2. Methodology of the MPC
This paper presents a predictive strategy MPC that anticipates any disruptive event in the building, such as changes in the weather or occupancy scenarios, and optimizes the control of the heating system. Optimization is a multicriteria aspect, and therefore, it involves a compromise between perceived thermal comfort and energy consumption. To achieve this, a building model capable of predicting the building’s response to different weather conditions and heating scenarios is required.
The proposed strategy is based on a black-box structure using two models of the building, where the first one predicts the indoor air temperature, and the second predicts the energy consumption. An hourly timestep is considered, which is suitable for slow-moving processes in HVAC systems [
34]. As shown in
Figure 1, the strategy is designed as three nested loops.
This loop turns for 24 iterations. It focuses on hourly predictions of the building’s indoor air temperature and gas consumption over a 24-h prediction horizon (from timestep t to t + 23). In this paper, the prediction is based on machine learning models, using historical data of the building (such as indoor air temperature, outdoor air temperature, gas consumption, heating setpoint temperature, horizontal radiation, and occupancy), the weather and occupancy forecasts for the next 24 h, and the proposed heating setpoint (sequence of 24 setpoint temperature values to be optimized). Using these input data, the predicted indoor air temperature is generated by the ANN model, and the predicted boiler’s gas consumption is generated by the SVM model, both over a 24-h prediction horizon. Both models are explained in
Section 4.
- 2.
Loop 2: Multicriteria optimization:
Following a defined number of iterations, and according to defined constraints, a genetic algorithm (GA) tests different heating setpoint temperature sequences and calculates a score for each proposed 24-h heating scenario. Optimizing sequences of 24 continuous values creates a large and complex search space, making genetic algorithms a justified choice for this task.
The values of the predicted indoor temperature and gas consumption vary with each tested scenario. Taking into account weather forecasts and occupancy, the genetic algorithm uses the prediction models to assess the building’s response to each tested scenario (noted «i») in terms of indoor temperature and energy consumption, and consequently to calculate the final score of the objective function. The output of this second loop is the best solution found by the genetic algorithm, corresponding to the heating scenario with the best score. The calculation of this score is presented in
Section 2.3.
- 3.
Loop 3: Recalculation and receding horizon:
Once the best solution among those tested by the genetic algorithm is found, the setpoint temperature value of the first timestep (t) is sent to the control, the resulting indoor temperature and energy consumption values are collected to be injected back into the prediction loop ((t), (t)), and the optimization is run again for a prediction horizon of 24 h, shifting by one timestep each time, forming a receding horizon of one hour. Recalculating every hour allows the predicted values to be replaced by the actual measured values of indoor temperature and gas consumption, therefore updating these values in the loop. Consequently, this avoids the accumulation of potential prediction errors throughout the prediction horizon.
Thus, the methodology can therefore be summarized as follows: the indoor air temperature and the gas consumption are predicted over a 24 h period, and every hour, this horizon moves by one timestep and the optimization is restarted in order to propose a sequence of 24 control signals for the next 24 h at each timestep.
2.1. Case Study
In order to implement the strategy and test the relevance of the method, a digital medium was used as a case study. Thus, the method presented in
Section 2 was applied to data generated from a building model created in TRNSYS18 (version 18.0). A simple case of a parallelepiped building was modeled. For the architectural design, nature of the materials, heating, and control system, the model was inspired by a real building located in Lille, northern France, facing northwest. Thus, the model is conceptually based on that building, but it is not calibrated to it, and that is due to the lack of data measured on the building. In fact, the main objective remains to find a strategy that optimizes the control in the modeled building, and thus, from the perspective of applying the MPC on another building, new prediction models and controls will be elaborated.
Figure 2 shows the picture of the building that was modeled. It is a commercial building composed of three floors. Referring to standard values for buildings constructed before 2012 [
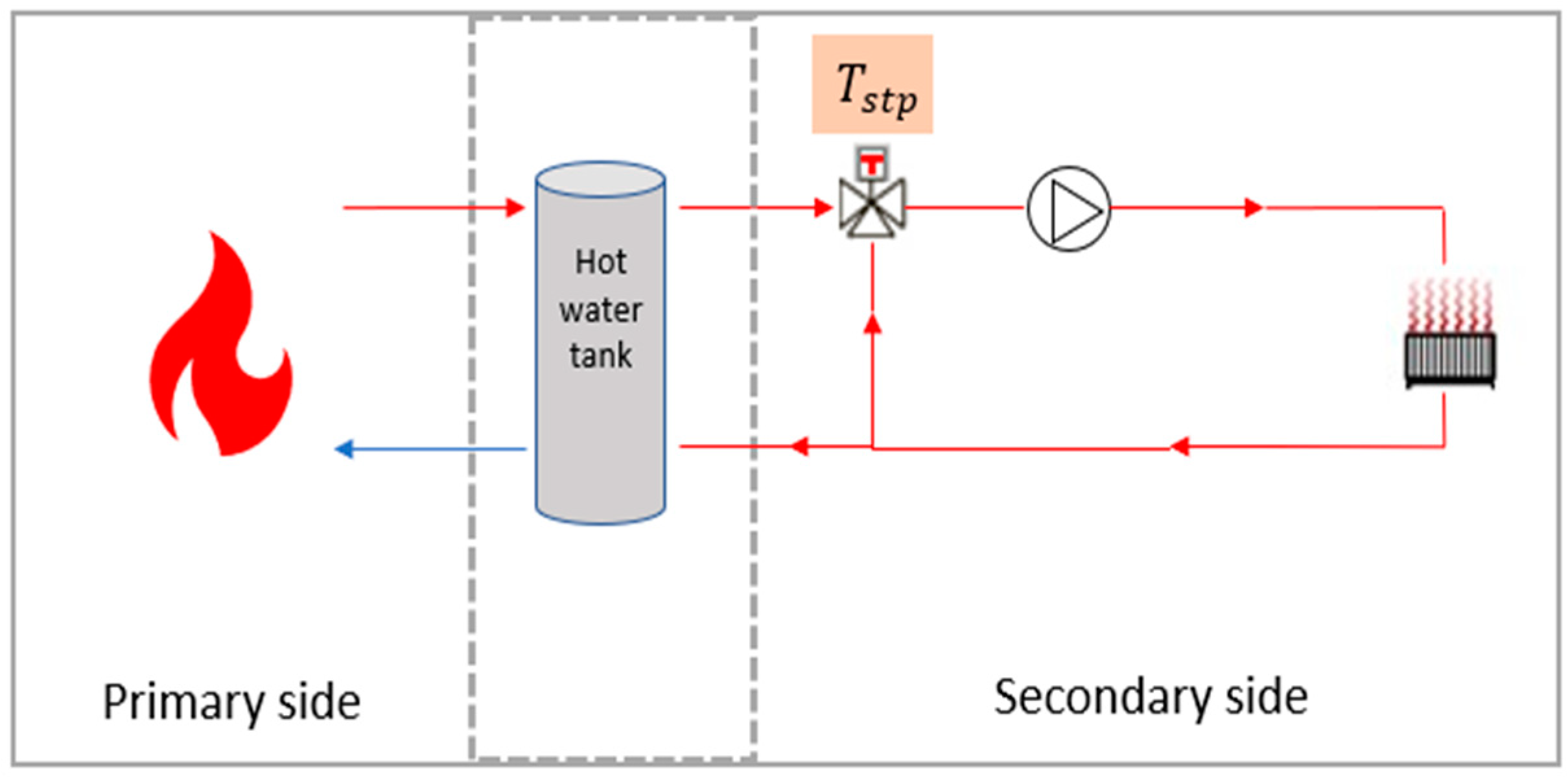
21], the external walls are modeled in brick, with 6 cm of insulation, the floor in insulated reinforced concrete, and the attic insulated with 15 cm of mineral wool. Double-glazed windows are added on both sides of the building. Concerning the heating, the building is heated by a hot water radiators system, which is a very common installation in France. This type of system is often composed of two circuits: a primary and a secondary circuit [
35].
Figure 3 shows the modeled heating network. The hot water heating system is based on two interconnected circuits: a primary circuit and a secondary circuit. The primary circuit mainly consists of a gas boiler, whose function is to keep the water in a buffer tank at a high temperature. The secondary circuit, on the other hand, supplies a network of radiators distributed throughout the building. To heat the building, a pump ensures the circulation of hot water in this network. The regulation of the supply water temperature, denoted as
in
Figure 3, within the secondary circuit is carried out by a three-way valve, which adjusts the mix between the return water from the secondary circuit and the hotter water coming from the buffer tank.
In this paper, a type 526 radiator from the TESS library was used. The radiator surface was adjusted to emit the amount of heat required to heat the building. A constant flow rate was maintained on both sides of the heating network. The system adjusts the opening of the three-way valve based on the flow temperature according to the given setpoint. Thus, the setpoint temperature applied to the control valve governs the entire heating system. Buildings with this type of installation are typically controlled using a single heating curve that sets the supply temperature according to the outdoor temperature. This means that a single setpoint temperature is provided to the valves to regulate the various zones of the building. For this reason, the case study building was modeled as a single zone with a volume of 4968 m3, controlled by a single setpoint temperature. As the authors did not have access to real data for the building, the exact values of the parameters for the heating curve of the reference building were unknown. However, theoretical considerations suggest that the heating curve is adapted to the occupancy scenario, with reduced heating at night and during unoccupied periods.
It is evident that no simple relation exists between the heating power dissipated by the radiators and the setpoint temperature controlling the 3W valve, nor between the setpoint temperature and the energy consumed by the boiler.
The TRNSYS18 simulation was performed at hourly intervals over a full year. Weather data corresponding to northern France, available in the TRNSYS18 software files, were used for the simulation. This file contains weather prediction data over a complete year. The heat provided by the radiators was obviously taken into account, as well as internal gains made by the occupants, if present. An occupancy scenario was defined from 8 a.m. to 6 p.m., Monday to Friday. This is the occupancy level corresponding to our reference building and it specifies the periods of building occupancy and non-occupancy. A ventilation scenario of 0.2 vol/h was also imposed, as well as a low infiltration.
The goal of this work was to determine an optimal hourly sequence of setpoint temperature values for the heating system’s three-way control valve, over a receding prediction horizon. To simulate the building’s response to varying setpoints, changing weather conditions, and occupancy patterns, a random sequence of setpoint temperatures was applied to the control valve in our building model. These values, ranging from 16 °C to 80 °C, were selected based on domain knowledge to ensure their practical relevance and were generated using a uniform random distribution. The objective was to simulate the building’s response to setpoint temperatures that are independent of outdoor conditions. This aligned with the study’s goal of transitioning from conventional heating curves to optimal control sequences for setpoint management. The simulation was run using these random values, generating 8760 records (one record for each hour of the year). These data were then used to model the thermal behavior of the building and heating system.
