1. Introduction
The Bayesian statistical framework has been used extensively in the problem of system identification [
1] or model updating based on experimental test data [
2,
3]. The objective of using inverse problems to learn or calibrate model or latent parameters, including model error terms, lies in the fact that underlying parametrised computational models are uncertain, or erroneous [
4]. The experimental data when assimilated into the model, using the Bayesian inference framework, is expected to provide joint estimates of the model parameters conditional on the data and compensate for uncertainty/bias in the model predictions. However, operating only in the field of model parameters is problematic for a number of reasons. Firstly, the underlying computational models for any practical application is expensive. As a result working with a very high resolution numerical model at every stage is prohibitively expensive. Secondly, when using surrogate models in the parameter space in conjunction with a simulator, adaptive enrichment of the response surface does not take adaptive mesh refinement within its purview. This is not optimal since ensuring that the model error in the energy norm is bounded in the parameter space requires a uniformly high resolution and increases the associated computational overhead. Lastly the advanced adaptive mesh refinement techniques are rarely used in conjunction with parametric learning using Bayesian inference. There is significant room for improvement in this regard since a simultaneous control of both statistical and discretisation error would lead to substantially improved predictive numerical models both in terms of accuracy and computational efficiency.
At the root or our methodology is the estimation of errors due to the finite element approximation of the partial differential equation (PDE) of interest. Classically, spatial resolution of finite element models can be adaptively refined (also known as local
h-refinement) based on a posteriori error estimation techniques [
5,
6,
7], combined with re-meshing strategies. Within this, methods focussing on errors estimated in terms of specific quantities of interest (QoI), rather than the classical energy norm, constitute the goal-oriented adaptivity scheme [
8,
9,
10,
11,
12], which is of particular interest in the present study. Numerical studies have shown that these give better convergence in the local features of the solution compared to traditional approaches.
Integrating model reduction techniques with finite element model updating techniques has received some attention in recent years [
13], where the motivation is to use Bayesian model updating framework with an adaptive scheme of enriching the surrogate response surface. Multistage Bayesian inverse problems are quite important in this respect [
14,
15] and have important applications for system identification of vibrating systems. The prediction error is an important parameter to be calibrated in such cases, as the authors point out. But the improvement in model predictions, if solely focussed on obtaining the posterior probabilistic parameter estimates or for adaptive enrichment of the response surface in the parameter space, without considering simultaneous enhancement of the resolution of the numerical simulator would be unsatisfactory both from the standpoints of computational accuracy and efficiency.
The forward problem of uncertainty propagation has been investigated extensively for the solution of stochastically parametrised partial differential equations. These range from efficient stochastic Galerkin methods using polynomial chaos basis functions [
16,
17,
18,
19], stochastic collocation techniques [
20,
21], Monte-Carlo sampling based methods (and its various improvements) [
22,
23,
24] and other deterministic sampling methods [
25,
26,
27]. The main challenge is to obtain a good approximation of the lower order statistical moments of the state vector or specific quantities of interest. On the other hand, advances in the resolution of stochastic inverse problems has become a very active topic in engineering and mathematical research (see e.g., [
28]). Scalable Bayesian inversion algorithms for large-scale problems have been investigated [
29] and as well as Bayesian inversion to probabilistic robust optimization under uncertainty [
30]. The use of adaptive sparse-grid surrogates unified with Bayesian inversion for posterior density estimates of the model or design has also been studied parameters [
3,
31,
32]. This research focuses mostly on the definition of surrogates of the numerical model and having adaptive methods to control the statistical sampling error in the definition of the response surface. Lately there has been some research [
33] that defines adaptivity as the local enrichment of the surrogate model and uses error estimation to bound this error, with no mention of spatial discretisation. However, coupling engineering uncertainty quantification (UQ) with an adaptive scheme for goal-oriented finite element model refinement remains a sparsely studied domain and presents significant challenges. It is so both from the problem formulation perspective, owing to the choice of appropriate candidate estimates based on which adaptive model enrichment can be performed, as well as incorporating it into the general formulation of Bayesian inversion.
The main focus of the paper is to develop a robust methodology for the simultaneous control of errors from multiple sources—the goal-oriented finite element error and the uncertainty-driven statistical error—in a Bayesian identification framework for identification system parameters conditional on data (experimental or otherwise). The novel algorithmic approach proposed in this paper consists in running two Markov Chain Monte Carlo algorithms simultaneously to sample the posterior densities of the quantities of interest (component-wise MCMC). The first chain utilises the current finite element model, whilst the second chain runs with a corrected likelihood function that takes into account the discretisation error. The latter quantity may be constructed by making use of a posteriori finite element error estimates available in the literature. At any time during the sampling process, two empirical densities are available and may be compared to evaluate the effect of the discretisation error onto posterior densities. The second building block of our algorithmic methodology allows us to determine whether enough samples have been drawn by the component-wise MCMC. Using multiple parallel chains combined with bootstrap-based estimates of sampling errors, we automatically stop the MCMC algorithms when either (i) the required level of accuracy is achieved or (ii) we have generated enough statistical confidence in the fact that the discretisation error is too large for our purpose, and therefore that mesh refinement is necessary. While any available error estimate of the discretisation error may be used within the general strategy outlined above (a goal-oriented residual or recovery-based error estimate, for instance [
8,
9,
11,
34]), we choose instead to construct this estimate via a dedicated machine learning approach. This interesting feature, inspired by previous work in data-driven error modelling [
35,
36,
37,
38], will be briefly outlined in the paper.
The paper is organised as follows.
Section 2 introduces the Bayesian inverse problem based on a finite element model of a parametrised vibrating structure. This section also includes discussions on discretisation error. Some numerical examples are presented in
Section 3, which aims to demonstrate the convergence of the joint posterior distributions on the model parameters through successive stages of mesh refinement.
Section 4 discusses the total error as a combination of statistical and discretisation error that results from the MCMC algorithm used for sampling from posterior distributions.
Section 5 gives the methodology for robust, simultaneous control of all error sources within the adaptive inverse problem solver using a component-wise MCMC algorithm in conjunction with bootstrap-aggregated regression model for model parameters. Numerical examples are presented and discussed in
Section 6 to demonstrate the capabilities of the proposed methodology.
2. Finite Element Bayesian Inverse Problems
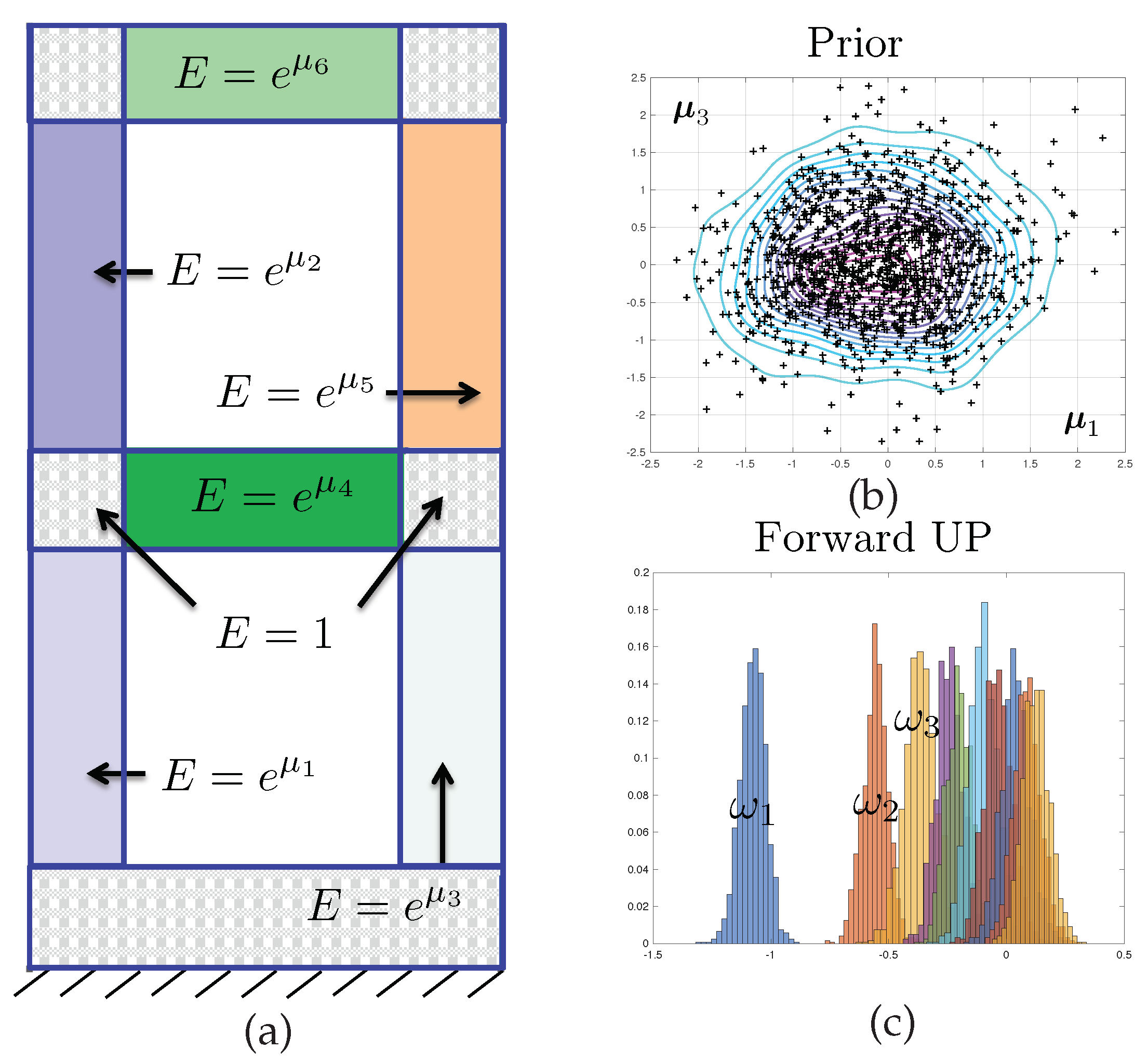
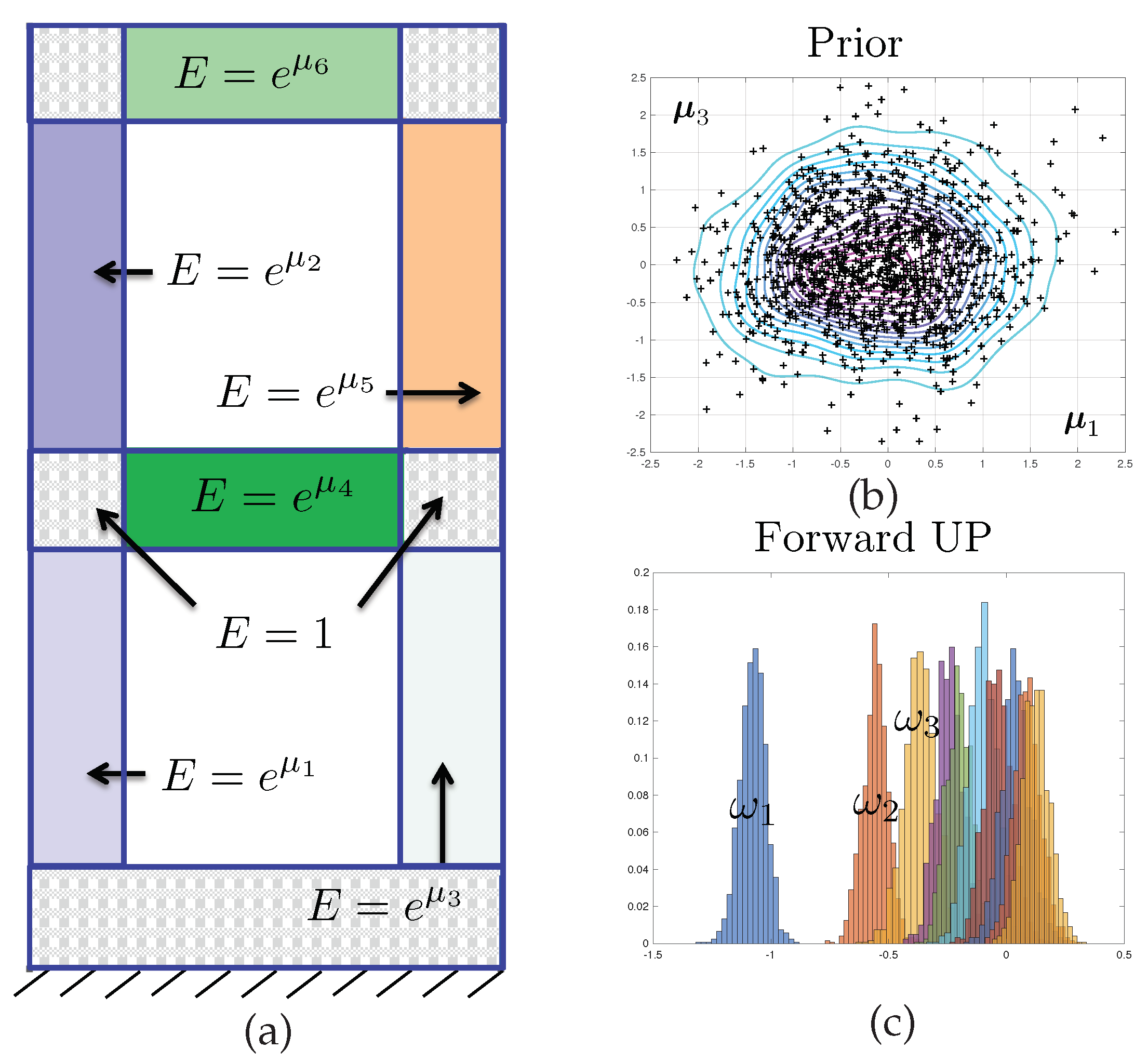
Although the methodology proposed in this paper is general, we will apply it to the verification of popular inverse finite element procedures used to monitor the integrity of structures during service. We will assume that the structure can be modelled as an elastic body, and that potential structural damage can be modelled by the evolution of a field of elastic constants characterised by a finite number of uncertain parameters. Assuming that the resonance frequencies of the structure have been measured physically, we attempt to identify this set of mathematical parameters, through the solution of an inverse problem. Significant deviations from the parameter values corresponding to an undamaged structural state may reveal structural failure. This is a typical condition monitoring method used for non-destructive structural testing.
