1. Introduction
Against the backdrop of increasingly severe global climate change, the promotion of carbon neutrality has become an urgent global task [
1]. Especially in terms of energy consumption and carbon emissions, the traditional high-carbon energy structure must be urgently transformed to gradually realize green and low-carbon energy utilization. In this context, the optimization of smart grids and energy management systems [
2] is particularly important, as they can significantly improve the efficiency of energy utilization and reduce carbon emissions. Therefore, how to realize more accurate energy consumption monitoring and management has become one of the key issues to be solved in the current energy field.
Non-invasive load monitoring (NILM) technology has gained widespread attention as an efficient, low-cost approach to load identification [
3]. Using only an existing smart meter, NILM leverages a home or building’s overall energy consumption data to identify the individual load profiles of various types of appliances and equipment, providing data support for sophisticated energy management [
4], demand response [
5], and power system optimization [
6]. This approach avoids the need to physically meter each device in traditional approaches, providing significant cost benefits and greater deployment flexibility.
The basic principle of NILM is to identify the operating state of various electrical devices by analyzing the changing characteristics in the power signals. Usually, the NILM system decomposes the instantaneous power, power factor, harmonics, and other information of the loads into different electrical load signals by collecting them using signal processing and machine learning algorithms. In recent years, with the rapid development of advanced technologies such as deep learning and convolutional neural networks (CNNs), the accuracy and robustness of NILM methods have been dramatically improved.
NILM can be roughly divided into two main steps: first, the features of various types of loads are obtained from the total power consumption data by feature extraction; second, the extracted features are classified by load recognition algorithms, which in turn realize load recognition at the device level. In this process, the selection of features and the design of recognition algorithms is one of the core issues in the study of NILM systems.
Although NILM technology has found applications in various fields, it still faces several challenges. First, NILM systems rely heavily on training data, and traditional methods require a large amount of labeled data for training. However, in real-world scenarios, especially in small-sample environments, the lack of labeled data severely limits the practical applications of NILM systems [
7]. Second, most of the existing NILM methods suffer from high computational complexity, especially when targeting personalized identification tasks for different households and appliances, existing algorithms are often difficult to cope with the diverse electricity consumption characteristics [
8]. In addition, the similarity between appliances and the noise interference of power load signals makes the performance of NILM in high complexity and high uncertainty environments somewhat limited.
Currently, non-invasive load monitoring (NILM) techniques are widely used in academia and industry, and the methods and techniques of NILM are constantly evolving with the improvement of data acquisition and computational power. Most traditional NILM methods are based on signal processing and statistical modeling techniques. These methods typically perform the decomposition of load signals by hand-crafted features such as instantaneous power, power factor, harmonics, and so on. These features are often based on assumptions of physical principles and have certain limitations, especially when faced with complex power load signals, the effectiveness of traditional feature extraction methods is often more limited. For example, traditional load decomposition methods based on thresholding and segmentation are difficult to effectively distinguish between devices with similar load signals, so the detection accuracy of traditional methods is not high in complex scenarios where multiple loads overlap. In addition, signal processing methods are more sensitive to the quality and noise of the data, and in real-world environments, when the signal is noisy or disturbed by load fluctuations from other devices, these methods often fail to ensure a stable detection effect.
With the advancement of machine learning and deep learning techniques, model-based statistical methods and deep learning methods have gradually become the mainstream of NILM research. Model-based statistical methods such as the hidden Markov model (HMM) [
9] and support vector machine (SVM) [
10] are widely used for load identification. These methods characterize the device loads by constructing specific models and classifying them on the basis of these models. Compared with traditional methods, model-based methods have strong modeling capabilities and can better cope with the non-linear relationship between different devices and their load variations. However, the limitations of such methods are also more obvious, especially when faced with large, complex power data, the model training and inference process is often very heavy and limited by the model’s assumptions, which often fail to fully explore all potential load characteristics.
In recent years, deep learning techniques such as convolutional neural networks (CNNs), long-short-term memory networks (LSTMs), and autoencoders (AEs) have been widely used in the field of NILM, especially convolutional neural networks have become one of the mainstream methods due to their powerful automatic feature learning capabilities [
7]. Several recent studies have explored attention mechanisms and temporal modeling to enhance NILM performance. Literature [
11] introduces a multi-branch CNN with self-attention, capturing multi-scale and contextual features, but suffers from high complexity and resource demands. Literature [
12] proposes the lightweight ECA module for efficient channel attention, though it lacks temporal modeling crucial for load identification. Literature [
13] combines spatial and channel attention to boost feature discrimination, yet incurs significant computational overhead. Literature [
14] presents a two-stage LSTM with feature and temporal attention for improved short-term prediction, but its complexity and lack of deployment optimization limit edge applicability. Deep learning methods are capable of automatically extracting complex features from raw power signals and have strong nonlinear modeling capabilities, which enables them to show excellent performance in complex power load identification tasks. Through end-to-end training, deep learning methods can effectively reduce the manual feature extraction process and improve the accuracy and robustness of load detection. However, one of the main problems of deep learning methods is the strong dependence on the amount of training data. A large amount of labeled data are crucial for training deep networks, but in practical applications, especially for electrical load data from different households or buildings, it is often difficult to obtain a large and diverse amount of training data. In addition, deep learning methods tend to be computationally intensive, take a long time to train, and can be susceptible to data imbalance, device heterogeneity, and environmental noise, which can degrade model performance.