2.2. Data-Driven Prediction Models
The data used for modeling are simulation data generated by TRNSYS18, so the prediction models detailed in this section were trained using these data. The study deliberately focused on commonly measured variables, despite the availability of many others through TRNSYS18 simulations. Above all, the aim was not to measure and use the supply and the return water temperatures, but instead to model the building’s response to the setpoint temperature imposed on the valve. This is the variable typically used to control this type of system. Thus, five variables represent the initial inputs of the models: setpoint temperature, outdoor temperature, horizontal radiation, indoor temperature, occupancy and gas consumption, noted, respectively, as follows: , , Rad, Occ, and .
Several research studies have been carried out to model the temperature of a building zone and have shown that the most accurate prediction is obtained by adding historical data measured in the building, i.e., by integrating lagged terms of the variables as input parameters to the model. The number of lags to be used varies from one building to another and has to be studied. It depends on the inertia of each building and on the type of its systems. Fu et al. [
36] worked on the prediction of a building’s air-conditioning load and found the best result by taking the values of the previous 48 h of electricity consumption. Mechaqrane et al. [
37] also implemented prediction models for building indoor temperature, comparing a linear autoregressive model of indoor temperature with a neural network that takes the building’s past measured data as parameters. They found that a neural network with 3 lagged terms of indoor temperature, 2 of outdoor temperature, 3 of horizontal radiation, and 2 of heating requirements gave the best prediction result with a linear activation function. Ma et al. [
29] used LSTM for time series prediction; thus, the future values of indoor temperature were predicted using the past measured values of parameters in the building.
In this paper, the building was modeled based on its historical measured data. Two predictive models were developed: one for forecasting indoor temperature and another for predicting gas consumption. The integration of historical data proved to be helpful when selecting the model structure. Indeed, it allowed for capturing the building’s thermal inertia, thereby significantly improving the accuracy of both models. Several machine learning algorithms were tested, including multiple linear regression, random forest, artificial neural networks, LSTM, GRU models, and support vector machines. In the following sections, only the models that yielded the best performance are discussed, which are ANN and SVM.
Model training was performed on part of the data, while another part was retained to test the model. Normalization was also applied to the data. In order to evaluate the model, besides the coefficient of determination, a prediction error rate was calculated on the test dataset. The model’s coefficient of determination
, which measures how well the observed data match those fitted, was also calculated. A coefficient of determination close to 1 indicates good model accuracy. Equation (1) shows the formula of
.
where
is the measured value,
is the predicted value,
is the mean of the observed values of y, and n is the number of observations of the test dataset.
Thus, in the presented work, three error metrics were used:
Mean Absolute Error (MAE), calculated as presented in Equation (2), yields the average of the absolute deviations from the observed values.
The Root Mean Square Error (RMSE) measures the square root of the mean of the square of the errors, as shown in Equation (3):
The Root Mean Squared Logarithmic Error (RMSLE), which is consistent with ASHRAE’s evaluation method in the Kaggle competition, is mainly used when predictions have large deviations, which is the case with the energy prediction. Also, it measures the relative error between predicted and actual values while being more robust to outliers [
38]. It is calculated as shown in Equation (4):
Concerning MAE, RMSE, and RMSLE, the smaller the values of these errors are, the better the model is.
2.2.1. Artificial Neural Network for Indoor Air Temperature
The first machine learning model developed was an artificial neural network. The ANN was chosen because it has proven its efficiency in many building studies, especially in the prediction of indoor air temperature. It provided the best results in [
6,
37,
39,
40,
41]. Also, numerical optimizations using a combination of artificial neural network and genetic algorithm can be efficient for building applications, which can save a significant amount of computational time [
42].
An artificial neural network is formed from layers of interconnected artificial neurons, whose role is to find the best relation between input and output. This relation is defined by an activation function found in each neuron, and by coefficients. These coefficients are the synaptic weights of the neural network. During learning, the neural network performs several iterations to adjust the weights in a way that minimizes the error between the predicted value and its real value y. In this paper, the ANN model was used to predict the building’s indoor temperature at the next hour, denoted as (t).
The main difficulty with neural network models is choosing the network architecture, that is, the number of layers and neurons. Several models were trained by varying the number of lagged terms n and the number of layers and neurons in the network and testing the activation function «linear», «softplus», and «sigmoid». By lagged terms, we refer to variables observed or recorded at a specific number of hours prior to the current time. Results show that the «softplus» gives the best prediction for this case study, consistently yielding the smallest error and the highest coefficient of determination compared to other activation functions in models trained with the same number of lagged terms. To avoid overloading the table, the results of ANN with «softplus» only are presented in
Table 1.
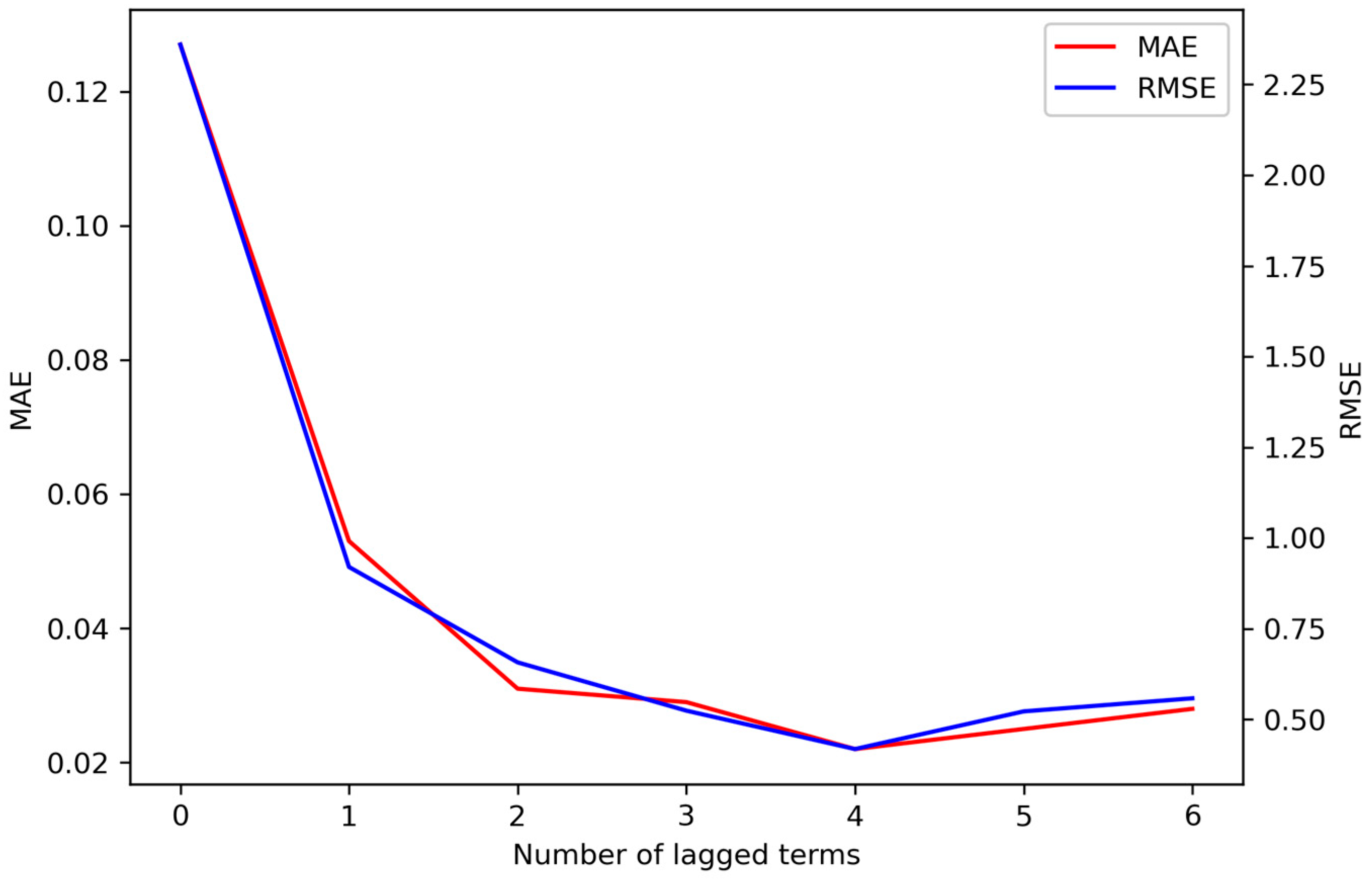
Figure 4 shows the evolution of the MAE with varying numbers of lags, ranging from 0 (no historical building data considered) to 6 lags.
Table 1 shows that the prediction error gradually decreases as the number of lagged terms increases, and remains in this trend up to 4 lagged terms. Beyond this point, the error tends to increase again. Therefore, the model that appears to be optimal for predicting indoor temperature in this study is an artificial neural network with n = 4 lags, one hidden layer with 50 neurons, and a nonlinear activation function, the «softplus» function, shown in Equation (5).
