
Machine Learning-Driven Design and Optimization of Multi-Metal Nitride Hard Coatings via Multi-Arc Ion Plating Using Genetic Algorithm and Support Vector Regression

 ,
,
Abstract
1. Introduction
2. Problem Description of Hardness Prediction Model
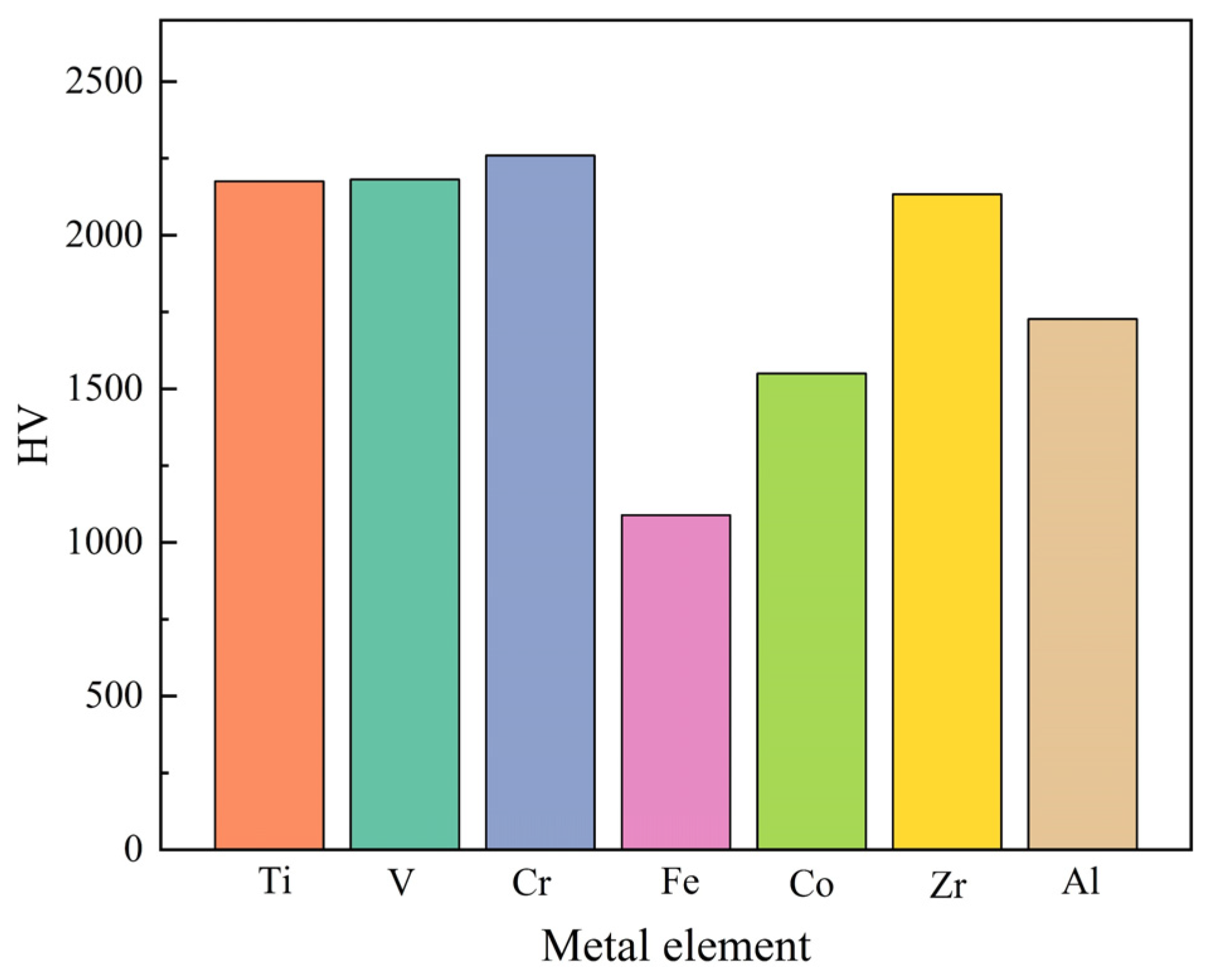
2.1. Establishment of Searching Space
2.2. Problem Description and Model Assumptions
- Case 1: Ternary Metal Nitride as Ideal Substitutional Solid Solutions
- Case 2: Ternary Metal Nitride as Complete Interstitial Solid Solutions
- Case 3: Mixed Solid Solutions
2.3. The Establishment of Model Constraints
2.4. Selection of Model Features and Establishment of Objective Function
3. The Establishment of an Intensity Prediction Model Algorithm
3.1. Fitness Function of Strength Prediction Model, Chromosome Coding, and Population Initialization
3.2. Chromosome Roulette Selection and Crossover Operator Design
3.3. Variation Operator Design and Elite Strategy
- Fitness Evaluation: Evaluate the fitness of all individuals in the population and identify the highest-performing individuals.
