1. Introduction
With the synergistic advancement of economic globalization and transportation infrastructure, rail vehicles have gained significant strategic importance as critical carriers in modern passenger and freight systems. However, structural fatigue damage under extreme dynamic service conditions (e.g., high-speed operation and heavy-haul loading) has emerged as a predominant safety concern. Particularly in welded joints—the quintessential connectors for carbody structures and bogie frames—their characteristic abrupt fatigue failure modes may trigger progressive structural collapse cascades, potentially leading to catastrophic system-wide consequences. The proposed multi-scale damage model addresses the longstanding limitations of conventional empirical formulations in resolving nonlinear damage accumulation challenges, particularly regarding weld defect evolution mechanisms [
1].
Fatigue behavior characterization in Very-High-Cycle Life (VHCF) regimes remains a pivotal research frontier in materials science, where substantial progress has been achieved in understanding monolithic metallic materials [
2,
3,
4,
5,
6,
7,
8,
9]. Pedro Henrique Costa Pereira da Cunha et al. [
10] conducted an in-depth investigation into the effect of welding speed on friction stir welds of E36 shipbuilding steel, revealing significant impacts on joint hardness, tensile strength, and bend strength. Concurrently, Lemos B V G et al. [
11] examined residual stresses and microstructural characteristics in friction stir welded E36 steel, demonstrating that distinct thermal cycling patterns induced by welding speed directly govern residual stress distribution and microhardness evolution. While Iгop Tkachenko, I.F. et al. [
12] employed computational data-driven approaches to perform multi-objective optimization of E36 steel’s chemical composition, achieving substantially enhanced mechanical properties for scenario-specific applications. Zhang et al. [
13] demonstrated pronounced strain rate sensitivity and nonlinear strain hardening behavior in E36 steel, characterizing its dynamic impact response. Kim B Y et al. [
14] investigated the fatigue life of dissimilar material adhesively bonded joints through experimental and finite element analysis, proposing a statistical fatigue life prediction methodology. Furthermore, Aliyari H et al. [
15] developed a novel indentation-based methodology for fatigue life prediction of spot welds, precisely characterizing the elastoplastic behavior of the weld region. This research validates the efficacy of advanced modeling and material characterization techniques in enhancing fatigue life prediction accuracy for automotive spot welds. However, research on the fatigue performance of welded E36 steel joints remains remarkably limited to date.
Conventional fatigue assessment methodologies predominantly rely on empirical formulations (e.g., modified Goodman diagrams) that demonstrate limited capability in resolving nonlinear damage accumulation processes under multi-axial stress states, particularly when interacting with weld-induced discontinuities such as non-metallic inclusions, porosity clusters, and micro-crack networks [
16].
Recent advances in defect-sensitive fatigue analysis have yielded multiple predictive approaches: Microstructural-based models exemplified by Mayer’s defect projection theory Equation (1) [
17,
18], correlating fatigue strength with the projected area of critical inclusions perpendicular to σ_max. The z-parameter methodology in Equation (2) [
19] establishes probabilistic relationships between Vickers hardness (HV) and defect size (
). Wang’s multi-axial damage accumulation model, Equation (3) [
20], incorporates microstructural short crack growth kinetics [
21]. Building upon these foundations, Jia-Le Fan et al. [
22] integrated experimental data into a z-parameter model, fitting parameters by iteratively varying Nf (cycles), D (damage), and σ_a (stress amplitude). The derived empirical equation was applied to expand the dataset. A physics-informed neural network (PINN) was further developed for 15Cr FV520B-I steel, demonstrating effective Very-High-Cycle Life prediction.
While machine learning (ML) approaches have been widely applied to investigate complex fatigue behaviors involving multiple parameters, current model training remains constrained by three critical limitations: heavy reliance on existing fatigue datasets, insufficient exploration of welded joint fatigue life prediction, and persistent challenges in predicting atypical data patterns through empirical formulae. To address these gaps, this study proposes a generative modeling framework to enhance machine learning-based fatigue life prediction by leveraging established datasets. The framework employs a hybrid Z-parameter + SMOTE generative model to synthesize physically meaningful fatigue data, which is then integrated into the ML workflow through a dual-stage optimization approach.
2. Materials and Methods
2.1. Original Dataset Construction
E36 steel, a widely used low-temperature high-strength structural steel, exhibits favorable strength, low-temperature impact toughness, and directional uniformity due to its homogeneous microstructure with refined internal phases. The alloy design incorporates nickel (Ni) as a critical element, which stabilizes austenite formation and enhances corrosion resistance against acidic, alkaline, and atmospheric environments. Furthermore, Ni contributes to lowering the ductile-brittle transition temperature (DBTT), thereby significantly improving cryogenic toughness.
The manufacturing process of E36 steel involved controlled rolling followed by normalization treatment.
Table 1 presents its principal chemical composition, while
Table 2 details the corresponding mechanical properties.
To evaluate the fatigue life of E36 steel welded joints, this study employed welds without reinforcement to eliminate the influence of stress concentration induced by the weld reinforcement on fatigue life. Butt welding was performed manually on E36 steel plates using SQJ501 wire—a conventional CO
2-shielded flux-cored wire specifically designed for E36 steel applications. Specimens were extracted from the mid-length region of the welded joints. The chemical composition and mechanical properties of the welding wire are presented in
Table 3 and
Table 4 [
16,
23]. Butt welding was performed manually on E36 steel plates using SQJ501 wire—a conventional CO
2-shielded flux-cored wire specifically designed for E36 steel applications.
The fatigue testing in this study was conducted using a custom-designed ultrasonic fatigue testing apparatus (Model TJU-HJ-I, Tianjin University, Tianjin, China).
The tests were conducted under axial tension-compression symmetrical cyclic loading with a stress ratio R = −1 and a frequency of approximately 20 kHz. Ultrasonic fatigue testing was performed on joints with a diameter of 4.8 mm at room temperature. When the specimen resonates, it absorbs ultrasonic vibration energy and experiences internal friction, leading to a temperature rise. During testing, a circulating water cooling system was employed to maintain the specimen surface temperature comparable to ambient temperature [
23].