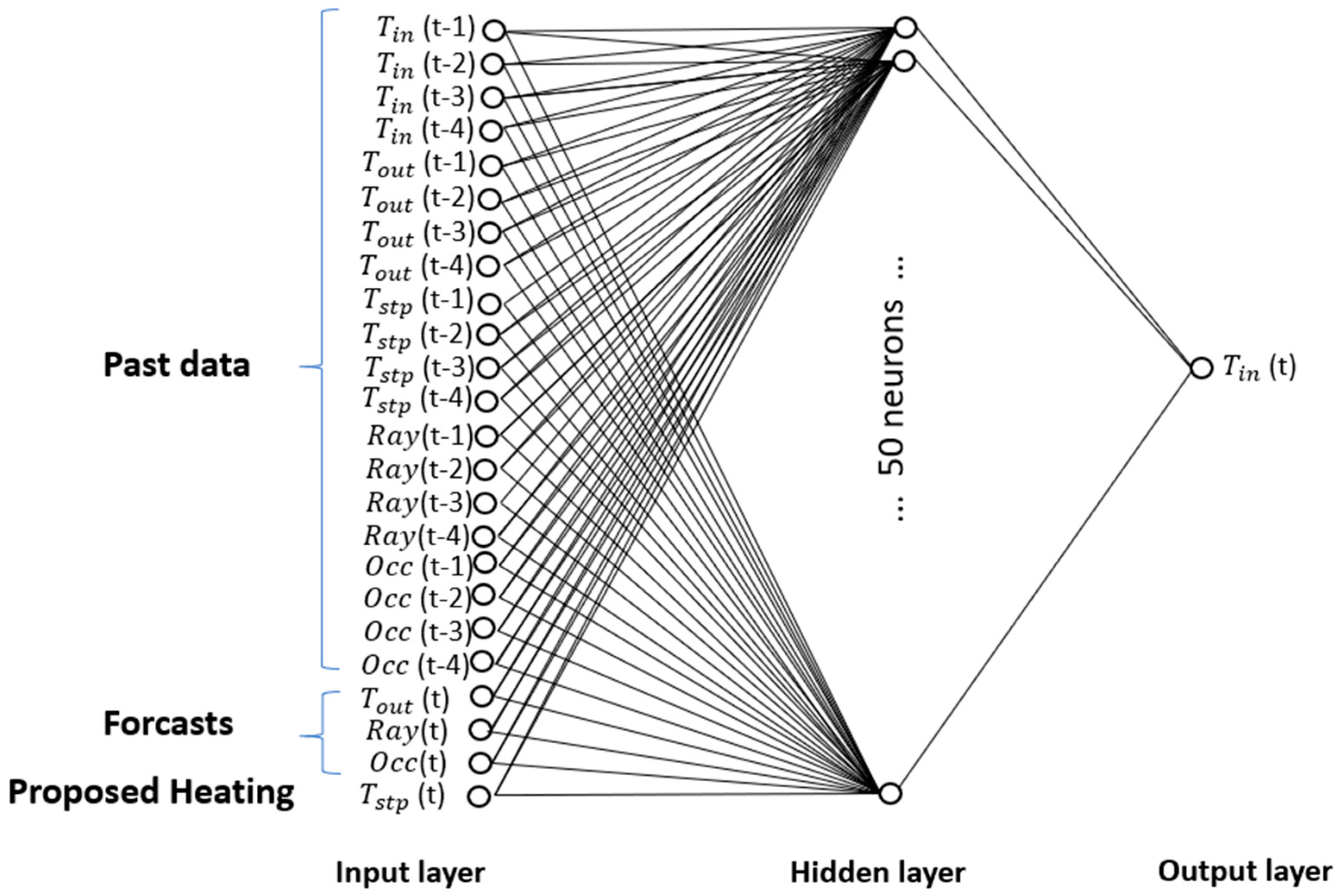
The topology of the adopted model is illustrated in
Figure 5. The model inputs are the historical measurements of indoor temperature, outdoor temperature, horizontal radiation, occupancy, and setpoint temperature, respectively, noted as
,
, Rad, Occ and
from time t − 1 to t − 4. Additionally, the model relies on forecasts for outdoor temperature, solar radiation, and occupancy (at time t), as well as the setpoint temperature value proposed by the genetic algorithm
(t). Consequently, the input layer of the neural network comprises 24 neurons:
(t − 1),
(t − 2),
(t − 3),
(t − 4),
(t − 1)
(t − 2),
(t − 3),
(t − 4), Rad(t − 1), Rad(t − 2), Rad(t − 3), Rad(t − 4), Occ(t − 1), Occ(t − 2), Occ(t − 3), Occ(t − 4),
(t − 1)
(t − 2),
(t − 3),
(t − 4),
(t), Rad(t), Occ(t),
(t). The error measurements of the adopted model are provided in
Table 2.
2.2.2. SVM for Gas Consumption Prediction
The second model is designed to predict the gas consumption of the boiler. As previously explained, there is no straightforward relationship between the control setpoint and gas consumption. To solve this task, several models are trained with the aim of finding the most accurate possible model, always with the available data. This raises several challenges regarding the choice of model and the choice of the number of lagged terms for any variables. The initial variables are therefore the same: , , Rad, Occ and .
In this study, random forest was used to calculate the importance of the characteristics of the model and then help in removing unnecessary variables. Random forest is a combination of decision trees. It improves the performance of a single tree by combining the randomization in the selection of partitioning data nodes in the construction of a decision tree. Hence, random forest determines feature importance by measuring each feature’s contribution to reducing impurity (like Gini impurity or MSE) across all splits and trees in the ensemble, with higher reductions indicating more important features [
43].
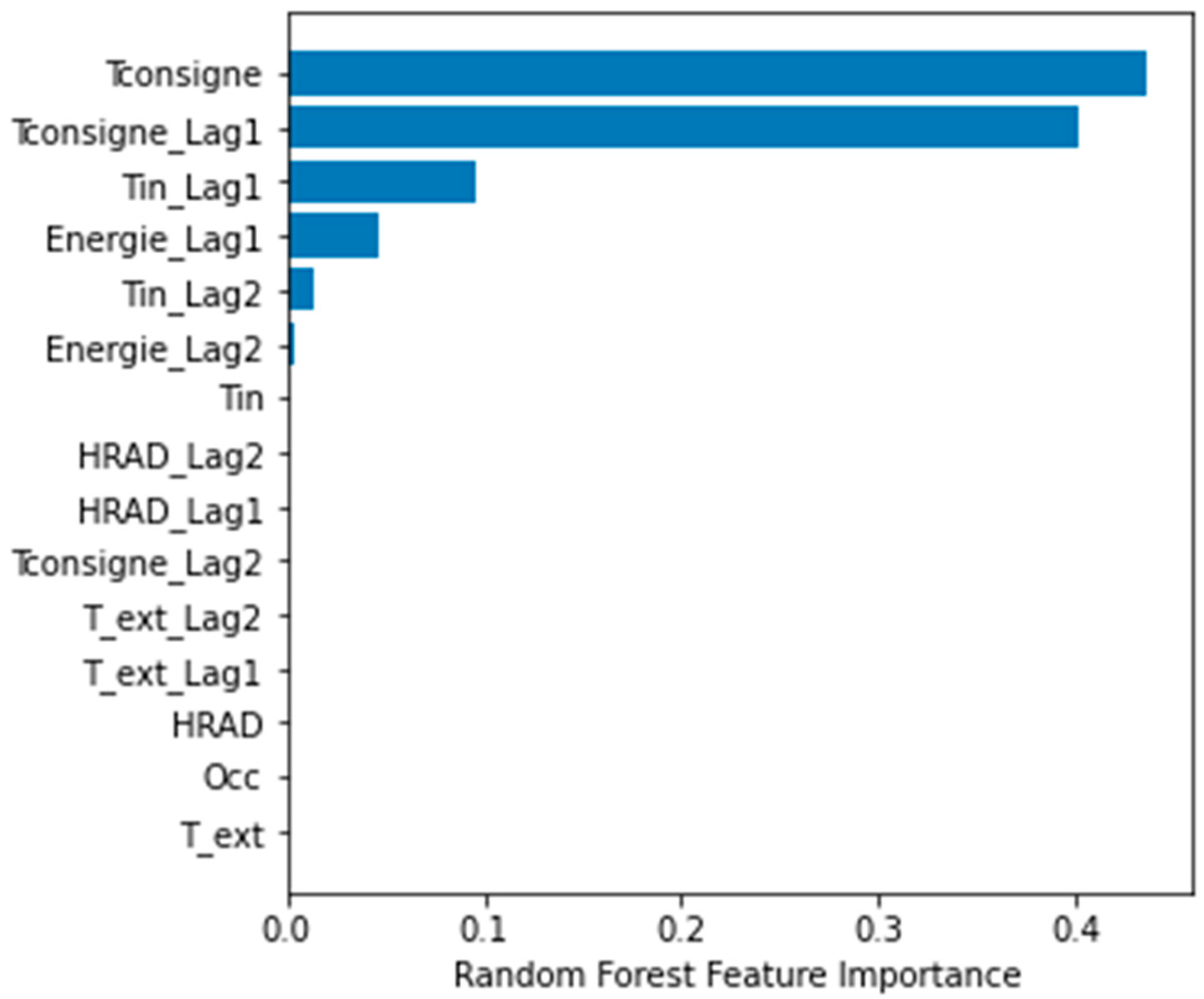
Figure 6 reveals the features’ importance by a random forest with n = 2 lagged terms. It appears that taking measurements more than 1 step back does not lead to a better prediction. The results of the trained models, using different number of lags of the variables show that the best prediction can be performed using only four variables:
,
(t − 1),
(t − 1),
(t − 1). Using these features, a support vector machine (SVM) model gives the most accurate prediction in this study.
SVM is a supervised machine learning algorithm that aims to find an optimal boundary between possible outputs by maximizing the separation margins between data points based on their responses. This transformation of inputs is achieved using the machine’s kernel function. In this study, Support Vector Regression (SVR) (a type of support vector machine) was used to analyze data for regression analysis. SVM has been commonly used for the energy prediction in buildings [
30,
33,
36,
44,
45].
In this study, the radial basis function (RBF), represented in Equation (6), was chosen due to the broad and nonlinear characteristics of the dataset [
46].
where γ is a parameter to determine the distribution of the kernel, and
−
is the Euclidean distance between the set of points [
30].
The adopted model is also based on the lag terms n = 1 of the building’s indoor temperature, gas consumption, and setpoint temperature value
(t) proposed by the genetic algorithm. The output of this model is the estimated gas consumption at time t. Among several models tested using the selected features, SVM gives the best prediction accuracy. The error measurements of the adopted model are provided in
Table 3.
2.3. Optimization
As mentioned previously, the objective of this study is to identify a sequence of 24 hourly setpoint temperatures for the heating system that balances thermal comfort and energy consumption. Therefore, a multicriteria optimization problem arises. Genetic algorithms are well suited for this type of problem [
47]; in particular, these algorithms have gained prominence in the optimization of building thermal systems [
48].
Genetic algorithms are inspired by the process of natural selection and evolutionary biology, where an individual is represented by a chromosome composed of genes containing hereditary traits. The process begins with a population of potential solutions represented by individuals, often in the form of binary strings encoding possible solutions. In this case study, the initial population consists of setpoint temperature scenarios, and each scenario comprises 24 temperature values. Moreover, each setpoint temperature value is encoded with 6 bits, with each individual represented by 144 bits. Since each bit can take 2 possible values (0 or 1), the number of possible solutions for each proposed temperature scenario reaches more than 2.2 × solutions.
The focus of this study is on the setpoint temperature of the water supplying the radiators in the secondary circuit, rather than on optimizing the boiler’s operation. Thus, the setpoint temperature values that can be chosen by the genetic algorithm range from 16 °C to 70 °C. The fitness of each solution in addressing the given problem is evaluated based on a predefined objective function. The individuals then go through genetic operations, including selection, crossover, and mutation. During selection, only the fittest solutions are chosen to become parents for the next generation. The number of generations is determined by the number of iterations. In crossover, genetic information is exchanged between parents to create offspring that exhibit a combination of their characteristics. Mutation introduces random changes in the genetic information of the offspring. This cycle of selection, crossover, and mutation repeats over multiple generations, gradually improving the overall fitness of the population and converging towards optimal solutions, or those with the best objective function scores.
In this study, the comfort score is simply estimated as a function of indoor air temperature, as in most cases [
17,
21,
27,
29]. This is because the temperature is an easily measurable parameter, compared to other parameters such as air speed or relative humidity which play a role in the notion of comfort. Therefore, ranges of comfort temperatures are defined for the genetic algorithm to adhere to. The details of these temperatures are shown in
Table 4. The objective is to maintain an indoor temperature between 20 °C and 22 °C during occupied hours (from 8 a.m. to 6 p.m. on weekdays). The comfort score of any solution that results in an indoor temperature outside this range will be penalized. Similarly, during unoccupied hours, temperatures below 15 °C are penalized. This approach aligns well with conventional control practices in real life, where similar steps are taken to prevent excessive temperature drops and the associated inefficiencies in recovery.