- Elite Retention: Directly copy the top 10 individuals with the highest fitness scores to the next generation.
- Standard Genetic Operations: Apply conventional genetic operations, such as crossover and mutation, to the remaining individuals to generate new candidate solutions.
- Generation of the New Population: Combine the retained elite individuals with the newly generated candidates to form the next generation.
4. Experimental Methods
4.1. Hardness Precipitate Details
4.2. SVR Model Accuracy Detection
4.3. Materials and Multi-Arc Ion Experiment
4.4. Test Equipment
5. Discussion
5.1. Feature Set Analysis
5.2. Different Feature Subset Models
5.3. Analysis of Prediction Results and Experimental Validation
- (1)
- Calculation of distances between samples: First, the distances between the 19 samples with hardness values greater than 3200 HV were calculated. The average of these distances was then obtained using Equation (31) to provide an overall distribution of the sample points.
- (2)
- Clustering analysis: The DBSCAN algorithm was employed to cluster the 19 sample points. The neighborhood radius was set to Rnei, with the minimum sample number MinPts set to 3. If a point had a neighborhood sample count greater than Rnei but fewer than MinPts, it was considered a noise point and excluded from the clustering process. This method effectively identifies and removes outliers, thereby enhancing the accuracy of the clustering analysis.
- (3)
- Objective function construction and gradient descent optimization: An objective function was established to compute the centroid coordinates (a,b) and the minimum radius rarea for each cluster, with the clustering areas labeled as Area 1, Area 2, and Area 3. This approach effectively extracts core data features within the clustering regions.
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mohan, K.S.S.; Gunasekaran, S.; Manjubashini, D.; Umayal, S.; Sivaranjani, S.; Subramanian, B. Metal Nitride Coatings of (Cr/Mo)N and (Cr/Ti)N by Ion-Assisted Co-sputtering for Corrosion-Resistant Applications. J. Mater. Eng. Perform. 2024, 33, 10614–10622. [Google Scholar] [CrossRef]
- Li, J.C.; Chen, Y.J.; Zhao, Y.M.; Shi, X.; Wang, S.; Zhang, S. Super-hard (MoSiTiVZr)Nx high-entropy nitride coatings. J. Alloys Compd. 2022, 926, 166807. [Google Scholar] [CrossRef]
- Park, H.J.; Kim, Y.S.; Lee, Y.H.; Hong, S.H.; Kim, K.S.; Park, Y.K.; Kim, K.B. Design of nano-scale multilayered nitride hard coatings deposited by arc ion plating process: Microstructural and mechanical characterization. J. Mater. Res. Technol. 2021, 15, 572–581. [Google Scholar] [CrossRef]
- Ghailane, A.; Makha, M.; Larhlimi, H.; Alami, J. Design of hard coatings deposited by HiPIMS and dcMS. Mater. Lett. 2020, 280, 128540. [Google Scholar] [CrossRef]
