1. Introduction and Background
Nuclear material accounting (NMA) is a component of nuclear safeguards, which are designed to detect illicit diversion of special nuclear material (SNM) from the peaceful fuel cycle to a potential weapons application. NMA consists of periodically comparing measured SNM inputs to measured SNM outputs, and adjusting for measured changes in inventory. Process monitoring (PM) data is a relatively recent component of safeguards that is collected more frequently than NMA data. PM data is often only an indirect measurement of the SNM, or is a direct measurement of bulk mass that includes SNM and non-SNM. PM data is typically used as a qualitative measure to supplement NMA, or to support indirect estimation of difficult-to-measure inventory for NMA [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12].
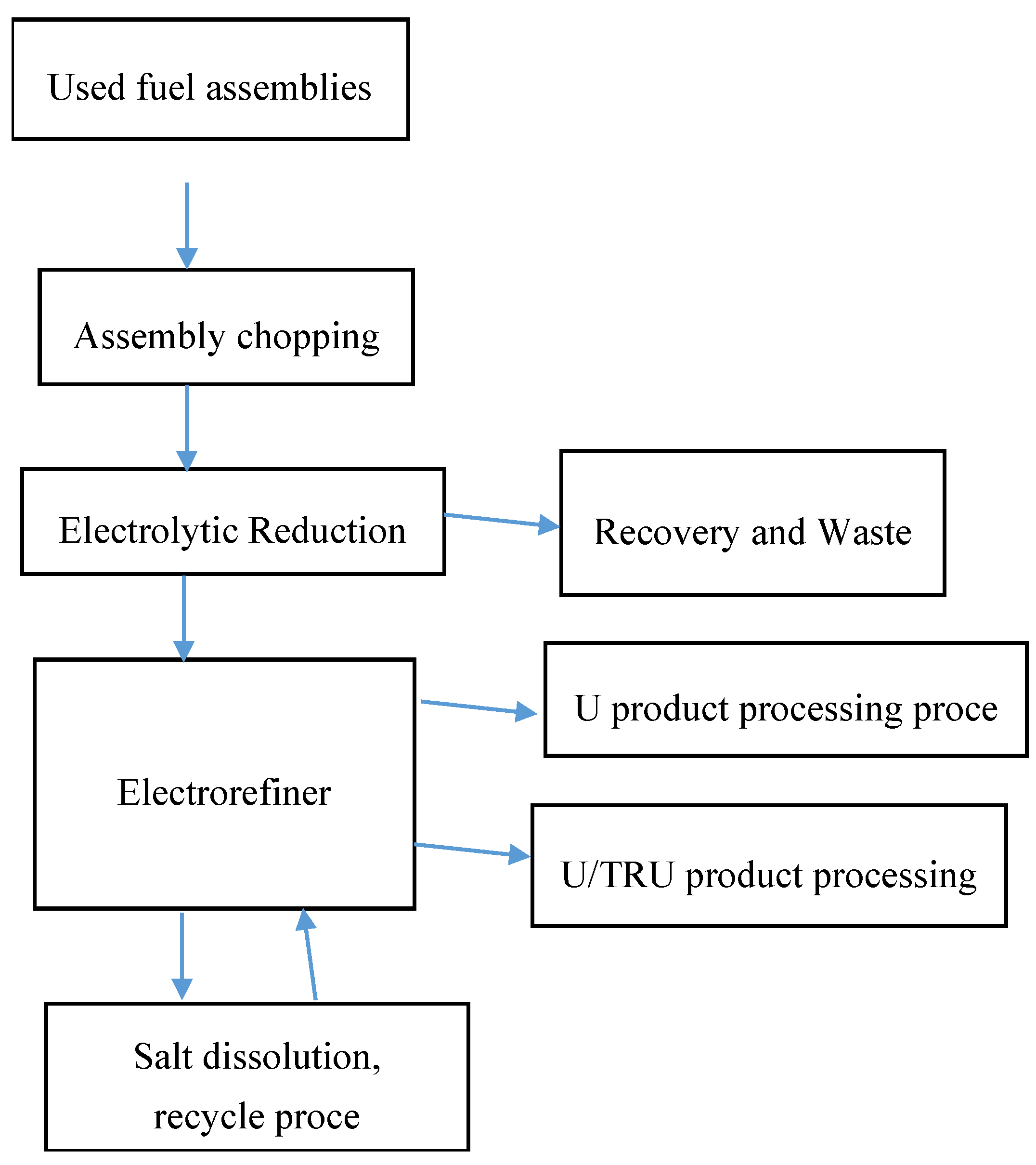
Nuclear safeguards are applied at all stages of the nuclear fuel cycle, from uranium conversion to SNM waste disposition. To focus this article, we only discuss reprocessing facilities. Traditional NMA at large reprocessing facilities closes the material balance (MB) approximately every 10 to 30 days around an entire material balance area, which typically consists of multiple process stages.
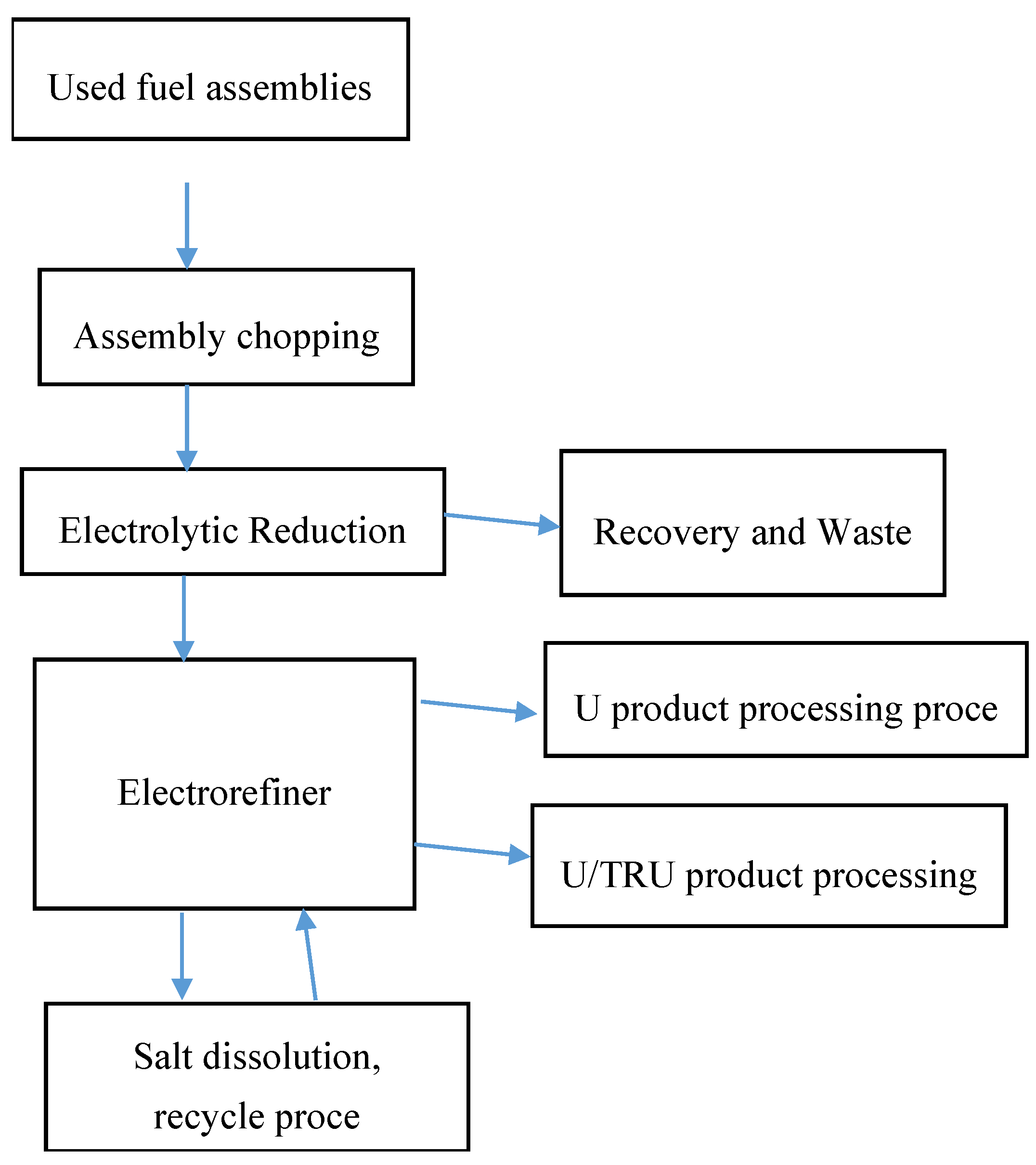
Figure 1 is a picture of SNM flows at a generic electrochemical reprocessing facility [
13,
14,
15,
16,
17,
18,
19], which is anticipated to have large SNM throughput but much less processing equipment than a similar-throughput aqueous reprocessing facility [
7,
8,
9]. Both PM and NMA measurements are available at aqueous and electrochemical reprocessing facilities. An electrochemical facility operates mostly in “batch mode”, such as batches of product baskets taken from the electrorefiner (
Figure 1). An aqueous facility has tanks and processes in both batch and continuous operation (the chemical separations vessels operate in continuous mode, so some tanks ship and receive continuously from the separations vessels).
Our proposed options to quantify the benefit of using both PM and NMA data define the system alarm probability as the conditional probability of an alarm given the true model parameters (such as the true SNM loss in each vessel over a specified time), denoted P(alarm|diversion scenario). We assume there are time series of p residuals r1, r2, …., rp, which include MBs from NMA, plus residuals generated from PM data. In both PM and NMA, a residual is computed as residual = measurement − prediction. The prediction can come from an engineering model or from purely empirical means on historical training data that is assumed to not contain SNM diversion. The probability P(alarm|diversion scenario) is a function of the true states of nature (which depend on whether SNM has been misdirected), the measurement system, the PM residual streams in use, and the alarm rule(s).
It has long been believed that PM can improve domestic and international safeguards; although the cost to the safeguards budget is relatively low because PM data is already being collected by the operator, PM benefits are difficult to quantify. This paper uses PM residuals as a simple extension of NMA to quantify PM benefits. One key assumption is that the safeguards approach includes model-based predictions that can be compared to corresponding measurements, resulting in time series of residuals. The requirement for high-quality predictions leads to technical challenges in safeguarding either aqueous or electrochemical reprocessing facilities. For example, there is ongoing work aimed at high-quality modeling of the electrorefiner in an electrochemical facility [
17]. Strictly speaking, our approach leads to high SNM loss detection probability (DP) only for the specified diversion routes; however, there is also high loss detection probability for any type of abrupt loss. See
Appendix 2 for more detail. Also, in the context of international safeguards, there is not yet an approach to authenticate operator PM data; authentication will depend on facility type and is under investigation.
The following sections include a description of NMA and of PM, pattern recognition, model-based prediction, discussion of simulated data, extensions to include additional PM residuals, example of combining PM and NMA data, and a summary. The simulated numerical example that combines NMA and PM data includes daily PM data from 13 vessels, including one input, eight inventory vessels, and four output vessels. PM data from each vessel consists of a time series of residuals. The overall MB can be computed at any desired frequency of 1 day or longer. Reference [
1] reviews related work in the nuclear safeguards and statistics communities.
Figure 1.
Generic electrochemical reprocessing facility with key activities shown.
Figure 1.
Generic electrochemical reprocessing facility with key activities shown.