To address these problems, some studies in recent years have begun to explore methods such as lightweight model update [
15] and transfer learning [
16] to alleviate the need for large amounts of labeled data in deep learning methods. Lightweight model update methods aim to optimize the model’s performance and reduce computational overhead by focusing on efficiently updating smaller portions of the model, especially when computational resources are limited or when fast model adaptation is needed. However, in the NILM task, lightweight model update still faces challenges such as how to effectively extract key features from power signals and how to improve the generalization ability of the model under limited data. Although there have been some attempts to use lightweight model update methods to improve NILM performance, most of the existing methods focus on single-device load identification and are still inadequate for complex scenarios with multiple devices and loads. In addition, phase diagram methods [
17] enhance appliance-specific signatures but rely on single grayscale features, limiting information utilization. Compression-based approaches [
18,
19] reduce sampling demands and enable signal reconstruction, yet require hardware modifications, large datasets, and complex optimization, hindering edge deployment. Overall, existing methods face trade-offs between feature richness and practical applicability.
Overall, although current NILM methods address the limitations of traditional methods to some extent, they still face challenges such as handling data scarcity, improving model robustness, and optimizing computational efficiency. Deep learning methods, despite breakthroughs in accuracy, still require effective training with less data and higher computational costs. Therefore, combining existing methods with advanced attention mechanisms, lightweight model update techniques, and other innovations to better cope with the complexity and challenges of power load identification remains an urgent problem.
To overcome the limitations of existing methods, this study proposes a NILM method that combines the channel attention mechanism and lightweight model update. The channel attention mechanism can adaptively adjust the importance of different channels, allowing the model to focus on the most relevant features among the signals of different device loads [
20]. In the lightweight model update scenario, the channel attention mechanism can improve the model’s performance in resource-constrained environments by selectively enhancing critical features, thus reducing the need for heavy computation.
Lightweight model update, as a technique for effective model adaptation with limited computational resources, has shown great potential in various fields such as image classification and natural language processing. In the NILM task, this method allows a load detection model to achieve better generalization with fewer updates, thus addressing the problem of data scarcity and improving overall model efficiency.
Existing NILM methods face several challenges in resource-constrained environments: First, traditional methods often require large amounts of labeled data, while deep learning methods, despite their powerful learning capability, struggle with small datasets, leading to decreased model accuracy [
21]. Second, existing deep learning models often fail to emphasize the importance of key features in power signals, resulting in information loss and reduced accuracy [
8]. Therefore, how to efficiently utilize critical features in power signals and improve recognition accuracy in scenarios with limited resources is a challenging problem for current NILM technologies.
By introducing the channel attention mechanism, the model can automatically focus on and enhance the most important features, overcoming the feature selection limitations of traditional methods and improving the model’s ability to recognize complex power signals. In addition, combined with lightweight model update techniques, the problem of insufficient training data and computational resources can be effectively alleviated, leading to better generalization performance in practical applications. With this innovative approach, this study aims to provide a solution that not only addresses the challenges of lightweight model updates but also improves the accuracy of NILM, offering a theoretical foundation and practical guidance for more efficient energy management and smart grid technologies.
The main contributions of this paper are as follows:
A lightweight model update method based on the channel attention mechanism is proposed to solve the load identification problem in NILM in a resource-constrained environment.
A small-scale hardware experimental platform is designed, and the effectiveness of the proposed method in practical applications is verified through experiments.
The advantages of the method in terms of detection accuracy and computational efficiency are demonstrated by comparisons with traditional NILM methods.
2. Materials and Methods
In this section, the core of the proposed small-sample learning load detection method based on the channel attention mechanism is presented in detail. The method mainly consists of several modules, including the pre-processing of voltage and current signals, the construction of color V-I trajectory plots, the convolutional neural network (CNN)-based load detection model, the integration of the channel attention mechanism module, and the training and validation of small-sample learning. By combining these modules, this method is able to maintain high recognition accuracy and model robustness even in data-poor environments. Each module is described in detail below.