- Kumar, D.D.; Kumar, N.; Kalaiselvam, S.; Dash, D.S.; Jayavel, A.R. Wear resistant super-hard multilayer transition metal-nitride coatings. Surf. Interfaces 2017, 7, 74–82. [Google Scholar] [CrossRef]
- Chang, Y.Y.; Weng, S.Y.; Chen, C.H.; Fu, F.X. High temperature oxidation and cutting performance of AlCrN, TiVN and multilayered AlCrN/TiVN hard coatings. Surf. Coat. Technol. 2017, 332, 494–503. [Google Scholar] [CrossRef]
- Wang, S.M.; Antonio, D.; Yu, X.H.; Zhang, J.; Cornelius, A.L.; He, D.; Zhao, Y. The Hardest Superconducting Metal Nitride. Sci. Rep. 2015, 5, 13733. [Google Scholar] [CrossRef] [PubMed]
- Li, X.L.; Jin, G.; Liu, F.; Sun, Y.F.; Guan, S.K.; Chen, Y. Simultaneous enhancements in strength and ductility of hexagonal BN nanosheet reinforced AlSi10Mg composites. J. Alloys Compd. 2024, 992, 174577. [Google Scholar] [CrossRef]
- Chen, Y.C.; Fan, F.Y.; Tsai, M.H.; Wu, C.H.; Chen, S.T.; Ou, S.F. Microstructure and mechanical properties of Ti nitride/Ni metal-based composites fabricated by reactive sintering. Ceram. Int. 2019, 45, 10834–10839. [Google Scholar] [CrossRef]
- Tao, Y.; Ke, G.S.; Xie, Y.; Chen, Y.G.; Shi, S.Q.; Guo, H.B. Adhesion strength and nucleation thermodynamics of four metals (Al, Cu, Ti, Zr) on AlN substrates. Appl. Surf. Sci. 2015, 357, 8–13. [Google Scholar] [CrossRef]
- Zhang, Z.L.; Ren, Y.X.; He, G.Y.; Yang, Z.F. Enhancing erosion resistance of ceramic/metal multilayer coating by crack inhibition design. J. Vac. Sci. Technol. A 2024, 42, 053107. [Google Scholar] [CrossRef]
- Zhang, M.C.; Ai, X.; Liang, X.; Chen, H.; Zou, X.X. Key Role of Local Chemistry in Lattice Nitrogen-Participated N2-to-NH3Electrocatalytic Cycle over Nitrides. Adv. Funct. Mater. 2023, 33, 2306358. [Google Scholar] [CrossRef]
- Tang, L.L.; Yao, D.X.; Xia, Y.F.; Liang, H.Q.; Zeng, Y.P. Effect of interfacial microstructure evolution on the peeling strength and fracture of silicon nitride/oxygen-free copper foil joints brazed with Ag-Cu-TiH2 filler. J. Eur. Ceram. Soc. 2023, 43, 4374–4385. [Google Scholar] [CrossRef]
- Chao, Q.; Mateti, S.; Annasamy, M.; Imran, M.; Joseph, J.; Cai, Q.R.; Li, L.H.; Cizek, P.; Hodgson, P.D.; Chen, Y.; et al. Nanoparticle-mediated ultra grain refinement and reinforcement in additively manufactured titanium alloys. Addit. Manuf. 2021, 46, 102173. [Google Scholar] [CrossRef]
- Grosso, B.F.; Davies, D.W.; Zhu, B.A.; Walsh, A.; Scanlon, D.O. Accessible chemical space for metal nitride perovskites. Chem. Sci. 2023, 14, 9175–9185. [Google Scholar] [CrossRef] [PubMed]
- Sun, W.H.; Bartel, C.J.; Arca, E.; Bauers, S.R.; Matthews, B.; Orvañanos, B.; Chen, B.R.; Toney, M.F.; Schelhas, L.T.; Tumas, W.; et al. A map of the inorganic ternary metal nitrides. Nat. Mater. 2019, 18, 732–752. [Google Scholar] [CrossRef] [PubMed]