3. Flow Rate Monitoring and Event Marking
Raw solution monitoring (SM) data are unlikely to be useful as input features for pattern recognition. Instead, raw SM data can be parsed into key events such as shipments and receipts, as done by some SM evaluation systems [
4,
6,
27]. This allows one to regard each tank as unit process area and generate residuals that are analogous to the MB from NMA. Alternatively, flow rates to and from tanks can be used to generate very frequent (every few minutes or hours or days) residuals from each tank, without event marking [
30]. The flow rate monitoring option is known [
30] to have challenges, including the following: flow rates can be difficult to measure; in-vessel measurements are unstable if the vessel contents are rapidly changing; synchronization errors arising from flow rate changes that occur at unknown times between the recorded data times; serial correlation in MBs due to successive residuals sharing the same estimation error effects, and larger data dimension than using residuals from marked events. For example,
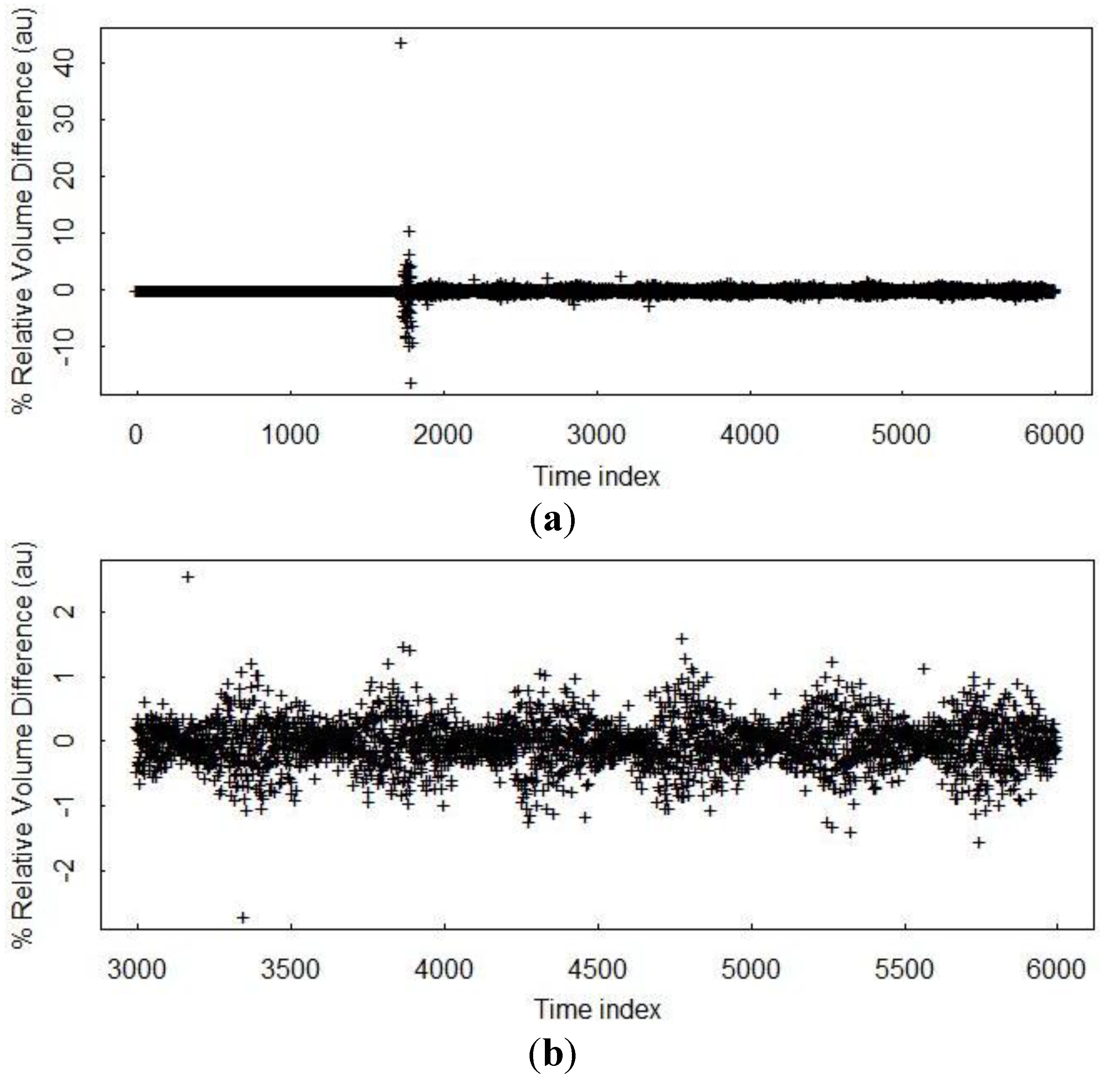
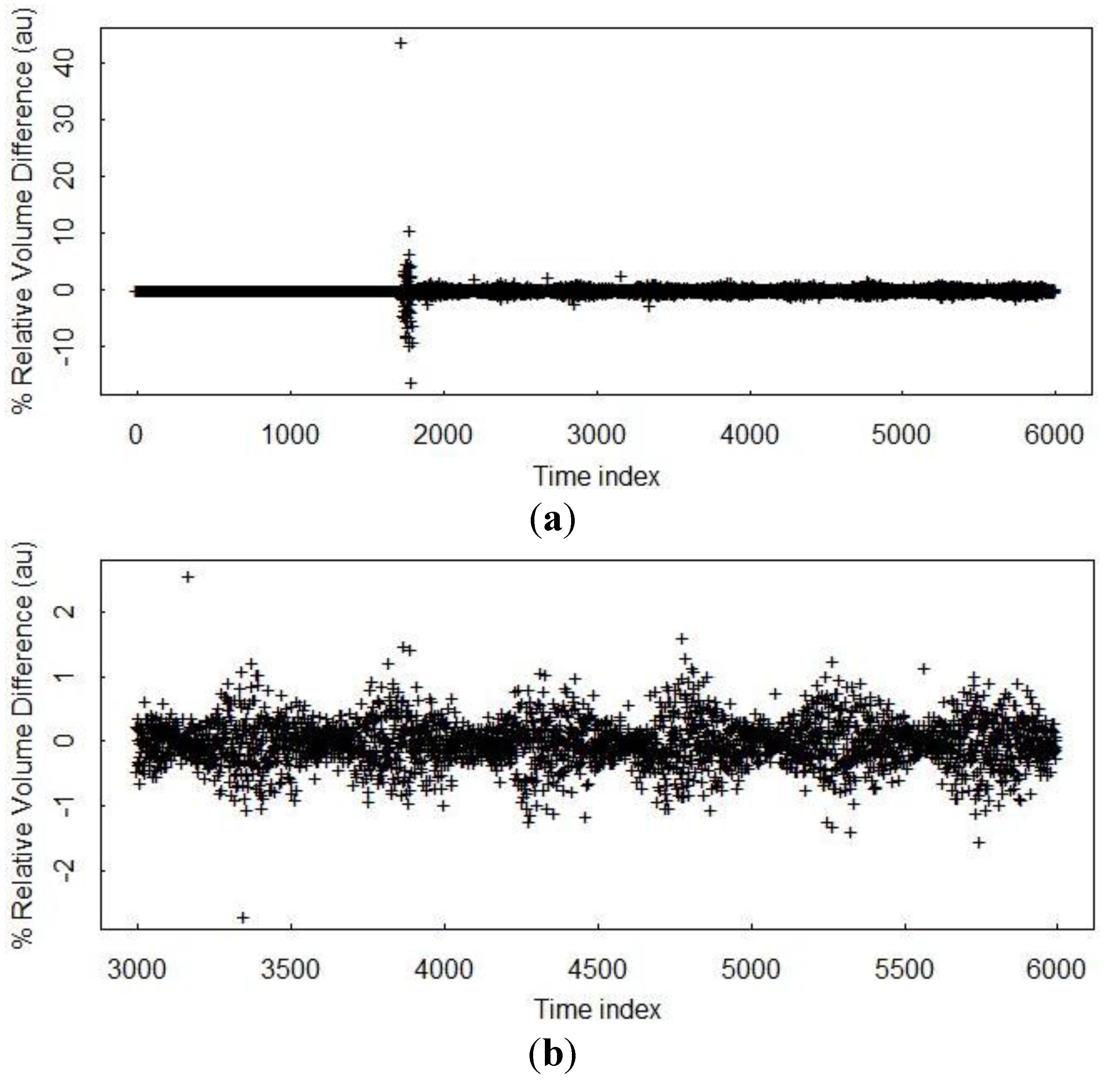
Figure 2 plots simulated bulk volume balance in one tank from the safeguards system performance model (SPM) [
30] before the effects of measurement errors are introduced. There is a large transient volume balance near 1700 min that masks the −1 to 2 percent relative volume balance that persists for the entire simulation.
Figure 2.
Illustration of synchronization error in an aqueous tank modeled in the System Performance Model (SPM). In (a), the synchronization error is present but a large volume residual occurred at the beginning of material flow near minute 1700 so synchronization errors are almost not visible. In (b), a relatively short section of time is plotted, and synchronization error is approximately a −1 to 2 percent effect (in arbitrary units, au, because this is percent relative change).
Figure 2.
Illustration of synchronization error in an aqueous tank modeled in the System Performance Model (SPM). In (a), the synchronization error is present but a large volume residual occurred at the beginning of material flow near minute 1700 so synchronization errors are almost not visible. In (b), a relatively short section of time is plotted, and synchronization error is approximately a −1 to 2 percent effect (in arbitrary units, au, because this is percent relative change).
These −1 to 2 percent relative volume balances are due to flow changes occurring at slightly different times than the times that the simulation records data, which we call a synchronization error. Synchronization errors also occur in real facility data, so there has not been an attempt to remove them from simulated data.
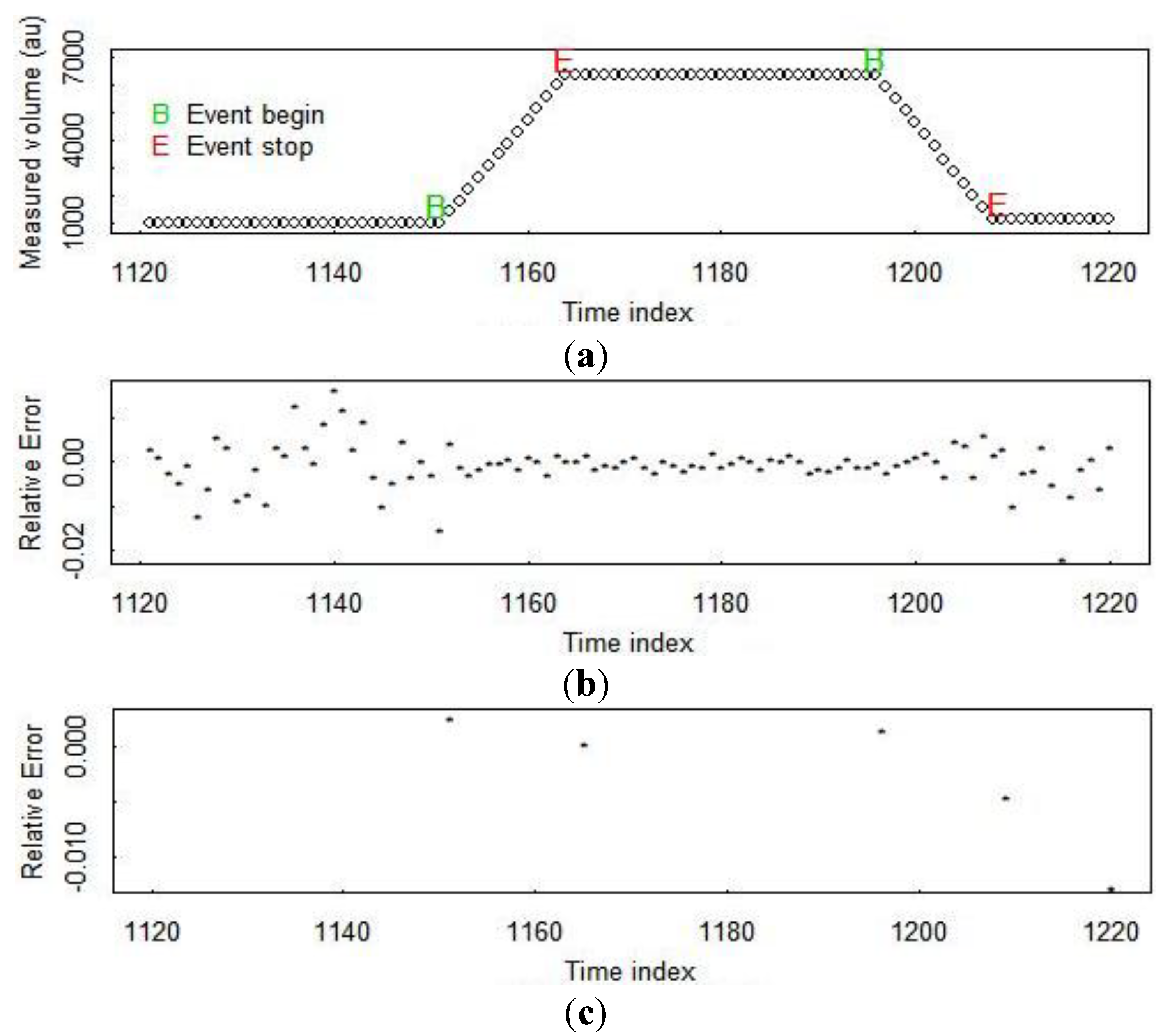
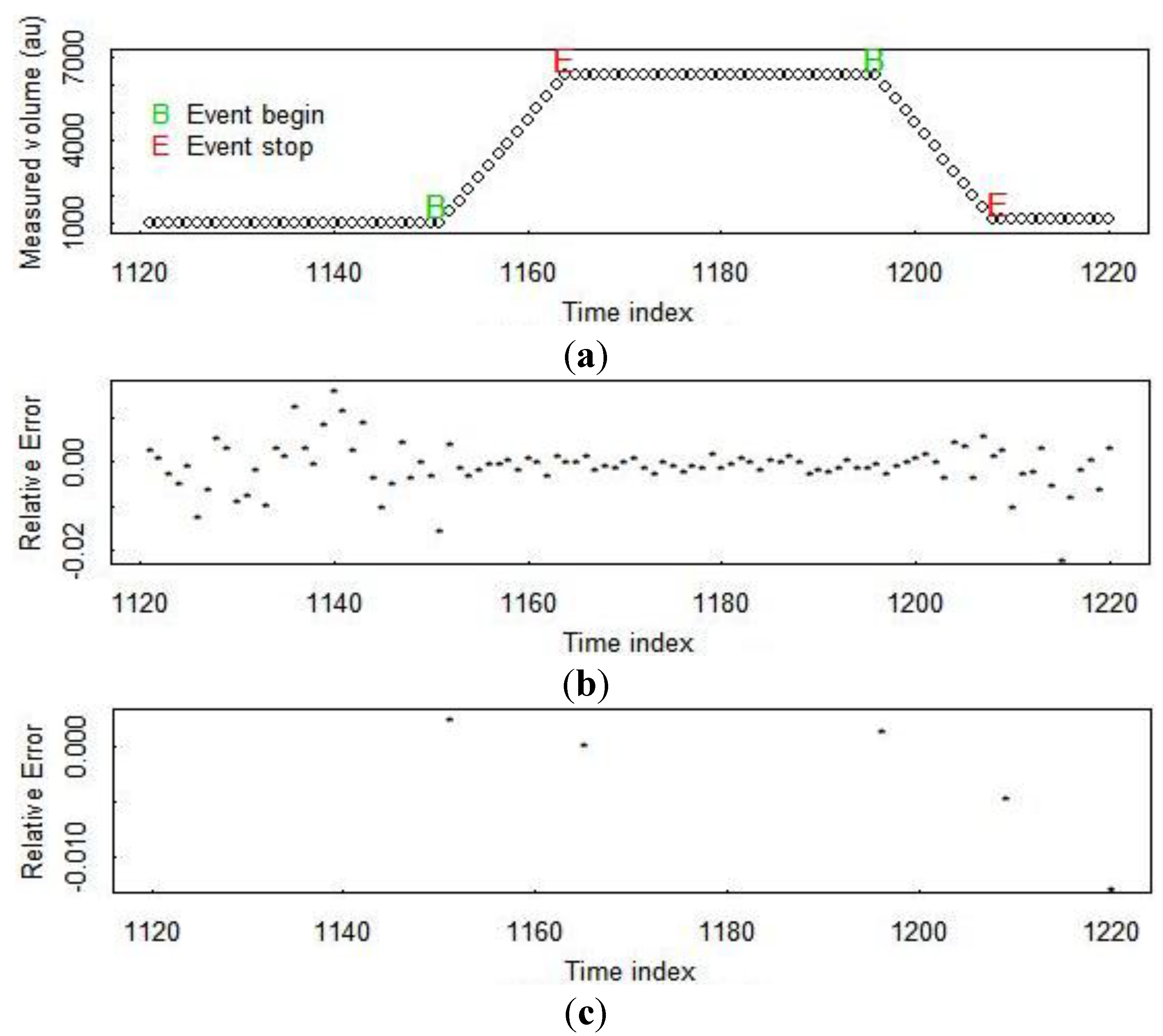
Figure 3 illustrates PM residuals from two options. Option 1 assumes flow rates are measured and that PM residuals can be generated on a fixed schedule, such as every 6 min, every hour, or every day [
30]. Option 2 uses event marking and so parses each vessel into wait and transfer modes [
1,
4,
6,
27]. Note that option 2 results in only 5 residuals while option 1 results in many more residuals over the same time period.
