
Monthly Load Forecasting in a Region Experiencing Demand Growth: A Case Study of Texas


Abstract
1. Introduction
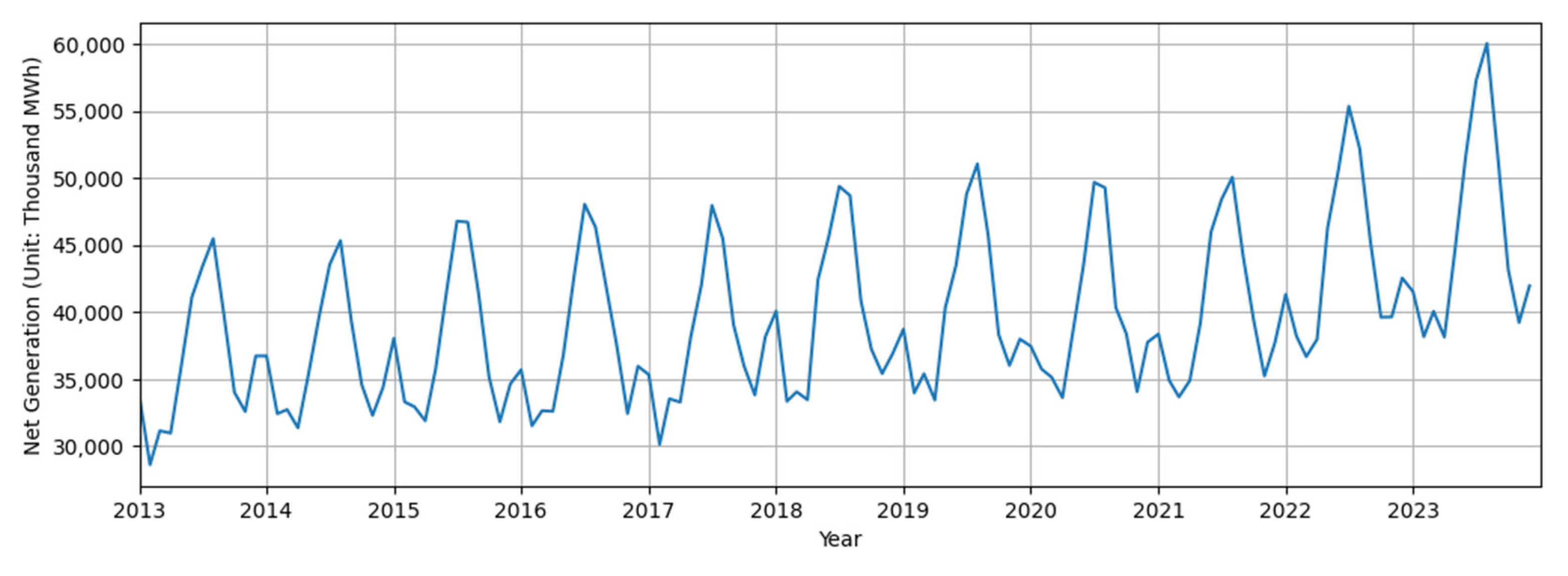
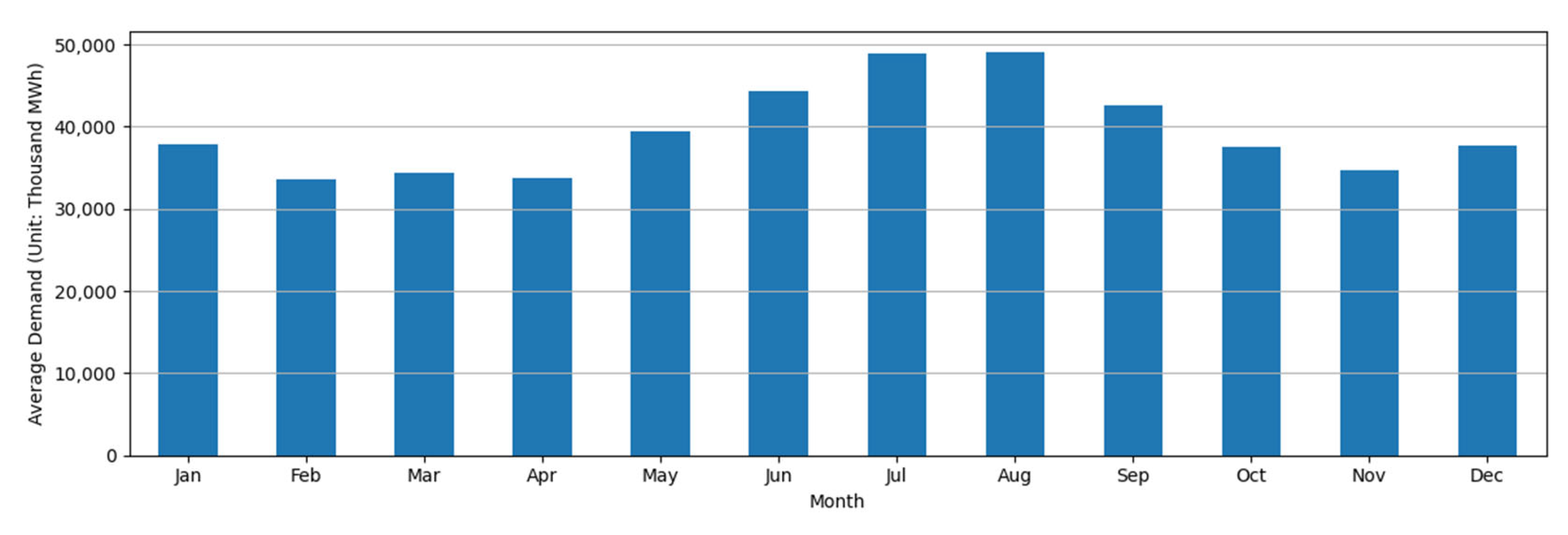
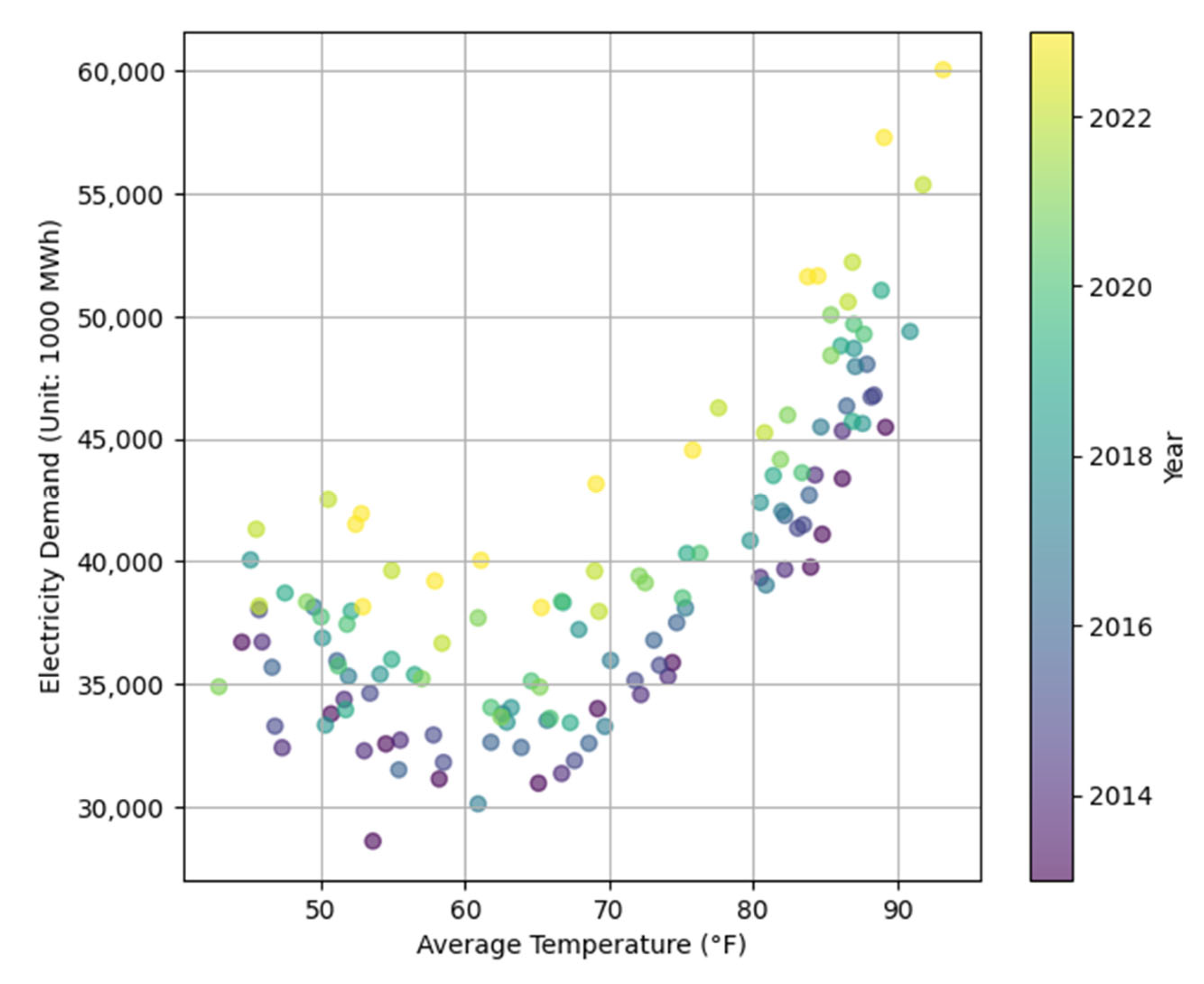
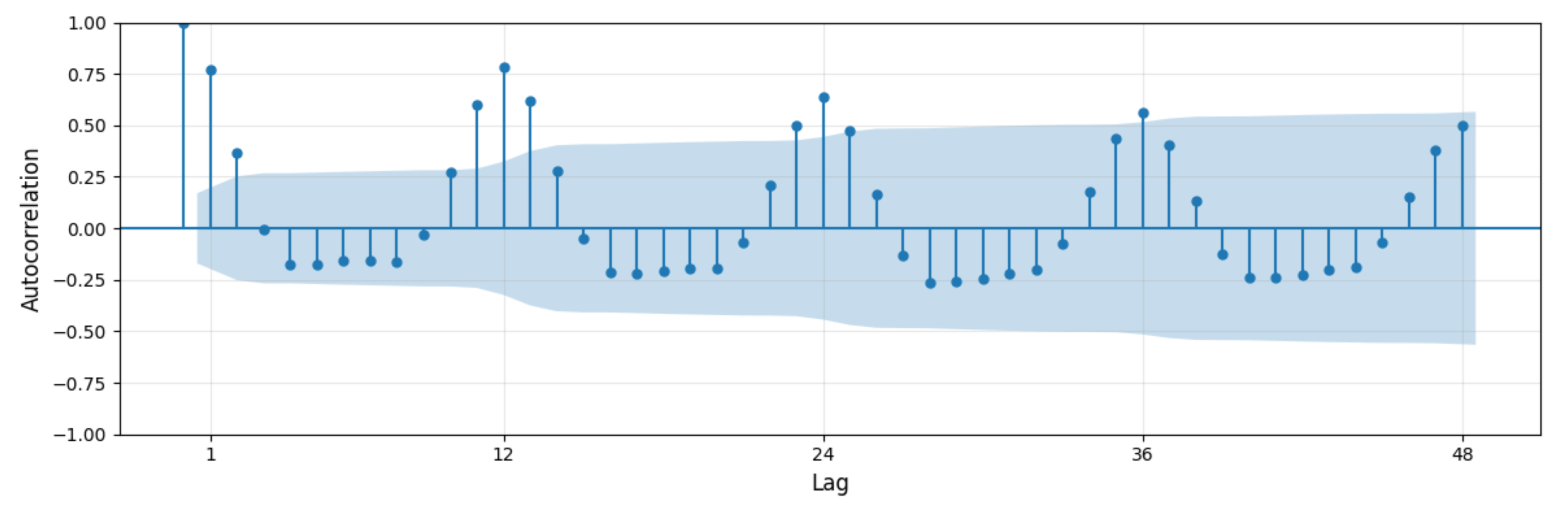
2. Data Analysis
3. Methodology
3.1. Input Variables
3.1.1. Trend
3.1.2. Autocorrelations
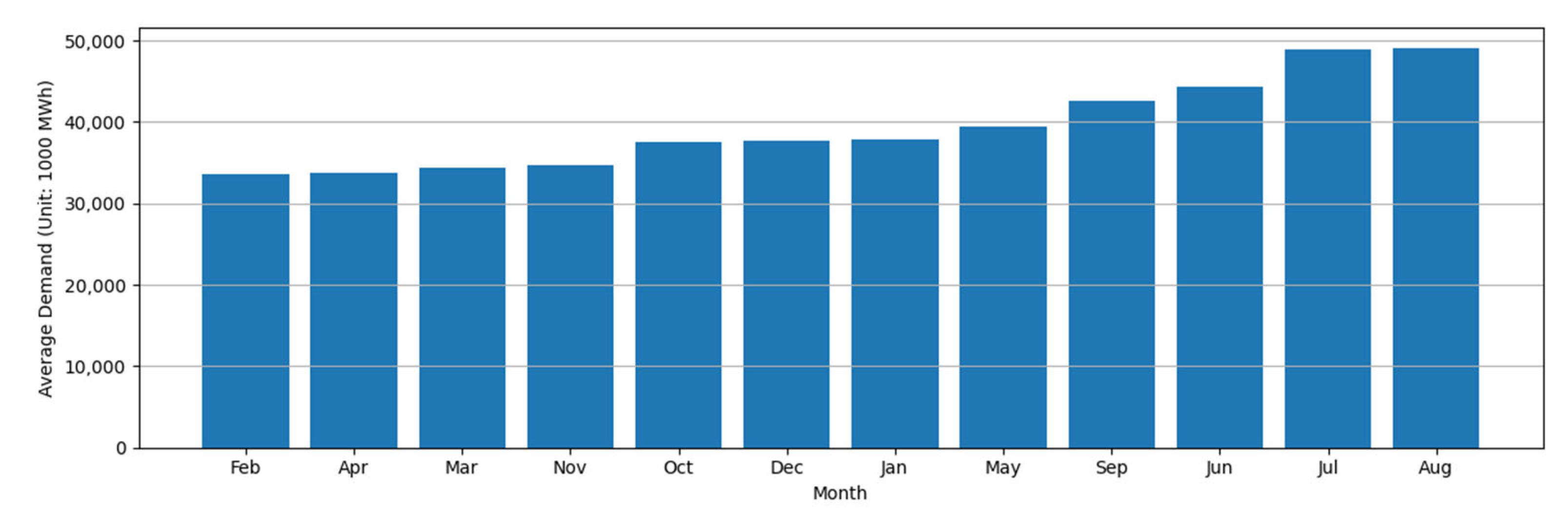
3.1.3. Seasonality
3.1.4. Temperature
3.1.5. Other Features
3.2. Proposed Regression Model
3.3. Forecasting Procedure with the Proposed Model
- Step 0. Specify the Forecasting and Training Periods
