Solution of the Simultaneous Routing and Bandwidth Allocation Problem in Energy-Aware Networks Using Augmented Lagrangian-Based Algorithms and Decomposition



Abstract
1. Introduction
2. Network Optimization Problem of Simultaneous Routing and Bandwidth Allocation in Energy-Aware Networks
3. Augmented Lagrangian Algorithms
4. Separable Problems and Their Decomposition Algorithms
4.1. Classical Separable Problem Formulation
4.2. Bertsekas Decomposition Method
4.3. Tanikawa–Mukai Decomposition Method
4.4. Tatjewski Decomposition Method
4.5. SALA Decomposition Algorithm in ADMM Version
5. Decomposition of the Network Problem
5.1. The Standard Multiplier Method without Decomposition
5.2. The Bertsekas Method
5.3. The Tatjewski Method
5.4. SALA ADMM Algorithm
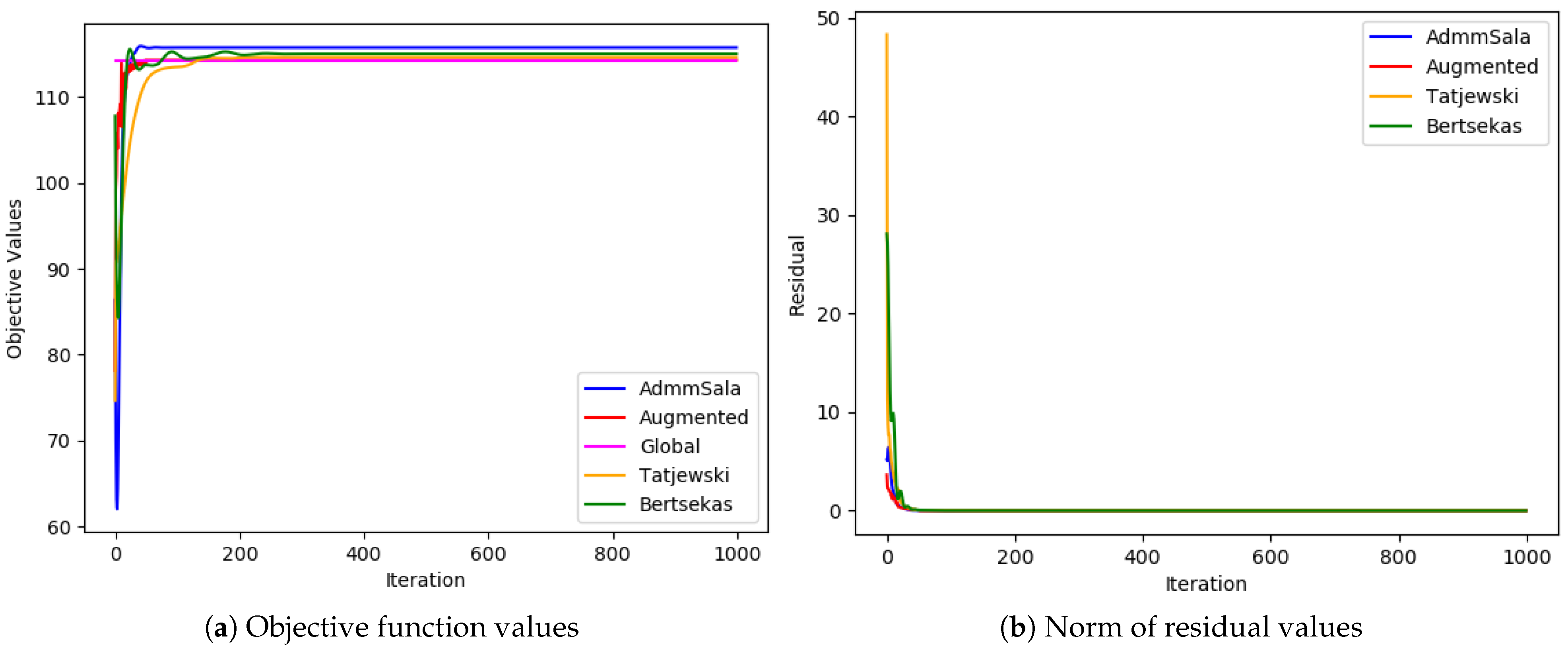
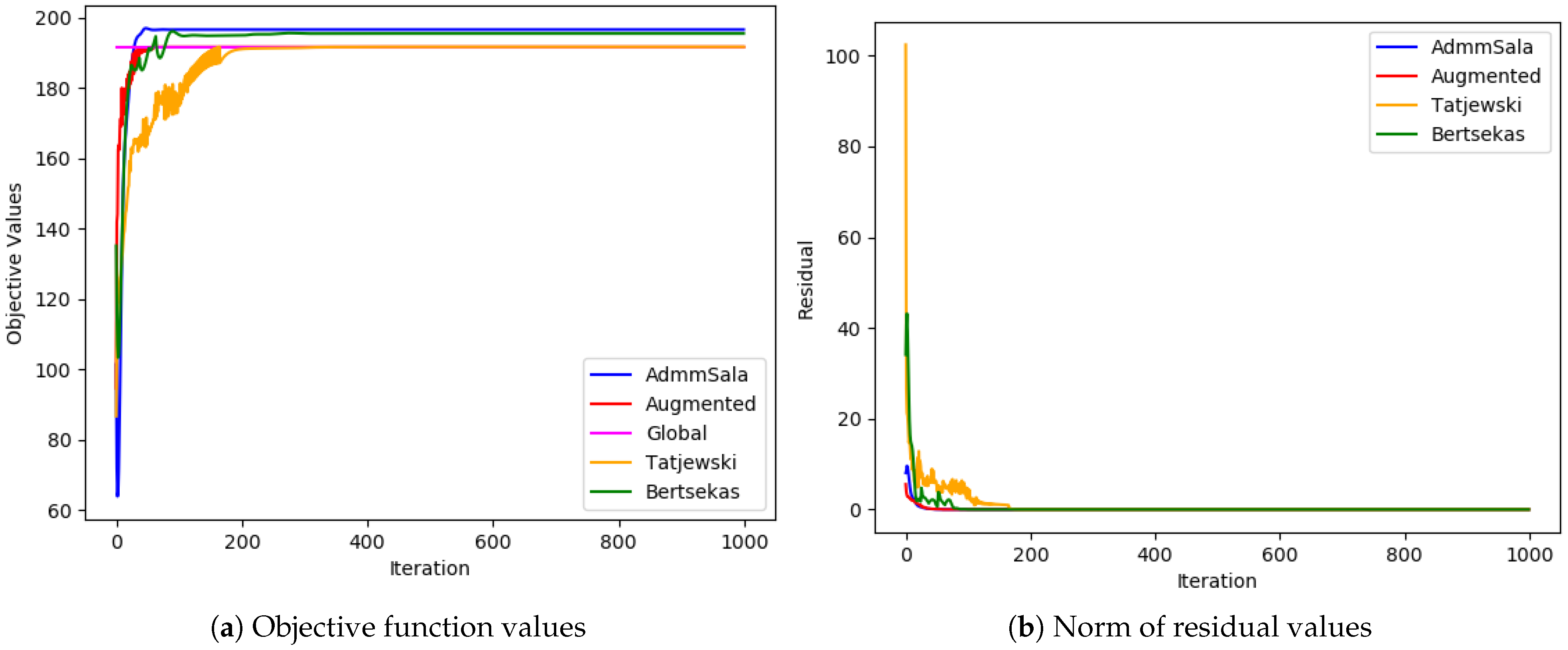
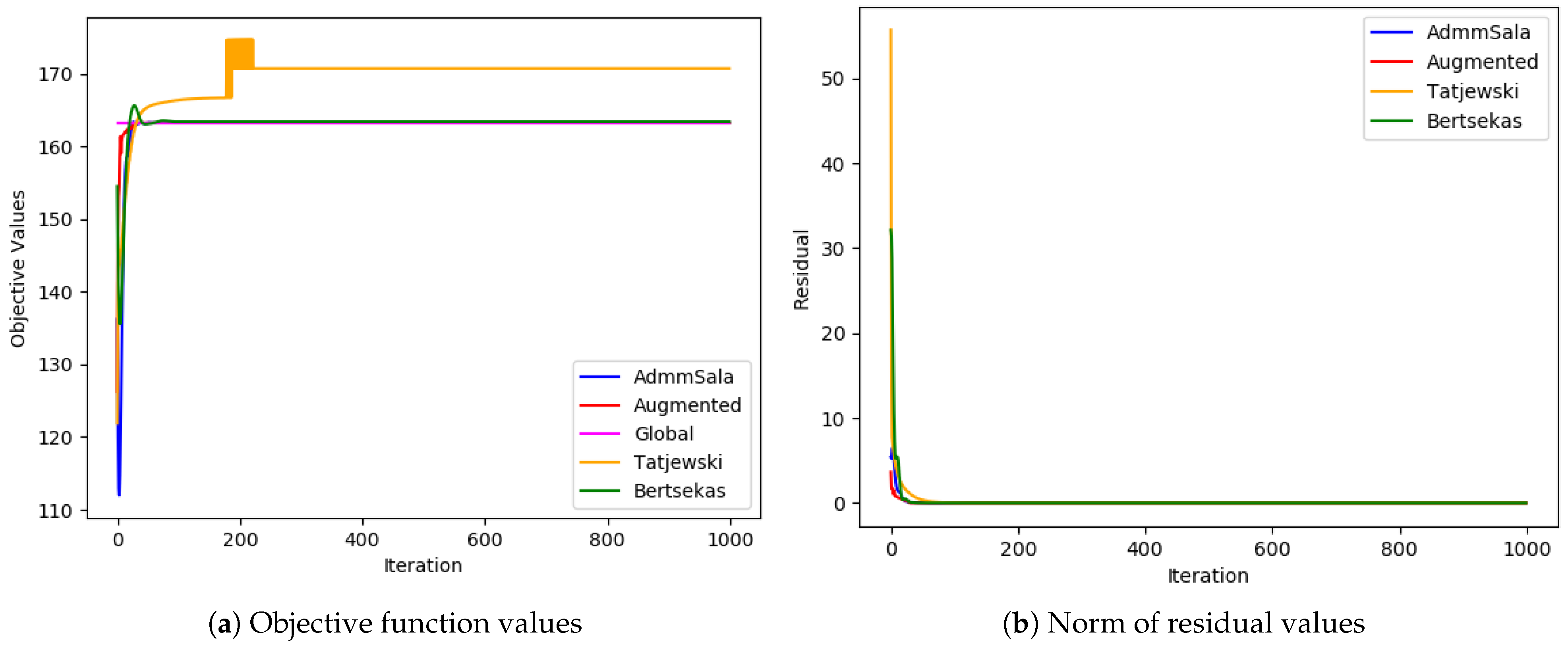
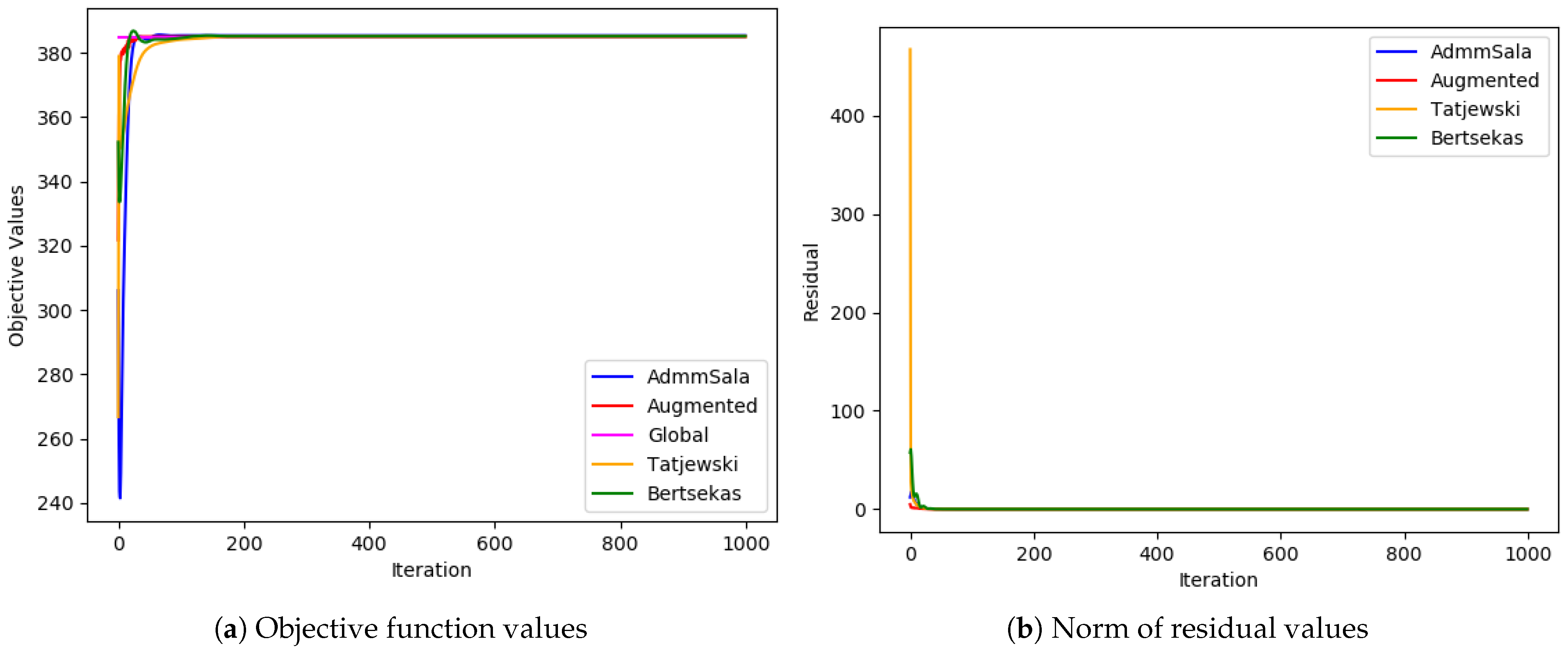
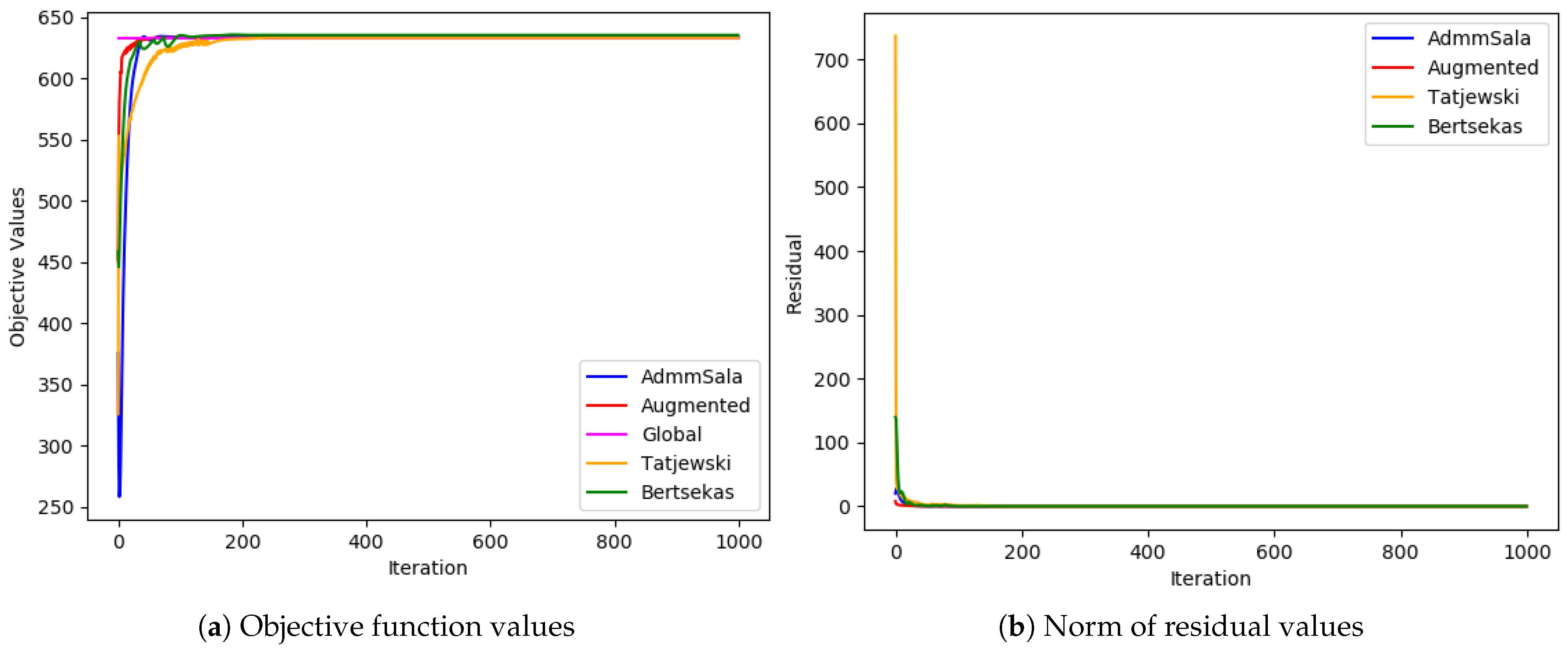
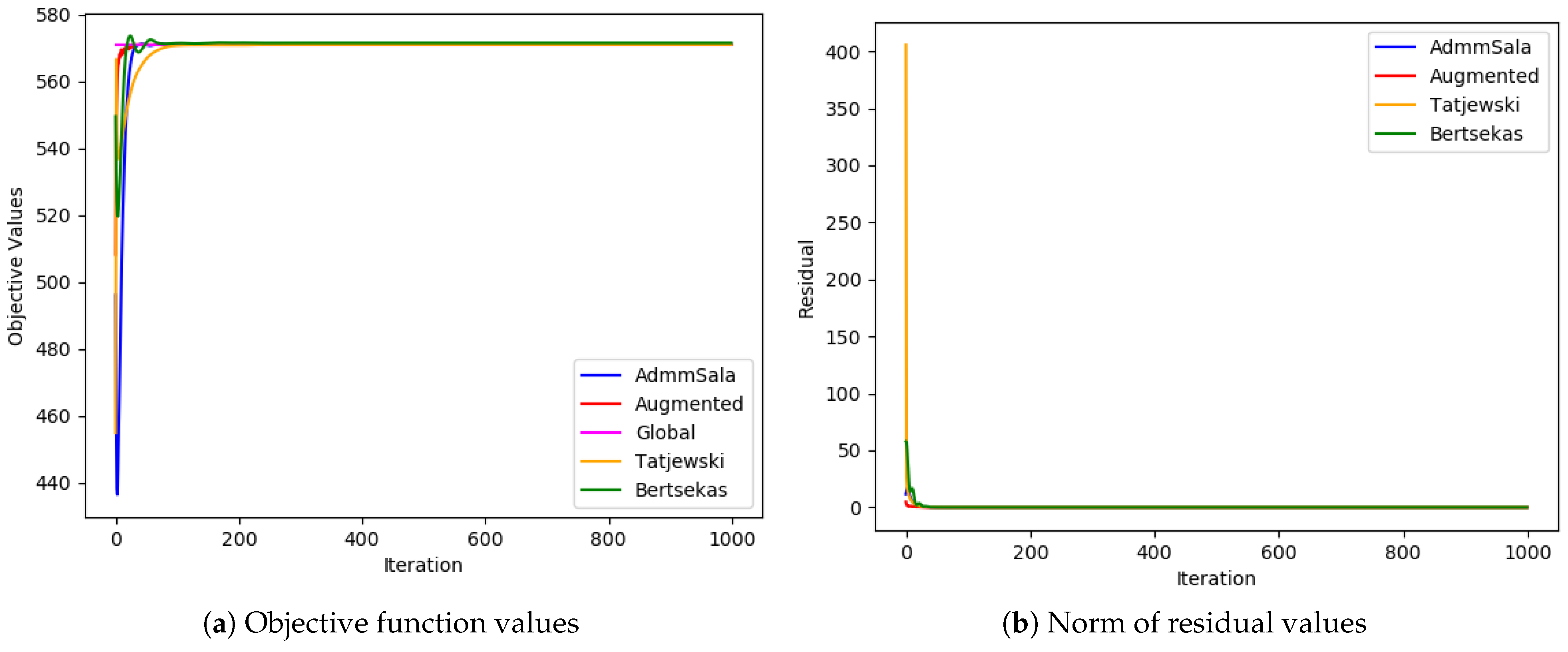
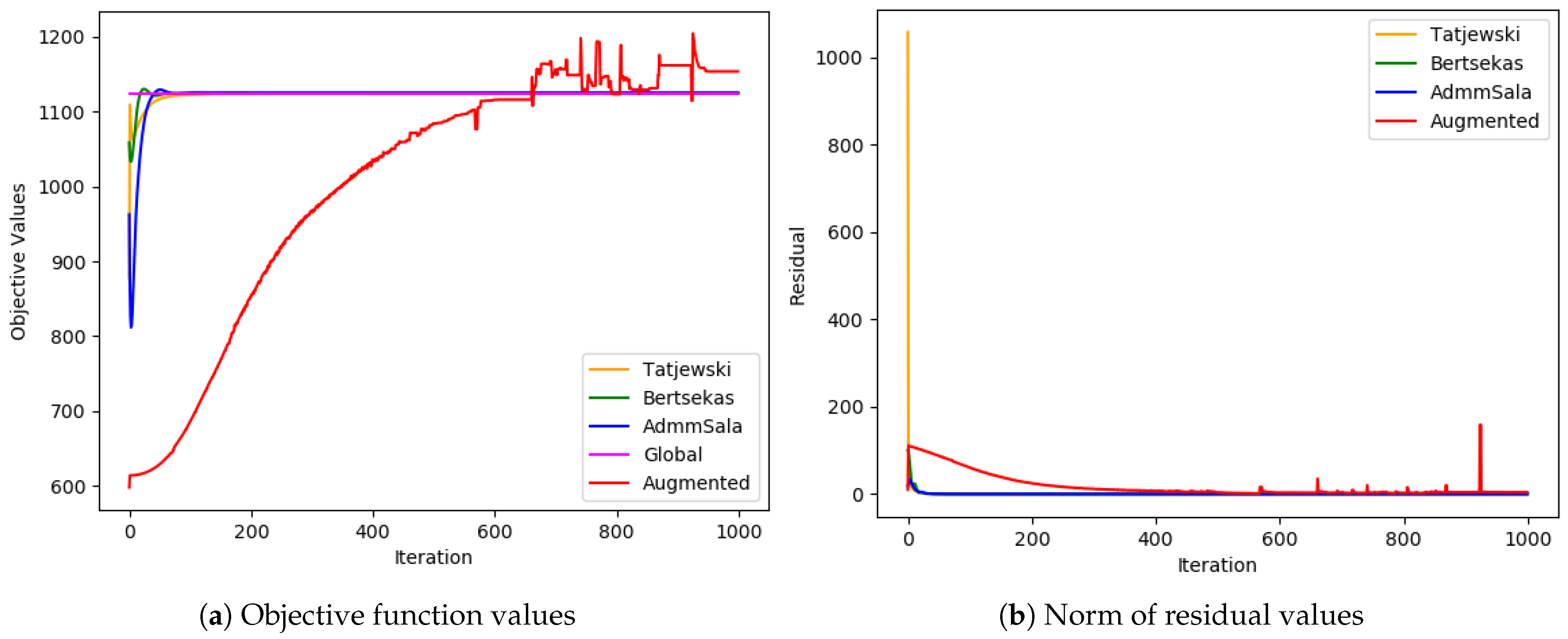
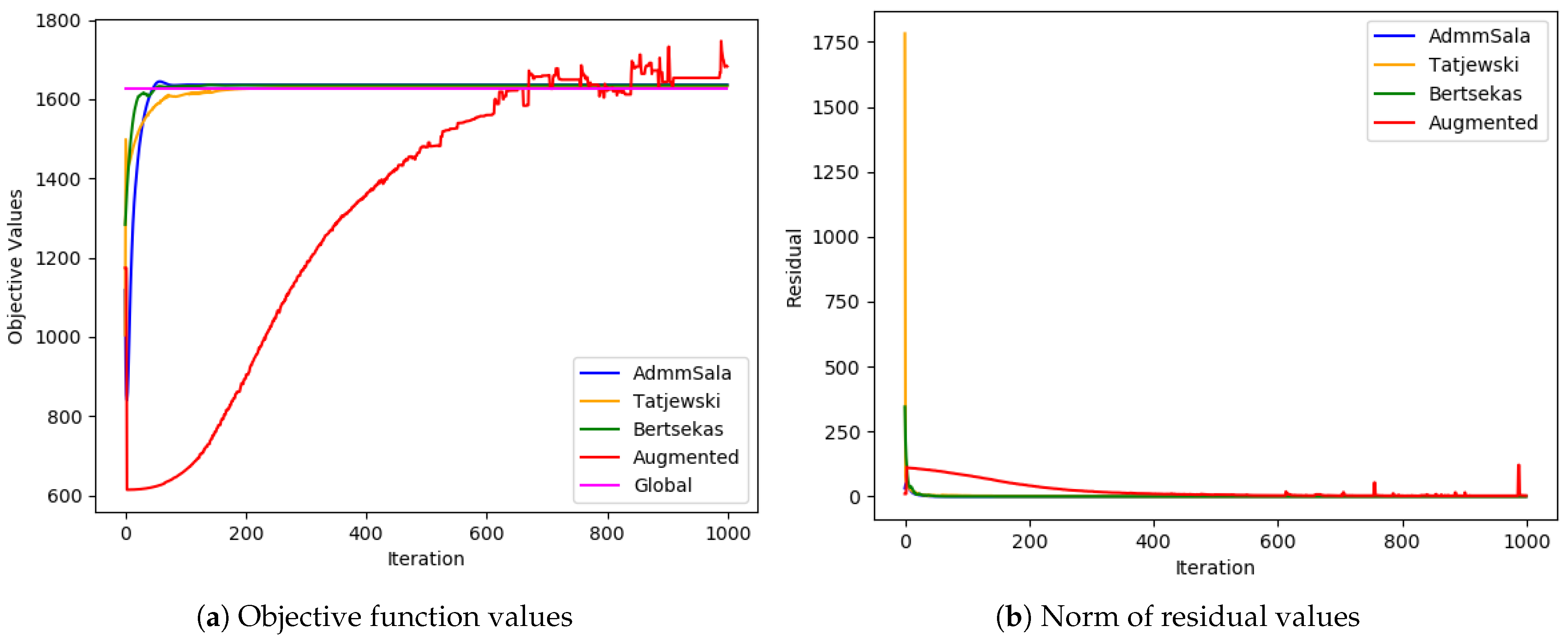
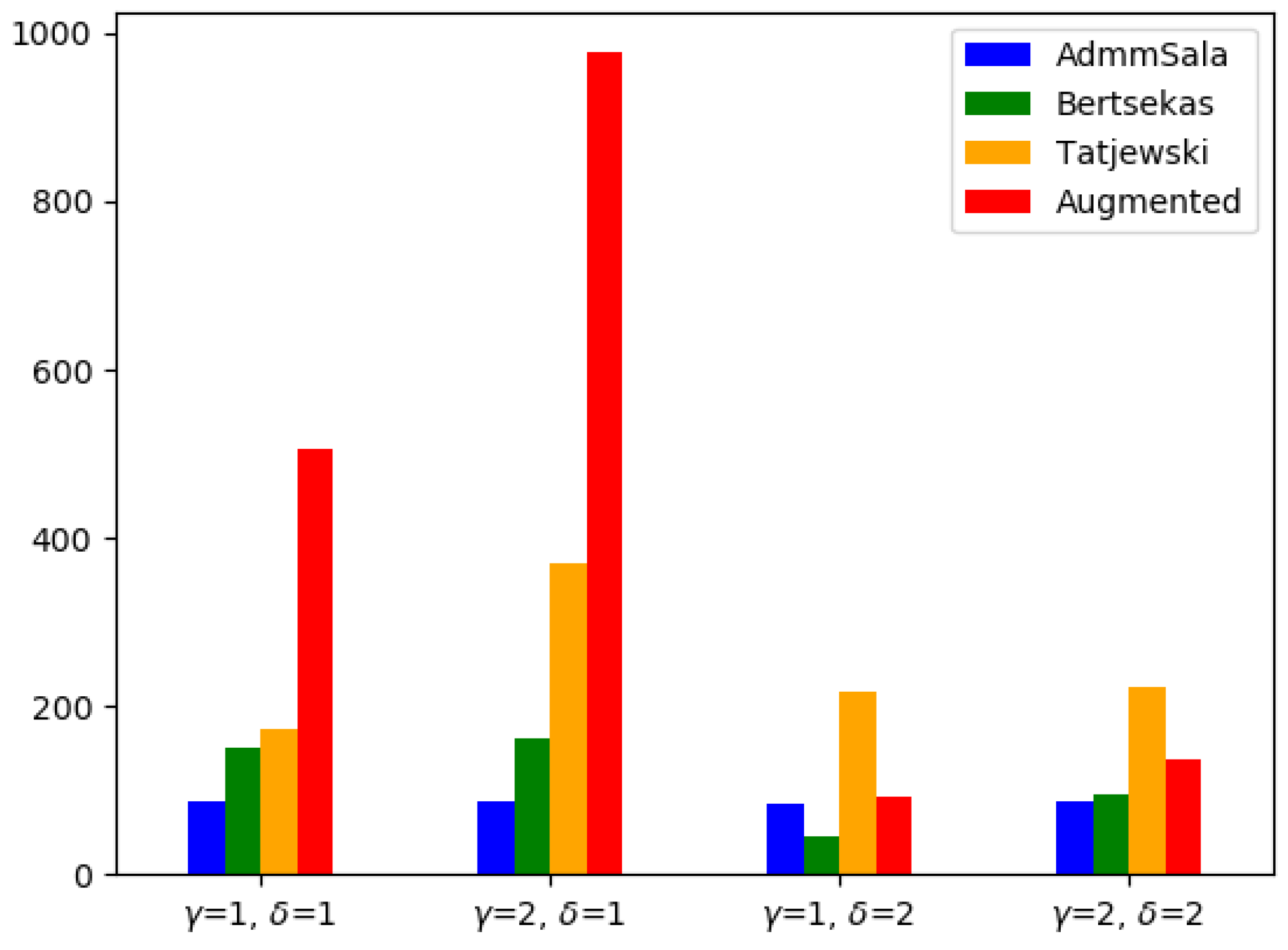
6. Numerical Tests
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| set of all network nodes and a single node, respectively; | |
| set of all network arcs and a single arc, respectively; | |
| set of all links labeled by subsequent natural numbers and a single labeled link, respectively; | |
| one-to-one mapping from arcs to links labeled by a single natural number; | |
| set of all demands (flows) and a single demand, respectively; | |
| source and destination node for the specific demand (flow) w, respectively; | |
| flow rate for the specific demand ; | |
| lower and upper bound on the flow rate for the demand w; we assume that ; | |
