
Artificial Intelligence-Driven Approach to Optimizing Boiler Power Generation Efficiency: The Advanced Boiler Combustion Control Model




Abstract
1. Introduction
1.1. Study Background
1.1.1. Global Climate Crisis and Carbon Reduction Efforts in Steel Mills
1.1.2. Improving Energy Efficiency Through By-Product Gases in Integrated Steel Mills
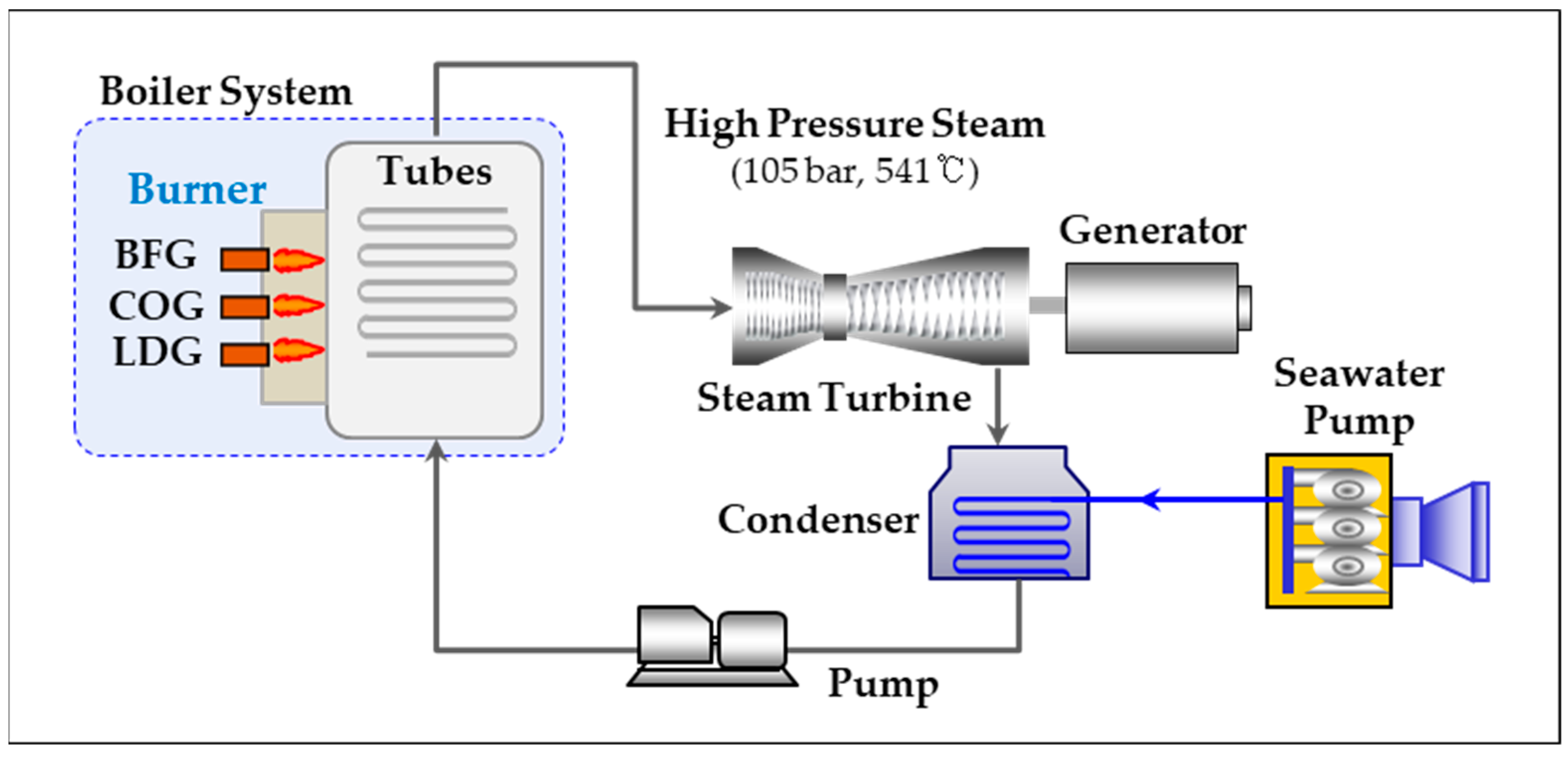
1.1.3. Status of By-Product Gas Power Generation and Features of Steam Power Boilers at Company P
1.2. Problem Statement and Research Objectives
1.3. Research Process
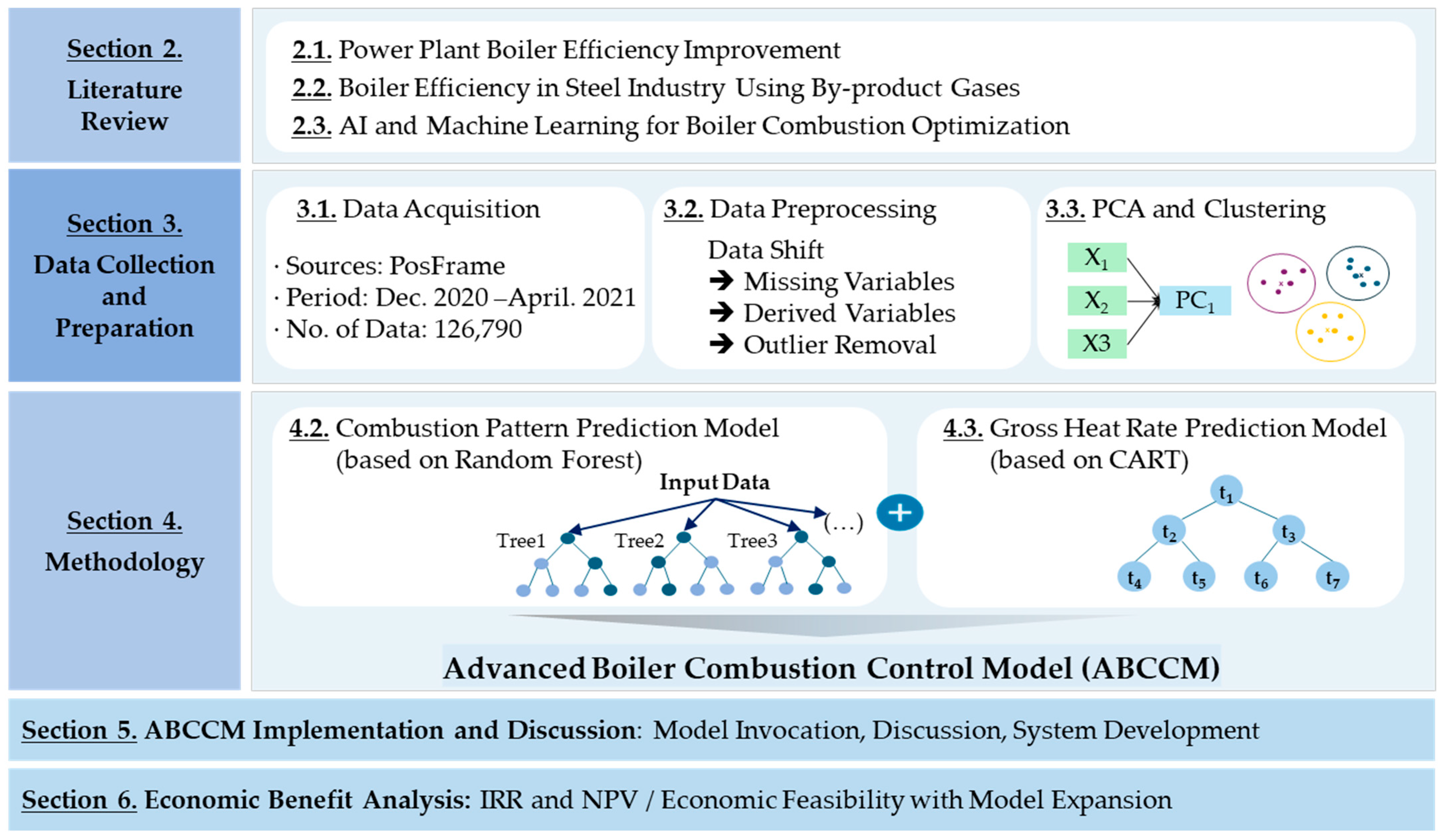
2. Literature Review
2.1. Studies on Performance and Efficiency Improvement of Power Boilers
2.2. Studies on Performance and Efficiency Improvement of Self-Generation Boilers
2.3. Studies on Boiler Combustion Optimization Using ML and AI
2.4. Recent Advances in the Application of AI for Industrial Optimization
2.5. Limitations of Previous Research
- Real-time data processing and variability management: Unlike traditional studies that rely on static data-based optimization, the ABCCM manages key variables based on real-time data, effectively addressing variability in operations.
- ML-based combustion optimization: In contrast to existing studies that use single algorithms, the ABCCM combines the RF and CART algorithms to simultaneously enhance combustion efficiency and prediction accuracy.
- Efficient use of by-product gases: Previous studies often failed to account for variations in the composition and supply of by-product gases, limiting fuel efficiency. The ABCCM effectively incorporates changes in the mixing ratios and compositions of by-product gases, such as BFG, COG, and LDG, contributing to energy efficiency and cost savings.
- Carbon emission reduction and sustainability: By optimizing the oxygen supply and minimizing fuel waste, the ABCCM reduces carbon emissions, supporting the carbon neutrality goals of the steel industry.
