
PowerModel-AI: A First On-the-Fly Machine-Learning Predictor for AC Power Flow Solutions


Abstract
1. Introduction
- The substantial data volume required to effectively train machine learning models.
- The uncertainties involved in selecting the right model, including decisions around input features, hyperparameters, and the feature engineering process.
- The absence of systematic validation procedures to ensure the accuracy and reliability of ML models post-deployment.
- Even with such validation procedures in place, a robust pipeline for continuous model retraining and updating is essential to maintain optimal model performance over time.
2. Methods
2.1. Power Flow Equations
- Slack (or swing) node:
- Generation node:
2.2. The Training Dataset
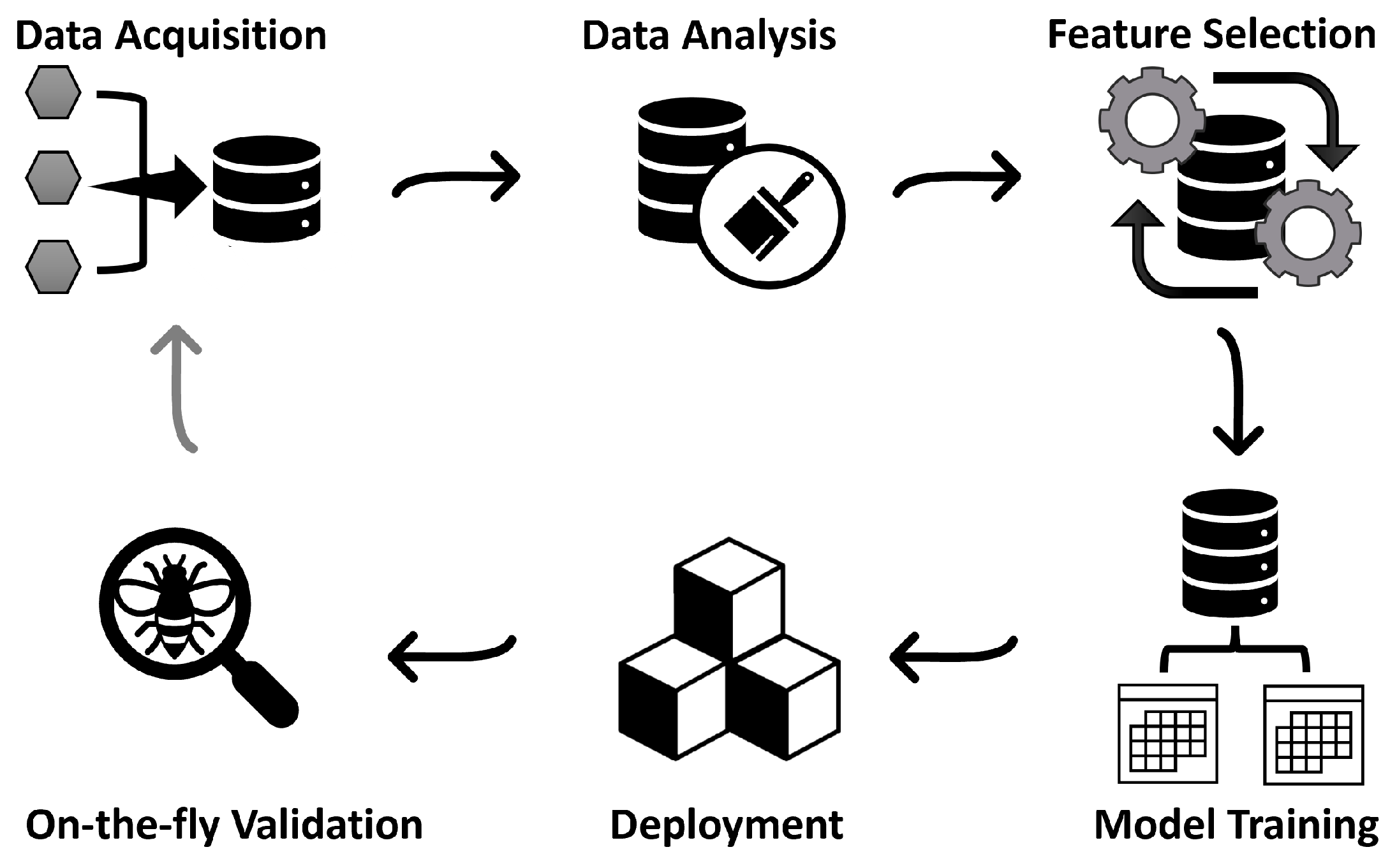
2.3. PowerModel-AI Architecture and Pipeline
- A. Base Stage
- Generate the initial training data using PowerModels.jl (refer to Section 2.2).