Figure 3.
(a) The measured volume in a tank during a receive, wait, ship cycle; (b) PM residuals for bulk volume using option 1 PM; (c) PM residuals for bulk volume using option 2 PM. In PM option 1, residuals are generated on a fixed time schedule. In PM option 2, residuals are generated at the end of each “wait” and “transfer” mode, and transfer-mode residuals compare the bulk volume change in the shipper tank to the corresponding change in the receiver tank.
Figure 3.
(a) The measured volume in a tank during a receive, wait, ship cycle; (b) PM residuals for bulk volume using option 1 PM; (c) PM residuals for bulk volume using option 2 PM. In PM option 1, residuals are generated on a fixed time schedule. In PM option 2, residuals are generated at the end of each “wait” and “transfer” mode, and transfer-mode residuals compare the bulk volume change in the shipper tank to the corresponding change in the receiver tank.
4. Model-Based Predictions
In NMA, the MB concept is based on a simple model of mass conservation which implies that the true MB should be zero. In PM, both first-principles and empirical models can be used to predict SNM mass in a given location. Also, models for how one might misdirect Pu can suggest what observables would be generated. For example, [
3] describes a simple model of the dissolver vessel in the head-end of an aqueous reprocessing plant. Excess Pu can be directed to the waste hulls by incomplete dissolution using off-normal nitric acid concentration and/or off-normal dissolver batch cycle times. In the example in [
3], PM data includes cycle times, temperatures, and acid concentrations, that are all inputs to the example’s model of dissolver operation, and so the PM data enabled a model-based prediction of the Pu in the hulls. This model-based prediction can provide the basis for having a PM residual associated with each batch of hulls, defined as residual = measurement − model prediction. Currently, a neutron-based hull monitor is used, but the hull monitor measurement is not compared to a model prediction. This article assumes that such a PM scheme is feasible, and provides a way to monitor for diversion to the hull waste stream.
PM (extended, if needed, beyond in-tank level, density, and temperature to include flow measurements and/or in-line Pu concentration measurements) can help provide a predicted or book value for waste streams. For example, recall that [
3] describes a model for the head end of an aqueous reprocessing plant that results in a model-based prediction (or “book value”) of the Pu mass in the hulls waste stream. Xerri
et al. [
31] distinguish holdup from “hidden inventory” and use by-difference PM data to estimate holdup. Assuming that diversion of excess Pu to the hulls is the only credible diversion route in the head end, it is valuable to have such a “model-based” prediction of the Pu in each hull batch that relies on easily measured quantities such as dissolver cycle time, temperature, and feed nitric acid concentration or bulk density.
Similarly, pulsed column models [
25] can provide a book value for effluent streams (an example is given in [
1]). For electrochemical facilities, a few models of the electrorefiner are being developed that would generate time series of PM residuals [
15,
16,
17,
18,
19]. The intent is to detect off-normal conditions that could indicate misdirection of Pu. Monitoring such profiles can lead to residuals as we have described for simpler models involving mass and/or volume balancing of SM data for each key process tank.
Model-based predictions as just described can provide a new way for PM plus NMA to detect diversion on the basis of monitoring the corresponding residuals. A key fact is that diversion to streams that should have relatively small amounts of Pu can be easily detected provided frequent PM data is available, and the model-based predictions are reasonably high quality (
i.e., have low total error variance; see
Section 8).
8. Example
We consider an material balance accounting (MBA) with 13 vessels, including one input, eight inventory vessels, and four output vessels.
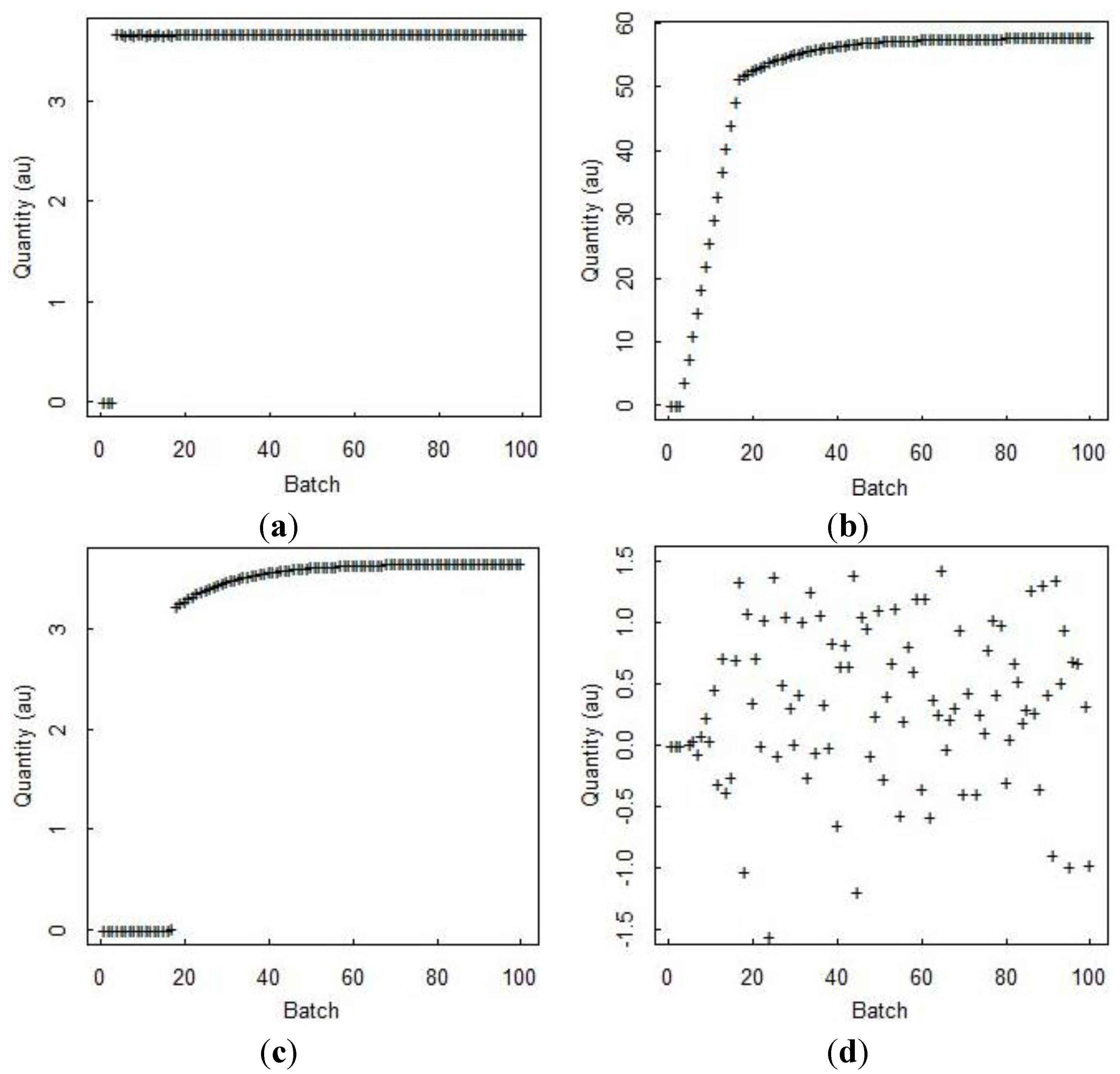
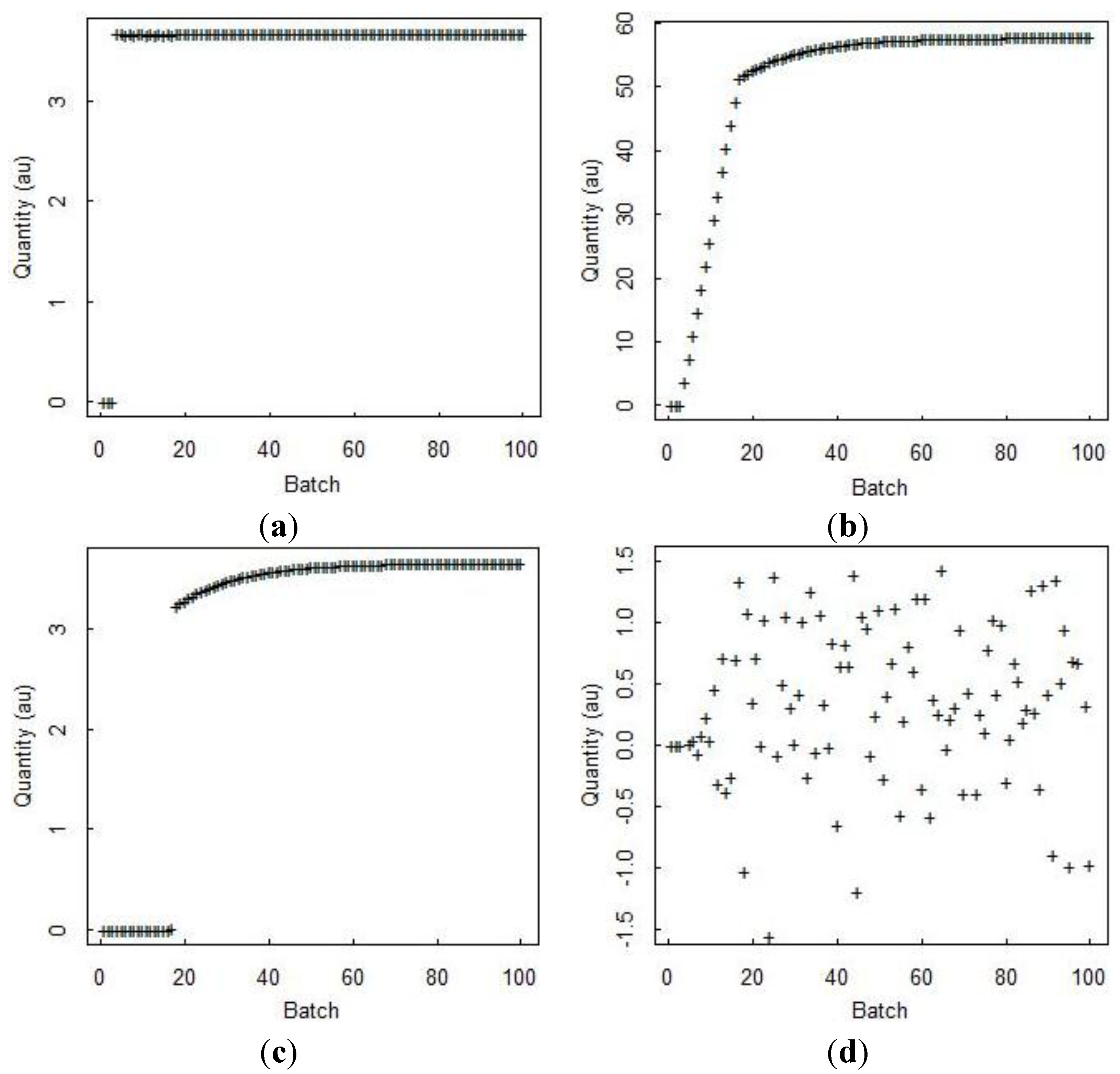
Figure 4 is simulated input, output, and inventory bulk mass data from a generic electrochemical reprocessing plant provided by Sandia National Laboratories from the SPM [
14]. Because there is far less experience with electrochemical reprocessing than with aqueous reprocessing, we are not in position to have a defensible estimate of measurement error variances. So, purely for illustration purposes, we assume 1% relative random error standard deviation on all measurements, and 0.5% relative systematic error standard deviation on all measurements (these are somewhat larger than typical values in aqueous reprocessing [
24]).
A time series of 100 simulated MBs (with measurement errors of 1% relative random error standard deviation and 0.5% relative systematic error standard deviation) in arbitrary units (au) is also shown in
Figure 4d for each time step.