3. Data Collection and Preparation
3.1. Data Acquisition
- Fuel data: This category included 16 variables that evaluated the physical properties and energy performance of the by-product gases (BFG, COG, LDG), such as the pressure, calorific value, and flow rate.
- Combustion data: Comprising 31 variables, this category encompassed the combustion state within the boiler, including the oxygen concentration, NOx concentration, and other relevant parameters.
- Power Generation data: This category comprised seven variables related to energy management and performance evaluation in the power plants, including the active power, reactive power, power consumption, current, and voltage.
3.2. Data Preprocessing
3.2.1. Data Shift and Missing Value Processing
3.2.2. Derived Variables and Outlier Processing
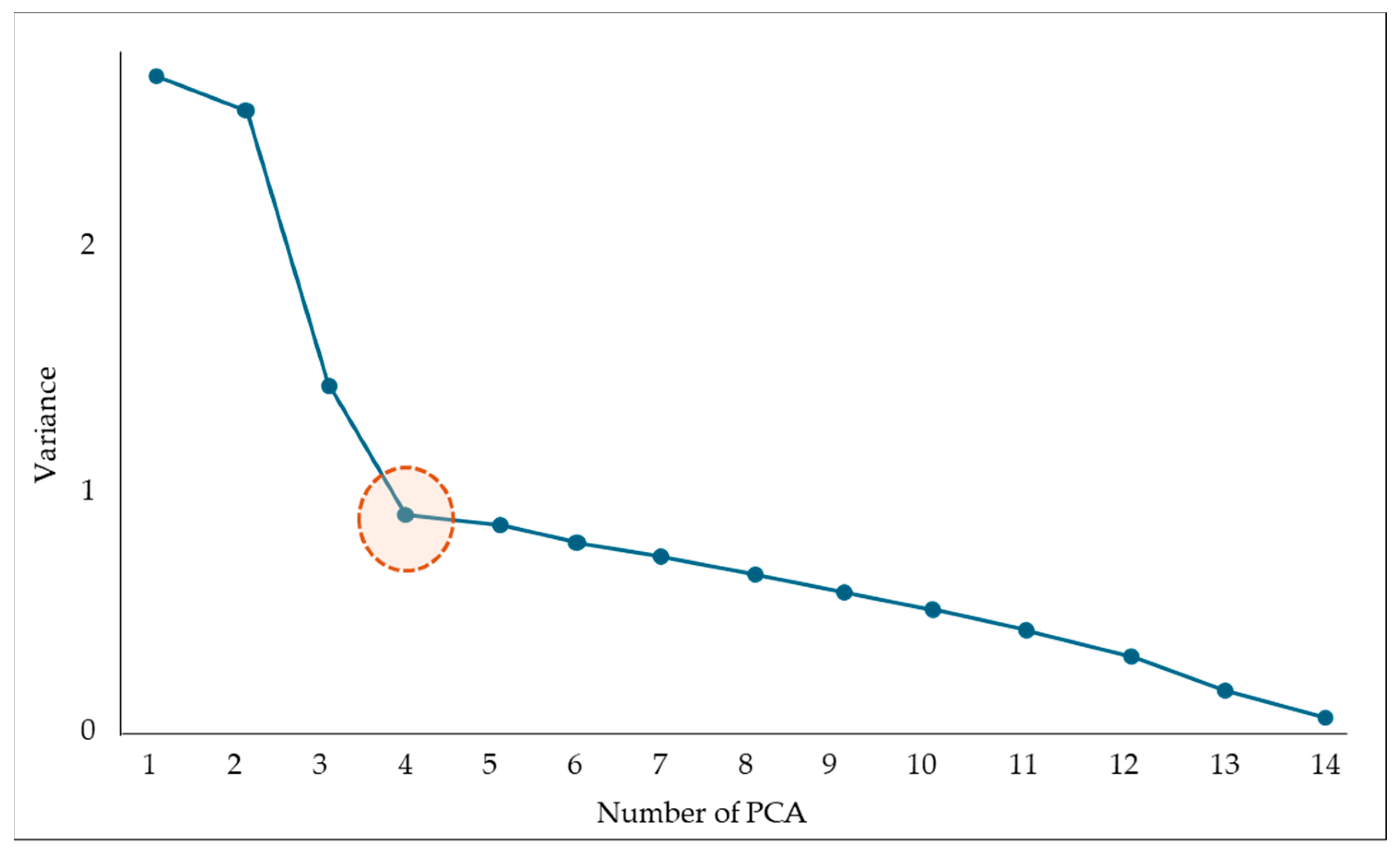
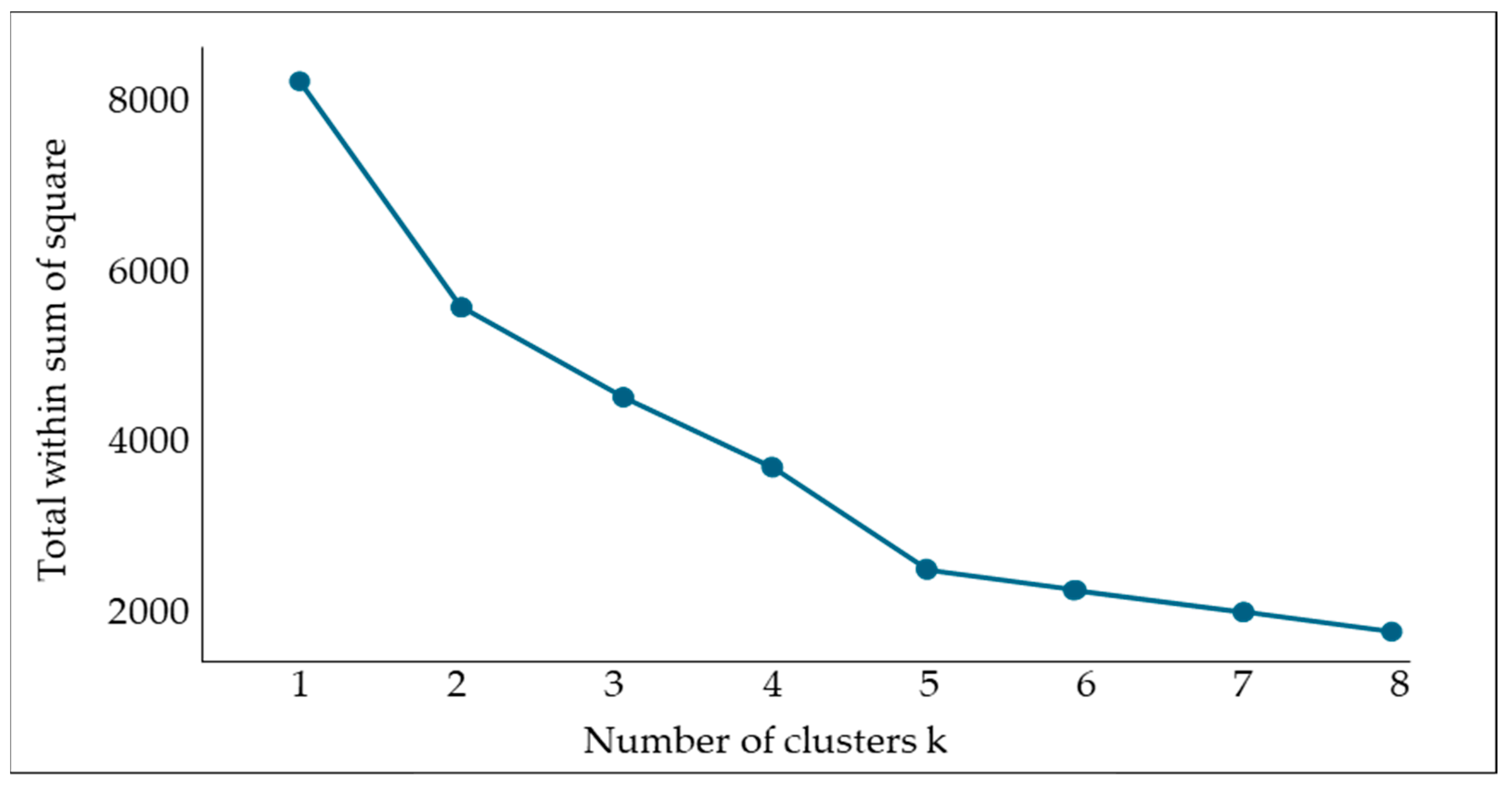
3.3. Data Scaling (PCA and Clustering)
4. Methodology
4.1. Introduction to Boiler Burner Operation and Relationship with Gross Heat Rate
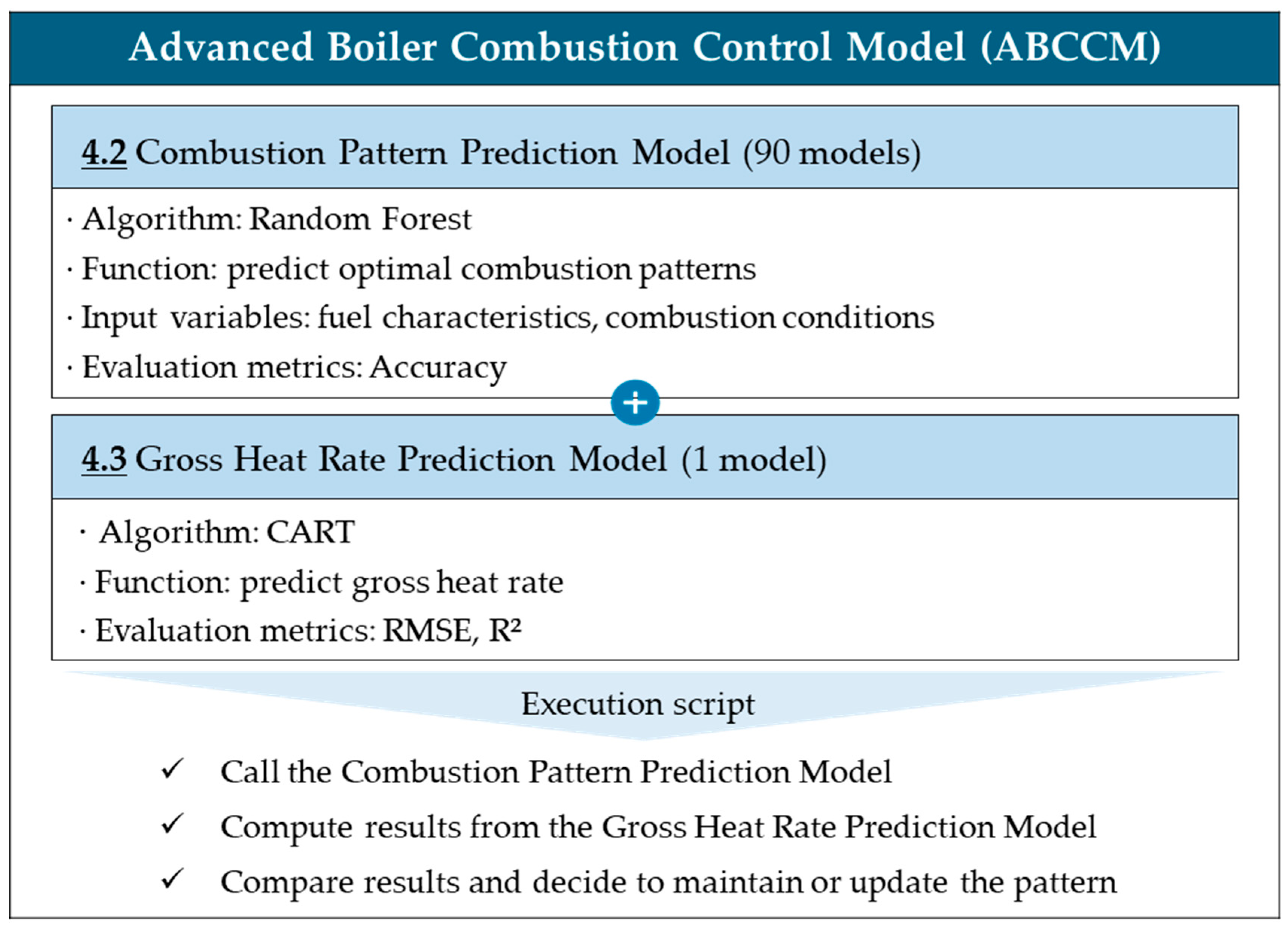
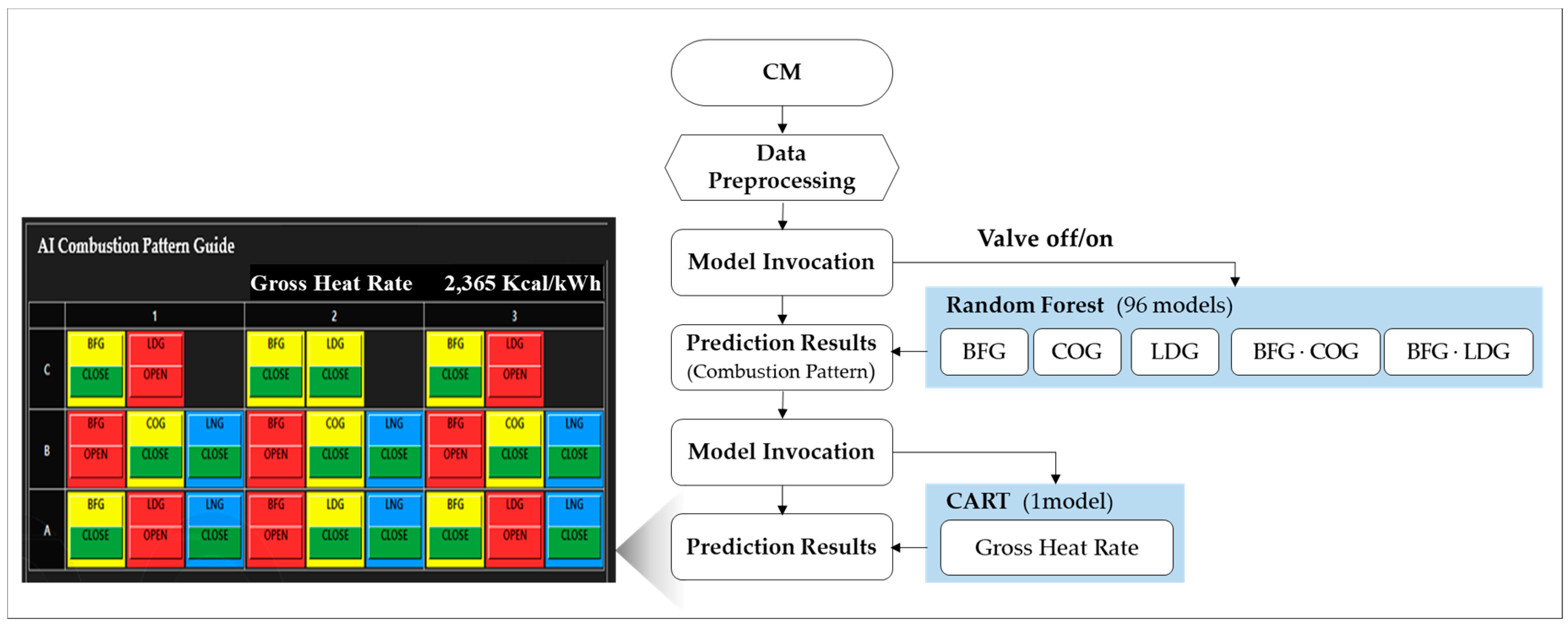
4.2. Optimal Combustion Pattern Prediction Model
4.2.1. Model Selection for Optimal Combustion Pattern Prediction
4.2.2. Modeling
4.2.3. RF Model Training and Hyper Parameters
4.2.4. Testing the Optimal Combustion Pattern Prediction Model
4.3. Gross Heat Rate Prediction Model
4.3.1. Model Selection for Gross Heat Rate Prediction
4.3.2. Modeling
4.3.3. CART Model Training
4.3.4. Testing the Gross Heat Rate Prediction Model
5. Results: ABCCM Implementation and Discussion
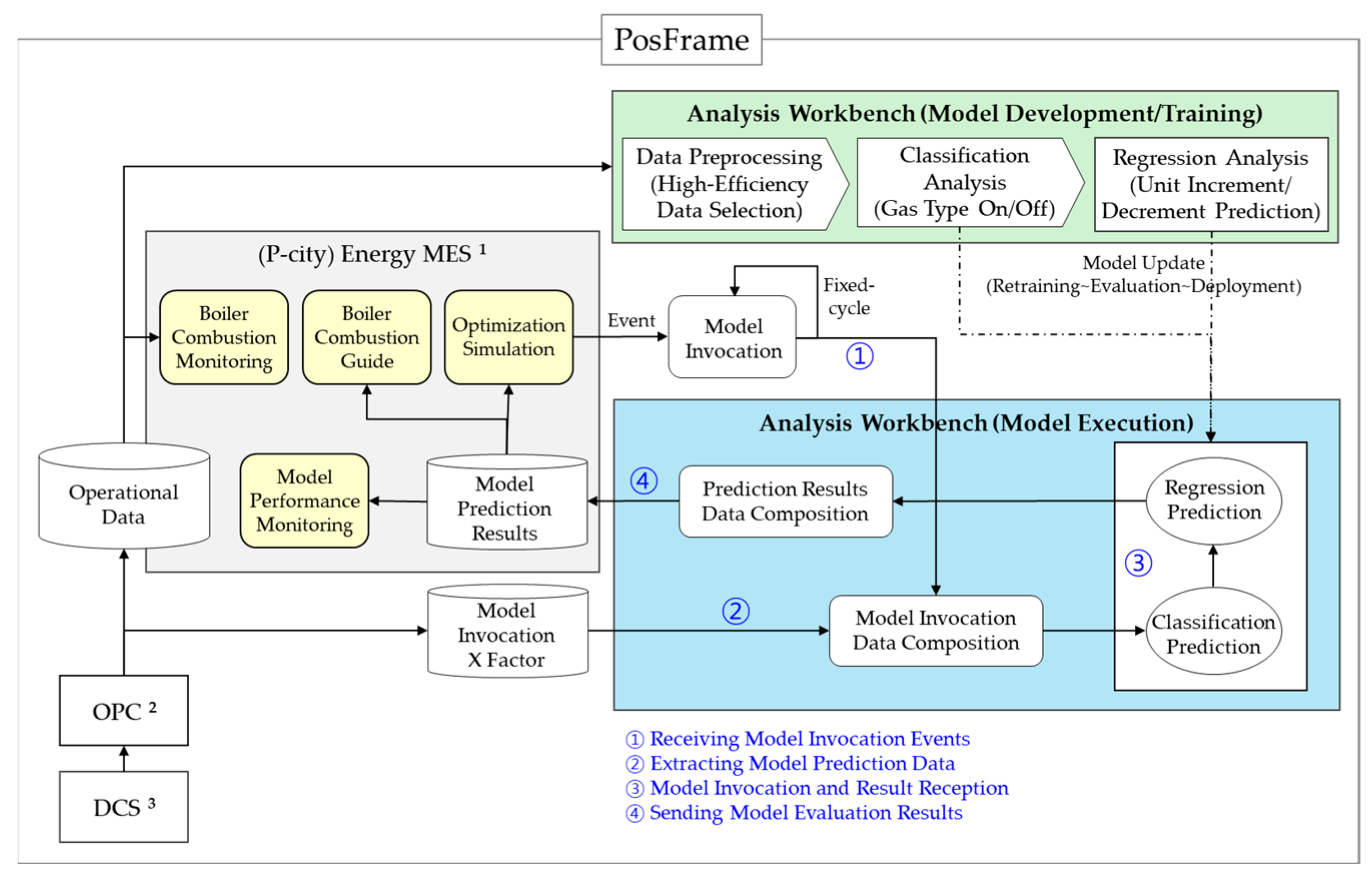
5.1. Implementation Set-Up of the ABCCM (Model Execution)
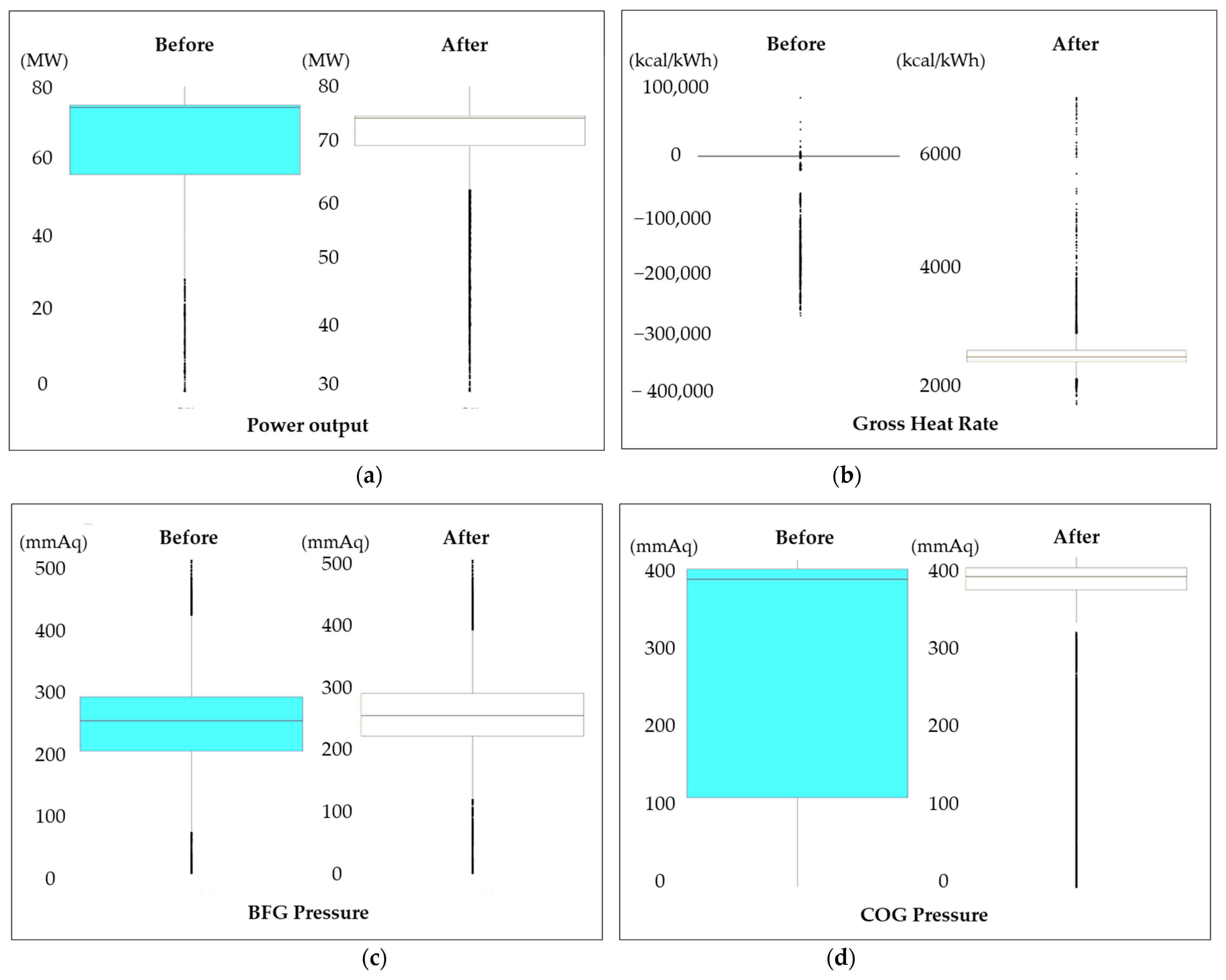
5.2. Implementation Results of the ABCCM (Test Results)
5.3. Discussion
5.4. System Development
6. Economic Benefits Analysis
7. Conclusions
7.1. Summary and Contributions
- Energy efficiency improvement: The ABCCM improved combustion efficiency by 0.86% compared to manual control methods, resulting in a 1.7% increase in power generation efficiency. Additionally, the gross heat rate decreased by 58.3 kcal/kWh, leading to reduced fuel consumption and improved energy efficiency.
- Economic impact: The improvement in combustion efficiency achieved annual energy cost savings of approximately USD 89.6 K, providing considerable evidence of operational cost reductions and enhanced profitability in the steel industry.