| capacity of the link l, ; | |
| binary routing decision variable, whether the link l is used by the demand w; | |
| vector of routing variables defining a path for the demand | |
| positive parameter—the weight of the QoS part of the objective function; | |
| positive parameter—the weight of the energy usage part of the objective function. |
References
- Data Centres and Data Transmission Networks. Available online: https://www.iea.org/reports/data-centres-and-data-transmission-networks (accessed on 12 February 2024).
- Koot, M.; Wijnhoven, F. Usage impact on data center electricity needs: A system dynamic forecasting model. Appl. Energy 2021, 291, 116798. [Google Scholar] [CrossRef]
- Jaskóła, P.; Arabas, P.; Karbowski, A. Simultaneous routing and flow rate optimization in energy-aware computer networks. Int. J. Appl. Math. Comput. Sci. 2016, 26, 231–243. [Google Scholar] [CrossRef]
- Wang, J.; Li, L.; Low, S.H.; Doyle, J.C. Cross-layer optimization in TCP/IP networks. IEEE/ACM Trans. Netw. 2005, 13, 582–595. [Google Scholar] [CrossRef]
- Jünger, M.; Liebling, T.; Naddef, D.; Nemhauser, G.; Pulleyblank, W.; Reinelt, G.; Rinaldi, G.; Wolsey, L.A. (Eds.) 50 Years of Integer Programming 1958–2008: From the Early Years to the State-of-the-Art; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Li, D.; Sun, X. Nonlinear Integer Programming; Springer: New York, NY, USA, 2006. [Google Scholar]
- Ruksha, I.; Karbowski, A. Decomposition Methods for the Network Optimization Problem of Simultaneous Routing and Bandwidth Allocation Based on Lagrangian Relaxation. Energies 2022, 15, 7634. [Google Scholar] [CrossRef]
- Rockafellar, R. Augmented Lagrange multiplier functions and duality in nonconvex programming. SIAM J. Control. 1974, 12, 268–285. [Google Scholar] [CrossRef]