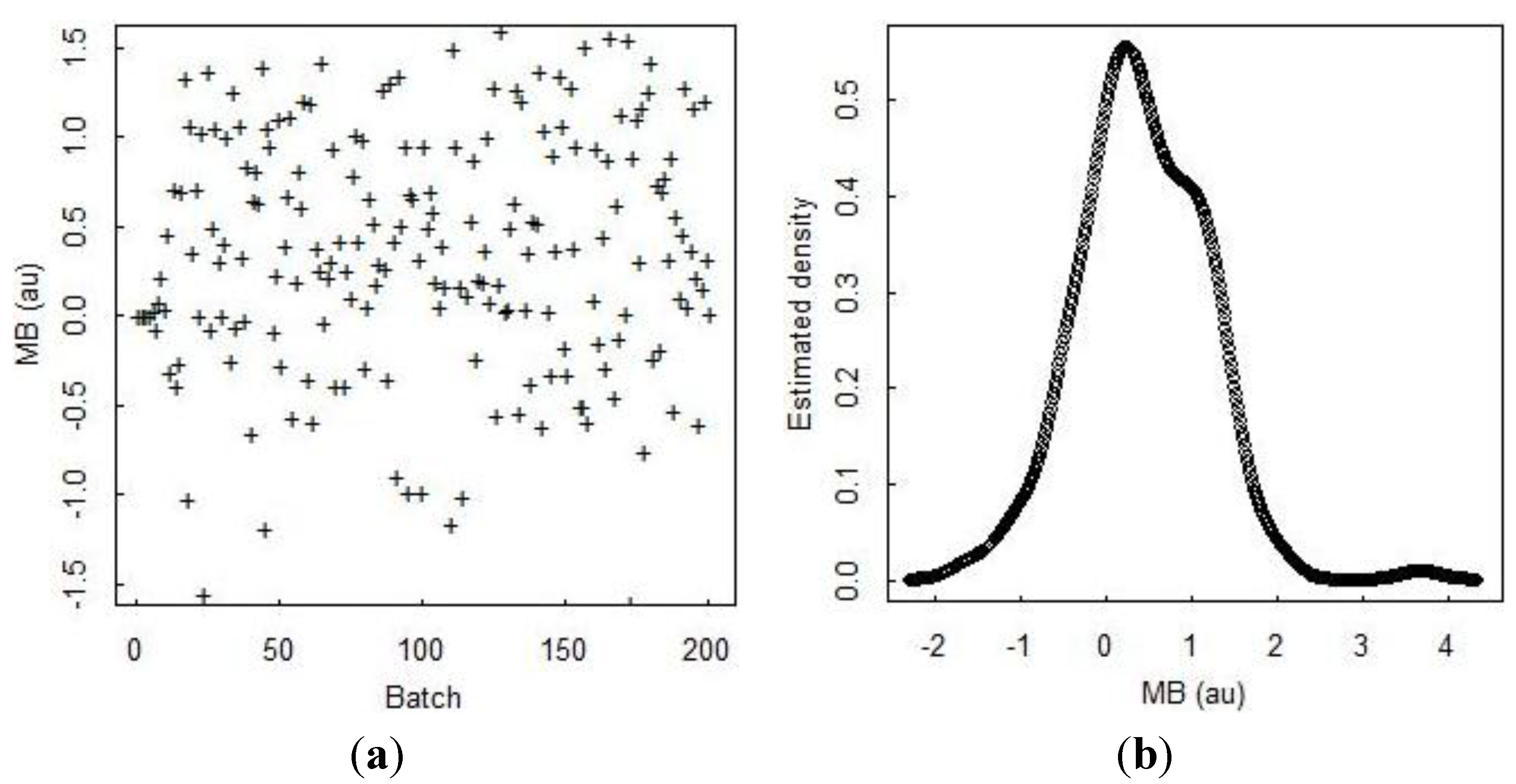
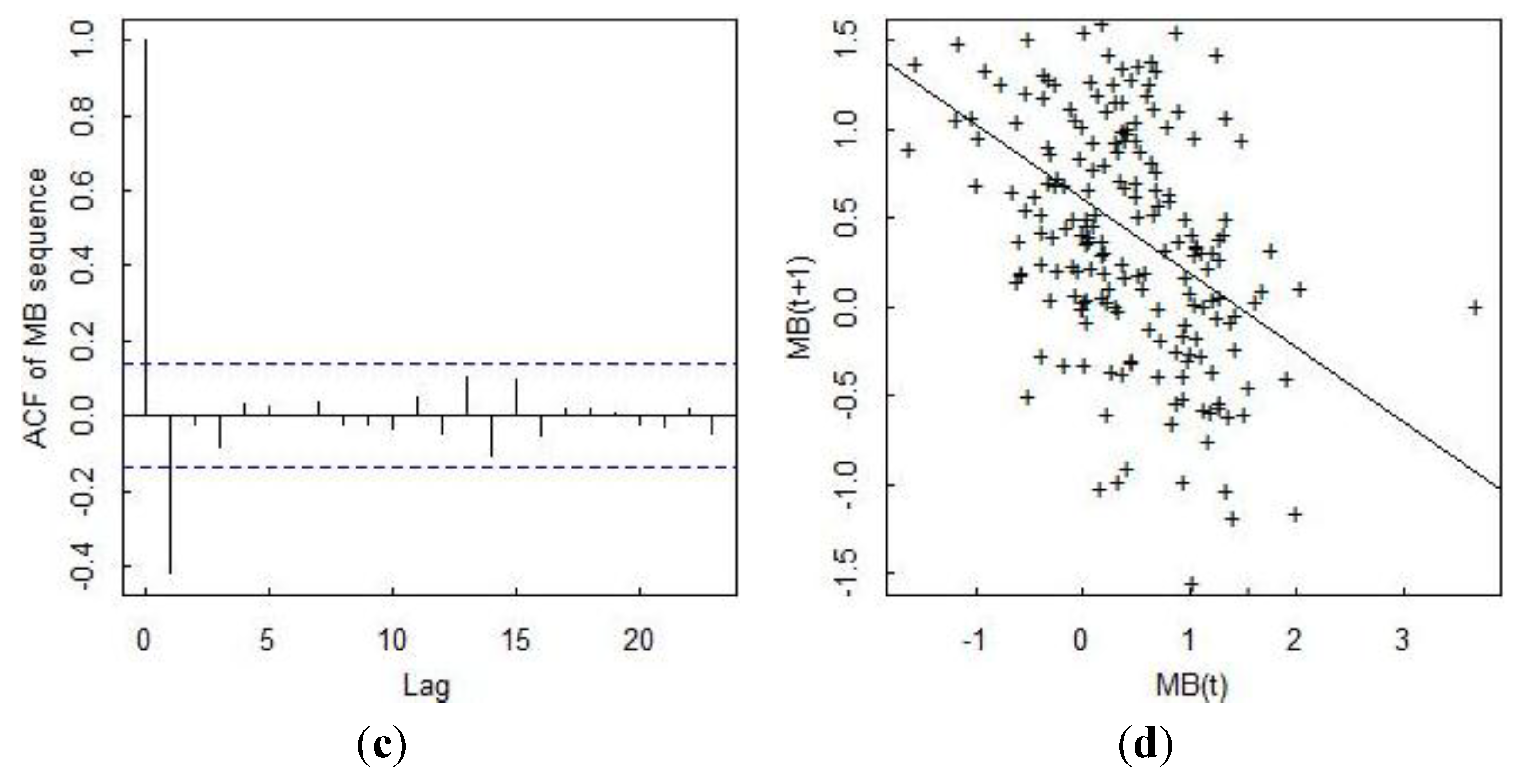
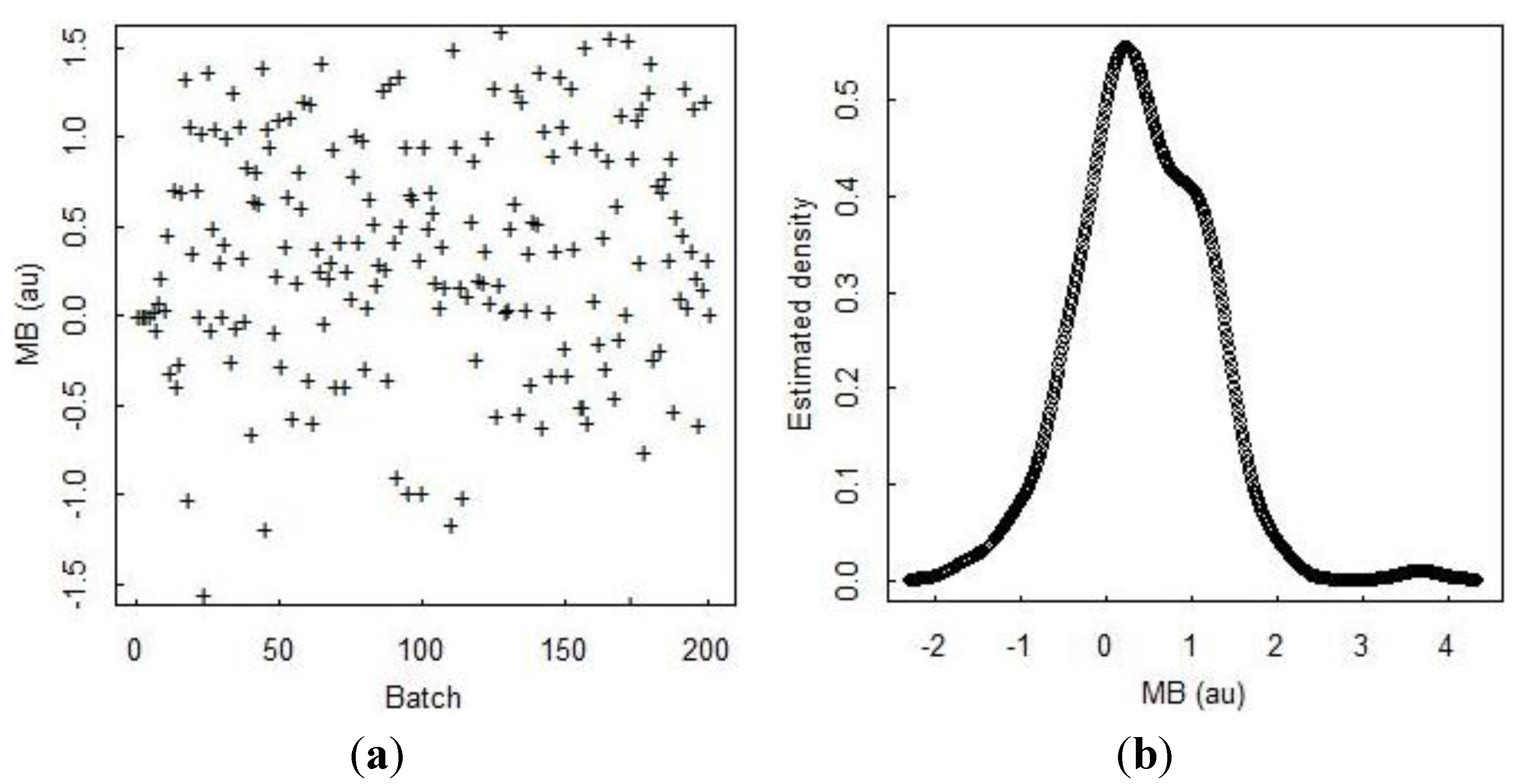
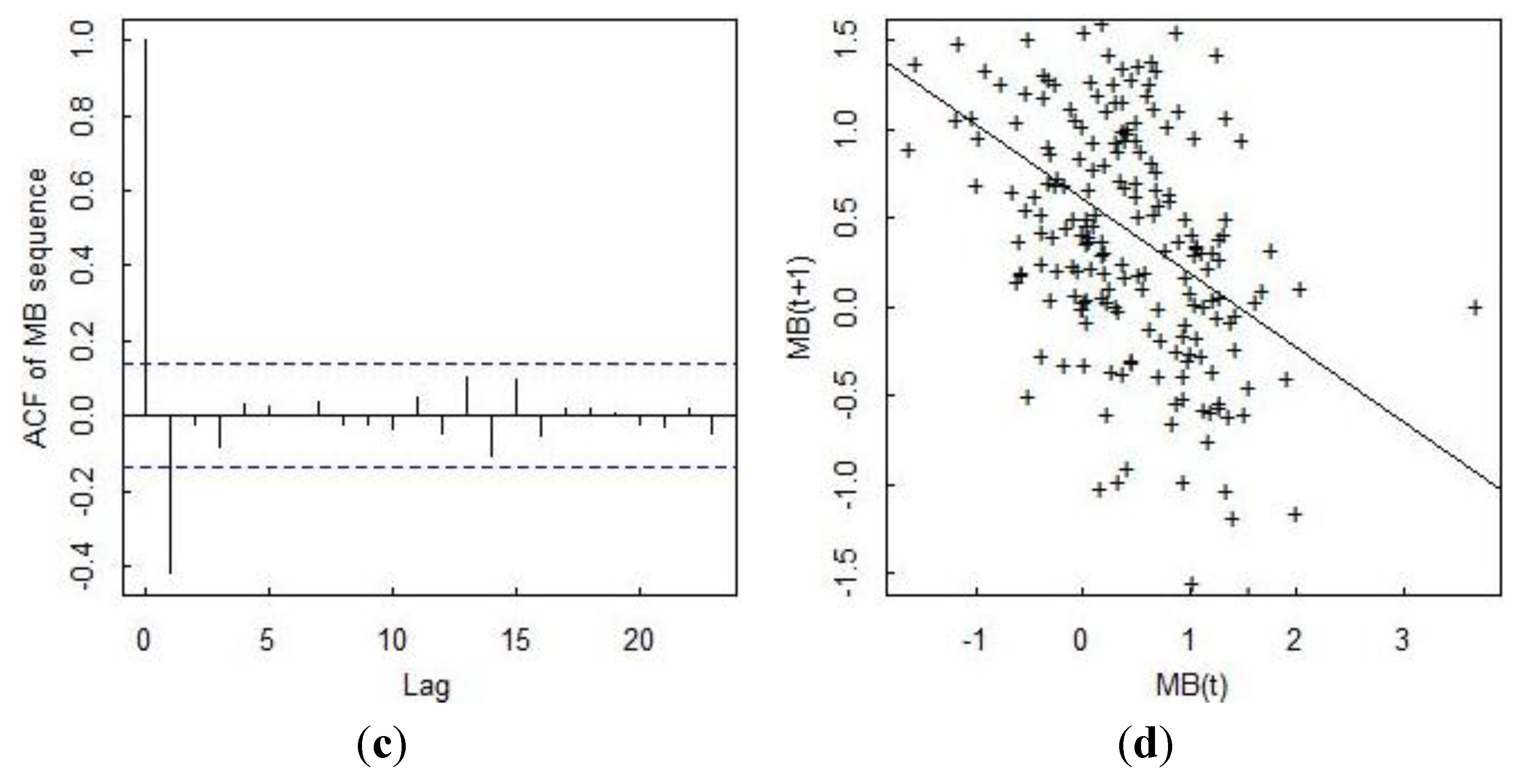
Figure 5 plots 200 MBs that are computed each day rather than each time step (so the values are somewhat different) in (a), the estimated probability density of the MB value in (b), the autocorrelation function (ACF) of the MB sequence in (c), and a lagged plot of the present MB
versus the previous MB in (d). The strong lag-one ACF in (c) indicates that the inventory measurement error is non-negligible. The variance of the MB sequence quickly increases to its stationary value, as evident from the scatter increasing in (a) from an initial small value to a larger stationary value as inventory vessels reach capacity later in the simulation.
