4.1. Graph Attention Network (GAT)
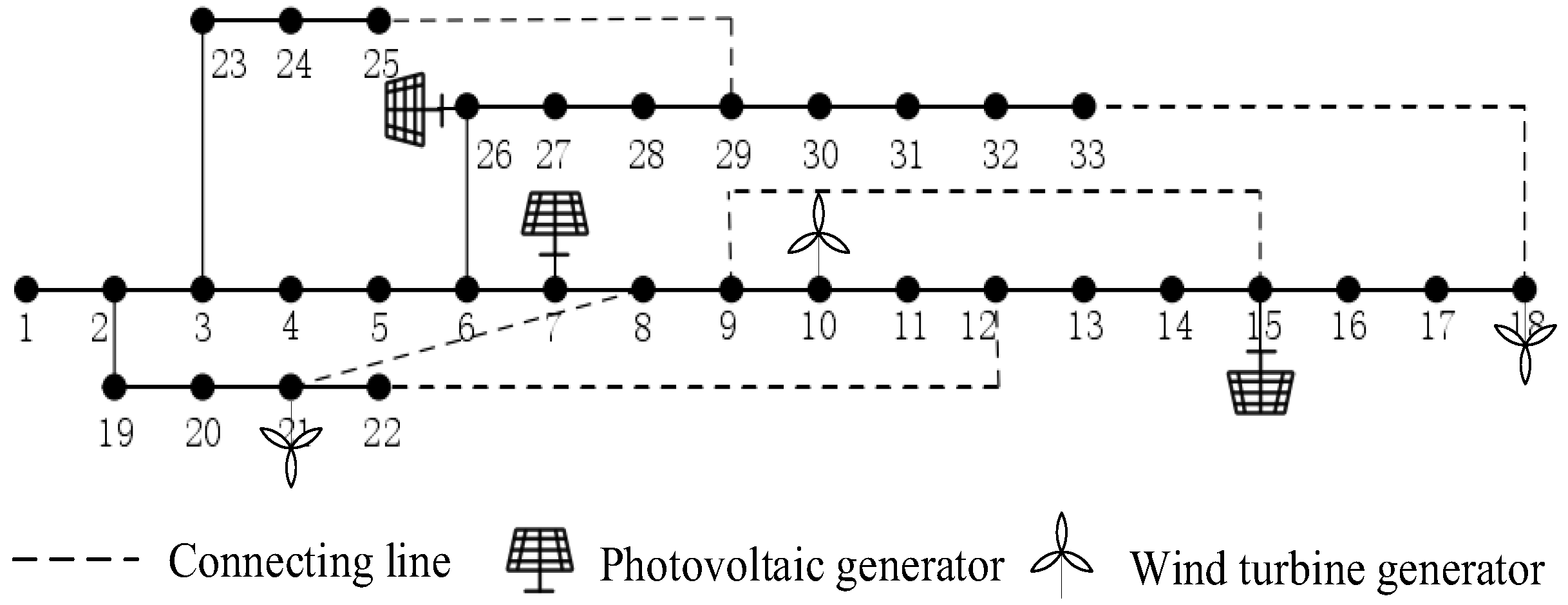
In this paper, the topology of the distribution network is described as an undirected network graph G = (V, E), where V contains all N nodes in the distribution network, vi V, and E represents the edge between nodes, which is the line of the distribution grid, (vi, vj) E. In addition, the topology structure of the distribution network is analyzed by using the undirected network diagram to represent the structural information. Based on this, to process the irregular non-Euclidean structured data, the GAT is adopted to capture complex relationships between nodes in the distribution network through graph methods, such as the connection methods between nodes, and learn different importance weights between nodes through attention mechanisms. The GAT algorithm excels at preserving the integrity of original data, minimizing information loss and distortion. Additionally, it effectively captures the intricate topology and electrical attributes within the distribution network. Consequently, it provides a deeper insight into the system’s operational status and potential hazards. During the ADNDR process, the layout of the distribution network undergoes constant alterations. GATs possess a specific level of flexibility, enabling them to address these changes in the network’s layout to a certain degree. This characteristic facilitates real-time surveillance of the distribution network and aids in devising reconfiguration strategies.