- Huang, X.; Yang, X. Duality and Exact Penalization via a Generalized Augmented Lagrangian Function. In Optimization and Control with Applications; Qi, L., Teo, K., Yang, X., Eds.; Springer: Boston, MA, USA, 2005; pp. 101–114. [Google Scholar]
- Huang, X.; Yang, X. Further study on augmented Lagrangian duality theory. J. Glob. Optim. 2005, 31, 193–210. [Google Scholar] [CrossRef]
- Burachik, R.S.; Rubinov, A. On the absence of duality gap for Lagrange-type functions. J. Ind. Manag. Optim. 2005, 1, 33–38. [Google Scholar] [CrossRef]
- Nedich, A.; Ozdaglar, A. A geometric framework for nonconvex optimization duality using augmented lagrangian functions. J. Glob. Optim. 2008, 40, 545–573. [Google Scholar] [CrossRef]
- Boland, N.; Eberhard, A. On the augmented Lagrangian dual for integer programming. Math. Program. 2015, 150, 491–509. [Google Scholar] [CrossRef]
- Gu, X.; Ahmed, S.; Dey, S.S. Exact augmented lagrangian duality for mixed integer quadratic programming. SIAM J. Optim. 2020, 30, 781–797. [Google Scholar] [CrossRef]
- Bertsekas, D.P. Constrained Optimization and Lagrange Multiplier Methods; Academic Press: New York, NY, USA, 1982. [Google Scholar]
- Bertsekas, D.P. Multiplier methods: A survey. Automatica 1976, 12, 133–145. [Google Scholar] [CrossRef]
- Wierzbicki, A.P. A penalty function shifting method in constrained static optimization and its convergence properties. Arch. Autom. I Telemech. 1971, 16, 395–416. [Google Scholar]
- Stein, O.; Oldenburg, J.; Marquardt, W. Continuous reformulations of discrete-continuous optimization problems. Comput. Chem. Eng. 2004, 28, 1951–1966. [Google Scholar] [CrossRef]
- Bragin, M.A.; Luh, P.B.; Yan, B.; Sun, X. A scalable solution methodology for mixed-integer linear programming problems arising in automation. IEEE Trans. Autom. Sci. Eng. 2019, 16, 531–541. [Google Scholar] [CrossRef]