- We first designate the forecasting period, and then set the training period as the time span from January 2013 up to the immediately preceding month of the forecasting year. Specifically, the training data consists of monthly observations from January 2013 to December 2022 when forecasting 2023, and from January 2013 to December 2023 when forecasting 2024, respectively.
- Step 1. Collect Data for the Training Period
- For the training data, we gather all input variables and the dependent variable from the designated training period. In this study, for each month within the training period, we collect or calculate the following data: the electricity demand for that month, the electricity demand from 12 and 13 months prior, the average monthly temperature in Dallas, the time index, and the modified month variable.
- Step 2. Fit the Proposed Regression Model
- Using the collected training data, we estimate the coefficients of the proposed multiple linear regression model. The fitted model provides a closed-form regression equation with estimated parameters.
- Step 3. Collect Data for the Forecasting Period
- We collect the same set of input variables for the forecasting period. Since this study performs 12-month-ahead forecasting, all input variable data for the entire forecasting year must be gathered in advance.
- Step 4. Generate Forecasts Using the Regression Equation
- The regression equation from Step 2 is applied to the input variable values collected in Step 3 to compute the forecasts for the forecasting period.
- Step 5. Evaluate Forecast Accuracy
- The forecast values are compared with the actual values in the forecasting period, if available, to assess the accuracy of the model. Forecasting performance can be evaluated using well-known error metrics.