2.1. Data Preprocessing: Extraction of Voltage and Current Signals
The prerequisite for load identification is the acquisition of stable and high-quality voltage and current signals from electrical equipment. In the steady state operation stage of electrical equipment, the voltage and current waveforms are relatively stable and regular, providing a reliable basis for subsequent load identification. At this stage, we use high-precision power monitoring instruments for data acquisition, usually with a high sampling rate (e.g., more than 1 kHz) for synchronous acquisition of voltage and current signals. Let the voltage signal be
v(
t) and the current signal be
i(
t), where
t ∈ [0,
T] is the time interval and
T is the length of the sampling time window. A set of signal fragments is obtained by acquiring signals within this time window:
We require that the acquired signals cover the full cycle of the device’s steady-state operation to ensure that the data are sufficiently representative. Signal preprocessing includes removing noise and outliers, and normalizing the signals to reduce the impact of possible amplitude differences between different appliances on model training. Through this process, we obtained the steady-state voltage and current signals of the devices.
2.2. V-I Trajectory Map Construction
To effectively visualize the device load and serve as input to the deep learning model, we transform the relationship between the voltage and current signals into a colored V-I trajectory graph, referred to [
22]. The relationship between voltage and current usually shows a certain regularity during the steady-state operation of a device, especially when the load is stable, the relationship between voltage and current forms a specific trajectory. By mapping the voltage and current value pairs in a two-dimensional space, we are able to obtain the V-I trajectory of the device load.
To transform these relational data into the input image format required by the deep learning model, we first obtained trajectories consisting of multiple sample points {v(ti), i(ti)} by discretizing each signal fragment, followed by mapping these points into a 2D image. For the color representation of the image, we use the RGB color space to express the electrical characteristics of the device by converting the voltage v(t) and current i(t) into specific color channels.
Based on the extracted voltage and current signals, the maximum values of the voltage and current signals are found as shown in Equations (2) and (3).
Based on the pixel size of the composition, the image is divided into equally spaced cells of the same size. Assuming that the length of the image is 2
L pixels and the width is 2
W pixels, the length and width of each cell are given by Equations (4) and (5), respectively.
The V-I trajectory is mapped into a V-I trajectory map. For a given instantaneous value of voltage as
ut and current as
it, the corresponding pixel point locations and image processing are shown in Equations (6) and (7).
where ceil(·) is the rounding function and
P(
a,
b) is the pixel at position (
a,
b) in the image.
Then the pixel points are colored, where the coloring includes three colors red (R), green (G), and blue (B). First, the H, S, V color model is constructed, where H denotes the hue, i.e., the type of color, 0° for red, 120° for green, 240° for blue; S denotes the saturation, i.e., the degree of vividness of the color, 0% means no color, 100% means the most saturated; V denotes the luminance, i.e., the brightness of the color, 0% is black, 100% is white.
First, the different evolution directions of the V-I trajectories are represented to capture the direction of the motion trajectory of the V-I trajectories as shown in Equations (8) and (9).
where arg(·) is the amplitude angle of taking the complex number. S denotes the relationship between the active and reactive components of the current, capturing the power factor of the V-I trajectory, as shown in Equation (10).
where
Urms and
Irms are the RMS values of the voltage and current signals.
V indicates the long-term steady-state operation of the voltage and current signals, using m cycles of voltage and current signals averaged, two-dimensional V-I trajectory grayscale map construction method as described above, the image is obtained after averaging, as shown in Equation (11).
To convert
H,
S, and
V into
R,
G, and
B images, the
H values are first converted into angles in the range of 0–360 degrees, and then, the
S and
V values are normalized to the range of 0–1, and finally, the values of
R,
G, and
B are calculated according to the formulas of the
H,
S, and
V color models as in Equations (12)–(16).
2.3. Feature Extraction with Convolutional Neural Network (CNN)
In appliance load detection, the convolutional neural network (CNN) has become a widely used deep learning method due to its powerful image feature learning capability. In this method, CNN is used to automatically extract features that contribute to load detection from the input color V-I trajectory map. The structure of a CNN usually consists of several convolutional layers, pooling layers, activation layers, and fully connected layers.
First, the color V-I trajectory map is fed into the input layer of the CNN, which is progressively processed by multiple convolutional and pooling layers to extract features at different levels. The convolutional layer locally scans the input image through a convolutional kernel, capturing the local spatial features in the image. The output of each convolutional layer is nonlinearly transformed by a ReLU activation function to enhance the expressiveness of the model. The pooling layer, on the other hand, reduces the size of the feature map through a maximal pooling operation, thereby reducing computational complexity and improving the robustness of the model.
Through this process, the CNN is able to gradually extract the spatial features in the colored V-I trajectory map, which are then combined and classified in the fully connected layer. The output of this network is the classification result of each electrical device, which indicates the type or state of each device.
2.4. Integration of Channel Attention Mechanism
To further improve the performance of the model and enhance the feature selection capability, we integrate the channel attention mechanism on top of the CNN. The channel attention mechanism can help the model better focus on the important feature channels by adaptively adjusting the weights of each feature channel, which improves the recognition accuracy of the model.