- Chen, Y.; Guo, Q.; Sun, H. Decentralized unit commitment in integrated heat and electricity systems using sdm-gs-alm. IEEE Trans. Power Syst. 2019, 34, 2322–2333. [Google Scholar] [CrossRef]
- Cordova, M.; Oliveira, W.d.; Sagastizábal, C. Revisiting augmented Lagrangian duals. Math. Program. 2022, 196, 235–277. [Google Scholar] [CrossRef]
- Liu, Z.; Stursberg, O. Distributed Solution of Mixed-Integer Programs by ADMM with Closed Duality Gap. In Proceedings of the IEEE Conference on Decision and Control, Cancun, Mexico, 6–9 December 2022; pp. 279–286. [Google Scholar] [CrossRef]
- Hong, M. A distributed, asynchronous, and incremental algorithm for nonconvex optimization: An ADMM approach. IEEE Trans. Control Netw. Syst. 2018, 5, 935–945. [Google Scholar] [CrossRef]
- Lin, Z.; Li, H.; Fang, C. Alternating Direction Method of Multipliers for Machine Learning; Springer: Singapore, 2022. [Google Scholar]
- Bertsekas, D.P. Convexification procedures and decomposition methods for nonconvex optimization problems. J. Optim. Theory Appl. 1979, 29, 169–197. [Google Scholar] [CrossRef]
- Tanikawa, A.; Mukai, H. A new technique for nonconvex primal-dual decomposition of a large-scale separable optimization problem. IEEE Trans. Autom. Control 1985, 30, 133–143. [Google Scholar] [CrossRef]
- Tatjewski, P. New dual-type decomposition algorithm for nonconvex separable optimization problems. Automatica 1989, 25, 233–242. [Google Scholar] [CrossRef]
- Tatjewski, P.; Engelmann, B. Two-level primal-dual decomposition technique for large-scale nonconvex optimization problems with constraints. J. Optim. Theory Appl. 1990, 64, 183–205. [Google Scholar] [CrossRef]