- Carbon emission reduction: The optimization of by-product gas combustion had enormous environmental benefits, primarily in the form of reduced carbon emissions. By preventing incomplete combustion and excessive oxygen supply, the system offers practical data supporting carbon neutrality goals.
- Effectiveness of ML-based optimization: By combining the RF and CART algorithms, the ABCCM simultaneously improved the model prediction accuracy and combustion efficiency, demonstrating the feasibility of automated, real-time combustion control based on data-driven insights.
- Versatility in industrial applications: Beyond the steel industry, the ABCCM has potential applications in other energy-intensive sectors, such as the power plant, cement production, and petrochemical sectors, setting itself apart from prior research that was limited to specific industries or conditions.
7.2. Limitations and Future Work
- Enhancing system performance for industrial efficiency: Future research should focus on optimizing system performance across its entire lifecycle through the integration of digital twin and ML technologies [57]. A critical aspect of this research involved improving predictive capabilities by accounting for the fluctuating nature of fuel characteristics under diverse fuel types and operating conditions. Moreover, the applicability and scalability of the ABCCM should be assessed using long-term data, while the model’s robustness and reliability must be validated.
- Adopting advanced AI techniques and automation: To enhance the adaptability and predictive performance of the ABCCM model, it is necessary to introduce advanced AI technologies. Advanced AI techniques, such as DL and reinforcement learning, can provide effective solutions for complex combustion environments. Moreover, to reduce the operator burden and enhance combustion optimization, it is necessary to build a fully automated control system capable of operating without operator intervention, going beyond guidance functionality. To this end, it is necessary to advance toward automation and real-time monitoring of combustion control by using advanced technologies such as AI, IoT, and big data.