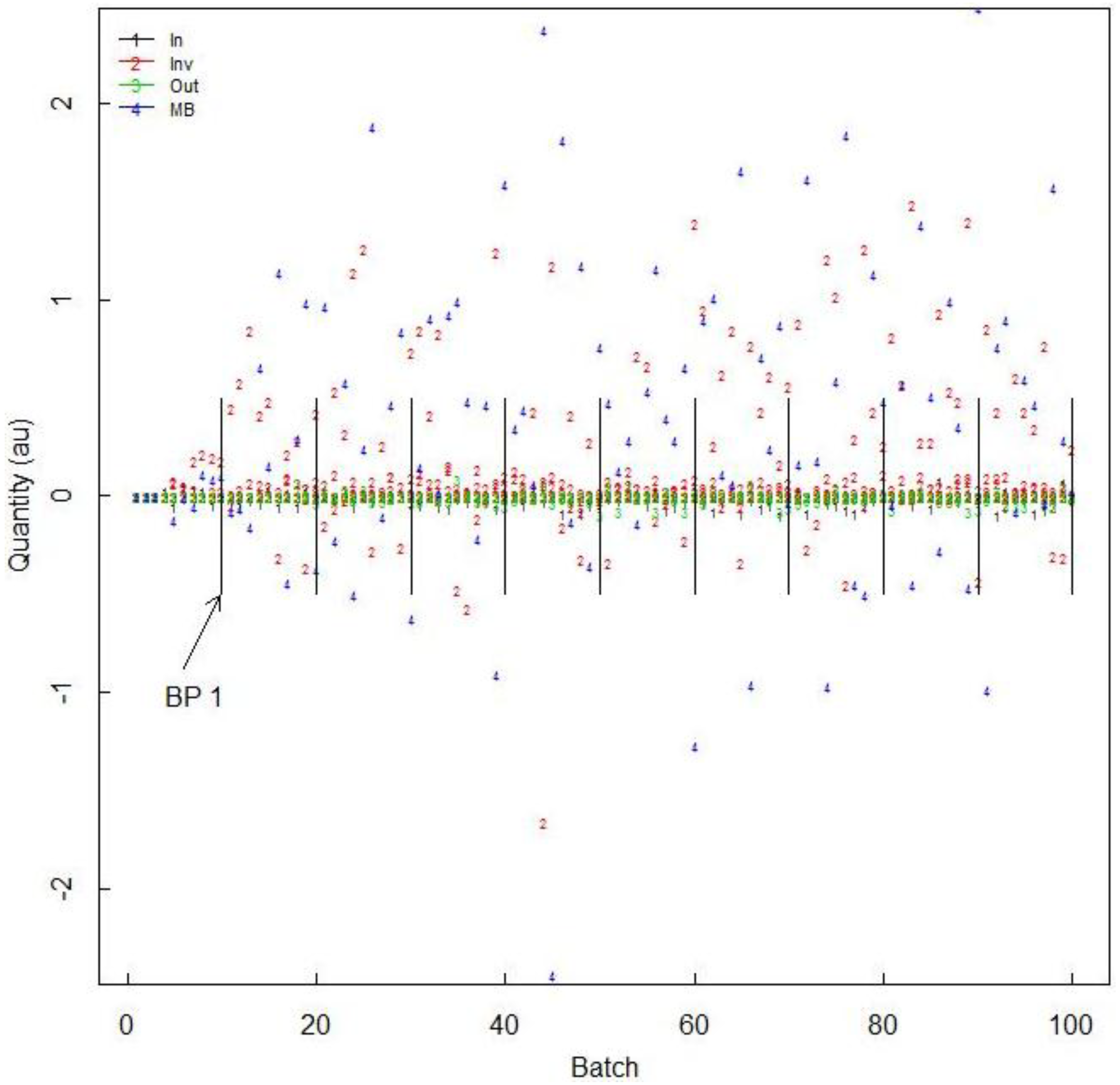
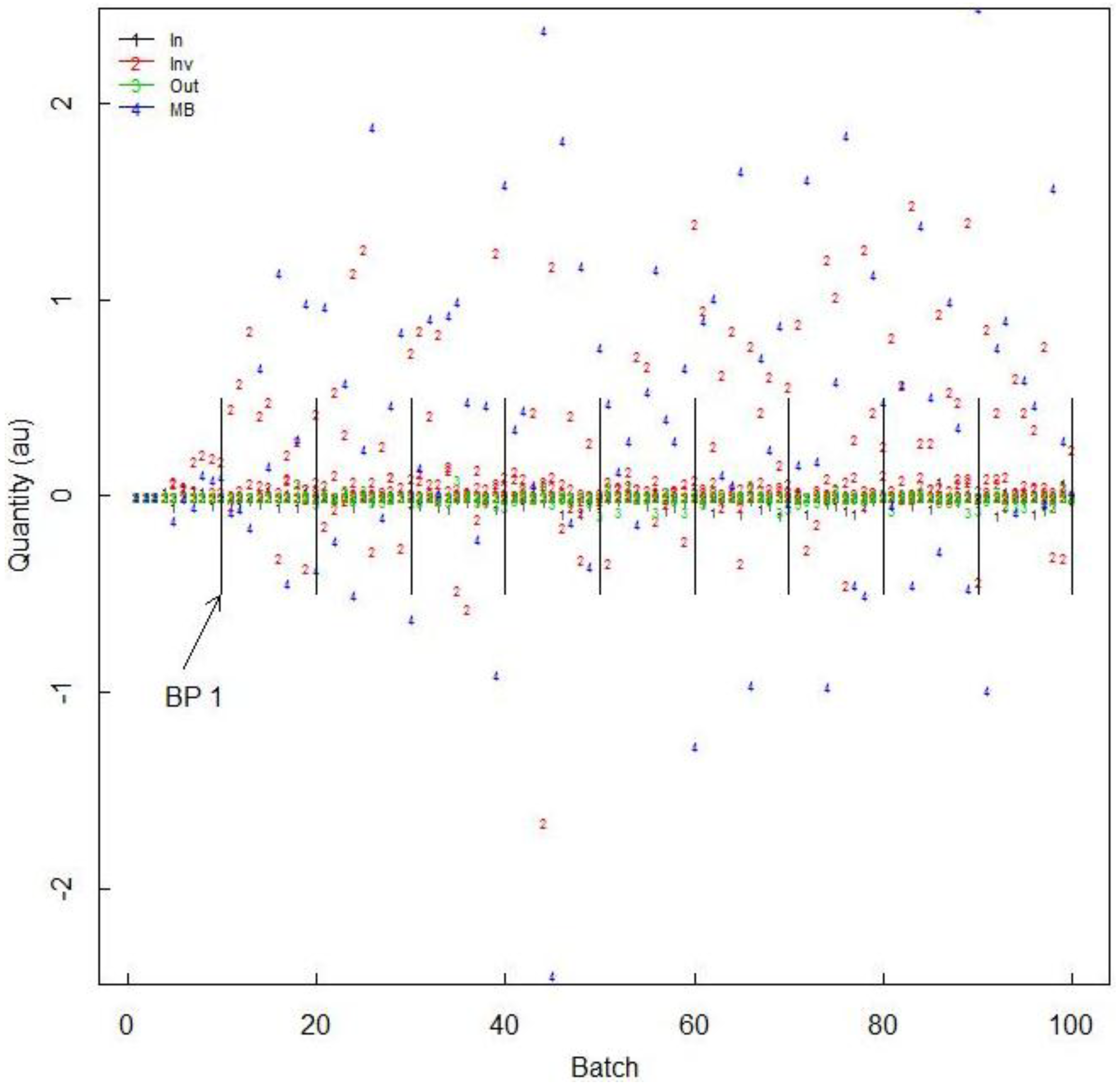
Figure 6 plots the 14 daily residuals (one input, eight inventory, four outputs, and one MB). For comparision,
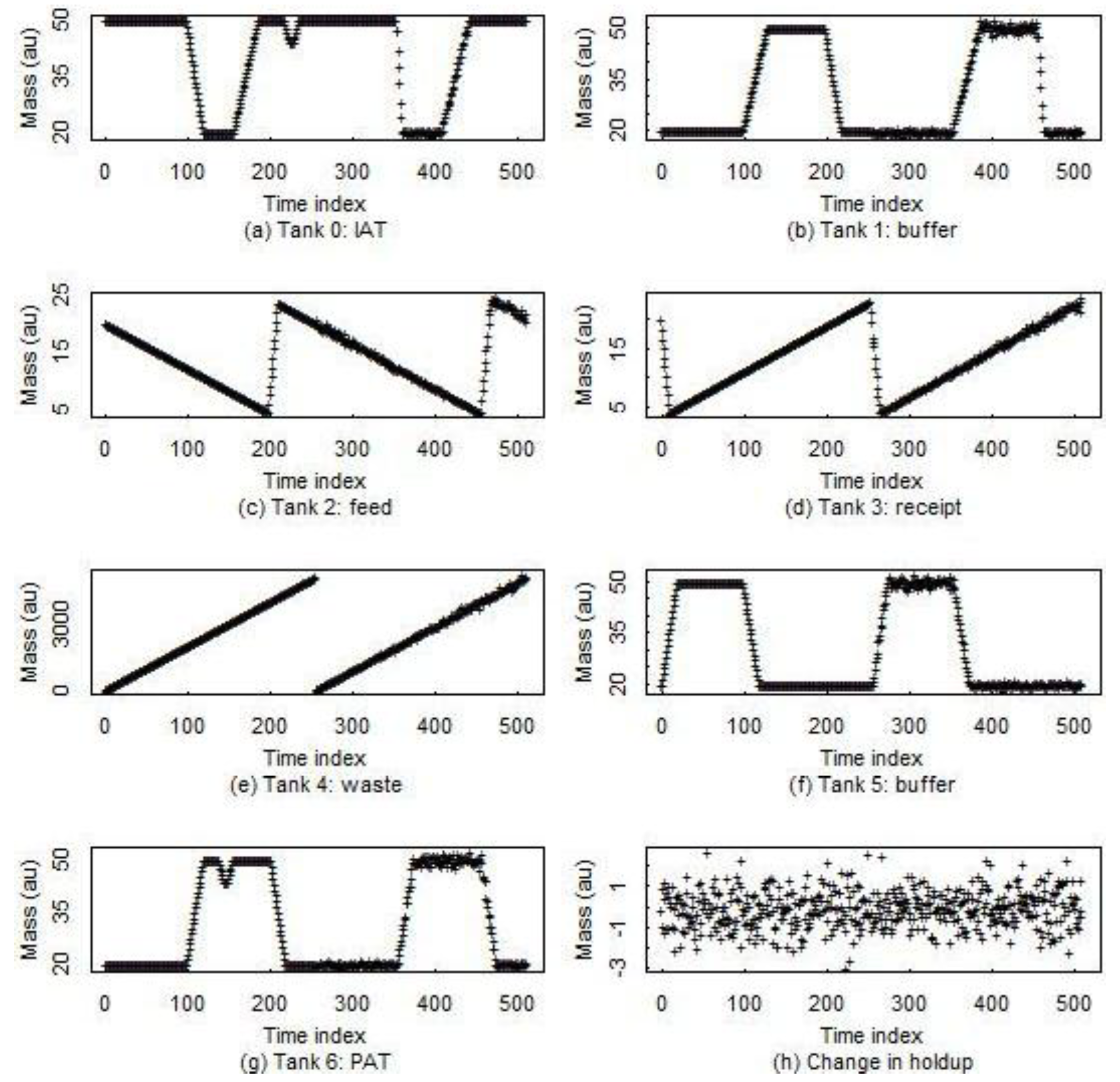
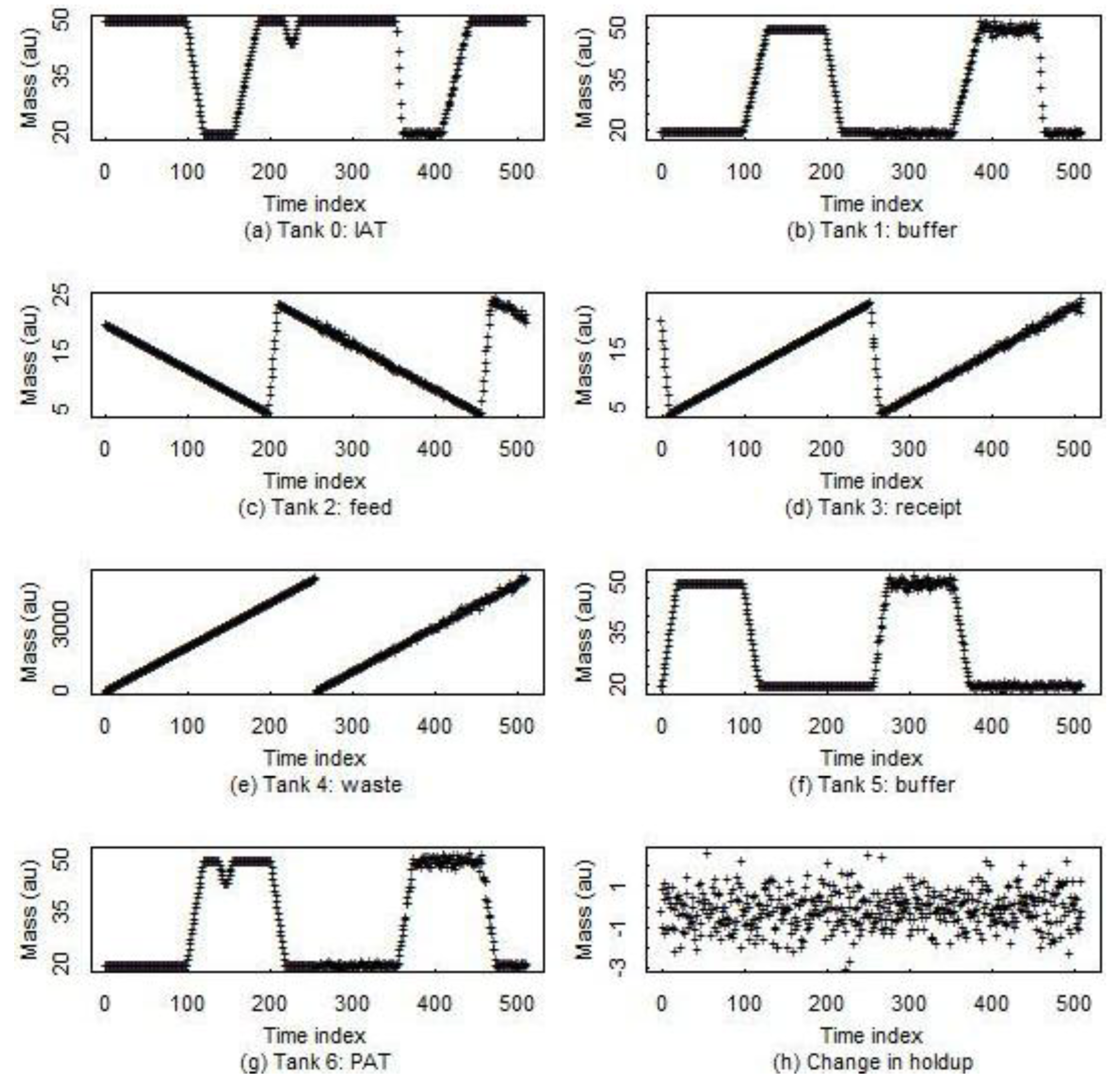
Figure 7 and
Figure 8 are for a 7-tank MBA at an aqueous facility described in [
1].
