
Energy and Environmental Efficiency for the N-Ammonia Removal Process in Wastewater Treatment Plants by Means of Reinforcement Learning




Abstract
:1. Introduction
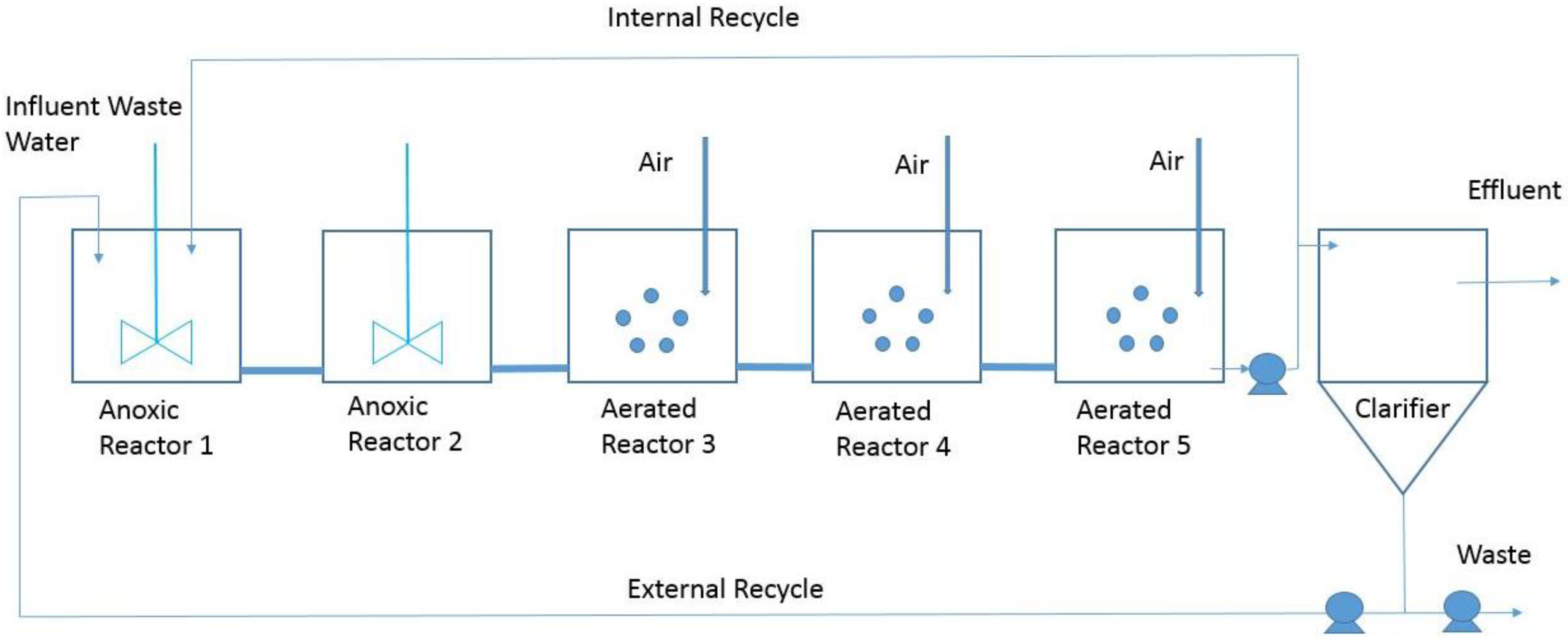
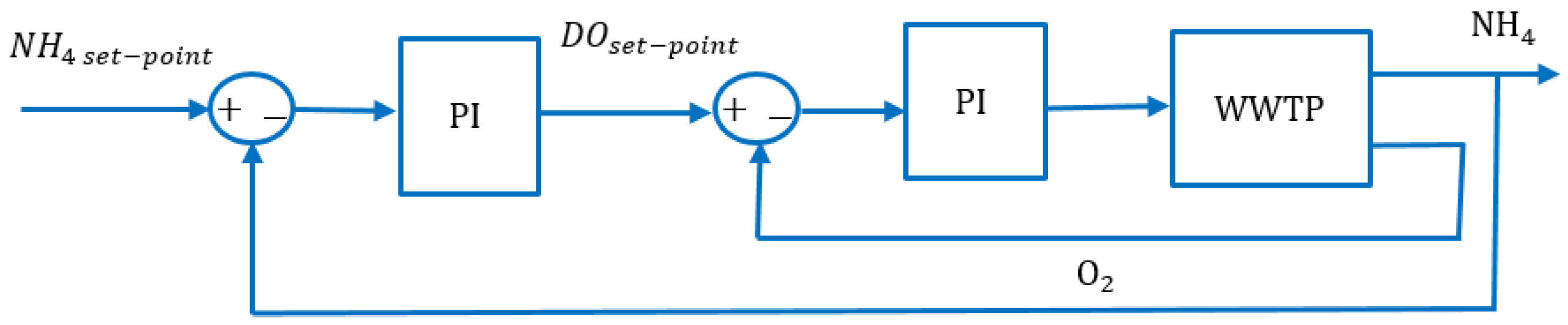
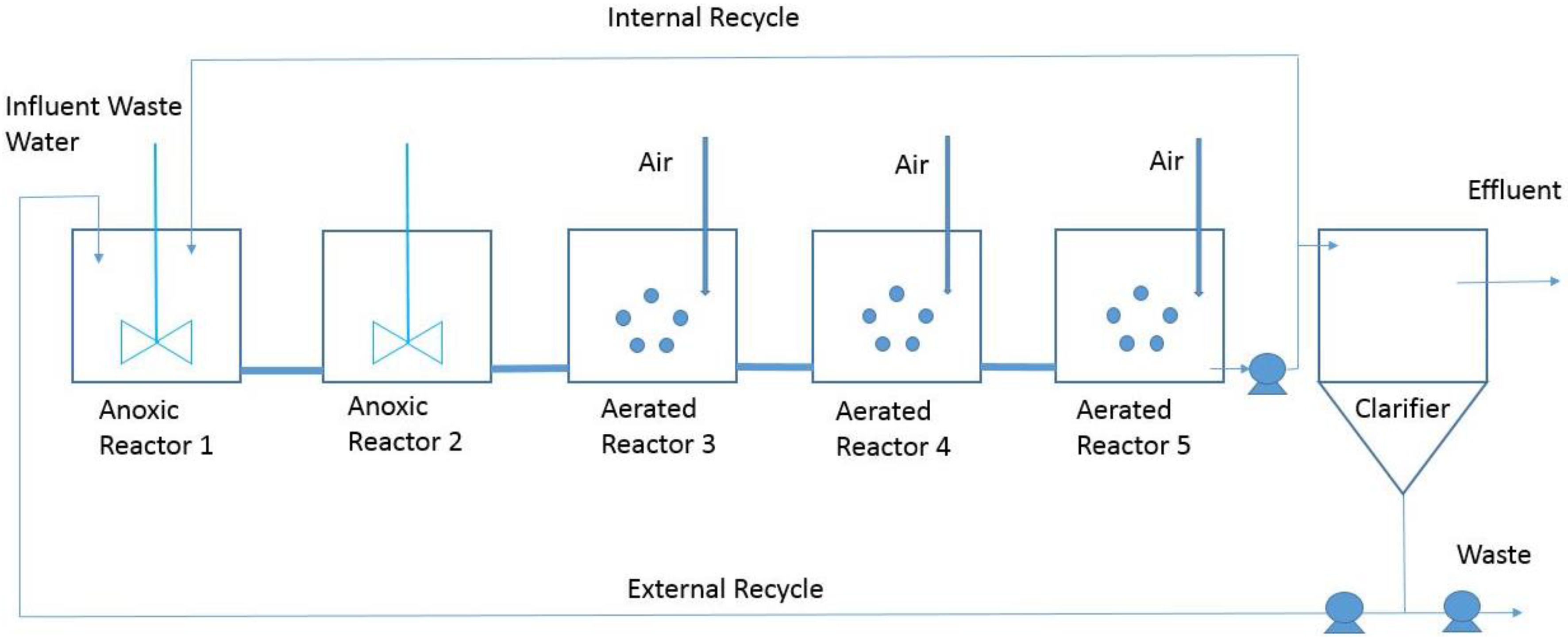
2. Working Scenario
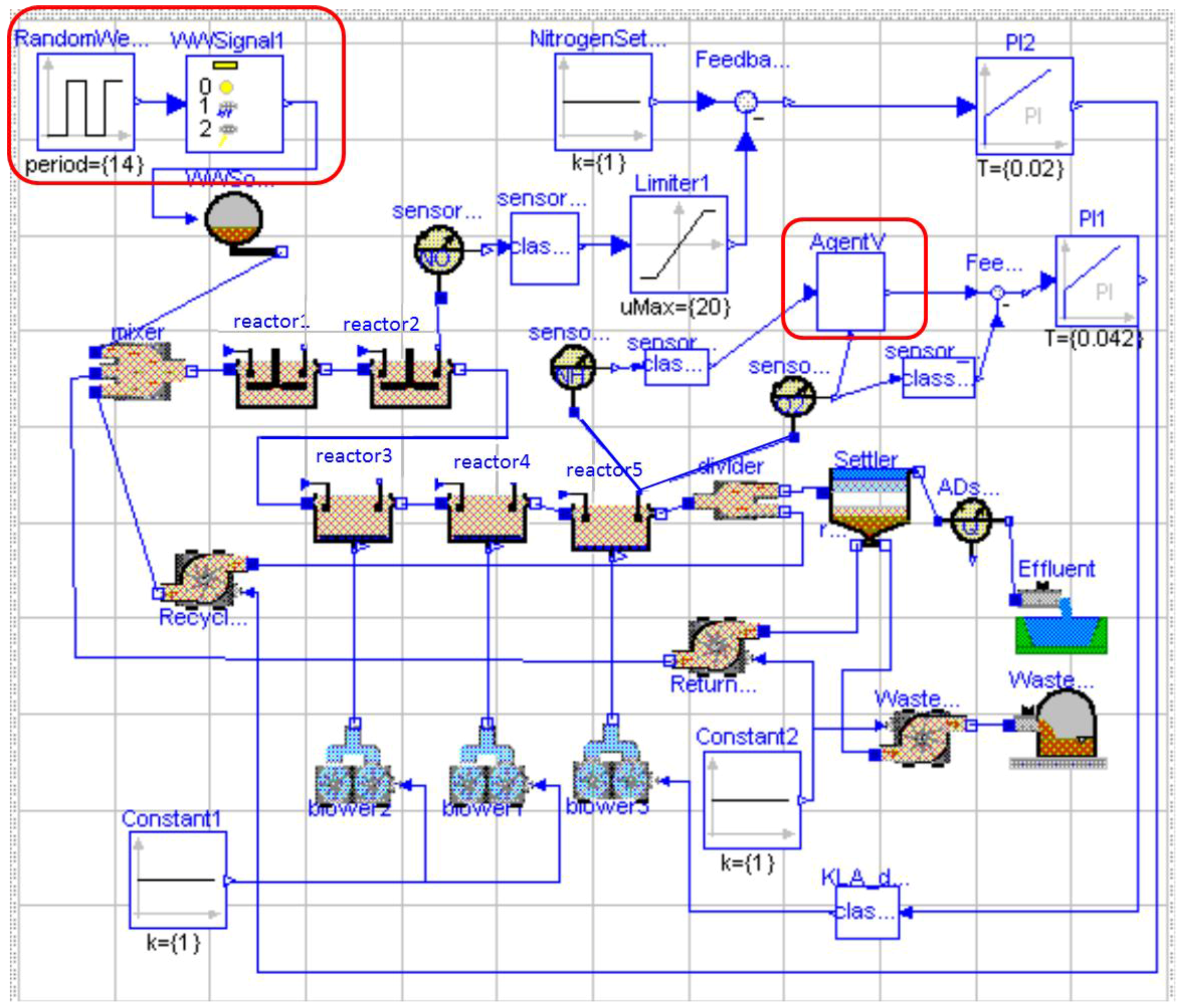
2.1. The BSM1
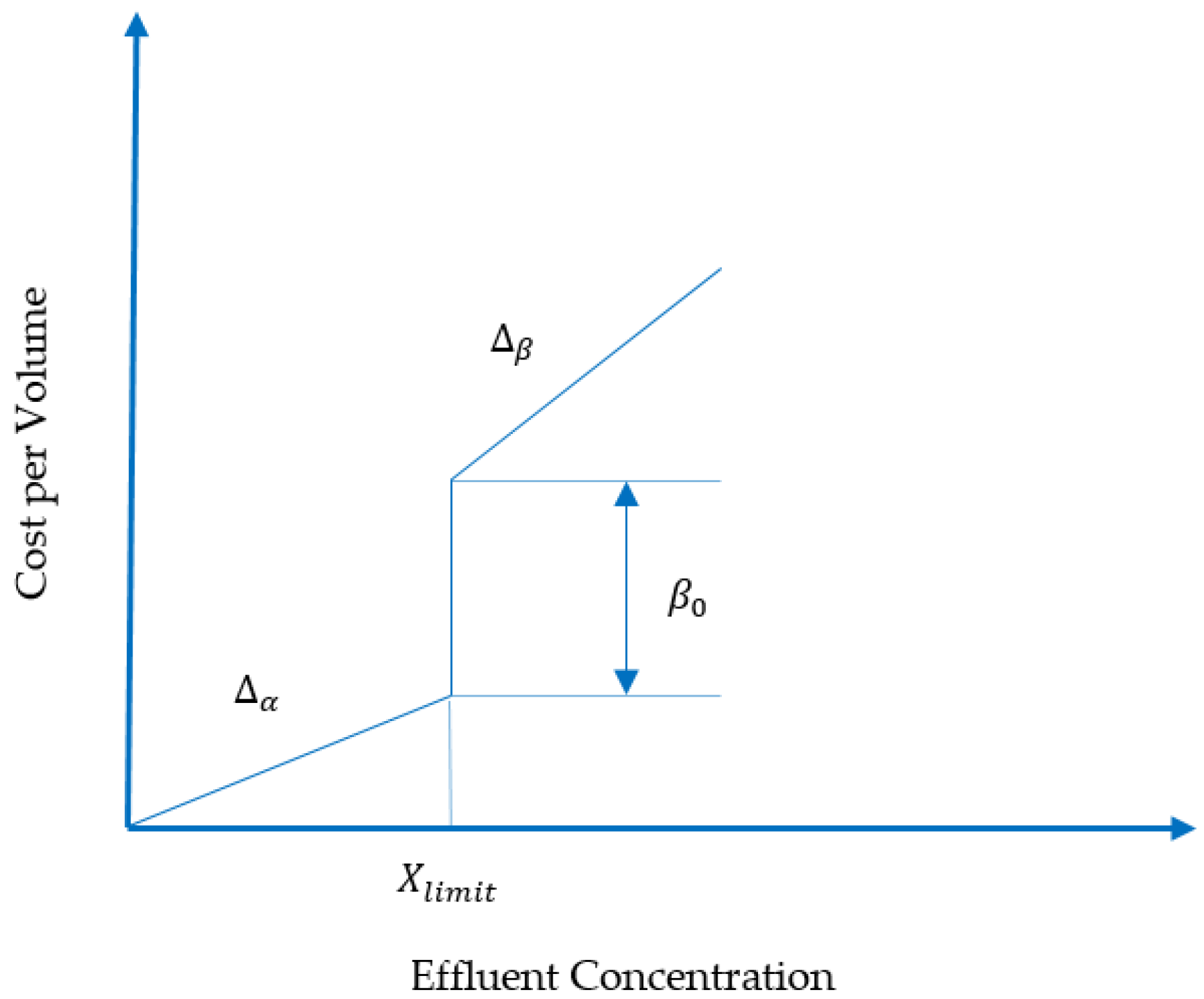
2.2. Performance Assessment
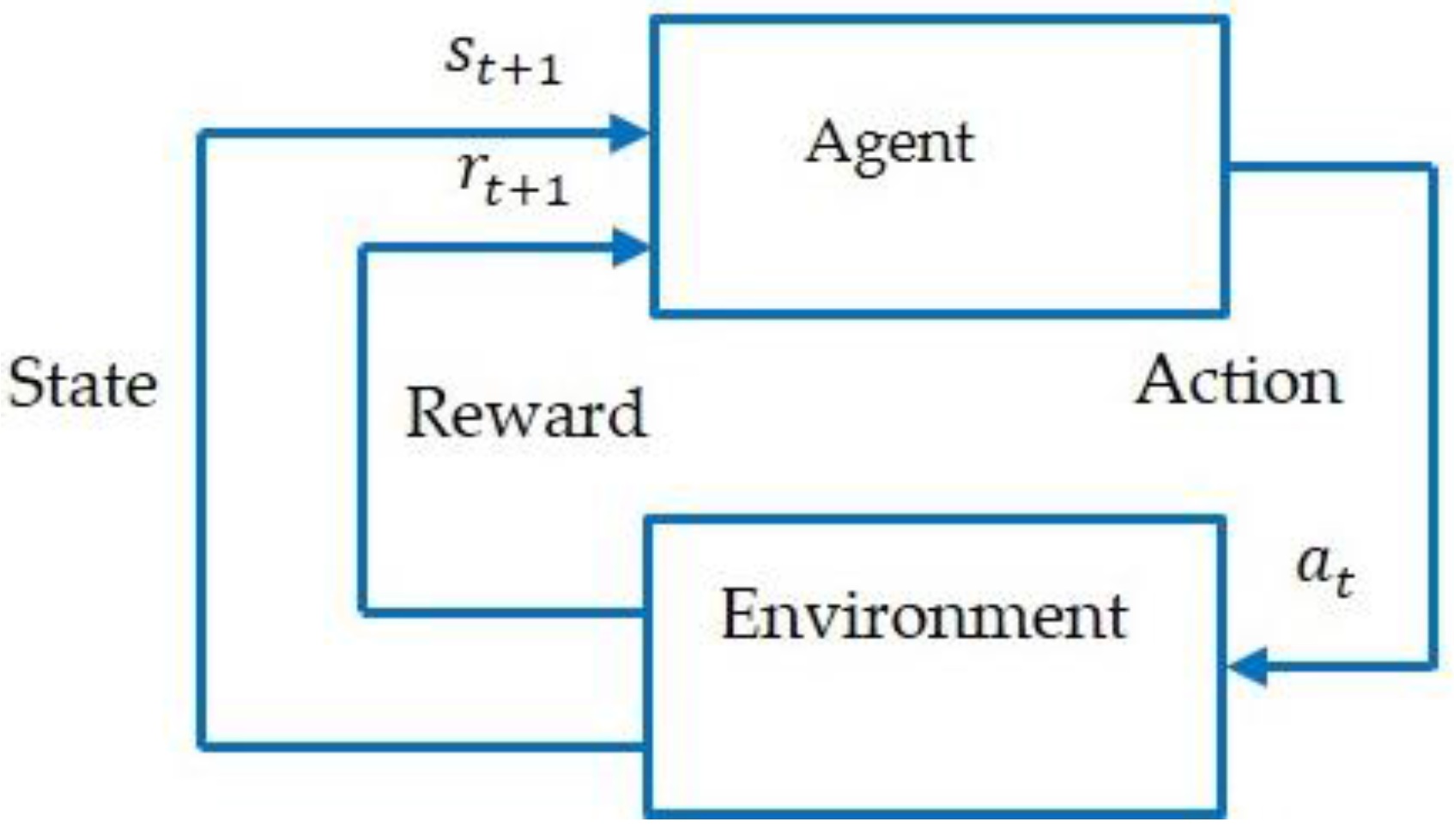
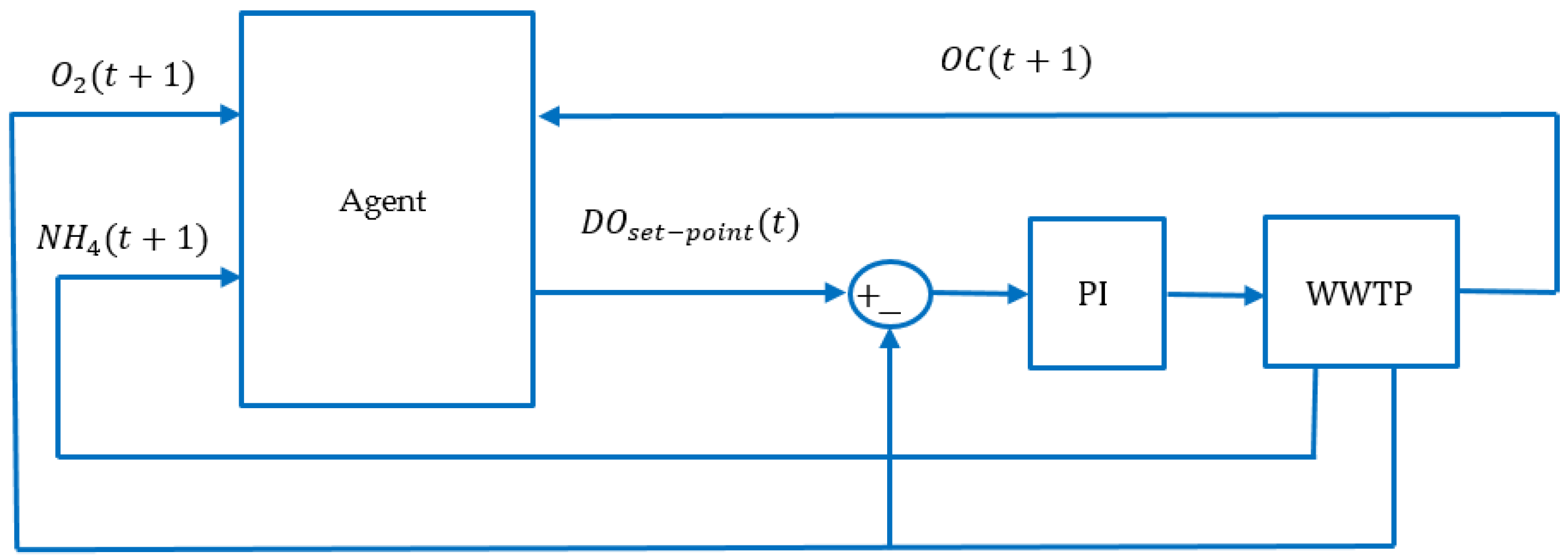
