


A Survey on the Use of Synthetic Data for Enhancing Key Aspects of Trustworthy AI in the Energy Domain: Challenges and Opportunities


Abstract
1. Introduction
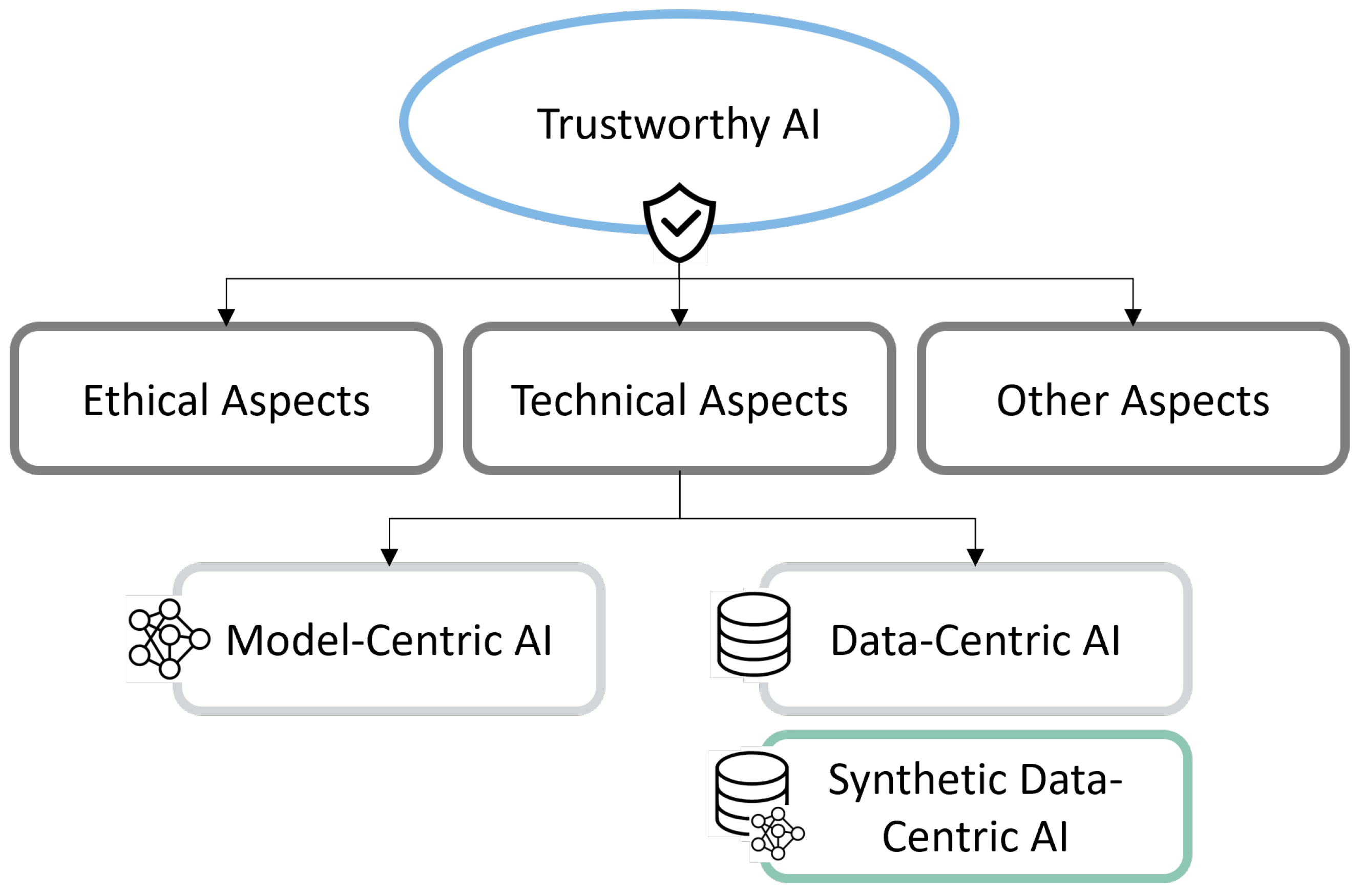
2. Trustworthy AI
3. Synthetic Data
3.1. Data Preparation
3.1.1. Real-World Data Collection
3.1.2. Data Preprocessing
3.2. Data Generation
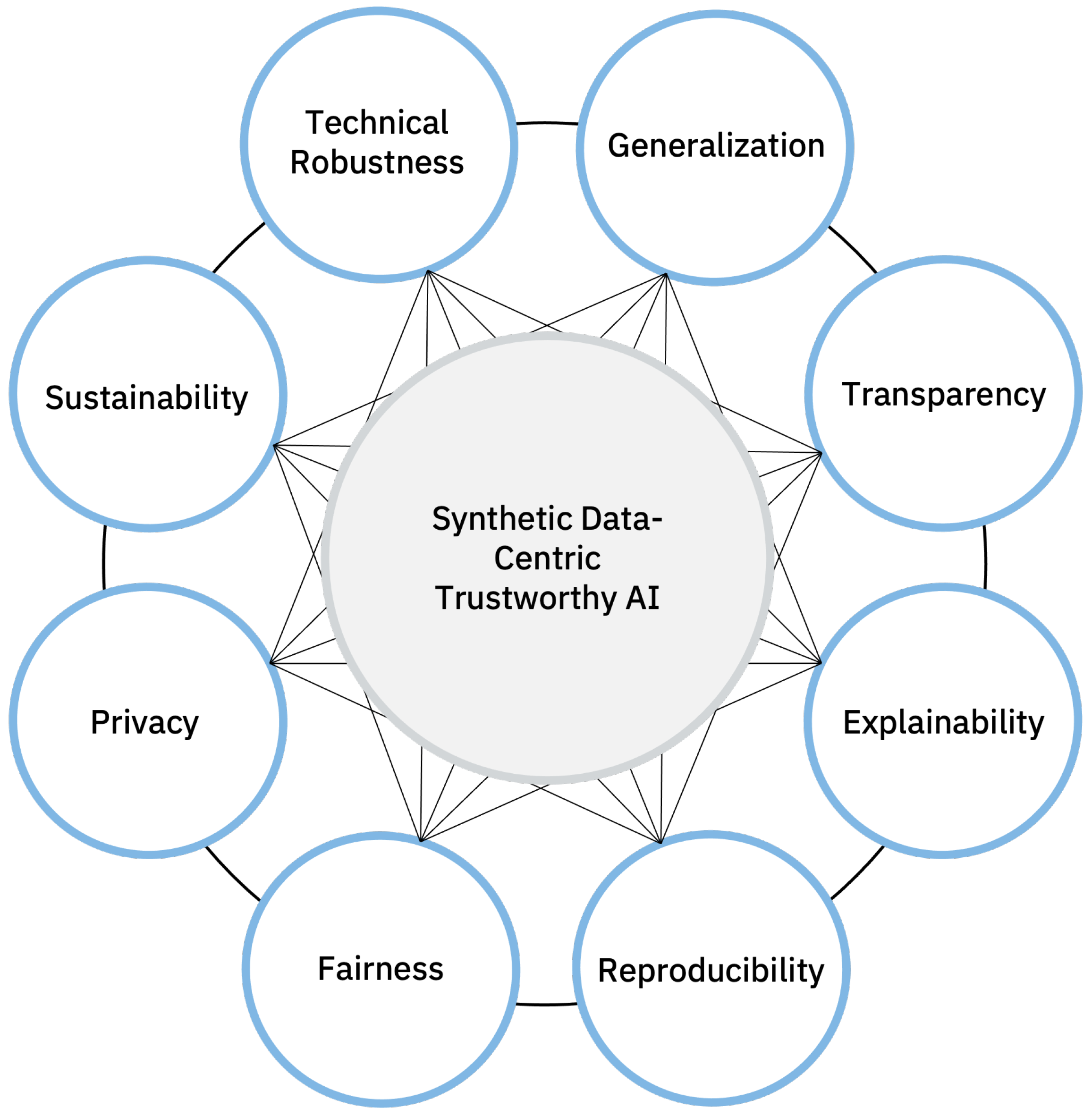
4. Aspects of Trustworthy Synthetic Data-Centric AI
4.1. Technical Robustness and Generalization
4.2. Transparency and Explainability
4.3. Reproducibility
4.4. Fairness
4.5. Privacy
4.6. Sustainability
5. Discussion: Open Issues and Further Directions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chu, S.; Majumdar, A. Opportunities and challenges for a sustainable energy future. Nature 2012, 488, 294–303. [Google Scholar] [CrossRef] [PubMed]
- Steg, L.; Perlaviciute, G.; Van der Werff, E. Understanding the human dimensions of a sustainable energy transition. Front. Psychol. 2015, 6, 805. [Google Scholar] [CrossRef]
- Dominković, D.F.; Bačeković, I.; Pedersen, A.S.; Krajačić, G. The future of transportation in sustainable energy systems: Opportunities and barriers in a clean energy transition. Renew. Sustain. Energy Rev. 2018, 82, 1823–1838. [Google Scholar] [CrossRef]
- Khalid, A.M.; Mitra, I.; Warmuth, W.; Schacht, V. Performance ratio–Crucial parameter for grid connected PV plants. Renew. Sustain. Energy Rev. 2016, 65, 1139–1158. [Google Scholar] [CrossRef]
- Višković, A.; Franki, V.; Jevtić, D. Artificial intelligence as a facilitator of the energy transition. In Proceedings of the 2022 45th Jubilee International Convention on Information, Communication and Electronic Technology (MIPRO), Opatija, Croatia, 23–27 May 2022; pp. 494–499. [Google Scholar]
- Griffiths, S. Energy diplomacy in a time of energy transition. Energy Strategy Rev. 2019, 26, 100386. [Google Scholar] [CrossRef]
- Jimenez, V.M.M.; Gonzalez, E.P. The Role of Artificial Intelligence in Latin Americas Energy Transition. IEEE Lat. Am. Trans. 2022, 20, 2404–2412. [Google Scholar] [CrossRef]
- Sulaiman, A.; Nagu, B.; Kaur, G.; Karuppaiah, P.; Alshahrani, H.; Reshan, M.S.A.; AlYami, S.; Shaikh, A. Artificial Intelligence-Based Secured Power Grid Protocol for Smart City. Sensors 2023, 23, 8016. [Google Scholar] [CrossRef]
- Chehri, A.; Fofana, I.; Yang, X. Security risk modeling in smart grid critical infrastructures in the era of big data and artificial intelligence. Sustainability 2021, 13, 3196. [Google Scholar] [CrossRef]
- Xie, J.; Alvarez-Fernandez, I.; Sun, W. A review of machine learning applications in power system resilience. In Proceedings of the 2020 IEEE Power & Energy Society General Meeting (PESGM), Montreal, QC, Canada, 2–6 August 2020; pp. 1–5. [Google Scholar]
- Shi, Z.; Yao, W.; Li, Z.; Zeng, L.; Zhao, Y.; Zhang, R.; Tang, Y.; Wen, J. Artificial intelligence techniques for stability analysis and control in smart grids: Methodologies, applications, challenges and future directions. Appl. Energy 2020, 278, 115733. [Google Scholar] [CrossRef]
- Omitaomu, O.A.; Niu, H. Artificial intelligence techniques in smart grid: A survey. Smart Cities 2021, 4, 548–568. [Google Scholar] [CrossRef]
- Song, Y.; Wan, C.; Hu, X.; Qin, H.; Lao, K. Resilient power grid for smart city. iEnergy 2022, 1, 325–340. [Google Scholar] [CrossRef]
- Massaoudi, M.; Abu-Rub, H.; Refaat, S.S.; Chihi, I.; Oueslati, F.S. Deep learning in smart grid technology: A review of recent advancements and future prospects. IEEE Access 2021, 9, 54558–54578. [Google Scholar] [CrossRef]
- Bose, B.K. Artificial intelligence techniques in smart grid and renewable energy systems—Some example applications. Proc. IEEE 2017, 105, 2262–2273. [Google Scholar] [CrossRef]
- Tang, Y.; Huang, Y.; Wang, H.; Wang, C.; Guo, Q.; Yao, W. Framework for artificial intelligence analysis in large-scale power grids based on digital simulation. CSEE J. Power Energy Syst. 2018, 4, 459–468. [Google Scholar] [CrossRef]
- Meiser, M.; Duppe, B.; Zinnikus, I. Generation of meaningful synthetic sensor data—Evaluated with a reliable transferability methodology. Energy AI 2024, 15, 100308. [Google Scholar] [CrossRef]
- Jin, D.; Ocone, R.; Jiao, K.; Xuan, J. Energy and AI. Energy AI 2020, 1, 100002. [Google Scholar] [CrossRef]
- Tomazzoli, C.; Scannapieco, S.; Cristani, M. Internet of things and artificial intelligence enable energy efficiency. J. Ambient. Intell. Humaniz. Comput. 2023, 14, 4933–4954. [Google Scholar] [CrossRef]
- Aguilar, J.; Garces-Jimenez, A.; R-moreno, M.; García, R. A systematic literature review on the use of artificial intelligence in energy self-management in smart buildings. Renew. Sustain. Energy Rev. 2021, 151, 111530. [Google Scholar] [CrossRef]
- Yu, K.H.; Beam, A.L.; Kohane, I.S. Artificial intelligence in healthcare. Nat. Biomed. Eng. 2018, 2, 719–731. [Google Scholar] [CrossRef]
- Panch, T.; Mattie, H.; Celi, L.A. The “inconvenient truth” about AI in healthcare. NPJ Digit. Med. 2019, 2, 77. [Google Scholar] [CrossRef]
- Cao, L. AI in finance: Challenges, techniques, and opportunities. ACM Comput. Surv. (CSUR) 2022, 55, 1–38. [Google Scholar]
- Buchanan, B.G. Artificial Intelligence in Finance; The Alan Turing Institute: London, UK, 2019. [Google Scholar]
- Hilpisch, Y. Artificial Intelligence in Finance; O’Reilly Media: Sebastopol, CA, USA, 2020. [Google Scholar]
- Castelvecchi, D. Can we open the black box of AI? Nat. News 2016, 538, 20. [Google Scholar] [CrossRef]
