

Hybrid Metaheuristic Algorithms for Optimization of Countrywide Primary Energy: Analysing Estimation and Year-Ahead Prediction



Abstract
1. Introduction
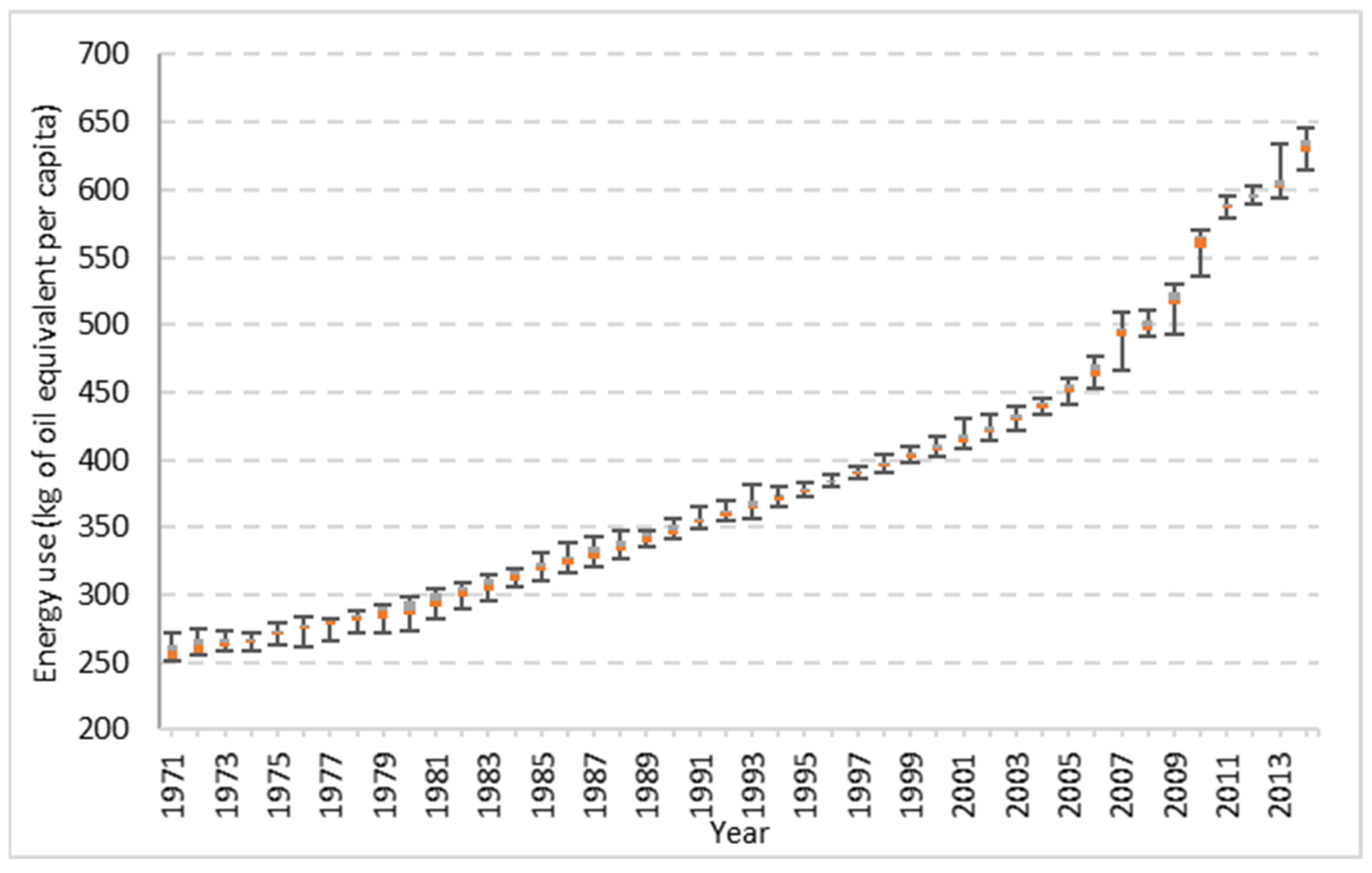
- Analyse long-term historical data of India’s energy use for the period (1971–2014).
- Quantify the performance of ensemble of algorithms (GE-DE) to the energy-use estimation and prediction problems.
- Analyse the associated uncertainties produced from the models in terms of statistical errors.
- Select the best model using the Global Performance Index (GPI) and compare the average estimations and projections with the one from the best model.
