
An Efficient Methodology to Identify Relevant Multiple Contingencies and Their Probability for Long-Term Resilience Studies



Abstract
1. Introduction
2. The Proposed Methodology
2.1. The Context: The RELIEF Risk-Based Resilience Assessment Framework
2.2. Requirements for Application to Large Systems
- Ensure scalability and computational efficiency for high values of the number of lines to be treated (for example, a whole department of the Italian transmission system contains up to 900 lines);
- Consider the correlation between failures, in fact that the same weather event (e.g., wet snowstorm or strong wind) can affect several lines in the same time frame.
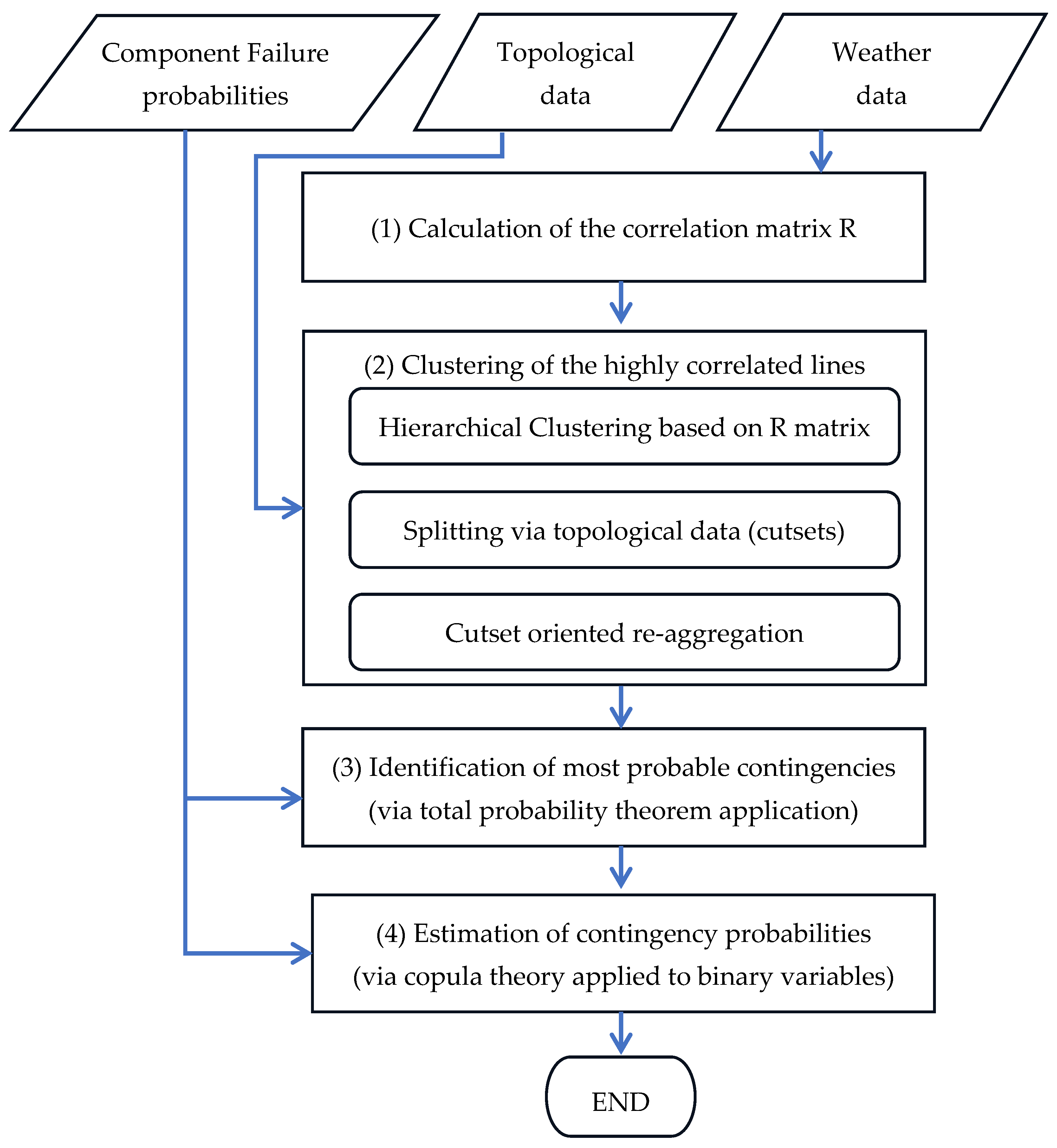
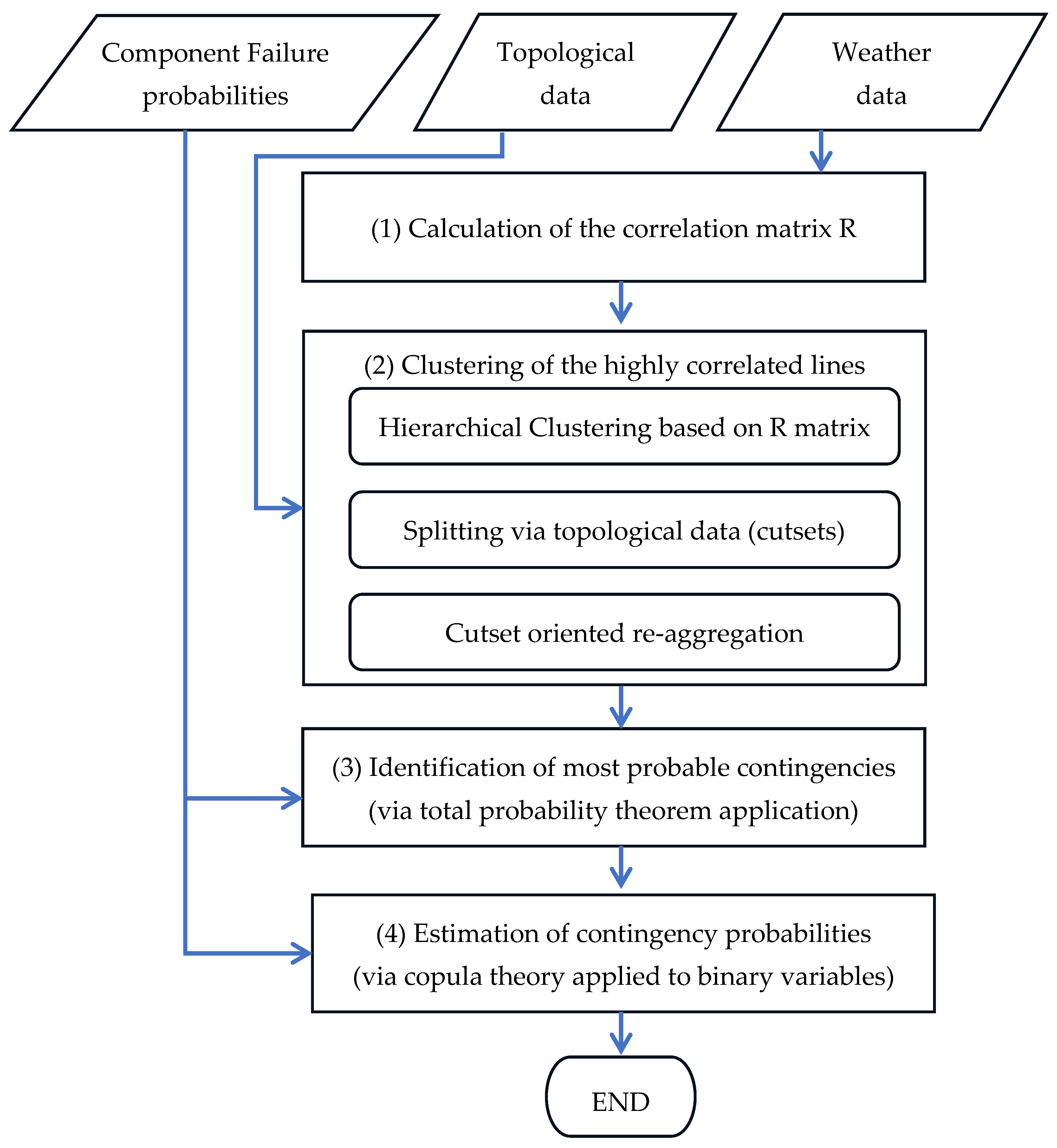
2.3. Overview of the Proposed Methodology
- Correlation Matrix Calculation (stage 1): This stage accounts for the possibility of multiple line failures due to a single event (like wet snow events). A correlation matrix is built, based on historical weather events (see Section 3.1), to quantify the likelihood of lines failing together during a specific time frame (e.g., an hour).
- Highly Correlated Line Clustering (stage 2): Based on the correlation matrix, this stage identifies groups of lines such that multiple line failures within each group are more likely than between groups (see Section 3.2). This clustering helps focus the contingency identification process on the most probable combinations of line failures.
- Contingency Identification within Clusters (stage 3): Within each identified cluster, this stage pinpoints relevant contingencies, representing specific combinations of line failures that have a significant probability of occurring together (see Section 4.3). To ensure efficiency, negligible probability scenarios are excluded.