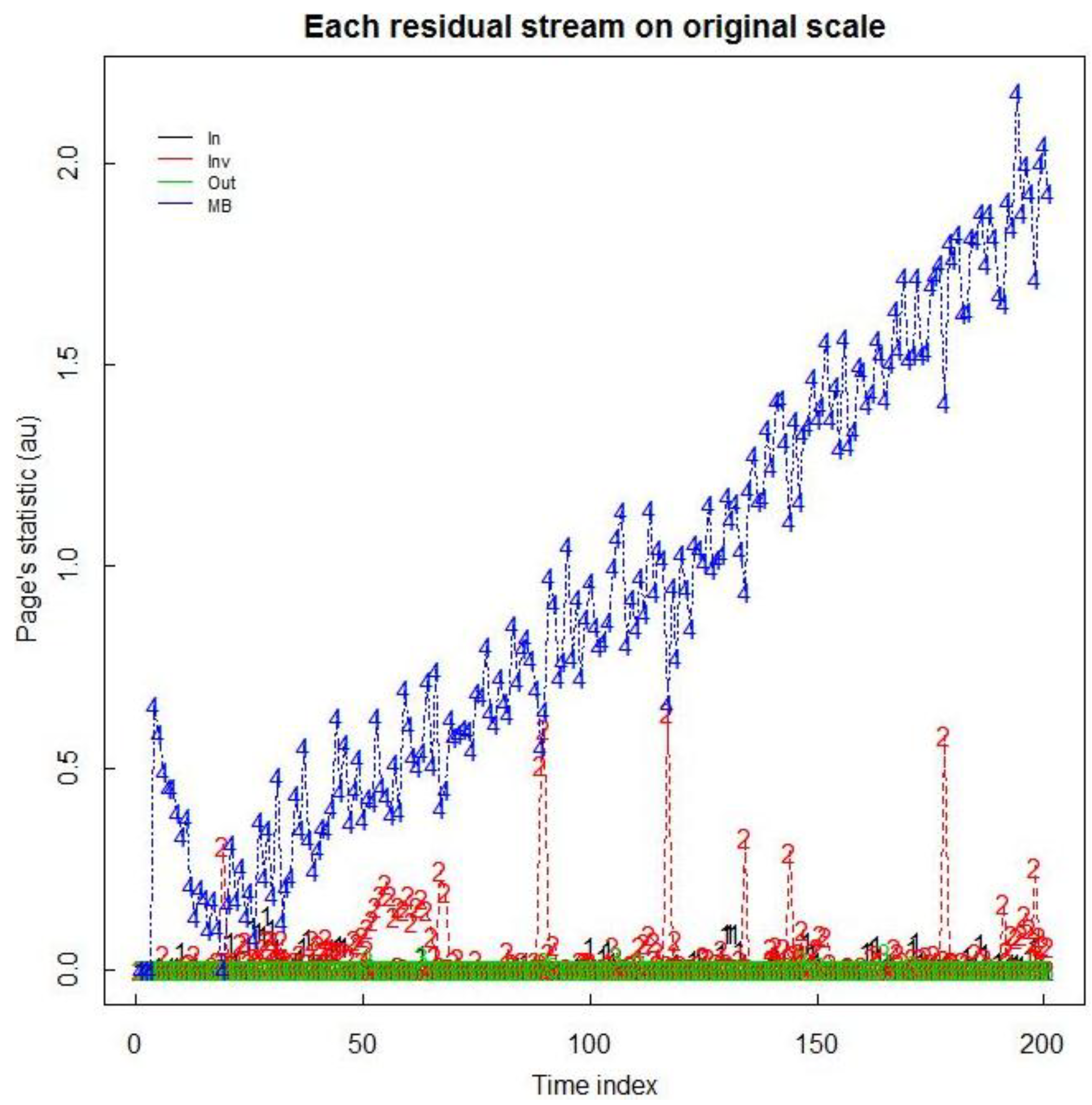
Figure 4.
(a) Daily total input; (b) total inventory in eight vessels; (c) total output from four streams; and (d) daily (“batch”) MB in generic electrochemical data simulated from the SPM.
Figure 4.
(a) Daily total input; (b) total inventory in eight vessels; (c) total output from four streams; and (d) daily (“batch”) MB in generic electrochemical data simulated from the SPM.
Figure 5.
Daily material balances (“batches”) in (a); the estimated probability density of the MB value in (b); the autocorrelation function of the MB sequence in (c); and a lagged plot of the present MB versus the previous MB in (d).
Figure 5.
Daily material balances (“batches”) in (a); the estimated probability density of the MB value in (b); the autocorrelation function of the MB sequence in (c); and a lagged plot of the present MB versus the previous MB in (d).
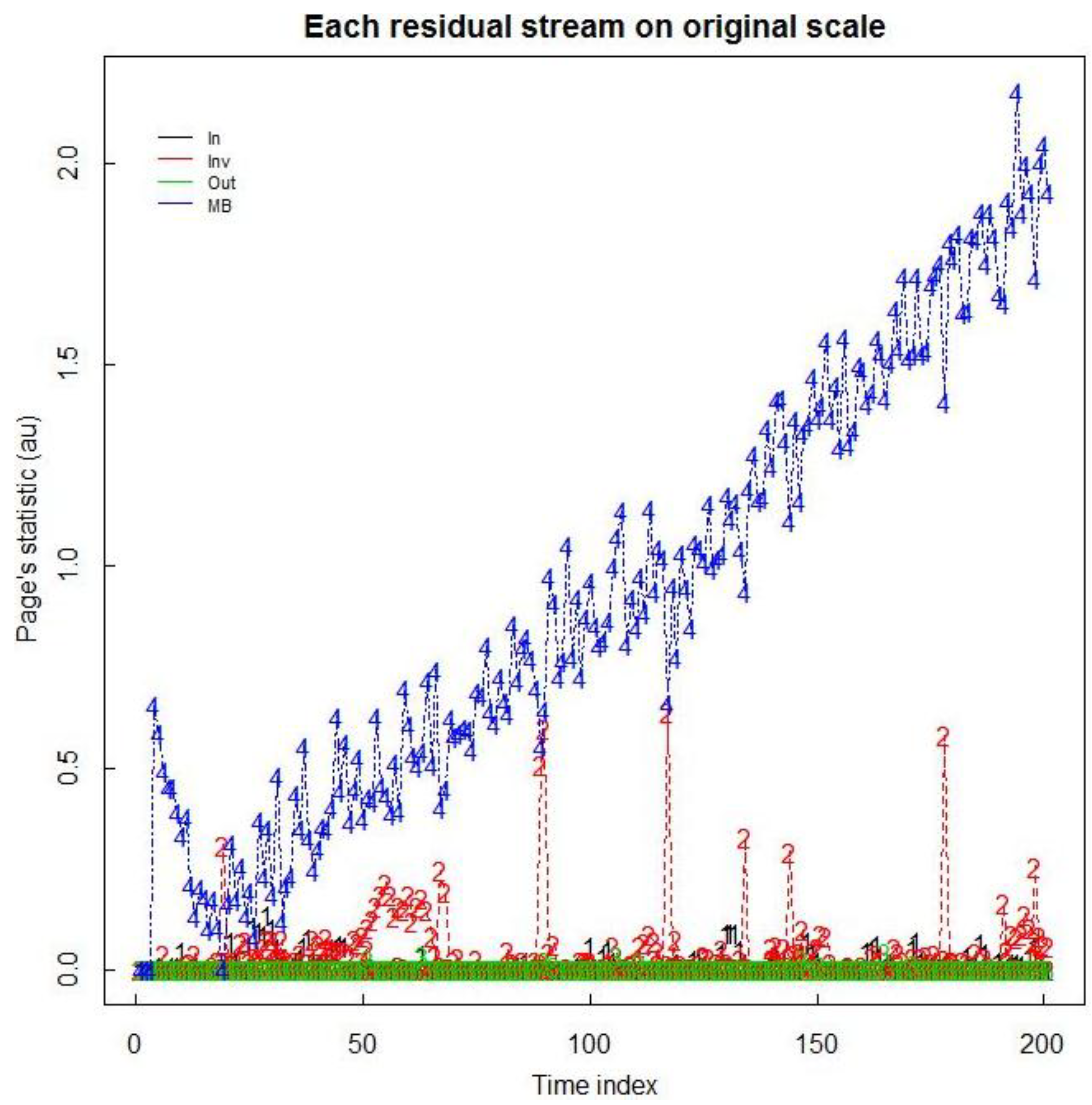
Figure 6.
Daily residuals from the one input, from each of the eight inventory vessels, from each of the four output vessels, and the daily MB. We also consider less frequent BPs, every 10 days.
Figure 6.
Daily residuals from the one input, from each of the eight inventory vessels, from each of the four output vessels, and the daily MB. We also consider less frequent BPs, every 10 days.
Figure 7.
Example data from a 7-tank aqueous facility MBA. Some tanks are batch input, batch output (denoted B/B). Tanks that are just upstream or downstream from a separations vessel have a continous (C) mode. (a) Input accountability tank; (b) Buffer tank; (c) Feed tank; (d) Receipt tank; (e) Waste tank; (f) Buffer tank; (g) Output accountability tank; (h) Change in holdup.
Figure 7.
Example data from a 7-tank aqueous facility MBA. Some tanks are batch input, batch output (denoted B/B). Tanks that are just upstream or downstream from a separations vessel have a continous (C) mode. (a) Input accountability tank; (b) Buffer tank; (c) Feed tank; (d) Receipt tank; (e) Waste tank; (f) Buffer tank; (g) Output accountability tank; (h) Change in holdup.
