Wareham presented several reductions when discussing parameterized complexity issues for DFA-
Intersection in [
15]. In particular, Lemma 6 describes a reduction from
Dominating Set that produces from a given
n-vertex graph (and parameter
) a set of
DFAs, each of at most
states and with an
n-letter input alphabet, so that we can rule out
algorithms for DFA-
Intersection in this way. In the long version of [
18], it is shown that SUBSET SUM, parameterized by the number
n of numbers, does not allow for an algorithm running in time
, unless ETH fails. Looking at the proof, it becomes clear that (under ETH) there is also no algorithm
-algorithm for
Subset Sum, parameterized by the maximum number
N of bits per number. Karakostas, Lipton and Viglas, apparently unaware of the ETH framework at that time, showed in [
19] that an
-algorithm for DFA-
Intersection would entail a
-algorithms for
Subset Sum, for any
. Although the latter condition looks rather like SETH, it is at least an indication that we could also make use of other reductions in the literature to obtain the kinds of bounds we are looking for. Also, Wehar showed in [
20] that there is no
-algorithm for DFA-
Intersection, unless NL equals P. This indicates another way of showing lower bounds, connecting to questions of classical Complexity Theory rather than using (S)ETH.
5. SETH-Based Bounds: Length-Bounded Problem Variants
Cho and Huynh studied in [
32] the complexity of a so-called bounded version of
Universality, where in addition to the automaton
A with input alphabet Σ, a number
k (encoded in unary) is input, and the question is if
. This problem is again CoNP-complete for general alphabets. The proof given in [
32] is by reduction from the
n-
Step Halting Problem for NTMS, somehow modifying earlier constructions of [
33]. Our reduction from 3-
Coloring given above also shows the mentioned CoNP-completeness result in a more standard way. Our ETH-based result also transfers into this setting; possibly, there are now better algorithms for solving
Bounded Universality, as this problem might be a bit easier compared to
Universality. We will discuss this a bit further below.
Notice that in [
29], another SETH-based result relating to synchronizing words was derived. Namely, it was shown that (under SETH) there is no algorithm that determines, given a deterministic finite semi-automaton
and an integer
ℓ, whether or not there is a synchronizing word for
A, and that runs in time
for any
. Here, Σ is part of the input; the statement is also true for fixed binary input alphabets. We will use this result now to show some lower bounds for the bounded versions of more classical problems we considered above.
Theorem 7. There is an algorithm with running time that, given k DFAs over the input alphabet Σ and an integer ℓ, decides whether or not there is a word accepted by all these DFAs. Conversely, there is no algorithm that solves this problem in time for any , unless SETH fails.
Proof. The mentioned algorithm simply tests all words of length up to ℓ. We show how to find a synchronizing word of length at most ℓ for a given DFSA and an integer ℓ that runs in time , assuming for the sake of contradiction that there is an algorithm with such a running time for Bounded DFA-Intersection. From A, we build many DFAs (namely, with start state s and with unique final state f, while the transition function of all is identical, corresponding to ). Furthermore, let be the automaton that accepts any word of length at most ℓ. Now, we create many instances of of Bounded DFA-Intersection. Namely, is given by . Now, A has a synchronizing word of length at most ℓ if and only if for some , is a YES-instance.
Clearly, the above reasoning implies that there is no -time algorithm for Bounded NFA-Intersection, unless SETH fails. More interestingly, we can use state complementation and a variant of the NFA union construction to show the following result.
Corollary 4. There is an algorithm with running time that, given some NFA over the input alphabet Σ and an integer ℓ, decides whether or not there is a word not accepted by this NFA. Conversely, there is no algorithm that solves this problem in time for any , unless SETH fails.
Clearly, this implies a similar result for Bounded NFA-Equivalence.
Corollary 5. There is an algorithm with running time that, given two NFAs over the input alphabet Σ and an integer ℓ, decides whether or not there is a word not accepted by exactly one NFA. Conversely, there is no algorithm that solves this problem in time for any , unless SETH fails.