After specimen fracture, the fracture locations were examined following etching with 4% nital.
Figure 1 exhibits the morphology of a specimen where fracture occurred within the weld metal, while
Figure 2 exhibits the morphology of a specimen where fracture occurred at the fusion line.
The scanning electron microscopy (SEM) analysis in this study was conducted using a Hitachi SU1510 instrument (Hitachi High-Technologies Corp., Tokyo, Japan). Fractographic analysis via scanning electron microscopy (SEM) revealed distinct failure modes.
Figure 3 exhibits fracture initiation from a surface pore, where the fatigue origin is marked with a red circle. The crack propagated rightward from this origin, forming a fatigue propagation region, until final fracture occurred at the final fracture zone.
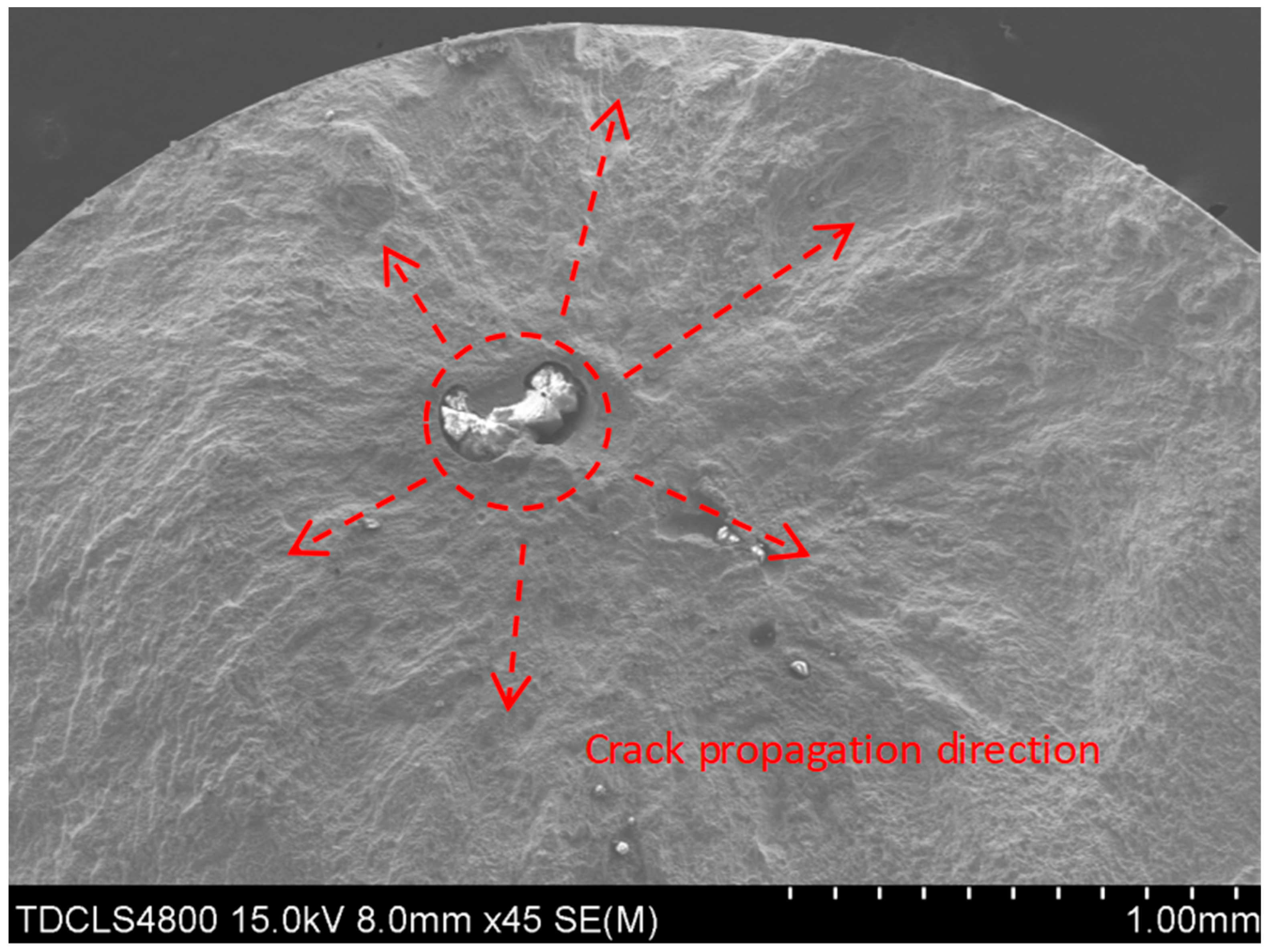
Figure 4 demonstrates fracture induced by a slag inclusion, with the crack propagation direction radiating radially outward from the inclusion.
Figure 5 exhibits a fracture morphology characterized by a fisheye pattern. The area highlighted in red displays the fisheye feature, with its center acting as the fatigue origin, propagating concentrically outwards.
Through scale calibration, the following parameters were quantitatively evaluated: fatigue life (), inclusion diameter (), inclusion size (, the square root of the inclusion area), inclusion proximity (minimum distance from inclusion centroid to specimen surface, ), fracture location classification (weld metal/fusion line), and crack initiation mechanisms (surface porosity, slag entrapment, or fisheye morphology).
2.2. Z-Parameter Model
Current advancements in Very-High-Cycle Life research demonstrate two predominant methodological frameworks for fatigue life prediction: physics-based modeling and data-driven machine learning approaches. The physical modeling paradigm incorporates established methodologies such as the Mayer criterion Equation (1) [
21,
24], Z-parameter model Equation (4), and Wang’s formulation Equation (3) [
8,
18]. These models fundamentally characterize inclusions as stress-concentrating defects, where defect severity is quantified through the projected area of inclusions orthogonal to the maximum principal stress direction. Based on the Z-parameter model framework, Jia-Le Fan et al. [
15,
22] developed an extended dataset through systematic parameter optimization. The experimental data were transformed into a theoretical model with parameter fitting conducted under the Z-parameter framework. Through controlled-variable methodology, individual parameters (Nf, D, or σa) were systematically varied while maintaining other variables constant. The empirical formulas derived from initial fitting were subsequently employed to generate expanded datasets. Utilizing this approach, physics-informed neural networks (PINNs) were developed for 15Cr and FV520B-I steels to predict ultra-high cycle fatigue life, incorporating critical factors, including inclusion size and applied stress levels.