The input of the GAT is
I = (
G,
X), where
is the eigenvector matrix of each node and
G = (
V,
E) is the undirected graph corresponding to the distribution network, where
N is the number of nodes and
C is the eigenvector dimension of each node. To improve the expression ability of each node’s features, the GAT uses a self-attention mechanism for each node, with a self-attention coefficient of:
where
a is a single-layer feedforward neural network;
xi and
xj are the feature vectors of node
i and node
j, respectively; and
W is the weight matrix. Unlike the global attention mechanism, which considers all positional information of feature vectors, the GAT employs a masked attention mechanism. This mechanism focuses only on partial positional information; specifically, it only computes the
eij for the first-order neighboring nodes of node
i and normalizes the attention coefficients of different nodes using the softmax function to obtain normalized coefficients
. These normalized coefficients
are then used to compare the attention coefficients among different nodes. The expression is as follows:
After obtaining the normalization coefficient
, a nonlinear activation function is used to update the node’s own features as output by linearly combining the features of adjacent nodes:
where
Ni is the set of adjacency matrices for node
i, and
is a nonlinear activation function. To enhance the stability of the self-attention learning process, the GAT employs a multi-head attention mechanism. This mechanism involves combining
K separate attention mechanisms. After transforming the node features according to the aforementioned process, these mechanisms are concatenated to produce updated node output features. The resulting output features are as follows:
4.2. Deep Deterministic Policy Gradient (DDPG)
The ADNDR model for an active distribution network, which is dynamic in nature, poses a challenging high-dimensional, mixed-integer, nonlinear optimization problem that incorporates stochastic elements. Traditional optimization techniques, including mathematical algorithms and heuristic methods, face challenges in addressing this intricate problem, particularly regarding computational efficiency and precision. DRL interacts with its environment to continually refine behavioral strategies. Its ultimate goal is to secure the highest possible long-term average cumulative rewards, along with the respective optimal strategies. It also utilizes deep neural network approximation functions and policy functions to handle more complex state and action spaces, improving the applicability and performance of the algorithm.
The DRL algorithm has four advantages in solving the ADNDR problem: (1) The DRL algorithm has strong adaptability to uncertain factors. Traditional mathematical optimization algorithms have many shortcomings in dealing with uncertain factors, while DRL algorithms can learn and formulate optimal strategies in uncertain environments through interaction and feedback with the environment, thus adapting well to changes in uncertain factors. (2) The DRL algorithm does not require predicting load and renewable energy output. At present, most algorithms are based on distributed energy and load prediction data for ADNDR [
15,
16]. However, there exists a degree of discrepancy between the forecasted data and the real-world scenario. This discrepancy has the potential to trigger operational hazards, including voltage deviations beyond acceptable limits, excessive power loads, and heightened network losses. During the actual implementation of the reconfiguration strategy, these risks may manifest. The DRL algorithm possesses the capability to directly derive decisions from the present system state and the associated action value functions. Consequently, forecasting renewable energy and load output becomes unnecessary. (3) The DRL algorithm does not require distribution network parameters for model construction. For complex distribution network structures, parameter acquisition is often not directly possible, while the DRL algorithm can learn directly from the environment and find the optimal decision action through reward and punishment signal feedback from the environment, which belongs to a model-free algorithm. (4) The DRL algorithm takes into account the long-term returns associated with the operation of the distribution network. In the dynamic reconfiguration problem of active distribution networks, the state of the distribution network changes dynamically, including changes in load, topology, etc. The objective function is usually described as cumulative benefits over some time, as shown in Equations (1)–(4). DRL determines the most suitable reconfiguration strategy by taking into account long-term benefits and possessing a level of dynamic adaptability. This enables it to tackle the sequential decision-making optimization challenge in dynamic distribution networks efficiently, ultimately fulfilling the long-term operational requirements of these networks more effectively. In summary, the DRL algorithm is very suitable for solving the ADNDR problem.