Figure 7 details the calculation of the comfort score of each hour of the day: if the building is in its occupation period (as shown in
Table 4) and the indoor temperature is below the lower limit of the defined comfort temperature range, the difference between these two temperatures is added to that score. Similarly, if the indoor temperature exceeds the upper limit of the defined comfort temperature range, the difference between these two temperatures is added to the comfort score. However, if the indoor temperature is within the defined comfort temperature range, the score is not penalized. The calculation is performed similarly during non-occupation hours; if the temperature drops below 15 °C, the score is penalized.
In this study, the comfort and gas consumption scores are normalized to facilitate balancing their weights effectively. For the comfort score calculation, an individual score is computed for each of the 24 h (as shown in
Figure 7). These hourly scores are then summed up and divided by 24, as the maximum possible score for a single hour is approximately 1, resulting in a normalization factor of 24 × 1, as in Equation (7), so the value of the comfort score ranges between 0 and 1:
Concerning the consumption score, it represents the gas consumed over 24 h, as shown in Equation (8). It is normalized by dividing the summation by the maximum value of gas consumption over 24 h, so the value of the consumption score falls between 0 and 1.
Since the objective of this study is to achieve a trade-off between comfort and consumption, the score for each solution is calculated by adding the score of comfort to the score of consumption. The final score is thus calculated according to Equation (9). The goal is to minimize the final score over a 24 h period.
With this definition of the comfort final score (), the strategy enables users to define the priority of comfort relative to energy consumption. A lower value of ω places greater emphasis on consumption, while a higher value prioritizes comfort. This way, with both sub-scores being normalized, theoretically, ω can tolerate values between 0 and 1. Thus, it becomes evident that ω = 1 only considers comfort and ω = 0 only considers consumption. But from a practical perspective, ω values should avoid extreme settings. Specifically, ω = 0 would result in the algorithm deactivating the system, thereby eliminating comfort entirely, which is inconsistent with the intended goals of the strategy. Conversely, ω = 1 would prioritize comfort to the exclusion of energy efficiency, potentially leading to excessive energy consumption, which similarly contradicts the strategy’s overarching objectives.
The choice of the value of ω is left to the discretion of the building manager. The weight ω specifies the priority level of comfort relative to consumption, meaning ω can be adjusted to favor one score over the other. Since the comfort score and the energy consumption score are qualitatively different metrics, they cannot be rigorously balanced against one another. In this study, the authors selected a value of ω = 0.5, a midpoint of the [0, 1] interval, to serve as a neutral baseline, in order to combine the two criteria in one objective function. We proceeded under the hypothesis that this value aligns with the overarching aim of the strategy to optimize system performance while maintaining a practical equilibrium between the competing priorities. Therefore, the results presented in this article were obtained with a weight of ω = 0.5.
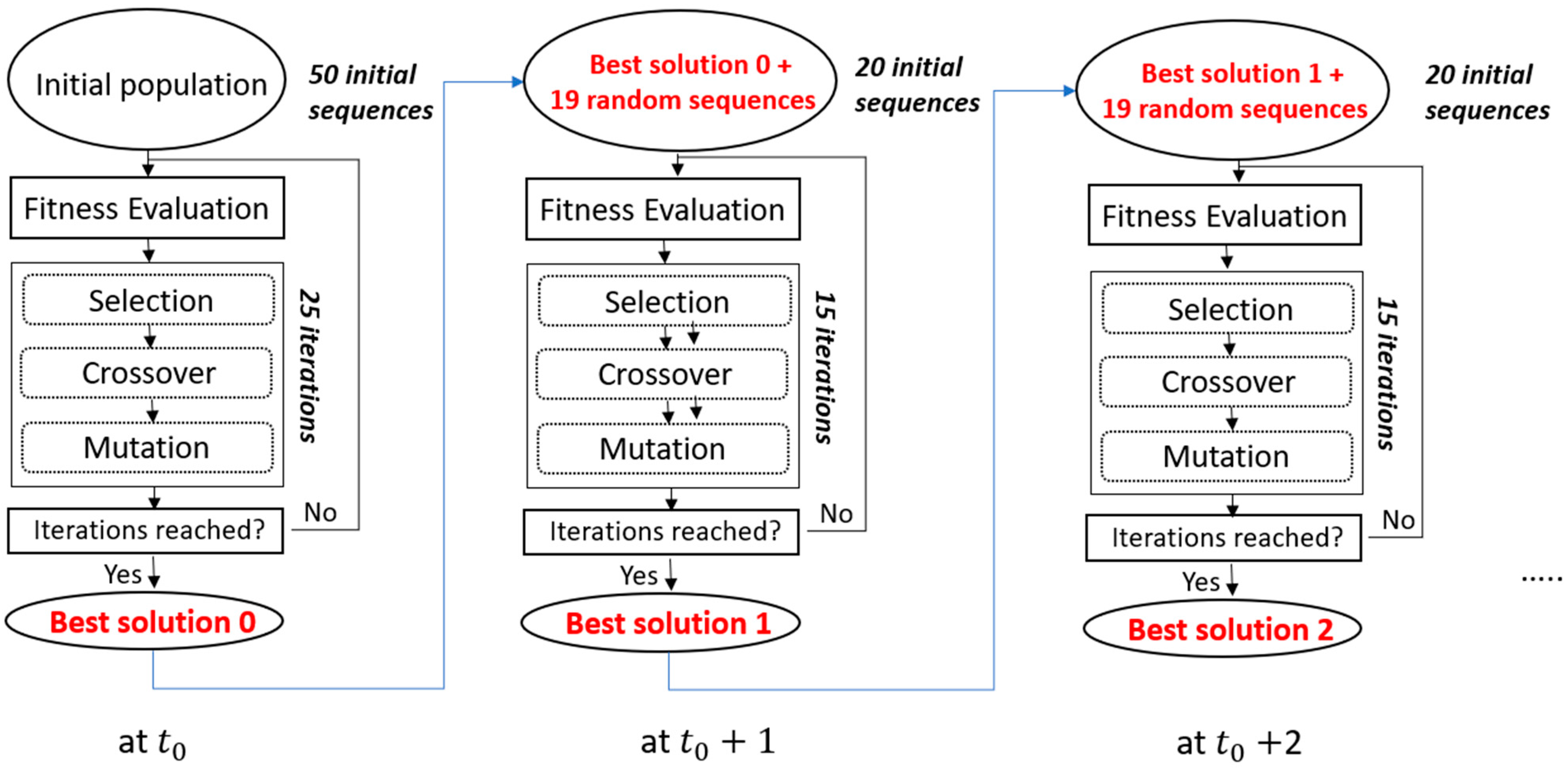
As explained, the optimization using the genetic algorithm is initiated every hour in an infinite loop (loop 3 of the methodology as explained in
Section 2), enabling a receding horizon. Each iteration of this loop represents the calculation of an optimal sequence for 24 h. At time
, the GA finds an optimal solution, adhering to the defined number of solutions for the initial population and the number of iterations to be performed. In this study, we focused on reducing the computational complexity by helping the genetic algorithm find the best solution at time
+ 1 by injecting the best solution found at the first optimization (
). The process is explained in
Figure 8. During the second iteration, i.e., at time
+ 1, the GA can use the previous solution, including it in the new initial population of 20 solutions instead of 50. In addition, the GA performs 15 iterations instead of 25, thereby reducing execution time while maintaining the efficiency of the process (more details are presented in
Section 3). Therefore, the number of sequences is limited to 50 for the first iteration of the receding horizon loop (loop 3), and then reduced to 20 for the remaining 47 iterations in this case study (since the loop turns for 48 h).
3. Results
In this study, the first loop of the proposed MPC represents the prediction of indoor temperature and gas consumption over a 24 h horizon, while the second loop denotes the optimization process of the setpoint temperature. Concerning the third one, it represents the receding horizon where the prediction and the optimization are performed at each timestep (every hour), for the next 24 h, in order to adjust the heating scenario if needed. In real-world scenarios, the third loop operates continuously from the moment the strategy is activated until it is deactivated. This means that the forecasting horizon advances incrementally on an hourly basis throughout the duration of the strategy’s implementation. However, in this study, to reduce computational effort and time, the authors chose to validate the strategy by running it for a fixed duration of 48 h loops, applied to 10 randomly selected days. The computation of the optimal solution for one timestep, if the loop can range from 10 to 40 min, is carried out using a relatively high-performance machine (DELL PRECISION 3581, with a 13th Gen Intel Core i9-13900H processor, 64 GB of RAM, and a 64-bit architecture), making it challenging to perform large-scale calculations, such as those spanning an entire year.
The proposed MPC strategy was validated on the modeled building using TRNSYS18.