In order to clarify the proposed study, we will assume that we have measured the
first dynamic eigenfrequencies
of the structure represented in
Figure 1. The purpose of the model inversion is to identify the values of
parameters
of the structural dynamics model, here the log of the elastic modulii of the subdomains represented in
Figure 1. We will also aim to predict the remaining
frequencies
. The relationships
and
, i.e., the computational model, are defined implicitly through the evaluation of a standard finite element model of the steady-state, undamped structural vibrations.
2.1. Bayesian Inverse Problem
We assume that the quantities
that are measured experimentally are described by the mathematical model, up to an error, which is modelled in a probabilistic manner. Following standard Bayesian procedures, this error is modelled as a white Gaussian noise,
with
a positive definite covariance matrix.
is the mathematical prediction that corresponds to the experimental observation. Model
is a deterministic function of
uncertain model parameters that we organise in a
-dimensional vector
. Bayesian inversion requires to associate a prior probability density with the model parameters
. This prior probability density, denoted by
in the following, encodes the knowledge that we possess about
before making any physical observations.
Seen from a different point of view, the probabilistic inversion setting amounts to the definition of a joint probability distribution for
and
:
The formal expression of likelihood function
is a direct consequence of assumption (
1), namely
It is now possible to formally proceed to the inversion itself by conditioning the joint distribution to actually observed quantities. Applying Bayes’ formula, the posterior probability density of the model parameters is
where
is a normalising constant, whose computation requires a usually intractable integration. Bayes formula provides us with an updated knowledge about the uncertain part of our mathematical model. It is now possible to predict unobserved quantities i.e.,
by formally propagating the posterior uncertainty through model
. The posterior predictive probability density of
will be denoted by symbol
.
2.2. Finite Element Modelling of Inverse Structural Vibration Problems
2.2.1. Direct Finite element Procedure for Frequency-Domain Vibrations
The numerical model
is implicitly defined through the solution of a continuum mechanics problem. The components of
and
are the logarithm of the eigenvalues corresponding to the following parametrised eigenvalue problem:
Find and such that In the previous variational statement,
is the domain occupied by the structure of interest,
is the space of functions defined over
, with values in
, that are zero on part
of the boundary of the domain, and whose derivatives up to order one are square integrable.