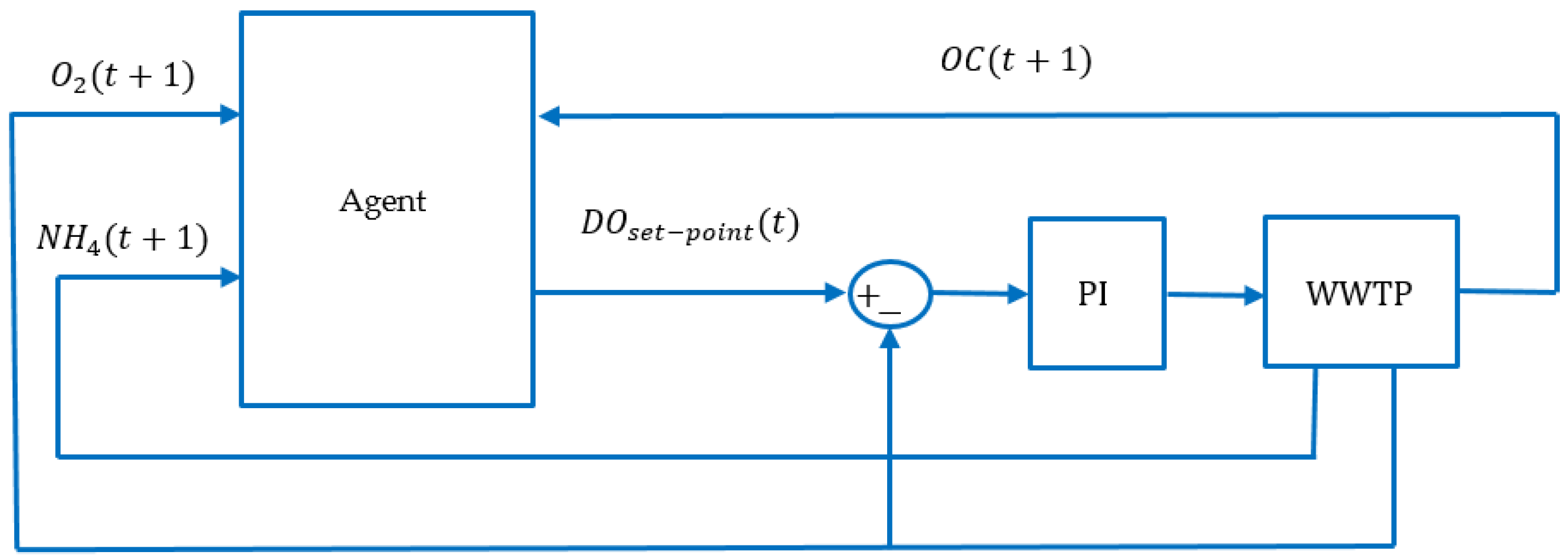
3. Reinforcement Learning Approach
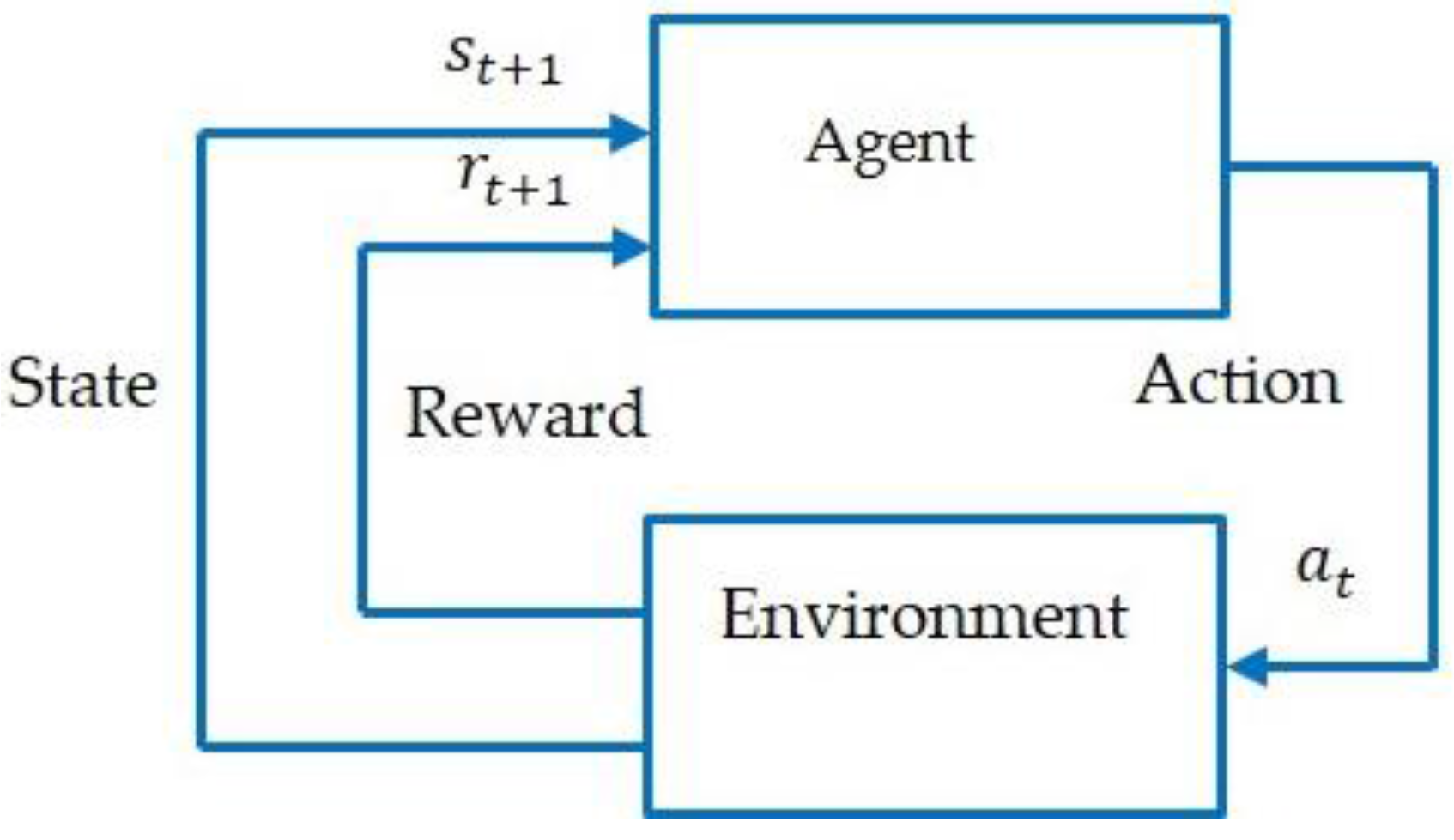
3.1. Background
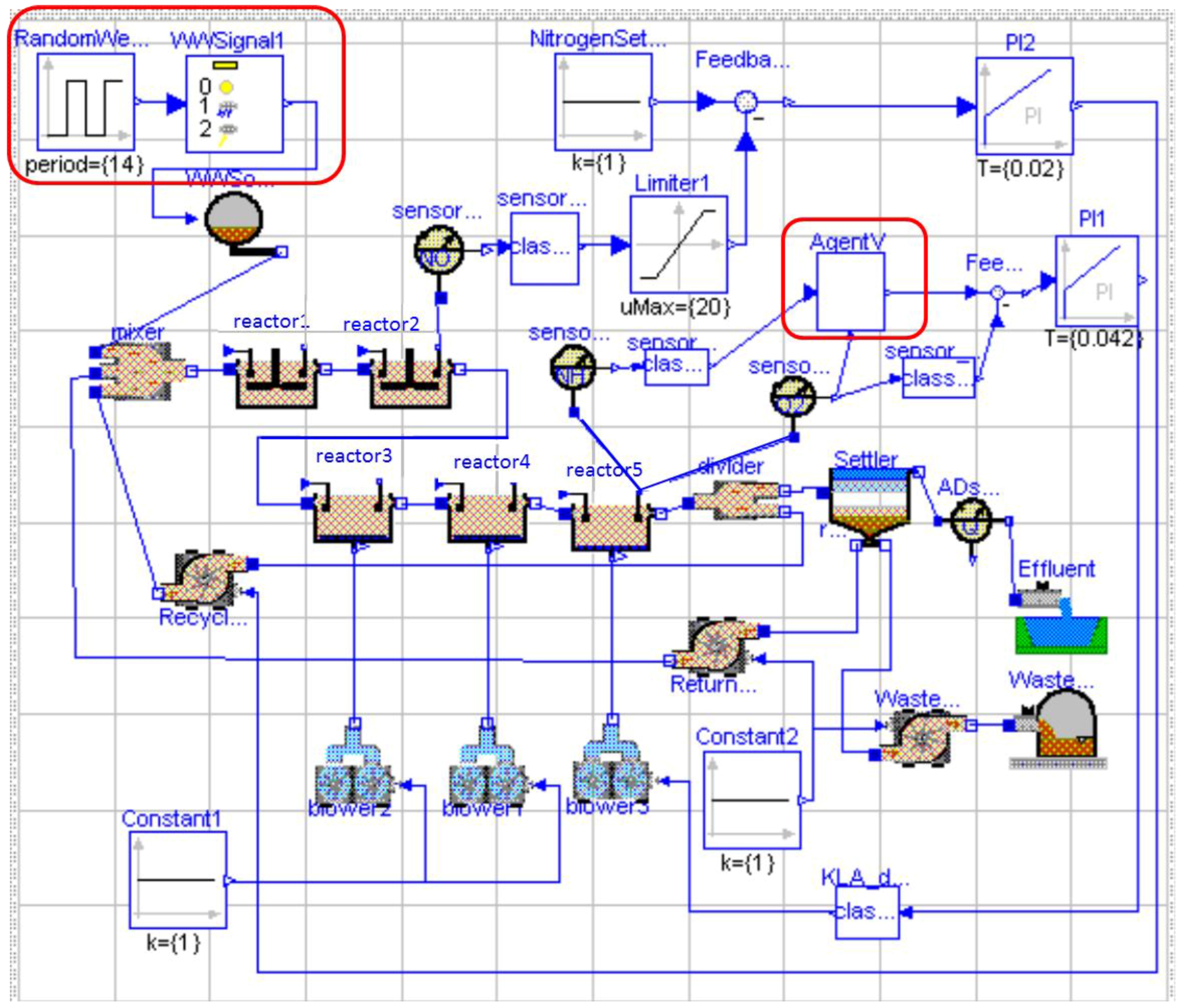
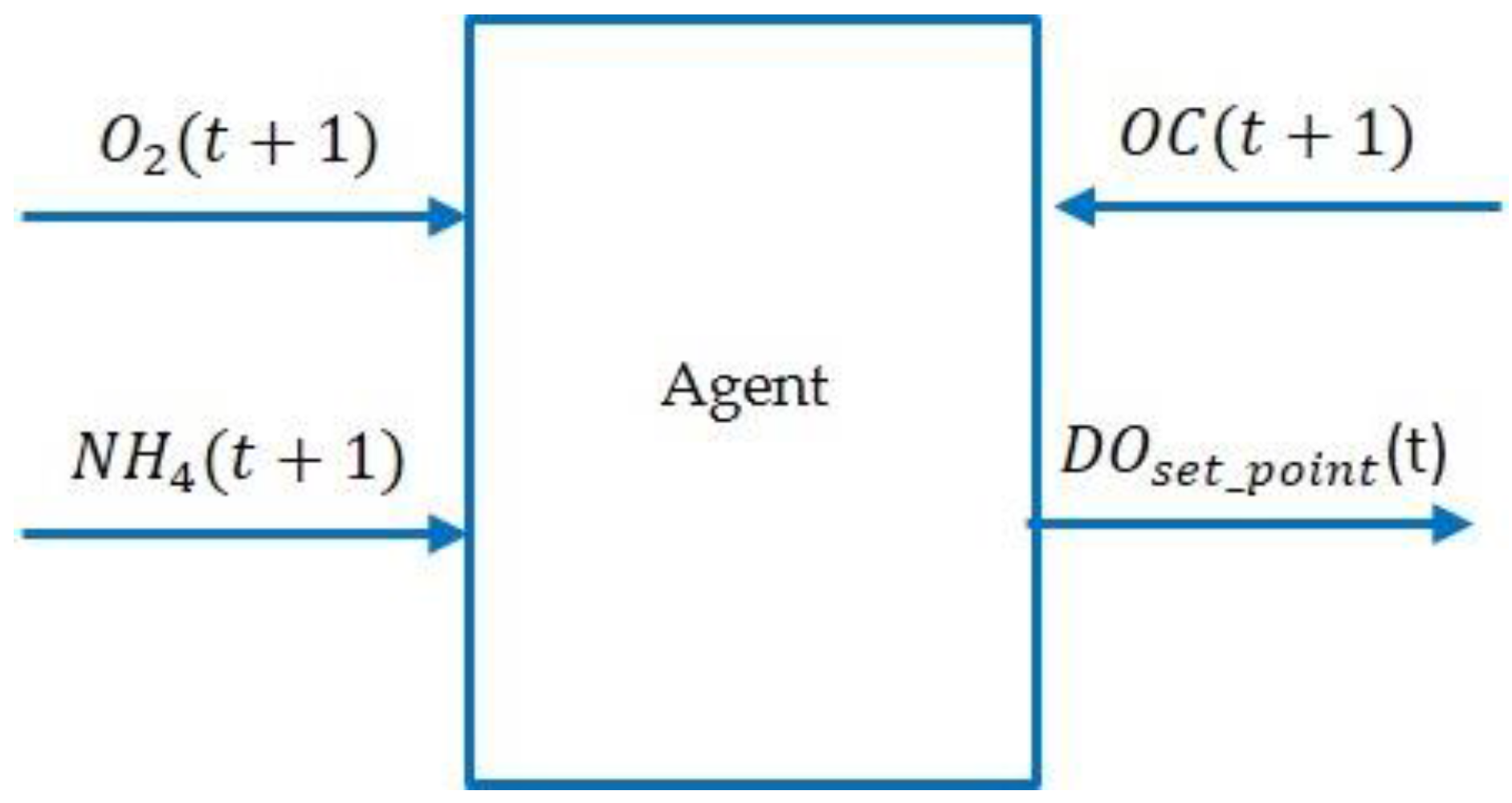
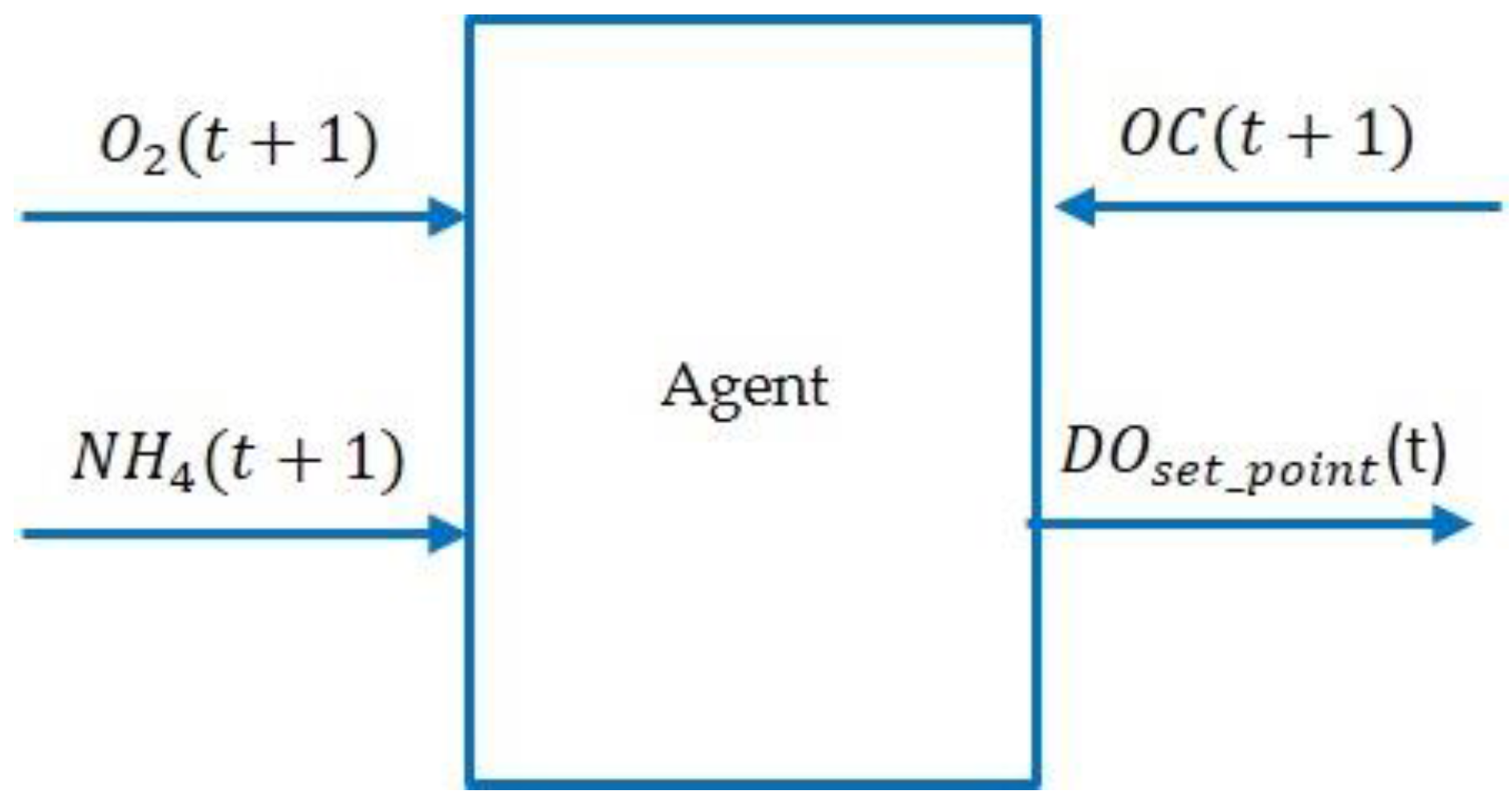
3.2. Description of the Model-Free RL Agent
| Algorithm 1: RL agent method |
| Configuration γ: Time horizon max_actions = 2//maximum number of actions DO_max: Set-point max DO_min: Set-point min DO_step: Set-point step (DO_step = (DO_max-DO_min)/(max_actions+1)) Inputs s(t) = [NH4(t),O2(t)]: State of the environment r(t) = −OC(t): reward Output DO: Real Internal Q(s,a): initialize arbitrarily a: action (0..max_actions) Algorithm Initialize Q(s,a); while (true) {//execute every 15 minutes s(t) = [NH4,O2]; r(t) = −OC(t); a = next_action(Q,s); update_Q(s,a,r); DO = DO_min + a*DO_step; execute(DO); } |
4. Simulation Results
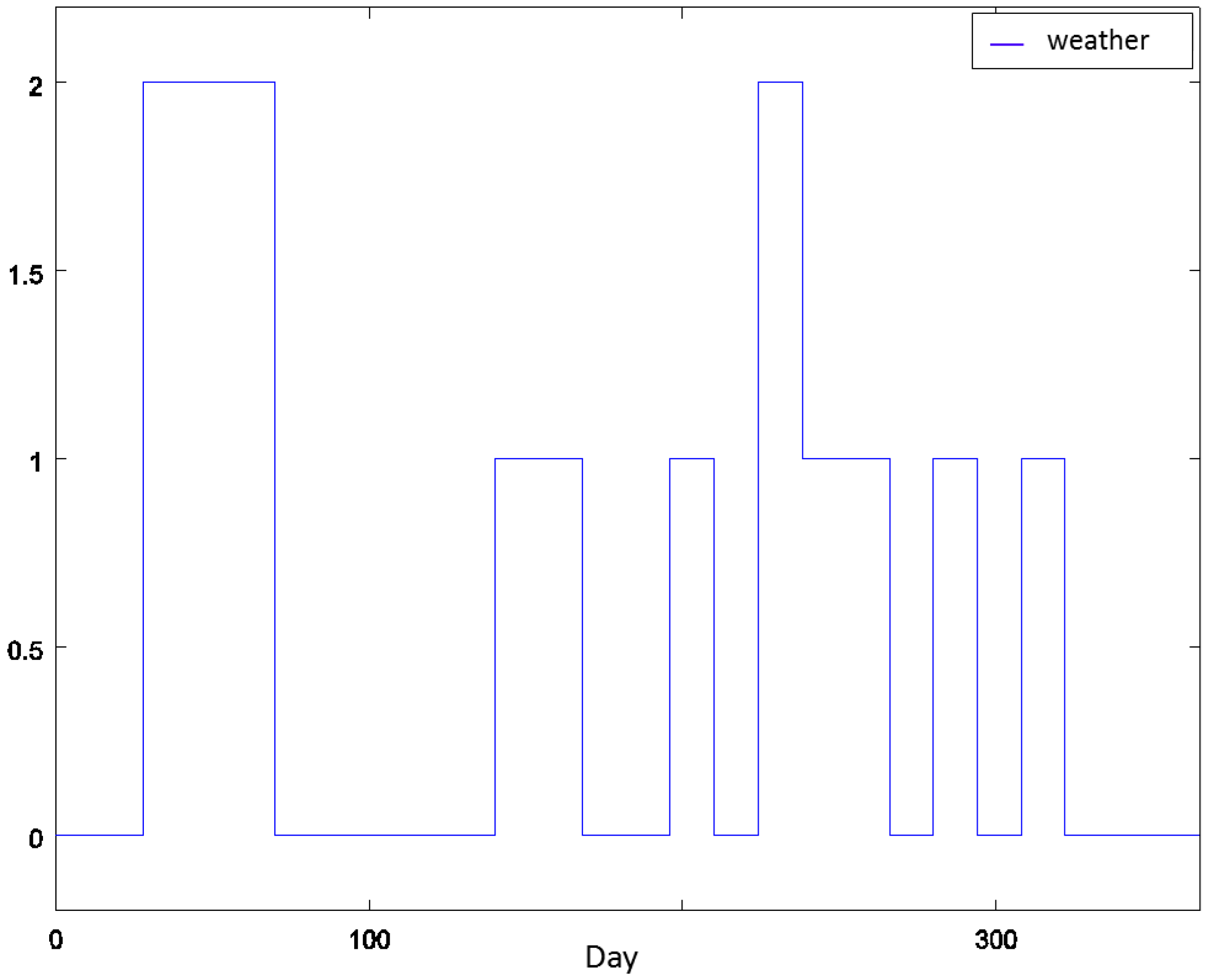
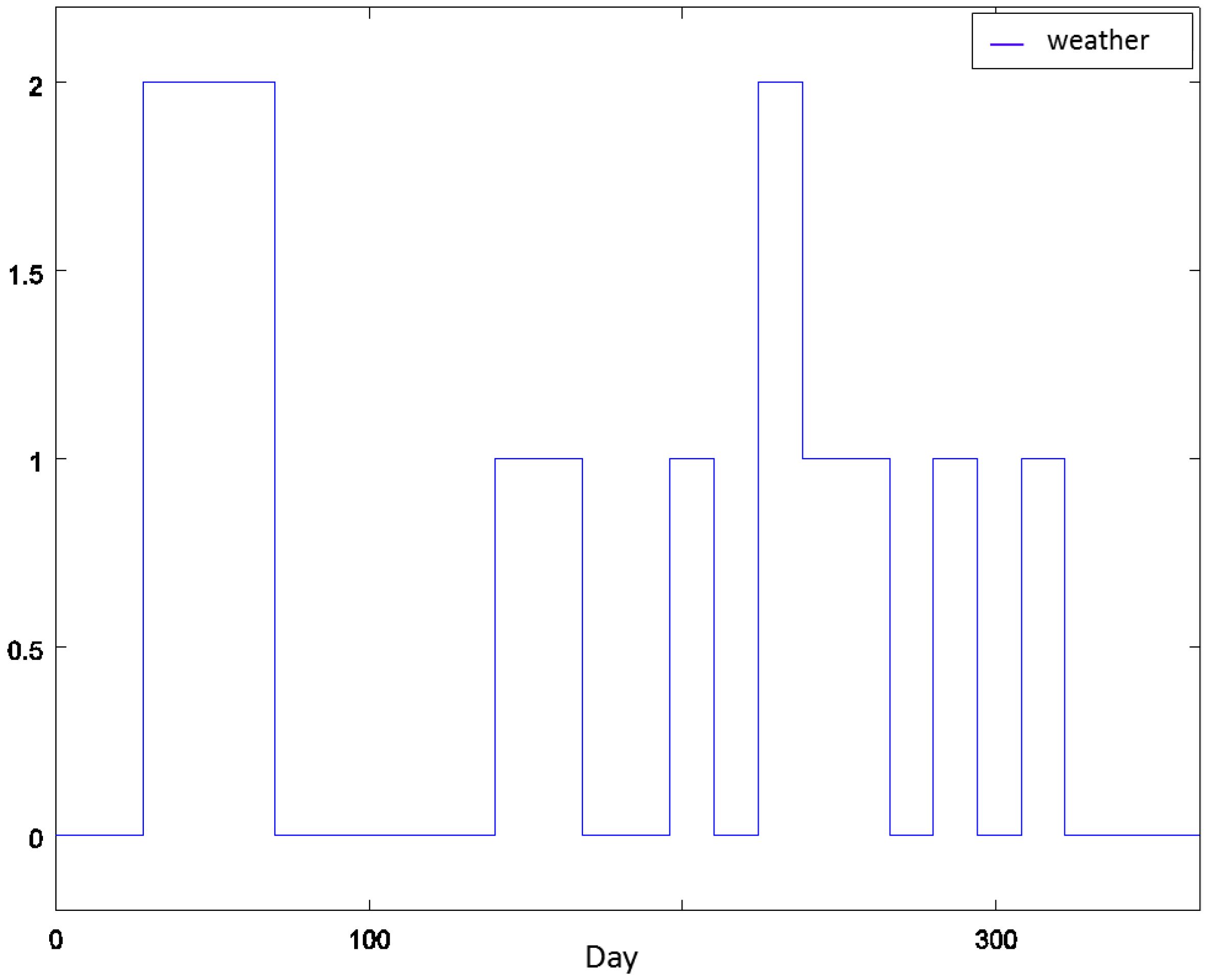
4.1. Experiment Settings