- Kaur, D.; Uslu, S.; Rittichier, K.J.; Durresi, A. Trustworthy artificial intelligence: A review. ACM Comput. Surv. (CSUR) 2022, 55, 1–38. [Google Scholar] [CrossRef]
- Thiebes, S.; Lins, S.; Sunyaev, A. Trustworthy artificial intelligence. Electron. Mark. 2021, 31, 447–464. [Google Scholar] [CrossRef]
- Floridi, L. Establishing the rules for building trustworthy AI. In Ethics, Governance, and Policies in Artificial Intelligence; Springer: Cham, Switzerland, 2021; pp. 41–45. [Google Scholar]
- Hamid, O.H. From model-centric to data-centric AI: A paradigm shift or rather a complementary approach? In Proceedings of the 2022 8th International Conference on Information Technology Trends (ITT), Dubai, United Arab Emirates, 25–26 May 2022; pp. 196–199. [Google Scholar]
- Zha, D.; Bhat, Z.P.; Lai, K.H.; Yang, F.; Hu, X. Data-centric AI: Perspectives and challenges. In Proceedings of the 2023 SIAM International Conference on Data Mining (SDM), Minneapolis, MN, USA, 27–29 April 2023; pp. 945–948. [Google Scholar]
- Sambasivan, N.; Kapania, S.; Highfill, H.; Akrong, D.; Paritosh, P.; Aroyo, L.M. “Everyone wants to do the model work, not the data work”: Data Cascades in High-Stakes AI. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021; pp. 1–15. [Google Scholar]
- Roh, Y.; Heo, G.; Whang, S.E. A survey on data collection for machine learning: A big data-ai integration perspective. IEEE Trans. Knowl. Data Eng. 2019, 33, 1328–1347. [Google Scholar] [CrossRef]
- Taori, R.; Dave, A.; Shankar, V.; Carlini, N.; Recht, B.; Schmidt, L. Measuring robustness to natural distribution shifts in image classification. Adv. Neural Inf. Process. Syst. 2020, 33, 18583–18599. [Google Scholar]
- Whang, S.E.; Roh, Y.; Song, H.; Lee, J.G. Data collection and quality challenges in deep learning: A data-centric ai perspective. VLDB J. 2023, 32, 791–813. [Google Scholar] [CrossRef]
- Najeh, H.; Singh, M.P.; Ploix, S.; Chabir, K.; Abdelkrim, M.N. Automatic thresholding for sensor data gap detection using statistical approach. In Sustainability in Energy and Buildings: Proceedings of SEB 2019; Springer: Berlin/Heidelberg, Germany, 2020; pp. 455–467. [Google Scholar]
- Klemenjak, C.; Reinhardt, A.; Pereira, L.; Makonin, S.; Bergés, M.; Elmenreich, W. Electricity consumption data sets: Pitfalls and opportunities. In Proceedings of the 6th ACM International Conference on Systems for Energy-Efficient Buildings, Cities, and Transportation, New York, NY, USA, 13–14 November 2019; pp. 159–162. [Google Scholar]
- Ma, B.; Zheng, X. Biased data revisions: Unintended consequences of China’s energy-saving mandates. China Econ. Rev. 2018, 48, 102–113. [Google Scholar] [CrossRef]
- de Vos, A.; Preiser, R.; Masterson, V.A. Participatory data collection. In The Routledge Handbook of Research Methods for Social-Ecological Systems; Taylor & Francis: Abingdon, UK, 2021; p. 119. [Google Scholar]
- Xu, Y.; Maitland, C. Participatory data collection and management in low-resource contexts: A field trial with urban refugees. In Proceedings of the Tenth International Conference on Information and Communication Technologies and Development, Ahmedabad, India, 4–7 January 2019; pp. 1–12. [Google Scholar]
- Shilton, K. Participatory personal data: An emerging research challenge for the information sciences. J. Am. Soc. Inf. Sci. Technol. 2012, 63, 1905–1915. [Google Scholar] [CrossRef]
- Marwala, T.; Fournier-Tombs, E.; Stinckwich, S. The Use of Synthetic Data to Train AI Models: Opportunities and Risks for Sustainable Development. arXiv 2023, arXiv:2309.00652. [Google Scholar]
- Nikolenko, S.I. Synthetic Data for Deep Learning; Springer: Berlin/Heidelberg, Germany, 2021; Volume 174. [Google Scholar]
- Zhang, C.; Kuppannagari, S.R.; Kannan, R.; Prasanna, V.K. Generative adversarial network for synthetic time series data generation in smart grids. In Proceedings of the 2018 IEEE International Conference on Communications, Control, and Computing Technologies for Smart Grids (SmartGridComm), Aalborg, Denmark, 29–31 October 2018; pp. 1–6. [Google Scholar]
- Klemenjak, C.; Kovatsch, C.; Herold, M.; Elmenreich, W. A synthetic energy dataset for non-intrusive load monitoring in households. Sci. Data 2020, 7, 108. [Google Scholar] [CrossRef]
- Reddy, T.; Claridge, D. Using synthetic data to evaluate multiple regression and principal component analyses for statistical modeling of daily building energy consumption. Energy Build. 1994, 21, 35–44. [Google Scholar] [CrossRef]
- Giuffrè, M.; Shung, D.L. Harnessing the power of synthetic data in healthcare: Innovation, application, and privacy. NPJ Digit. Med. 2023, 6, 186. [Google Scholar] [CrossRef]
- Benaim, A.R.; Almog, R.; Gorelik, Y.; Hochberg, I.; Nassar, L.; Mashiach, T.; Khamaisi, M.; Lurie, Y.; Azzam, Z.S.; Khoury, J.; et al. Analyzing medical research results based on synthetic data and their relation to real data results: Systematic comparison from five observational studies. JMIR Med. Inform. 2020, 8, e16492. [Google Scholar] [CrossRef]
- Ive, J.; Viani, N.; Kam, J.; Yin, L.; Verma, S.; Puntis, S.; Cardinal, R.N.; Roberts, A.; Stewart, R.; Velupillai, S. Generation and evaluation of artificial mental health records for natural language processing. NPJ Digit. Med. 2020, 3, 69. [Google Scholar] [CrossRef]
- Assefa, S.A.; Dervovic, D.; Mahfouz, M.; Tillman, R.E.; Reddy, P.; Veloso, M. Generating synthetic data in finance: Opportunities, challenges and pitfalls. In Proceedings of the First ACM International Conference on AI in Finance, New York, NY, USA, 15–16 October 2020; pp. 1–8. [Google Scholar]