- Project the energy-use behaviour for India until the year 2022.
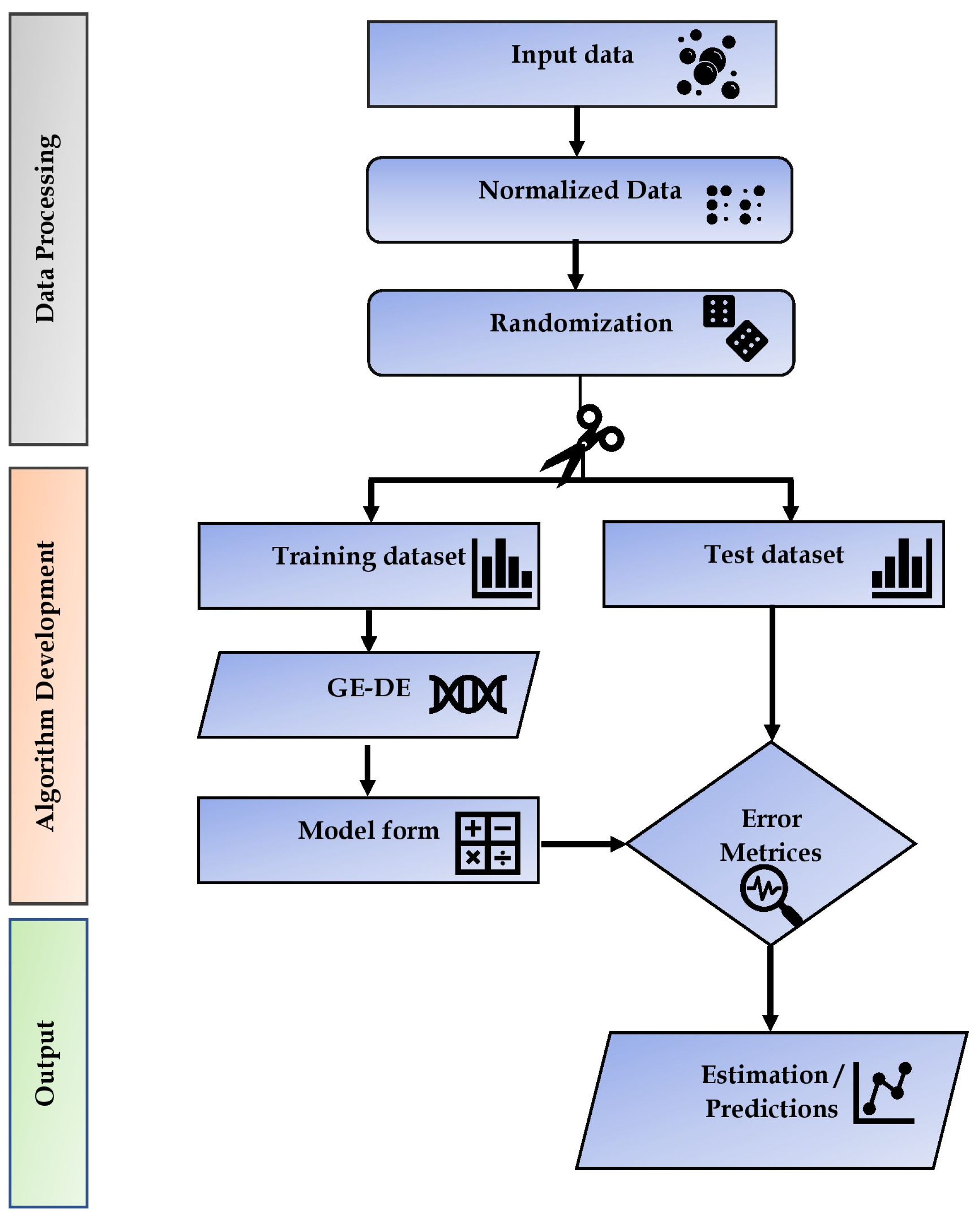
2. Methodology
2.1. Selection of Data
2.2. Selection of Training and Test Datasets
2.3. Problem Definition
2.4. Algorithmic Methods
2.5. Objective Function and Error Analysis
2.6. GPI and Ranks of the Models
3. Results and Discussion
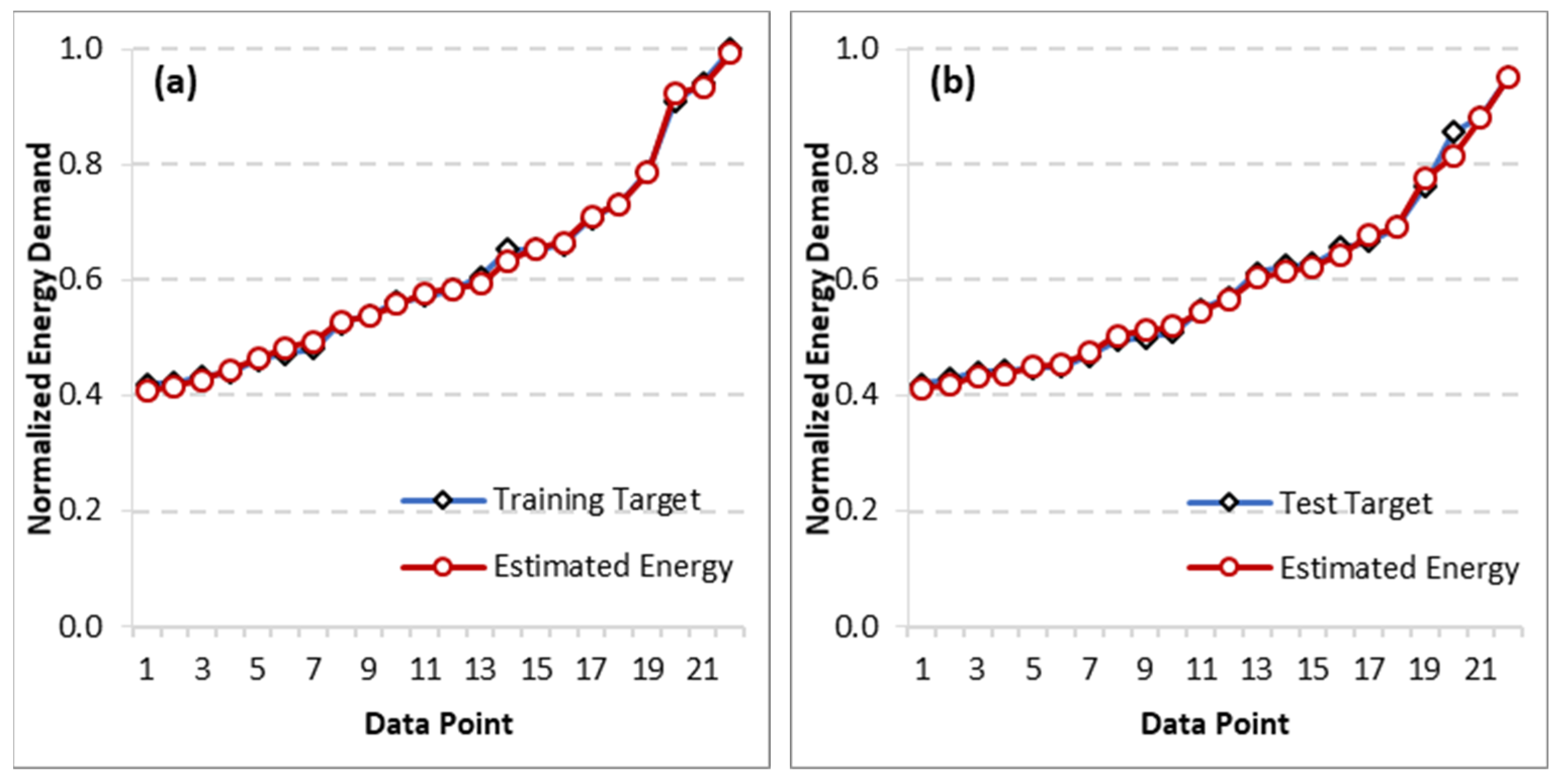
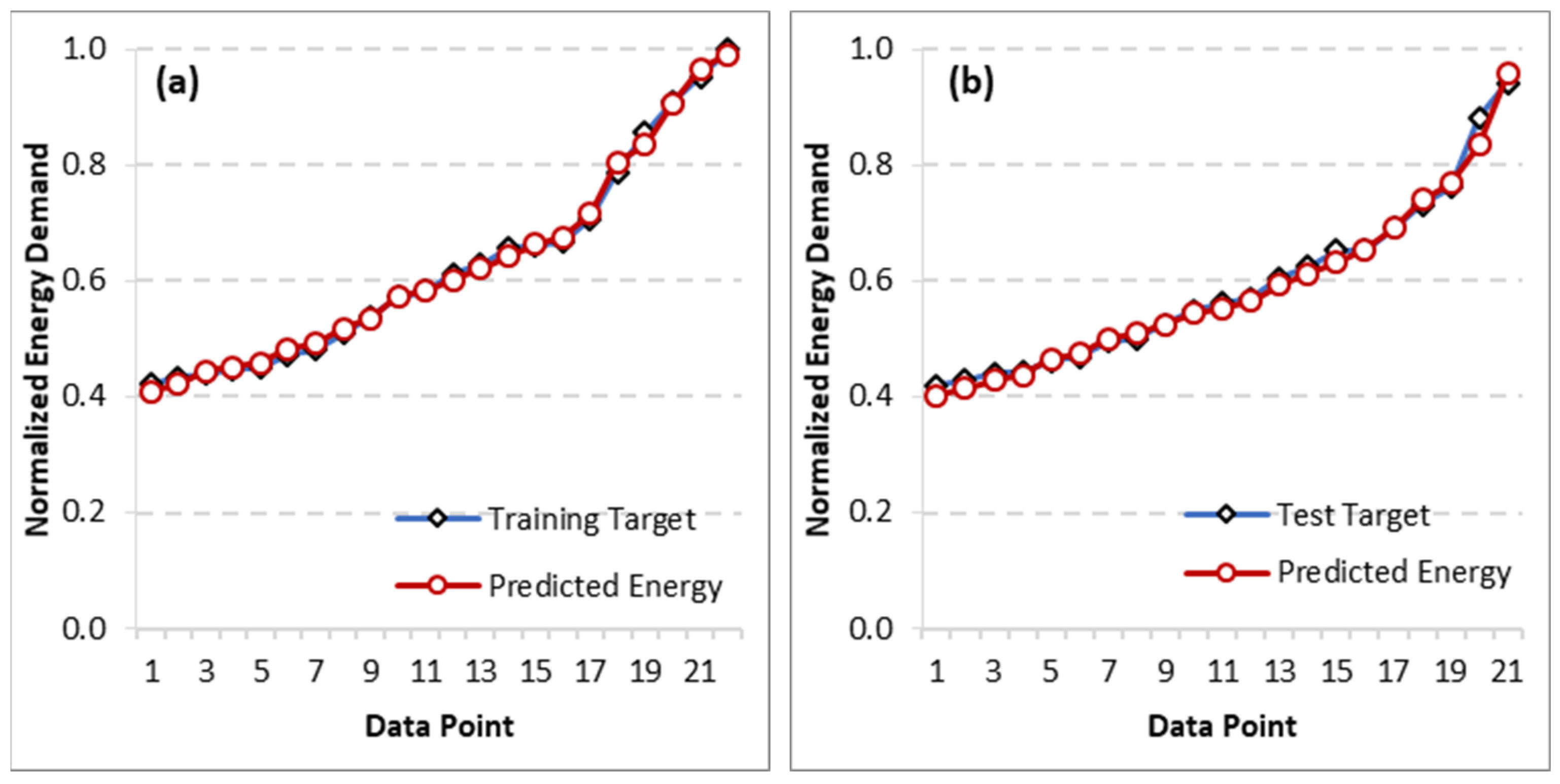
3.1. Estimation Results
3.2. Prediction Results
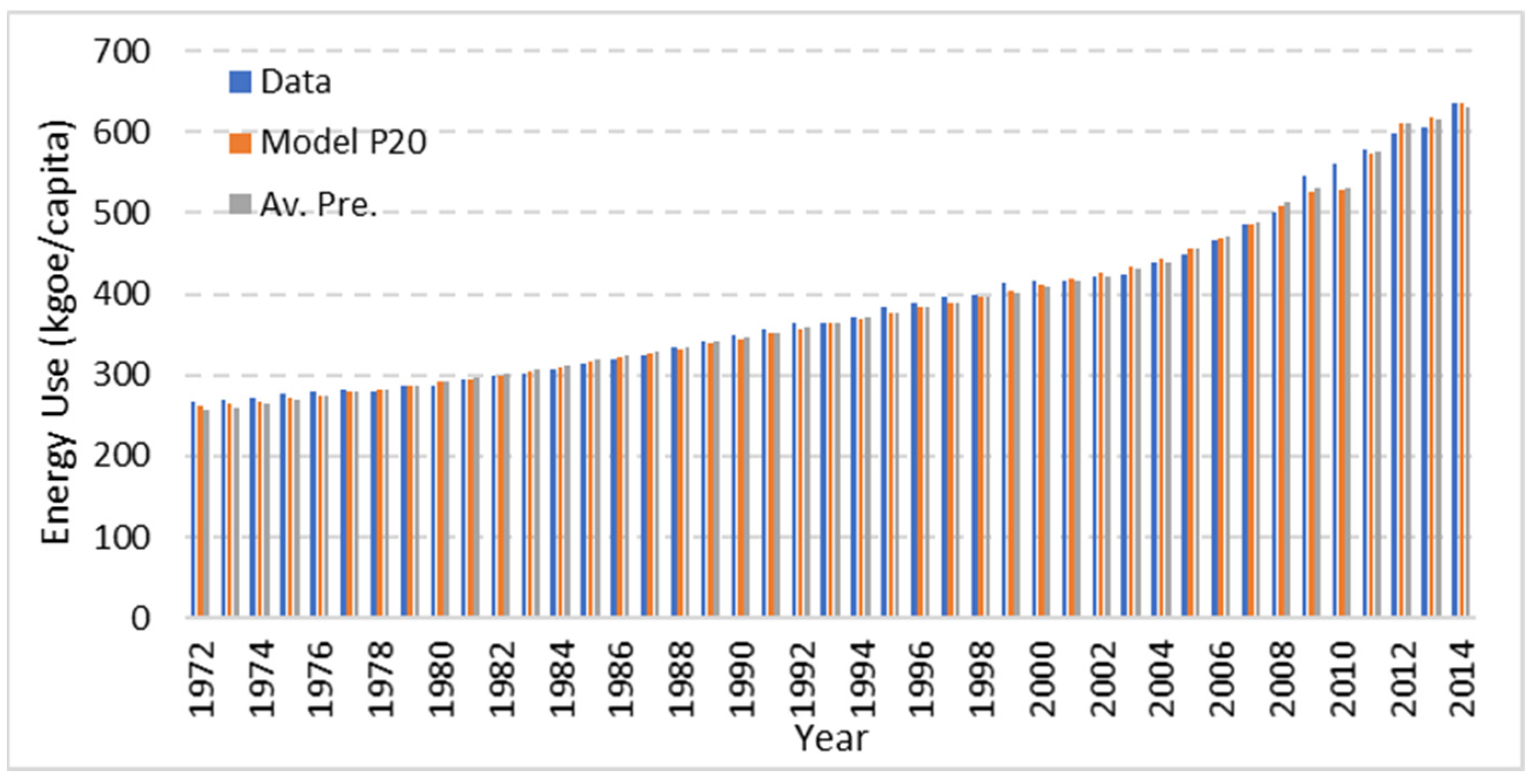