- Build the generation active power model. The input features are the new active and reactive power demand in the nodes with load, as well as the preset generation active and reactive power (before any changes in power demand). The target is the new generation active power.
- Repeat Step 2 for the generation reactive power model. The input features remain the same, but the new generation reactive power is set as the target.
- Build the bus voltage magnitude model using the new power demands (active and reactive) and their corresponding generation reactive power as the input feature. The new bus voltage magnitudes are set as the target.
- Repeat Step 4 for bus voltage angles. For the input feature, the generation reactive power replaces its active counterpart. Also, the new bus voltage angles are the target.
- Save all four models for deployment.
- B. Deployment Stage
- 7.
- Import the base models.
- 8.
- User inputs new power demands (active and reactive) for the selected nodes.
- 9.
- Use the generation power models to predict the generation active and reactive power, based on new power demand.
- 10.
- Use the predicted generation power and the new power demand to predict the bus voltage magnitudes and angles.
- C. On-the-Fly Stage
- 11.
- Automate on-the-fly criteria validation using the predicted data from the deployment stage.
- 12.
- If criteria are met, validate results and models. Otherwise,
- 13.
- If criteria fail, compute new power flow data in the failure region using PowerModels.jl, then retrain the base model parameters to obtain the updated model.
- 14.
- If desired, replace the base model with the updated model.
2.4. PowerModel-AI Hyperparameters
2.5. The On-the-Fly Learning Implementation
2.5.1. Training Domain
2.5.2. Power Conservation
2.5.3. Generation Power Saturation
3. Result & Discussion
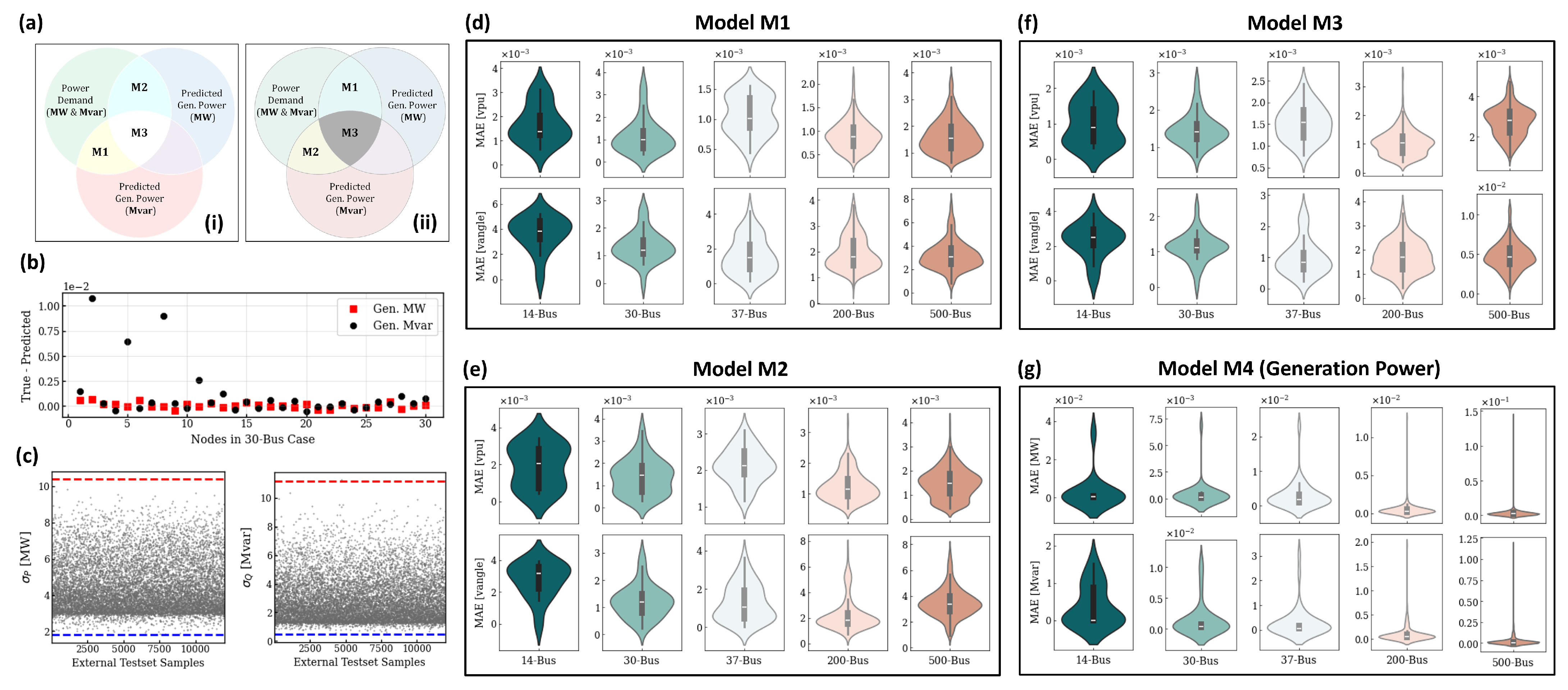
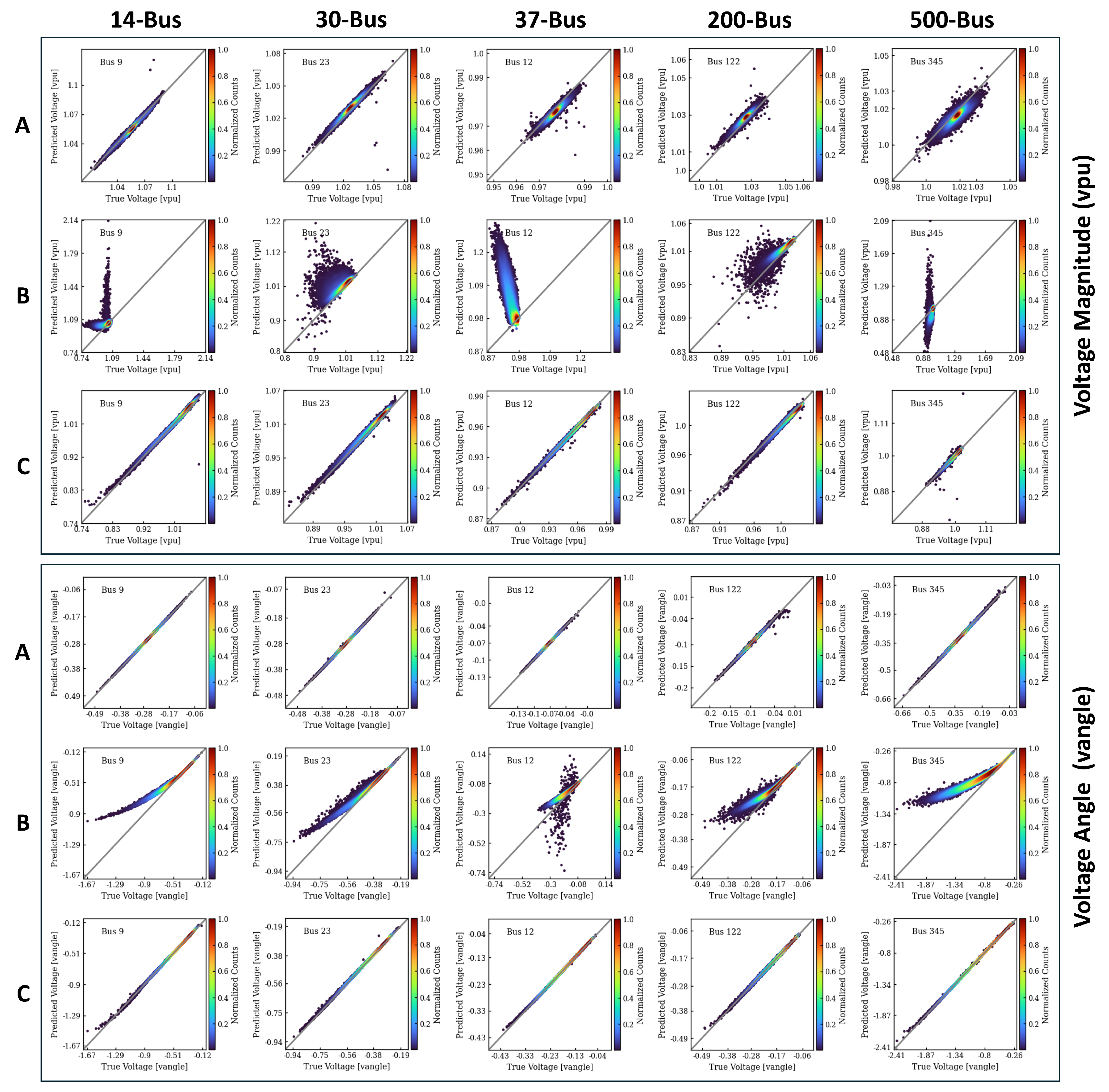
3.1. Model Selection and Assessment
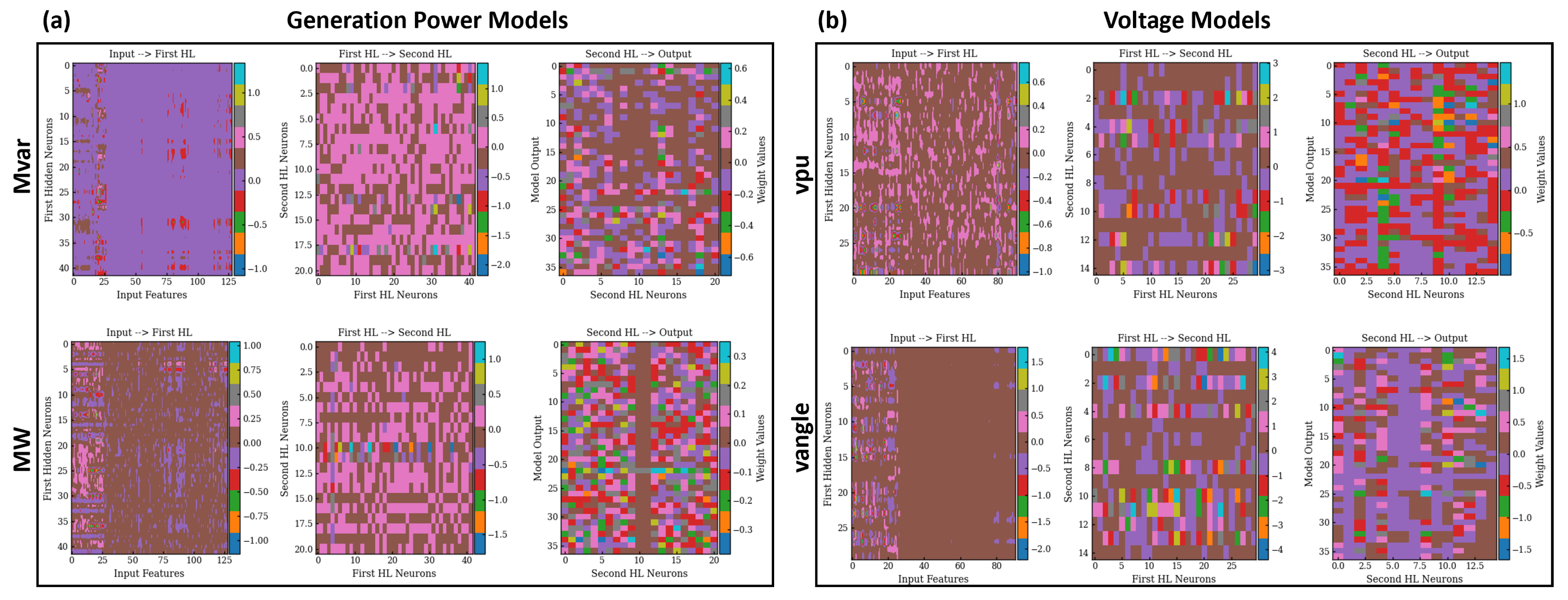
3.1.1. Node Dependencies
3.1.2. Load Flow Decoupling in Power Systems



- M1 (C1) includes the predicted (true) generation reactive power for the voltage magnitude prediction and the active generation power for voltage angle prediction.