- Hamdi, A.; Mahey, P.; Dussault, J.P. A New Decomposition Method in Nonconvex Programming Via a Separable Augmented Lagrangian. In Recent Advances in Optimization; Gritzmann, P., Horst, R., Sachs, E., Tichatschke, R., Eds.; Springer: Berlin/Heidelberg, Germany, 1997; pp. 90–104. [Google Scholar]
- Sun, K.; Sun, X.A. A two-level distributed algorithm for nonconvex constrained optimization. Comput. Optim. Appl. 2023, 84, 609–649. [Google Scholar] [CrossRef]
- Houska, B.; Frasch, J.; Diehl, M. An Augmented Lagrangian Based Algorithm for Distributed Nonconvex Optimization. SIAM J. Optim. 2016, 26, 1101–1127. [Google Scholar] [CrossRef]
- Boland, N.; Christiansen, J.; Dandurand, B.; Eberhard, A.; Oliveira, F. A parallelizable augmented Lagrangian method applied to large-scale non-convex-constrained optimization problems. Math. Program. 2019, 175, 503–536. [Google Scholar] [CrossRef]
- Kuhn, H.W.; Tucker, A.W. Nonlinear programming. In Proceedings of the Second Berkeley Symposium on Mathematical Statistics and Probability; Neyman, J., Ed.; University of California Press: Berkeley, CA, USA, 1951; Volume 2, pp. 481–492. [Google Scholar]
- Arrow, K.J.; Hurwicz, L. Reduction of constrained maxima to saddlepoint problems. In Proceedings of the Third Berkeley Symposium on Mathematical Statistics and Probability; Neyman, J., Ed.; University of California Press: Berkeley, CA, USA, 1956; Volume 5, pp. 1–20. [Google Scholar]
- Arrow, K.; Hurwicz, L.; Uzawa, H. Studies in Linear and Nonlinear Programming; Stanford Mathematical Studies in the Social Sciences; Stanford University Press: Redwood City, CA, USA, 1958. [Google Scholar]
- Powell, M.J.D. A Method for Nonlinear Constraints in Minimization Problems; Fletcher, R., Ed.; Optimization, Academic Press: New York, NY, USA, 1969; pp. 283–298. [Google Scholar]