- Multiple Contingency Probability Estimation (stage 4): This stage calculates the probability of each identified contingency within the clusters, exploiting the correlation between line failures and the individual failure probabilities of each line (see Section 4.4).
3. Clustering of Correlated Lines
3.1. Calculation of the Correlation Matrix
- n11 is the number of severe events for which both lines L1 and L2 are affected by a weather variable exceeding a threshold Th (e.g., in m/s for wind and kg/m for wet snow);
- n10 is the number of severe events for which line L1 is affected while line L2 is not affected by a weather variable exceeding a threshold Th;
- n01 is the number of severe events for which line L2 is affected while line L1 is not affected by a weather variable exceeding a threshold Th;
- n00 is the number of severe events for which neither line is affected by a weather variable exceeding a threshold Th.
3.2. Clustering
- Create clusters with a user-defined threshold of minimum internal correlation between the lines in each cluster;
- Create clusters with a maximum cardinality (NMAX, LI);
- Subdividing clusters that are too large (with cardinality higher than NMAX, LI) into smaller clusters of maximum cardinality NMAX, LI based on topological information.
- Step 1: identification of the clusters based on the correlation matrix R;
- Step 2: identification of subclusters using topological indications;
- Step 3: aggregation of individual clusters through a mix of topological indications and correlation factors.