- M2 (C2) uses the predicted (true) generation reactive power to infer the voltage angles and the active generation power for voltage magnitude.
- M3 (C3) incorporates both the predicted (true) reactive and active generation power to infer the voltage magnitude and angles.
3.2. On-the-Fly Model Update
- Training Domain Criterion → 1 points
- Power Conservation Criterion → 1 points
- Generation Power Saturation Criterion → 3 points
3.3. The PowerModel-AI Software Application
4. Conclusions and Prospects
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chatterjee, S.; Mandal, S. A novel comparison of gauss-seidel and newton- raphson methods for load flow analysis. In Proceedings of the 2017 International Conference on Power and Embedded Drive Control (ICPEDC), Chennai, India, 16–18 March 2017; pp. 1–7. [Google Scholar] [CrossRef]
- Glover, J.D.; Overbye, T.J.; Sarma, M.S. Power System Analysis & Design, 6th ed.; Cengage Learning: Boston, MA, USA, 2017; Chapter 6. [Google Scholar]
- Fikri, M.; Haidi, T.; Cheddadi, B.; Sabri, O.; Majdoub, M.; Aziz, B. Power Flow Calculations by Deterministic Methods and Artificial Intelligence Method. Int. J. Adv. Eng. Res. Sci. 2018, 5, 148–152. [Google Scholar] [CrossRef]
- Huang, B.; Wang, J. Applications of Physics-Informed Neural Networks in Power Systems - A Review. IEEE Trans. Power Syst. 2023, 38, 572–588. [Google Scholar] [CrossRef]
- Bolz, V.; Rueß, J.; Zell, A. Power Flow Approximation Based on Graph Convolutional Networks. In Proceedings of the 2019 18th IEEE International Conference On Machine Learning And Applications (ICMLA), Boca Raton, FL, USA, 16–19 December 2019; pp. 1679–1686. [Google Scholar] [CrossRef]
- Pham, T.; Li, X. Neural Network-based Power Flow Model. In Proceedings of the 2022 IEEE Green Technologies Conference (GreenTech), Houston, TX, USA, 30 March–1 April 2022; pp. 105–109. [Google Scholar] [CrossRef]
- Fikri, M.; Sabri, O.; Cheddadi, B. Calculating voltage magnitudes and voltage phase angles of real electrical networks using artificial intelligence techniques. Int. J. Electr. Comput. Eng. (2088-8708) 2020, 10, 5749–5757. [Google Scholar] [CrossRef]
- Lopez-Garcia, T.B.; Domínguez-Navarro, J.A. Graph Neural Network Power Flow Solver for Dynamical Electrical Networks. In Proceedings of the 2022 IEEE 21st Mediterranean Electrotechnical Conference (MELECON), Palermo, Italy, 14–16 June 2022; pp. 825–830. [Google Scholar] [CrossRef]
- Liao, W.; Bak-Jensen, B.; Pillai, J.R.; Wang, Y.; Wang, Y. A Review of Graph Neural Networks and Their Applications in Power Systems. J. Mod. Power Syst. Clean Energy 2022, 10, 345–360. [Google Scholar] [CrossRef]
- Birchfield, A.B.; Xu, T.; Gegner, K.M.; Shetye, K.S.; Overbye, T.J. Grid Structural Characteristics as Validation Criteria for Synthetic Networks. IEEE Trans. Power Syst. 2017, 32, 3258–3265. [Google Scholar] [CrossRef]
- Coffrin, C.; Bent, R.; Sundar, K.; Ng, Y.; Lubin, M. PowerModels.jl: An Open-Source Framework for Exploring Power Flow Formulations. In Proceedings of the 2018 Power Systems Computation Conference (PSCC), Dublin, Ireland, 11–15 June 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Doerr, S.; De Fabritiis, G. On-the-Fly Learning and Sampling of Ligand Binding by High-Throughput Molecular Simulations. J. Chem. Theory Comput. 2014, 10, 2064–2069. [Google Scholar] [CrossRef] [PubMed]
- Jinnouchi, R.; Miwa, K.; Karsai, F.; Kresse, G.; Asahi, R. On-the-Fly Active Learning of Interatomic Potentials for Large-Scale Atomistic Simulations. J. Phys. Chem. Lett. 2020, 11, 6946–6955. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Kermode, J.R.; De Vita, A. Molecular dynamics with on-the-fly machine learning of quantum-mechanical forces. Phys. Rev. Lett. 2015, 114, 096405. [Google Scholar] [CrossRef] [PubMed]
- Stippell, E.; Alzate-Vargas, L.; Subedi, K.N.; Tutchton, R.M.; Cooper, M.W.; Tretiak, S.; Gibson, T.; Messerly, R.A. Building a DFT+U machine learning interatomic potential for uranium dioxide. Artif. Intell. Chem. 2024, 2, 100042. [Google Scholar] [CrossRef]
- Ugwumadu, C.; Tabarez, J.; Drabold, D.; Pandey, A. PowerModel-AI Software. Available online: https://powermodel-ai.streamlit.app/ (accessed on 28 March 2025).