3.3. Verification of the Predictions Using Public Data
4. Conclusions
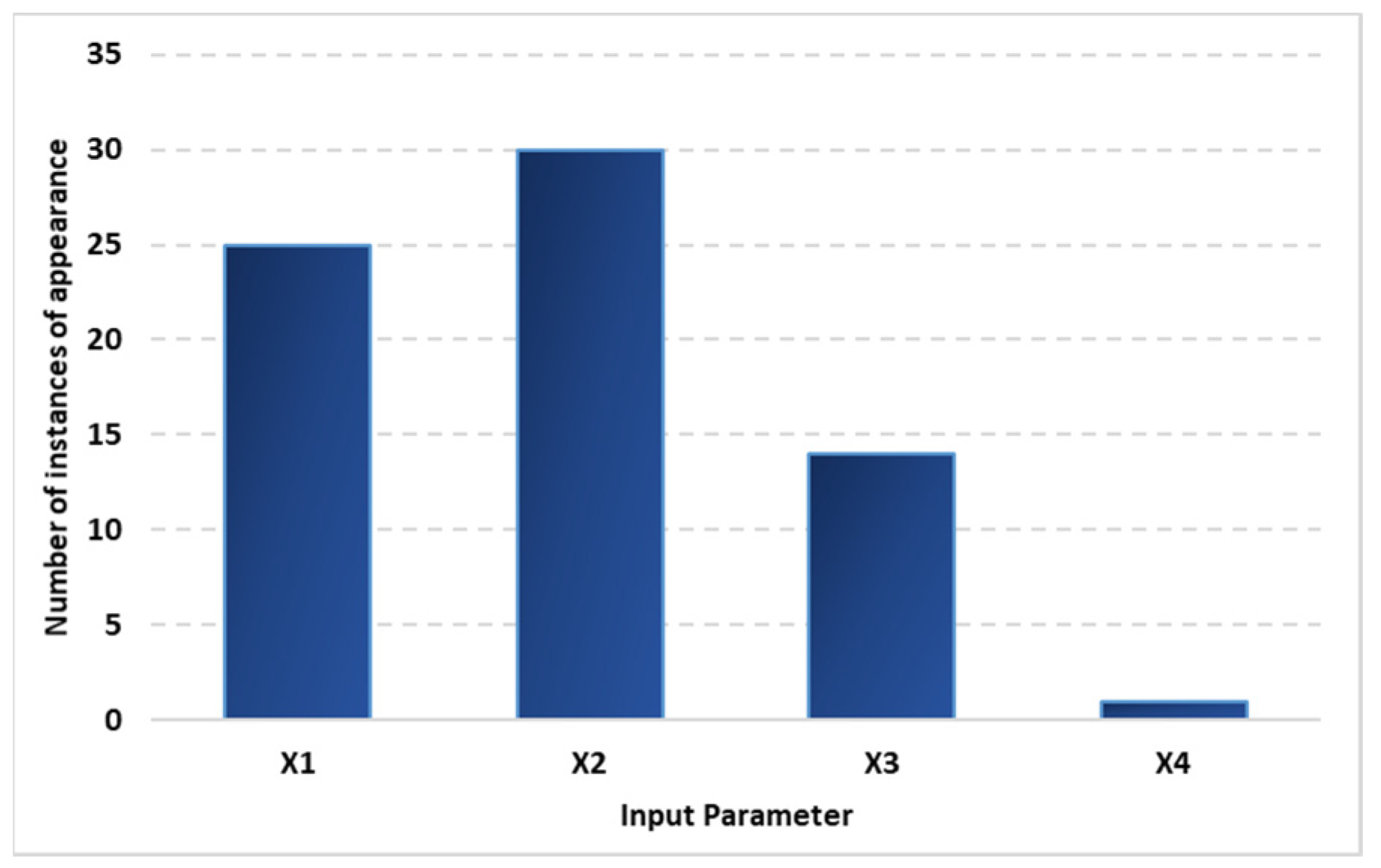
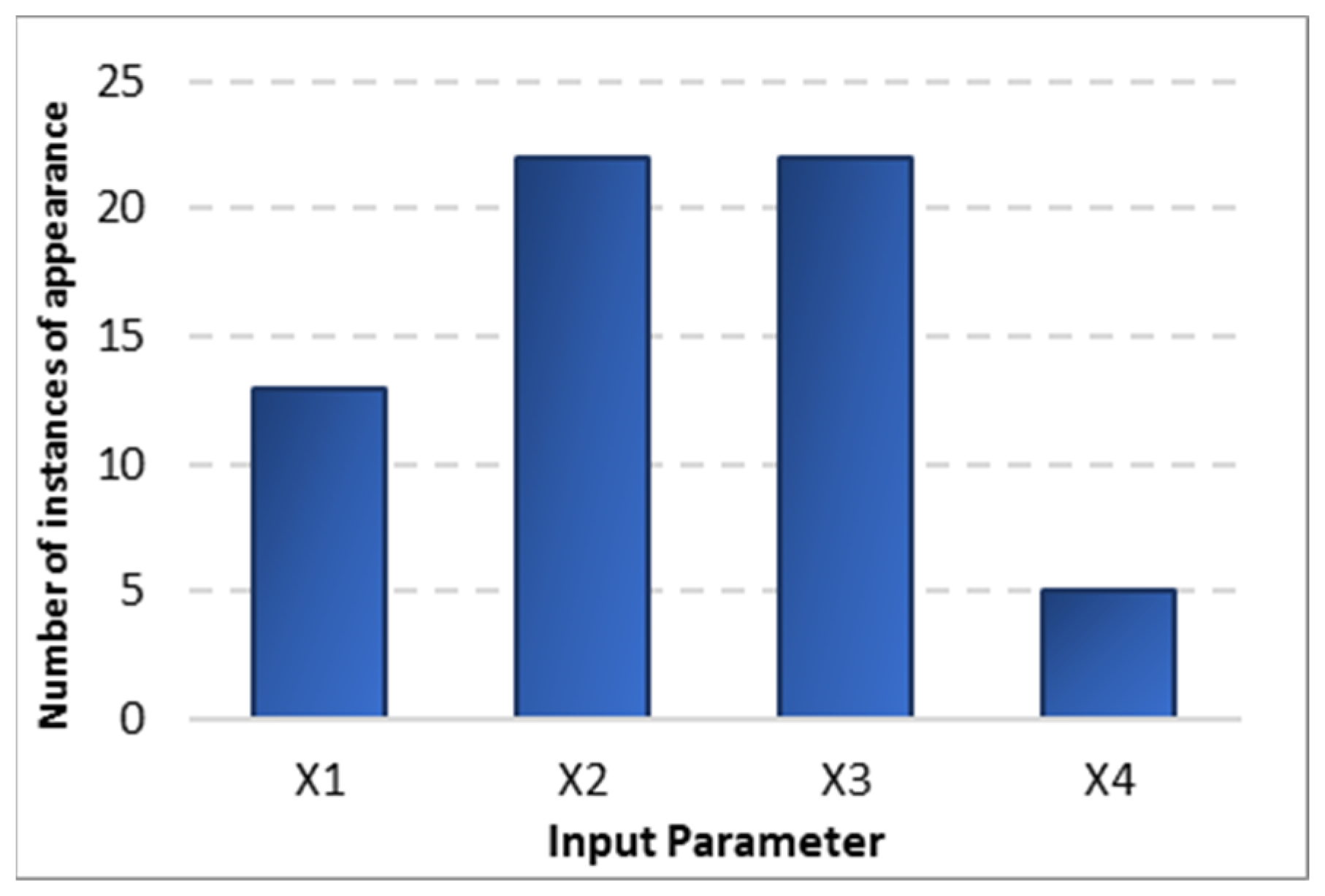
- The estimation of energy use based on the ensemble of GE-DE was found to have good accuracy, and the RMSE (based on average estimations) was quantified as 6.3749 kgoe/capita (1.25%). Based on the statistical analysis and the ranking established by GPI, Model E10 was the best model for the estimation with an RMSE and GPI of 5.8183 kgoe/capita and 1.7249, (meaning 1.03%). Population and GDP were found to have the highest number of instances of appearance in the estimation models and were, therefore, regarded as the influential parameters.
- The energy prediction problem, with a year-ahead prediction, was found to have a good agreement with the data, and the RMSE was obtained as 7.8857 kgoe/capita (1.56% error); model P20, with an RMSE of 7.9201 (or 1.42%) and a GPI of 1.8836, was found to be the most accurate. Population and the value of exports were found to be the most influential parameters for the case of prediction equations (based on the number of times they appeared).