denotes the symmetric part of the gradient operator.
is the fourth order Hooke tensor and
is the mass density of the solid material. The problem possesses an infinite number of solutions
called free vibration modes. We order the free vibration frequencies in increasing order
. The free vibration modes are functions of uncertain material parameters
through the definition of the Hooke tensor. Specifically,
with the parametrised Lamé constants
Solving the continuum mechanics model is equivalent to evaluating the mapping
There is, in general, no analytical solution to the continuous vibration problem, and a standard way to obtain approximate solutions is to substitute a finite element space
for infinite dimensional search space
[
39]. Too coarse a finite element discretisation may result in poorly predictive results, while too fine a mesh will lead to numerically intractable results, or, in any case, to a waste of computing resources.
2.2.2. Finite Element Approximation of the Bayesian Inverse Problem
Whilst using the continuum mechanics model exactly would deliver the posterior density
as solution of the Bayesian inverse problem, we now have an approximate posterior density
where the finite element likelihood
is obtained by substituting finite element mapping
for
in Equation (
3). Similarly, the approximate posterior density of
is denoted by
and obtained by evaluating finite element mapping
instead of
when propagating the posterior uncertainties forward.
2.2.3. Discretisation Error
The finite element error is the mismatch between
and
on the one hand, and
and
on the other hand. Various measures can be used to quantify this mismatch, amongst which the Hellinger distance, defined by
the Kullback-Leibler divergence, the total variation distance and the Kolmogorov-Smirnov (KS) distance, defined by
where the capital symbols
denotes the cumulative probability density corresponding to
, and
is the finite element approximation of
. This contribution will make use of the latter measure, in a one-dimensional setting (i.e., it will be applied to control the accuracy of the posterior density of one of the elements of
or one of the elements of
). The attractiveness of the Kolmogorov–Smirnov distance is its straightforward application in the context of Monte-Carlo procedures, where only empirical densities are available, and its closeness to confidence intervals (CIs), which makes its values relatively easy to interpret within the context of a posteriori error estimation. Notice that the
is lower bounded by 0 (identical density functions) and upper bounded by 1 (non-overlapping support for the probability density functions).
3. Numerical Examples—Part I: Effect of Discretisation Errors Onto Posterior Densities
This section introduces the numerical examples that will be investigated in this paper, and aims to provide a first qualitative understanding of the effect of mesh refinement onto the quality of posterior probability densities.