- Addressing environmentally friendly steelmaking processes and carbon neutrality: It is necessary to develop models that reflect the combustion environment and fuel characteristics of environmentally friendly steelmaking processes such as hydrogen-based direct reduction. Optimization studies are also needed to improve the energy efficiency and reduce the operating costs in electric arc furnace-based steelmaking processes. Moreover, as the reduction of by-product gas generation in processes such as blast furnaces and converters is expected owing to the reduction in these processes, research is needed to address this problem and prepare for the phased closure of existing thermal power plants. In particular, the possibility of converting to hydrogen co-firing technology for steam turbines should be explored to minimize carbon emissions and maximize energy efficiency.
- Extensive field research: To strengthen the applicability of the ABCCM, extensive field research is required in various steel production processes and power generation facilities. Accordingly, the economic and environmental effects should be quantitatively verified and developed into sustainable technology solutions. Field research will play a key role in proving the universality of the model and confirming its applicability in various industrial environments.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ABCCM | Advanced Boiler Combustion Control Model |
| BFG | Blast furnace gas |
| BOP | Balance of plant |
| CART | Classification and regression tree |
| CM | Configuration Manager |
| COG | Coke oven gas |
| CP | Complexity parameter |
| H/R | Heat rate |
| KDD | Knowledge Discovery in Database |
| LDG | Linz–Donawiz converter gas |
| LNG | Liquefied natural gas |
| LR | Logistic regression |
| MAE | Mean absolute error |
| MES | Manufacturing execution system |
| ML | Machine learning |
| PLSR | Partial least squares regression |
| UCC | Utility control center |
References
- The International Energy Agency (IEA). Emissions Measurement and Data Collection for a Net Zero Steel Industry. Available online: https://www.iea.org/reports/emissions-measurement-and-data-collection-for-a-net-zero-steel-industry (accessed on 24 September 2024).
- The International Energy Agency (IEA). Net Zero Road Map A Global Pathway to Keep the 1.5 °C Goal in Reach. Available online: https://www.iea.org/reports/net-zero-roadmap-a-global-pathway-to-keep-the-15-0c-goal-in-reach (accessed on 12 September 2024).