- The predictions were further made for 2015–2022, and the results showed a slowdown in energy-use behaviour for 2020 and 2021. Further, a steady increase was found in energy use, with a median value of 770.29 kgoe/capita and an average value of 780.02 kgoe/capita.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Nomenclature
| Artificial Intelligence | |
| ABC | Artificial Bee Colony Method |
| ABPA | Adaptive Back Propagation Algorithm |
| ACO | Ant Colony Optimization |
| AFD | Adaptive Fourier Decomposition |
| AMRIO | Adaptive Multiregional Input–Output |
| ANFIS | Adaptive Network-Based Fuzzy Inference System |
| ANN | Artificial Neural Network |
| ARIMAH | Auto-Regressive Integrated Moving Average and Holtz-Winters |
| ELM | Extreme Learning Machine |
| FNN | Feedforward Neural Network |
| GA | Genetic Algorithm |
| GRU-NN | Gated Recurrent Unit Neural Network |
| HS | Harmonic Search |
| LSSVM | Least Squares Support Vector Machine |
| LSTM | Long-Short Term Memory |
| MFO | Moth-Flame Optimization |
| MGM | Metabolic Grey Model |
| MGM-ARIMA | Metabolic Grey Auto-Regressive Integrated Moving Average Model |
| MOSCOA | Multi-Objective Sine Cosine Optimization Algorithm |
| NMGM | Non-Linear Metabolic Grey Model |
| PSO | Particle Swarm Optimisation |
| RNN | Recurrent Neural Network |
| SARIMA | Seasonal Auto-Regressive Integrated Moving Average |
| SVM | Support Vector Machine |
| TS-FIS | Takagi-Sugeno-Type Fuzzy Inference System |
| VNS | Variable Neighbourhood Search |
| Statistical Indicators | |
| MAE | Mean Absolute Error |
| MAE | Mean Absolute Error |
| MAPE | Mean Absolute Percentage Error |
| MSPE | Mean Square Percent Error |
| RMSE | Root Mean Square Error |
| Variables | |
| E_price | Electricity price |
| EC | Electricity consumption |
| EC_A | Agricultural Consumption of Electricity |
| EC_C | Commercial Consumption of Electricity |
| EC_D | Domestic Consumption of Electricity |
| EC_G | Governmental Consumption of Electricity |
| EC_I | Industrial Consumption of Electricity |
| ED | Electricity Demand |
| EL | Electricity Loads |
| GDP | Gross Domestic Product |
| Po | Population |
References
- Jiang, P.; Li, R.; Lu, H.; Zhang, X. Modeling of Electricity Demand Forecast for Power System. Neural Comput. Appl. 2020, 32, 6857–6875. [Google Scholar] [CrossRef]
- Debnath, A.; Singh, S.V.; Singh, Y.P. Comparative Assessment of Energy Requirements for Different Types of Residential Buildings in India. Energy Build. 1995, 23, 141–146. [Google Scholar] [CrossRef]
- Das, A.; Paul, S.K. Changes in Energy Requirements of the Residential Sector in India between 1993–94 and 2006–07. Energy Policy 2013, 53, 27–40. [Google Scholar] [CrossRef]
- Dhawan, V.; Prasad, N. India: Transforming to a Net-Zero Emissions Energy System; The Energy and Resources Institute (TERI): Mithapur, India, 2020. [Google Scholar]
- Parikh, K.S.; Karandikar, V.; Rana, A.; Dani, P. Projecting India’s Energy Requirements for Policy Formulation. Energy 2009, 34, 928–941. [Google Scholar] [CrossRef]
- Chaturvedi, S.; Rajasekar, E.; Natarajan, S.; McCullen, N. A Comparative Assessment of SARIMA, LSTM RNN and Fb Prophet Models to Forecast Total and Peak Monthly Energy Demand for India. Energy Policy 2022, 168, 113097. [Google Scholar] [CrossRef]
- Islam, M.A.; Che, H.S.; Hasanuzzaman, M.; Rahim, N.A. Chapter 5—Energy Demand Forecasting. In Energy for Sustainable Development; Hasanuzzaman, M.D., Rahim, N.A., Eds.; Academic Press: Cambridge, UK, 2020; pp. 105–123. ISBN 978-0-12-814645-3. [Google Scholar]
- Löschel, A.; Managi, S. Recent Advances in Energy Demand Analysis—Insights for Industry and Households. Resour. Energy Econ. 2019, 56, 1–5. [Google Scholar] [CrossRef]
- Huang, C.; Zhang, Z.; Li, N.; Liu, Y.; Chen, X.; Liu, F. Estimating Economic Impacts from Future Energy Demand Changes Due to Climate Change and Economic Development in China. J. Clean. Prod. 2021, 311, 127576. [Google Scholar] [CrossRef]
- Wang, H.; Chen, Z.; Wang, W.; Wu, Z.; Wu, K.; Li, W. Improving Energy Demand Estimation Using an Adaptive Firefly Algorithm BT—Computational Intelligence and Intelligent Systems; Li, K., Li, W., Chen, Z., Liu, Y., Eds.; Springer: Singapore, 2018; pp. 171–181. [Google Scholar]
- Jamil, B.; Serrano-Luján, L.; Colmenar, J.M. On the Prediction of One-Year Ahead Energy Demand in Turkey Using Metaheuristic Algorithms. Adv. Sci. Technol. Eng. Syst. J. 2022, 7, 79–91. [Google Scholar] [CrossRef]
- Sajadi, S.M.; Asadzadeh, S.M.; Majazi Dalfard, V.; Nazari Asli, M.; Nazari-Shirkouhi, S. A New Adaptive Fuzzy Inference System for Electricity Consumption Forecasting with Hike in Prices. Neural Comput. Appl. 2013, 23, 2405–2416. [Google Scholar] [CrossRef]
- Majazi Dalfard, V.; Nazari Asli, M.; Nazari-Shirkouhi, S.; Sajadi, S.M.; Asadzadeh, S.M. Incorporating the Effects of Hike in Energy Prices into Energy Consumption Forecasting: A Fuzzy Expert System. Neural Comput. Appl. 2013, 23, 153–169. [Google Scholar] [CrossRef]
- Daş, G.S. Forecasting the Energy Demand of Turkey with a NN Based on an Improved Particle Swarm Optimization. Neural Comput. Appl. 2017, 28, 539–549. [Google Scholar] [CrossRef]
- Salcedo-Sanz, S.; Muñoz-Bulnes, J.; Portilla-Figueras, J.A.; Del Ser, J. One-Year-Ahead Energy Demand Estimation from Macroeconomic Variables Using Computational Intelligence Algorithms. Energy Convers. Manag. 2015, 99, 62–71. [Google Scholar] [CrossRef]
- Sánchez-Oro, J.; Duarte, A.; Salcedo-Sanz, S. Robust Total Energy Demand Estimation with a Hybrid Variable Neighborhood Search—Extreme Learning Machine Algorithm. Energy Convers. Manag. 2016, 123, 445–452. [Google Scholar] [CrossRef]
- Duran Toksarı, M. Ant Colony Optimization Approach to Estimate Energy Demand of Turkey. Energy Policy 2007, 35, 3984–3990. [Google Scholar] [CrossRef]
- Ünler, A. Improvement of Energy Demand Forecasts Using Swarm Intelligence: The Case of Turkey with Projections to 2025. Energy Policy 2008, 36, 1937–1944. [Google Scholar] [CrossRef]
- Yu, S.; Wei, Y.-M.; Wang, K. A PSO–GA Optimal Model to Estimate Primary Energy Demand of China. Energy Policy 2012, 42, 329–340. [Google Scholar] [CrossRef]
- Wang, Q.; Li, S.; Li, R. Forecasting Energy Demand in China and India: Using Single-Linear, Hybrid-Linear, and Non-Linear Time Series Forecast Techniques. Energy 2018, 161, 821–831. [Google Scholar] [CrossRef]
- Özdemir, D.; Dörterler, S.; Aydın, D. A New Modified Artificial Bee Colony Algorithm for Energy Demand Forecasting Problem. Neural Comput. Appl. 2022, 7, 17455–17471. [Google Scholar] [CrossRef]
- Incremona, A.; De Nicolao, G. Short-Term Forecasting of the Italian Load Demand during the Easter Week. Neural Comput. Appl. 2022, 34, 6257–6271. [Google Scholar] [CrossRef]
- Torres, J.F.; Martínez-Álvarez, F.; Troncoso, A. A Deep LSTM Network for the Spanish Electricity Consumption Forecasting. Neural Comput. Appl. 2022, 34, 10533–10545. [Google Scholar] [CrossRef]
- Li, R.; Chen, X.; Balezentis, T.; Streimikiene, D.; Niu, Z. Multi-Step Least Squares Support Vector Machine Modeling Approach for Forecasting Short-Term Electricity Demand with Application. Neural Comput. Appl. 2021, 33, 301–320. [Google Scholar] [CrossRef]
- Stergiou, K.; Karakasidis, T.E. Application of Deep Learning and Chaos Theory for Load Forecasting in Greece. Neural Comput. Appl. 2021, 33, 16713–16731. [Google Scholar] [CrossRef]
- Michell, K.; Kristjanpoller, W.; Minutolo, M.C. Electrical Consumption Forecasting: A Framework for High Frequency Data. Neural Comput. Appl. 2022, 34, 5577–5586. [Google Scholar] [CrossRef]
- Mohammed, N.A.; Al-Bazi, A. An Adaptive Backpropagation Algorithm for Long-Term Electricity Load Forecasting. Neural Comput. Appl. 2022, 34, 477–491. [Google Scholar] [CrossRef] [PubMed]
- IBRD IDA. The World Bank Data. Available online: https://databank.worldbank.org/home.aspx (accessed on 11 August 2022).
