

A Data Imputation Approach for Missing Power Consumption Measurements in Water-Cooled Centrifugal Chillers

Abstract
1. Introduction
1.1. Research Background and Objectives
1.2. Limitations of Previous Studies
- A.
- Many prior works applied a single imputation method without conducting a thorough analysis of the missing data mechanism, such as missing completely at random (MCAR) or missing at random (MAR). As a result, the selected methods often failed to reflect the true nature of the data, leading to reduced imputation quality [5];
- B.
- In high-dimensional and dynamically changing environments, such as time-series sensor data, traditional studies have predominantly relied on simplistic statistical approaches such as mean substitution, linear interpolation, or regression-based imputation. While computationally efficient, these methods are limited in their ability to capture complex temporal patterns and inter-cluster heterogeneity [6];
- C.
- Conventional data-driven methods such as k-nearest neighbors (KNNs) rely on fixed-distance similarity measures, which fail to consider the existence of clustered structures or local variations. As a result, their performance tends to degrade under varying operational conditions or device-specific patterns [7];
- D.
- There is a lack of advanced imputation techniques tailored to real-world sensor-based environments. Particularly in physical systems such as water-cooled chillers, various types of missing data may occur due to environmental disturbances, sensor malfunctions, or communication failures. However, case studies addressing such practical scenarios remain limited [8].
1.3. Research Objectives and Scope
- A.
- Variable-specific importance weighting
- Computed via correlation coefficients, mutual information, or domain-specific feature ranking;
- Integrated directly into the distance function, allowing more relevant variables to exert greater influence.
- B.
- Cluster-based neighbor selection
- Respect local data topology;
- Reduce contamination from out-of-distribution points;
- Preserve the semantic integrity of imputed values.
1.4. Key Contributions of This Study
- A.
- Introduction of a novel approach to address missing data in chiller operation data:
- Analyzes the limitations of commonly used imputation methods, such as mean imputation, median imputation, linear interpolation, and KNN imputation;
- Develops a new DC-KNN imputation method that improves upon conventional KNNs by incorporating clustering-based filtering and dynamic weighting, leading to more precise missing data imputation.
- B.
- Demonstration of practical applicability using real operational data:
- The dataset consists of 118,464 chiller sensor records collected over three years in a real-world operational environment, ensuring high practical applicability;
- The analysis is conducted based on long-term observed data, enhancing the reliability of the imputed results by utilizing an extensive dataset.
- C.
- Analysis of the optimal combination of missing data rates and imputation techniques:
- This study compares and analyzes various missing data imputation techniques to identify the optimal imputation method based on different missing rates (10%, 20%, and 30%). This research provides valuable insights into data-driven chiller performance optimization and offers a robust guideline for handling missing data in HVAC system analysis.
2. Theoretical Review
2.1. Outlier Detection
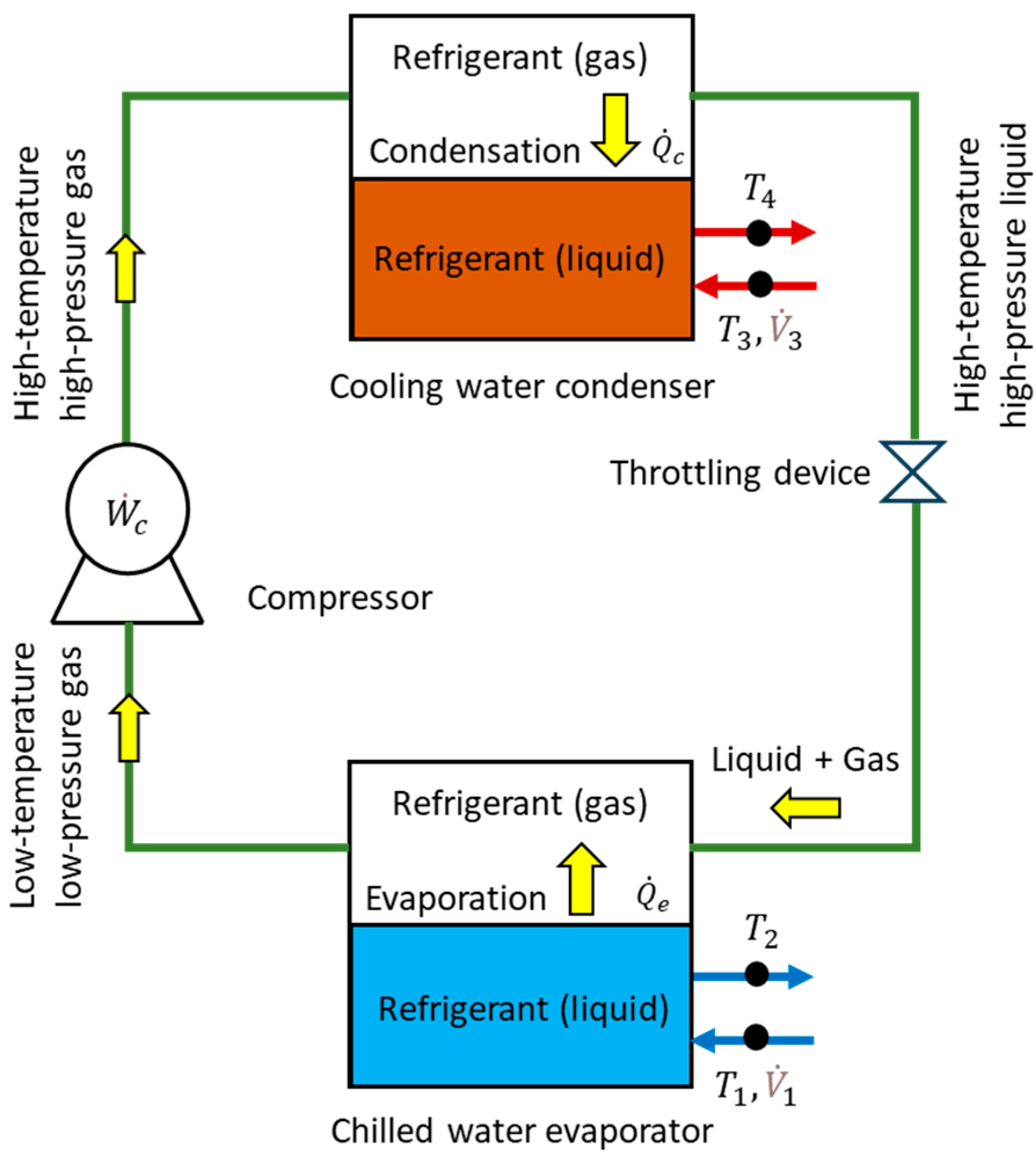
2.1.1. Thermodynamic Characteristics of Chillers
2.1.2. Energy Balance Error (EB)
2.1.3. Coefficient of Performance (COP)
2.2. Imputation Methods
2.2.1. Mean Imputation
2.2.2. Median Imputation
2.2.3. Linear Interpolation
2.2.4. Multiple Imputation
2.2.5. Simple Random Imputation
2.2.6. KNN Imputation
2.2.7. Euclidean Distance
2.2.8. Cosine Similarity
2.2.9. DC-KNN Imputation
| Algorithm 1. The step-by-step procedure of the proposed DC-KNN imputation method. |
| DC-KNN Imputation Input: (dataset with missing values), (observed variables), (number of clusters), and (neighbors). 1. Normalize input variables ; 2. Apply K-means clustering to group data into clusters; 3. For each missing value : a. Find cluster containing ; b. In , find the k-nearest neighbors based on Euclidean distance; c. Assign weights: = 1/distance; d. Compute the imputed value: = Σ( ∗ )/Σ() 4. Return the imputed dataset. |
2.3. Validation Methods
2.3.1. MAPE
2.3.2. CVRMSE
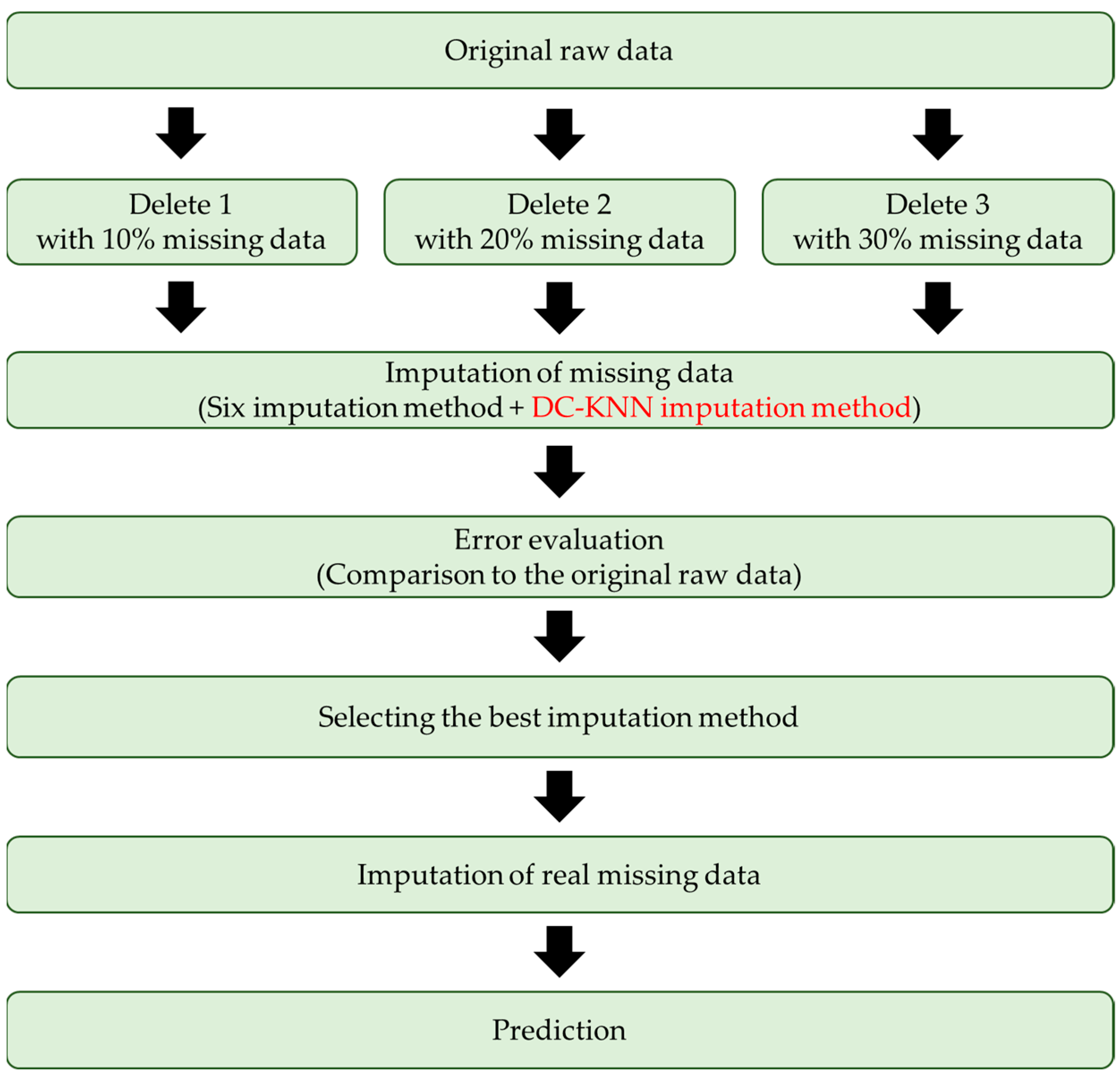
3. Research Methodology
3.1. Measurement Target and Period
- A.