4. Computational Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| SARIMA | Seasonal AutoRegressive Integrated Moving Average |
| RNN | Recurrent Neural Network |
| LSTM | Long Short-Term Memory |
| MAPE | Mean Absolute Percentage Error |
| AI | Artificial Intelligence |
| LLM | Large Language Model |
| IEA | International Energy Agency |
| ERCOT | Electric Reliability Council of Texas |
| STLF | Short-Term Load Forecasting |
| GRU | Gated Recurrent Unit |
| EIA | Energy Information Administration |
| ACF | AutoCorrelation Function |
| MAE | Mean Absolute Error |
| RMSE | Root Mean Square Error |
Appendix A
Appendix A.1

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Month Variables | |
|---|---|---|
| P | yt = β0 | mt |
| C1 | yt = β0 + β7ht + β8(Tt⋅ot) + ϵt | ot |
| C2 | ||
| Models | Number of Independent Variables | Adj. R2 | F-Statistic | BIC |
|---|---|---|---|---|
| P | 8 | 0.966 | 463.3 | 2269 |
| C1 | 8 | 0.959 | 381.4 | 2294 |
| C2 | 28 | 0.973 | 171.2 | 2311 |
| Models | MAE | RMSE | MAPE |
|---|---|---|---|
| P | 998.9 | 1423.6 | 2.05% |
| C1 | 1217.5 | 1521.0 | 2.59% |
| C2 | 1182.7 | 1581.9 | 2.44% |
Appendix A.2
| Models | Temperature Variables | |
|---|---|---|
| P | yt = β0 + β7ht + β8(Tt⋅mt) + ϵt | Tt |
| C3 | yt = β0 + β7ht + ϵt | |
| C4 | yt = β0 + β9ht + ϵt | |
| Models | Number of Independent Variables | Adj. R2 | F-Statistic | BIC |
|---|---|---|---|---|
| P | 8 | 0.966 | 463.3 | 2269 |
| C3 | 17 | 0.970 | 254.2 | 2283 |
| C4 | 19 | 0.973 | 253.2 | 2277 |
| Models | MAE | RMSE | MAPE |
|---|---|---|---|
| P | 998.9 | 1423.6 | 2.05% |
| C3 | 1146.1 | 1496.0 | 2.37% |
| C4 | 1068.1 | 1372.5 | 2.24% |
Appendix B
| Models | Hyperparameter Configurations |
|---|---|
| RNN | Hidden Units=50; Layers=2; Epochs=100; Batch Size=32; Sequence Length=12; Optimizer=Adam; Loss Function=MSE; Return Sequences=False; Scaling=MinMaxScaler(0,1); Random Seeds=42,43,44; Number of Runs=3 |
| LSTM | Hidden Units=50; Layers=2; Epochs=100; Batch Size=32; Sequence Length=12; Optimizer=Adam; Loss Function=MSE; Return Sequences=False; Scaling=MinMaxScaler(0,1); Random Seeds=42,43,44; Number of Runs=3 |
| Transformer | d_model=64; nhead=4; num_layers=2; Epochs=100; Batch Size=32; Sequence Length=12; Learning Rate=0.001; Optimizer=Adam; Loss Function=MSE; Dropout=0.1; Feed Forward Dim=256; Output Layers=Linear(64→32)→ReLU→Dropout(0.1)→Linear(32→1); LR Scheduler=ReduceLROnPlateau(patience=10, factor=0.5); Scaling=MinMaxScaler(0,1); Random Seeds=42,43,44; Number of Runs=3 |
| Random Forest | n_estimators=100; random_state=42; n_jobs=-1; Features=[Load_12, Load_13, Dallas, WkHols, Mon, t]; Target=Load; Missing Values=dropna(); Scaling=None; Number of Runs=1 |
| LightGBM | n_estimators=100; random_state=42; n_jobs=-1; Features=[Load_12, Load_13, Dallas, WkHols, Mon, t]; Target=Load; Missing Values=dropna(); Scaling=None; Number of Runs=1 |
| XGBoost | n_estimators=100; random_state=42; n_jobs=-1; Features=[Load_12, Load_13, Dallas, WkHols, Mon, t]; Target=Load; Missing Values=dropna(); Scaling=None; Number of Runs=1 |
References
- Wang, H.; Alattas, K.A.; Mohammadzadeh, A.; Sabzalian, M.H.; Aly, A.A.; Mosavi, A. Comprehensive Review of Load Forecasting with Emphasis on Intelligent Computing Approaches. Energy Rep. 2022, 8, 13189–13198. [Google Scholar] [CrossRef]
- Kuster, C.; Rezgui, Y.; Mourshed, M. Electrical Load Forecasting Models: A Critical Systematic Review. Sustain. Cities Soc. 2017, 35, 257–270. [Google Scholar] [CrossRef]
- IEA. Energy and AI. World Energy Outlook Special Report, International Energy Agency. 2025. Available online: https://www.iea.org/reports/energy-and-ai (accessed on 1 May 2025).