The channel attention mechanism consists of two main parts: global descriptor generation and channel reweighting. In the global descriptor generation phase, a global average pooling operation is first performed on each feature channel to obtain a global information description of each channel. Let the input feature map be
X∈
, where
H and
W denote the height and width of the feature map, respectively, and
C is the number of channels of the feature map. The global average pooling operation compresses all the spatial information of each channel into a scalar value:
In the channel reweighting phase, the channel attention mechanism models the global description of each channel by a fully connected layer and computes the attention weights for each channel:
where
is the sigmoid activation function,
is the ReLU activation function, and
and
are the trainable weight matrices. Finally, the channel attention mechanism inputs the computed weights
into the feature map by re-weighting them, which allows the model to pay attention to more important channels during processing.
By introducing the channel attention mechanism, the model is able to adaptively adjust the contributions of different channels, which effectively improves the accuracy of appliance load detection, especially when faced with the complex differences between different electrical appliances, and enables better feature selection and focusing.
The proposed channel attention module has been demonstrated to possess favorable interpretability, with its generated channel weights having the capacity to intuitively reflect the importance of each feature channel to the final decision. A potential benefit of analyzing and visualizing the channel weights of the feature maps is that it can facilitate understanding of the feature regions that the model focuses on under different inputs. Conversely, the proposed channel attention module facilitates a transparent decision-making process, rendering the entire process more straightforward to track and explain.
The proposed channel attention module possesses extensibility, as it is a standalone, lightweight module that can be easily integrated into various network architectures by simply aligning the number of its input channels and output channels with those of the original model. It has been demonstrated that the proposed module exhibits low computational overhead and requires only a modest introduction of additional parameters to enhance its performance. Notably, the module maintains a high level of efficiency throughout the process. Consequently, the proposed channel attention module exhibits high scalability.
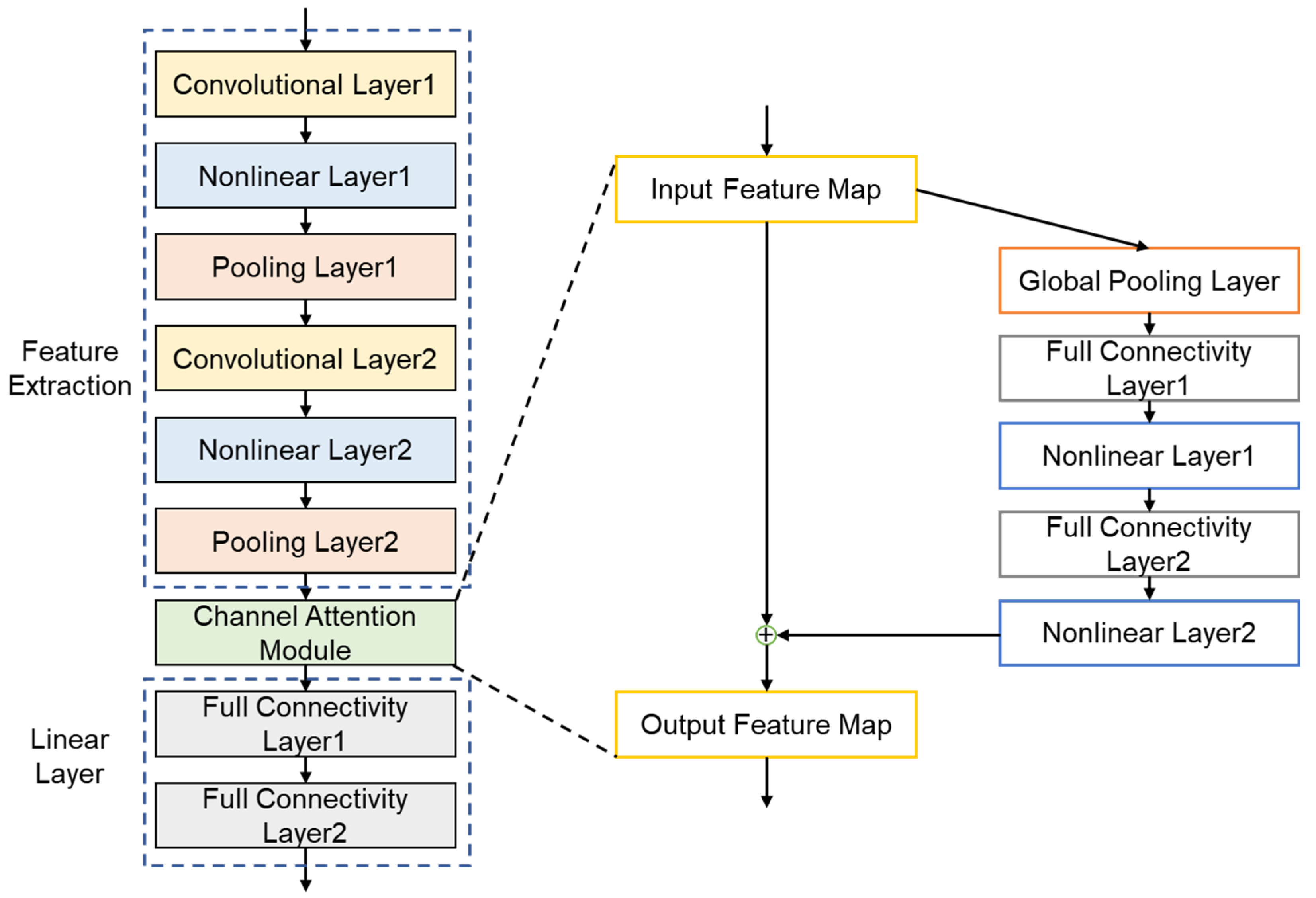
2.5. Model Structure
The complete structure of the model includes a feature extraction layer, a linear layer, and a channel attention mechanism module. The feature extraction layer includes a convolutional layer, a pooling layer, and a nonlinear layer. It should be noted that the model should include at least 2 convolutional layers to extract the features of the image as much as possible. The channel attention mechanism module includes a global pooling layer, a fully connected layer, a nonlinear layer, and a sigmoid function. The input feature maps of the channel attention mechanism module are the output feature maps of the feature extraction layer and follow the global pooling layer. The sliding window size of the global pooling layer is the same as the size of the input feature map, thus transforming the input feature map into a map with only one pixel while its channel number remains unchanged. The first fully connected layer of the channel attention mechanism module compresses the number of channels to
C/
r, where
r is the compression factor, while the second fully connected layer reduces the compressed feature map. The complete model structure is shown in
Figure 1. The model parameters are shown in
Table 1.