- Ice-making mode: The process of freezing capsule-type media inside the thermal storage tank. The chiller is designed to operate at an average temperature of −4.5 °C. Ice storage primarily occurs during late-night hours, and the system stops after 10 h of operation or when the storage reaches 100% capacity;
- B.
- TES-only operation: The cooling load is handled solely by the thermal storage tank without operating the chiller. This mode is mainly used during transitional seasons or at night when the cooling demand is low;
- C.
- Parallel operation of the chiller and the TES: The chiller and the TES tank operate together to meet peak cooling loads. In this mode, the chiller operates at ambient conditions;
- D.
- Chiller-only operation: The chiller independently handles the cooling load without utilizing the TES system. This mode is used when the TES system malfunctions or when the thermal storage is completely depleted.
3.2. Data Measurement
3.2.1. Data Measurement Method
3.2.2. Uncertainty Analysis
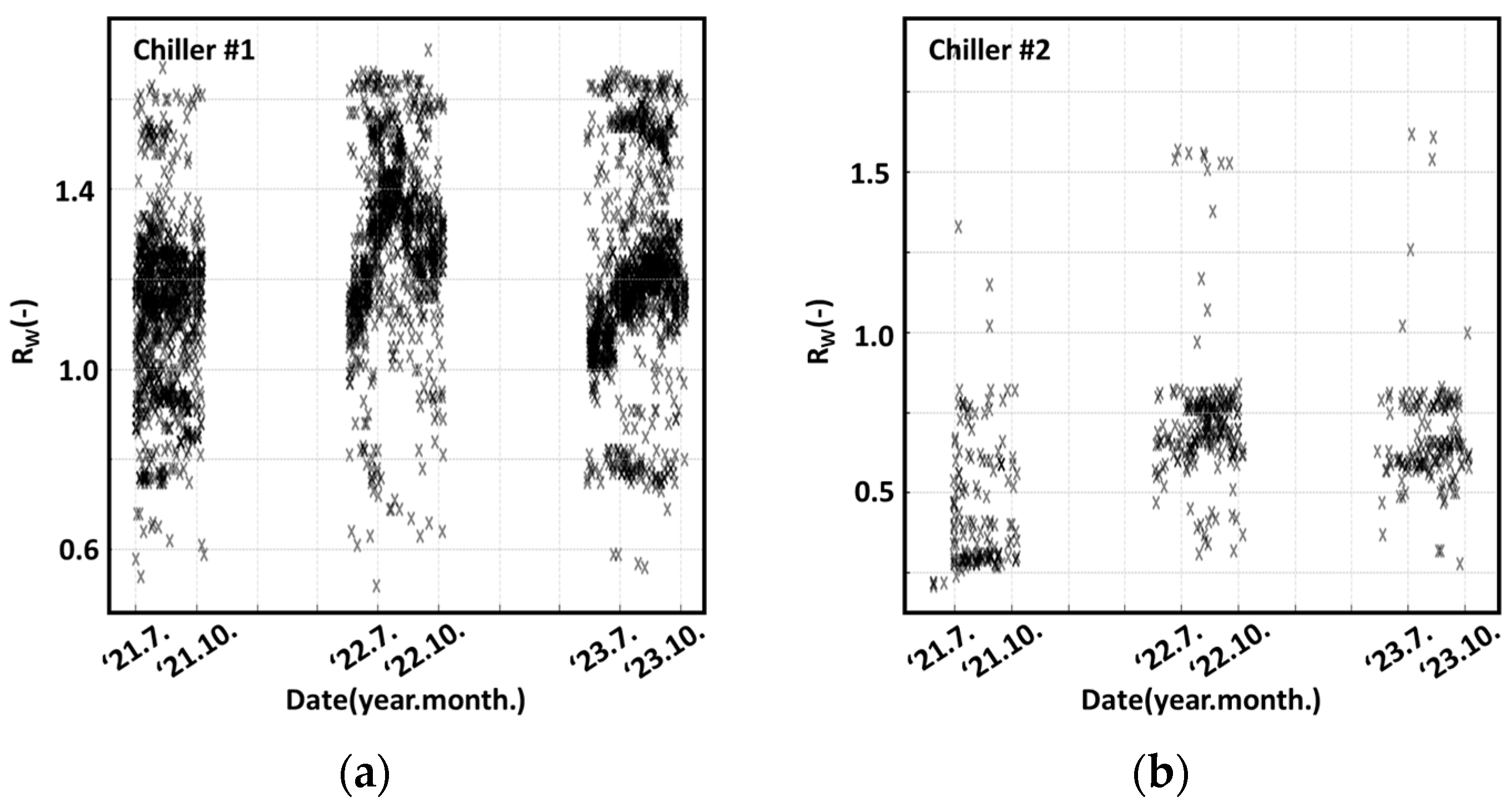
3.2.3. Initial Review of Collected Power Consumption Data
- : The actual capacity exceeds the nominal capacity, indicating that the chiller is operating beyond its design conditions. This situation is typically caused by high load conditions or unexpected external environmental changes;
- : The actual capacity matches the nominal capacity, meaning that the system is operating as per the design conditions;
- : The actual capacity is lower than the nominal capacity, suggesting that the chiller is operating under partial load conditions. This state frequently occurs in energy-saving modes or low-load conditions.
3.2.4. Review of Valid Data
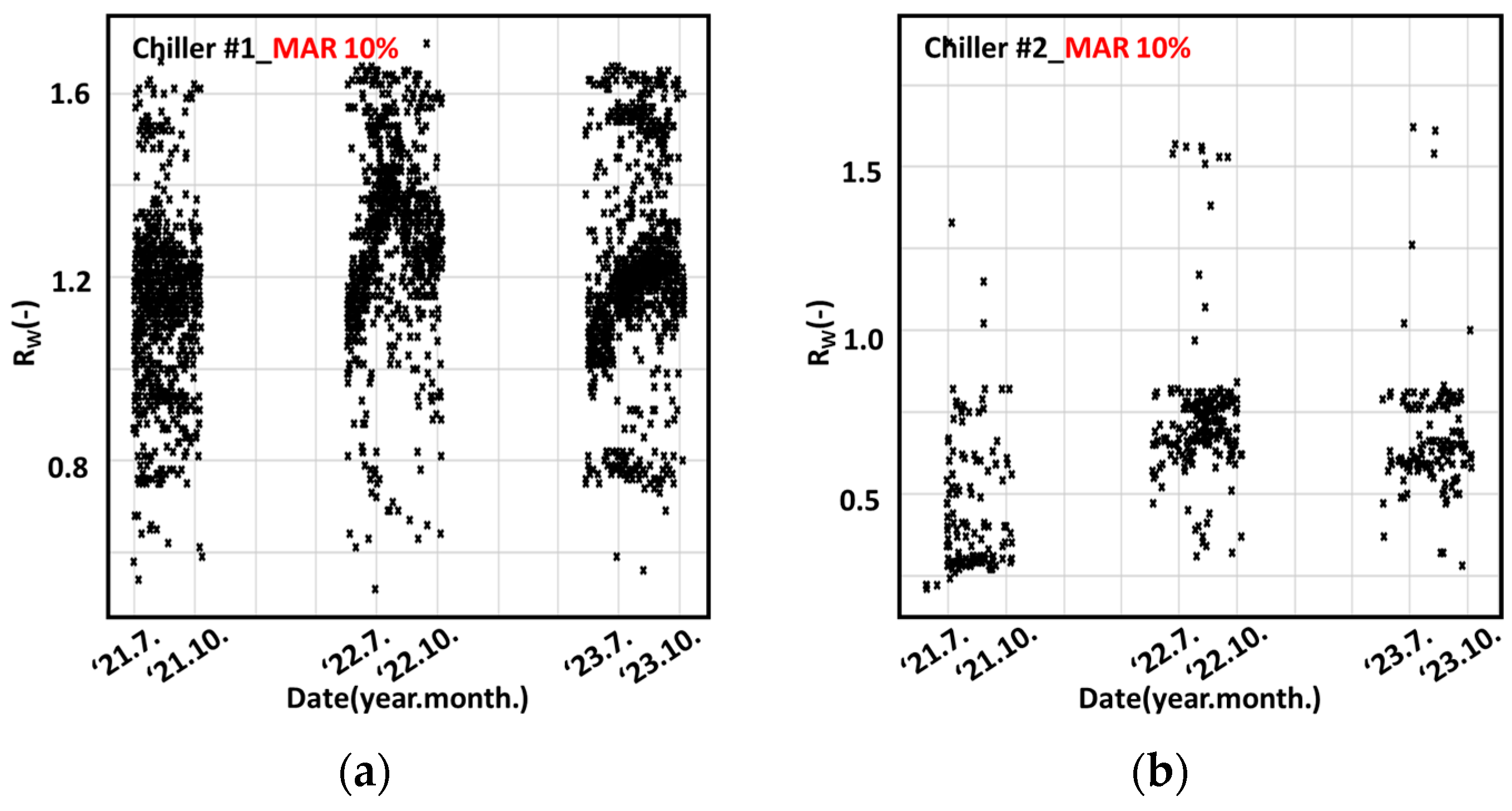
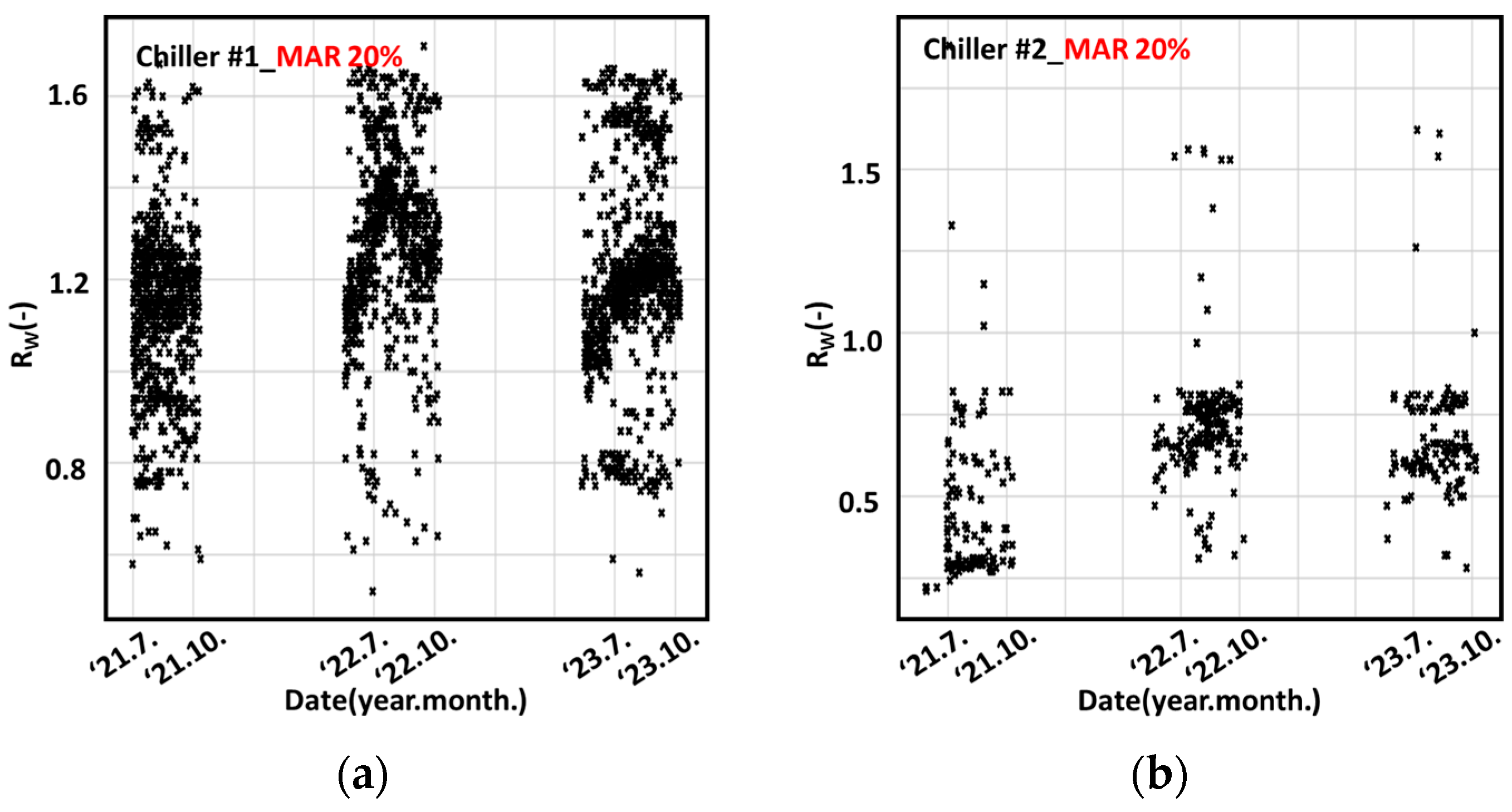
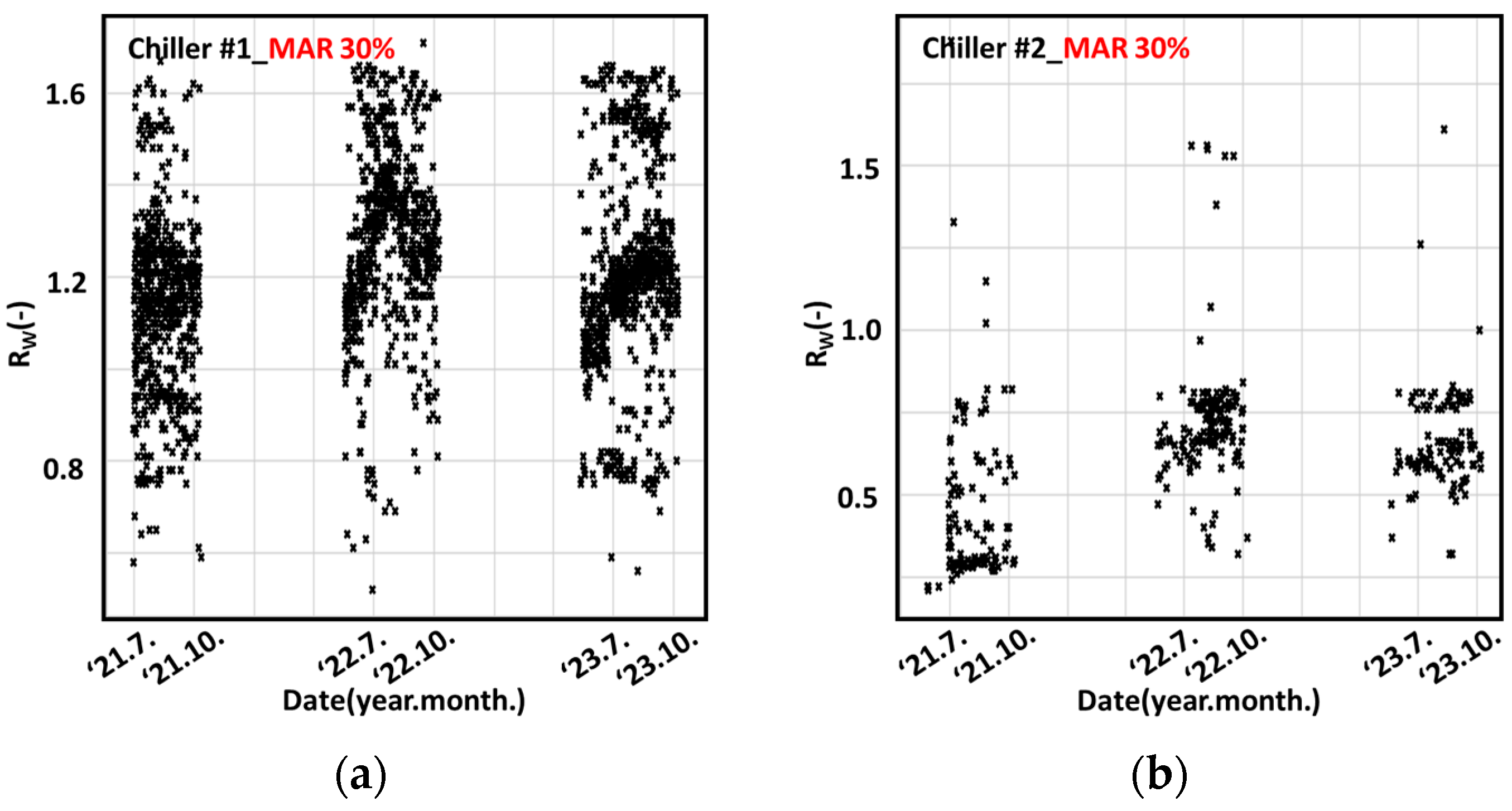
3.3. Partially MAR Data
4. Experimental Results and Discussion
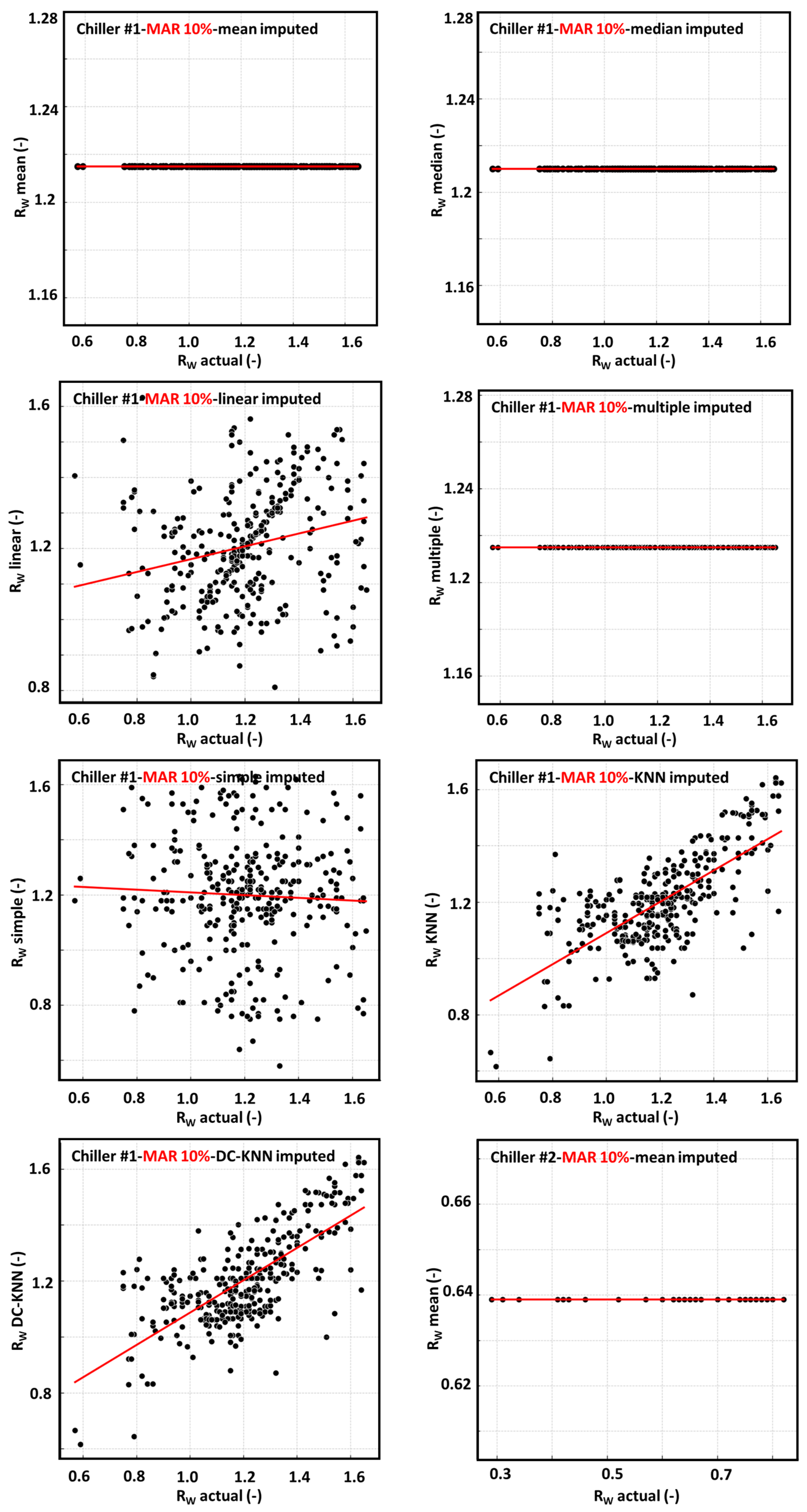
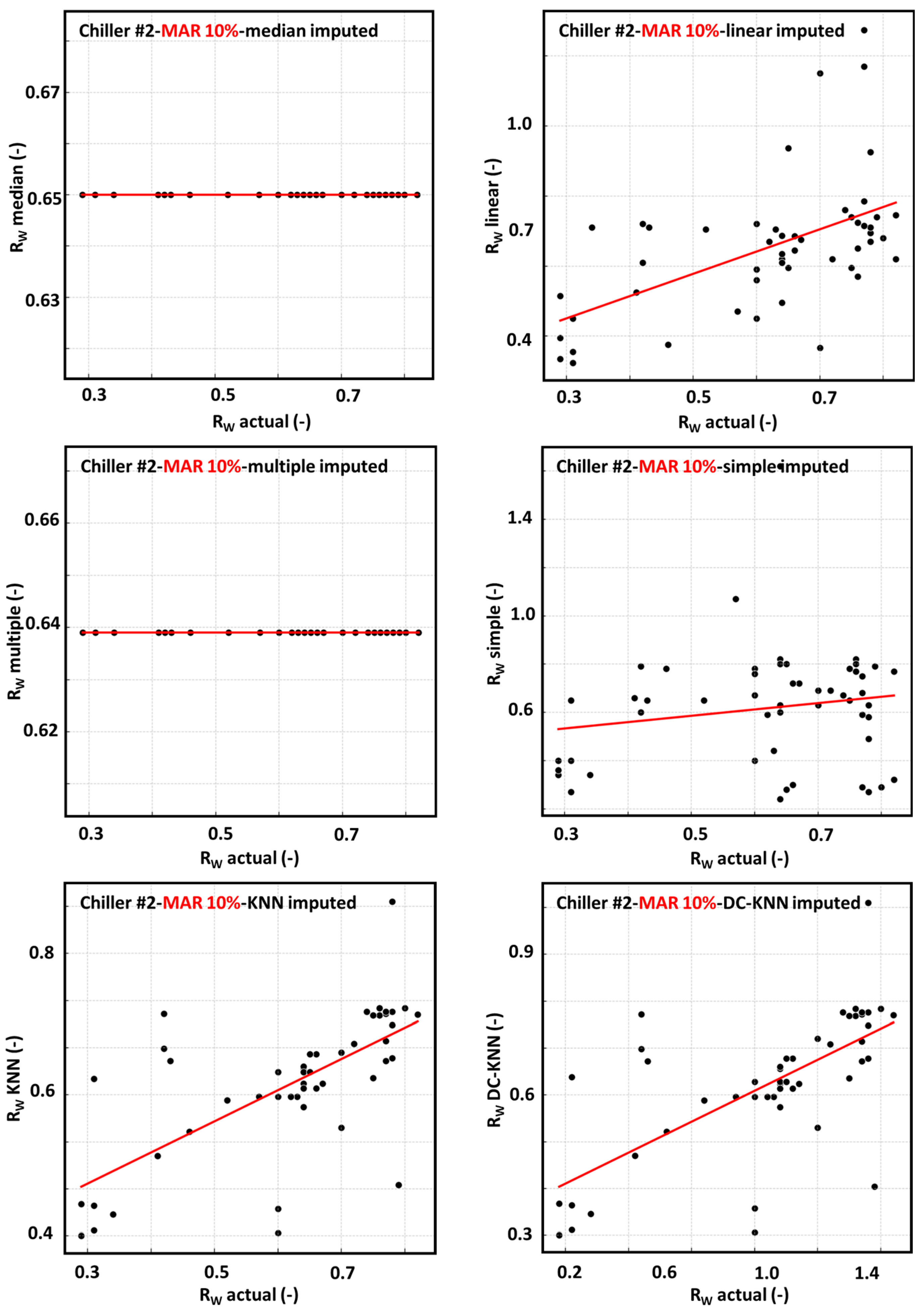
4.1. Results of Replacing Partially Missing-at-Random Data
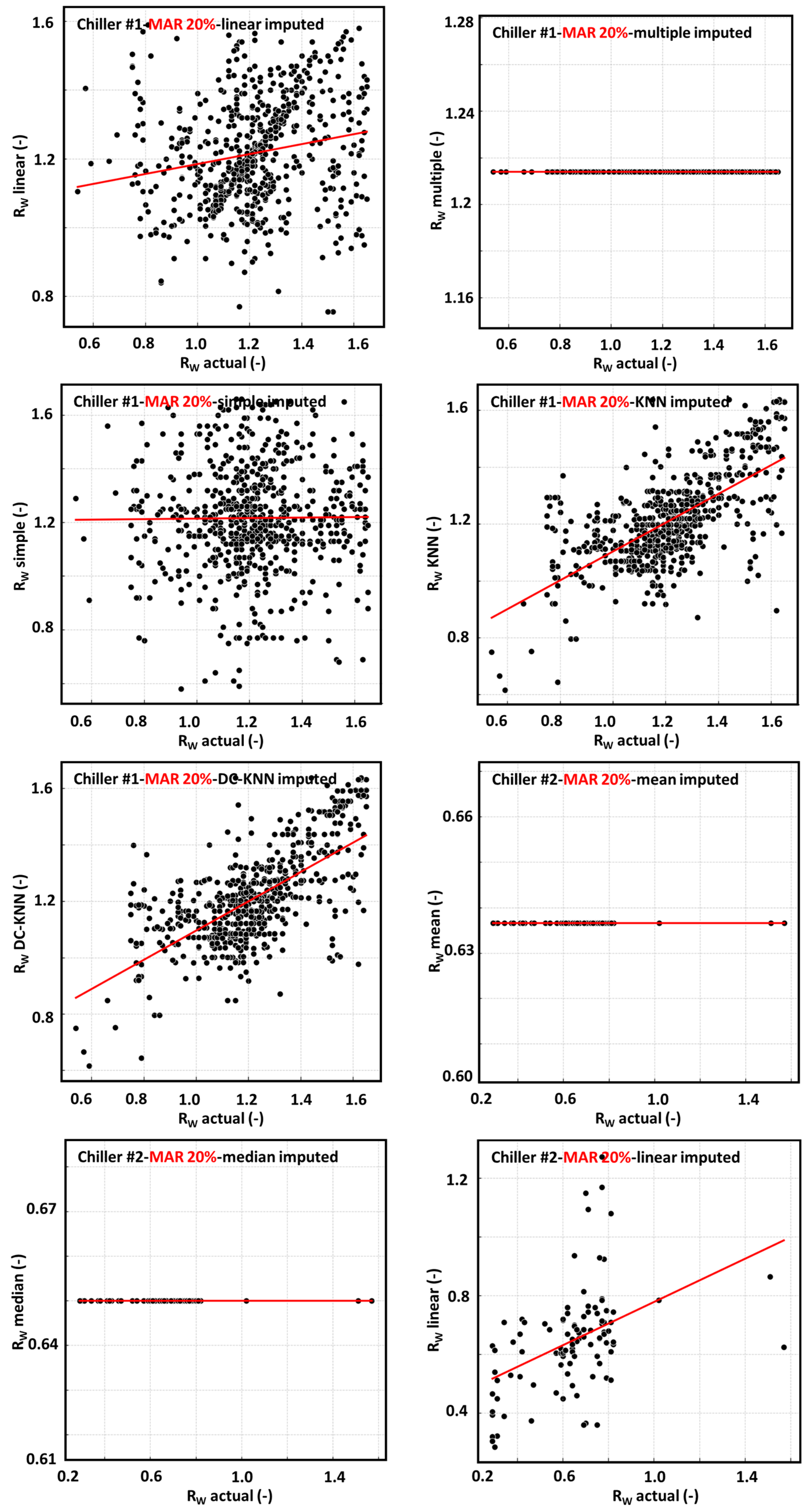
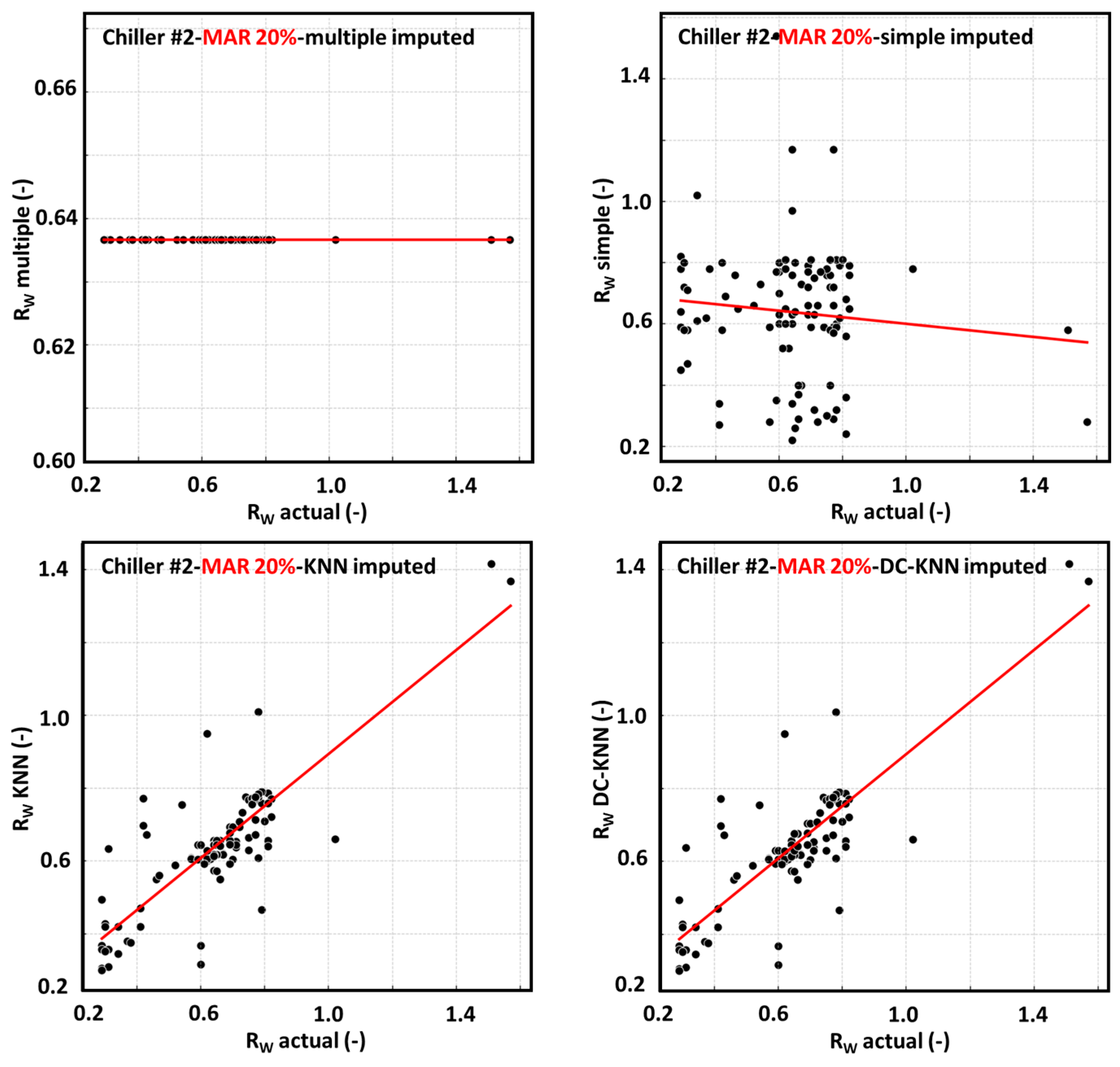
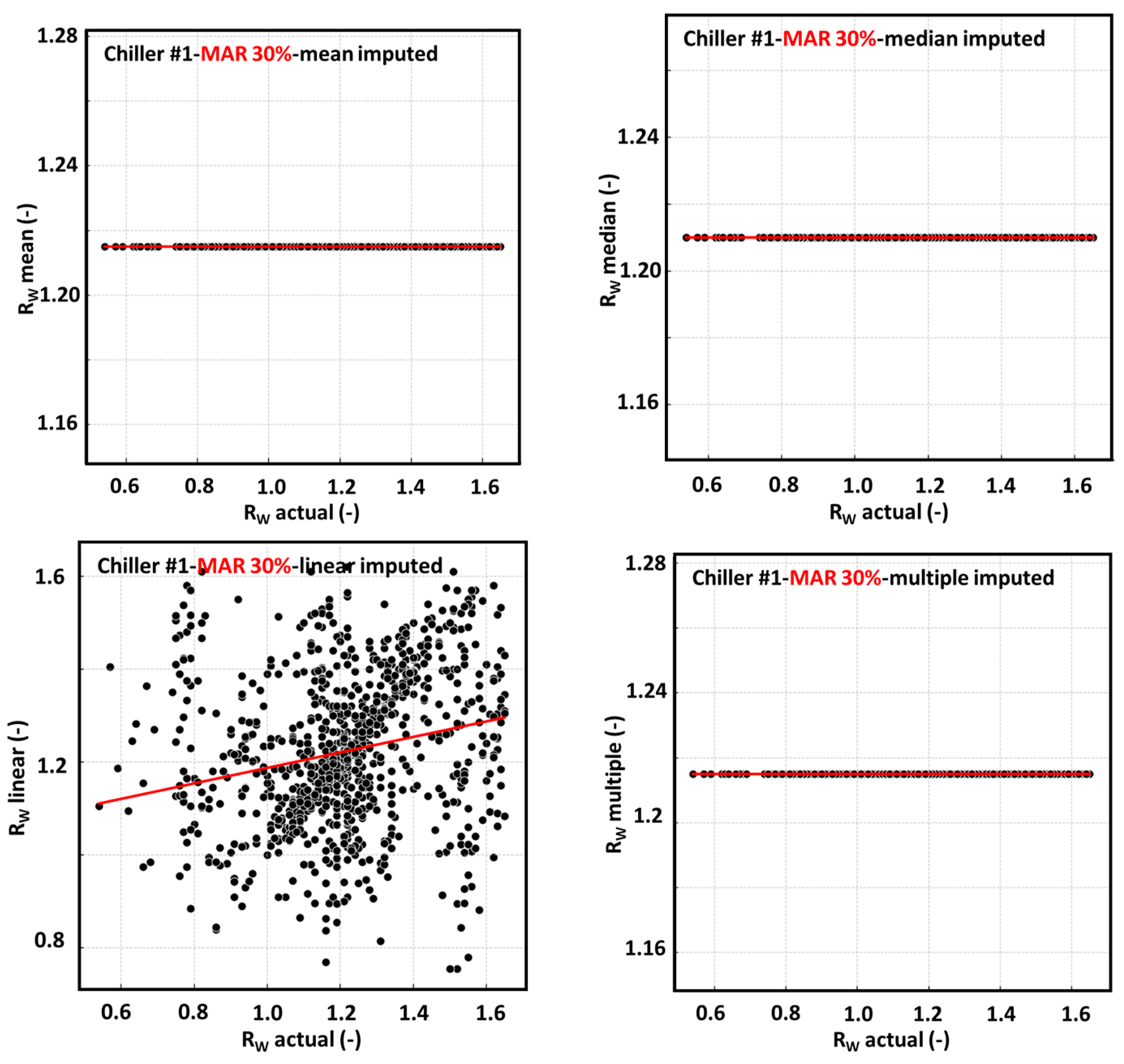
4.1.1. Mean Imputation
4.1.2. Median Imputation
4.1.3. Linear Interpolation
4.1.4. Multiple Imputation
4.1.5. Simple Random Imputation
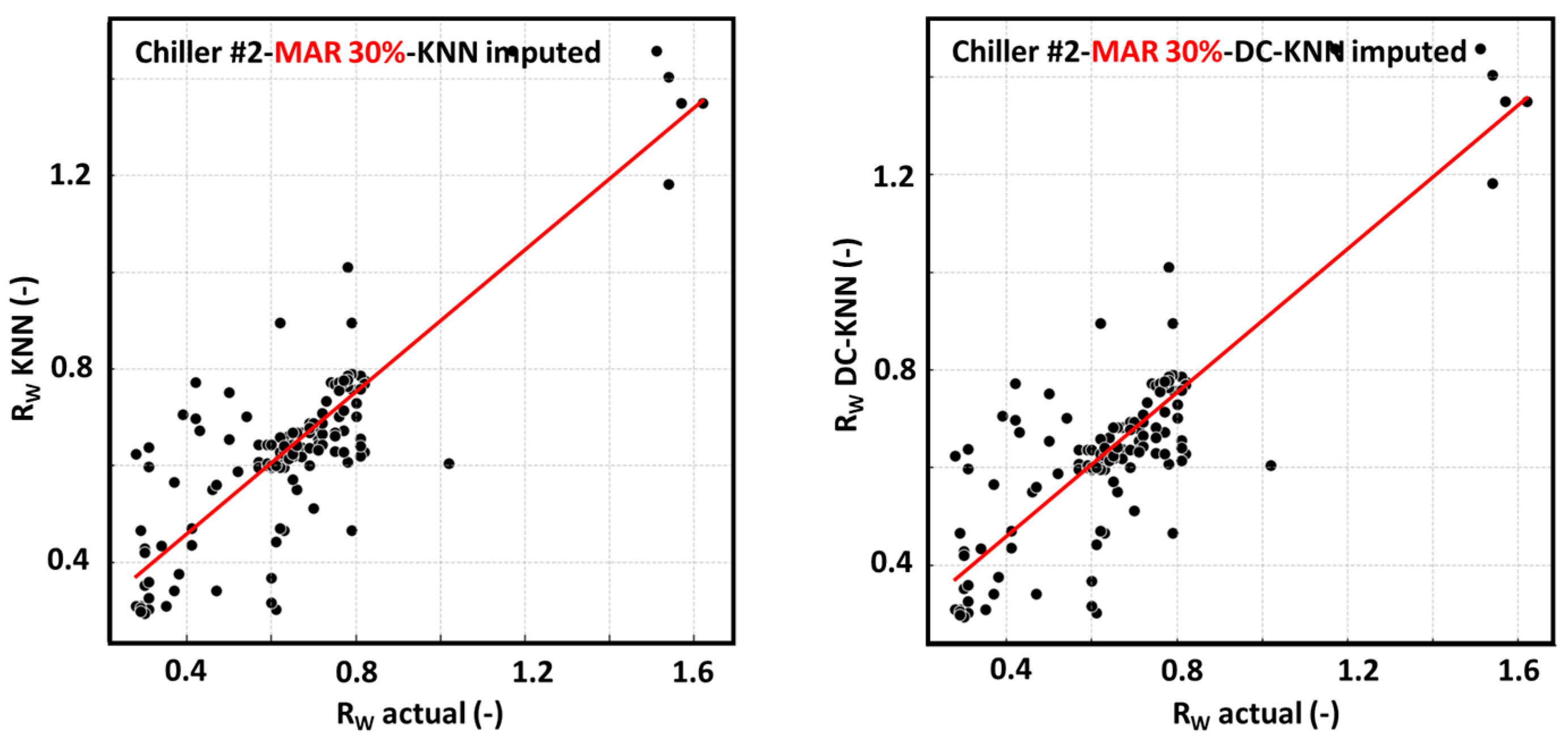
4.1.6. KNN Imputation
4.1.7. DC-KNN Imputation