- Da Silva, B.; Shi, S.S. Style transfer with time series: Generating synthetic financial data. arXiv 2019, arXiv:1906.03232. [Google Scholar]
- Papacharalampopoulos, A.; Tzimanis, K.; Sabatakakis, K.; Stavropoulos, P. Deep quality assessment of a solar reflector based on synthetic data: Detecting surficial defects from manufacturing and use phase. Sensors 2020, 20, 5481. [Google Scholar] [CrossRef]
- Manettas, C.; Nikolakis, N.; Alexopoulos, K. Synthetic datasets for Deep Learning in computer-vision assisted tasks in manufacturing. Procedia CIRP 2021, 103, 237–242. [Google Scholar] [CrossRef]
- Jordon, J.; Szpruch, L.; Houssiau, F.; Bottarelli, M.; Cherubin, G.; Maple, C.; Cohen, S.N.; Weller, A. Synthetic Data–what, why and how? arXiv 2022, arXiv:2205.03257. [Google Scholar]
- Ala-Pietilä, P.; Bonnet, Y.; Bergmann, U.; Bielikova, M.; Bonefeld-Dahl, C.; Bauer, W.; Bouarfa, L.; Chatila, R.; Coeckelbergh, M.; Dignum, V.; et al. The Assessment List for Trustworthy Artificial Intelligence (ALTAI); European Commission: Luxembourg, 2020. [Google Scholar]
- TAILOR EU Project. The TAILOR Handbook of Trustworthy AI. 2022. Available online: http://tailor.isti.cnr.it/handbookTAI/TAILOR.html#id1 (accessed on 15 April 2024).
- Yeung, K. Recommendation of the Council on Artificial Intelligence (OECD). Int. Leg. Mater. 2020, 59, 27–34. [Google Scholar] [CrossRef]
- The White House, Guidance for Regulation of Artificial Intelligence Applications. In Memorandum for the Heads of Executive Departments and Agencies. 2020. Available online: https://www.whitehouse.gov/wp-content/uploads/2020/01/Draft-OMB-Memo-on-Regulation-of-AI-1-7-19.pdf (accessed on 15 April 2024).
- National Institute of Standards and Technology, U.S. Department of Commerce. AI Risks and Trustworthiness. Available online: https://airc.nist.gov/AI_RMF_Knowledge_Base/AI_RMF/Foundational_Information/3-sec-characteristics (accessed on 15 April 2024).
- National Institute of Standards and Technology. Artificial Intelligence Risk Management Framework. 2023. Available online: https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.100-1.pdf (accessed on 15 April 2024).
- Schwartz, R.; Vassilev, A.; Greene, K.; Perine, L.; Burt, A.; Hall, P. Towards a Standard for Identifying and Managing Bias in Artificial Intelligence; NIST Special Publication; US Department of Commerce, National Institute of Standards and Technology: Washington, DC, USA, 2022; Volume 1270.
- Bundesamt für Sicherheit in der Informationstechnik. AI Cloud Service Compliance Criteria Catalogue (AIC4); Federal Office for Information Security: Bonn, Germany, 2021; Available online: https://www.bsi.bund.de/SharedDocs/Downloads/EN/BSI/CloudComputing/AIC4/AI-Cloud-Service-Compliance-Criteria-Catalogue_AIC4.html (accessed on 15 April 2024).
- Liang, W.; Tadesse, G.A.; Ho, D.; Fei-Fei, L.; Zaharia, M.; Zhang, C.; Zou, J. Advances, challenges and opportunities in creating data for trustworthy AI. Nat. Mach. Intell. 2022, 4, 669–677. [Google Scholar] [CrossRef]
- Harrison, R.L. Introduction to monte carlo simulation. In AIP Conference Proceedings; American Institute of Physics: College Park, MD, USA, 2010; Volume 1204, pp. 17–21. [Google Scholar]
- Rahane, W.; Dalvi, H.; Magar, Y.; Kalane, A.; Jondhale, S. Lung cancer detection using image processing and machine learning healthcare. In Proceedings of the 2018 International Conference on Current Trends towards Converging Technologies (ICCTCT), Coimbatore, India, 1–3 March 2018; pp. 1–5. [Google Scholar]
- Qayyum, A.; Qadir, J.; Bilal, M.; Al-Fuqaha, A. Secure and robust machine learning for healthcare: A survey. IEEE Rev. Biomed. Eng. 2020, 14, 156–180. [Google Scholar] [CrossRef]
- Shi, J.; Guo, J.; Zheng, S. Evaluation of hybrid forecasting approaches for wind speed and power generation time series. Renew. Sustain. Energy Rev. 2012, 16, 3471–3480. [Google Scholar] [CrossRef]
- Sharadga, H.; Hajimirza, S.; Balog, R.S. Time series forecasting of solar power generation for large-scale photovoltaic plants. Renew. Energy 2020, 150, 797–807. [Google Scholar] [CrossRef]
- Hossain, M.S.; Mahmood, H. Short-term photovoltaic power forecasting using an LSTM neural network and synthetic weather forecast. IEEE Access 2020, 8, 172524–172533. [Google Scholar] [CrossRef]
- Yoon, J.; Jarrett, D.; Van der Schaar, M. Time-series generative adversarial networks. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Ribeiro, M.H.D.M.; da Silva, R.G.; Moreno, S.R.; Mariani, V.C.; dos Santos Coelho, L. Efficient bootstrap stacking ensemble learning model applied to wind power generation forecasting. Int. J. Electr. Power Energy Syst. 2022, 136, 107712. [Google Scholar] [CrossRef]
- Li, B.; Qi, P.; Liu, B.; Di, S.; Liu, J.; Pei, J.; Yi, J.; Zhou, B. Trustworthy AI: From principles to practices. ACM Comput. Surv. 2023, 55, 1–46. [Google Scholar] [CrossRef]
- Minh, D.; Wang, H.X.; Li, Y.F.; Nguyen, T.N. Explainable artificial intelligence: A comprehensive review. Artif. Intell. Rev. 2022, 55, 3503–3568. [Google Scholar] [CrossRef]
- Kaselimi, M.; Protopapadakis, E.; Voulodimos, A.; Doulamis, N.; Doulamis, A. Towards trustworthy energy disaggregation: A review of challenges, methods, and perspectives for non-intrusive load monitoring. Sensors 2022, 22, 5872. [Google Scholar] [CrossRef]
- Firth, S.; Kane, T.; Dimitriou, V.; Hassan, T.; Fouchal, F.; Coleman, M.; Webb, L. REFIT Smart Home Dataset. 2017. Available online: https://repository.lboro.ac.uk/articles/dataset/REFIT_Smart_Home_dataset/2070091/1 (accessed on 15 April 2024).