- Shehabi, A.; Smith, S.J.; Hubbard, A.; Newkirk, A.; Lei, N.; Siddik, M.A.B.; Holecek, B.; Koomey, J.; Masanet, E.; Sartor, D. 2024 United States Data Center Energy Usage Report; Lawrence Berkeley National Laboratory: Berkeley, CA, USA, 2024; LBNL-2001637. [Google Scholar]
- Bolner, A. 5 Reasons Why a Dallas Data Center Still Makes Good Sense. Stream Data Centers Excecutive Brief. 23 March 2021. Available online: https://www.streamdatacenters.com/articles/markets/why-dallas/ (accessed on 20 May 2025).
- Khuntia, S.R.; Rueda, J.L.; van der Meijden, M.A.M.M. Forecasting the Load of Electrical Power Systems in Mid- and Long-Term Horizons: A Review. IET Gener. Transm. Distrib. 2016, 10, 3971–3977. [Google Scholar] [CrossRef]
- Sharma, A.; Jain, S.K. A Novel Two-Stage Framework for Mid-Term Electric Load Forecasting. IEEE Trans. Ind. Inform. 2024, 20, 247–255. [Google Scholar] [CrossRef]
- Rubasinghe, O.; Zhang, X.; Chau, T.K.; Chow, Y.H.; Fernando, T.; Iu, H.H.-C. A Novel Sequence to Sequence Data Modelling Based CNN-LSTM Algorithm for Three Years Ahead Monthly Peak Load Forecasting. IEEE Trans. Power Syst. 2024, 39, 1932–1947. [Google Scholar] [CrossRef]
- Li, J.; Lei, Y.; Yang, S. Mid-Long Term Load Forecasting Model Based on Support Vector Machine Optimized by Improved Sparrow Search Algorithm. Energy Rep. 2022, 8, 491–497. [Google Scholar] [CrossRef]
- Dudek, G.; Pełka, P. Pattern Similarity-Based Machine Learning Methods for Mid-Term Load Forecasting: A Comparative Study. Appl. Soft Comput. 2021, 104, 107223. [Google Scholar] [CrossRef]
- Oreshkin, B.N.; Dudek, G.; Pełka, P.; Turkina, E. N-BEATS Neural Network for Mid-Term Electricity Load Forecasting. Appl. Energy 2021, 293, 116918. [Google Scholar] [CrossRef]
- Popik, T.; Humphreys, R. The 2021 Texas Blackouts: Causes, Consequences, and Cures. J. Crit. Infrastruct. Policy 2021, 2, 47–73. [Google Scholar] [CrossRef]
- Ali, M. Electricity Load Forecasting in Texas Using Neural Networks to Enhance the Power Grid Stability. Master’s Dissertation, Texas Tech University, Lubbock, TX, USA, 2024. [Google Scholar]
- Derner, R.; Butler, R.; Neff, A.; Ruthford, A. Reevaluating Texas Energy Market Forecasts in The Wake of Recent Extreme Weather Events. SMU Data Sci. Rev. 2024, 8, 8. [Google Scholar]
- Eysenbach, J.; Franklin, B.; Larsen, A.; Lindsey, J. Predicting Power Using Time Series Analysis of Power Generation and Consumption in Texas. SMU Data Sci. Rev. 2021, 5, 5. [Google Scholar]
- Hossain, R. Machine Learning Tools in the Predictive Analysis of ERCOT Load Demand Data. Master’s Dissertation, The University of Texas Rio Grande Valley, Edinburg, TX, USA, 2022. [Google Scholar]
- Mostafa, T.; Fouda, M.M.; Abdo, M.G. Short-Term Load Forecasting Employing Recurrent Neural Networks. In Proceedings of the 2024 International Conference on Smart Applications, Communications and Networking (SmartNets), Washington, DC, USA, 28–30 May 2024; pp. 1–6. [Google Scholar]
- Rice, R.; North, K.; Hansen, G.; Pearson, D.; Schaer, O.; Sherman, T.; Vassallo, D. Time-Series Forecasting Energy Loads: A Case Study in Texas. In Proceedings of the 2022 Systems and Information Engineering Design Symposium (SIEDS), Charlottesville, VA, USA, 28–29 April 2022; pp. 196–201. [Google Scholar]