3.2.1. Step 1: Clustering of the Lines Based on the Correlation Matrix R
- The parameters of minimum value of the intra-cluster average correlation () and the distance limit between two distinct clusters () are set;
- The distance matrix between the lines is calculated, defined as D = 1—R’, where R’ is the correlation matrix with all zeros set along the main diagonal and 1 is an N × N matrix entirely filled with ones;
- N groups are defined, each containing one line of the set;
- Lines i and j are identified s.t. D(i, j) = min(min(D));
- Lines i and j are grouped into a new group “N + 1”;
- The cophenetic distance is calculated between the group made up of i and j and the remaining N − 2 groups (excluding the groups related to rows i and j). Ψ is defined as the set of N − 2 groups. This distance is defined as max(max(D([i j], h)));
- The matrix D is updated, in particular D(N + 1, h) and D(h, N + 1) with h ∈ Ψ;
- The rows and columns associated with the original groups i and j are deleted;
- Steps 3 to 7 are repeated until one of the following conditions occurs:
- The minimum value of the intra-cluster mean correlation (calculated as the average value of the linear correlation coefficient between any pair of lines belonging to the same cluster) becomes less than a threshold ;
- The minimum distance between two distinct clusters becomes greater than a threshold .
- Steps 2–9 are repeated on several pairs of parameters , , defined as the Cartesian product of two sets containing reasonable values for both of the aforementioned parameters, in order to select the pair that provides the best performance indicator according to the indications at step 11;
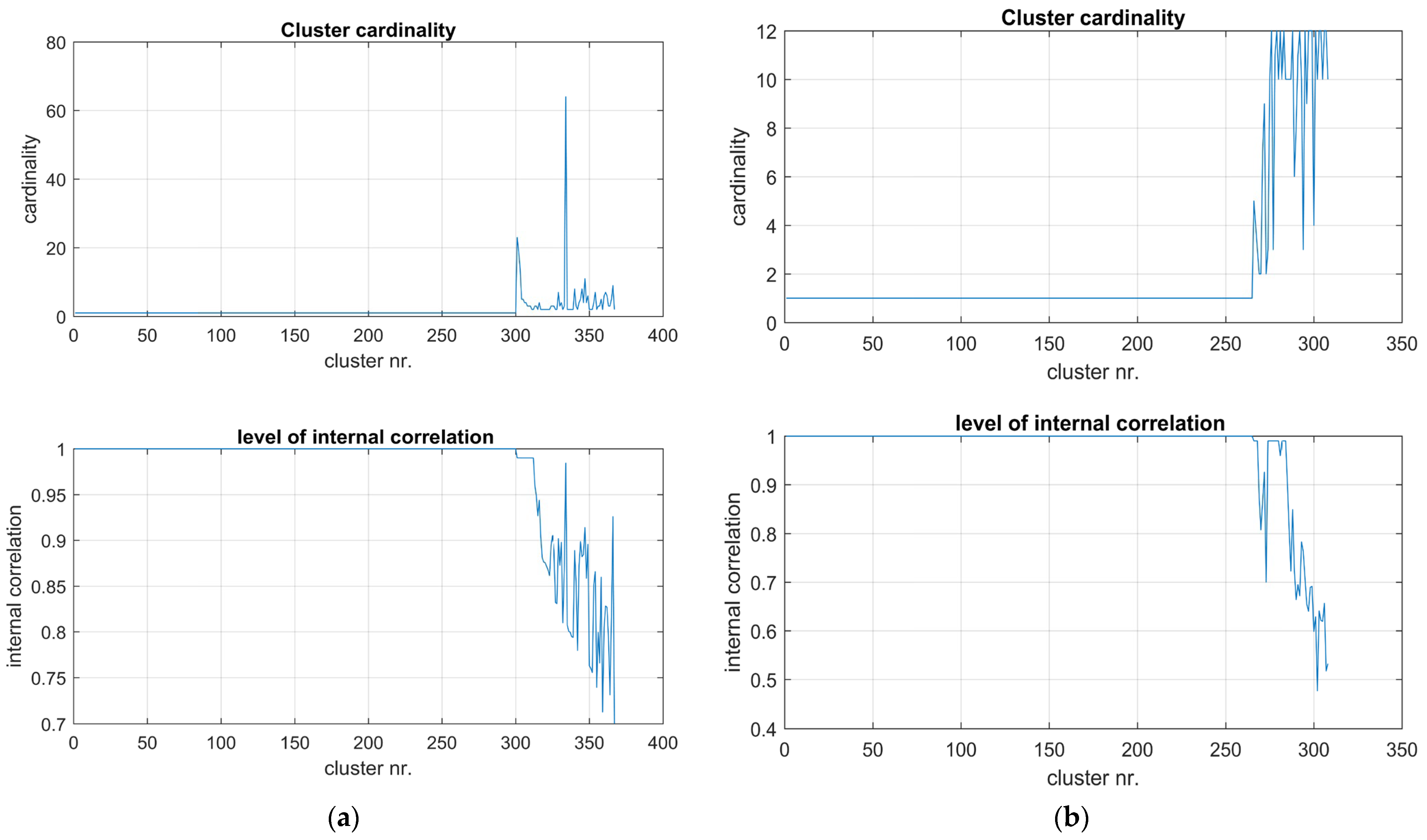
- The pair of parameters that ensures the highest performance index is selected, indicated as the weighted sum of the 5% quantiles of the silhouette coefficient and the internal correlation value of the non-single clusters. This guarantees the best separation between the groups and at the same time a good cohesion within the groups. Values between 0.50 and 0.70 for the silhouette indicate reliable groups, while values between 0.7 and 1 very reliable groups (as they are cohesive and well separated from the others).