3. Results
In order to verify the effectiveness and practical value of the proposed small-sample learning load detection method based on the channel attention mechanism, experimental validation is designed. Through the experimental results, we are able to demonstrate the performance of the method in a small-sample learning environment and compare it with traditional load recognition methods to further verify its advantages.
3.1. Small-Scale Hardware Experimental Platform
In order to verify the feasibility and effectiveness of the proposed method, a small-scale hardware experimental platform was designed. It should be noted that the small-scale hardware experimental platform is not strictly limited to hardware models, but is a design scheme where any hardware type with the same effectiveness can be used as an alternative.
The small-scale hardware experimental platform includes a socket, an electrical energy sampling unit, a data transmission unit, and a data processing unit. The socket provides electrical energy for the electrical devices, and the electrical energy sampling unit collects voltage and current data with higher sampling frequency through its built-in sensors to provide data support for the construction of the V-I trajectory diagram. The data transmission unit is used to establish a connection bridge between the power sampling unit and the data processing unit. After receiving the data, the data processing unit draws the V-I trajectory diagram of the electrical appliances and recognizes the type of electrical appliances by the model. It should be noted that in order to verify the effectiveness of small-sample learning, the small-scale hardware experimental platform should be equipped with a sample recording function and a model training function to realize the lightweight model update. The schematic design of the small-scale hardware experimental platform is shown in
Figure 2.
For the purposes of example, we select the ZHTPT107W voltage transformer (Nanjing Zhen Hengtong Electronics Co., Ltd., Nanjing, China), ZHTCT501A current transformer (Nanjing Zhen Hengtong Electronics Co., Ltd.), and BL0956 power metering chip (Shenzhen Entway Electronic Components Co., Ltd., Shenzhen, China) to form a power sampling unit. The secondary signal of the transformer is input to the energy metering chip and input to the data processing unit through UART. The data processing unit can be implemented as either a computer or a microcontroller. The selection of the STM32H750 microcontroller (STMicroelectronics, Geneva, Switzerland) as the data processing unit is driven by its capacity to facilitate the load identification task and to present the results directly at the edge end. It is imperative to acknowledge that the proposed design method is intended for a small-scale hardware experimental platform. Alternative chips with equivalent effectiveness can be utilized in place of the specified microcontroller.
3.2. Experimental Platform
This experiment is conducted on a high-performance computing platform equipped with an NVIDIA GeForce RTX 1660 SUPER GPU (Shenzhen, China), which has 6 GB of video memory and is able to efficiently support the training and inference of deep learning models. During the training process, we use CUDA acceleration technology to enable the GPU to significantly improve the computational efficiency, thus accelerating the model iteration.
All experiments were conducted in the Python 3.8 environment, using the PyTorch (2.5.1) deep learning framework for model construction and training to ensure code compatibility and execution efficiency.
3.3. Evaluation Metrics
In order to comprehensively evaluate the performance of the proposed method, we use a variety of evaluation metrics. These metrics not only help to measure the accuracy of the model, but also reveal the performance of the model in practical applications in several dimensions.