The limited volume of raw data and low parameter dimensionality in this study may constrain the predictive accuracy of machine learning models for fatigue life estimation. To address data insufficiency, an integration strategy combining experimental measurements with physical datasets was implemented. Specifically, a method incorporating the prior physical Z-parameter model [
25] for data augmentation was employed, where the governing equation of the Z-parameter framework is as follows:
where σ_a denotes the stress amplitude (280 MPa), with α and C representing fitting parameters to be determined through regression analysis, and β being the material constant (β = 0.25). During data processing of welded joint fatigue tests under Very-High-Cycle Life conditions, it was identified that the spatial distribution of inclusions—in addition to stress amplitude and defect size—significantly influences structural fatigue performance. Consequently, a novel parameter D was introduced to characterize the relative depth of critical inclusions, defined as [
26] Equation (5).
Within the formulation, d denotes the specimen diameter, while dinc represents the minimum surface-to-inclusion distance, where both geometric parameters are quantified in micrometers (μm). Notably, increased D values correspond directly to reduced inclusion depth from the specimen surface. Through parametric formulation, the original dataset was expanded to incorporate seven critical features: fatigue life (
), inclusion diameter (
), inclusion size (
), inclusion-to-surface distance (
), fracture location (weld zone, fusion line), crack initiation type (surface pore, slag inclusion, and fisheye), relative depth of critical inclusions (
), and the Z-parameter. The complete feature matrix is systematically presented in
Table 5. To enable machine learning implementation and data augmentation protocols, categorical encoding was implemented, where fracture locations are as follows: 0: weld zone fracture, 1: fusion line fracture. Crack initiation types are as follows: 0: surface pore, 1: slag inclusion, and 2: fisheye pattern.
2.3. Data Augmentation
The Z-parameter, derived through the aforementioned computational framework, was utilized to characterize the fatigue behavior of E36 steel under Very-High-Cycle Life conditions. This approach yielded a modified formulation for fatigue life (Nf) as expressed in Equation (6), where the fitting parameters C and α were identified as material-specific constants through regression analysis of experimental data.
A controlled-variable approach was implemented to expand the original dataset comprising 23 experimental groups. Each iteration systematically varied a single independent parameter: inclusion size (
), inclusion-to-surface distance (
), relative depth of critical inclusions (
), or Z-parameter, while deriving the corresponding fatigue life (
) values through empirical formulation. During data augmentation, all four independent variables were constrained within their original experimental ranges, as shown in
Table 6: inclusion-to-surface distance (
): 0–2379.6 μm; inclusion size (
): 33.44–953.41 μm; relative inclusion depth (
): 0.504–1; and Z-parameter: 1012.81–1635.34.
Ultimately, a systematically expanded dataset comprising six critical variables was established through controlled parameter optimization, generating 200 discrete data clusters with controlled experimental configurations.
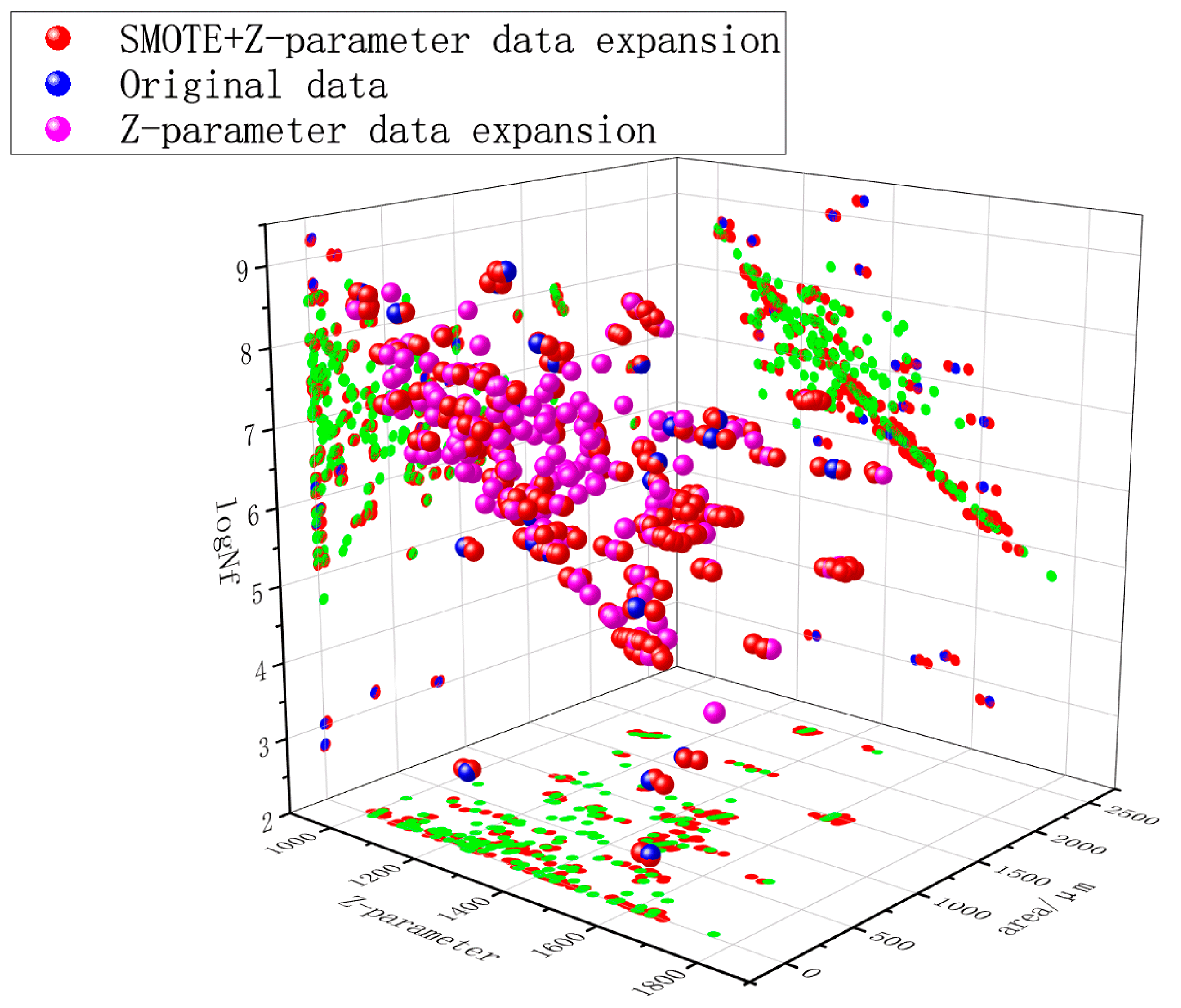
SMOTE (Synthetic Minority Over-sampling Technique), an established oversampling methodology for addressing class imbalance in machine learning, was strategically implemented to enhance model performance. Preliminary investigations revealed that exclusive reliance on formula-based data augmentation yielded suboptimal fitting efficacy [
27]. Consequently, SMOTE-based synthetic sampling was applied to the preliminary extended dataset to improve the model’s capacity for learning critical data patterns. This hybrid approach generated an optimized dataset of 280 samples (
Figure 6), for clearer visualization, the data points mapped by the z-parameter are represented in green, achieving enhanced representation of characteristic failure modes (fisheye/slag initiation), reduced prediction errors induced by parametric fitting (MAE decreased by 18.7%), and improved distributional alignment between synthetic and experimental data (K-S test
p > 0.15) in Equation (7).