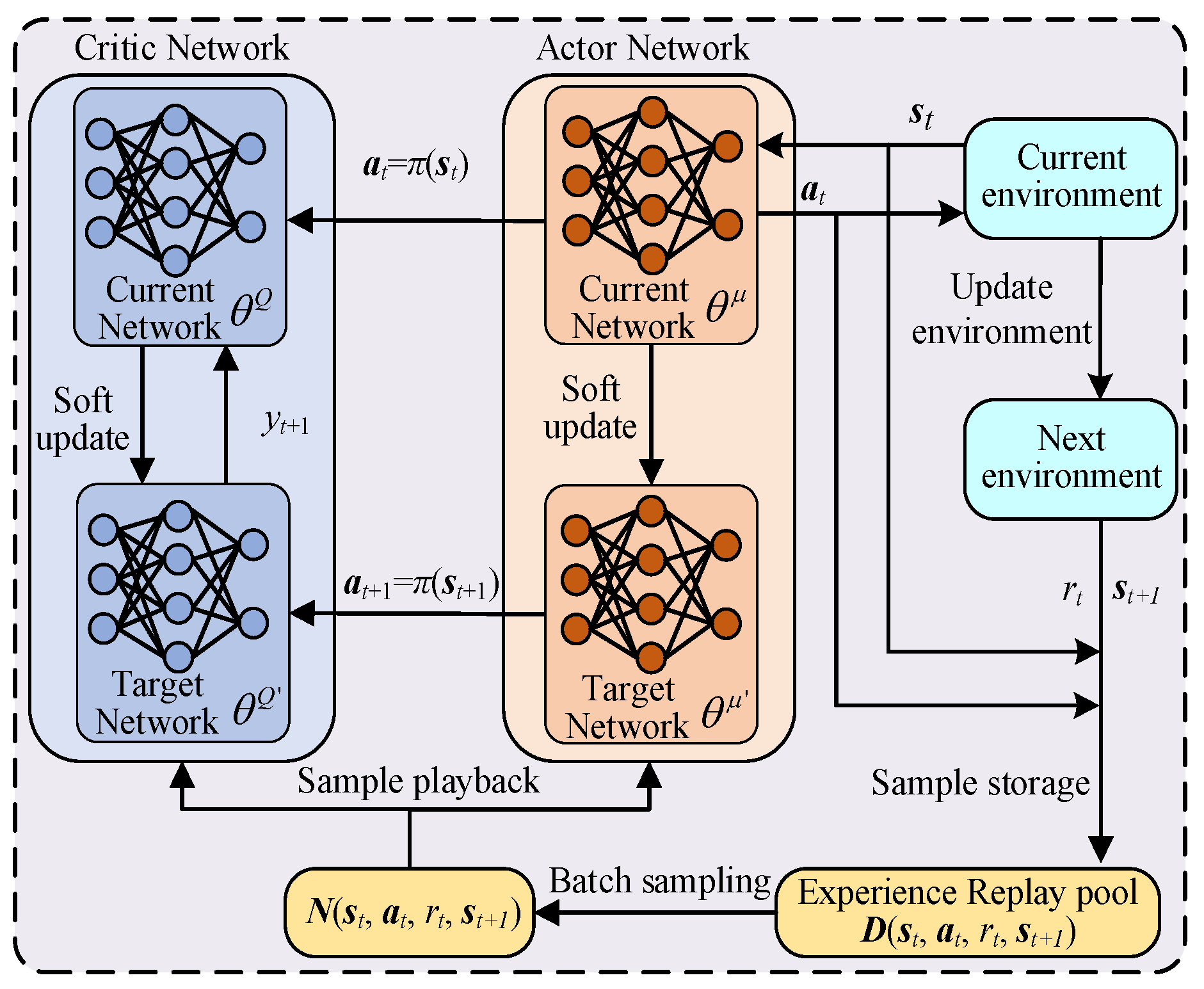
Based on how intelligent agents make choices, reinforcement learning algorithms can be categorized into three distinct types. These include algorithms that are value-based, those that are policy-based, and those that integrate both value and policy considerations. Value-based algorithms are often able to better utilize data and learn more accurate estimates of value functions. Policy-based algorithms can often better explore the action space by directly parameterizing policies. The DDPG algorithm is seen as a combination of value-based and policy-based algorithms, which update parameters through approximation functions and deterministic strategies. Hence, it integrates the swift convergence characteristics of policy-based algorithms with the stability and reliable convergence traits of value-based approaches. The DDPG algorithm, utilizing the actor–critic architecture, is capable of efficiently leveraging data throughout the learning phase. It achieves a balance between exploring new possibilities and utilizing known information. The structure diagram of DDPG is demonstrated in
Figure 2. In
Figure 2, it can be found that the DDPG model consists of two neural networks: one actor network
is used to decide the action at the current moment, and the other critic network
is used to estimate the action value function and the quality of the current state value. DDPG stores all transition states (
st,
at,
rt,
st+1) experienced in the experience replay pool
D, where
st represents the current state,
at represents the current action,
rt represents the reward function value, and
st+1 represents the next state.