- Hestenes, M.R. Multiplier and gradient methods. J. Optim. Theory Appl. 1969, 4, 303–320. [Google Scholar] [CrossRef]
- Fletcher, R. A class of methods for nonlinear programming with termination and convergence properties. In Integer and Nonlinear Programming; Abadie, J., Ed.; North-Holland: Amsterdam, The Netherland, 1970; pp. 157–173. [Google Scholar]
- Mukai, H.; Polak, E. A quadratically convergent primal-dual algorithm with global convergence properties for solving optimization problems with equality constraints. Math. Program. 1975, 9, 336–349. [Google Scholar] [CrossRef]
- Bertsekas, D.P.; Tsitsiklis, J.N. Parallel and Distributed Computation: Numerical Methods; Prentice Hall Inc.: Englewood Cliffs, NJ, USA, 1989. [Google Scholar]
- Glowinski, R.; Marroco, A. On the approximation, by finite elements of order one, and the resolution, by penalization-duality of a class of non-Dirichlet problems linéaires. Math. Model. Numer. Anal. Math. Model. Numer. Anal. 1975, 9, 41–76. [Google Scholar]
- Gabay, D.; Mercier, B. A dual algorithm for the solution of nonlinear variational problems via finite element approximation. Comput. Math. Appl. 1976, 2, 17–40. [Google Scholar] [CrossRef]
- Hamdi, A. Two-level primal-dual proximal decomposition technique to solve large scale optimization problems. Appl. Math. Comput. 2005, 160, 921–938. [Google Scholar] [CrossRef]
- Hamdi, A.; Mishra, S.K. Decomposition methods based on augmented lagrangians: A survey. In Topics in Nonconvex Optimization: Theory and Applications; Springer: New York, NY, USA, 2011; Volume 50, pp. 175–203. [Google Scholar] [CrossRef]
- AMPL Optimization Inc.—Amplpy: Python API for AMPL. Available online: https://github.com/ampl/amplpy/ (accessed on 21 February 2024).