- Lee, J.-Y.T.; Tak, E.M.; Kim, J.H. The Impact of the EU’s Carbon Border Adjustment Mechanism on the Korean Steel Trade, with Implications for Policy; KIET: Sejong, Republic of Korea, 2024. [Google Scholar] [CrossRef]
- Solutions for Our Climate. The South Korean Steel Industry and Carbon Neutrality. Available online: https://forourclimate.org/research/426 (accessed on 21 October 2024).
- Kang, B.-U. Scenario Analysis of Iron and Steel Production Process for Carbon Neutrality; KEEI: Seoul, Republic of Korea, 2022; Available online: https://www.keei.re.kr/board.es?mid=a20102000000&bid=0028 (accessed on 27 September 2024).
- Kumar, B.; Roy, G.G.; Sen, P.K. Comparative exergy analysis between rotary hearth furnace-electric arc furnace and blast furnace-basic oxygen furnace steelmaking routes. Energy Clim. Chang. 2020, 1, 100016. [Google Scholar] [CrossRef]
- Teo, P.T.; Zakaria, S.K.; Salleh, S.Z.; Taib, M.A.A.; Mohd Sharif, N.; Abu Seman, A.; Mohamed, J.J.; Yusoff, M.; Yusoff, A.H.; Mohamad, M. Assessment of electric arc furnace (EAF) steel slag waste’s recycling options into value added green products: A review. Metals 2020, 10, 1347. [Google Scholar] [CrossRef]
- Nduagu, E.I.; Yadav, D.; Bhardwaj, N.; Elango, S.; Biswas, T.; Banerjee, R.; Rajagopalan, S. Comparative life cycle assessment of natural gas and coal-based directly reduced iron (DRI) production: A case study for India. J. Clean. Prod. 2022, 347, 131196. [Google Scholar] [CrossRef]
- DePree, P.J.; Ferry, C.T. Mitigation of expansive electric arc furnace slag in brownfield redevelopment. In Proceedings of the GeoCongress 2008: Geosustainability and Geohazard Mitigation, New Orleans, LA, USA, 9 March 2008; pp. 271–278. [Google Scholar] [CrossRef]
- Uribe-Soto, W.; Portha, J.-F.; Commenge, J.-M.; Falk, L. A review of thermochemical processes and technologies to use steelworks off-gases. Renew. Sustain. Energy Rev. 2017, 74, 809–823. [Google Scholar] [CrossRef]
- Hou, S.S.; Chen, C.H.; Chang, C.Y.; Wu, C.W.; Ou, J.J.; Lin, T.H. Firing blast furnace gas without support fuel in steel mill boilers. Energy Convers. Manag. 2011, 52, 2758–2767. [Google Scholar] [CrossRef]
- World Steel Association. Energy Use in the Steel Industry. Available online: https://worldsteel.org/wp-content/uploads/Fact-sheet-energy-in-the-steel-industry-2021-1.pdf (accessed on 26 October 2024).
- Branca, T.A.; Colla, V.; Algermissen, D.; Granbom, H.; Martini, U.; Morillon, A.; Pietruck, R.; Rosendahl, S. Reuse and recycling of by-products in the steel sector: Recent achievements paving the way to circular economy and industrial symbiosis in Europe. Metals 2020, 10, 345. [Google Scholar] [CrossRef]
- Kamran, M. Fundamentals of Smart Grid Systems; Elsevier: Amsterdam, The Netherlands, 2022. [Google Scholar] [CrossRef]
- POSCO. Great Conversion to Low-Carbon Eco-Friendly Steelmaking Process. Available online: http://product.posco.com/homepage/product/eng/jsp/news/s91w4000120v.jsp?SEQ=526 (accessed on 17 November 2024).
- Elwardany, M. Enhancing steam boiler efficiency through comprehensive energy and exergy analysis: A review. Process Saf. Environ. Prot. 2024, 184, 1222–1250. [Google Scholar] [CrossRef]
- Zhu, C.; Huang, P.; Li, Y. Closed-loop combustion optimization based on dynamic and adaptive models with application to a coal-fired boiler. Energies 2022, 15, 5289. [Google Scholar] [CrossRef]
- Jin, Y.; Sun, Y.; Zhang, Y.; Jiang, Z. Research on air distribution control strategy of supercritical boiler. Energies 2022, 16, 458. [Google Scholar] [CrossRef]
- Li, S.; Wang, Y. Performance assessment of a boiler combustion process control system based on a data-driven approach. Processes 2018, 6, 200. [Google Scholar] [CrossRef]
- Lee, T.; Han, E.; Moon, U.-C.; Lee, K.Y. Supplementary control of air–fuel ratio using dynamic matrix control for thermal power plant emission. Energies 2020, 13, 226. [Google Scholar] [CrossRef]
- Wang, Z.; Xue, W.; Li, K.; Tang, Z.; Liu, Y.; Zhang, F.; Cao, S.; Peng, X.; Wu, E.Q.; Zhou, H. Dynamic combustion optimization of a pulverized coal boiler considering the wall temperature constraints: A deep reinforcement learning-based framework. Appl. Therm. Eng. 2025, 259, 124923. [Google Scholar] [CrossRef]
- Wu, F.; Zhou, H.; Zhao, J.-P.; Cen, K.-F. A comparative study of the multi-objective optimization algorithms for coal-fired boilers. Expert Syst. Appl. 2011, 38, 7179–7185. [Google Scholar] [CrossRef]
- Zhao, H.; Shen, J.; Li, Y.; Bentsman, J. Coal-fired utility boiler modelling for advanced economical low-NOx combustion controller design. Control. Eng. Pract. 2017, 58, 127–141. [Google Scholar] [CrossRef]
- Rahat, A.A.M.; Wang, C.; Everson, R.M.; Fieldsend, J.E. Data-driven multi-objective optimisation of coal-fired boiler combustion systems. Appl. Energy 2018, 229, 446–458. [Google Scholar] [CrossRef]
- Sinha, A.; Das, D.; Palavalasa, S.K. dClink: A data-driven based clinkering prediction framework with automatic feature selection capability in 500 MW coal-fired boilers. Energy 2023, 276, 127448. [Google Scholar] [CrossRef]
- Wu, Y.; Wang, Z.; Shi, C.; Jin, X.; Xu, Z. A novel data-driven approach for coal-fired boiler under deep peak shaving to predict and optimize NOx emission and heat exchange performance. Energy 2024, 304, 132106. [Google Scholar] [CrossRef]
- Xu, W.; Poh, K.; Song, S.; Huang, Y. Research on reducing pollutant, improving efficiency and enhancing running safety for 1000 MW coal-fired boiler based on data-driven evolutionary optimization and online retrieval method. Appl. Energy 2025, 377, 123958. [Google Scholar] [CrossRef]
- de Oliveira Junior, V.B.; Pena, J.G.C.; Salles, J.L.F. An improved plant-wide multiperiod optimization model of a byproduct gas supply system in the iron and steel-making process. Appl. Energy 2016, 164, 462–474. [Google Scholar] [CrossRef]
- Zhao, J.; Sheng, C.; Wang, W.; Pedrycz, W.; Liu, Q. Data-based predictive optimization for byproduct gas system in steel industry. IEEE Trans. Autom. Sci. Eng. 2017, 14, 1761–1770. [Google Scholar] [CrossRef]
- Zeng, Y.; Xiao, X.; Li, J.; Sun, L.; Floudas, C.A.; Li, H. A novel multi-period mixed-integer linear optimization model for optimal distribution of byproduct gases, steam and power in an iron and steel plant. Energy 2018, 143, 881–899. [Google Scholar] [CrossRef]
- Kim, Y.-K.; Lee, E.-B. Optimization simulation, using steel plant off-gas for power generation: A life-cycle cost analysis approach. Energies 2018, 11, 2884. [Google Scholar] [CrossRef]
- EN 12952-15; Water-Tube Boilers and Auxiliary Installations—Part 15: Acceptance Tests. European Committee for Standardization: Brussels, Belgium, 2003.