4.1.8. Visual Comparison and Interpretation of Algorithm Performance
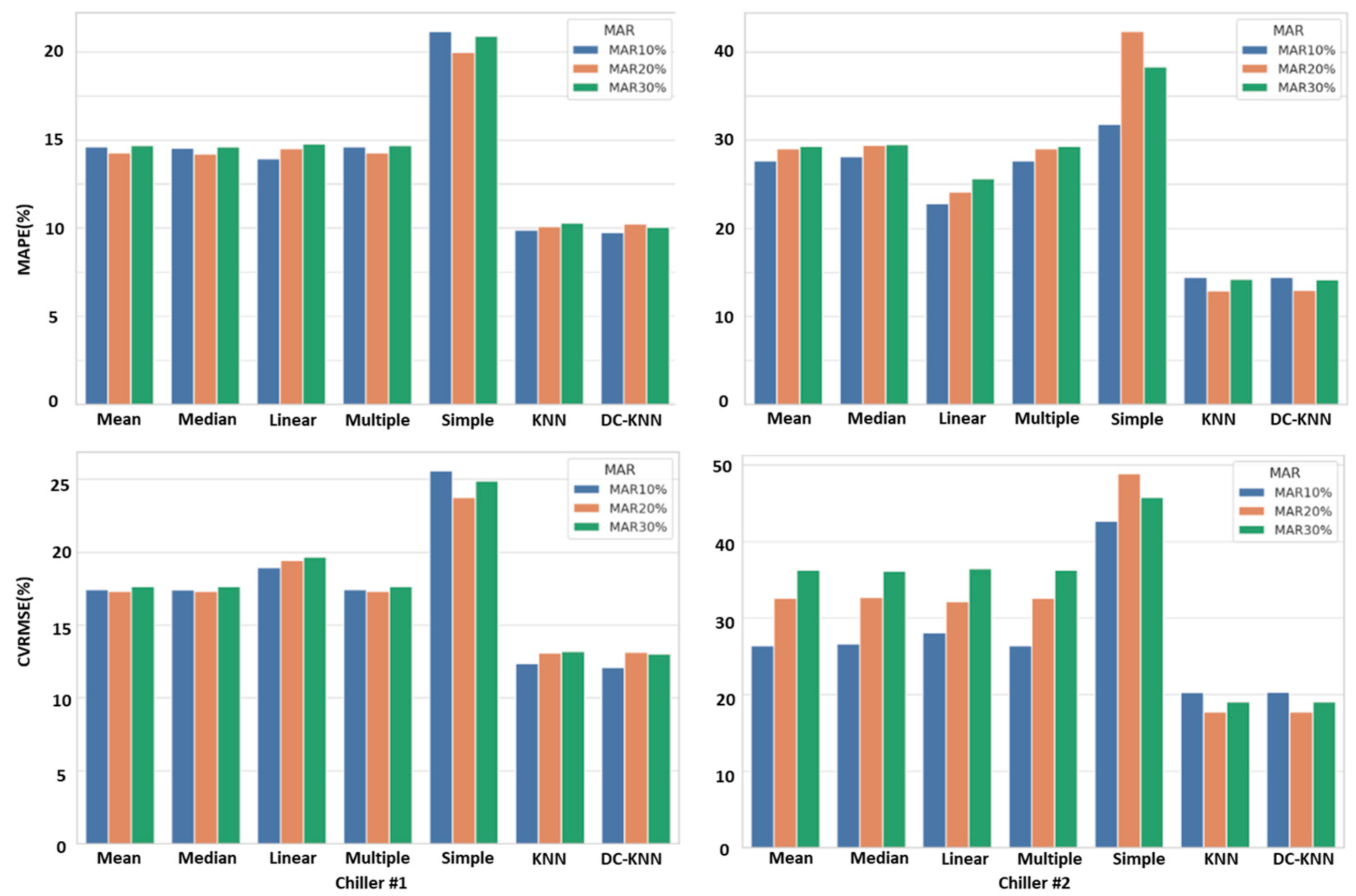
4.2. Selection of Optimal Imputation Methods
4.2.1. Optimal Imputation Method Based on MAPE
4.2.2. Optimal Imputation Method Based on CVRMSE
4.2.3. Changes According to MAR Levels
4.2.4. Derivation of the Optimal Imputation Method
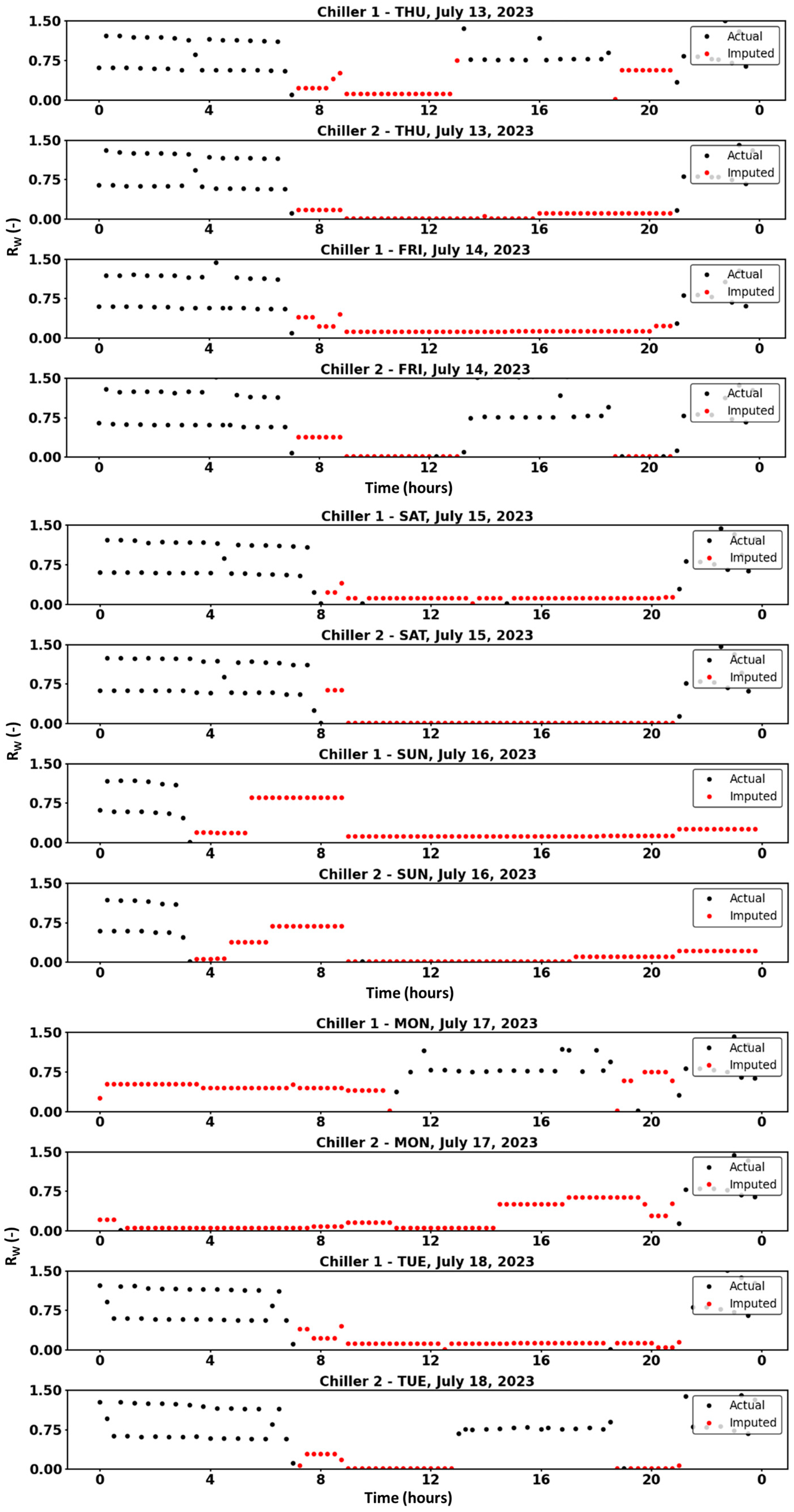
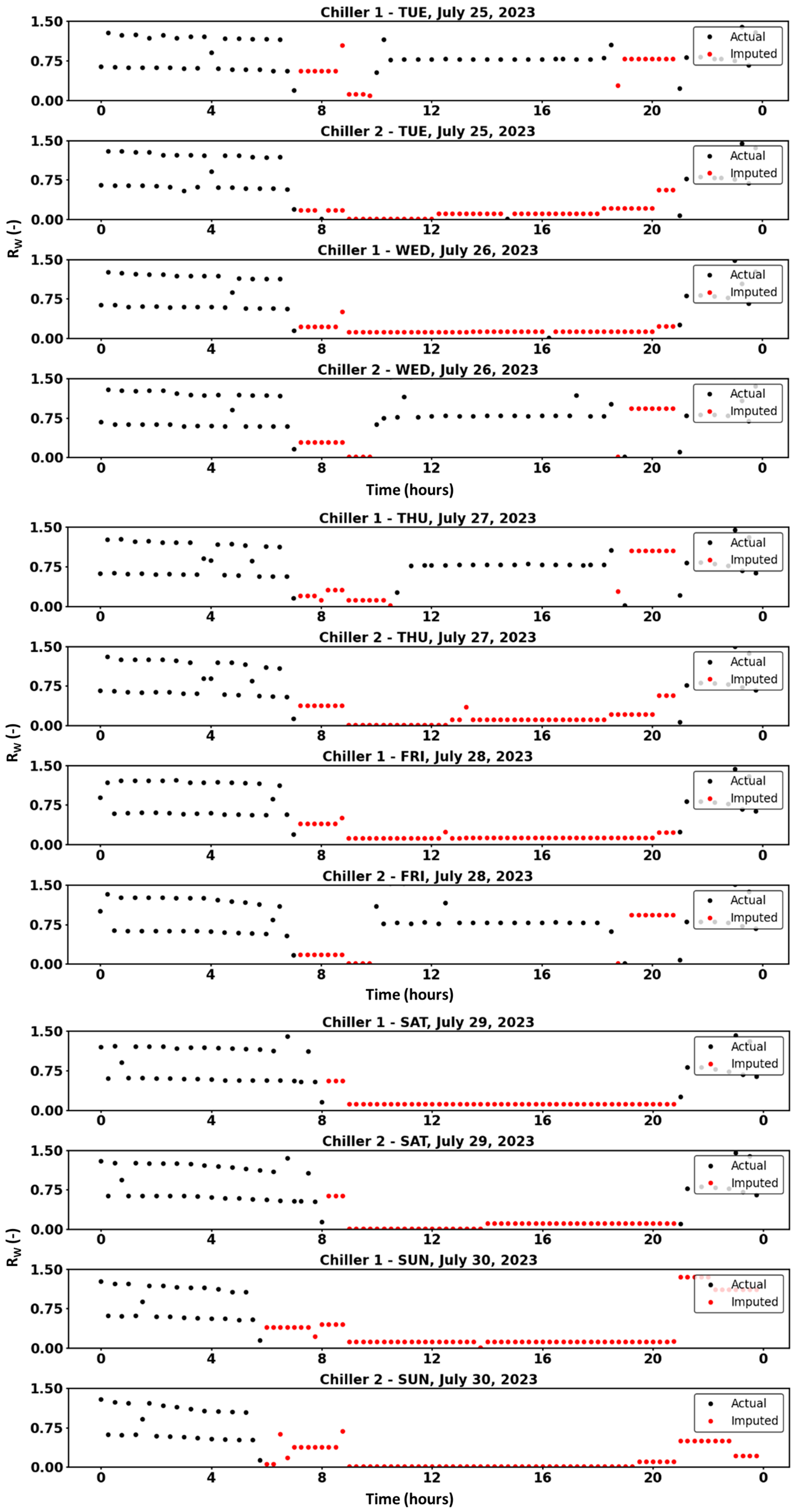
4.3. DC-KNN Imputation for Actual Missing Data
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Nomenclature
| COP | Coefficient of performance (-) |
| COPa | Actual COP (-) |
| COPo | Nominal COP (-) |
| COPp | Predicted daytime COP (-) |
| COPm | Mean COP (-) |
| Imputed value | |
| Observed value | |
| Missing value | |
| Neighboring value in KNNs | |
| Predicted value | |
| Distance function | |
| Weight in KNNs | |
| Number of data points | |
| Mean of value | |
| Euclidean distance | |
| Cosine similarity | |
| EB | Energy balance (%) |
| BEMS | Building energy management system |
| RSS | Residual sum of squares |
| MSE | Mean squared error |
| RMSE | Root mean square error |
| CVRMSE | Coefficient of variation of the root mean squared error |
| Coefficient of determination | |
| Heat transfer ratio (-) | |
| Power consumption ratio (-) | |
| COP ratio (-) | |
| Water temperature ratio (-) | |
| Circulation flow ratio (-) | |
| Standard deviation | |
| Rate of heat transfer (kW) | |
| Rate of heat transfer on the evaporator side (kW) | |
| Rate of heat transfer on the condenser side (kW) | |
| Actual heat transfer (kW) | |
| Nominal heat transfer (kW) | |
| Power consumed by the compressor (kW) | |
| Actual power consumption (kW) | |
| Nominal power consumption (kW) | |
| Observed data | |
| Missing data | |
| Probability of missingness considering both observed and missing data | |
| Fluid density (kg/m3) | |
| Specific heat of fluid (kJ/kg°C) | |
| Specific heat of water (kJ/kg°C) | |
| Actual water temperature (°C) | |
| Nominal water temperature (°C) | |
| Specific heat of brine (kJ/kg°C) | |
| Volumetric flow rate (L/min) | |
| Chilled water volumetric flow rate (L/min) | |
| Cooling water volumetric flow rate (L/min) | |
| Actual chilled water circulation volumetric flow (L/min) | |
| Nominal chilled water circulation volumetric flow (L/min) | |
| Actual cooling water circulation volumetric flow (L/min) | |