- Fourer, R.; Gay, D.M.; Kernighan, B.W. AMPL: A Modeling Language For Mathematical Programming, 2nd ed.; Duxbury Press: Belmont, CA, USA, 2003; Available online: https://ampl.com/resources/the-ampl-book/ (accessed on 21 February 2024).
- NetworkX—Network Analysis in Python. Available online: https://networkx.org/ (accessed on 12 February 2024).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Nodes | Number of Arcs | Number of Demands | Flow Rate Bounds | Capacity Bounds | |
|---|---|---|---|---|---|
| Medium Problem | 25 | 84 | 12 | [0.001, 3] | [0.3, 1] |
| Large Problem | 49 | 143 | 32 | [0.001, 3] | [0.3, 1] |
| Extra-Large Problem | 77 | 227 | 64 | [0.001, 3] | [0.3, 1] |
| Objective | Time (s) | Status | |
|---|---|---|---|
| Global | 114.31 (0.0) | 0 | Optimal |
| Augmented | 114.31 (0.0) | 504 | Optimal |
| Bertsekas | 115.03 (0.63) | 149 | Optimal |
| Tatjewski | 114.64 (0.29) | 171 | Optimal |
| AdmmSala | 115.78 (1.29) | 87 | Optimal |
| Global | 191.61 (0.0) | 1 | Optimal |
| Augmented | 191.61 (0.0) | 976 | Optimal |
| Bertsekas | 195.45 (2.0) | 162 | Optimal |
| Tatjewski | 191.63 (0.01) | 368 | Optimal |
| AdmmSala | 196.55 (2.58) | 85 | Optimal |
| Global | 163.26 (0.0) | 0 | Optimal |
| Augmented | 163.26 (0.0) | 93 | Optimal |
| Bertsekas | 163.42 (0.1) | 44 | Optimal |
| Tatjewski | 170.75 (4.59) | 216 | Optimal |
| AdmmSala | 163.26 (0.0) | 84 | Optimal |
| Global | 246.52 (0.0) | 2 | Optimal |
| Augmented | 246.52 (0.0) | 137 | Optimal |
| Bertsekas | 247.74 (0.49) | 95 | Optimal |
| Tatjewski | 246.5 (0.01) | 222 | Optimal |
| AdmmSala | 246.55 (0.01) | 85 | Optimal |
| Objective | Time (s) | Status | |
|---|---|---|---|
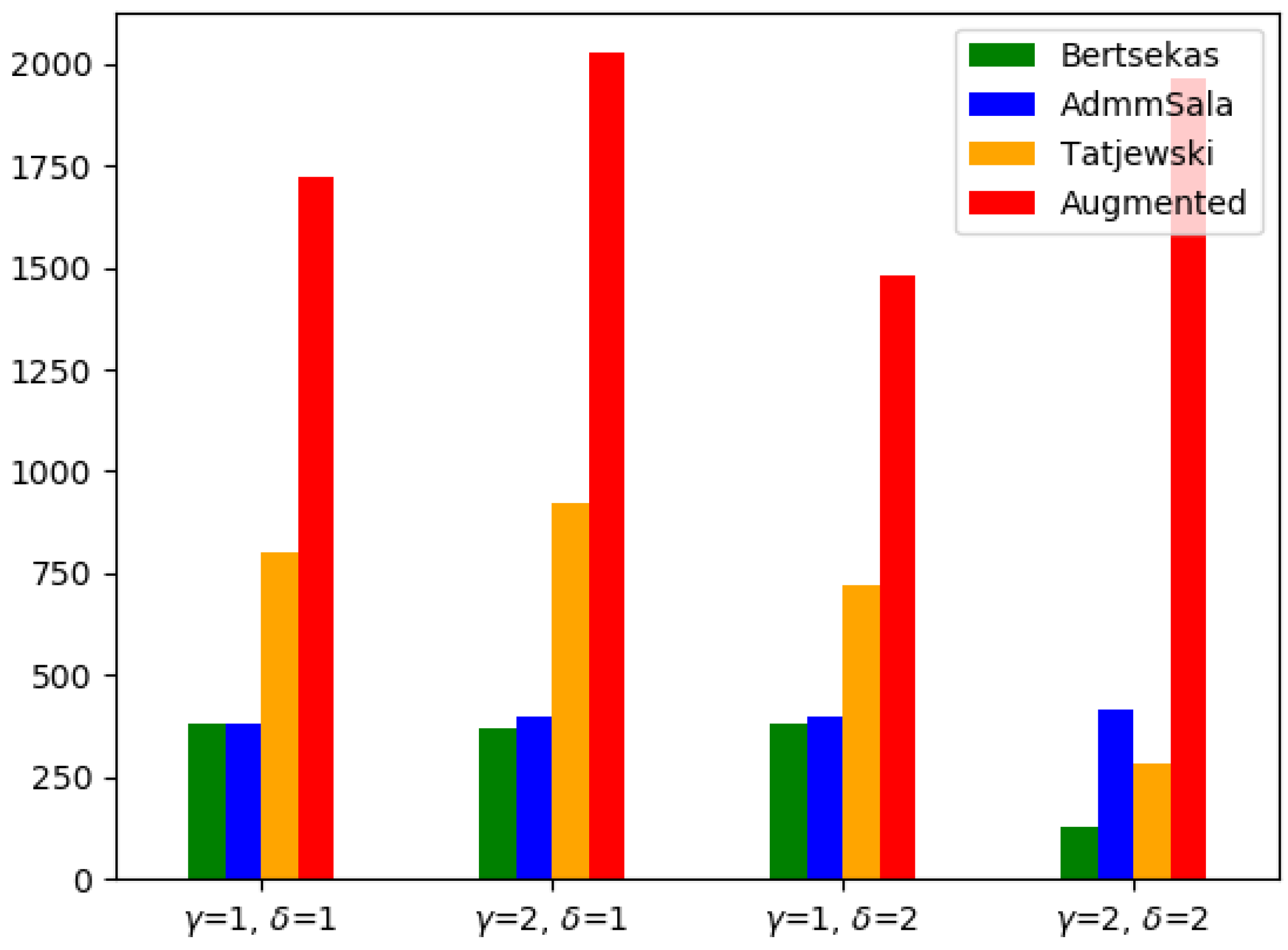
| Global | 384.96 (0.0) | 4005 | Timeout |
| Augmented | 384.96 (0.0) | 1723 | Optimal |
| Bertsekas | 385.09 (0.03) | 379 | Optimal |
| Tatjewski | 384.98 (0.0) | 800 | Optimal |
| AdmmSala | 385.32 (0.09) | 383 | Optimal |
| Global | 632.92 (0.0) | 4003 | Timeout |
| Augmented | 632.92 (0.0) | 2026 | Optimal |
| Bertsekas | 635.18 (0.36) | 369 | Optimal |
| Tatjewski | 632.95 (0.0) | 920 | Optimal |
| AdmmSala | 633.67 (0.12) | 396 | Optimal |