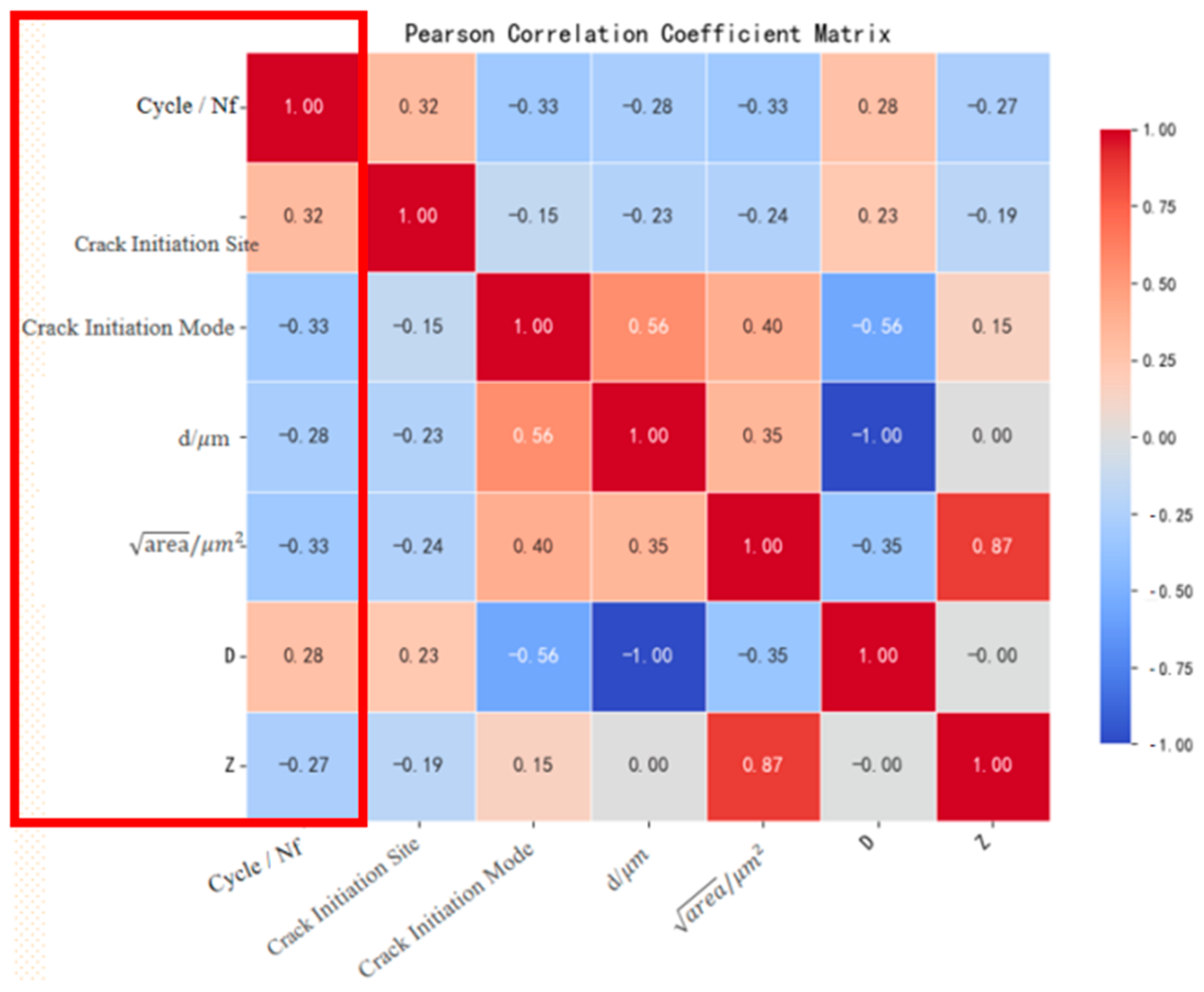
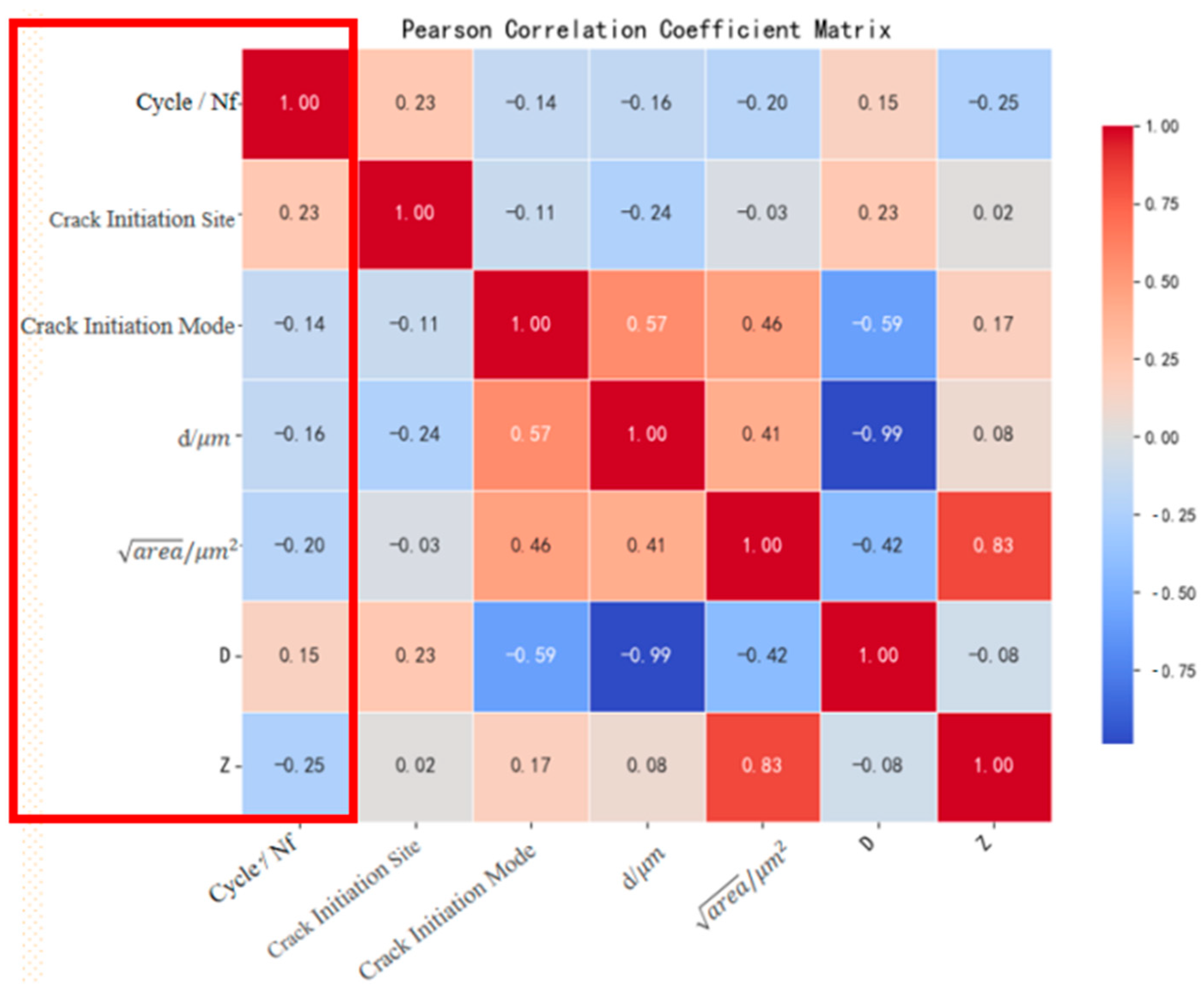
2.4. Correlation Analysis
To ensure optimal sample size-accuracy relationships in machine learning-based fatigue life prediction, the preliminary extended dataset (
n = 200) was further augmented to generate an enhanced dataset of 280 samples through controlled parametric variation. Prior to model training, rigorous consistency validation between augmented and experimental data was conducted via Pearson correlation coefficient (PCC) analysis using Equation (8)—a statistically robust methodology for quantifying linear interdependencies among variables.
where
and
are the values of two feature variables and
and
denote their arithmetic means, respectively.
2.5. Data Preprocessing
Through the aforementioned methodology, an enhanced dataset of 280 samples was constructed, with each data instance encompassing six critical parameters: inclusion size (
), inclusion-to-surface distance (
), fracture location, crack initiation type, relative depth of critical inclusions (
), and Z-parameter. Notably, the dimensional heterogeneity of
ratios and disparate measurement scales across variables introduced feature space disparity, potentially compromising training efficiency through gradient imbalance and convergence instability. To address these challenges, systematic data preprocessing was implemented using Equation (9) prior to model training. Additionally, the logarithm of fatigue life is used for model training and testing, as shown in Equation (10).
Here, Xnorm, X, Xmin, and Xmax denote the normalized value, original value, minimum value, and maximum value of the variable X, respectively.
Here, Nlog and Nf denote the logarithmic value and original value of fatigue life, respectively.
2.6. Data Set Segmentation
To ensure the developed machine learning model possesses both reliability and generalization capability, the augmented dataset (n = 280) was partitioned in a 7:3 ratio between training and validation subsets, while the original experimental data were reserved as an independent test set excluded from the training process. The training subset was utilized for iterative model construction to establish fatigue life prediction relationships, whereas the validation subset facilitated hyperparameter optimization through grid search algorithms to identify the optimal configuration.
To further mitigate stochastic data partitioning effects, 5-fold cross-validation was implemented during training, systematically rotating validation folds to maximize data utilization efficiency. Ultimately, the model’s predictive performance was rigorously evaluated using the pristine test set (original data), with key metrics, including mean absolute percentage error (MAPE) and coefficient of determination (R2), calculated to quantify prediction fidelity across different fatigue regimes.