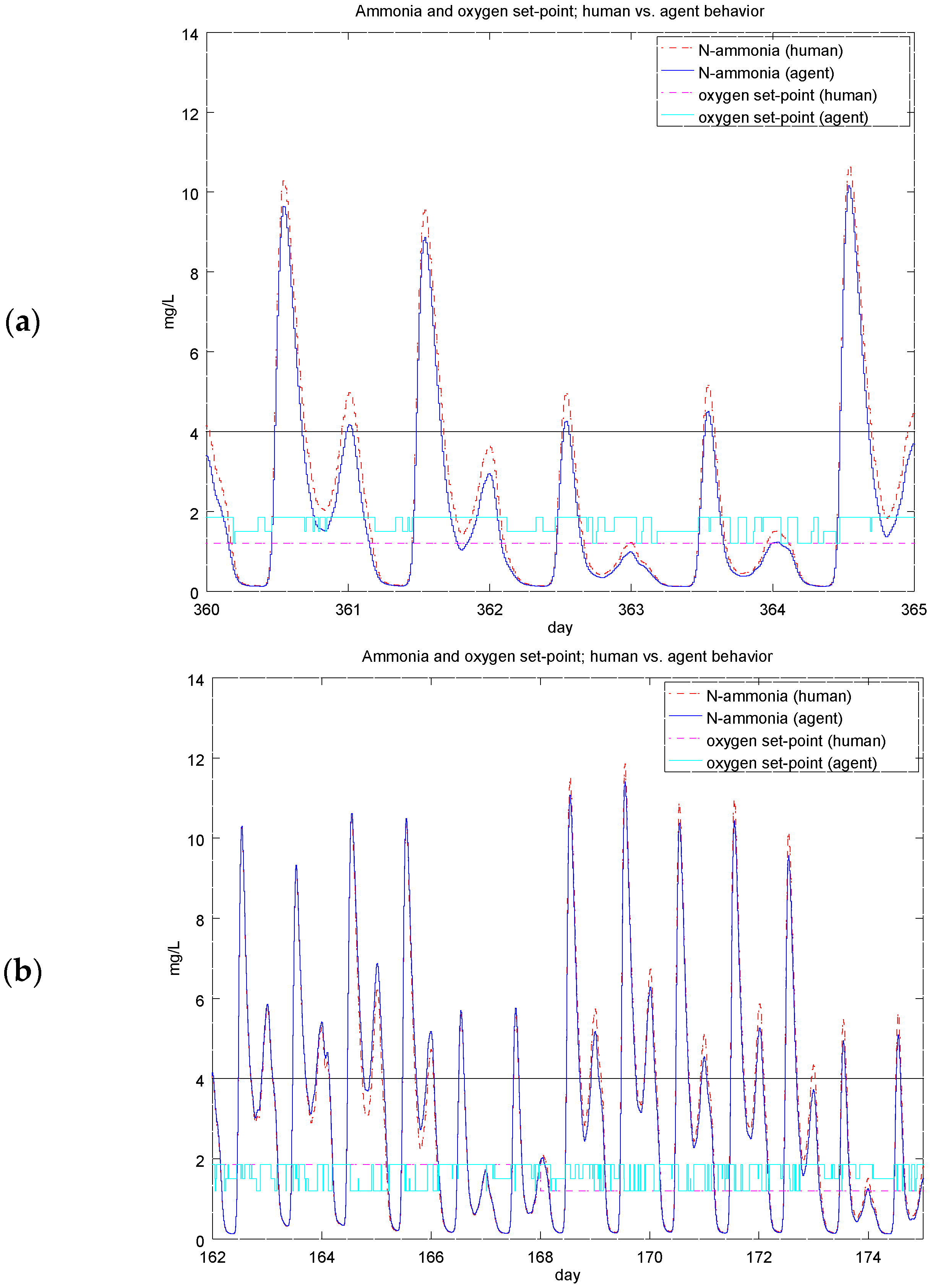
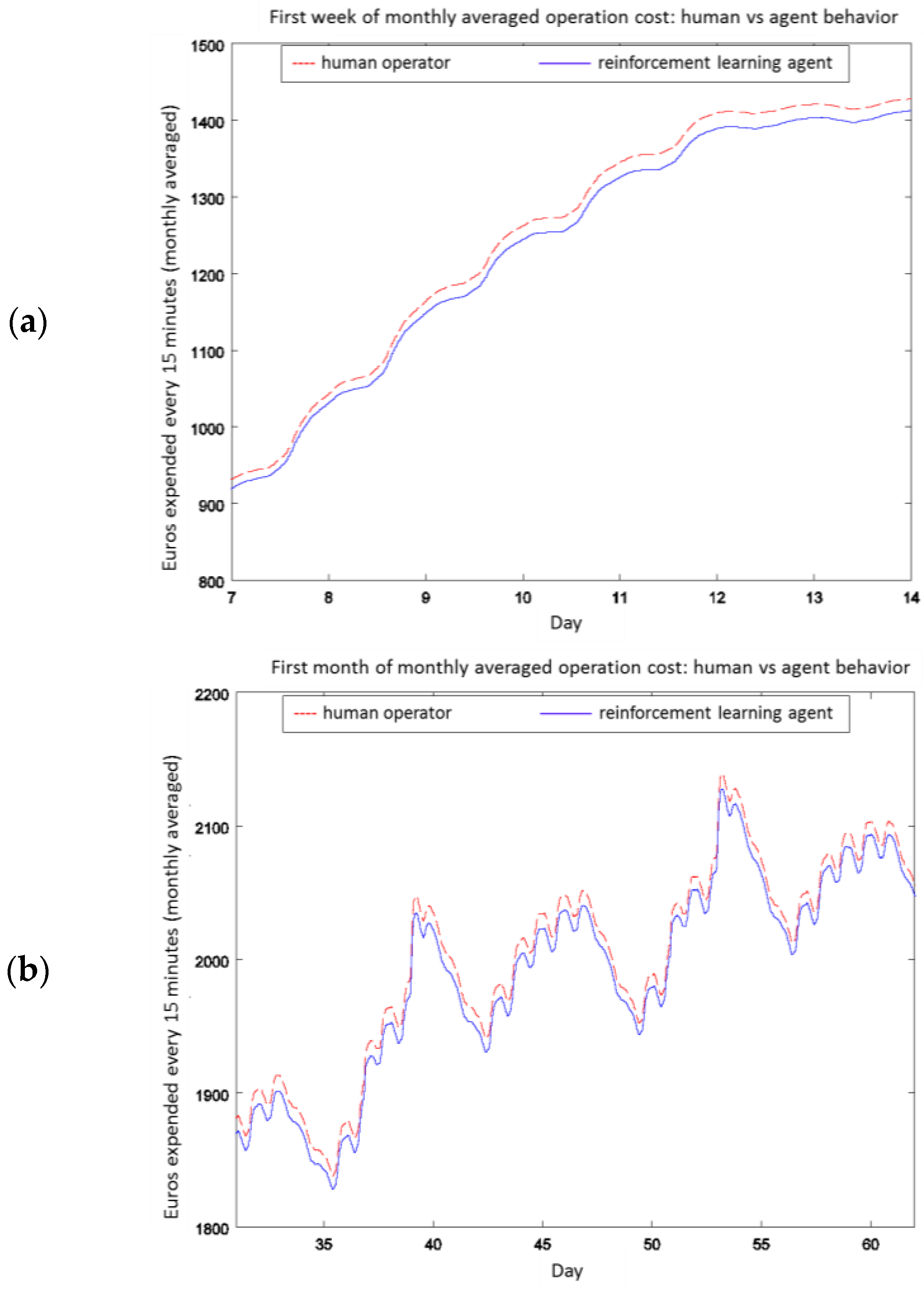
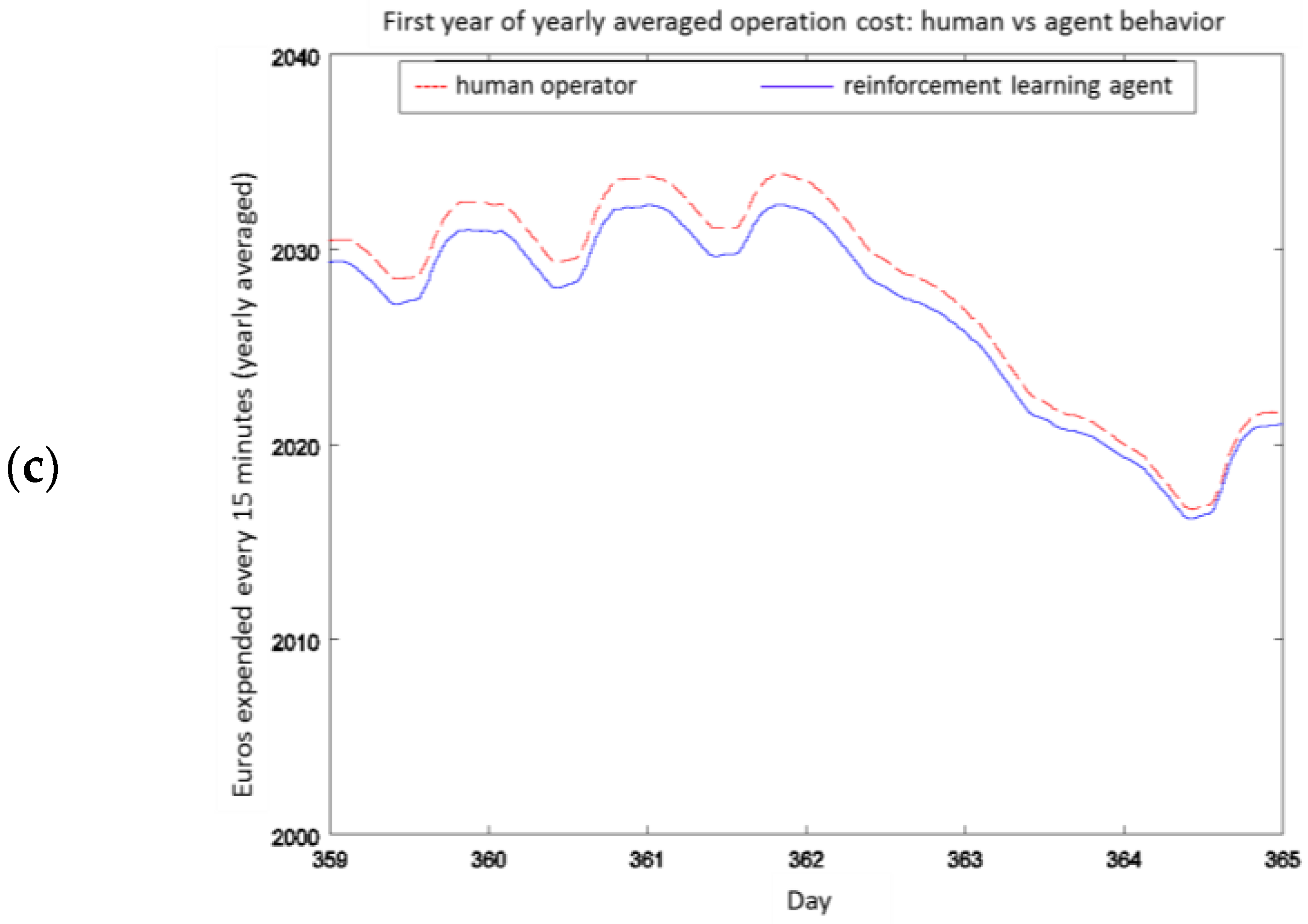
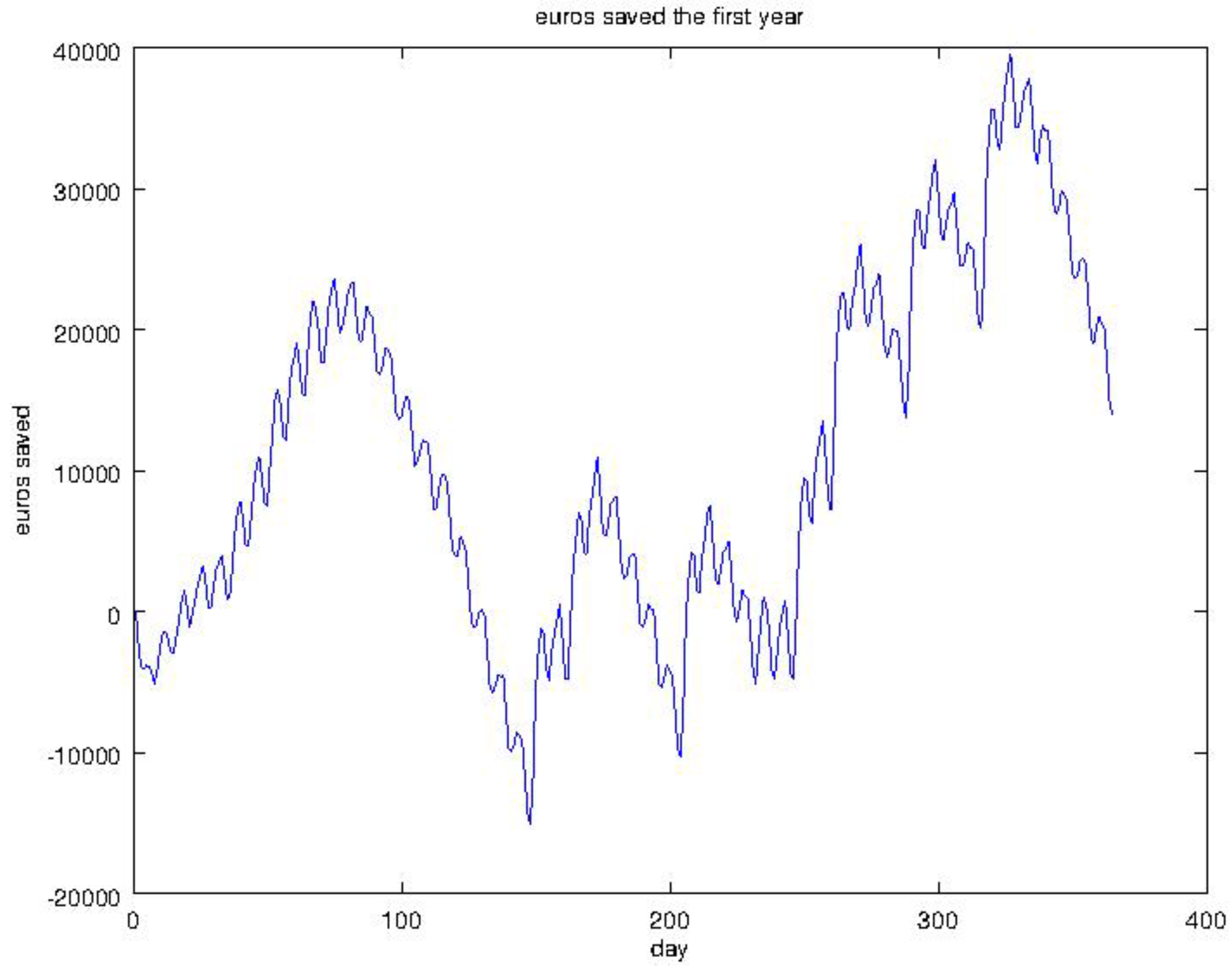
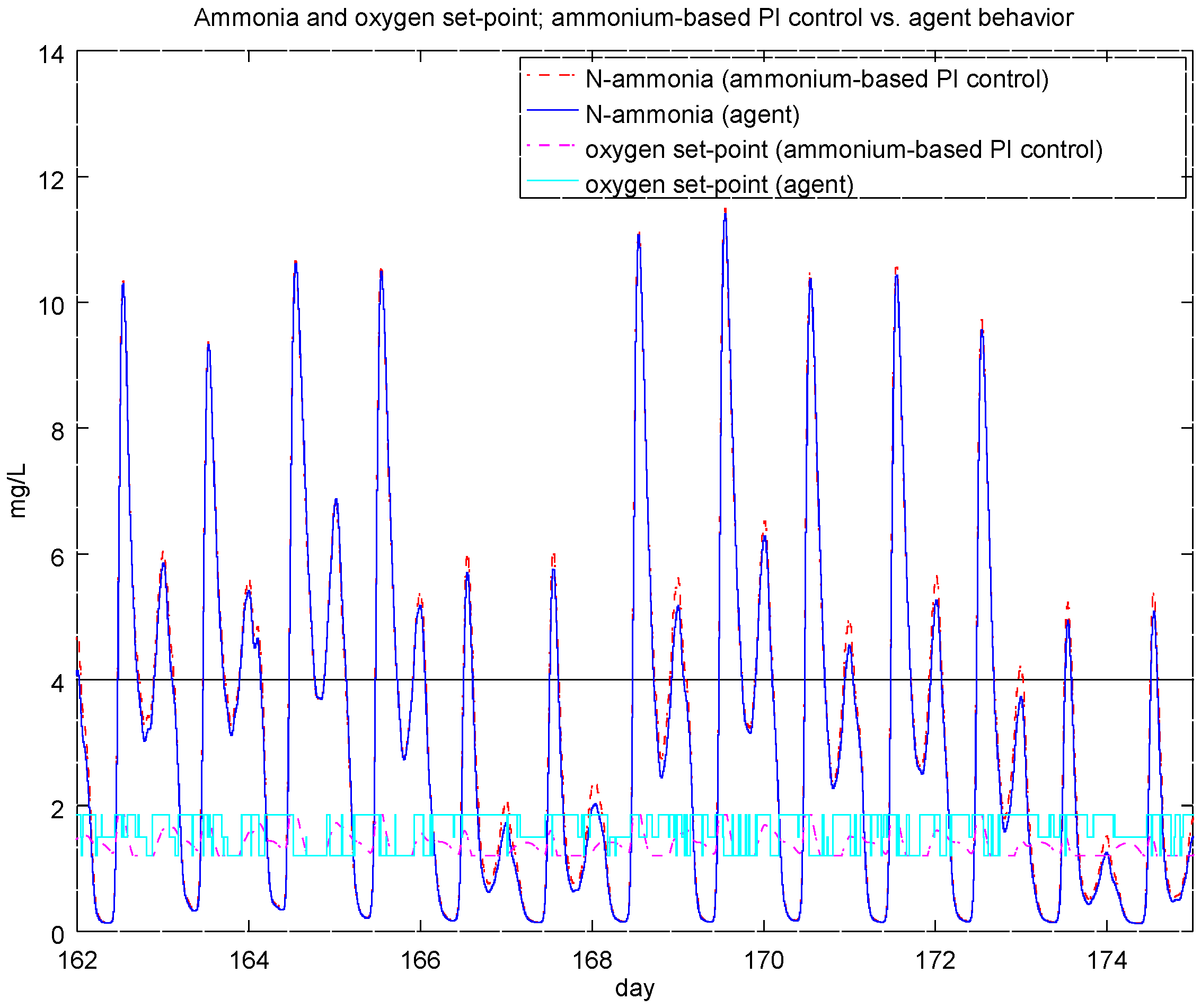
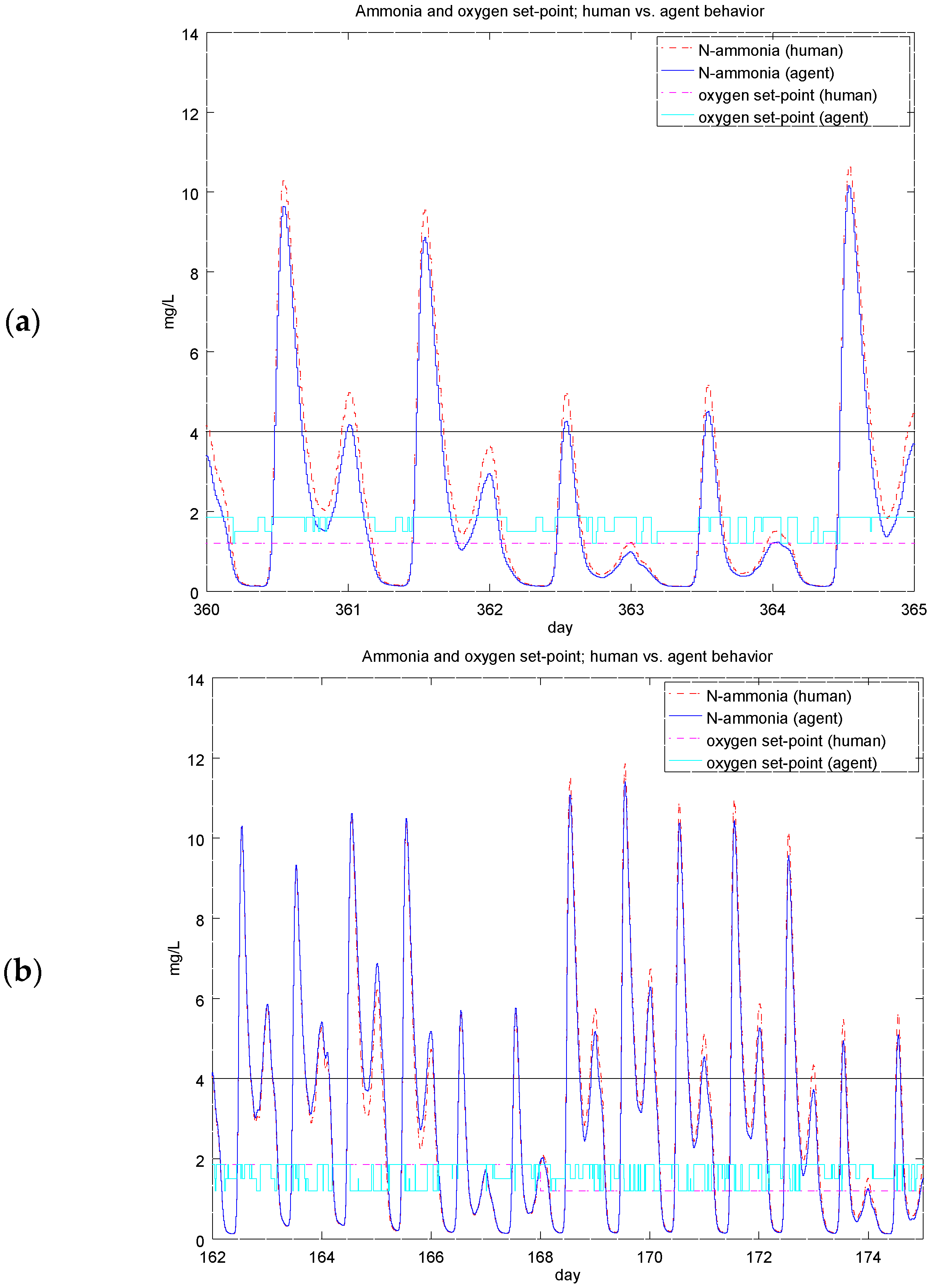
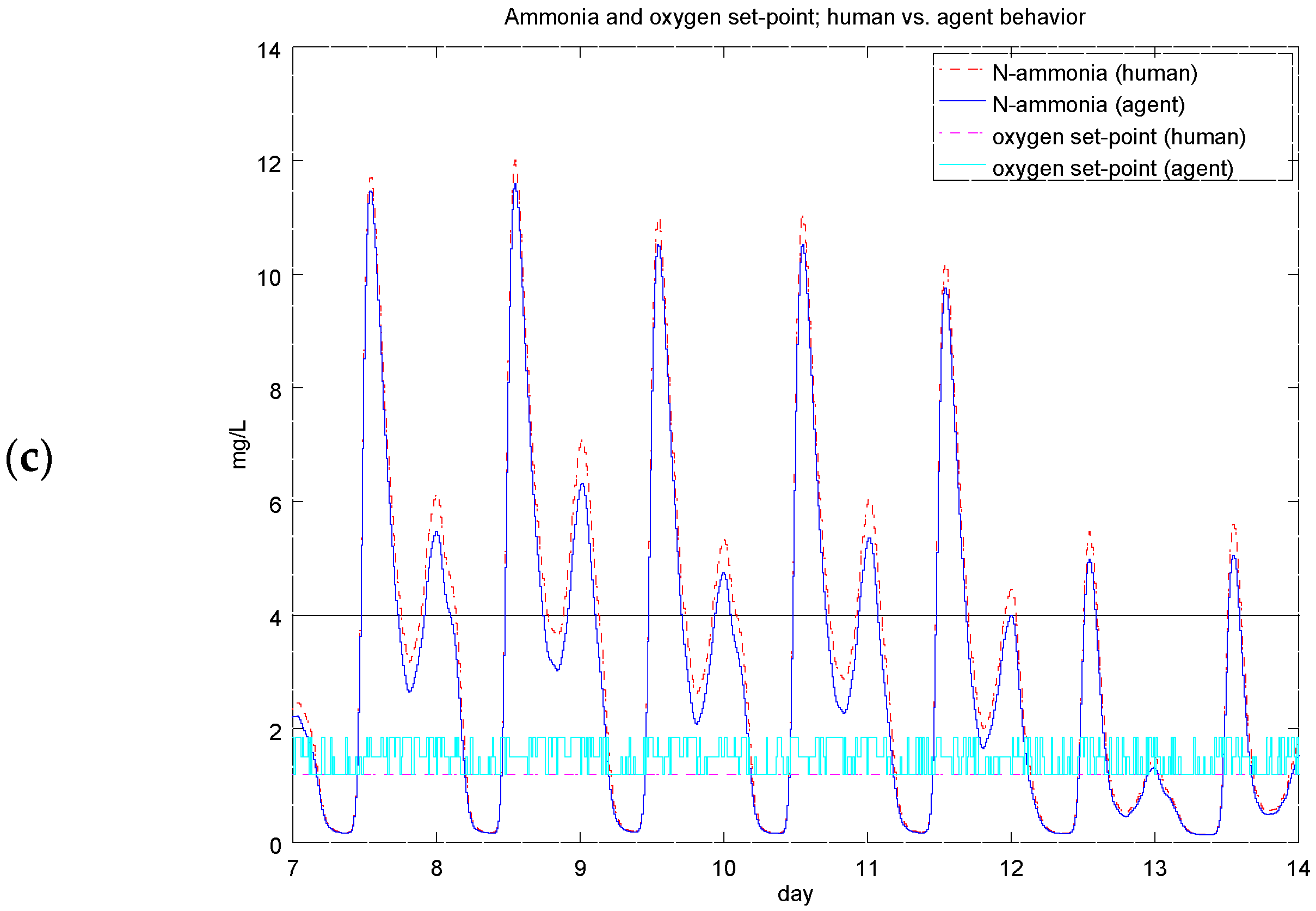
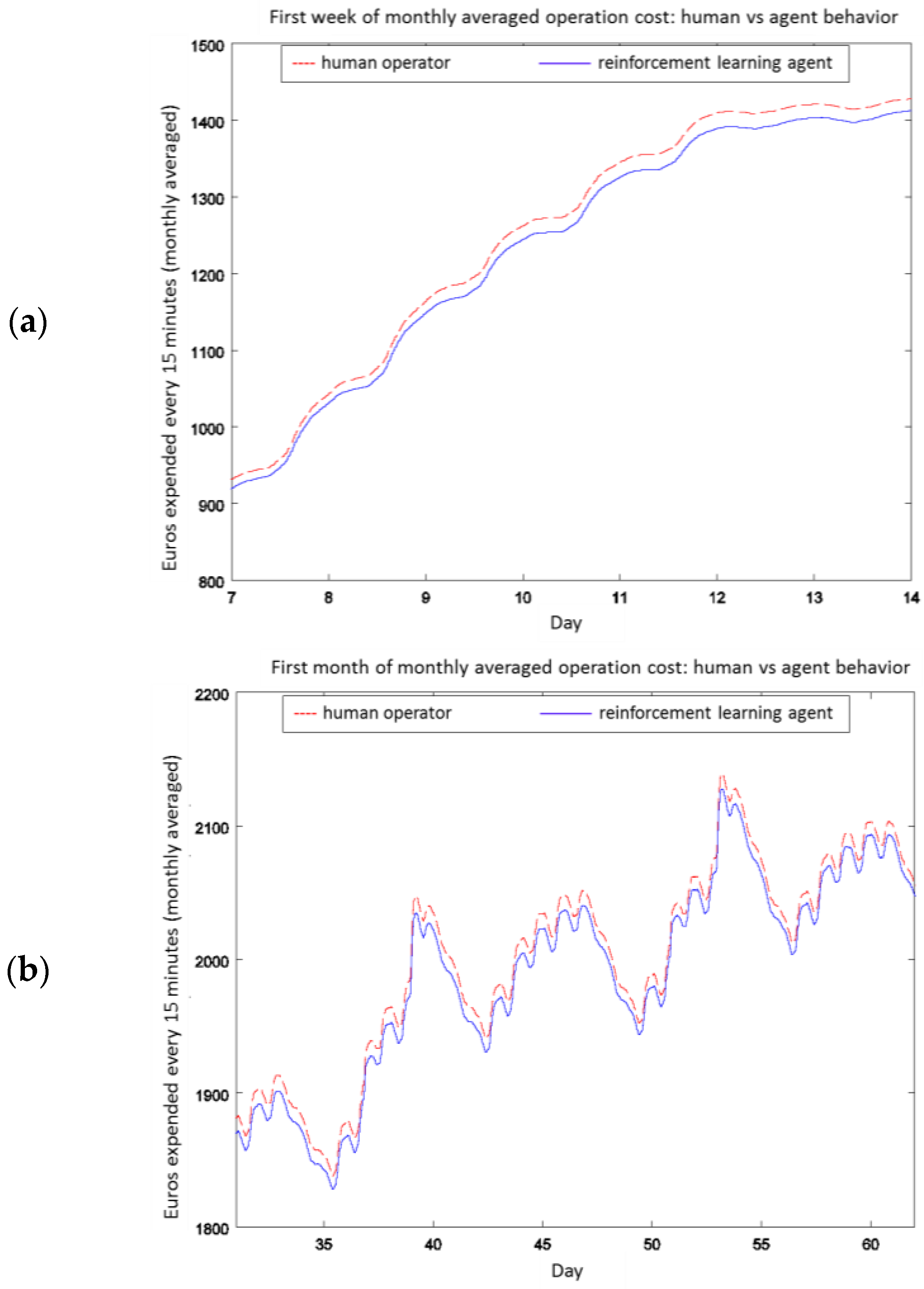
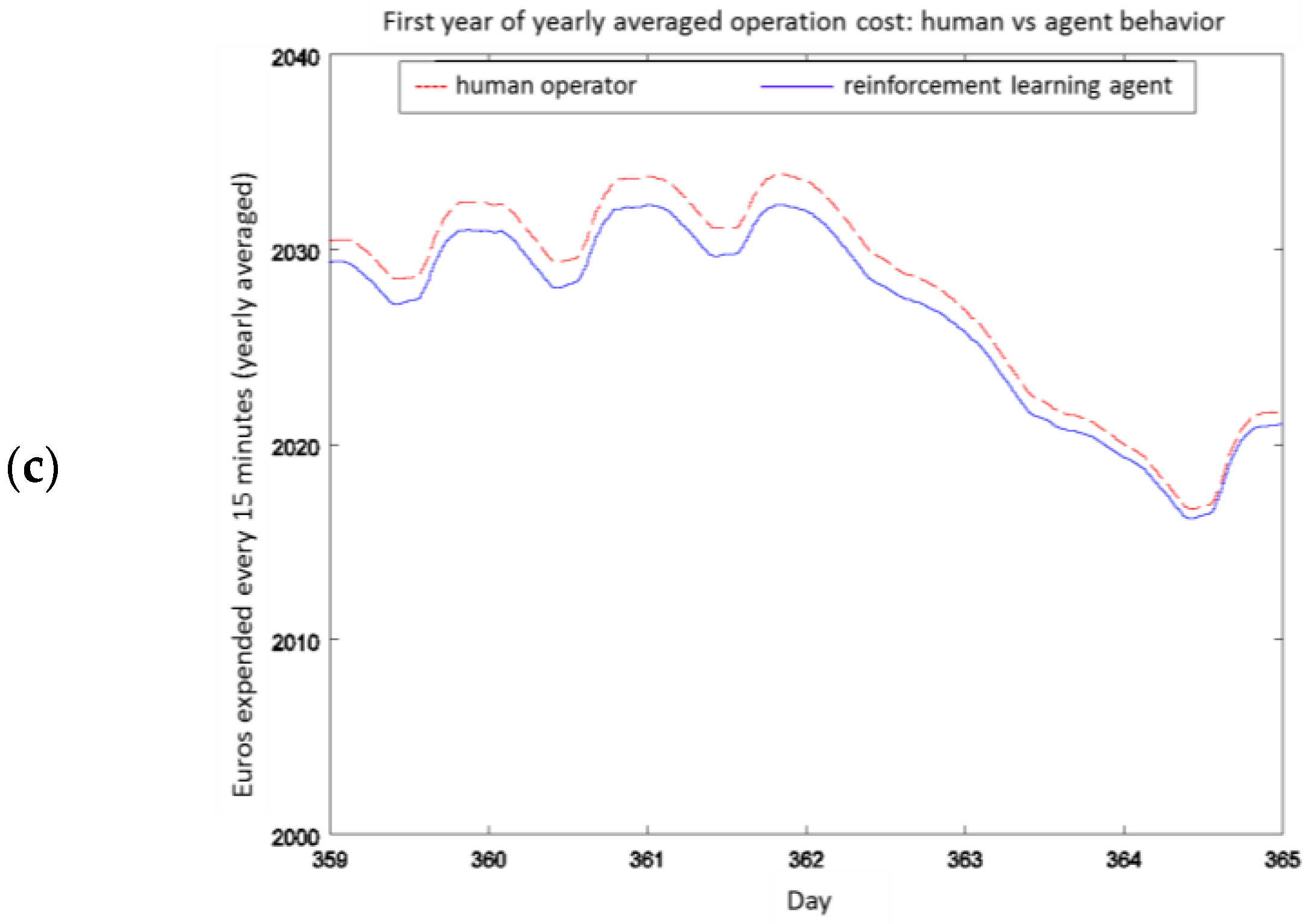
4.2. Experiment 1: Analysis of the RL Agent's Behavior
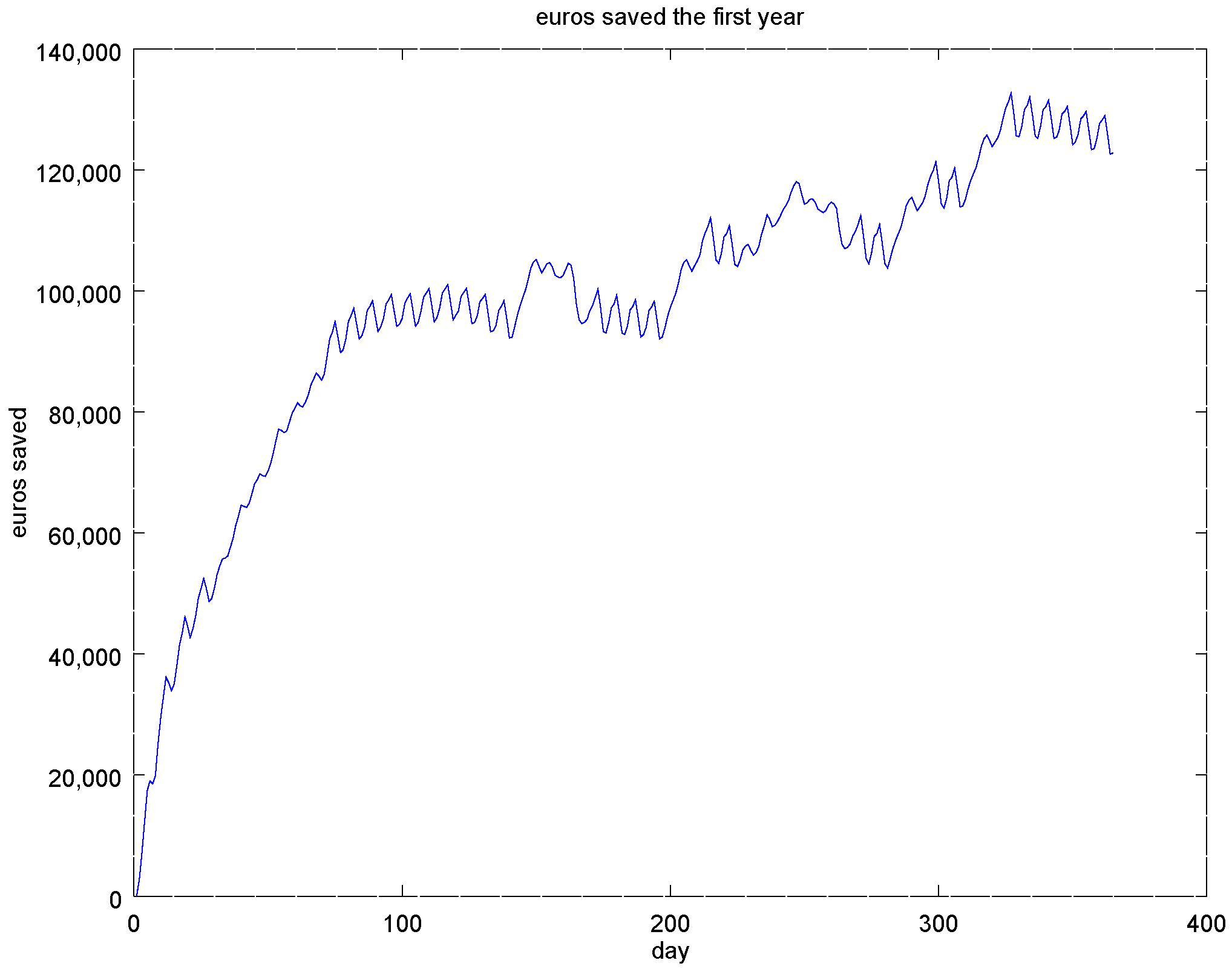
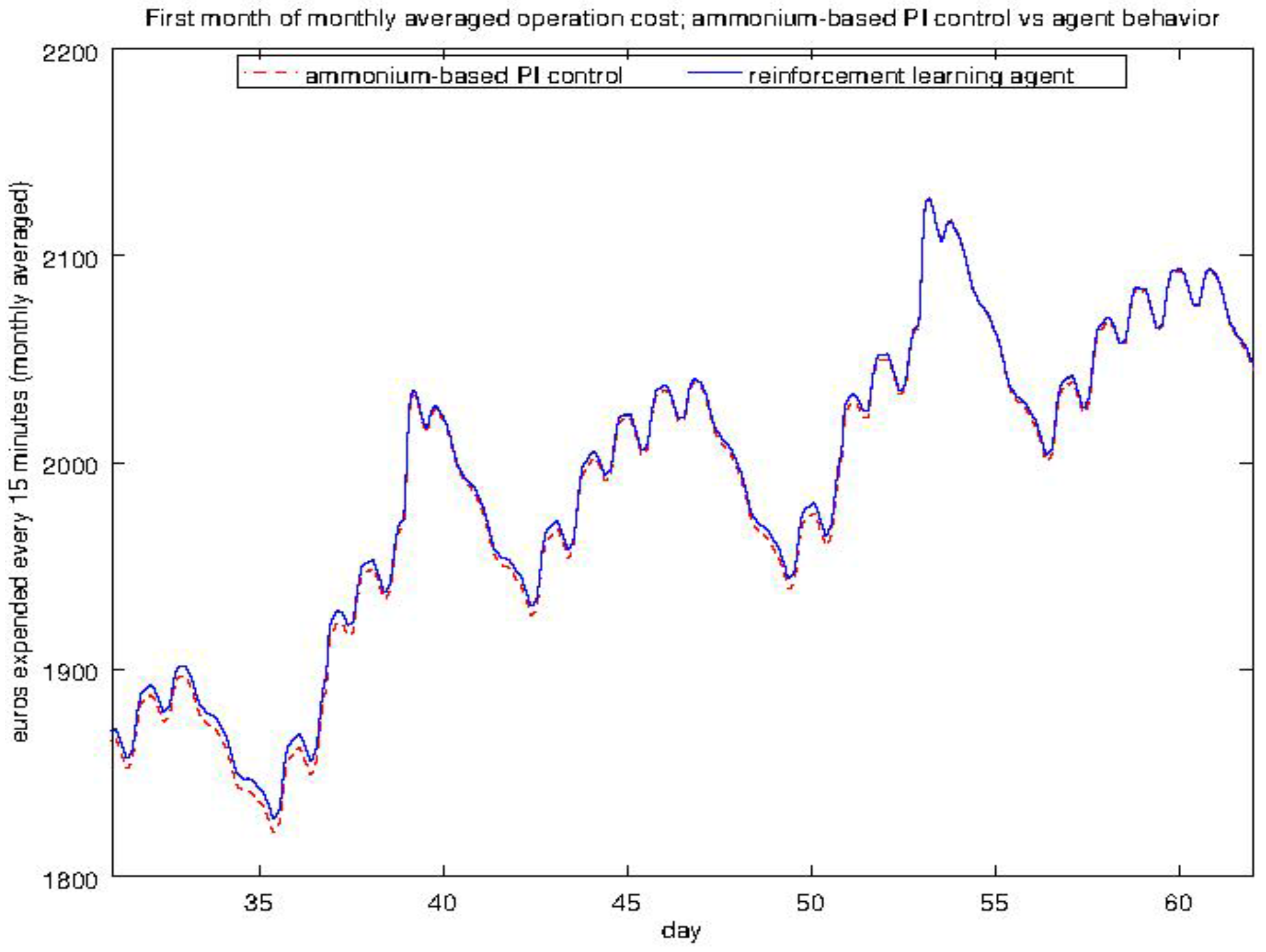