3.2.2. Step 2: Splitting of Wide Clusters According to Topological Information (Cutsets)
- The cutsets of lines that lead to the disconnection of the substations (primary substations, PSs) of the network portion are identified. Then, the connectivity matrix A of dimensions N × NPS is defined where N is the number of lines and NPS is the number of PSs of the considered network, s.t. A(i, j) = 1 if PS j is terminal 1 of line i and A(i, j) = −1 if PS j is terminal 2 of line i, A(i, j) = 0 otherwise;
- For each PS j, a vector Xj of dimensions NPS × 1 is set such that Xj(j) = −1, it is 1 otherwise;
- Yj = A × Xj gives a vector NL × 1 where the non-zero terms represent the minimum subset of lines which cuts PS j;
- For each cluster larger than NMAX, LI:
- The sub-matrix S of matrix A corresponding to the lines belonging to the cluster to be disaggregated is obtained;
- The columns of S are sorted according to the decreasing number of non-zero terms. We obtain the Sord reordered matrix;
- The sub-cluster is identified as the set Lsc of lines associated with the first column of the Sord matrix. The lines of the sub-cluster Lsc are discarded from the lines of the original cluster Lco, redefining the matrix S on the basis of the set Lco’ of the remaining lines to be clustered where card(Lco’) = card(Lco) − card(Lsc), “card” being the “cardinality” operator which indicates the number of elements of the set.
- tems ii and iii are repeated on the new matrix S, updating the set of Lco’ lines to be clustered until the set Lco’ has a cardinality lower than or equal to NMAX, LI;
- The subclusters are reaggregated on the basis of the following criteria:
- The subclusters in pairs form a cutset of the network;
- The sum of the dimensions of the reaggregated subclusters are at most equal to NMAX, LI.
3.2.3. Step 3: Cutset-Oriented Re-Aggregation of Clusters
- There are still some groups composed of a single line that have high correlations with already clustered lines;
- There may be relatively small clusters that can be increased with a small decrease in the intra-cluster correlation.
- To increase cluster size with little detriment on cluster internal correlation;
- To aggregate unpaired lines with already clustered lines.
- For each cluster i1 = 1 … NG − 1, the clusters i2 = i1 + 1 …. NG are analyzed and the following are calculated:
- The mean value of the correlation between each pair of clusters i1 and i2 (defined as the arithmetic mean of the absolute values of the linear correlation coefficients, each calculated on a different pair of lines, one belonging to cluster i1 and the other to cluster i2) reported in position (i, j) of matrix MR;
- The maximum value of the correlation between two lines of clusters, i1 and i2;
- The best candidates for aggregation between clusters are identified according to the following criteria:
- Clusters that fully define a cutset (topological clusters) and have an average inter-cluster correlation at least equal to a fixed value ;
- Clusters that have an inter-cluster correlation no less than a fixed value ;
- Topological clusters that have a maximum correlation value at least equal to a fixed value equal to .
- Two matrices, M1 and M2, of dimension NG × NG are defined s.t. in position (i, j) if they contain 1 or 0, respectively, depending on whether the following criteria are verified or not:
- criterion c.i or c.ii for matrix M1;
- criterion c.iii for matrix M2.
- The conditionality matrix MC between clusters i1 and i2 is also defined such that MC(i1, i2) = 0 if the sum of the dimensions of clusters i1 and i2 is greater than a defined value (parameter NMAX, LI); it is 0 otherwise;
- For the candidates selected in point 1.c, the Matrix_total of the performance indicators is calculated as in (3):where α is the weight given to the cutset-based topological clustering;
- The previous steps 1 and 2 are repeated until:
- the residual correlation between the “single” groups and the multi-line groups does not fall below an established threshold (), or;
- the maximum number of iterations is exceeded.
3.3. Management of Greenfield Lines and Partially Buried Lines
- Consider the clusters Ch h = 1 … NC identified in the pre-intervention analysis;
- Modify matrix M in the columns of the partially buried lines q = 1 … Npi;
- The partially buried lines that are part of singleton clusters in the pre-intervention analysis remain in the singleton cluster;
- Increase the number of matrix M columns by adding the columns of greenfield lines i = 1 … Ngreen (on the basis of the hypothetical layout of the greenfield lines, the events of exceeding the threshold in the greenfield lines are counted considering the same weather events of the pre-intervention analysis);
- Calculate the correlation coefficients Rqj between each partially buried line q = 1 … Npi not belonging to singleton clusters and the other lines j;
- Calculate the correlation coefficients Rij between the greenfield line i = 1 … Ngreen and the other lines j;
- Greenfield line i is attributed to cluster h*, which has the highest median value calculated on the absolute values of the coefficients Ris with s ∈ Ch, i.e., ;
- Steps 6 and 7 are repeated for all greenfield lines.
4. Selection of Contingencies and Probability Computation
- Computation of the probability of the “AND” event of multiple line trippings;
- Iterative filtering based on total probability theorem;
- Calculation of the probability of occurrence of retained contingencies.