- Szega, M.; Czyż, T. Problems of calculation the energy efficiency of a dual-fuel steam boiler fired with industrial waste gases. Energy 2019, 178, 134–144. [Google Scholar] [CrossRef]
- Lee, S.-M.; Choi, S.-W.; Lee, E.-B. Prediction modeling of flue gas control for combustion efficiency optimization for steel mill power plant boilers based on partial least squares regression (PLSR). Energies 2023, 16, 6907. [Google Scholar] [CrossRef]
- Majeed, A.; Ali, P.; Mir, A.; Alshammari, B.M.; Kolsi, L. Three-stage Lobatto analysis on hydrodynamic Eyring-powell flow of nanofluid: Impact of viscous dissipation, thermal radiation, and wall slip dynamics. J. Radiat. Res. Appl. Sci. 2024, 17, 101207. [Google Scholar] [CrossRef]
- Feng, Y.; Hao, H.; Chow, C.L.; Lau, D. Exploring reaction mechanisms and kinetics of cellulose combustion via ReaxFF molecular dynamics simulations. Chem. Eng. J. 2024, 488, 151023. [Google Scholar] [CrossRef]
- Iliev, I.K.; Filimonova, A.A.; Chichirov, A.A.; Chichirova, N.D.; Kangalov, P.G. Computational and Experimental Research on the Influence of Supplied Gas Fuel Mixture on High-Temperature Fuel Cell Performance Characteristics. Energies 2024, 17, 2452. [Google Scholar] [CrossRef]
- Neves, F.; Soares, A.A.; Rouboa, A. A Comparison of Different Biomass Combustion Mechanisms in the Transient State. Energies 2024, 17, 2092. [Google Scholar] [CrossRef]
- Mondal, M.N.A.; Karimi, N.; Jackson, S.D.; Paul, M.C. Enhancing the performance of catalysts in turbulent premixed fuel-lean hydrogen/air combustion. Chem. Eng. Sci. 2025, 301, 120747. [Google Scholar] [CrossRef]
- Liu, X.; Bansal, R.C. Integrating multi-objective optimization with computational fluid dynamics to optimize boiler combustion process of a coal fired power plant. Appl. Energy 2014, 130, 658–669. [Google Scholar] [CrossRef]
- Tang, Z.; Zhang, H.; Yang, H. Artificial neural networks model for predicting oxygen content in flue gas of power plant. In Proceedings of the 2017 29th Chinese Control and Decision Conference (CCDC), Chongqing, China, 28–30 May 2017; IEEE: New York, NY, USA, 2017; pp. 1379–1382. [Google Scholar] [CrossRef]
- Safdarnejad, S.M.; Tuttle, J.F.; Powell, K.M. Dynamic modeling and optimization of a coal-fired utility boiler to forecast and minimize NOx and CO emissions simultaneously. Comput. Chem. Eng. 2019, 124, 62–79. [Google Scholar] [CrossRef]
- Shi, Y.; Zhong, W.; Chen, X.; Yu, A.B.; Li, J. Combustion optimization of ultra supercritical boiler based on artificial intelligence. Energy 2019, 170, 804–817. [Google Scholar] [CrossRef]
- Fedorov, R.; Kovalnogov, V.; Generalov, D.; Sapunov, V.; Busygin, S. Predicting the optimal operation of burners based on random forest. In International Conference Artificial Intelligence in Engineering and Science; Springer: Berlin/Heidelberg, Germany, 2022; pp. 383–394. [Google Scholar] [CrossRef]
- Kovalnogov, V.; Fedorov, R.; Klyachkin, V.; Generalov, D.; Kuvayskova, Y.; Busygin, S. Applying the random forest method to improve burner efficiency. Mathematics 2022, 10, 2143. [Google Scholar] [CrossRef]
- Butakov, E.; Abdurakipov, S. The application of machine learning techniques to detect combustion modes in a pulverised coal boiler. E3S Web Conf. 2023, 459, 07012. [Google Scholar] [CrossRef]
- Nemitallah, M.A.; Nabhan, M.A.; Alowaifeer, M.; Haeruman, A.; Alzahrani, F.; Habib, M.A.; Elshafei, M.; Abouheaf, M.I.; Aliyu, M.; Alfarraj, M. Artificial intelligence for control and optimization of boilers’ performance and emissions: A review. J. Clean. Prod. 2023, 417, 138109. [Google Scholar] [CrossRef]
- Ronquillo-Lomeli, G.; García-Moreno, A.-I. A machine learning-based approach for flames classification in industrial heavy oil-fire boilers. Expert Syst. Appl. 2024, 238, 122188. [Google Scholar] [CrossRef]
- Priya, A.; Devarajan, B.; Alagumalai, A.; Song, H. Artificial intelligence enabled carbon capture: A review. Sci. Total Environ. 2023, 886, 163913. [Google Scholar] [CrossRef] [PubMed]
- Shin, D.; Lee, J.; Son, J.; Yun, Y.; Song, Y.; Song, J. Intelligent Combustion Control in Waste-to-Energy Facilities: Enhancing Efficiency and Reducing Emissions Using AI and IoT. Energies 2024, 17, 4634. [Google Scholar] [CrossRef]
- Chen, M.; Zou, Z.; Zhou, K.; Liu, D. A novel AI-based combustion diagnostic technology for the identification of chemical source information via flame images: Fuel type and reaction condition. Combust. Flame 2024, 260, 113208. [Google Scholar] [CrossRef]
- Olawade, D.B.; Wada, O.Z.; David-Olawade, A.C.; Fapohunda, O.; Ige, A.O.; Ling, J. Artificial intelligence potential for net zero sustainability: Current evidence and prospects. Next Sustain. 2024, 4, 100041. [Google Scholar] [CrossRef]
- Bounaceur, R.; Glaude, P.-A.; Fournet, R.; Sirjean, B.; Montagne, P.; Auvray, A.; Impellizzeri, E.; Biehler, P.; Molière, M. Advancing AI modeling for prediction of safety parameters for combustion of hydrogen/syngas/natural gas mixtures. In Turbo Expo: Power for Land, Sea, and Air; American Society of Mechanical Engineers: New York, NY, USA, 2024; p. V002T003A036. [Google Scholar] [CrossRef]
- Teimoori, Z.; Yassine, A. User-centric Charging Service Recommendation for Electric Vehicles. In Proceedings of the 2024 IEEE 22nd Mediterranean Electrotechnical Conference (MELECON), Porto, Portugal, 25–27 June 2024; pp. 739–743. [Google Scholar] [CrossRef]
- Bhattacharya, A.; Majumdar, P. Artificial intelligence-machine learning algorithms for the simulation of combustion thermal analysis. Heat Transf. Eng. 2024, 45, 176–193. [Google Scholar] [CrossRef]
- Wang, X.; Chan, C.W.; Li, T. High accuracy prediction of the post-combustion carbon capture process parameters using the Decision Forest approach. Chem. Eng. Sci. 2024, 290, 119878. [Google Scholar] [CrossRef]
- Marinković, D.; Dezső, G.; Milojević, S. Application of machine learning during maintenance and exploitation of electric vehicles. Adv. Eng. Lett. 2024, 3, 132–140. [Google Scholar] [CrossRef]
- Zhang, L.; Xie, W.; Ren, Z. Combustion stability analysis for non-standard low-calorific gases: Blast furnace gas and coke oven gas. Fuel 2020, 278, 118216. [Google Scholar] [CrossRef]
- Deng, L.; Adams, T.A., II. Techno-economic analysis of coke oven gas and blast furnace gas to methanol process with carbon dioxide capture and utilization. Energy Convers. Manag. 2020, 204, 112315. [Google Scholar] [CrossRef]
- Rosado, D.J.M.; Chávez, S.B.R.; Gutierrez, J.A.; de Araújo, F.H.M.; de Carvalho, J.A., Jr.; Mendiburu, A.Z. Energetic analysis of reheating furnaces in the combustion of coke oven gas, Linz-Donawitz gas and blast furnace gas in the steel industry. Appl. Therm. Eng. 2020, 169, 114905. [Google Scholar] [CrossRef]
- POSCO. PosFrame. Available online: http://psmartfatory.posco.co.kr (accessed on 28 November 2024).
- Chakraborty, S.; Islam, S.H.; Samanta, D. Introduction to data mining and knowledge discovery. In Data Classification and Incremental Clustering in Data Mining and Machine Learning; Springer International Publishing: Cham, Switzerland, 2022; pp. 1–22. [Google Scholar] [CrossRef]
- Lee, H.; Yun, S. Strategies for imputing missing values and removing outliers in the dataset for machine learning-based construction cost prediction. Buildings 2024, 14, 933. [Google Scholar] [CrossRef]
- Gaddam, A.; Wilkin, T.; Angelova, M.; Gaddam, J. Detecting sensor faults, anomalies and outliers in the Internet of Things: A survey on the challenges and solutions. Electronics 2020, 9, 511. [Google Scholar] [CrossRef]
- Dastjerdy, B.; Saeidi, A.; Heidarzadeh, S. Review of applicable outlier detection methods to treat geomechanical data. Geotechnics 2023, 3, 375–396. [Google Scholar] [CrossRef]
- Ossai, C.I. A data-driven machine learning approach for corrosion risk assessment—A comparative study. Big Data Cogn. Comput. 2019, 3, 28. [Google Scholar] [CrossRef]
- Li, H. Clustering. In Machine Learning Methods; Springer Nature: Singapore, 2024; pp. 293–309. [Google Scholar] [CrossRef]
- Kim, H.-Y.; Kim, B.-C.; Byun, S.-H. A study on efficiency improvement by fine tuning of power plant control. Trans. Korean Inst. Electr. Eng. 2012, 61, 1496–1501. [Google Scholar] [CrossRef]
- Climate Technology Centre and Network (CTCN). Reducing CO2 Emissions by Improving the Efficiency of the Existing Coal-Fired Power Plant Fleet. Available online: https://www.ctc-n.org/resources/reducing-carbon-dioxide-co2-emissions-improving-efficiency-existing-coal-fired-power-plant/ (accessed on 16 December 2024).
- Mrzljak, V. Low power steam turbine energy efficiency and losses during the developed power variation. Teh. Glas. 2018, 12, 174–180. [Google Scholar] [CrossRef]
- Büchs, J.; Zoels, B. Evaluation of maximum to specific power consumption ratio in shaking bioreactors. J. Chem. Eng. Jpn. 2001, 34, 647–653. [Google Scholar] [CrossRef]
- Wilson, D. The design of a low specific fuel consumption turbocompound engine. SAE Trans. 1986, 95, 445–459. Available online: https://www.jstor.org/stable/44721670 (accessed on 29 October 2024).