- Ruthford, A.; Sadler, B. Modeling Electric Energy Generation in ERCOT during Extreme Weather Events and the Impact Renewable Energy Has on Grid Reliability. SMU Data Sci. Rev. 2021, 5, 6. [Google Scholar]
- Singh, G. Comparative Analysis of Machine Learning Models for ERCOT Short Term Load Forecasting. Master’s Dissertation, Virginia Tech, Blacksburg, VA, USA, 2025. [Google Scholar]
- Yang, J.; Tuo, M.; Lu, J.; Li, X. Analysis of Weather and Time Features in Machine Learning-Aided ERCOT Load Forecasting. In Proceedings of the 2024 IEEE Texas Power and Energy Conference (TPEC), College Station, TX, USA, 12–13 February 2024; pp. 1–6. [Google Scholar]
- NKF Research. Data Center Market Overview: Second Half 2019; Newmark Knight Frank: New York, NY, USA, 2019. [Google Scholar]
- LCG Consulting. 2025 ERCOT Electricity Market Outlook. August 2024. Available online: https://www.energyonline.com/reports/2025_ERCOT_Outlook.pdf (accessed on 5 June 2025).
- Skiles, M.J.; Rhodes, J.D.; Webber, M.E. Perspectives on Peak Demand: How Is ERCOT Peak Electric Load Evolving in the Context of Changing Weather and Heating Electrification? Electr. J. 2023, 36, 107254. [Google Scholar] [CrossRef]
- Winters, P.R. Forecasting Sales by Exponentially Weighted Moving Averages. Manag. Sci. 1960, 6, 324–342. [Google Scholar] [CrossRef]
- Box, G.E.P.; Jenkins, G.M.; Reinsel, G.C. Time Series Analysis Forecasting and Control, 4th ed.; John Wiley and Sons: Hoboken, NJ, USA, 2008. [Google Scholar]
- Taylor, S.J.; Letham, B. Forecasting at Scale. PeerJ, 2017; preprint. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning Representations by Back-Propagating Errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2023, arXiv:1706.03762. [Google Scholar] [CrossRef] [PubMed]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD’16, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Schwarz, G. Estimating the Dimension of a Model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]


| Papers | Timeframes | Target Regions | Models Used | Key Features |
|---|---|---|---|---|
| Ali (2024) [13] | Hourly | Texas | RNN–LSTM–GRU | Past load and weather data |
| Derner et al. (2024) [14] | Daily | Texas | ARIMA and Linear Model | Past load, weather, calendar, and fuel type data |
| Eysenbach et al. (2021) [15] | Daily | Texas | RNN–LSTM, ARUMA, and VAR | Past load, weather, and population data |
| Hossain (2022) [16] | Hourly | West Texas | LSTM and GRU | Past load and weather data |
| Mostafa et al. (2024) [17] | Hourly | West Texas | RNN, LSTM, and GRU | Past load, weather, and calendar data |
| Rice et al. (2022) [18] | Hourly | Texas | Ridge and Lasso regressions | Past load and calendar data |
| Ruthford and Sadler (2021) [19] | Hourly | Texas | ARIMA and TSLM | Past load and weather data |
| Singh (2024) [20] | Hourly | Texas | Generalized Additive Models | Past load and weather and calendar data |
| Yang et al. (2024) [21] | Hourly | Texas | LSTM and FCNN | Past load, weather, and calendar data |
