
Power Estimation and Energy Efficiency of AI Accelerators on Embedded Systems


Abstract
1. Introduction
2. Related Works
3. Estimation of Power Consumption
3.1. Target Embedded Hardware and Accelerators
3.2. Power Estimation Method
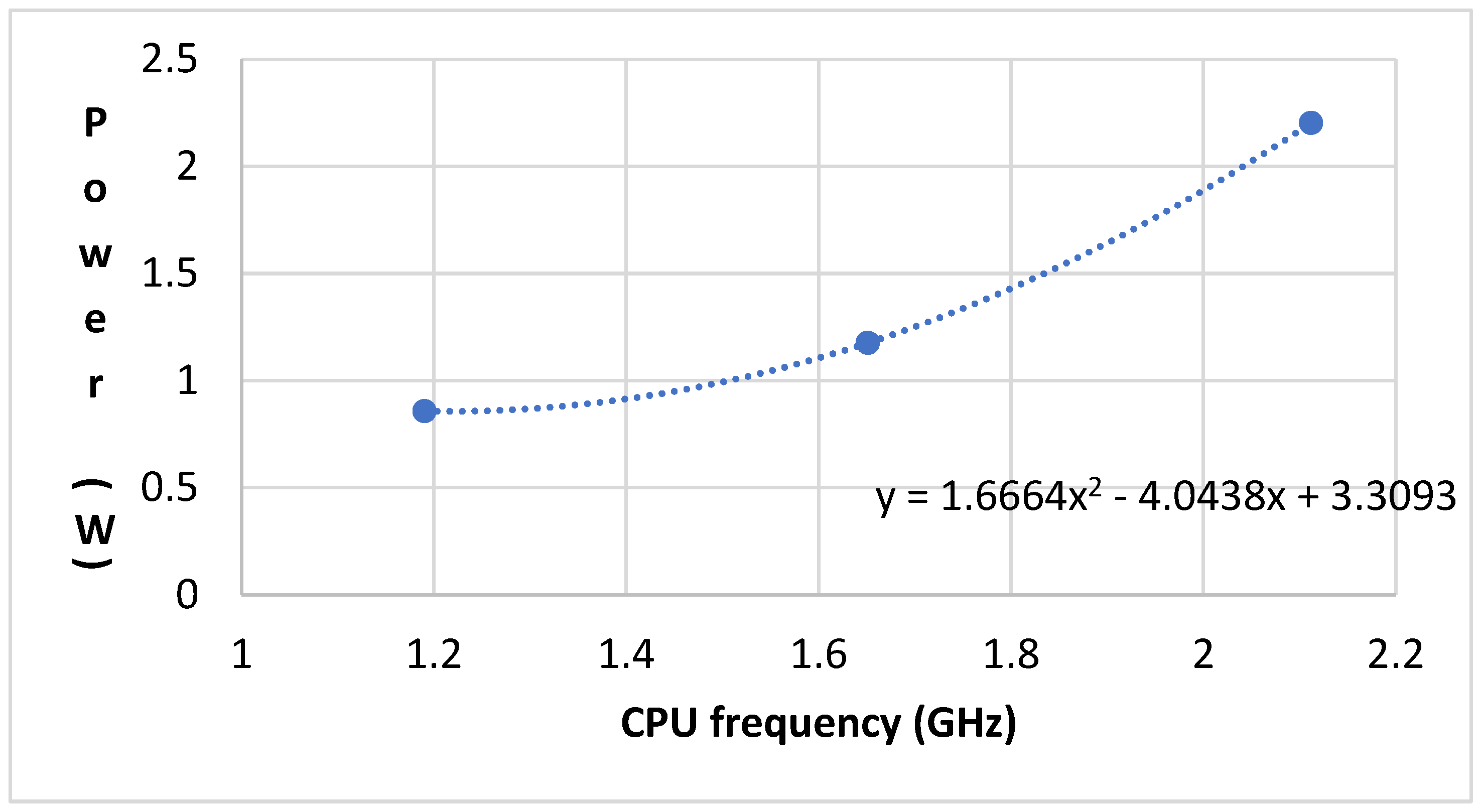
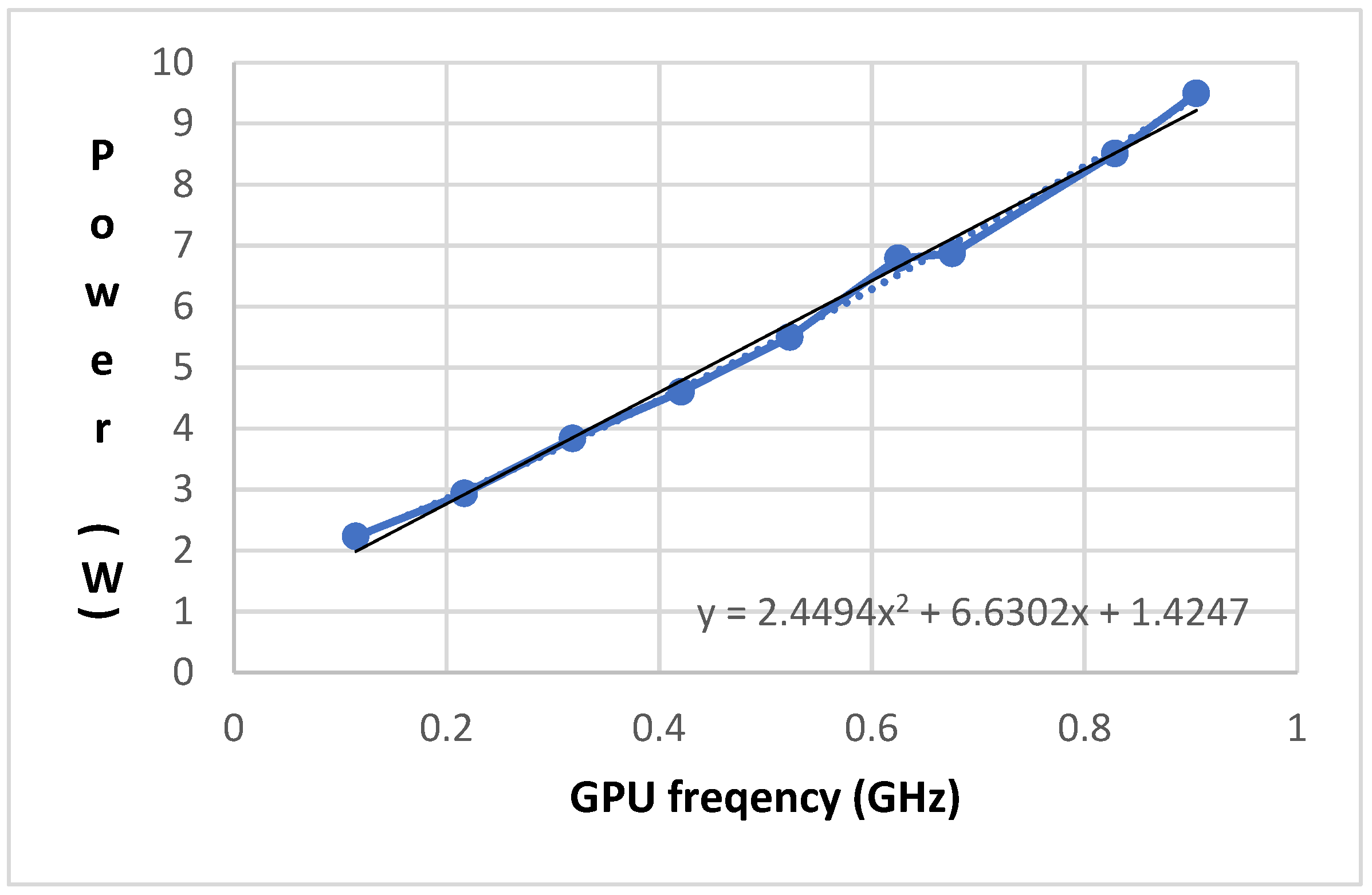
3.3. Data Collection for Power Estimation
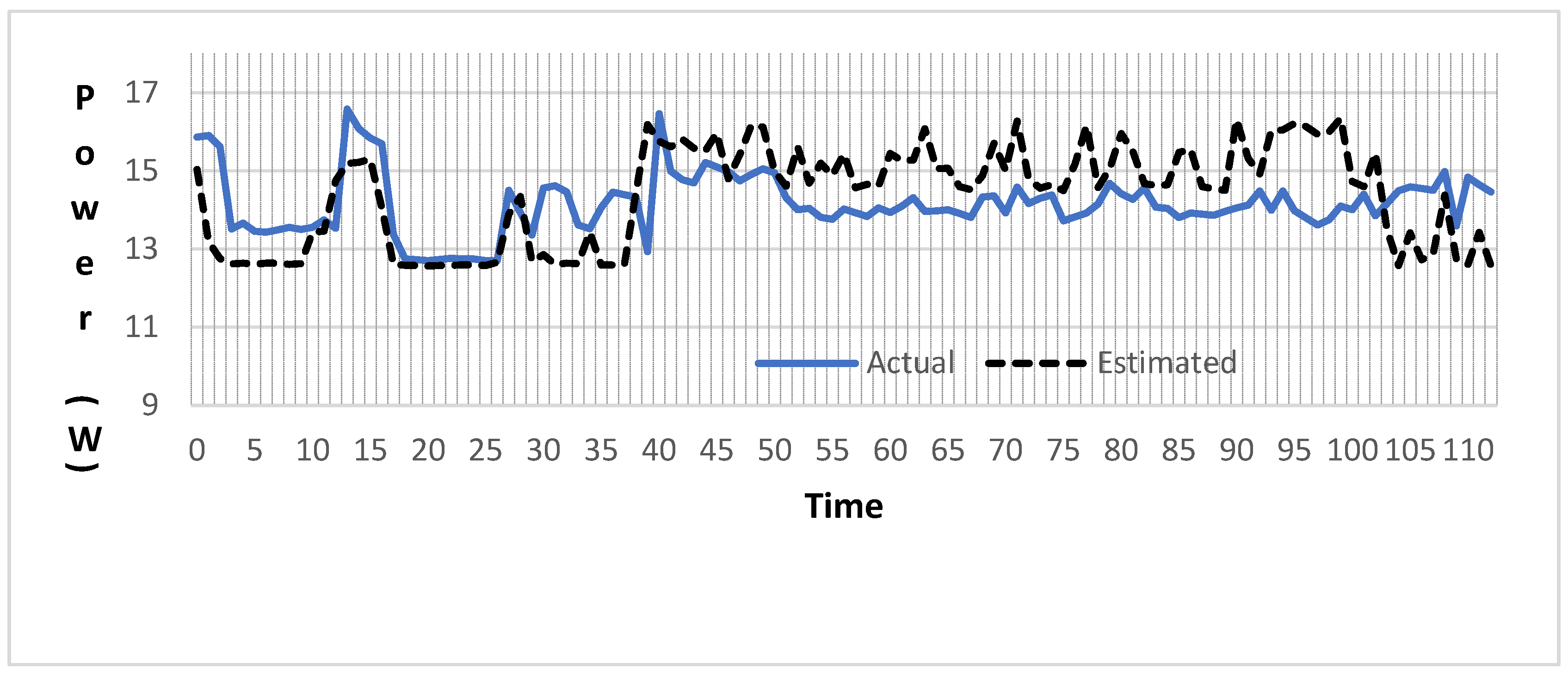
4. Evaluation of Power Estimation Method
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Energy and AI, International Energy Agency, April 2025. Available online: https://www.iea.org/reports/energy-and-ai (accessed on 28 May 2025).