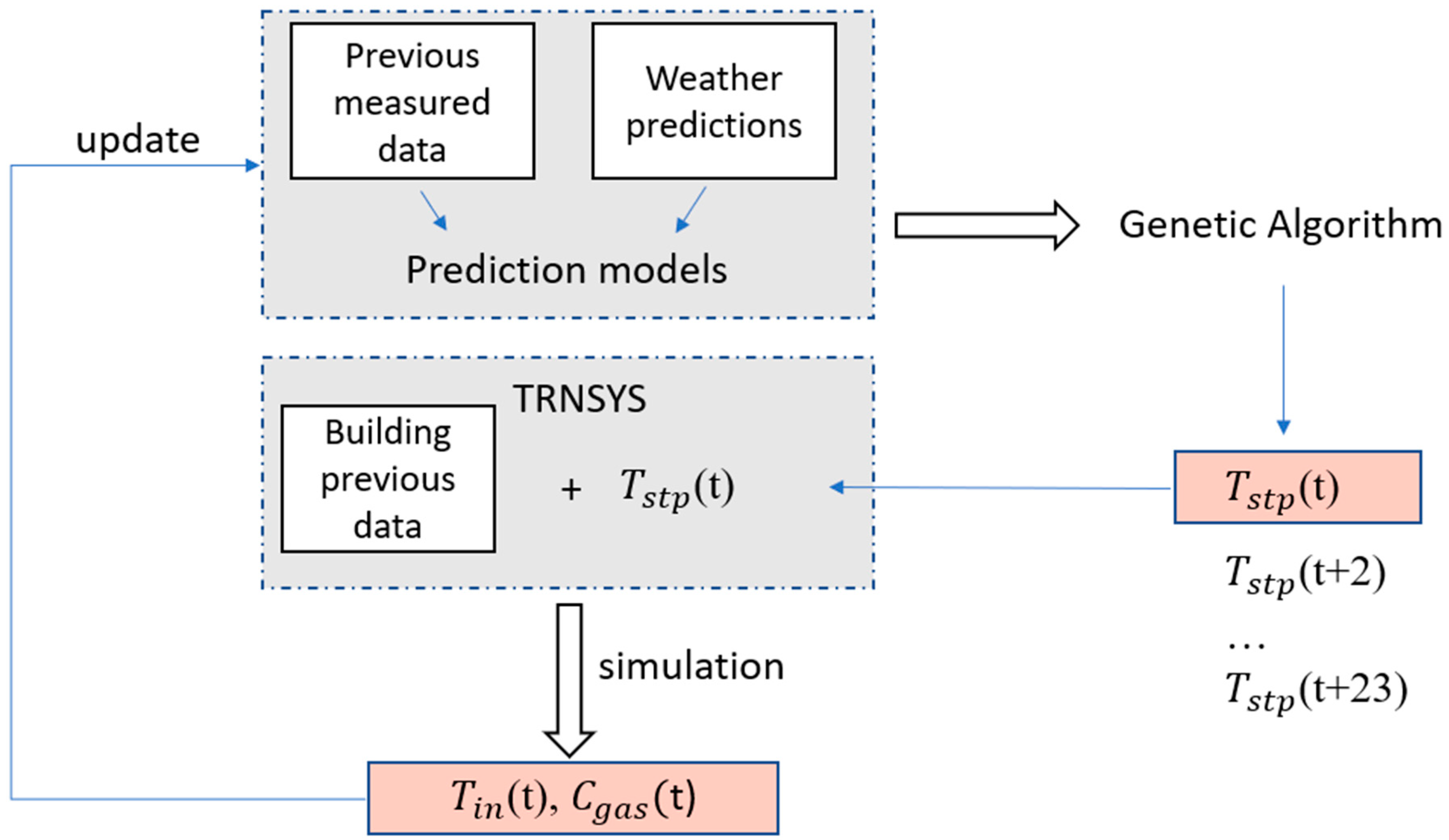
Figure 9 explains the mechanism of this loop. At each iteration, the first setpoint temperature (
(t)) of the proposed 24 h scenario is applied to the heating system of the simulated building model in TRNSYS18 as a control signal. This allows for the collection of output data, including the indoor air temperature and gas consumption associated with the specified heating setpoint. The simulation is then executed using the building’s historical data, maintaining consistent initial conditions for both the prediction process and the simulation, up to the considered timestep. Once the simulation on TRNSYS18 is performed, the output values of indoor temperature and energy consumption
(t) and
(t), respectively) are passed to update the dataset used for the prediction and optimization processes at the next timestep. This study was conducted in hourly steps, i.e., one timestep is equal to one hour.
As explained in
Section 2, at each timestep, the genetic algorithm attempts to find a solution that best accommodates changes or uncertainties in weather and occupancy.
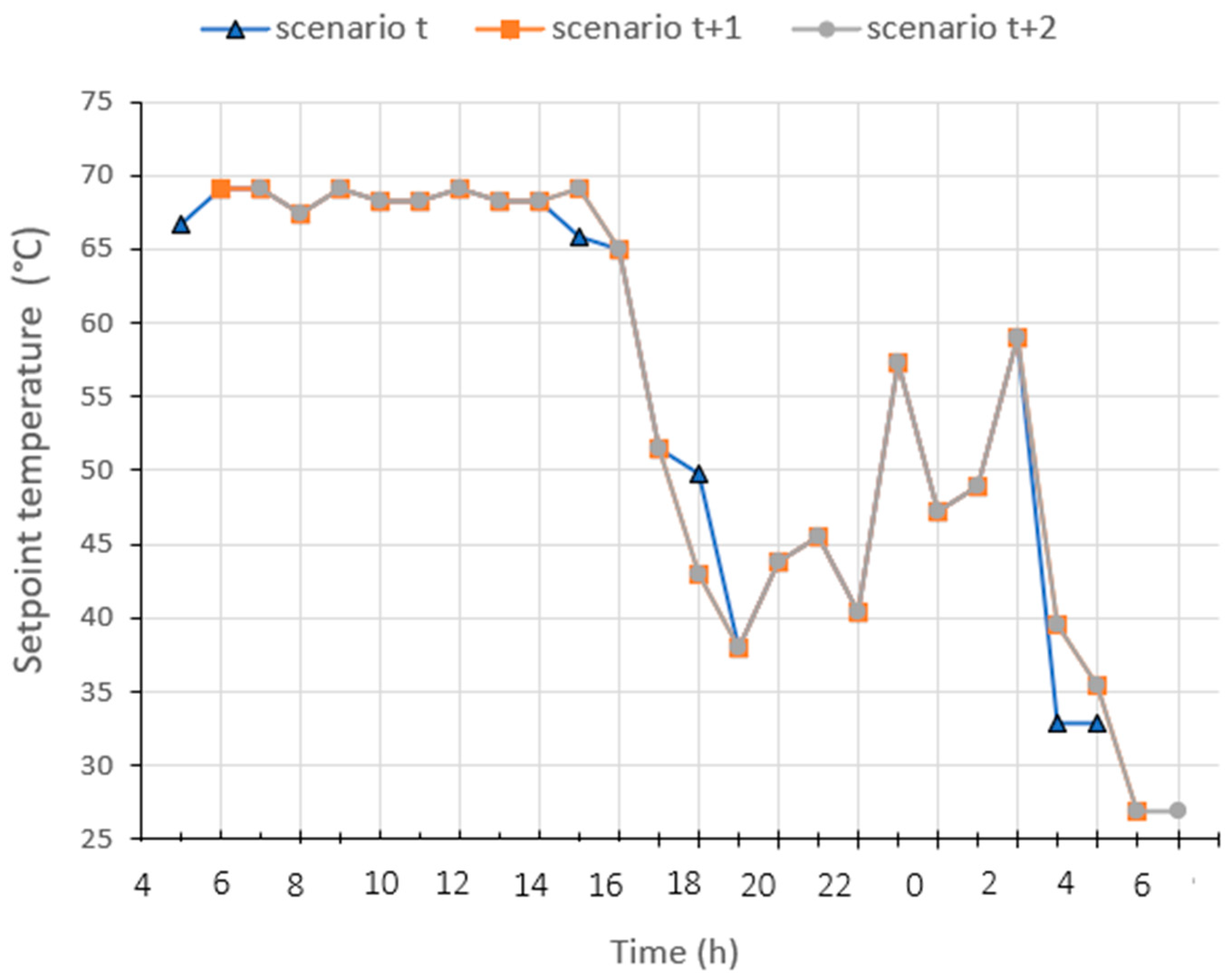
Figure 10 shows an example of evolution of the heating scenarios during three consecutive iterations (from the timestep t at 5 a.m. (scenario t), to scenario t + 1 at 6 a.m., and scenario t + 2 at 7 a.m.). The heating scenario dynamically adjusts to explore improved solutions that enhance comfort while incorporating updated values. This can be more explicit in real-life application, where potential weather or occupancy changes may occur.
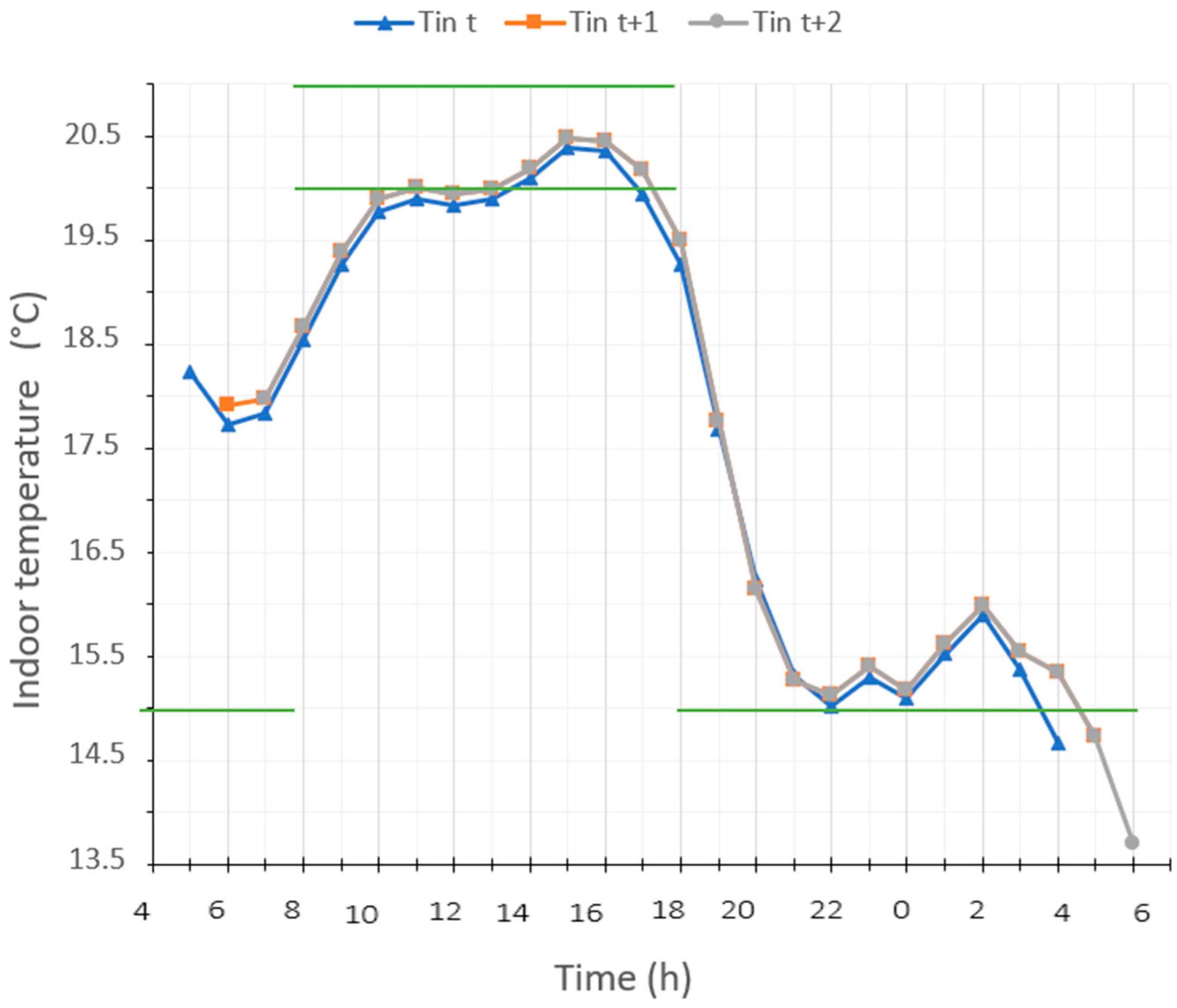
Figure 11 shows the indoor temperature that results from each heating scenario presented in
Figure 10. The adjustment of the scenario at t + 2 raises the indoor temperature a bit more to try to reach the comfort range temperatures during the occupancy period.