- O’Neill, M.; Ryan, C. Grammatical Evolution. IEEE Trans. Evol. Comput. 2001, 5, 349–358. [Google Scholar] [CrossRef]
- Despotovic, M.; Nedic, V.; Despotovic, D.; Cvetanovic, S. Review and Statistical Analysis of Different Global Solar Radiation Sunshine Models. Renew. Sustain. Energy Rev. 2015, 52, 1869–1880. [Google Scholar] [CrossRef]
- MacroTrends Global Metrics. Available online: https://www.macrotrends.net/ (accessed on 10 October 2022).
- Ritchie, H.; Roser, M.; Rosado, P. Energy. Available online: https://ourworldindata.org/energy (accessed on 15 October 2022).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Year | Region | Output | Input Parameters | Modelling Techniques | Accuracy Assessment |
|---|---|---|---|---|---|---|
| Toksari [17] | 2007 | Turkey | Energy demand | Yearly GDP, population, import, and export | ACO | Largest deviation: Linear model 3.87% Quadratic model 2.83% |
| Yu and Wang [19] | 2012 | China | Energy consumption | Economic growth, total population, economic structure, urbanization rate, energy structure and energy price | PSO-GA | R2 0.9991, average MAPE 0.93, standard deviation 0.0001 |
| Sajadi et al. [12] | 2013 | Iran | Yearly EC | Yearly GDP, population, E_price | Log. Regression, ANN, ANFIS, TS-FIS | MAPE: Logistic Regression 1.69 ANN 3.62 ANFIS 2.67 TS-FIS 1.46 |
| Dalfard et al. [13] | 2013 | Iran | Ec estimation and forecast | Yearly GDP, population, E_price | ANFIS | MAPE: Electricity-FIS 1.39 Natural Gas-FIS 3.79 NGPG-ANFIS 0.89 |
| Salcedo-Sanz et al. [15] | 2015 | Spain | Energy demand | Yearly data of e 14 macroeconomic variables | HS optimization algorithm | Relative MAE 2.36% |
| Sánchez-Oro et al. [16] | 2016 | Spain | Energy demand | Yearly data of 14 macroeconomic variables | VNS–ELM | Best MAE 1.66% Average MAE 3.9% |
| Daş [14] | 2017 | Turkey | Energy demand | Yearly GDP, population, import, and export | PSOM-NN | Relative error 2.42 Absolute Relative Error 8.42 |
| Wang et al. [20] | 2018 | China and India | ED | Yearly ED | MGM, MGM-ARIMA, NMGM | (China) MAPE MGM 3.078%, ARIMA 2.571% NMGM 2.189% (India) MAPE MGM 1.298%, ARIMA 0.804%, NMGM 2.061% |
| Jiang et al. [1] | 2020 | Australia | Half -hourly Ec | Raw electricity demand | AFD-S-OLSSVM | MAE 12.338 RMSE 18.989 MAPE 0.926 |
| Li et al. [24] | 2021 | Australia | 0.5–3 h of ED | 30 min ED | VM, MOSCOA | (Best results, 1-step ahead) MAE 22.77, MAPE 1.63%, MBE −0.57, THI 2.09 × 10−5 |
| Stergiou and Karakasidis [25] | 2021 | Greece | 10 and 20 days ahead EL | Hourly EL | FFNN, GRU-NN, LSTM, LSTM-NN | (1-step) RMSE 115.98, MAPE 1.37% (10-step) RMSE 256.18, MAPE 3.45% (20-step) RMSE 506.49, MAPE 7.77% |
| Huang et al. [9] | 2021 | China | Annual energy consumption | GDP, population, and monthly electricity consumption data | AMRIO | NA |
| Chaturvedi et al. [6] | 2022 | India | ED | Monthly energy demand | SARIMA, LSTM RNN, and Facebook Prophet | Monthly total: RMSE 4.23 GWh, MAPE 3.3% Peak demand RMSE 6.51 GW, MAPE 3.01% |
| Özdemir et al. [21] | 2022 | Turkey | Yearly energy demand | Yearly GDP, population, imports, export | M-ABC | (Linear) R2 0.9598, RMSE 1.2821, MAE 1.0551, MAPE 0.0129) (Quadratic) R2 0.9843, RMSE 0.7999, MAE 0.6417, MAPE 0.0082 |
| Incremona and Nicolao [22] | 2022 | Italy | Country EL quarter-hour | Quarter-hourly electric load demands | Gaussian Process estimator | MAPE 1.77 RMSE 0.64 MAE 0.51 [GW] |
| Torres et al. [23] | 2022 | Spain | 10 min ED | 10 min EC | LSTM | MAE 398.7652 MAPE 1.4472% RMSE 545.8998 (MW) |
| Michell et al. [26] | 2022 | USA | Hourly EC | Hourly EC | LSTMN, ARIMAH | MCS MSE 1 (1.000) MSE 66,215.85 MAPE 0.587% |
| Mohammed & Al-Bazi [27] | 2022 | Iraq | Monthly ED | Monthly EL, EC_D, EC_C, EC_I, EC_G, EC_A | ANN (ABPA) | MSE: 1.195.650 MAPE 0.045 |
| Energy Use (E) | GDP (X1) | Population (X2) | Exports (X3) | Imports (X4) | |
|---|---|---|---|---|---|
| Energy use (E) | 1.0000 | 0.9655 | 0.9515 | 0.9354 | 0.9268 |
| GDP (X1) | 0.9655 | 1.0000 | 0.8596 | 0.9925 | 0.9893 |
| Population (X2) | 0.9515 | 0.8596 | 1.0000 | 0.8061 | 0.7961 |
| Exports (X3) | 0.9354 | 0.9925 | 0.8061 | 1.0000 | 0.9978 |
| Imports (X4) | 0.9268 | 0.9893 | 0.7961 | 0.9978 | 1.0000 |
| Properties of GE | |
|---|---|
| Generations | 50 |
| Crossover Probability | 0.65 |
| Population | 20 |
| Mutation Probability | 0.1 |
| Max Wraps | 3 |
| Number of Codons | 100 |
| Tournament | 2 |
| Number of Runs | 20 |
| Properties of DE | |
| Recombination Factor: | 0.88 |