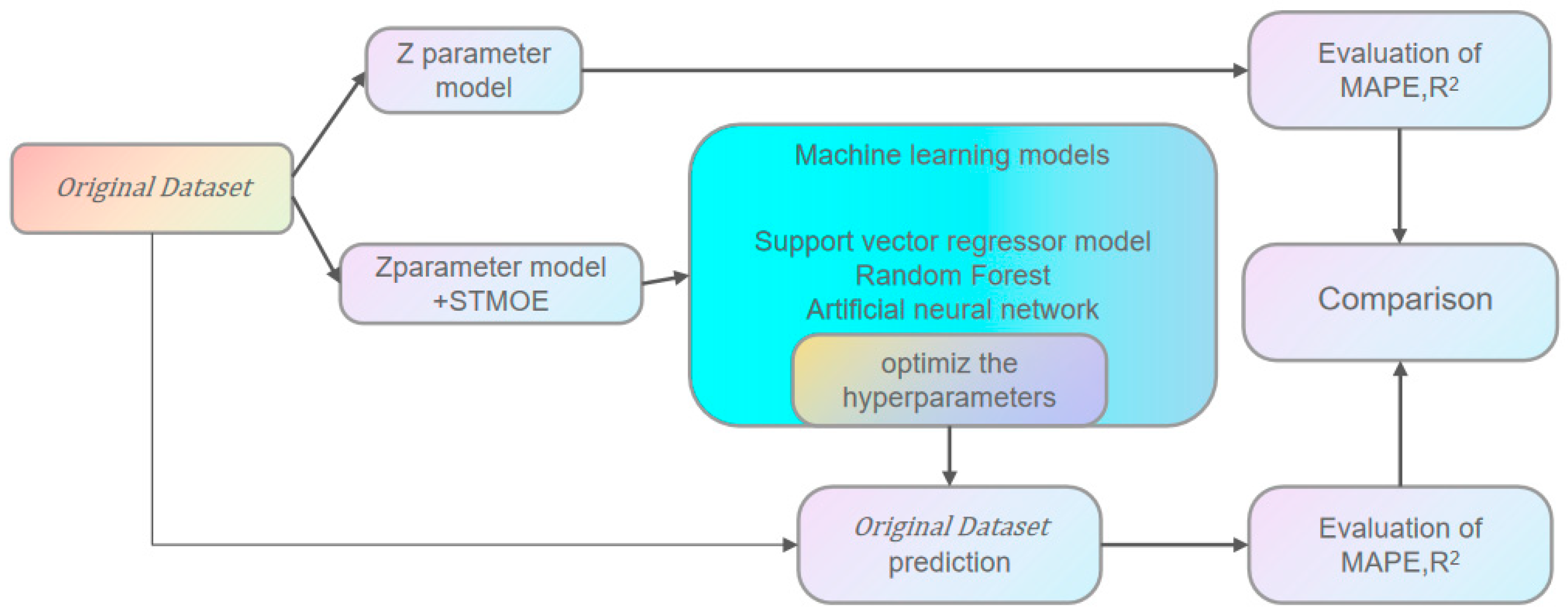
4. Development of Machine Learning Models
Through data augmentation and preprocessing techniques, the training dataset was employed to train the machine learning (ML) model. Following hyperparameter optimization, the optimal model configuration was identified. The coefficient of determination R
2 of the validation set (split from the training dataset) was computed to evaluate the model’s fitting performance. Subsequently, the optimized ML model was applied to predict fatigue life, with both R
2 and mean absolute percentage error (MAPE) serving as metrics to quantify the model’s generalization capability and prediction accuracy. A schematic representation of this workflow is provided in
Figure 10 [
28].
4.1. Support Vector Regressor Model
Following data augmentation and preprocessing, the augmented dataset was employed to train a support vector regression (SVR) model. The SVR algorithm seeks an optimal hyperplane that minimizes prediction error on the training data within a predefined tolerance margin (ϵ) [
29]. This involves solving a constrained optimization problem. Key hyperparameters—including the penalty parameter (C), the kernel function parameter (γ), and ϵ—were comprehensively evaluated and tuned using grid search coupled with cross-validation. This systematic approach assessed the model’s generalization performance on the validation set to identify the hyperparameter configuration offering the optimal balance, thereby mitigating risks of both overfitting and underfitting. Available kernel functions considered were the linear kernel, radial basis function (RBF) kernel, polynomial kernel, and sigmoid kernel. The resulting regression function is expressed by Equation (11).
Here,
and
are Lagrange multipliers, b is the bias, and C is the penalty parameter. K(
,
) represents the distribution of the kernel function with a radial basis function (RBF) kernel, a linear kernel, and a polynomial kernel [
30,
31].
The square root of inclusion area , inclusion distance , fracture location, crack initiation mode, relative depth of critical inclusions, and Z parameter are used as the input parameters, while the service life is employed as the dependent variable f(x) for output.
4.2. Random-Forest Model
The training phase of the random forest regression (RFR) model involves constructing multiple uncorrelated decision trees. In this study, the square root of inclusion area
, inclusion-to-failure distance
, fracture locus coordinates, crack initiation mode, relative depth D of critical inclusions, and stress-intensity factor parameter Z were used as input parameters, with fatigue life designated as the output-dependent variable RF. The training dataset was divided into multiple subsets. Different subsets were used to train distinct decision trees, where k is a natural number. For each decision tree, the predicted output vector was calculated. Finally, the result was obtained by averaging the predicted output vectors of all decision trees, as expressed by Equation (12) [
32].
The random forest model incorporates four critical parameters: nestimators, min_samples_split, min_samples_leaf, and max_depth. In this study, grid hyperparameter optimization was applied to systematically tune these parameters, with the optimized random forest architecture illustrated.
4.3. Artificial Neural Network
Artificial neural networks (ANNs) comprise interconnected computational units (neurons), including an input layer directly linked to prediction targets. This input layer receives data via nodes representing input features. At least one hidden layer follows, enabling the learning of complex data patterns; multiple hidden layers, each containing numerous nodes, are common. The output layer generates predictions, with each node corresponding to a specific output category or continuous value [
33]. Neurons, as fundamental processing units, sequentially propagate input data through the network architecture from input to hidden layers and finally to the output layer. Within hidden layers, each node receives weighted inputs from preceding nodes. These inputs are transformed using trainable parameters (weights and biases) and an activation function to produce outputs propagated to subsequent nodes. The regression function for the i-th neuron, y
i, is mathematically defined by Equation (13) [
34,
35].