In order to validate the performance of the strategy, 10 random days were selected throughout the heating period. It is important to clarify that these are independent tests. For each of these days, the implementation of the MPC strategy was initiated 24 h in advance to avoid the transition phase between the conventional control strategy and the predictive control strategy. The changes in indoor temperature and gas consumption over the last 24 h of each period were used to calculate the scores. The calculation was thus launched in a 48 h receding horizon loop. That means that 48 iterations of loop 3 were performed for every selected day. The optimization starts at the first timestep t, calculating the 24 values of setpoint temperatures for the next 24 h, considering the next 24 h occupation scenario and weather forecasts. Then, at the next timestep, the calculation of the heating scenario is repeated for the 24 next ones, and so on, for 48 iterations.
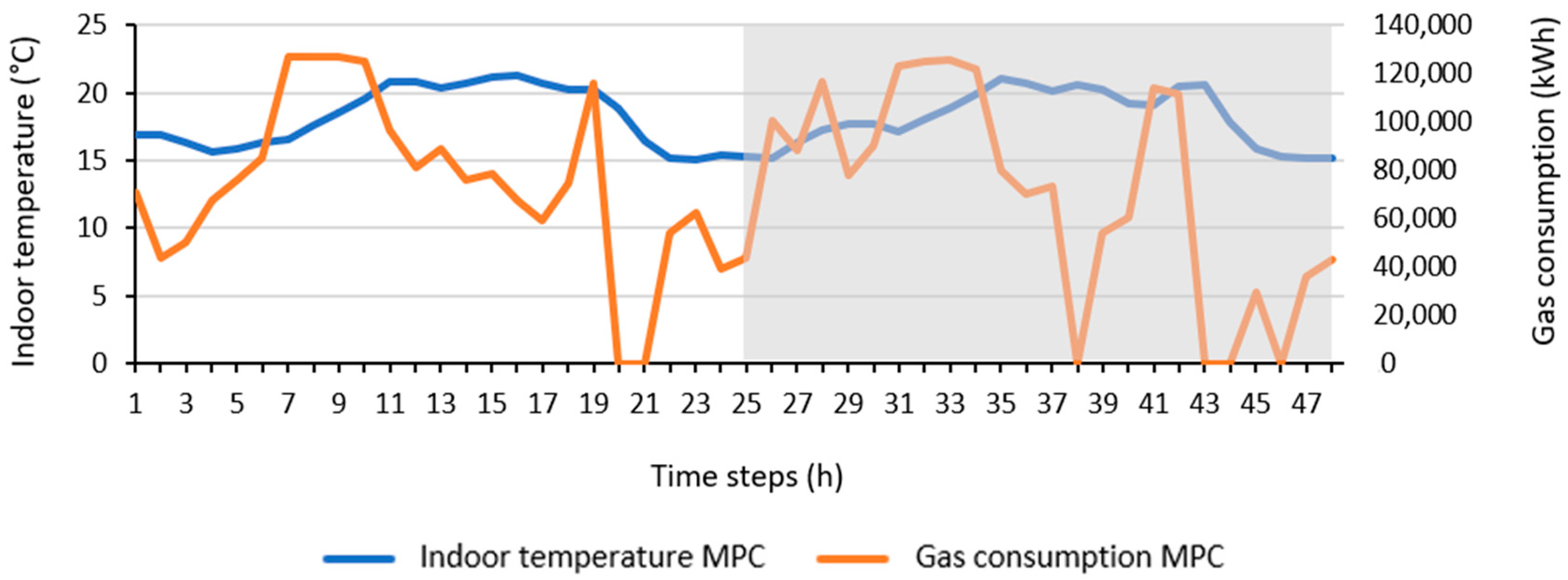
Figure 12 shows an example of indoor temperature and gas consumption that result from the MPC strategy applied to 1 selected test day, over 48 h. Only the values of the second day were used to evaluate the applied strategy (the part selected in the grey frame on the graph).
Values of indoor air temperature and energy consumption from the last 24 h were compared to those simulated using a conventional control strategy for the heating system of the same building. This conventional control operates based on a heating curve, a function of the outdoor temperature. The parameters of this heating curve were carefully chosen to ensure an indoor temperature between 20 °C and 22 °C during occupation hours (8 a.m. to 6 p.m.). The heating setpoint temperature starts to increase at 6 a.m. (2 h before the occupation to guarantee a comfort temperature at 8 a.m.), with a night-time setback also implemented. The heating curve was optimally adjusted to provide a credible reference strategy. In other words, the baseline method with which we compared our strategy is already a fairly energy-efficient heating curve, and a heating cutdown is carried out during the night.
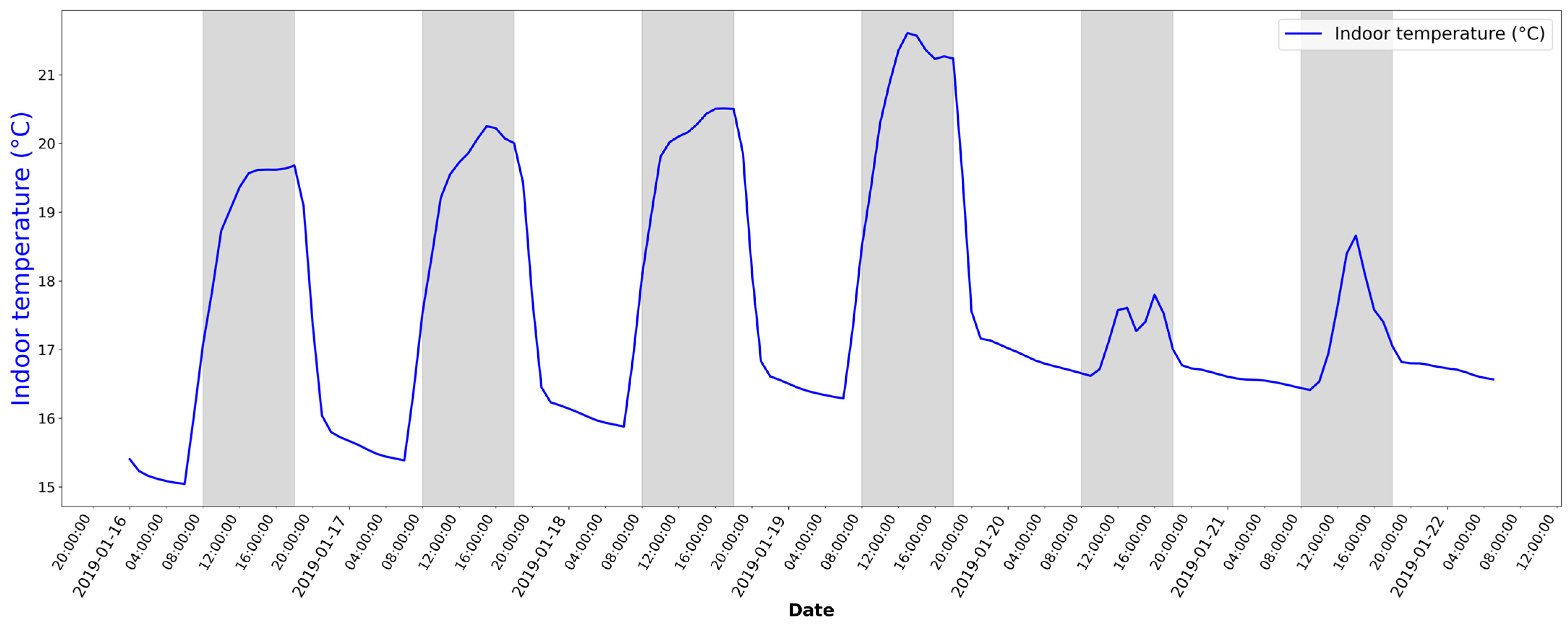
Figure 13 shows the indoor air temperature in the building, with heating based on the selected heating curve over the course of a week. It is clear that it takes hours to reach a comfortable temperature. The proposed MPC aims to avoid this delay. The results presented in this section correspond to the comparison of the strategy with this selected conventional heating strategy.
Since the aim of the strategy is to balance energy consumption and thermal comfort, the comparison is based on two scores: a comfort score and an energy consumption score. The MPC strategy aims to minimize the final score, which is the sum of both scores, as defined in Equation (9).
Table 5 shows the results of both control methods over ten randomly selected days, representing different weather conditions (varying outdoor temperatures, solar radiation). The control using the baseline heating curve is abbreviated as RBC (Rule-Based Control). The calculation is performed over 48 hourly steps for each day as mentioned, meaning that during these 48 h, the optimization is reinitiated every hour with a 24 h horizon each time. The scores presented in
Table 5 are calculated on the second day (the last 24 h) to ensure that the strategy is evaluated based on a steady-state regime.
Table 5 shows the comfort scores of both strategies in every selected test day. We can see that, in almost all cases, the MPC comfort scores are equal or lower than the RBC scores (days 1, 2, 6, 9, and 10), while an energy consumption reduction is proved by the MPC strategy in all presented days. Here, it is worth mentioning that, since there is a comfort range of temperature that is defined for the occupation and the unoccupancy period as well, the comfort score could be penalized for the violation of both. That means that, even during unoccupancy, if the temperature drops below 15 °C (
Table 4), the comfort score will increase; however, this does not imply that the building occupants feel discomfort.