4.1. Probabilistic Modeling of Multiple Contingencies
4.2. Copula-Based Computation of Contingency Probability
4.3. Filtering of Failure Combinations Based on Total Probability Theorem
4.4. Calculation of the Probability of Occurrence of Multiple Contingencies
5. Case Study
5.1. Test System and Simulations
5.2. Simulation CLU: Line Clustering for Wet Snow Events
5.3. Simulation PRO: Tests on the Algorithm for Contingency Probability Computation
- Different numbers of lines in the cluster, with the same correlation matrix R;
- Different values for the return periods, with the same cluster cardinality and matrix R;
- Different correlation matrices R among the lines, with the same line cardinality.
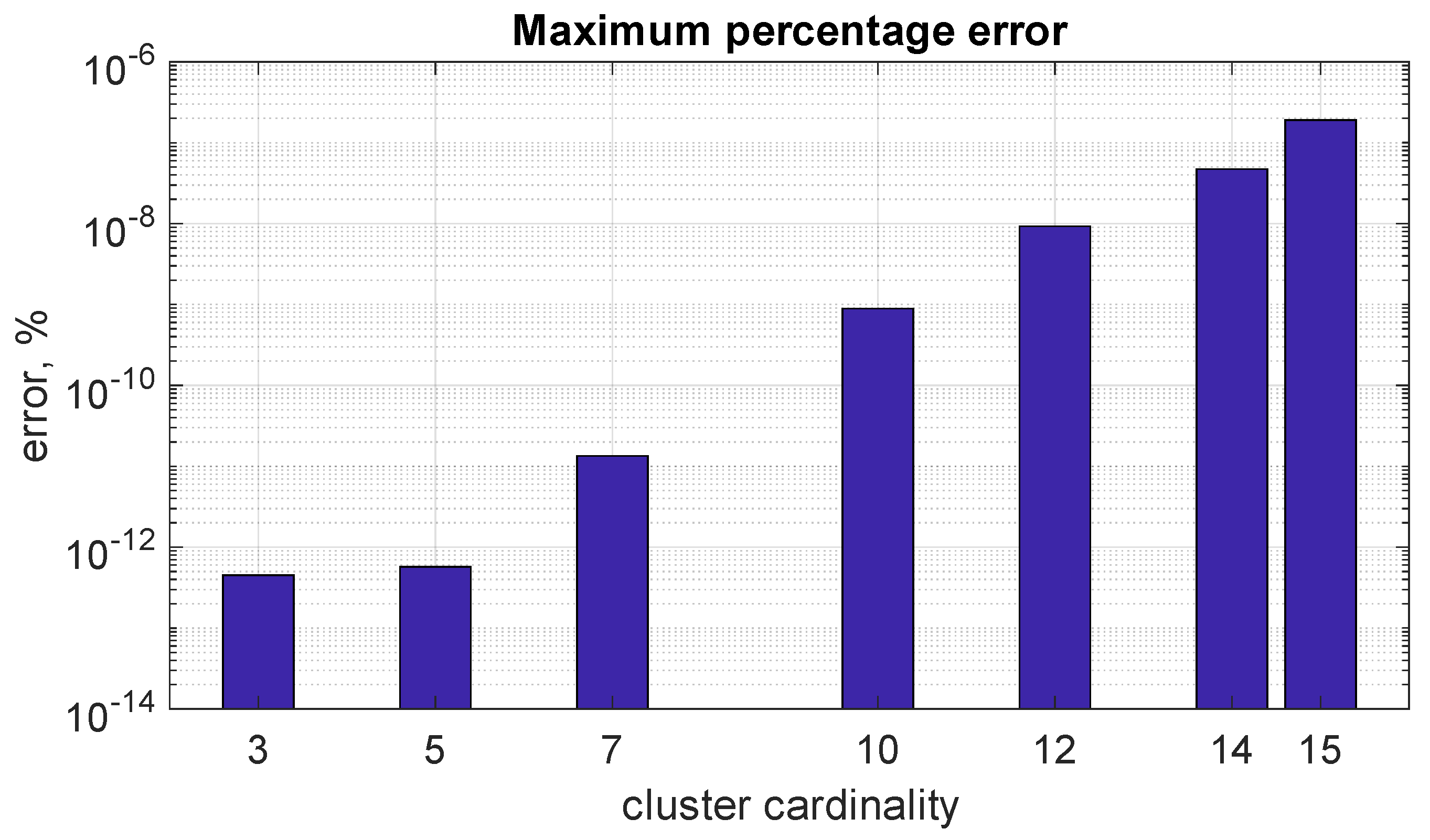
5.3.1. Subcase (a): Comparison of the Two Algorithms with Different Line Cardinalities
5.3.2. Subcase (b): Comparison of the Two Algorithms with Different RP Values
5.3.3. Subcase (c): Comparison of the Two Algorithms with Different Correlation Levels
5.3.4. Some Remarks
- Enhanced speed and accuracy: compared to algorithm A, Botev’s algorithm boasts significantly faster execution times and demonstrably higher accuracy, at least for contingency probability computations in power system resilience assessment. This improved accuracy is particularly crucial, as even small deviations in contingency probabilities can have substantial consequences.
- Robustness across scenarios: algorithm B exhibits remarkable stability to various input characteristics. Its calculation time remains independent of the specific line failure probabilities within a cluster, unlike algorithm A, which can be sensitive to these values. This robustness ensures reliable performance across diverse situations.