First, accuracy (
Acc) is one of the most commonly used categorization metrics, which indicates the proportion of samples correctly predicted by the model out of all samples. For the load detection task, accuracy reflects how well the model detects the device type on the test set and is calculated as shown in Equation (19).
where
TP (true positive) is the number of samples correctly identified as positive categories,
TN (true negative) is the number of samples correctly identified as negative categories,
FP (false positive) is the number of samples incorrectly identified as positive categories, and
FN (false negative) is the number of samples incorrectly identified as negative categories.
Second, precision (
Pre) and recall (
Rec) are important metrics used to evaluate the performance of a classification model on different categories. Precision measures the proportion of samples predicted by the model as positive categories that actually belong to positive categories, while recall measures the proportion of actual positive categories that are correctly identified by the model. They are calculated as Equations (20) and (21), respectively.
In the load detection task, precision rate and recall rate help to evaluate the model’s detection ability on different appliance categories (e.g., air conditioners, refrigerators, etc.), especially in the case of appliance category imbalance, and these two metrics reflect the model’s performance in a more comprehensive way than precision rate.
In addition, the
F1-
score is the reconciled average of precision rate and recall rate, which provides a comprehensive evaluation result. The
F1-
score is especially suitable for the case of category imbalance, and can effectively balance the trade-off between precision rate and recall rate. The
F1-
score is calculated as shown in Equation (22).
Finally, we are also concerned with the multiply accumulate operations (MACs) of the model and the number of model parameters.
3.4. Experimental Results
In this study, we conducted model training and evaluation on the publicly available load recognition dataset WHITED [
23], and then compared the experimental results with those of traditional load recognition methods. Specifically, the WHITED dataset contains 54 categories of commonly used home appliances, including Fans, Coffee Machines, Deep Fryers, Washing Machines, Flat Irons, Mixers, Juice Makers, Monitors, Microwaves, and Refrigerators, among others. Each appliance is characterized by a distinct set of brand types, e.g., the Fan category encompasses ChingHai35W, Cyclone3000, HoneywellCL25AE, Krisbow50W, Salco-STT23-1, and VOV, etc. Consequently, the amount of data varies among the different appliance types. To assess the efficacy of the proposed method, it is essential to identify the performance of a larger range of appliances and to circumvent inadequate generalization due to insufficient data. To this end, a selection of five appliance types, namely LEDLight, Kettle, LightBulb, Fan, and Charger, was chosen as the experimental dataset, based on the number of samples and the type ordering of the original dataset. The amount of raw data for these selected appliances is shown in
Table 2.
To augment the dataset for the designated appliances, a random noise signal is introduced, with a mean of 0 and a variance equal to 1/10 of the current amplitude of the appliance during its standard operation. This noise is incorporated into the dataset to enhance the generalization performance of the proposed model, so that each appliance contains 400 samples.
Table 3 shows the raw current signals of some of the selected appliances.
In accordance with the V-I trajectory map construction method outlined in
Section 2.2 of the manuscript, the V-I trajectory maps have been plotted for some of the selected appliances as shown in
Table 4.
We randomly selected 80% of samples from each category for training, while retaining approximately 20% of the samples for testing. The experiments were set up for 50 rounds of training, using the Adam optimizer with a learning rate of 0.001.
The experimental results are presented in
Table 5. The results demonstrate that the proposed small-sample learning load recognition method based on the channel attention mechanism exhibits superior performance in several evaluation metrics. In terms of accuracy, the proposed method achieves approximately 98% accuracy on the test set, which is significantly higher than that of other methods. The model also demonstrates significant advantages in precision, recall, and F1-score, with precision and recall reaching 97.8% and 97.9%, respectively, and an F1-score of 0.978. In comparison, the F1-score of the conventional convolutional neural network (CNN) on the same dataset is only 92.6%, indicating that the channel attention mechanism proposed in this study effectively improves the load recognition ability of the model.
In recent years, other attention mechanisms have been proposed, including the BAM mechanism and the transformer self-attention mechanism. The BAM mechanism employs parallel channel and spatial attention mechanisms, which exhibit greater adaptability to deep network structures, thereby enhancing the model’s expressive capabilities. The transformer self-attention mechanism utilizes the global Query–Key mechanism to capture long-distance dependencies, a capability that surpasses that of conventional CNNs and LSTMs in capturing global features. This mechanism is well-suited for tasks that demand global context modeling; however, it imposes a substantial computational overhead. In order to compare the effect of the proposed method with those of the aforementioned works, the backbone network of
Section 2.5 is kept unchanged, and only the proposed attention module is replaced. The ensuing experimental results are presented in Table.
The results in
Table 6 show that the proposed channel attention module is theoretically better able to mine features in the channel dimension of the feature graph, has better interpretability and extensibility, and compared with other work in recent years, the model performance has a high improvement, while the number of model floating-point computations and the number of model parameters have only a small improvement, which is more suitable for load detection in the lightweight edge deployment. The task is more suitable for load detection in lightweight edge deployment.