- Wilhelm, S.; Jakob, D.; Kasbauer, J.; Ahrens, D. GeLaP: German labeled dataset for power consumption. In Proceedings of the Sixth International Congress on Information and Communication Technology: ICICT 2021, London, UK, 25–26 February 2021; Springer: Singapore, 2022; Volume 1, pp. 21–33. [Google Scholar]
- Shin, C.; Lee, E.; Han, J.; Yim, J.; Rhee, W.; Lee, H. The ENERTALK dataset, 15 Hz electricity consumption data from 22 houses in Korea. Sci. Data 2019, 6, 193. [Google Scholar] [CrossRef] [PubMed]
- Monacchi, A.; Egarter, D.; Elmenreich, W.; D’Alessandro, S.; Tonello, A.M. GREEND: An energy consumption dataset of households in Italy and Austria. In Proceedings of the 2014 IEEE International Conference on Smart Grid Communications (SmartGridComm), Venice, Italy, 3–6 November 2014; pp. 511–516. [Google Scholar]
- Chavan, D.R.; More, D.S.; Khot, A.M. IEDL: Indian Energy Dataset with Low frequency for NILM. Energy Rep. 2022, 8, 701–709. [Google Scholar] [CrossRef]
- Kelly, J.; Knottenbelt, W. The UK-DALE dataset, domestic appliance-level electricity demand and whole-house demand from five UK homes. Sci. Data 2015, 2, 150007. [Google Scholar] [CrossRef]
- Schlemminger, M.; Ohrdes, T.; Schneider, E.; Knoop, M. Dataset on electrical single-family house and heat pump load profiles in Germany. Sci. Data 2022, 9, 56. [Google Scholar] [CrossRef]
- Pullinger, M.; Kilgour, J.; Goddard, N.; Berliner, N.; Webb, L.; Dzikovska, M.; Lovell, H.; Mann, J.; Sutton, C.; Webb, J.; et al. The IDEAL household energy dataset, electricity, gas, contextual sensor data and survey data for 255 UK homes. Sci. Data 2021, 8, 146. [Google Scholar] [CrossRef] [PubMed]
- Sartori, I.; Walnum, H.T.; Skeie, K.S.; Georges, L.; Knudsen, M.D.; Bacher, P.; Candanedo, J.; Sigounis, A.M.; Prakash, A.K.; Pritoni, M.; et al. Sub-hourly measurement datasets from 6 real buildings: Energy use and indoor climate. Data Brief 2023, 48, 109149. [Google Scholar] [CrossRef] [PubMed]
- Delfosse, A.; Hebrail, G.; Zerroug, A. Deep learning applied to nilm: Is data augmentation worth for energy disaggregation? In ECAI 2020; IOS Press: Amsterdam, The Netherlands, 2020; pp. 2972–2977. [Google Scholar]
- Chen, D.; Irwin, D.; Shenoy, P. Smartsim: A device-accurate smart home simulator for energy analytics. In Proceedings of the 2016 IEEE International Conference on Smart Grid Communications (SmartGridComm), Sydney, NSW, Australia, 6–9 November 2016; pp. 686–692. [Google Scholar]
- Meiser, M.; Duppe, B.; Zinnikus, I. SynTiSeD–Synthetic Time Series Data Generator. In Proceedings of the 2023 11th Workshop on Modelling and Simulation of Cyber-Physical Energy Systems (MSCPES), San Antonio, TX, USA, 9 May 2023; pp. 1–6. [Google Scholar]
- Long, L.; Ye, H. The roles of thermal insulation and heat storage in the energy performance of the wall materials: A simulation study. Sci. Rep. 2016, 6, 24181. [Google Scholar] [CrossRef] [PubMed]
- Wei, S.; Jones, R.; De Wilde, P. Driving factors for occupant-controlled space heating in residential buildings. Energy Build. 2014, 70, 36–44. [Google Scholar] [CrossRef]
- Ji, R.; Zhang, Z.; He, Y.; Liu, J.; Qu, S. Simulating the effects of anchors on the thermal performance of building insulation systems. Energy Build. 2017, 140, 501–507. [Google Scholar] [CrossRef]
- Pérez-Andreu, V.; Aparicio-Fernández, C.; Vivancos, J.L.; Cárcel-Carrasco, J. Experimental data and simulations of performance and thermal comfort in a typical mediterranean house. Energies 2021, 14, 3311. [Google Scholar] [CrossRef]
- Badiei, A.; Allinson, D.; Lomas, K. Automated dynamic thermal simulation of houses and housing stocks using readily available reduced data. Energy Build. 2019, 203, 109431. [Google Scholar] [CrossRef]
- Gaetani, I.; Hoes, P.J.; Hensen, J.L. Occupant behavior in building energy simulation: Towards a fit-for-purpose modeling strategy. Energy Build. 2016, 121, 188–204. [Google Scholar] [CrossRef]
- Chen, S.; Wu, J.; Pan, Y.; Ge, J.; Huang, Z. Simulation and case study on residential stochastic energy use behaviors based on human dynamics. Energy Build. 2020, 223, 110182. [Google Scholar] [CrossRef]
- Peng, C.; Yan, D.; Wu, R.; Wang, C.; Zhou, X.; Jiang, Y. Quantitative description and simulation of human behavior in residential buildings. Build. Simul. 2012, 5, 85–94. [Google Scholar] [CrossRef]
- Chai, C.; Li, G. Human-in-the-loop Techniques in Machine Learning. IEEE Data Eng. Bull. 2020, 43, 37–52. [Google Scholar]
- El Emam, K.; Mosquera, L.; Hoptroff, R. Practical Synthetic Data Generation: Balancing Privacy and the Broad Availability of Data; O’Reilly Media: Sebastopol, CA, USA, 2020. [Google Scholar]
- Binderbauer, P.J.; Kienberger, T.; Staubmann, T. Synthetic load profile generation for production chains in energy intensive industrial subsectors via a bottom-up approach. J. Clean. Prod. 2022, 331, 130024. [Google Scholar] [CrossRef]
- Sandhaas, A.; Kim, H.; Hartmann, N. Methodology for Generating Synthetic Load Profiles for Different Industry Types. Energies 2022, 15, 3683. [Google Scholar] [CrossRef]
- Hong, T.; Macumber, D.; Li, H.; Fleming, K.; Wang, Z. Generation and representation of synthetic smart meter data. Build. Simul. 2020, 13, 1205–1220. [Google Scholar] [CrossRef]
- Behm, C.; Nolting, L.; Praktiknjo, A. How to model European electricity load profiles using artificial neural networks. Appl. Energy 2020, 277, 115564. [Google Scholar] [CrossRef]
- Reinhardt, A.; Klemenjak, C. How does load disaggregation performance depend on data characteristics? Insights from a benchmarking study. In Proceedings of the eleventh ACM International Conference on Future Energy Systems, Virtual Event, 22–26 June 2020; pp. 167–177. [Google Scholar]
- Harell, A.; Jones, R.; Makonin, S.; Bajić, I.V. TraceGAN: Synthesizing appliance power signatures using generative adversarial networks. IEEE Trans. Smart Grid 2021, 12, 4553–4563. [Google Scholar] [CrossRef]
- Buneeva, N.; Reinhardt, A. AMBAL: Realistic load signature generation for load disaggregation performance evaluation. In Proceedings of the 2017 IEEE International Conference on Smart Grid Communications (smartgridcomm), Dresden, Germany, 23–26 October 2017; pp. 443–448. [Google Scholar]
- Dankar, F.K.; Ibrahim, M. Fake it till you make it: Guidelines for effective synthetic data generation. Appl. Sci. 2021, 11, 2158. [Google Scholar] [CrossRef]
- Snoke, J.; Raab, G.M.; Nowok, B.; Dibben, C.; Slavkovic, A. General and specific utility measures for synthetic data. J. R. Stat. Soc. Ser. A Stat. Soc. 2018, 181, 663–688. [Google Scholar] [CrossRef]
- Woo, M.J.; Reiter, J.P.; Oganian, A.; Karr, A.F. Global measures of data utility for microdata masked for disclosure limitation. J. Priv. Confid. 2009, 1. [Google Scholar] [CrossRef]
- Schenker, N.; Gentleman, J.F. On judging the significance of differences by examining the overlap between confidence intervals. Am. Stat. 2001, 55, 182–186. [Google Scholar] [CrossRef]
- Loong, B.; Zaslavsky, A.M.; He, Y.; Harrington, D.P. Disclosure control using partially synthetic data for large-scale health surveys, with applications to CanCORS. Stat. Med. 2013, 32, 4139–4161. [Google Scholar] [CrossRef] [PubMed]
- Majumdar, S. Fairness, explainability, privacy, and robustness for trustworthy algorithmic decision-making. In Big Data Analytics in Chemoinformatics and Bioinformatics; Elsevier: Amsterdam, The Netherlands, 2023; pp. 61–95. [Google Scholar]