3.1. Forward Stochastic Model
The stochastic field of Young’s modulus that will be used to exemplify the error control approach proposed in this paper is defined via a decomposition of domain
into
non-overlapping subdomains
such that
and
for
. The domain decomposition is represented in
Figure 1. Then, the proposed model is such that
Hence, the scalar parameters contained in vector are the logarithms of the Young’s modulii corresponding to each of the subdomains.
The prior density is a multivariate Gaussian, and is given by equation
The prior mean
is the null vector, and the prior variance
, where
is the identity matrix, is diagonal and isotropic. The prior density is represented in dimensions
in
Figure 1.
Finally, we model the error as a zero-mean multivariate Gaussian (consistently with what was described in previous section), with independent components and isotropic variance, i.e., .
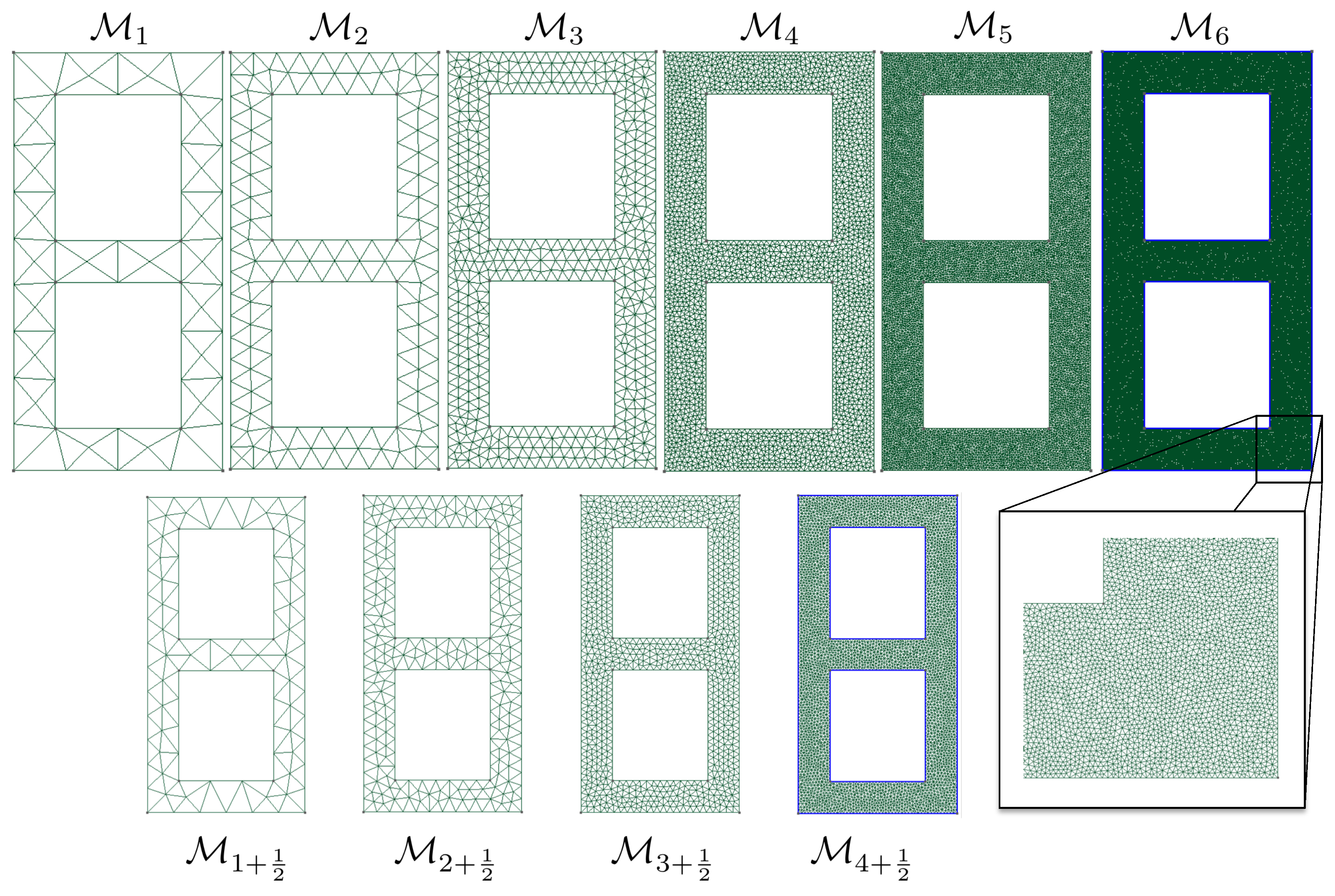
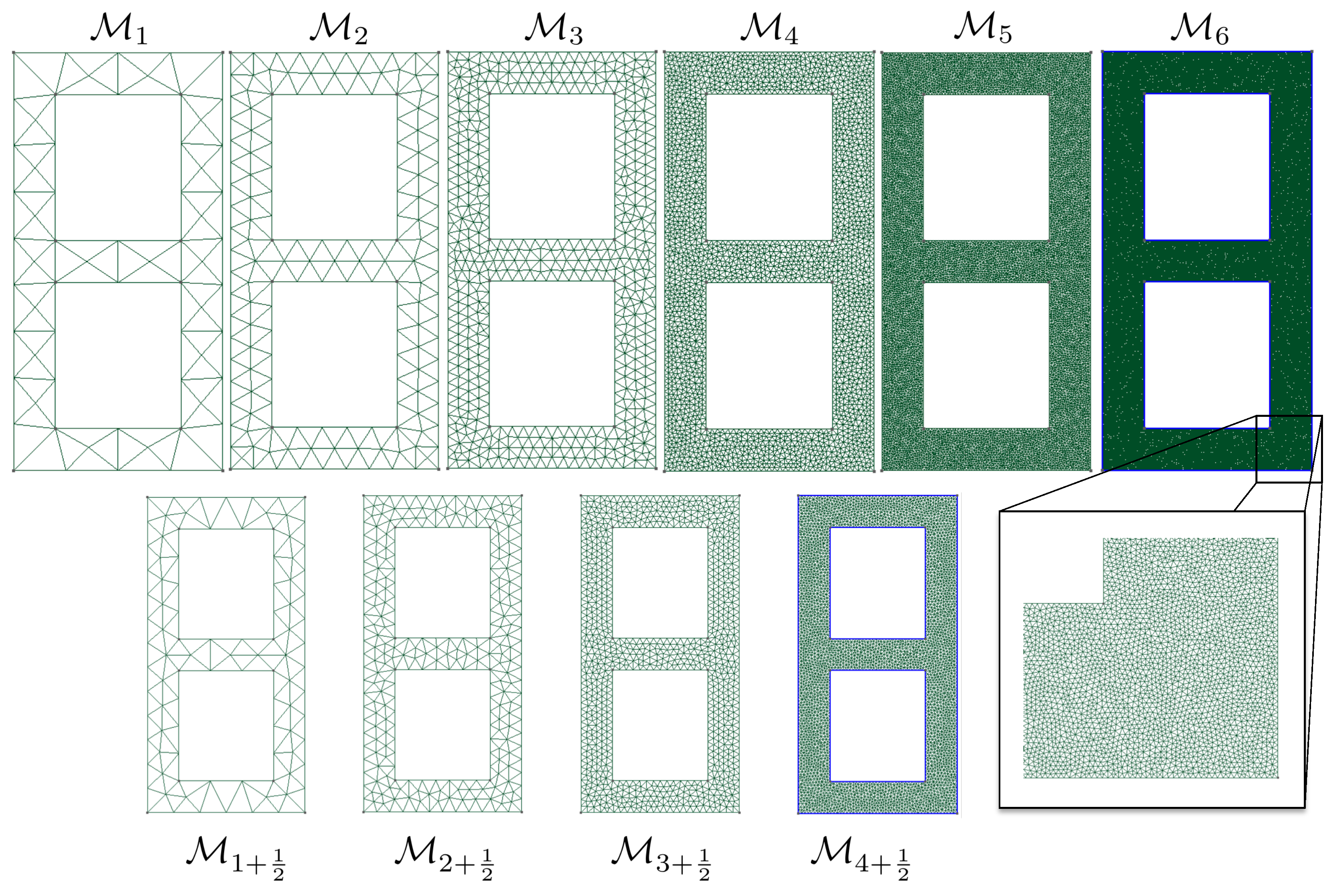
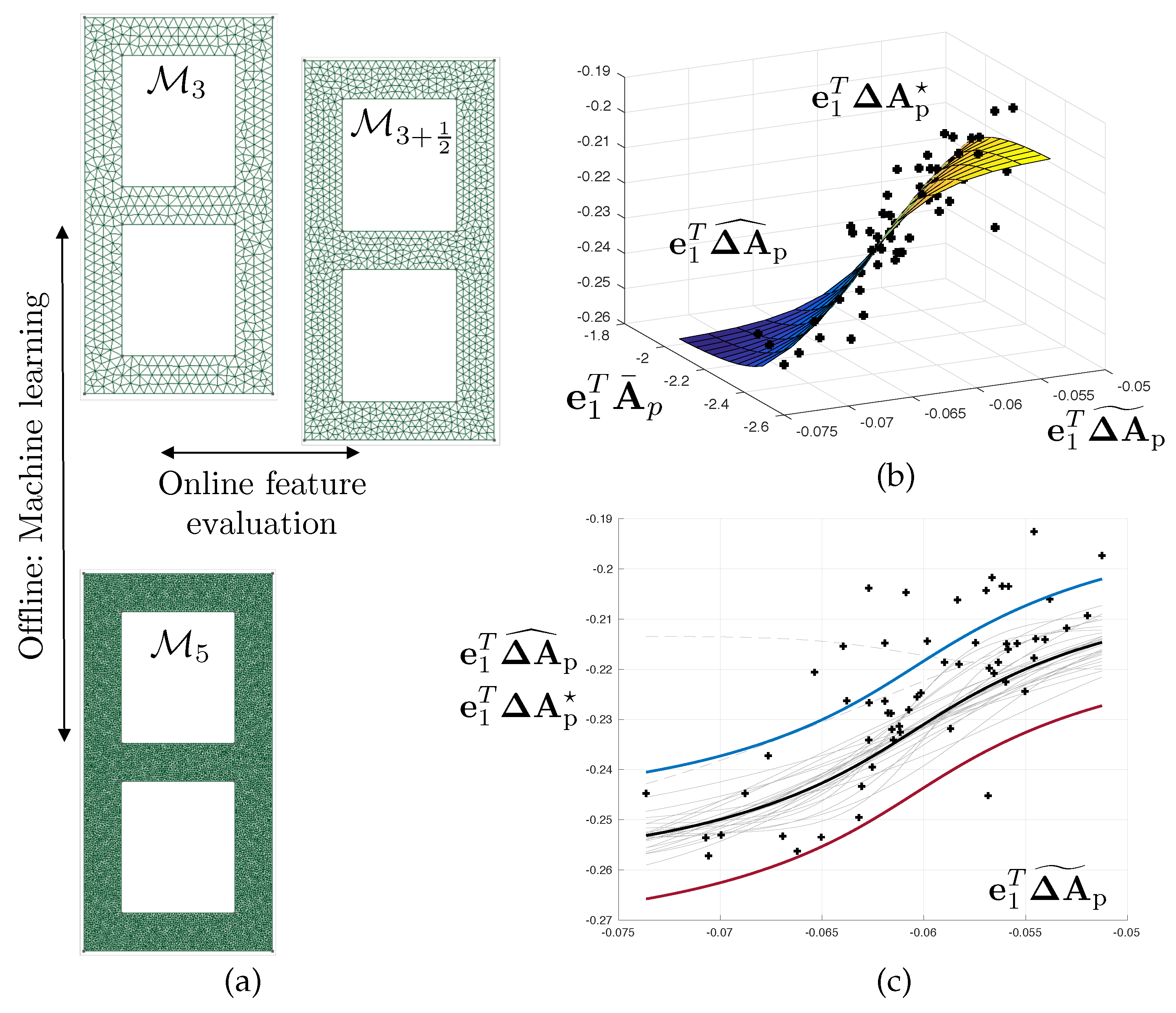
3.2. Computational Meshes
The evaluation of the likelihood function appearing in solution (
11) of the Bayesian inverse problem requires solving the continuum mechanics problem using the finite element method. In this example, we use a sequence of meshes
associated with a monotonically increasing number of degrees of freedom. These meshes are represented in
Figure 2. Although the sequence of meshes is not strictly hierarchical, we see that the typically uniform element size is divided by
when moving from mesh
to mesh
. The intermediate meshes
represented in
Figure 2 will be used later on.
3.3. Inverse Problems and First Results
Two tests will now be investigated:
Test 1(weakly informative data): only the first eigenvalue is measured, i.e., is scalar. This can be interpreted as a task of model updating, where new data is used to update an existing knowledge.
Test 2 (strongly informative data): the first three eigenvalues of the structure are measured. This can be interpreted as an inverse problem, where rich information is used to identify all the unknown of the model, and the probabilistic setting acts as a regulariser.
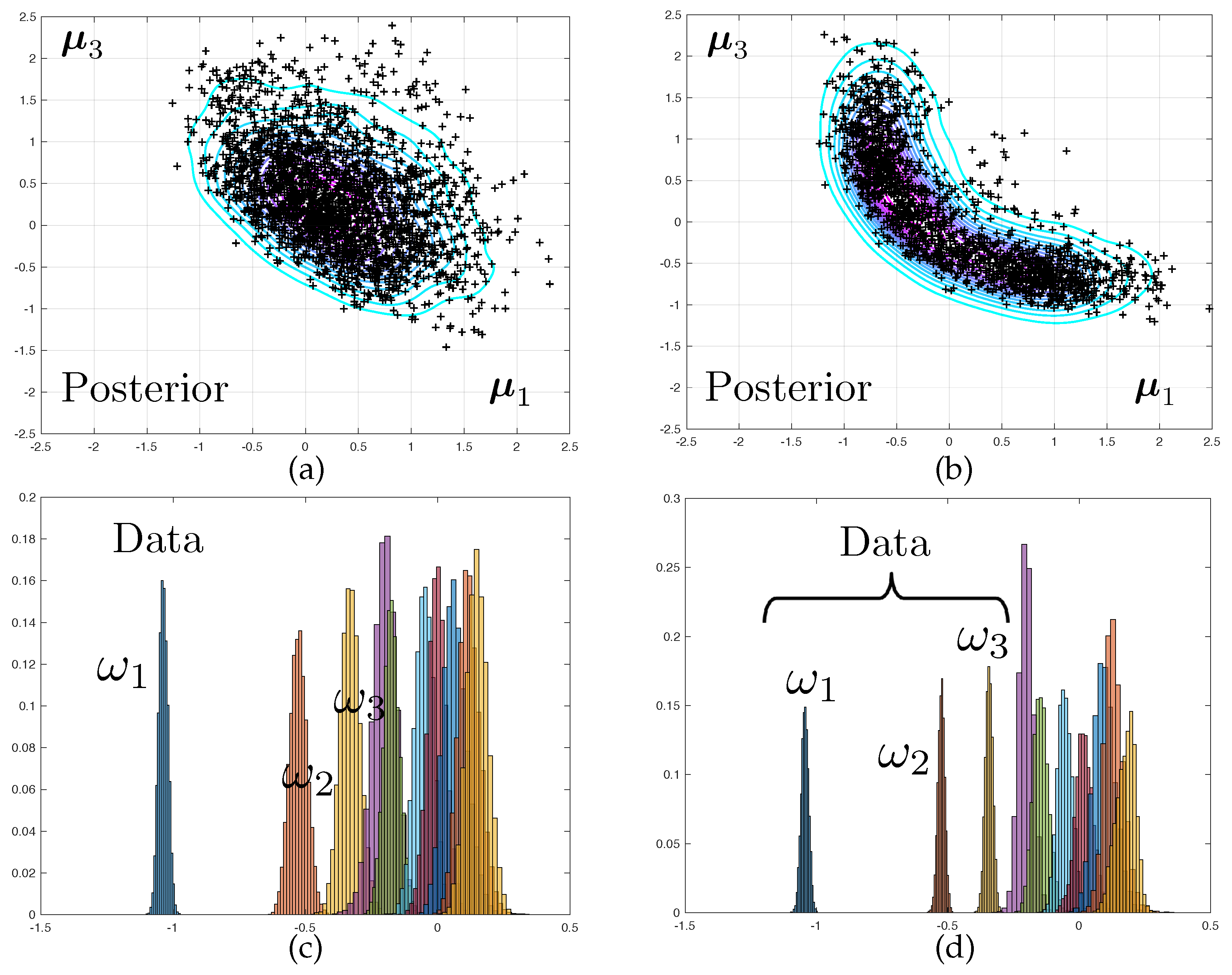
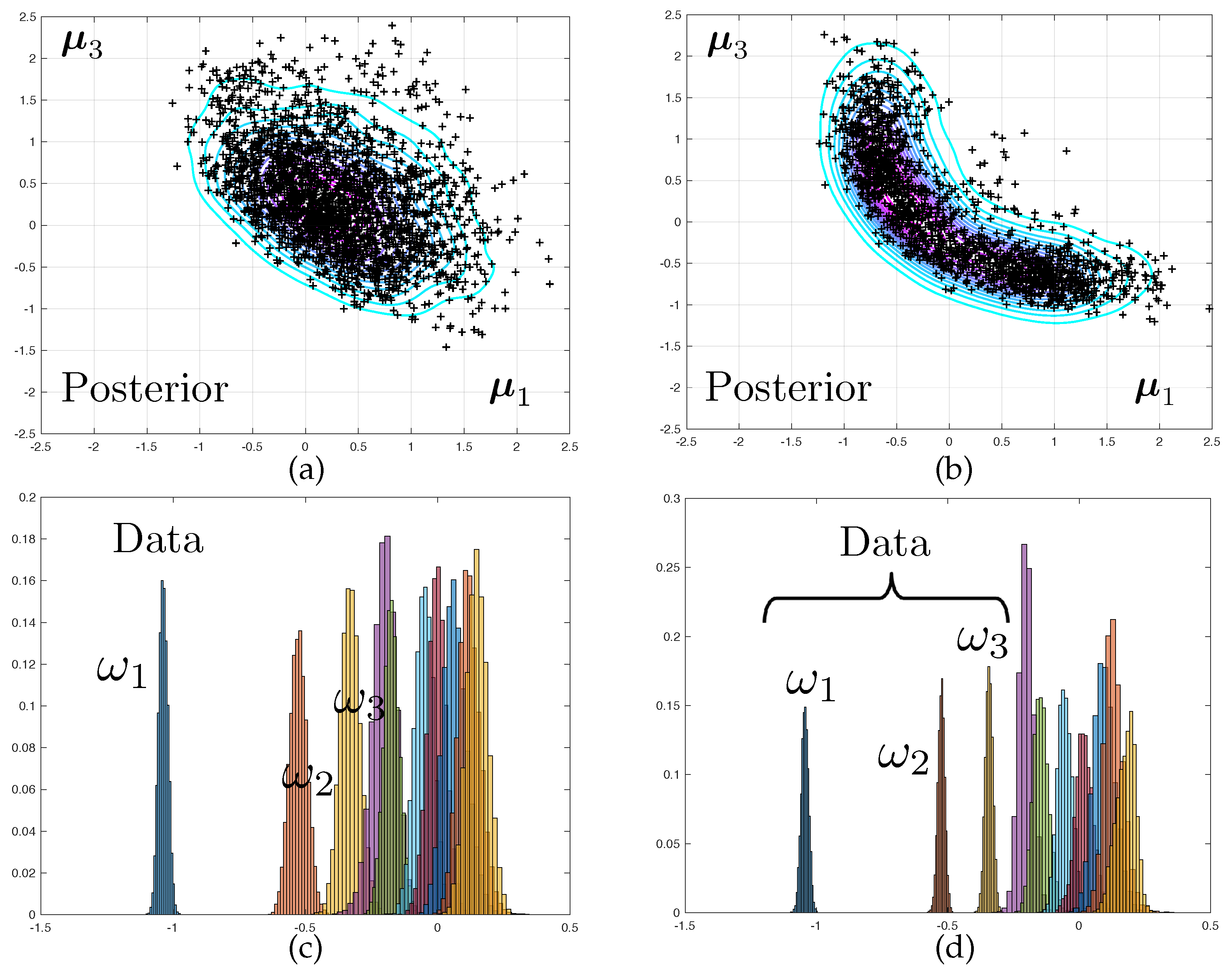
The two corresponding marginal posterior density
obtained when using mesh
are represented in
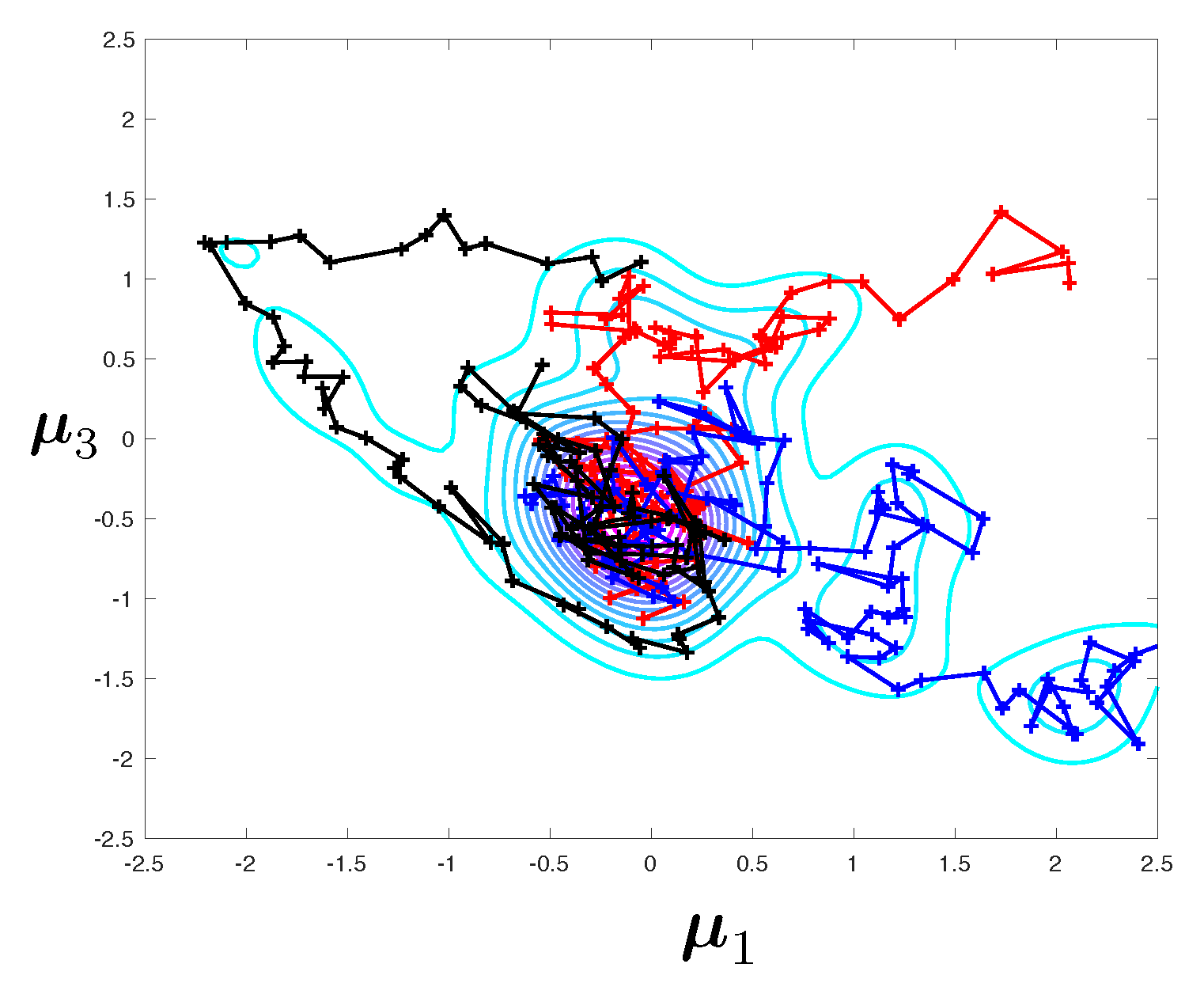
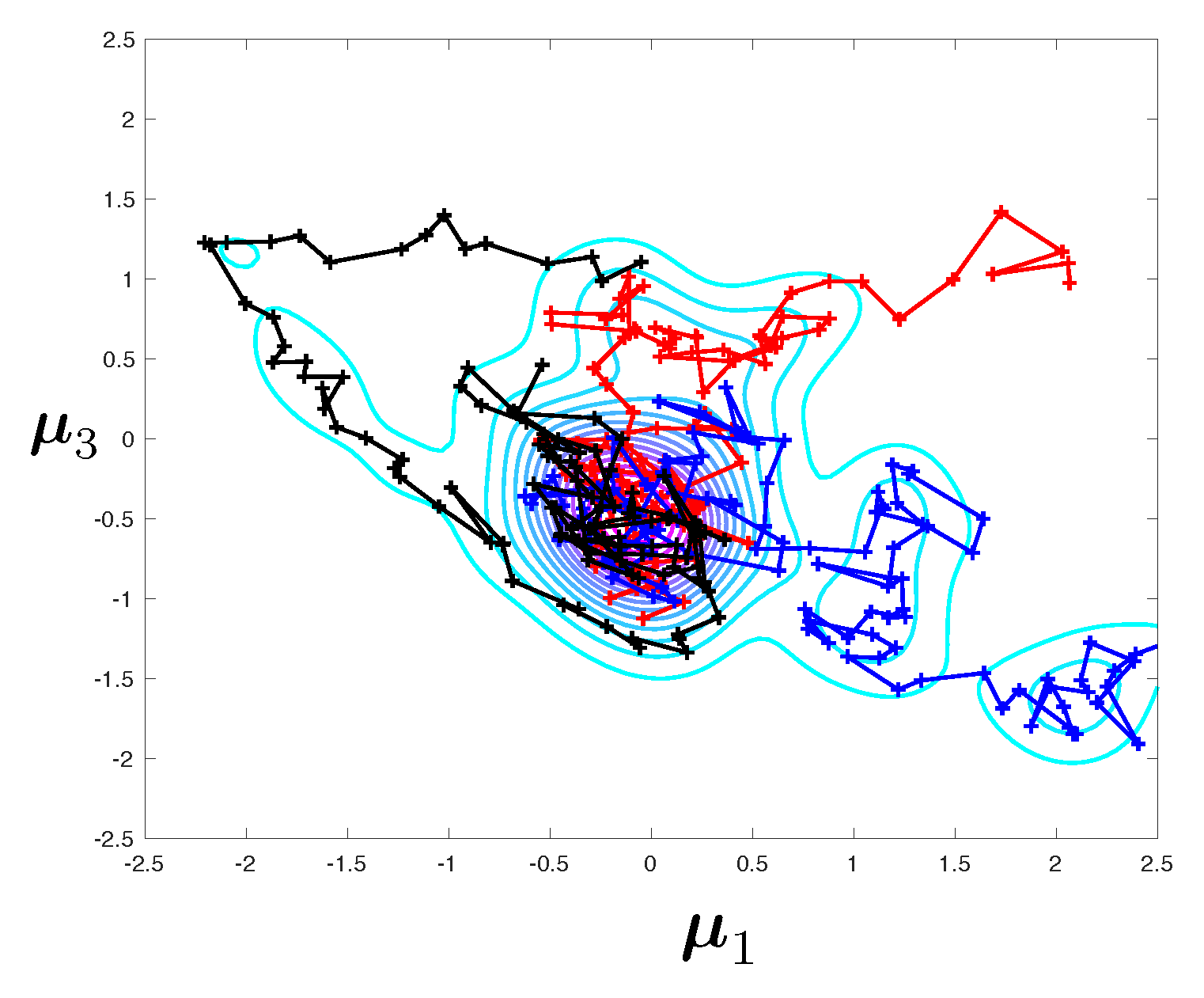
Figure 3. Samples from this density are obtained by a Monte-Carlo sampler, as presented in next section. A Kernel Density Estimate (KDE) is used as a smoother for illustration purposes only. Notice that for the predictive posterior densities, the histograms correspond to the marginal densities of each individual eigenvalue, which explains their overlap.