- Sun, W.H.; Holder, A.; Orvañanos, B.; Arca, E.; Zakutayev, A.; Lany, S.; Ceder, G. Thermodynamic Routes to Novel Metastable Nitrogen-Rich Nitrides. Chem. Mater. 2017, 29, 6936–6946. [Google Scholar] [CrossRef]
- Owolabi, T.O.; Akande, K.O.; Olatunji, S.O. Estimation of average surface energies of transition metal nitrides using computational intelligence technique. Soft Comput. 2017, 21, 6175–6182. [Google Scholar] [CrossRef]
- Junrear, J.; Sakunasinha, P.; Chiangga, S. The Optimization of Metal Nitride Coupled Plasmon Waveguide Resonance Sensors Using a Genetic Algorithm for Sensing the Thickness and Refractive Index of Diamond-like Carbon Thin Films. Photonics 2022, 9, 332. [Google Scholar] [CrossRef]
- Zhang, C.; Sun, Y.; Zhang, F.; Ho, K.M.; Wang, C.Z. An ultra-incompressible Mn3N compound predicted by first-principles genetic algorithm. J. Appl. Phys. 2020, 128, 055112. [Google Scholar] [CrossRef]
- Fang, S.F.; Wang, M.P.; Qi, W.H.; Zheng, F. Hybrid genetic algorithms and support vector regression in forecasting atmospheric corrosion of metallic materials. Comput. Mater. Sci. 2008, 44, 647–655. [Google Scholar] [CrossRef]
- Abdesselam, Y.; Rezgui, I.; Naoun, M.; Belloufi, A.; Mezoudj, M.; Zerrouki, D. Experimental investigation and optimization of manufacturing processes of Ni-P-Y2O3composite coatings by multiple linear regression method based on genetic algorithm. Int. J. Adv. Manuf. Technol. 2023, 9, 3995–4019. [Google Scholar] [CrossRef]
- Metni, H.; Takeuchi, I.; Stanev, V. Predicting the superconducting critical temperature in transition metal carbides and nitrides using machine learning. Phys. C Supercond. Appl. 2023, 605, 1354209. [Google Scholar] [CrossRef]
- Qian, C.F.; Sun, K.W.; Bao, W.Z. Recent advance on machine learning of MXenes for energy storage and kandaoconversion. Int. J. Energy Res. 2022, 46, 21511–21522. [Google Scholar] [CrossRef]
- Denny, S.R.; Lin, Z.X.; Porter, W.N.; Artrith, N.; Chen, J.G. Machine learning prediction and experimental verification of Pt-modified nitride catalysts for ethanol reforming with reduced precious metal loading. Appl. Catal. B Environ. 2022, 312, 121380. [Google Scholar] [CrossRef]
- Ohkubo, I.; Hou, Z.; Lee, J.N.; Aizawa, T.; Lippmaa, M.; Chikyow, T.; Tsuda, K.; Mori, T. Realization of closed-loop optimization of epitaxial titanium nitride thin-film growth via machine learning. Mater. Today Phys. 2021, 16, 100296. [Google Scholar] [CrossRef]
- Xia, K.; Gao, H.; Liu, C.; Yuan, J.N.; Sun, J.; Wang, H.T.; Xing, D.Y. A novel superhard tungsten nitride predicted by machine-learning accelerated crystal structure search. Sci. Bull. 2018, 63, 817–824. [Google Scholar] [CrossRef] [PubMed]
- Tian, Y.J. The hardest transition metal nitride predicted from machine learning. Sci. Bull. 2018, 63, 947–948. [Google Scholar] [CrossRef] [PubMed]