- Balagopalan, A.; Zhang, H.; Hamidieh, K.; Hartvigsen, T.; Rudzicz, F.; Ghassemi, M. The road to explainability is paved with bias: Measuring the fairness of explanations. In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, Seoul, Republic of Korea, 21–24 June 2022; pp. 1194–1206. [Google Scholar]
- Xu, H.; Mannor, S. Robustness and generalization. Mach. Learn. 2012, 86, 391–423. [Google Scholar] [CrossRef]
- Tsipras, D.; Santurkar, S.; Engstrom, L.; Turner, A.; Madry, A. Robustness may be at odds with accuracy. arXiv 2018, arXiv:1805.12152. [Google Scholar]
- Raghunathan, A.; Xie, S.M.; Yang, F.; Duchi, J.C.; Liang, P. Adversarial training can hurt generalization. arXiv 2019, arXiv:1906.06032. [Google Scholar]
- Mehrabi, N.; Morstatter, F.; Saxena, N.; Lerman, K.; Galstyan, A. A survey on bias and fairness in machine learning. ACM Comput. Surv. (CSUR) 2021, 54, 1–35. [Google Scholar] [CrossRef]
- Tsirikoglou, A. Synthetic Data for Visual Machine Learning: A Data-Centric Approach. Ph.D. Thesis, Linköping University, Linköping, Sweden, 2022. [Google Scholar]
- Wang, A.X.; Chukova, S.S.; Nguyen, B.P. Data-Centric AI to Improve Churn Prediction with Synthetic Data. In Proceedings of the 2023 3rd International Conference on Computer, Control and Robotics (ICCCR), Shanghai, China, 24–26 March 2023; pp. 409–413. [Google Scholar]
- Qi, B.; Xiao, X.; Liang, J.; Po, L.c.C.; Zhang, L.; Tong, J. An open time-series simulated dataset covering various accidents for nuclear power plants. Sci. Data 2022, 9, 766. [Google Scholar] [CrossRef]
- Marcu, A.; Costea, D.; Licaret, V.; Pîrvu, M.; Slusanschi, E.; Leordeanu, M. SafeUAV: Learning to estimate depth and safe landing areas for UAVs from synthetic data. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Milano, Italy, 8–14 September 2018. [Google Scholar]
- Gambi, A.; Nguyen, V.; Ahmed, J.; Fraser, G. Generating critical driving scenarios from accident sketches. In Proceedings of the 2022 IEEE International Conference On Artificial Intelligence Testing (AITest), Newark, CA, USA, 15–18 August 2022; pp. 95–102. [Google Scholar]
- Kaufmann, D.; Klampfl, L.; Klück, F.; Zimmermann, M.; Tao, J. Critical and challenging scenario generation based on automatic action behavior sequence optimization: 2021 ieee autonomous driving ai test challenge group 108. In Proceedings of the 2021 IEEE International Conference On Artificial Intelligence Testing (AITest), Oxford, UK, 23–26 August 2021; pp. 118–127. [Google Scholar]
- Tian, H.; Wu, G.; Yan, J.; Jiang, Y.; Wei, J.; Chen, W.; Li, S.; Ye, D. Generating critical test scenarios for autonomous driving systems via influential behavior patterns. In Proceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering, Rochester, MI, USA, 10–14 October 2022; pp. 1–12. [Google Scholar]
- Ding, W.; Chen, B.; Xu, M.; Zhao, D. Learning to collide: An adaptive safety-critical scenarios generating method. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 2243–2250. [Google Scholar]
- Murray, D.; Stankovic, L.; Stankovic, V.; Lulic, S.; Sladojevic, S. Transferability of neural network approaches for low-rate energy disaggregation. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8330–8334. [Google Scholar]
- Martinez-Soto, A.; Jentsch, M.F. A transferable energy model for determining the future energy demand and its uncertainty in a country’s residential sector. Build. Res. Inf. 2020, 48, 587–612. [Google Scholar] [CrossRef]
- Klemenjak, C.; Faustine, A.; Makonin, S.; Elmenreich, W. On metrics to assess the transferability of machine learning models in non-intrusive load monitoring. arXiv 2019, arXiv:1912.06200. [Google Scholar]
- Tommasi, T.; Patricia, N.; Caputo, B.; Tuytelaars, T. A deeper look at dataset bias. In Domain Adaptation in Computer Vision Applications; Springer: Cham, Switzerland, 2017; pp. 37–55. [Google Scholar]
- Torralba, A.; Efros, A.A. Unbiased look at dataset bias. In Proceedings of the CVPR 2011, Washington, DC, USA, 20–25 June 2011; pp. 1521–1528. [Google Scholar]
- Khosla, A.; Zhou, T.; Malisiewicz, T.; Efros, A.A.; Torralba, A. Undoing the damage of dataset bias. In Proceedings of the Computer Vision—ECCV 2012: 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Proceedings, Part I 12. Springer: Berlin/Heidelberg, Germany, 2012; pp. 158–171. [Google Scholar]
- Zerilli, J.; Bhatt, U.; Weller, A. How transparency modulates trust in artificial intelligence. Patterns 2022, 3. [Google Scholar] [CrossRef] [PubMed]
- Xu, F.; Uszkoreit, H.; Du, Y.; Fan, W.; Zhao, D.; Zhu, J. Explainable AI: A brief survey on history, research areas, approaches and challenges. In Proceedings of the Natural Language Processing and Chinese Computing: 8th CCF International Conference, NLPCC 2019, Dunhuang, China, 9–14 October 2019; Proceedings, Part II 8. Springer: Berlin/Heidelberg, Germany, 2019; pp. 563–574. [Google Scholar]
- Pearl, J. The limitations of opaque learning machines. Possible Minds 2019, 25, 13–19. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Holm, E.A. In defense of the black box. Science 2019, 364, 26–27. [Google Scholar] [CrossRef] [PubMed]
- Hassija, V.; Chamola, V.; Mahapatra, A.; Singal, A.; Goel, D.; Huang, K.; Scardapane, S.; Spinelli, I.; Mahmud, M.; Hussain, A. Interpreting black-box models: A review on explainable artificial intelligence. Cogn. Comput. 2024, 16, 45–74. [Google Scholar] [CrossRef]
- Holzinger, A.; Saranti, A.; Molnar, C.; Biecek, P.; Samek, W. Explainable AI methods-a brief overview. In International Workshop on Extending Explainable AI Beyond Deep Models and Classifiers; Springer: Cham, Switzerland, 2022; pp. 13–38. [Google Scholar]
- Reddy, G.T.; Reddy, M.P.K.; Lakshmanna, K.; Kaluri, R.; Rajput, D.S.; Srivastava, G.; Baker, T. Analysis of dimensionality reduction techniques on big data. IEEE Access 2020, 8, 54776–54788. [Google Scholar] [CrossRef]
- Gogtay, N.J.; Thatte, U.M. Principles of correlation analysis. J. Assoc. Physicians India 2017, 65, 78–81. [Google Scholar] [PubMed]
- Alaa, A.; Breugel, B.; Saveliev, E.; Schaar, M. How Faithful Is Your Synthetic Data? Sample-Level Metrics for Evaluating and Auditing Generative Models. In International Conference on Machine Learning; PMLR: Baltimore, MD, USA, 2022; pp. 290–306. [Google Scholar]
- Wu, X.; Xiao, L.; Sun, Y.; Zhang, J.; Ma, T.; He, L. A survey of human-in-the-loop for machine learning. Future Gener. Comput. Syst. 2022, 135, 364–381. [Google Scholar] [CrossRef]
- Stoyanovich, J.; Howe, B. Nutritional labels for data and models. Q. Bull. Comput. Soc. IEEE Tech. Comm. Data Eng. 2019, 42, 13–23. [Google Scholar]
- Gebru, T.; Morgenstern, J.; Vecchione, B.; Vaughan, J.W.; Wallach, H.; Iii, H.D.; Crawford, K. Datasheets for datasets. Commun. ACM 2021, 64, 86–92. [Google Scholar] [CrossRef]
- Weller, A. Transparency: Motivations and challenges. In Explainable AI: Interpreting, Explaining and Visualizing Deep Learning; Springer: Berlin/Heidelberg, Germany, 2019; pp. 23–40. [Google Scholar]
- Kilbertus, N.; Gascón, A.; Kusner, M.; Veale, M.; Gummadi, K.; Weller, A. Blind justice: Fairness with encrypted sensitive attributes. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 2630–2639. [Google Scholar]
- Sarkar, A.; Yang, Y.; Vihinen, M. Variation benchmark datasets: Update, criteria, quality and applications. Database 2020, 2020, baz117. [Google Scholar] [CrossRef] [PubMed]