| Mutation Factor | 0.47 |
| Population Size | 20 |
| Training Dataset | Test Dataset | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Model | RMSE | Av. Error | R2 | Ab. Error | Rel. Error | RMSE | Av. Error | R2 | Ab. Error | Rel. Error |
| E1 | 0.0108 | 0.0086 | 0.9959 | 0.1899 | 0.0161 | 0.0135 | 0.0107 | 0.9925 | 0.2361 | 0.0189 |
| E2 | 0.0111 | 0.0090 | 0.9956 | 0.1988 | 0.0167 | 0.0138 | 0.0110 | 0.9922 | 0.2429 | 0.0194 |
| E3 | 0.0085 | 0.0062 | 0.9974 | 0.1371 | 0.0103 | 0.0160 | 0.0104 | 0.9896 | 0.2294 | 0.0151 |
| E4 | 0.0108 | 0.0090 | 0.9975 | 0.1981 | 0.0153 | 0.0143 | 0.0112 | 0.9950 | 0.2461 | 0.0193 |
| E5 | 0.0112 | 0.0097 | 0.9958 | 0.2129 | 0.0160 | 0.0231 | 0.0135 | 0.9792 | 0.2971 | 0.0193 |
| E6 | 0.0111 | 0.0090 | 0.9956 | 0.1988 | 0.0167 | 0.0138 | 0.0110 | 0.9922 | 0.2429 | 0.0194 |
| E7 | 0.0154 | 0.0143 | 0.9917 | 0.3141 | 0.0240 | 0.0160 | 0.0139 | 0.9892 | 0.3058 | 0.0237 |
| E8 | 0.0115 | 0.0092 | 0.9960 | 0.2019 | 0.0155 | 0.0190 | 0.0151 | 0.9875 | 0.3330 | 0.0256 |
| E9 | 0.0121 | 0.0094 | 0.9948 | 0.2079 | 0.0151 | 0.0132 | 0.0102 | 0.9934 | 0.2233 | 0.0164 |
| E10 | 0.0078 | 0.0060 | 0.9979 | 0.1328 | 0.0099 | 0.0103 | 0.0069 | 0.9958 | 0.1515 | 0.0108 |
| E11 | 0.0081 | 0.0071 | 0.9977 | 0.1552 | 0.0117 | 0.0110 | 0.0074 | 0.9951 | 0.1632 | 0.0116 |
| E12 | 0.0097 | 0.0076 | 0.9967 | 0.1666 | 0.0135 | 0.0170 | 0.0136 | 0.9879 | 0.3000 | 0.0251 |
| E13 | 0.0115 | 0.0100 | 0.9953 | 0.2208 | 0.0171 | 0.0128 | 0.0109 | 0.9931 | 0.2395 | 0.0185 |
| E14 | 0.0117 | 0.0098 | 0.9957 | 0.2159 | 0.0170 | 0.0137 | 0.0082 | 0.9930 | 0.1798 | 0.0141 |
| E15 | 0.0127 | 0.0098 | 0.9943 | 0.2158 | 0.0165 | 0.0176 | 0.0110 | 0.9889 | 0.2412 | 0.0171 |
| E16 | 0.0118 | 0.0098 | 0.9951 | 0.2167 | 0.0179 | 0.0143 | 0.0122 | 0.9916 | 0.2693 | 0.0208 |
| E17 | 0.0108 | 0.0086 | 0.9959 | 0.1894 | 0.0161 | 0.0136 | 0.0106 | 0.9924 | 0.2341 | 0.0187 |
| E18 | 0.0080 | 0.0061 | 0.9977 | 0.1349 | 0.0105 | 0.0109 | 0.0074 | 0.9954 | 0.1623 | 0.0118 |
| E19 | 0.0141 | 0.0128 | 0.9929 | 0.2824 | 0.0226 | 0.0154 | 0.0133 | 0.9900 | 0.2922 | 0.0233 |
| E20 | 0.0102 | 0.0079 | 0.9965 | 0.1739 | 0.0134 | 0.0139 | 0.0116 | 0.9918 | 0.2553 | 0.0204 |
| Model | RMSE | Average Error | R2 | Absolute Error | Relative Error |
|---|---|---|---|---|---|
| E1 | 7.7848 | 0.2791 | 0.9943 | 6.1628 | 0.0175 |
| E2 | 7.9891 | −0.1134 | 0.9940 | 6.3903 | 0.0180 |
| E3 | 8.1561 | −1.0204 | 0.9938 | 5.3027 | 0.0127 |
| E4 | 8.0769 | −5.1273 | 0.9963 | 6.4256 | 0.0173 |
| E5 | 11.5509 | −1.7066 | 0.9876 | 7.3791 | 0.0176 |
| E6 | 7.9894 | −0.0920 | 0.9940 | 6.3912 | 0.0180 |
| E7 | 9.9752 | −0.5650 | 0.9906 | 8.9674 | 0.0239 |
| E8 | 9.9787 | −3.9315 | 0.9920 | 7.7387 | 0.0205 |
| E9 | 8.0673 | −1.0981 | 0.9941 | 6.2383 | 0.0157 |
| E10 | 5.8183 | −0.7111 | 0.9969 | 4.1126 | 0.0103 |
| E11 | 6.1505 | −0.5451 | 0.9965 | 4.6057 | 0.0116 |
| E12 | 8.8273 | −0.1168 | 0.9927 | 6.7507 | 0.0193 |
| E13 | 7.7427 | 0.3319 | 0.9943 | 6.6594 | 0.0178 |
| E14 | 8.1162 | −1.7528 | 0.9942 | 5.7251 | 0.0156 |
| E15 | 9.7573 | −1.7161 | 0.9914 | 6.6119 | 0.0168 |
| E16 | 8.3510 | 0.1795 | 0.9934 | 7.0310 | 0.0193 |
| E17 | 7.8158 | 0.1059 | 0.9943 | 6.1266 | 0.0174 |
| E18 | 6.0823 | −0.9723 | 0.9966 | 4.2995 | 0.0111 |
| E19 | 9.4171 | 0.2882 | 0.9916 | 8.3122 | 0.0229 |
| E20 | 7.7695 | 0.2433 | 0.9944 | 6.2092 | 0.0169 |
| Average | 6.3749 | −0.9020 | 0.9962 | 4.6263 | 0.0125 |
| S. No. | Model | GPI | Rank |
|---|---|---|---|
| 1 | E1 | −0.0307 | 10 |
| 2 | E2 | −0.1143 | 11 |
| 3 | E3 | 0.6171 | 5 |
| 4 | E4 | 1.0844 | 4 |
| 5 | E5 | −1.3052 | 18 |
| 6 | E6 | −0.1186 | 12 |
| 7 | E7 | −1.7070 | 20 |
| 8 | E8 | −0.4355 | 15 |
| 9 | E9 | 0.2598 | 7 |
| 10 | E10 | 1.7249 | 1 |
| 11 | E11 | 1.3906 | 3 |
| 12 | E12 | −0.5750 | 17 |
| 13 | E13 | −0.1576 | 13 |
| 14 | E14 | 0.5077 | 6 |
| 15 | E15 | −0.3665 | 14 |
| 16 | E16 | −0.5197 | 16 |
| 17 | E17 | 0.0038 | 9 |
| 18 | E18 | 1.5958 | 2 |
| 19 | E19 | −1.4532 | 19 |
| 20 | E20 | 0.0220 | 8 |
| Training Dataset | Testing Dataset | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Model | RMSE | Avg. Error | R2 | Ab. Error | Rel. Error | RMSE | Avg. Error | R2 | Ab. Error | Rel. Error |
| P1 | 0.0098 | 0.0090 | 0.9969 | 0.1984 | 0.0150 | 0.0159 | 0.0108 | 0.9890 | 0.2260 | 0.0172 |
| P2 | 0.0159 | 0.0112 | 0.9920 | 0.2466 | 0.0169 | 0.0123 | 0.0077 | 0.9932 | 0.1613 | 0.0122 |
| P3 | 0.0099 | 0.0082 | 0.9967 | 0.1801 | 0.0137 | 0.0188 | 0.0118 | 0.9849 | 0.2469 | 0.0194 |