| Cities | Dallas | Houston | Austin | San Antonio | Average |
|---|---|---|---|---|---|
| Correlation Coefficients | 0.715 | 0.707 | 0.714 | 0.702 | 0.711 |
| Variables | Coefficients | Standard Errors | t-Statistics | p-Values |
|---|---|---|---|---|
| Intercept | 73,680 | 4868.246 | 15.135 | <0.001 |
| t2 | 0.3235 | 0.024 | 13.548 | <0.001 |
| yt−12 | 0.1672 | 0.065 | 2.587 | 0.011 |
| yt−13 | 0.0038 | 0.029 | 0.131 | 0.896 |
| mt | 961.6119 | 279.012 | 3.446 | 0.001 |
| Tt | −1683.94 | 142.579 | −11.811 | <0.001 |
| 14.2224 | 1.304 | 10.903 | <0.001 | |
| ht | −104.056 | 145.193 | −0.717 | 0.475 |
| Tt⋅mt | −9.0074 | 4.744 | −1.898 | 0.060 |
| Models | Adj. R2 | |
|---|---|---|
| Proposed Model | yt = β0 + β7ht + β8(Tt⋅mt) + ϵt | 0.966 |
| Comparative Models | yt = β0 + β7ht + β8(Tt⋅mt) + ϵt | 0.959 |
| yt = β0 + β1t2 + β2yt−12 + β3yt−13 + β4mt + β5Tt + β6ht + β7(Tt⋅mt) + ϵt | 0.933 | |
| yt = β0dt + β7ht + β8(Tt⋅ot) + ϵt | 0.959 | |
| yt = β0dt + β7ht + ϵt | 0.965 | |
| Methods | MAE | RMSE | MAPE | ||
|---|---|---|---|---|---|
| Proposed Model | 998.9 | 1423.6 | 2.05% | ||
| Benchmarks | Univariate Models | Holt–Winters | 1678.4 | 2201.3 | 3.57% |
| SARIMA | 1754.4 | 2229.5 | 3.75% | ||
| Prophet | 1733.8 | 2212.1 | 3.65% | ||
| Neural Networks | RNN | 2012.1 | 2605.1 | 4.30% | |
| LSTM | 2704.6 | 3305.3 | 5.89% | ||
| Transformer | 2485.2 | 3076.9 | 5.29% | ||
| Machine Learning | Random Forest | 2224.5 | 2944.8 | 4.64% | |
| LightGBM | 2662.0 | 3394.7 | 5.40% | ||
| XGBoost | 2544.7 | 3181.0 | 5.38% | ||
| Methods | Mean (i.e., MAPE) | Median | Standard Deviation | Maximum |
|---|---|---|---|---|
| Proposed Model | 2.05% | 1.28% | 1.96% | 5.54% |
| Holt–Winters | 3.57% | 2.76% | 2.77% | 12.04% |
| SARIMA | 3.75% | 3.24% | 2.63% | 9.02% |
| Prophet | 3.65% | 3.20% | 2.59% | 9.55% |
| RNN | 4.30% | 4.31% | 3.09% | 12.89% |
| LSTM | 5.89% | 5.11% | 4.10% | 17.89% |
| Transformer | 5.29% | 4.73% | 3.44% | 13.35% |
| Random Forest | 4.64% | 4.03% | 3.62% | 12.15% |
| LightGBM | 5.40% | 4.82% | 3.54% | 15.62% |
| XGBoost | 5.38% | 4.38% | 3.77% | 12.56% |
| Holt–Winters | SARIMA | Prophet | RNN | LSTM | Transformer | Random Forest | LightGBM | XGBoost | |
|---|---|---|---|---|---|---|---|---|---|
| p-values | 0.043 * | 0.021 * | 0.017 * | 0.007 † | 0.001 † | 0.001 † | <0.001 † | <0.001 † | <0.001 † |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hong, J.-H.; Lee, G.-C. Monthly Load Forecasting in a Region Experiencing Demand Growth: A Case Study of Texas. Energies 2025, 18, 4135. https://doi.org/10.3390/en18154135
Hong J-H, Lee G-C. Monthly Load Forecasting in a Region Experiencing Demand Growth: A Case Study of Texas. Energies. 2025; 18(15):4135. https://doi.org/10.3390/en18154135
Chicago/Turabian StyleHong, Jeong-Hee, and Geun-Cheol Lee. 2025. "Monthly Load Forecasting in a Region Experiencing Demand Growth: A Case Study of Texas" Energies 18, no. 15: 4135. https://doi.org/10.3390/en18154135
APA StyleHong, J.-H., & Lee, G.-C. (2025). Monthly Load Forecasting in a Region Experiencing Demand Growth: A Case Study of Texas. Energies, 18(15), 4135. https://doi.org/10.3390/en18154135