


An Adaptive Energy Management Strategy for Off-Road Hybrid Tracked Vehicles


Abstract
1. Introduction
2. Modeling and Optimal Control Problem
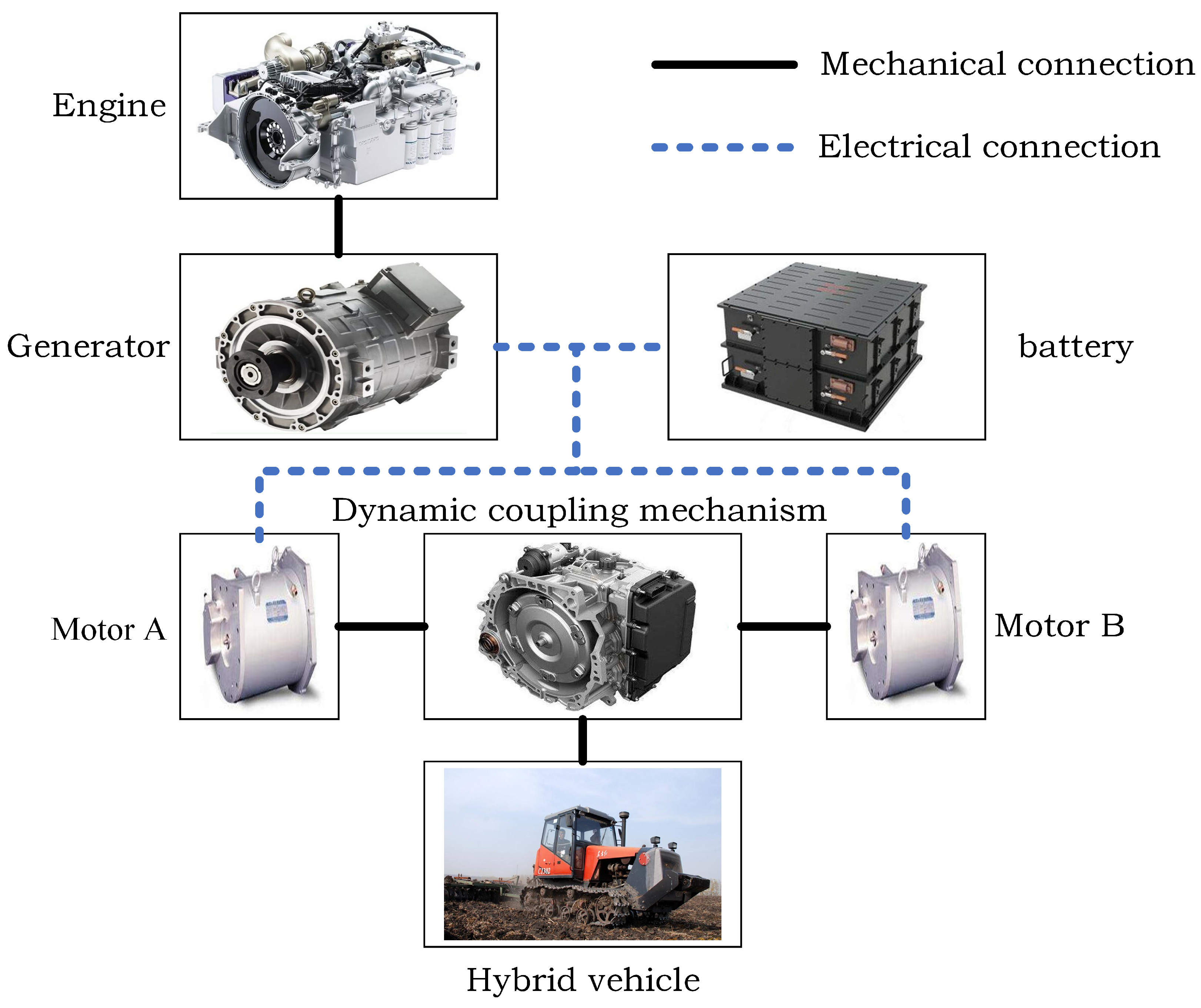
2.1. Hybrid Vehicle Configuration
2.2. Modeling the Hybrid Tracked Vehicle
2.3. Optimal Control Problem
3. Adaptive Reinforcement-Learning-Based Energy Management Strategy
3.1. Demand Power Model Based on Online-Updated Markov Chain
3.1.1. Higher-Order Markov Chain
3.1.2. Online Updating of the MC Model
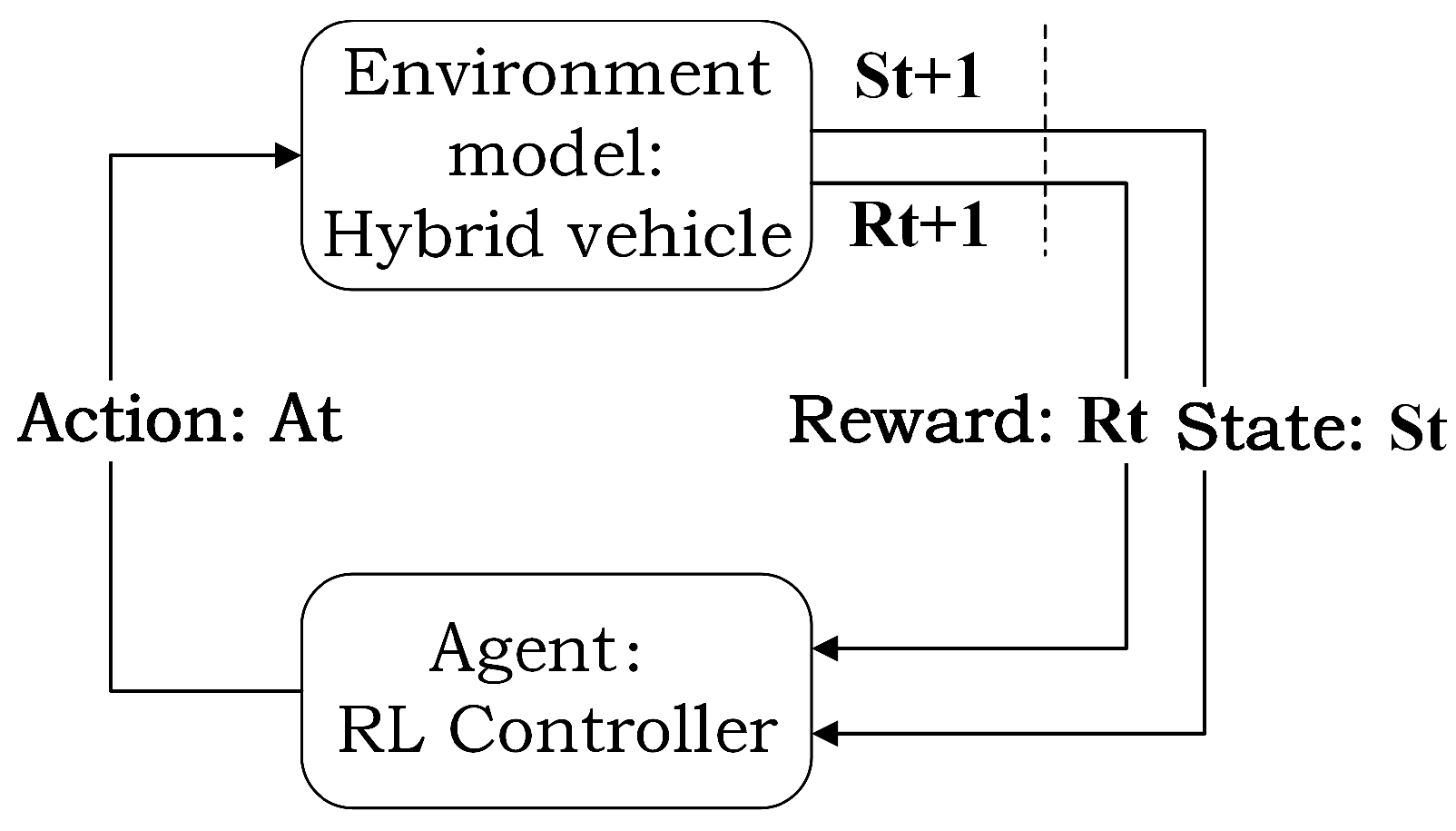
3.2. Reinforcement Learning Approach
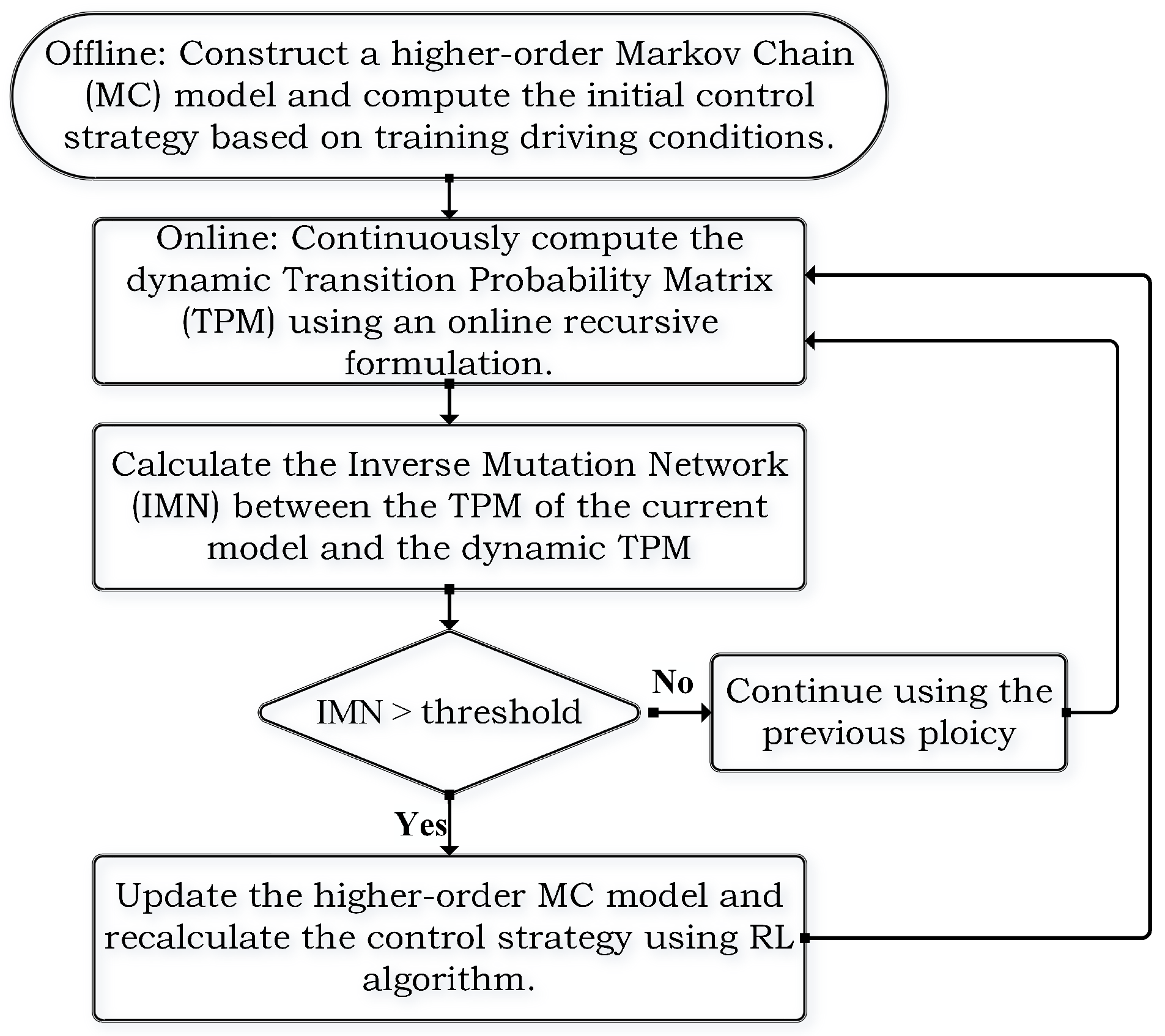
3.3. Adaptive Energy Management Strategy
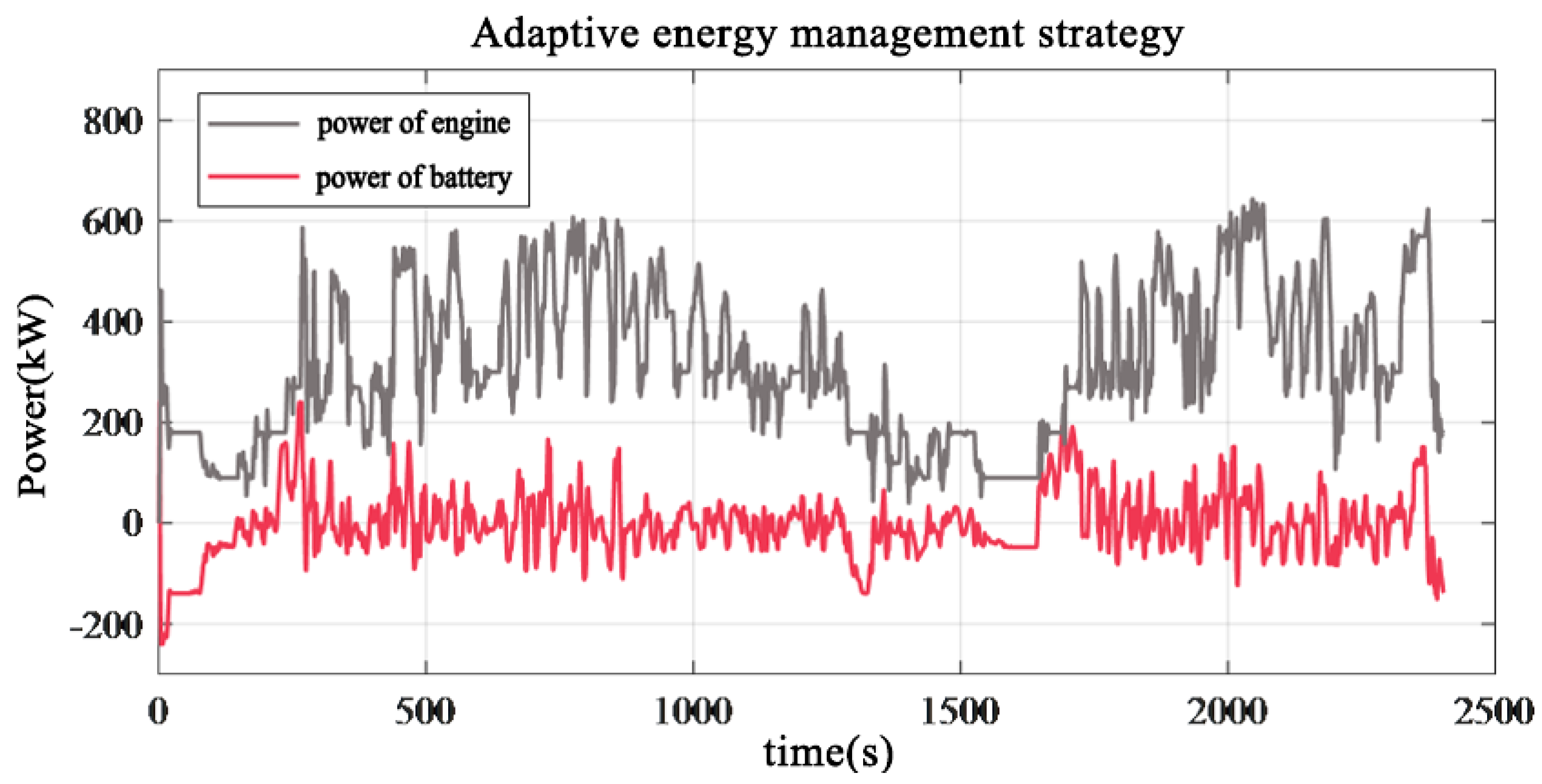
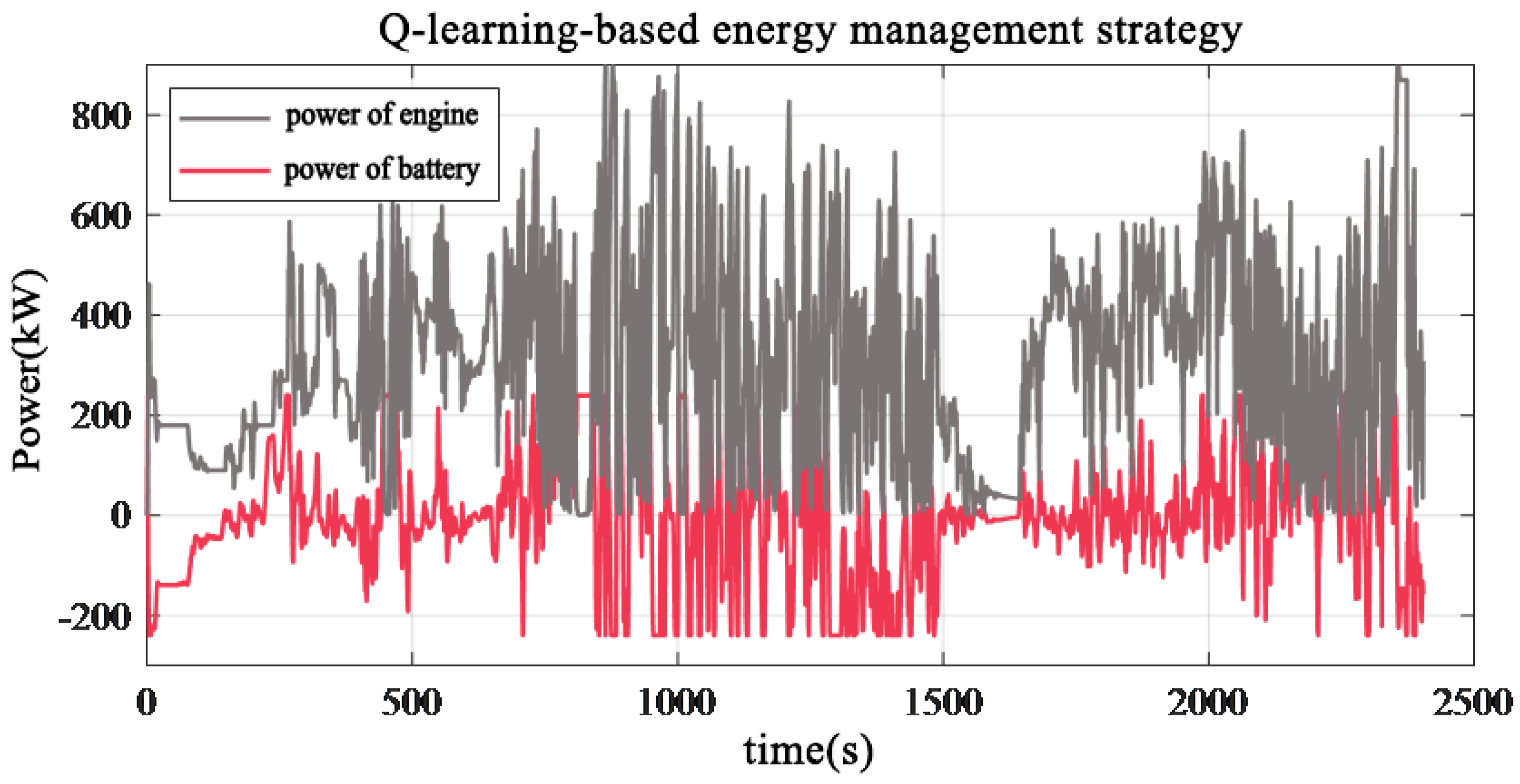
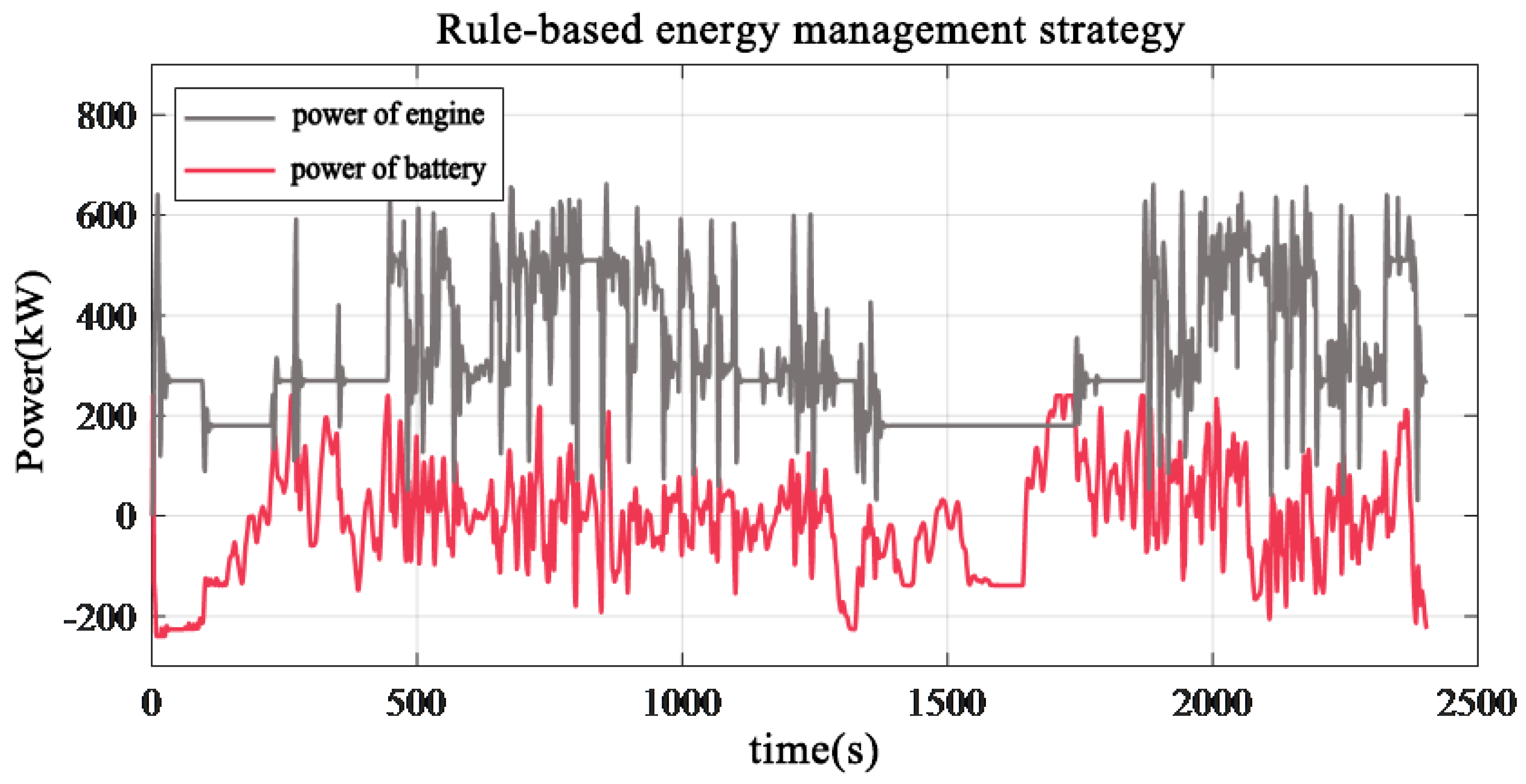
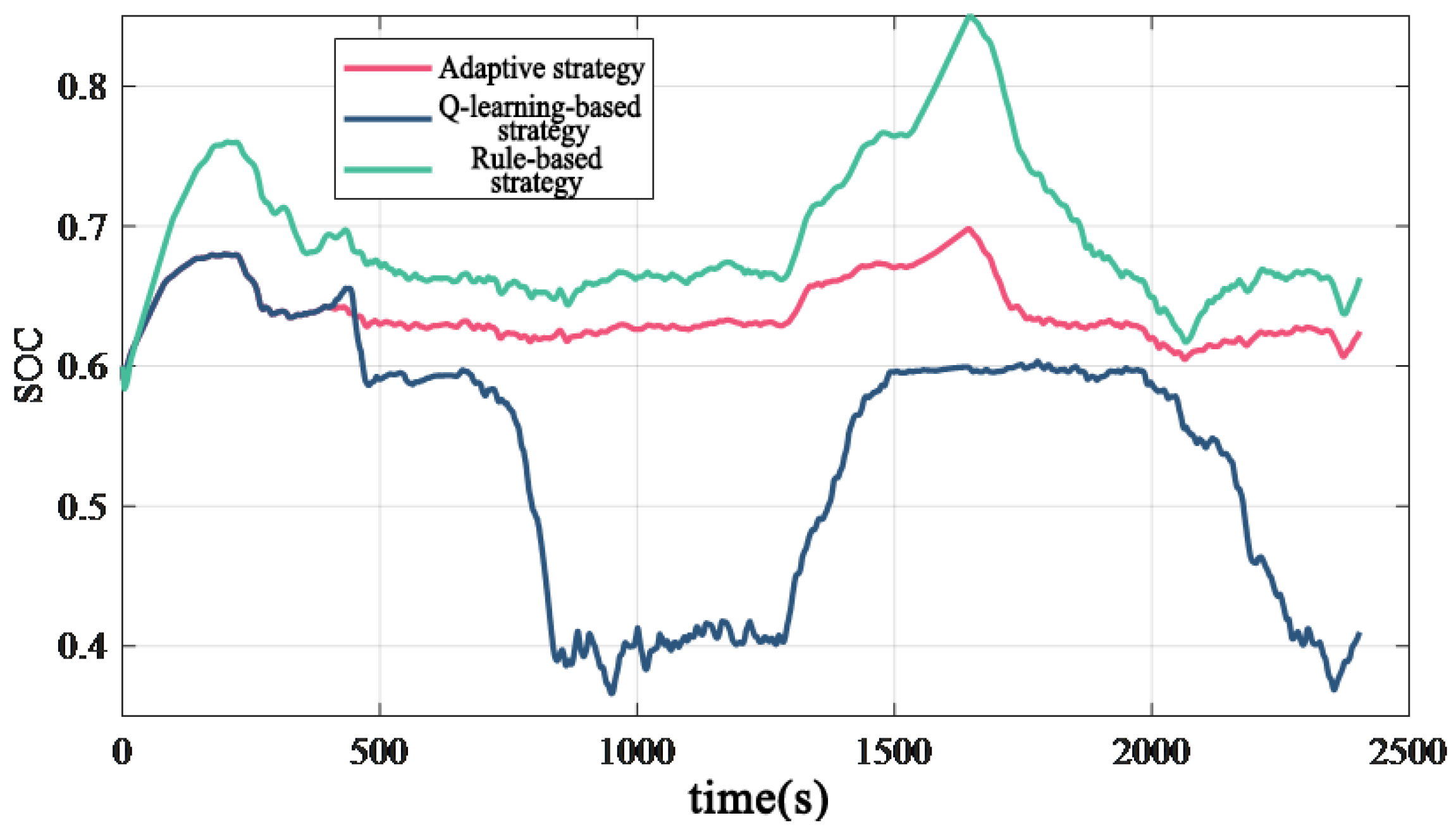
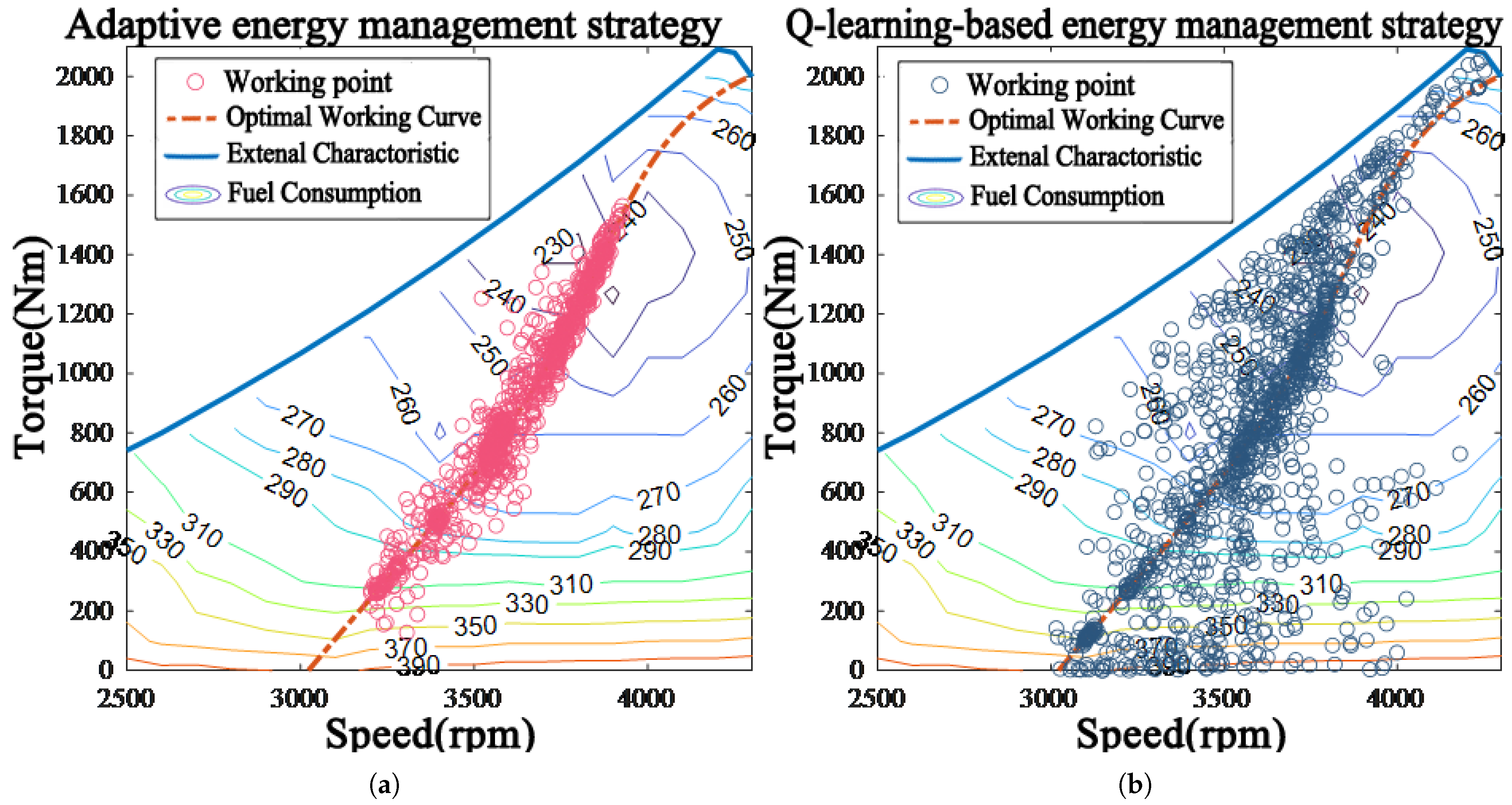
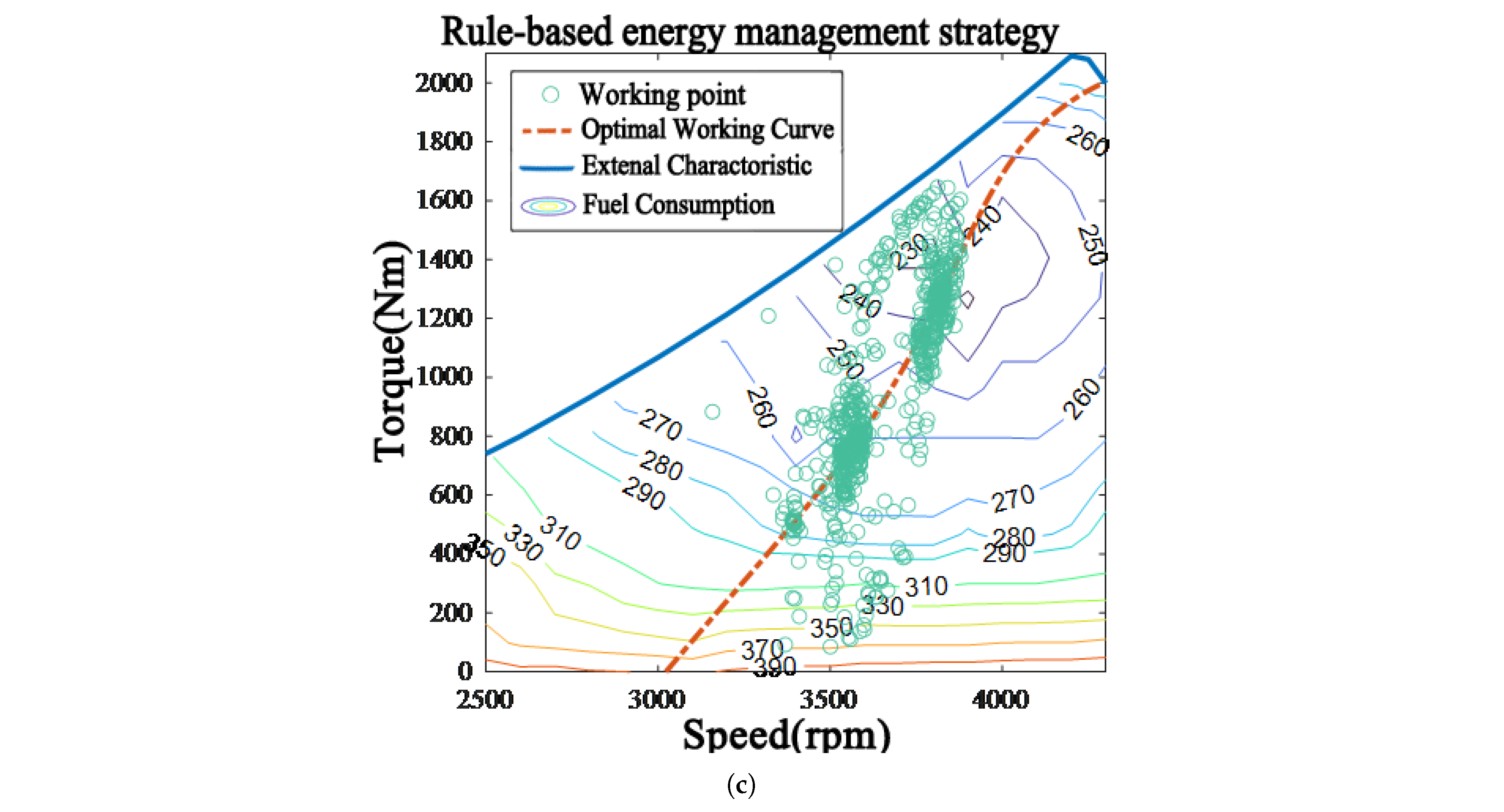