- Wu, H.; Judd, P.; Zhang, X.; Isaev, M.; Micikevicius, P. Integer quantization for deep learning inference: Principles and empirical evaluation. arXiv 2020, arXiv:2004.09602. [Google Scholar] [CrossRef]
- Hadidi, R.; Cao, J.; Xie, Y.; Asgari, B.; Krishna, T.; Kim, H. Characterizing the deployment of deep neural networks on commercial edge devices. In Proceedings of the 2019 IEEE International Symposium on Workload Characterization, Orlando, FL, USA, 3–5 November 2019. [Google Scholar]
- Power Management for Jetson Xavier NX Series and Jetson AGX Xavier Series Devices. Available online: https://docs.nvidia.com/jetson/archives/l4t-archived/l4t-3275/index.html#page/Tegra%20Linux%20Driver%20Package%20Development%20Guide/power_management_jetson_xavier.html (accessed on 26 June 2025).
- USB Accelerator. Available online: https://coral.ai/products/accelerator/ (accessed on 30 May 2025).
- Intel Neural Compute Stick 2 (Intel NCS2). Available online: https://software.intel.com/content/www/us/en/develop/hardware/neural-compute-stick.html (accessed on 30 May 2025).
- Wisultschew, C.; Otero, A.; Protilla, J.; de la Torre, E. Artificial Vision on Edge IoT Devices: A Practical Case for 3D Data Classification. In Proceedings of the 34th Conference on Design of Circuits and Integrated Circuits, Bilbao, Spain, 20–22 November 2019. [Google Scholar]
- Kljucaric, L.; Johnson, A.; George, A.D. Architectural Analysis of Deep Learning on Edge Accelerators. In Proceedings of the IEEE Conference on High Performance Extreme Computing, Waltham, MA, USA, 22–24 September 2020. [Google Scholar]
- Hosseininoorbin, S.; Layeghy, S.; Sarhan, M.; Jurda, R.; Portmann, M. Exploring Edge TPU for Network Intrusion Detection in IoT. J. Parallel Distrib. Comput. 2023, 179, 104712. [Google Scholar] [CrossRef]
- Hosseininoorbin, S.; Layeghy, S.; Kusy, B.; Jurdak, R.; Portmann, M. Exploring Edge TPU for Deep Feed-Forward Neural Networks. Internet Things 2023, 22, 100749. [Google Scholar] [CrossRef]
- Tu, X.; Mallik, A.; Chen, D.; Han, K.; Altintas, O.; Wang, H.; Xie, J. Unveiling Energy Efficiency in Deep Learning: Measurement, Prediction, and Scoring across Edge Devices. In Proceedings of the 8th ACM/IEEE Symposium on Edge Computing, Wilmington, DE, USA, 6–9 December 2023. [Google Scholar]
- Tschand, A.; Rajan, A.T.R.; Idgunji, S.; Ghosh, A.; Holleman, J.; Király, C.; Ambalkar, P.; Borkar, R.; Chukka, R.; Cockrell, T.; et al. MLPerf Power: Benchmarking the Energy Efficiency of Machine Learning Systems from μWatts to MWatts for Sustainable AI. In Proceedings of the IEEE International Symposium on High-Performance Computer Architecture, Las Vegas, NV, USA, 1–5 March 2025. [Google Scholar]
- Ning, Z.; Vandersteegen, M.; Beeck, K.V.; Goedemé, T.; Vandewalle, P. Power Consumption Benchmark for Embedded AI Inference. In Proceedings of the 21st International Conference on Applied Computing, Zagreb, Croatia, 26–28 October 2024. [Google Scholar]
- Nabavinejad, S.M.; Salami, B. On the Impact of Device-Level Techniques on Energy-Efficiency of Neural Network Accelerators. arXiv 2021, arXiv:2106.14079. [Google Scholar]
- Power Meter & Analyzer (HPM-300A). Available online: https://adpower21com.cafe24.com/shop2/product/power-meter-analyzer-hpm-300a/18/category/51/display/1/ (accessed on 26 June 2025).