The actor policy network in DDPG is divided into the current network and the target network . The current network selects the optimal action based on the current state st provided by the environment, thereby generating the next state st+1, obtaining a reward rt, and updating the current network parameters based on the Q value calculated by the critic network . The target network selects the optimal next action at+1 based on the next state st+1 sampled from the experience replay pool. The target network parameters are updated at fixed intervals based on the current network parameters .
For the actor architecture, traditional implementations employ MLPs to process state features. In contrast, our GAT-DDPG framework introduces Graph Attention Layers to model state representations as graph-structured data. Specifically, the GAT dynamically assigns attention weights to neighboring nodes through learnable coefficients, enabling the actor to focus on critical interactions (e.g., agent dependencies in multi-agent systems) while filtering irrelevant connections. This replaces MLP’s fixed-weight aggregation with adaptive relational reasoning, significantly enhancing action generation in environments with implicit or evolving dependencies.
The critic network in DDPG is divided into the current network
and the target network
. The current network
calculates the current
Q value
based on the action
at selected by the actor current network
and the current state
st, which is used to update the actor’s current network parameters and the commentator’s current network parameters
. The target network is responsible for calculating
in the target
Q value
yi, and the expression for the target
Q value
yi is as follows:
where
yi is the target
Q value;
is the attenuation factor; and
is the
Q value calculated by the target critic network
based on the next state
st+1 and the optimal action
at+1. The network parameters
are updated at fixed intervals based on the current network
.
Unlike standard DDPG, where the critic concatenates state–action vectors as MLP inputs, our GAT-based critic constructs a hybrid graph where nodes encode state features and edges integrate action attributes. GAT layers propagate features across this graph, computing attention-based Q-values that capture both local action impacts and global interactions (e.g., long-term dependencies in continuous control tasks). This design ensures nuanced modeling of state–action interdependencies, particularly in partially observable environments.
The goal of the actor network in DDPG is to obtain a larger
Q value as much as possible, and the smaller the feedback
Q value obtained, the greater the loss. Therefore, as long as a negative sign is taken on the
Q value returned by the commentator’s current network
, it is called the loss function, and its expression is as follows:
where
is the loss function value of the actor current network
;
m is the number of samples with batch gradient descent; and
is the
Q value calculated by the critic network
based on the current state
st, current action
at, and current network parameters
. The actor current network
updates the network parameters using a backpropagation algorithm based on the loss function.
The commentator in DDPG’s current network
loss function is a mean square error, which is expressed as follows:
where
is the loss function value of the commentator’s current network
;
m is the number of samples with batch gradient descent;
yi is the target
Q value; and
is the
Q value calculated by the critic’s network
based on the current state
st, current action
at, and current network parameters
. The critic current network
uses a backpropagation algorithm to update network parameters based on this loss function.