- Mamalakis, A.; Ebert-Uphoff, I.; Barnes, E.A. Neural network attribution methods for problems in geoscience: A novel synthetic benchmark dataset. Environ. Data Sci. 2022, 1, e8. [Google Scholar] [CrossRef]
- Colbois, L.; de Freitas Pereira, T.; Marcel, S. On the use of automatically generated synthetic image datasets for benchmarking face recognition. In Proceedings of the 2021 IEEE International Joint Conference on Biometrics (IJCB), Shenzhen, China, 4–7 August 2021; pp. 1–8. [Google Scholar]
- Peng, X.; Usman, B.; Kaushik, N.; Wang, D.; Hoffman, J.; Saenko, K. Visda: A synthetic-to-real benchmark for visual domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2021–2026. [Google Scholar]
- Zhang, J.; Cao, Y.; Zha, Z.J.; Tao, D. Nighttime dehazing with a synthetic benchmark. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2355–2363. [Google Scholar]
- Gundersen, O.E. The fundamental principles of reproducibility. Philos. Trans. R. Soc. A 2021, 379, 20200210. [Google Scholar] [CrossRef] [PubMed]
- Baker, M. 1,500 scientists lift the lid on reproducibility. Nature 2016, 533, 452–454. [Google Scholar] [CrossRef] [PubMed]
- Pineau, J.; Vincent-Lamarre, P.; Sinha, K.; Larivière, V.; Beygelzimer, A.; d’Alché Buc, F.; Fox, E.; Larochelle, H. Improving reproducibility in machine learning research (a report from the neurips 2019 reproducibility program). J. Mach. Learn. Res. 2021, 22, 7459–7478. [Google Scholar]
- Henderson, P.; Islam, R.; Bachman, P.; Pineau, J.; Precup, D.; Meger, D. Deep reinforcement learning that matters. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Goodman, S.N.; Fanelli, D.; Ioannidis, J.P. What does research reproducibility mean? Sci. Transl. Med. 2016, 8, 341ps12. [Google Scholar] [CrossRef] [PubMed]
- Grund, S.; Lüdtke, O.; Robitzsch, A. Using synthetic data to improve the reproducibility of statistical results in psychological research. Psychol. Methods 2022. [Google Scholar] [CrossRef] [PubMed]
- El Hachimi, C.; Belaqziz, S.; Khabba, S.; Ousanouan, Y.; Sebbar, B.e.; Kharrou, M.H.; Chehbouni, A. ClimateFiller: A Python framework for climate time series gap-filling and diagnosis based on artificial intelligence and multi-source reanalysis data. Softw. Impacts 2023, 18, 100575. [Google Scholar] [CrossRef]
- Arriagada, P.; Karelovic, B.; Link, O. Automatic gap-filling of daily streamflow time series in data-scarce regions using a machine learning algorithm. J. Hydrol. 2021, 598, 126454. [Google Scholar] [CrossRef]
- Fu, C.; Quintana, M.; Nagy, Z.; Miller, C. Filling time-series gaps using image techniques: Multidimensional context autoencoder approach for building energy data imputation. Appl. Therm. Eng. 2024, 236, 121545. [Google Scholar] [CrossRef]
- Quintana, D.S. A synthetic dataset primer for the biobehavioural sciences to promote reproducibility and hypothesis generation. Elife 2020, 9, e53275. [Google Scholar] [CrossRef] [PubMed]
- Chen, R.J.; Lu, M.Y.; Chen, T.Y.; Williamson, D.F.; Mahmood, F. Synthetic data in machine learning for medicine and healthcare. Nat. Biomed. Eng. 2021, 5, 493–497. [Google Scholar] [CrossRef] [PubMed]
- Jessop-Fabre, M.M.; Sonnenschein, N. Improving reproducibility in synthetic biology. Front. Bioeng. Biotechnol. 2019, 7, 18. [Google Scholar] [CrossRef]
- Heil, B.J.; Hoffman, M.M.; Markowetz, F.; Lee, S.I.; Greene, C.S.; Hicks, S.C. Reproducibility standards for machine learning in the life sciences. Nat. Methods 2021, 18, 1132–1135. [Google Scholar] [CrossRef] [PubMed]
- Cochran, W.G. Sampling Techniques; John Wiley & Sons: Hoboken, NJ, USA, 1977. [Google Scholar]
- Kusner, M.J.; Loftus, J.; Russell, C.; Silva, R. Counterfactual fairness. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Hardt, M.; Price, E.; Srebro, N. Equality of opportunity in supervised learning. Adv. Neural Inf. Process. Syst. 2016, 29. [Google Scholar]
- Dwork, C.; Hardt, M.; Pitassi, T.; Reingold, O.; Zemel, R. Fairness through awareness. In Proceedings of the 3rd Innovations in Theoretical Computer Science Conference, Cambridge, MA, USA, 8–10 January 2012; pp. 214–226. [Google Scholar]
- Kleinberg, J.; Mullainathan, S.; Raghavan, M. Inherent trade-offs in the fair determination of risk scores. arXiv 2016, arXiv:1609.05807. [Google Scholar]
- Dastin, J. Amazon scraps secret AI recruiting tool that showed bias against women. In Ethics of Data and Analytics; Auerbach Publications: Boca Raton, FL, USA, 2022; pp. 296–299. [Google Scholar]
- Segal, B.; Rubin, D.M.; Rubin, G.; Pantanowitz, A. Evaluating the clinical realism of synthetic chest x-rays generated using progressively growing gans. SN Comput. Sci. 2021, 2, 321. [Google Scholar] [CrossRef]
- van Breugel, B.; Kyono, T.; Berrevoets, J.; van der Schaar, M. Decaf: Generating fair synthetic data using causally-aware generative networks. Adv. Neural Inf. Process. Syst. 2021, 34, 22221–22233. [Google Scholar]
- Lu, K.; Mardziel, P.; Wu, F.; Amancharla, P.; Datta, A. Gender bias in neural natural language processing. In Logic, Language, and Security: Essays Dedicated to Andre Scedrov on the Occasion of His 65th Birthday; Springer: Cham, Switzerland, 2020; pp. 189–202. [Google Scholar]
- Buolamwini, J.; Gebru, T. Gender shades: Intersectional accuracy disparities in commercial gender classification. In Proceedings of the Conference on Fairness, Accountability and Transparency, New York, NY, USA, 23–24 February 2018; pp. 77–91. [Google Scholar]
- Calmon, F.; Wei, D.; Vinzamuri, B.; Natesan Ramamurthy, K.; Varshney, K.R. Optimized pre-processing for discrimination prevention. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Feldman, M.; Friedler, S.A.; Moeller, J.; Scheidegger, C.; Venkatasubramanian, S. Certifying and removing disparate impact. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, 10–13 August 2015; pp. 259–268. [Google Scholar]
- Zhang, L.; Wu, Y.; Wu, X. A causal framework for discovering and removing direct and indirect discrimination. arXiv 2016, arXiv:1611.07509. [Google Scholar]
- Bohren, J.A.; Imas, A.; Rosenberg, M. The dynamics of discrimination: Theory and evidence. Am. Econ. Rev. 2019, 109, 3395–3436. [Google Scholar] [CrossRef]
- Willborn, S.L. The disparate impact model of discrimination: Theory and limits. Am. UL Rev. 1984, 34, 799. [Google Scholar]
- Romei, A.; Ruggieri, S. A multidisciplinary survey on discrimination analysis. Knowl. Eng. Rev. 2014, 29, 582–638. [Google Scholar] [CrossRef]
- Marshall, R. The economics of racial discrimination: A survey. J. Econ. Lit. 1974, 12, 849–871. [Google Scholar]
- Raji, I.D.; Buolamwini, J. Actionable auditing: Investigating the impact of publicly naming biased performance results of commercial ai products. In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, Honolulu, HI, USA, 27–28 January 2019; pp. 429–435. [Google Scholar]
- Schnabel, T.; Swaminathan, A.; Singh, A.; Chandak, N.; Joachims, T. Recommendations as treatments: Debiasing learning and evaluation. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1670–1679. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Krasin, I.; Duerig, T.; Alldrin, N.; Ferrari, V.; Abu-El-Haija, S.; Kuznetsova, A.; Rom, H.; Uijlings, J.; Popov, S.; Veit, A.; et al. Openimages: A public dataset for large-scale multi-label and multi-class image classification. Dataset 2017, 2, 18. Available online: https://github.com/openimages (accessed on 15 April 2024).