It is interesting to notice that the posterior densities observed in Test 2 are much sharper than that of Test 1, owing to the quality of the data. The symmetry in the results are a consequence of structural and probabilistic symmetries (see
Figure 1 and the definition of the prior probability density).
Synthetic data for this problem is generated by computing the average of the spectra delivered by meshes and , for a reference parameter vector but situated in the vicinity of the prior mode. The model averaging, together with selecting relatively coarse finite element meshes in sequence , is meant to circumvent the “inverse crime" problem.
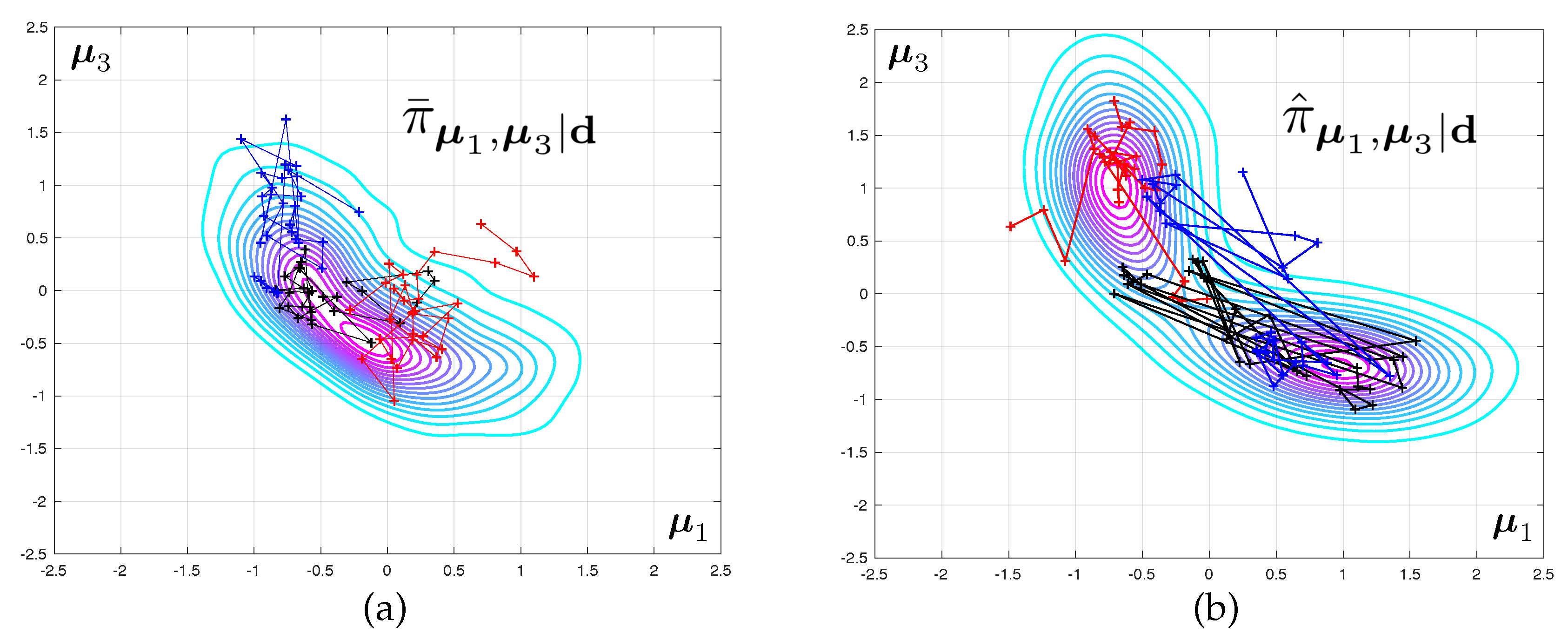
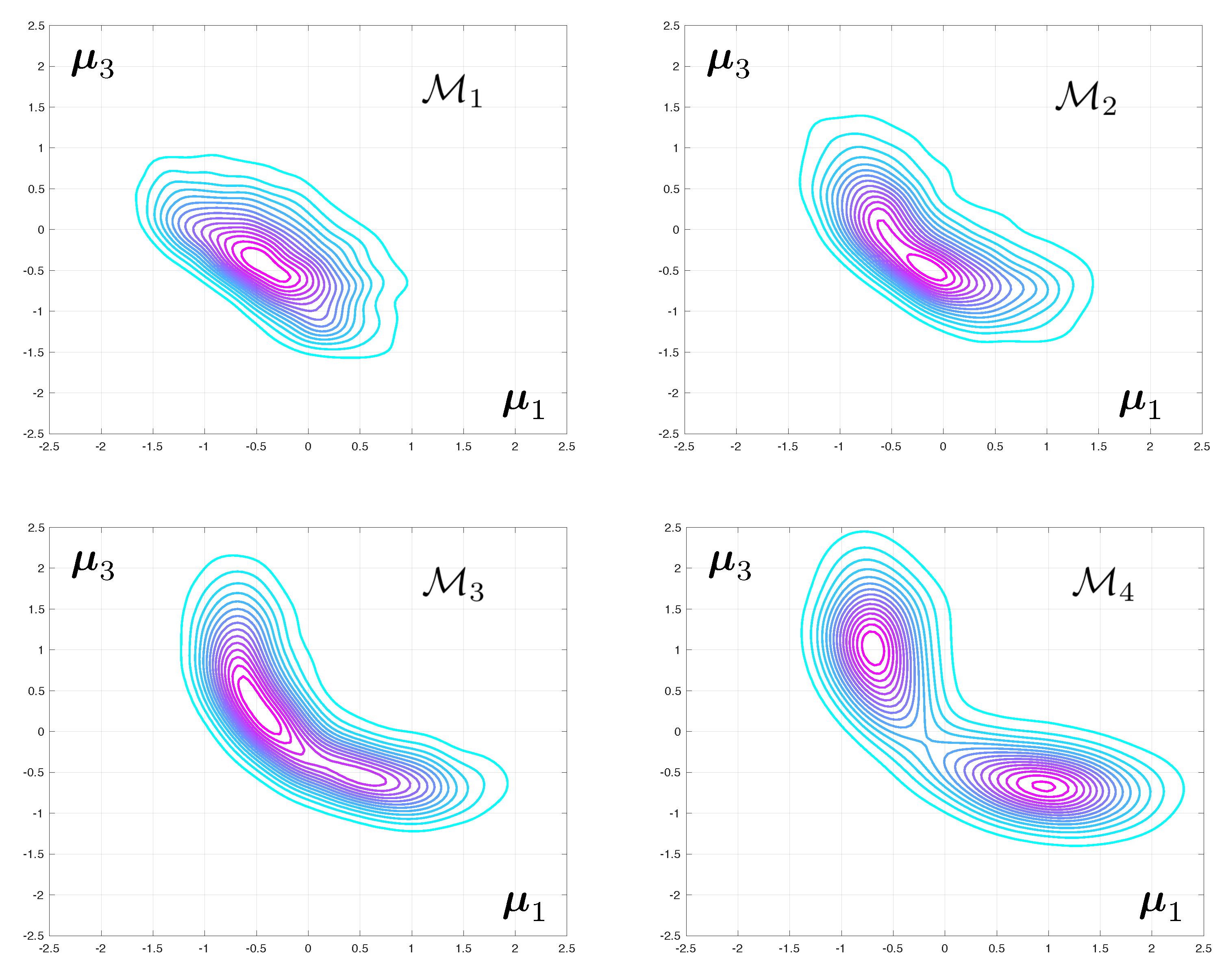
3.4. Convergence with Mesh Refinement
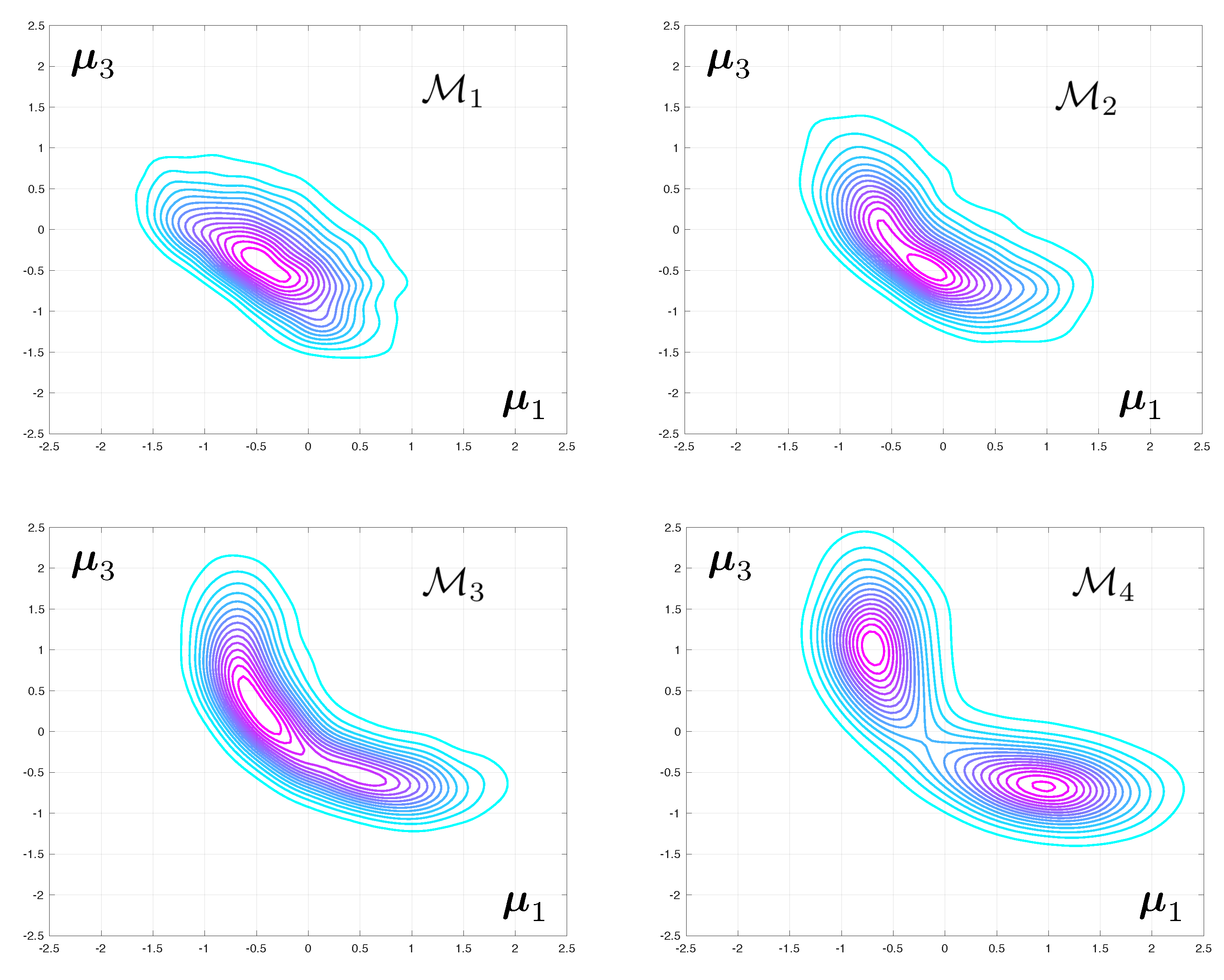
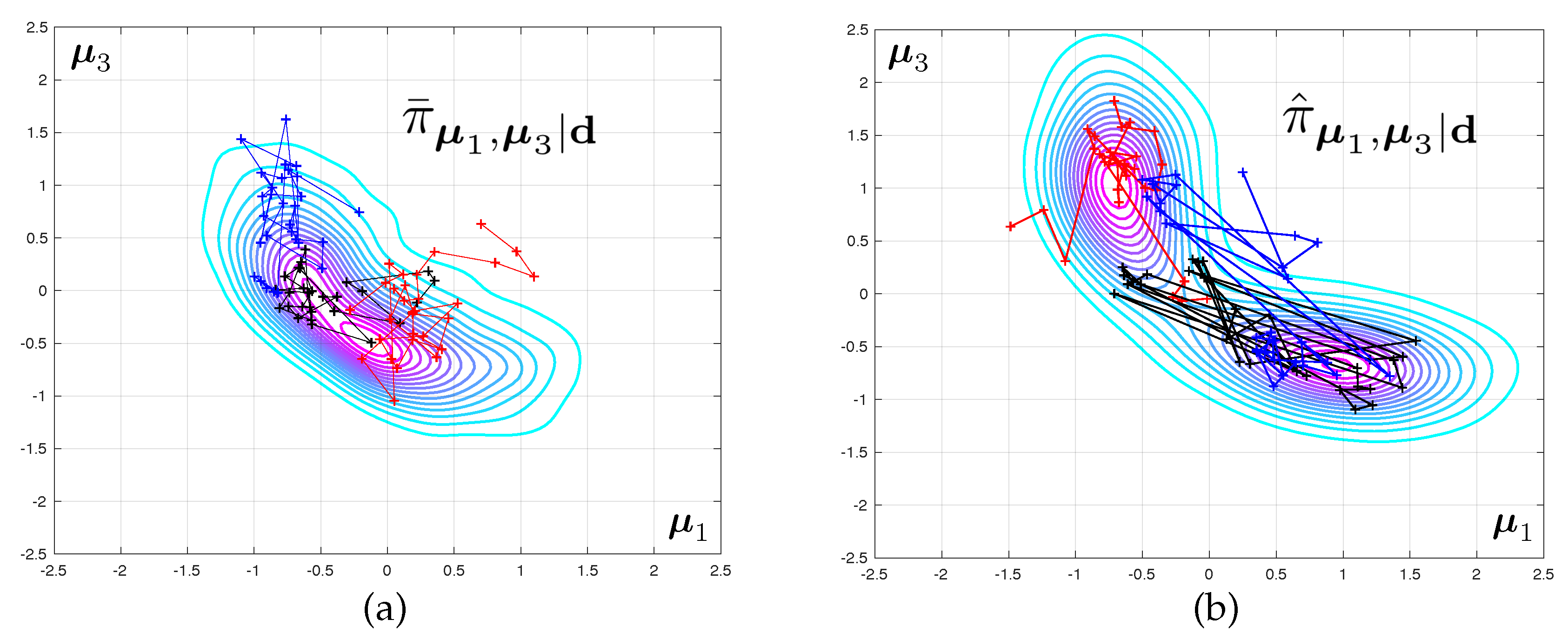
The posterior densities corresponding to Test 2 and to various level of mesh refinement are displayed in
Figure 4. The difference between the modes of the predicted eigenvalues that are obtained with coarse and fine meshes are very large. The fact that this discrepancy increases with the mode number is to be expected as the spatial wave length of the deformations in the continuum can be shown to increase linearly with the eigenfrequency. As a consequence, a good mesh for the first range of frequencies might be unable to capture the faster spatial variations associated with higher vibration mode.