- Yang, Z.; Ren, Y.; Zhang, Y.; Zhang, Z.L.; He, G.Y.; Zhang, Z.L. Structure Optimization and Failure Mechanism of Metal Nitride Coatings for Enhancing the Sand Erosion Resistance of Aluminum Alloys. Coatings 2023, 13, 2074. [Google Scholar] [CrossRef]
- Li, X.; Xin, W.; Zheng, X.; Ren, Z.A.; Sun, D.Q.; Lu, W.L. Microstructural Characterization and Formation Mechanism of Nitrided Layers on Aluminum Substrates by Thermal Plasma Nitriding. Metals 2019, 9, 523. [Google Scholar] [CrossRef]
- Batsanov, S.S. Energy Electronegativity and Chemical Bonding. Molecules 2022, 27, 8251. [Google Scholar] [CrossRef] [PubMed]
- Mizoguchi, T.; Sasaki, T.; Tanaka, S.; Matsunaga, K.; Yamamoto, T.; Kohyama, M.; Ikuhara, Y. Chemical bonding, interface strength, and oxygen K electron-energy-loss near-edge structure of the Cu/Al2O3 interface. Phys. Rev. B 2006, 74, 235408. [Google Scholar] [CrossRef]
- Johnson, D.D. Electronic Basis of the Strength of Materials. Phys. Today 2004, 57, 56–57. [Google Scholar] [CrossRef]
- Freiesleben, T.; König, G.; Molnar, C.; Tejero-Cantero, A. Scientific Inference with Interpretable Machine Learning: Analyzing Models to Learn About Real-World Phenomena. Minds Mach. 2024, 34, 32. [Google Scholar] [CrossRef]
- Walbrühl, M.; Linder, D.; Ågren, J.; Borgenstam, A. Modelling of solid solution strengthening in multicomponent alloys. Mater. Sci. Eng. A 2017, 700, 301–311. [Google Scholar] [CrossRef]
- Lugovy, M.; Slyunyayev, V.; Brodnikovskyy, M. Solid solution strengthening in multicomponent fcc and bcc alloys: Analytical approach. Prog. Nat. Sci. Mater. Int. 2021, 31, 95–104. [Google Scholar] [CrossRef]
- Jacob, K.T.; Raj, S.; Rannesh, L. Vegard’s law: A fundamental relation or an approximation? Int. J. Mater. Res. 2007, 98, 776–779. [Google Scholar] [CrossRef]
- Bullard, J.W.; Scherer, G.W. An Ideal Solid Solution Model for C-S-H. J. Am. Ceram. Soc. 2016, 99, 4137–4145. [Google Scholar] [CrossRef] [PubMed]
- Myhill, R.; Connolly, J.A.D. Notes on the creation and manipulation of solid solution models. Contrib. Mineral. Petrol. 2021, 176, 86. [Google Scholar] [CrossRef]
- Goldschmidt, H.J. Interstitial Solid Solutions. In Interstitial Alloys; Goldschmidt, H.J., Ed.; Springer: Boston, MA, USA, 1967; pp. 60–87. [Google Scholar]
- Liu, C.; Lu, W.; Xia, W.; Du, C.W.; Rao, Z.Y.; Best, J.P.; Brinckmann, S.; Lu, J.; Gault, B.; Dehm, G.; et al. Massive interstitial solid solution alloys achieve near-theoretical strength. Nat. Commun. 2022, 13, 1102. [Google Scholar] [CrossRef] [PubMed]
- Kadulkar, S.; Sherman, Z.M.; Ganesan, V.; Truskett, T.M. Machine Learning-Assisted Design of Material Properties. Annu. Rev. Chem. Biomol. Eng. 2022, 13, 235–254. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.L.; Niu, C.; Wang, Z.; Gan, Y.; Zhu, Y.; Sun, S.H.; Shen, T. Machine learning in materials genome initiative: A review. J. Mater. Sci. Technol. 2020, 57, 113–122. [Google Scholar] [CrossRef]