- Mittal, S. A Survey of Techniques for Improving Energy Efficiency in Embedded Computing Systems. Int. J. Comput. Aided Eng. Technol. 2014, 6, 440–459. [Google Scholar] [CrossRef]
- Burd, T.D.; Brodersen, R.W. Energy efficient CMOS microprocessor design. In Proceedings of the 28th Annual Hawaii International Conference on System Sciences, Wailea, HI, USA, 3–6 January 1995; pp. 288–297. [Google Scholar]
- Chandrakasan, A.; Sheng, S.; Brodersen, R. Low-power CMOS digital design. IEEE J. Solid-State Circuit 1992, 27, 473–484. [Google Scholar] [CrossRef]
- Hong, I.; Kirovski, D.; Qu, G.; Potkonjak, M.; Srivastava, M. Power optimization of variable voltage core-based systems. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 1999, 18, 1702–1714. [Google Scholar] [CrossRef]
- Corcoran, P.; Coughlin, T. Safe Advanced Mobile Power Workshop. IEEE Consum. Electron. Mag. 2015, 4, 10–20. [Google Scholar] [CrossRef]
- Available online: https://github.com/ereyes01/linpack (accessed on 30 May 2025).
- Available online: https://github.com/NVIDIA/cuda-samples (accessed on 30 May 2025).
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar] [CrossRef]
- Available online: https://www.kaggle.com/competitions/mu-cifar10 (accessed on 4 June 2025).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristic | Description |
|---|---|
| GPU | 512 Volta GPU with Tensor cores |
| CPU | 8-core ARM v8.2 |
| Memory | 32 GB 256-bit LPDDR4x @ 137 GB/s |
| Storage | 32 GB eMMC 5.1 |
| Property | Power Mode | |||||||
|---|---|---|---|---|---|---|---|---|
| MAXN | 10 W | 15 W | 30 W | 30 W | 30 W | 30 W | 15 W | |
| Online CPU cores | 8 | 2 | 4 | 8 | 6 | 4 | 2 | 4 |
| CPU maximal frequency (MHz) | 2265.6 | 1200 | 1200 | 1200 | 1450 | 1780 | 2100 | 2188 |
| GPU maximal frequency (MHz) | 1377 | 520 | 670 | 900 | 900 | 900 | 900 | 670 |
| Mode | 10 W | 15 W | 30 W | 30 W | 30 W | 30 W | 15 W |
|---|---|---|---|---|---|---|---|
| Power | 8.772 | 8.871 | 9.796 | 8.837 | 9.878 | 9.150 | 10.487 |
| Accelerator | Energy Used | Estimation | Error |
|---|---|---|---|
| Edge TPU | 910.20 J | 978.72 J | 68.52 J (7.53%) |
| GPU | 950.44 J | 896.29 J | −54.15 J (−5.70%) |
| On-Chip Memory | Cache | Off-Chip Memory |
|---|---|---|
| 7.74 MB | 512 B | 1.73 MB |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kang, M.; Park, M. Power Estimation and Energy Efficiency of AI Accelerators on Embedded Systems. Energies 2025, 18, 3840. https://doi.org/10.3390/en18143840
Kang M, Park M. Power Estimation and Energy Efficiency of AI Accelerators on Embedded Systems. Energies. 2025; 18(14):3840. https://doi.org/10.3390/en18143840
Chicago/Turabian StyleKang, Minseon, and Moonju Park. 2025. "Power Estimation and Energy Efficiency of AI Accelerators on Embedded Systems" Energies 18, no. 14: 3840. https://doi.org/10.3390/en18143840
APA StyleKang, M., & Park, M. (2025). Power Estimation and Energy Efficiency of AI Accelerators on Embedded Systems. Energies, 18(14), 3840. https://doi.org/10.3390/en18143840