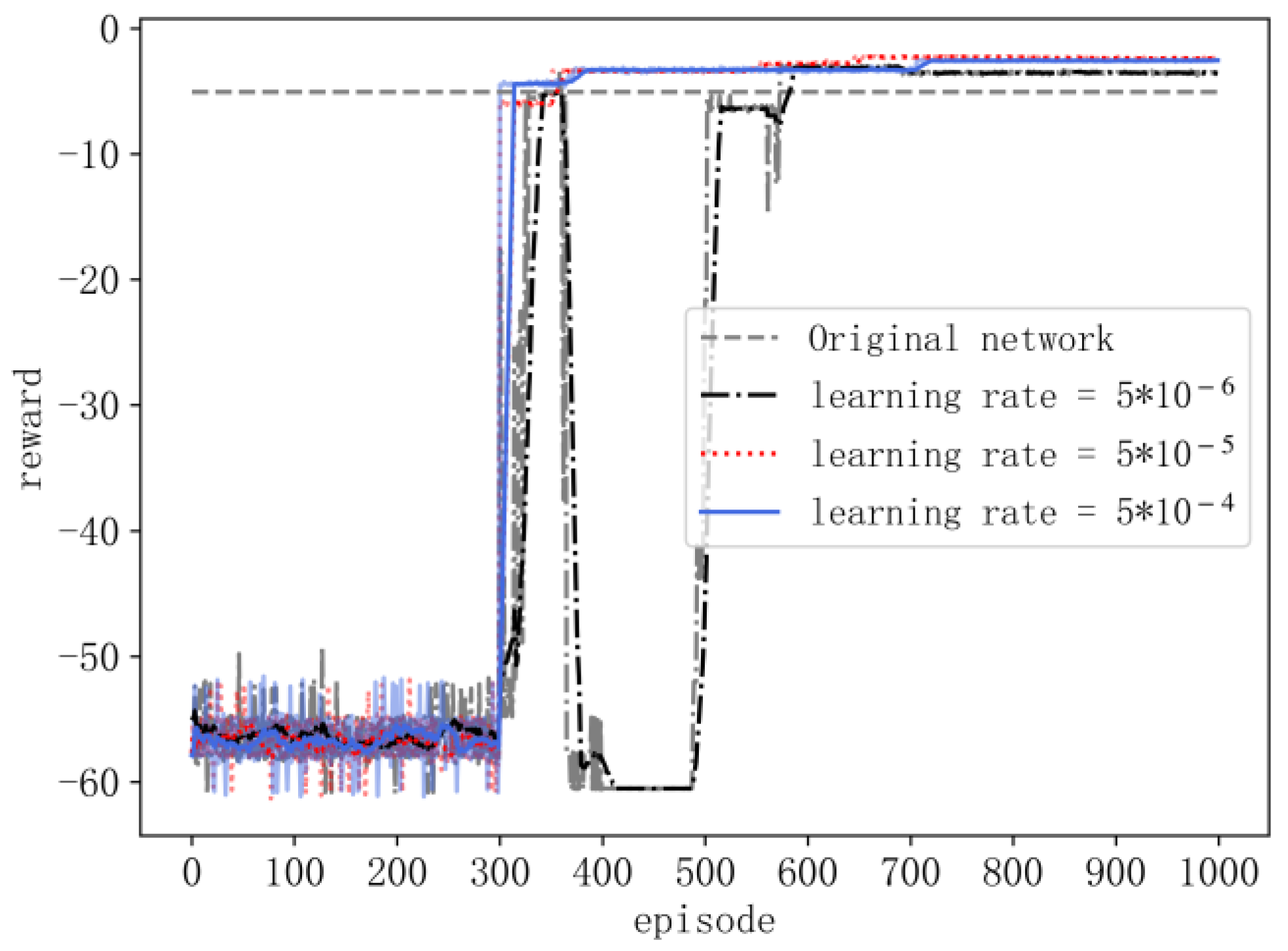
The soft-update technique is utilized for modifying the settings of the actor target network, as detailed below:
where
is the update coefficient, and in this paper,
is used.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}