| Global | 570.92 (0.0) | 4007 | Timeout |
| Augmented | 570.92 (0.0) | 1482 | Optimal |
| Bertsekas | 571.49 (0.1) | 379 | Optimal |
| Tatjewski | 570.91 (0.0) | 718 | Optimal |
| AdmmSala | 571.06 (0.03) | 395 | Optimal |
| Global | 819.84 (0.0) | 4006 | Timeout |
| Augmented | 819.84 (0.0) | 1965 | Optimal |
| Bertsekas | 820.57 (0.09) | 127 | Optimal |
| Tatjewski | 820.36 (0.06) | 280 | Optimal |
| AdmmSala | 820.16 (0.04) | 416 | Optimal |
| Objective | Time (s) | Status | |
|---|---|---|---|
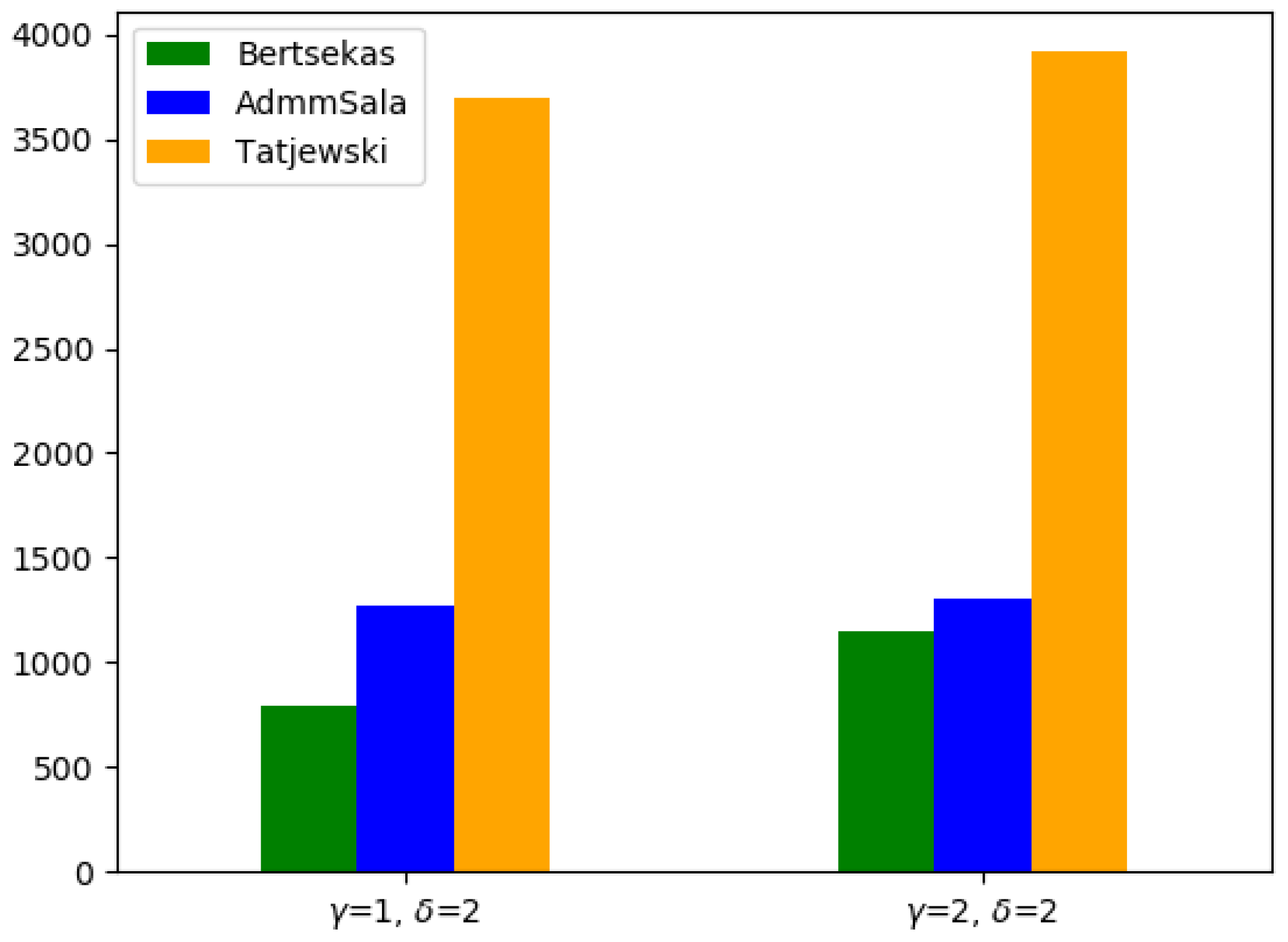
| Global | 1123.49 (0.0) | 6013 | Timeout |
| Augmented | 1153.63 (2.68) | 30,938 | MaxIter |
| Bertsekas | 1124.75 (0.11) | 796 | Optimal |
| Tatjewski | 1124.0 (0.05) | 3692 | Optimal |
| AdmmSala | 1125.1 (0.14) | 1268 | Optimal |
| Global | 1627.31 (0.0) | 30,042 | Timeout |
| Augmented | 1682.76 (3.41) | 31,040 | MaxIter |
| Bertsekas | 1635.12 (0.48) | 1147 | Optimal |
| Tatjewski | 1632.81 (0.34) | 3917 | Optimal |
| AdmmSala | 1636.19 (0.55) | 1302 | Optimal |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nwachukwu, A.C.; Karbowski, A. Solution of the Simultaneous Routing and Bandwidth Allocation Problem in Energy-Aware Networks Using Augmented Lagrangian-Based Algorithms and Decomposition. Energies 2024, 17, 1233. https://doi.org/10.3390/en17051233
Nwachukwu AC, Karbowski A. Solution of the Simultaneous Routing and Bandwidth Allocation Problem in Energy-Aware Networks Using Augmented Lagrangian-Based Algorithms and Decomposition. Energies. 2024; 17(5):1233. https://doi.org/10.3390/en17051233
Chicago/Turabian StyleNwachukwu, Anthony Chukwuemeka, and Andrzej Karbowski. 2024. "Solution of the Simultaneous Routing and Bandwidth Allocation Problem in Energy-Aware Networks Using Augmented Lagrangian-Based Algorithms and Decomposition" Energies 17, no. 5: 1233. https://doi.org/10.3390/en17051233
APA StyleNwachukwu, A. C., & Karbowski, A. (2024). Solution of the Simultaneous Routing and Bandwidth Allocation Problem in Energy-Aware Networks Using Augmented Lagrangian-Based Algorithms and Decomposition. Energies, 17(5), 1233. https://doi.org/10.3390/en17051233