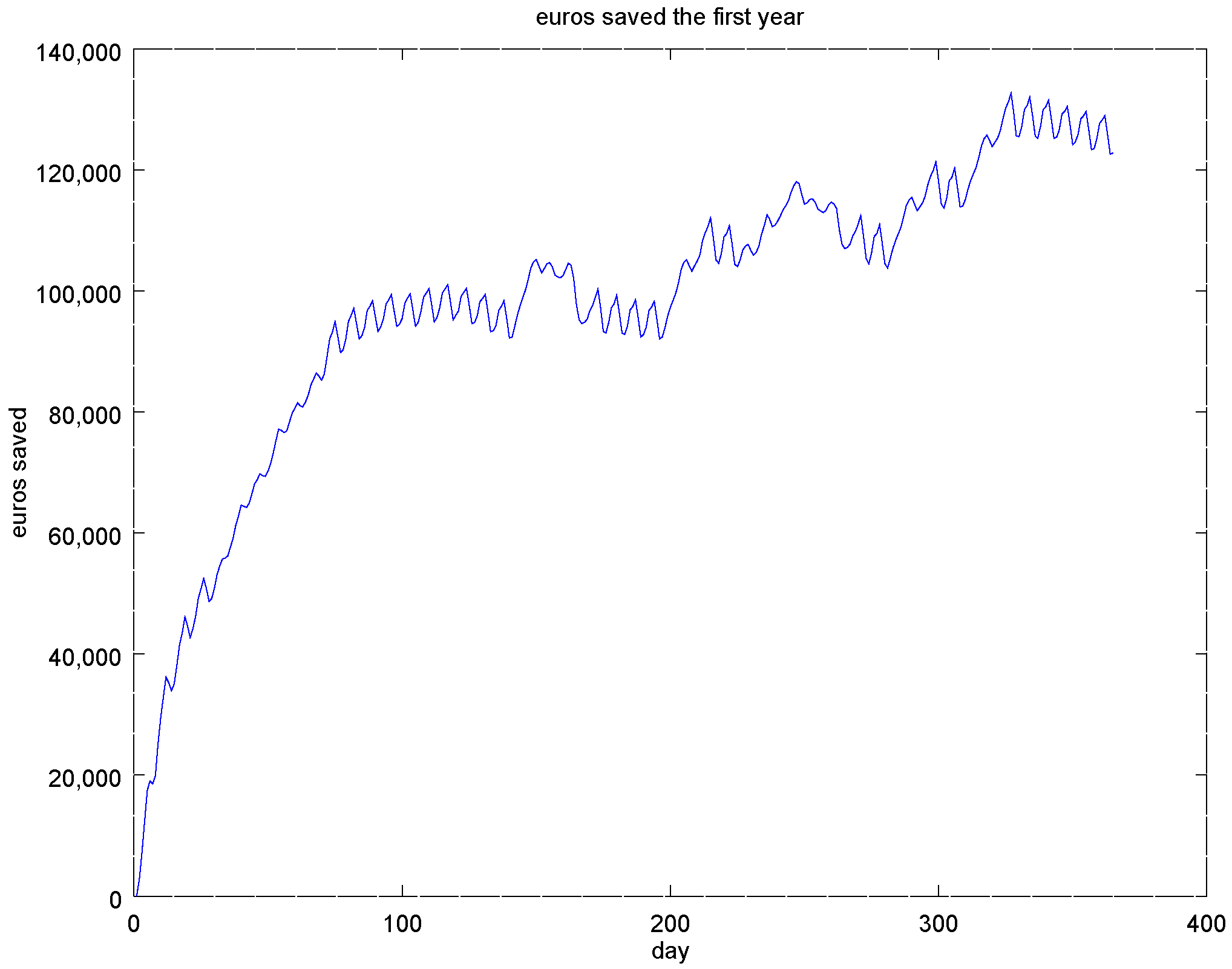
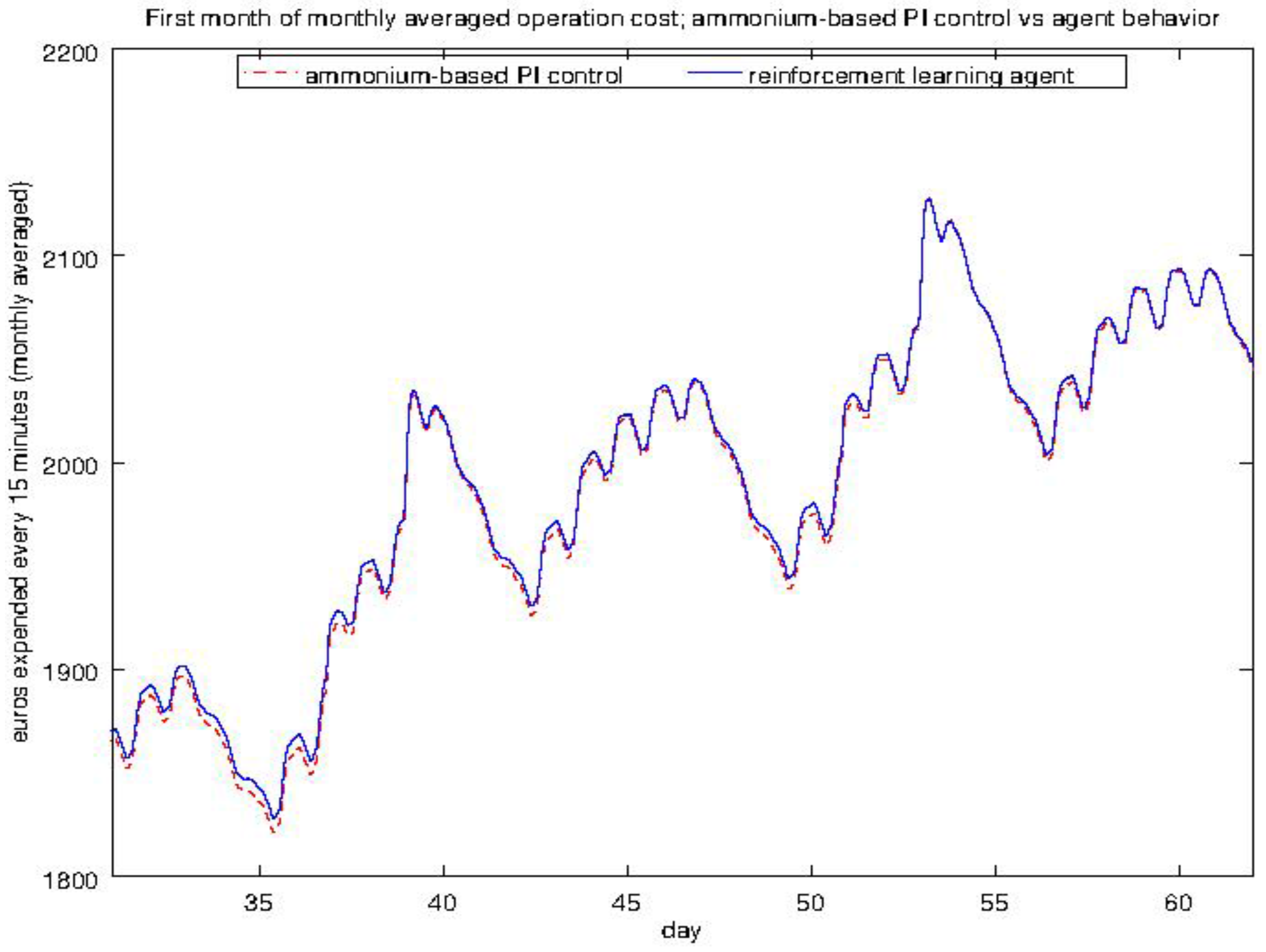
4.3. Experiment 2: Analysis of the Energy Efficiency and Environmental Costs
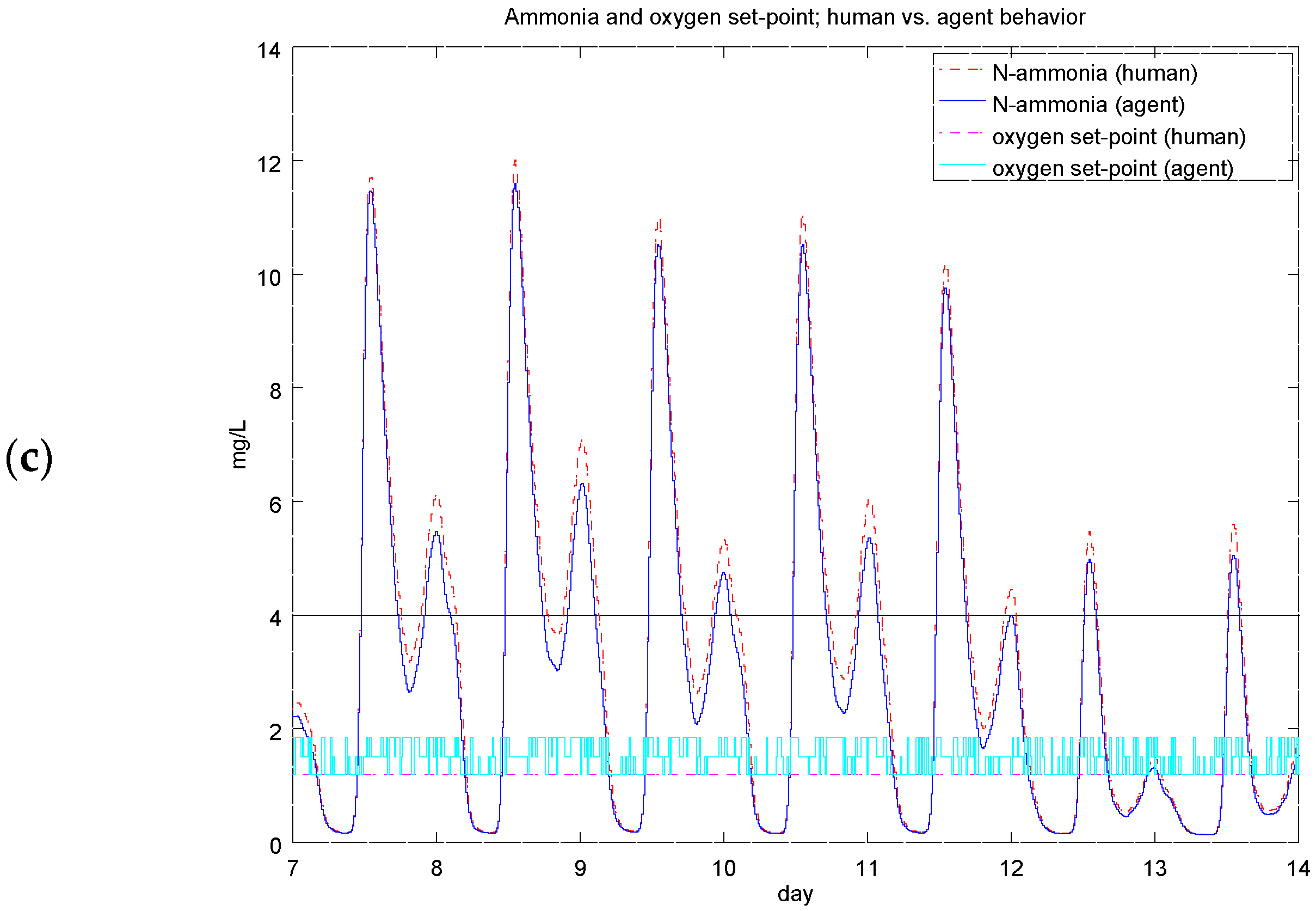
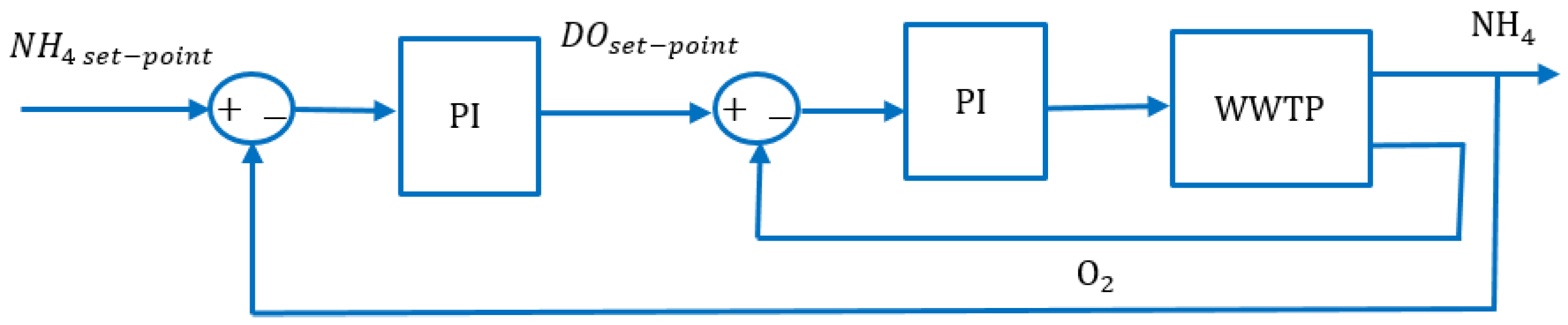
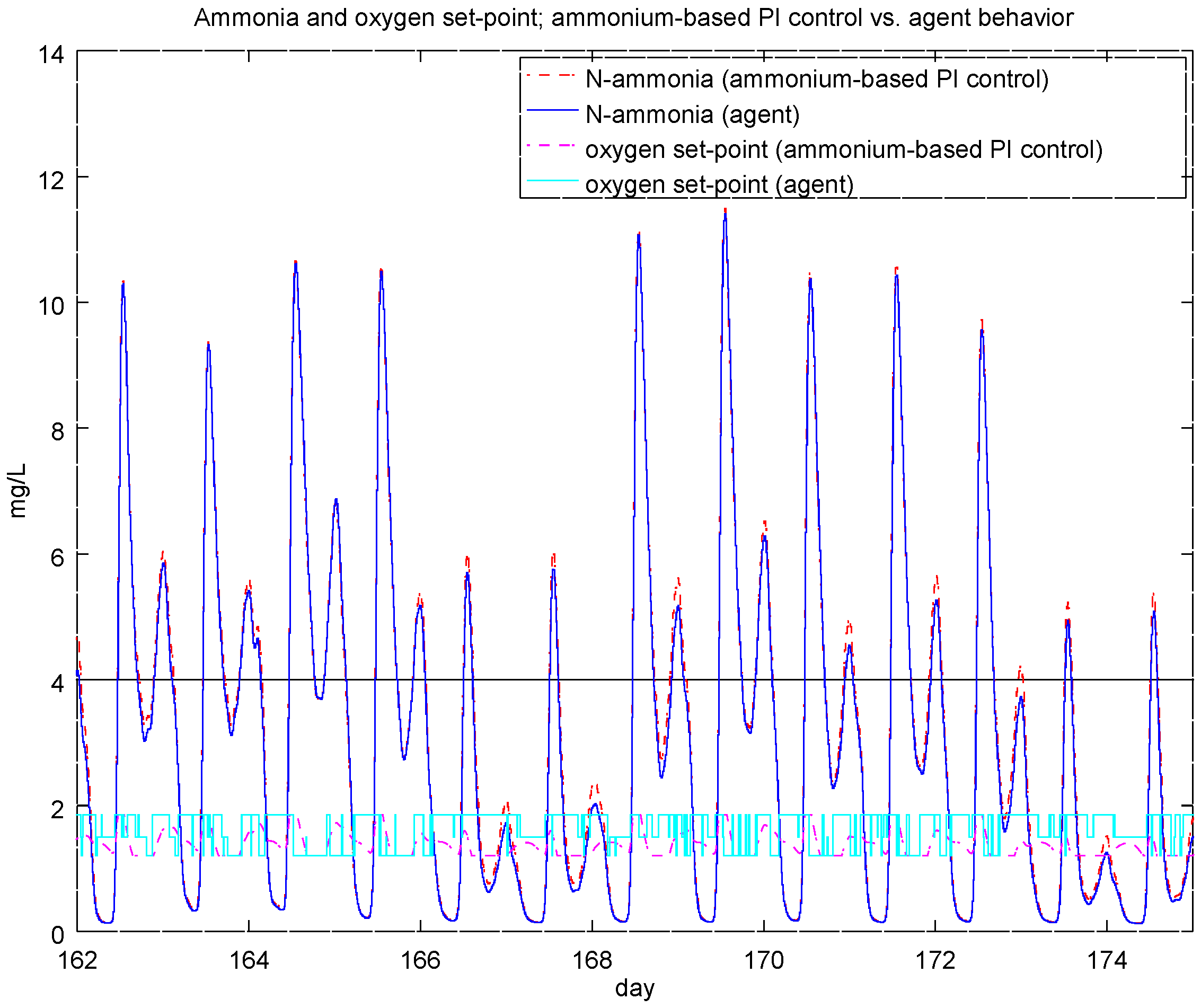
4.4. Experiment 3: Ammonium-Based PI Control versus the RL Agent Approach
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Al-Dosary, S.; Galal, M.M.; Abdel-Halim, H. Environmental Impact Assessment of Wastewater