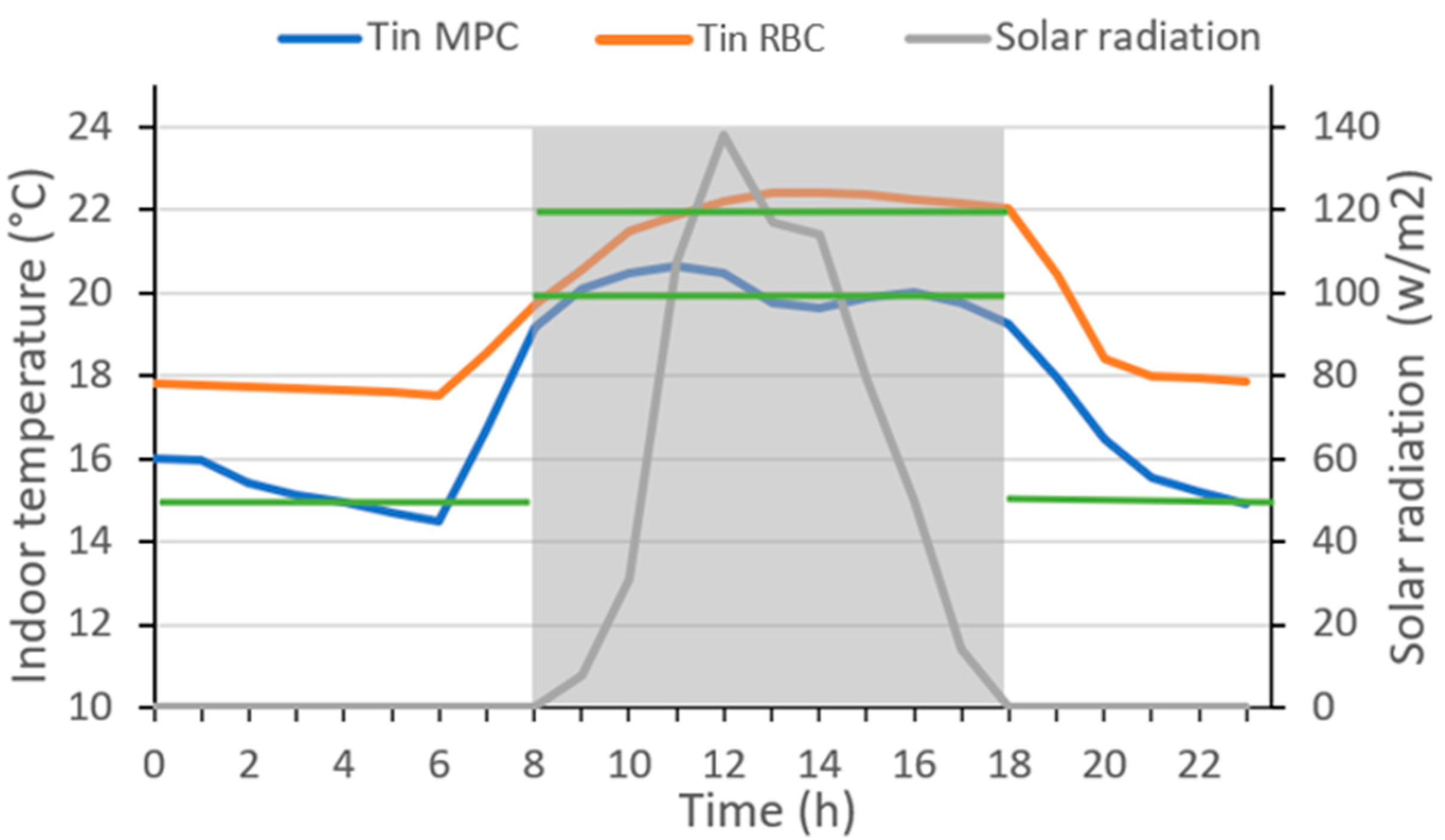
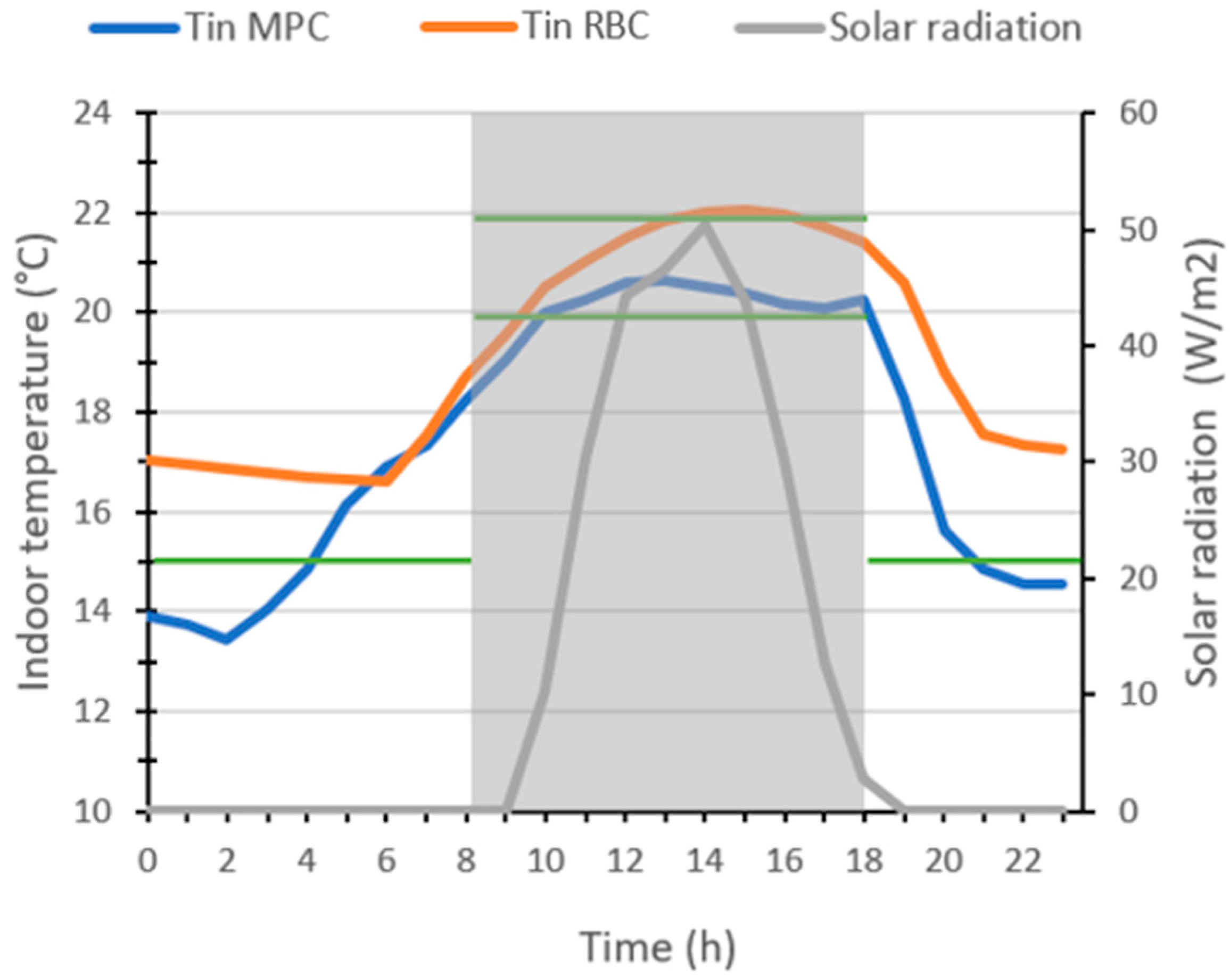
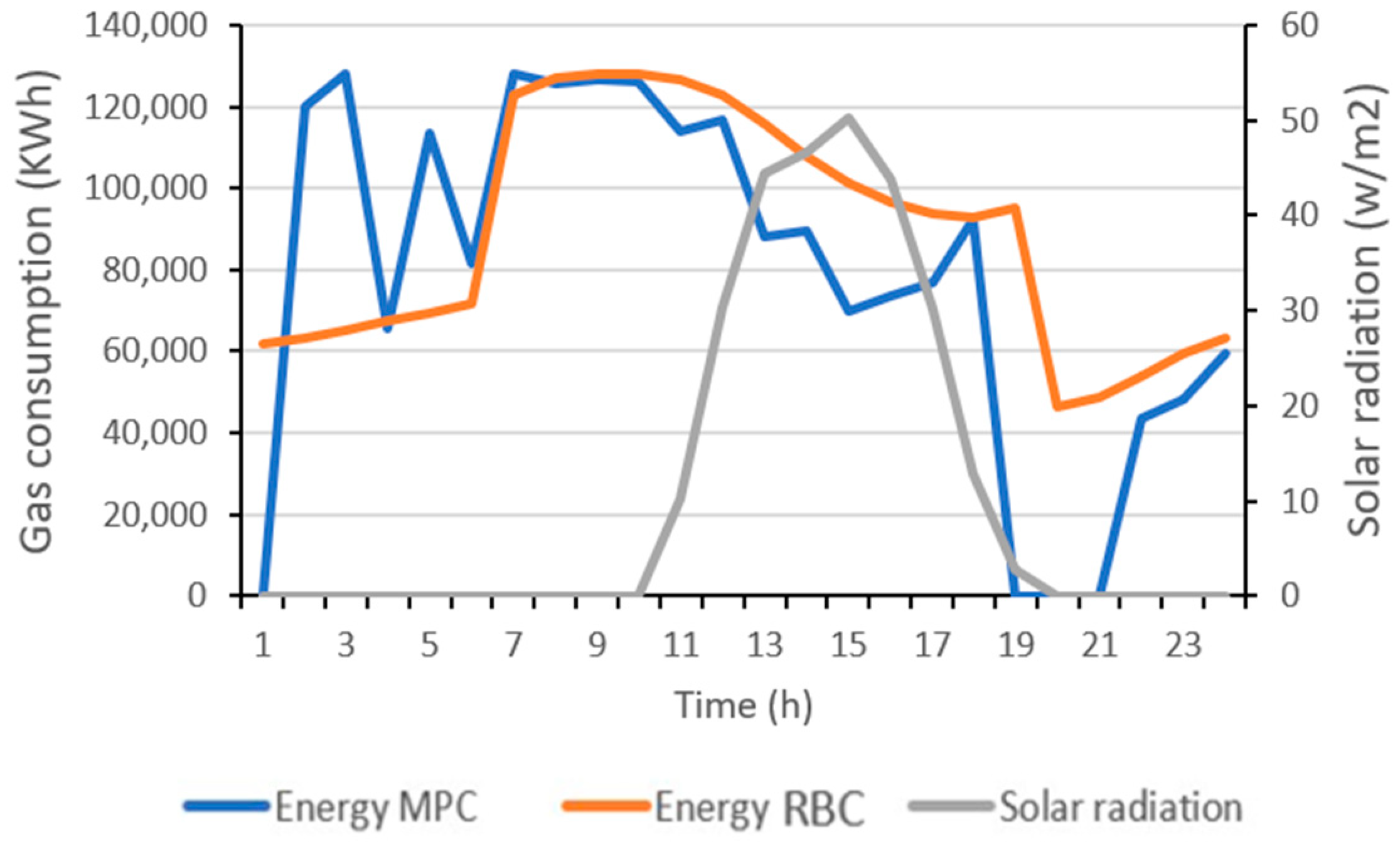
Figure 14 and
Figure 15 compare, respectively, the indoor temperature and the energy consumption of both strategies on day 4 presented in
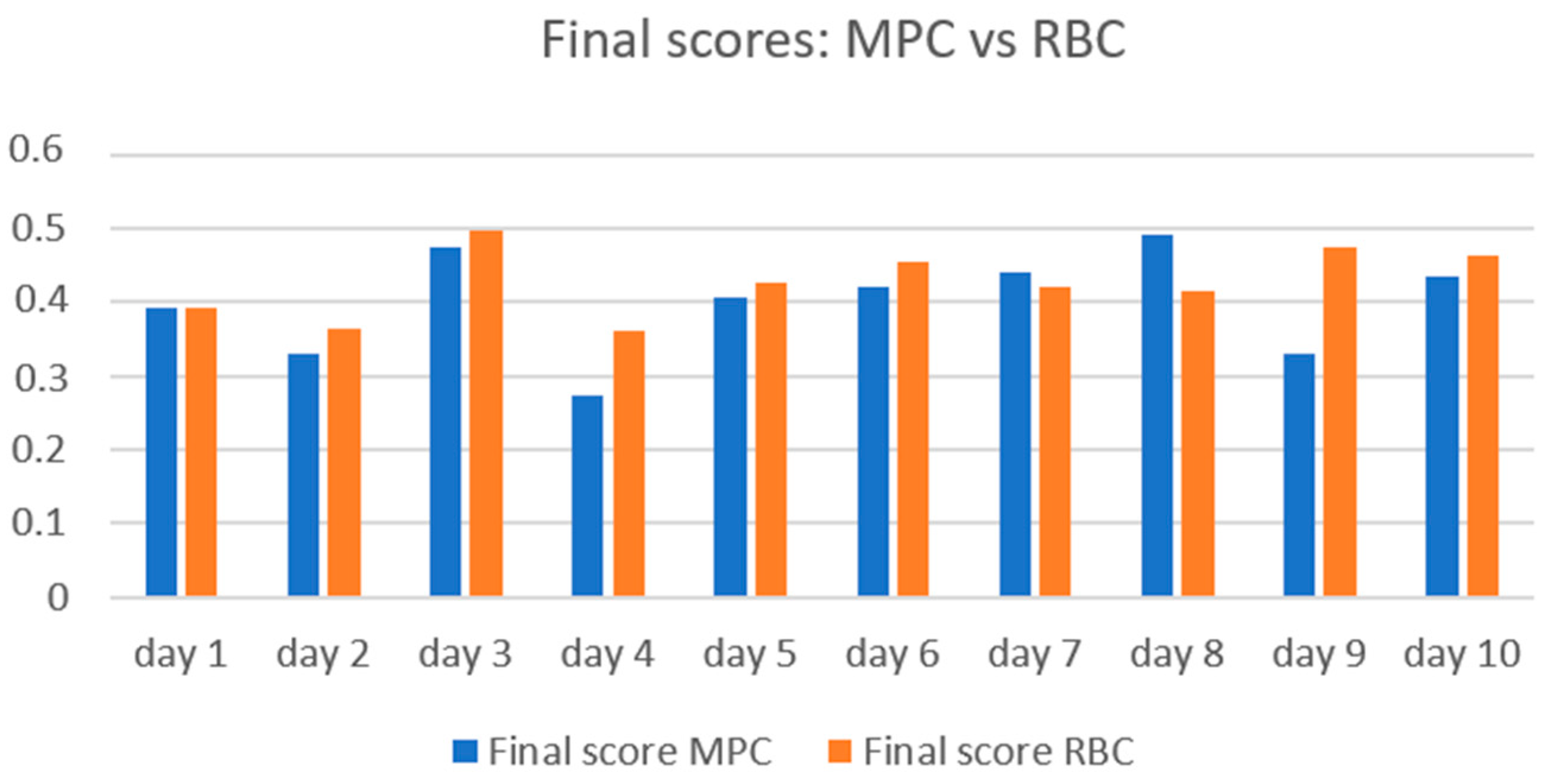
Table 5. The MPC strategy was able to anticipate the solar radiation expected during the day, to keep the indoor temperature within the comfort range (between 20 °C and 22 °C) during occupancy hours (grey frame). The results show lower gas consumption in the case of the MPC strategy, compared to that of the RBC where the indoor temperature exceeded the defined comfort range (above 22 °C). The comparison of the final scores over the 10 selected days is visualized in
Figure 16. It shows that the MPC strategy outperforms the conventional strategy in most cases (lower final scores for MPC), except for days 7 and 8. This is due to the MPC comfort score which is higher than that of the RBC during these two days.
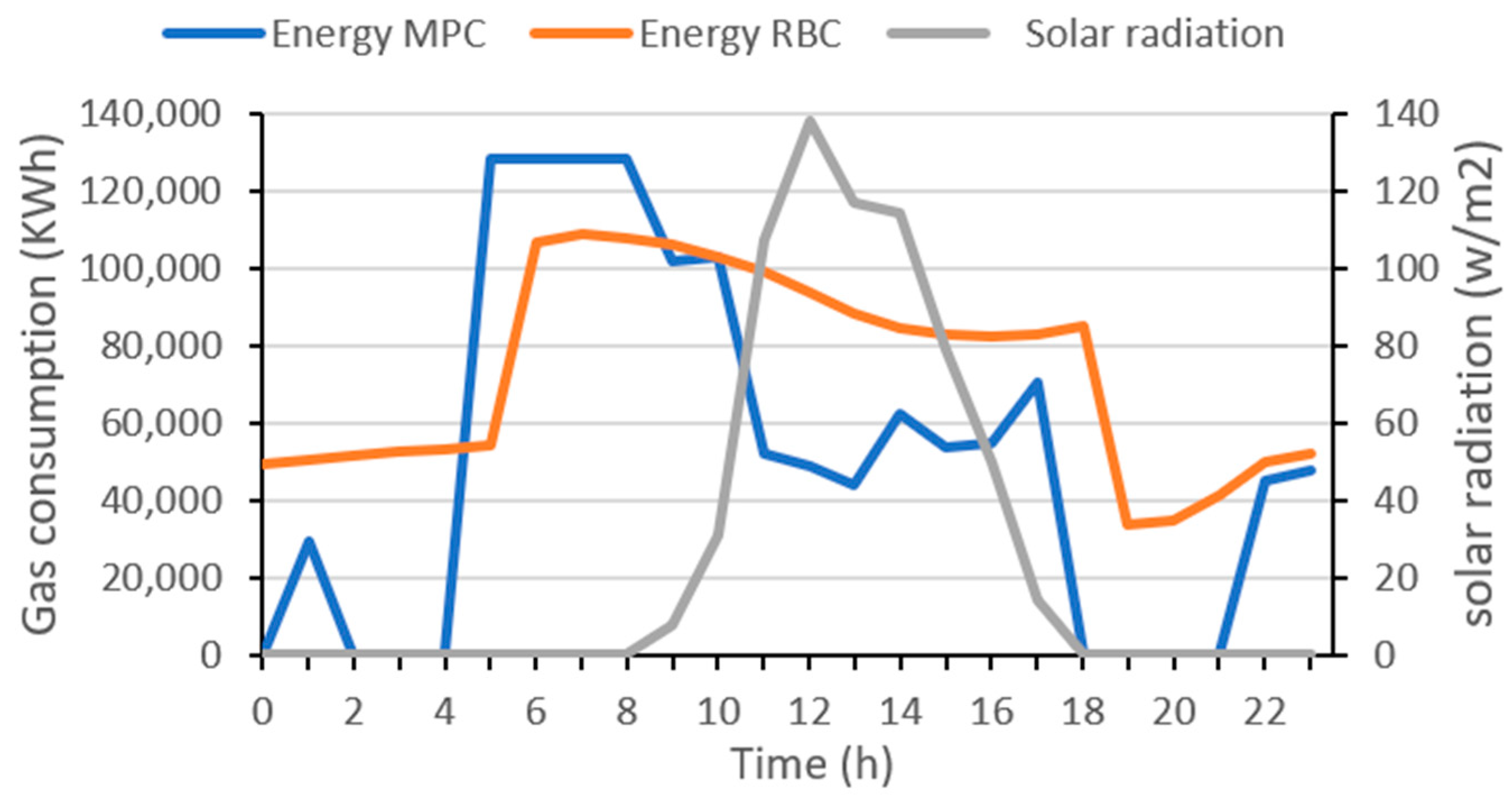
Figure 17 compares the values of indoor temperature corresponding to the MPC against those of the RBC strategy over the 24 h timesteps of day 8. The reason behind the higher comfort score of the MPC is the decrease in temperatures during unoccupancy, as already explained. This cutdown of heating did not prohibit the strategy of restoring the comfort temperatures during occupation hours. Results show that in day 8, the MPC strategy consumed 11.6% less energy compared to the RBC strategy. This demonstrates that the proposed strategy was able to anticipate the expected solar radiation for the day and suggested heating setpoints that maintain comfort temperatures while minimizing energy consumption.
Figure 18 compares the gas consumption of both strategies for day 8.
4. Discussion
In this paper, a predictive control strategy for a building’s heating system with radiators powered by a gas boiler was proposed aiming to balance thermal comfort and gas consumption. For this study, the occupant’s comfort was represented by the indoor air temperature, a common criterion in current building regulation systems. While future work may consider factors such as indoor air relative humidity, the study focused solely on temperature as the comfort indicator.
The proposed method relies on two prediction models informed by conventional building data, integrating weather and occupancy forecasts. The selection of these models was discussed in the paper, where several machine learning models were tested, and those demonstrating the highest prediction accuracy were chosen. The integration of historical data significantly improved precision. The neural network model aimed at predicting indoor temperature proved to be highly accurate, but the support vector machine model selected for predicting gas consumption, crucial for implementing the method, appears to have