- Ugwumadu, C.; Tabarez, J.; Drabold, D.; Pandey, A. [Data set] PowerModel-AI: A First On-the-fly Machine-Learning Predictor for AC Power Flow Solutions. Zenodo, Version 1; 2024. Available online: https://doi.org/10.5281/zenodo.13843934 (accessed on 28 March 2025).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32, pp. 8024–8035. [Google Scholar]
- Schultheiss, L.A.; Heiliger, E.M. Techniques of flow-charting. In Proceedings of the 1963 Clinic on Library Applications of Data Processing; Graduate School of Library Science: University of Illinois, Urbana-Champaign, IL, USA, 1963; pp. 62–78. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 17–19 June 2013; Volume 30, p. 3. [Google Scholar]
- Bai, Y. RELU-Function and Derived Function Review. SHS Web Conf. 2022, 144, 02006. [Google Scholar] [CrossRef]
- PowerWorld Corporaton. Switched Shunt Display. Available online: https://www.powerworld.com/WebHelp/Content/MainDocumentation_HTML/Switched_Shunt_Display.htm (accessed on 6 April 2025).
- Stott, B.; Alsac, O. Fast Decoupled Load Flow. IEEE Trans. Power Appar. Syst. 1974, PAS-93, 859–869. [Google Scholar] [CrossRef]
- Geman, S.; Bienenstock, E.; Doursat, R. Neural networks and the bias/variance dilemma. Neural Comput. 1992, 4, 1–58. [Google Scholar] [CrossRef]
- Charles, P.; Mehazzem, F.; Soubdhan, T. A Review on Optimal Power Flow Problems: Conventional and Metaheuristic Solutions. In Proceedings of the 2020 2nd International Conference on Smart Power & Internet Energy Systems (SPIES), Bangkok, Thailand, 15–18 September 2020; pp. 577–582. [Google Scholar] [CrossRef]
- Yang, K.; Gao, W.; Fan, R. Optimal Power Flow Estimation Using One-Dimensional Convolutional Neural Network. In Proceedings of the 2021 North American Power Symposium (NAPS), College Station, TX, USA, 14–16 November 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Gan, L.; Low, S.H. Optimal power flow in direct current networks. In Proceedings of the 52nd IEEE Conference on Decision and Control, Firenze, Italy, 10–13 December 2013; pp. 5614–5619. [Google Scholar] [CrossRef]
- Chen, Q.; McCalley, J. Identifying high risk N-k contingencies for online security assessment. IEEE Trans. Power Syst. 2005, 20, 823–834. [Google Scholar] [CrossRef]
- Huang, Z.; Chen, Y.; Nieplocha, J. Massive contingency analysis with high performance computing. In Proceedings of the 2009 IEEE Power & Energy Society GeneralMeeting, Calgary, AB, Canada, 26–30 July 2009; pp. 1–8. [Google Scholar] [CrossRef]
- Tabassum, A.; Chinthavali, S.; Lee, S.; Stenvig, N.; Kay, B.; Kuruganti, T.; Aditya Prakash, B. Efficient Contingency Analysis in Power Systems via Network Trigger Nodes. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021; pp. 1964–1973. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | 14-Bus | 30-Bus | 37-Bus | 200-Bus | 500-Bus |
|---|---|---|---|---|---|
| 12,000 | 12,000 | 12,000 | 12,000 | 12,000 | |