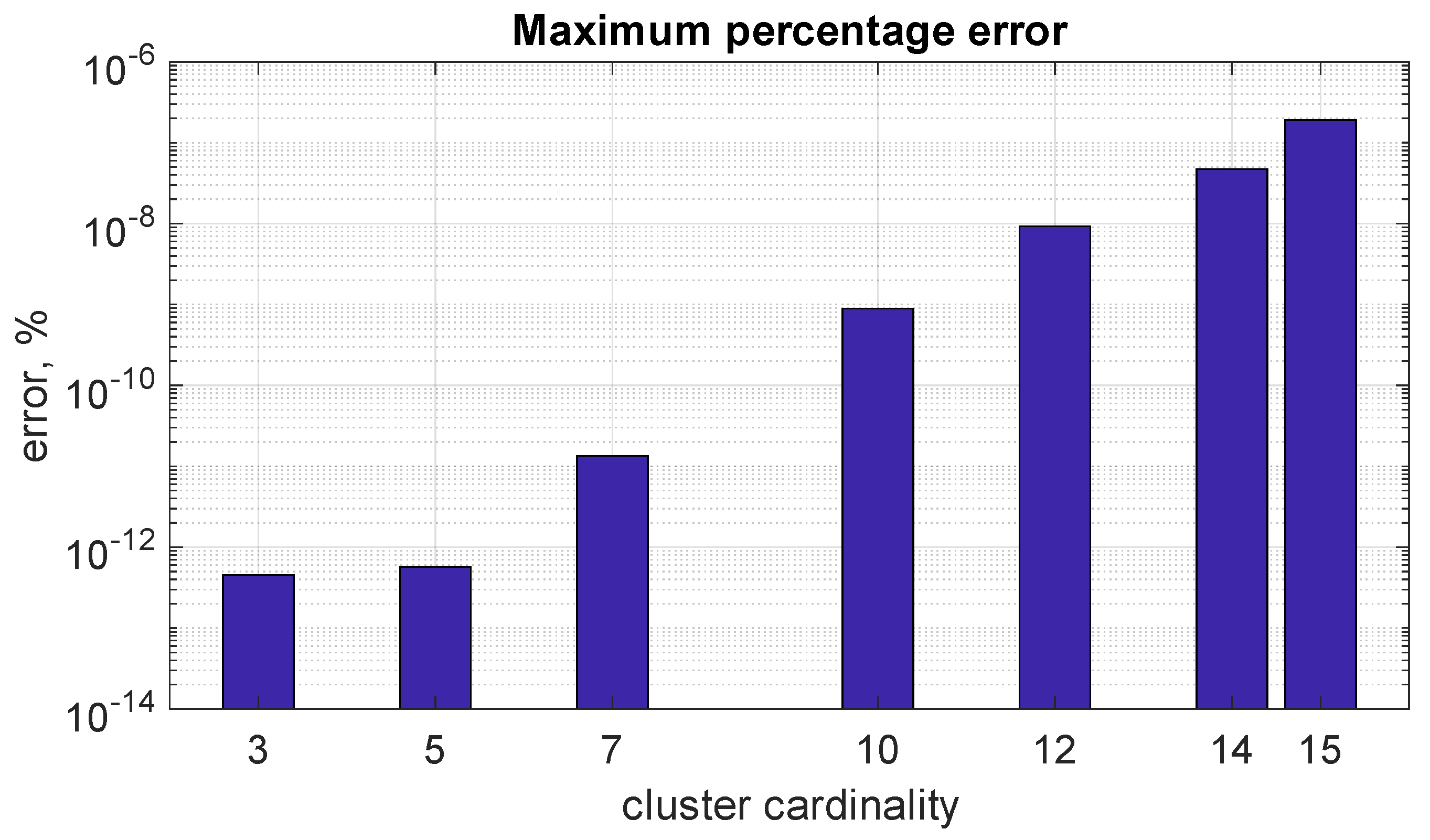
- Accuracy maintained for large clusters: even when dealing with very large clusters (tested up to a size of 15, often considered the upper limit) and significant variations in line reliability parameters (RPs), algorithm B delivers exceptional accuracy. This characteristic makes it ideal for real-world power system analysis, where large clusters and diverse RP values are common.