- Li, M. Reducing specific energy consumption of seawater desalination: Staged RO or RO-PRO? Desalination 2017, 422, 124–133. [Google Scholar] [CrossRef]
- Chen, L.; Xu, Y.; Tian, S.; Lu, H. Numerical simulation study of combustion under different excess air factors in a flow pulverized coal burner. Processes 2024, 12, 1607. [Google Scholar] [CrossRef]
- Ou, H.; Yao, Y.; He, Y. Missing data imputation method combining random forest and generative adversarial imputation network. Sensors 2024, 24, 1112. [Google Scholar] [CrossRef] [PubMed]
- Bansal, M.; Goyal, A.; Choudhary, A. A comparative analysis of K-nearest neighbor, genetic, support vector machine, decision tree, and long short term memory algorithms in machine learning. Decis. Anal. J. 2022, 3, 100071. [Google Scholar] [CrossRef]
- Asselman, A.; Khaldi, M.; Aammou, S. Enhancing the prediction of student performance based on the machine learning XGBoost algorithm. Interact. Learn. Environ. 2023, 31, 3360–3379. [Google Scholar] [CrossRef]
- Li, S.; Jin, N.; Dogani, A.; Yang, Y.; Zhang, M.; Gu, X. Enhancing LightGBM for Industrial Fault Warning: An Innovative Hybrid Algorithm. Processes 2024, 12, 221. [Google Scholar] [CrossRef]
- DeVore, R.; Hanin, B.; Petrova, G. Neural network approximation. Acta Numer. 2021, 30, 327–444. [Google Scholar] [CrossRef]
- Kamwa, I.; Samantaray, S.R.; Joos, G. Catastrophe predictors from ensemble decision-tree learning of wide-area severity indices. IEEE Trans. Smart Grid 2010, 1, 144–158. [Google Scholar] [CrossRef]
- Choi, S.-W.; Lee, E.-B. Contractor’s risk analysis of engineering procurement and construction (EPC) contracts using ontological semantic model and Bi-long short-term memory (LSTM) technology. Sustainability 2022, 14, 6938. [Google Scholar] [CrossRef]
- Priyam, A.; Abhijeeta, G.R.; Rathee, A.; Srivastava, S. Comparative analysis of decision tree classification algorithms. Int. J. Curr. Eng. Technol. 2013, 3, 334–337. [Google Scholar]
- Tatachar, A.V. Comparative assessment of regression models based on model evaluation metrics. Int. J. Innov. Technol. Explor. Eng. 2021, 8, 853–860. [Google Scholar]
- Wang, L. Low-latency, high-throughput load balancing algorithms. J. Comput. Technol. Appl. Math. 2024, 1, 1–9. [Google Scholar] [CrossRef]
- Weber, T.A. On the (non-)equivalence of IRR and NPV. J. Math. Econ. 2014, 52, 25–39. [Google Scholar] [CrossRef]
- Ratnasingam, S.; Muñoz-Lopez, J. Distance correlation-based feature selection in random forest. Entropy 2023, 25, 1250. [Google Scholar] [CrossRef] [PubMed]
- Ma, Z.; Cui, S.; Joe, I. An enhanced proximal policy optimization-based reinforcement learning method with random forest for hyperparameter optimization. Appl. Sci. 2022, 12, 7006. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Production Method | Primary Energy Source | Energy Consumption (GJ/ton) 1 | Features |
|---|---|---|---|
| BF-BOF | BFG, COG, LDG | 19–22 | Suitable for large-scale production, high CO2 emissions. |
| EAF | Electricity, natural gas | 2–6 | High energy efficiency, uses recycled steel |
| DRI | Natural gas, hydrogen | 10–14 | Low-carbon technology, enables high-quality steel production |
| OHF (Traditional Method) | Coal | Very High | Low efficiency, rarely used in modern times |
| By-Product Gas | Component (%) | Calorific Value (kcal/Nm3) | Production Volume (Nm3/tHM) | |||||
|---|---|---|---|---|---|---|---|---|
| CO2 | CO | CH4 | H2 | N2 | Etc. | |||
| BFG | 20.7 | 20.0 | - | 3.2 | 54.1 | - | 750–1000 | 1400–1600 |
| COG | 3.1 | 8.4 | 26.6 | 56.4 | 2.3 | 2.0 | 4000–5000 | 300–350 |
| LDG | 17.8 | 64.2 | - | 2.0 | 15.9 | - | 2000 | 80–100 |
| By-Product Gas | Production Process | Key Characteristics | Recycling Methods | Treatment Methods | Key Challenges |
|---|---|---|---|---|---|
| BFG | Blast furnace—melting iron ore and coke | Low calorific value, high nitrogen, and carbon dioxide content | Power generation, hot blast preheating, industrial heat source | Dust removal, gas scrubbing | Low calorific value, high impurity content |
| COG | Coke oven—producing coke from coal | High calorific value, contains tar and sulfur | Power generation, chemical feedstock (ammonia, methanol) | Desulfurization, tar removal | High tar content, mandatory desulfurization |
| LDG | Basic oxygen furnace (BOF)—converting molten iron to steel | Medium calorific value, high CO content | Power generation, heat recovery | Dust and CO removal | Variable gas composition, CO management |
| Category | Detail | Unit |
|---|---|---|
| Manufacturer | BHI | - |
| Year of initial installation/modernization | 1981/2020 | Year |
| Power generation capacity | 75 | MW |
| Boiler capacity | 240 | Ton/Hour |
| Low-pressure steam capacity | 70 | Ton/Hour |
| Design efficiency | 35 | % |
| Fuel used | BFG, COG, LDG, LNG | - |
| Burner type | Combination combustion | - |
| No. of burners | 9 | ea |
| Category | Main Content | Limitation |
|---|---|---|
| Studies on performance and efficiency improvement of power boilers | Various data-driven and optimization techniques were applied to improve the performance and combustion efficiency of power boilers | Limited ability to handle data variability and uncertainties arising in real-time operational environments |
| Studies on self-generation in steel plants using by-product gases | Research aimed at managing the variability of by-product gases and maximizing the efficiency of self-generation boilers in steel plants | High variability in the composition and supply of by-product gases makes stable model application in actual operational environments difficult |
| Studies on boiler combustion optimization using machine learning and AI | Research using AI techniques to improve boiler combustion efficiency and achieve emission reductions | Dependence on large-scale data for model training and validation, low interpretability of AI models, and limited reliability and applicability in industrial settings |
| Category | Class | Features | Number of Data |
|---|---|---|---|
| Fuel (16) | BFG (6) | Pressure, calorific value 1, calorific value 2, calorific value 3, calorific value 4, flow rate | 1,036,824 |
| COG (3) | Pressure, calorific value, flow rate | 518,412 | |
| LDG (3) | Pressure, calorific value, flow rate | 518,412 | |
| LNG (3) | Pressure, calorific value, flow rate | 518,412 | |
| Others (1) | Seawater flow rate | 172,804 | |
| Combustion (31) | BFG (9) | A1, A2, A3, B1, B2, B3, C1, C2, C3 | 1,555,236 |
| COG (3) | B1, B2, B3 | 518,412 | |
| COG(S) (9) | A1, A2, A3, B1, B2, B3, C1, C2, C3 | 1,555,236 | |
| LDG (6) | A1, A2, A3, C1, C2, C3 | 1,036,824 | |
| Others (4) | O2 Concentration 1, O2 Conc. 2, O2 Conc. 3, NOx Conc. | 691,216 | |
| Power Generation (7) | Power (5) | Reactive power consumption, active power consumption, power consumption a, power consumption b, output power | 864,020 |
| Output (2) | output current, output voltage, output | 345,608 | |
| Total | 9,331,416 | ||
| Raw Data | Change of Variable Name | Data Type |
|---|---|---|
| FCS01056GWQ-001.PV | Power | Categorical → Numeric |
| FCS0105.8BPI-011.PV | COG pressure | |
| FCS0105.8BPI-012.PV | LDG pressure |
| Derived Variables | Calculation |
|---|---|
| LNG flow rate | Flow rate A + Flow rate B |
| BFG calorific value | Holder 1 + Holder 4 + 3BF + 4BF/4 |