From these reductions, we can borrow quite a lot of other results from [
29], dealing with inapproximability and parameterized intractability.
[
29], Theorem 3, yields:
Bounded NFA
Universality is hard for W[2], when parameterized by
ℓ. Similar results hold also for the intersection and equivalence problems that we usually consider.
Using (in addition) recent results due to Dinur and Steurer [
34], we can conclude that there is no polynomial-time algorithm that computes an approximate synchronizing word of length at most a factor of
off from the optimum, unless P equals NP. (This sharpens [
29], Corollary 4. Neither is it possible to approximate the shortest word accepted by some NFA up to a factor of
.
It would be interesting to obtain more inapproximability results in this way.
7. Conclusions
So far, there has been no systematic study of hard problems for finite automata under ETH. Frankly speaking, we are only aware of the papers [
29,
37] on these topics. Returning to the survey of Holzer and Kutrib [
7], it becomes clear that there are quite a many hard problems related to finite automata and regular expressions that have not yet been examined with respect to exact algorithms and ETH. This hence gives ample room for future research. Also, there are quite a many modifications of finite automata with hard decision problems. One (relatively recent) such example are finite-memory automata [
48,
49].
It might be also interesting to study these problems under different yet related hypotheses, Pătraşcu and Williams list some of such hypotheses in [
50]. Notice that even the Strong ETH was barely used in this paper.
It should be also interesting to rule out certain types of XP algorithms for parameterized automata problems, as this was started out in [
51] (relating to assumptions from Parameterized Complexity) and also mentioned in [
1,
5] (with assumptions like (S)ETH). In this connection, we would also like to point to the fact that if the two basic Parameterized Complexity classes FPT and W[1] coincide, then ETH would fail, which provides another link to the considerations of this paper.
More generally speaking, we believe that it is now high time to interconnect the classical Formal Language area with the modern areas of Parameterized Complexity and Exact Exponential-Time Algorithms, including several lower bound techniques. Both communities can profit from such an interconnection. For the Parameterized Complexity community, it might be interesting to learn about results as in [
52], where the authors show that
Intersection Emptiness for
k tree automata can be solved in time
, but not (and this is an unconditional not, independent of the belief in some complexity assumptions) in time
, for some suitable constants
. Maybe, we can obtain similar results also in other areas of combinatorics. It should be noted that
Intersection Emptiness is EXPTIME-complete even for deterministic top-down tree automata.
In relation to the idea of approximating automata, Holzer and Jacobi [
53] recently introduced and discussed the following problem(s). Given an NFA
A, decide if one of the six variants of an
a-boundary of
is finite. By reduction from DFA-
Intersection, they proved all variants to be PSPACE-hard. Membership of the problems can be easily seen by reducing the problems to a reachability problem of some DFA closely related to the NFA
A. Although the hardness reductions in Lemma 15 slightly differ in each case
i, all in all the number of states of the resulting NFA
is just the total number of states of all DFAs used as input in the reduction, plus a constant. In particular, if the number of states per input DFA is bounded, say, by 3, and if we use unbounded input alphabets, then our previous results immediately entail that, unless ETH fails, none of the six variants of the
a-boundary problems admit an algorithm with running time
, where
q is now the number of states of the given NFA
A. This bound is matched by the sketched reduction to prove PSPACE-membership, as the subset construction to obtain the desired equivalent DFA gives a single-exponential blow-up.
In short, this area offers quite a rich ground for further studies.




 . For each vertex v, we define the DFA , and for each edge and each color a, we define the DFA , as described in Figure 2. Clearly, we have many of these DFAs .
. For each vertex v, we define the DFA , and for each edge and each color a, we define the DFA , as described in Figure 2. Clearly, we have many of these DFAs .

{kind=link}
{kind=link}
{kind=link}