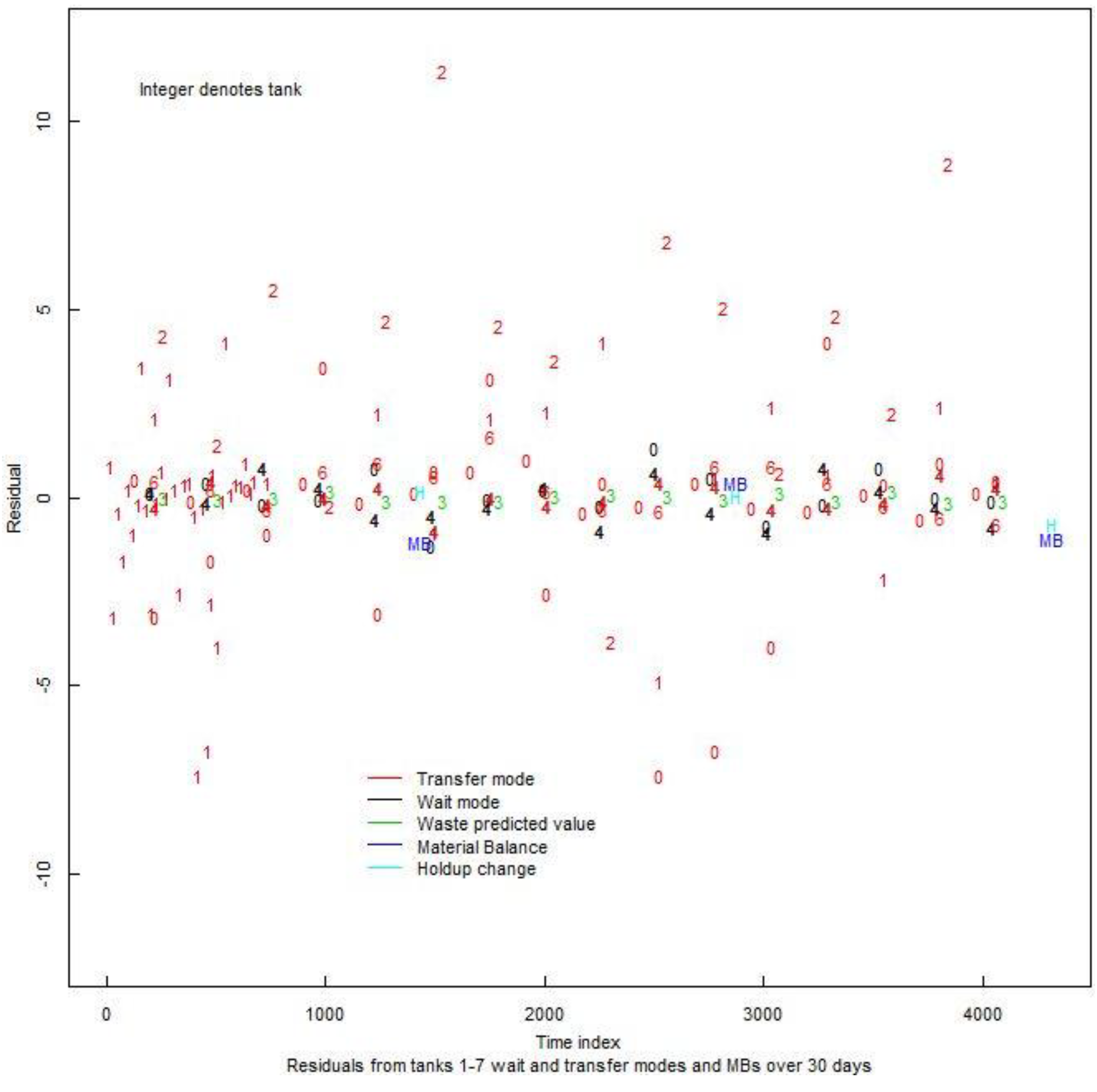
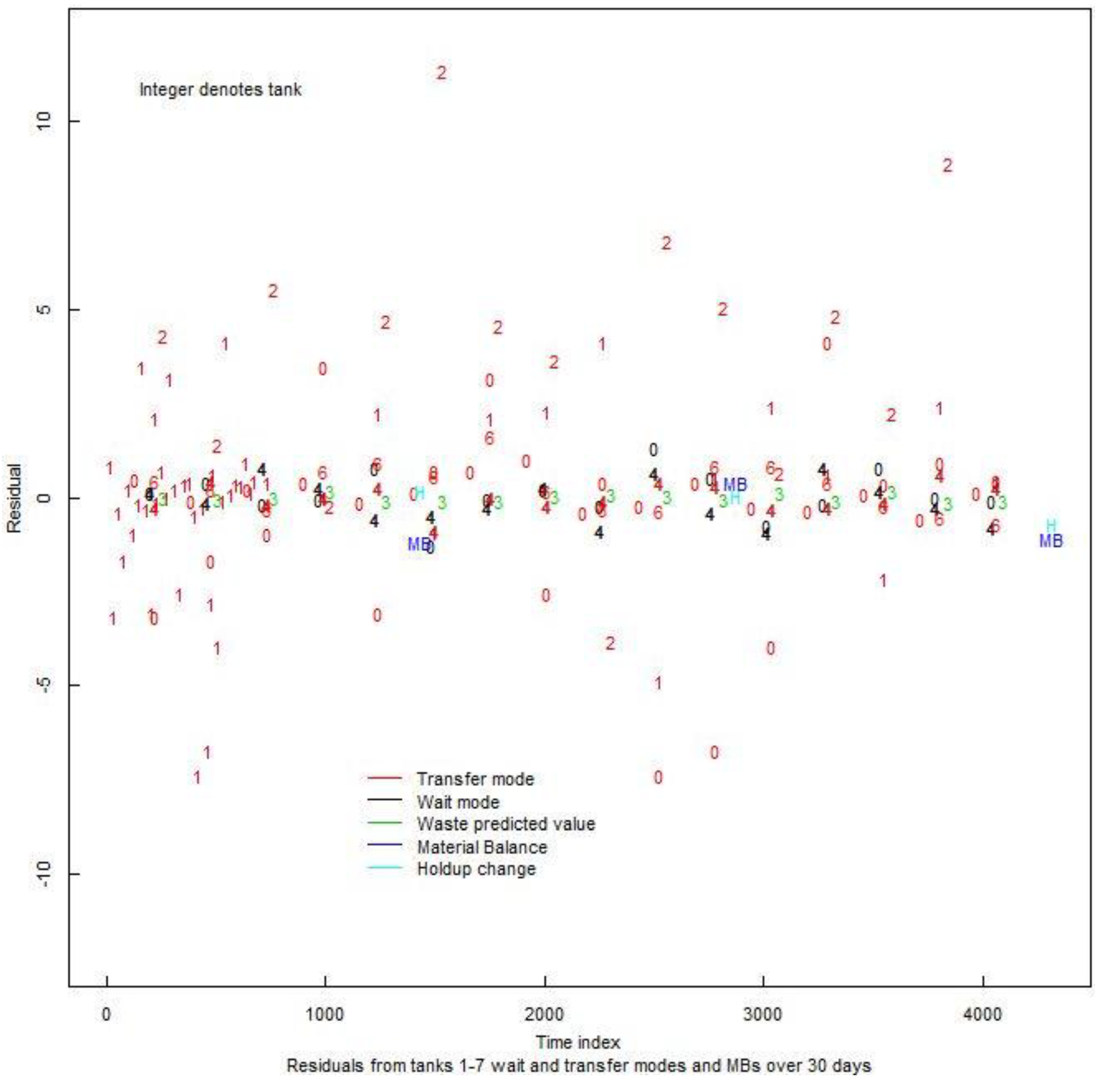
Figure 8.
Residuals from PM and NMA for the 7-tank MBA in an aqueous facility. The PM residuals occur at the end of each wait event and after each transfer event. The NMA residuals are the usual MBs every 10 days.
Figure 8.
Residuals from PM and NMA for the 7-tank MBA in an aqueous facility. The PM residuals occur at the end of each wait event and after each transfer event. The NMA residuals are the usual MBs every 10 days.
We return now to the electrochemical example as in
Figure 6, and apply the 2-part hybrid test described in
Section 6 and
Appendix 2 in which we: (A) Stop each Page’s cusum (cumulative sum, [
1]) at the end of each balance period (BP) and then use a test statistic that is based on the maximum values during the BP of the 14 Page’s cusums for period-driven testing; and (B) Carry along the incremental cusum into a multivarite (Crosier) version of Page’s cusum across BPs ([
1,
3]). Output from an electrorefiner model in [
17] could lead to a PM time series as assumed for the input, eight inventory vessels, and the four output vessels in the example electrochemical facility.
The hybrid statistical testing strategy is a two-part hybrid. The first part of the hybrid is a Page’s cusm at the end of each BP, using a test statistic based on values of the 14 Page’s cusums. The second part of the hybrid is the incremental Crosier’s cusum across BPs. For the first part of the hybrid, we experimented with two test statistics. One option for a test statistic is simply the maximum of the 14 maximum values of the individual Page’s cusums; this option is intended for SNM loss in one or a few residual streams.. Another option for a test statistic that is intended for wide-spread loss across several residual streams is the average of the 14 maximum values of the individual Page’s cusums.
Figure 9 is Page’s cusum test applied to each of the residual streams in
Figure 6. Page’s cusum test applied to a residual time series
is given by
, where
k is a control parameter. Page’s cusum test has close to the highest possible DP for many loss scenarios. Different tests will have the best DP for different loss scenarios, which partly explains why so many sequential tests have been proposed for NMA [
23,
26].
Figure 9.
Page’s cusum test applied to each of the 14 (13 PM, one NMA) residual streams. To avoid cluttering the figure, only some residual streams are shown, as indicated.
Figure 9.
Page’s cusum test applied to each of the 14 (13 PM, one NMA) residual streams. To avoid cluttering the figure, only some residual streams are shown, as indicated.
Note 1: The cusum test
which sums all MBs since the last period ignores individual transfers from tank 1 to tank 2 and has the highest DP among all possible tests for the equal-loss-per-balance-period case [
1,
23]. This means that evaluating each tank-to-tank transfer has lower DP than comparing the sum of tank 1 transfers to the sum of tank 2 transfers. Analogously, there is no free lunch regarding the use of SM and NMA data. That is, including SM data is an extension of NMA to include more sub-MBAs (each tank is a sub-MB area) and more frequent balance closures. Therefore, there are scenarios for which using NMA data alone leads to the highest DP. Such scenarios will involve widespread diversion over multiple tanks and time periods (unless such scenarios produce observables that could be monitored, which we are not considering here). The motives for evaluating SM data include resolving NMA alarm, detecting diversion to waste streams that should have relatively small amounts of Pu, and improving abrupt loss detection over more scenarios, meaning that there can be at least moderate DP for a wide range of diversion scenarios, which is not true for NMA data alone.
Note 2: In our context with a wide range of possible diversion scenarios, there cannot be a most powerful statistical test (a most powerful test is a test that has the highest DP for a specified scenario). Therefore, we cannot claim that using the average of the values of the individual maximum-over-the-BP Page’s cusum has higher DP than the alternative test that we evaluated that alarms if the maximum of the individual maximum Page’s cusum exceeds its threshold. We anticipate that ease of implementation and ease of estimating alarm thresholds for desired false alarm probabilities (FAPs) (such as 0.05 per year) will be important factors in choosing which hybrid option is preferred.
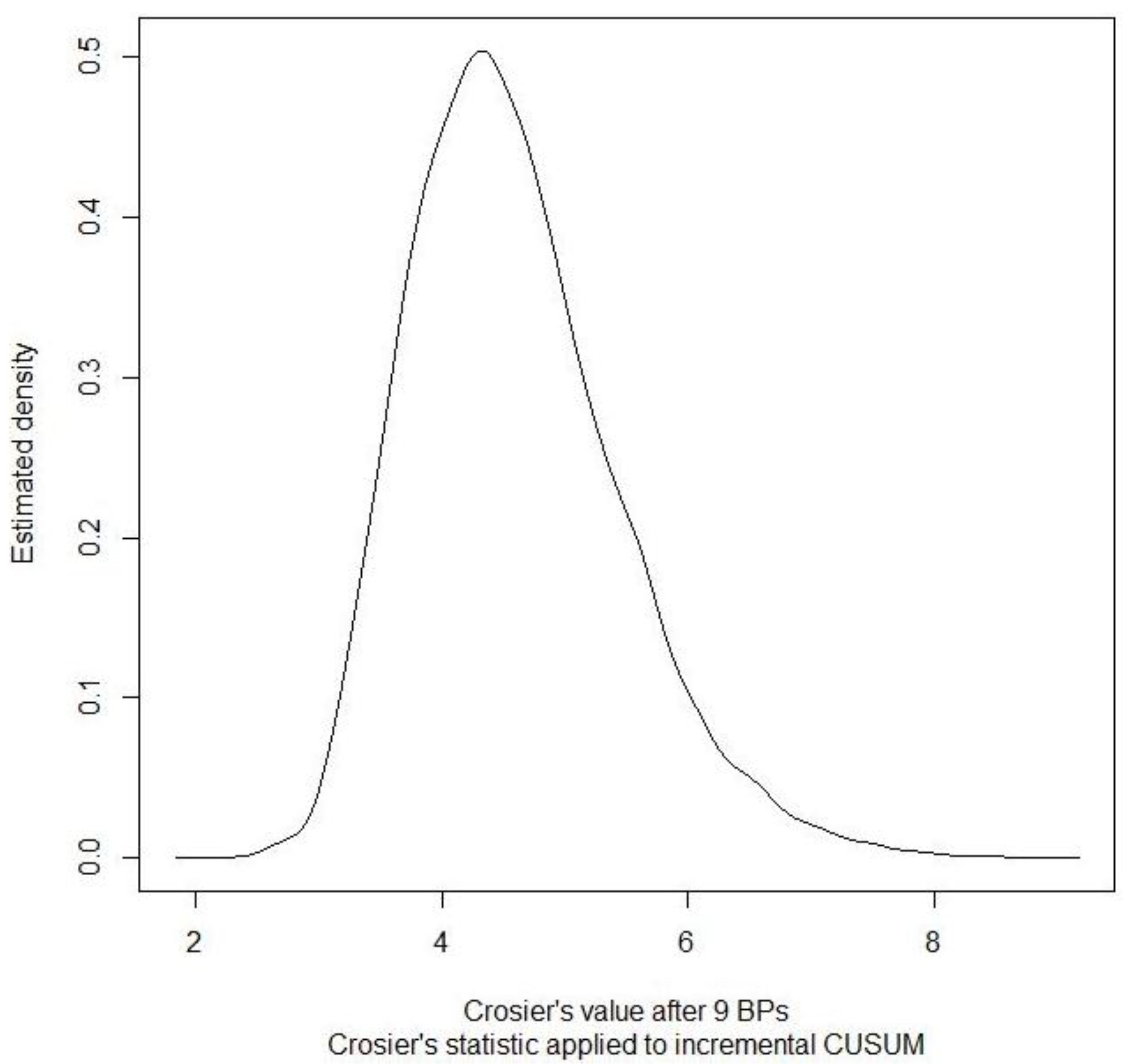
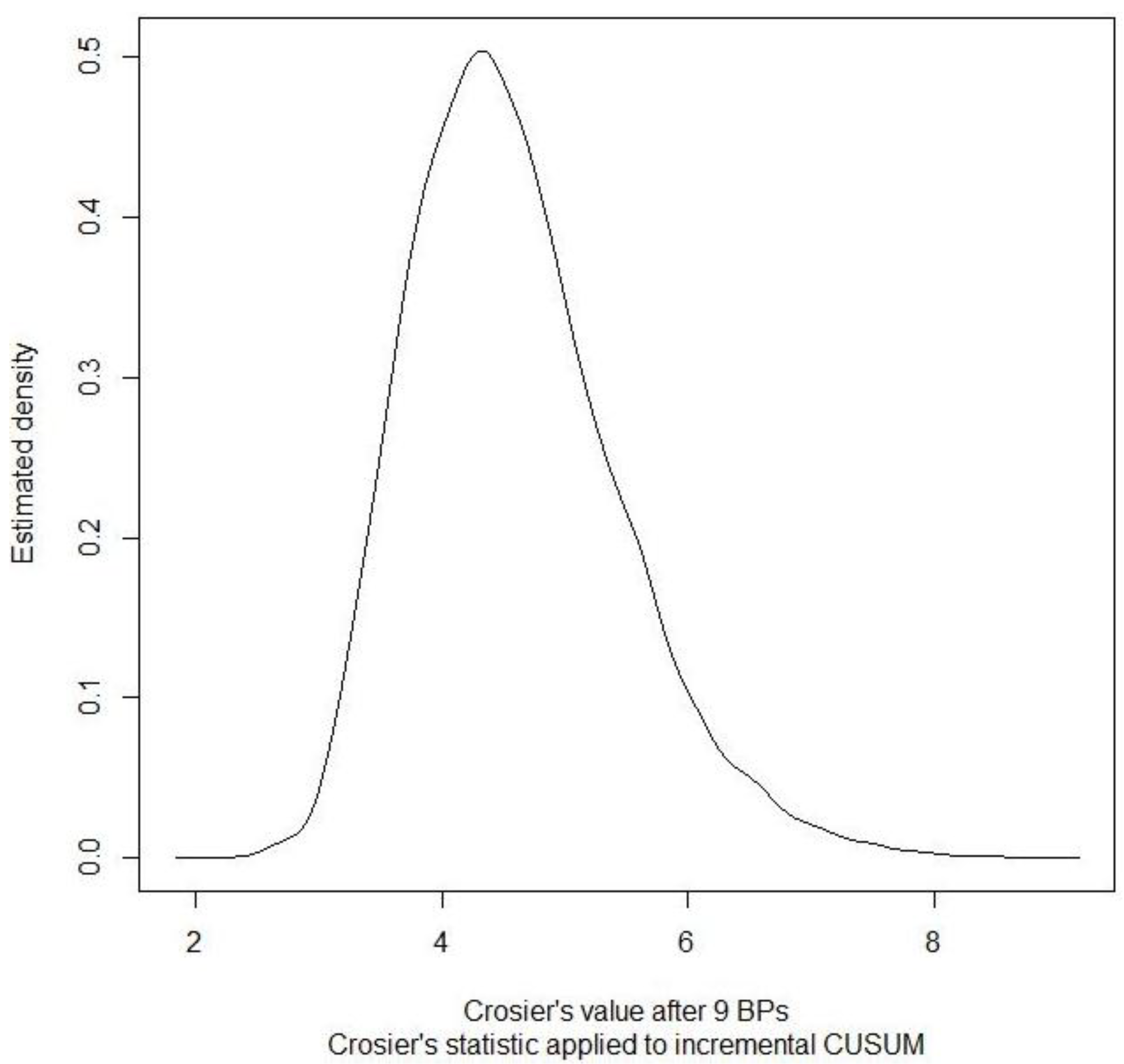
Figure 10 plots an example of the estimated probability density of Crosier’s statistic applied to incremental cusums in the 2-part hybrid described above at BP 9.