| Nominal cooling water circulation volumetric flow (L/min) | |
| Fluid temperature difference (°C) | |
| Chilled water inlet temperature (°C) | |
| Chilled water outlet temperature (°C) | |
| Cooling water inlet temperature (°C) | |
| Cooling water outlet temperature (°C) | |
| Independent variables | |
| Regression coefficients | |
| Estimation error (residuals) | |
| Number of data points | |
| Mean of the data | |
| Total uncertainty |
References
- Korean Society of Air-Conditioning and Refrigerating Engineers (SAREK). Handbook of Air-Conditioning and Refrigeration, 4th ed.; SAREK: Seoul, Republic of Korea, 2007. [Google Scholar]
- Korean Meteorological Administration. 2023 Abnormal Climate Report; Korea Meteorological Administration: Daejeon, Republic of Korea, 2024.
- Kim, Y.I. Performance of a Water-Cooled Chiller by Controlling Chilled Water Exit Temperature. In Proceedings of the SAREK 2010 Summer Annual Conference, Pyeongchang, Republic of Korea, 23–25 June 2010; pp. 1136–1141. [Google Scholar]
- Lee, C.W.; Seong, N.C.; Choi, W.C. Performance Improvement and Comparative Evaluation of the Chiller Energy Consumption Forecasting Model Using Python. J. KIAEBS 2021, 15, 252–264. [Google Scholar]
- Alsaber, A.; Al-Herz, A.; Pan, J.; Al-Sultan, A.T.; Mishra, D.; KRRD Group. Handling Missing Data in a Rheumatoid Arthritis Registry Using Random Forest Approach. Int. J. Rheum. Dis. 2021, 24, 1282–1293. [Google Scholar] [CrossRef] [PubMed]
- Sun, Y.; Li, J.; Xu, Y.; Zhang, T.; Wang, X. Deep Learning versus Conventional Methods for Missing Data Imputation: A Review and Comparative Study. Expert Syst. Appl. 2023, 227, 120201. [Google Scholar] [CrossRef]
- Burgette, L.F.; Reiter, J.P. Multiple Imputation for Missing Data via Sequential Regression Trees. Am. J. Epidemiol. 2010, 172, 1070–1076. [Google Scholar] [CrossRef]
- Algarni, A.; Ragab, M.; Alamri, W.; Mostafa, S.M. Towards Improving Predictive Statistical Learning Model Accuracy by Enhancing Learning Technique. Comput. Syst. Sci. Eng. 2022, 42, 304–318. [Google Scholar] [CrossRef]
- Li, T.; Hutfless, S.; Scharfstein, D.O.; Daniels, M.J.; Hogan, J.W.; Little, R.J.A.; Roy, J.A.; Law, A.H.; Dickersin, K. Standards Should Be Applied in the Prevention and Handling of Missing Data for Patient-Centered Outcomes Research: A Systematic Review and Expert Consensus. J. Clin. Epidemiol. 2014, 67, 15–32. [Google Scholar] [CrossRef]