Treatment Plants. Int. J. Curr. Microbiol. App. Sci. 2015, 4, 953–964. [Google Scholar]
- Awad, E.S.; Al Obaidy, A.H.; Al Mendilawi, H.R. Environmental Assessment of Wastewater Treatment Plants (WWIPs) for Old Rustamiya Project. Int. J. Sci. Eng. Technol. Res. 2014, 3, 3455–3459. [Google Scholar]
- Jeon, E.C.; Son, H.K.; Sa, J.H. Emission Characteristics and Factors of Selected Odorous Compounds at a Wastewater Treatment Plant. Sensors 2009, 9, 311–326. [Google Scholar] [CrossRef] [PubMed]
- Eslamian, S. Urban Water Reuse Handbook; Taylor & Francis Group: New York, NY, USA, 2016. [Google Scholar]
- Brandt, M.J.; Middleton, R.A.; Wang, S. Energy Efficiency in the Water Industry: A Compendium of Best Practices and Case Studies UKWIR Report 10/CL/11/3; Water Research Foundation: London, UK, 2010. [Google Scholar]
- Energy Best Practices Guide: Water & WateWater Industry. Available online: http://dnr.wi.gov/aid/documents/eif/focusonenergy_waterandwastewater_guidebook.pdf (accessed on 29 June 2016).