| P4 | 0.0096 | 0.0082 | 0.9970 | 0.1801 | 0.0132 | 0.0147 | 0.0101 | 0.9909 | 0.2115 | 0.0156 |
| P5 | 0.0120 | 0.0093 | 0.9952 | 0.2055 | 0.0154 | 0.0151 | 0.0121 | 0.9906 | 0.2536 | 0.0208 |
| P6 | 0.0104 | 0.0091 | 0.9964 | 0.2012 | 0.0156 | 0.0165 | 0.0119 | 0.9882 | 0.2509 | 0.0201 |
| P7 | 0.0115 | 0.0097 | 0.9956 | 0.2139 | 0.0155 | 0.0145 | 0.0114 | 0.9917 | 0.2395 | 0.0187 |
| P8 | 0.0109 | 0.0093 | 0.9961 | 0.2051 | 0.0157 | 0.0153 | 0.0117 | 0.9900 | 0.2448 | 0.0196 |
| P9 | 0.0127 | 0.0101 | 0.9946 | 0.2212 | 0.0158 | 0.0122 | 0.0096 | 0.9936 | 0.2023 | 0.0168 |
| P10 | 0.0108 | 0.0093 | 0.9962 | 0.2051 | 0.0156 | 0.0150 | 0.0113 | 0.9901 | 0.2374 | 0.0188 |
| P11 | 0.0113 | 0.0096 | 0.9958 | 0.2114 | 0.0162 | 0.0156 | 0.0121 | 0.9896 | 0.2540 | 0.0206 |
| P12 | 0.0106 | 0.0089 | 0.9962 | 0.1953 | 0.0148 | 0.0153 | 0.0112 | 0.9901 | 0.2362 | 0.0191 |
| P13 | 0.0106 | 0.0090 | 0.9962 | 0.1990 | 0.0151 | 0.0154 | 0.0113 | 0.9901 | 0.2381 | 0.0191 |
| P14 | 0.0097 | 0.0088 | 0.9969 | 0.1935 | 0.0145 | 0.0154 | 0.0099 | 0.9900 | 0.2084 | 0.0161 |
| P15 | 0.0115 | 0.0089 | 0.9956 | 0.1949 | 0.0141 | 0.0146 | 0.0100 | 0.9914 | 0.2102 | 0.0164 |
| P16 | 0.0120 | 0.0102 | 0.9952 | 0.2235 | 0.0163 | 0.0133 | 0.0104 | 0.9926 | 0.2184 | 0.0169 |
| P17 | 0.0109 | 0.0093 | 0.9961 | 0.2051 | 0.0157 | 0.0153 | 0.0117 | 0.9899 | 0.2447 | 0.0196 |
| P18 | 0.0106 | 0.0090 | 0.9962 | 0.1973 | 0.0150 | 0.0153 | 0.0113 | 0.9900 | 0.2368 | 0.0190 |
| P19 | 0.0143 | 0.0109 | 0.9932 | 0.2404 | 0.0174 | 0.0134 | 0.0103 | 0.9924 | 0.2165 | 0.0184 |
| P20 | 0.0100 | 0.0082 | 0.9966 | 0.1800 | 0.0129 | 0.0145 | 0.0098 | 0.9913 | 0.2060 | 0.0156 |
| Model | RMSE | Average Error | R2 | Absolute Error | Relative Error |
|---|---|---|---|---|---|
| P1 | 8.3746 | −1.2916 | 0.9935 | 6.2829 | 0.0160 |
| P2 | 9.0543 | 0.1174 | 0.9922 | 6.0381 | 0.0146 |
| P3 | 9.4985 | −1.9342 | 0.9917 | 6.3226 | 0.0165 |
| P4 | 7.8402 | −1.4635 | 0.9944 | 5.7976 | 0.0143 |
| P5 | 8.6785 | −1.3759 | 0.9932 | 6.7962 | 0.0180 |
| P6 | 8.7244 | −1.5289 | 0.9930 | 6.6930 | 0.0178 |
| P7 | 8.3090 | −2.2318 | 0.9939 | 6.7123 | 0.0170 |
| P8 | 8.4253 | −1.6442 | 0.9935 | 6.6605 | 0.0176 |
| P9 | 7.9373 | −1.1287 | 0.9941 | 6.2691 | 0.0163 |
| P10 | 8.2998 | −1.3320 | 0.9936 | 6.5515 | 0.0172 |
| P11 | 8.6435 | −1.6301 | 0.9931 | 6.8898 | 0.0184 |
| P12 | 8.3512 | −1.6938 | 0.9936 | 6.3867 | 0.0169 |
| P13 | 8.3858 | −1.8642 | 0.9936 | 6.4712 | 0.0171 |
| P14 | 8.1465 | −1.6484 | 0.9939 | 5.9488 | 0.0153 |
| P15 | 8.3469 | −1.8089 | 0.9937 | 5.9979 | 0.0152 |
| P16 | 8.0485 | −1.4057 | 0.9940 | 6.5411 | 0.0166 |
| P17 | 8.4260 | −1.6339 | 0.9935 | 6.6590 | 0.0176 |
| P18 | 8.3498 | −1.5544 | 0.9936 | 6.4264 | 0.0170 |
| P19 | 8.8482 | −1.4056 | 0.9927 | 6.7643 | 0.0179 |
| P20 | 7.9201 | −1.7356 | 0.9943 | 5.7149 | 0.0142 |
| Average | 7.8857 | −1.5097 | 0.9943 | 6.0013 | 0.0156 |
| S. No. | Model | GPI | Rank |
|---|---|---|---|
| 1. | P1 | 0.1916 | 7 |
| 2. | P2 | −0.7583 | 15 |
| 3. | P3 | −1.0235 | 18 |
| 4. | P4 | 1.7364 | 2 |
| 5. | P5 | −0.9730 | 17 |
| 6. | P6 | −0.8855 | 16 |
| 7. | P7 | 0.1754 | 8 |
| 8. | P8 | −0.3910 | 13 |
| 9. | P9 | 0.5594 | 5 |
| 10. | P10 | −0.2261 | 12 |
| 11. | P11 | −1.0328 | 19 |
| 12. | P12 | 0.1325 | 9 |
| 13 | P13 | 0.0620 | 10 |
| 14. | P14 | 1.1044 | 3 |
| 15. | P15 | 0.9507 | 4 |
| 16. | P16 | 0.2854 | 6 |
| 17. | P17 | −0.3954 | 14 |
| 18. | P18 | 0.0020 | 11 |
| 19. | P19 | −1.1839 | 20 |
| 20. | P20 | 1.8836 | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jamil, B.; Serrano-Luján, L. Hybrid Metaheuristic Algorithms for Optimization of Countrywide Primary Energy: Analysing Estimation and Year-Ahead Prediction. Energies 2024, 17, 1697. https://doi.org/10.3390/en17071697
Jamil B, Serrano-Luján L. Hybrid Metaheuristic Algorithms for Optimization of Countrywide Primary Energy: Analysing Estimation and Year-Ahead Prediction. Energies. 2024; 17(7):1697. https://doi.org/10.3390/en17071697
Chicago/Turabian StyleJamil, Basharat, and Lucía Serrano-Luján. 2024. "Hybrid Metaheuristic Algorithms for Optimization of Countrywide Primary Energy: Analysing Estimation and Year-Ahead Prediction" Energies 17, no. 7: 1697. https://doi.org/10.3390/en17071697
APA StyleJamil, B., & Serrano-Luján, L. (2024). Hybrid Metaheuristic Algorithms for Optimization of Countrywide Primary Energy: Analysing Estimation and Year-Ahead Prediction. Energies, 17(7), 1697. https://doi.org/10.3390/en17071697