- Çengel, Y.A. Fundamentals of Thermal-Fluid Sciences, 5th ed.; McGraw Hill Education: New York, NY, USA, 2015; p. 253. [Google Scholar]
- Chang, Y.S.; Shin, Y.; Kim, Y.I.; Baik, Y.J. In-Situ Performance Analysis of Centrifugal Chiller According to Varying Conditions of Chilled and Cooling Water. Trans. Korean Soc. Mech. Eng. B 2002, 26, 482–490. [Google Scholar]
- Liu, P.L.; Chuang, B.S.; Lee, W.S.; Yeh, P.L. An Analytical Solution of the Optimal Chillers Operation Problems Based on ASHRAE Guideline 14. J. Build. Eng. 2022, 46, 103800. [Google Scholar] [CrossRef]
- Lee, T.S.; Lu, W.C. An Evaluation of Empirically-Based Models for Predicting Energy Performance of Vapor-Compression Water Chillers. Appl. Energy 2010, 87, 3486–3493. [Google Scholar] [CrossRef]
- Li, J.; Guo, S.; Ma, R.; He, J.; Zhang, X.; Rui, D.; Ding, Y.; Li, Y.; Jian, L.; Cheng, J.; et al. Comparison of the Effects of Imputation Methods for Missing Data in Predictive Modelling of Cohort Study Datasets. BMC Med. Res. Methodol. 2024, 24, 41. [Google Scholar] [CrossRef]
- Anderson, P.; Gupta, S. Identify the Most Appropriate Imputation Method for Handling Missing Values in Clinical Structured Datasets: A Systematic Review. J. Med. Inform. 2023, 29, 215–230. [Google Scholar]
- Van Buuren, S. Flexible Imputation of Missing Data; CRC Press: Boca Raton, FL, USA, 2012. [Google Scholar]
- Crambes, C.; Daayeb, C.; Gannoun, A.; Henchiri, Y. Multiple imputation in the functional linear model with partially observed covariate and missing values in the response. Commun. Stat.-Theory Methods 2025, 54, 49–69. [Google Scholar] [CrossRef]
- Qu, H.; Zhang, Z. A Time Series Data Augmentation Method Based on SMOTE. In Proceedings of the 2024 36th Chinese Control and Decision Conference (CCDC), Xi’an, China, 25–27 May 2024; pp. 5336–5341. [Google Scholar]
- Niako, N.; Melgarejo, J.D.; Maestre, G.E.; Vatcheva, K.P. Effects of Missing Data Imputation Methods on Univariate Blood Pressure Time Series Data Analysis and Forecasting with ARIMA and LSTM. BMC Med. Res. Methodol. 2024, 24, 320. [Google Scholar] [CrossRef]
- Tiwaskar, S.; Rashid, M.; Gokhale, P. Ensemble Technique for Imputing Missing Values in MAR Missingness. In Proceedings of the 2023 6th International Conference on Contemporary Computing and Informatics (IC3I), Gautam Buddha Nagar, India, 14–16 September 2023; IEEE: New York, NY, USA, 2023; pp. 880–883. [Google Scholar]