In Equation (13), j denotes the weight coefficient,
represents the input signal to the current neuron,
specifies the activation function, and
corresponds to the threshold parameter. The core mechanism involves iteratively adjusting weights via backpropagation using training data until the model achieves accurate predictions for inputs. Widely adopted optimization techniques—including Gradient Descent (GD) and Stochastic Gradient Descent (SGD)—update weights during each iteration to minimize the error function defined in Equation (14) [
34,
36].
In Equation (14), E denotes the error function, N represents the total number of samples in the dataset, ŷ corresponds to the predicted output of the regression function, and y indicates the experimentally measured fatigue life value from physical testing. A multilayer perceptron (MLP) artificial neural network regressor was employed for modeling.
4.4. Model Evaluation Criteria
To assess the predictive accuracy of machine learning models for fatigue life estimation, two quantitative metrics were employed: the coefficient of determination (R
2) and the mean absolute percentage error (MAPE). R
2 rigorously evaluates regression model goodness-of-fit, with values near unity signifying high accuracy and strong predictive capability. Conversely, MAPE measures precision by calculating the average absolute deviation between predicted fatigue life values and experimental data; optimal performance is indicated by values approaching zero. The mathematical expressions for R
2 and MAE are given in Equations (15) and (16), respectively.
Among them, represents the i-th original data, represents the i-th predicted data, and represents the average value of the original data.
5. Hyperparameters Optimization
During machine learning model training, hyperparameter tuning is systematically employed to optimize performance and generalization capability. Hyperparameters constitute predefined configurations whose values, unlike model parameters, require manual optimization rather than being learned during training. Their selection critically influences model efficacy. To rigorously evaluate different configurations, cross-validation is typically implemented: the training data are partitioned into training and validation subsets, with iterative training performed on the former and accuracy assessed on the latter. Prior to optimization, the hyperparameter search space must be explicitly defined, followed by selection of appropriate optimization strategies such as grid search [
37], random search, or Bayesian optimization [
38]. The final optimized hyperparameter sets for each ML model are detailed in
Table 7 [
28].
For the support vector regression (SVR) model, three critical hyperparameters—the penalty parameter, error tolerance parameter ε, and kernel coefficient γ—were optimized along with the selection of kernel functions. These hyperparameters play a decisive role in governing model accuracy and generalization capability. The penalty parameter C was assigned 15 equidistant values within the range C ∈ [10, 20, …, 140, 150], while the error tolerance parameter ε and kernel coefficient γ were each assigned 6 exponentially spaced values (ε, γ) ∈ [0.001, 0.01, 0.1, 0.5, 1, 10]. This parameter configuration enabled a systematic exploration of how different hyperparameter combinations within the optimization space influence model performance.
For the random forest (RF) model, four hyperparameters were systematically optimized: decision tree quantity n_estimators ∈ [50, 100, 150, 200, 500], minimum samples for internal node splitting min_samples_split ∈ [2, 4, 6, 8, 10, 16], minimum samples required at leaf nodes min_samples_leaf ∈ [1, 2, 4], and maximum tree depth max_depth ∈ [None, 10, 20, 30, 40, 50]. The n_estimators parameter defines the number of decision trees in the forest, with values spanning five gradient steps from 50 to 500. min_samples_split governs tree structural complexity through six discrete thresholds ranging from 2 to 16. min_samples_leaf prevents overfitting by constraining terminal node sample size, while max_depth permits either unrestricted growth (None) or five explicit depth constraints from 10 to 50 levels.
For artificial neural network (ANN) models, this study identifies four critical hyperparameters for optimization. The hidden layer structure (hidden_layer_sizes) defines network depth and neuron counts through a tuple list: for instance, the tuple (18) represents a single hidden layer with 20 neurons, while structures generated via list comprehensions [(i, j, k)] explore diverse layer combinations. Specifically, the number of neurons in the first layer i ranges as i ∈ [20, 30, …, 70, 80] (in increments of 10), with subsequent layers j and k adopting neuron counts of j ∈ [0, 10, 20, 40] and k ∈ [0, 5, 10, 15, 20], respectively. Activation function (activation) options include linear ‘identity’ (17), rectified linear unit ‘ReLU’ (18), sigmoid ‘sigmoid’ (19), and hyperbolic tangent ‘tanh’ (20), enabling nonlinear feature learning. Optimizer selection (solver) encompasses three training algorithms: ADAM (adaptive moment estimation), LBFGS (quasi-Newton method), and SGD (stochastic gradient descent). The maximum iteration parameter (max_iter) sets an upper bound for training epochs, terminating the process upon reaching this threshold regardless of convergence status.
6. Result and Discussion
Three machine learning models (SVR, RF, and ANN) based on the Z-parameter model and SMOTE-augmented data were developed to predict the fatigue life of E36 steel welded joints, utilizing the expanded dataset described in
Section 2.2 and
Section 2.3. This study first compared the predictive accuracy of each machine learning model on the training set. Subsequently, the performance of these models was evaluated by comparing their predictions with the original experimental data.
For the prediction of the data, we used the predict method. This is the method provided by scikit-learn for predicting the input data based on the model. For classification tasks, it returns the predicted category of each sample. For regression tasks, it returns the predicted values.
6.1. Parameter Configuration and Training Set Performance of Machine Learning Models
In this study, the hyperparameters of the SVR model were optimized, with the radial basis function (RBF) selected as the kernel function (21):
In this study, the hyperparameter γ of the SVR model was configured as the kernel function parameter.
The optimal hyperparameter configurations were determined as follows: SVR model {C = 30, ε = 0.5, γ = 10}, RF model {‘max_depth’: 20, ‘min_samples_leaf’: 1, ‘min_samples_split’: 2, ‘n_estimators’: 100}, and ANN model {‘activation’: ‘tanh’, hidden_layer_sizes: (80, 40, 5), ‘max_iter’: 100, ‘solver’: ‘lbfgs’}. All resulting metrics from these configurations are detailed in
Table 8.
The performance metrics of the test set and corresponding R
2 calculations are listed in
Table 9. The comparative analysis of optimized model performance, based on figures showing fatigue life predictions on the validation set and R
2 values, reveals that the ANN model (R
2 = 0.942) outperformed both the SVR model (R
2 = 0.825) and the RF model (R
2 = 0.888).