potential for improvement. The decision not to rely on internal measurements of technical equipment, such as various temperatures from the primary and secondary parts of the heating system, adds complexity to the modeling process. This aspect could be the focus of specific future research efforts. The two models, used to predict temperature and consumption over a 24 h forecasting horizon, are integrated within an optimization loop using genetic algorithms. The optimization phase aims to define an optimal sequence of setpoint temperatures for the secondary circuit’s water supply in the heating system on an hourly basis. The process of prediction and the calculation of the 24 h sequence of heating setpoint temperatures is repeated every hour, replacing the predicted values of indoor temperature and gas consumption at the next timestep, by the values simulated on the modeled building, preventing the accumulation of prediction errors throughout the horizon.
The method was developed using data generated in TRNSYS18. A case study building was modeled, and the simulation tool was employed to test and compare the predictive control strategy against a conventional Rule-Based Control strategy typically used in such buildings. It has been confirmed that the proposed MPC strategy can anticipate potential events (weather disturbances or internal gains) that could disrupt the building’s behavior, while achieving energy savings and maintaining occupant thermal comfort.
Because MPC strategies are implemented in buildings that vary in heating systems, environmental and weather conditions, and initial operating states, directly comparing their performance across studies is inherently challenging. Instead, comparison was performed against a reference model tailored to the same building, departing from the same initial conditions. By comparing our MPC-based strategy with an already optimized heating curve, we demonstrated additional energy savings, ranging between 3% and 30% across various randomly tested days. These results were obtained by combining a comfort score and a consumption score for each of these test days. A weighting between the two scores had to be chosen to achieve a compromise between thermal comfort and energy consumption. This weighting determines the balance of this compromise, and the choice of its value is left to the discretion of the operators, based on their priority for each part of the objective function.
This study shows that an MPC strategy can indeed be deployed with only a small set of readily obtained measurements, enabling straightforward transfer to other buildings with similar heating systems. Moving forward with the research, the goal is to implement the proposed control method on a real case study building. Measurements are currently being collected, and a predictive strategy is expected to be developed.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}