- Rao, A.R.; Reimherr, M. Modern Multiple Imputation with Functional Data. Stat 2021, 10, e331. [Google Scholar] [CrossRef]
- DiazOrdaz, K.; Kenward, M.G.; Gomes, M.; Grieve, R. Multiple Imputation Methods for Bivariate Outcomes in Cluster Randomised Trials. Stat. Med. 2016, 35, 3482–3496. [Google Scholar] [CrossRef]
- Cai, S.; Qin, Y.; Rao, J.N.K.; Winiszewska, M. Empirical Likelihood Confidence Intervals under Imputation for Missing Survey Data from Stratified Simple Random Sampling. Can. J. Stat. 2019, 47, 281–301. [Google Scholar] [CrossRef]
- Wang, C.; Ren, B.; Li, X.; Chen, L. A CNN-BiLSTM and KNN-Based Missing Data Imputation for Wind Power Generation Forecasting. In Proceedings of the 2023 IEEE 6th International Electrical and Energy Conference (CIEEC), Hefei, China, 12–14 May 2023; IEEE: New York, NY, USA, 2023; pp. 4065–4070. [Google Scholar] [CrossRef]
- Alabadla, M.; Sidi, F.; Ishak, I.; Ibrahim, H.; Affendey, L.S.; Che Ani, Z.; Jabar, M.A.; Bukar, U.A.; Devaraj, N.K.; Muda, A.S.; et al. Systematic Review of Using Machine Learning in Imputing Missing Values. IEEE Access 2022, 10, 44483–44502. [Google Scholar] [CrossRef]
- Hwang, H.; Min, D. A Transfer Learning for Missing Value Imputation and Its Relationship with Prediction Performance in Time Series Data. J. Korean Inst. Ind. Eng. 2023, 49, 294–308. [Google Scholar]
- Aziz, R.Z.A.; Lestari, S.; Fitria; Arianto, F. Imputation Missing Value to Overcome Sparsity Problems. Telkomnika 2024, 22, 949–955. [Google Scholar] [CrossRef]
- Yoon, Y.R.; Shin, S.H.; Moon, H.J. Analysis of Building Energy Consumption Patterns according to Building Types Using Clustering Methods. J. Korean Soc. Living Environ. Syst. 2017, 24, 232–237. [Google Scholar] [CrossRef]
- Kim, C.; Kang, K.-H. Comparison of Data Reconstruction Methods for Missing Value Imputation. J. Converg. Cult. Technol. 2024, 10, 603–608. [Google Scholar]
- Altukhova, O. Choice of Method Imputation Missing Values for Obstetrics Clinical Data. Procedia Comput. Sci. 2020, 176, 976–984. [Google Scholar] [CrossRef]