- Shankar, S.; Halpern, Y.; Breck, E.; Atwood, J.; Wilson, J.; Sculley, D. No classification without representation: Assessing geodiversity issues in open data sets for the developing world. arXiv 2017, arXiv:1711.08536. [Google Scholar]
- Klare, B.F.; Klein, B.; Taborsky, E.; Blanton, A.; Cheney, J.; Allen, K.; Grother, P.; Mah, A.; Jain, A.K. Pushing the frontiers of unconstrained face detection and recognition: Iarpa janus benchmark a. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1931–1939. [Google Scholar]
- Eidinger, E.; Enbar, R.; Hassner, T. Age and gender estimation of unfiltered faces. IEEE Trans. Inf. Forensics Secur. 2014, 9, 2170–2179. [Google Scholar] [CrossRef]
- Liu, J.; Shen, Z.; He, Y.; Zhang, X.; Xu, R.; Yu, H.; Cui, P. Towards out-of-distribution generalization: A survey. arXiv 2021, arXiv:2108.13624. [Google Scholar]
- Moller, F.; Botache, D.; Huseljic, D.; Heidecker, F.; Bieshaar, M.; Sick, B. Out-of-distribution detection and generation using soft brownian offset sampling and autoencoders. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 46–55. [Google Scholar]
- Xu, D.; Yuan, S.; Zhang, L.; Wu, X. Fairgan: Fairness-aware generative adversarial networks. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 570–575. [Google Scholar]
- Xu, D.; Wu, Y.; Yuan, S.; Zhang, L.; Wu, X. Achieving causal fairness through generative adversarial networks. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019. [Google Scholar]
- Kortylewski, A.; Egger, B.; Schneider, A.; Gerig, T.; Morel-Forster, A.; Vetter, T. Analyzing and reducing the damage of dataset bias to face recognition with synthetic data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Srivastava, S.; Li, C.; Lingelbach, M.; Martín-Martín, R.; Xia, F.; Vainio, K.E.; Lian, Z.; Gokmen, C.; Buch, S.; Liu, K.; et al. Behavior: Benchmark for everyday household activities in virtual, interactive, and ecological environments. In Proceedings of the Conference on Robot Learning, Auckland, New Zealand, 14–18 December 2022; pp. 477–490. [Google Scholar]
- Bender, E.M.; Friedman, B. Data statements for natural language processing: Toward mitigating system bias and enabling better science. Trans. Assoc. Comput. Linguist. 2018, 6, 587–604. [Google Scholar] [CrossRef]
- Holland, S.; Hosny, A.; Newman, S.; Joseph, J.; Chmielinski, K. The dataset nutrition label. Data Prot. Priv. 2020, 12, 1. [Google Scholar]
- Kievit, R.A.; Frankenhuis, W.E.; Waldorp, L.J.; Borsboom, D. Simpson’s paradox in psychological science: A practical guide. Front. Psychol. 2013, 4, 513. [Google Scholar] [CrossRef] [PubMed]
- Alipourfard, N.; Fennell, P.G.; Lerman, K. Can you trust the trend? discovering simpson’s paradoxes in social data. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Marina Del Rey, CA, USA, 5–9 February 2018; pp. 19–27. [Google Scholar]
- Kamiran, F.; Calders, T. Data preprocessing techniques for classification without discrimination. Knowl. Inf. Syst. 2012, 33, 1–33. [Google Scholar] [CrossRef]
- Mannino, M.; Abouzied, A. Is this real? Generating synthetic data that looks real. In Proceedings of the 32nd Annual ACM Symposium on User Interface Software and Technology, New Orleans, LA, USA, 20–23 October 2019; pp. 549–561. [Google Scholar]
- Georgopoulos, M.; Oldfield, J.; Nicolaou, M.A.; Panagakis, Y.; Pantic, M. Mitigating demographic bias in facial datasets with style-based multi-attribute transfer. Int. J. Comput. Vis. 2021, 129, 2288–2307. [Google Scholar] [CrossRef]
- Bhanot, K.; Qi, M.; Erickson, J.S.; Guyon, I.; Bennett, K.P. The problem of fairness in synthetic healthcare data. Entropy 2021, 23, 1165. [Google Scholar] [CrossRef] [PubMed]
- Van Noorden, R. The ethical questions that haunt facial-recognition research. Nature 2020, 587, 354–359. [Google Scholar] [CrossRef] [PubMed]
- Hittmeir, M.; Mayer, R.; Ekelhart, A. A baseline for attribute disclosure risk in synthetic data. In Proceedings of the Tenth ACM Conference on Data and Application Security and Privacy, New Orleans, LA, USA, 16–18 March 2020; pp. 133–143. [Google Scholar]
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A. Calibrating noise to sensitivity in private data analysis. In Proceedings of the Theory of Cryptography: Third Theory of Cryptography Conference, TCC 2006, New York, NY, USA, 4–7 March 2006; Proceedings 3. Springer: Berlin/Heidelberg, Germany, 2006; pp. 265–284. [Google Scholar]
- Majeed, A.; Lee, S. Anonymization techniques for privacy preserving data publishing: A comprehensive survey. IEEE Access 2020, 9, 8512–8545. [Google Scholar] [CrossRef]
- Stadler, T.; Oprisanu, B.; Troncoso, C. Synthetic data–anonymisation groundhog day. In Proceedings of the 31st USENIX Security Symposium (USENIX Security 22), Boston, MA, USA, 10–12 August 2022; pp. 1451–1468. [Google Scholar]
- Brauneck, A.; Schmalhorst, L.; Kazemi Majdabadi, M.M.; Bakhtiari, M.; Völker, U.; Baumbach, J.; Baumbach, L.; Buchholtz, G. Federated machine learning, privacy-enhancing technologies, and data protection laws in medical research: Scoping review. J. Med. Internet Res. 2023, 25, e41588. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Dwork, C. Differential privacy. In International Colloquium on Automata, Languages, and Programming; Springer: Berlin/Heidelberg, Germany, 2006; pp. 1–12. [Google Scholar]
- Liu, Y.; Zhang, L.; Ge, N.; Li, G. A systematic literature review on federated learning: From a model quality perspective. arXiv 2020, arXiv:2012.01973. [Google Scholar]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and open problems in federated learning. Found. Trends® Mach. Learn. 2021, 14, 1–210. [Google Scholar] [CrossRef]
- Hong, T.; Pinson, P.; Wang, Y.; Weron, R.; Yang, D.; Zareipour, H. Energy forecasting: A review and outlook. IEEE Open Access J. Power Energy 2020, 7, 376–388. [Google Scholar] [CrossRef]
- Gu, F.; Chung, M.H.; Chignell, M.; Valaee, S.; Zhou, B.; Liu, X. A survey on deep learning for human activity recognition. ACM Comput. Surv. (CSUR) 2021, 54, 1–34. [Google Scholar] [CrossRef]
- Zhang, Y.; Tang, G.; Huang, Q.; Wang, Y.; Wu, K.; Yu, K.; Shao, X. Fednilm: Applying federated learning to nilm applications at the edge. IEEE Trans. Green Commun. Netw. 2022, 7, 857–868. [Google Scholar] [CrossRef]
- Savi, M.; Olivadese, F. Short-term energy consumption forecasting at the edge: A federated learning approach. IEEE Access 2021, 9, 95949–95969. [Google Scholar] [CrossRef]
- Xiao, Z.; Xu, X.; Xing, H.; Song, F.; Wang, X.; Zhao, B. A federated learning system with enhanced feature extraction for human activity recognition. Knowl.-Based Syst. 2021, 229, 107338. [Google Scholar] [CrossRef]
- Lyu, L.; Yu, H.; Yang, Q. Threats to federated learning: A survey. arXiv 2020, arXiv:2003.02133. [Google Scholar]
- Mugunthan, V.; Polychroniadou, A.; Byrd, D.; Balch, T.H. Smpai: Secure multi-party computation for federated learning. In Proceedings of the NeurIPS 2019 Workshop on Robust AI in Financial Services, Vancouver, BC, Canada, 13 December 2019; MIT Press: Cambridge, MA, USA, 2019; pp. 1–9. [Google Scholar]
- Brundage, M.; Avin, S.; Wang, J.; Belfield, H.; Krueger, G.; Hadfield, G.; Khlaaf, H.; Yang, J.; Toner, H.; Fong, R.; et al. Toward trustworthy AI development: Mechanisms for supporting verifiable claims. arXiv 2020, arXiv:2004.07213. [Google Scholar]
- Xin, B.; Geng, Y.; Hu, T.; Chen, S.; Yang, W.; Wang, S.; Huang, L. Federated synthetic data generation with differential privacy. Neurocomputing 2022, 468, 1–10. [Google Scholar] [CrossRef]
- Rodríguez-Barroso, N.; Stipcich, G.; Jiménez-López, D.; Ruiz-Millán, J.A.; Martínez-Cámara, E.; González-Seco, G.; Luzón, M.V.; Veganzones, M.A.; Herrera, F. Federated Learning and Differential Privacy: Software tools analysis, the Sherpa. ai FL framework and methodological guidelines for preserving data privacy. Inf. Fusion 2020, 64, 270–292. [Google Scholar] [CrossRef]
- Xin, B.; Yang, W.; Geng, Y.; Chen, S.; Wang, S.; Huang, L. Private fl-gan: Differential privacy synthetic data generation based on federated learning. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 2927–2931. [Google Scholar]
- McClure, D.; Reiter, J.P. Differential Privacy and Statistical Disclosure Risk Measures: An Investigation with Binary Synthetic Data. Trans. Data Priv. 2012, 5, 535–552. [Google Scholar]
- Varma, G.; Chauhan, R.; Singh, D. Sarve: Synthetic data and local differential privacy for private frequency estimation. Cybersecurity 2022, 5, 26. [Google Scholar] [CrossRef] [PubMed]
- Rosenblatt, L.; Liu, X.; Pouyanfar, S.; de Leon, E.; Desai, A.; Allen, J. Differentially private synthetic data: Applied evaluations and enhancements. arXiv 2020, arXiv:2011.05537. [Google Scholar]
- Jordon, J.; Yoon, J.; Van Der Schaar, M. PATE-GAN: Generating synthetic data with differential privacy guarantees. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Arora, A.; Arora, A. Synthetic patient data in health care: A widening legal loophole. Lancet 2022, 399, 1601–1602. [Google Scholar] [CrossRef]
- Haddad, F. How to Evaluate the Quality of the Synthetic Data. In AWS Machine Learning Blog. 2022. Available online: https://aws.amazon.com/blogs/machine-learning/how-to-evaluate-the-quality-of-the-synthetic-data-measuring-from-the-perspective-of-fidelity-utility-and-privacy/ (accessed on 15 April 2024).