The difference between the posteriori densities corresponding to meshes and is qualitatively small. The solution of the Bayesian inverse problem converges with mesh refinement. Notice that the posterior distribution for the model parameters goes from mono-modal to multi-modal, which may prove a stumbling block when selecting an appropriate Monte-Carlo sampler.
5. Robust, Automatised and Comprehensive Error Control
5.1. Simulation of the Discretisation Error
The finite element method introduces an error in computational mapping
. Mapping
contains all the scalar quantities that need to be evaluated through calls to the finite element solver, namely the numerical predictions of the physical measurements
, and the posterior predictions
. We define the error in the simulated data as
and the error in the posteriori predictions as
For now, we assume that both these quantities can be estimated, at affordable numerical cost and in a reliable manner. Therefore, for any value of parameter
, a corrected computational model is available, which reads as
where symbol
denotes computable estimates.
5.2. Component-Wise MCMC
It is now posible to sample the corrected posterior distribution
using MCMC. It should be clear that the corrected posterior distribution is simply obtained by replacing the corrected computational model (
26) into the expression of the likelihood function, Equation (
3). Notice that the normalising constant is affected by modifications of the computational model. This is of no practical consequence as MCMC samplers work with unnormalised densities, and the KS distance uses empirical cumulative distributions directly, without the need for smoothing or marginalisation.
We formally define a component-wise MCMC were the uncorrected and corrected computational models are sampled at the same time. This will yield an estimate of the effect of the discretisation error on posteriori densities at any stage of the Markov process, which, in turn, will allow us to develop an early-stopping methodology. The Component-wise MCMC iteration proceeds as follows, given a current sample of the uncorrected/corrected finite element posteriori densities,
Draw
such that
Accept
if and only if
set
otherwise.
Accept
if and only if
set
otherwise.
The MCMC algorithm is initialised by state , where both and are drawn from distribution .
In the field of a posteriori finite element error estimation, the error estimate is usually a post-processing operation of the coarse finite element solution. This adapts seamlessly to non-Markovian Monte-Carlo samplers, by post-processing each of the independent samples. Here, unfortunately, the finite element model has to be called twice at every iteration of the Markov process. Whether this can be avoided or not, for instance by making use of elements of sequential Monte-Carlo samplers, is unclear to us at this stage.
5.3. Machine Learning-Based Simulation of the Discretisation Error
At this stage, any numerical error estimator can be used, provided that it is goal-oriented. A method of choice could be a residual-based [
5,
6] or smoothing-based a posteriori error estimator [
12,
46] in conjunction with the adjoint methodology [
8,
9,
11]. In addition, nothing prevents us from using a meta-modelling approach, such as projection-based reduced order modelling [
47,
48,
49,
50,
51,
52] or polynomial chaos expansions [
16,
17] to approximate the variations of the computed quantities of interest with parameter variation. Error estimates also exist for such two-level approximations.
In this contribution, we develop and use a feature-based method, that finds its roots in data-science methodologies and is much more “black-box” than the previously mentioned strategies. The proposed technique is inspired by the work of [
35,
36,
37].
The exact continuum mechanics model is well approximated by a very refined numerical strategy (e.g., no meta-modelling and a very fine mesh). However, this very refined numerical model cannot be used at every iteration of MCMC as its evaluation is very costly. We propose to train a model that will map parameter
to the output of the generally intractable very fine model through the combination of (i) a dedicated feature extractor and (ii) a weakly parametric regression model. This combination is defined as
where the
denote quantities that are delivered by the overkill (but computable) numerical model and
is a weakly parametrised regression model, here a neural network regression (a Gaussian process could be used as well, but a random forest would probably have been the most efficient choice, given the way we bootstrap the regression model to generate estimates of generalisation errors), parametrised by a set of parameters
(we do not explicitly distinguish parameters and hyper-parameters in our notations).
is a mapping from input
to a feature space. Its careful design is critical to the success of the machine learning procedure. We choose to construct the following features:
where
are
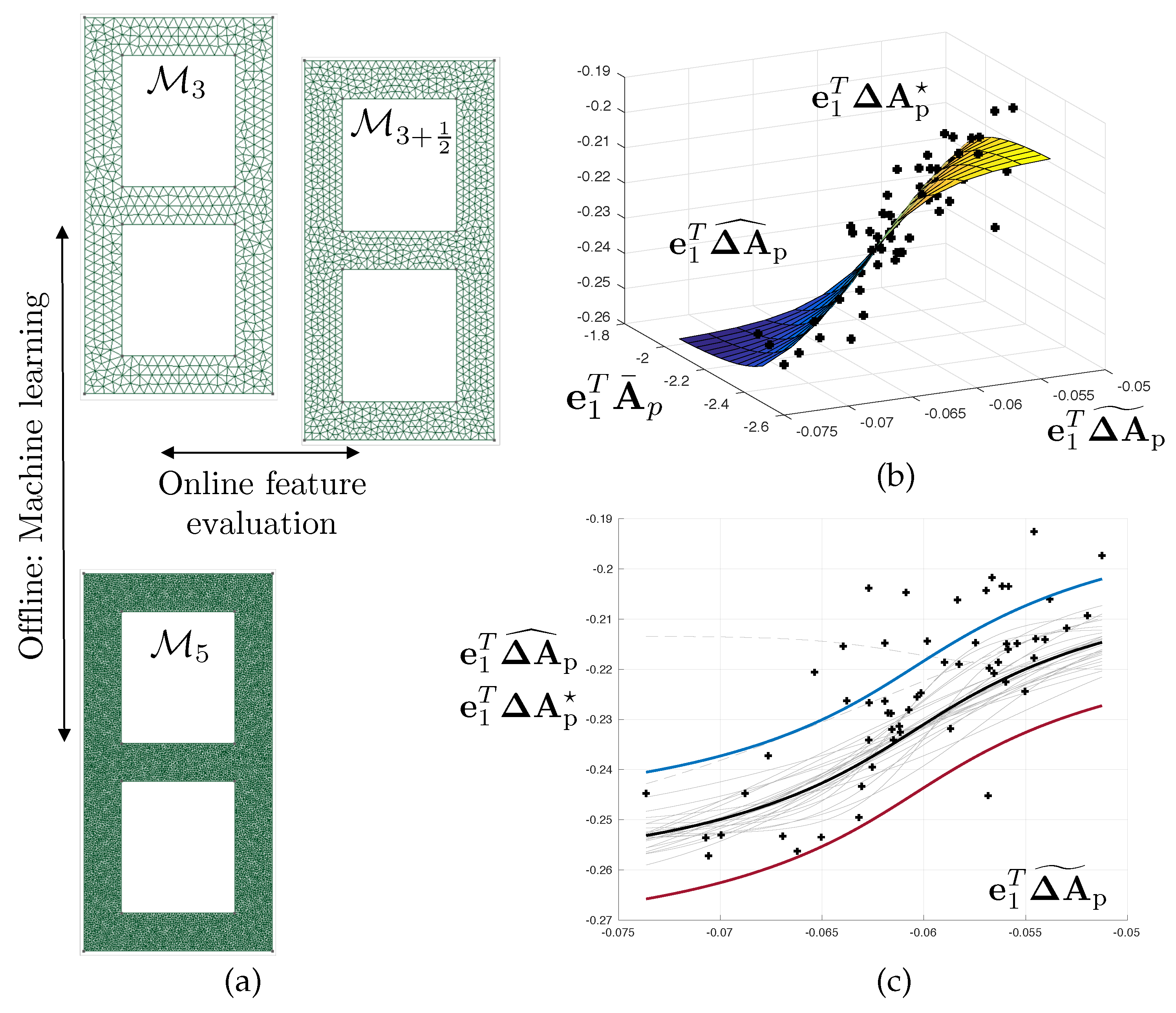
slighlty corrected computational models, here generated by refining the mesh by a moderate factor. In our examples, the typical mesh size is divided by 1.5 (see
Figure 2 and
Figure 6 where we use mesh
to correct mesh
, whilst the overkill solution is computed using
). In this fashion, the generation of features will remain of the order of the computation of the finite element solution itself.
Now, we train
multivariate neural network regression models
where
denotes the jth canonical vector of
.
Each of the regression
is a single-hidden layer bootstrap-aggregated neural network model with
neurons and
bootstrap replicates.
Training
We sample artificial “data” by running the overkill computational model times, after sampling the training set parameters from prior . The number of neurons and the cardinality of the training set is chosen automatically by making use of an automatised early-stopping methodology that aims to maximise the predictive coefficient of determination. We will not detail this procedure here. Fitting of the nonlinear regression coefficients is performed by employing standard least-squares method, solved by a gradient descent algorithm with randomised initialisation. Outliers of the set of bootstrap replicates are identified and eliminated to decrease the variance of the boostrap-aggregated regression model.