- Wang, Y.; Jin, X.; Shi, W.; Wang, J. Online Chiller Loading Strategy Based on the Near-Optimal Performance Map for Energy Conservation. Appl. Energy 2019, 238, 1444–1451. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, H.; Wang, S. Energy Performance Analysis of Multi-Chiller Cooling Systems for Data Centers Concerning Progressive Loading Throughout the Lifecycle Under Typical Climates. Build. Simul. 2024, 17, 1693–1708. [Google Scholar] [CrossRef]
- Kim, S.W.; Kim, Y.I. Performance Prediction of a Water-Cooled Centrifugal Chiller in Standard Temperature Conditions Using In-Situ Measurement Data. Sustainability 2025, 17, 2196. [Google Scholar] [CrossRef]
- Es-sakali, N.; Zoubir, Z.; Kaitouni, S.I.; Mghazli, M.O.; Cherkaoui, M.; Pfafferott, J. Advanced predictive maintenance and fault diagnosis strategy for enhanced HVAC efficiency in buildings. Appl. Therm. Eng. 2024, 254, 123910. [Google Scholar] [CrossRef]
- Dong, W.; Sheng, K.; Huang, B.; Xiong, K.; Liu, K.; Cheng, X. Stretchable self-powered TENG sensor array for human robot interaction based on conductive ionic gels and LSTM neural network. IEEE Sens. J. 2024, 24, 37962–37969. [Google Scholar] [CrossRef]
- Lee, J.W.; Kim, Y.I. Energy saving of a university building using a motion detection sensor and room management system. Sustainability 2020, 12, 9471. [Google Scholar] [CrossRef]
- Xie, L.J.; Jiang, J.C.; Huang, A.C.; Tang, Y.; Liu, Y.C.; Zhou, H.L.; Xing, Z.X. Calorimetric evaluation of thermal stability of organic liquid hydrogen storage materials and metal oxide additives. Energies 2022, 15, 2236. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Ultrasonic Flow Meter | Temperature Sensor | AC Power Meter |
|---|---|---|---|
| Manufacturer | AutoFLO | Hankyung electric | BMT |
| Model | AUDS-100M | NT-320G | GEMS3512 |
| Measurement principle | Transit time | Insertion type | CT or Rogowski coil |
| Measurement range | ±0.02~15 m/s | −50~150 °C | 0~415 VAC |
| Error | ±1% | ±0.5% | ±0.5% |
| Parameters | Chiller #1 | Chiller #2 | ||||
|---|---|---|---|---|---|---|
| 59,232 Data Doints | 59,232 Data Points | |||||
| Min | Mean | Max | Min | Mean | Max | |
| 0.01 | 0.94 | 42.10 | 0.01 | 0.89 | 51.70 | |
| Parameters | Chiller #1 | Chiller #2 | ||
|---|---|---|---|---|
| 59,232 Data Points | 59,232 Data Points | |||
| Daytime | Nighttime | Daytime | Nighttime | |
| Missing data | 26,838 | 16,460 | 24,727 | 14,789 |
| data | 1474 | 8769 | 3504 | 12,493 |
| Parameters | Chiller #1 | Chiller #2 | ||||
|---|---|---|---|---|---|---|