- Puri, R.; Spring, R.; Patwary, M.; Shoeybi, M.; Catanzaro, B. Training question answering models from synthetic data. arXiv 2020, arXiv:2002.09599. [Google Scholar]
- van Breugel, B.; Sun, H.; Qian, Z.; van der Schaar, M. Membership inference attacks against synthetic data through overfitting detection. arXiv 2023, arXiv:2302.12580. [Google Scholar]
- Carlini, N.; Chien, S.; Nasr, M.; Song, S.; Terzis, A.; Tramer, F. Membership inference attacks from first principles. In Proceedings of the 2022 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 22–26 May 2022; pp. 1897–1914. [Google Scholar]
- Shokri, R.; Stronati, M.; Song, C.; Shmatikov, V. Membership inference attacks against machine learning models. In Proceedings of the 2017 IEEE symposium on security and privacy (SP), San Jose, CA, USA, 22–24 May 2017; pp. 3–18. [Google Scholar]
- Arjunan, P.; Poolla, K.; Miller, C. EnergyStar++: Towards more accurate and explanatory building energy benchmarking. Appl. Energy 2020, 276, 115413. [Google Scholar] [CrossRef]
- Chen, Y.; Hong, T.; Luo, X.; Hooper, B. Development of city buildings dataset for urban building energy modeling. Energy Build. 2019, 183, 252–265. [Google Scholar] [CrossRef]
- Ribeiro, M.; Pereira, L.; Quintal, F.; Nunes, N. SustDataED: A public dataset for electric energy disaggregation research. In ICT for Sustainability 2016; Atlantis Press: Amsterdam, The Netherlands, 2016; pp. 244–245. [Google Scholar]
- Filip, A. Blued: A fully labeled public dataset for event-based nonintrusive load monitoring research. In Proceedings of the 2nd Workshop on Data Mining Applications in Sustainability (SustKDD), San Diego, CA, USA, 21 August 2011; Volume 2012. [Google Scholar]
- Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the Protection of Natural Persons. In Official Journal of the European Union. European Union. 2016. Available online: http://data.europa.eu/eli/reg/2016/679/oj (accessed on 15 April 2024).
- Young, M.; Rodriguez, L.; Keller, E.; Sun, F.; Sa, B.; Whittington, J.; Howe, B. Beyond open vs. closed: Balancing individual privacy and public accountability in data sharing. In Proceedings of the Conference on Fairness, Accountability, and Transparency, Atlanta, GA, USA, 29–31 January 2019; pp. 191–200. [Google Scholar]
- Van Wynsberghe, A. Sustainable AI: AI for sustainability and the sustainability of AI. AI Ethics 2021, 1, 213–218. [Google Scholar] [CrossRef]
- Strubell, E.; Ganesh, A.; McCallum, A. Energy and policy considerations for deep learning in NLP. arXiv 2019, arXiv:1906.02243. [Google Scholar]
- Ray, P.P. ChatGPT: A comprehensive review on background, applications, key challenges, bias, ethics, limitations and future scope. Internet Things Cyber-Phys. Syst. 2023, 2, 121–154. [Google Scholar] [CrossRef]
- Lacoste, A.; Luccioni, A.; Schmidt, V.; Dandres, T. Quantifying the carbon emissions of machine learning. arXiv 2019, arXiv:1910.09700. [Google Scholar]
- Henderson, P.; Hu, J.; Romoff, J.; Brunskill, E.; Jurafsky, D.; Pineau, J. Towards the systematic reporting of the energy and carbon footprints of machine learning. J. Mach. Learn. Res. 2020, 21, 10039–10081. [Google Scholar]
- Patterson, D.; Gonzalez, J.; Hölzle, U.; Le, Q.; Liang, C.; Munguia, L.M.; Rothchild, D.; So, D.R.; Texier, M.; Dean, J. The carbon footprint of machine learning training will plateau, then shrink. Computer 2022, 55, 18–28. [Google Scholar] [CrossRef]
- Yigitcanlar, T.; Mehmood, R.; Corchado, J.M. Green artificial intelligence: Towards an efficient, sustainable and equitable technology for smart cities and futures. Sustainability 2021, 13, 8952. [Google Scholar] [CrossRef]
- Kumar, S.; Buyya, R. Green cloud computing and environmental sustainability. In Harnessing Green IT: Principles and Practices; Wiley: Hoboken, NJ, USA, 2012; pp. 315–339. [Google Scholar]
- Graybill, R.; Melhem, R. Power Aware Computing; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Sachan, V.K.; Imam, S.A.; Beg, M.T. Energy-efficient communication methods in wireless sensor networks: A critical review. Int. J. Comput. Appl. 2012, 39, 35–48. [Google Scholar]
- Ali, A.S.; Zanzinger, Z.; Debose, D.; Stephens, B. Open Source Building Science Sensors (OSBSS): A low-cost Arduino-based platform for long-term indoor environmental data collection. Build. Environ. 2016, 100, 114–126. [Google Scholar] [CrossRef]
- Lovett, T.; Gabe-Thomas, E.; Natarajan, S.; Brown, M.; Padget, J. Designing sensor sets for capturing energy events in buildings. In Proceedings of the 5th International Conference on Future Energy Systems, Cambridge, UK, 11–13 June 2014; pp. 229–230. [Google Scholar]
- Abdella, G.M.; Kucukvar, M.; Onat, N.C.; Al-Yafay, H.M.; Bulak, M.E. Sustainability assessment and modeling based on supervised machine learning techniques: The case for food consumption. J. Clean. Prod. 2020, 251, 119661. [Google Scholar] [CrossRef]
- De Las Heras, A.; Luque-Sendra, A.; Zamora-Polo, F. Machine learning technologies for sustainability in smart cities in the post-covid era. Sustainability 2020, 12, 9320. [Google Scholar] [CrossRef]
- Pham, A.D.; Ngo, N.T.; Truong, T.T.H.; Huynh, N.T.; Truong, N.S. Predicting energy consumption in multiple buildings using machine learning for improving energy efficiency and sustainability. J. Clean. Prod. 2020, 260, 121082. [Google Scholar] [CrossRef]
- So, H.Y.; Chen, P.P.; Wong, G.K.C.; Chan, T.T.N. Simulation in medical education. J. R. Coll. Physicians Edinb. 2019, 49, 52–57. [Google Scholar] [CrossRef] [PubMed]
- de Paula Ferreira, W.; Armellini, F.; De Santa-Eulalia, L.A. Simulation in industry 4.0: A state-of-the-art review. Comput. Ind. Eng. 2020, 149, 106868. [Google Scholar] [CrossRef]
- Kato, T.; Kamoshida, R. Multi-agent simulation environment for logistics warehouse design based on self-contained agents. Appl. Sci. 2020, 10, 7552. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Technical Aspect | Literature | Potentials by Using Synthetic Data |
|---|---|---|
| Technical Robustness and Generalization | [54,72,109,110,111,112,113,114,115,116,117,118,119,120,121,122,123,124,125,126,127,128] | Data of critical and unusual situations Divers training and testing datasets Synthetic Benchmark datasets |
| Transparency and Explainability | [55,61,74,95,96,129,130,131,132,133,134,135,136,137,138,139,140,141,142,143,144,145,146,147,148] | Training Black Box Models Provision of Metadata Synthetic Benchmark datasets |
| Reproducibility | [17,149,150,151,152,153,154,155,156,157,158,159,160,161,162] | Replacing missing data Synthetic Benchmark datasets |
| Fairness | [43,47,54,61,114,141,163,164,165,166,167,168,169,170,171,172,173,174,175,176,177,178,179,180,181,182,183,184,185,186,187,188,189,190,191,192,193,194,195,196,197,198,199] | Data augmentation Fair Data design |
| Privacy | [33,54,74,200,201,202,203,204,205,206,207,208,209,210,211,212,213,214,215,216,217,218,219,220,221,222,223,224,225,226,227,228,229,230,231,232,233,234,235,236] | Federated Learning Differential Privacy Data anonymization and randomization |
| Sustainability | [237,238,239,240,241,242,243,244,245,246,247,248,249,250,251,252,253,254] | Reducing Real-World Data Collection Reducing real-world Data Preparing and Preprocessing |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meiser, M.; Zinnikus, I. A Survey on the Use of Synthetic Data for Enhancing Key Aspects of Trustworthy AI in the Energy Domain: Challenges and Opportunities. Energies 2024, 17, 1992. https://doi.org/10.3390/en17091992
Meiser M, Zinnikus I. A Survey on the Use of Synthetic Data for Enhancing Key Aspects of Trustworthy AI in the Energy Domain: Challenges and Opportunities. Energies. 2024; 17(9):1992. https://doi.org/10.3390/en17091992
Chicago/Turabian StyleMeiser, Michael, and Ingo Zinnikus. 2024. "A Survey on the Use of Synthetic Data for Enhancing Key Aspects of Trustworthy AI in the Energy Domain: Challenges and Opportunities" Energies 17, no. 9: 1992. https://doi.org/10.3390/en17091992
APA StyleMeiser, M., & Zinnikus, I. (2024). A Survey on the Use of Synthetic Data for Enhancing Key Aspects of Trustworthy AI in the Energy Domain: Challenges and Opportunities. Energies, 17(9), 1992. https://doi.org/10.3390/en17091992