In order to verify the generalizability of the proposed method to different datasets, experiments were conducted on the PLAID dataset [
24]. The PLAID dataset was formed in the summer of 2013 from 56 households in Pittsburgh, PA, USA, and consists of the raw voltage and current waveform data of 11 electrical appliances with a sampling frequency of up to 30 kHz. The effectiveness of the proposed channel attention mechanism in the load identification problem is verified under the same experimental condition settings. The results of this study are presented in
Table 3, with an improvement of 11.8% in accuracy and 0.106 in F1-score on the test set, which validates the effectiveness of the proposed channel attention mechanism.
3.5. Hyperparameter Selection
To investigate the impact of different compression rates and learning rates on the model’s performance, extensive experiments were conducted under varying settings. The compression rate
r, defined as the ratio between the input and output channels of the 12th linear layer as shown in
Table 1, plays a crucial role in determining the degree of dimensionality reduction applied to the intermediate features. Similarly, the learning rate
lr governs the optimization trajectory and convergence speed of the training process.
Table 7 presents the model’s performance at different compression rates while keeping the learning rate fixed at
lr = 0.001. It is observed that the model achieves the highest F1-score of 0.978 at
r = 8, with an accuracy of 98.0%, precision of 97.8%, and recall of 97.9%. While higher compression rates (e.g.,
r = 16) lead to reduced performance due to excessive loss of discriminative features, lower compression rates (e.g.,
r = 1) result in redundant information and increased parameter complexity, thereby limiting the model’s generalization capability.
Table 8 illustrates the performance of the model under various learning rates at a fixed compression rate of
r = 8. Learning rates of
lr = 0.001 and
lr = 0.0005 both yield the best performance, with an F1-score of 0.978. In contrast, a high learning rate such as
lr = 0.01 causes training instability, reflected in a sharp drop in accuracy and F1-score. On the other hand, an overly small learning rate (
lr = 0.0001) slows down the convergence and slightly degrades performance.
The experimental results suggest that the proposed channel attention mechanism attains optimal performance when the compression rate is set to r=8 and the learning rate is selected as either lr = 0.001 or lr = 0.0005. These settings achieve a balance between feature abstraction and optimization stability, effectively mitigating underfitting or overfitting tendencies. Accordingly, we adopt r = 8 and lr = 0.001 as the default hyperparameters in the following experiments.
3.6. Comparison with Lightweight Baselines
To further validate the effectiveness of the proposed channel attention mechanism, we conduct a comprehensive comparison with existing lightweight strategies, including MobileNet-V2 [
25], various pruning levels [
26], and model quantization [
27]. These methods represent widely adopted solutions for model compression and edge deployment in the domain of load identification.
As shown in
Table 9, the baseline model MobileNet-V2 achieves an F1-score of 0.791, with an accuracy of 83.2%, while requiring only 6.52 million MACs and 2.23 M parameters. In contrast, the proposed channel attention module significantly outperforms MobileNet-V2, achieving an F1-score of 0.978 and an accuracy of 98.0%, with a similar parameter scale (2.17M) but a higher MAC due to the attention mechanism (219.17M). However, the training convergence of the proposed model is considerably faster, typically requiring fewer than 10 iterations under a standard learning rate. Moreover, unlike MobileNet-V2 which mandates full parameter updates, the proposed approach allows for partial and adaptive updates, rendering it more suitable for on-device continual learning in edge scenarios.
Performance metrics of models with different pruning ratios and model quantization are detailed in
Table 10. While a 20% pruning ratio still maintains acceptable performance (F1-score 0.921), aggressive pruning (e.g., 80%) leads to a dramatic drop in F1-score to 0.589. Notably, across all pruning levels, the MAC remains unchanged at 219.13M, indicating that the pruned parameters, though functionally negligible, still contribute to computational overhead due to zero-padding and matrix calculation inclusion. Model quantization performs slightly better, yielding an F1-score of 0.949, yet still inferior to the channel attention module.
Experimental results demonstrate that conventional lightweight strategies, while effective in reducing parameter counts, often come at the cost of degraded model performance and limited flexibility during incremental updates. The channel attention mechanism introduced in this paper circumvents this trade-off by preserving feature representation capacity and enabling modular, fine-grained model adjustments. In summary, the proposed module not only boosts identification accuracy, but also offers better adaptability for dynamic edge environments, where rapid and partial updates are required without retraining the entire model.