4. Simulation and Validation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhu, Y.; Li, X.; Liu, Q.; Li, S.; Xu, Y. Review article: A comprehensive review of energy management strategies for hybrid electric vehicles. Mech. Sci. 2022, 13, 147–188. [Google Scholar] [CrossRef]
- Ali, A.M.; Moulik, B.; Soffker, D. Intelligent Real-Time Power Management of Multi-Source HEVs Based on Driving State Recognition and Offline Optimization. IEEE Trans. Intell. Transp. Syst. 2023, 24, 247–257. [Google Scholar] [CrossRef]
- Maghfiroh, H.; Wahyunggoro, O.; Cahyadi, A.I. Energy Management in Hybrid Electric and Hybrid Energy Storage System Vehicles: A Fuzzy Logic Controller Review. IEEE Access 2024, 12, 56097–56109. [Google Scholar] [CrossRef]
- Jiang, F.; Yuan, X.; Hu, L.; Xie, G.; Zhang, Z.; Li, X.; Hu, J.; Wang, C.; Wang, H. A comprehensive review of energy storage technology development and application for pure electric vehicles. J. Energy Storage 2024, 86, 111159. [Google Scholar] [CrossRef]
- Nguyen, C.T.P.; Nguyen, B.H.; Trovao, J.P.F.; Ta, M.C. Optimal Energy Management Strategy Based on Driving Pattern Recognition for a Dual-Motor Dual-Source Electric Vehicle. IEEE Trans. Veh. Technol. 2024, 73, 4554–4566. [Google Scholar] [CrossRef]
- Xiao, R.; Liu, B.; Shen, J.; Guo, N.; Yan, W.; Chen, Z. Comparisons of energy management methods for a parallel plug-in hybrid electric vehicle between the convex optimization and dynamic programming. Appl. Sci. 2018, 8, 218. [Google Scholar] [CrossRef]
- Xu, N.; Kong, Y.; Yan, J.; Zhang, Y.; Sui, Y.; Ju, H.; Liu, H.; Xu, Z. Global optimization energy management for multi-energy source vehicles based on “Information layer—Physical layer—Energy layer—Dynamic programming” (IPE-DP). Appl. Energy 2022, 312, 118668. [Google Scholar] [CrossRef]