- Adaptability to correlation matrices: Botev’s algorithm maintains its high accuracy regardless of the correlation matrix configuration. It performs equally well with highly correlated, moderately correlated, or weakly correlated line failures, providing a versatile solution for various power system scenarios.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Billinton, R.; Li, W. Reliability Assessment of Electric Power Systems Using Monte Carlo Methods; Plenum Press: New York, NY, USA, 1994. [Google Scholar]
- Panteli, M.; Mancarella, P. Influence of extreme weather and climate change on the resilience of power systems: Impacts and possible mitigation strategies. Electr. Power Syst. Res. 2015, 127, 259–270. [Google Scholar] [CrossRef]
- Zhang, D.; Li, C.; Goh, H.H.; Ahmad, T.; Zhu, H.; Liu, H.; Wu, T. A comprehensive overview of modeling approaches and optimal control strategies for cyber-physical resilience in power systems. Renew. Energy 2022, 189, 1383–1406. [Google Scholar] [CrossRef]
- Paul, S.; Poudyal, A.; Poudel, S.; Dubey, A.; Wang, Z. Resilience assessment and planning in power distribution systems: Past and future considerations. Renew. Sustain. Energy Rev. 2024, 189, 113991. [Google Scholar] [CrossRef]
- Kjølle, G.H.; Gjerde, O. The OPAL Methodology for Reliability Analysis of Power Systems; Technical Report; SINTEF Energy Research: Trondheim, Norway, 2012. [Google Scholar]
- Lieber, D.; Nemirovskii, A.; Rubinstein, R.Y. A fast Monte Carlo method for evaluating reliability indexes. IEEE Trans. Reliab. 1999, 48, 256–261. [Google Scholar] [CrossRef]
- Cervan, D.; Coronado, A.M.; Luyo, J.E. Cluster-based stratified sampling for fast reliability evaluation of composite power systems based on sequential Monte Carlo simulation. Int. J. Electr. Power Energy Syst. 2023, 147, 108813. [Google Scholar] [CrossRef]
- González-Fernández, R.A.; Leite da Silva, A.M.; Resende, L.C.; Schilling, M.T. Composite Systems Reliability Evaluation Based on Monte Carlo Simulation and Cross-Entropy Methods. IEEE Trans. Power Syst. 2013, 28, 4598–4606. [Google Scholar] [CrossRef]
- Hua, B.; Bie, Z.; Au, S.-K.; Li, W.; Wang, X. Extracting Rare Failure Events in Composite System Reliability Evaluation Via Subset Simulation. IEEE Trans. Power Syst. 2015, 30, 753–762. [Google Scholar] [CrossRef]
- Zhao, Y.; Han, Y.; Liu, Y.; Xie, K.; Li, W.; Yu, J. Cross-Entropy-Based Composite System Reliability Evaluation Using Subset Simulation and Minimum Computational Burden Criterion. IEEE Trans. Power Syst. 2021, 36, 5189–5209. [Google Scholar] [CrossRef]
- Liu, Y.; Singh, C. Reliability evaluation of composite power systems using markov cut-set method. IEEE Trans. Power Syst. 2010, 25, 777–785. [Google Scholar] [CrossRef]
- Wang, M.; Xiang, Y.; Wang, L. Identification of critical contingencies using solution space pruning and intelligent search. Electr. Power Syst. Res. 2017, 149, 220–229. [Google Scholar] [CrossRef]
- Ciapessoni, E.; Cirio, D.; Pitto, A.; Pirovano, G.; Faggian, P.; Marzullo, F.; Lazzarini, A.; Falorni, F.; Scavo, F. A methodology for resilience oriented planning in the Italian transmission system. In Proceedings of the 2021 AEIT International Annual Conference (AEIT), Catania, Italy, 4–8 October 2021; pp. 1–6. [Google Scholar]
- Faustino Agreira, C.I.; Machado Ferreira, C.M.; Maciel Barbosa, F.P. Electric Power System Multiple Contingencies Analysis Using the Rough Set Theory. In Proceedings of the UPEC 2003 Conference, Thessalonica, Greece, 1–3 September 2003. [Google Scholar]
- Eppstein, M.J.; Hines, P.D.H. A “Random Chemistry” Algorithm for Identifying Collections of Multiple Contingencies That Initiate Cascading Failure. IEEE Trans. Power Syst. 2012, 27, 1698–1705. [Google Scholar] [CrossRef]
- Lesieutre, B.; Roy, S.; Donde, V.; Pinar, A. Power System Extreme Event Screening using Graph Partitioning. In Proceedings of the North American Power Symposium, Carbondale, IL, USA, 17–19 September 2006. [Google Scholar]
- Kiel, E.S.; Kjølle, G.H. A Monte Carlo sampling procedure for rare events applied to power system reliability analysis. In Proceedings of the 2023 IEEE PES Innovative Smart Grid Technologies Europe (ISGT EUROPE), Grenoble, France, 23–26 October 2023; pp. 1–5. [Google Scholar]
- Ciapessoni, E.; Cirio, D.; Pitto, A.; Van Harte, M.; Panteli, M.; Mak, C. Defining power system resilience. Electra CIGRE J. 2019, 316, 1–3. [Google Scholar]
- Ciapessoni, E.; Cirio, D.; Pitto, A.; Sforna, M. Quantification of the Benefits for Power System of Resilience Boosting Measures. Appl. Sci. 2020, 10, 5402. [Google Scholar] [CrossRef]
- Ciapessoni, E.; Cirio, D.; Ferrario, E.; Lacavalla, M.; Marcacci, P.; Pirovano, G.; Pitto, A.; Marzullo, F.; Falorni, F.; Scavo, F.; et al. Validation and application of the methodology to compute resilience indicators in the Italian EHV transmission system. In Proceedings of the 2022 CIGRE Session, Paris, France, 28 August–2 September 2022; pp. 1–14. [Google Scholar]