Further analysis shows that the channel attention mechanism is particularly effective in lightweight model updates. The channel attention mechanism has been demonstrated to be effective in mitigating the risks of overfitting or underfitting, particularly in scenarios where model parameters are constrained or the dataset is limited in size. The efficacy of channel attention in mitigating overfitting in lightweight models is primarily attributable to its ability to direct the model to focus on more effective feature channels and suppress redundant information. This, in turn, enhances the utilization efficiency of features and reduces the risk of invalid or noisy learning. In contrast to traditional methods, such as the no-attention mechanism, manual feature selection, or Dropout/L2 regularization, the discriminative power of channel features is enhanced, leading to improved data-driven feature screening. Consequently, the proposed channel attention mechanism has been shown to enhance performance significantly in real-deployment contexts involving lightweight updates.
3.7. Tests on a Real Hardware Platform
To further verify the feasibility of the model in practical applications, we also conducted online tests on a real hardware platform. The results are shown in
Table 11. Among them, after freezing the feature extraction layer and the channel attention mechanism module, we only need to update the linear layers, and the parameters that the model needs to update are only 34 KB using Int8 encoding, which is much smaller than the number of parameters in the model itself. What is more, its updating effect is improved by 5.4% compared to the no-channel attention mechanism module, which verifies the effectiveness of lightweight model updates.
According to the theory, in the STM32H750 microcontroller utilized, quantizing the model into Float32 format results in a total of 438.34 MFLOPs required for inference, with 219.17 MMAC. However, the STM32H750 operates at a main frequency of 480 MHz and a theoretical peak computation speed of 2 FLOPs/cycle in single precision × 480 MHz = 960 MFLOPs. Consequently, the theoretical inference time is calculated to be 438.34MFLOPs/960 MFLOPs, which equates to 0.456 s. Therefore, when running on the experimental platform, the lightweight model update based on the channel attention mechanism is able to detect power signals from various electrical devices in real time, and the detection accuracy is consistent with the results in the laboratory environment. The experiments show that the proposed method is able to maintain high robustness in practical applications and adapt to the power detection needs of different electrical devices.
Overall, compared with the traditional methods, the experimental results fully validate the superiority of the small-sample learning load recognition method based on the channel attention mechanism in the load recognition task, especially in the case of data scarcity, and prove its potential application value in smart grid and home electrical device management.
4. Discussion
The lightweight model update method for load detection based on the channel attention mechanism proposed in this study demonstrates significant advantages in resource-constrained environments. The channel attention mechanism dynamically adjusts the weights of feature channels, enhancing the model’s focus on key features. This approach effectively mitigates overfitting and improves the model’s detection accuracy, especially in environments with limited data. Experimental results show that, under conditions of data scarcity, the model incorporating the channel attention mechanism outperforms traditional convolutional neural networks (CNNs), particularly in terms of precision and recall. The proposed method requires only a 0.04 MMAC and 0.04 M increase in model parameters, with a theoretical inference time of 0.456 s. A few parameters need to be added for “plug and play” use, which is lightweight and highly efficient.
Furthermore, the construction of color V-I trajectory maps provides richer feature representations for voltage and current signals, further enhancing the model’s robustness and recognition capability. This allows the model to better handle signal noise and the unstable behavior of devices, improving its overall reliability in practical applications.
However, the current method has certain limitations, particularly in rapidly changing or transitional states. For instance, when contemplating appliances such as inverter air conditioners and refrigerators, which operate with frequent power fluctuations, the method proposed herein will continuously detect the cyclical events of plugging in and unplugging such appliances, but in reality, these appliances have been operating normally. However, for microwave ovens, induction cookers, and other electrical devices with extended transient states, whose power change process ranges from a few seconds to tens of seconds, the efficacy of the proposed method may be limited in detecting access or unplugging events. The incorporation of a multi-timescale feature extraction mechanism, or the extension of the proposed channel attention mechanism through the introduction of an appliance state awareness mechanism, could facilitate the capture of such dynamic behaviors.
Future work could explore the integration of time-series modeling techniques or focus on optimizing the computational efficiency of the channel attention mechanism to enhance real-time performance in large-scale applications. Specifically, the application of compression, quantization, pruning, low-rank decomposition, weight sharing, or hardware-aware architecture exploration techniques to further compress the parameters and computational scales of the massively deployed channel-attention mechanisms is recommended, with the aim of improving computational efficiency. Additionally, expanding the model’s ability to handle more complex device behaviors and diverse operational conditions could further enhance its applicability. For instance, decreasing the degree of compression of channel features has the potential to enhance applicability across a more extensive range of appliance types. Concurrently, the implementation of lightweight channel attention mechanisms can be adapted to a diverse array of complex environments.
For large-scale deployment in smart grid scenarios, several key challenges remain: (1) Interoperability. Load identification methods must function across diverse smart meters, sensors, and energy systems to enable practical edge deployment. (2) Data security and privacy. Voltage and current waveforms may reveal user behaviors, necessitating localized processing and robust network safeguards. and (3) System-level integration. Linking load identification with grid operations such as dispatch, forecasting, and demand response requires further investigation, as it serves as a foundational step for broader grid intelligence.





{kind=link}
{kind=link}