- Jinquan, G.; Hongwen, H.; Jianwei, L.; Qingwu, L. Real-time energy management of fuel cell hybrid electric buses: Fuel cell engines friendly intersection speed planning. Energy 2021, 226, 120440. [Google Scholar] [CrossRef]
- Li, Q.; Yang, H. Evaluation of two model predictive control schemes with different error compensation strategies for power management in fuel cell hybrid electric buses. J. Energy Storage 2023, 72, 108148. [Google Scholar] [CrossRef]
- Wu, W.; Luo, J.; Zou, T.; Liu, Y.; Yuan, S.; Xiao, B. Systematic design and power management of a novel parallel hybrid electric powertrain for heavy-duty vehicles. Energy 2022, 253, 124165. [Google Scholar] [CrossRef]
- Liu, T.; Wang, B.; Yang, C. Online Markov Chain-based energy management for a hybrid tracked vehicle with speedy Q-learning. Energy 2018, 160, 544–555. [Google Scholar] [CrossRef]
- Liu, R.; Wang, C.; Tang, A.; Zhang, Y.; Yu, Q. A twin delayed deep deterministic policy gradient-based energy management strategy for a battery-ultracapacitor electric vehicle considering driving condition recognition with learning vector quantization neural network. J. Energy Storage 2023, 71, 108147. [Google Scholar] [CrossRef]
- Wang, D.; Mei, L.; Xiao, F.; Song, C.; Qi, C.; Song, S. Energy management strategy for fuel cell electric vehicles based on scalable reinforcement learning in novel environment. Int. J. Hydrogen Energy 2024, 59, 668–678. [Google Scholar] [CrossRef]
- Ibrahim, M.; Jemei, S.; Wimmer, G.; Hissel, D. Nonlinear autoregressive neural network in an energy management strategy for battery/ultra-capacitor hybrid electrical vehicles. Electr. Power Syst. Res. 2016, 136, 262–269. [Google Scholar] [CrossRef]