- Di Schino, A.; Testani, C. Microstructure and Properties in Metals and Alloys. Metals 2023, 13, 1320. [Google Scholar] [CrossRef]
- Dolzhenko, A.; Tikhonova, M.; Kaibyshev, R.; Belyakov, A. Microstructures and Mechanical Properties of Steels and Alloys Subjected to Large-Strain Cold-to-Warm Deformation. Metals 2022, 12, 454. [Google Scholar] [CrossRef]
- Wang, J.; Xiao, X. Thermodynamic, Kinetic and Strength Calculation of High Zinc Containing Al-Zn-Mg-Cu Alloys. Crystals 2022, 12, 181. [Google Scholar] [CrossRef]
- Heaton, J. An empirical analysis of feature engineering for predictive modeling. In Proceedings of the SoutheastCon 2016, Norfolk, VA, USA, 30 March–3 April 2016; pp. 1–6. [Google Scholar]
- Shi, M.L.; Lv, L.Y.; Guo, Z.G.; Sun, W.; Song, X.G.; Li, H.Y. High-Low Level Support Vector Regression Prediction Approach (HL-SVR) for Data Modeling with Input Parameters of Unequal Sample Sizes. Int. J. Comput. Methods 2021, 18, 2150029. [Google Scholar] [CrossRef]
- Nguyen, H.; Choi, Y.; Bui, X.N.; Trung, N.T. Predicting Blast-Induced Ground Vibration in Open-Pit Mines Using Vibration Sensors and Support Vector Regression-Based Optimization Algorithms. Sensors 2020, 20, 132. [Google Scholar] [CrossRef] [PubMed]
- Peng, C.; Che, Z.Y.; Liao, T.W.; Zhang, Z.W. Prediction using multi-objective slime mould algorithm optimized support vector regression model. Appl. Soft Comput. 2023, 145, 110580. [Google Scholar] [CrossRef]
- Akour, M.; Alenezi, M.; Alsghaier, H. Software Refactoring Prediction Using SVM and Optimization Algorithms. Processes 2022, 10, 1611. [Google Scholar] [CrossRef]
- Tao, P.Y.; Sun, Z.; Sun, Z.X. An Improved Intrusion Detection Algorithm Based on GA and SVM. IEEE Access 2018, 6, 13624–13631. [Google Scholar] [CrossRef]
- Cox, T.; Motevalli, B.; Opletal, G.; Barnard, A.S. Feature Engineering of Solid-State Crystalline Lattices for Machine Learning. Adv. Theory Simul. 2020, 3, 1900190. [Google Scholar] [CrossRef]
- Cisty, M.; Danko, M.; Kohnova, S.; Povazanová, B.; Trizna, A. Machine Learning Enhanced by Feature Engineering for Estimating Snow Water Equivalent. Water 2024, 16, 2285. [Google Scholar] [CrossRef]
- Wei, J.; Chu, X.; Sun, X.Y.; Xu, K.; Deng, H.X.; Chen, J.G.; Wei, Z.M.; Lei, M. Machine learning in materials science. InfoMat 2019, 1, 338–358. [Google Scholar] [CrossRef]
- Wagner, N.; Rondinelli, J.M. Theory-guided Machine learning in Materials science. Front. Mater. 2016, 3, 28. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Times | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| AUC | 0.945 | 0.901 | 0.899 | 0.915 | 0.963 | 0.959 | 0.891 | 0.932 | 0.964 | 0.941 |
| Model | Feature Subset |
|---|---|
| GA-SVR-1 | Subset 1 + subset 4 |
| GA-SVR-2 | Subset 2 + subset 3 + subset 4 |
| GA-SVR-3 | Subset 2 + subset 4 |
| GA-SVR-4 | Subset 1 + subset 3 + subset 4 |