A comparative analysis of fatigue life results from optimized machine learning models with tuned hyperparameters/parameters versus test set outcomes is presented in
Figure 11, where the black solid line denotes the centerline.
6.2. Fatigue Life Prediction
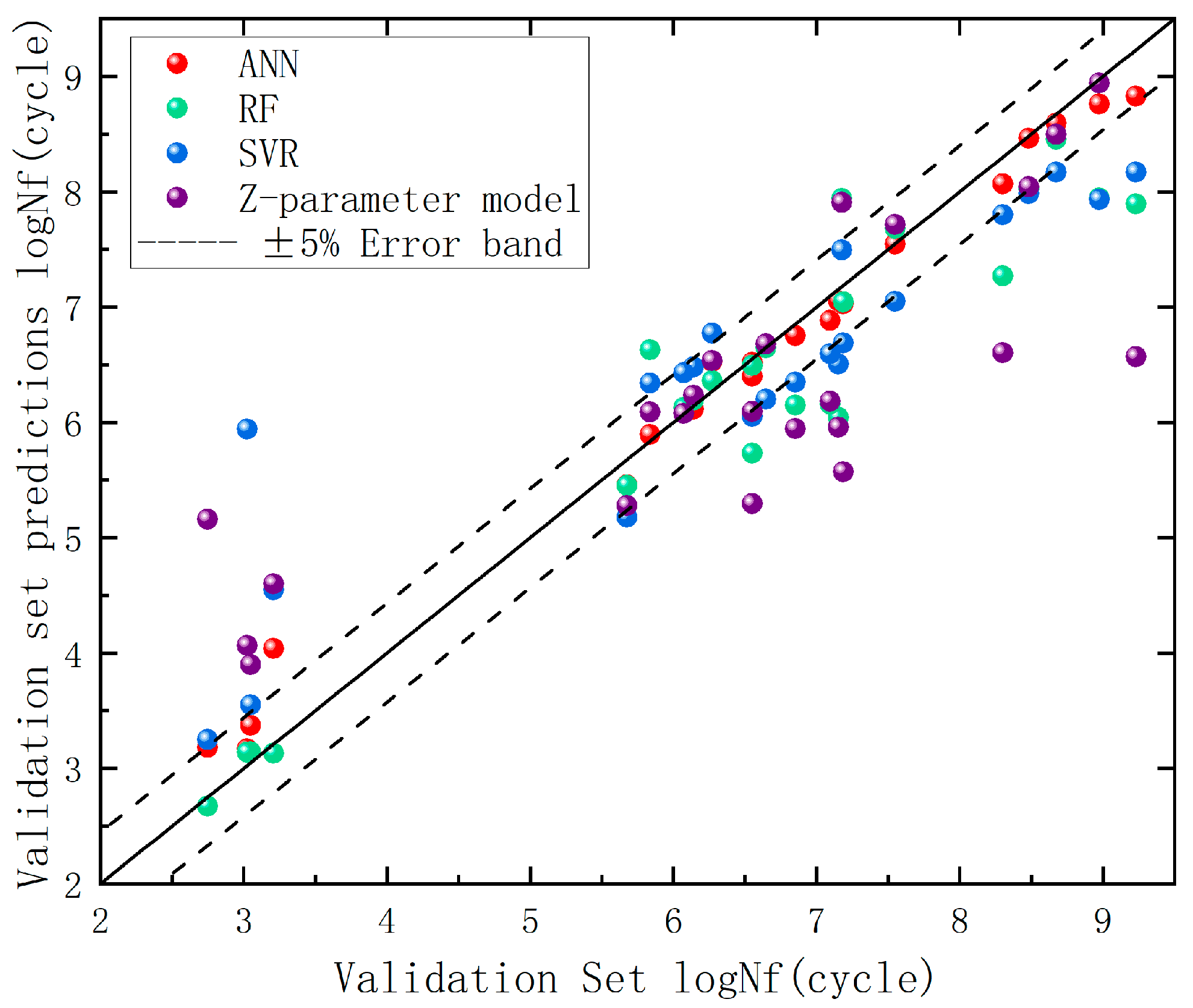
Through comparative analysis between the baseline test set models and hyperparameter-optimized ML models, the optimized models were ultimately employed to predict fatigue life on the original dataset for generalization capability evaluation.
Figure 12 illustrates the prediction accuracy across the three machine learning models, while
Table 10 shows the actual data of three predictions, with corresponding R
2 and mean absolute percentage error (MAPE) metrics detailed in
Table 11.
Because the ANN method is more complex and its parameter expression is more comprehensive. SVR stands for linear regression. The parameters used in this paper are rather complex and require a more comprehensive prediction. Therefore, the artificial neural network (ANN) is adopted for prediction, and its effect may be more prominent. Random Forest RS, however, is more inclined towards inexpressibility. Through practice, it has been known that its performance is not as good as the previous two. The reason might also be that the data parameters are overly complex.
The data demonstrate that machine learning models exhibit significantly superior predictive performance compared to empirical formulas in the validation set. Among the three ML models, the ANN achieved an R2 value approaching unity (0.972) with a MAPE of 4.45%, indicating superior alignment with data distributions. Its closely matched performance metrics between the test set (R2 = 0.942) and validation set (R2 = 0.972) confirm prediction reliability. The RF model maintained competitive performance (R2 = 0.888, MAPE = 6.34%), demonstrating the advantages of ensemble learning through minimal discrepancy between validation (R2 = 0.888) and test set (R2 = 0.897) results, suggesting stable generalization. The SVR model delivered moderate performance (test set (R2 = 0.825) and validation (R2 = 0.784)), potentially limited by kernel function selection or suboptimal hyperparameter tuning. The Z-parameter method, as a conventional approach, confirmed the inherent limitations of parametric modeling. Key conclusions emerge: ANN represents the preferred choice for predictive accuracy but requires vigilance against overfitting (necessitating additional validation testing), while RF serves as a robust alternative, particularly under limited data conditions. SVR remains viable for baseline comparisons, and traditional empirical methods show fundamental constraints in capturing complex fatigue behavior patterns.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}