- Lu, Z.; Tian, H.; Sun, Y.; Li, R.; Tian, G. Neural network energy management strategy with optimal input features for plug-in hybrid electric vehicles. Energy 2023, 285, 129399. [Google Scholar] [CrossRef]
- Huo, D.; Meckl, P. Power Management of a Plug-in Hybrid Electric Vehicle Using Neural Networks with Comparison to Other Approaches. Energies 2022, 15, 5735. [Google Scholar] [CrossRef]
- Sun, H.; Fu, Z.; Tao, F.; Zhu, L.; Si, P. Data-driven reinforcement-learning-based hierarchical energy management strategy for fuel cell/battery/ultracapacitor hybrid electric vehicles. J. Power Sources 2020, 455, 227964. [Google Scholar] [CrossRef]
- Lian, R.; Peng, J.; Wu, Y.; Tan, H.; Zhang, H. Rule-interposing deep reinforcement learning based energy management strategy for power-split hybrid electric vehicle. Energy 2020, 197, 117297. [Google Scholar] [CrossRef]
- Xu, B.; Rathod, D.; Zhang, D.; Yebi, A.; Zhang, X.; Li, X.; Filipi, Z. Parametric study on reinforcement learning optimized energy management strategy for a hybrid electric vehicle. Appl. Energy 2020, 259, 114200. [Google Scholar] [CrossRef]
- Liu, T.; Zou, Y.; Liu, D.; Sun, F. Reinforcement learning-based energy management strategy for a hybrid electric tracked vehicle. Energies 2015, 8, 7243–7260. [Google Scholar] [CrossRef]
- Sutton, R.; Barto, A. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Value | Unit |
|---|---|---|
| Vehicle mass M | 25,000 | kg |
| Minimum State of Charge | 0.3 | / |
| Maximum State of Charge | 0.9 | / |
| Battery capacity | 80 | Ah |
| Engine inertia | 3 | |
| Windward area A | 5 | |
| Air resistance coefficient | 0.6 | / |
| Strategy | Final SOC | Equivalent Fuel Consumption (L) | Relative Reduction (%) |
|---|---|---|---|
| adaptive strategy | 0.625 | 62.32 | 100 |
| Q-learning-based strategy | 0.410 | 67.49 | 92.3 |
| rule-based strategy | 0.663 | 66.52 | 93.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, L.; Shi, W.; Yang, N. An Adaptive Energy Management Strategy for Off-Road Hybrid Tracked Vehicles. Energies 2025, 18, 1371. https://doi.org/10.3390/en18061371
Han L, Shi W, Yang N. An Adaptive Energy Management Strategy for Off-Road Hybrid Tracked Vehicles. Energies. 2025; 18(6):1371. https://doi.org/10.3390/en18061371
Chicago/Turabian StyleHan, Lijin, Wenhui Shi, and Ningkang Yang. 2025. "An Adaptive Energy Management Strategy for Off-Road Hybrid Tracked Vehicles" Energies 18, no. 6: 1371. https://doi.org/10.3390/en18061371
APA StyleHan, L., Shi, W., & Yang, N. (2025). An Adaptive Energy Management Strategy for Off-Road Hybrid Tracked Vehicles. Energies, 18(6), 1371. https://doi.org/10.3390/en18061371