- CEI (Italian Electrotechnical Committee). Norme Tecniche per la Costruzione di Linee Elettriche Aeree Esterne; CEI 11-4; CEI Press: Milan, Italy, 1998. (In Italian) [Google Scholar]
- Maimon, O.; Rokach, L. Clustering methods. In Data Mining and Knowledge Discovery Handbook; Springer: Berlin/Heidelberg, Germany, 2006; pp. 321–352. [Google Scholar]
- Saraçli, S.; Dogan, N.; Dogan, I. Comparison of hierarchical cluster analysis methods by cophenetic correlation. J. Inequalities Appl. 2013, 2013, 203. [Google Scholar] [CrossRef]
- Kaufman, L.; Rousseeuw, P. Finding Groups. In Data: An Introduction to Cluster Analysis; John Wiley & Sons: Hoboken, NJ, USA, 1990. [Google Scholar]
- Nelsen, R.B. An Introduction to Copulas; Springer: New York, NY, USA, 2006. [Google Scholar]
- Genz, A. Numerical Computation of Rectangular Bivariate and Trivariate Normal and t Probabilities. Stat. Comput. 2004, 14, 251–260. [Google Scholar] [CrossRef]
- Botev, Z.I. The Normal Law Under Linear Restrictions: Simulation and Estimation via Minimax Tilting. J. R. Stat. Soc. 2017, 79, 125–148. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| L2 | Not L2 | Totals | |
|---|---|---|---|
| L1 | n11 | n10 | n1* |
| not L1 | n01 | n00 | n0* |
| Totals | n*1 | n*0 |
| Sim ID | Description | Goal |
|---|---|---|
| CLU | Three-step clustering algorithm application to the set of 647 lines, assuming a maximum cardinality NMAX, LI = 12. | To verify the representativeness of the identified clusters with respect to historical weather events. |
| PRO | Copula-based algorithm application via two alternative algorithms to one specific cluster of the line set analyzed in sim CLU. | To verify the accuracy and the robustness in the copula CDF computation method adopted in the methodology. |
| Probability | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| Quantile | 0.2176 | 0.6806 | 0.9671 | 1.0000 | 1.0000 |
| Probability | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| Quantile | 0.3162 | 0.4709 | 0.6005 | 0.7857 | 0.9901 |
| Probability | 0.05 | 0.25 | 0.5 | 0.75 | 0.95 |
| Quantile | 0.5272 | 0.6583 | 0.7826 | 0.9901 | 0.9901 |
| Subcase | Set of RPs (Year) | Cluster Cardinality | Minimum Correlation in the Cluster |
|---|---|---|---|
| (a) | 22, 2743, 32, 33, 38, 46, 959, 1374, 150, 150, 10, 72, 400, 90, 120 | 5, 7, 10, 12, 14, 15 | >0.9 |
| (b) | 22, 100(*), 32, 33, 38, 46,959, 1374, 50(*), 50(*), 10, 72, 400, 90, 120 | 10, 12 | >0.9 |
| (c) | Same as subcase (a) | 12 | >0.9, 0.8, 0.5, 0.3 |
| Maximum Percentage Error (%) | Computational Time (s) | |||
|---|---|---|---|---|
| Cluster Cardinality | Algorithm A | Algorithm B | Algorithm A | Algorithm B |
| 3 | 4.43 × 10−13 | 4.51 × 10−13 | 0.9 | 1.5 |
| 5 | 3.2 | 5.72 × 10−13 | 3.6 | 2.7 |
| 7 | 10.5 | 1.35 × 10−11 | 16 | 5.8 |
| 10 | 413.5 | 8.93 × 10−10 | 217.9 | 38 |
| 12 | 1945 | 9.30 × 10−9 | 1067 | 175 |
| Maximum Percentage Error (%) | ||
|---|---|---|
| Cluster Cardinality | Algorithm A | Algorithm B |
| 10 | 228 | 2.41 × 10−10 |
| 12 | 1430 | 2.75 × 10−8 |
| Computational Time (s) | Speed up Ratio | ||
|---|---|---|---|
| Cluster Cardinality | Algorithm A | Algorithm B | |
| 10 | 164 | 38 | 4.3 |
| 12 | 816 | 175 | 4.7 |
| Correlation Level | Algorithm A, % | Algorithm B, % | ||
|---|---|---|---|---|
| Maximum Percentual Error, % | Computational Time, s | Maximum Percentual Error, % | Computational Time, s | |
| Very high (min corr > 0.9) | 41.7 | 40.0 | 6.91 × 10−11 | 9.9 |
| High (min 0.8) | 59.5 | 35.0 | 0.21 | 10.0 |
| Medium (min 0.5) | 22.2 | 12.3 | 0.03 | 10.1 |
| Low (min 0.3) | 4.0 | 8.2 | 2.86 × 10−3 | 10.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ciapessoni, E.; Cirio, D.; Pitto, A. An Efficient Methodology to Identify Relevant Multiple Contingencies and Their Probability for Long-Term Resilience Studies. Energies 2024, 17, 2028. https://doi.org/10.3390/en17092028
Ciapessoni E, Cirio D, Pitto A. An Efficient Methodology to Identify Relevant Multiple Contingencies and Their Probability for Long-Term Resilience Studies. Energies. 2024; 17(9):2028. https://doi.org/10.3390/en17092028
Chicago/Turabian StyleCiapessoni, Emanuele, Diego Cirio, and Andrea Pitto. 2024. "An Efficient Methodology to Identify Relevant Multiple Contingencies and Their Probability for Long-Term Resilience Studies" Energies 17, no. 9: 2028. https://doi.org/10.3390/en17092028
APA StyleCiapessoni, E., Cirio, D., & Pitto, A. (2024). An Efficient Methodology to Identify Relevant Multiple Contingencies and Their Probability for Long-Term Resilience Studies. Energies, 17(9), 2028. https://doi.org/10.3390/en17092028