| 3236 Data Points | 524 Data Points | |||||
| Min | Mean | Max | Min | Mean | Max | |
| 0.52 | 1.21 | 1.71 | 0.21 | 0.64 | 1.88 | |
| Parameters | Chiller #1 | Chiller #2 | ||
|---|---|---|---|---|
| 3236 Data Points | 524 Data Points | |||
| Remain | Missing | Remain | Missing | |
| MAR 10% | 2913 | 323 | 472 | 52 |
| MAR 20% | 2589 | 647 | 420 | 104 |
| MAR 30% | 2266 | 970 | 367 | 157 |
| Method | MAR | Chiller #1 | Chiller #2 | ||
|---|---|---|---|---|---|
| MAPE | CVRMSE | MAPE | CVRMSE | ||
| Mean | 10% | 14.62% | 17.43% | 13.76% | 16.91% |
| 20% | 14.28% | 17.33% | 13.52% | 16.66% | |
| 30% | 14.69% | 17.65% | 13.86% | 17.01% | |
| Median | 10% | 14.96% | 17.66% | 14.06% | 17.13% |
| 20% | 14.71% | 17.63% | 13.87% | 16.94% | |
| 30% | 15.10% | 17.94% | 14.22% | 17.27% | |
| Linear | 10% | 14.57% | 19.39% | 14.44% | 18.98% |
| 20% | 15.08% | 19.81% | 14.26% | 18.79% | |
| 30% | 15.37% | 20.06% | 14.61% | 19.08% | |
| Multiple | 10% | 14.62% | 17.43% | 13.76% | 16.91% |
| 20% | 14.28% | 17.33% | 13.52% | 16.66% | |
| 30% | 14.69% | 17.65% | 13.86% | 17.01% | |
| Simple | 10% | 21.51% | 25.78% | 20.94% | 24.98% |
| 20% | 20.27% | 23.95% | 20.14% | 23.81% | |
| 30% | 21.15% | 25.02% | 20.53% | 24.46% | |
| KNNs | 10% | 9.92% | 12.37% | 10.04% | 12.87% |
| 20% | 10.23% | 13.20% | 10.42% | 13.41% | |
| 30% | 10.35% | 13.23% | 10.58% | 13.62% | |
| DC-KNNs | 10% | 9.86% | 12.19% | 9.74% | 12.65% |
| 20% | 10.30% | 13.19% | 10.17% | 13.32% | |
| 30% | 10.08% | 13.06% | 10.29% | 13.43% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, S.W.; Kim, Y.I. A Data Imputation Approach for Missing Power Consumption Measurements in Water-Cooled Centrifugal Chillers. Energies 2025, 18, 2779. https://doi.org/10.3390/en18112779
Kim SW, Kim YI. A Data Imputation Approach for Missing Power Consumption Measurements in Water-Cooled Centrifugal Chillers. Energies. 2025; 18(11):2779. https://doi.org/10.3390/en18112779
Chicago/Turabian StyleKim, Sung Won, and Young Il Kim. 2025. "A Data Imputation Approach for Missing Power Consumption Measurements in Water-Cooled Centrifugal Chillers" Energies 18, no. 11: 2779. https://doi.org/10.3390/en18112779
APA StyleKim, S. W., & Kim, Y. I. (2025). A Data Imputation Approach for Missing Power Consumption Measurements in Water-Cooled Centrifugal Chillers. Energies, 18(11), 2779. https://doi.org/10.3390/en18112779