Figure 10.
Example of the estimated probability density of Crosier’s statistic applied to incremental CUSUMs in the 2-part hybrid at BP 9. The data is simulated from the SPM of an electrochemical facility.
Figure 10.
Example of the estimated probability density of Crosier’s statistic applied to incremental CUSUMs in the 2-part hybrid at BP 9. The data is simulated from the SPM of an electrochemical facility.
In general, we propose to estimate the DP of the safeguards system by estimating the system DP from PM combined with NMA using the following two steps (see
Appendix 2):
- a)
Describe diversion scenarios to inform how PM data should be evaluated to provide a means of event detection using expert elicitation if possible, and
- b)
Evaluate P(alarm|diversion scenario), the conditional probability of an alarm for a given scenario. The alarm rule operates on p residuals r1, r2, …., rp which include MB values from NMA, plus residuals from monitoring “wait” and “transfer” modes in tank SM data. The probability P(alarm|diversion scenario) is a function of the true states of nature, the measurement system, and the alarm rule(s).
More specifically, we continue with the 13-vessel example to illustrate the two-part hybrid statistical test. It is straightforward to develop simulation-based estimates (see
Figure 10) of alarm thresholds to maintain an overall 0.05 FAP per year following current convention with NMA data alone. However, because there are two tests in the hybrid test, there are two alarm thresholds, and one can allocate more of the 0.05 false alarm probability to one part of the hybrid or the other, using trial-and-error in simulation. For selecting alarm thresholds and comparing to standard time series such as sequences of independent and identically distributed (iid) normal random variables, it is convenient to transform each residual time series using the SITMUF-type transform (see
Appendix A1); SITMUF stands for standardized independently transformed material unaccounted for. Upon doing so, we find that the alarm thresholds for the hybrid test consisting of the average value of the maximum of the Page’s cusums and Crosier’s cusum applied to incremental cusums are close to those for corresponding iid normal residuals. We do not expect exact agreement with independent normal residuals because the MB is strongly correlated with the other 13 residual streams.
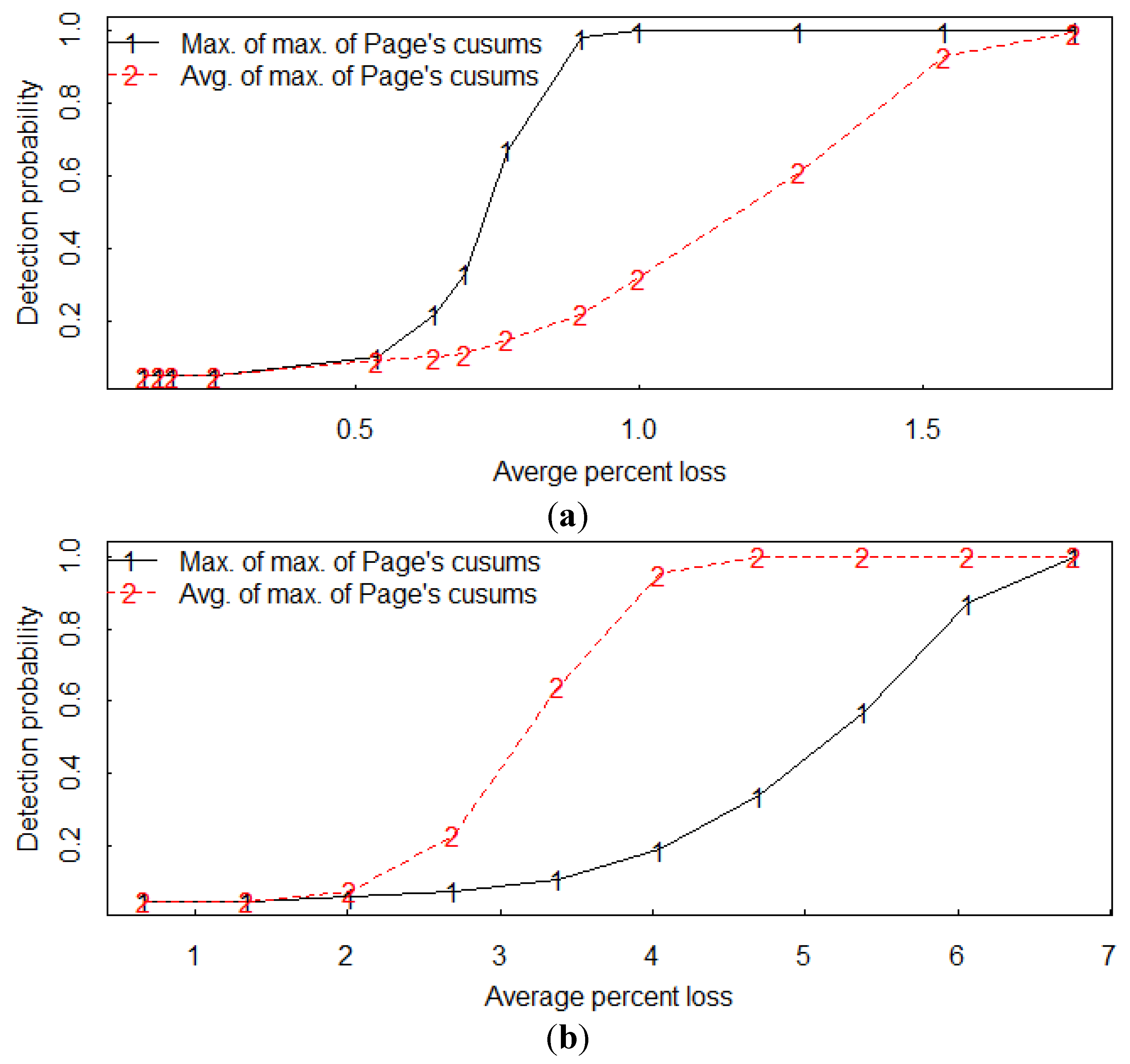
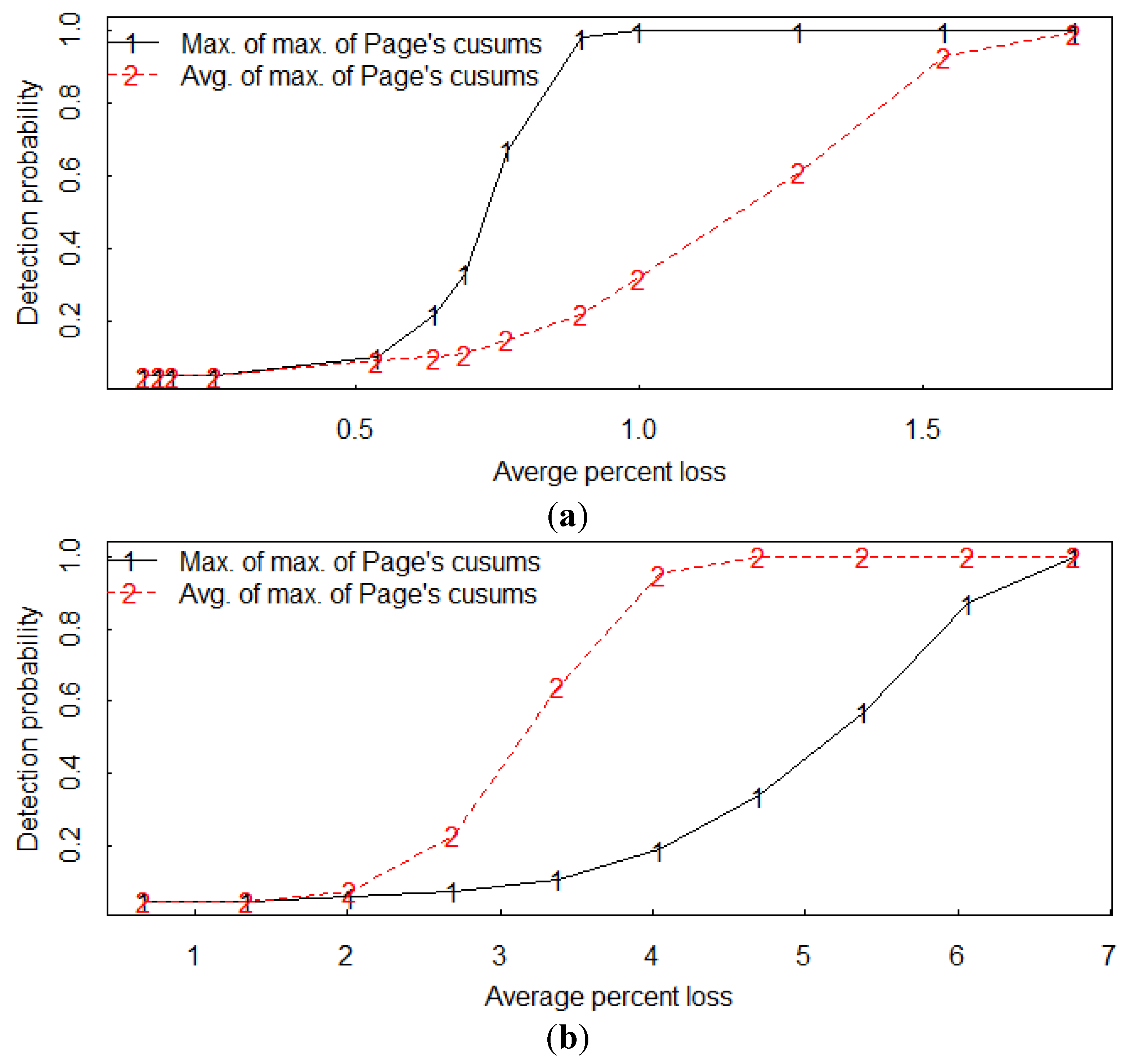
Having estimated the two alarm thresholds to achieve a 0.05 false alarm probability per operating year, we can easily inject various loss scenario effects in additional simulations to estimate system detection probabilities of the two-part hybrid statistical test. We have done simulations for both the average distance option applied to the maximum of the 14 individual Page’s cusums and also for using the maximum of the maximum of the 14 individual Page’s cusums. For example,
Figure 11a is the estimated detection probability
versus the average (over the 14 residual streams) one-day-abrupt loss from the input (the loss is expressed as an average of the total true amounts in each residual stream at a given time step) using the maximum of the maximum of the 14 Page’s cusums option and also using the average of the maximums.
Figure 11b is the same as
Figure 11a, but is for a wide-spread loss over all 13 residual streams. In
Figure 11a,b, the loss occurred during one time step.
In
Figure 11a, the maximum of the 14 maximum Page’s cusums has higher detection probability than the average of the 14 maximum Page’s cusums; this is expected because the loss occurred from only the single input residual stream. In
Figure 11b, the opposite is true; again this is expected because the loss is spread over all 13 residual streams, so the average of the maximum of the 14 Page’s cusums has a relatively strong signal. The value of σ
MB is approximately 0.70 units each day, most of which arises from the large in-process inventory. The value of σ for the input residual is approximately 0.04. It makes sense to monitor residuals from any stream for which there is a predicted value and corresponding measured value; this example assumes there is a predicted value for all 13 residual streams, plus the MB stream (whose predicted value is, of course, zero).
Figure 11.
Example estimated detection probabilities versus the average percent loss in a (a) local loss from the input and in a (b) non-local (widespread) loss from all 13 residual streams. The average is over all 13 residual streams during the one-time-step duration of the loss.
Figure 11.
Example estimated detection probabilities versus the average percent loss in a (a) local loss from the input and in a (b) non-local (widespread) loss from all 13 residual streams. The average is over all 13 residual streams during the one-time-step duration of the loss.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}