An example of fitted regression model is represented in
Figure 6, where the output is the discretisation error in the first free vibration circular frequency (i.e., regression model
).
5.4. Bootstrap Confidence Intervals for the MCMC Sampler
At any iteration
n of the MCMC sampler, a Monte-Carlo estimate of the discretisation error for the posterior density of the ith component of
is given by
where
and
Crucially, is a random variable whose statistics, and in particular its bias and variance, strongly depend on the length of the Markov chain. Unfortunately, evaluating the convergence of any statistics provided by MCMC is difficult, due to the statistical dependency between successively drawn samples.
Following standard diagnostic approaches for MCMC samplers (e.g., the Gelman-Rubin convergence test [
53,
54]), we will run
independent (tempered) MCMC chains in parallel and pool all the resulting samples, after discarding the first 25% of every individual chain as burn-in (see
Figure 7 as a visual aid). The pooled samples at iteration
n of the multiple-chain MCMC (MC
) algorithm are
where ∏ denotes the cartesian product. In the previous expression, the sample set from chain
i (at ambient temperature) is
is now the pooled KS distance estimate provided by the MC
algorithm (we will keep the same notation for the sake of simplicity). Formally, we simply replace Equation (
37) by
and perform a similar operation to define the pooled corrected empirical distribution.
The independence of the
MCMC chains allows us to compute confidence intervals for
by making use of the non-parametric bootstrap. This is done by resampling
and
with replacement, generating bootstrap replicates of the pooled sample sets
and
,
where
is such that each element of this set is drawn uniformly over
and
k varies between 1 and a large number
, typically set to 1000. For each replicate, statistics
, denoted by
, can be computed in a straightforward manner by using the bootstrap replicates of the pooled empirical distributions
which reads as
Finally, the bootstrap confidence intervals are calculated by calculating the
Xth and
th bootstrap percentiles such that the
Xth percentile reads as
where
is an operator that extracts the
Xth and
Yth percentile of the set passed as argument.
It is important to understand that the derived bootstrap confidence interval stands for a chain of finite length n, and not for the asymptotic limit. In fact, estimate of is strongly biased (upward for small asymptotic errors and typically downward for large asymptotic errors), which is due to two factors:
The variance of decreases with the number of chains of the MC algorithm (which is not a free parameter as overall CPU cost increases linearly with ). Of course, bias and variance are both expected to decrease with the length n of the run.
5.5. Simultaneous Control of All Sources of Errors
We now make use of the CI derived for to construct an adaptive inverse problem solver that jointly controls the quality of the mesh, and that of the statistical evaluation of the posterior densities. The algorithm is as follows. Given a current mesh and number of iterations n of the Monte-Carlo solver, do:
If , perform iterations of the MC algorithm and set .
Evaluate mesh convergence criterion . If this criterion is satisfied, exit the adaptation procedure;
If is not satisfied, evaluate statistical convergence criterion
- -
If is satisfied, set , reinitialise the MC algorithm and set ;
- -
otherwise perform iterations of the MC algorithm and set (m should be an exponentially increasing function).
5.5.1. Criterion
Convergence of the finite element-based Bayesian inverse problem is achieved when
, where
is a numerical tolerance that will typically be chosen between
and
. As we only have Monte-Carlo estimates of
, we require instead that
Criterion is an indicator of the combined effect of the discretisation and statistical errors onto the posterior densities. The discretisation error is evaluated through the choice of measure as reliability indicator, whilst the statistical error is taken into account by making use of the upper limit of the bootstrap confidence interval for . The risk of falsely detecting mesh convergence due to a high statistical error is small, due to the fact that is an upwardly biased estimate of for small . Confidence in the result can be increased through a loose Gelman-Rubin convergence test in order to eliminate the risk of stopping the MC algorithm in its non-ergodic phase. However, this has proved to be unnecessary in our numerical tests. This is because is a rather strict criterion.
5.5.2. Criterion
The second criterion will help us determine whether mesh refinement is actually needed, or whether the statistical error is too large for use to take a robust decision regarding mesh refinement. The ideal criterion is , where . The obvious strategy that would require does not work. This is due to the previously explained upward bias of estimator , which would eventually lead to the spurious satisfaction , and consequently to systematic mesh refinement operations for low n count even when the mesh becomes fine enough for to be well below target . In order to derive an appropriate criterion , we remark that whilst the ideal criterion cannot be statistically evaluated for general values of , criterion can be. More precisely, we propose to estimate the statistical error by evaluation whether, at current n, the corrected and uncorrected posterior distributions can be statistically distinguished.
We postulate the following null hypothesis: Hypothesis 0 (H0): the corrected and uncorrected posterior densities are identical.
The rejection of the null hypothesis will indicate that the two densities are significantly different. Now, the criterion for the need for mesh refinement becomes the following:
The probability density of
under null hypothesis H0 can be approximated by adapting the previously described bootstrap procedure. We will estimate the density of
where
and
are obtained, respectively, by pooling the result of two independent runs of
Markov chains of lengths
n and corresponding to the uncorrected finite element model only (one can equally choose the corrected one). Notice, to clarify the idea, that
tends to 0 as
n tends to infinity: this is a measure of the statistical error only. The desired density can be estimated by resampling
twice, computing the KS distance between the two pooled sets of samples, and repeating the operation
times, which generates a sequence of real numbers
. The replicated empirical cumulative distributions are
with the sampling sets
where
or
and
and
are sets of
constructed such that each element of these two sets is drawn uniformly over
. We can now extract the
th percentile
corresponding to
p-value
, and evaluate whether
. If so, test
is true. If not, the statistical sampling error is too large to allow us to decide whether mesh refinement should be performed or not. In this case, and assuming that mesh convergence criterion
is not satisfied, we need to continue sampling with MCMC.
Notice that the use of a larger percentile Z yields a less conservative indicator for the need for mesh refinement, which can be compensated by decreasing p-value . The criterion that is arguably the easiest to interpret is , where is directly the KS distance (i.e., computed without bootstrapping).
6. Numerical Examples—Part II. Automatised Error Control and Discussion
We now come back to the numerical examples introduced in
Section 3 and produce three series of results, illustrating three difference aspects of the proposed approach.
6.1. MCMC Iterations Only When Needed
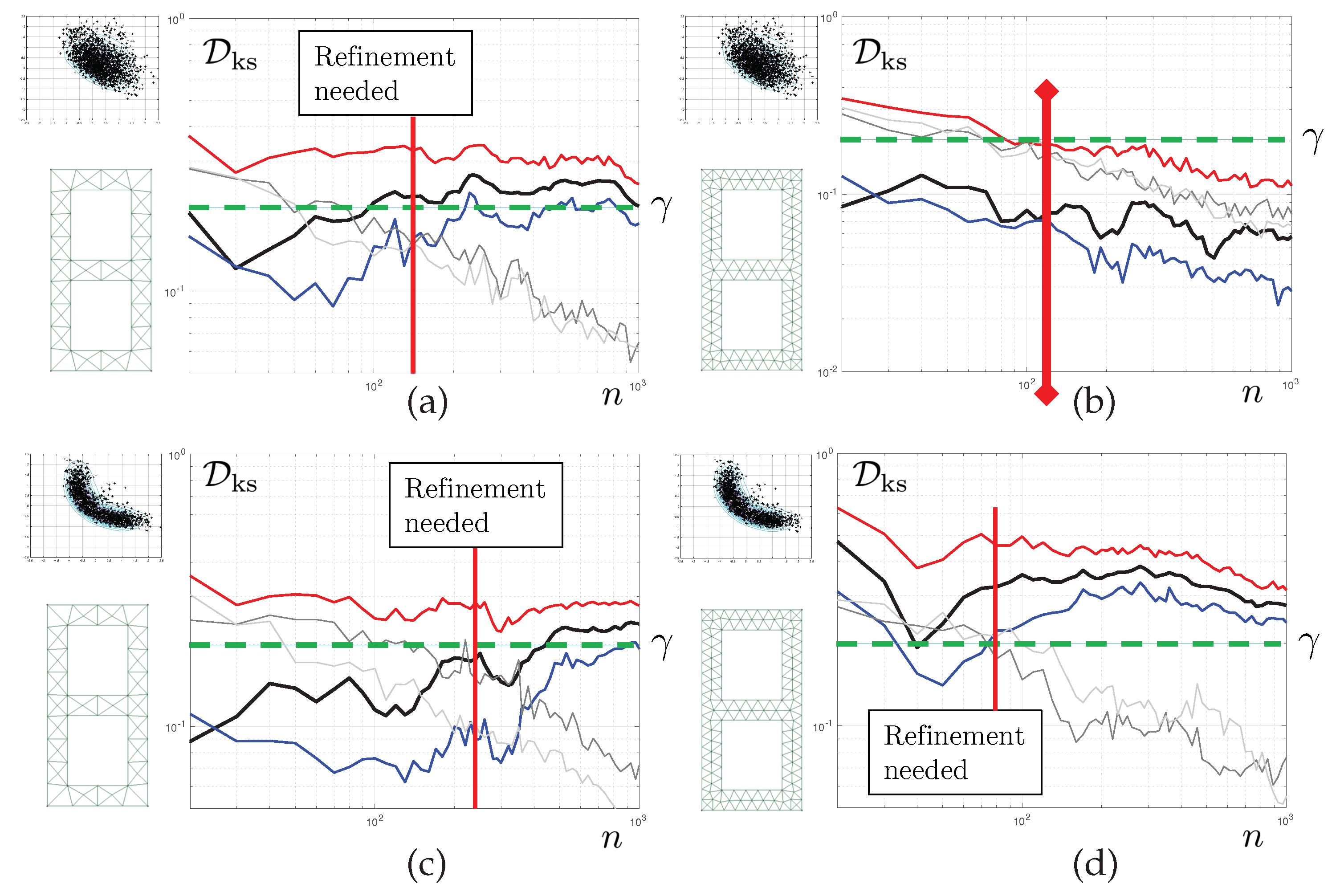
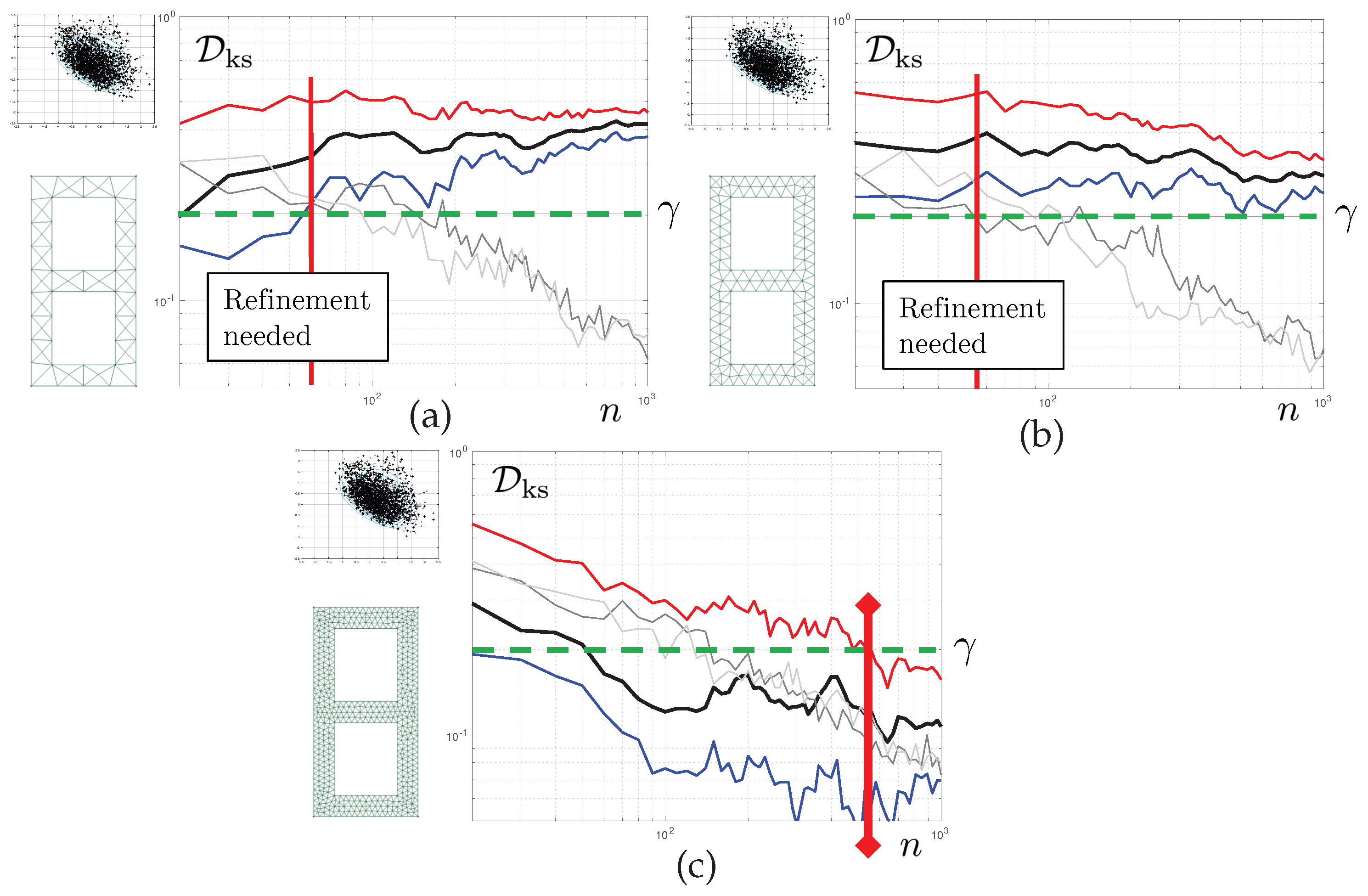
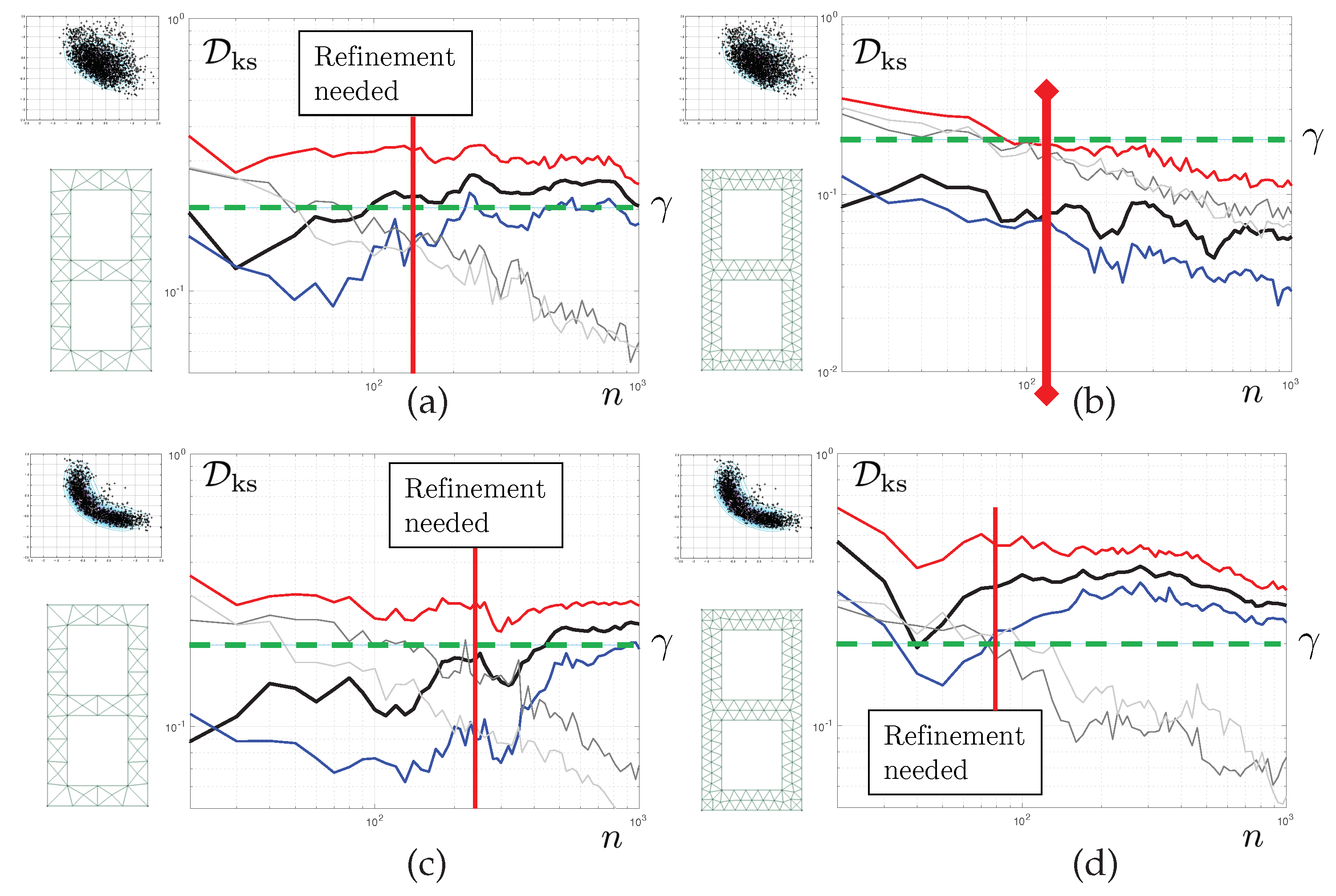
The results reported in
Figure 8 correspond to Test 1. For now, we aim to control the quality of the posterior density of the first parameter