| 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | |
| 4.7 | 3.5 | 5.0 | 3.0 | 3.5 | |
| 50 | 102 | 128 | 616 | 1400 | |
| 36 | 72 | 91 | 416 | 900 | |
| 1.67 × | 4.0 × | 4.9 × | 6.0 × | 1.8 × | |
| 9.4 × | 1.5 × | 3.3 × | 1.5 × | 4.9 × | |
| 5.0 × | 9.2 × | 2.0 × | 1.0× | 4.0 × | |
| 1.1 × | 3.0 × | 6.0 × | 7.0 × | 1.7 × | |
| 1.338 | 1.808 | 10.522 | 19.087 | 48.907 | |
| 15.092 | 10.408 | 48.963 | 44.176 | 108.341 | |
| 0.109 | 0.474 | −0.034 | 3.465 | 1.587 | |
| 20.916 | 11.154 | 15.001 | 41.206 | 168.881 |
| Hyperparameter | Description | Value |
|---|---|---|
| Number of Layers | Total number of hidden layers in the network | 2 |
| Batch Size | Number of samples per gradient update | 32 |
| Number of Epochs | Total number of passes through the training dataset | 300 |
| Learning Rate | Step size for updating weights during training | 0.001 |
| Number of Neurons | Number of neurons per hidden layer | Varies a |
| Loss Function | Evaluates accuracy of the model’s predictions | MSEloss b |
| Activation Function | Function applied to the output of each neuron | Leaky ReLU |
| Weight Initialization | Strategy for setting initial weights | Xavier Initializer |
| Optimization Algorithm | Method for updating weights based on gradients | Adam Optimizer |
| MAE | MSE | |||||||
|---|---|---|---|---|---|---|---|---|
| Grid | MW | MVAR | lMW | MVAR | ||||
| 14-Bus | 1.71 | 3.66 | 3.00 | 3.82 | 2.92 | 13.4 | 8.98 | 14.6 |
| 30-Bus | 1.16 | 1.33 | 0.43 | 1.46 | 1.35 | 1.76 | 0.19 | 2.13 |
| 37-Bus | 1.07 | 1.61 | 2.94 | 3.08 | 1.14 | 2.60 | 8.62 | 9.47 |
| 200-Bus | 0.92 | 1.96 | 0.47 | 1.02 | 0.84 | 3.85 | 0.23 | 1.03 |
| 500-Bus | 1.63 | 3.18 | 3.00 | 2.45 | 2.67 | 10.1 | 9.00 | 6.01 |
| Parameters | 14-Bus | 30-Bus | 37-Bus | 200-Bus | 500-Bus |
|---|---|---|---|---|---|
| 2.0 | 2.0 | 2.0 | 2.0 | 2.0 | |
| 0.830 | 1.261 | 7.007 | 16.381 | 42.273 | |
| 4.897 | 5.080 | 17.144 | 28.805 | 60.734 | |
| −0.172 | 0.091 | −0.197 | 2.338 | −2.939 | |
| 2.642 | 3.347 | 0.830 | 10.786 | 12.379 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ugwumadu, C.; Tabarez, J.; Drabold, D.A.; Pandey, A. PowerModel-AI: A First On-the-Fly Machine-Learning Predictor for AC Power Flow Solutions. Energies 2025, 18, 1968. https://doi.org/10.3390/en18081968
Ugwumadu C, Tabarez J, Drabold DA, Pandey A. PowerModel-AI: A First On-the-Fly Machine-Learning Predictor for AC Power Flow Solutions. Energies. 2025; 18(8):1968. https://doi.org/10.3390/en18081968
Chicago/Turabian StyleUgwumadu, C., J. Tabarez, D. A. Drabold, and A. Pandey. 2025. "PowerModel-AI: A First On-the-Fly Machine-Learning Predictor for AC Power Flow Solutions" Energies 18, no. 8: 1968. https://doi.org/10.3390/en18081968
APA StyleUgwumadu, C., Tabarez, J., Drabold, D. A., & Pandey, A. (2025). PowerModel-AI: A First On-the-Fly Machine-Learning Predictor for AC Power Flow Solutions. Energies, 18(8), 1968. https://doi.org/10.3390/en18081968