- Crawford, G.; Sandino, J. Energy Efficiency in Wastewater Treatment in North America: A Compendium of Best Practices and Case Studies of Novel Approaches; Water Research Foundation: London, UK, 2010. [Google Scholar]
- Eskaf, S. Four Trends in Government Spending on Water and Wastewater Utilities since 1956. Available online: http://efc.web.unc.edu/2015/09/09/four-trends-government-spending-water/ (accessed on 30 June 2016).
- Cristea, S.; de Prada, C.; Sarabia, D.; Gutiérrez, G. Aeration control of a wastewater treatment plant using hybrid NMPC. Comput. Chem. Eng. 2011, 35, 638–650. [Google Scholar] [CrossRef]
- Chachuat, B.; Roche, N.; Latifi, M.A. Dynamic optimisation of small size wastewater treatment plants including nitrification and denitrification processes. Comput. Chem. Eng. 2001, 25, 585–593. [Google Scholar] [CrossRef]
- Revollar, S.; Vega, P.; Vilanova, R. Economic optimization of Wastewater Treatment Plants using Non Linear Model Predictive Control. In Proceedings of the 2015 19th International Conference on System Theory, Control and Computing (ICSTCC), Judetul Brasov, Romania, 14–16 October 2015; pp. 583–588.
- Metcalf-Eddy Inc.; Tchobanoglous, G.; Burton, F.L.; Stensel, H.L. Wastewater Engineering: Treatment and Reuse, 4th ed.; McGraw-Hill Higher Education: New York, NY, USA, 2002. [Google Scholar]
- Yang, T.; Qiu, W.; Ma, Y.; Chadli, M.; Zhang, L. Fuzzy model-based predictive control of dissolved oxygen in activated sludge processes. Neurocomputing 2014, 136, 88–95. [Google Scholar] [CrossRef]
- Holenda, B.; Domokos, E.; Rédey, Á.; Fazakas, J. Dissolved oxygen control of the activated sludge wastewater treatment process using model predictive control. Comput. Chem. Eng. 2008, 32, 1270–1278. [Google Scholar] [CrossRef]
- Vilanova, R.; Katebi, R.; Wahab, N. N-Removal on Wastewater Treatment Plants: A Process Control Approach. J. Water Resour. Prot. 2011, 3, 1–11. [Google Scholar] [CrossRef]
- Samuelsson, P.; Halvarsson, B.; Carlsson, B. Cost-efficient operation of a denitrifying activated sludge process. Water Res. 2007, 41, 2325–2332. [Google Scholar] [CrossRef] [PubMed]
- Rojas, J.; Zhelev, T. Energy efficiency optimization of wastewater treatment: Study of ATAD. Comput. Chem. Eng. 2012, 38, 52–63. [Google Scholar] [CrossRef]
- Henze, M.; Gujer, W.; Mino, T.; van Loosdrecht, M.C.M. Activated Sludge Models ASM1, ASM2, ASM2d and ASM3 Technical Report; International Water Association (IWA): London, UK, 2000. [Google Scholar]
- Olsson, G.; Nielsen, M.; Yuan, Z.; Lynggaard-Jensen, A.; Steyer, J. Instrumentation, Control and Automation in Wastewater Systems; International Water Association (IWA): London, UK, 2005. [Google Scholar]
- Bennett, A. Energy efficiency: Wastewater treatment and energy production. Filtr. Sep. 2007, 44, 16–19. [Google Scholar] [CrossRef]
- Meneses, M.; Concepción, H.; Vilanova, R. Joint Environmental and Economical Analysis of Wastewater Treatment Plants Control Strategies: A Benchmark Scenario Analysis. Sustainability 2016, 8, 360. [Google Scholar] [CrossRef]
- Caraman, S.; Sbarciog, M.; Barbu, M. Predictive Control of a Wastewater Treatment Process. IFAC Proc. Vol. 2006, 39, 155–160. [Google Scholar] [CrossRef]
- O’Brien, M.; Mack, J.; Lennox, B.; Lovett, D.; Wall, A. Model predictive control of an activated sludge process: A case study. Control Eng. Pract. 2011, 19, 54–61. [Google Scholar] [CrossRef]
- Lindberg, C.; Carlsson, B. Nonlinear and set-point control of the dissolved oxygen concentration in an activated sludge process. Water Sci. Technol. 1996, 34, 135–142. [Google Scholar] [CrossRef]
- Hong, G.; Kwanho, J.; Jiyeon, L.; Jeongwon, J.; Young, M.K.; Jong, P.P.; Joon, H.K.; Kyung, H.C. Prediction of effluent concentration in a wastewater treatment plant using machine learning models. J. Environ. Sci. 2015, 101, 32–90. [Google Scholar]
- Celik, U.; Yuntay, N.; Sertkaya, C. Wastewater effluent prediction based on decisión tree. J. Selcuk Univ. Nat. Appl. Sci. 2013, 138–148. [Google Scholar]
- Huang, M.; Ma, Y.; Wan, J.; Chen, X. A sensor-software based on a genetic algorithm-based neural fuzzy system for modeling and simulating a wastewater treatment process. Appl. Soft Comput. 2015, 27, 1–10. [Google Scholar] [CrossRef]
- Bagheri, M.; Mirbagheri, S.A.; Bagheri, Z.; Kamarkhani, A.M. Modeling and optimization of activated sludge bulking for a real wastewater treatment plant using hybrid artificial neural networks-genetic algorithm approach. Process Saf. Environ. Prot. 2015, 95, 12–25. [Google Scholar] [CrossRef]
- Han, H.; Qiao, J.; Chen, Q. Model predictive control of dissolved oxygen concentration based on a self-organizing RBF neural network. Control Eng. Pract. 2012, 20, 465–476. [Google Scholar] [CrossRef]
- Syafiie, S.; Tadeo, F.; Martinez, E.; Alvarez, T. Model-free control based on reinforcement learning for a wastewater treatment problem. Appl. Soft Comput. 2011, 11, 73–82. [Google Scholar] [CrossRef]
- Alex, J.; Benedetti, L.; Copp, J.B.; Gernaey, K.V.; Jeppsson, U.; Nopens, I.; Pons, M.N.; Rieger, L.; Rosen, C.; Steyer, J.P.; et al. Benchmark Simulation Model No. 1 (BSM1). Available online: http//www.iea.lth.se/publications/Reports/LTH-IEA-7229.pdf (accessed on 26 May 2016).
- Copp, J. The COST Simulation Benchmark: Description and Simulator Manual; Office for Official Publications of the European Community: Luxembourg, Luxembourg, 2002. [Google Scholar]
- Takács, I.; Patry, G.G.; Nolasco, D. A dynamic model of the clarification thickening process. Water Res. 1991, 25, 1263–1271. [Google Scholar] [CrossRef]
- Stare, A.; Vrecko, D.; Hvala, N.; Strmcnik, S. Comparison of control strategies for nitrogen removal in activated sludge process in terms of operating costs: A simulation study. Water Res. 2007, 41, 2004–2014. [Google Scholar] [CrossRef] [PubMed]
- Vanrolleghem, P.A.; Jeppsson, U.; Carstensen, J.; Carlsson, B.; Olsson, G. Integration of wastewater treatment plant design and operation—A systematic approach using cost functions. Water Sci. Technol. 1996, 34, 159–171. [Google Scholar] [CrossRef]
- Hernández-del-Olmo, F.; Gaudioso, E. Reinforcement Learning Techniques for the Control of WasteWater Treatment Plants. Lecture Notes Comput. Sci. 2011, 6687, 215–222. [Google Scholar]
- Busoniu, L.; Babuska, R.; De Schutter, B.; Ernst, D. Reinforcement Learning and Dynamic Programming Using Function Approximators; CRC Press: Boca Raton, FL, USA, 2010. [Google Scholar]
- Hernández-del-Olmo, F.; Llanes, F.H.; Gaudioso, E. An emergent approach for the control of wastewater treatment plants by means of reinforcement learning techniques. Expert Syst. Appl. 2012, 39, 2355–2360. [Google Scholar] [CrossRef]
- Hernández-del-Olmo, F.; Gaudioso, E.; Nevado, A. Autonomous adaptive and active tuning up of the dissolved oxygen setpoint in a wastewater treatment plant using reinforcement learning. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2012, 42, 768–774. [Google Scholar] [CrossRef]
- Fritzson, P. Principles of Object-Oriented Modeling and Simulation with Modelica 3.3: A Cyber-Physical Approach; Wiley-IEEE Press: Pistacaway, NJ, USA, 2014. [Google Scholar]
- Åmand, L.; Olsson, G.; Carlsson, B. Aeration control—A review. Water Sci. Technol. 2013, 67, 2374–2398. [Google Scholar] [CrossRef] [PubMed]
- Belia, E.; Neumann, M.B.; Benedetti, L.; Johnson, B.; Murthy, S.; Weijers, S.; Vanrolleghem, P.A. Uncertainty in Wastewater Treatment Design and Operation: Addressing Current Practices and Future Directions; Scientific and Technical Report Series; International Water Association (IWA): London, UK, 2016. [Google Scholar]
- Sin, G.; Gernaey, K.V.; Neumann, M.V.; Van Loosdrecht, M.C.; Gujer, W. A Global sensitivity analysis in wastewater treatment plant model applications: Priorizing sources of uncertainty. Water Res. 2011, 45, 639–651. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ∆βNH | ∆βTN | β0,NH | β0,TN |
|---|---|---|---|
| 12 €/kg | 8.1 €/kg | 2.7 €/1000 m3 | 1.4 €/1000 m3 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hernández-del-Olmo, F.; Gaudioso, E.; Dormido, R.; Duro, N. Energy and Environmental Efficiency for the N-Ammonia Removal Process in Wastewater Treatment Plants by Means of Reinforcement Learning. Energies 2016, 9, 755. https://doi.org/10.3390/en9090755
Hernández-del-Olmo F, Gaudioso E, Dormido R, Duro N. Energy and Environmental Efficiency for the N-Ammonia Removal Process in Wastewater Treatment Plants by Means of Reinforcement Learning. Energies. 2016; 9(9):755. https://doi.org/10.3390/en9090755
Chicago/Turabian StyleHernández-del-Olmo, Félix, Elena Gaudioso, Raquel Dormido, and Natividad Duro. 2016. "Energy and Environmental Efficiency for the N-Ammonia Removal Process in Wastewater Treatment Plants by Means of Reinforcement Learning" Energies 9, no. 9: 755. https://doi.org/10.3390/en9090755
APA StyleHernández-del-Olmo, F., Gaudioso, E., Dormido, R., & Duro, N. (2016). Energy and Environmental Efficiency for the N-Ammonia Removal Process in Wastewater Treatment Plants by Means of Reinforcement Learning. Energies, 9(9), 755. https://doi.org/10.3390/en9090755