. Each of the graphs shows the evolution of various statistics of the corresponding KS distance as a function of the number of iteration
n of the tempered MC
algorithm. The mesh used is displayed on the left-hand side of each of the graphs. The solid black line represents the evolution
itself. The 5th and and 95th bootstrap percentiles of this quantity are also reported, in solid blue line and solid red line, respectively. We set convergence criterion
such that
and
for the pure discretisation error. Therefore, convergence with respect to the finite element discretisation is obtained when, for sufficient long chains, the red line (upper limit of the bootstrap CI for
) is below
.
In grey colours, we report evolution of for the coarse scale (light grey), consistently with the derivations of the previous section, but also, for reference, a similar statistics constructed with the corrected finite element model (dark grey). Both curves have similar evolutions and, of course, tend to 0 as n tends to infinity. We set , and . This means that the statistical error is considered small enough once the blue line (lower limit of the bootstrap CI for ) is above the 95th percentile of . Here, “small enough” is to be understood, as small enough for a decision regarding the need to refine the mesh one step further to be taken.
The results are as follows. For the coarsest mesh, we detect a separation of the discretisation and statistical errors at iteration 60 (vertical solid red line). is satisfied. As is not satisfied, we can stop the MCMC sampler and refine the mesh. A similar behaviour is seen for mesh . For the last mesh, convergence is achieved after 530 iterations, never reaching satisfaction. The discretisation and sampling errors remain entangled, but the sum of them is below the desired target.
We can see here that the proposed algorithm allows us to stop the MCMC sampler early, moving directly to the level of mesh refinement that will yield the desired quality of the posterior densities.
6.2. Goal-Oriented Error Control
The second set of results correspond to Test 1, still. However, we now monitor the convergence of the posterior predictive density of the fourth eigenvalue. This is reported in the top two graphs of
Figure 9. For
Early-stopping is performed at iteration 40 of the MCMC sampler. For
, global convergence is achieved after 120 iterations, and this error keeps decreasing. The MCMC is allowed to continue generating samples, meaning that the discretisation error is actually a lot smaller than the requested tolerance
. It is interesting to see that the convergence is much faster than for the first parameter, whose convergence was studied in the previous subsection. This shows that for the same inverse problem, the algorithm may spend more or less resources depending on the engineering quantity of interest.
6.3. Uncertainty-Driven Error Control
Finally, the last set of results concerns Test 2. Here, remember that the three first eigenvalues are used as measurements. We control the convergence of the fourth eigenvalue, which was controlled in the context of Test 1 in the previous subsection. We see here that for mesh , the posterior density of the fourth eigenvalue is still far from convergence, whilst it was evaluated in a very precise way in Test 1. This shows that the proposed error control algorithm automatically adapts to the level of posterior uncertainty. Qualitatively, a wide posterior density is associated with a high uncertainty concerning the value of QoIs. Consequently, the mesh does not need to be very refined to capture the posterior density correctly. Conversely, for Test 2, the posterior density is sharper, and similar levels of discretisation errors have a much stronger impact on the KS distance.
7. Concluding Remarks and Discussion
We have presented a methodology to control the various sources of errors arising in finite-element based Bayesian inverse problems. We have focussed on a simple numerical approximation chain consisting of (i) a finite element discretisation of the continuum mechanics problem and (ii) a MCMC solver to draw samples from posterior density distributions. So far we did not consider further error sources such as that engendered by meta-modelling. We have showed that it was possible to drive the mesh refinement process in a goal-oriented manner, by quantifying the impact of the associated error onto posterior density distributions. In order to do so, we run two independent MCMC simultaneously, one of them using a corrected likelihood function that takes the discretisation error. Any a posteriori error estimate available for the PDE under consideration may be used to obtain this correction. Of course, the accuracy (effectivity) of the chosen error estimate will impact the accuracy of the methodology developed in this paper. The study and control of this effect will require further research to be carried out,
We have shown that by using multiple replicates of the component-wise MCMC, it was also possible to (i) derive bootstrap-based confidence intervals for the error in posterior densities engendered by the spatial discretisation of the underlying PDE. Importantly, this approach allows us to stop the MCMC iteration as soon as we can be sufficiently confident in the fact that the posterior densities obtained with the current mesh are not accurate enough for our purpose. The approach is goal-oriented: the adaptivity is performed in the sense of the posterior distribution of either some of the latent parameters, or in the sense of the predictive posterior density of engineering QoIs. Finally, we have shown that the approach is uncertainty driven: it will only refine the mesh and/or request additional samples to be drawn by the MCMC algorithm if the effect on the QoIs can be felt when measured using a statistical distance between their posterior densities. In particular, model updating problems with wider priors tend to require less computational effort than parameter estimation problems with very rich observed data and/or narrow prior densities. The proposed methodology establishes a bridge between the field of reliability estimation for the sampling-based algorithms used to solve probabilistic inverse problems, and the field of deterministic, goal-oriented finite element error estimation.
Although the results presented in this paper are encouraging, the proposed approach has shortcomings that need to be addressed in future research work. The error estimation procedure is relatively wasteful for two reasons. Firstly, multiple MCMC algorithms need to run independently for bootstrapping to be possible. These chains all exhibit their own burn-in phase, which increases the amount of discarded samples. Secondly, the finite element error estimation procedure is not merely a post-processing operation any longer; one cannot post-process the finite element results corresponding to the uncorrected chain in order to compute the corrected likelihood. This is because both chains are independent and require running the coarse finite element simulations at different points of the parameter domain. Finally, let us acknowledge that Bayesian finite element inverse problems should not be solved by a MCMC solver without constructing a surrogate model first. The number of finite element computations involved, even if the proposal distribution is well designed, is in the tens of thousands. We are currently investigating the use of Polynomial Chaos surrogates, which adds another layer of numerical approximation that needs to be controlled in a robust and efficient manner. In this context, an elegant approach to separate the sources of errors (i.e., Finite Element discretisation error and Polynomial Chaos error) may be found in [
55], which may constitute a solid starting point for the next step of our investigations.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}