| GA-SVR-5 | Subset 3 + subset 4 |
| GA-SVR-6 | Subset 1 + subset 2 + subset 4 |
| GA-SVR-A | All sets (subset 1 + subset 2 + subset 3 + subset 4) |
| Area | Ti | Al | Cr | Zr |
|---|---|---|---|---|
| Area 1 | 0 | 0.0855~0.125 | 0.106~0.153 | 0.218~0.290 |
| Area 2 | 0.0865~0.115 | 0.189~0.269 | 0.187~0.215 | 0 |
| Area 3 | 0.218~0.255 | 0.185~0.166 | 0.147~0.181 | 0 |
| Area | Experimental Sample | Element Ratio | Test Strength (HV) | Model Prediction Strength (HV) | Prediction Accuracy |
|---|---|---|---|---|---|
| Area 1 | Area1-XN1 | Al0.08Cr0.13Zr0.22N0.5 | 3189 | 3230 | 98.73% |
| Area1-XN2 | Al0.06Cr0.06Zr0.13N0.5 | 3160 | 3164 | 99.87% | |
| Area1-XN3 | Al0.085Cr0.15Zr0.265N0.5 | 3140 | 3244 | 96.79% | |
| Area1-XN4 | Al0.10Cr0.12Zr0.22N0.57 | 3100 | 3253 | 95.30% | |
| Area1-XN5 | Al0.10Cr0.145Zr0.26N0.5 | 3017 | 3241 | 93.09% | |
| Area 2 | Area2-XN1 | Ti0.1qAl0.19Cr0.21N0.5 | 3356 | 3293 | 98.12% |
| Area2-XN2 | Ti0.09Al0.20Cr0.21N0.5 | 3207 | 3348 | 95.79% | |
| Area2-XN3 | Ti0.09Al0.17Cr0.18N0.57 | 3178 | 3362 | 94.53% | |
| Area2-XN4 | Ti0.095Al0.20Cr0.2N0.5 | 3385 | 3271 | 96.63% | |
| Area2-XN5 | Ti0.11Al0.19Cr0.2N0.5 | 3115 | 3398 | 91.67% | |
| Area 3 | Area3-XN1 | Ti0.21Al0.26Cr0.28N0.25 | 3314 | 3241 | 97.79% |
| Area3-XN2 | Ti0.13Al0.04Cr0.08N0.5 | 3260 | 3292 | 99.03% | |
| Area3-XN3 | Ti0.15Al0.27Cr0.33N0.25 | 3243 | 3287 | 98.66% | |
| Area3-XN4 | Ti0.23Al0.10Cr0.17N0.5 | 3220 | 3291 | 97.84% | |
| Area3-XN5 | Ti0.23Al0.08Cr0.17N0.5 | 3162 | 3282 | 96.34% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gu, Y.; Wang, J.; Zhang, J.; Zhang, Y.; Dai, B.; Li, Y.; Liu, G.; Bao, L.; Lu, R. Machine Learning-Driven Design and Optimization of Multi-Metal Nitride Hard Coatings via Multi-Arc Ion Plating Using Genetic Algorithm and Support Vector Regression. Materials 2025, 18, 3478. https://doi.org/10.3390/ma18153478
Gu Y, Wang J, Zhang J, Zhang Y, Dai B, Li Y, Liu G, Bao L, Lu R. Machine Learning-Driven Design and Optimization of Multi-Metal Nitride Hard Coatings via Multi-Arc Ion Plating Using Genetic Algorithm and Support Vector Regression. Materials. 2025; 18(15):3478. https://doi.org/10.3390/ma18153478
Chicago/Turabian StyleGu, Yu, Jiayue Wang, Jun Zhang, Yu Zhang, Bushi Dai, Yu Li, Guangchao Liu, Li Bao, and Rihuan Lu. 2025. "Machine Learning-Driven Design and Optimization of Multi-Metal Nitride Hard Coatings via Multi-Arc Ion Plating Using Genetic Algorithm and Support Vector Regression" Materials 18, no. 15: 3478. https://doi.org/10.3390/ma18153478
APA StyleGu, Y., Wang, J., Zhang, J., Zhang, Y., Dai, B., Li, Y., Liu, G., Bao, L., & Lu, R. (2025). Machine Learning-Driven Design and Optimization of Multi-Metal Nitride Hard Coatings via Multi-Arc Ion Plating Using Genetic Algorithm and Support Vector Regression. Materials, 18(15), 3478. https://doi.org/10.3390/ma18153478