| Fuel heat rate (A) | Flow rate × Heat quantity/Power/1000 |
| Power consumption heat rate (B) | (Power consumption A + Power consumption B) × 2230)/Power |
| Cooling water heat rate (C) | Seawater flow rate × 140 × 2.5 × 60/Power/1000 |
| Gross heat rate | A + B + C |
| Category | Management Criteria (Unit) | Manufacturer (Model) | Calibration Interval (h) |
|---|---|---|---|
| BFG flow transmitter | SEQ (mA) | ADDITEL (ADT-761) | 1095 |
| COG flow transmitter | SEQ (mA) | ADDITEL (ADT-761) | 1095 |
| LDG flow transmitter | SEQ (mA) | ADDITEL (ADT-761) | 1095 |
| Category | Standard Deviation | Proportion of Variance | Cumulative Proportion | Selection |
|---|---|---|---|---|
| PC1 | 1.649 | 19.42% | 19.42% | ✓ |
| PC2 | 1.600 | 18.30% | 37.72% | ✓ |
| PC3 | 1.200 | 10.29% | 48.01% | ✓ |
| PC4 | 1.024 | 7.49% | 55.50% | ✓ |
| PC5 | 1.007 | 7.24% | 62.74% | |
| PC6 | 0.981 | 6.88% | 69.61% | |
| … | … | … | … | |
| PC14 | 0.245 | 0.43% | 100% |
| Algorithm | Advantages | Disadvantages |
|---|---|---|
| Logistic Regression (LR) | Easy to interpret and computationally efficient; provides probabilistic predictions | Limited to linear relationships; sensitive to multicollinearity |
| CART | Interpretable and handles nonlinear relationships; identifies important variables | Prone to overfitting; unstable with small datasets |
| Random Forest (RF) | High accuracy and reduces overfitting; evaluates variable importance | Complex and less interpretable; high computational cost |
| Category | Accuracy of Pattern (%) | ||||
|---|---|---|---|---|---|
| BFG | COG | LDG | BFG, COG | BFG, LDG | |
| Training dataset | 99.9415 | 100 | 99.9707 | 99.9829 | 99.9362 |
| Test dataset | 99.6471 | 99.8046 | 99.7653 | 99.785 | 99.7448 |
| Category | Neural Network |
|---|---|
| Data input | 67 variables |
| Dependent variable | Gross heat rate |
| Training dataset | 70% |
| Hyperparameter | Repeated cross-validation (Fold 3, Repeat 3) |
| Complexity parameter | 0.00000001, 0.0000001, 0.000001, 0.00001, 0.0001, 0.001, 0.01 |
| CP | RMSE | R2 | MAE | Model Select |
| 1.00 × 10−8 | 37.01628 | 0.95297 | 25.53985 | |
| 1.00 × 10−7 | 37.01627 | 0.95297 | 25.53983 | *✓ |
| 0.000001 | 37.04204 | 0.95290 | 25.57579 | |
| 0.00001 | 38.79154 | 0.94828 | 27.35463 | |
| 0.0001 | 46.76034 | 0.92476 | 34.09299 | |
| 0.001 | 62.64028 | 0.86494 | 46.15539 | |
| 0.01 | 85.63810 | 0.74755 | 62.26553 | |
| CP | RMSESD | R2SD | MAESD | Model Select |
| 1.00 × 10−8 | 0.46904 | 0.00121 | 0.14661 | |
| 1.00 × 10−7 | 0.46905 | 0.00121 | 0.14664 | *✓ |
| 0.000001 | 0.47497 | 0.00123 | 0.15426 | |
| 0.00001 | 0.39497 | 0.00112 | 0.10449 | |
| 0.0001 | 0.48615 | 0.00174 | 0.30794 | |
| 0.001 | 0.81471 | 0.00343 | 0.45590 | |
| 0.01 | 1.20941 | 0.00714 | 0.77237 |
| Category | No. of Data | RMSE | R2 | MAE |
|---|---|---|---|---|
| Training dataset | 88,754 | 22.42368 | 98.269 | 15.25892 |
| Testing dataset | 38,036 | 33.45220 | 96.180 | 23.61632 |
| Derived Variable | Calculations |
|---|---|
| BFG pattern | BFG Combustion A1 × 256 + BFG Combustion A2 × 128 BFG Combustion A3 × 64 + BFG Combustion B1 × 32 + BFG Combustion B2 × 16 + BFG Combustion B3 × 8 + BFG Combustion C1 × 4 + BFG Combustion C2 × 2 + BFG Combustion C3 × 1 |
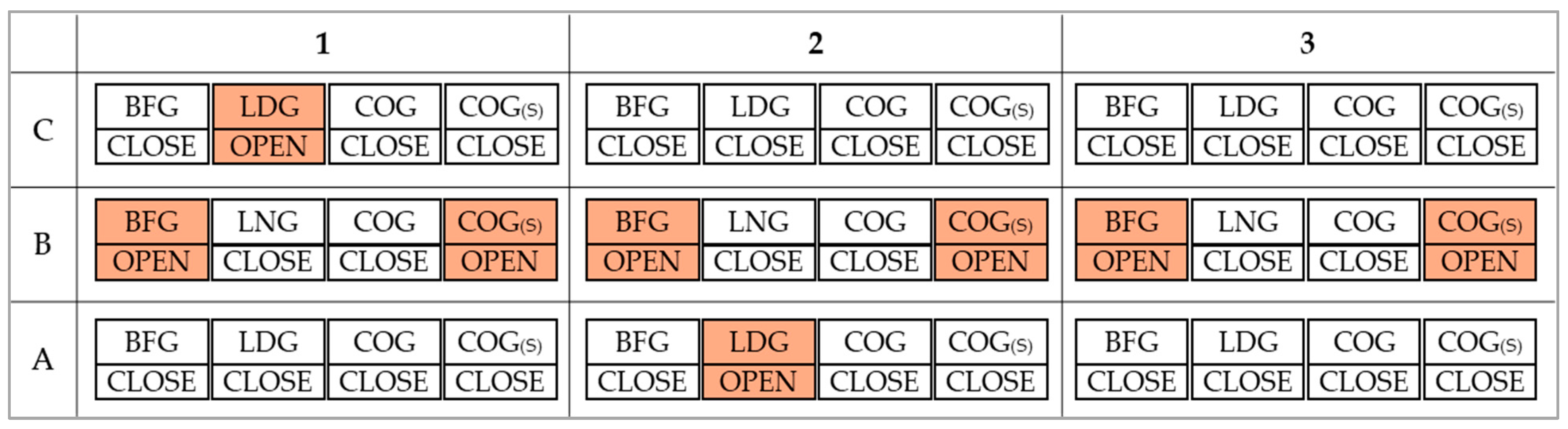
| Time | Present Pattern | Prediction Pattern | ||||||
|---|---|---|---|---|---|---|---|---|
| LDG | COG | BFG | Gross H/R | LDG | COG | BFG | Gross H/R | |
| 1 | 30 | 0 | 441 | 2368 | 31 | 0 | 440 | 2343 |
| 2 | 30 | 0 | 441 | 2404 | 30 | 0 | 440 | 2400 |
| 3 | 30 | 0 | 441 | 2378 | 31 | 0 | 440 | 2376 |
| 4 | 30 | 0 | 441 | 2427 | 31 | 0 | 440 | 2422 |
| 5 | 30 | 0 | 441 | 2413 | 31 | 0 | 440 | 2394 |
| 6 | 30 | 0 | 441 | 2382 | 31 | 0 | 440 | 2370 |
| Result | - | - | - | 2395 | 30 | 0 | 440 | 2384 |
| Category | Manual Control | ABCCM Implementation | Improvement |
|---|---|---|---|
| Combustion efficiency | Lack of consistency, reliant on operator experience | Provides automated optimal combustion patterns | Improved combustion efficiency by 0.86% |
| Power generation efficiency | Average 35.23% | Average 36.09% | Increased by approximately 0.86 percentage points |
| Gross heat rate | Approximately 4100 kcal/kWh | Approximately 4041.7 kcal/kWh | Decreased by an average of 58.3 kcal/kWh |
| Energy cost savings | Limited efficiency improvement | Annual savings of approximately USD 89.6 K | Reduced energy costs |
| Carbon emission reduction | Limited by incomplete combustion and variability | Reduced emissions through efficient combustion, reduced carbon emissions owing to reduced fuel consumption | Reduced fuel consumption leading to reduced carbon emissions |
| Real-time response | Difficulty in reflecting real-time data through manual adjustments | Real-time data-based optimization possible | Increased operational efficiency and stability |
| Operational convenience | Requires high operator skill | Minimized operator intervention through automation | Improved operational consistency and convenience |
| Category | Specification |
|---|---|
| Platform | PosFrame, Workbench 2024 |
| Programming language | Block coding based on R language |
| Programming language version | R version 3.3.3 (6 March 2017) to R version 3.4.0 |
| Operating system | x86_64-redhat-linux-gnu (64-bit) |
| IDE (1) | Drag-and-drop interface with support for custom R scripting |
| Hardware | System ×3650 M5 |
| Database | Oracle 12C_R1, PostgreSQL 9.3, PosFrame supported |
| Category | Before (Manual Operation) | After (ABCCM) | Difference |
|---|---|---|---|
| Heat gross rate (kcal/kWh) | 2441.0 | 2382.7 | 58.3 |
| Efficiency of power plant (%) | 35.23 | 36.09 | 0.86 |
| Category | Value |
|---|---|
| IRR (%) | 60.8 |
| NPV (USD 1) | 542 K |
| Heat gross rate improvement (kcal/kWh) | 58.3 |
| Difference in efficiency (%) | 0.86 |
| Additional power generation (kWh) | 1570 |
| Power unit price (USD/kW) | 0.13 |
| Power cost saving (USD/Year) | 89.6 K |
| Investment cost (USD) | 147.4 K |
| Corporate tax (%) | 27.5 |
| Discount rate (%) | 9.8 |
| Research contribution rate (%) | 5 |
| Category | Calculation |
|---|---|
| Power cost saving | Additional power generation (1570 × 8760) × Power unit price (0.13) × Research contribution rate (0.05) = USD 89.6 K/year |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, K.-J.; Choi, S.-W.; Lee, E.-B. Artificial Intelligence-Driven Approach to Optimizing Boiler Power Generation Efficiency: The Advanced Boiler Combustion Control Model. Energies 2025, 18, 820. https://doi.org/10.3390/en18040820
Lee K-J, Choi S-W, Lee E-B. Artificial Intelligence-Driven Approach to Optimizing Boiler Power Generation Efficiency: The Advanced Boiler Combustion Control Model. Energies. 2025; 18(4):820. https://doi.org/10.3390/en18040820
Chicago/Turabian StyleLee, Kyu-Jeong, So-Won Choi, and Eul-Bum Lee. 2025. "Artificial Intelligence-Driven Approach to Optimizing Boiler Power Generation Efficiency: The Advanced Boiler Combustion Control Model" Energies 18, no. 4: 820. https://doi.org/10.3390/en18040820
APA StyleLee, K.-J., Choi, S.-W., & Lee, E.-B. (2025). Artificial Intelligence-Driven Approach to Optimizing Boiler Power Generation Efficiency: The Advanced Boiler Combustion Control Model. Energies, 18(4), 820. https://doi.org/10.3390/en18040820